Материалы по тегу: ускоритель
|
07.07.2026 [23:59], Владимир Мироненко
Китайская DeepSeek скрытно занимается разработкой собственного ИИ-ускорителя для инференсаКитайский стартап DeepSeek работает над созданием собственного чипа для ИИ-инференса, что позволит ему снизить зависимость от NVIDIA и Huawei, чьи ускорители используются для обучения и запуска его ИИ-моделей, сообщило агентство Reuters со ссылкой на информированные источники. По данным источников, работа DeepSeek над этим проектом началась около года назад и пока находится на ранней стадии: сейчас стартап ведёт переговоры с компаниями, занимающимися проектированием чипов, производством микросхем и памяти. В последние месяцы он увеличил найм инженеров-разработчиков микросхем, причём набор ведётся в частном порядке, без особой огласки и без размещения вакансий на публичных платформах. Для DeepSeek эта инициатива имеют дополнительное стратегическое измерение, поскольку США ввели экспортные ограничения на поставку китайским компаниям передовых чипов NVIDIA, а власти Китая оказывает давление на местные компании, продвигая разработку и внедрение отечественных альтернатив. 
Источник изображения: He Junhui/unsplash.com DeepSeek не единственная компания, кто стремится снизить зависимость от NVIDIA, доминирующей на рынке ИИ-чипов. Помимо гиперскейлеров Amazon (Trainium), Alibaba (Zhenwu), Google (TPU), Meta✴ (MTIA) и Microsoft (Maia), расширяющих использование собственных чипов, ещё ряд компаний предпринимает шаги в этом направлении. Например, в прошлом месяце OpenAI представила Jalapeño, свой первый кастомный чип для инференса, разработанный совместно с Broadcom. Anthropic тоже рассматривает возможность создания собственных ИИ-чипов.
01.07.2026 [17:45], Владимир Мироненко
Etched заключил контракты на поставку чипов для ИИ-инференса более чем на $1 млрдСтартап Etched, вышел из скрытого режима (stealth), объявив о разработке ИИ-чипа для инференса и подписанных контрактах на его поставку более чем на $1 млрд. Также стартап сообщил о привлечении $800 млн инвестиций в рамках нескольких ранее не разглашавшихся раундов финансирования. Последний раунд финансирования прошёл в декабре 2025 года. Компания привлекла тогда $500 млн инвестиций при оценке в $5 млрд. В числе инвесторов Etched — VentureTech Alliance, Питер Тиль (Peter Thiel), Jane Street, Hudson River Trading, Jump Trading, Two Sigma, Stripes, Ribbit Capital, Radical Ventures, Primary VC, Positive Sum, а также несколько известных исследователей и предпринимателей в области ИИ. 
Источник изображений: Etched Компания сообщила, что первые прототипы чипов (A0) сошли с производственной линии N4P TSMC в начале этого года и что она планирует начать поставки своих первых стоечных систем для инференса этим летом. В настоящее время они проходят тестирование у клиентов. По данным Etched, предварительные испытания у клиентов продемонстрировали передовые показатели пропускной способности, задержки и энергоэффективности ИИ-систем при выполнении инференса.  Etched разрабатывает вертикально интегрированную инфраструктуру для ИИ-инференса, которая объединяет кастомные микросхемы, стойки, сетевое оборудование, системы охлаждения, ПО и производство. Компания сообщила, что её системы уже работают с популярными ИИ-моделями, включая DeepSeek, Qwen, Mamba и Llama, и предназначены для поддержки моделей от плотных архитектур до больших MoE-систем с произвольно большим количеством параметров.  Как сообщает ресурс Converge! Network Digest, для поддержки производства Etched открыла завод на Тайване, а также построила ЦОД мощностью 2 МВт, испытательный центр и лабораторию для прототипирования новых продуктов (NPI) в своей штаб-квартире в Сан-Хосе, с планом достижения ИИ-инфраструктурой для инференса гигаваттного масштаба к 2027 году.  Etched также сообщила о внедрении двух технологий. Первая — Low Voltage Inference (LVI), которая позволяет чипу работать с вполовину меньшим напряжением по сравнени с типовыми ускорителями, при этом устоявшаяся производительность составляет более 80 % от пиковой при разреженном инференсе триллионных MoE-моделей. Результатом является отсутствие троттлинга значительное ускорение инференса. Вторая технология, Cluster Scale Memory (CSM), сочетает SRAM и HBM с общей архитектурой памяти с низкой задержкой и запатентованный интерконнект. В итоге и задержка снижается, и высокая пропускная способность памяти сохраняется.
24.06.2026 [18:24], Владимир Мироненко
OpenAI и Broadcom представили кастомный ускоритель Jalapeño для ИИ-инференсаOpenAI и Broadcom представили кастомный чип Jalapeño, разработанный в тесном сотрудничестве «в соответствии с видением OpenAI будущего инференса LLM». Согласно первым тестам, ускоритель первого поколения обеспечивает производительность на ватт значительно выше, чем у современных аналогов. Как сообщает OpenAI, Jalapeño был разработан с нуля для текущих и будущих LLM. Благодаря использованию ИИ-моделей OpenAI от начала проектирования до выхода на производство чипа потребовалось всего лишь девять месяцев. OpenAI отметила, что разрабатывала Jalapeño, «руководствуясь своим планом развития моделей, ядер, систем обслуживания и потребностей продукта, совместно с партнёрами Broadcom и Celestica». Чип спроектирован не как отдельный ускоритель, а как часть масштабируемого програмнно-аппаратного комплекса. Инженерные образцы Jalapeño работают в лаборатории с задачами машинного обучения на целевой частоте и энергопотреблении, включая GPT‑5.3‑Codex‑Spark. Компания пообещала предоставить подробный технический отчёт о производительности ускорителя в ближайшие месяцы. Как сообщает Bloomberg, по словам генерального директора Broadcom Хока Тана (Hock Tan), на данный момент ускоритель демонстрирует экономию средств примерно на 50 % по сравнению с типовыми ИИ-ускорителями. 
Источник изображения: OpenAI Сообщается, что архитектура чипа снижает перемещение данных и обеспечивает баланс вычислительных и сетевых ресурсов, а также памяти для достижения фактического использования, гораздо более близкого к теоретической пиковой производительности. Реализация аппаратных и сетевых технологий Broadcom, включая Tomahawk, помогают вывести платформу на крупномасштабный производственный уровень. OpenAI отметила, что стремится создать полный стек для продукта. Она не только разрабатывает передовые модели и решения на их основе. Компания проектирует инфраструктуру под ними: архитектуру чипов, ядра, системы памяти, сети, управление, системы развёртывания и пользовательский опыт. Благодаря этому каждый слой стека может быть оптимизирован для достижения главной цели компании: сделать свои модели быстрее, надёжнее и доступнее для пользователей. Стремясь оптимизировать затраты на ИИ-инфраструктуру, Amazon (Trainium), Google (TPU), Meta✴ (MTIA) и Microsoft (Maia) тоже работают над собственными кастомными ИИ-ускорителями. Во многом это связано и с желанием снизить зависимость от чипов NVIDIA.
19.06.2026 [19:34], Владимир Мироненко
«Логарифмический» ИИ-ускоритель Tensordyne Napier обещает выскоую производительность при минимальном энергопотребленииИИ-стартап Tensordyne (ранее Recogni) анонсировал платформу Tensordyne Napier (TDN) для ИИ-инференса, разработанную в партнёрстве с Broadcom и HPE Juniper Networks, которая «сочетает в себе инновационные логарифмические математические вычисления в области ИИ, тесно интегрированную архитектуру памяти и высокопроизводительный масштабируемый интерконнект, обеспечивая существенно более высокую пропускную способность, меньшее энергопотребление и улучшенную экономику инфраструктуры для крупномасштабных задач ИИ-инференса». По словам Tensordyne, новый «логарифмический» чип позволит решить, как проблему скорости, так и стоимости ИИ-инференса. В нём компания заменила крупномасштабные операции умножения упрощёнными вычислениями на основе сложения, значительно повысив эффективность на Вт. Сумматоры меньше размером и как правило потребляют меньше энергии, чем умножители, поэтому их использование обеспечит больше полезной площади для SRAM и лучшую сбалансированность системы. 
Источник изображений: Tensordyne Чип включает 138 млрд транзисторов и поддерживает обработку данных в режимах NVFP4, FP8 и FP16. Tensordyne сообщила о 2,1 Пфлопс в формате плотных вычислений FP8 на кристалл. Частота ядра ускорителя составляет 1,33 ГГц, поддерживающих ядер RISC-V — 1,5 ГГц. Чип получил четыре блока HBM4 (по данным ServeTheHome — HBM3E), каждый по 36 Гбайт (144 Гбайт в сумме) с пропускной способностью 4,7 Тбайт/с. Также на чипе размещено 256 Мбайт SRAM с суммарной пропускной способностью 40 Тбайт/с. Интеграция значительного объёма быстрой SRAM с HBM позволила минимизировать циклы простоя вычислений и обеспечить эффективную поддержку выполнения самых больших моделей в отрасли.  Как рассказал ресурсу The Next Platform Р.К. Ананд (RK Anand), сооснователь и директор по продуктам Tensordyne, ускоритель имеет 48 ядер, которые связаны с блоками обработки векторов. В векторном блоке тоже есть ALU, но он также может использовать таблицу поиска (LUT) и работать полностью параллельно. В целом доступны чередование операций и управляемый конвейер. По словам Ананд, Napier потребляет всего 300 Вт по сравнению с 1200-Вт NVIDIA B300, поскольку новый чип довольно компактен. Ананд не уточнил, состоит ли чип Napier из чиплетов или представляет собой монолитный кристалл. 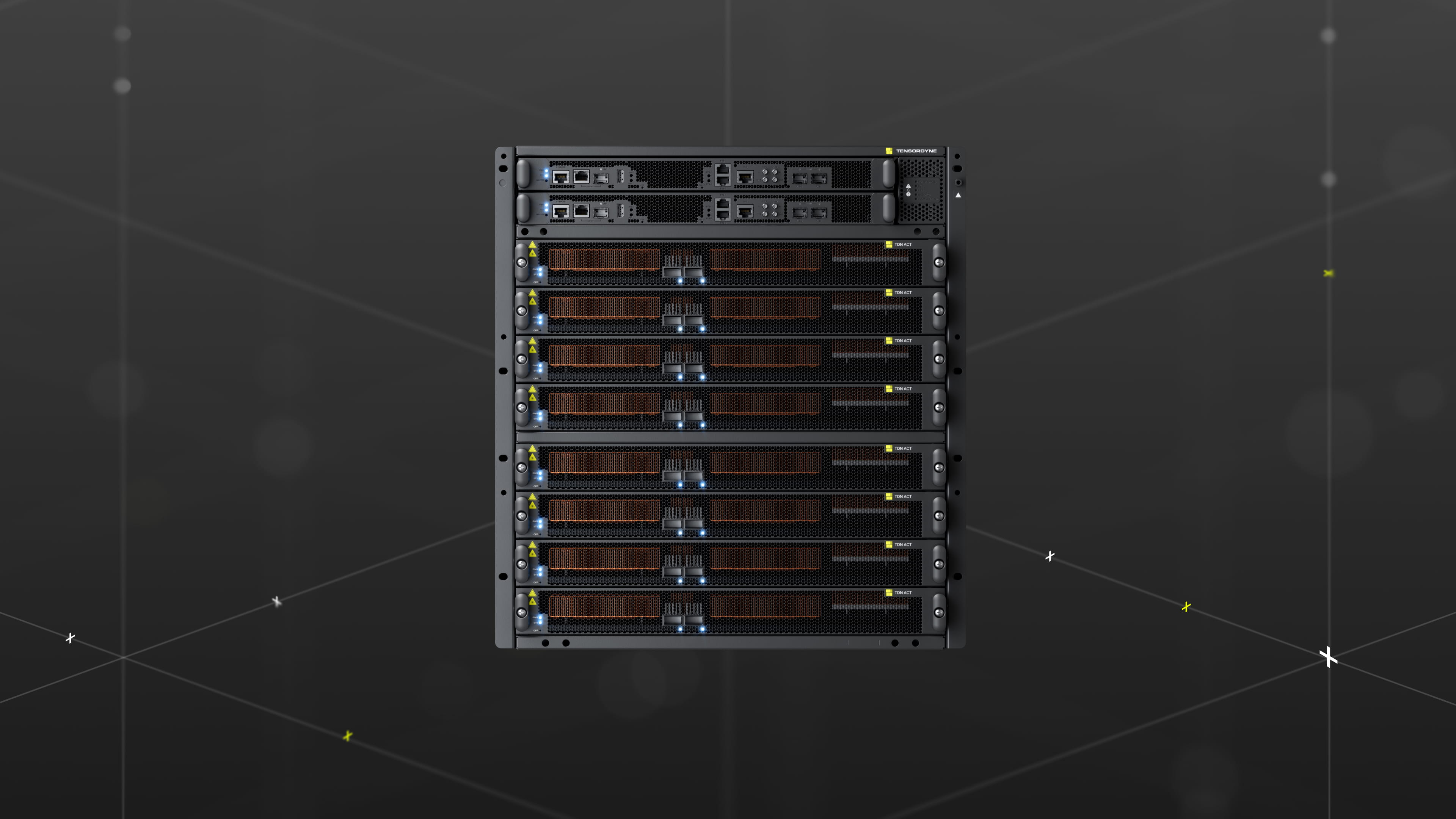 Девять чипов TDN могут размещаться в 1U-узле, в котором установлен 40-ядерный процессор Xeon для управления хостом и выполнения некоторых задач декодирования, а также 8-Тбайт NVMe SSD. Узел имеет два 200GbE-порта QSFP, а на задней панели расположены шесть портов для фирменного интерконнекта TDNLink, используемого для соединения 72 чипов TDN. Узел обеспечивает 19 Пфлопс в режиме FP8, 1,3 Тбайт HBM и 2,25 Гбайт SRAM с агрегированной пропускной способностью 42 Тбайт/с и 360 Тбайт/с соответственно. Узлы Napier, подобно NVIDIA NVLink, соединены через объединительную плату посредством проприетарного интерконнекта TDNLink. Суперускоритель TDN72 объединяет 72 чипа TDN (восемь узлов), причём TDNLink способен обеспечить задержку менее микросекунды между чипами при пропускной способности 1 Тбайт/с.  TDN72 ориентирован на модели с количеством параметров от 10 до 20 трлн, для работы с которыми важны объём памяти и MoE-маршрутизация. «В каждом TDN72 у нас 320 ядер Xeon и 4608 ядер RISC-V», — отметил сооснователь и вице-президент Tensordyne Жиль Бакхус (Gilles Backhus). «Мы применяем двухуровневый подход к решению проблемы с CPU. Вся работа, выполняемая непосредственно вблизи вычислительных процессов ИИ в рамках цикла обработки токенов и авторегрессионного цикла LLM, в основном проводится на ядрах RISC-V. Здесь же осуществляется маршрутизация MoE, проверка по словарю для отбрасывания определённых токенов и т.д. Прочая обработка данных для инференса происходит на процессорах Intel Xeon».  Четыре TDN72 помещаются в стандартную 52U-стойку Tensordyne Napier, что даёт 608 Пфлопс (FP8), 42 Тбайт HBM, 74 Гбайт SRAM, 256 Тбайт NVMe SSD, 275-Тбайт/с соединение TDNLink и 64 порта 200GbE. При этом такая стойка потребляет всего 120 кВт и может обходиться воздушным охлаждением. Как сообщила компания, стойка Tensordyne Napier обеспечивает по сравнению с полноразмерной стойкой NVIDIA NVL72:
Система поддерживает дезагрегированное обслуживание и выполнение моделей с многотриллионными параметрами со скоростью более 1000 токенов в секунду на пользователя. Для достижения той же пропускной способности потребовалось бы как минимум девять стоек NVIDIA Rubin + Groq LPX, отметила Tensordyne.
Самой сложной составляющей запуска платформы может стать ПО. Tensordyne сообщила о выпуске на платформе Hugging Face центра моделей со своим SDK, прямой компиляцией моделей для PyTorch/Triton и кастомным eDSL для Python. Следует отметить, что одним из важных преимуществ ускорителей NVIDIA является экосистема CUDA — огромная база фреймворков, ядер, инструментов профилирования, шаблонов развёртывания и моделей поведения разработчиков. Любой новый ИИ-ускоритель должен сопровождаться достаточно простым ПО, чтобы клиенты захотели его внедрять в своих системах.
05.06.2026 [01:27], Владимир Мироненко
Сбербанк представил универсальный оптический вычислитель для ИИ-задачСбербанк представил универсальный оптический вычислитель, созданный для реальных задач ИИ. В его основе лежит фотонная интегральная схема, разработанная специалистами компании, пишет ТАСС. По словам компании, данная разработка является первой в России и одной из первых в мире. Как сообщили в «Сбере», в задачах ИИ устройства фотоники обеспечивают принципиально новый уровень скорости и энергоэффективности. «Уже первый прототип способен выполнять более 1 млрд операций матричного умножения в секунду, и мы видим путь к увеличению частоты оптических операций до 10 ГГц и более. Само умножение в оптике происходит за доли наносекунды; при этом энергопотребление оптического ядра более чем на 30 % ниже электронных аналогов», — отметили в компании. 
Источник изображения: Paul Hanaoka/unsplash.com Также сообщается, что чип выполняет самую энергозатратную часть вычислений в ИИ — умножение матриц, на которое приходится основная нагрузка при обучении и работе LLM. В компании отметили, что переход на фотонику — один из реальных способов справиться с ростом энергопотребления ЦОД и выстроить более эффективную и масштабируемую вычислительную инфраструктуру. К тому же для страны преимущество использования оптических чипов заключается в том, что их производство локализуется проще, чем электронных.
02.06.2026 [01:04], Владимир Мироненко
ИИ-ускоритель Intel Crescent Island получит до 480 Гбайт LPDDR5XIntel сообщила новые подробности о своём будущем ИИ-ускорителе для ЦОД с кодовым именем Crescent Island, который был анонсирован в прошлом году. Новый GPU основан на архитектуре Xe3P, представляющей усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake. Ожидается, что Xe3P также будет использоваться в GPU Intel серии Arc-C для клиентских устройств. Компания отметила, что чип разработан специально для рабочих нагрузок агентного ИИ. В то время как традиционные ИИ-ускорители от NVIDIA и AMD полагаются на дорогую память HBM, в новом чипе Intel используется LPDDR5X, и он предназначен для работы в серверах с воздушным охлаждением, а не с жидкостным. Crescent Island будет поддерживать до 480 Гбайт памяти LPDDR5X, хотя базовая эталонная конфигурация рассчитана на 160 Гбайт. Intel заявила, что Crescent Island оптимизирован по производительности на Вт — до TDP 350 Вт в версии с воздушным охлаждением и интерфейсом PCIe. 
Источник изображений: Intel Сообщается, что GPU будет поддерживать широкий спектр форматов данных от FP4 до FP64, а также полностью открытый программный стек oneAPI, что идеально подходит для поставщиков услуг «токены как услуга» и сценариев использования для инференса. Концептуально новинка напоминает Rubin CPX, от которого NVIDIA отказалась.  Intel уже оценивает свой открытый унифицированный программный стек для гетерогенных систем ИИ с помощью существующей линейки Arc Pro B-серии, поэтому будущие версии чипов получат доступ к этим оптимизациям на ранних этапах. Intel планирует начать тестирование GPU Crescent Island для клиентов во II половине 2026 года с общей доступностью в 2027 году.
29.05.2026 [21:36], Владимир Мироненко
FuriosaAI и Broadcom создадут ИИ-ускоритель для платформы инференса для агентной эрыЮжнокорейский стартап FuriosaAI объявил о заключении соглашения о стратегическом партнёрстве с Broadcom для разработки тензорного (TCP) ИИ-ускорителя третьего поколения в качестве основы масштабируемой платформы инференса, предназначенной для обслуживания передовых агентных систем гиперскейлеров. Стартап намерен объединить передовые возможности Broadcom по упаковке, позволяющие интегрировать несколько кремниевых кристаллов в ИИ-ускоритель, и её достижения в масштабируемых сетевых решениях для ИИ со своей ИИ-архитектурой и программным стеком для создания платформы инференса в масштабе стойки По словам FuriosaAI, в результате сотрудничества с Broadcom архитектура процессора Tensor Contraction Processor (TCP) «превратится в многокристальную систему», которая лучше подходит для «высокопроизводительных требований к токенам» рабочих нагрузок инференса и агентного ИИ, пишет DataCenter Dynamics. FuriosaAI отметила, что эта архитектура сделает чипы более подходящими для «реальных рабочих ИИ-нагрузок» и что, сосредоточившись на высокоскоростной передаче данных, а не на управлении потоками вычислений, ускорители обеспечат более высокую производительность на ватт и большую «плотность» токенов, чем «передовые GPU». 
Источник изображения: FuriosaAI Сообщается, что чип третьего поколения FuriosaAI будет включать вычислительный 2-нм кристалл, выделенный IO-кристалл SUE-интерконнекта и двуслойную память HBM4/4E. Благодаря интеграции Scale-Up Ethernet (SUE) и PCIe-решений Broadcom, система будет обеспечивать низкую задержку и высокую пропускную способность интерконнекта All-to-All между сотнями чипов в масштабе стойки. Существующие системы могут объединять не более восьми ИИ-ускорителей RNGD. Как отметил президент группы полупроводниковых решений Broadcom, производительность инференса больше не определяется исключительно вычислительными ресурсами. Она всё больше зависит от повторного использования данных и эффективности обмена данными между серверами и стойками: «Сочетая архитектуру TCP FuriosaAI с ведущей на рынке технологией XPU и IP-платформой Broadcom, масштабируемым Ethernet и коммутаторами сетевых фабрик, мы создаём платформу, которая решает ключевые проблемы крупномасштабного агентного ИИ», — заявил он. «Объединение инфраструктурных возможностей Broadcom и архитектуры Tensor Contraction Processor от FuriosaAI, а также её определяющего отрасль программного стека, позволяет нам выйти за рамки уровня чипа и предложить комплексное решение для эпохи фабрик токенов», — отметил соучредитель и генеральный директор FuriosaAI. 
Источник изображения: Broadcom Хотя вычислительная мощность по-прежнему важна для рабочих ИИ-нагрузок, особенно на этапе предварительного заполнения, FuriosaAI сосредоточилась на перемещении данных между HBM и DRAM. «TCP ориентирован на высокоскоростную передачу данных и масштабные тензорные операции, а не на управление тысячами крошечных потоков. Он рассматривает доступ к памяти как первостепенную задачу, устраняя “обрыв” эффективности, с которым сталкиваются GPU, когда модели выходят за рамки жёстких иерархий кеша», — сообщается в блоге компании. Аппаратное обеспечение FuriosaAI поддерживается программным стеком, который позволяет разработчикам быстро развёртывать приложения, а также легко переключаться на новые модели и новые методы оптимизации. В то время как устаревшие платформы требуют обширной ручной настройки ядер для каждой новой модели, SDK FuriosaAI использует универсальный компилятор, который автоматически сопоставляет высокоуровневый код PyTorch с полупроводниковой архитектурой. Для разработчиков, которым требуется более детальный контроль, виртуальная архитектура набора команд FuriosaAI предлагает декларативную модель программирования, которая обеспечивает управление оборудованием без недетерминированной сложности традиционного программирования для GPU, отметила компания. Ранее сообщалось, что Broadcom продлила сотрудничество с Meta✴ для разработки нескольких поколений кастомных ИИ-чипов. Также она расширила контракт с Google по снабжению её новыми поколениями ИИ-чипов. Создаёт Broadcom специализированные чипы и для OpenAI. Всего у компании в разработке порядка десяти кастомных ASIC.
25.05.2026 [09:20], Владимир Мироненко
Аппаратный «ZIP-ускоритель» Huawei сжимает архивные данные в 90 разHuawei анонсировала аппаратный ускоритель для СХД для резервного копирования Huawei OceanProtect, который использует «алгоритмы HZU для глубокого сжатия с коэффициентом до 90:1», что, как утверждает производитель, на 20 % выше, чем у лучшего аналога, передаёт Blocks & Files. Кроме того, по словам Huawei, она имеет единственную в отрасли эффективную гарантию ёмкости, «исключая необходимость в оценке коэффициента компрессии». Huawei использует комбинацию многоуровневой, встроенной дедупликации данных с блоками переменной длины (VLD) с сжатием на основе свойств и компактизацией на уровне байтов, применяемой к резервным копиям. Как правило, они отличаются высокой избыточностью данных. Особенно это касается таких операций, как ежедневное полные снимки виртуальных машин. Семейство алгоритмов сжатия HZU (HZBC), разработанных Huawei, включает в себя «быстрое нелинейное преобразование и упрощённый метод прогнозирования контекста». Как утверждает Huawei эти алгоритмы могут обеспечить результаты, превосходящие результаты LZ-алгоритмов и повысить коэффициент сжатия примерно на 30 %». 
Источник изображения: Tim Johnson / Unsplash Как полагает Blocks & Files, используется четырёхэтапная схема компрессии:
Huawei запатентовала используемые алгоритмы дедупликации и сжатия. Технология включает выбор алгоритмов сжатия, наиболее подходящих для резервного копирования конкретных типов данных, а фактический коэффициент сжатия зависит от типа приложения и политики резервного копирования. Утверждается, что аппаратный ускоритель разгружает основной процессор СХД до 22 %. Поскольку системы OceanProtect используют All-Flash-накопители, а не более дешёвые диски, то чем эффективнее компрессии, тем лучше. Huawei использует QLC-накопители с выделенной адаптивной SLC-зоной для обработки «горячих» данных и более быстрого восстановления данных. У Everpure также есть аппаратный ускоритель DirectCompress Accelerator на базе FPGA для сжатия данных на лету и разгрузки CPU хранилища. Портфолио Huawei включает системы OceanProtect X3000, X6000 и E8000. Недавно были анонсированы также Huawei X8100 и X9100. Более ранние системы, использующие технологии сжатия предыдущих поколений, поддерживали коэффициент сжатия до 72:1. А новые системы к тому же работают до 50 % быстрее. Также отмечается, что OceanProtect X8100 обеспечивает защиту от программ-вымогателей на 99,99 %.
20.05.2026 [20:05], Владимир Мироненко
Alibaba представила ИИ-ускоритель Zhenwu M890, который втрое быстрее предшественникаAlibaba Group представила ИИ-ускоритель Zhenwu M890, разработанный её подразделением T-Head Semiconductor (Pingtouge Semiconductor), сообщило агентство Reuters. Согласно опубликованным сведениям о Zhenwu M890, это самый высокопроизводительный продукт, созданный T-Head на сегодняшний день. Он позиционируется как конкурент ускорителю NVIDIA H100, хотя и уступает ему по ряду показателей. Чип поддерживает форматы FP32/BF16/FP16 для обучения и FP8/FP4/INT8/INT4 — для инференса. Новый ускоритель был специально разработан для новой волны ИИ-агентов. Сообщается, что новинка примерно в три раза превосходит предшественника Zhenwu 810E по производительности, но точные характеристики не приводятся. Ускоритель имеет 144 Гбайт HBM и интерфейс PCI 5.0 x16. Каждый M890 имеет 8 портов интерконнекта ICN (800 Гбайт/с) и поддерживает бесшовное объединение до 64 карт. Также была представлена серверная система Panjiu AL128, которая объединяет 128 ускорителей Zhenwu M890 в одной стойке. Система вместе с фирменным стеком T-SAIL уже сейчас доступна китайским корпоративным клиентам через платформу Alibaba Cloud для внутреннего рынка, известную как Bailian. 
Источник изображений: T-Head По словам компании, новый чип хорошо подходит для обработки больших объёмов памяти и коммуникационных нагрузок агентских приложений, для которых модели должны сохранять длительные периоды контекста и координировать свои действия в реальном времени. T-Head сообщила, что на сегодняшний день отгрузила более 560 тыс. ускорителей семейства Zhenwu, и более 400 внешних клиентов из 20 отраслей, включая автопроизводителей и финансовые компании, уже их внедрили. В начале апреля Alibaba и оператор China Telecom заявили о запуске ЦОД на юге Китая, работающего на собственных чипах компании.  Alibaba также представила план разработки чипов на несколько лет вперёд, согласно которому в III квартале 2027 года выйдет преемник под названием V900, а в III квартале 2028 года — чип следующего поколения — J900. Согласно заявлению Alibaba, запланированный к выпуску в следующем году V900 обеспечит примерно трёхкратное увеличение производительности по сравнению с M890. По имеющейся информации, ускорители Alibaba Group производятся по техпроцессам, которые китайские заводы могут использовать без контролируемого США литографического оборудования, что является ограничивающим фактором, определяющим весь цикл производства микросхем в Китае. Поскольку ни один экземпляр H200 из одобренных США для поставки десяти китайским покупателям так и не был отгружен, китайские клиенты ускоряют переход к альтернативам местных компаний: Alibaba Zhenwu, Huawei Ascend, Cambricon Siyuan и др. По мнению Counterpoint Research, Zhenwu даст местным компаниям ещё один вариант для их ИИ-инфраструктуры, хотя остаются вопросы о том, сколько чипов Alibaba сможет выпустить на местных полупроводниковых заводах (SMIC): «M890 — это небольшой, но реальный вклад в самодостаточность Китая в области ИИ… С точки зрения чистой производительности кремния, M890 не является настоящим конкурентом H200. Но в этом и нет нужды. Для китайского рынка это достойная замена H200».
20.05.2026 [10:31], Сергей Карасёв
«Байкал Электроникс» готовит ИИ-ускорители с FP8-производительностью до 1 Пфлопс и совместимостью с CUDAРоссийская компания «Байкал Электроникс» на конференции ЦИПР 2026 в Нижнем Новгороде раскрыла информацию о собственных ИИ-ускорителях Baikal-AI-E1000 и Baikal-AI-D1000. Первый ориентирован на выполнение задач на периферии, второй — в дата-центрах. Известно, что изделие Baikal BE-AI-D1000 получит от 48 до 64 Гбайт памяти типа GDDR. Производительность в режиме FP8 заявлена на уровне 1000 Тфлопс (1 Пфлопс), на операциях FP16 — 500 Тфлопс. Таким образом, новинка сможет составить конкуренцию решениям NVIDIA L40S. Ориентировочная цена составит $10 тыс. 
Источник изображений: «Байкал Электроникс» Для ускорителя Baikal BE-AI-D1000 планируется реализовать совместимость с экосистемой CUDA. По заявлениям «Байкал Электроникс», устройство рассматривается в качестве компонента суверенных дата-центров, ориентированных на ИИ-нагрузки. Вывести устройство на коммерческий рынок компания рассчитывает в 2029–2030 гг.  В свою очередь, Baikal-AI-E1000 станет альтернативой модулю NVIDIA Jetson Orin NX. Указываются тактовая частота и энергопотребление — до 2 ГГц и не более 30 Вт. Для решений уже разработано GPGPU-ядро, построенное на базе FPGA.  Кроме того, «Байкал Электроникс» представила архитектуру ИИ ЦОД с серверами, оснащёнными отечественными комплектующими. Помимо ускорителя Baikal BE-AI-D1000, в таких системах предлагается задействовать процессор Baikal S2, выполненный на архитектуре Neoverse-N2 (ARMv9). Ранее говорилось, что чип получит 128 ядер с частотой на уровне 3 ГГц, 8 каналов DDR5, 192 линии PCIe 5.0, поддержку CXL 2.0 и CCIX 2.0.  Нужно также отметить, что «Байкал Электроникс» столкнулась с трудностями при производстве своих процессоров из-за сформировавшейся геополитической обстановки. В результате, компания была вынуждена отменить выпуск и продажи изделий Baikal-S. Позднее появилась информация, что отгрузки этих чипов будут возобновлены. |
|


