Материалы по тегу: rocm
|
17.06.2025 [23:55], Владимир Мироненко
AMD анонсировала платформу ROCm 7.0, облако для разработчиков AMD Developer Cloud и программу Radeon Test DriveAMD вместе с ускорителями Instinct MI350X/MI355X представила 7-ю версию своего открытого программного стека ROCm (Radeon open compute). Как сообщает компания, ROCm 7.0 предназначен для удовлетворения растущих потребностей рабочих нагрузок генеративного ИИ и HPC, одновременно расширяя возможности разработчиков за счёт доступности, эффективности и активного сотрудничества сообщества. По данным AMD, платформа ROCm 7 предлагает более чем в 3,5 раза большую производительность инференса, чем ROCm 6, и в 3 раза большую эффективность обучения. Это стало возможным благодаря улучшениям производительности и поддержке типов данных с меньшей точностью, таких как FP4 и FP6. Дальнейшие улучшения в коммуникационных стеках позволили оптимизировать использование ускорителя и перемещение данных. ROCm 7 поддерживает распределённый инференс, а также фреймворки SGLang, vLLM и llm-d. Платформа ROCm 7 создавалась совместно с этими партнёрами, включая разработку общих интерфейсов и примитивов для обеспечения эффективного распределённого инференса на платформах AMD. 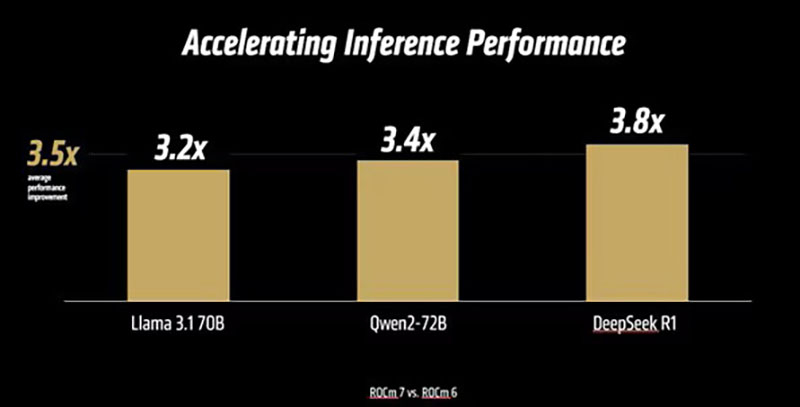
Источник изображений: AMD Вместе с ROCm 7 компания представила MLOps-платформу ROCm Enterprise AI для бесперебойных ИИ-операций в корпоративном сегменте. Платформа предлагает инструменты для тонкой настройки модели и интеграции как со структурированными, так и неструктурированными рабочими процессами. AMD заявила, что работает с партнёрами по экосистеме над созданием эталонных реализаций для таких приложений, как чат-боты и обобщение документов. 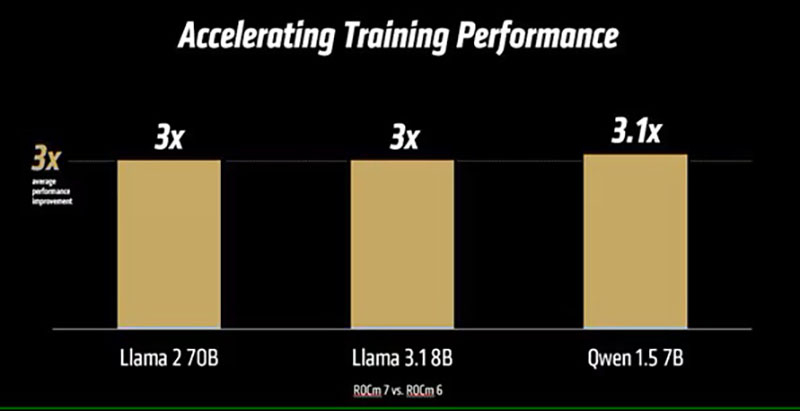 AMD отметила, что тесное партнёрство гарантирует разработчикам доступ к лучшим в своем классе инструментам, постоянному улучшению производительности и открытой среде для быстрой итерации и развёртывания. Также AMD представила партнёров экосистемы ROCm, которые используют преимущества данной платформы:
Кроме того, AMD представила «простую в использовании платформу для разработчиков» AMD Developer Cloud, обеспечивающую быстрый доступ к AMD Instinct с возможностью масштабирования от одного (192 Гбайт памяти) до восьми AMD Instinct MI300X (1536 Гбайт памяти). Сообщается, что конфигурации с одним ускорителем в основном используются для рабочих нагрузок инференса на «лёгких» моделях, тогда как максимальная конфигурация обеспечивает распределённое обучение, тонкую настройку и высокопроизводительный инференс для крупномасштабных моделей.  AMD сообщила, что платформа AMD Developer Cloud была разработана с учётом четырёх основных целей:
По словам компании, AMD Developer Cloud предполагает различные варианты использования. Решение идеально подходит для независимых разработчиков AI/ML, работающих над низкоуровневым программированием, разработкой ядер (kernel) или корпоративных приложений и проектов, нацеленных на нативную поддержку AMD. Также платформу можно использовать для мероприятий и хакатонов, обеспечивая масштабируемую поддержку образовательных и практических мероприятий с предоставлением кредитов на использование ускорителей во время семинаров, хакатонов, конкурсов и демонстраций.  Также с выходом ROCm 7 появилась поддержка ноутбуков и рабочих станциях на Windows с видеокартами Radeon и процессорами Ryzen AI. С этим связан ещё один важный анонс — компания представила программу ROCm on Radeon Test Drive, которая будет запущена этим летом партнёрстве с различными поставщиками оборудования (первыми стали Colfax и System76), чтобы упростить разработчикам возможность опробовать ROCm на GPU Radeon, передаёт Phoronix. В рамках Radeon Test Drive предоставляется возможность удалённо протестировать GPU Radeon (PRO).
15.06.2025 [23:29], Владимир Мироненко
Большая жатва: AMD назначила вице-президентом по ИИ гендиректора ИИ-стартапа Lamini, в который сама же и вложиласьAMD продолжает укреплять команду специалистов в сфере ИИ за счёт привлечения талантливых разработчиков, а также поглощения ИИ-стартапов. На минувшей неделе Шарон Чжоу (Sharon Zhou, вторая справа на фото ниже), соучредитель и гендиректор ИИ-стартапа Lamini (PowerML Inc.) сообщила в соцсети X, что она и несколько сотрудников присоединяются к AMD. Комментируя переход, представитель AMD сообщил ресурсу CRN, что это было наймом специалистов, а не приобретением команды, как это было в случае с разработчиком ИИ-чипов Untether AI, который фактически прекратил существование после сделки. В настоящее время неизвестно, какой будет дальнейшая судьба Lamini, которую в прошлом году покинул Грег Диамос (Greg Diamos), бывший архитектор ПО NVIDIA CUDA, основавший компанию вместе с Чжоу в 2022 году. До основания Lamini Чжоу работала менеджером по ML-продуктам в Google, менеджером по продуктам в ИИ-стартапах Kensho Technologies и Tamr, а также занимала должность внештатного преподавателя компьютерных наук в Стэнфордском университете, где она получила докторскую степень по этой же специальности. В AMD её назначили на должность вице-президента по ИИ. 
Источник изображения: Sharon Zhou/X Платформа Lamini позволяет компаниям настраивать и кастомизировать большие языковые модели (LLM) с использованием собственных данных. В частности, Lamini предложила новый подход под названием Mixture of Memory Experts (MoME), направленный на повышение производительности LLM и фактической точности путем радикального снижения частоты галлюцинаций с 50 % до 5 %. Утверждается, что этот подход позволяет значительно сократить объём вычислительных ресурсов для обучения LLM, а также продолжительность этого процесса. В 2023 году AMD представила Lamini как одного из первых независимых поставщиков ПО, поддержавших её ускорители Instinct. В сентябре того же года Lamini сообщила, что использует более чем 100 ускорителей серии Instinct MI200 и что платформа AMD ROCm «достигла программного паритета» с NVIDIA CUDA. До определённого момента ИИ-платформа Lamini была единственной коммерческой платформой, целиком и полностью работающей на базе AMD Instinct.  В прошлом году стартап привлек финансирование в размере $25 млн от нескольких инвесторов, включая венчурное подразделение AMD, Эндрю Ына (Andrew Ng), гендиректора Dropbox Дрю Хьюстона (Drew Houston), и Лип-Бу Тана (Lip-Bu Tan), который в начале этого года стал гендиректором Intel. Помимо команды Untether AI, AMD приобрела в течение последних нескольких неделе разработчика систем кремниевой фотоники Enosemi и стартапа Brium, специализирующегося на инструментах оптимизации ИИ ПО для различной аппаратной инфраструктуры. |
|

