Материалы по тегу: instinct
|
16.10.2025 [16:44], Сергей Карасёв
Pegatron представила ИИ-сервер AS501-4A1-16I1 с СЖО и 16 ускорителями AMD Instinct MI355XPegatron анонсировала высокопроизводительный сервер AS501-4A1-16I1 с СЖО для задач НРС, а также ресурсоёмких приложений ИИ, включая инференс и обучение больших языковых моделей. Устройство выполнено в форм-факторе 5OU на аппаратной платформе AMD. До восьми серверов AS501-4A1-16I1 могут быть установлены в стойку RA5100-128I1. Это позволяет сформировать ИИ-систему высокой плотности, насчитывающую до 32 процессоров EPYC 9005 и до 128 ускорителей Instinct MI355X. Конструкция системы включает два CPU-узла и два лотка GPU. Каждая из CPU-секций допускает установку двух процессоров AMD EPYC 9005 Turin с показателем TDP до 500 Вт и 24 модулей оперативной памяти DDR5-6400 RDIMM. Таким образом, в общей сложности могут быть задействованы четыре чипа EPYC и 48 модулей ОЗУ. В свою очередь, каждый из GPU-лотков оснащается восемью ускорителями AMD Instinct MI355X, которые несут на борту 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. В общей сложности реализованы 12 слотов PCIe 5.0 x16 FHHL, в которые установлены десять однопортовых сетевых адаптеров 400GbE и два двухпортовых адаптера 10GbE 
Источник изображения: Pegatron В оснащение входят контроллер Aspeed AST2600, два сетевых порта 1GbE (RJ45), выделенный сетевой порт управления (RJ45), последовательный порт (разъём Micro-USB), интерфейсы USB 2.0 Type-C и Mini-DP. В дополнение к СЖО имеются десять вентиляторов охлаждения. Применяется шина питания ORv3 на 48 В DC.
15.10.2025 [12:14], Владимир Мироненко
Oracle запустит в 2026 году ИИ-кластер на базе 50 тыс. AMD Instinct MI450Oracle объявила о расширении сотрудничества с AMD, в рамках которого Oracle Cloud Infrastructure (OCI) запустит первый публично доступный ИИ-суперкластер на базе 50 тыс. ускорителей AMD Instinct MI450. Согласно пресс-релизу, первоначальное развёртывание кластера начнётся в III квартале 2026 года, после чего он будет расширяться в 2027 году, а также в дальнейшем. Будущие ИИ-кластеры OCI будут основаны на стоечной архитектуре AMD Helios с использованием ускорителей AMD Instinct серии MI450, процессоров AMD EPYC следующего поколения с кодовым названием Venice и сетевой системы AMD Pensando следующего поколения с кодовым названием Vulcano. Махеш Тиагараджан (Mahesh Thiagarajan), исполнительный вице-президент OCI отметил, что благодаря десятилетнему сотрудничеству с AMD — от ускорителей EPYC до AMD Instinct — компания продолжает предоставлять «оптимальную по соотношению цены и производительности, открытую, безопасную и масштабируемую облачную платформу в партнерстве с AMD, чтобы удовлетворить потребности клиентов в новой эре ИИ». Ускоритель AMD Instinct MI450 основан на архитектуре CDNA 5 и изготавливается по 2-нм техпроцессу TSMC. Ускоритель будет обладать до 432 Гбайт памяти HBM4 с пропускной способностью 20 Тбайт/с. Стойка AMD Helios с 72 ускорителями AMD Instinct MI450 объединяет возможности масштабирования UALoE и масштабируемую сеть на базе Ethernet, соответствующую стандартам Ultra Ethernet (UEC), для минимизации задержек и максимальной пропускной способности между модулями и стойками. 
Источник изображения: Oracle Сообщается, что процессоры EPYC (Venice) будут предлагать возможности конфиденциальных вычислений и встроенные функции безопасности для комплексной защиты конфиденциальных рабочих ИИ-нагрузок. Конвергентные сети с DPU, созданные на основе полностью программируемой технологии AMD Pensando, обеспечат безопасность и производительность, необходимые ЦОД для работы с ИИ следующего поколения, включая обучение, инференс и облачные рабочие нагрузки. Каждый ускоритель может быть оснащён до трёх DPU Vulcano со скоростью передачи данных 800 Гбит/с. Несколько месяцев назад Oracle и AMD объявили, что провайдер облачных вычислений развернёт кластер, включающий до 131 072 ускорителей AMD MI355X, на основе ранее запущенного кластера на базе AMD Instinct MI300X. Ранее в этом месяце стало известно о соглашении AMD с OpenAI на поставку ИИ-ускорителей AMD нескольких поколений общей мощностью 6 ГВт на сумму около $60–$80 млрд для обеспечения её ИИ-инфраструктуры.
06.10.2025 [16:45], Владимир Мироненко
AMD поставит OpenAI ИИ-ускорители на 6 ГВт, а OpenAI получит долю в AMDAMD и OpenAI объявили о заключении многолетнего соглашения о стратегическом партнёрстве, в рамках которого будет построена ИИ-инфраструктура на базе сотен тысяч ИИ-ускорителей AMD нескольких поколений общей мощностью 6 ГВт общей стоимостью, по предварительным оценкам, $60–$80 млрд. После объявления о сделке акции AMD выросли на 28 % до $211,18 в начале торгов, что само по себе тянет на рекорд, пишет Bloomberg. В рамках соглашения AMD предоставила OpenAI возможность покупки до 160 млн обыкновенных акций, которые будут переданы по мере достижения контрольных целей. Первый транш будет предоставлен после развёртывания инфраструктуры на 1 ГВт, которое начнется во II половине следующего года. ИИ-системы будут основаны на чипах AMD Instinct MI450. Последующие транши будут выделяться по мере развёртывания оборудования в ЦОД до итогового показателя мощности в 6 ГВт. Выпуск акций также привязан к достижению AMD целей по цене акций и достижению OpenAI технических и коммерческих целей. Исходя из текущего количества выпущенных акций AMD к завершению сделки у OpenAI будет 10 % её акций. 
Источник изображения: AMD «Мы рассматриваем эту сделку как безусловно преобразующую не только для AMD, но и для динамики всей отрасли», — заявил исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) агентству Reuters в воскресенье. В AMD также сообщили, что партнёрство с OpenAI принесет компании десятки миллиардов долларов дохода, значительно увеличит прибыль AMD на акцию и ускорит развитие инфраструктуры ИИ OpenAI. Для AMD эта сделка станет отправной точкой для более широкого внедрения её технологий, что может увеличить доход компании в этой области до более чем $100 млрд, заявили руководители компании, не уточняя конкретных сроков, пишет Bloomberg. Для OpenAI сотрудничество с AMD обеспечит более надёжную альтернативу решениям NVIDIA, на которые OpenAI и операторы ЦОД тратят значительную часть своих бюджетов. В прошлом месяце стало известно о соглашении OpenAI с NVIDIA, в рамках которого производитель чипов инвестирует в стартап до $100 млрд, включая поставку ускорителей общей мощностью не менее 10 ГВт. Ускорители AMD будут использоваться преимущественно для инференса, а NVIDIA — для обучения. Попутно OpenAI при поддержке Broadcom разрабатывает собственные ИИ-ускорители, которые должны появиться в 2026 году.
27.09.2025 [15:32], Сергей Карасёв
Майнинговая компания Iren увеличила мощность ИИ-облака, закупив тысячи ускорителей NVIDIA и AMD за $674 млнКриптомайнинговая компания Iren (ранее известная как Iris Energy), по сообщению Datacenter Dynamics, увеличила количество ИИ-ускорителей в своём облаке примерно в два раза. Стоимость приобретённого оборудования оценивается в $674 млн. Компании прочат статус серьёзного игрока на рынке неооблаков. Компания находится в процессе перехода от майнинга криптовалют к облачному бизнесу на базе ИИ. В частности, закуплены 7100 ускорителей NVIDIA B300 и 4200 изделий NVIDIA B200, а также 1100 AMD Instinct MI350X. В результате, общее количество ускорителей в составе платформы Iren достигло приблизительно 23 тыс. Новое оборудование в ближайшие месяцы будет развёрнуто в кампусе Iren в городе Принс-Джордже (Prince George) в северной части провинции Британская Колумбия в Канаде. В настоящее время на этой площадке ведётся строительство вычислительного комплекса с жидкостным охлаждением мощностью 10 МВт (ИТ-нагрузка), который сможет поддерживать более 4500 суперускорителей NVIDIA GB300. В конце августа нынешнего года Iren сообщила о приобретении 1200 ускорителей NVIDIA B300 для серверов с воздушным охлаждением и 1200 изделий NVIDIA GB300 для систем с жидкостным охлаждением: стоимость данной партии составила примерно $168 млн. Эти чипы также предназначены для ЦОД в Принс-Джордже. Тогда говорилось, что Iren привлекла финансирование в размере около $96 млн для покупки GB300: средства получены по схеме лизинга сроком на два года. 
Источник изображения: Iren В настоящее время Iren управляет пятью кампусами ЦОД общей мощностью 810 МВт, расположенными в Северной Америке: два в Техасе (США) и три в Британской Колумбии (Канада). Ещё 2,1 ГВт находятся в стадии строительства, причём 2 ГВт из них приходится на новый кампус в Техасе. Как отмечает Дэниел Робертс (Daniel Roberts), соучредитель и содиректор Iren, удвоение парка GPU позволит удовлетворить растущие потребности клиентов в масштабируемых вычислительных мощностях.
25.09.2025 [11:37], Сергей Карасёв
Edgecore Networks представила ИИ-сервер AGS8600 на базе AMD EPYC Turin и Instinct MI325XКомпания Edgecore Networks анонсировала сервер AGS8600 формата 8U, построенный на аппаратной платформе AMD. Устройство, уже доступное для заказа, предназначено для решения ресурсоёмких задач в сферах ИИ, машинного обучения, НРС, научных исследований и пр. Система несёт на борту два 64-ядерных процессора EPYC 9575F поколения Turin с показателем TDP в 400 Вт. Доступны 24 слота для модулей оперативной памяти DDR5. Во фронтальной части расположены восемь отсеков для SFF-накопителей U.2 (NVMe): базовая конфигурация включает шесть SSD вместимостью 7,68 Тбайт каждый и два SSD на 1,92 Тбайт. Сервер укомплектован восемью GPU-ускорителями Instinct MI325X с 256 Гбайт памяти HBM3e и производительностью до 2,6 Пфлопс в режиме FP8. Задействованы семь линий Infinity Fabric в расчёте на GPU. В оснащение включены восемь однопортовых сетевых адаптеров BCM957608-P1400GDF00 400G QSFP112-DD PCIe Ethernet NIC. Кроме того, присутствуют два двухпортовых адаптера BCM957608-P2200GQF00 200GbE QSFP112 PCIe Ethernet NIC, выделенный сетевой порт управления 1GbE, контроллер ASPEED AST2600, два порта USB 3.0 и интерфейс D-Sub. 
Источник изображения: Edgecore Networks За возможности расширения отвечают восемь слотов PCIe 5.0 x16 для карт половинной высоты и четыре разъёма PCIe 5.0 x16 для карт полной высоты. Питание обеспечивают шесть блоков мощностью 3300 Вт с сертификатом 80 Plus Titanium. Применена система воздушного охлаждения с 15 вентиляторами, допускающими горячую замену. Габариты составляют 448 × 850 × 351 мм. Диапазон рабочих температур — от +10 до +35 °C. На сервере используется ОС с ядром Linux. Среди поддерживаемого ПО упомянуты ROCm 6.2.4, RCCL 2.20.5, PyTorch 2.3/2.2/2.1/2.0/1.13, TensorFlow 2.16.1/2.15.1/2.14.1, JAX 0.4.26 и ONNX Runtime 1.17.3.
10.09.2025 [12:44], Сергей Карасёв
В облаке Vultr по всему миру стали доступны ускорители AMD Instinct MI355XЧастный облачный провайдер Vultr объявил о том, что в его глобальной инфраструктуре стали доступны ускорители AMD Instinct MI355X, официально представленные в июне нынешнего года. Утверждается, что эти изделия устанавливают новый стандарт соотношения цены и производительности для ресурсоёмких ИИ-задач, в частности, инференса. Решение Instinct MI355X построено на архитектуре AMD CDNA 4-го поколения. Устройство располагает 288 Гбайт памяти HBM3E, пропускная способность которой достигает 8 Тбайт/с. Применяется жидкостное охлаждение. Упомянута поддержка программного стека AMD ROCm. На сайте Vultr говорится, что теоретическая производительность ИИ при использовании в конфигурации 8 × Instinct MI355X OAM достигает 20,1 Пфлопс в режиме FP16, 40,3 Пфлопс на операциях INT8/FP8 и 80,5 Пфлопс в режиме FP4. 
Источник изображения: Vultr При развёртывании ускорителей Instinct MI355X в своём облаке Vultr тесно сотрудничала с AMD и Supermicro. Благодаря 32 облачным регионам на шести континентах Vultr гарантирует низкую задержку и высокую доступность вычислительных мощностей. Стоимость услуг, как утверждается, ниже по сравнению с аналогичными предложениями гиперскейлеров. Ускорители Instinct MI355X подходят не только для инференса и обучения ИИ-моделей, но и для других нагрузок HPC, таких как симуляции, сложное моделирование или обработка больших массивов данных.
05.09.2025 [11:39], Сергей Карасёв
AMD готовит суперускоритель Mega Pod с 256 ускорителями Instinct MI500Компания AMD, по сообщению ресурса Tom's Hardware, готовит платформу MI500 Scale Up MegaPod для наиболее ресурсоёмких нагрузок ИИ. Эта система, как ожидается, выйдет в 2027 году и составит конкуренцию стоечным решениям NVIDIA следующего поколения. Известно, что в основу MI500 Scale Up MegaPod лягут 64 процессора EPYC поколения Verano и 256 ускорителей серии Instinct MI500. Для сравнения: платформа AMD Helios, выход которой запланирован на 2026 год, сможет объединять до 72 ускорителей Instinct MI400, тогда как в состав системы NVIDIA NVL576 на основе стойки Kyber войдут 144 ускорителя поколения Rubin Ultra. В конструктивном плане MI500 Scale Up MegaPod, согласно имеющейся информации, будет представлять собой платформу с тремя серверными стойками. В боковых разместятся по 32 вычислительных лотка с одним процессором EPYC Verona и четырьмя ИИ-ускорителями Instinct MI500, тогда как центральная стойка получит 18 лотков, предназначенных для коммутаторов UALink. В целом, в состав системы войдут 64 узла, насчитывающих в общей сложности 256 ускорителей. 
Источник изображения: AMD По сравнению с NVIDIA NVL576 со 144 ускорителями новая платформа AMD обеспечит примерно на 78 % больше карт в расчёте на систему. Однако пока не ясно, сможет ли AMD MI500 Scale Up MegaPod превзойти решение NVIDIA по производительности: NVL576, как ожидается, получит 147 Тбайт памяти HBM4, тогда как быстродействие этой системы будет достигать 14 400 Пфлопс на операциях FP4. Отмечается также, что для AMD MI500 Scale Up MegaPod предусмотрено использование исключительно жидкостного охлаждения — как для вычислительных, так и для сетевых узлов. Предполагается, что система поступит в продажу в конце 2027 года — примерно в то же время, когда, вероятно, дебютирует NVIDIA NVL576.
16.07.2025 [12:44], Владимир Мироненко
AMD сообщила о грядущем возобновлении поставок MI308 в КитайAMD объявила о планах возобновить поставки ускорителей Instinct MI308 в Китай, разработанных с учётом ограничений США специально для этой страны, после чего акции компании выросли почти на 7 %. «Министерство торговли США недавно сообщило нам, что заявки на получение лицензий на экспорт продукции MI308 в Китай будут переданы на рассмотрение», — сообщили в AMD изданию The Register. «Мы планируем возобновить поставки по мере одобрения лицензий. Мы приветствуем прогресс, достигнутый администрацией Трампа в продвижении торговых переговоров, и её приверженность лидерству США в области ИИ», — подчеркнули в компании. Днём ранее стало известно, что власти США подтвердили готовность дать добро NVIDIA на возобновление отгрузок ускорителей H20 в Китай. Они тоже были созданы с учётом экспортных ограничений Министерства торговли США для этого рынка, но после очередного витка роста напряжённости между Вашингтоном и Пекином администрация США установила запрет на их поставку. Сейчас компания подаёт заявки на получение необходимых экспортных лицензий, которые гарантированно будут одобрены, после чего вновь начнёт поставки. 
Источник изображения: AMD По данным NVIDIA, из-за экспортных ограничений на поставки H20 в Китай, лишние расходы в I квартале 2026 финансового года составили $4,5 млрд. Также было недополучено $2,5 млрд выручки, хотя ранее ожидалось, что потери составят $5,5 млрд. В свою очередь, AMD сообщила в апреле, что из-за ограничений США её потери в 2024 финансовом году составят около $800 млн из-за складских расходов, закупочных обязательств и связанных с ними созданными резервами. Послабления для NVIDIA были предоставлены после встречи на прошлой неделе основателя и гендиректора NVIDIA Дженсена Хуанга (Jensen Huang) с Дональдом Трампом и американскими политиками, в ходе которой ему удалось их убедить в отсутствии угрозы для США поставок этих чипов. Возобновление поставок ускорителей в Китай является отступлением от курса администрации, которая неоднократно утверждала, что ограничения на поставки чипов не подлежат обсуждению, сообщил Bloomberg.
17.06.2025 [23:55], Владимир Мироненко
AMD анонсировала платформу ROCm 7.0, облако для разработчиков AMD Developer Cloud и программу Radeon Test DriveAMD вместе с ускорителями Instinct MI350X/MI355X представила 7-ю версию своего открытого программного стека ROCm (Radeon open compute). Как сообщает компания, ROCm 7.0 предназначен для удовлетворения растущих потребностей рабочих нагрузок генеративного ИИ и HPC, одновременно расширяя возможности разработчиков за счёт доступности, эффективности и активного сотрудничества сообщества. По данным AMD, платформа ROCm 7 предлагает более чем в 3,5 раза большую производительность инференса, чем ROCm 6, и в 3 раза большую эффективность обучения. Это стало возможным благодаря улучшениям производительности и поддержке типов данных с меньшей точностью, таких как FP4 и FP6. Дальнейшие улучшения в коммуникационных стеках позволили оптимизировать использование ускорителя и перемещение данных. ROCm 7 поддерживает распределённый инференс, а также фреймворки SGLang, vLLM и llm-d. Платформа ROCm 7 создавалась совместно с этими партнёрами, включая разработку общих интерфейсов и примитивов для обеспечения эффективного распределённого инференса на платформах AMD. 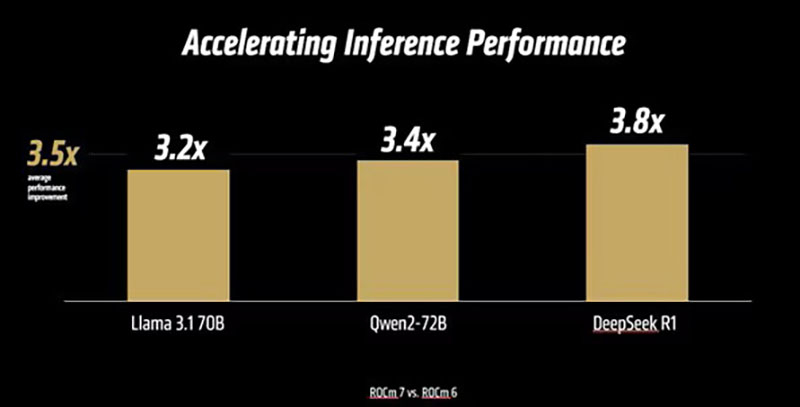
Источник изображений: AMD Вместе с ROCm 7 компания представила MLOps-платформу ROCm Enterprise AI для бесперебойных ИИ-операций в корпоративном сегменте. Платформа предлагает инструменты для тонкой настройки модели и интеграции как со структурированными, так и неструктурированными рабочими процессами. AMD заявила, что работает с партнёрами по экосистеме над созданием эталонных реализаций для таких приложений, как чат-боты и обобщение документов.  AMD отметила, что тесное партнёрство гарантирует разработчикам доступ к лучшим в своем классе инструментам, постоянному улучшению производительности и открытой среде для быстрой итерации и развёртывания. Также AMD представила партнёров экосистемы ROCm, которые используют преимущества данной платформы:
Кроме того, AMD представила «простую в использовании платформу для разработчиков» AMD Developer Cloud, обеспечивающую быстрый доступ к AMD Instinct с возможностью масштабирования от одного (192 Гбайт памяти) до восьми AMD Instinct MI300X (1536 Гбайт памяти). Сообщается, что конфигурации с одним ускорителем в основном используются для рабочих нагрузок инференса на «лёгких» моделях, тогда как максимальная конфигурация обеспечивает распределённое обучение, тонкую настройку и высокопроизводительный инференс для крупномасштабных моделей.  AMD сообщила, что платформа AMD Developer Cloud была разработана с учётом четырёх основных целей:
По словам компании, AMD Developer Cloud предполагает различные варианты использования. Решение идеально подходит для независимых разработчиков AI/ML, работающих над низкоуровневым программированием, разработкой ядер (kernel) или корпоративных приложений и проектов, нацеленных на нативную поддержку AMD. Также платформу можно использовать для мероприятий и хакатонов, обеспечивая масштабируемую поддержку образовательных и практических мероприятий с предоставлением кредитов на использование ускорителей во время семинаров, хакатонов, конкурсов и демонстраций.  Также с выходом ROCm 7 появилась поддержка ноутбуков и рабочих станциях на Windows с видеокартами Radeon и процессорами Ryzen AI. С этим связан ещё один важный анонс — компания представила программу ROCm on Radeon Test Drive, которая будет запущена этим летом партнёрстве с различными поставщиками оборудования (первыми стали Colfax и System76), чтобы упростить разработчикам возможность опробовать ROCm на GPU Radeon, передаёт Phoronix. В рамках Radeon Test Drive предоставляется возможность удалённо протестировать GPU Radeon (PRO).
13.06.2025 [02:20], Владимир Мироненко
AMD готовит ИИ-стойки Helios AI двойной ширины с Instinct MI400, AMD EPYC Venice и 800GbE DPU Pensando Vulcano
amd
dpu
epyc
hardware
instinct
mi400
pensando systems
ualink
ultra ethernet
venice
ии
стойка
ускоритель
Вместе с анонсом ускорителей MI350X и MI355X также рассказала о планах на ближайшее будущее, включая выпуск ускорителей серий MI400 (Altair) в 2026 году и MI500 (Altair+) в 2027 году, а также решений UALink, Ultra Ethernet, DPU Pensando и стоечных архитектур, которые послужат основой ИИ-кластеров. Так, AMD анонсировала новую архитектуру Helios AI с стойками двойной ширины, которая объединит процессоры AMD EPYC Venice с ядрами Zen 6, ускорители Instinct MI400 и DPU Vulcano. Благодаря приобретению ZT Systems компания смогла существенно ускорить разработку и интеграцию решений уровня стойки — Helios AI появятся уже в 2026 году. Как сообщает DataCenter Dynamics, Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер AMD по ЦОД рассказал перед мероприятием, что решение об увеличении ширины стойки было принято в сотрудничестве с «ключевыми партнёрами» AMD, поскольку предложение должно соответствовать «правильной точке проектирования между сложностью, надёжностью и предоставлением преимуществ производительности». По словам AMD, это позволит объединить тысячи чипов таким образом, чтобы их можно было использовать как единую систему «стоечного масштаба». «Впервые мы спроектировали каждую часть стойки как единую систему», — заявила генеральный директор AMD Лиза Су (Lisa Su) на мероприятии, пишет CNBC. 
Источник изображений: AMD Дикманн заявил, что Helios предложит на 50 % больше пропускной способности памяти и на 50 % больше горизонтальной пропускной способности (по сравнению с NVIDIA Vera Rubin), поэтому «компромисс [за счёт увеличения ширины стойки] был признан приемлемым, поскольку крупные ЦОД, как правило, ограничены не квадратными метрами, а мегаваттами». 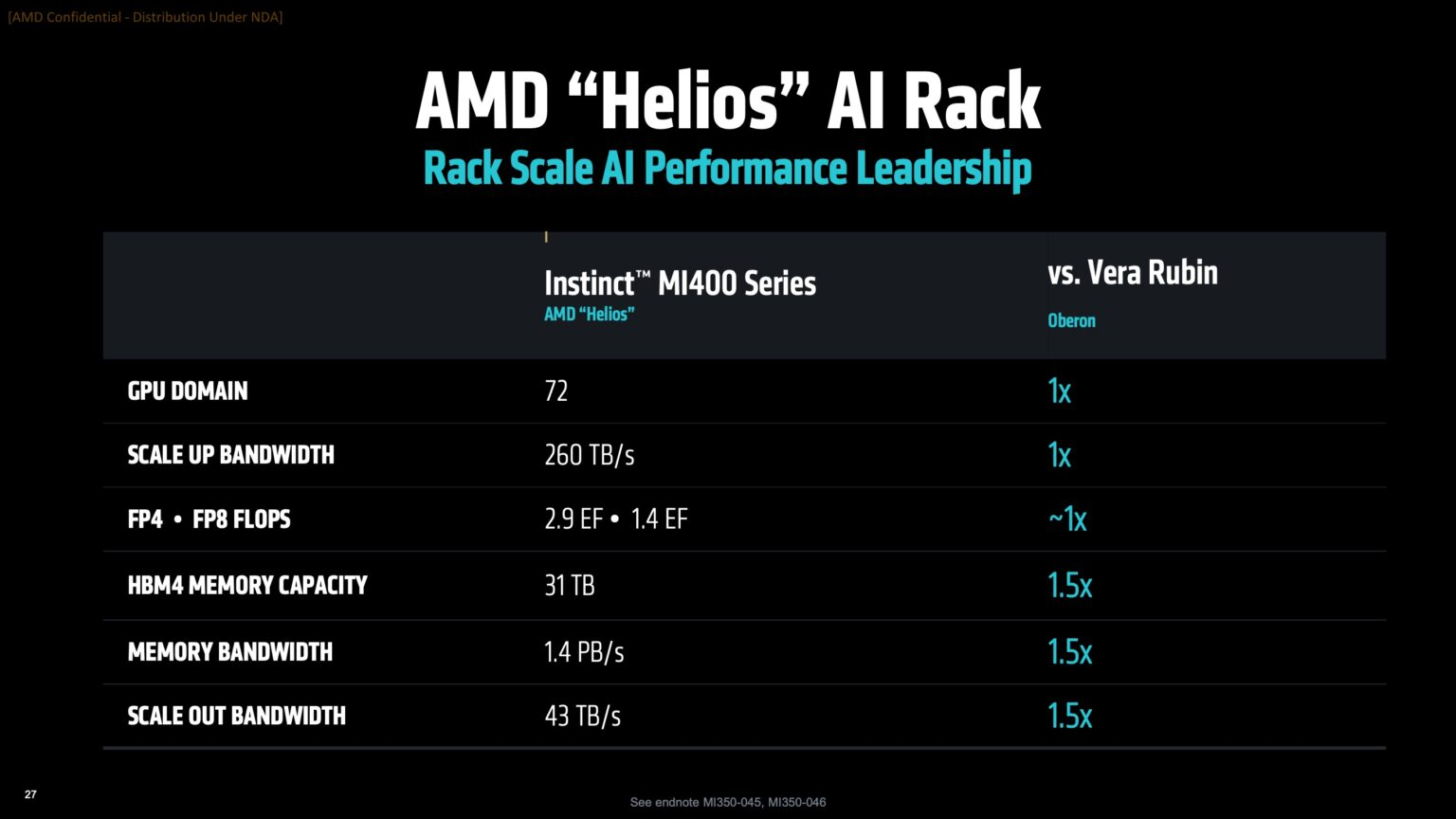 Как указано в блоге компании, «Helios создана для обеспечения вычислительной плотности, пропускной способности памяти, производительности и горизонтального масштабирования, необходимых для самых требовательных рабочих ИИ-нагрузок, в готовом к развёртыванию решении, которое ускоряет время выхода на рынок».  Helios представляет собой сочетание технологий AMD следующего поколения, включая:
 AMD отказалась сообщить стоимость анонсированных чипов, но, по словам Дикманна, ИИ-ускорители компании будут дешевле и в эксплуатации, и в приобретении в сравнении с чипами NVIDIA. «В целом, есть существенная разница в стоимости приобретения, которую мы затем накладываем на наше конкурентное преимущество в производительности, поэтому выходит значительная, исчисляемая двузначными процентами экономия», — сказал он.  AMD ожидает, что общий рынок ИИ-чипов превысит к 2028 году $500 млрд. Компания не указала, на какую долю общего пирога она будет претендовать — по оценкам аналитиков, в настоящее время у NVIDIA более 90 % рынка. Обе компании взяли на себя обязательство выпускать новые ИИ-чипы ежегодно, а не раз в два года, что говорит о том, насколько жёстче стала конкуренция и насколько важны передовые ИИ-технологии для гиперскейлеров. 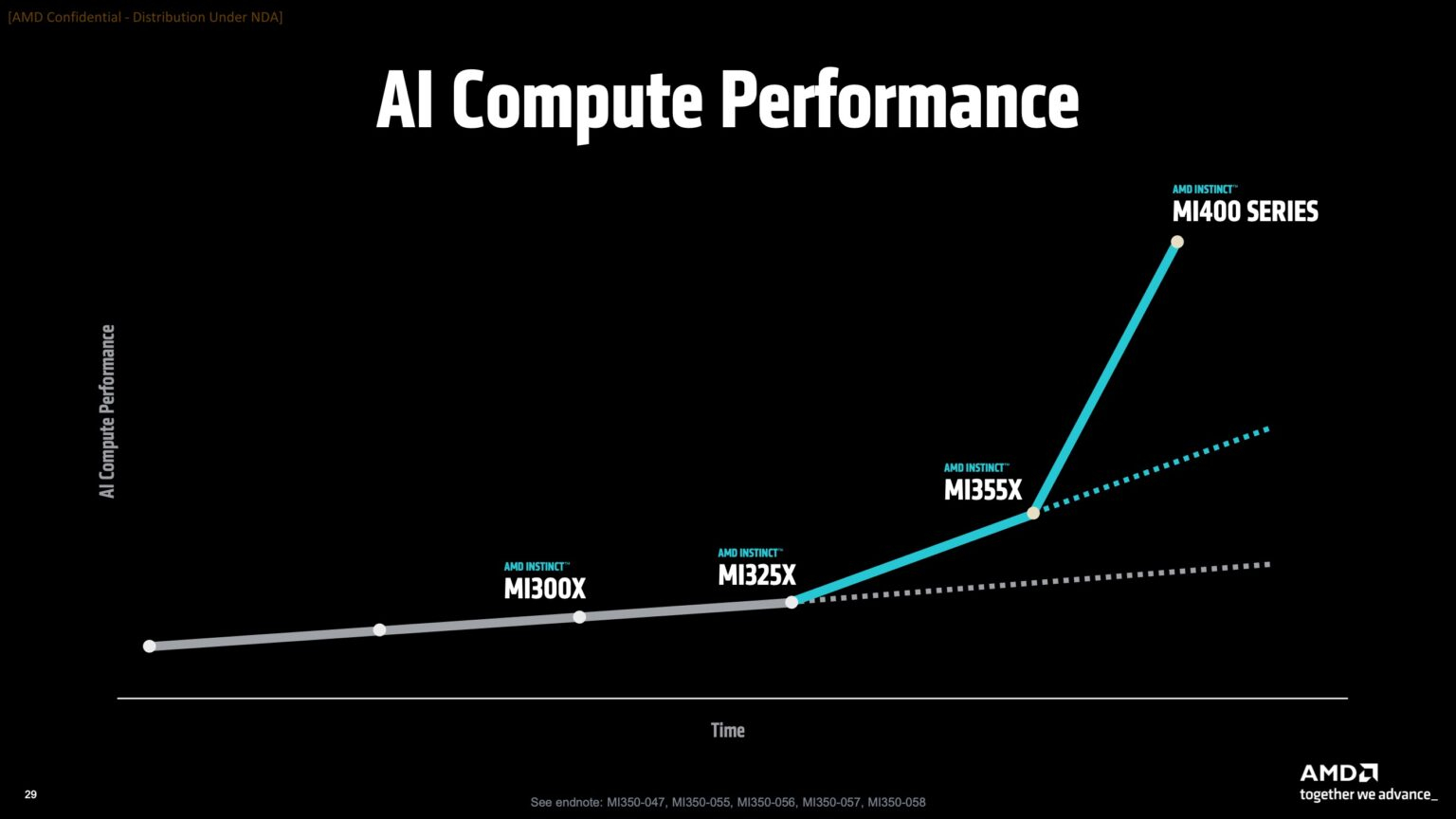 AMD сообщила, что её чипы Instinct используются семью из десяти крупнейших игроков ИИ-рынка, включая OpenAI, Tesla, xAI и Cohere. По словам AMD, Oracle планирует предложить своим клиентам кластеры с более чем 131 тыс. ускорителей MI355X. Meta✴ сообщила, что уже использует AMD-кластеры для инференса Llama и что она планирует купить серверы с чипами AMD следующего поколения. В свою очередь, представитель Microsoft сказал, что компания использует чипы AMD для обслуживания ИИ-функций чат-бота Copilot. |
|

