Материалы по тегу: nvidia
|
26.03.2026 [23:43], Владимир Мироненко
В США арестовали ещё трёх подозреваемых в контрабанде в Китай ИИ-серверов Supermicro с подсанкционными чипами NVIDIAСпустя несколько дней после ареста соучредителя Supermicro И-Шьян Лиау (Yih-Shyan Liaw) в США арестовали ещё трёх человек по обвинению в попытке контрабанды ускорителей NVIDIA в Китай, сообщил ресурс The Register со ссылкой на заявление Министерства юстиции США. Акционеры тем временем подали к Supermicro коллективный иск в связи с резким падением стоимости ценных бумаг компании. Они полагают, что компания не могла не знать, что заметная доля выручки приходится на незаконные поставки оборудования в КНР, хотя часть таких сделок была заблокирована. Министерство юстиции США предъявило обвинения гражданину Китая Стэнли И Чжэну (Stanley Yi Zheng) из Гонконга, а также гражданам США Мэтью Келли (Matthew Kelly) и Томми Шаду Инглишу (Tommy Shad English) в сговоре с целью нарушения экспортного контроля и законов о контрабанде. Они обвиняются в попытке купить ускорители на миллионы долларов у «калифорнийской компании по производству компьютерного оборудования» для незаконной поставки в Китай через предприятия в Таиланде. Название производителя не приводится, но в обнародованном в судебных документах заказе указан номер модели сервера SYS-821GE-TNHR, что соответствует 8U-системе Supermicro для NVIDIA H100 и H200. Согласно обвинительным заключениям, сговор начался ещё в мае 2023 года. В октябре того же года Инглиш, представившись сотрудником компании из Таиланда, заказал у компании, проходящей документах как «Компания-1» (Supermicro), 750 серверов на сумму около $170 млн. Из этих серверов 600 содержали GPU, находящийся под контролем Управления по контролю за экспортом США (TEC) и требующий лицензии для экспорта в Китай. Размещая заказ, Инглиш подписал «Сертификат передовых вычислительных систем», подтверждающий, что серверы не предназначены для Китая или любой другой страны, на которые распространяются экспортные ограничения. 
Источник изображения: Rendy Novantino / Unsplash В январе 2024 года Инглиш перевел «Компании-1» более $20 млн в качестве частичной оплаты за заказ от октября 2023 года и, обсуждая по электронной почте предстоящую проверку соответствия заказу, попросил добавить Чжэна и Келли в переписку. «Компания-1» отметила в переписке, что компания Чжэна базируется в Китае и что «странно», что никто из компании, базирующейся в Таиланде, не был включен в список получателей копии письма. В начале февраля 2024 года калифорнийский производитель компьютерных чипов, указанный в документах как «Компания-2» (NVIDIA), провёл дополнительную проверку заказа от октября 2023 года, но не смог подтвердить конечного покупателя своей продукции в Таиланде. В конечном итоге этот заказ был заблокирован. 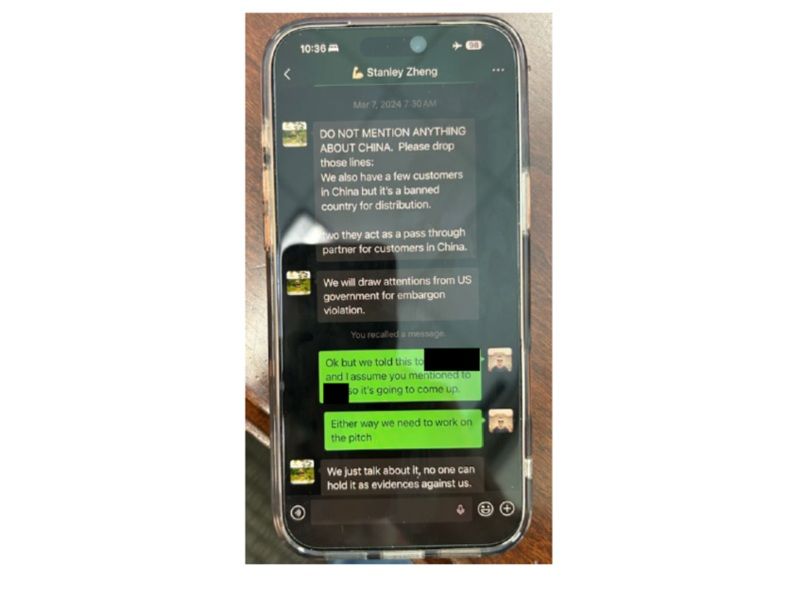
Источник изображения: U.S. Department of Justice В апреле 2024 года Инглиш снова предпринял попытку заказать у «Компании-1» 500 серверов с подсанкционными ускорителями, утверждая, что действует от имени другой тайской компании. При этом он снова подписал сертификат, подтверждающий, что конечным пользователем продукции является тайская компания. Эта сделка тоже не была завершена благодаря бдительности Supermicro и NVIDIA. Министерство юстиции США привело в качестве подтверждения обвинений переписку задержанных, свидетельствующую о том, что они знали, что конечным пунктом поставки серверов является Китай. Все трое находятся под стражей, а Чжэн уже предстал перед судьей Северного округа Калифорнии. Министерство юстиции США подчеркнуло, что на данном этапе обвинения являются лишь предположениями, и обвиняемые считаются невиновными, пока судебное разбирательство не докажет обратное.
26.03.2026 [14:33], Руслан Авдеев
ИИ от Microsoft и NVIDIA ускорит создание новых атомных реакторов
microsoft
microsoft azure
nvidia
software
аэс
документооборот
ии
строительство
сша
цифровой двойник
энергетика
Microsoft и NVIDIA сотрудничают в сфере атомной энергетики, но речь идёт не о непосредственном строительстве мощностей, а о «бумажной работе», которая будет выполняться с помощью ИИ-инструментов. Они должны помочь справиться с бюрократией, помогут в проектировании и оптимизации работы АЭС, сообщает The Register. По словам президента Microsoft Брэда Смита (Brad Smith), сотрудничество охватывает весь жизненный цикл АЭС, от получения разрешений и проектирования до строительства и эксплуатации. По словам Смита, атомная энергетика отлично зарекомендовала себя как источник безуглеродного электричества, и новая инициатива поможет масштабному вводу АЭС в эксплуатацию. Microsoft подчёркивает, что строительство АЭС — весьма сложный процесс, а приведение работы в соответствие с правилами регуляторов может занять годы, обойтись в сотни миллионов долларов и потребовать обработки огромных объёмов данных с последующим составлением отчётов. Администрация США стремится упростить делособственными методами — ослабить требования к безопасности, включая отказ от полной экологической экспертизы новых реакторов. Microsoft и NVIDIA считают, что ИИ поможет сократить сроки разработки, упростить выполнение сложных задач без ущерба безопасности и др. При этом система готовит и документацию, которую могут проверить регуляторы, где каждое инженерное решение обосновано в соответствии с правилами и готово для аудита. 
Источник изображения: Energie-portal.sk/unsplash.com По данным Microsoft, предлагаемый компанией инструмент Generative AI for Permitting уже сократил работы по получению разрешений на 92 % для компании Aalo Atomics, готовящей создание массовых малых модульных реакторов (SMR). Southern Nuclear разработала и внедрила ИИ-агентов, применяющих Microsoft Copilot для оптимизации проектирования и лицензирования. NVIDIA будет способствовать развёртыванию АЭС с помощью технологии цифровых двойников и высокоточных симуляций. Рост использования атомной энергии рассматривается как решение проблемы увеличения спроса на электричества, вызванного бумом строительства ИИ ЦОД. При этом строительство АЭС обычно занимает не менее пяти лет, а вот больше энергии для ИИ требуется уже сейчас. Сама Microsoft заключила соглашение сроком на 20 лет о покупке энергии (PPA) с Constellation Energy для перезапуска АЭС Three Mile Island, но та вряд ли заработает раньше 2028 года. Новая инициатива по внедрению ИИ в ядерную энергетику объединяет решения Omniverse, Earth 2, CUDA-X, AI Enterprise, PhysicsNeMo, Isaac Sim и Metropolis компании NVIDIA с Generative AI for Permitting и Planetary Computer компании Microsoft. По данным последней, это позволяет сформировать цифровую ИИ-экосистему для ядерной энергетики на платформе Azure. Аналогичные платформы разрабатывают Google и Palantir.
26.03.2026 [11:10], Сергей Карасёв
HP представила рабочую станцию Z8 Fury G6i с поддержкой четырёх ускорителей NVIDIA RTX Pro 6000 Blackwell Max-Q Workstation EditionКомпания HP анонсировала настольную рабочую станцию Z8 Fury G6i, предназначенную для решения сложных задач в области моделирования, анализа данных, создания визуальных эффектов и разработки ИИ. Новинка построена на аппаратной платформе Intel Xeon 600. Максимальная конфигурация включает процессор Xeon 698X с P-ядрами (86C/172T, 2/4,8 ГГц). Применена материнская плата на наборе логики Intel W890. Объём оперативной памяти DDR5-6400 ECC может достигать 2 Тбайт (доступны 16 слотов для модулей DIMM). Суммарная вместимость подсистемы хранения данных составляет до 104 Тбайт. При этом допускается использование накопителей разных типов, включая HDD корпоративного класса с интерфейсом SATA-3 вместимостью до 12 Тбайт (7200 об/мин), SSD формата М.2 (например, HP Z Turbo Drive NVMe на 8 Тбайт), а также устройства U.2 и U.3. Во фронтальной части расположены посадочные места для четырёх NVMe-накопителей с возможностью горячей замены. Дополнительно может быть установлен оптический привод HP Slim DVD-ROM или HP Slim DVD-Writer. Рабочая станция может нести на борту до четырёх ускорителей NVIDIA RTX Pro 6000 Blackwell Max-Q Workstation Edition с 96 Гбайт памяти GDDR7 каждый (пропускная способность — 1792 Гбайт/с). Слоты расширения выполнены по схеме 4 × PCIe 5.0 x16, 3 × PCIe 5.0 x8,1 × PCIe 5.0 x4 и 1 × PCIe 4.0 x4. В оснащение включены сетевой контроллер Intel I219-LM PCIe стандарта 1GbE и звуковой кодек Realtek ALC3205-CG. Предлагаются гибкие опции по установке дополнительных сетевых адаптеров, включая 10GbE и 25GbE. Кроме того, упомянут модуль MediaTek MT7925 с поддержкой Wi-Fi 7 и Bluetooth 5.4. 
Источник изображения: HP Габариты составляют 44,51 × 21,95 × 55,9 см, масса — 22,2 кг. На фронтальную панель выведены четыре порта USB 3.0 Type-A (5 Гбит/с), комбинированное аудиогнездо на 3,5 мм и SD-ридер. Сзади сосредоточены пять портов USB 3.0 Type-A (5 Гбит/с), разъём USB 3.2 Type-C (20 Гбит/с), гнездо RJ45 для сетевого кабеля и пр. Возможна установка одного или двух блоков питания мощностью 1350 или 1700 Вт. Говорится о совместимости с Windows 11 Pro for Workstations, Ubuntu 24.04 LTS, Red Hat Enterprise Linux.
25.03.2026 [14:49], Руслан Авдеев
Гагарин получил 512 ИИ-ускорителей B300 — Eleveight AI развернула чипы NVIDIA в 2-МВт ЦОД в АрменииБазирующаяся в Армении компания Eleveight AI развернула в местном дата-центре, расположенном в селе Гагарин, 512 ИИ-ускорителей NVIDIA B300. Строительство объекта должны закончить до конца марта, сообщает Datacenter Dynamics. ЦОД разработан для работы от комбинированных источников питания со значительной долей возобновляемой энергии. Стартап утверждает, что речь идёт о первом внедрении ускорителей NVIDIA B300 в Армении, и это важная веха в строительстве ИИ-инфраструктуры страны. В компании ожидают, что новые вычислительные мощности будут использоваться корпоративными клиентами, стартапами и исследовательскими организациями со II квартала 2026 года. Компания предупредила, что спрос уже превысил исходные 2 МВт мощности. Заявлено, что Армения выходит на мировой уровень в области ИИ-инфраструктуры, а проект Eleveight знаменует собой решающий шаг в этом направлении. С внедрением новейших ускорителей NVIDIA B300, компания «задаёт новые мировые стандарты производительности и возможностей». 
Источник изображения: Aram/unspalsh.com Компания подчеркнула, что в первую очередь сосредоточилась на том, чтобы заложить основу, обеспечив электроснабжение, охлаждение и стабильность в долгосрочной перспективе. Речь идёт только о первом шаге, в следующем году планируется расширять как вычислительные мощности ИИ-проекта, так и его географию. Основанная в 2025 году компания Eleveight AI заявляет, что фокусирует внимание на строительстве инфраструктуры И ЦОД в Гагарине. Вычислительные ресурсы предназначены для коммерческих компаний, стартапов и исследований. В ноябре 2025 года США одобрили экспорт передовых ИИ-чипов в ряд стран, включая Армению. В феврале сообщалось, что страна получит ещё 41 тыс. NVIDIA GB300. Firebird намерена построить ИИ ЦОД на 100 МВт.
25.03.2026 [12:08], Сергей Карасёв
ZutaCore представила водоблок для NVIDIA RTX Pro 6000 Blackwell Server EditionРазработчик систем прямого безводного двухфазного жидкостного охлаждения ZutaCore анонсировал водоблок OmniTherm для ускорителя NVIDIA RTX Pro 6000 Blackwell Server Edition. Новинка позволяет повысить плотность монтажа ИИ-карт в составе серверов, ориентированных на корпоративные и облачные среды. Решение OmniTherm обеспечивает возможность применения двухфазного охлаждения. При этом используется герметичная конструкция с диэлектрической жидкостью. Теплоноситель при контакте с чипом закипает и превращается в пар, который конденсируется в отдельном контуре. Блок OmniTherm позволяет реализовать однослотовую систему охлаждения, благодаря чему достигается экономия пространства внутри сервера. 
Источник изображения: ZutaCore Переход на СЖО также помогает повысить энергетическую эффективность оборудования, снизить уровень шума и вибрации (благодаря отсутствию вентиляторов). ZutaCore отмечает, что OmniTherm отводит тепло не только от кристалла GPU, но и от других расположенных рядом дорогостоящих компонентов, включая чипы памяти НВМ. Снижение тепловой нагрузки на эти элементы может повысить долговременную стабильность и минимизировать вероятность сбоев. Кроме того, ZutaCore представила облачную платформу HyperCool Cloud, предназначенную для управления системами жидкостного охлаждения в комплексных средах. Эта платформа практически в режиме реального времени предоставляет информацию о работе различного оборудования, включая блоки распределения охлаждающей жидкости (CDU).
23.03.2026 [12:55], Владимир Мироненко
Сначала Kyber, потом Feynman: NVIDIA раскрыла планы по выпуску ИИ-решений до 2028 годаВслед за анонсом ИИ-ускорителя LPU Groq 3 в составе платформы Vera Rubin компания NVIDIA представила обновлённую дорожную карту решений для ЦОД на период до 2028 года, включив в нее три поколения оборудования, пишет Data Center Dynamics. В рамках перехода на ежегодный цикл выпуска новых архитектур — Hopper, Blackwell (Ultra), Vera Rubin, компания после приобретения Groq за рекордные $20 млрд теперь планирует также ежегодно представлять новую архитектуру LPU. Выпуск LPU NVIDIA Groq 3 запланирован на II половину 2026 года. Также во II половине этого года выйдет платформа NVIDIA Vera Rubin, включающая, помимо NVIDIA Groq 3, Arm-процессоры Vera, ускорители Rubin, интерконнект NVLink 6, адаптеры ConnectX-9 SuperNIC и DPU BlueField-4, а также коммутаторы Spectrum/Quantum-6. На II половину 2027 года намечен выход ускорителя Rubin Ultra с четырьмя вычислительными чиплетами и 1 Тбайт HBM4E. Также во II половине следующего года выйдет второй LPU от NVIDIA — Groq LP35. Кроме того, в 2027 году компания планирует выпустить своё стоечное решение Kyber NVL144/NVL72. Система включает 144 ускорителя Rubin Ultra с NVLink 7, обеспечивая четырёхкратное повышение производительности по сравнению с системой Blackwell NVL72 (Oberon). 
Источник изображения: NVIDIA После анонса Rubin Ultra генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) заявил в 2025 году, что переход на эту платформу потребует «годы планирования». «Это не то же самое, что покупка ноутбука, — сказал он. — Нам нужно планировать с учётом территории и электроснабжения ЦОД вместе с инженерными командами на два-три года вперёд, поэтому я [показываю] дорожную карту». Планы NVIDIA на 2028 год включают масштабный запуск новых процессоров, ускорителей и LPU, получивших названия Rosa, Feynman и LP40 соответственно. По словам разработчика, в Feynman будет использоваться многослойная архитектура кристалла и высокоскоростная память для масштабирования производительности и увеличения пропускной способности. Также Feynman станет первым решением NVIDIA, в котором используются коммутаторы NVLink с интегрированной оптикой. Хуанг заявил, что спрос на продукцию NVIDIA к 2027 году достигнет отметки в $1 трлн, фактически удвоив свой прошлый прогноз. Финансовый директор Колетт Кресс (Colette Kress) уточнила позже, что эта цифра относится только к продуктам Blackwell и Rubin, а также к сопутствующему сетевому оборудованию, и не включает новые продукты, такие как LPU Groq и используемые отдельно процессоры. «Триллион долларов — это огромная сумма для инфраструктуры, — отметил Хуанг. — Вы должны быть полностью уверены, что триллион долларов, которые вы вкладываете, будут использованы, обеспечат высокую производительность, невероятную экономическую эффективность и будут иметь полезный срок службы на протяжении всего периода инвестиций в инфраструктуру. [NVIDIA] — единственная в мире инфраструктура, которую вы можете построить в любой точке мира с полной уверенностью».
23.03.2026 [09:31], Сергей Карасёв
HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения семейства NVIDIA AI Computing by HPE, ориентированные на крупномасштабные ИИ-платформы и суперкомпьютерные системы. О намерении использовать такие инфраструктурные продукты в числе прочих сообщили Аргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE), Hudson River Trading (HRT), Корейский институт научно-технической информации (KISTI) и Центр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии. В частности, представлены новые узлы для суперкомпьютерной платформы HPE Cray Supercomputing GX5000 — blade-серверы HPE Cray Supercomputing GX240. Эти устройства могут нести на борту до 16 процессоров NVIDIA Vera (88C/176T). В одной стойке могут быть размещены до 40 узлов, что в сумме даёт 640 чипов Vera и 56 320 ядер Olympus. Реализовано жидкостное охлаждение. Система предназначена для решения наиболее ресурсоёмких вычислительных задач в области ИИ. Новые серверы появятся на рынке в следующем году. Для платформы HPE Cray Supercomputing GX5000 также будут доступны коммутаторы NVIDIA Quantum-X800 InfiniBand, предоставляющие 144 порта с пропускной способностью до 800 Гбит/с. В этих устройствах реализованы развитые функции снижения энергопотребления. Кроме того, HPE готовит OCP-серверы высокой плотности Compute XD700 для обучения LLM и инференса. В основу данной системы положена платформа NVIDIA HGX Rubin NVL8, а одна стойка может насчитывать до 128 ускорителей Rubin. Данное решение появится в начале 2027-го. 
Источник изображений: HPE Помимо этого, анонсирована стоечная система нового поколения NVIDIA Vera Rubin NVL72 by HPE — это флагманская ИИ-платформа, разработанная для моделей с более чем 1 трлн параметров. Конфигурация включает 36 процессоров Vera, 72 чипа Rubin, интерконнект NVIDIA NVLink шестого поколения, сетевые адаптеры NVIDIA ConnectX-9 SuperNIC и DPU NVIDIA BlueField-4. Система поступит в продажу в декабре 2026 года. 
20.03.2026 [19:45], Владимир Мироненко
Сооснователь Supermicro арестован за контрабанду в Китай ИИ-серверов на $2,5 млрдВ США предъявили обвинения трём людям, связанным с производителем ИИ-серверов Super Micro Computer (Supermicro), включая его соучредителя, в сговоре с целью контрабанды передовых чипов NVIDIA в Китай и нарушении американского экспортного контроля, запрещающего их продажу в КНР без лицензии. Об этом сообщило агентство Reuters со ссылкой на заявление Министерства юстиции США. Акции компании рухнули более чем на четверть. Согласно обвинительному заключению прокуратуры Южного округа Нью-Йорка, И-Шьян Лиау (Yih-Shyan Liaw), известный как Уолли (Wally), Руэй-Цанг Чанг (Ruei-Tsang Chang), известный как Стивен (Steven), и Тин-Вэй Сунь (Ting-Wei Sun), известный как Вилли (Willy) вступили в сговор с целью продажи серверов с запрещёнными для экспорта в Китай чипами. 71-летний Лиау, соучредитель Supermicro и член совета директоров компании, был арестован в четверг в Калифорнии и освобождён под залог. 44-летний Сунь, подрядчик Supermicro, находится под стражей в ожидании слушания по вопросу о мере пресечения. 53-летний Чанг, работавший в тайваньском офисе Supermicro, пока находится на свободе, скрываясь от правосудия. Всем им предъявлено обвинение в сговоре с целью нарушения Закона о реформе экспортного контроля, за что, в случае осуждения, предусмотрено максимальное тюремное заключение сроком на 20 лет. Также они обвиняются по одному пункту обвинения в сговоре с целью контрабанды товаров и по одному пункту в сговоре с целью обмана Соединённых Штатов, за каждый из которых предусмотрено максимальное тюремное заключение сроком на пять лет. 
Источник изображения: Joshua Wordel / Unsplash По словам прокуроров, серверы зачастую собирались в США и сначала отправлялись на предприятия Supermicro на Тайване, затем доставлялись подставному юрлицу из Юго-Восточной Азии, которое в судебных документах обозначено как «Компания-1», а затем пересылались покупателям в Китае через сторонних брокеров. Сообщается, что китайские клиенты получали «флагманские» продукты Supermicro — серверы с NVIDIA B200 и H200. Как указано в обвинительном заключении, обвиняемые сотрудничали с руководителями компании-посредника, предоставляя производителю серверов фальшивые документы. Они использовали транспортно-логистическую компанию для переупаковки серверов в немаркированные коробки, чтобы скрыть их содержимое перед отправкой в Китай. Чтобы обмануть аудиторов производителя, которые проверяли компанию-посредника на соответствие экспортному законодательству, обвиняемые предъявляли им неработающие макеты серверов, тогда как настоящие серверы были отправлены в Китай. Согласно обвинительному заключению, двое из обвиняемых занимались размещением поддельных серверов на складе, арендованном компанией-посредником. Сунь передал фотографии и видео поддельных серверов одному из аудиторов, который вместо проведения проверки «находился вне офиса, наслаждаясь развлечениями, оплаченными» компанией-посредником. 
Источник изображения: Elevate / Unsplash Также у следствия имеются видео с камер видеонаблюдения, зафиксировавших, как мошенники использовали строительные фены для замены этикеток и наклеек с серийными номерами на коробках и макетах серверов. «Схемы перенаправления, подобные тем, которые были раскрыты сегодня, приносят миллиарды долларов незаконной прибыли и представляют прямую угрозу национальной безопасности США», — заявил Джей Клейтон (Jay Clayton), прокурор Южного округа Нью-Йорка. «Преступления, связанные с чувствительными технологиями, должны пресекаться незамедлительно, иначе закон теряет смысл», — добавил он. Компания Supermicro не была прямо упомянута в обвинительном заключении, но подтвердила причастность всех трёх лиц к правонарушению. В своём заявлении она указала, что отстранила Лиау и Чанга от работы и прекратила сотрудничество с Сунем. Компания сообщила, что «в полной мере сотрудничает» с расследованием правительства. Ранее компанию обвинили в поставках подсанкционных изделий в РФ. Кроме того, Supermicro оштрафовали за нелегальные поставки оборудования в Иран. «Действия лиц, указанных в обвинительном заключении, являются нарушением политики компании и мер контроля за соблюдением нормативных требований, включая попытки обойти применимые законы и правила экспортного контроля. Supermicro поддерживает надёжную программу соблюдения нормативных требований и обязуется полностью соблюдать все применимые законы и правила США об экспортном и реэкспортном контроле», — сообщила компания в заявлении для СМИ.
20.03.2026 [11:44], Сергей Карасёв
Платформа NVIDIA DGX Rubin NVL8 использует процессоры Intel Xeon 6Корпорация Intel сообщила о том, что в составе платформы NVIDIA DGX Rubin NVL8 для агентного ИИ применяются CPU поколения Xeon 6. Эти чипы отвечают за критически важные функции, такие как управление памятью, оркестрация задач и распределение рабочей нагрузки. Система DGX Rubin NVL8 несёт на борту два процессора Xeon 6776P семейства Granite Rapids. Изделия содержат 64 вычислительных ядра с возможностью одновременной обработки до 128 потоков инструкций. Базовая тактовая частота составляет 2,3 ГГц, максимальная — 3,9 ГГц. В режиме Priority Core Turbo (PCT) с восемью ядрами частота достигает 4,6 ГГц. Показатель TDP равен 350 Вт. CPU специально оптимизированы Intel для ИИ-узлов. «Intel Xeon 6 обеспечивает превосходную производительность, эффективность и совместимость с обширной экосистемой программного обеспечения x86, на которую полагаются клиенты при выполнении инференса в масштабе», — говорит Джефф Маквей (Jeff McVeigh), корпоративный вице-президент и генеральный директор стратегических ЦОД-программ Intel. 
Источник изображения: NVIDIA В состав DGX Rubin NVL8 входят восемь ускорителей Rubin с суммарным объёмом памяти 2,3 Тбайт (пропускная способность — 160 Тбайт/с). Задействованы восемь однопортовых адаптеров NVIDIA ConnectX-9 VPI (до 800 Гбит/с NVIDIA Infiniband и Ethernet), а также два DPU NVIDIA BlueField-4. Общая пропускная способность шины NVIDIA NVLink достигает 28,8 Тбайт/с. Энергопотребление — приблизительно 24 кВт. Заявленное ИИ-быстродействие на задачах инференса NVFP4 составляет до 400 Пфлопс, при обучении моделей NVFP4 — 280 Пфлопс, при обучении FP8/FP6 — 140 Пфлопс. Среди поддерживаемого софта упомянуты NVIDIA DGX OS, Ubuntu, Red Hat Enterprise Linux, Rocky Linux.
20.03.2026 [11:35], Сергей Карасёв
NVIDIA представила архитектуру хранения данных BlueField-4 STX для ИИ-системКомпания NVIDIA анонсировала модульную эталонную архитектуру BlueField-4 STX, которая поможет предприятиям, облачным провайдерам и операторам дата-центров в создании высокопроизводительных платформ хранения данных, оптимизированных для задач ИИ. Отмечается, что в традиционных ЦОД применяются хранилища общего назначения, обладающие большой вместимостью. Однако они зачастую не способны обеспечивать скорость отклика, необходимую для работы ИИ-агентов: таким системам требуются доступ к информации в реальном времени и контекстная память. Архитектура STX призвана устранить существующие узкие места. Технологической основой STX является DPU NVIDIA BlueField-4, который объединяет Arm-процессор NVIDIA Grace/Vera, 128 Гбайт LPDDR5, 512 Гбайт SSD, сетевой адаптер NVIDIA ConnectX-9 SuperNic (1,6 Тбит/с) и коммутатор PCIe 6.0 с 48 линиями. Используются микросервисы NVIDIA DOCA и программное обеспечение NVIDIA AI Enterprise. Утверждается, что архитектура STX обеспечивает в четыре раза более высокую энергоэффективность по сравнению с традиционными архитектурами хранения, построенными на основе CPU. В целом, как отмечается, STX предоставляет основу для создания универсального механизма обработки данных, ускоряющего полный жизненный цикл ИИ — от обучения и аналитики до инференса на базе агентов. 
Источник изображения: NVIDIA Первой реализацией STX в масштабе стойки является новая платформа хранения NVIDIA CMX с контекстной памятью, которая расширяет память GPU. О поддержке NVIDIA STX сообщили такие компании, как Cloudian, DDN, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data и WEKA. Производством систем на базе STX займутся AIC, Supermicro и Quanta Cloud Technology (QCT). Внедрить платформу в числе прочих намерены CoreWeave, Crusoe, IREN, Lambda, Mistral AI, Nebius, OCI и Vultr. Решения на базе STX станут доступны во II половине текущего года. |
|

