Материалы по тегу: semianalysis
|
05.01.2026 [18:25], Владимир Мироненко
Anthropic купит сотни тысяч ИИ-ускорителей Google TPU напрямую у BroadcomAnthropic приобретёт около 1 млн Google TPU v7 (Ironwood) с тем, чтобы запустить их на контролируемых ею объектах, сообщил в соцсети Х ресурс SemiAnalysis. Ранее сообщалось, что примерно 400 тыс. компания купит напрямую у Broadcom в стойках за примерно $10 млрд, а остальные 600 тыс. единиц TPU v7 будут доступны посредством Google Cloud Platform (GCP) в рамках сделки на сумму около $42 млрд, что составляет большую часть увеличения портфеля заказов GCP на $49 млрд или на 46 %, о котором сообщалось в отчёте за III квартал 2025 года. В случае с закупаемыми напрямую ускорителями TeraWulf и Cipher Mining будут ответственны за инфраструктуру ЦОД, а европейское неооблако Fluidstack будет заниматься настройкой оборудования на месте, прокладкой кабелей, первичным тестированием, испытаниями при приёмке и удалённым обслуживанием, освободив Anthropic от бремени управления физическими серверами. По слухам, эти системы получат упрощённую топологию интерконнекта. Сделки Fluidstack с обоими операторами ЦОД, ранее ориентированными на криптомайнинг, финансово застрахованы Google, которая к тому же является совладельцем TeraWulf и может получить долю в Cipher Mining. Любопытно, что оба оператора частично связаны и с AWS. Хотя Google закупает TPU через Broadcom, которая тоже хочет свою маржу, это всё равно лучше, чем та маржа, что требует NVIDIA не только за продаваемые ускорители, но и за всю систему целиком, включая процессоры, коммутаторы, сетевые карты, системную память, кабели, разъёмы и т.п. По оценкам, SemiAnalysis, совокупная стоимость владения (TCO) на один чип Ironwood для полной конфигурации с топологией 3D-тор примерно на 44 % ниже, чем у серверов GB200, что с лихвой компенсирует примерно 10-% отставание TPU от GB200 по пиковым производительности и пропускной способности памяти. 
Источник изображения: Google При этом реальная, а не теоретическая производительность (Model FLOP Utilization, MFU) у TPU, по мнению SemiAnalysis, может быть выше, чем у конкурентов. Основная причина заключается в том, что заявляемые NVIDIA и AMD показатели производительности (Флопс) значительно завышены. Даже в синтетических тестах, значительно отличающиеся от реальных рабочих нагрузок, Hopper достиг лишь около 80 % пиковой производительности, Blackwell — около 70 %, а серия MI300 от AMD — 50–60 %. Как полагают в SemiAnalysis, даже сдача ускорителей на сторону выгодна Google за счёт того, что TCO в пересчёте на час аренды может быть примерно на 30 % ниже, чем у GB200, и примерно на 41 % ниже, чем у GB300. Несмотря на высокий спрос, Google не может поставлять TPU в желаемом темпе, отметил SemiAnalysis, полагая, что основная проблема заключается в бюрократии Google — от первоначальных обсуждений до подписания генерального соглашения об оказании услуг (Master Services Agreement) проходит до трёх лет. Неооблака, включая Fluidstack, отличаются гибкостью и оперативностью, что облегчает им взаимодействие с новыми поставщиками услуг дата-центров, например, с реорганизованными криптомайнерами. Однако у неооблаков, среди инвесторов которых числится NVIDIA, таких как CoreWeave, Nebius, Crusoe, Together, Lambda, Firmus и Nscale, есть существенный стимул не внедрять конкурирующие технологии в своих дата-центрах: TPU, ускорители AMD и даже коммутаторы Arista — всё это под запретом. Это оставляет огромную нишу на рынке хостинга TPU, которая в настоящее время заполняется комбинацией майнеров криптовалют и Fluidstack, сообщил SemiAnalysis. По мнению SemiAnalysis, в ближайшие месяцы всё большему числу компаний-неооблаков предстоит принимать непростое решение между развитием возможностей хостинга TPU и получением квот на новейшие и лучшие системы NVIDIA Rubin.
13.10.2025 [00:30], Владимир Мироненко
Вложи $5 млн — получи $75 млн: NVIDIA похвасталась новыми рекордами в комплексном бенчмарке InferenceMAX v1
b200
gb200
hardware
nvidia
open source
semianalysis
бенчмарк
ии
инференс
рекорд
финансы
энергоэффективность
NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка. Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца. NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM). 
Источник изображений: NVIDIA Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов. 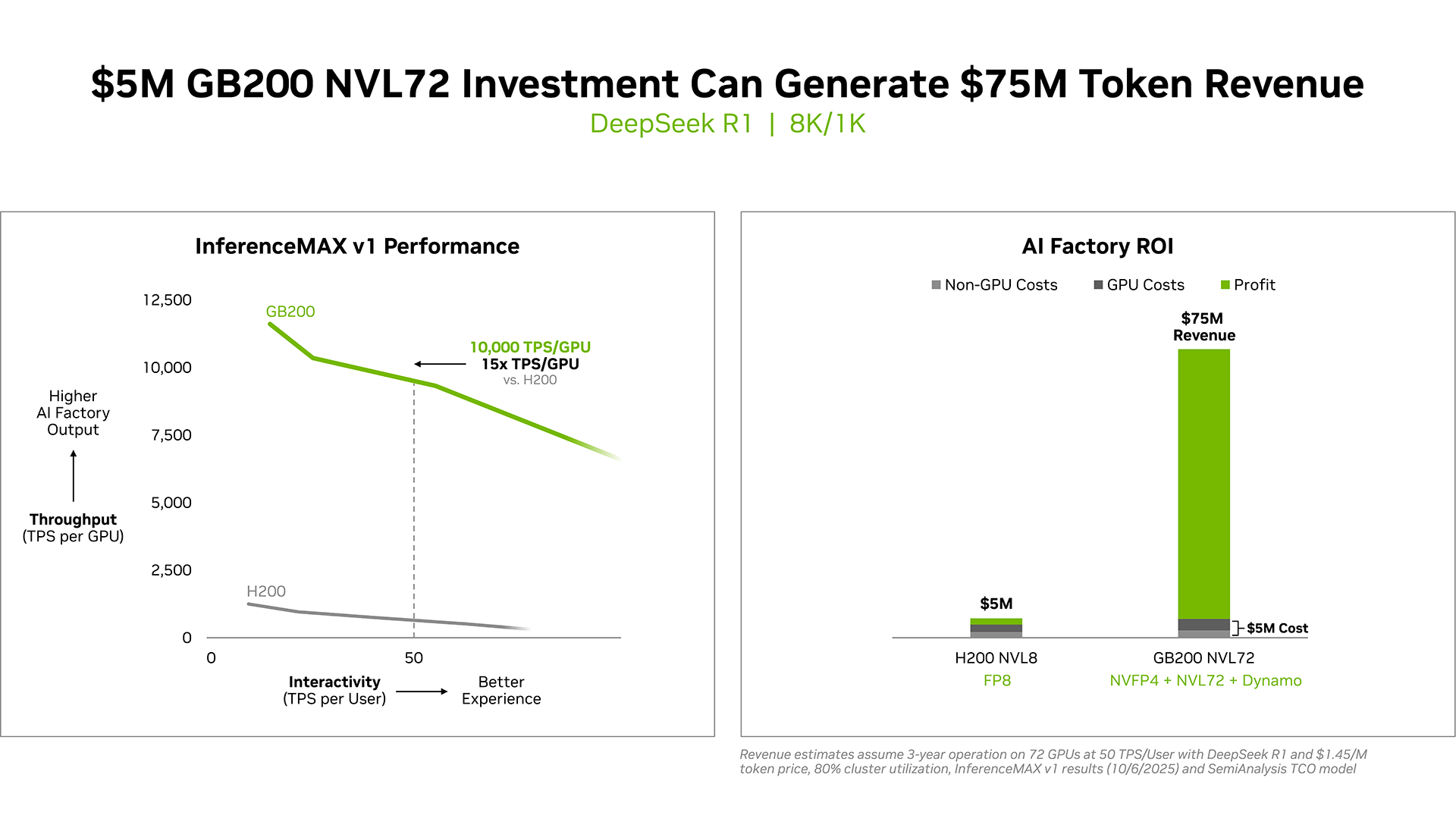 Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200. 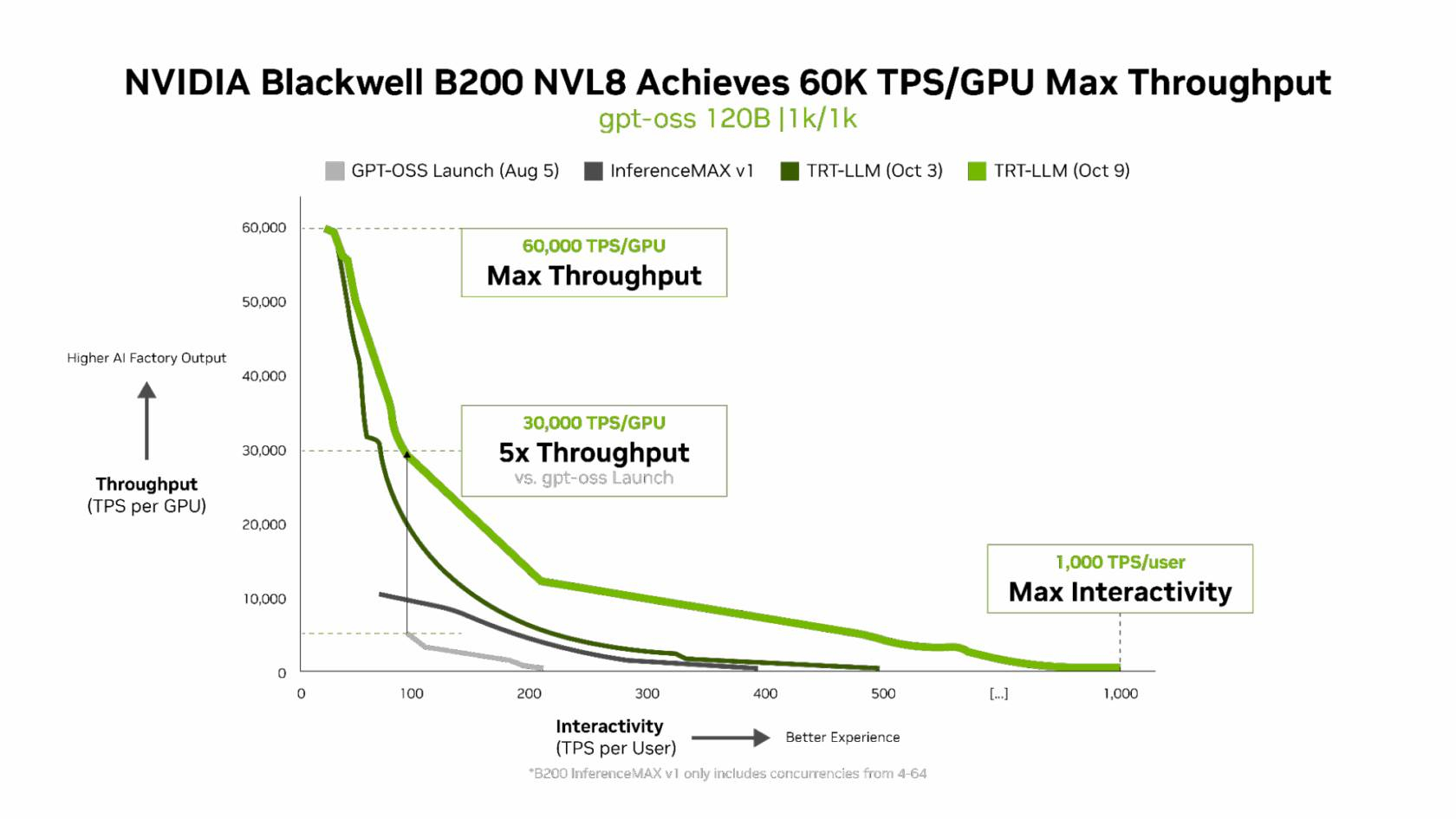 NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов. 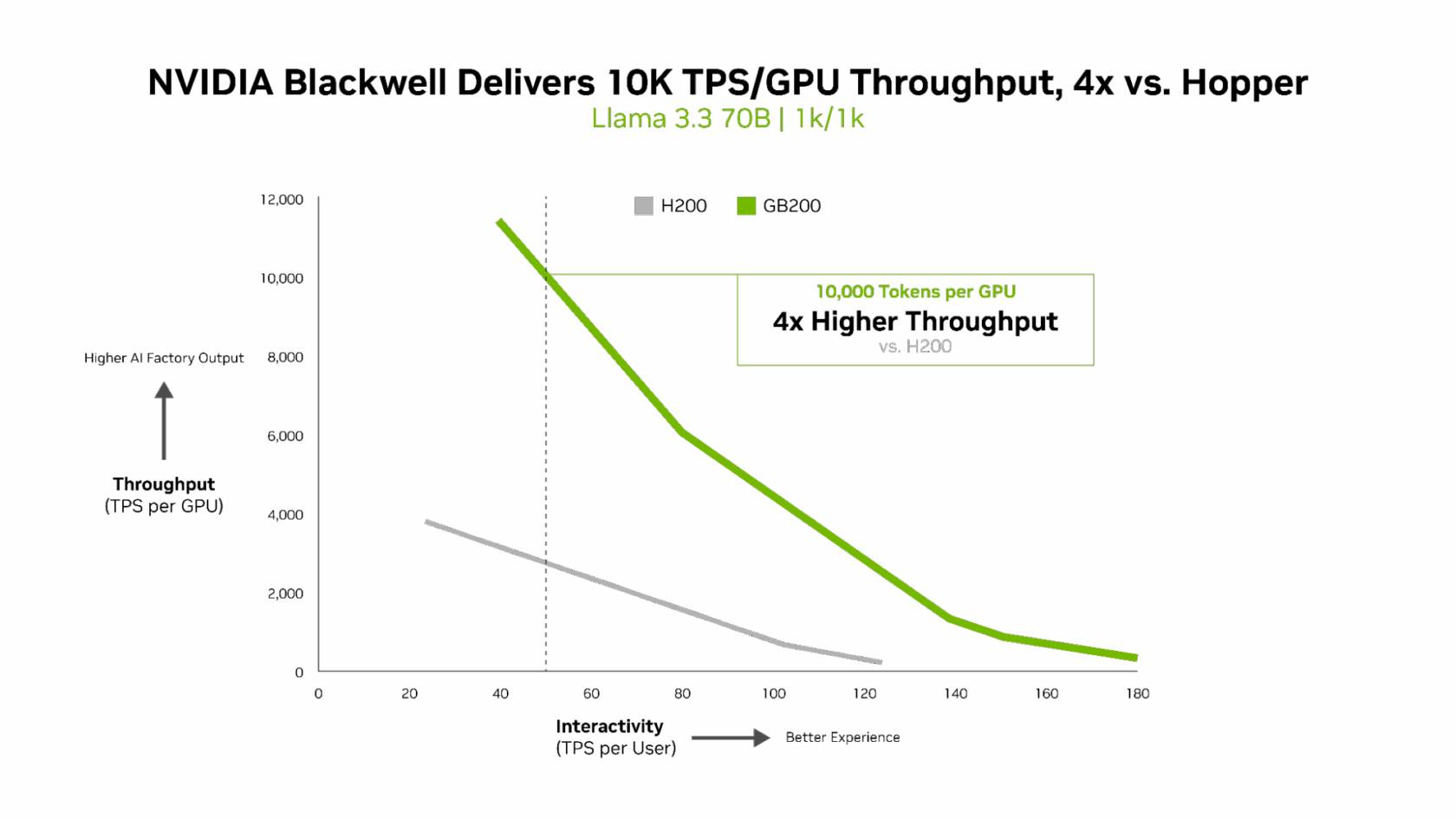 Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением. 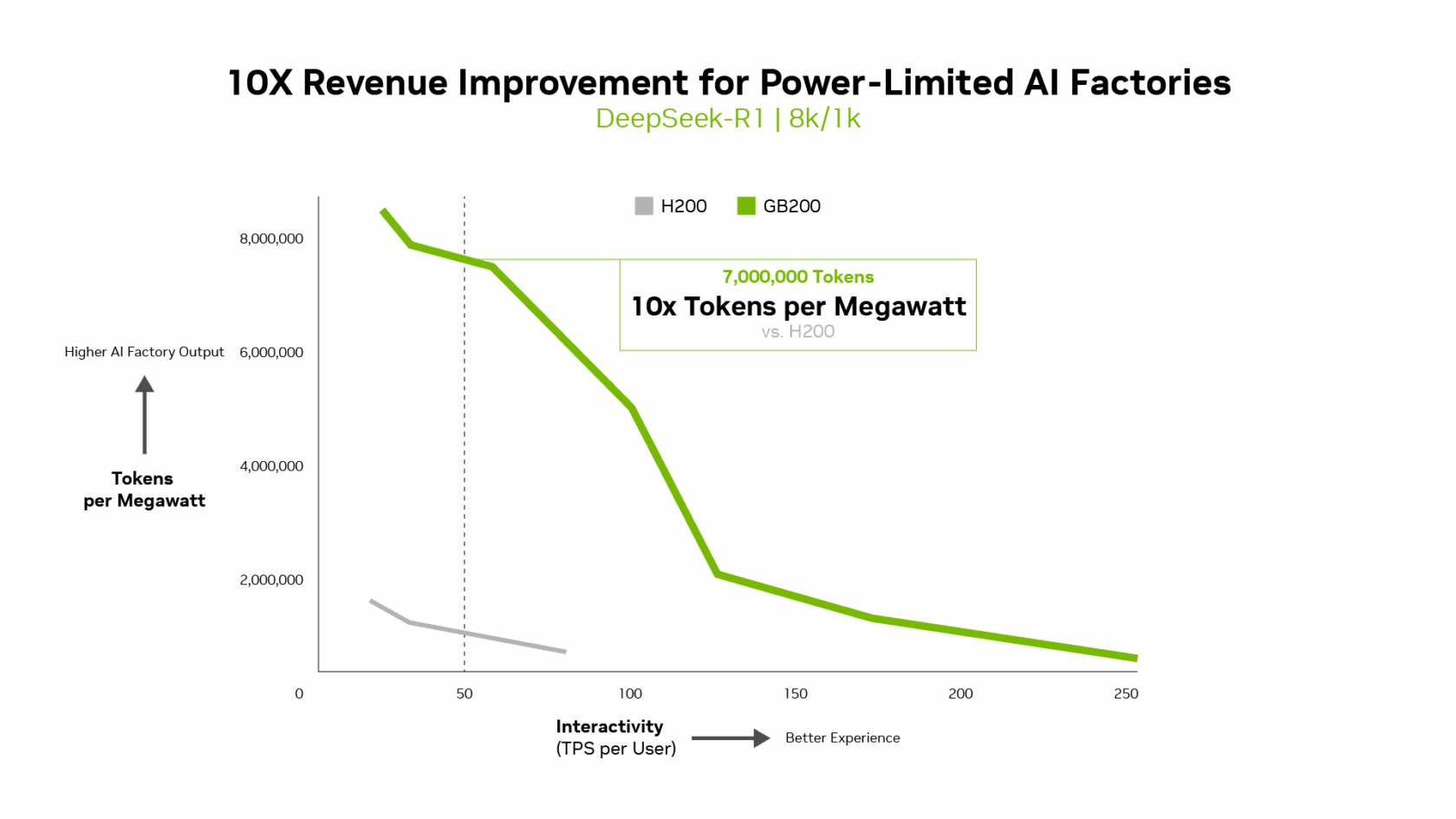 В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах. 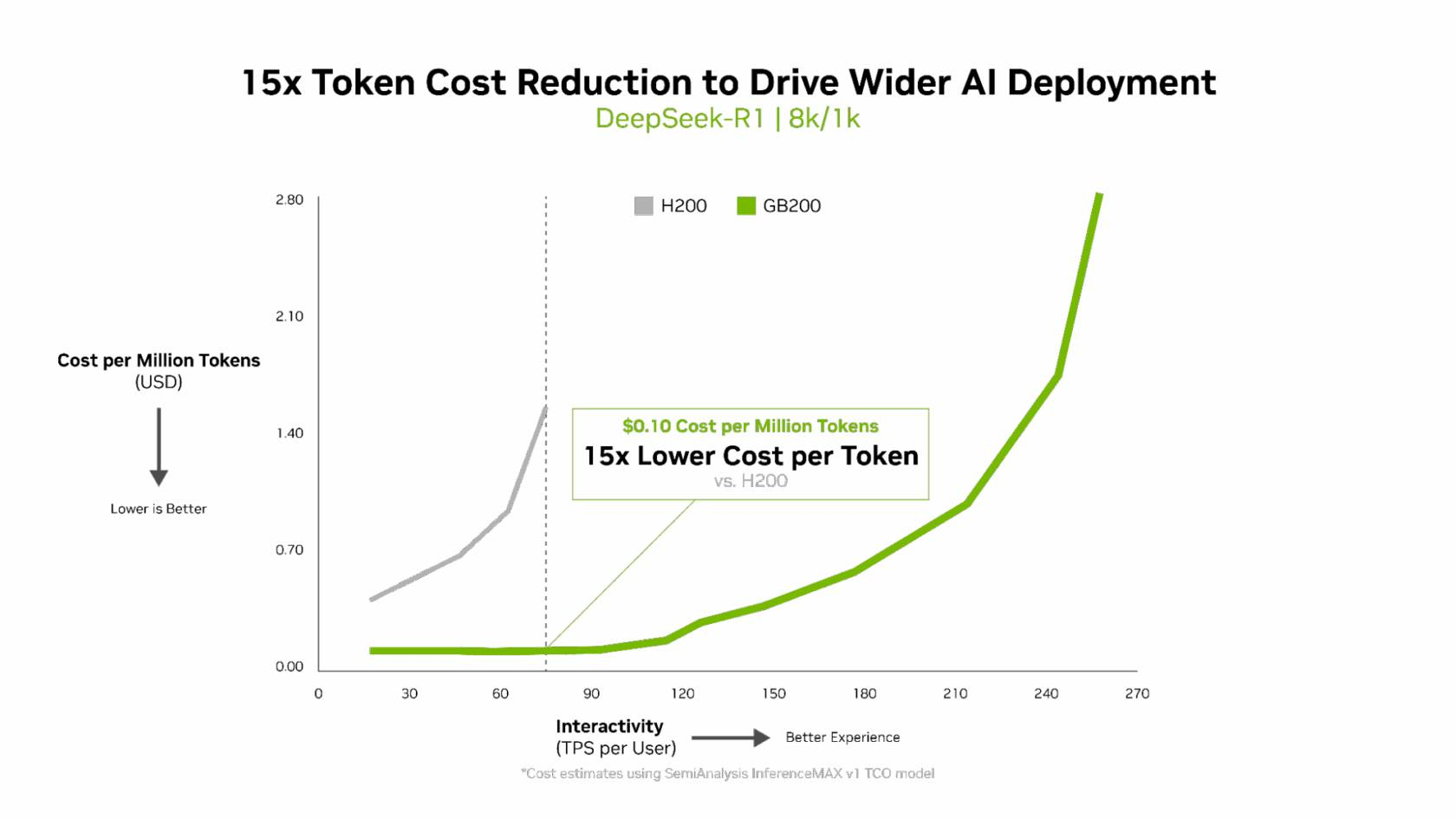 Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций. Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
25.12.2024 [01:00], Владимир Мироненко
Гладко было на бумаге: забагованное ПО AMD не позволяет раскрыть потенциал ускорителей Instinct MI300XАналитическая компания SemiAnalysis опубликовала результаты исследования, длившегося пять месяцев и выявившего большие проблемы в ПО AMD для работы с ИИ, из-за чего на данном этапе невозможно в полной мере раскрыть имеющийся у ускорителей AMD Instinct MI300X потенциал. Проще говоря, из-за забагованности ПО AMD не может на равных соперничать с лидером рынка ИИ-чипов NVIDIA. При этом примерно три четверти сотрудников последней заняты именно разработкой софта. Как сообщает SemiAnalysis, из-за обилия ошибок в ПО обучение ИИ-моделей с помощью ускорителей AMD практически невозможно без значительной отладки и существенных трудозатрат. Более того, масштабирование процесса обучения как в рамках одного узла, так и на несколько узлов показало ещё более существенное отставание решения AMD. И пока AMD занимается обеспечением базового качества и простоты использования ускорителей, NVIDIA всё дальше уходит в отрыв, добавляя новые функции, библиотеки и повышая производительность своих решений, отметили исследователи. 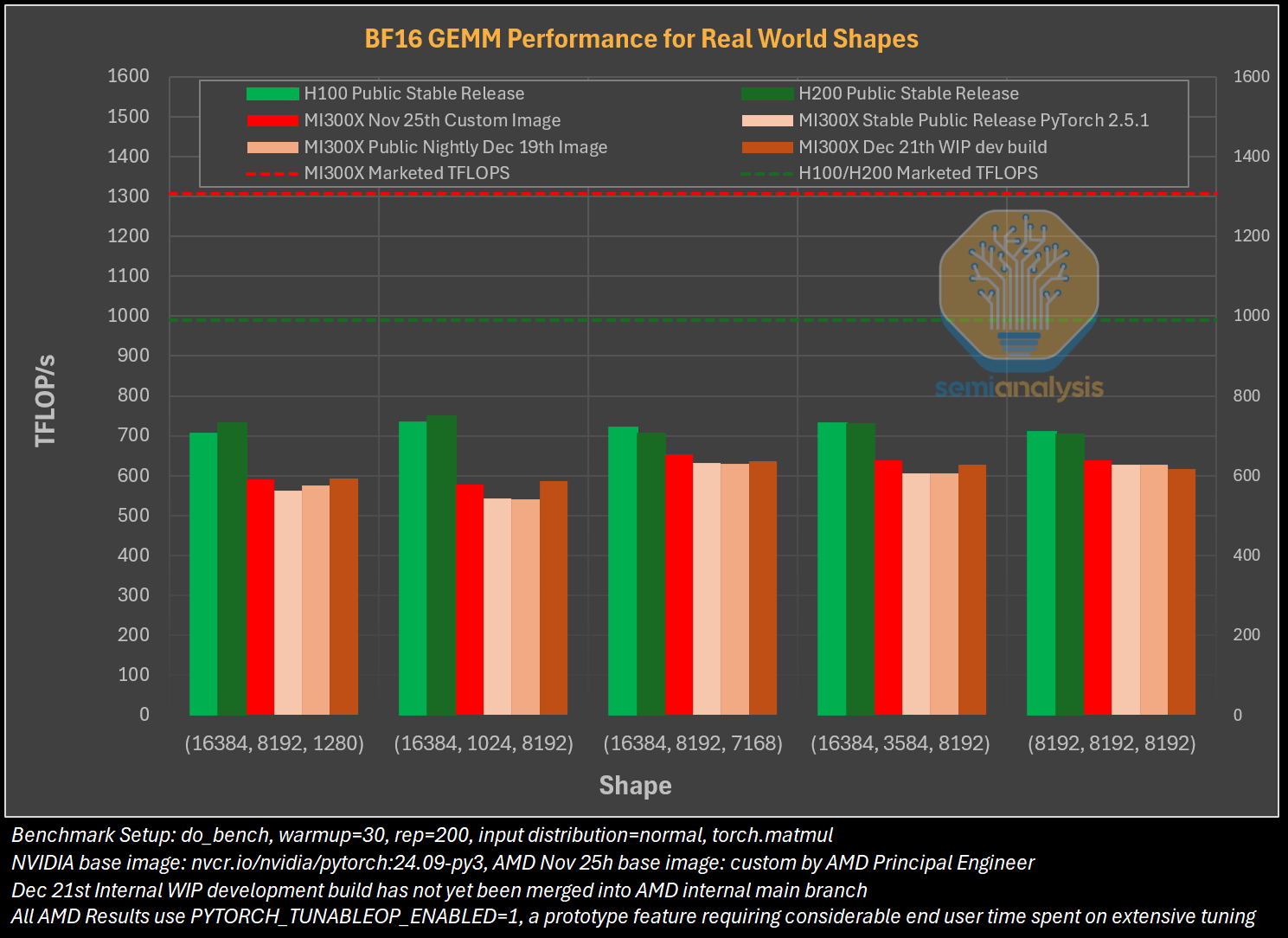
Источник изображений: SemiAnalysis На бумаге чип AMD Instinct MI300X выглядит впечатляюще с FP16-производительностью 1307 Тфлопс и 192 Гбайт памяти HBM3 в сравнении с 989 Тфлопс и 80 Гбайт памяти у NVIDIA H100. К тому же чипы AMD предлагают более низкую общую стоимость владения (TCO) благодаря более низким ценам и использованию более дешёвого интерконнекта на базе Ethernet. Но проблемы с софтом сводят это преимущество на нет и не находят реализации на практике. При этом исследователи отметили, что в NVIDIA H200 объём памяти составляет 141 Гбайт, что означает сокращение разрыва с чипами AMD по этому параметру. Кроме того, внутренняя шина xGMI лишь формально обеспечивает пропускную способность 448 Гбайт/с для связки из восьми ускорителей MI300X. Фактически же P2P-общение между парой ускорителей ограничено 64 Гбайт/с, тогда как для объединения H100 используется NVSwitch, что позволяет любому ускорителю общаться с другим ускорителем на скорости 450 Гбайт/с. А включённый по умолчанию механизм NVLink SHARP делает часть коллективных операций непосредственно внутри коммутатора, снижая объём передаваемых данных. 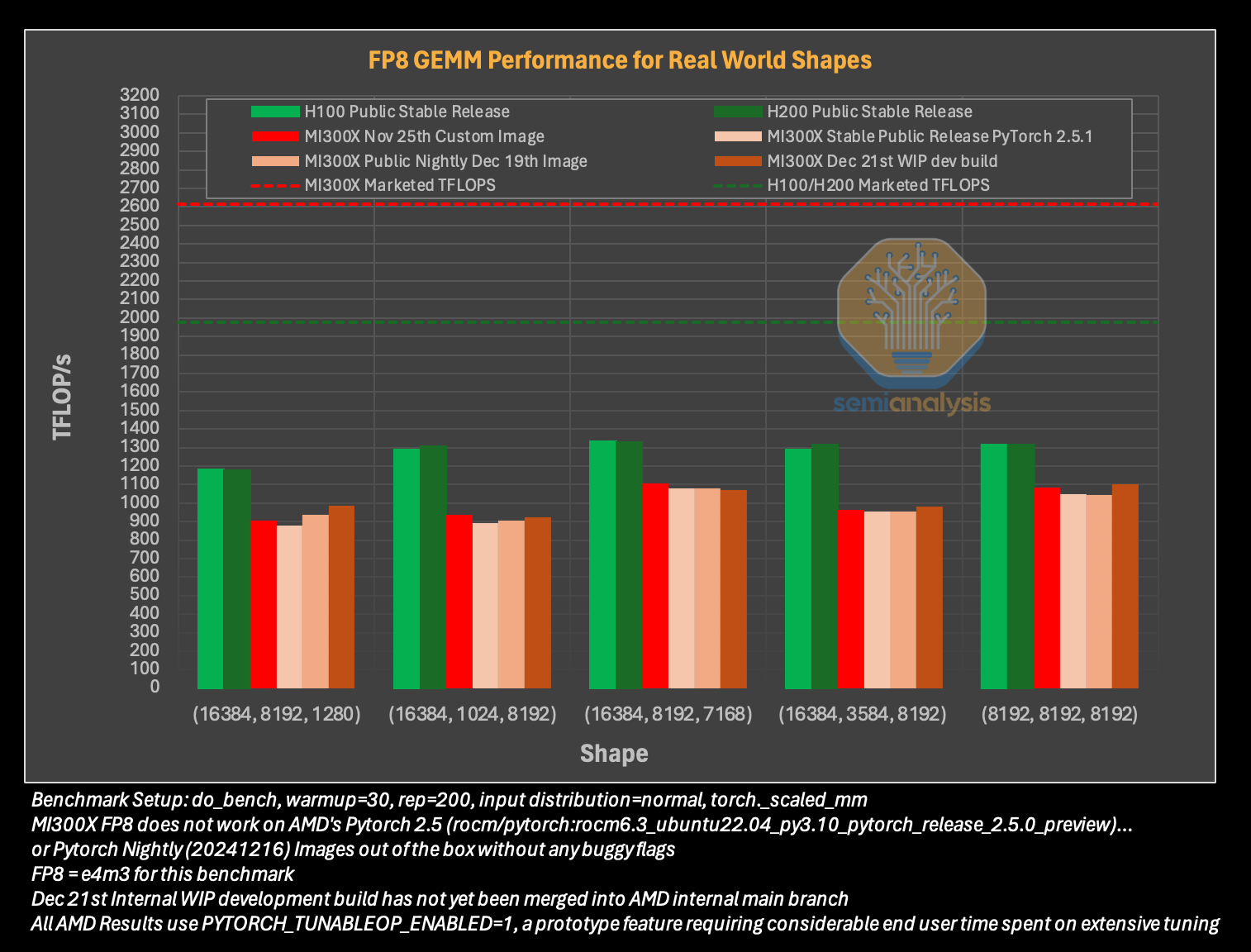 Как отметили в SemiAnalysis, сравнение спецификаций чипов двух компаний похоже на «сравнение камер, когда просто сверяют количество мегапикселей», и AMD просто «играет с числами», не обеспечивая достаточной производительности в реальных задачах. Чтобы получить пригодные для аналитики результаты тестов, специалистам SemiAnalysis пришлось работать напрямую с инженерами AMD над исправлением многочисленных ошибок, в то время как системы на базе NVIDIA работали сразу «из коробки», без необходимости в дополнительной многочасовой отладке и самостоятельной сборке ПО. В качестве показательного примера SemiAnalysis рассказала о случае, когда Tensorwave, крупнейшему провайдеру облачных вычислений на базе ускорителей AMD, пришлось предоставить целой команде специалистов AMD из разных отделов доступ к оборудованию с её же ускорителями, чтобы те устранили проблемы с софтом. Обучение с использованием FP8 в принципе не было возможно без вмешательства инженеров AMD. Со стороны NVIDIA был выделен только один инженер, за помощью к которому фактически не пришлось обращаться. 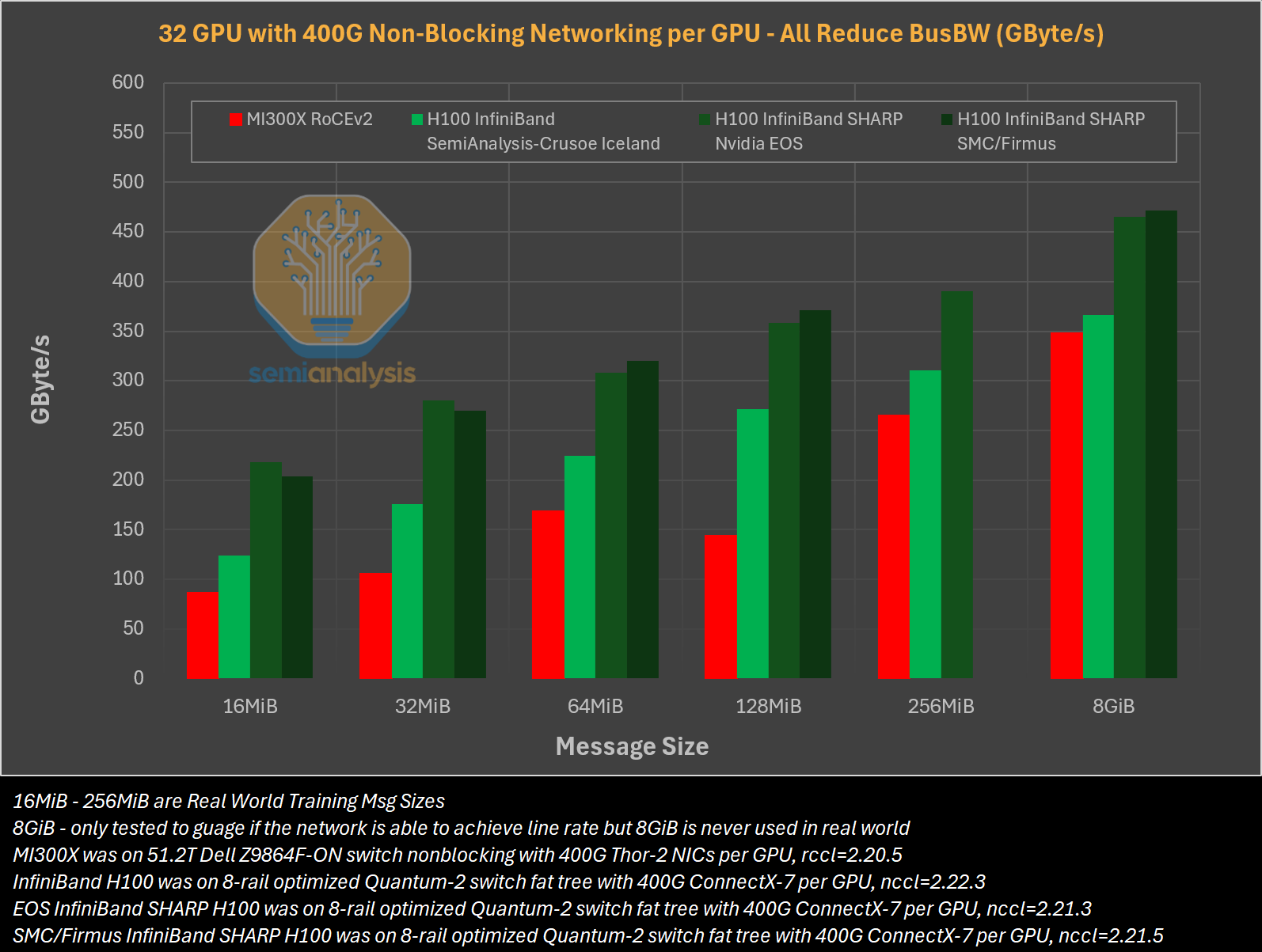 У AMD есть лишь один выход — вложить значительные средства в разработку и тестирование ПО, считают в SemiAnalysis. Аналитики также предложили выделить тысячи чипов MI300X для автоматизированного тестирования, как это делает NVIDIA, и упростить подготовку окружения, одновременно внедряя лучшие настройки по умолчанию. Проблемы с ПО — основная причина, почему AMD не хотела показывать результаты бенчмарка MLPerf и не давала такой возможности другим. В SemiAnalysis отметили, что AMD предстоит немало сделать, чтобы устранить выявленные проблемы. Без серьёзных улучшений своего ПО AMD рискует еще больше отстать от NVIDIA, готовящей к выпуску чипы Blackwell следующего поколения. Для финальных тестов Instinct использовался специально подготовленный инженерами AMD набор ПО, который станет доступен обычным пользователям лишь через один-два квартала. Речь не идёт о Microsoft или Meta✴, которые самостоятельно пишут ПО для Instinct. Один из автором исследования уже провёл встречу с главой AMD Лизой Су (Lisa Su), которая пообещала приложить все усилия для исправления ситуации. |
|

