Материалы по тегу: nvidia
|
18.03.2026 [10:39], Руслан Авдеев
Глава NVIDIA объявил о запуске производства ускорителей H200 для КитаяПосле длительной паузы в торговле на огромном рынке китайских ИИ-проектов NVIDIA готовится к возвращению. Её глава Дженсен Хуанг (Jensen Huang) заявил о том, что компания будет поставлять ИИ-ускорители некоторым клиентам в КНР, сообщает CNBC. По словам Хуанга, компания уже получила заказы из Китая и находится «в процессе» возобновления производства, а цепочка поставок наращивает активность. Хуанг подчеркнул, что ситуация отличается от того, что было три или даже две недели назад. Ранее сообщалось, что поставки NVIDIA H200 одобрили как американские, так и китайские власти. Теперь эти данные подтвердил и Дженсен Хуанг. В своё время на Китай приходилось около 20 % выручки NVIDIA в сегменте продуктов для ЦОД, но компании фактически запретили работать с КНР после того, как в апреле 2025 года администрация США объявила о необходимости для компании получать лицензии на экспорт чипов в Китай и некоторые другие страны. NVIDIA заявила, что экспортные ограничения привели к убыткам в объёме $5,5 млрд. Действовавшие ранее ограничения заставили NVIDIA специально разработать для китайского рынка ослабленные ускорители H20, но даже их продажи были приостановлены. В декабре 2025 года политика изменилась и NVIDIA разрешили поставлять в Китай более производительные ускорители H200 — при условии, что США будут забирать 25 % от выручки. 
Источник изображения: NVIDIA При этом в прошлом месяце никаких изменений на рынке не наблюдалось. После публикации финансового отчёта 25 февраля компания сообщила, что американские власти одобрили продажу в КНР «небольшого количества» H200, но никаких поступлений на тот момент ещё не было. Задержка с возвращением на рынок была связана с ужесточением требований к обеспечению безопасности в обеих странах — несмотря на то, что Хуанг активно занимался лоббированием в США, а в начале 2026 года посетил и Китай. Впрочем, даже без учёта продаж в КНР NVIDIA отчиталась о росте выручки в последнем квартале на 73 % год к году — это уже 11-й подряд период роста, превышающего 55 % ежеквартально. В текущем квартале NVIDIA рассчитывает на рост в 77 % и подчёркивает, что таких показателей она намерена добиться без учёта выручки от рынка дата-центров в Китае. Пока в США требования к получению экспортных лицензий остаются весьма обременительными: ограничиваются объёмы поставок, требуется обязательное тестирование продукции сторонними организациями, а доля от продаж, подлежащая передаче в государственный бюджет, остаётся значительной. При этом стоит отметить, что недавно Министерство торговли США отозвало законопроект, ограничивавший новый порядок экспорта ИИ-чипов в любую точку мира без разрешения американских властей.
18.03.2026 [08:44], Сергей Карасёв
NVIDIA выпустила однослотовый ускоритель RTX Pro 4500 Blackwell Server Edition с 32 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 4500 Blackwell Server Edition, подходящий для решения таких задач, как ИИ-инференс, анализ данных, обработка видеоматериалов и пр. Новинка ориентирована на дата-центры, облачные платформы и периферийные инфраструктуры. Решение выполнено на архитектуре Blackwell. Конфигурация включает 10 496 ядер CUDA, 82 ядра RT четвёртого поколения, а также 32 Гбайт GDDR7 с 256-бит шиной и пропускной способностью 800 Гбайт/с. Задействованы тензорные ядра пятого поколения, которые обеспечивают до трёх раз более высокую производительность по сравнению с более ранними изделиями и предлагают поддержку режима FP4. Карта получила однослотовое исполнение FHFL и пассивное охлаждение. Заявленное энергопотребление составляет 165 Вт. Для подключения служит интерфейс PCIe 5.0 x16. ИИ-быстродействие на операциях FP4 (Tensor Core) достигает 1,6 Пфлопс, FP8 (Tensor Core) — 811 Тфлопс, FP16/BF16 (Tensor Core) — 406 Тфлопс, TF32 (Tensor Core) — 203 Тфлопс. Как отмечает NVIDIA, по сравнению с системами, работающими только на основе CPU, ускоритель RTX Pro 4500 Blackwell Server Edition обеспечивает до 100 раз более высокую производительность при анализе видеоматериалов с помощью алгоритмов ИИ. Благодаря этому компании могут извлекать данные из видеопотока в режиме реального времени, ускоряя работу приложений компьютерного зрения — как в ЦОД, так и на периферии. 
Источник изображения: NVIDIA Предусмотрены три аппаратных движка NVIDIA NVENC девятого поколения. Они имеют поддержку кодирования 4:2:2 H.264 и HEVC, а также улучшают качество при работе с HEVC и AV1. Вместе с тем три движка NVIDIA NVDEC шестого поколения демонстрируют вдвое более высокую пропускную способность при декодировании материалов H.264, а также поддерживают 4:2:2 H.264 и HEVC.
17.03.2026 [19:23], Руслан Авдеев
Amazon и NVIDIA расширят сотрудничество: в течение года AWS развернёт более 1 млн ИИ-ускорителей NVIDIAAWS и NVIDIA анонсировали расширение технологического сотрудничества. Речь идёт о взаимодействии в сфере ускоренных вычислений, технологий интерконнекта, настройки ИИ-моделей и инференса. План включают развёртывание AWS в облачных регионах по всему миру более 1 млн новых ИИ-ускорителей NVIDIA, в т.ч. семейств Blackwell и Rubin, и сетевых технологий NVIDIA Spectrum. Ведётся подготовка к запуску новых инстансов EC2 на основе ускорителей NVIDIA RTX Pro 4500 Blackwell Server Edition. AWS стала первым крупным облачным провайдером, анонсировавшим поддержку этих ускорителей. Эти инстансы предназначены для аналитики, «говорящих» ИИ-систем, генерации контента, рекомендательных систем, видеостриминга, видеорендеринга и др. Они будут построены на архитектуре AWS Nitro С ростом инфраструктуры ключевой проблемой становится взаимодействие между ускорителями NVIDIA и AWS Trainium. Компании объявили о поддержке NVIDIA Inference Xfer Library (NIXL) и AWS Elastic Fabric Adapter (EFA), что позволяет ускорить распределённый инференс ИИ-моделей на EC2. Подобная архитектура распределённого инференса позволяет эффективно совмещать вычисления и передачу данных, снижать задержки и максимизировать использование ИИ-ускорителей. NIXL с EFA интегрируются с популярными открытыми фреймворками, включая NVIDIA Dynamo, vLLM и SGLang. 
Источник изображения: AWS Дополнительно AWS и NVIDIA объявили об использовании Apache Spark в конфигурации Amazon EMR на Amazon EKS с инстансами G7e на основе ускорителей NVIDIA RTX Pro 6000 Blackwell, что втрое ускорит аналитику данных. При этом сохраняется совместимость с имеющимися приложениями Spark. Наконец, компании объявили о расширении поддержки ИИ-моделей NVIDIA Nemotron в Amazon Bedrock с адаптацией моделей для юриспруденции, здравоохранения, финансов и других специализированных областей. Вся инфраструктура управляется Bedrock, что значительно упрощает задачи разработчиков. Вскоре ожидается появление гибридной MoE-модели NVIDIA Nemotron 3 Super для финансовых сервисов, кибербезопасности, ретейла, разработки ПО и др. В целом компании создали полный стек ИИ-инфраструктуры — от ИИ-ускорителей и сетей до управляемых сервисов. Это позволит клиентам быстрее внедрять ИИ-решения, не конструируя инфраструктуру из разрозненных компонентов. Как сообщает Datacenter Dynamics, в феврале 2026 года глава AWS Мэтт Гарман (Matt Garman) заявил, что компания всё ещё использовала устаревшие ускорители NVIDIA A100 в некоторых серверах, поскольку спрос был высок даже на них. Широкий доступ к NVIDIA Blackwell Ultra появился в декабре 2025 года, в скором будущем планируется организовать доступ и к ускорителям Rubin. В то же время компания намерена инвестировать в собственные ускорители Trainium. В феврале OpenAI объявила, что будет использовать 2 ГВт мощностей на основе Trainium и других ускорителей в облаке AWS, во многом благодаря $50 млрд инвестиций со стороны Amazon.
17.03.2026 [10:32], Руслан Авдеев
NVIDIA анонсировала Space-1 Vera Rubin Module — ИИ-ускоритель для орбитальных ЦОД, который в 25 раз быстрее H100Глава NVIDIA Дженсен Хуанг (Jensen Huang) представил космический вычислительный модуль на архитектуре Vera Rubin. По его словам, модуль до 25 раз производительнее, чем NVIDIA H100, и шесть коммерческих космических компаний уже внедрили платформу, сообщает Tom’s Hardware. Space-1 Vera Rubin Module предназначен для орбитальных дата-центров, работающих с ИИ-моделями непосредственно в космосе. Он имеет тесно интегрированную архитектуру CPU–GPU и высокоскоростной интерконнект для работы с большими потоками данных от космических инструментов в режиме реального времени. Также предлагается вариант NVIDIA IGX Thor для критически важных периферийных сред с поддержкой выполнения ИИ-задач в режиме реального времени, безопасной загрузки, автономных операций и др. Наиболее компактный вариант NVIDIA Jetson Orin рассчитан на использование в спутниках с ограниченными размерами, весом и энергопотреблением — для систем бортового «зрения», навигации и обработки данных с датчиков. По данным NVIDIA, сейчас её новые платформы на Земле и в космосе используют компании Aetherflux, Axiom Space, Kepler Communications, Planet Labs PBC, Sophia Space и Starcloud. Kepler внедряет Jetson Orin в своей спутниковой группировке для управления данными и их маршрутизацией с помощью ИИ-инструментов. Jetson Orin применяется непосредственно в спутниках. 
Источник изображения: NVIDIA В октябре 2025 года основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) прогнозировал, что через 10–20 лет на орбите появятся ЦОД гигаваттного масштаба. Основными преимуществами таких решений назывались возможность непрерывного электроснабжения группировки с помощью солнечной энергии, а также упрощённая система охлаждения в космосе. Starcloud уже строит специальные орбитальные ИИ-ЦОД, предназначенные для обучения моделей и инференса непосредственно на орбите. Космические ЦОД — весьма перспективное направление в сфере ИИ. Одним из наиболее громких событий стала заявка SpaceX, попросившей у американских властей разрешение на вывод на орбиту миллиона микро-ЦОД. Инициатива подверглась критике Amazon как «спекулятивная», но компания столкнулась с критикой Федеральной комиссии по связи с США, потребовавшей навести порядок в собственном космическом бизнесе.
17.03.2026 [10:21], Сергей Карасёв
NVIDIA представила серверные Arm-процессоры Vera с 88 ядрами Olympus для ИИ и не толькоNVIDIA анонсировала процессоры Vera, спроектированные с прицелом на современные ресурсоёмкие задачи в области ИИ. Изделия, как утверждается, обеспечивают исключительную производительность каждого ядра, а также высокую пропускную способность памяти и коммутационной сети. В основу Vera положены ядра Olympus — это первые CPU-решения NVIDIA, специально разработанные для дата-центров. Olympus используют интерфейс выборки и декодирования шириной в 10 инструкций, а также нейронный алгоритм предсказания ветвлений, позволяющий оценивать два варианта ветвления за каждый цикл. Изделие полностью совместимо с набором инструкций Arm v9.2 и существующим ПО. 
Источник изображений: NVIDIA Конфигурация Vera предусматривает наличие 88 ядер Olympus с возможностью одновременной обработки до 176 потоков инструкций. Объём кеша L3 составляет 162 Мбайт. Задействована шина NVIDIA Scalable Coherency Fabric (SCF) второго поколения, первоначально разработанная для CPU Grace. В составе процессора SCF отвечает за связь вычислительных ядер Olympus с общим кешем L3 и подсистемой памяти, обеспечивая стабильную задержку и пропускную способность на уровне 3,4 Тбайт/с: это позволяет использовать более 90 % пиковой пропускной способности памяти под нагрузкой. Каждому ядру Olympus доступна полоса до 14 Гбайт/с, что примерно в три раза превышает пропускную способность на ядро в традиционных CPU для дата-центров, говорит NVIDIA. 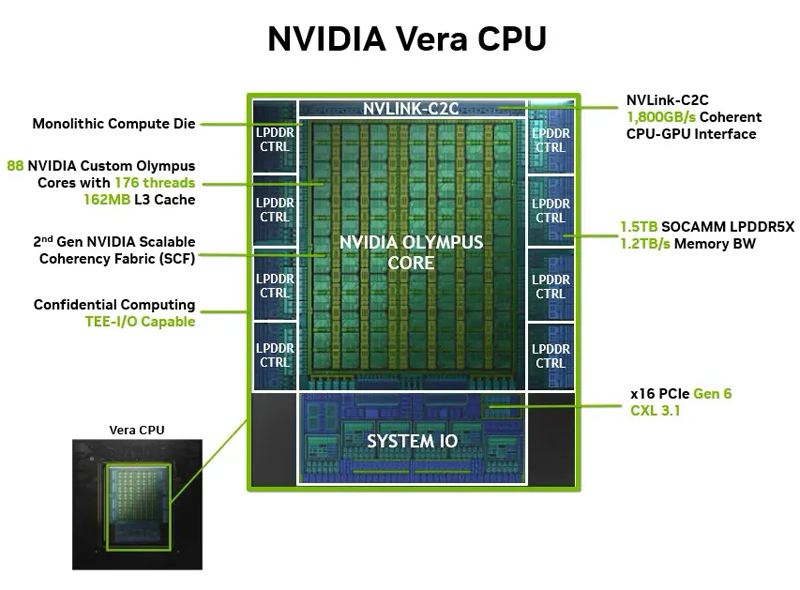 В составе Vera применяется подсистема памяти LPDDR5X на основе модулей SOCAMM. Суммарная ёмкость может составлять до 1,5 Тбайт, что втрое больше по сравнению с решениями предыдущего поколения. Пропускная способность памяти достигает 1,2 Тбайт/с, тогда как энергопотребление составляет менее 50% по сравнению с традиционными конфигурациями DDR. При этом модули SOCAMM являются заменяемыми, что упрощает модернизацию и обслуживание систем.  Процессор Vera выполнен на основе единого монолитного вычислительного кристалла. Каждое ядро обеспечивается единообразной пропускной способностью. Большинство операций, чувствительных к задержкам, выполняются локально, что позволяет минимизировать межкристальный трафик, который обычно присутствует в традиционных CPU. В целом, как утверждается, реализованные архитектурные особенности позволяют чипам Vera демонстрировать до 1,5 раз более высокую производительность одного ядра по сравнению с конкурирующими решениями x86 при выполнении задач в песочнице с максимальной нагрузкой на сокет. 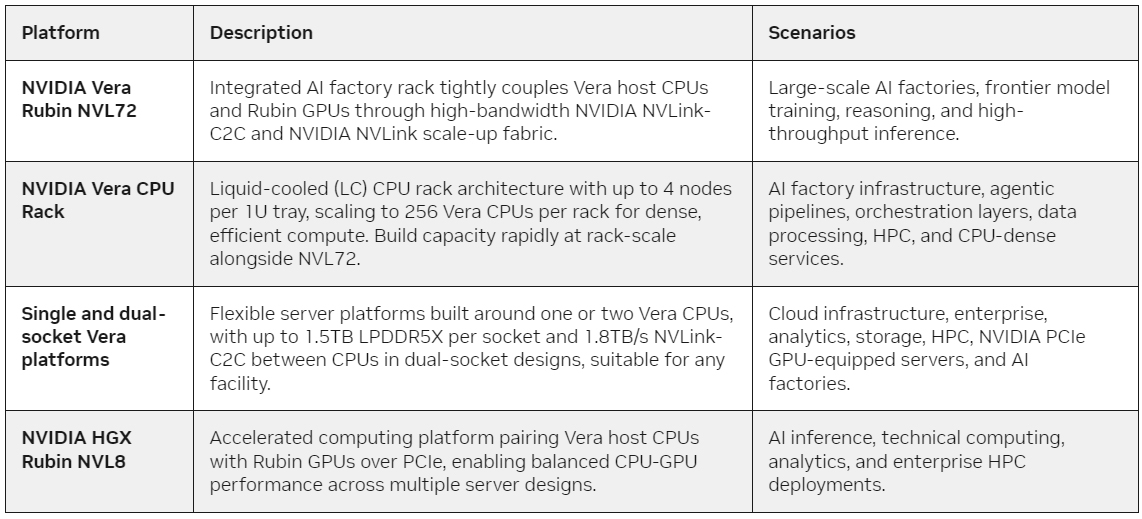 NVIDIA разработала семейство платформ на базе Vera для решения разнообразных задач в сфере ИИ. Это, в частности, CPU-стойки с жидкостным охлаждением, а также системы с ускорителями Rubin. Устройства на базе Vera будут поставляться крупными OEM-производителями, включая Cisco, Dell, HPE, Lenovo и Supermicro. Такие машины станут доступны во II половине текущего года.
17.03.2026 [02:00], Владимир Мироненко
ИИ-ускорители Groq прописались в платформе NVIDIA Vera RubinNVIDIA объявила о том, что платформа Vera Rubin, объединяющая теперь уже семь различных чипов (ещё в январе их было шесть), которые вместе откроют новые горизонты агентного ИИ, запущена в производство. Платформа включает Arm-процессоры Vera, ускорители Rubin, интерконнект NVLink 6, адаптеры ConnectX-9 SuperNIC и DPU BlueField-4, а также Ethernet-коммутаторы Spectrum/Quantum-6. Седьмым чипом стал LPU Groq 3 — NVIDIA купила Groq за рекордные $20 млрд всего три месяца назад и активно наращивает производство LPU. Благодаря такому сочетанию компонентов платформа обеспечивает обработку ИИ-нагрузок на всех этапах — от масштабного предварительного обучения, постобучения и масштабирования во время тестирования до инференса агентных задач в реальном времени, говорит NVIDIA. «Vera Rubin — это скачок в развитии — семь прорывных чипов, пять стоек, один гигантский суперкомпьютер — созданный для обеспечения всех этапов работы ИИ», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. Он отметил, что с появлением Vera Rubin в развитии агентного ИИ наступил переломный момент, положившей начало «крупнейшему в истории развёртыванию инфраструктуры». 
Источник изображений: NVIDIA «Платформа NVIDIA Vera Rubin предоставляет нам вычислительные ресурсы, сетевые возможности и системную архитектуру, позволяющие продолжать работу, одновременно повышая безопасность и надёжность, на которые полагаются наши клиенты», — подтвердил Дарио Амодеи (Dario Amodei), генеральный директор и соучредитель Anthropic. «Инфраструктура NVIDIA — это основа, которая позволяет нам расширять границы ИИ, — заявил Сэм Альтман (Sam Altman), генеральный директор OpenAI. — С NVIDIA Vera Rubin мы будем запускать более мощные модели и агентов в огромных масштабах и предоставлять более быстрые и надёжные системы сотням миллионов людей». Как отметила компания, Vera Rubin предлагает самую обширную комплексную ИИ-платформу — суперкомпьютер с множеством стоек, специально разработанных для ИИ, работающих как одна массивная, целостная система. NVIDIA Vera Rubin NVL72 обеспечивает высокую эффективность в обучение больших MoE-моделей с использованием вчетверо меньшего количества ускорителей по сравнению с платформой Blackwell и достижение до 10 раз большей пропускной способности инференса на ватт при в десять раз меньшей стоимости токена.  CPU-стойка Vera — это высокоплотная MGX-платформа с СЖО, объединяющая 256 процессоров Vera для обеспечения масштабируемой, энергоэффективной производительности с первоклассной однопоточной обработкой, что обеспечивает возможности для масштабируемого агентного ИИ. Стойки Vera имеют тесную синхронизацию сред во всей ИИ-фабрике. Вместе со стойками Rubin они обеспечивают основу крупномасштабных систем агентного ИИ и обучения с подкреплением — при этом Vera обеспечивает результаты в два раза эффективнее и наполовину быстрее, чем традиционные CPU (впрочем, в NVL8 по-прежнему будут Intel Xeon). Стойки Groq 3 LPX (тоже с СЖО и тоже на базе MGX) и Vera Rubin, разработанные для обеспечения низкой задержки и обработки больших контекстов, необходимых для агентных систем, обеспечивают до 35 раз более высокую пропускную способность инференса на мегаватт и до 10 раз больший потенциал дохода для моделей с триллионами параметров. В масштабе предприятия парк LPU функционирует как единый гигантский процессор для быстрого и детерминированного ускорения инференса.  Стойка LPX с 256 LPU-чипами имеет 128 Гбайт SRAM с агрегированной пропускной способностью 640 Тбайт/с. В сочетании с Vera Rubin NVL72 чипы LPU повышают эффективность декодирования, совместно вычисляя каждый слой модели ИИ для каждого выходного токена. Всё это позволяет работать с моделями с триллионами параметров и контектсным окном в миллионы токенов, сохраняя максимальную эффективность по энергопотреблению, памяти и вычислительным ресурсам. Любопытно, что Rubin CPX в этот раз NVIDIA решила особо не упоминать. Анонсированная вместе с Vera Rubin СХД BlueField-4 STX разработана специально для ИИ-нагрузок, обеспечивая бесперебойное расширение памяти GPU по всему POD-кластеру. Впрочем, теперь компания говорит, что BlueField-4 включает CPU Vera, а не Grace, и ConnectX-9 SuperNIC. STX обеспечивает высокоскоростной общий слой данных, оптимизированный для хранения и извлечения больших объёмов KV-кеша, генерируемых LLM и рабочими процессами агентного ИИ. А программная платформа DOCA Memos позволяет использовать выделенное KV-хранилище для увеличения пропускной способности инференса до пяти раз, также повышая энергоэффективность по сравнению с архитектурами хранения общего назначения.  Также NVIDIA совместно с более чем 200 партнёрами анонсировала платформу NVIDIA DSX для Vera Rubin, которая включает технологию DSX Max-Q, позволяющую динамически управлять питанием всей ИИ-фабрики целиком, позволяя увеличить на 30 % ИИ-инфраструктуру в ЦОД при том же энергопотреблении. ПО DSX Flex обеспечивает ИИ-фабрикам гибкость в работе с энергосетями, позволяя освоить до 100 ГВт неиспользуемой мощности сетей. Кроме того, NVIDIA выпустила эталонный проект Vera Rubin DSX AI Factory — схему для совместно разработанной ИИ-инфраструктуры, которая максимизирует количество токенов на ватт и общую пропускную способность, повышая отказоустойчивость системы и ускоряя развётывание. 
В Microsoft Azure появились первые Vera Rubin (Источник изображения: X/@satyanadella) Продукты на базе Vera Rubin будут доступны у партнёров NVIDIA, начиная со II половины этого года. В их число входят гиперскейлеры AWS, Google Cloud, Microsoft Azure и Oracle Cloud, а также партнёры NVIDIA Cloud — CoreWeave, Crusoe, Lambda, Nebius, Nscale и Together AI. Ожидается, что широкий спектр серверов на базе продуктов Vera Rubin будут поставлять глобальные производители систем Cisco, Dell Technologies, HPE, Lenovo и Supermicro, а также Aivres, ASUS, Foxconn, GIGABYTE, Inventec, Pegatron, Quanta Cloud Technology (QCT), Wistron и Wiwynn.
13.03.2026 [14:12], Руслан Авдеев
Китайская ByteDance обойдёт санкции США и получит доступ к чипам NVIDIA B200 на $2,5 млрдМатеринская компания TikTok — китайская ByteDance — получила доступ к современным американским ускорителям NVIDIA. Она обошла введённые властями США ограничения на доступ к технологиям, заключив соглашение с Aolani Cloud из Юго-Восточной Азии, сообщает The Wall Street Journal. В Малайзии для ByteDance будет развёрнуто около 36 тыс. ИИ-ускорителей NVIDIA B200. Источники сообщают, что Aolani закупает серверы у компании Aivres, занимающейся их сборкой. Последняя, по словам HPE, фактически принадлежит Inspur и уже давно поставляет подсанкционное оборудование в КНР и другие страны. Стоимость оборудования, вероятно, составит более $2,5 млрд. При этом Aolani сообщает, что пока располагает оборудованием на сумму $100 млн. Источники сообщают, что ByteDance намерена организовать исследования в сфере ИИ за пределами КНР и удовлетворить спрос клиентов со всего мира на решения на основе искусственного интеллекта. Уже сегодня она предлагает обычным пользователям разнообразные ИИ-приложения, бросая вызов Google, OpenAI и другим американским компаниям; четверть выручки уже поступает из-за пределов Китая. Так, она разработала более десятка приложений с ИИ-функциями, включая китайские и глобальные версии. 
Источник изображения: Esmonde Yong/unspalsh.com Согласно январскому рейтингу Andreessen Horowitz, компания курирует 5 из 50 наиболее популярных в мире пользовательских ИИ-приложений по количеству ежемесячных активных пользователей. В ByteDance работают команды исследователей в филиалах в Сингапуре и даже США. Напряжённость в отношениях между США и Китаем мешает бизнесу ByteDance: в январе компании пришлось передать американское подразделение TikTok под контроль «дружественно настроенным» к США инвесторам. Более трёх лет китайские технобизнесы имеют дело с американским экспортным контролем, не позволяющим напрямую продавать Китаю передовые ИИ-чипы вроде моделей серии Blackwell. Для развития технологий китайские компании вынуждены тратить всё больше средств на доступ к вычислительным мощностям за рубежом, благодаря чему возникла целая индустрия посредников, строящих ЦОД на продуктах NVIDIA для сдачи в аренду китайским клиентам. По имеющимся данным, в конце 2023 года инвесторы создали компанию Aolani с материнским холдингом на Каймановых островах. В числе инвесторов — сингапурская K3 Ventures. Aolani является приоритетным облачным партнёром NVIDIA, имеющим доступ к её новейшим чипам. С февраля 2025 года Aolani сдаёт ByteDance в аренду ИИ-серверы в Малайзии на основе ускорителей NVIDIA H100. За ускорители Blackwell компания ByteDance уже внесла предварительные платежи. Они будут развёрнуты в Малайзии. Помимо Малайзии, компания намерена создать мощности в Южной Корее, Австралии и Европе. 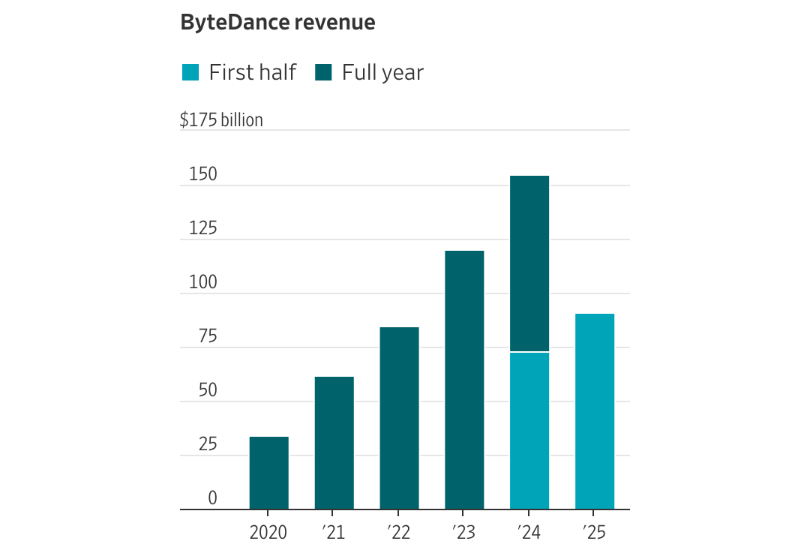
Источник изображения: Bloomberg Подчёркивается, что бизнес сотрудничает с американской юридической компанией, чтобы соответствовать американским требованиям. По мнению юристов, изменения правовых норм будут носить «перспективный, а не ретроспективный характер». Отмечается, что Aolani соблюдает все правила экспортного контроля, а ускорители не передаются клиентам и те не имеют на них никаких прав. В NVIDIA также придерживаются позиции, что американские правила экспорта позволяют создавать облачные сервисы вне стран, подпадающих под ограничения, вроде Китая, а сам вендор проверял всех облачных партнёров, прежде чем продавать чипы прямо или косвенно. По информации The Wall Street Journal, ByteDance вела переговоры об использовании ИИ-серверов с более чем 7 тыс. B200 в ЦОД в Индонезии, а Reuters сообщает, что компания также вела переговоры с США о разрешении покупки ускорителей NVIDIA H200, но её не удовлетворили условия их использования. Ещё в 2024 году сообщалось, что китайские компании нашли лазейку в законах США для доступа к передовым ИИ-ускорителям и моделям в облаках AWS и Azure, причём на территории самих Соединённых Штатов. Также в конце 2025 года появилась информация, что китайская INF Tech обошла санкции США на доступ к ускорителям NVIDIA Blackwell через индонезийское облако.
12.03.2026 [10:05], Руслан Авдеев
NVIDIA инвестирует в Nebius $2 млрд в рамках стратегического партнёрства в сфере ИИ ЦОДNVIDIA объявила о намерении инвестировать $2 млрд в компанию Nebius Group в рамках стратегического партнёрства, предусматривающего разработку и строительство ИИ ЦОД, сообщает Bloomberg. В последние дни новости об очередных миллиардных инвестициях NVIDIA публикуются почти регулярно. В этот раз NVIDIA потратит средства на Nebius в рамках стратегического партнёрства — фактически компания нередко вкладывает средства в бизнесы, покупающие её ускорители. Базирующаяся в Амстердаме Nebius к концу 2030 года намерена внедрить более 5 ГВт систем на решениях NVIDIA. Речь идёт о сотрудничестве, касающемся полного стека ИИ-технологий — от разработки архитектуры ИИ-фабрик до взаимодействия в сфере программного обеспечения. Это позволит Nebius ускорить строительство передовой облачной платформы. Nebius активно внедряет технологии NVIDIA на глобальном уровне, включая строительство многочисленных ИИ-фабрик гигаваттного уровня в США. Чтобы Nebius смогла обеспечить более 5 ГВт к концу 2030 года, NVIDIA поддержит раннее внедрение компанией своих ИИ-ускорителей новейшего поколения. 
Источник изображения: NVIDIA В рамках партнёрства предусмотрено несколько векторов взаимодействия:
NVIDIA нередко использует свои, почти неисчерпаемые финансовые ресурсы для финансирования расширения ИИ-инфраструктуры на своих чипах. Это уже вызвало критику экспертов, допускающих, что такие циркулярные инвестиции способствуют возникновению пузыря на рынке ИИ. В январе 2026 года NVIDIA анонсировала вложение $2 млрд в конкурента Nebius — компанию CoreWeave для внедрения своих продуктов, а совсем недавно NVIDIA поддержала развёртывание 1 ГВт мощностей стартапом Thinking Machines Lab. Неооблачный провайдер Nebius появился после раскола «Яндекса» и продажи его российской части бизнеса в 2024 году за $5,2 млрд российским покупателям. В конце того же года Nebius привлекла $700 млн от группы инвесторов, включавшей NVIDIA. По состоянию на конец 2024 года NVIDIA владела акциями компании на сумму $33 млн. Совсем недавно IT-гигант выделил ещё $4 млрд на связанные с ИИ проекты. NVIDIA инвестировала по $2 млрд в поставщиков лазеров и фотоники для ИИ ЦОД — компании Lumentum и Coherent.
11.03.2026 [09:39], Руслан Авдеев
Thinking Machines Lab развернёт 1 ГВт мощностей на основе Vera Rubin при поддержке NVIDIANVIDIA заключила соглашение с Thinking Machines Lab о развёртывании оборудования на основе ускорителей Vera Rubin мощностью не менее 1 ГВт. Проект будет реализован для поддержки обучения передовых моделей стартапа, сообщает Datacenter Dynamics. Глава NVIDIA Дженсен Хуанга (Jensen Huang) заявил, что ИИ — мощнейший инструмент познания в истории человечества, и компания рада сотрудничать с Thinking Machines для воплощения в жизнь захватывающего видения будущего ИИ, предложенного стартапом. NVIDIA также добавила, что вложила в Thinking Machines значительные средства. Кроме того, в рамках партнёрства компании намерены совместно разрабатывать системы обучения, оптимизированные для архитектуры NVIDIA, а также расширять доступ к передовым ИИ-моделям. Где и когда будет развёрнуто оборудование, объявят позже; финансовые подробности сделки также пока не раскрываются. NVIDIA сообщила, что развёртывание оборудования на основе Vera Rubin планируется в начале 2027 года. 
Источник изображения: NVIDIA Thinking Machines, основанная в феврале 2025 года бывшим техническим директором OpenAI Мирой Мурати (Mira Murati), по данным самой компании, разрабатывает «мультимодальные системы, работающие совместно с людьми» — в противовес полностью автономным ИИ-системам, над которыми работают другие ИИ-компании. В октябре 2025 года Thinking Machines анонсировала так называемый API Tinker — он разработан для упрощения тонкой настройки open source-моделей. По данным Reuters, на июль 2025 года компания привлекла $2 млрд инвестиций от NVIDIA, AMD, Cisco и других инвесторов; её капитализация составляла $12 млрд. Впрочем, не всё идёт гладко: в январе она лишилась двух соучредителей, которые предпочли вернуться в OpenAI. При этом NVIDIA активно инвестирует и в OpenAI — недавно стороны договорились о вложении в последнюю $30 млрд в обмен на её акции.
10.03.2026 [17:49], Владимир Мироненко
Groq увеличил заказ на производство ИИ-чипов у Samsung более чем в 1,5 разаИИ-стартап Groq, приобретённый NVIDIA за $20 млрд, направил Samsung Electronics запрос на увеличение производства своих чипов, сообщил Chosunbiz со ссылкой на информированные источники. Источники утверждают, что Groq недавно принял решение увеличить производство ИИ-чипов, которое в прошлом году было передано на аутсорсинг подразделению Samsung Electronics, с примерно 9 тыс. пластин до примерно 15 тыс. Если в прошлом году объём производства был ограничен изготовлением опытных образцов чипов для определения их эффективности при использовании для ИИ-инференса, то в этом году, судя по объёму, Groq находится на ранней стадии массового производства для выхода на коммерческие рельсы. 
Источник изображения: Groq Как отметил Chosunbiz, хотя объём поставок Groq для Samsung Electronics невелик, подразделение Samsung Electronics активно работает с потенциальными клиентами, чтобы заложить основу для получения крупных заказов на поставку ИИ-чипов. Помимо Groq, подразделение Samsung Electronics также производит весь ассортимент процессоров для HyperExcel — южнокорейского стартапа по разработке чипов для ИИ-инференса. Samsung Electronics производит ИИ-чипы для Groq и HyperExcel по 4-нм техпроцессу. По словам источника в полупроводниковой отрасли, «4-нм техпроцесс, используемый Samsung Electronics для массового производства чипов Groq для ИИ-нагрузок, включает ряд улучшенных процессов для повышения производительности чипа. Учитывая высокую стоимость процесса и самый высокий спрос в отрасли на 4–5-нм техпроцессы, это также имеет важное значение для обеспечения конкурентного преимущества перед TSMC». Собеседник ресурса Chosunbiz прогнозирует, что с учётом выхода NVIDIA на рынок ИИ-чипов и увеличения производства Groq ожидается бурный рост рынка чипов для ИИ-инференса. Ожидается, что на мероприятии GTC 2026 NVIDIA представит чип для ИИ-инференса на основе дизайна, разработанного Groq, в котором используется память SRAM вместо HBM. Как сообщают источники, одним из заказчиков нового чипа будет OpenAI. |
|

