Материалы по тегу: instinct
|
04.12.2025 [12:21], Руслан Авдеев
Скромно, но со вкусом: Vultr при поддержке AMD построит за $1 млрд ИИ-кластер с 24 тыс. Instinct MI355XОблачный провайдер Vultr строит кластер мощностью 50 МВт из ИИ-ускорителей AMD в дата-центре в Огайо. Новый проект призван обеспечить дополнительные вычислительные мощности по сниженным ценам, сообщает Bloomberg. Поддерживаемая AMD компания намерена инвестировать в объект более $1 млрд, клиенты смогут обучать и эксплуатировать ИИ-модели. Ввод в эксплуатацию запланирован на I квартал 2026 года. Vultr входит в группу облачных провайдеров, желающих заработать на ажиотажном спросе на ИИ. Новый кластер гораздо меньше гигантских объектов Microsoft, Meta✴ и Google. При этом вычислительные мощности, по словам компании, будут предлагаться по более доступным тарифам. Облако Vultr, как правило, вдвое дешевле, чем предложения гиперскейлеров, сообщают в компании. Утверждается, что её 50-МВт ЦОД с 24 тыс. AMD Instinct MI355X сопоставим с некоторыми гигаваттными проектами по эффективности. Vultr одной из первых получила MI355X, а вскоре перейдёт на MI450. Кластер называют «беспрецедентным» для облачной компании такого масштаба, но для него пока нет готовых к подписанию соглашений клиентов, хотя активные переговоры уже ведутся. По имеющимся данным, действующие клиенты вроде Clarifai Inc. и LiquidMetal AI, а также биотехнологическая MindWalk Holdings уже пользуются сервисами Vultr на базе решений AMD. В общей сложности компания обслуживает «сотни тысяч» клиентов в 185 странах. 
Источник изображения: Vultr Vultr была основана в 2014 году и многие годы предлагала доступ к решениям на базе CPU. В 2021 году Vultr начала закупать GPU. В последние пару лет ИИ-инфраструктура стала самой быстрорастущей частью бизнеса компании, т.ч. теперь она обеспечивает большую часть выручки. В 2026 году бизнес намерен уделять ИИ ещё больше внимания. В прошлом году компания привлекла $333 млн, в ходе раунда, возглавленного LuminArx Capital Management и AMD, её капитализация составила $3,5 млрд. В июне 2025 года дополнительно получены $329 млн кредитного финансирования, преимущественно от JPMorgan Chase, Bank of America и Wells Fargo. В эту сумму вошли $74 млн, обеспеченных активами компании, в т.ч. ИИ-ускорителями. Vultr значительно расширила кредитную линию для финансирования кластера AMD. Разрабатывающие ИИ-инфраструктуру компании всё чаще опасаются, что отрасль ожидает формирование пузыря. Также не исключается, что ИИ-ускорителя быстро обесценятся, что тоже способно привести рынок к кризису. В Vultr уверены, что ИИ-инфраструктура всё ещё остаётся «крайне неразвитой», даже если некоторые, чрезвычайно разросшиеся на этом рынке IT-гиганты, вероятно, потерпят неудачу. Что касается времени «обесценивания» технологий, Vultr уверена, что срок службы в шесть лет для ИИ-ускорителей — «разумная, консервативная оценка».
03.12.2025 [20:51], Владимир Мироненко
HPE одной из первых начнёт выпускать интегрированные стоечные ИИ-платформы AMD Helios AI
amd
broadcom
epyc
hardware
hpc
hpe
instinct
juniper networks
mi400
ocp
ualink
venice
германия
ии
суперкомпьютер
AMD объявила о расширении сотрудничества с HPE, в рамках которого HPE станет одним из первых поставщиков стоечных систем AMD Helios AI, которые получат коммутаторы Juniper Networking (компания с недавних пор принадлежит HPE), разработанные совместно с Broadcom, и ПО для бесперебойного высокоскоростного подключения по Ethernet. AMD Helios AI — открытая полнофункциональная ИИ-платформа на базе архитектуры OCP Open Rack Wide (ORW), разработанная для крупномасштабных рабочих нагрузок и обеспечивающая FP4-производительность до 2,9 Эфлопс на стойку благодаря ускорителям AMD Instinct MI455X, процессорам EPYC Venice шестого поколения и DPU Pensando Vulcano, работающими под управлением открытой программной экосистемы ROCm для нагрузок ИИ и HPC. Как отметил The Register, сетевая архитектура этой системы будет представлять собой масштабируемую реализацию UALink over Ethernet (UALoE) и специализированным коммутатором Juniper Networks на базе сетевого чипа Broadcom Tomahawk 6 (102,4 Тбит/с). Система разработана для упрощения развёртывания крупномасштабных ИИ-кластеров, что позволяет сократить время разработки решений и повысить гибкость инфраструктуры. В отличие от NVIDIA, AMD не выпускает коммутаторы, предлагая открытую экосистему, так что HPE и другие компании могут интегрировать собственные сетевые решения. The Register полагает, что HPE и Broadcom решили не гнаться за отдельной аппаратной реализацией UALink, если данные можно передавать поверх Ethernet. «Это первое в отрасли масштабируемое решение, использующее Ethernet, стандартный Ethernet. Это означает, что оно полностью соответствует открытому стандарту и позволяет избежать привязки к проприетарному поставщику, использует проверенную сетевую технологию HPE Juniper для обеспечения масштабируемости и оптимальной производительности для рабочих нагрузок ИИ», — заявила HPE. 
Источник изображения: HPE HPE заявила, что это позволит её стоечной системе поддерживать трафик, необходимый для обучения модели с триллионами параметров, а также обеспечить высокую пропускную способность инференса. Стоечная система HPE будет включать 72 ускорителя AMD Instinct MI455X с 31 Тбайт HBM4 с агрегиированной пропускной способностью 1,4 Пбайт/с. Агрегированная скорость интерконнекта составит 260 Тбайт/с. Новинка будет доступна в 2026 году. AMD также сообщила, что Herder, новый суперкомпьютер для Центра высокопроизводительных вычислений в Штутгарте (HLRS) (Германия), получит Instinct MI430X и EPYC Venice. Он будет построена на платформе HPE Cray Supercomputing GX5000. Поставка Herder запланирована на II половину 2027 года, а ввод в эксплуатацию — к концу 2027 года. Herder заменит используемый центром суперкомпьютер Hunter.
01.12.2025 [12:28], Сергей Карасёв
MiTAC представила ИИ-сервер G4826Z5 с ускорителями AMD Instinct MI355X и СЖОКомпания MiTAC анонсировала высокопроизводительный GPU-сервер G4826Z5 на аппаратной платформе AMD, предназначенный для ресурсоёмких задач ИИ и НРС. Кроме того, представлены стойки и вычислительные кластеры на его основе. Сервер G4826Z5U2BC-355X-755 выполнен в форм-факторе 4U. Нижняя 2U-секция содержит два процессора AMD EPYC 9005 Turin и 24 слота для модулей оперативной памяти DDR5-6400. Во фронтальной части расположены восемь отсеков для SFF-накопителей; кроме того, есть два внутренних коннектора M.2 для SSD (NVMe). Верхний 2U-модуль несёт на борту восемь ускорителей AMD Instinct MI355X, оборудованных 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Машина G4826Z5 получила систему жидкостного охлаждения, которая охватывает CPU- и GPU-секции. Предусмотрена функция обнаружения утечек. Подсистема питания с резервированием выполнена по схеме: 1+1 мощностью 3200 Вт и 3+3 мощностью 15 600 Вт. Все блоки питания имеют сертификат 80 Plus Titanium и допускают горячую замену. 
Источник изображений: MiTAC На основе G4826Z5 формируется стоечная система (MR1100L-64355X-01): она содержит восемь GPU-серверов, что в сумме даёт 64 ускорителя и 18,4 Тбайт памяти HBM3E. Стойка также укомплектована коммутаторами 400GbE на 64 и 32 порта, двумя коммутаторами 1GbE на 48 портов, сервером управления B8056G68CE12HR-2T-TU, сервером хранения B8056T70AE26HR-2T-HE-TU и блоком распределения охлаждающей жидкости (CDU) в формате 4U.  В свою очередь, стойки объединяются в кластеры из четырёх и восьми штук. Это в сумме обеспечивает 32 и 64 сервера GPU и 256 и 512 ускорителей Instinct MI355X соответственно. Таким образом, максимальная конфигурация включает приблизительно 147 Тбайт памяти HBM3E.
26.11.2025 [12:50], Сергей Карасёв
Сервер Giga Computing G4L3-ZX1 с поддержкой AMD EPYC 9005 Turin и Instinct MI355X оснащён СЖОКомпания Giga Computing, подразделение Gigabyte, анонсировала сервер G4L3-ZX1-LAT4, предназначенный для задачи ИИ и НРС. Эта мощная машина на аппаратной платформе AMD оснащена системой прямого жидкостного охлаждения (DLC), отводящей тепло и от CPU, и от GPU. Сервер выполнен в форм-факторе 4U. Он может нести на борту два процессора EPYC 9004 Genoa или EPYC 9005 Turin (до 192 вычислительных ядер) в исполнении Socket SP5 с показателем TDP до 500 Вт. Доступны 24 слота для модулей оперативной памяти DDR5-6400. Во фронтальной части находятся восемь отсеков для SFF-накопителей NVMe; кроме того, есть два внутренних коннектора M.2 2280/22110 для SSD с интерфейсом PCIe 3.0 x4 и x1. Новинка располагает восемью ускорителями AMD Instinct MI355X OAM. Предусмотрены восемь разъёмов для однослотовых карт FHHL с интерфейсом PCIe 5.0 x16 и четыре разъёма для двухслотовых карт FHHL (также PCIe 5.0 x16). Питание обеспечивают шесть блоков с резервирование мощностью 5200 Вт (сертификат 80 PLUS Titanium). Помимо СЖО, задействован ряд системных вентиляторов: 4 × 60 мм в зоне материнской платы, 4 × 80 мм в области слотов PCIe и 4 × 60 мм в лотке GPU. Диапазон рабочих температур — от +10 до +30 °C. 
Источник изображения: Giga Computing Сервер оснащён двумя сетевыми портами 10GbE на основе адаптера Intel X710-AT2, выделенными сетевыми портами 1GbE во фронтальной и тыльной частях, контроллером Aspeed AST2600, двумя портами USB 3.2 Gen1 Type-A и аналоговым разъёмом D-Sub. Опционально может быть добавлен модуль TPM 2.0. Габариты сервера составляют 447 × 175,5 × 901 мм.
21.11.2025 [11:14], Сергей Карасёв
Supermicro представила ИИ-сервер 10U на базе AMD Instinct MI355X с воздушным охлаждениемКомпания Supermicro анонсировала высокопроизводительный GPU-сервер AS-A126GS-TNMR, построенный на аппаратной платформе AMD. Система, выполненная в форм-факторе 10U, ориентирована на НРС-нагрузки и решение ресурсоёмких задач в сфере ИИ. Сервер может нести на борту два процессора AMD EPYC 9005 Turin или EPYC 9004 Genoa со 192 ядрами каждый (показатель TDP до 500 Вт). Доступны 24 слота для модулей оперативной памяти DDR5-6400 суммарным объёмом до 6 Тбайт. Во фронтальной части расположены десять отсеков для SFF-накопителей в конфигурации 8 × NVMe (PCIe 5.0 x4) и 2 × SATA с возможностью горячей замены. Кроме того, есть два лицевых слота для SSD формата M.2 (NVMe). В оснащение входят восемь ускорителей AMD Instinct MI355X, оборудованных 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Применяется интерконнект AMD Infinity Fabric. Реализовано воздушное охлаждение: спереди размещены пять вентиляторных блоков, сзади — десять (все они допускают горячую замену). Диапазон рабочих температур простирается от +10 до +35 °C. 
Источник изображения: Supermicro Сервер располагает двумя сетевыми портами 10GbE RJ45 на базе контроллера Intel X710, выделенным сетевым портом управления 1GbE, двумя портами USB 3.0 Type-A, аналоговым разъёмом D-Sub, модулем TPM 2.0, восемью слотами PCIe 5.0 x16 для низкопрофильных (LP) карт расширения и двумя слотами PCIe 5.0 x16 для карт FHHL. Габариты составляют 438,8 × 449 × 843,28 мм, масса — 133 кг. Питание обеспечивают шесть блоков мощностью 5250 Вт с резервированием (3 + 3), которые имеют сертификацию 80 Plus Titanium. Поставки системы AS-A126GS-TNMR уже начались.
20.11.2025 [14:00], Руслан Авдеев
AMD, Cisco и Humain развернут ИИ-инфраструктуру на 1 ГВт — первые 100 МВт с Instinct MI450 появятся в Саудовской АравииКомпании AMD, Cisco и саудовская инвестиционная компания Humain, участвующая в комплексных ИИ-проектах, объявили о создании совместного предприятия. Ожидается, что оно поддержит укрепление позиций Саудовской Аравии в качестве ведущего поставщика ИИ-решений мирового класса для клиентов регионального и мирового уровней. Совместное предприятие должно заработать в 2026 году. Партнёры рассчитывают объединить передовые ИИ ЦОД Humain и технологическими решениями AMD и Cisco, обеспечив современную вычислительную инфраструктуру с низкими капитальными затратами и эффективным энергопотреблением. Эксклюзивными технологическими партнёрами предприятия выступят AMD и Cisco, к 2030 году с помощью их продуктов и сервисов планируется обеспечить до 1 ГВт ИИ-инфраструктуры. Компании уже объявили о реализации первой очереди проекта — пока мощностью на 100 МВт, в т.ч. включающую мощности современного дата-центра Humain, ИИ-ускорители AMD Instinct MI450 и инфраструктуру Cisco. Ранее в 2025 году Cisco и AMD объявили о совместной инициативе с Humain, направленной на строительство самой открытой, масштабируемой и экономически эффективной ИИ-инфраструктуры. Новый анонс дополняет планы созданием совместного предприятия для того, чтобы ускорить преобразования и предоставить экономическую инфраструктуру для поддержки использования ИИ заказчиками. 
Источник изображения: NEOM/unsplash.com По словам главы AMD Лизы Су (Lisa Su), в рамках расширения сотрудничества в Саудовской Аравии также создаётся Центр передового опыта AMD (AMD Center of Excellence) для углубленной интеграции страны в ИИ-проекты. По данным Cisco, индекс готовности к развитию ИИ (AI Readiness Index) показывает, что, хотя 91 % организаций Саудовской Аравии готовятся к внедрению ИИ-агентов, только 29 % из них уже имеют доступ к значительным мощностям ИИ-ускорителей, что ещё раз подчёркивает острую потребность в современной инфраструктуре ЦОД. Ожидается, что партнёрство не только обеспечит вычислительные мощности для масштабного внедрения ИИ, но и будет способствовать укреплению цифровой экономики страны. Это лишь один из многих проектов для Саудовской Аравии. В 2025 году сообщалось, что Oracle выделит $14 млрд на развитие ИИ и облака в стране, xAI ведёт с Humain переговоры о создании ИИ ЦОД там же, в августе появилась информация, что саудовская center3 потратит $10 млрд на ЦОД общей мощностью 1 ГВт.
19.11.2025 [11:49], Сергей Карасёв
Второй европейский экзафлопсный суперкомпьютер Alice Recoque получит чипы AMD EPYC Venice и ускорители Instinct MI430XЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) и французско-нидерландский Консорциум Жюля Верна объявили о том, что в создании суперкомпьютера Alice Recoque примут участие компании Eviden (входит в состав Atos Group), AMD и SiPearl. О проекте Alice Recoque впервые стало известно в июне прошлого года. Это будет второй европейский суперкомпьютер экзафлопсного класса после системы JUPITER, смонтированной в Юлихском исследовательском центре (FZJ) в Германии. Соглашение о создании Alice Recoque подписано между EuroHPC JU и французским национальным агентством высокопроизводительных вычислений (GENCI). Комплекс будет смонтирован в дата-центре на территории Брюйер-ле-Шатель (Bruyères-le-Châtel), к юго-западу от Парижа. Как сообщается, в состав Alice Recoque войдут унифицированный вычислительный раздел и скалярный раздел. Основой первого послужит новая платформа Eviden BullSequana XH3500, содержащая серверы с 256-ядерными процессорами AMD EPYC Venice и ускорителями Instinct MI430X, оснащёнными 432 Гбайт памяти HBM4 с пропускной способностью 19,6 Тбайт/с. Кроме того, говорится о применении AMD FPGA и высокопроизводительной подсистемы хранения данных DDN. Суперкомпьютер объединит 94 стойки с суммарным энергопотреблением «менее 15 МВт». В свою очередь, скалярный раздел будет использовать 128-ядерные Arm-процессоры SiPearl Rhea2. Общее количество таких ядер превысит 100 тыс. В качестве интерконнекта в составе Alice Recoque планируется использовать технологию BullSequana eXascale Interconnect (BXI v3), обеспечивающую скорость передачи данных до 400 и 800 Гбит/с для CPU- и GPU-узлов соответственно. 
Источник изображения: AMD Машина получит систему прямого жидкостного охлаждения (DLC) пятого поколения (с тёплой водой) разработки Eviden для унифицированных стоек и технологию охлаждаемых дверей для скалярных стоек. Интеллектуальное программное обеспечение Eviden Argos обеспечит мониторинг в режиме реального времени и оптимизацию энергопотребления. Говорится о широком применении компонентов с открытым исходным кодом, таких как SLURM, Kubernetes, LUSTRE, Grafana и Prometheus. Монтаж суперкомпьютера Alice Recoque начнётся в 2026 году. Затраты на приобретение, доставку, установку и обслуживание системы составят €354,8 млн. EuroHPC JU предоставит половину этой суммы, ещё столько же обеспечат Франция, Нидерланды и Греция в рамках Консорциума Жюля Верна. Общие инвестиции в проект на протяжении пяти лет оцениваются в €554 млн. Использовать новый вычислительный комплекс планируется для решения сложных задач в сферах моделирования климата, разработки передовых материалов, энергетики и пр. Система также поможет в развитии европейских моделей ИИ следующего поколения и цифровых двойников для персонализированной медицины.
14.11.2025 [09:38], Сергей Карасёв
«За пределы экзафлопсного уровня»: Eviden представила суперкомпьютерную платформу BullSequana XH3500Компания Eviden, входящая в Atos Group, анонсировала конвергентную суперкомпьютерную платформу BullSequana XH3500 для ресурсоёмких нагрузок ИИ и HPC. Новинка сочетает передовые аппаратные решения с комплексной экосистемой ПО, обеспечивая возможность масштабирования «за пределы экзафлопсного уровня». BullSequana XH3500 использует открытую модульную конструкцию. Такой подход позволяет свободно комбинировать блоки CPU, GPU и сетевые компоненты от различных производителей, адаптируя конфигурации под определённые потребности. При этом устраняется зависимость от какого-либо конкретного поставщика оборудования, что обеспечивает полную технологическую свободу. По заявлениям Eviden, платформа BullSequana XH3500 по сравнению с системой предыдущего поколения позволяет добиться повышения электрической мощности более чем на 80 % в расчёте на 1 м2 и увеличения эффективности охлаждения на 30 % в расчёт на 1 кВт. Это даёт возможность удовлетворить растущие потребности в вычислительных ресурсах без необходимости расширения площадей в дата-центрах. Габариты стойки BullSequana XH3500 без модуля ультраконденсатора составляют 2270 × 900 × 1457 мм. Мощность AC достигает 284 кВт (с одной помпой). Задействовано на 100 % безвентиляторное прямое жидкостное охлаждение (DLC) пятого поколения с возможностью использования горячей воды с температурой до 40 °C. Подсистемы питания и охлаждения выполнены по схеме с резервированием N+1. Доступны 38 универсальных слотов 1U. 
Источник изображения: Eviden Для платформы BullSequana XH3500 разработаны узлы BullSequana XH3515B и BullSequana AI1242. Первый соответствует типоразмеру 1U: это одноузловое изделие оборудовано двумя чипами NVIDIA Grace CPU и четырьмя ускорителями NVIDIA Blackwell B200. Возможна установка до девяти NVMe SSD в форм-факторе E1.S. Говорится о поддержке четырёх сетевых устройств Eviden BXI V3 или InfiniBand NDR/XDR. В свою очередь, сервер BullSequana AI1242 имеет исполнение 2U. Данное решение несёт на борту два процессора AMD EPYC Turin и GPU-ускоритель AMD Instinct MI355X. Реализована поддержка восьми устройств Eviden BXI V3 или InfiniBand NDR/XDR, а также четырёх накопителей E1.S NVMe SSD.
14.11.2025 [09:36], Сергей Карасёв
HPE представила CPU- и GPU-узлы суперкомпьютерной платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения для НРС-задач, являющиеся частью суперкомпьютерной платформы Cray Supercomputing GX5000. В частности, дебютировали узлы GX250 Compute Blade, GX350a Accelerated Blade и GX440n Accelerated Blade, а также высокопроизводительная СХД Storage Systems K3000. Устройство HPE Cray Supercomputing GX250 Compute Blade представляет собой CPU-сервер, оснащённый восемью процессорами AMD EPYC Venice (появятся во II половине 2026 года). В одной стойке могут быть размещены до 40 таких серверов, что обеспечивает самую высокую в отрасли плотность компоновки x86-ядер следующего поколения, говорит компания. В паре с CPU-узлами могут функционировать новые GPU-модули. Так, изделие HPE Cray Supercomputing GX350a Accelerated Blade несёт на борту один чип AMD EPYC Venice и четыре ускорителя AMD Instinct MI430X. В стойку могут устанавливаться до 28 таких серверов, что даёт в сумме 112 ускорителей MI430X. В свою очередь, HPE Cray Supercomputing GX440n Accelerated Blade содержит четыре NVIDIA Vera CPU и восемь NVIDIA Rubin GPU. Допускается монтаж до 24 подобных серверов на стойку, что обеспечивает 192 ускорителя Rubin. Все новинки оборудованы жидкостным охлаждением. СХД HPE Cray Supercomputing Storage Systems K3000 выполнена на сервере HPE ProLiant Compute DL360 Gen12. Могут устанавливаться 8, 12, 16 или 20 накопителей NVMe вместимостью 3,84, 7,68 или 15,36 Тбайт каждый. Объём памяти DRAM — 512 Гбайт, 1 или 2 Тбайт. Применяется платформа DAOS, разработанная для требовательных рабочих нагрузок, таких как анализ данных и машинное обучение. Поддерживаются технологии HPE Slingshot 200, HPE Slingshot 400, InfiniBand NDR и 400GbE. 
Источник изображения: HPE via The Next Platform Кроме того, HPE сообщила о том, что для платформы HPE Cray Supercomputing GX5000 доступен интерконнект HPE Slingshot 400. Соответствующие коммутаторы с прямым жидкостным охлаждением наделены 64 портами на 400 Гбит/с. Возможны конфигурации с 8, 16 и 32 коммутаторами, что в сумме позволяет использовать до 512, 1024 и 2048 портов соответственно. 
Источник изображения: HPE О выборе платформы HPE Cray Supercomputing GX5000 для НРС-комплексов нового поколения уже объявили Центр высокопроизводительных вычислений Штутгартского университета (HLRS) и Центр суперкомпьютеров имени Лейбница (LRZ) Баварской академии естественных и гуманитарных наук (BADW). Кроме того, новая платформа является основой суперкомпьютера Discovery Министерства энергетики США (DOE).
12.11.2025 [23:23], Владимир Мироненко
От ИИ ЦОД до роботов: AMD анонсировала долгосрочную стратегию роста
amd
cpu
dpu
epyc
hardware
instinct
mi400
mi500
ocp
pensando systems
ualink
ultra ethernet
venice
verano
xilinx
ии
ускоритель
финансы
AMD представила на мероприятии Financial Analyst Day 2025 план по достижению лидерства на рынке вычислительных технологий объёмом $1 трлн. Долгосрочная стратегия роста AMD построена на четырех столпах: лидерство в сфере ЦОД, повышение производительности ИИ, открытое ПО и расширение присутствия на рынках встраиваемых и полукастомных кремниевых решений. AMD ожидает, что только её бизнес в сфере ЦОД будет приносить более $100 млрд годовой выручки, с увеличением совокупного среднегодового темпа роста (CAGR) до более чем 60 %, при этом CAGR дохода от ИИ-решений увеличится до более чем 80 %. Генеральный директор AMD Лиза Су (Lisa Su) заявила, что следующий этап будет основан на унифицированной вычислительной платформе AMD, объединяющей процессоры EPYC, ускорители Instinct, сетевые решения Pensando и ПО ROCm. Новый план развития AMD призван обеспечить ей конкуренцию с NVIDIA и Intel на корпоративных рынках и в борьбе за заказы гиперскейлеров. 
Источник изображений: AMD  Ускорители серии Instinct MI350, уже развёрнутые Oracle (ещё 50 тыс. MI450 будут развёрнуты во II половине 2026 г.), являются самыми популярными ускорителями AMD на сегодняшний день. Следующей платформой станет серия MI450, которая будет запущена вместе со стоечной платформой Helios в III квартале 2026 года. Helios обеспечит пропускную способность интерконнекта 3,6 Тбайт/с на каждый ускоритель и до 72 ускорителей на стойку с совокупной пропускной способностью 260 Тбайт/с, соединённых между собой посредством UALink и Ultra Ethernet (UEC). Система поддерживает разделяемую память между ускорителями, что обеспечивает обучение крупномасштабных моделей с бесперебойным доступом к памяти и отказоустойчивой сетью с шестью плоскостями. 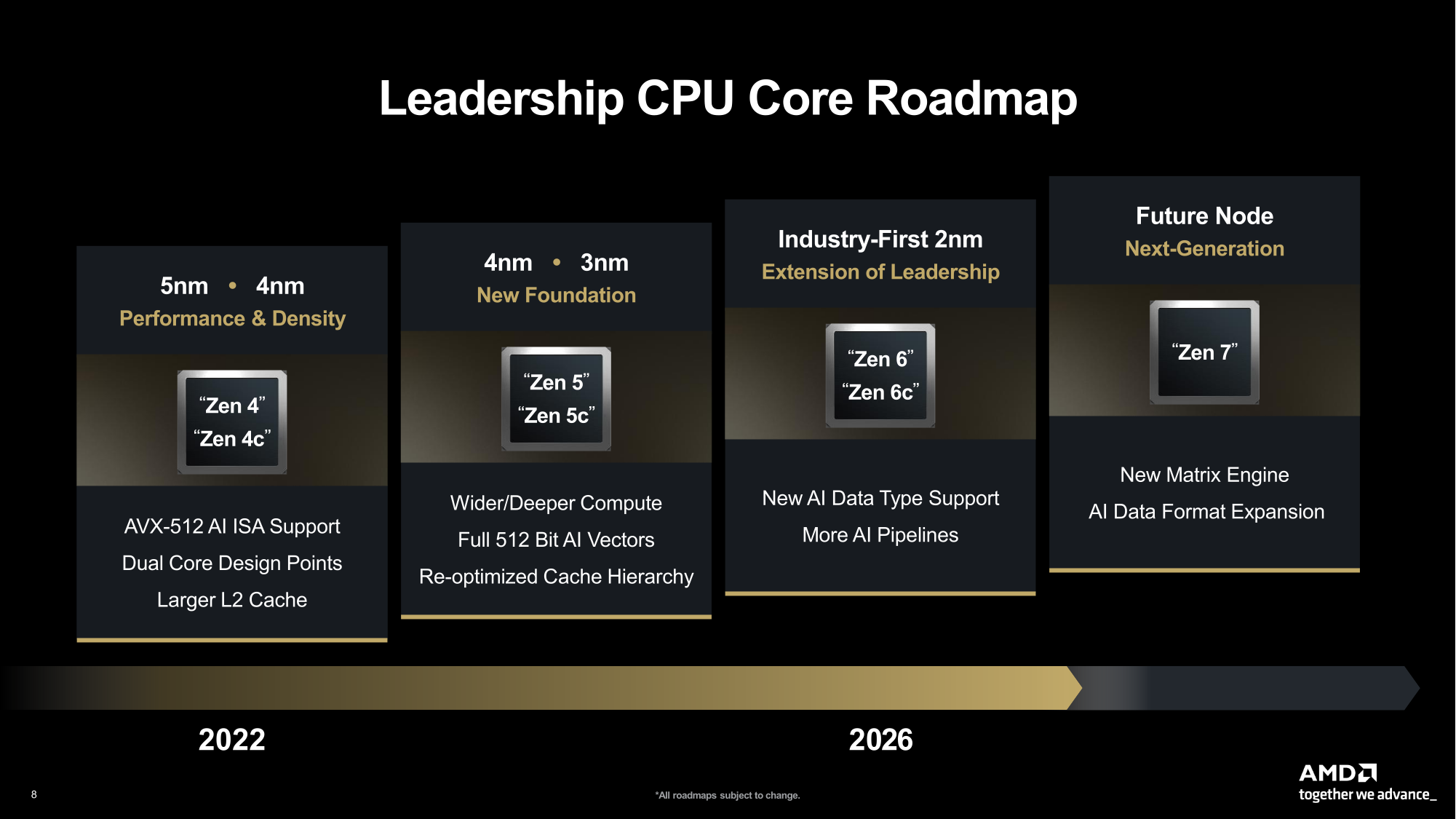 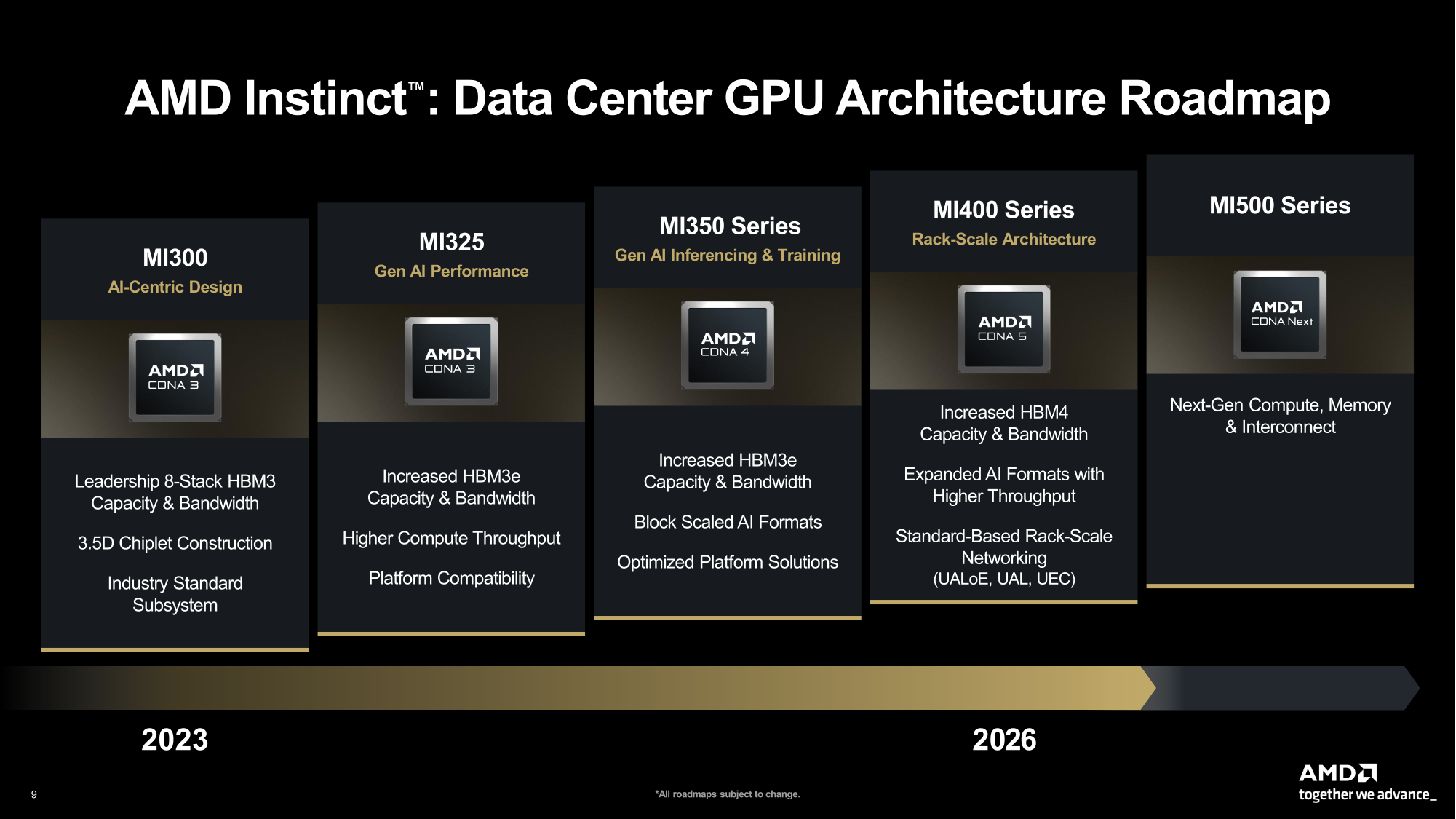 AMD характеризует Helios как свою первую ИИ-платформу стоечного масштаба — полностью интегрированную систему с открытой архитектурой, которая объединяет вычислительные мощности, ускорение, сетевые технологии и ПО в единую структуру. В отличие от традиционных серверных кластеров, Helios реализует всю стойку как единый высокопроизводительный вычислительный домен. Каждая стойка объединяет процессоры AMD EPYC Venice, CDNA5-ускорители Instinct MI450X (будет и вариант MI430X с полноценными FP64-блоками) и 400G/800G-карты Pensando Vulcano, связанные Infinity Fabric пятого поколения (PCIe 6.0, CXL 3.1, UCIe) и UALink.  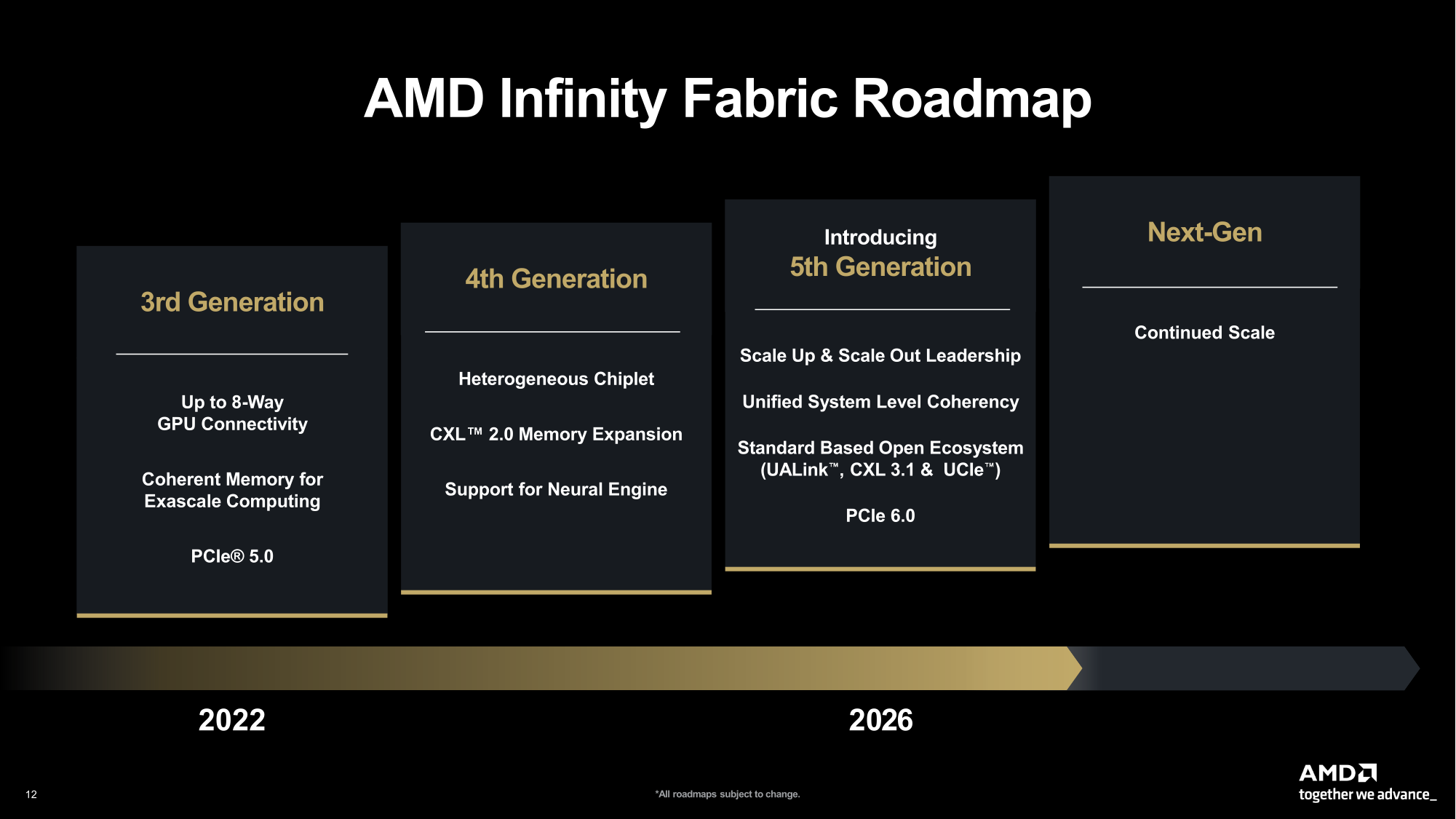 Эта архитектура минимизирует накладные расходы на перемещение данных, увеличивает пропускную способность между ускорителями и обеспечивает эффективность класса экзафлопсных вычислений в компактном корпусе. Helios фактически представляет собой проект AMD для ИИ-фабрики будущего с возможностью модульного расширения, позволяя объединять сотни стоек в одну систему в ЦОД.  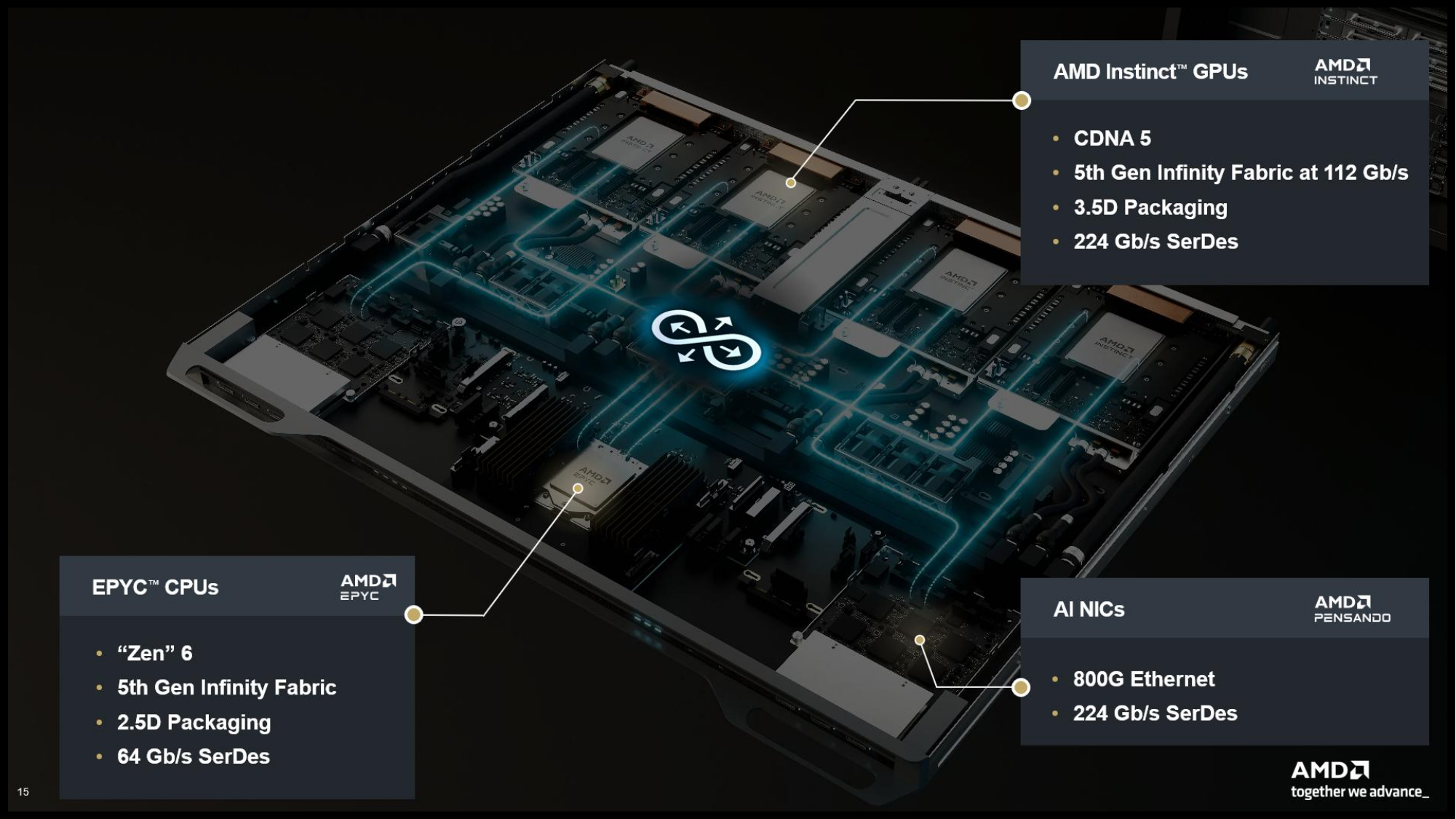 В 2027 году AMD планирует выпустить ускорители серии MI500 и процессоры EPYC Verano, продолжая тем самым ежегодный цикл совместной разработки процессоров, ускорителей и сетей. AMD заявила, что EPYC Venice, намеченные к выпуску в 2026 году, будут обладать лучшими в отрасли показателями плотности (1,3x по количеству потоков в сравнении с текущими решениями) и энергоэффективности (1,7x). Они пополнятся оптимизированными для ИИ наборами инструкций для обработки инференса и выполнения вычислений общего назначения. Указанные компоненты станут основой ИИ-фабрики, способной масштабироваться от одной стойки до глобально распределённых кластеров.  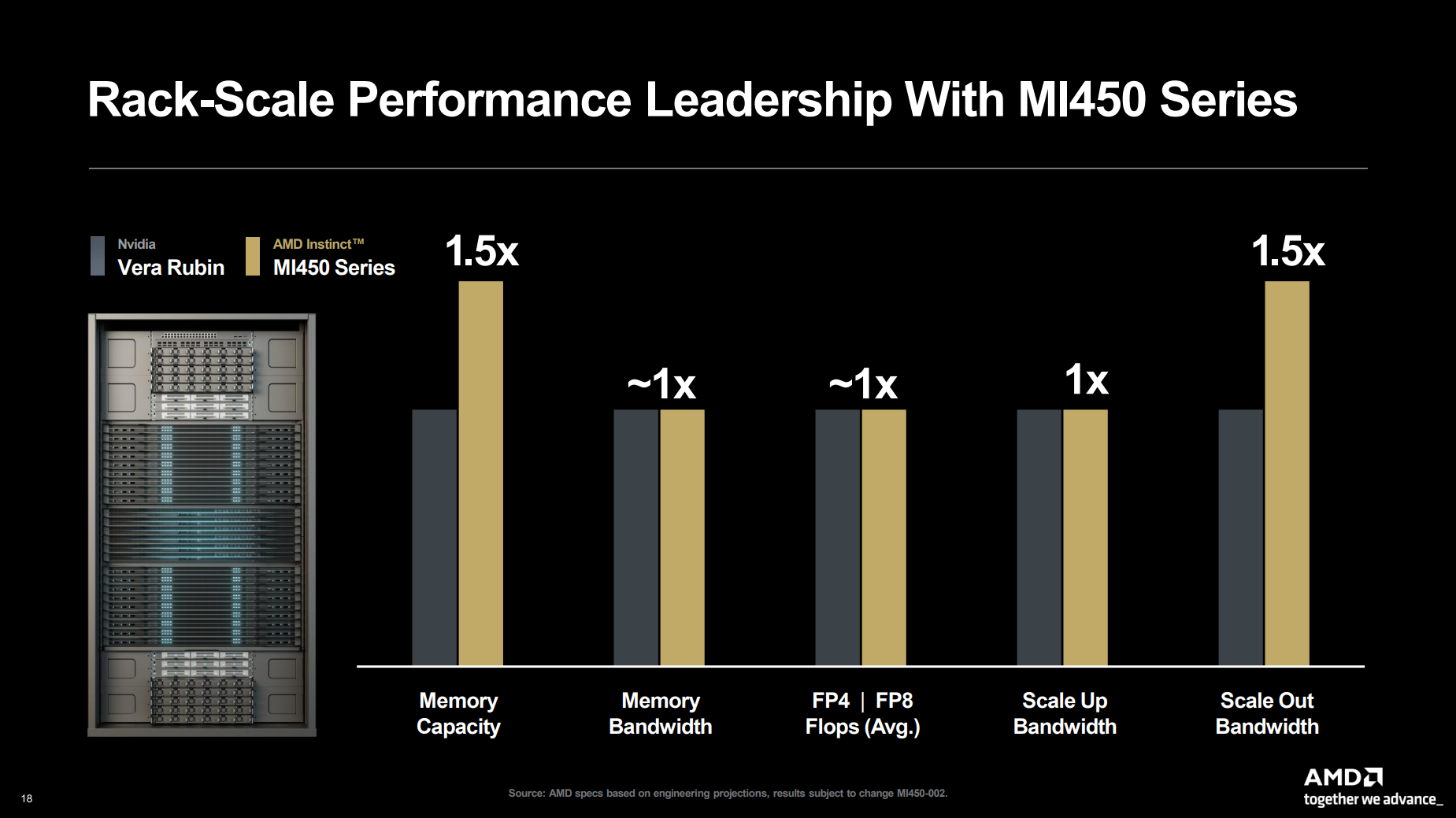 Исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) подчеркнул в своём выступлении, что производительность ИИ всё больше зависит от сети. Сетевые карты AMD Pensando Pollara и Vulcano для ИИ образуют связующую ткань архитектуры Helios. Сетевая карта Pollara 400 обеспечивает пропускную способность 400 Гбит/с, а готовящаяся к выходу сетевая карта Vulcano удвоит её до 800 Гбит/с, обеспечивая связь Ultra Ethernet между крупными кластерами ускорителей.   AMD представила четырёхуровневую архитектуру сети для масштабных ИИ-инфраструктур. Front-End часть обслуживает пользователей, хранилище и приложения. Она опирается на DPU Pensando и P4-движки, отвечающие за разгрузку сетевых функций, функции безопасности и шифрования, и работу с СХД. Вертикальное масштабирование в пределах стойки обеспечивает 3,6-Тбайт/с подключение на каждый GPU. Горизонтальное масштабирование реализуется благодаря UEC — внутренние тесты показали снижение затрат на коммутацию до 58 % по сравнению с традиционными сетями типа Fat-Tree. Наконец, Scale-Across (пространственное масштабирование) позволит объединить географически распределённые ЦОД в кластеры с интеллектуальным управлением трафиком и адаптивной балансировкой нагрузки.   AMD отметила, что открытый программный стек ROCm (Radeon open compute) по-прежнему лежит в основе её стратегии в области ИИ-платформ. По сравнению с прошлым годом число его загрузок выросло в десять раз и теперь на HuggingFace поддерживается более 2 млн моделей. ROCm интегрируется с ведущими фреймворками, включая PyTorch, TensorFlow, JAX, Triton, vLLM, ComfyUI и Ollama, и поддерживает проекты с открытым исходным кодом, такие как Unsloth. 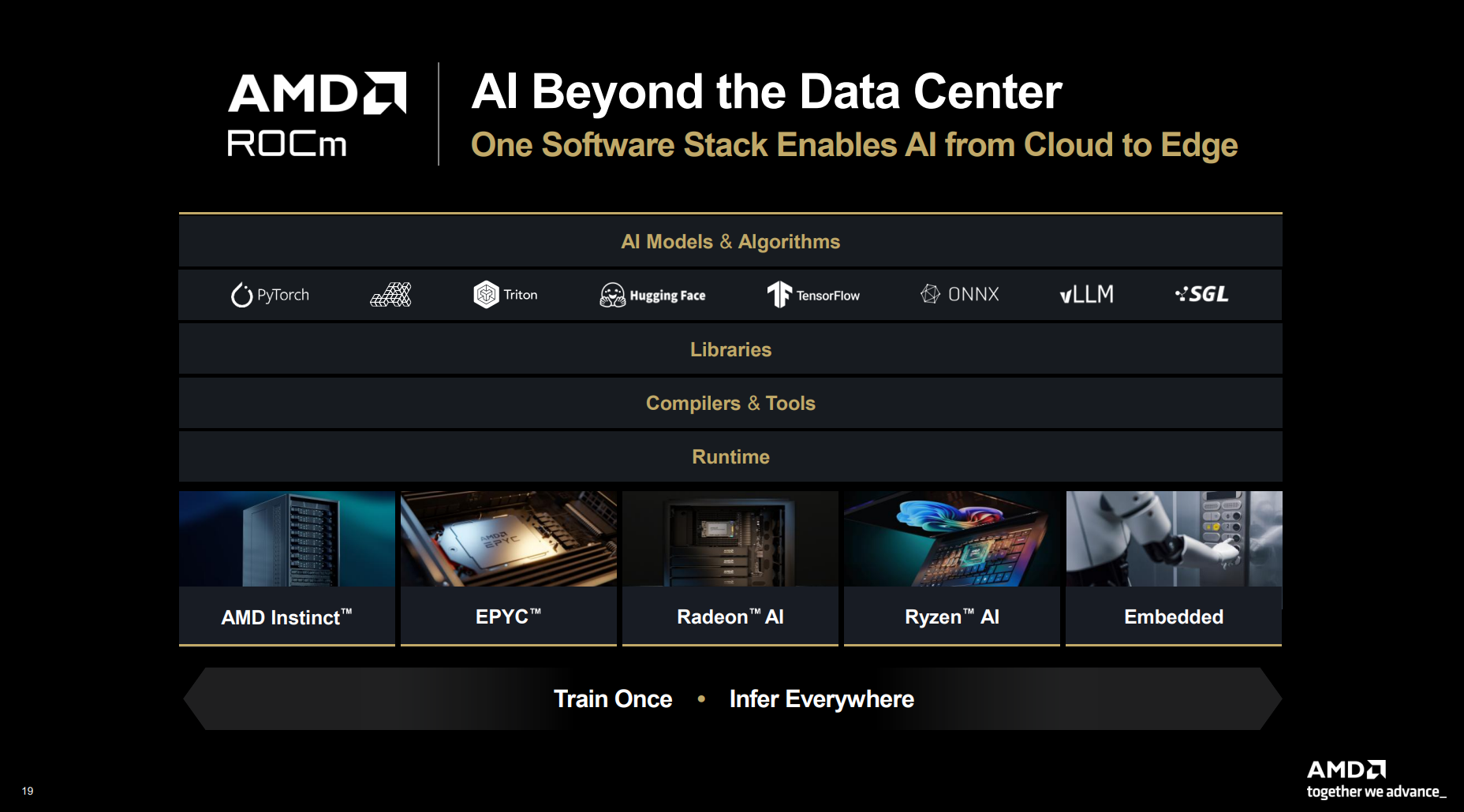  AMD также расширила своё видение «физического ИИ», когда вычисления выходят за рамки облака и охватывают роботов, транспортные средства и промышленные системы. Подразделение встраиваемых систем, усиленное приобретением Xilinx в 2022 году, превратилось из бизнеса, ориентированного на FPGA, в многоплатформенный двигатель роста, охватывающий адаптивные системы на кристалле (SoC), встраиваемые x86-процессоры и заказные кремниевые решения. По словам компании, с 2022 года решения в этой области принесли более $50 млрд. AMD рассчитывает превысить 70 % доли рынка адаптивных вычислений.   Говоря о перспективах, компания отметила, что ЦОД остаются основным драйвером роста, но наряду с этим она будет диверсифицировать свою деятельность по всем сегментам. Финансовые цели AMD включают:
|
|

