Материалы по тегу: instinct
|
19.06.2026 [14:01], Руслан Авдеев
Rackspace развернёт ИИ-оборудование AMD на 30 МВт в ЦОД по всему мируКомпании AMD и Rackspace Technology подписали соглашение, посвящённое внедрению первых 30 МВт ИИ-оборудования на основе чипов AMD. Оно будет использоваться в дата-центрах Rackspace по всему миру. Внедрение начнётся в конце текущего года и продлится до 2028-го. В рамках нового соглашения AMD становится стратегическим поставщиком чипов для реализации ИИ-стратегии Rackspace. Для поддержки обучения ИИ-моделей, инференса и корпоративных нагрузок будут использоваться ИИ-ускорители AMD Instinct, включая модели MI355X, MI350P и чипы будущих поколений, а также серверные процессоры семейства AMD EPYC. Соглашение также предусматривает совместную деятельность по освоению рынков. Компании выделят маркетинговые ресурсы и персонал для разработки и продвижения предложений на базе инфраструктуры AMD — для клиентов из регулируемых отраслей. После полного внедрения экосистема мощностью 30 МВт обеспечит вычислительные ресурсы для корпоративных пользователей, включая организации из сферы здравоохранения и прочие компании из регулируемых секторов. В Rackspace сообщают, что соответствующая инфраструктура необходима для поддержки масштабных ИИ-инициатив в медицине, для инференса и выполнения других задач, требующих администрирования, отчётности и операционного надзора. 
Источник изображения: AMD Компании рассчитывают интегрировать аппаратный стек AMD в архитектуру Enterprise AI Cloud компании Rackspace. Платформа будет автоматически подбирать вычислительные ресурсы под конкретные нагрузки, в то же время обеспечивая централизованное управление и оперативный учёт работы всей инфраструктуры. По словам Rackspace, регулируемые отрасли требуют полностью управляемой инфраструктуры, а не подборки решений от независимых вендоров. Сотрудничество позволит объединить вычислительные мощности и операционные сервисы в одну управляемую экосистему, с ответственностью от аппаратного уровня до конечных бизнес-результатов. В AMD подчеркнули, что корпоративные проекты всё чаще требуют комбинации вычислительных ресурсов, использующих как классические аппаратные решения, так и ИИ-ускорители для разных типов нагрузок. Предполагается, что проект ускорит запуск сервисов, предусмотренных меморандумом о взаимопонимании, подписанным ранее:
В целом решения формируют управляемый инфраструктурный ИИ-стек от выделенных физических серверов до полностью обслуживаемых сервисов инференса. Компании позиционируют инициативу, как альтернативу традиционным «самоуправляемым» ИИ-кластерам на базе bare-metal серверов. Основная аудитория — компании, переходящие от пилотных ИИ-проектов к полномасштабному внедрению ИИ и агентных рабочих процессов в ключевые бизнес-системы.
16.06.2026 [16:21], Сергей Карасёв
В Кембриджском университете запущен AMD-суперкомпьютер ZenithВ Кембриджском университете (University of Cambridge) в Великобритании состоялась церемония запуска высокопроизводительного вычислительного комплекса Zenith, предназначенного для научных исследований с использованием ИИ. Инвестиции в проект составили около £36 млн ($48,3 млн). В создании суперкомпьютера приняли участие компании AMD и Dell Technologies. Полностью характеристики машины пока не раскрываются. Известно, что в её основу положены серверы PowerEdge, оборудованные процессорами AMD EPYC поколения Turin. Кроме того, задействованы ИИ-ускорители Instinct MI355X с 288 Гбайт памяти HBM3E (8 Тбайт/с). Вместе с тем AMD, Dell и Кембриджский университет объявили о планах создания на территории Великобритании Лаборатории инноваций в области суверенного ИИ (Sovereign AI Innovation Lab — SAIL). Инициатива, как ожидается, позволит расширить доступ к передовой ИИ-инфраструктуре и НРС-ресурсам для исследователей, медицинских организаций, государственных учреждений и других участников отрасли. На площадке SAIL компании смогут разрабатывать, оценивать и внедрять передовые технологии ИИ. Ключевой задачей SAIL названо формирование открытой ИИ-экосистемы на базе вычислительных платформ AMD, программного обеспечения AMD ROCm и облачных технологий. Отмечается, что благодаря появлению SAIL исследователи смогут масштабировать ИИ-решения с применением суверенной инфраструктуры, что ускорит инновации в таких областях, как здравоохранение, энергетика, экология, передовые инженерные разработки и пр. 
Источник изображения: University of Cambridge Одновременно AMD и Dell занимаются созданием ещё одного британского ИИ-суперкомпьютера — системы Sunrise. Этот проект финансируется Департаментом энергетической безопасности и достижения нулевого уровня выбросов (DESNZ) в составе Агентства по атомной энергии Великобритании (UKAEA).
09.06.2026 [13:58], Руслан Авдеев
AMD поддержит суверенный ИИ в Великобритании, инвестировав в ИИ-отрасль страны £2 млрд
amd
dell
epyc
hardware
hpc
instinct
великобритания
ии
инвестиции
инференс
суперкомпьютер
финансы
фотоника
В следующие пять лет AMD рассчитывает инвестировать в усиление ИИ-экосистемы Великобритании до £2 млрд ($2,7 млрд), создав новую инфраструктуру, программы совместных исследований и подготовки кадров. По словам представителя техногиганта, новая стратегия согласуется с правительственным проектом AI Opportunities Action Plan и стратегией AI Hardware Strategy, с основным акцентом на суверенные ИИ-возможности, научные вычисления и передовые исследования, сообщает Converge! Digest. Ключевой компонент инициативы — расширение вычислительной ИИ-инфраструктуры. AMD и Dell Technologies поддерживают две новые суперкомпьютерные системы в Кембриджском университете. Суперкомпьютер Zenith AI, финансирование которого осуществляется Министерством науки, инноваций и технологий (DSIT) и структурой UK Research and Innovation (UKRI), строится как платформа для использования ИИ в науке. Система Sunrise создаётся совместно с Управлением по атомной энергии Великобритании для поддержки исследований в сфере термоядерных технологий. Оба суперкомпьютера будут использовать ускорители AMD Instinct, процессоры EPYC и ПО AMD для решения задач в сфере здравоохранения, климатологии, материаловедения, разработки научных ИИ-моделей и др. Также AMD анонсировала исследовательские партнёрства с Имперским колледжем Лондона и компанией Oriole Networks. В первом случае взаимодействие сосредоточено на вычислительных дисциплинах, здравоохранении, моделировании климата, ИИ-оптимизации, обработке значительных объёмов данных и др. В то же время AMD и Oriole Networks принимают участие в проекте Scaling Inference Lab британского агентства ARIA (Advanced Research and Invention Agency). Проект стоимостью £50 млн направлен на устранение ряда проблем современной ИИ-инфраструктуры. Он объединяет фотонную сетевую архитектуру PRISM компании Oriole, ускорители AMD Instinct, а также процессоры EPYC для оценки новых подходов к масштабированию задач ИИ-инференса с меньшей задержкой и повышенной энергоэффективностью. 
Источник изображения: Robert Bye/unsplash.com По словам Converge!, лондонский стартап Oriole Networks намерен преодолеть традиционные ограничения классических ИИ-кластеров. Если в стандартных сетях на основе InfiniBand или Ethernet многократные преобразования оптического сигнала в электрический и обратно создают дополнительные задержки, то архитектура PRISM (Photonic Routing Infrastructure for Scalable Models) заменяет активные электронные коммутаторы «пассивным» оптическим ядром маршрутизации. Прямые оптические соединения узлов позволяют сократить время простоя GPU, связанное с ожиданием обмена данными, что мешает масштабным ИИ-нагрузкам. PRISM обеспечивает обработку динамического ИИ-трафика без использования электрических буферов пакетов данных. Многомерная коммутация каналов позволяет перенастраивать соединения в режиме реального времени и оптимизировать сеть под интенсивный обмен данными, характерный для больших языковых моделей. Кроме того, Oriole утверждает, что её технология позволяет объединять до миллиона оконечных устройств. В конечном счёте сокращение энергопотребления сетевого ядра может составить до 81 %. Ключевым элементом архитектуры PRISM является независимость от конкретного типа используемых процессоров и ускорителей. Вместо использования проприетарных интерконнектов, «привязывающих» операторов к определённой аппаратной платформе, Oriole разделяет транспортный и вычислительный уровни инфраструктуры. Компания заявляет, что её технологии интегрируются в существующие стеки ПО через стандартные драйверы PCIe и специализированные библиотеки ускорения вроде NCCL для NVIDIA или RCCL для AMD. Благодаря этому можно поддерживать разные аппаратные платформы без трансформации базовых ИИ-фреймворков. Будущее внедрение технологии в рамках ARIA Scaling Inference Lab станет значимой проверкой её жизнеспособности для отрасли и продемонстрирует, способны ли полностью фотонные сети гарантировать предсказуемую производительность и обеспечивать открытость проприетарных вычислительных систем в промышленных масштабах.
12.05.2026 [13:23], Сергей Карасёв
Dell выпустила ИИ-сервер PowerEdge XE9785 с ускорителями AMD Instinct MI355XКомпания Dell анонсировала сервер PowerEdge XE9785 на аппаратной платформе AMD, предназначенный для ресурсоёмких задач в области ИИ, включая обучение моделей и инференс. Двухсокетное устройство выполнено в форм-факторе 10U и оснащено воздушным охлаждением. Допускается установка двух процессоров AMD EPYC 9005 Turin, насчитывающих до 192 вычислительных ядер. Доступны 24 слота для модулей оперативной памяти DDR5-6400 RDIMM суммарным объёмом до 6 Тбайт. Во фронтальной части могут быть установлены до 16 NVMe-накопителей E3.S (PCIe 5.0) общей вместимостью до 245,76 Тбайт или до 10 NVMe-изделий U.2 суммарной ёмкостью до 153,6 Тбайт. Кроме того, есть два внутренних коннектора для SSD типоразмера М.2. Сервер несёт на борту восемь ускорителей AMD Instinct MI355X с 288 Гбайт памяти HBM3E (8 Тбайт/с). Задействован интерконнект AMD Infinity Fabric. В качестве альтернативного варианта предлагается конфигурация с восемью ускорителями NVIDIA HGX B300 и технологией NVIDIA NVLink. Питание обеспечивают 12 блоков мощностью 3200 Вт с сертификатом 80 Plus Titanium (с возможностью горячей замены). 
Источник изображения: Dell Габариты системы составляют 439,5 × 482,3 × 1044,7 мм, масса — 172,3 кг (с установленными картами MI355X). В зоне GPU находятся 15 вентиляторов, в области CPU — пять (все с поддержкой горячей замены). Среди прочего упомянуты слот OCP 3.0 (PCIe 5.0 x8), два сетевых порта RJ45, интерфейс Mini-DisplayPort, по одному порту USB Type-A и Type-C. Кроме того, компания Dell объявила о возможности использования ускорителей AMD Instinct MI350P в составе своих серверов PowerEdge XE7745 и R7725. Эти устройства рассчитаны на приложения ИИ, платформы виртуализации, базы данных и пр.
08.05.2026 [01:10], Владимир Мироненко
AMD представила ускоритель Instinct MI350P — CDNA 4 в формате PCIeAMD представила Instinct MI350P с интерфейсом PCIe — двухслотовую FHFL-карту для стандартных серверов с воздушным охлаждением. MI350P предназначена для локального развёртывания инференса в рамках существующей инфраструктуры электропитания, охлаждения и серверных стоек ЦОД предприятий. AMD отметила, что новинки с возможностью установки до 8 ед. в одно шасси «идеально подходят для инференса малых, средних и крупных ИИ-моделей и конвейеров RAG». Это первая PCIe-карта Instinct, выпущенная AMD за последние четыре года после выхода модели Instinct MI210. 600-Вт чип MI350P, по сути, представляет собой половинку MI350X (четыре XCD). У MI350P PCIe вдвое меньше вычислительных блоков — 128, что соответствует 8192 потоковым процессорам и 512 матричным ядрам. Пиковая частота составляет 2200 МГц. Кроме того, вместо двух IOD-кристаллов тут только один, он изготовлен по 6-нм техпроцессу TSMC. Сам ускоритель сделан по 3-нм технологии TSMC как MI350X. Весь чип содержит 73 млрд транзисторов. 
Источник изображений: AMD Ускоритель оснащён 128 Мбайт кеш-памяти Infinity Cache и 144 Гбайт памяти HBM3E с 4096-бит шиной, обеспечивающей пропускную способность 4 Тбайт/с. Для сравнения, MI350X оснащён 288 Гбайт памяти HBM3E с 8192-бит шиной. Плата 16-контактный разъём для подачи дополнительного питания. TBP можно установить на уровне 450 Вт вместо стандартных 600 Вт, что снизит производительность и ещё больше — энергопотребление. Интерфейс — PCIe 5.0 x16. Чуть позже будет реализована поддержка SR-IOV и возможность поделить чип на два или четыре vGPU. 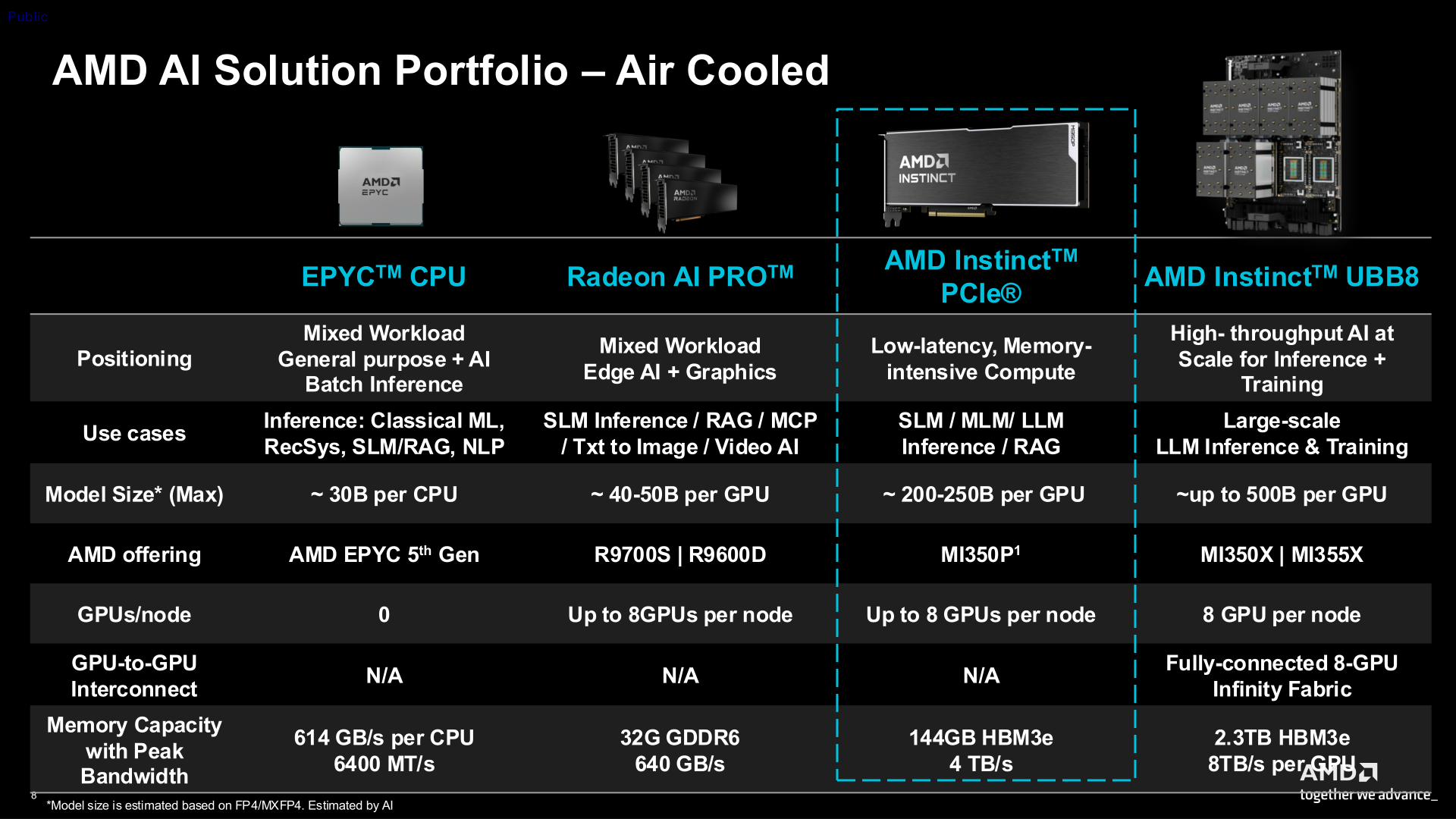 Расчётная производительность Instinct MI350P в MXFP4-расчётах составляет 2,3 Пфлопс, а пиковая — 4,6 Пфлопс. Это самая высокая производительность среди PCIe-ускорителей корпоративного класса, отметила компания. Предусмотрена поддержка разрежённости для форматов FP16, BF16, INT8 и OCP-FP8, что позволяет ускорить обработку данных. Векторная и матричная FP64-производительности составляет 36 Тфлопс. Кроме того, ускоритель снабжён декодерами HEVC/H.265, AVC/h.264, VP9 и AV1, а также кодеками (M)JPEG. 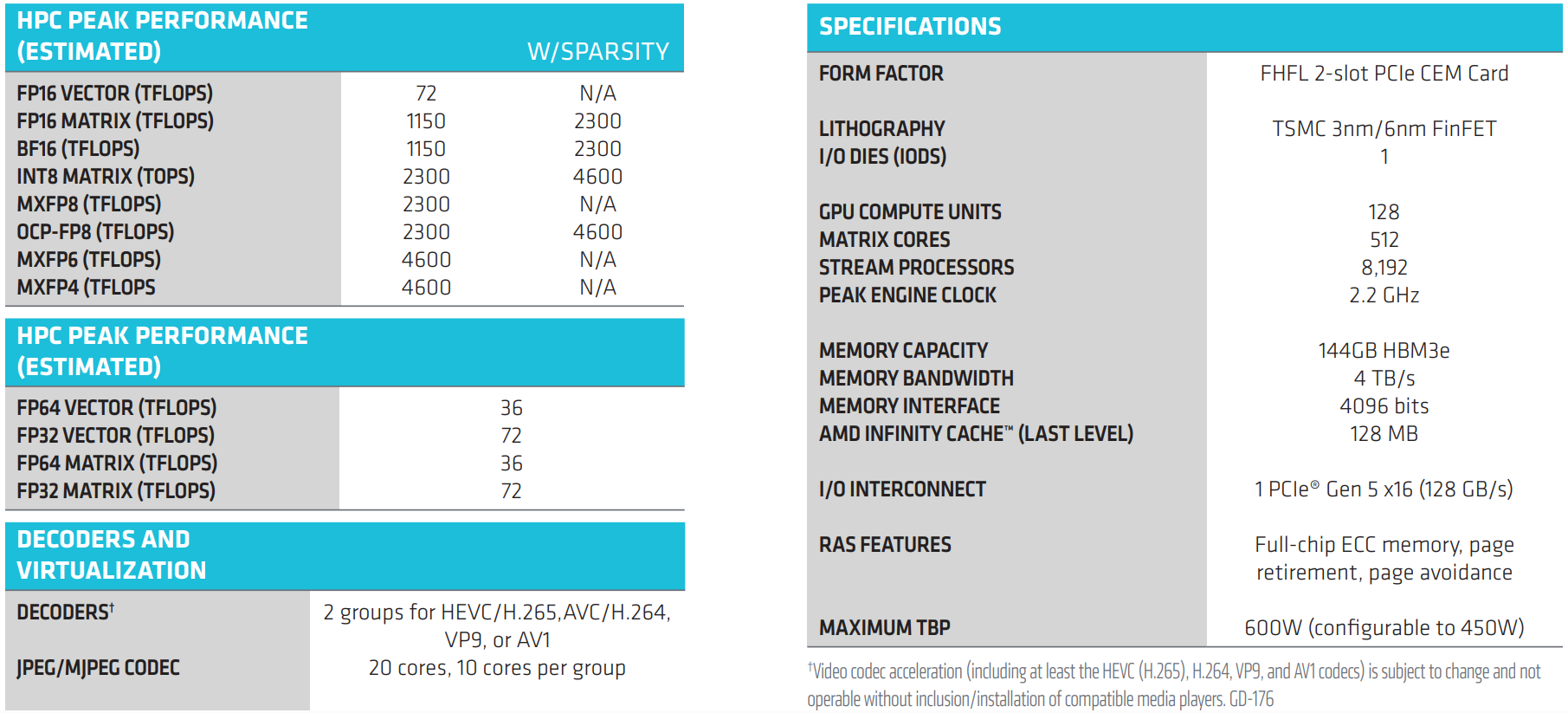 Самым существенным недостатком новинки — это отсутствие прямой связи между ускорителями посредством Infinity Fabric. Всё общение внутри одного узла происходит посредством PCIe-шины, так что наличие восьми MI350P в одном сервере позволит эффективно обслуживать восемь отдельных моделей (до 200–250 млрд параметров), а не одну большую, которая не помещается в памяти единичного ускорителя. NVIDIA попыталась чуть смягчить эту проблему, представив для своих PCIe-ускорителей плату с адаптерами ConnectX-8 SuperNIC со встроенными коммутаторами PCIe 6.0.  Сообщается, что Instinct MI350P доступны у различных партнёров компании. Они предлагают полностью открытую экосистему и программный стек Enterprise Ready AI с поддержкой ROCm. AMD заявила, что её эталонный open source пакет AMD Enterprise AI предоставляется партнёрам без каких-либо затрат на лицензирование. Это обеспечивает большую прозрачность кода и помогает снизить операционные расходы. В сочетании с картами Instinct MI350P и решениями от партнёров этот стек позволяет компаниям быстро развёртывать локальные системы без постоянных затрат на токены, говорит AMD.
07.05.2026 [16:26], Владимир Мироненко
200 Тфлопс в FP64: AMD поделилась первыми подробностями об Instinct MI430XAMD поделилась информацией о производительности Instinct MI430X. Это не ИИ-ускоритель — чип ориентирован на задачи в сегменте высокопроизводительных вычислений (HPC): вычисления с двойной точностью (FP64) остаются чрезвычайно важными в науке, моделировании и многих других приложениях, пишет ресурс ComputerBase. AMD официально подтвердила выпуск чипа прошлой осенью, когда уже получила первые крупные заказы. Теперь компания демонстрирует первые показатели решения с 432 Гбайт HBM4. Обладая производительностью более 200 TFLOPS в нативном режиме FP64, он будет «более чем в шесть раз быстрее» ускорителя NVIDIA Rubin. Однако следует отметить, что сравнение несколько некорректно. Во-первых, Rubin — это чистый ИИ-ускоритель, ориентированный на FP4 и аналогичные форматы, а не на FP64. Во-вторых, AMD прямо не уточняет, идёт ли речь о векторных и/или матричных вычислениях. Хотя, вероятно, речь всё-таки о векторных расчётах, поскольку в режиме эмуляции со схемой Озаки Rubin, как обещает NVIDIA, будет выдавать те же 200 Тфлопс в FP64. 
Источник изображений: AMD При этом реального конкурента, кроме Instinct M430X, у Rubin в FP64 нет. С другой стороны, Rubin, в свою очередь, по всей видимости, превосходит MI430X в приложениях FP4 — AMD пока не раскрыла его возможности в таких вычислениях. Кроме того, компания сама говорила о возможности поддержки схемы Озаки (Ozaki) для чипов Instinct. Фактически AMD в своих же чипах «отклонилась от курса», решив наращивать ИИ-производительность. В Instinct MI355X FP64-производительность и векторных, и матричных вычислений была на уровне 78,6 Тфлопс, тогда как вышедший ранее MI325X выдавал 81,6 Тфлопс, а ещё более «древний» MI300X — 81,7 Тфлопс.  О решении AMD нарастить нативную FP64-производительность ускорителя Instinct MI430X стало известно этой весной. До этого компания усомнилась в эффективности эмуляции научных расчётов на тензорных ядрах NVIDIA. NVIDIA же давно сделала ставку исключительно на ИИ, отказавшись от развития в новейших ускорителях FP64-блоков, но учёные указывают на то, что отказ от поддержки этого направления грозит лидерству США в HPC и дальнейшим инновациям. В Министерстве энергетики США (DoE) также отметили, что FP64-вычисления по-прежнему «очень важны» для «Миссии Генезис» (Genesis Mission) и для реализации её цели — ускорения научных открытий с помощью ИИ.  AMD добилась больших успехов в сегменте HPC, поставляя оборудование для самых быстрых в мире суперкомпьютеров. Именно этот рынок является целевым для Instinct MI430X, о чем свидетельствуют первые заказы, включая машину Discovery Национальной лаборатории Ок-Ридж (ORNL) в США и Alice Recoque во Франции. Как сообщается, производительность Alice Recoque составит более 1 Эфлопс в FP64, что сделает его одной из самых быстрых HPC-систем в Европе.
08.04.2026 [09:22], Владимир Мироненко
Стране нужен FP64: AMD пообещала повысить HPC-производительность ускорителей Instinct MI430XПосле анализа ограничений эмуляции FP64-вычислений с использованием схемы Озаки разработчики AMD пришли к выводу, что в настоящее время нет замены «сырой» производительности FP64. Как сообщил научный сотрудник AMD Николас Малайя (Nicholas Malaya) ресурсу HPCwire, чтобы обеспечить точность традиционных задач моделирования и симуляции, компания намерена нарастить нативную FP64-производительность ускорителя Instinct MI430X. Ускоритель станет основой суперкомпьютера Discovery, который будет установлен в Национальной лаборатории Ок-Ридж (ORNL) в 2028 году. Как отметил Кацухиса Озаки (Katsuhisa Ozaki) и два других японских исследователя, схема Ozaki — это многообещающая новая техника эмуляции, призванная позволить учёным выполнять высокоточные умножения матриц на оборудовании с поддержкой INT8/FP8, к которому относятся современные ИИ-ускорители, путём многократных вычислений с более низкой точностью. Текущие реализации Ozaki-I и Ozaki-II имеют ограничения, которые исключают их использование в реальных условиях, сообщил Малайя. Он указал на две основные проблемы. Во-первых, ПО не соответствует стандарту IEEE и не даёт того же результата, что и запуск кода на реальном оборудовании с поддержкой FP64. «В некоторых случаях это нормально, — сказал он. — Но во многих распространённых матрицах, которые мы наблюдали, влияние на точность довольно существенно.». Во-вторых, схема Озаки нацелена на квадратные матрицы. Если таковые в расчётах не используется, то итоговая производительность оказывается ниже, чем у нативного FP64-исполнения, говорит Малайя. 
Источник изображения: AMD Кроме того, HPC-приложения традиционно опираются на векторные вычисления, а не на тензорные или матричные, которые характерны для ИИ-нагрузок. Фактически ситуация ещё хуже — менее 10 % реальных HPC-приложений внесли изменения в DGEMM-коды, которые позволяют воспользоваться преимуществами Ozaki. «Насколько мне известно, с Ozaki-I, Ozaki-II или любой другой существующий метод нельзя применить к векторным инструкциям, — говорит Малайя. — Это ключевой нюанс, который, как мне кажется, упускается». На DGEMM действительно уходит много вычислительных ресурсов, что позволяет использовать схему Ozaki, «но она не решает 90 % HPC-задач». AMD собирается поддерживать эмуляцию Ozaki на своих чипах, сообщил Малайя. «Нет причин этого не делать. Это ПО. <…> И у вас могут быть библиотеки, которые позволяют динамически переключаться между нативными расчётами и Ozaki и, вероятно, оценивать его», — сказал он, добавив, что программную эмуляцию можно иметь в виду в качестве резервного варианта для FP64-вычислений. Но в конечном итоге Ozaki не является работоспособной альтернативой «железу» с FP64, сказал Малайя, уточнив, что не он один так считает. 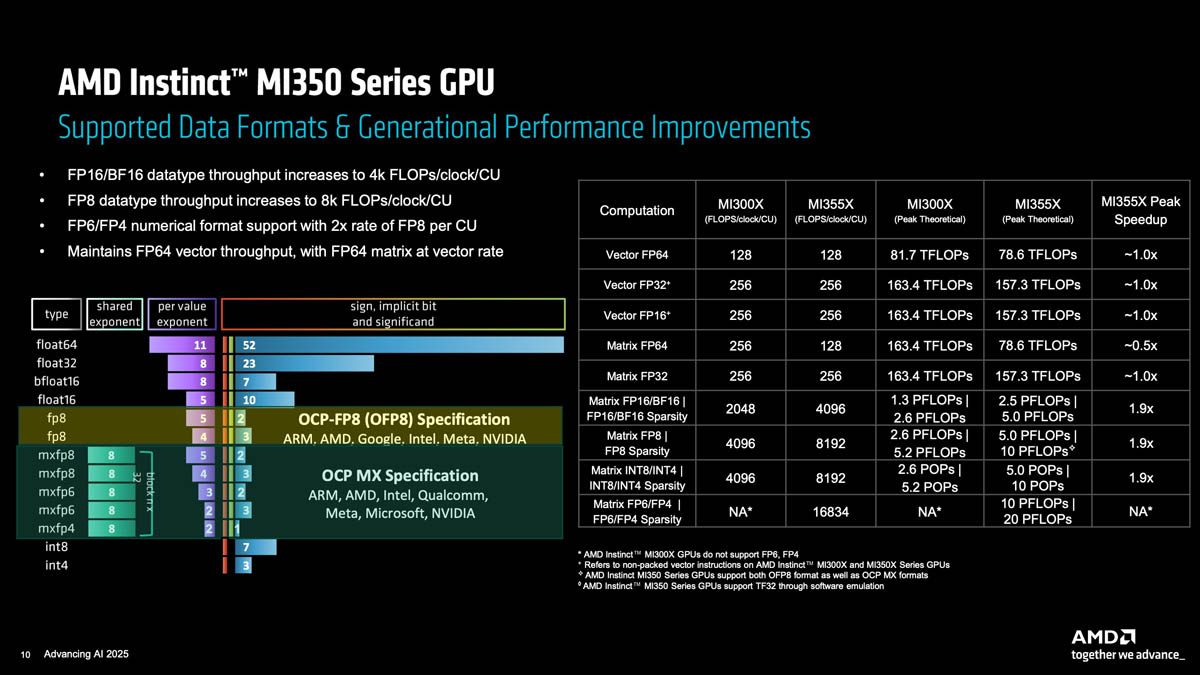
Источник изображения: AMD В настоящее время компания разрабатывает MI430X, специализированную версию ускорителя следующего поколения MI450, который будет обладать значительной FP64-производительностью. По словам Малайи, она будет значительно больше, чем у ускорителя MI355X, который обеспечивает 78,6 Тфлопс. По факту, это меньше, чем у предыдущей модели MI325X, которая обеспечивала 81,7 Тфлопс — в обоих случаях речь и про векторные, и про матричные FP64-вычисления. В любом случае, у всех этих чипов — от MI325 до MI430 — производительность больше, чем у чипов NVIDIA. И Hopper (34 Тфлопс), и Blackwell (40 Тфлопс) уже были медленнее в векторных FP64-вычислениях, но у Hopper хотя бы были нативные 67 Тфлопс в матричных расчётах, тогда как Blackwell в этом случае уже перешёл к схеме Озаки с «ненативными» 150 Тфлопс. Про Blackwell Ultra, где FP64-производительность упала до 1,3 Тфлопс, NVIDIA в данном контексте вообще не вспоминает, но обещает, что у Rubin будет 33 Тфлопс в векторных FP64-расчётах и 200 Тфлопс в матричных (тоже с Озаки). 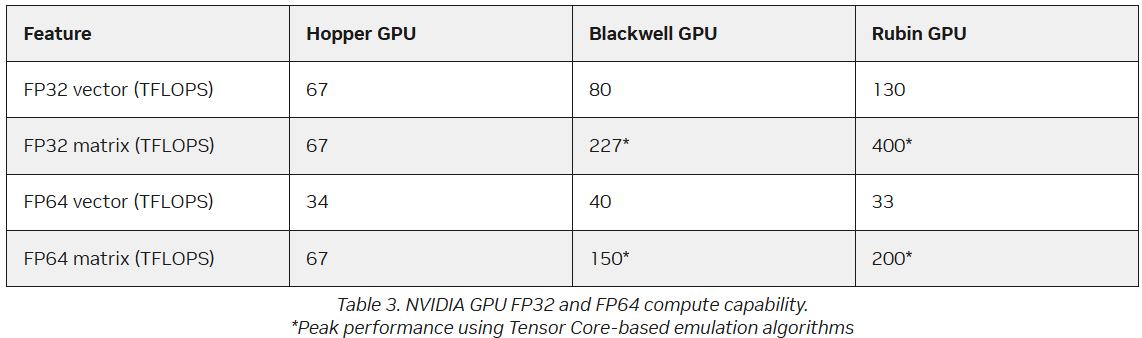
Источник изображения: NVIDIA NVIDIA обосновывает отказ от развития аппаратных FP64-блоков тем, что увеличение собственно вычислительной мощности FP64 на самом деле не ускорит научные приложения, поскольку на практике они упрутся в возможности регистров, кешей и HBM. Rubin обеспечит пропускную способность HBM до 22 Тбайт/с, что в 2,8 раза больше, чем у Blackwell. Instinct MI325X предлагает 6 Тбайт/с, MI355X — 8 Тбайт/с, а у MI430X будет уже 19,6 Тбайт/с, сообщил Малайя. По словам Малайи, лучше всего синхронно «вкладываться» и в HBM, и в количество операций с плавающей запятой. «На самом деле важен коэффициент байт/флопс. С нашей точки зрения, необходимо поддерживать гораздо более близкое соотношение к тому, что мы видим в современных продуктах, — сказал он. — Необходимо значительно приблизиться к этому соотношению с точки зрения увеличения производительности FP64, чтобы сохранить тот же уровень, как это называют, арифметической интенсивности». 
Источник изображения: NVIDIA Поскольку AMD обеспечит 2,5-кратное увеличение ПСП HBM от MI355 до MI430X, аналогичное 2,5-кратное увеличение производительности FP64 также будет оправдано. Таким образом можно примерно прикинуть, что MI430X может обеспечить производительность FP64 от 192 до 204 Тфлопс в зависимости от того, какой из них будет базовым: более новый MI355 или более быстрый MI325, сообщил HPCwire, добавив, что это всего лишь предположение, поскольку компания пока не сообщила точные характеристики будущих чипов. Кроме того, не до конца ясно, будет ли FP64-производительность одинакова для векторных и матричных расчётов. FP64-вычисления «очень важны» для «Миссии Генезис» (Genesis Mission), заявил ранее заместитель министра энергетики США (DoE) по науке и инновациям Дарио Гил (Darío Gil). Он отметил, что и глава AMD Лиза Су (Lisa Su), и глава NVIDIA Дженсен Хуанг (Jensen Huang), выразили твёрдую приверженность FP64, подтвердив, что поддержка формата будет продолжаться. «FP64 имеет решающее значение для поддержки рабочих нагрузок моделирования и симуляции, не только для дальнейшего развития традиционных научных исследований, но и для предоставления исходных данных для обучения новых ИИ-моделей», — добавил Гил. 
Источник изображения: AMD «Всегда существует баланс между тем, сколько требуется FP64- и FP16-вычислений», — сказал Малайя. «AMD утверждает, что нам необходимо поддерживать широкий спектр типов данных в зависимости от их потребностей. Не получится, чтобы всем были нужны FP64, которых хватит для всего.», — отметил он. Малайя сообщил, что всегда бывают исключения. Например, ИИ-симуляции сворачивания белков, такие как AlphaFold и Openfold, используют FP32. Да и некоторым традиционным HPC-задачам, таким как молекулярная динамика, не требуется FP64-точность. Тем не менее, сейчас существует значительный неудовлетворенный спрос на FP64, утверждает учёный. «Что касается высокопроизводительных вычислений, мы считаем, что им по-прежнему потребуется много FP64, — сказал он. — Будут использоваться некоторые коды, которые полностью ограничены пропускной способностью памяти, и им не нужно так много. Но есть, например, коды вычислительной химии и некоторые другие, которые действительно имеют высокую арифметическую интенсивность, и они будут использовать FP64».
03.03.2026 [14:27], Руслан Авдеев
Сделано в США: Flex начала выпуск американских ИИ-серверов с AMD InstinctАмериканская производственная компания Flex, поставляющая решения для дата-центров, анонсировала расширение стратегического сотрудничества с AMD для выпуска решений на платформе Instinct. По словам Flex, это важная веха на пути укрепления локального производства на территории США, в том числе передовых ИИ- и HPC-продуктов. В рамках партнёрства выпуск платформы AMD Instinct MI355X организован на территории головного подразделения Flex в Остине (Техас). В следующем квартале объёмы выпуска должны увеличиться. Речь идёт не только о платформе текущего поколения, компания намерена поддержать выпуск и новых платформ Instinct для удовлетворения спроса со стороны крупномасштабных ИИ-проектов. Сейчас Flex выпускает высокоплотные системы с восемью ускорителями и сопутствующей обвязкой. Каждая платформа, как утверждают в компании, проходит строгие заводские испытания и оценку. Системы оснащаются СЖО JetCool, принадлежащей Flex. По данным производителя, комбинация передовых индустриальных мощностей Flex, надёжной цепочки поставок и производственных мощностей в США с передовыми позициями AMD в HPC-сегменте позволяет клиентам масштабировать свои ИИ-проекты быстрее и с повышенной надёжностью. Головная структура Flex в Техасе занимает площадь более 130 тыс. м2 и создана для поддержки комплексного производства в больших объёмах. Всего у Flex в США есть более 650 тыс. м2 площадей на 17 объектах. 
Источник изображения: Flex Планы AMD по локализации производства включают и выпуск чипов на американских фабриках TSMC. NVIDIA идёт по тому же пути, но в части выпуска или хотя бы сборки серверов на территории США, в том числе для обслуживания гиперскейлеров, у неё гораздо больше возможностей. Но и AMD укрепила свои позиции в этой области в результате сделки с ZT Systems и Sanmina. США всеми силами стремятся локализовать производство и разработки на своей территории. В декабре 2025 года было объявлено о заключении партнёрских отношений с 24 ведущими IT-компаниями в рамках «Миссии Генезис», призванной стимулировать ИИ-разработки и производство на американской территории. Например, в конце января 2026 года сообщалось, что Corning построит крупнейшее в мире производство оптоволоконного кабеля для ЦОД в рамках сделки с Meta✴ на $6 млрд.
03.03.2026 [14:10], Сергей Карасёв
Gigabyte представила ИИ-сервер G893-ZX1-AAX4 на базе AMD Instinct MI355XGigabyte Technology анонсировала сервер G893-ZX1-AAX4, предназначенный для выполнения ресурсоёмких задач, таких как ИИ-инференс, сложное моделирование и пр. Новинка построена на аппаратной платформе AMD. Устройство типоразмера 8U рассчитано на два процессора EPYC 9005 Turin или EPYC 9004 Genoa в исполнении Socket SP5 (LGA 6096) с показателем TDP до 500 Вт. Доступны 24 слота для модулей оперативной памяти DDR5-4800/6400. Во фронтальной части расположены восемь отсеков для SFF-накопителей с интерфейсом PCIe 5.0 (NVMe). Кроме того, есть два внутренних коннектора для SSD формата M.2 2280/22110 с интерфейсом PCIe 3.0 x4 и PCIe 3.0 x1. Реализованы восемь разъёмов PCIe 5.0 x16 для однослотовых карт расширения FHHL и четыре разъёма PCIe 5.0 x16 для двухслотовых карт FHHL. В оснащение входят восемь ускорителей AMD Instinct MI355X OAM. Применяется полностью воздушное охлаждение с 15 вентиляторами диаметром 80 мм в области GPU-лотка, шестью кулерами на 60 мм в зоне материнской платы и четырьмя вентиляторами диаметром 80 мм в секции PCIe. Питание обеспечивают 12 блоков мощностью 3000 Вт каждый с сертификатом 80 PLUS Titanium. 
Источник изображения: Gigabyte Technology Сервер оборудован контроллером ASPEED AST2600, двумя сетевыми портами 10GbE на базе Intel X710-AT2 (RJ45), выделенным сетевым портом управления 1GbE (RJ45), двумя портами USB 3.2 Gen1 (5 Гбит/с), аналоговым разъёмом D-Sub. Диапазон рабочих температур — от +10 до +30 °C. Габариты составляют 447 × 351 × 923 мм.
20.02.2026 [09:10], Руслан Авдеев
AMD, Classiq и Comcast «квантово» улучшили интернетРазработчик программного обеспечения для квантовых вычислений Classiq совместно с Comcast и AMD объявили о завершении испытаний, направленных на совершенствование доставки интернет-трафика путём использования квантовых алгоритмов для повышения надёжности маршрутизации в Сети, сообщает HPC Wire. Comcast заявила, что клиентам нужно быстрое, безопасное и надёжное подключение, но при управлении большой и динамичной сетью достижение этой цели становится сложной задачей, особенно в условиях растущего спроса. Поэтому в прошлом году были начаты эксперименты по выяснению того, как квантовое ПО и технологии могут решать реальные сетевые задачи. Результаты показали, что квантовые вычисления для оптимизации сети — не теория, а вполне практическое, масштабируемое решение. В ходе тестов решалась фундаментальная задача проектирования сети — определение независимых резервных маршрутов для сетевых узлов в общей конкурентной среде при проведении технического обслуживания и изменении топологии сети, причём с сохранением минимально возможной задержки, высокой устойчивостью к одновременным сбоям и высокой же пропускной способностью. Такая задача регулярно возникает на реальных сетях, где и без планового обслуживания не обойтись, и от одновременных сбоев никто застрахован. 
Источник изображения: Dynamic Wang/unsplash.com В ходе эксперимента с использованием квантовых технологий и HPC-платформ AMD на базе ускорителей Instinct MI300X проверялась возможность квантовых алгоритмов успешно определять резервные пути для трафика в режиме реального времени в различных сценариях. Использовались как моделирование с использованием Instinct для достижения значимых вычислительных мощностей (кубитного уровня), что позволило быстро перебирать различные алгоритмы, так и реальный квантовый компьютер IonQ Forte с 29 алгоритмическими кубитами для проверки успешности реализации алгоритмов. 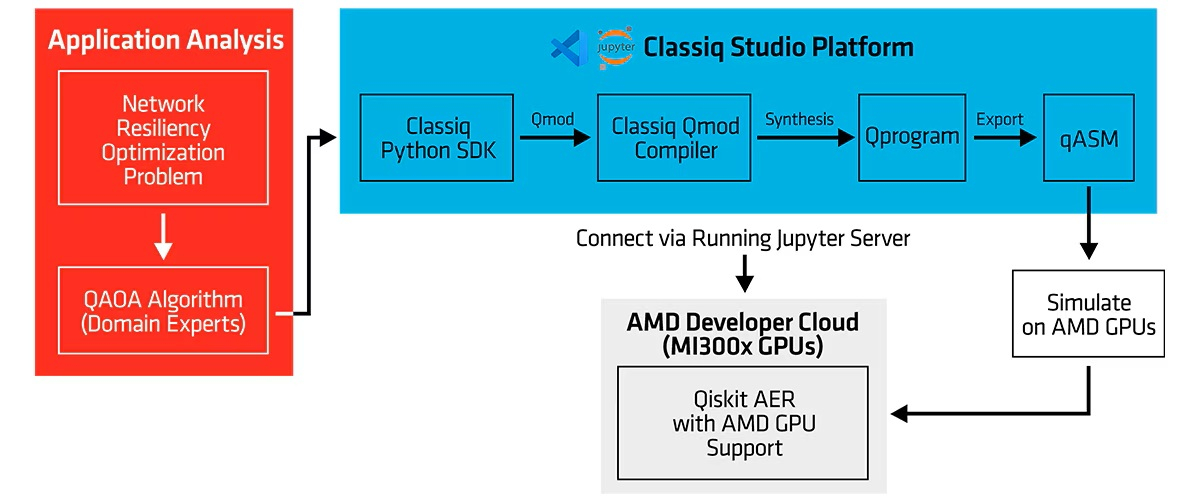
Источник изображения: AMD Задача оптимизации глобальных телекоммуникационных сетей — крайне ресурсоёмкая комбинаторная задача, экспоненциально усложняющаяся по мере роста размера сети. Такая задача является идеальным вызовом для систем квантовых вычислений. По словам представителя Classiq, исследования и разработки в сфере квантовых технологий требуют быстрых итераций с внесением улучшений на каждом цикле и воспроизводимых рабочих процессов. AMD заявила, что будущее HPC — в конвергенции классических и квантовых вычислений. |
|

