Материалы по тегу: nvidia
|
10.04.2026 [13:53], Руслан Авдеев
Bridge Data Centres выгнала из своих ЦОД сингапурское ИИ-неооблако Megaspeed, подозреваемое в нарушении антикитайских санкций СШАПодконтрольный американской инвесткомпании Bain Capital оператор ЦОД Bridge Data Centres (BDC) отказал в размещении на своём объекте в Малайзии облачному провайдеру Megaspeed из Юго-Восточной Азии, которого США подозревают в незаконном предоставлении чипов NVIDIA Китаю, сообщает Bloomberg. Как сообщают знакомые с ситуацией источники, компанию Megaspeed International на объекте в Малайзии заменит облачный провайдер Zenlayer. Об этом свидетельствует служебная записка, направленная Bridge Data Centres своим кредиторам в феврале. Причина замены не называется, но источники сообщают, что оператор ЦОД пошёл на разрыв отношений с Megaspeed после того, как США инициировали расследование относительно структуры собственности компании, желая выяснить, не занималась ли она организацией доступа к передовым ИИ-чипам NVIDIA для Китая в нарушение американских экспортных ограничений. Для Megaspeed одним из ключевых вопросов является судьба ИИ-серверов на основе ускорителей NVIDIA, обнаруженных на объектах Bridge Data Centres прошлой осенью. Сингапурская Megaspeed является неооблачным ИИ-провайдером, объект в Малайзии был её крупнейшим активом. Megaspeed была сформирована в 2023 году путём отделения от китайской игровой компании. NVIDIA отказалась сообщать, известно ли ей об инциденте с участием BDC и посещали ли её представители объекты Megaspeed в последние месяцы в этом регионе. В 2025 году производитель проводил выборочные проверки Megaspeed в Юго-Восточнйо Азии. В декабре сообщалось, что компания намерена снова проверить бизнес «в ближайшем будущем». BDC объявила, что все 68,4 МВт мощности ЦОД, зарезервированные для Megaspeed, передадут облачному провайдеру Zenlayer из Лос-Анджелеса. Он специализируется на обучении ИИ-моделей. 
Источник изображения: Hongwei FAN/unspalsh.com BDC считается одним из крупнейших операторов ЦОД в Азии, куда, по прогнозам экспертов, к 2030 году инвестируют к 2030 году около $800 млрд. Кредиты — ключевое средство финансирования масштабирования BDC, поэтому компания должна демонстрировать кредиторам стабильный приток средств от арендаторов. Чтобы развиваться дальше, Bridge Data Centres нужны миллиарды долларов. Минувшей зимой она начала привлекать дополнительный капитал. В марте оператор ЦОД вёл переговоры о привлечении $6 млрд для выхода на рынок Таиланда, тогда же компания намеревалась удвоить существующий кредит для расширения в Малайзии до $5 млрд. По данным Datacenter Dynamics, Megaspeed отрицает участие в любом нелегальном трафике чипов и сдаче в аренду вычислительных мощностей киатйским структурам. По словам её представителей, компания неоднократно проходила проверки со стороны американских и малайзийских властей, а также NVIDIA. Ранее она подчёркивала, что информация СМИ вводит в заблуждение, а сама компания действует строго в рамках всех правил экспортного контроля, в соответствии с самыми высокими «юридическими и этическими стандартами». Ещё несколько лет назад сообщалось, что китайские компании нашли лазейку в законах США для доступа к передовым ИИ-ускорителям и моделям в облаках AWS и Azure, а позже появилась информация, что Alibaba и ByteDance начали тренировать передовые ИИ-модели в ЦОД Юго-Восточной Азии. Тем не менее, в начале 2026 года в США принят «Закон о безопасности удалённого доступа» (Remote Access Security Act), расширяющий действие «Закона о реформе экспортного контроля». Это позволяет федеральным властям США «ограничивать возможности иностранных противников получать удалённый доступ к технологиям, включая ИИ-чипы, через облачные вычислительные сервисы». Другими словами, китайским компаниям запрещён доступ к передовым ускорителям в ЦОД и облаках за пределами КНР.
09.04.2026 [12:22], Руслан Авдеев
TrendForce: начало поставок NVIDIA Rubin задержится, а Hopper для Китая выпустят меньше, чем ожидалосьВысока вероятность, что поставки ИИ-ускорителей семейства NVIDIA Rubin начнутся позже, чем планировалось и в меньших объёмах, чем рассчитывали ранее. По данным The Register, это связано с вероятными проблемами с цепочками поставок. По словам экспертов TrendForce, на долю Rubin придётся 22 % всех поставок передовых ускорителей NVIDIA в 2026 году, хотя раньше в прогнозах речь шла о 29 %. Причинами называются задержки с проверкой новейшей памяти HBM4, применяемой с ускорителями, трудности с переходом на адаптеры NVIDIA ConnectX‑9, а также увеличение энергопотребления ИИ-систем и повышение требований к СЖО. Более того, будут ниже прежних прогнозов поставки ускорителей на архитектуре Hopper, включая модели H200, предназначенные для поставок в Китай. В январе 2026 года одобрили поставки в обмен на 25 % от выручки от продаж этих изделий. Пришлось уговаривать и сам Пекин, который одобрил импорт H200 в КНР лишь недавно. В марте глава NVIDIA Дженсен Хуанг (Jensen Huang) сообщил, что компания наращивает производственные мощности по выпуску H200 для Китая, и уже имеются заказы. 
Источник изображения: Jakub Żerdzicki/unsplash.com TrendForce прогнозирует, что в 2026 году доля поставок ускорителей Hopper составит 7 % от общего объёма поставок NVIDIA, это ниже 10 %, как ожидалось ранее. Впрочем, в TrendForce предполагают, что их место и место недопоставленных Rubin займут чипы Blackwell, включая Blackwell Ultra. На долю Blackwell, вероятно, придётся 71 % об общего объёма продаж ускорителей NVIDIA за 2026 год. Кроме того, TrendForce предрекает неплохие перспективы недавно анонсированным инференс-ускорителям NVIDIA LPU Groq, предназначенным для совместной работы с «классическими» GPU вроде Rubin. Впрочем, из-за ограничений встроенной SRAM-памяти такие модели понадобятся в больших количествах, говорит TrendForce, предрекая спрос в «сотни тысяч единиц» в 2026 году и приблизительно вдвое больше — в следующем. При этом эксперты подчёркивают, что во II квартале цены на DRAM могут вырасти на 45–50 % дополнительно, вдобавок к росту на 75–80 %, отмеченному в I квартале. В последние месяцы цена на память, включая продукты вроде DDR5 и SSD, стремительно растут, они более чем втрое дороже, чем стоили год назад. В значительной степени это обусловлено спросом на ИИ-инфраструктуру и высокой цикличностью ценообразования на рынках модулей памяти.
08.04.2026 [09:22], Владимир Мироненко
Стране нужен FP64: AMD пообещала повысить HPC-производительность ускорителей Instinct MI430XПосле анализа ограничений эмуляции FP64-вычислений с использованием схемы Озаки разработчики AMD пришли к выводу, что в настоящее время нет замены «сырой» производительности FP64. Как сообщил научный сотрудник AMD Николас Малайя (Nicholas Malaya) ресурсу HPCwire, чтобы обеспечить точность традиционных задач моделирования и симуляции, компания намерена нарастить нативную FP64-производительность ускорителя Instinct MI430X. Ускоритель станет основой суперкомпьютера Discovery, который будет установлен в Национальной лаборатории Ок-Ридж (ORNL) в 2028 году. Как отметил Кацухиса Озаки (Katsuhisa Ozaki) и два других японских исследователя, схема Ozaki — это многообещающая новая техника эмуляции, призванная позволить учёным выполнять высокоточные умножения матриц на оборудовании с поддержкой INT8/FP8, к которому относятся современные ИИ-ускорители, путём многократных вычислений с более низкой точностью. Текущие реализации Ozaki-I и Ozaki-II имеют ограничения, которые исключают их использование в реальных условиях, сообщил Малайя. Он указал на две основные проблемы. Во-первых, ПО не соответствует стандарту IEEE и не даёт того же результата, что и запуск кода на реальном оборудовании с поддержкой FP64. «В некоторых случаях это нормально, — сказал он. — Но во многих распространённых матрицах, которые мы наблюдали, влияние на точность довольно существенно.». Во-вторых, схема Озаки нацелена на квадратные матрицы. Если таковые в расчётах не используется, то итоговая производительность оказывается ниже, чем у нативного FP64-исполнения, говорит Малайя. 
Источник изображения: AMD Кроме того, HPC-приложения традиционно опираются на векторные вычисления, а не на тензорные или матричные, которые характерны для ИИ-нагрузок. Фактически ситуация ещё хуже — менее 10 % реальных HPC-приложений внесли изменения в DGEMM-коды, которые позволяют воспользоваться преимуществами Ozaki. «Насколько мне известно, с Ozaki-I, Ozaki-II или любой другой существующий метод нельзя применить к векторным инструкциям, — говорит Малайя. — Это ключевой нюанс, который, как мне кажется, упускается». На DGEMM действительно уходит много вычислительных ресурсов, что позволяет использовать схему Ozaki, «но она не решает 90 % HPC-задач». AMD собирается поддерживать эмуляцию Ozaki на своих чипах, сообщил Малайя. «Нет причин этого не делать. Это ПО. <…> И у вас могут быть библиотеки, которые позволяют динамически переключаться между нативными расчётами и Ozaki и, вероятно, оценивать его», — сказал он, добавив, что программную эмуляцию можно иметь в виду в качестве резервного варианта для FP64-вычислений. Но в конечном итоге Ozaki не является работоспособной альтернативой «железу» с FP64, сказал Малайя, уточнив, что не он один так считает. 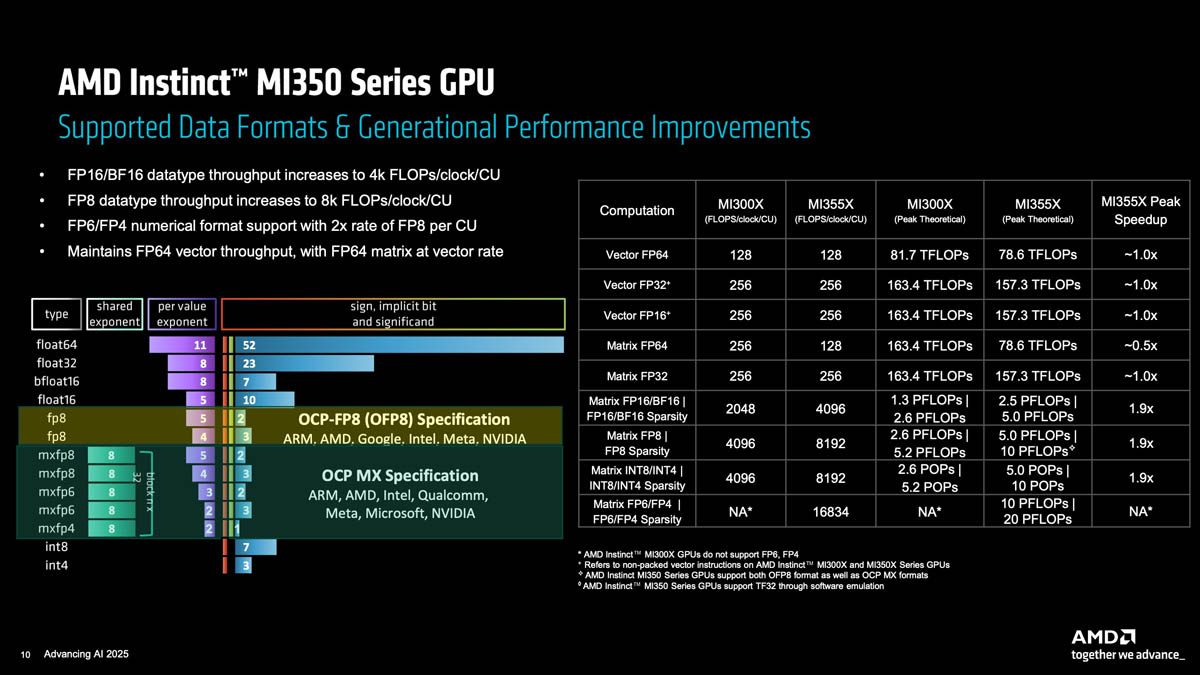
Источник изображения: AMD В настоящее время компания разрабатывает MI430X, специализированную версию ускорителя следующего поколения MI450, который будет обладать значительной FP64-производительностью. По словам Малайи, она будет значительно больше, чем у ускорителя MI355X, который обеспечивает 78,6 Тфлопс. По факту, это меньше, чем у предыдущей модели MI325X, которая обеспечивала 81,7 Тфлопс — в обоих случаях речь и про векторные, и про матричные FP64-вычисления. В любом случае, у всех этих чипов — от MI325 до MI430 — производительность больше, чем у чипов NVIDIA. И Hopper (34 Тфлопс), и Blackwell (40 Тфлопс) уже были медленнее в векторных FP64-вычислениях, но у Hopper хотя бы были нативные 67 Тфлопс в матричных расчётах, тогда как Blackwell в этом случае уже перешёл к схеме Озаки с «ненативными» 150 Тфлопс. Про Blackwell Ultra, где FP64-производительность упала до 1,3 Тфлопс, NVIDIA в данном контексте вообще не вспоминает, но обещает, что у Rubin будет 33 Тфлопс в векторных FP64-расчётах и 200 Тфлопс в матричных (тоже с Озаки). 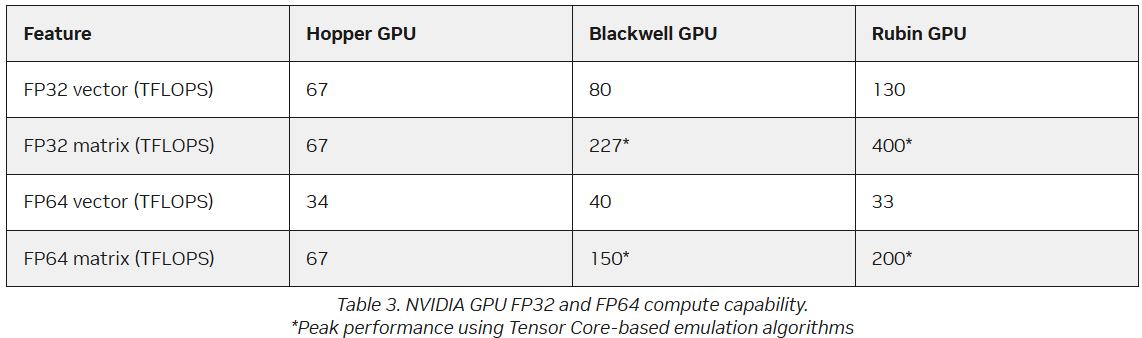
Источник изображения: NVIDIA NVIDIA обосновывает отказ от развития аппаратных FP64-блоков тем, что увеличение собственно вычислительной мощности FP64 на самом деле не ускорит научные приложения, поскольку на практике они упрутся в возможности регистров, кешей и HBM. Rubin обеспечит пропускную способность HBM до 22 Тбайт/с, что в 2,8 раза больше, чем у Blackwell. Instinct MI325X предлагает 6 Тбайт/с, MI355X — 8 Тбайт/с, а у MI430X будет уже 19,6 Тбайт/с, сообщил Малайя. По словам Малайи, лучше всего синхронно «вкладываться» и в HBM, и в количество операций с плавающей запятой. «На самом деле важен коэффициент байт/флопс. С нашей точки зрения, необходимо поддерживать гораздо более близкое соотношение к тому, что мы видим в современных продуктах, — сказал он. — Необходимо значительно приблизиться к этому соотношению с точки зрения увеличения производительности FP64, чтобы сохранить тот же уровень, как это называют, арифметической интенсивности». 
Источник изображения: NVIDIA Поскольку AMD обеспечит 2,5-кратное увеличение ПСП HBM от MI355 до MI430X, аналогичное 2,5-кратное увеличение производительности FP64 также будет оправдано. Таким образом можно примерно прикинуть, что MI430X может обеспечить производительность FP64 от 192 до 204 Тфлопс в зависимости от того, какой из них будет базовым: более новый MI355 или более быстрый MI325, сообщил HPCwire, добавив, что это всего лишь предположение, поскольку компания пока не сообщила точные характеристики будущих чипов. Кроме того, не до конца ясно, будет ли FP64-производительность одинакова для векторных и матричных расчётов. FP64-вычисления «очень важны» для «Миссии Генезис» (Genesis Mission), заявил ранее заместитель министра энергетики США (DoE) по науке и инновациям Дарио Гил (Darío Gil). Он отметил, что и глава AMD Лиза Су (Lisa Su), и глава NVIDIA Дженсен Хуанг (Jensen Huang), выразили твёрдую приверженность FP64, подтвердив, что поддержка формата будет продолжаться. «FP64 имеет решающее значение для поддержки рабочих нагрузок моделирования и симуляции, не только для дальнейшего развития традиционных научных исследований, но и для предоставления исходных данных для обучения новых ИИ-моделей», — добавил Гил. 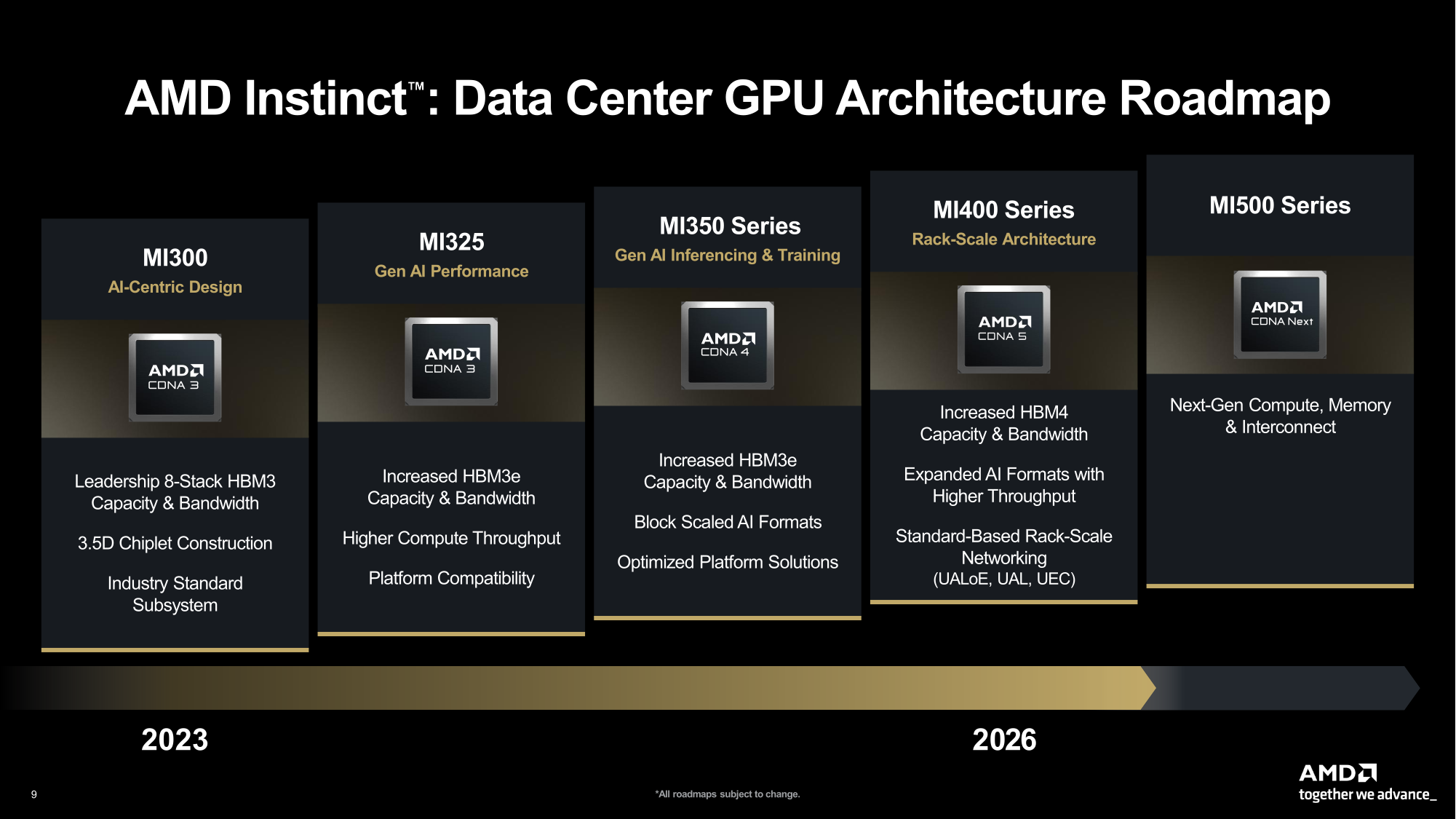
Источник изображения: AMD «Всегда существует баланс между тем, сколько требуется FP64- и FP16-вычислений», — сказал Малайя. «AMD утверждает, что нам необходимо поддерживать широкий спектр типов данных в зависимости от их потребностей. Не получится, чтобы всем были нужны FP64, которых хватит для всего.», — отметил он. Малайя сообщил, что всегда бывают исключения. Например, ИИ-симуляции сворачивания белков, такие как AlphaFold и Openfold, используют FP32. Да и некоторым традиционным HPC-задачам, таким как молекулярная динамика, не требуется FP64-точность. Тем не менее, сейчас существует значительный неудовлетворенный спрос на FP64, утверждает учёный. «Что касается высокопроизводительных вычислений, мы считаем, что им по-прежнему потребуется много FP64, — сказал он. — Будут использоваться некоторые коды, которые полностью ограничены пропускной способностью памяти, и им не нужно так много. Но есть, например, коды вычислительной химии и некоторые другие, которые действительно имеют высокую арифметическую интенсивность, и они будут использовать FP64».
07.04.2026 [17:25], Руслан Авдеев
Австралийское неооблако Firmus при поддержке NVIDIA привлекло $505 млн и нарастило капитализацию до $5,5 млрд в преддверии IPOСпециализирующаяся на строительстве и эксплуатации ИИ ЦОД австралийская Firmus Technologies, поддерживаемая NVIDIA, привлекла $505 млн инвестиции при оценке капитализации в $5,5 млрд. Средства получены в ходе нового раунда финансирования перед выходом на IPO на Австралийской фондовой бирже (ASX) в конце 2026 года, сообщает Silicon Angle. Основанная в 2019 году Firmus строит и эксплуатирует ИИ-инфраструктуру на базе кластеров ускорителей. Дата-центры компании оптимизированы для использования с аппаратными решениями NVIDIA. Это позволяет клиентам развёртывать стандартизированные среды как для обучения ИИ-моделей, так и для инференса. Системы распределения питания и охлаждения обеспечивают работу при высоких вычислительных нагрузках. Доступ к вычислительным мощностям Firmus обеспечен через управляемые инфраструктурные экосистемы, в которых развёртывание, настройка и текущая работа осуществляется в рамках единой платформы. Сегодня компания строит флагманский кампус за $1,37 млрд в Лонсестоне (Launceston) на севере Тасмании. Для ЦОД предусмотрено использование систем рециркуляции воды, АКБ, а также питание от местной ГЭС. Предполагается, что ЦОД получит 36 тыс. NVIDIA GB300. 
Источник изображения: Michael Jerrard/unspalsh.com Раунд финансирования возглавила Coatue Management при поддержке NVIDIA, играющей активную роль инвестора и стратегического партнёра. Полученные средства используют для масштабирования мощностей ЦОД: строительства новых объектов, развёртывания ИИ-ускорителей и создания необходимой инфраструктуры для энергоснабжения и охлаждения. В 2025 году компания уже привлекла порядка $715 млн, включая раунд на $327 млн в ноябре. В феврале она привлекла $10 млрд в кредит на строительство ИИ-фабрик Project Southgate. Минувший раунд был третьим и последним перед IPO в июне или июле. Оператор рассчитывает привлечь около $2 млрд дополнительных средств. Morgans Financial и Morgan Stanley представят информацию потенциальным инвесторам в ближайшие дни. Если IPO состоится, оно станет одним из крупнейших в Австралии за текущее десятилетие, более того — одним из крупнейших в истории страны, если принимать в расчёт только технологические компании. Обычно австралийские технобизнесы предпочитают для IPO биржи вне континента. Firmus на этом фоне выглядит довольно белой вороной, решившей сделать ставку на Australian Stock Exchange. В конце марта сообщалось, что австралийские власти принимают меры по ужесточению контроля за развитием ИИ-инфраструктуры на территории страны. В частности, они внедряют новую систему, связывающую утверждение проектов новых ЦОД с вливаниями в энергетику, управлением ресурсами и влиянием дата-центров на внутреннюю экономику.
04.04.2026 [00:24], Владимир Мироненко
Соучредитель Supermicro с соучастником отрицают участие в контрабанде ИИ-чипов NVIDIA в КитайНа прошедших слушаниях в окружном суде США Южного округа Нью-Йорка (Манхэттен) соучредитель Supermicro И-Шьян Лиау (Yih-Shyan Liaw) отказался признать свою вину по обвинению в содействии незаконной поставке серверов NVIDIA на миллиарды долларов в Китай, сообщил Bloomberg. Аналогичным образом поступил внешний подрядчик Тин-Вэй Сунь (Ting-Wei Sun). Оба были арестованы, но И-Шьян вскоре был освобождён под залог в $5 млн, а Сунь находится под стражей, пока его адвокат обсуждает с прокуратурой условия освобождения под залог. Третий фигурант дела — Руэй-Цанг Чанг (Ruei-Tsang Chang), генеральный директор тайваньского офиса Supermicro, пока скрывается от правосудия. Всем троим предъявлено обвинение в сговоре с целью с целью контрабанды передовых чипов NVIDIA в Китай, что является нарушением Закона о реформе экспортного контроля. Согласно обвинительному заключению прокуратуры Южного округа Нью-Йорка, обвиняемые незаконно переправили в Китай под видом продажи неназванной компании-посреднику из Юго-Восточной Азии подсанкционного оборудования на $2,5 млрд. Ранее стало известно, что четыре китайских университета, связанных с Народно-освободительной армией Китая, каким-то образом смогли приобрести подсанкционные ИИ-серверы Supermicro. 
Источник изображения: Supermicro Это дело представляет собой самую громкую операцию по борьбе с предполагаемой контрабандой запрещённых к экспорту ИИ-технологий в Китай, отметил Bloomberg. После обнародования обвинений 19 марта акции Supermicro рухнули более чем на четверть, и в результате она потеряла $6 млрд рыночной стоимости. Соучредителя Supermicro И-Шьян Лиау вывели из совета директоров, а акционеры подали на компанию в суд, обвинив её в мошенничестве с ценными бумагами в связи с сокрытием зависимости от незаконных поставок в Китай. Ранее компания попалась на незаконных поставках оборудования в Иран. Возглавляет судебный процесс «США против Лиау» окружной судья США Эдгардо Рамос (Edgardo Ramos), назначивший судебное заседания на 2 ноября. В случае признания виновными по обвинению в сговоре с целью нарушения Закона о реформе экспортного контроля фигурантом грозит максимальное тюремное заключение сроком на 20 лет. Также они обвиняются по одному пункту обвинения в сговоре с целью контрабанды товаров и по одному пункту в сговоре с целью обмана Соединённых Штатов, за каждый из которых предусмотрено максимальное тюремное заключение сроком на пять лет. Ни Supermicro, ни NVIDIA никаких обвинений не предъявлено.
03.04.2026 [16:28], Руслан Авдеев
От ИИ-стартапа Poolside разом отвернулись NVIDIA, CoreWeave и GoogleИИ-стартап Poolside пытается вести переговоры с облачными провайдерами, включая Google, в попытке найти нового партнёра для строительства 2-ГВт дата-центра Project Horizon в Техасе, сообщает Datacenter Dynamics. От компании отвернулись CoreWeave и NVIDIA, отказавшиеся финансировать развитие ИИ-инфраструктуры стартапа после срыва графиков. Poolside основана в 2023 году и разрабатывает ПО для автоматического написания кода, достаточно безопасного и корректного для использования государственными структурами. Также ведутся работы над созданием «общего искусственного интеллекта». Стартап является клиентом Fluidstack и Iren. В 2024 года стартап привлёк $500 млн при оценке капитализации на уровне $3 млрд. Project Horizon предполагал создание 2-ГВт кампуса ЦОД на участке площадью 230 га, запитанного от природного газа. Участок расположен в Пермском бассейне (США) и потенциально может обеспечить 10 ГВт. Также на территории кампуса планировалось развивать солнечную и ветряную энергетику, которые совокупно дали бы 2,5 ГВт. 
Источник изображения: Austin Distel/unspalsh.com Основным арендатором должна была стать компания CoreWeave. На первом этапе планировалось предоставить последней 250 МВт в аренду на 15 лет с дальнейшим увеличением до 500 МВт. Тогда же NVIDIA выразила желание инвестировать в Poolside до $1 млрд в рамках раунда финансирования на сумму $2 млрд. CoreWeave разорвала отношения в конце 2025 года, поскольку стартап не смог обеспечить запуск первой партии ИИ-ускорителей в соответствии с графиком. По словам представителя CoreWeave, компании «избрали разные пути по собственным стратегическим причинам и в связи с временными ограничениями». Кроме того, по данным The Financial Times, стартапу не удалось убедить инвесторов в способности создавать конкурентные ИИ-модели. В результате Poolside обратилась к другим облачным провайдерам, включая Google, в надежде реанимировать проект в Техасе под гарантии клиентов на мощности до 400 МВт. Впрочем, источники сообщают, что и Google больше не желает вести переговоры с Poolside. NVIDIA также передумала инвестировать в Poolside.
31.03.2026 [20:09], Владимир Мироненко
NVIDIA инвестировала $2 млрд в Marvell, приобщив её к своей ИИ-экосистеме и NVLink FusionАкции Marvell Technology подскочили более чем на 9 % на предрыночных торгах после объявления NVIDIA об инвестициях в размере $2 млрд в рамках стратегического партнёрства с интеграцией решений Marvell в экосистему NVIDIA. Это позволит Marvell подключиться к ИИ-фабрике NVIDIA и экосистеме AI-RAN посредством NVIDIA NVLink Fusion, предоставляя клиентам, использующим архитектуры NVIDIA, больший выбор и гибкость при разработке инфраструктуры следующего поколения. Marvell предоставит клиентам специализированные XPU и масштабируемые сетевые решения, совместимые с NVLink Fusion, а NVIDIA — вспомогательные технологии, включая процессоры Vera, сетевые решения ConnectX и Bluefield, интерконнект NVLink и коммутаторы Spectrum-X, а также вычислительные ИИ-мощности в стоечном исполнении. Для клиентов, разрабатывающих специализированные XPU, NVLink Fusion предлагает гетерогенную ИИ-инфраструктуру, полностью совместимую с системами NVIDIA, обеспечивая бесшовную интеграцию с платформами NVIDIA GPU, LPU, сетевыми и СХД-платформами, используя технологический стек NVIDIA и глобальную экосистему поставок. Ранее NVIDIA заключила похожие соглашения в отношении NVLink с SiFive, AWS, Arm, Fujitsu, Intel и MediaTek. Компании также будут сотрудничать в ключевых областях, таких как кремниевая фотоника и телекоммуникационные сети с целью преобразования сетей в инфраструктуру ИИ с помощью NVIDIA Aerial AI-RAN для 5G/6G и развития передовых решений для оптического интерконнекта. «Вместе с Marvell мы даём клиентам возможность использовать экосистему ИИ-инфраструктуры NVIDIA и масштабировать её для создания специализированных вычислительных ИИ-мощностей», — заявил гендиректор NVIDIA Дженсен Хуанг (Jensen Huang). 
Источник изображения: NVIDIA Эта сделка является частью более широкой стратегии NVIDIA по инвестированию в ИИ-экосистему с целью укрепления своего лидерства на ИИ-рынке. Недавно NVIDIA инвестировала аналогичные суммы в несколько компаний, включая Synopsys, Nokia, CoreWeave, Coherent, Lumentum и Nebius, тем самым укрепляя свое влияние по всей цепочке создания стоимости. Таким образом NVIDIA стремится удовлетворить экспоненциальный рост спроса на вычислительные мощности, обусловленный ИИ-инференсом и генерацией контента. Используя стратегические партнёрства, NVIDIA намерена ускорить развёртывание специализированной инфраструктуры и обеспечить разработку необходимых технологий для роста сегмента.
30.03.2026 [11:59], Сергей Карасёв
ИИ-сервер Gigabyte G894-AD3 использует платформу NVIDIA HGX B300 и чипы Intel Xeon 6900Компания Gigabyte пополнила ассортимент серверов мощной моделью G894-AD3-AAX7, предназначенной для решения ресурсоёмких задач в сфере ИИ. Система выполнена на платформе NVIDIA HGX B300 с восемью SXM-ускорителями Blackwell Ultra. Допускается установка двух процессоров Intel Xeon 6900P поколения Granite Rapids-SP в исполнении LGA 7529 (Socket BR) с показателем TDP до 500 Вт. Доступны 24 слота для модулей DDR5-6400/8800 RDIMM/MRDIMM, два внутренних коннектора M.2 2280/22110 для SSD с интерфейсом PCIe 5.0 x4 и PCIe 5.0 x2, а также восемь отсеков для SFF-накопителей (NVMe) с доступом через фронтальную панель (возможна горячая замена). Реализованы четыре слота PCIe 5.0 x16 для карт расширения FHHL. В оснащение входят контроллер ASPEED AST2600, два сетевых порта 10GbE на основе Intel X710-AT2, выделенный сетевой порт управления 1GbE, а также восемь портов 800G OSFP InfiniBand XDR (NVIDIA ConnectX-8 SuperNIC). Подсистема питания включает 12 блоков мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Реализовано воздушное охлаждение с 27 вентиляторами в следующей конфигурации: 6 × 60 мм в области материнской платы, 4 × 40 мм в зоне портов OSFP, 2 × 80 мм в секции PCIe-слотов и 15 × 80 мм в лотке GPU. 
Источник изображения: Gigabyte Сервер выполнен в форм-факторе 8U с габаритами 447 × 351 × 923 мм, а масса составляет 91,6 кг. Диапазон рабочих температур — от +10 до +30 °C. Среди прочего упомянуты два порта USB 3.0 Type-A (5 Гбит/с), аналоговый интерфейс D-Sub, а также три гнезда RJ45 для сетевых кабелей. Опционально может быть добавлен модуль TPM 2.0 для обеспечения безопасности.
29.03.2026 [19:24], Сергей Карасёв
MSI XpertStation WS300 — рабочая станция для ИИ на базе NVIDIA GB300Компания MSI официально представила мощную рабочую станцию XpertStation WS300, ориентированную на задачи ИИ. Новинка построена на платформе NVIDIA DGX Station, сердцем которой является суперчип GB300. Утверждается, что устройство предлагает производительность уровня ЦОД в формате десктопа. Габариты системы составляют 247,8 × 527,9 × 567,7 мм. Задействованы процессор NVIDIA Grace с 72 ядрами Arm Neoverse V2 (Demeter) и ускоритель Blackwell Ultra. При этом CPU использует 496 Гбайт LPDDR5X с пропускной способностью до 396 Гбайт/с, а GPU — 252 Гбайт HBM3e (ПСП 7,1 Тбайт/с). Применён модуль жидкостного охлаждения (CPU+GPU). Доступны по два разъёма M.2 2280/22110 для SSD с интерфейсом PCIe 5.0 x4 и PCIe 6.0 x4, а также коннектор M.2 2230 для комбинированного адаптера Wi-Fi/Bluetooth. Есть один слот PCIe 5.0 x16 для карты расширения FHFL двойной ширины и два слота PCIe 5.0 x16 для карт FHFL одинарной ширины. В качестве опции предлагается установка ускорителей RTX PRO 6000 Blackwell Workstation Edition, RTX PRO 6000 Blackwell Max-Q Workstation Edition, RTX PRO 4000 Blackwell SFF Edition и RTX PRO 2000 Blackwell. 
Источник изображения: MSI В оснащение входят контроллер ASPEED AST2600 с выделенным портом управления 1GbE, сетевой адаптер NVIDIA ConnectX-8 SuperNIC с двумя портами QSFP112, а также 10GbE-контроллер Marvell AQC113. Есть четыре порта USB 3.1 Type-A, интерфейсы Mini-DP и Micro-USB (COM). Питание обеспечивает блок мощностью 1600 Вт с сертификатом 80 PLUS Titanium. За безопасность отвечает модуль TPM 2.0. Диапазон рабочих температур — от +10 до +35 °C.
27.03.2026 [21:04], Руслан Авдеев
«Не хотите ускорители? Возьмите хотя бы сеть!» — NVIDIA открыла свои ИИ-стойки для чужих чиповNVIDIA занялась разработкой серверных стоек, подходящих для решений на основе сторонних ИИ-ускорителей, сообщает The Information со ссылкой на знакомые с вопросом источники. Компания стремится остаться ключевым игроком на рынке ИИ-систем даже по мере того, как всё больше её клиентов разрабатывают решения, прямо конкурирующие с продуктами самой NVIDIA. На прошлой неделе компания представила новые стойки MGX ETL, специально разработанные для поддержки чипов как самой NVIDIA, так и поставщиков-конкурентов. Система основана на модульной архитектуре MGX (OCP), представленной в 2023 году и уже довольно распространённой. ETL предполагает использование сетевых решений NVIDIA Spectrum-X. Таким образом, «зелёные» чипы всё равно оказываются в инфраструктуре, даже если она базируется на сторонних решениях. Похожим образом компания развивает и фирменный интерконнект NVLink. NVLink Fusion можно интегрировать в другие чипы, что опять-таки даёт NVIDIA возможность заработать на чужих ИИ-системах. Но в случае ETL применяются широко поддерживаемые в индустрии стандарты Ethernet, что снижает для клиентов «порог вхождения» при внедрении оборудования NVIDIA. Модульный дизайн позволяет облачным гиперскейлерам одновременно использовать ускорители разных производителей, при этом оставаясь в сетевой и программной экосистемах NVIDIA. 
Источник изображения: NVIDIA NVIDIA позиционировала MGX как открытую «эталонную» архитектуру, не мешающую партнёрам использовать альтернативные компоненты. Гибкость также позволяет NVIDIA «проложить дорогу» на китайский рынок, где компании смогут применять со стойками NVIDIA чипы домашней разработки. Новый дизайн стоек также может помочь NVIDIA устранить обеспокоенность регуляторов практикой, когда компания связывала использование сетевого оборудования с определёнными ИИ-чипами. На этом фоне происходит ужесточение конкуренции на рынке технологий интерконнектов. Открытый стандарт UALink позиционируется как альтернатива NVLink и призван обеспечить высокоскоростную связь между ИИ-чипами без применения проприетарных технологий. Параллельно развивается и открытый стандарт Ultra Ethernet, который призван конкурировать и с технологией Infiniband, фактически единолично контролируемой NVIDIA. Сетевые решения являются чрезвычайно важной частью бизнеса NVIDIA. По итогам последнего квартала выручка компании в этом сегменте достигла $10,98 млрд (а за год все $31 млрд) — она выросла год к году на 268 % и составила более 15 % от всей выручки компании. При этом значительная часть сетевого оборудования продаётся не сама по себе, а в составе платформенных решений NVIDIA. |
|

