Материалы по тегу: gb200
|
24.06.2026 [01:23], Владимир Мироненко
Европа получит 35 суперкомпьютеров на чипах NVIDIANVIDIA объявила о разработке по всей Европе 35 суперкомпьютеров на базе её чипов, которые позволят более 3 млн исследователей ускорить проведение научных исследований и внедрение промышленных инноваций в сфере ИИ. Это крупнейшее за год расширение в Европе сети суперкомпьютеров, охватывающее национальные суперкомпьютерные центры, ИИ-фабрики и академические исследовательские институты. Эти системы будут поддерживать исследования в области климатологии, здравоохранения, декарбонизации чистой энергетики, квантовых вычислений и фундаментальной науки. Работу большей части европейских ИИ-фабрик обеспечивают платформы Blackwell и Hopper, при этом с прошлого года было развернуто или анонсировано 800 Эфлопс вычислительных мощностей для ИИ. Эти суперкомпьютеры, включая обновлённый EuroHPC MareNostrum5 AI Барселонского суперкомпьютерного центра (BSC-CNS), Blue Swan (BavariaAI), IT4LIA, HammerHAI Центра высокопроизводительных вычислений в Штутгарте (HLRS) и ИИ-фабрика Mimer Национальной академической суперкомпьютерной инфраструктуры Швеции (NAISS), основаны на передовой ИИ-инфраструктуре NVIDIA, говорит компания. Так, суперкомпьютер MareNostrum 5 будет дооснащён системами GB300 NVL72 и GB200 NVL4, объединённых интерконнектом NVIDIA Quantum-X800 InfiniBand. Система, обеспечивающая производительность до 20 Эфлопс при обучении ИИ и 33 Эфлопс при ИИ-инференсе, позволит ускорить работу генеративного ИИ, климатическое моделирование, исследования в области здравоохранения и биотехнологий, устойчивого сельского хозяйства, энергетических систем и госсервисов. 
Источник изображения: NVIDIA Система Blue Swan (BavariaAI) добавит 1 тыс. ускорителей (GB200 NVL4 и Quantum-2 InfiniBand) суперкомпьютерным центрам FAU Erlangen и LRZ. Платформа обеспечит производительность до 11 Эфлопс при обучении ИИ и 22 Эфлопс при ИИ-инференсе. Она будет поддерживать инициативу Баварии по созданию базовых моделей, продвигая открытые мультимодальные модели для науки, государственного управления, исследований в области здравоохранения, робототехники и т.д. HammerHAI (HLRS) представляет собой первую в Германии ИИ-фабрику с более чем 850 GPU на базе GB200 NVL4 с Quantum-X800 InfiniBand. Суперкомпьютер HammerHAI, обеспечивающий производительность до 8 Эфлопс при обучении ИИ и 15 Эфлопс при ИИ-инференсе, обеспечит исследователям и промышленным пользователям безопасную ИИ-инфраструктуру для инженерного моделирования, инференса и научных исследования. Суперкомпьютер Mimer EuroHPC AI Factory (NAISS), размещённый в Линчёпингском университете (LiU, Швеция), будет использовать 100 систем GB200 NVL4 и сеть ConnectX-8. Обеспечивая производительность до 4 Эфлопс при обучении ИИ и около 7 Эфлопс при ИИ-инференсе, Mimer AI Factory будет способствовать развитию шведской ИИ-экосистемы в таких областях, как биологические науки, материаловедение, автономные системы, доверенный ИИ и т.д. Наконец, ИИ-фабрика IT4LIA с более чем 8 тыс. GPU на базе GB200 NVL4 с Quantum-X800 InfiniBand и ПО NVIDIA AI Enterprise обеспечивает производительность в размере 82 Эфлопс при обучении ИИ и 164 Эфлопс при ИИ-инференсе.
23.06.2026 [11:33], Сергей Карасёв
В Японии появился гибридный квантово-классический суперкомпьютер Roquo производительностью 19,8 ПфлопсВ Центре вычислительных наук японского Института физико-химических исследований (R-CCS) введён в строй гибридный квантово-классический суперкомпьютер Roquo, названный в честь горы Рокко к северу от города Кобе. В создании НРС-системы приняли участие DTS, NVIDIA, Giga Computing, DDN и ScaleWorX. Roquo состоит из 135 вычислительных узлов на базе NVIDIA GB200 NVL4. В общей сложности задействованы 540 чипов Blackwell и 270 чипов NVIDIA Grace. Применяется интерконнект NVIDIA Quantum-X800 InfiniBand с общей пропускной способностью до 3,2 Тбит/с (установлены коммутаторы Q3400, поддерживающие скорость передачи данных 800 Гбит/с на порт). Реализовано жидкостное охлаждение. Заявленная производительность на операциях FP64 составляет 19,8 Пфлопс, а теоретическое пиковое быстродействие на операциях FP8 превышает 5 Эфлопс. Суперкомпьютер использует интерфейс SQC, что позволяет формировать гибридные среды с поддержкой традиционных и квантовых вычислений. 
Источник изображения: RIKEN В рамках проекта по созданию Roquo корпорация DTS осуществляла общую разработку платформы в соответствии с требованиями R-CCS. В свою очередь, NVIDIA предоставила базовые вычислительные и сетевые компоненты, тогда как Giga Computing отвечала за проектирование и производство серверов. DDN предоставила высокоскоростное файловое хранилище. Наконец, специалисты ScaleWorX осуществили общую системную интеграцию. Суперкомпьютер Roquo, как ожидается, поможет ускорить разработку и оценку эффективности новых квантовых алгоритмов. Кроме того, система будет использоваться для решения сложных задач, с которыми не в состоянии справиться классические НРС-комплексы.
14.06.2026 [11:51], Сергей Карасёв
В Австралии запущен суперкомпьютер MAVERIC на базе NVIDIA GB200 NVL72Университет Монаша (Monash University) в Австралии в партнёрстве с компаниями NVIDIA, Dell Technologies и ЦОД-оператором CDC Data Centres объявил о запуске суперкомпьютера MAVERIC (Monash AdVanced Environment for Research and Intelligent Computing). Новый НРС-комплекс смонтирован в Бруклинском центре CDC в Мельбурне. В основу системы положены серверы Dell PowerEdge XE9712 на платформе NVIDIA GB200 NVL72. Эти суперускорители объединяют 72 чипа B200 и 36 процессоров Grace. При этом каждое изделие B200 содержит 16 896 ядер CUDA, 528 тензорных ядер и 192 Гбайт памяти HBM3Е. MAVERIC использует передовую технологию жидкостного охлаждения с замкнутым контуром, благодаря чему отпадает необходимость в постоянном водоснабжении. Утверждается, что такое конструктивное решение не только снижает негативное влияние на окружающую среду, но и устанавливает новый стандарт для устойчивых высокопроизводительных вычислений. 
Источник изображения: Университет Монаша Показатели производительности MAVERIC не раскрываются. Но отмечается, что суперкомпьютер специально разработан для крупномасштабных задач ИИ и обработки больших объемов данных. Предполагается, что запуск машины поможет в решении важнейших глобальных проблем здравоохранения, включая раннюю диагностику рака, лечение хронических заболеваний, открытие новых лекарств и пр. Использовать ресурсы системы планируется и в других областях, включая моделирование климата и обработку конфиденциальной информации.
03.06.2026 [15:14], Руслан Авдеев
ЦОД проекта Microsoft Fairwater заработал в Висконсине, и он уже готов принять NVIDIA Vera RubinКомпания Microsoft запустила новую ИИ-фабрику проекта Fairwater в Висконсине. Ввод в эксплуатацию состоялся раньше запланированного срока, на объекте заработали сотни тысяч ИИ-систем NVIDIA Grace Blackwell, в частности NVIDIA GB200. Объект подключён к аналогичной ИИ-фабрике в Джорджии. В результате сформирована масштабируемая распределённая вычислительная система для самых требовательных передовых ИИ-моделей. Благодаря совместной работе над системами электроснабжения, охлаждения и сетевой инфраструктурой NVIDIA Spectrum-X Ethernet, а также новому сетевому протоколу Multipath Reliable Connection (MRC) с распределением пакетов данных по множественным маршрутам, архитектура Fairwater позволяет оптимизировать «экономику токенов» — стоимость обработки и генерации данных искусственным интеллектом. Дополнительно Microsoft завершила проверку платформы NVIDIA Vera Rubin. Облачный гигант подтвердил готовность платформы к развёртыванию в дата-центрах Microsoft Azure. NVIDIA Vera Rubin может использоваться наряду с системами Blackwell без необходимости модернизации инфраструктуры. Она обеспечивает производительность при инференсе до 10 раз выше на каждый затраченный мегаватт потребляемой мощности по сравнению с платформой-предшественницей. Интегрированная технология NVIDIA Confidential Computing защищает модели и данные в процессе работы ИИ-агентов. 
Источник изображения: NVIDIA Платформа NVIDIA Dynamo представляет собой программное решение для высокопроизводительного инференса, ускоряющее запуск и эксплуатацию ИИ-моделей. Кроме того, она ускоряет запуск моделей в среде AKS (Azure Kubernetes Service). Технология NVIDIA Grove отвечает за распределённую оркестрацию инференса в инфраструктуре Kubernetes. Речь идёт о запуске новой ИИ-фабрики Fairwater в США. Не так давно в эксплуатацию ввели объект в Атланте, хотя строительство в Висконсине началось довольно давно. В конце апреля глава Microsoft Сатья Наделла (Satya Nadella) заявил, что кампус строится ударными темпами и будет введён в эксплуатацию раньше намеченного срока.
22.04.2026 [10:45], Сергей Карасёв
Foxconn наладит массовое производство CPO-коммутаторов в III квартале 2026 годаТайваньский контрактный производитель электроники Foxconn начал пробные поставки коммутаторов с интегрированной оптикой CPO (Co-Packaged Optics). Об этом, как сообщает DigiTimes, рассказал Брэнд Ченг (Brand Cheng), председатель совета директоров Foxconn Industrial Internet (FII) — подразделения, которое специализируется на сетевых продуктах для облачных платформ. По его словам, отгрузки образцов CPO-коммутаторов FII организовала в I квартале 2026-го, тогда как их массовое производство запланировано на III четверть текущего года. Ожидается, что спрос на такое оборудование будет стремительно расти. По данным отраслевых исследований, продажи CPO-коммутаторов увеличатся с примерно 23 тыс. единиц в 2026 году до более чем 200 тыс. штук в 2030-м. Таким образом, прогнозируемый показатель CAGR (среднегодовой темп роста в сложных процентах) составляет 144 %. Как отмечает Ченг, FII рассчитывает на годовой объём продаж CPO-коммутаторов более 10 тыс. штук. По оценкам компании, выпуск таких устройств обеспечит существенно более высокую валовую прибыль по сравнению с нынешними продуктами 400–800G. Подчёркивается, что экосистема технологий CPO развивается в комплексе с архитектурами NVIDIA QuantumX и SpectrumX, а также Broadcom Tomahawk. Речь идёт о проектировании специализированных чипсетов и оптических компонентов, внедрении передовых технологий упаковки, системной интеграции и пр. По сложности такие решения значительно превосходят традиционные сетевые устройства. 
Источник изображения: Foxconn Ченг также сообщил о масштабировании производства ИИ-ускорителей NVIDIA GB200 и GB300. Кроме того, наблюдается рост заказов на выпуск ASIC-изделий со стороны крупнейших облачных провайдеров: ожидается, что отгрузки таких продуктов значительно увеличатся во II половине года. Ченг подчеркнул, что более 60 % основных элементов серверных ИИ-стоек теперь производится собственными силами. Компания сформировала необходимые запасы компонентов, в том числе чипов памяти, для выполнения заказов в сфере ИИ, включая выпуск GB200 и GB300. В 2025 году выручка FII составила ¥902,89 млрд ($132,36 млрд), что на 48,2 % больше, чем годом ранее. При этом чистая прибыль поднялась на 51,99 %, достигнув ¥35,286 млрд ($5,17 млрд). Выручка в облачном сегменте составила ¥602,679 млрд ($88,35 млрд), увеличившись на 88,7 % в годовом исчислении: на неё пришлось почти 70 % от общего объёма поступлений.
21.04.2026 [18:29], Руслан Авдеев
Глава Microsoft пообещал досрочно ввести в эксплуатацию самый мощный в мире ИИ ЦОД проекта FairwaterМногоцелевой ИИ-кампус Microsoft Fairwater в Висконсине строится ускоренными темпами и будет введён в эксплуатацию раньше запланированного срока, сообщает Datacenter Dynamics. Об этом на днях упомянул глава Microsoft Сатья Наделла (Satya Nadella). По его словам, это самый мощный в мире ИИ ЦОД, объединяющий «сотни тысяч» NVIDIA GB200, а оптоволокна в нём хватит, чтобы «обернуть планету четыре раза». Пока нет данных, готова ли уже площадка Fairwater к эксплуатации или просто будет сдана несколько раньше. О том, что кампус в городке Маунт-Плезант (Mount Pleasant) будет вот-вот достроен, сообщалось ещё осенью 2025 года. Тогда же компания объявила, что суммарные инвестиции в площадку в течение нескольких лет составят $7,3 млрд. Строительство началось ещё в 2023 году на территории производственной площадки Foxconn. Первоначально планировалось застроить более 127 га. Впоследствии компания получила разрешение застроить ещё 405 га, а чуть позже она купила за $43 млн ещё 65 га. В январе 2026 года Microsoft дано разрешение на строительство на территории кампуса ещё 15 зданий ЦОД. На данный момент Fairwater включает три больших объекта общей площадью около 11,5 тыс. м2. Для строительства понадобилось 74,9 км глубоких свай для фундамента, более 12 тыс. т строительной стали, 193 км подземного кабеля среднего напряжения и 116,8 км трубопроводов. 
Источник изображения: Microsoft Похожий кампус Fairwater в Атланте (Джорджия) заработал в ноябре 2025 года, он будет напрямую связан с кампусом в Висконсине. Есть и планы строительства ЦОД в Лидсе (Leeds, Великобритания). По имеющимся данным компания, «близка» к получению разрешения на строительство в Западном Йоркшире. Кампус планируется построить на территории бывшей электростанции, он будет включать три трёхэтажных ЦОД (LBA10, 11 и 12) объекта площадью около 39 тыс. м2 каждый. Также на территории комплекса разместится электроподстанция. Строительство может стартовать в начале 2027 года.
06.03.2026 [17:01], Руслан Авдеев
Инференс-нагрузки Perplexity прописались в облаке CoreWeaveКомпания CoreWeave объявила о заключении долгосрочного соглашения с Perplexity. Стратегическое партнёрство призвано обеспечить выполнение рабочих ИИ-нагрузок последней, также предусмотрено пилотное внедрение в обеих организациях новых сервисов. Утверждается, что CoreWeave позволяет клиентам переходить от разработки непосредственно к внедрению без перепроектирования систем и инструментов. Соглашение предусматривает, что платформа CoreWeave будет использоваться Perplexity для инференса нового поколения. Выделенные кластеры на основе суперускорителей NVIDIA GB200 NVL72 гарантируют соответствие инфраструктуры облачного провайдера изменению задач Perplexity и высоким требованиям экосистемы на основе Sonar и Search API. В своё время Perplexity начинала с выполнения задач инференса с помощью CoreWeave Kubernetes Service и применения платформы W&B Models для (до-)обучения моделей и управления ими на всех этапах, от экспериментального до ввода в эксплуатацию. Дополнительно CoreWeave повсеместно внедрит в своей организации инструменты Perplexity Enterprise Max, что позволит её специалистам искать информацию в интернете и внутренней базе данных, проводить углублённые исследования, анализировать данные и визуализировать их. Партнёрство является свидетельством «мультиоблачной» стратегии Perplexity. Чуть более месяца назад Microsoft заключила крупную облачную сделку с Perplexity, но ключевым провайдером ИИ-поисковика останется AWS. 
Источник изображения: CoreWeave/Perplexity Это лишь последняя из удачных сделок CoreWeave, сдающей в аренду мощности даже таким компаниям, как Microsoft, Meta✴ и OpenAI. В 2025 году компания получила средства от NVIDIA, которая арендовала свои же ускорители у CoreWeave. В сентябре 2025 года компания обязалась выкупить у неооблачного оператора все нераспроданные мощности. CoreWeave на волне роста спроса на облачные услуги удвоит в 2026 году капитальные затраты, хотя некоторые инвесторы сомневаются в целесообразности таких мер.
18.02.2026 [18:50], Владимир Мироненко
Власти Индии закупят ещё 20 тыс. ускорителей NVIDIA для ускорения развития ИИ в странеНа проходящем в Нью-Дели саммите India AI Impact Summit министр электроники и информационных технологий Индии Ашвини Вайшнау (Ashwini Vaishnaw) заявил, что Индия расширит свои вычислительные мощности для ИИ-нагрузок свыше имеющихся 38 тыс. ускорители, добавив еще 20 тыс. еди. в ближайшее время в рамках программы «Миссия ИИ 2.0». Вайшнау сообщил ресурсу EE Times, что заказы на новые GPU будут размещены в течение недели, и ожидается, что они будут развёрнуты в течение следующих шести месяцев. Расширение вычислительных мощностей происходит в ходе реализации рамочного соглашения между Индией и США на 2026 год, в соответствии с которым две страны договорились значительно увеличить торговлю технологическими продуктами, включая ускорители и другие компоненты для ЦОД. Соглашение предусматривает намерение Индии закупить в течение пяти лет американские энергоносители, самолёты, технологические товары и критически важные материалы на сумму $500 млрд, расширяя при этом совместное технологическое сотрудничество. Заявление Вайшнау говорит о дальнейшем развитии программы IndiaAI Mission, утверждённой в марте 2024 года с бюджетом около $1,14 млрд на пять лет. Первоначально программой планировалось развёртывание 10 тыс. GPU, но их количество уже достигло 38 тыс. Ускорители предоставляются местным компаниям по субсидированной ставке ₹65/час (около $0,72/час). 
Источник изображения: NVIDIA С момента запуска в рамках программы IndiaAI Mission разрабатывались семь основных направлений, включая субсидированные вычислительные ресурсы, разработку базовых моделей, финансирование стартапов и безопасное управление ИИ. Двенадцать стартапов уже были отобраны для разработки отечественных многомодальных базовых моделей с использованием специфических для Индии наборов данных. NVIDIA сообщила о поддержке приоритетов IndiaAI Mission, включая, расширение вычислительных мощностей благодаря поставке ускорителей NVIDIA, разработку передовых ИИ-моделей и исследования и инновации в области ИИ. В рамках программы IndiaAI Mission компания сотрудничает с поставщиками облачных услуг Yotta, L&T и E2E Networks для создания передовых ИИ-фабрик. Yotta — поставщик облачных услуг, создающий крупномасштабную суверенную ИИ-инфраструктуру для Индии под брендом Shakti Cloud, работающую на базе более чем 20 тыс. ускорителей NVIDIA Blackwell Ultra. Его кампусы в Нави Мумбаи (Navi Mumbai) и Большой Нойде (Greater Noida) предоставляют индийским предприятиям и госсектору услуги облачных ИИ-сервисов с высокой пропускной способностью и большим количеством GPU с оплатой по мере использования. 
Источник изображения: NVIDIA В свою очередь, компания E2E Networks создаёт кластер ускорителей NVIDIA Blackwell на своей платформе TIR, размещённый в ЦОД L&T Vyoma в Ченнаи (Chennai). Облачная платформа TIR будет включать системы NVIDIA HGX B200 и корпоративное ПО NVIDIA, а также открытые модели NVIDIA Nemotron для ускорения развития ИИ в таких областях, как агентный ИИ, здравоохранение, финансы, производство и сельское хозяйство. Третий индийский партнёр NVIDIA на ИИ-рынке — компания Netweb Technologies, которая запускает суперкомпьютерные системы Tyrone Camarero AI, построенные на узлах NVIDIA GB200 NVL4, произведённых в рамках государственной программы «Сделано в Индии». Сообщается, что облачная ИИ-инфраструктура в Индии будет размещать рабочие нагрузки, а также обеспечивать интеллектуальные возможности для обучения моделей, тонкой настройки и масштабного инференса. Мощности в этих ЦОД будут зарезервированы для разработчиков моделей, стартапов, исследователей и предприятий для создания, тонкой настройки и развёртывания ИИ в Индии. Ранее глава OpenAI Сэм Альтман (Sam Altman) заявил, что Индия способна стать одним из мировых ИИ-лидеров, особенно в создании малых рассуждающих моделей (SLM).
27.01.2026 [12:53], Сергей Карасёв
Giga Computing представила ИИ-сервер на базе NVIDIA GB200 NVL4 с СЖОКомпания Giga Computing, подразделение Gigabyte Group, пополнила ассортимент серверов моделью XN24-VC0-LA61, ориентированной на ИИ-задачи и другие ресурсоёмкие нагрузки. Устройство выполнено в форм-факторе 2U на аппаратной платформе NVIDIA GB200 NVL4. В общей сложности задействованы четыре GPU поколения Blackwell со 186 Гбайт памяти HBM3E каждый (пропускная способность до 8 Тбайт/с) и два CPU Grace с 480 Гбайт памяти LPDDR5X (пропускная способность до 512 Гбайт/с). Применяется GPU — GPU интерконнект NVIDIA NVLink и CPU — GPU интерконнект NVIDIA NVLink-C2C. Реализована система прямого жидкостного охлаждения. Доступны четыре сетевых порта OSFP InfiniBand XDR на 800 Гбит/с или два порта Ethernet на 400 Гбит/с на базе NVIDIA ConnectX-8 SuperNIC. Кроме того, имеется порт 1GbE на основе Intel I210-AT и выделенный сетевой порт управления 1GbE. В оснащение входит контроллер ASPEED AST2600. Во фронтальной части расположены восемь посадочных мест для SFF-накопителей с интерфейсом PCIe 5.0 (NVMe) с жидкостным охлаждением. Опционально может быть установлен DPU NVIDIA BlueField-3. 
Источник изображений: Giga Computing Есть внутренний разъём для SSD типоразмера M.2 2242/2260/2280/22110 с интерфейсом PCIe 5.0 x4, слот PCIe 5.0 х16 для карты FHHL с СЖО и ещё один разъём PCIe 5.0 х16 FHHL. Предусмотерны коннекторы USB 3.2 Gen1 Type-A, Micro-USB, Mini-DP и RJ45.  Сервер имеет габариты 438 × 87 × 900 мм и массу 42,8 кг. За питание отвечают четыре блока мощностью 3200 Вт с сертификатом 80 PLUS Titanium. Диапазон рабочих температур простирается от +10 до +35 °C.
05.12.2025 [17:29], Руслан Авдеев
Малайзия стала на шаг ближе к ИИ-суверенитету — запущен 600-МВт дата-центр с суперускорителями NVIDIAМалайзия сделала очередной важный шаг на пути достижения суверенитета в области технологий искусственного интеллекта. В Кулае (Kulai, штат Джохор) введена в эксплуатацию первая очередь дата-центра на основе технологий NVIDIA мощностью 600 МВт, сообщает Converge! Digest. Это позволит существенно снизить зависимость от иностранной ИИ-инфраструктуры. Построенный совместно с NVIDIA и YTL Power International (YTLP) центр находится на территории принадлежащего последней технопарка Green Data Center Park. Объект оснастили ИИ-системами NVIDIA GB200 NVL72 для обучения крупных ИИ-моделей и корпоративного инференса. Запуск последовал за дебютом малайзийской ИИ-модели ILMU — первого национального варианта LLM, разработанного в самой стране. Это свидетельствует о желании малайзийского правительства развивать собственные ИИ-компетенции, а не полагаться исключительно на сторонних поставщиков облачных услуг. При этом под давлением США выбор был сделан в пользу американских, а не китайских технологий. 
Источник изображения: Ven Jiun (Greg) Chee/unsplash.com Дата-центр укрепляет долгосрочные амбиции страны по превращению в ведущий ИИ-хаб АСЕАН к 2030 году. Власти подчёркивали стратегическую важность суверенных вычислений в ходе недавних переговоров с главой NVIDIA Дженсеном Хуангом (Jensen Huang). В бюджете на 2026 год выделено RM5,9 млрд (более $1,4 млрд) на расширение ИИ-инфраструктуры, масштабирование внедрения ИИ в промышленности и повышение цифровой конкурентоспособности в производстве, телеком-секторе и сфере услуг. Развитие инфраструктуры соответствует общей динамике развития региона, в т.ч. речь про крупные инвестиции в Джохоре и его окрестностях. В настоящее время регион является одним из самых быстрорастущих хабов ЦОД в Юго-Восточной Азии. Всё новые и новые проекты ЦОД указывают на устойчивый спрос на мощности, близость к IT-экосистеме Сингапура и выгодные условия в области энергетики. Конкуренцию Малайзии пытается составить Индонезия. 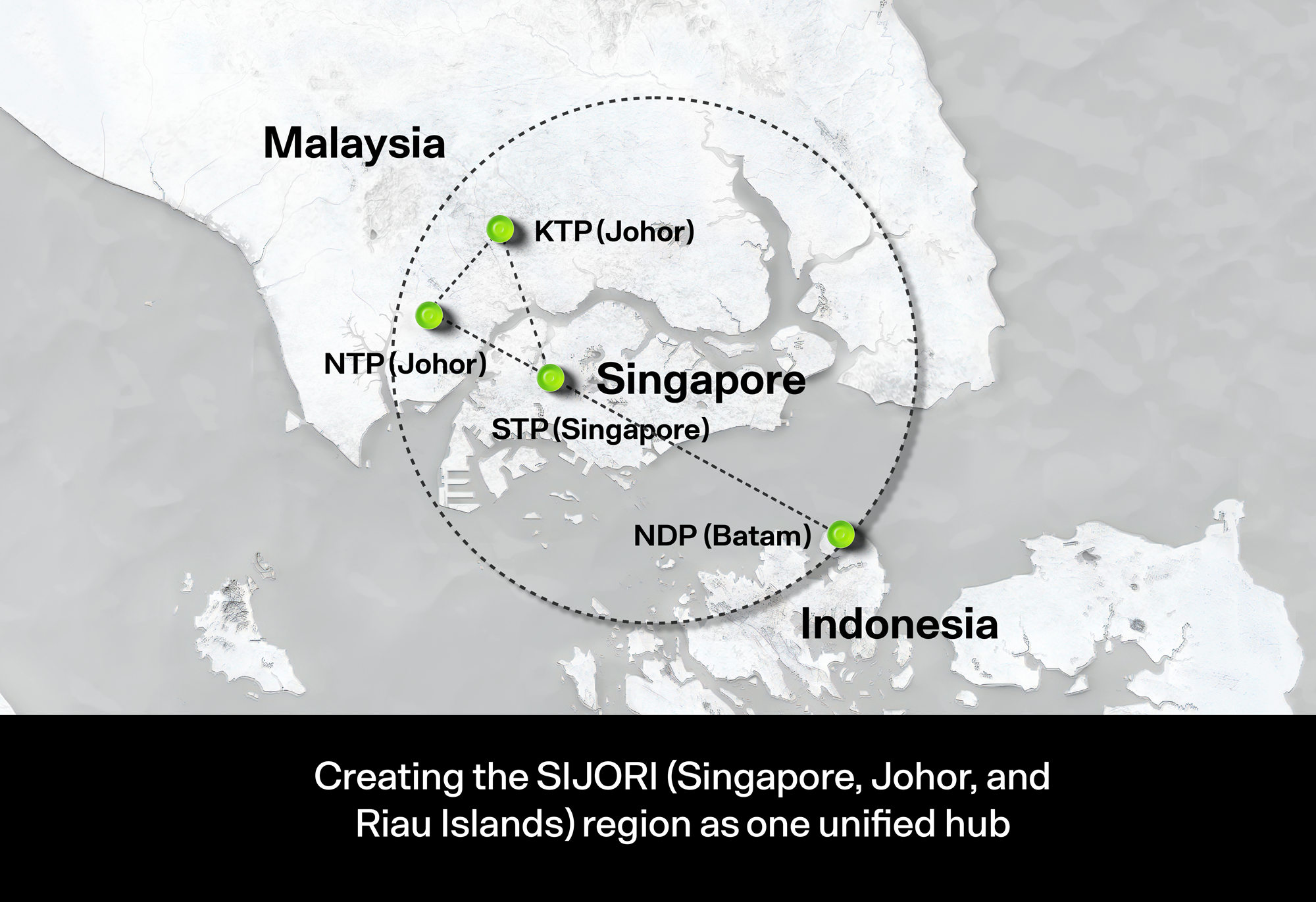
Источник изображения: DayOne Малайзия определяет создание суверенных вычислительных мощностей и государственно-частное партнёрство как основные принципы стратегии развития цифровой индустрии. Как считают в Converge! Digest, действия Малайзии отражает аналогичные инвестиции в ИИ-вычисления, основанные на принципах суверенитета, осуществляющиеся в Сингапуре, Индонезии, Южной Корее, Японии и на Ближнем Востоке. Повсеместно страны создают специальные кластеры ускорителей для поддержки ИИ-индустрии. Укрепление партнёрства NVIDIA с поддерживаемыми государствами игроками в области ИИ от Сингапура до Саудовской Аравии отражает и растущий спрос на локализованные мощности и специализированные стоечные архитектуры. По мере развития ИИ-проектов в Джохоре Малайзия становится крупным ИИ-хабом с конкурентоспособными ценами в региональной гонке за развитие инфраструктуры. В августе сообщалось, что во II квартале 2025 года штат Джохор (Малайзия) одобрил 42 проекта строительства ЦОД. |
|

