Материалы по тегу:
|
31.07.2026 [16:44], Руслан Авдеев
Crusoe и Aalo развернут первую ИИ-фабрику с питанием от SMRКомпании Crusoe Energy и Aalo Atomics объявили о партнёрстве, в рамках которого планируется создать первую ИИ-фабрику с питанием от атомных реакторов. Модульная ИИ-инфраструктура будет комбинироваться с малыми модульными реакторами (SMR) для демонстрации возможностей поддержки АЭС крупномасштабных ИИ-вычислений, сообщает Converge Digest. Первый пилотный проект предполагается запустить в 2027 году на территории Национальной лаборатории Айдахо (Idaho National Laboratory, INL). Там реактор Aalo будет снабжать энергией модульный ЦОД Crusoe Spark, в котором разместятся мощности облака Crusoe Cloud. Партнёры намерены расширить взаимодействие и к концу 2029 года организовать коммерческое использование реакторов Aalo дата-центрами Crusoe. Согласно договору Aalo намерена интегрировать свои модульные мини-АЭС Aalo Pods на основе реакторов с 50-МВт электрической мощности с будущими ЦОД Crusoe. Недавно Aalo удалось добиться в своём реакторе самоподдерживающейся цепной реакции в рамках пилотной программы Министерства энергетики (DoE). Aalo уже начала строить второй реактор в дополнение к расположенному на территории INR объекту Aalo-X. Он будет генерировать электричество, поставляя энергию расположенному там же модульному ЦОД Crusoe Spark. Новое партнёрство — очередное свидетельство потребности ЦОД в надёжных бесперебойных источниках энергии, способных поддержать быстрое масштабирование ИИ-инфраструктуры. 
Источник изображения: Aalo Atomics Crusoe позиционирует себя как вертикально интегрированного провайдера ИИ-инфраструктуры, участвующего в энергетических проектах, занимающегося строительством ИИ ЦОД и обеспечением облачных сервисов. Aalo получит благодаря взаимодействию возможность опробовать предварительный коммерческий сценарий своих малых модульных реакторов, специально предназначенных для ИИ ЦОД. Основанная в 2023 году в Техасе компания уже привлекла $136 млн от инвесторов, включая Valor Equity Partners, NRG Energy, Hitachi Ventures и Tishman Speyer. Взаимодействие Crusoe и Aalo — часть более широкого тренда. Технологические компании, включая Microsoft, Amazon, Google и Oracle уже анонсировали связанные с атомной энергетикой инициативы или инвестиции для поддержки расширения парка ЦОД в дальнейшем. Тем временем разработчики реакторов вроде Oklo, Kairos Power, TerraPower и X-energy продолжают продвигать создание коммерческих решений. В отличие от многих подобных проектов, партнёры намерены продемонстрировать на базе INL реальное применение модульного ядерного реактора с настоящим ЦОД и ИИ-нагрузками до того, как перейти к созданию коммерческих ИИ-кампусов.
31.07.2026 [15:37], Руслан Авдеев
NOAA откажется от суперкомпьютеров HPE Cray для прогнозирования погоды, отдав предпочтение Google CloudСША более не намерены использовать государственные суперкомпьютеры для прогнозирования погоды. Национальное управление океанических и атмосферных исследований (NOAA) решило использовать для своих операций в этой сфере мощности Google Cloud, сообщает The Register. Объявлено, что управление станет первым национальным центром прогнозирования погоды, использующим ресурсы коммерческого облака. Впрочем, метеослужба Великобритании тоже переходит на гибридную схему, переводя свои ресурсы в Microsoft Azure. Обычно же все национальные метеорологические службы в мире используют либо собственные суперкомпьютеры, либо сторонние мощности, финансируемые за счёт государства. Ранее контрактом на управление суперкомпьютерами NOAA обладала General Dynamics, последними стали машины HPE Cray в дата-центрах в Аризоне и Вирджинии. Системы Dogwood и Cactus могли обеспечивать около 14 Пфлопс вычислительных мощностей. Теперь управление намерено перенести свою систему Weather and Climate Operational Supercomputing System в облако к декабрю 2027 года, вместе с ПО, применяемым для анализа данных Национальной метеорологической службой США (National Weather Service, NWS), входящей в состав NOAA. 
Источник изображения: Raychel Sanner/unsplash.com В управлении считают, что использование облака сделает подготовку прогнозов более быстрой и гибкой, что позволит обнародовать соответствующие данные значительно быстрее, эффективнее оповещать об экстремальных погодных явлениях и др. Вероятно, локальные системы не справлялись с задачами достаточно эффективно, во всяком случае в NOAA заявляют, что именно облако позволит устранить традиционные «узкие места» стационарных систем. Так, в сезон тропических штормов можно будет наращивать вычислительные мощности за счёт облачных ресурсов и сокращать их использование, когда погода успокоится. В рамках нового соглашения NOAA также может использовать ИИ-инструменты Google DeepMind для создания системы прогнозирования AI Global Forecast System. Это, как ожидается, позволит давать точные прогнозы погоды с использованием на 99,7 % меньшего количества вычислительных циклов — на прогнозирование будут уходить не часы, а минуты. NWS уже занимается обновлением ПО, работающего с данными от математических моделей GFS и GEFS. В марте ведомство заключило контракты с Accenture и Booz Allen Hamilton, которые будут курировать разработку ПО для облачных ресурсов (HIVE и CIRRUS). Это программное обеспечение предназначено для региональных подразделений и будет рассылать экстренные предупреждения, заменяя действующие локальные программы. Для выполнения новых задач Google рассчитывает использовать инстансы Google Cloud H4D на базе AMD EPYC Turin, предоставляющие до 192 vCPU (полноценное ядро, а не SMT), 1488 Гбайт RAM и 200G-интерконнект. Для выполнения задач, требующих использования суперкомпьютеров, можно использовать Cluster Toolkit для развёртывания кластеров и Cluster Director для их обслуживания. Служба Batch берёт на себя управление очередями, планированием и выделением ресурсов.
31.07.2026 [14:43], Андрей Крупин
Объём российского рынка IaaS к 2030 году более чем удвоится и достигнет 241 млрд рублейВ 2025 году объём рынка публичных инфраструктурных облачных сервисов (IaaS) в России составил 96 млрд руб. К 2030 году при среднегодовом темпе роста около 20 % он более чем удвоится и достигнет 241 млрд руб. Такой прогноз содержится в исследовании, проведённом аналитической компанией Apple Hills Digital. В настоящий момент ключевыми игроками в упомянутом сегменте IT-отрасли являются Cloud.ru, K2 Cloud, MWS, РТК ЦОД / «Турбо облако», Selectel, T1 Cloud, VK Cloud, Yandex Cloud. Рост IaaS-рынка поддерживают цифровизация отраслей, потребность в гибком доступе к вычислительным ресурсам без капитальных вложений и импортозамещение. Среди сдерживающих факторов — высокая совокупная стоимость владения и низкая зрелость Developer Experience (удобство и скорость работы инженерных команд с облачной платформой — от развёртывания «из коробки» до готовых инструментов интеграции). 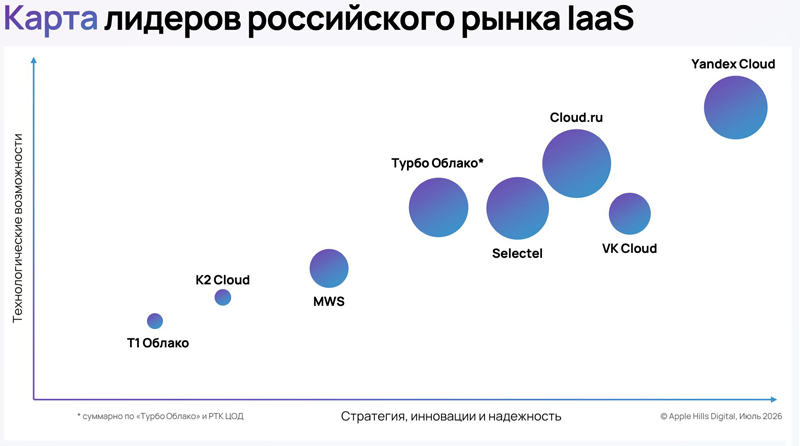
Источник изображения: Apple Hills Digital / apple-hills.com Согласно представленным аналитиками Apple Hills Digital сведениям, надёжность облачных платформ остаётся приоритетом №1 у российского бизнеса. 72 % заказчиков называют стабильность cloud-инфраструктуры главным критерием выбора провайдера. Безопасность и соответствие стандартам ставят на второе место 54 % респондентов. 52 % компаний используют гибридную инфраструктуру, свыше 80 % отмечают влияние искусственного интеллекта на потребление ресурсов, а 24 % фиксируют резкий рост использования GPU-инстансов. Среди тех, кто планирует увеличить бюджет на IaaS, 42 % закладывают в него именно AI/ML-нагрузки. «По мере повышения зрелости рынка конкуренция между лидерами принимает более многоплановую форму. Исследование показало, что цена уже не является главным фактором выбора провайдера: организации переносят в облако все более серьёзные нагрузки и чувствительные данные и применяют широкий набор критериев выбора, отдавая приоритет надёжности, безопасности и удобства интеграции облачного сегмента в свой IT-ландшафт», — говорится в исследовании Apple Hills Digital.
31.07.2026 [13:02], Андрей Крупин
Исследование: российский бизнес переходит к гибридным СУБД-ландшафтамОтечественные системы управления базами данных доминируют в корпоративной IT-инфраструктуре, однако параллельно активно используются решения с открытым исходным кодом и зарубежные платформы. Об этом свидетельствуют результаты исследования компании Nexign — российского разработчика enterprise-решений для различных отраслей экономики. По данным опроса Nexign, СУБД от отечественных вендоров доминируют в инфраструктуре российских компаний — об их использовании сообщили 66 % респондентов. Более половины — 54 % — опрошенных применяют решения open source, 40 % продолжают эксплуатировать зарубежные продукты, ещё 6 % затруднились с ответом. По мнению аналитиков, такие результаты отражают переходный характер текущего этапа развития IT-ландшафта в России. Существенная доля зарубежных решений объясняется значительным объёмом устаревшей инфраструктуры в слое прикладных корпоративных систем. Многие бизнес-критичные приложения исторически разрабатывались и внедрялись в тесной связке с конкретными СУБД. Пока прикладной слой не модернизирован или не заменён, полная миграция баз данных зачастую оказывается либо технически сложной, либо экономически неоправданной. 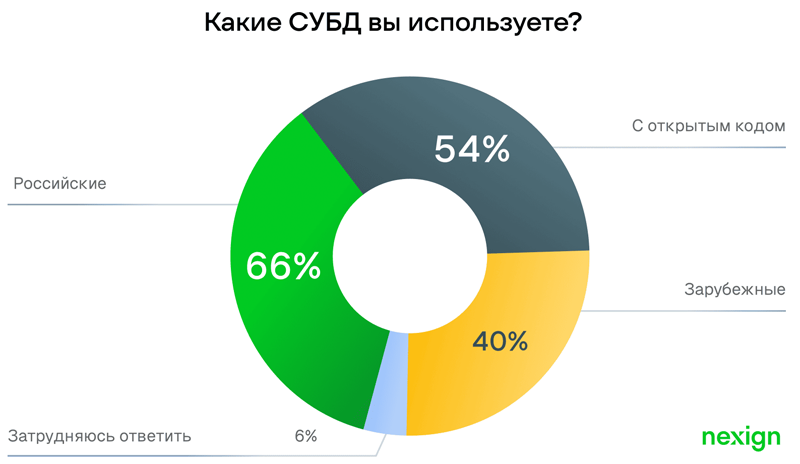
Источник изображения: Nexign / nexign.com По данным исследования, компании в среднем используют более одного типа СУБД, комбинируя вендорские продукты и open source. Такой подход продиктован несколькими важными факторами. Во-первых, бизнес стремится снизить риски зависимости от вендора. Во-вторых, значительная часть существующих систем не может быть быстро выведена из эксплуатации без ущерба для бизнес-процессов. В-третьих, использование различных СУБД позволяет организациям балансировать между стоимостью владения, доступностью квалифицированной поддержки и надёжностью решения. Также наличие открытого кода даёт необходимую гибкость и свободу в настройке, в то время как вендорские решения обеспечивают формальные гарантии и SLA. Однако гибридный подход несёт и определённые риски, отмечают эксперты Nexign. Главный из них — возрастающая сложность администрирования и поддержки разнородной инфраструктуры. Кроме того, усложняются процессы мониторинга и обеспечения безопасности: при неграмотном использовании открытого кода в системе могут образовываться серьёзные уязвимости. Существует также риск непредсказуемого роста совокупной стоимости владения (TCO) при недостаточно продуманной архитектуре. Что касается критериев, на которые заказчики обращают внимание при выборе СУБД, то для 68 % опрошенных организаций ключевыми требованиями являются отказоустойчивость, поддержка кластеризации и возможность быстрого восстановления после сбоев. Для 66 % важны поддержка высокой нагрузки и масштабируемость, включая горизонтальное масштабирование и репликацию. Соответствие требованиям ФСТЭК и Роскомнадзора, а также наличие сертификации по защите данных, указывают своим приоритетом 38 % опрошенных. Это говорит о том, что для заказчиков становятся важны не только функциональность СУБД, но и технические характеристики, которым ранее уделялось меньше внимания. Компаниям сейчас не нужен «комбайн» со множеством новых функций. Прежде всего они ждут, что СУБД легко впишется в IT-среду и обеспечит безболезненный перенос данных.
31.07.2026 [11:09], Сергей Карасёв
Форматы E3.S, E1.S, SFF и ёмкость до 61,44 Тбайт: Kioxia представила свои первые корпоративные SSD с интерфейсом PCIe 6.0Компания Kioxia анонсировала SSD семейства CM10 — свои первые твердотельные накопители корпоративного класса, оснащённые интерфейсом PCIe 6.0. Устройства, спроектированные для ресурсоёмких нагрузок, включая ИИ-инференс, будут предлагаться в различных вариантах исполнения, в том числе E3.S, E1.S и SFF. Изделия выполнены на основе чипов Kioxia BiCS FLASH 10-го поколения (332 слоя) в соответствии со спецификациями NVMe 2.1, OCP Datacenter NVMe SSD 2.7 и NVMe Flexible Data Placement (FDP). Говорится о поддержке различных средств обеспечения безопасности — SIE, SED, SED FIPS 140-3 и постквантовой криптографии. Вместимость в зависимости от варианта исполнения варьируется от 1,6 до 61,44 Тбайт. Накопители типоразмера E3.S и E1.S толщиной 9,5 мм будут выпускаться в модификациях с жидкостным охлаждением, тогда как все другие решения довольствуются традиционным воздушным охлаждением. Предусмотрены версии для интенсивного чтения с возможностью одной полной перезаписи в сутки (1 DWPD) и смешанного использования с показателем 3 DWPD. 
Источник изображения: Kioxia По заявлениям Kioxia, устройства серии CM10 по быстродействию значительно превосходят накопители предыдущего поколения CM9, которые дебютировали весной 2025 года. Эти SSD наделены интерфейсом PCIe 5.0, а ёмкость достигает 61,44 Тбайт. Утверждается, что по сравнению с предшественниками решения CM10 обеспечивают на 92 % более высокую производительность в режиме последовательного чтения и примерно на 85 % большую скорость на операциях случайного чтения. Пробные поставки новинок уже начались.
31.07.2026 [05:35], Руслан Авдеев
Электрическая «выделенка» для ЦОД: Amazon просит разрешить ей модернизировать энергосети за свой счётAmazon призвала регуляторов штата Вирджиния разрешить гиперскейлерам добровольно финансировать модернизацию электросетей, обслуживающих их кампусы ЦОД. Это стало началом дискуссии о том, кто именно должен платить за расширение сетей в интересах ИИ-проектов, сообщает Datacenter Knowledge. Представители Amazon заявили Корпоративной комиссии штата Вирджиния (Virginia State Corporation Commission, SCC), что крупным потребителям электричества необходимо разрешить финансирование сетевых объектов, создаваемых специально под их проекты. Для этого можно использовать целевые взносы на строительство (CIAC). По словам представителя E9 Insight, выступавшего «свидетелем» со стороны Amazon, гиперскейлеры могли бы таким образом рисковать собственным капиталом, снижая расходы остальных потребителей электроэнергии. Энергокомпания Dominion Energy возразила, что вопрос гораздо шире и касается регионального планирования оператора электросетей PJM Interconnection, юрисдикции регулятора Federal Energy Regulatory Commission (FERC) и структуры тарифов в целом. Финансирование за счёт пользователей — обычная практика в случае подключения генерирующих мощностей и в некоторых распределительных проектах, но прибегать к CIAC в случае с магистральными электросетями сложнее, поскольку они, в частности, нередко обслуживают сразу несколько клиентов. 
Источник изображения: American Public Power Association/unsplash.com По мнению экспертов, взносы CIAC могут стать частичным решением проблемы, если бенефициары модернизации сетей чётко определены и готовы к расходам. При этом подчёркивается, что нередко грань между затратами конкретного клиента и расходами, которые следовало бы распределить на всю сеть, весьма размыта. В комиссии пожелали знать, не получится ли так, что на самом деле остальные клиенты будут дважды платить за одну и ту же инфраструктуру. Как заявили в Persistence Analytics Group, проблема в том, что сетевой проект редко существует изолированно, и новая ЛЭП для снабжения крупного ЦОД повлияет на конфигурацию всей инфраструктуры. Подчёркивается, что разрешение на частное финансирование не должно привести к созданию «выделенной полосы», способной вытеснить боле зрелые или эффективные для всей энергосистемы PJM проекты. Подчёркивается, что регуляторы должны определить, сохранит ли PJM способность эффективно планировать региональную систему, если частные компании полностью возьмут на себя финансовые нагрузки. Коммунальные компании и региональные сетевые операторы также нередко сталкиваются с подачей «спекулятивных» заявок, вероятность реализации проектов по которым крайне невелика. По мнению экспертов, например, запрошенная, законтрактованная, обеспеченная залогом, действующая нагрузка и др. должны иметь разный «вес» при планировании. Так или иначе, утверждённая в Вирджинии минимальная плата за сетевую мощность уже позволяет перекладывать всё больше расходов на крупных потребителей.
31.07.2026 [05:24], Руслан Авдеев
Brookfield и NextEra Energy запустят 1,2-ГВт ИИ ЦОД на месте бывшего завода по обогащению урана в КентуккиBrookfield и NextEra Energy намерена превратить часть бывшего завода по обогащению урана Paducah Gaseous Diffusion Plant в Падьюке (Paducah, Кентукки) в один из крупнейших в США кампусов ЦОД. Проект с расчётной мощностью более 1,2 ГВт предусматривает собственную генерацию энергии. Общий объём инвестиций составит около $100 млрд, сообщает Datacenter Knowledge. Представленный коалицией Paducah American Energy Hub проект предполагает, что Brookfield будет строить кампус и управлять им, а NextEra создаст генерирующие мощности и энергохранилище. Предложенная концепция предполагает создание газовых генерирующих мощностей до 2 ГВт, а также аккумуляторного хранилища до 2,6 ГВт. При этом отмечается, что к 2032 году кампус сможет получать до 1,8 ГВт от магистральных электросетей. В консорциуме участвуют Big Rivers Electric Power Corporation, Jackson Purchase Energy Cooperative и Paducah Power System. Проект ещё должен получить все согласования и получить разрешения от регуляторов. Предполагается, что проект позволит продемонстрировать подход, при котором наращивать ИИ-мощности можно без перекладывания расходов на модернизацию энергосетей на рядовых потребителей электричества. ЦОД сам обеспечит себя энергией, сам оплатит энергетическую инфраструктуру и вдобавок создаст новые рабочие места для местного населения. При этом энергетика начинает рассматриваться как неотъемлемая часть самого кампуса — всё более распространённый тренд в США и мире. 
Источник изображения: Joylynn Goh/unsplash.com Модель с собственной генерацией может сократить время присоединения к энергосети и снизить необходимость распределения затрат на инфраструктуру на обычных потребителей электричества. Впрочем, эксперты подчёркивают, что простое «сложение» заявленных ресурсов в данном случае не работает, поскольку гигаватт ёмкости АКБ — совсем не то же, что гигаватт непрерывно доступных генерирующих мощностей. Критически важно, какую гарантированную мощность кампус сможет поддержать в периоды пиковых нагрузок и какая поддержка потребуется от общей энергосистемы, а оценивать придётся, в частности, наличие топливной инфраструктуры, обязательства по резервам энергии и др. Бывший завод в Падьюке выбрали благодаря уже имеющемуся доступу к ЛЭП, водоснабжению, ВОЛС, дорогам и наличию больших свободных участков земли под застройку. Такие преимущества могут ускорить сроки реализации в сравнении со строительством с нуля. В Министерстве энергетики проект назвали потенциальным образцом для будущих инициатив по развитию ИИ-инфраструктуры. При этом пока не названы ни ключевой клиент кампуса, ни даже дата начала его строительства. Бывшие площадки по работе с ядерным топливом на федеральных землях стали привлекательным местом для строительства кампусов ЦОД, во многом благодаря уже имеющейся вспомогательной инфраструктуре. Так, в марте сообщалось, что SoftBank построит 10-ГВт ИИ ЦОД и газовую электростанцию на территории бывшего ядерного объекта в США в интересах OpenAI, а на днях появились данные, что NVIDIA готова выделить $250 млрд на поддержку строительства этого кампуса.
31.07.2026 [05:15], Владимир Мироненко
Qualcomm намерена заработать в 2029 году на чипах для ЦОД $15 млрдСогласно планам Qualcomm, выход на рынок чипов для ЦОД принесёт ей $15 млрд годового дохода к 2029 финансовому году. Это огромный рост, но объём продаж выглядит довольно скромно по сравнению с уже закрепившимися на рынке конкурентами, отметил The Register. Qualcomm объявила итоги III квартала 2026 финансового года, завершившегося 28 июня. Результаты вполне соответствуют прогнозам аналитиков, но компания предоставила сдержанный прогноз по прибыли и выручке за текущий квартал, объяснив его продолжающимся дефицитом поставок компьютерных комплектующих, особенно памяти. При этом Qualcomm предупредила, что вынуждена принять жёсткие меры для защиты рентабельности продукции в будущем. В их числе — повышение цен на все компоненты, начиная с 1 сентября, и поиск новых способов защиты своей цепочки поставок. Генеральный директор Qualcomm Кристиано Амон (Cristiano Amon) во время телефонной конференции с аналитиками отметил, что не ожидает, что это решение негативно повлияет на и без того ослабленный рынок смартфонов. 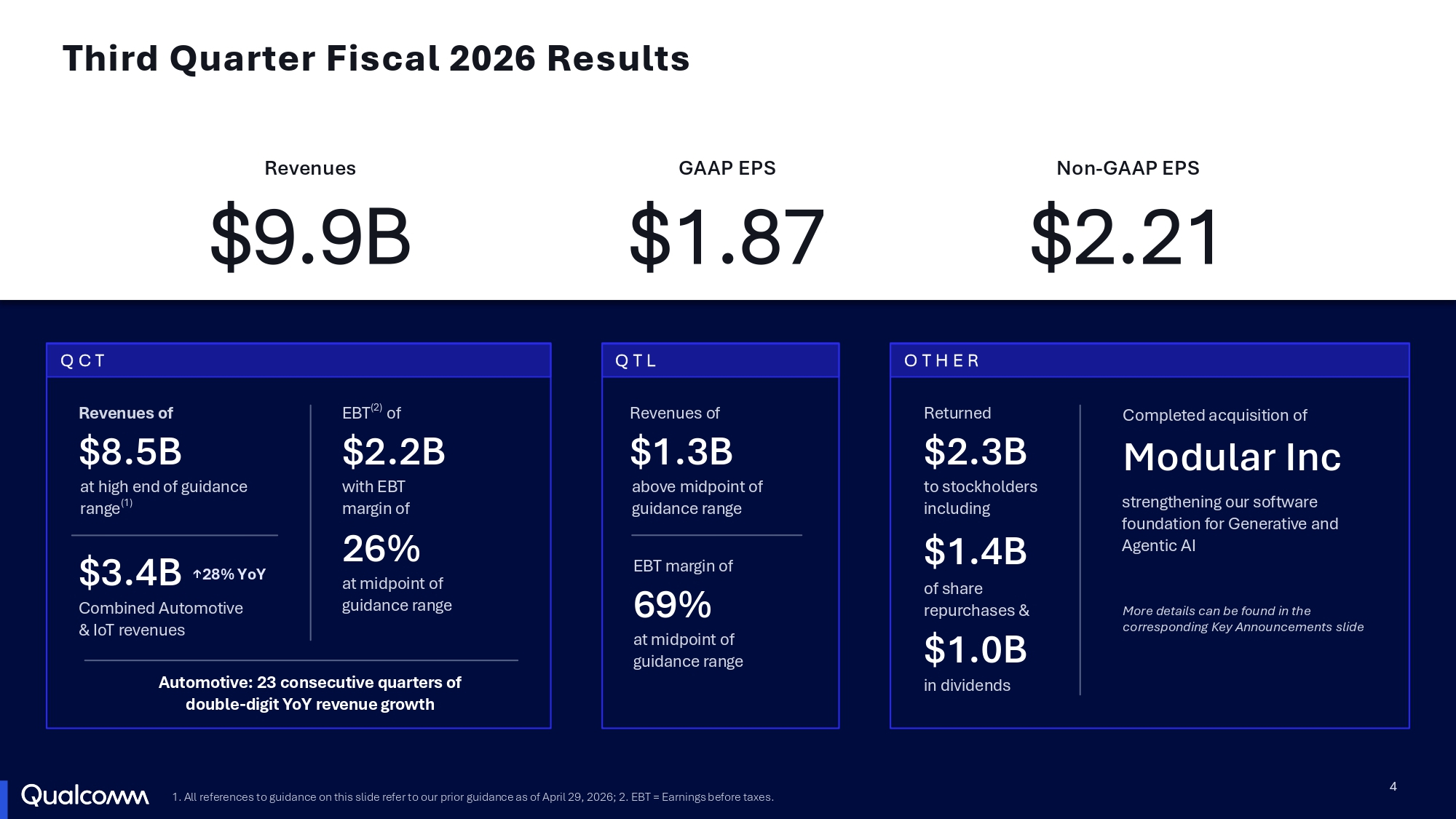
Источник изображений: Qualcomm «Даже двузначное повышение цен, которое является лишь следствием увеличения себестоимости сырья и кремниевых пластин, на самом деле незначительно по сравнению с величиной стоимости компонентов памяти», — сказал Амон, объяснив слабые продажи смартфонов высокой стоимостью оперативной памяти. Также Qualcomm сообщила инвесторам, что ограничения в цепочке поставок означают, что Qualcomm ожидает «ускорения снижения доходов от продукции Apple», поскольку её вклад в iPhone следующего поколения «ожидается существенно ниже, чем наша предыдущая оценка в 20 %». Компания предупредила инвесторов, что в следующем году выручка от продаж компании Apple составит менее $2 млрд. Вместе с тем финансовый директор Акаш Палхивала (Akash Palkhiwala) заявил, что рост бизнеса Qualcomm, не связанного с мобильными телефонами, в 2027 финансовом году, как ожидается, позволит полностью заменить выручку от поставок Apple. Руководители компании сообщило, что к 2029 финансовому году, как ожидается, объём продаж продукции, не связанной с мобильными телефонами, достигнет $40 млрд в год, при этом выручка от продаж автомобильной продукции составит $10 млрд, а от устройств IoT — $14 млрд. 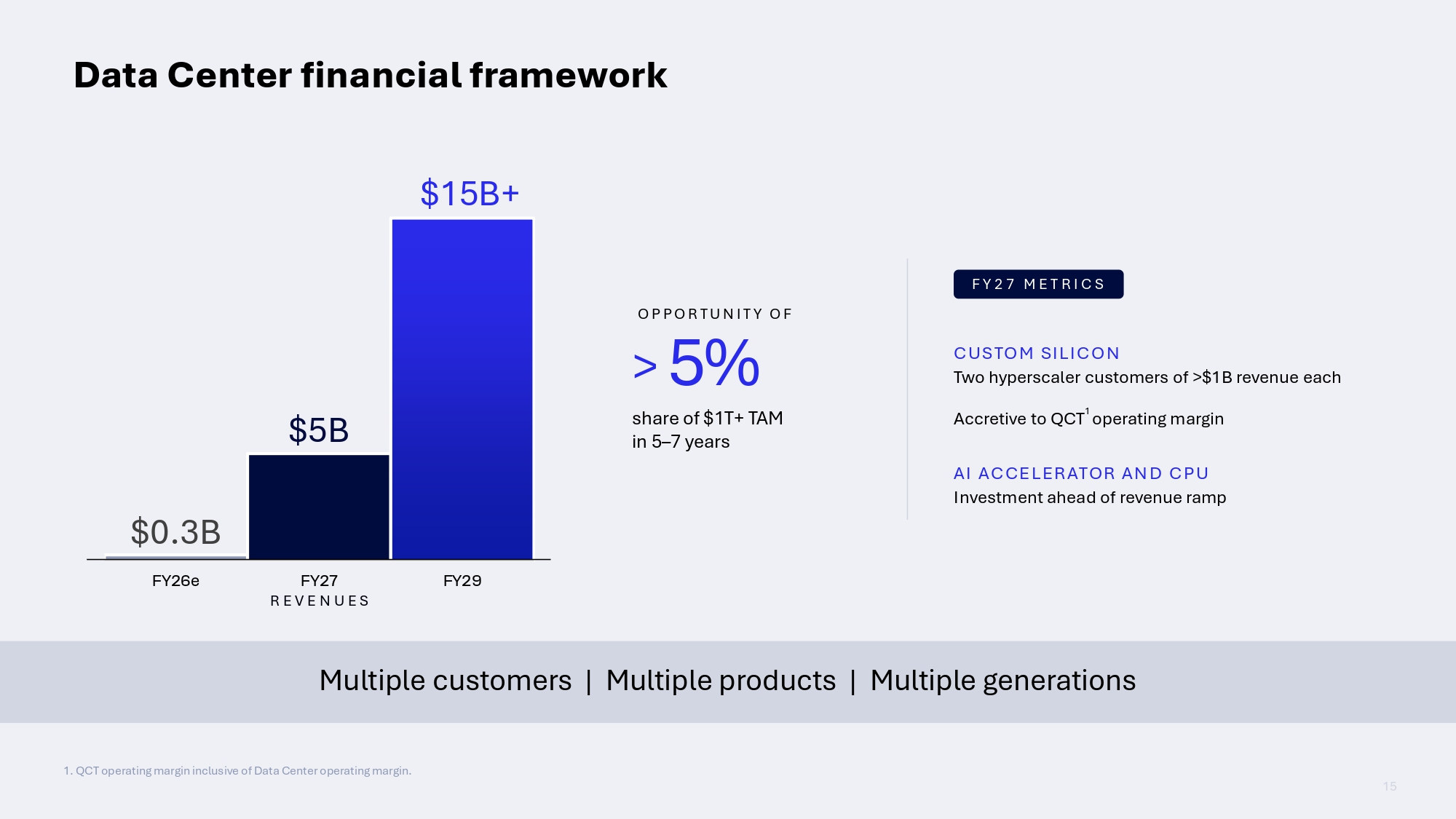 Амон сказал, что компания находится на пути к достижению выручки в $5 млрд от продажи чипов для ЦОД в следующем году. В этом компании поможет недавнее приобретение Modular Inc., компании-разработчика ПО для ИИ-инфраструктуры. Производитель чипов заявил, что планирует представить новую программную платформу ИИ на основе технологии Modular в следующем месяце. В ближайшей перспективе компания ожидает, что рост выручки от продаж, не связанных с мобильными телефонами, включая ЦОД, увеличится с 24 % в 2026 финансовом году до более чем 60 % в 2027 финансовом году. «Хорошая новость в долгосрочной перспективе заключается в том, что компания быстро переориентируется на доходы, не связанные с мобильными телефонами, достигнув рекордных показателей в сегменте чипов для автомобильной промышленности и запуска своих первых крупных продуктов для дата-центров в конце этого года», — сообщил агентству Reuters Боб О'Доннелл (Bob O'Donnell), главный аналитик TECHnalysis Research. 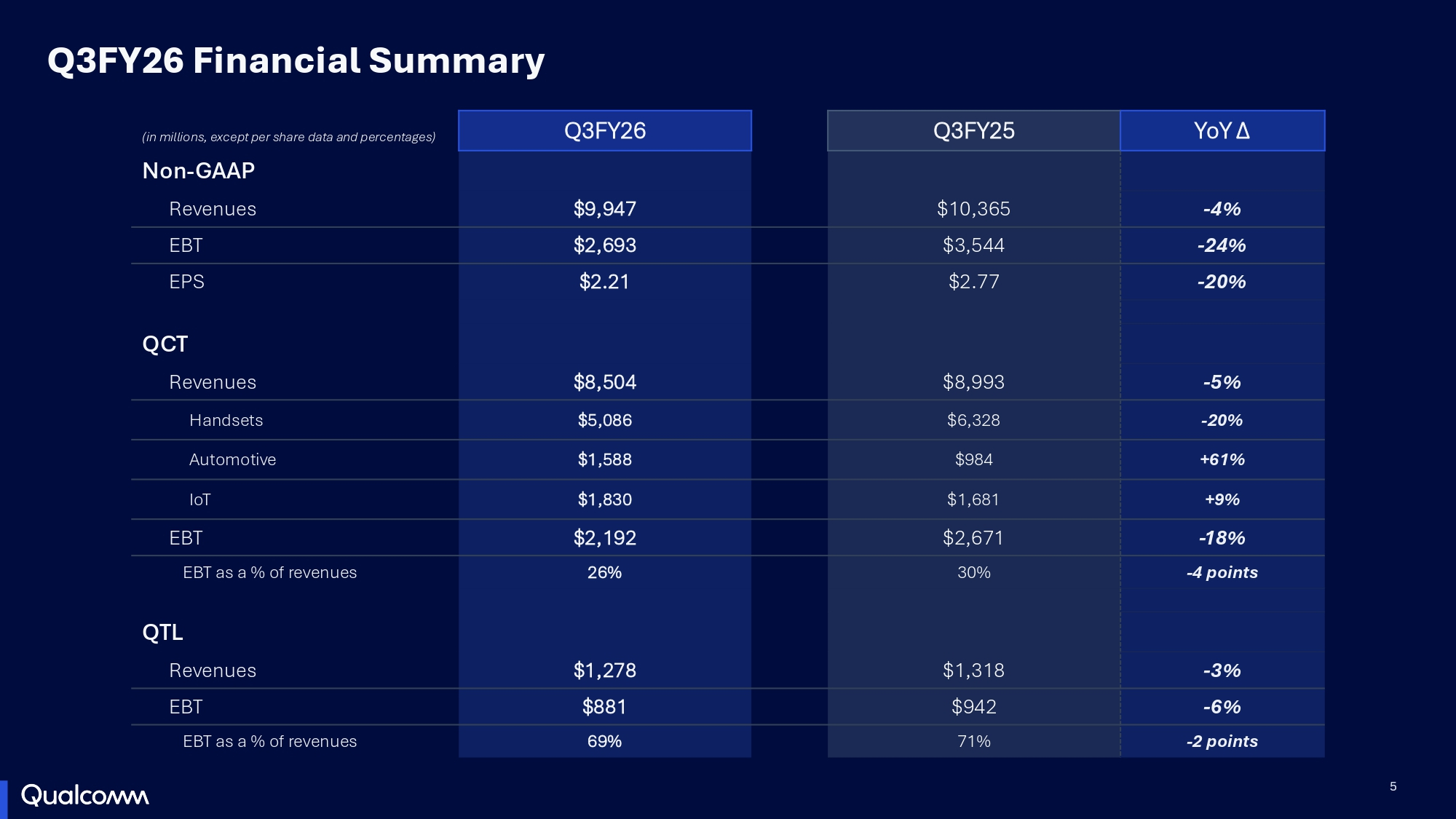 Выручка Qualcomm в III финансовом квартале снизилась на 4 % до $9,95 млрд, что выше консенсус-прогноза аналитиков, опрошенных LSEG, в $9,67 млрд (по данным CNBC). Скорректированная прибыль (Non-GAAP) составила $2,21 на разводнённую акцию по сравнению с прогнозом в $2,23. В полупроводниковом секторе (QCT) выручка упала на 5 % — до $8,50 млрд с $8,99 млрд годом ранее. При этом выручка в автомобильном сегменте выросла на 61 % до $1,59 млрд, в сегменте IoT — на 9 % до $1,83 млрд, а в сегменте мобильных устройств упала на 20 % до $5,09 млрд. Выручка от лицензий (QTL) за квартал составила $1,28 млрд (падение — 3 %), что выше прогноза StreetAccount в $1,26 млрд. В текущем квартале Qualcomm планирует получить скорректированную прибыль (Non-GAAP) на разводнённую акцию в диапазоне от $2,05 до $2,25 при выручке от $9,7 до $10,5 млрд. Аналитики, опрошенные LSEG, ожидают скорректированную прибыль на разводнённую акцию в размере $2,36 при выручке в $10,02 млрд.
30.07.2026 [13:12], Андрей Крупин
Yandex B2B Tech выпустит универсального ИИ-агента — он сможет автоматизировать до половины бизнес-задачYandex B2B Tech анонсировала нового ИИ-агента для бизнеса. Он будет построен на базе Yandex AI Studio и возьмёт на себя до половины задач офисных сотрудников (от бухгалтеров до маркетологов), на которые обычно уходит до трети рабочего времени. Выпуск решения планируется до конца сентября 2026 года. В отличие от остальных ИИ-агентов, это будет своего рода операционная ИИ-система для бизнеса. В ней любой сотрудник сможет использовать привычные ему рабочие сервисы и инструменты (условный Excel), но работать с ними можно будет через ИИ-агентов. Такой интеллектуальный помощник, например, сможет вести документооборот, сравнивать коммерческие предложения от поставщиков и проверять заявки, анализировать кандидатов на вакантные должности и т. д. 
Источник изображения: yandex.cloud Пользователи смогут предоставить ИИ-ассистенту доступ к корпоративным сервисам от своего имени. Он получит те же права и сможет запрашивать актуальную информацию для решения задачи. Для безопасного использования агента предусмотрены средства ограничения доступа к внутренним, а каждое важное действие потребует подтверждения от человека. Также будет доступна возможность анализировать поведение ИИ-агента: проверять всю цепочку его действий и решений, какие инструменты он использовал и к каким данным и системам обращался внутри организации. По словам разработчиков, ИИ-агент для бизнеса можно будет использовать для решения задач, которые требуют специфических знаний и умений. Для этого предусмотрена система навыков. Компании смогут использовать готовые навыки из каталога, например «Финансист» или «HR-специалист», либо создать собственные. Уметь писать код для этого не требуется. Достаточно указать источники данных — это может быть почта, внутренние базы знаний и так далее — и своими словами описать процесс решения задачи.
30.07.2026 [12:54], Сергей Карасёв
MSI анонсировала серверы на базе AMD EPYC Venice с воздушным и жидкостным охлаждениемКомпания MSI представила широкий ассортимент серверов на аппаратной платформе AMD EPYC Venice. Дебютировали модели разных классов для задач ИИ и НРС, облачных инфраструктур, виртуализации и критических бизнес-приложений. В семейство вошли модели для 19″ и 21″ серверных стоек с воздушным и жидкостным охлаждением, в том числе многоузловые машины. Одной из новинок стала GPU-платформа CG681-S6093 типоразмера 6U с жидкостным охлаждением. Устройство допускает установку двух чипов Venice и восьми ИИ-ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7, которые также входят в контур СЖО. Доступны 32 слота для модулей оперативной памяти DDR5. Задействованы сетевые адаптеры NVIDIA ConnectX-8 SuperNIC и SSD формата E1.S (NVMe). 
Источник изображения: MSI Анонсированы также системы, оптимизированные по показателям производительности и экономической эффективности. Кроме того, выйдут ORv3-решения для построения вычислительных инфраструктур высокой плотности. В целом, в новое семейство вошли следующие серверы:
|
|

