Материалы по тегу: амортизация
|
11.05.2026 [23:59], Руслан Авдеев
Meta✴ пришлось продлить срок службы серверов из-за дефицита памятиMeta✴ вынуждена продлить срок эксплуатации некоторых из своих серверов общего назначения из-за дефицита DRAM с шести до семи лет, сообщает The Wall Street Journal со ссылкой на внутреннюю документацию техногиганта, где говорится о том, что компания не ожидала существенного дефицита поставок оборудования, в основном именно из-за нехватки оперативной памяти, а также жёстких дисков. Предполагается, что дефицит продлится минимум до 2027 года. Ежегодно компания инвестирует огромные средства в инфраструктуру ЦОД и является одним из крупнейших заказчиков серверного оборудования в мире. Однако даже увеличение капзатрат до $125–$145 млрд в этом году не позволяет обновлять серверы прежними темпами. Внутренне моделирование Meta✴ показало, что увеличение срока эксплуатации серверов компании увеличит ожидаемую годовую интенсивность отказов (AFR) с 4,8 % до 7,4 % ежегодно. Такой риск считается приемлемым, хотя до восьми лет срок службы оборудования решили не продлевать. 95 % мирового выпуска DRAM приходится на Samsung Electronics, SK hynix и Micron Technology, которые в последние полтора года делают ставку на увеличение выпуска HBM для ИИ-ускорителей, поскольку такая память значительно маржинальнее обычной серверной DRAM. По оценкам IDC, речь может идти уже не о временном, «циклическом» дефиците, а о стратегическом перераспределении производственных ресурсов. Согласно прогнозам, на HBM в 2026 году придётся порядка 25 % выпуска всех пластин DRAM, спрос на неё растёт приблизительно на 70 % ежегодно. 
Источник изображений: Meta✴ В результате цена DDR5 и других модулей резко выросла. Впрочем, с другими компонентами ситуация не лучше. Western Digital уже распродала даже не выпущенные HDD, у Seagate дела тоже идут отлично (для неё самой), а время поставок некоторых моделей серверных процессоров выросло до полугода. Таким образом, один из ключевых мировых покупателей серверного оборудования, в отличие от многих экспертов, не полагается на падение цен на память и другие компоненты к концу 2026 года, а предпочитает увеличить срок эксплуатации уже развёрнутого оборудования. Для более мелких покупателей это может служить сигналом всё более серьёзных проблем с закупками в обозримой перспективе. Если получить достаточно памяти по приемлемой цене не рассчитывает гиперскейлер, прочие могут столкнуться с более длительными сроками поставок, частичным выполнением заказов и значительным ростом цен. Вполне может оказаться, что продление сроков службы оборудования — оптимальный сценарий не только для Meta✴, что, помимо прочего, приведёт к переносу капитальных затрат и замедлению внедрения более энергоэффективных и высокопроизводительных платформ.  Более того, дефициту HDD и SSD уделяется намного меньше внимания, чем нехватке DRAM, что, по-видимому, является ошибкой при планировании закупок. Массовая скупка HDD и рост цен на NAND оставляют всё меньше места для манёвра при формировании инфраструктуры для хранения данных. По мнению экспертов, новые производственные мощности для модулей памяти заработают ещё нескоро, и дефицит может постепенно снизиться в 2027–2028 гг., когда свои плоды начнут приносить инвестиции 2024–2025 гг. В качестве временной меры возможно повышение эффективности использования имеющегося оборудования программными средствами. Например, NVIDIA анонсировала новое ПО для мониторинга и продления жизни ИИ-ускорителей в ЦОД. С другой стороны, индустрия не в первый раз прибегает к увеличению сроков службы оборудования. Так поступали Microsoft, Google, CloudFlare, Scaleway и др.
07.02.2026 [17:23], Руслан Авдеев
AWS: ни один сервер с NVIDIA A100 не выведен из эксплуатации, а некоторые клиенты всё ещё используют Intel Haswell — не всем нужен ИИПо словам главы AWS Мэтта Гармана (Matt Garman), клиенты до сих пор использует серверы на основе ИИ-ускорителей NVIDIA A100, представленных в 2020 году. Отчасти это происходит потому, что спрос на вычислительные ресурсы превышает предложение, так что устаревшие чипы по-прежнему востребованы, передаёт Datacenter Dynamics. По словам Гармана, все ресурсы фактически распроданы, а серверы с A100 из эксплуатации никогда не выводились. Комментарии Гармана перекликаются с прошлогодним заявлением Амина Вахдата (Amin Vahdat), отвечающего в Google за ИИ и инфраструктуру. По его словам, в Google одновременно работают семь поколений тензорных ускорителей (TPU). Ускорители возрастом семь-восемь лет загружены на 100 %, а спрос на TPU так высок, что Google вынуждена отказывать некоторым клиентам. Впрочем, оба топ-менеджера, возможно, несколько кривят душой и пытаются развеять опасения инвесторов относительно того, что ИИ-ускорители, на которые тратятся огромные деньги, через два-три года придётся выкинуть, чтобы купить более современные, энергоэффективные и, конечно же, дорогие. И что за это время они не успеют окупиться. Хотя Гарман назвал главной причиной сохранения работы серверов на A100 высокий спрос, он признал, что есть и другие причины. В частности, современные ИИ-чипы снижают точность вычислений с плавающей запятой. В результате некоторые клиенты попросту не могут перейти на Blackwell или вовсе вынуждены использовать Intel Xeon Haswell десятилетней давности для HPC-подобных вычислений, поскольку точности у современных ИИ-ускорителей недостаточно. В июне 2025 года AWS заявила о снижении цены доступа к устаревшим NVIDIA H100, H200 и A100 на своей платформе, причём для A100 стоимость снизилась на треть. 
Источник изображения: NVIDIA Стоит отметить, что «устаревшие» ускорители долго остаются востребованными, поскольку всё равно обладают большой производительностью. Наиболее яркий пример — разрешение на поставку в Китай чипов NVIDIA H200. Хотя США и их союзники готовятся к внедрению ускорителей поколения Vera Rubin, китайский бизнес готов покупать H200, поскольку те значительно производительнее, экономически выгоднее и удобнее отечественных ускорителей.
17.01.2026 [13:25], Владимир Мироненко
Дефицит — не оправдание: Dell против б/у SSD в СХДDell предостерегла компании от повторного использования SSD на фоне острого дефицита флеш-памяти, связанного с бурным развитием ИИ-технологий. По словам компании, флеш-накопители изнашиваются со временем, а повторное использование старых носителей увеличивает вероятность ускоренного выхода из строя, недоступности, а в худшем случае катастрофической потери данных. В связи с тем, что ситуация с дефицитом SSD может продолжаться в течение ближайших 12 мес. и даже более, VAST Data стала придерживаться стратегии Flash Reclaim, в рамках которой предполагается повторное использование клиентами накопителей, перемещая SSD из СХД её конкурента, например, Dell PowerScale, в шасси под управлением ПО VAST. Как утверждает VAST, её ПО позволяет лучше справляться с сокращением объёма данных и требует меньше места на SSD при защите от сбоев, что обеспечивает возможность хранения большего объёма данных. Дэвид Ной (David Noy), вице-президент по управлению продуктами в Dell, ранее занимавший пост вице-президента по управлению продуктами в VAST Data, отметил, что предложенная VAST Data «переработка» флеш-накопителей как стратегия — отличный маркетинговый ход, но не более. «Это может звучать прагматично, но несёт в себе реальный риск. Для поставщиков ПО для хранения данных это признак того, что в отчаянные времена требуются отчаянные меры», — заявил он ресурсу Blocks & Files. 
Источник изображения: Sigmund / Unsplash В отличие от поставщиков AFA, таких как VAST и Pure, Dell поддерживает многоуровневое хранение данных на устройствах All-Flash, гибридных и дисковых массивах. Это даёт гибкость и возможность задействовать меньше SSD. Ной утверждает, что у компаний, специализирующихся только на поставках AFA, мало места для манёвра при изменении рыночной конъюнктуры. Нет многоуровневого хранения, нет гибкости и нет запаса прочности на случай роста цен на флеш-память или увеличения сроков поставки. «Мы не заставляем клиентов переходить на флеш-память. И это важно — особенно с учётом того, что цены на флеш-память растут быстрее, чем на жёсткие диски, в то время как дисковые накопители остаются в несколько раз более экономичными для больших объёмов данных», — заявил он.
12.12.2025 [17:21], Руслан Авдеев
Никаких закладок: NVIDIA анонсировала новое ПО для мониторинга и продления жизни ИИ-ускорителей в ЦОД
dcim
nvidia
open source
software
амортизация
ии
мониторинг
охлаждение
цод
электропитание
энергоэффективность
NVIDIA разрабатывает новое открытое ПО, благодаря которому операторы ЦОД смогут получать более подробные данные о тепловом состоянии и иных параметрах работы ИИ-ускорителей. Предполагается, что это поможет решать проблемы, связанные с перегревом оборудования и его надёжностью, увеличив его срок службы и производительность. NVIDIA отдельно подчёркивает, что телеметрия собирается только в режиме чтения без слежки за оборудованием, а в ПО нет «аварийных выключателей» и бэкдоров. Да и в целом использование новинки опционально. ПО обеспечивает операторам ЦОД доступ к мониторингу потребления энергии, загрузки, пропускной способности памяти и других ключевых параметров в масштабах всего парка ускорителей. Это помогает выявлять на ранних стадиях риски и проблемные компоненты и условия работы, отслеживать использование ИИ-ускорителей, их конфигурации и ошибки. Детализированная телеметрия становится всё важнее для планирования и управления масштабными инфраструктурами, говорит компания. ПО позволит:

Источник изображения: NVIDIA Такой мониторинг особенно важен на фоне недавнего отчёта учёных Принстонского университета, в котором сообщается, что интенсивные тепловые и электрические нагрузки способны сократить срок службы ИИ-чипов до года-двух, хотя обычно предполагается, что они способны стабильно проработать до трёх лет. Современные ускорители потребляют 700 Вт и более, а высокоплотные системы — от 6 кВт. Из-за этого формируются зоны перегрева, происходят колебания энергопотребления и растёт риск деградации интерконнектов в высокоплотных стойках. Телеметрия, позволяющая оценить потребление энергии в реальном времени, состояние интерконнектов, систем воздушного охлаждения и др. позволяет перейти от реактивного мониторинга к проактивному проектированию. Рабочие нагрузки можно размещать с учётом теплового режима, быстрее внедрять СЖО или гибридные системы охлаждения, оптимизировать работу сетей с уменьшением тепловыделения. Также ПО может помочь операторам ЦОД выявлять скрытые ошибки, вызванные несоответствием версий прошивки или драйверов. Благодаря этому можно повысить общую стабильность парка ускорителей. Кроме того, без задержек передаваемые данные об ошибках и состоянии компонентов могут значительно сократить среднее время восстановления работы и упростить анализ причин сбоев. Соответствующие данные могут влиять на решения о тратах на инфраструктуру и стратегию её развития на уровне предприятия. 
Источник изображения: NVIDIA Как заявляют в Gartner, современный ИИ представляет собой «энергоёмкого и сильно нагревающегося монстра», разрушающего экономику и принципы работы ЦОД. В результате, предприятиям нужны специальные инструменты мониторинга и управления для того, чтобы ситуация не вышла из-под контроля. В ближайшие годы использование подобных решений, вероятно, станет обязательным. Кроме того, прозрачность на уровне всего парка оборудования становится необходимой для обоснования роста бюджетов на ИИ-инфраструктуру. По словам экспертов, такие программные инструменты позволяют оптимизировать капитальные и операционные затраты на ЦОД и инфраструктуру, запланированные на ближайшие годы. «Каждый доллар и каждый ватт» должны быть учтены при эффективном использовании ресурсов.
10.12.2025 [18:14], Руслан Авдеев
Omdia: капитальные затраты на ЦОД вырастут до $1,6 трлн к 2030 году — если раньше не лопнет ИИ-пузырьСогласно прогнозам аналитиков Omdia, капитальные затраты на дата-центры будут расти на 17 % ежегодно до 2030 года. В итоге они достигнут $1,6 трлн, а ограничения в цепочках поставок вызовут рост цен на компоненты вычислительной инфраструктуры. В своём последнем обзоре рынка облаков и дата-центров (Cloud and Data Center Market Snapshot) компания сообщила, что инвестиции в ИИ-инфраструктуру продолжают расти быстрыми темпами, хотя разговоры о том, что на рынке формируется готовый лопнуть пузырь, не утихают. Впрочем, уровень внедрения ИИ пока остаётся относительно низким, в будущем ожидается, что вырастет как количество пользователей, так и средняя интенсивность использования ими ИИ-инструментов. В то же время ИИ-модели становятся всё более громоздкими и используют больше вычислительных ресурсов для инференса. В результате операторы наращивают производительность инфраструктуры. Вместе с этим растёт потребление электроэнергии, увеличивается энергетическая плотность серверов, стоек и самих дата-центров. Окупятся ли все эти гигантские инвестиции, никто пока точно сказать не может. Bain & Company полагает, что к 2030 году доходы отрасли должны вырасти до $2 трлн/год, чтоб окупить прогнозируемый уровень инвестиций. Окупаемость затрат под вопросом как для поставщиков услуг, так и для пользователей. Как сообщает The Register, на днях представители ряда технологических компаний заявили, что ИИ — не пузырь, не находя аналогий с крахом «доткомов». 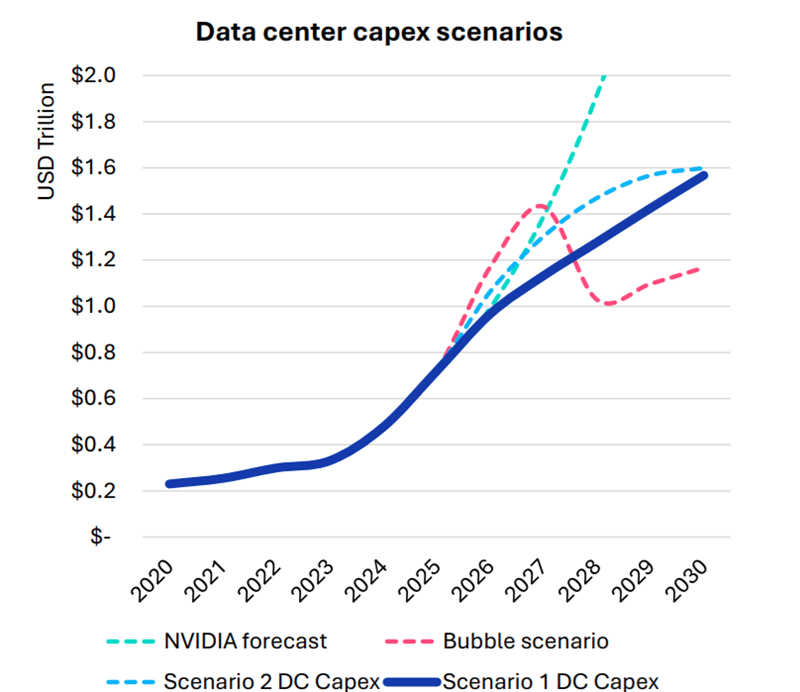
Источник изображения: Omdia Omdia рассмотрела четыре сценария развития рынка:
Рост расходов на ЦОД обусловлен и увеличением поставок серверов, цикл обновления которых начался в 2025 году и продолжится 6–8 кварталов. Ранее Omdia сообщала, что крупные операторы ЦОД, в основном гиперскейлеры, откладывали замену серверов разных типов. Новые серверы способны заменить оборудование сразу нескольких поколений. При этом ожидается, что к 2030 году серверы с Blackwell будут ещё в ходу. Рост инвестиций ожидается во всех сегментах, включая ниши неооблаков (CoreWeave, Nebius, xAI и др.), колокейшн-провайдеров первого и второго уровней, гиперскейлеров и корпоративных пользователей. 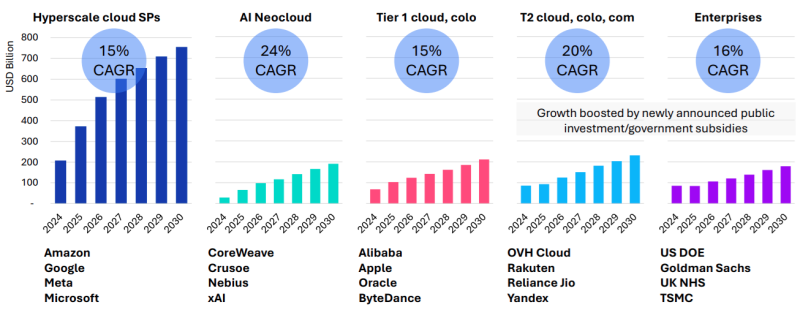
Источник изображения: Omdia Ограничения в цепочках поставок ведут к росту стоимости некоторых компонентов, например, памяти. По данным источников The Register, это, вероятно, приведёт к росту цен на серверы на 15 %. Omdia утверждает, что новые ЦОД, вероятно, будут проектироваться не так, как сегодня — спрос на ИИ приводит к быстрой смене внутренней инфраструктуры. Это касается всех компонентов, от микросхем до серверов и стоек, систем терморегуляции, распределения энергии, резервного питания и др. В докладе имеются рекомендации на будущее как для вендоров, так и для пользователей. Кроме того, Omdia прогнозирует, что, несмотря на спекуляции относительно ИИ-пузыря, быстрое внедрение ИИ-технологий и инвестиции продолжатся, а мощности по-прежнему будут в дефиците.
02.11.2024 [21:47], Владимир Мироненко
Облако AWS стало основным драйвером роста выручки Amazon — компания готова и дальше вкладываться в ИИ-инфраструктуруAmazon объявила результаты III квартала 2024 года, завершившегося 30 сентября, в котором облачные сервисы вновь стали одним из основных драйверов роста. Выручка Amazon составила $158,88 млрд, превысив показатель аналогичного квартала прошлого года на 11 %, а также консенсус-прогноз аналитиков, опрошенных LSEG, в размере $157,2 млрд. При этом выручка облачного подразделения Amazon Web Services (AWS) выросла на 19 % до $27,4 млрд, немного не дотянув до прогноза аналитиков StreetAccount в размере $27,52 млрд, пишет CNBC. Увеличение выручки AWS ускоряется уже пятый квартал подряд. Доля ИИ-решений в выручке AWS составляет миллиарды долларов и более чем вдвое увеличилась по сравнению с прошлым годом, сообщил гендиректор Amazon Энди Джесси (Andy Jassy), ранее возглавлявший AWS: «Я считаю, что у нас больше спроса, чем мы могли бы удовлетворить, если бы у нас было ещё больше (вычислительных) мощностей сегодня». «Думаю, что сегодня у всех меньше мощностей, чем имеется спроса», — отметил он, добавив, что именно увеличение поставок чипов позволило бы решить эту проблему. 
Источник изображений: AWS Операционная прибыль AWS достигла $10,45 млрд, что на 50 % больше показателя годичной давности и составляет 60% операционной прибыли её материнской компании. Аналитики ожидали рост до $9,15 млрд. В отчётном квартале операционная маржа AWS, ключевой показатель прибыльности в процентах от продаж, достигла нового максимума в 38,1 %. Для сравнения, квартальная операционная маржа Google Cloud составила 17,1 % при прибыли в размере $1,9 млрд и выручке в $11,4 млрд. Финансовый директор Amazon Брайан Олсавски (Brian Olsavsky) назвал в числе факторов, повышающих маржу AWS ускорение спроса на её услуги и стремление к эффективности и контролю затрат во всём бизнесе, включая более продуманный найм персонала. Кроме того, он сообщил о продлении AWS в 2024 году срока службы своих серверов. 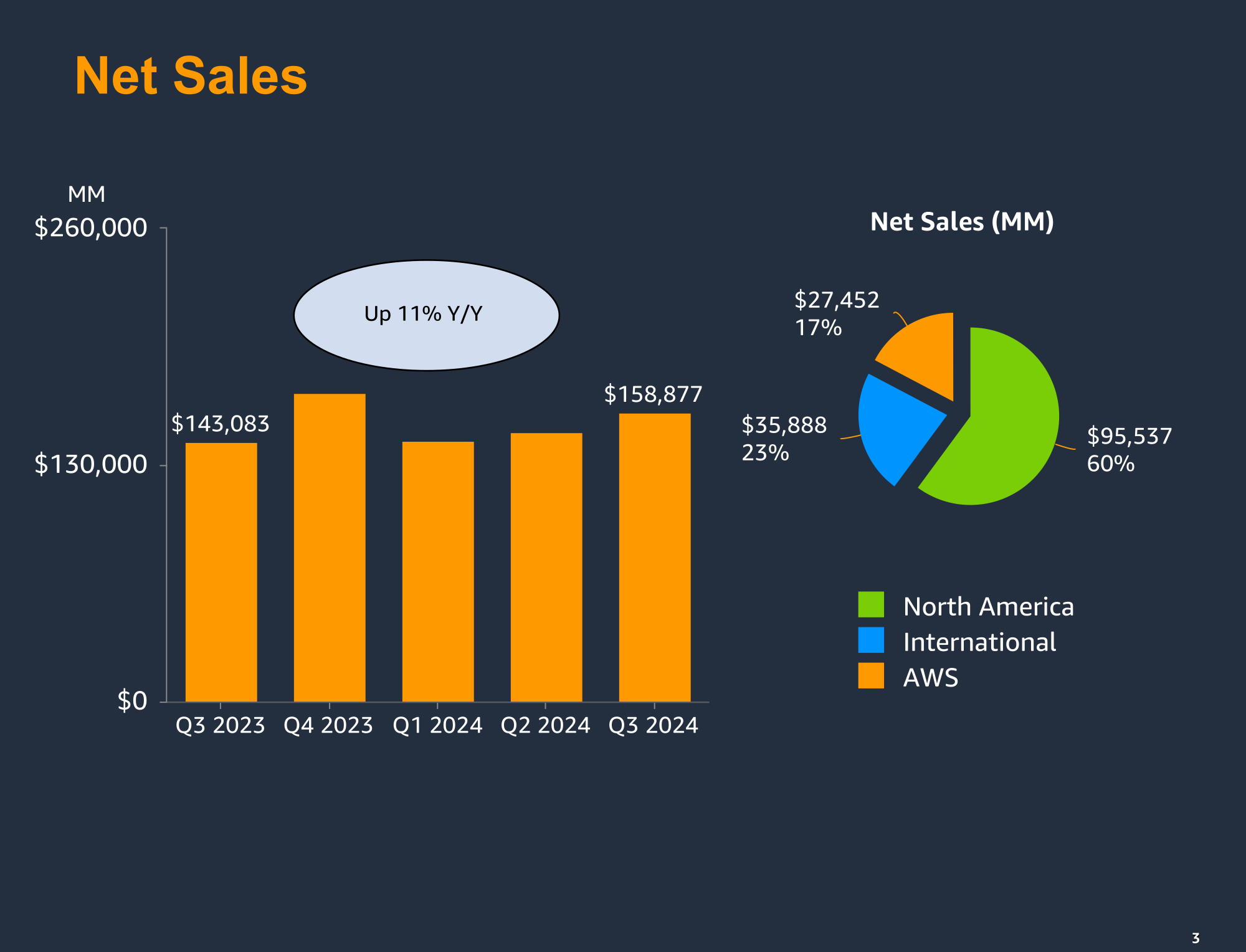 Олсавски рассказал, что Amazon ожидает около $75 млрд капитальных затрат в 2024 году, большая часть которых будет направлена на технологическую инфраструктуру, связанную в первую очередь с AWS. В свою очередь, Джесси предположил, что капитальные расходы компании будут ещё выше в 2025 году, отметив, что рост «действительно обусловлен генеративным ИИ», и добавив, что, по его мнению, инвестиции в конечном итоге окупятся. «Наш бизнес в сфере ИИ — это многомиллиардный бизнес, рост которого исчисляется трехзначными процентами из года в год, и на данном этапе развития он растёт в три раза быстрее, чем AWS», — цитирует слова Джесси ресурс geekwire.com. Джесси отметил, что платформа в целом AWS тоже «росла довольно быстро». 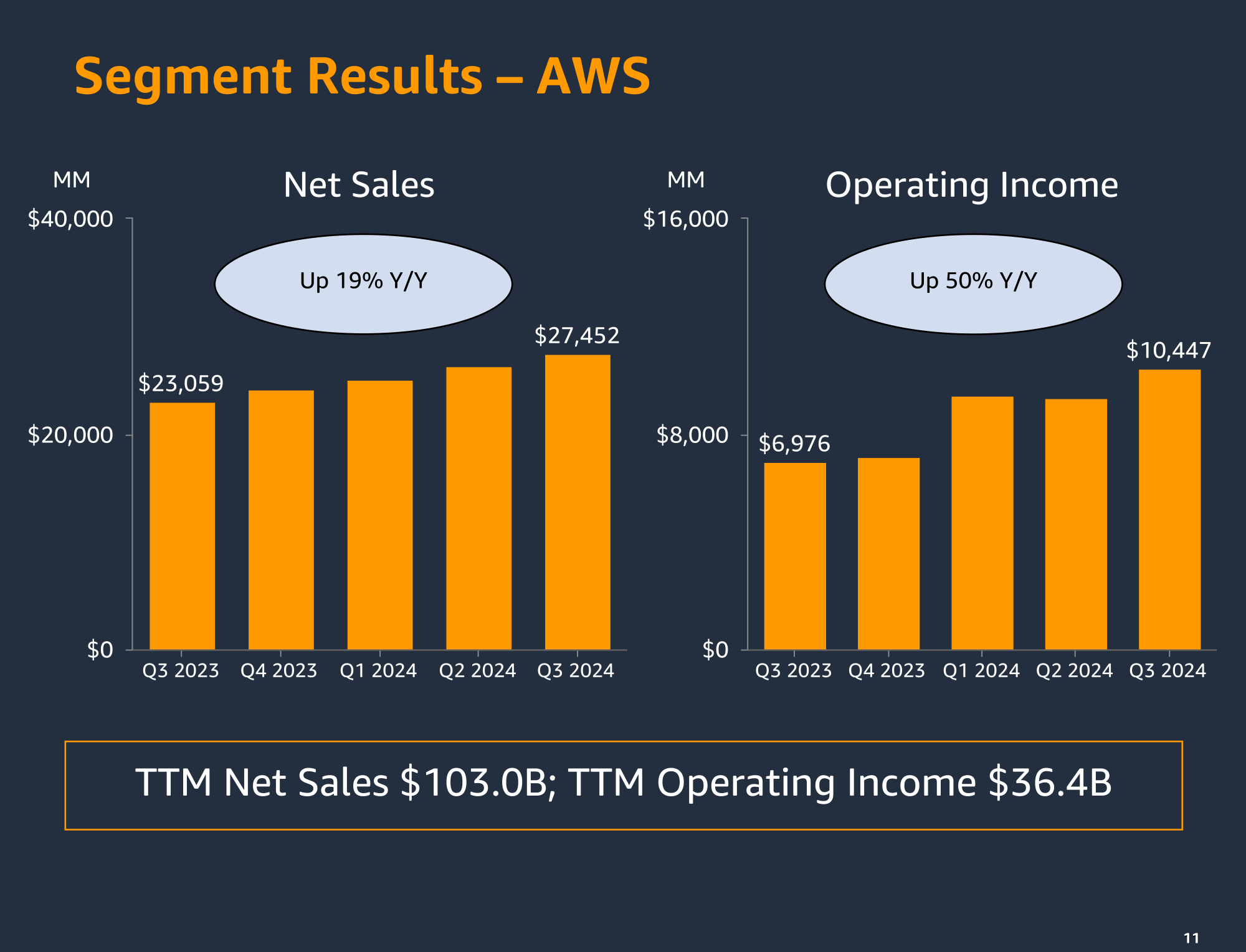 Также в отчётном квартале AWS объявила в соцсети X о решении закрыть некоторые сервисы, включая CodeCommit. Гендиректор AWS Мэтт Гарман (Matt Garman) объяснил ресурсу TechCrunch, что AWS «не может инвестировать во всё подряд». В текущем квартале Amazon прогнозирует выручку в диапазоне от $181,5 до $188,5 млрд, что означает рост на 7–11 % в годовом исчислении. Средняя точка этого диапазона, $185 млрд, немного ниже консенсус-прогноза аналитиков в $186,2 млрд (LSEG).
01.11.2024 [11:14], Сергей Карасёв
Марк Цукерберг: для обучения ИИ-модели Llama-4 используются более 100 тыс. ускорителей NVIDIA H100Председатель правления и генеральный директор Meta✴ Марк Цукерберг (Mark Zuckerberg), по сообщению ресурса Tom's Hardware, раскрыл масштабы кластера, который используется для обучения ИИ-модели нового поколения Llama-4. По его словам, для этих целей задействованы более 100 тыс. ускорителей NVIDIA H100. Напомним, в начале сентября нынешнего года стартап xAI, курируемый Илоном Маском (Elon Musk), объявил о запуске ИИ-суперкомпьютера Colossus, в основу которого положены 100 тыс. штук H100. В дальнейшем количество ускорителей в составе Colossus планируется увеличить вдвое. Теперь об эксплуатации кластера схожего масштаба рассказал Цукерберг. Глава Meta✴ не стал вдаваться в подробности о характеристиках Llama-4, ограничившись лишь фразами вроде «новые модальности», «более сильные рассуждения» и «повышенное быстродействие». Ранее Meta✴ заявляла о намерении потратить в 2024-м от $30 млрд до $37 млрд на развитие своей инфраструктуры — прежде всего для задач ИИ. Кроме того, говорилось, что к концу текущего года компания рассчитывает оперировать мощностями, эквивалентными более чем 500 тыс. ускорителей NVIDIA H100. 
Источник изображения: Meta✴ Вместе с тем, как отмечается, возникают сложности при обеспечении питанием столь масштабных ИИ-кластеров. Дело в том, что один современный GPU может потреблять до 3,7 МВт·ч электроэнергии в год. Это означает, что массив из 100 тыс. таких ускорителей потребует не менее 370 ГВт·ч в год, чего достаточно для обеспечения энергией более 34 млн среднестатистических американских домохозяйств. Цукерберг признаёт, что трудности, связанные с доступностью энергоресурсов, в перспективе могут ограничить темпы роста отрасли ИИ. Как добавляет ComputerWeekly, Meta✴ также отказалась от практики увеличения срока службы серверов с целью сокращения расходов. Ранее компания сообщила о продлении периода эксплуатации оборудования до пяти лет вместо прежних четырёх с половиной: это, как ожидалось, даст экономию в $1,5 млрд. Однако теперь финансовый директор Meta✴ Сьюзан Ли (Susan Li) заявила, что компания в свете стремительного развития ИИ намерена применять серверы последнего поколения, чтобы максимально эффективно использовать доступную ёмкость существующих дата-центров.
20.09.2024 [09:19], Владимир Мироненко
В iKS-Consulting назвали основные тренды российского рынка ЦОДАналитическое агентство iKS-Consulting провело исследование с целью определить основные тренды российского рынка ЦОД, пишут «Ведомости». В исследовании приняли участие топ-менеджеры ИТ-отрасли — более 50 технических директоров, руководителей службы эксплуатации и проектировщиков дата-центров. Участникам опроса было предложено оценить по 10-балльной шкале по степени вероятности и силе влияния на CAPEX/OPEX ЦОД 19 трендов, которые в перспективе 2028 года или раньше могут оказать влияние на рынок и инженерную инфраструктуру дата-центров в РФ. По словам директора по развитию бизнеса iKS-Consulting Дмитрия Горкавенко, наиболее заметным трендом участники рынка считают увеличение срока эксплуатации инженерного оборудования ЦОД. Как правило, большую модернизацию ЦОД начинают через 10 лет службы, хотя батареи, например, меняют уже через пять лет. Теперь же срок службы оборудования может быть увеличен на 30 %. Это стало ответом на рост стоимости оборудования и проблемой с его доступностью из-за санкций и попыткой оптимизировать затраты. По словам Горкавенко, на этом фоне параллельно растёт стоимость ЦОД в пересчёте на 1 кВт потребления. Растёт и средняя плотность мощности дата-центров — проектировщики закладывают 10–12 кВт на стойку, хотя два-три года назад базовый диапазон составлял 5–7 кВт. 
Источник изображения: dlohner/Pixabay ЦОД по-прежнему сконцентрированы в Москве и Московской области. Так, в 2023 году на столицу приходилось 76 % всего российского рынка, или 53,4 тыс. стойко-мест, на Санкт-Петербурге — 9,3 % от общего объёма рынка, или 7,3 тыс. стойко-мест. Доля остальных регионов составила 14,8 %, или 9,61 тыс. стойко-мест. Однако спрос на региональные дата-центры растёт. Их развитие поддерживают «РТК-ЦОД», «Атомдата» и KeyPoint. Кроме того, распределённые сети ЦОД постепенно формируются крупнейшими цифровыми платформами, такими как «Яндекс», VK, Rutube и операторам связи. Формирование таких сетей позволит не только быть ближе к данным, но и повысить отказоустойчивость. В 2024 году рост регионального рынка ЦОД может составить порядка 27,1 %, тогда как в 2023 году он был на уровне 8,5 %. По словам Горкавенко, относительно небольшие объекты на 800–1200 стоек будут появляться в городах с населением от 500 тыс. человек. На столичном и петербургском рынках ЦОД ожидается более сдержанный рост — около 17 % против 26,1 % в 2023 году. В Петербурге в 2023 году ввели в эксплуатацию на 3,5 % стоек больше год к году, а в этом году прогнозируется рост на уровне 5 %. Наконец, респонденты ожидают рост спроса со стороны государства на ЦОД со специфическими требованиями к их физической и виртуальной защищённости. Кроме того, возможно ужесточение требований к этим параметрам, в том числе на уровне законов. Отечественная классификация физической защищённости ЦОД сейчас применяется добровольно, но позже может быть прописана в нормативных документах, приводят «Ведомости» слова Горкавенко.
10.02.2024 [14:31], Сергей Карасёв
Cloudflare увеличит срок службы серверов до пяти лет, сэкономив миллионы долларовАмериканская компания Cloudflare в ходе оглашения финансовых показателей за последнюю четверть и 2023 год в целом сообщила об увеличении срока эксплуатации своего серверного оборудования на один год. Ожидается, что это позволит экономить миллионы долларов. Традиционно серверы в ЦОД служат от трёх до пяти лет, после чего осуществляется их обновление. Однако в связи с экономическими сложностями и высоким уровнем инфляции многие гиперскейлеры, такие как AWS, Google, Meta✴ и Microsoft, вынуждены увеличивать жизненный цикл своего оборудования. А облачный провайдер Scaleway установил своеобразный рекорд, подняв этот показатель до 10 лет. 
Источник изображения: Cloudflare Теперь об аналогичной инициативе объявил финансовый директор Cloudflare Томас Сейферт (Thomas Seifert). По его словам, компания пришла к выводу, что постоянное развитие аппаратных технологий и усовершенствование архитектуры дата-центров повысили эффективность эксплуатации оборудования, в результате чего предполагаемый срок его полезного использования увеличится с четырёх до пяти лет. По оценкам, только в 2024-м это позволит сэкономить около $20 млн. Сообщается, что в IV квартале 2023 года Cloudflare получила выручку в размере $362,5 млн, что на 32 % больше результата годичной давности. За год в целом выручка достигла $1,3 млрд, показав прибавку на уровне 33 % по сравнению с 2022-м. Вместе с тем компания продолжает нести убытки: квартальные потери зафиксированы в размере $27,9 млн, годовые — $183,9 млн. Для сравнения: годом ранее эти значения равнялись соответственно $45,9 млн и $193,4 млн. В I квартале 2024 года компания рассчитывает получить выручку в размере от $372,5 млн до $373,5 млн, тогда как за год эта цифра прогнозируется в диапазоне от $1,648 млрд до $1,652 млрд.
03.02.2024 [23:45], Владимир Мироненко
В 2023 году Alphabet сэкономил $3,9 млрд, продлив срок службы серверов, но увеличил расходы на ИИ-инфраструктуруХолдинг Alphabet сообщил результаты работы в IV квартале и 2023 году, завершившемся 31 декабря. Выручка облачного подразделения Google Cloud составила около $9,2 млрд, увеличившись год к году на 25,66 %. Что примечательно, подразделение сработало с операционной прибылью в размере $864 млн, в то время годом ранее у него были убытки в $186 млн. Выручка всего Alphabet в IV квартале составила $86,31 млрд по сравнению с $76,048 млрд годом ранее. Выручка за весь 2023 год — $307,394 млрд, что значительно превышает результат 2022 года, равный $282,836 млрд. Чистая прибыль холдинга выросла в 2023 году до $73,795 млрд с $59,972 млрд годом ранее, отчасти благодаря решению компании продлить срок службы серверов и сетевого оборудования. Alphabet впервые продлил срок службы своего оборудования в 2021 году, увеличив продолжительность работы серверов с трёх до четырёх лет, а сетевого оборудования — с четырёх до пяти. В 2023 году Alphabet вновь продлил срок эксплуатации оборудования, на этот раз — до шести лет. Благодаря этому только в IV квартале 2023 года расходы компании на амортизацию оборудования упали на $983 млн, а чистая прибыль увеличилась на $765 млн. За весь год амортизация оборудования Alphabet снизилась на $3,9 млрд, а чистая прибыль увеличилась на $3 млрд. 
Изображение: Google При этом компания вложила значительные средства в новую инфраструктуру. В IV квартале общие капитальные затраты составили $11 млрд, что, по словам президента и главного инвестиционного директора Alphabet и Google Рут Порат (Ruth Porat), было обусловлено «инвестициями в техническую инфраструктуру, причём самый крупный компонент — серверы, за которыми следуют ЦОД». В предыдущем квартале капзатраты составили $7,6 млрд. Резкое увеличение капзатрат обусловлено «перспективами создания уникальных приложений ИИ для пользователей, рекламодателей, разработчиков, облачных корпоративных клиентов и правительств во всем мире, а также возможностями долгосрочного роста, которые они предлагают». Порат добавила, что компания будет придерживаться этой политики и в 2024 году. «Мы ожидаем, что капитальные затраты в 2024 году будут значительно больше, чем в 2023 году», — отметила она. Порат также подчеркнула, что фактором роста Google Cloud Platform (GCP) является ИИ. Гендиректор Сундар Пичаи (Sundar Pichai) заявил, что компания продолжит инвестировать в инфраструктуру, как в ЦОД, так и в вычислительную технику, чтобы поддержать рост возможностей ИИ-технологий. 
Изображение: Google Подразделение Google Cloud снова стало самым быстрорастущим сегментом. После значительного замедления роста с +28 % год к году во II квартале до +22 % в III квартале рост облака вновь ускорился до +26 %. Более того, в этот раз ускорение темпов роста было сильнее, чем у AWS и Azure. Рост доходов от облачных технологий вновь ускорился на 4 п. п. Также резко выросла операционная маржа Google Cloud — последовательно на 6 п.п. до 9 %. Компания объяснила замедление темпов роста в III квартале проведением оптимизации рабочей нагрузки. В ходе нынешнего отчёта Сундар Пичаи сообщил, что этот вопрос «в основном был проработан». Темпы роста Google Cloud по-прежнему опережают рынок: по оценкам Synergy Research Group, общемировой прирост рынка облаков составил +20 % в годовом исчислении до $74 млрд в IV квартале, ускорившись с 18 % в годовом исчислении в III квартале. Доминирует Amazon (31 % рынка), за ним следуют Microsoft (24 %) и Google (11 %). Большая тройка занимает 67 % рынка. Причём Microsoft и Google нарастили свои доли, а AWS — снизила. |
|

