NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка.
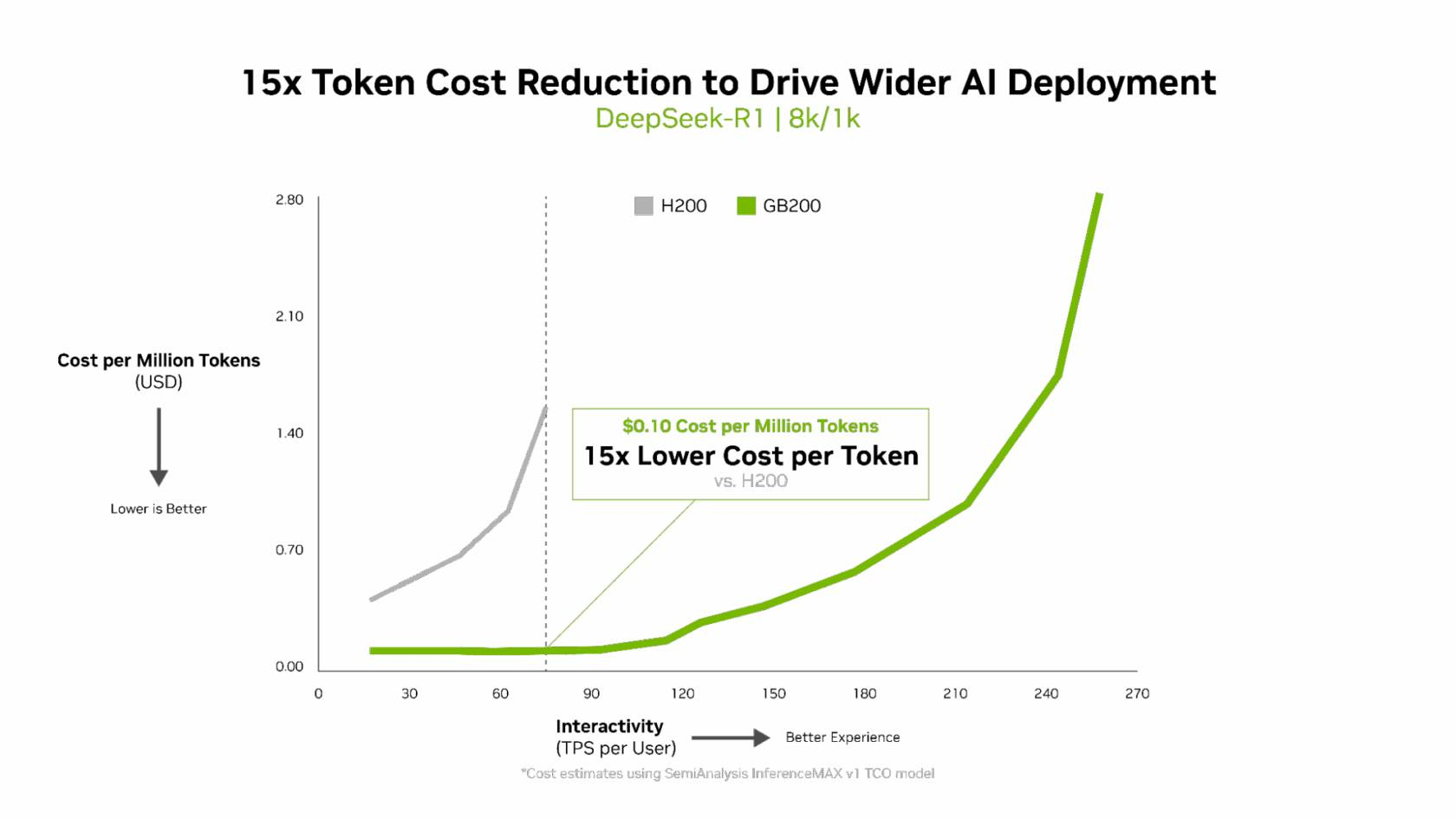
Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца.
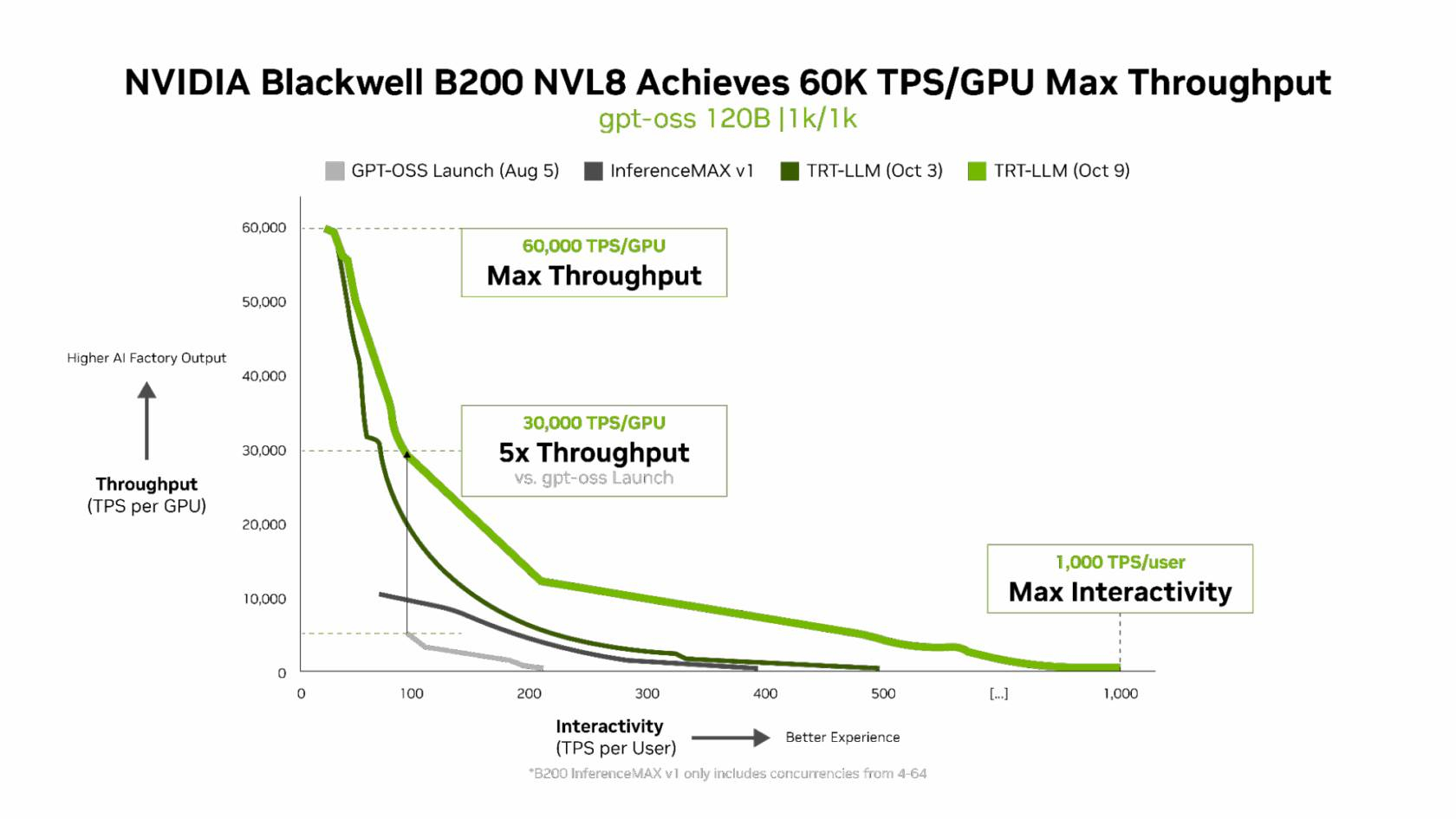
NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM).

Источник изображений: NVIDIA
Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов.
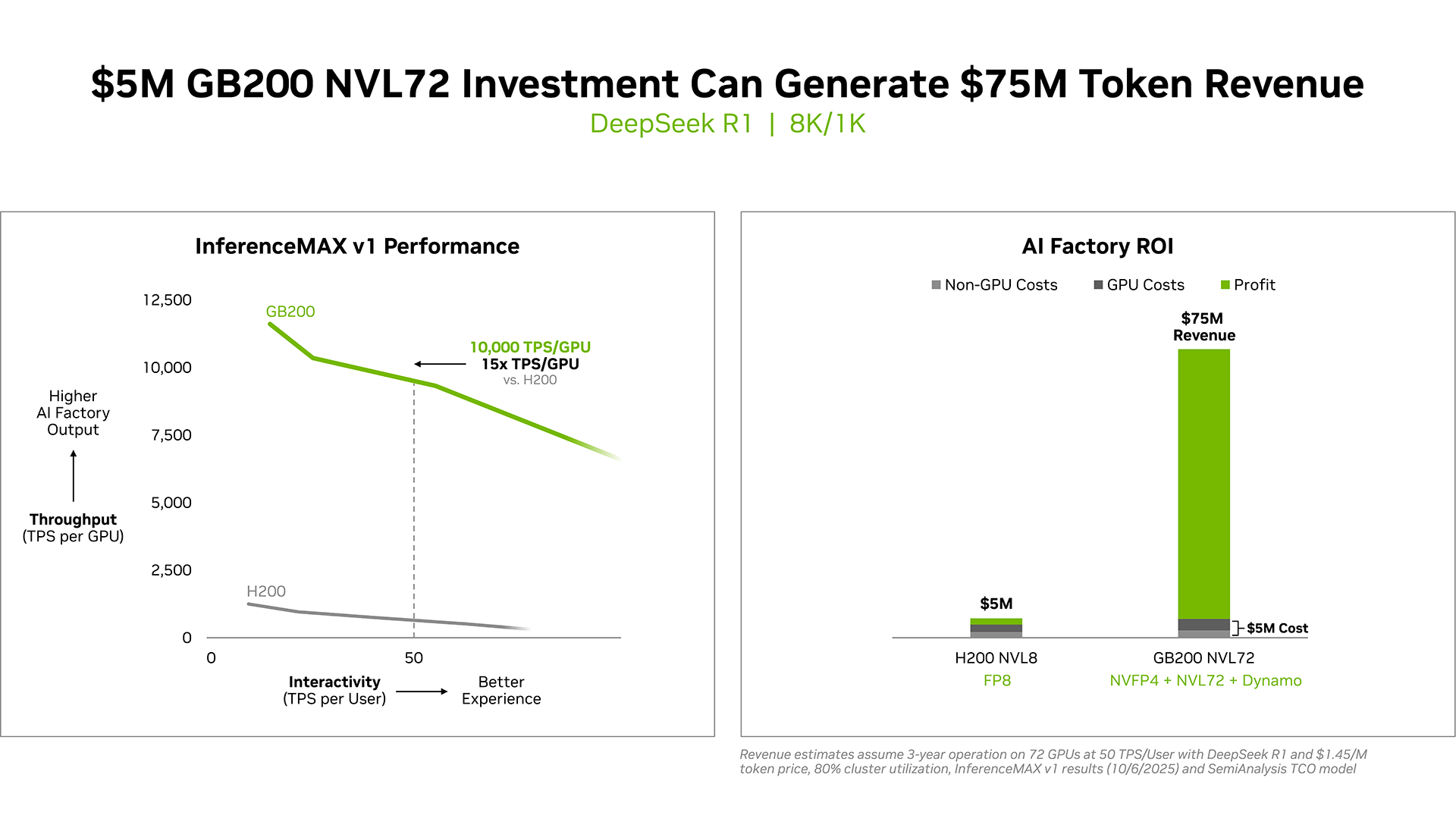
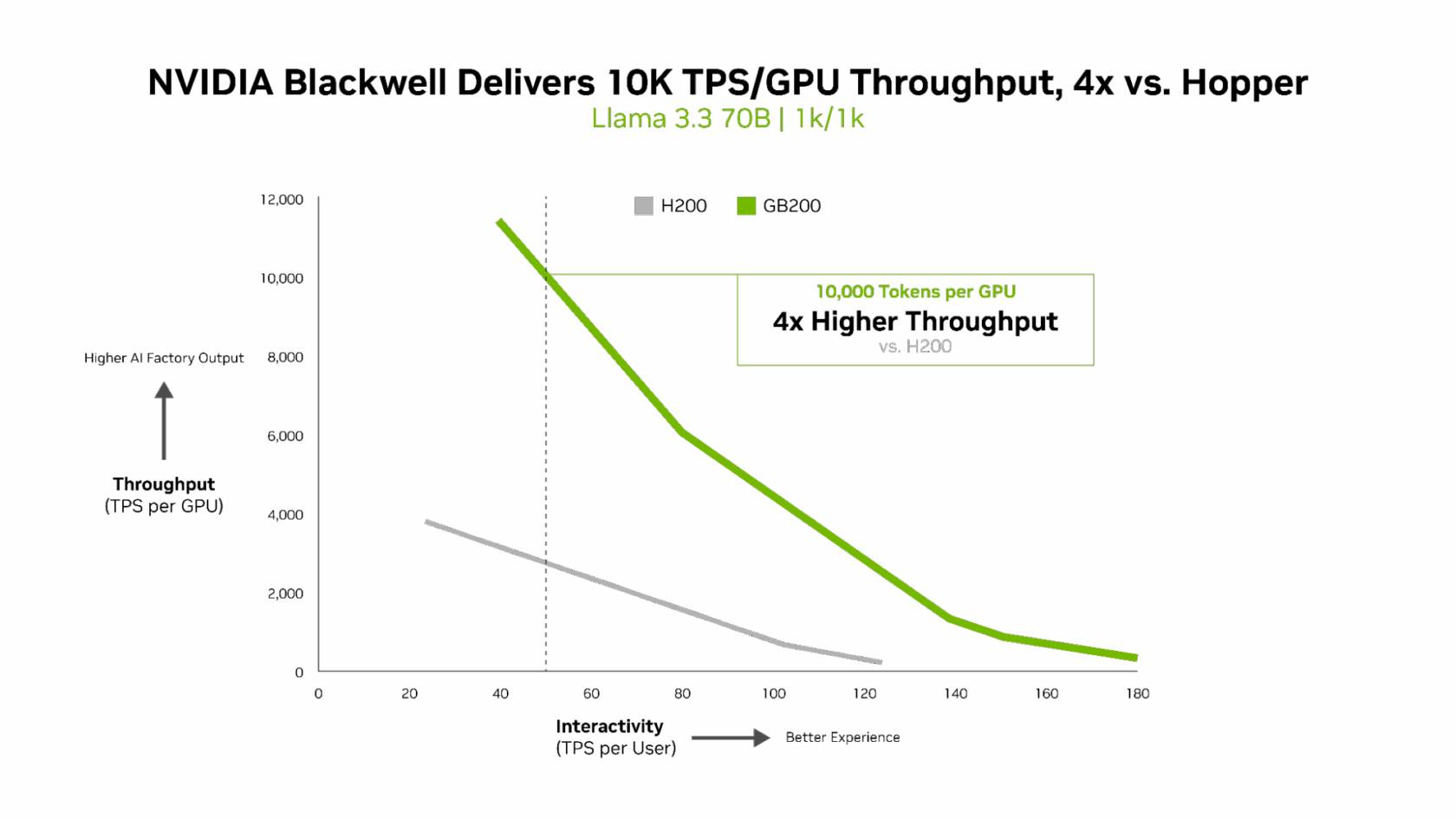
Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200.
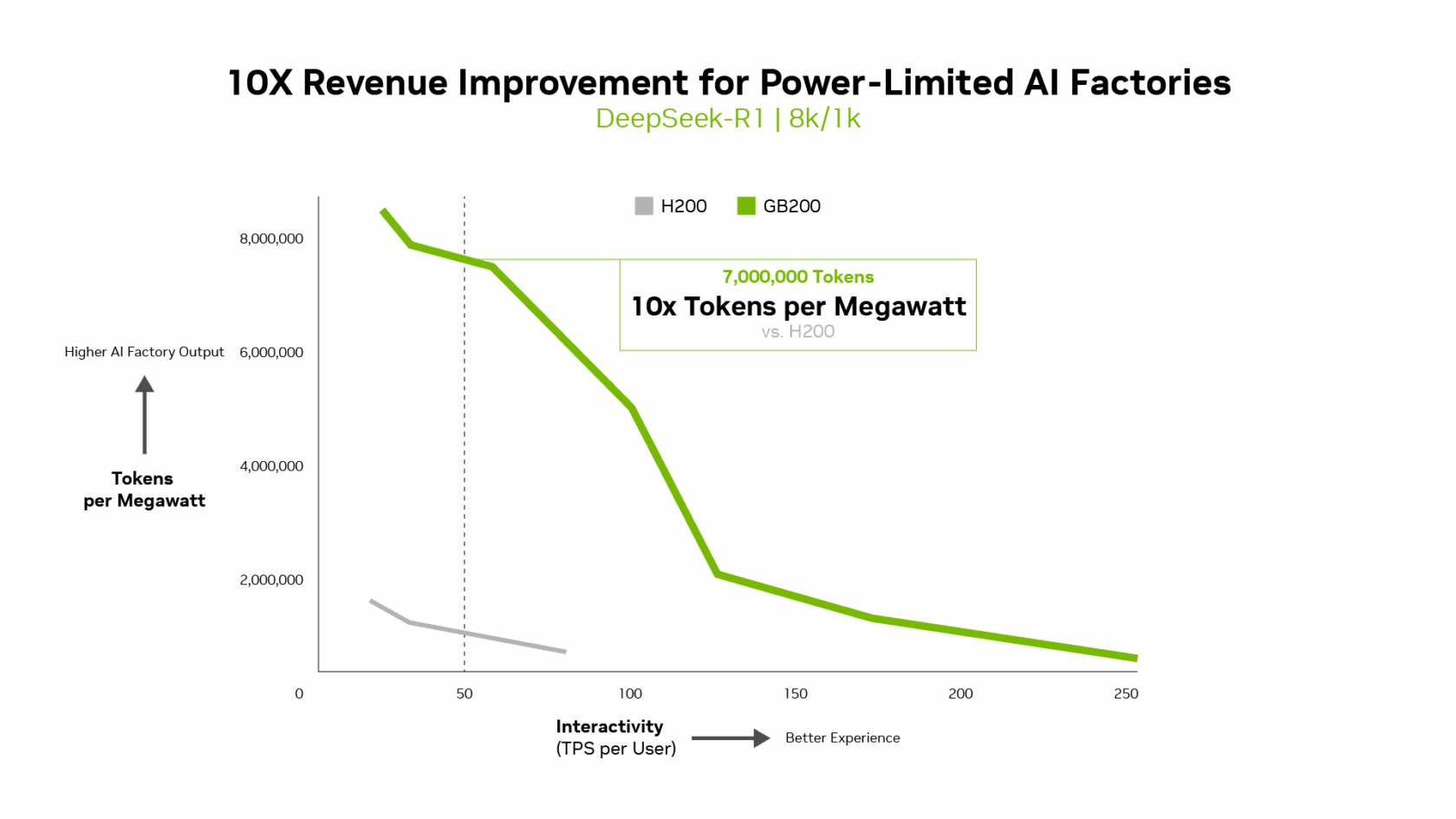
NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов.
Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением.
В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах.
Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций.
Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
Источник:

