Материалы по тегу: ии
|
30.03.2026 [09:00], Сергей Карасёв
«Базис» реализовал в Basis Workplace поддержку геораспределённой инфраструктурыКомпания «Базис», лидер российского рынка ПО управления динамической инфраструктурой, выпустила обновление платформы для управления инфраструктурой виртуальных рабочих столов (VDI) — Basis Workplace 3.2. Ключевыми нововведениями релиза стали система агрегации ресурсов VDI для организаций с территориально распределённой инфраструктурой, модульная архитектура подключения к платформам виртуализации с нативной поддержкой Basis Dynamix Enterprise и OpenStack, а также ряд улучшений в области администрирования и безопасности. Геораспределённая VDI: единое пространство для территориально распределённых организацийВ Basis Workplace 3.2 реализована система агрегации ресурсов виртуальных рабочих столов с нескольких географически распределённых площадок (геораспределённая VDI). Пользователи получают одновременный доступ к рабочим столам в разных ЦОД, а при сбое на одной из площадок система автоматически перенаправляет подключения на доступные ресурсы, обеспечивая необходимую катастрофоустойчивость. Для крупных организаций с филиальной сетью это означает возможность построить единую отказоустойчивую VDI-инфраструктуру, в которой сотрудники подключаются к ближайшему к ним ЦОД с минимальной задержкой передачи данных. Администраторы при этом управляют всей распределённой средой из единой панели. Удобным дополнением к геораспределённой VDI стали терминальные суперпулы — возможность объединить несколько терминальных пулов в группу для централизованного управления настройками, запуском, остановкой и мониторингом виртуальных машин. 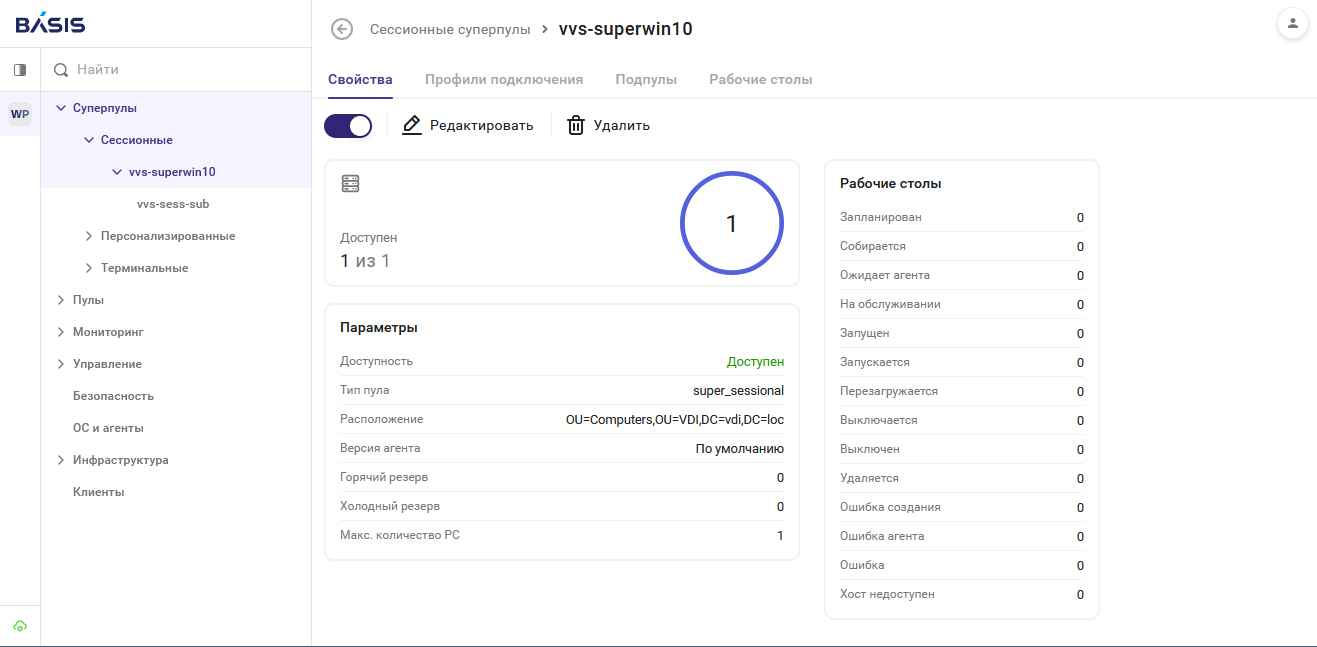
Источник изображений: «Базис» Прямое подключение к платформам виртуализацииОдним из наиболее значимых архитектурных изменений в Basis Workplace 3.2 стал переход к модульной системе драйверов для работы с платформами виртуализации. Ранее Basis Workplace взаимодействовал с гипервизорами через модуль vControl, что создавало дополнительные зависимости при развёртывании и обслуживании. Теперь для каждой поддерживаемой платформы разрабатывается отдельный драйвер, который обеспечивает прямое взаимодействие без посредников. Такой подход даёт сразу несколько преимуществ. Драйверы изолированы друг от друга, что позволяет обновлять и дорабатывать модуль для одной платформы, не затрагивая работу остальных. Добавление поддержки новых платформ виртуализации также становится проще и безопаснее — достаточно разработать новый драйвер, не внося изменений в существующие компоненты системы. В версии 3.2 добавлены драйверы для Basis Dynamix Enterprise и платформ на базе OpenStack. Драйвер для Dynamix Enterprise обеспечивает полноценное управление виртуальными машинами — создание, удаление, включение, выключение и перезагрузку — напрямую, без промежуточных компонентов. Аналогичный драйвер для OpenStack открывает возможности использования Basis Workplace в облачных средах, построенных на этой платформе.  Расширенные инструменты администрированияВерсия Basis Workplace 3.2 принесла заметные улучшения в повседневной работе администраторов. Появилась возможность удалённого подключения к активной сессии пользователя по протоколу VNC прямо из панели управления — для оперативной технической поддержки без необходимости использования сторонних инструментов. Управление настройками теперь разделено на два уровня — системный и организационный, что упрощает конфигурирование в мультитенантных средах. Реализован мониторинг загрузки виртуальных машин по ключевым параметрам — CPU, RAM и дисковое пространство — с возможностью визуализации в виде графиков. Расширены возможности работы с таблицами в панели управления: добавлены инструменты сортировки, сравнения и фильтрации. А управление сервисами — добавление и обновление программных компонентов — теперь доступно непосредственно из веб-интерфейса. Переработан подход к управлению политиками доступа (ACL). Вместо формирования отдельного набора правил для каждого объекта теперь ведётся централизованный список политик, которые при необходимости назначаются профилям пулов, устройствам или группам устройств доступа. Это существенно сокращает время на настройку и снижает вероятность ошибок. Периферия и поддержка нескольких мониторовОбновлённый клиент Basis Workplace получил инструменты для работы с несколькими мониторами — при изменении конфигурации дисплеев происходит автоматическое переподключение к виртуальному рабочему месту с применением новых параметров. Расширены возможности проброса периферийных устройств в виртуальные рабочие места по протоколу RDP/xRDP собственными средствами платформы: реализована поддержка смарткарт Рутокен, принтеров и видеокамер для подключений Windows–Linux, Linux–Linux и Linux–Windows. 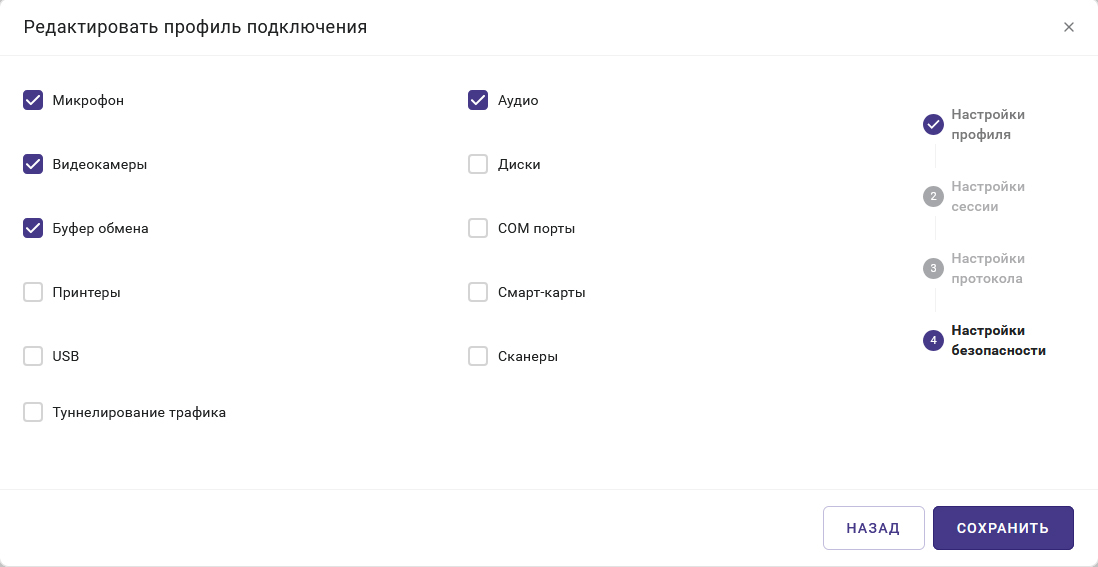 Безопасность и совместимостьВ части безопасности усовершенствован механизм передачи паролей и токенов при авторизации, реализована поддержка работы сервисов с двумя CA-сертификатами — отдельно для взаимодействия с базами данных и для межсервисной коммуникации. Клиент Basis Workplace теперь автоматически загружает CA-сертификат с брокера для службы туннелирования. Расширена совместимость с российскими и открытыми платформами: добавлена поддержка службы каталогов ALDpro и операционной системы Ubuntu 22.04. «В новом релизе мы уделили особое внимание двум направлениям, которые востребованы у наших ключевых заказчиков. Крупному бизнесу с территориально распределённой и неоднородной ИТ-инфраструктурой нужна VDI-платформа, которая одинаково хорошо работает с разными средами виртуализации и обеспечивает бесперебойный доступ сотрудников к рабочим столам независимо от площадки. Basis Workplace 3.2 закрывает эту потребность, а кроме того предлагает ряд новых инструментов для комфортного администрирования динамической инфраструктуры», — отметил Дмитрий Сорокин, технический директор компании «Базис».
29.03.2026 [19:24], Сергей Карасёв
MSI XpertStation WS300 — рабочая станция для ИИ на базе NVIDIA GB300Компания MSI официально представила мощную рабочую станцию XpertStation WS300, ориентированную на задачи ИИ. Новинка построена на платформе NVIDIA DGX Station, сердцем которой является суперчип GB300. Утверждается, что устройство предлагает производительность уровня ЦОД в формате десктопа. Габариты системы составляют 247,8 × 527,9 × 567,7 мм. Задействованы процессор NVIDIA Grace с 72 ядрами Arm Neoverse V2 (Demeter) и ускоритель Blackwell Ultra. При этом CPU использует 496 Гбайт LPDDR5X с пропускной способностью до 396 Гбайт/с, а GPU — 252 Гбайт HBM3e (ПСП 7,1 Тбайт/с). Применён модуль жидкостного охлаждения (CPU+GPU). Доступны по два разъёма M.2 2280/22110 для SSD с интерфейсом PCIe 5.0 x4 и PCIe 6.0 x4, а также коннектор M.2 2230 для комбинированного адаптера Wi-Fi/Bluetooth. Есть один слот PCIe 5.0 x16 для карты расширения FHFL двойной ширины и два слота PCIe 5.0 x16 для карт FHFL одинарной ширины. В качестве опции предлагается установка ускорителей RTX PRO 6000 Blackwell Workstation Edition, RTX PRO 6000 Blackwell Max-Q Workstation Edition, RTX PRO 4000 Blackwell SFF Edition и RTX PRO 2000 Blackwell. 
Источник изображения: MSI В оснащение входят контроллер ASPEED AST2600 с выделенным портом управления 1GbE, сетевой адаптер NVIDIA ConnectX-8 SuperNIC с двумя портами QSFP112, а также 10GbE-контроллер Marvell AQC113. Есть четыре порта USB 3.1 Type-A, интерфейсы Mini-DP и Micro-USB (COM). Питание обеспечивает блок мощностью 1600 Вт с сертификатом 80 PLUS Titanium. За безопасность отвечает модуль TPM 2.0. Диапазон рабочих температур — от +10 до +35 °C.
29.03.2026 [19:05], Руслан Авдеев
«Кремниевая прерия»: Crusoe пристроит к ИИ ЦОД OpenAI Stargate ещё 900 МВт, но уже для MicrosoftCrusoe готовится расширить присутствие на западе Техаса. В Абилине (Abilene) рядом с первым кампусом OpenAI Stargate появится ещё один — мощностью 900 МВт, предназаченный для Microsoft. Таким образом, общая мощность площадки будет увеличена до 2,1 ГВт и она войдёт в число крупнейших ИИ ЦОД США. Crusoe начала строить объект в Абилине в середине 2024 года на территоррии технопарка Lancium Clean Campus. ИИ ЦОД строится для Oracle, но в интересах OpenAI. Приблизительно за год были построены два здания мощностью около 200 МВт, что весьма быстро для проектов гиперскейлеров. Общая мощность кампуса составит 1,2 ГВт, он будет включать восемь зданий. Crusoe предложила расширить кампус, но OpenAI и Oracle отказались, зато интерес проявили Meta✴ и Microsoft. Crusoe подчёркивает, что в современных ЦОД важную роль играют не только вычислительные мощности, но и доступность электроэнергии. Проект включает собственнн электростанцию на 900 МВт, не зависящую от магистральной электросети, а также аккумуляторное энергохранилище. Кроме того, площадка в Абилине площадка получит доступ к «зелёной» энергии. Для Microsoft сделка позволяет расширить портфолио масштабных инфраструктурных партнёрств, направленных на развитие ИИ. 
Источник изображения: Crusoe Местные власти подчёркивают, что проект свидетельствует о превращении запада Техаса в хаб ИИ-инфраструктуры, некоторые даже говорят о становлении «Кремниевой прерии для ИИ» (по аналогии с «Кремниевой долиной»). По некоторым оценкам, на Техас приходится 15 % всех новых подключений ЦОД в США по мощности, что подчёркивает роль штата в развитии структур гиперскейл-уровня. По некоторым данным, в ближайшие годы 50–65 крупных ЦОД будут работать «за счётчиком», т.е. от автономных источников энергии. В целом речь идёт о новой модели, параметры которой определяются доступом к энергии, скоростью и гибкостью реализации, а не близостью к хабам традиционных электросетей.
28.03.2026 [13:40], Сергей Карасёв
В России наблюдаются массовые сбои оборудования в устаревающих ЦОДЗа последние полгода в России резко возросло количество аварий в дата-центрах, созданных 10–15 лет назад. Речь идёт, в частности, о многочисленных сбоях в небольших коммерческих ЦОД и на локальных площадках некрупных компаний. О проблеме сообщает РБК, ссылаясь на информацию, полученную от участников рынка, интеграторов и отраслевых аналитиков. «К2Теха» сообщила, что за шесть месяцев в компанию поступили более десятка обращений от владельцев дата-центров, у которых инженерная инфраструктура «находится в предсмертном состоянии». В I половине 2025-го и раньше подобных запросов вообще не фиксировалось. Об увеличении количества сбоев в устаревающих ЦОД также говорит «Ультиматек». По оценкам, с проблемой столкнулись около 20 % коммерческих дата-центров в России. Связано это с тем, что техника, которая находилась в эксплуатации более 10–15 лет, приблизилась к концу своего жизненного цикла. Из строя в массовом порядке выходят аккумуляторы в ИБП, дизель-генераторные установки, охлаждающее оборудование и другие компоненты. Наблюдающаяся ситуация может привести к крайне негативным последствиям, включая остановку конвейеров в промышленности, отключение кассовых аппаратов, нарушение логистики, а также коллапс сервисов в финансовом секторе, пишет РБК. 
Источник изображения: Evan Yang / Unsplash Проблема усугубляется из-за сформировавшейся экономической и геополитической обстановки. Из-за ухода зарубежных производителей из России отечественные компании столкнулись с трудностями при закупке необходимых запчастей и обновлении парка техники. При этом стоимость иностранной продукции растет, тогда как во многих организациях урезаны бюджеты, из-за чего средств на плановую модернизацию не хватает. Частично решить проблему можно путем замены узлов на китайские или российские альтернативы, однако такой подход возможен не во всех случаях. Некоторые участники рынка заблаговременно сформировали запас комплектующих. Так, IXcellerate сообщила, что у неё на складе есть достаточно компонентов для работы дата-центров без аварий и замены элементов инфраструктуры «в течение ближайших десяти лет». А РТК-ЦОД («Ростелеком») говорит, что нашла «доступные аналоги» и у неё нет проблем.
27.03.2026 [23:55], Владимир Мироненко
Meta✴ построит ещё семь газовых электростанций для своего гигантского ИИ ЦОД HyperionКомпания Meta✴ Platforms заключила новое соглашения с Entergy Corp. о строительстве ещё семи электростанций на природном газе в сельской местности Луизианы (США) для обеспечения электроэнергией гигантского кампуса ЦОД Hyperion в округе Ричленд (Richland Parish). Новые электростанции будут вырабатывать 5,2 ГВт электроэнергии, сообщил Bloomberg. Кроме того, Entergy в настоящее время строит три электростанции, работающие на природном газе, для поддержки проекта Meta✴ — две в округе Ричленд и еще одну недалеко от Батон-Руж (Baton Roug) — которые будут вырабатывать 2,2 ГВт электроэнергии. В общей сложности все десять электростанций будут вырабатывать 7,4 ГВт. Для сравнения, Entergy в настоящее время поставляет для всего населения штата 12 ГВт. По словам Meta✴, Hyperion будет обладать IT-мощностью около 5 ГВт, а оставшаяся электроэнергия пойдёт на обеспечение работы инфраструктуры кампуса. Entergy сообщила, что помимо финансирования комплексного строительства семи газовых электростанций, Meta✴ также оплатит в рамках соглашения прокладку 386 км ЛЭП, соединяющих Южную Луизиану с Северной Луизианой и Арканзасом, установку аккумуляторных систем хранения энергии и модернизацию АЭС. Соглашение также включает обязательство Meta✴ профинансировать до 2,5 ГВт новых возобновляемых источников энергии, а также меморандум о взаимопонимании по изучению будущего развития и использования атомной энергии. Entergy уточнила, что сделка с Meta✴ «структурирована таким образом, чтобы гарантировать, что Meta✴ оплачивает полную стоимость своих услуг», и что соглашение принесёт более $2 млрд экономии клиентам в течение 20 лет. Meta✴ отказалась раскрыть свои расходы на новые газовые электростанции и другую инфраструктуру, связанную с проектом Hyperion. 
Источник изображения: Meta✴ Планы Meta✴ и Entergy по строительству новых электростанций должны получить одобрение комиссии по коммунальным услугам Луизианы, которая регулирует деятельность монопольных коммунальных предприятий. «Я поддерживаю этот проект на 1000 %, — сообщил комиссар по коммунальным услугам Луизианы Фостер Кэмпбелл (Foster Campbell) изданию USA Today Network. — Если бы я считал, что есть хоть какой-то шанс переложить затраты на потребителя, я бы не смог его поддержать, но я уверен, что план принесёт пользу клиентам». Эти заявления прозвучали на фоне растущего давления со стороны защитников прав потребителей на технологические компании с целью покрытия растущих затрат на электроэнергию, связанных со строительством ИИ-инфраструктуры. Ранее в этом месяце президент США потребовал от компаний гарантировать, что счета за электроэнергию для потребителей не вырастут из-за реализации их проектов. Первоначально в 2024 году Meta✴ заявляла, что её дата-центр Hyperion начальною стоимостью $10 млрд станет крупнейшим в портфеле компании и займет площадь около 37,2 га. Но с тех пор эти цифры несколько раз менялись. Так, в прошлом году президент США сообщил, что Meta✴ намерена потратить на строительство комплекса $50 млрд. К концу прошлого года уже привлекла $30 млрд.
27.03.2026 [21:04], Руслан Авдеев
«Не хотите ускорители? Возьмите хотя бы сеть!» — NVIDIA открыла свои ИИ-стойки для чужих чиповNVIDIA занялась разработкой серверных стоек, подходящих для решений на основе сторонних ИИ-ускорителей, сообщает The Information со ссылкой на знакомые с вопросом источники. Компания стремится остаться ключевым игроком на рынке ИИ-систем даже по мере того, как всё больше её клиентов разрабатывают решения, прямо конкурирующие с продуктами самой NVIDIA. На прошлой неделе компания представила новые стойки MGX ETL, специально разработанные для поддержки чипов как самой NVIDIA, так и поставщиков-конкурентов. Система основана на модульной архитектуре MGX (OCP), представленной в 2023 году и уже довольно распространённой. ETL предполагает использование сетевых решений NVIDIA Spectrum-X. Таким образом, «зелёные» чипы всё равно оказываются в инфраструктуре, даже если она базируется на сторонних решениях. Похожим образом компания развивает и фирменный интерконнект NVLink. NVLink Fusion можно интегрировать в другие чипы, что опять-таки даёт NVIDIA возможность заработать на чужих ИИ-системах. Но в случае ETL применяются широко поддерживаемые в индустрии стандарты Ethernet, что снижает для клиентов «порог вхождения» при внедрении оборудования NVIDIA. Модульный дизайн позволяет облачным гиперскейлерам одновременно использовать ускорители разных производителей, при этом оставаясь в сетевой и программной экосистемах NVIDIA. 
Источник изображения: NVIDIA NVIDIA позиционировала MGX как открытую «эталонную» архитектуру, не мешающую партнёрам использовать альтернативные компоненты. Гибкость также позволяет NVIDIA «проложить дорогу» на китайский рынок, где компании смогут применять со стойками NVIDIA чипы домашней разработки. Новый дизайн стоек также может помочь NVIDIA устранить обеспокоенность регуляторов практикой, когда компания связывала использование сетевого оборудования с определёнными ИИ-чипами. На этом фоне происходит ужесточение конкуренции на рынке технологий интерконнектов. Открытый стандарт UALink позиционируется как альтернатива NVLink и призван обеспечить высокоскоростную связь между ИИ-чипами без применения проприетарных технологий. Параллельно развивается и открытый стандарт Ultra Ethernet, который призван конкурировать и с технологией Infiniband, фактически единолично контролируемой NVIDIA. Сетевые решения являются чрезвычайно важной частью бизнеса NVIDIA. По итогам последнего квартала выручка компании в этом сегменте достигла $10,98 млрд (а за год все $31 млрд) — она выросла год к году на 268 % и составила более 15 % от всей выручки компании. При этом значительная часть сетевого оборудования продаётся не сама по себе, а в составе платформенных решений NVIDIA.
27.03.2026 [15:36], Руслан Авдеев
Colliers: инвестиции в ЦОД впервые обогнали вложения в нефтяной сектор, но риски сохраняютсяПо данным Colliers, в 2025 году мировые инвестиции в дата-центры превысили $580 млрд, на 27 % больше год к году. Впервые вложения в ЦОД оказались больше, чем в очередные нефтяные мощности, сообщает Datacenter Dynamics. Отчёт Facilitating AI with Unprecedented Infrastructure свидетельствует, что рекордного показателя удалось добиться благодаря инвестициям в ИИ. При этом только от технологических компаний поступили $445 млрд. По словам экспертов Colliers, речь идёт о «структурном сдвиге», в результате которого дата-центры превратились в одну из капиталоёмких инфраструктурных категорий. Colliers утверждает, что развитие отрасли будет определяться тем, какие рынки будут способны обеспечить финансирование, электроэнергию и реалистичные сроки ввода в эксплуатацию. Экономика развития теперь ориентируется на обеспечение стабильного электроснабжения и создание инфраструктуры. Правда, имеются опасения относительно слишком медленной окупаемости проектов и значительных инвестиционных рисков. Крупные операторы ЦОД привлекают для строительства немалые средства, но нередко не могут строить так быстро, как это необходимо. Colliers сообщает, что в 2025 году крупные операторы ЦОД выпустили долговые обязательства на $120 млрд, это более чем впятеро больше, чем среднего показателя за пять лет. Впрочем, из-за задержек с получением разрешений, проблем с цепочками поставок и перебоев электроснабжения проекты общей стоимостью более $64 млрд отложены. 
Источник изображения: Jakub Żerdzicki/unsplash.com Colliers упомянула о серьёзном энергетическом кризисе, лежащем в основе проблем — коммунальным компаниям требуется $25–$75 млн в виде нередко невозвратных депозитов на каждый из проектов. Кроме того, в крупнейшем регионе размещения ЦОД — Северной Вирджинии присоединение к энергосети может занять до семи лет. В результате на энергетическую инфраструктуру нередко уходит 40–50 % общего бюджета проекта ЦОД. В отчёте компания подчеркнула роль долговых рисков для инвесторов в сферу ИИ. На основе анализа более 1,3 тыс. технологических компаний, сумма непогашенных кредитов превысила $1,3 трлн, более $1 трлн из них — на совести более дюжины крупных ИИ-бизнесов. На частные кредиты приходится 60–75 % капитала на ранних стадиях проектов. Это ускоряет их реализацию, но повышает риски. Инвестиции в развитие ЦОД осуществляются через частные фонды вместо традиционных банковских структур. Фонды имеют невысокую прозрачность, невысокую ликвидность и слабо контролируются регуляторами. Если условия для рефинансирования стунут хуже или окажется, что прогнозы спроса на ИИ завышены, могут возникнуть проблемы как в сегменте частного кредитования, так и во всей структуре капитала проектов. У экспертов имеются серьёзные опасения, что инвестиции частного сектора в ЦОД становятся всё объёмнее, при этом риски для инвесторов всё выше. Ранее в марте Moody’s прогнозировало, что существует риск избыточного строительства с низкой доходностью. Рейтинговое агентство предупреждало, что строительство дата-центра занимает 12–24 мес. с момента первоначальных вложений до того, как он начнёт приносить выручку. Также Moody's предупреждало, что если гиперскейлеры не смогут обеспечить тот рост прибыли, который от них ожидают, высокая долговая нагрузка и немалые капитальные затраты могут привести к пересмотру их кредитных рейтингов — в худшую сторону. В январе JLL сообщала, что к 2030 году на ЦОД будет потрачено $3 трлн, причём опасаться «пузыря» не стоит — речь идёт просто о крупнейшем «инвестиционном суперцикле» в истории.
27.03.2026 [15:17], Руслан Авдеев
В Дубне заработал второй собственный дата-центр WildberriesКомпания RWB, более всего известная маркетплейсом Wildberries, запустила в эксплуатацию второй собственный ЦОД в Подмосковье. Расположенный в ОЭЗ «Дубна» объект расширит вычислительные возможности торговой площадки и других цифровых сервисов в сфере ответственности компании. Новый дата-центр поможет обеспечивать стабильную работу торговой платформы в периоды пиковых нагрузок и призван стать основой для эволюции сервисов, помогающих оптимизировать бизнес продавцам и обеспечить максимальное удобство покупателям, говорит компания. Машинные залы рассчитаны на размещение более 500 серверных стоек, потенциально вмещающих до 8,6 тыс. серверов. Резервное питание будут обеспечивать шесть дизельных генераторов, показатель PUE объекта составит 1,1–1,15. 
Источник изображения: RWB Новый дата-центр общей площадью свыше 5,5 тыс. м2 и проектной мощностью 8 МВт представляет собой модульный объект с пятью помещениями, вместившими машинные залы, силовые блоки и генераторные установки, а также административно-бытовую инфраструктуру. 
Источник изображения: RWB По словам RWB, собственная инфраструктура для крупной коммерческой платформы — один из ключевых элементов дальнейшего устойчивого роста. Именно строительство собственных дата-центров даёт компании возможность повышать отказоустойчивость обслуживания, масштабировать вычислительные мощности в зависимости от нагрузок и развивать цифровые продукты, в т.ч. решения на основе ИИ. Ввод в эксплуатацию нового ЦОД — лишь часть стратегии развития технологической инфраструктуры RWB. В 2023 году в Электростали ввели в эксплуатацию первый ЦОД компании.
27.03.2026 [11:32], Владимир Мироненко
Altera и Arm объединят FPGA и Arm AGI для создания платформ для ИИ ЦОДAltera, специализирующаяся на разработке FPGA, объявила о расширении сотрудничества с Arm с целью объединения оптимизированных для ЦОД программируемых решений Altera с процессором Arm AGI, что позволит создавать вычислительные платформы с низкой задержкой, высокой гибкостью и масштабируемостью для ИИ ЦОД. «Следующее поколение инфраструктуры ЦОД будет формироваться под влиянием всё более интеллектуальных рабочих нагрузок ИИ и потребности в специализированных вычислительных ресурсах», — сообщил Мохамед Авад (Mohamed Awad), исполнительный вице-президент подразделения облачных вычислений ИИ компании Arm. Он добавил, что Arm AGI обеспечивает эффективную вычислительную основу, необходимую для этих систем, а сотрудничество с Altera помогает расширить эти возможности в рамках всей экосистемы. Компании отметили, что сочетание FPGA Altera и процессора Arm AGI открывает новые возможности в быстрорастущих ИИ ЦОД, где производительность в реальном времени, детерминированная обработка и адаптивность имеют решающее значение. 
Источник изображения: Arm Рагиб Хуссейн (Raghib Hussain), президент и генеральный директор Altera отметил, что у Altera и Arm имеется значительный опыт в разработке решений SoC на базе FPGA, ориентированных на рынки встраиваемых систем. Вместе с тем Altera прочно закрепилась на рынке инфраструктурных решений для ЦОД благодаря значительной базе установленных SmartNIC и DPU на основе FPGA. По его словам, расширение сотрудничества Altera с Arm позволит создать новый класс гетерогенных вычислительных систем, разработанных для удовлетворения растущих требований к производительности и гибкости ИИ ЦОД.
27.03.2026 [10:03], Руслан Авдеев
ЦЕРН: для самых больших открытий на БАК нужны самые маленькие ИИ-модели, которые «зашиты» прямо в чипыИИ-инфраструктура Большого адронного коллайдера (БАК) имеет мало общего с классическим решениями на основе TPU или GPU. Вместо этого ЦЕРН (CERN) буквально «выжигает» кастомные ИИ-модели в «кремнии» для фильтрации огромных массивов данных практически в реальном времени, сообщает The Register. Ежегодно коллайдер «генерирует» 40 тыс. Эбайт «сырых» данных от сенсоров — приблизительно четверть объёма всего интернета. Такую информацию CERN хранить не может, поэтому приходится выбирать в режиме реального времени то, что представляет какую-либо ценность. Речь идёт о потоке данных до сотен терабайт в секунду. Алгоритмы для их обработки должны быть чрезвычайно быстрыми. Именно поэтому их приходится буквально «выжигать» непосредственно в чипах. В 27-км кольце БАК субатомные частицы сталкиваются на скоростях, близких к скорости света. По кольцу постоянно перемещаются около 2,8 тыс. пучков протонов с 25-с интервалами. Хотя учёные «помогают» частицам, столкновения случаются сравнительно редко — из миллиардов протонов в каждой сессии сталкиваются лишь порядка 60 пар. При столкновении образуются новые частицы, улавливаемые детекторами CERN. 
Источник изображения: Brandon Style/unsplash.com Каждое столкновение пары частиц генерирует несколько мегабайт данных. В секунду происходит около миллиарда столкновений, что приблизительно даёт около 1 Пбайт информации. Естественно, собирать и хранить такие объёмы «сырой» информации технически невозможно, поэтому CERN создал гигантскую вычислительную систему для разделения данных на «интересные» и «неинтересные» ещё на уровне детекторов. 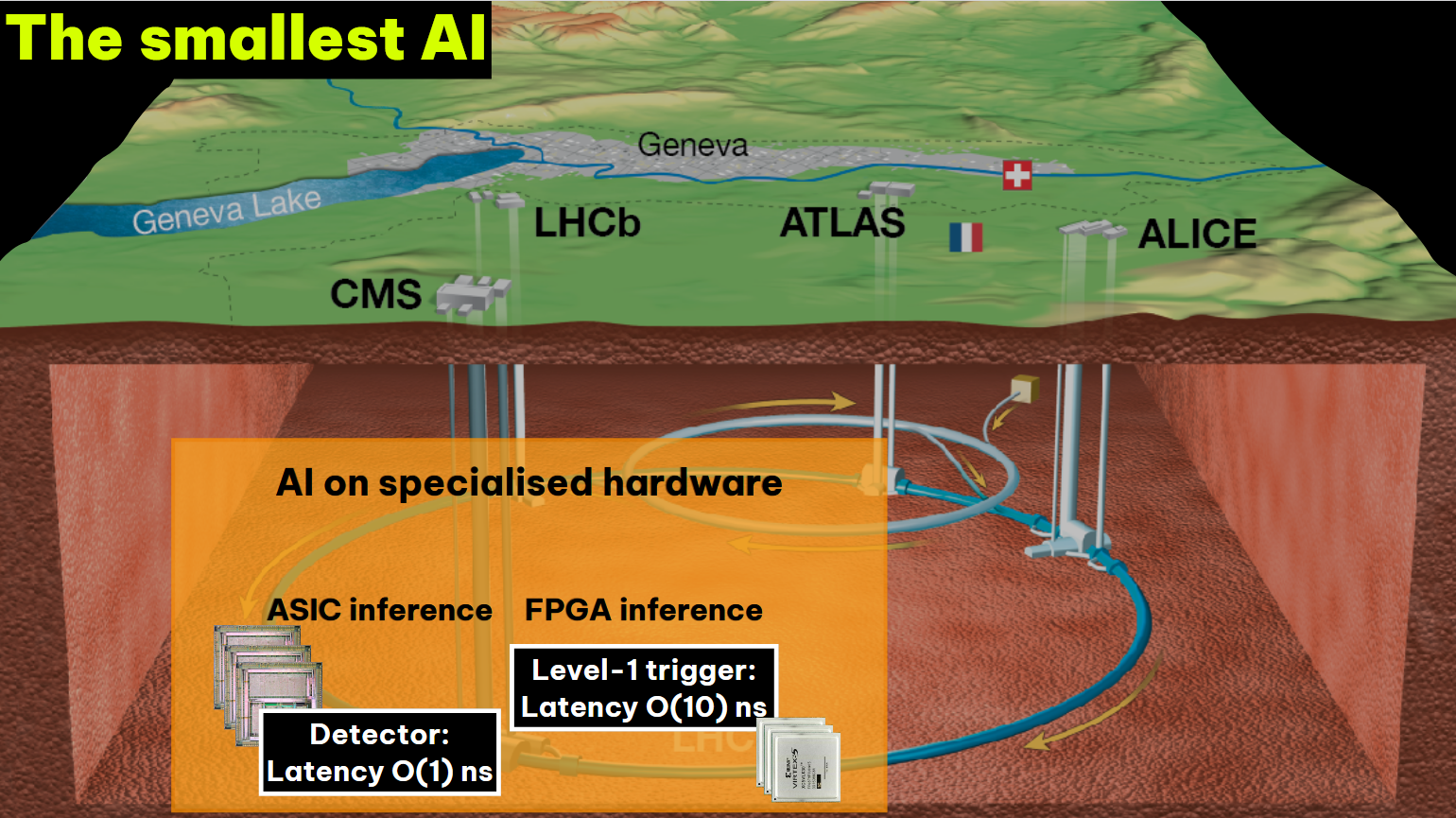
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Детекторы используют ASIC для буферизации данных за не более чем 4 мкс — они либо сохраняются, либо исчезают навсегда. Решение принимает фильтр Level One Trigger на базе порядка 1 тыс. FPGA, получающих данные по оптической линии на скорости около 10 Тбайт/с. Решения принимаются на лету силами самих чипов по мере поступления данных — даже самая быстрая внешняя память не справится с таким потоком информации. Специальный алгоритм AXOL1TL принимает решение не более чем за 50 нс. Фактически сохраняется лишь около 0,02 % информации о столкновениях, или приблизительно 110 тыс. событий в секунду. Отобранные сведения отправляются на поверхность, но даже после первичной фильтрации речь идёт о передаче терабайт данных ежесекундно. 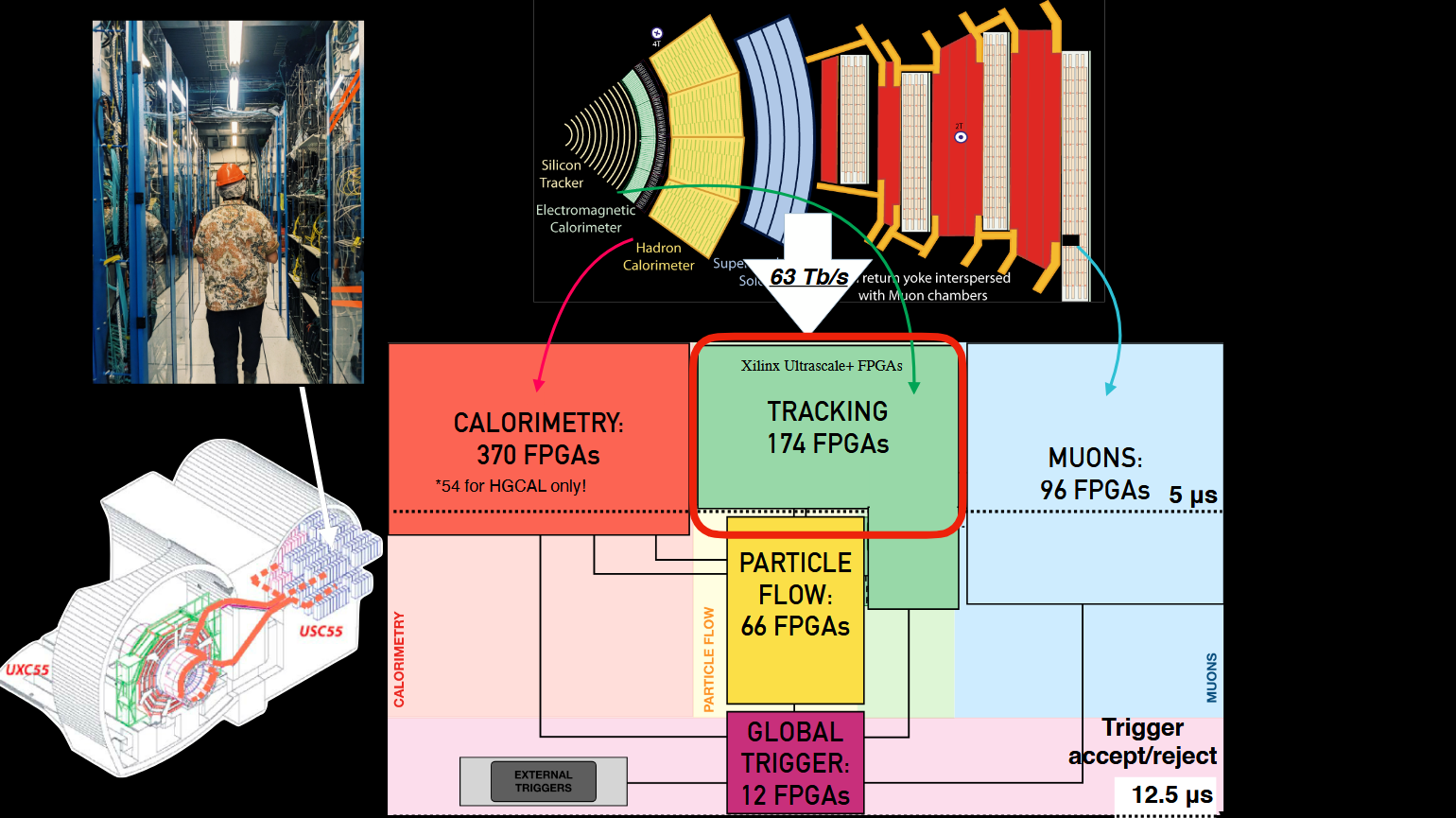
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) На поверхности второй фильтр — High Level Trigger — оставляет для изучения уже около 1 тыс. событий в секунду. Система оснащена 25,6 тыс. CPU и 400 GPU, которые реконструируют столкновения и отбирают наиболее интересные для анализа результатов. На выходе получается около 1 Пбайт/день новых данных, которые распределяются между 170 научными центрами в 42 странах, где их могут анализировать учёные со всего света. Совокупная вычислительная мощность всех участников проекта составляет около 1,4 млн ядер. CERN стремится измерить параметры столкновений с точностью 99,999 % — это «золотой стандарт», необходимый для заявлений о научных открытиях. 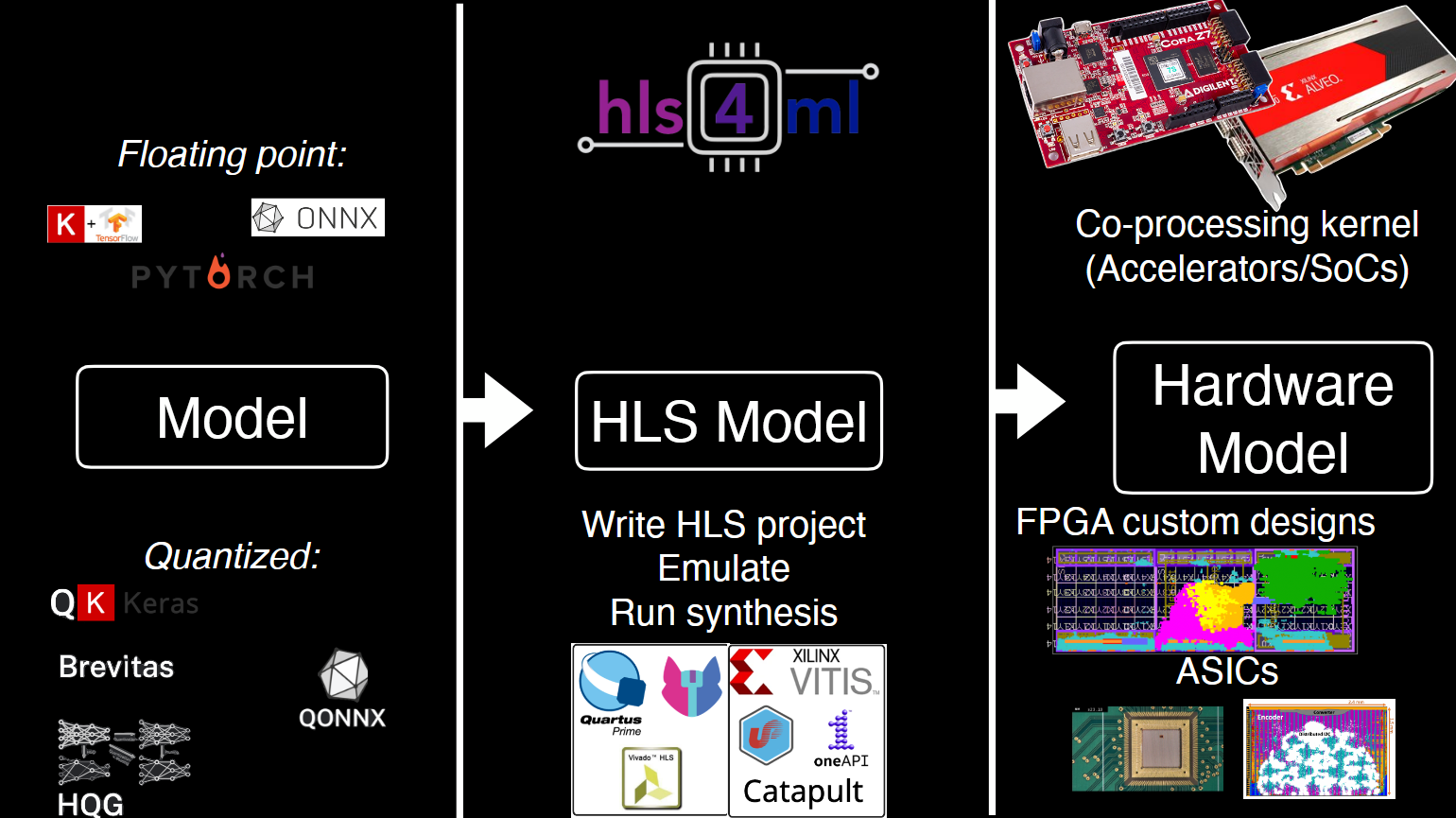
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Обычный ИИ-инструментарий плохо подходит для детекторов, поэтому инженерам CERN пришлось разработать собственный стек. ИИ-модели для БАК специально уменьшены, модернизированы, параллелизованы и «вымуштрованы» для выявления только действительно существенных данных. В случае с БАК они не менее производительны, но значительно «дешевле» традиционных ML-моделей. Для переноса моделей в аппаратную среду используется компилятор HLS4ML, конвертирующий модель в код C++, который можно запускать на ИИ-ускорителях, SoC, кастомных FPGA и даже «выжигать» в ASIC. При этом значительная часть ресурсов чипа отведена не под сам алгоритм, а под таблицы с предварительно рассчитанными результатами для типовых входящих значений, чтобы ещё быстрее фильтровать информацию. 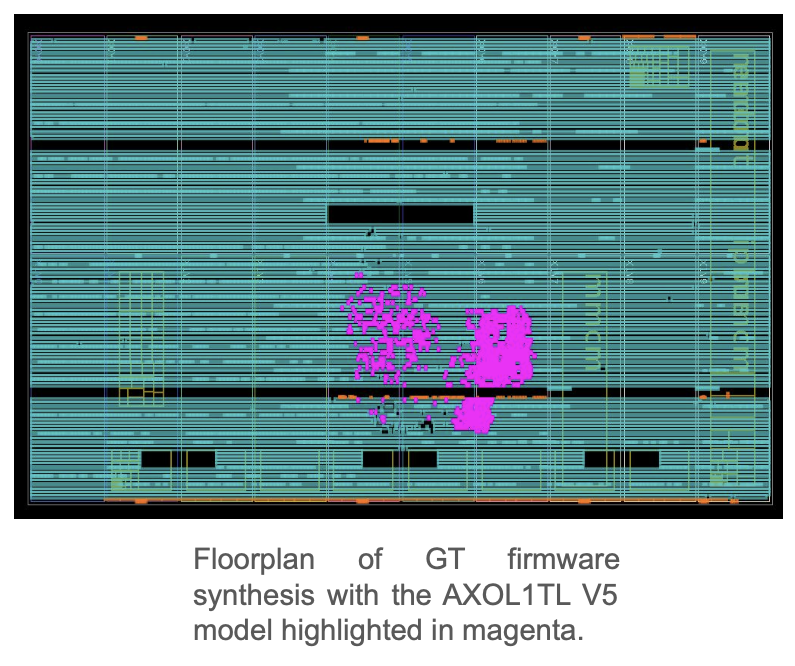
Источник изображения: CERN В конце года БАК закроют, а новый, более мощный коллайдер High Luminosity LHC должен заработать в 2031 году. Он получит более сильные магниты для фокусировки пучков частиц, сами пучки удвоятся в размерах, коллайдер будет генерировать в 10 раз больше данных, а объём информации от каждого события увеличится с 2 до 8 Мбайт. CERN уже накопил 1 Эбайт от БАК, но это лишь десятая часть от того, что предстоит хранить и обрабатывать в последующие 10 лет. И пока передовые ИИ-лаборатории создают LLM всё большего объёма, CERN движется в противоположном направлении, всеми силами упрощая и ускоряя выявление необычных событий с помощью искусственного интеллекта. |
|

