Материалы по тегу: enflame
|
14.12.2021 [21:11], Владимир Агапов
Китайская Enflame выпустила новый ИИ-ускоритель Cloudblazer Yunsui i20Компания Enflame, которая летом этого года представляла ускорители на базе второго поколения своих ИИ-чипов DTU, выпустила новый инференс-ускоритель Cloudblazer Yunsui i20 с чипом Suixi 2.5. Он изготовлен по 12-нм FinFET-техпроцессу GlobalFoundries и имеет обновлённую высокопроизводительную архитектуру вычислительных ядер GCU-CARE 2.0, благодаря чему, по словам создателей, удалось достичь эффективности, сопоставимой с массовыми 7-нм GPU. В числе ключевых особенностей новинки компания отмечает возросшую вычислительную мощность, возможность исполнения тензорных, векторных и скалярных вычислений, API для C++ и Python, а также поддержку основных фреймворков и форматов моделей (TensorFlow, PyTorch, ONNX). Комплектное ПО предоставляет гибкие возможности для миграции с поддержкой технологий виртуализации, а также многопользовательских и многозадачных окружений с безопасной изоляцией процессов.  Yunsui i20 обладает 16 Гбайт памяти HBM2e с пропускной способностью до 819 Гбайт/c. Новинка поддерживает работу со всеми ключевыми форматами и предоставляет универсальную инференс-платформу, в том числе для облаков. Пиковая вычислительная FP32-производительность достигает 32 Тфлопс, TF32 (не уточняется, идёт ли речь о совместимости с NVIDIA) — 128 Тфлопс, FP16/BF16 — 128 Тфлопс, а INT8 достигает 256 Топс. По сравнению с первым поколением продуктов, Yunsui i20 увеличил FP-производительность в 1,8 раза, а INT-вычислений — в 3,6 раза.  Для сравнения — у PCIe-версии NVIDIA A100 производительность в расчётах FP32, TF32, FP16/BF16 и INT8 составляет 19,5, 156, 312 и 624 Тфлопс (Топс для INT), а объём и пропускная способность памяти равны 40/80 Гбайт и 1555/1935 Гбайт/с соответственно. У AMD MI100 объём HBM2-памяти равен 32 Гбайт (1,23 Тбайт/с), а производительность FP32, FP16 и BF16 равна 46,1, 184,6 и 92,3 Тфлопс соответственно. Все три ускорителя имеют интерфейс PCIe 4.0. 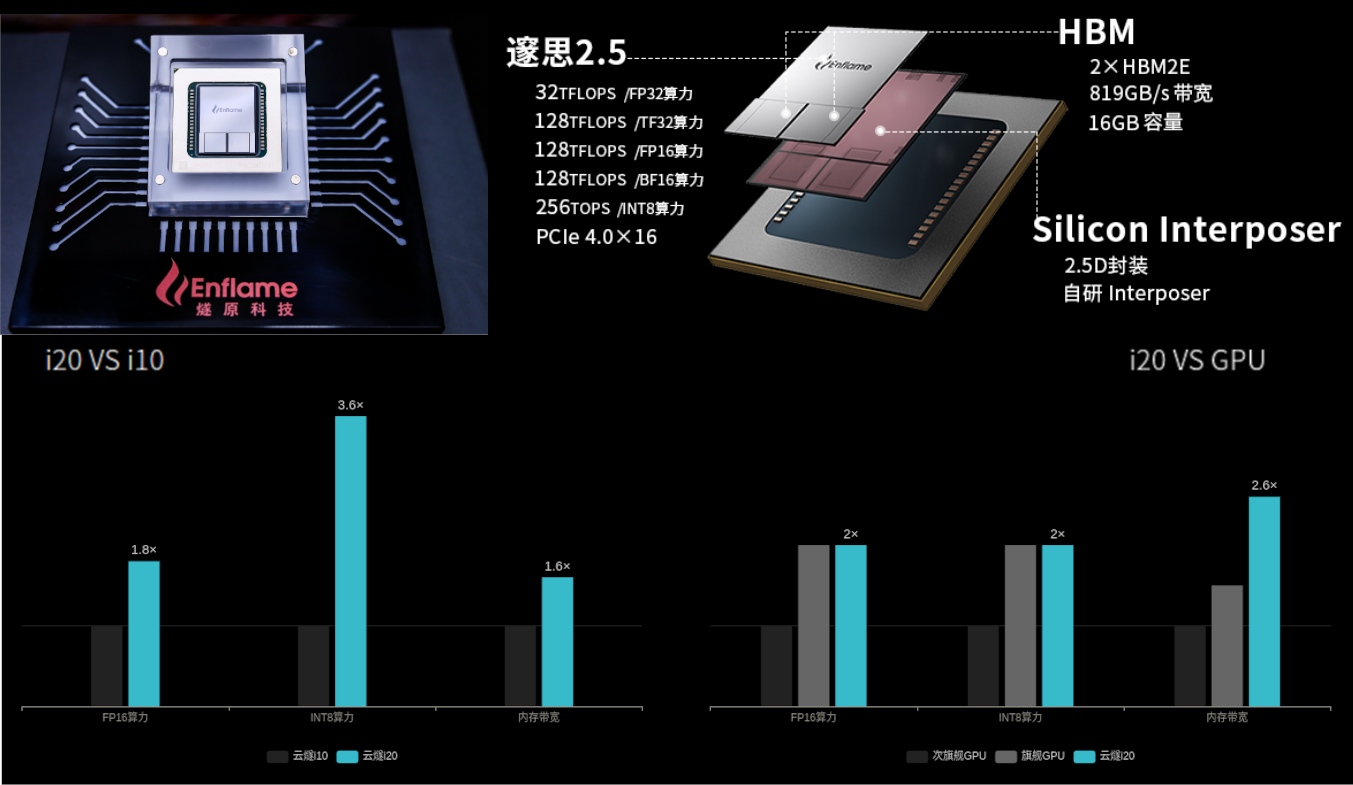 Значительный вклад в повышение производительности принесла оптимизация фирменного программного стека TopsRider, благодаря которой снизилась нагрузка на подсистему памяти. В результате средняя производительность исполнения моделей увеличилась в 3,5 раза, а эффективность использование вычислительной мощности — в среднем в 2 раза. Кроме того, новая модель программирования и технологии автоматизации позволяют ускорить эффективность разработки и снизить стоимость миграции моделей. В компании убеждены, что всё это сделает Yunsui i20 более конкурентноспособным решением. 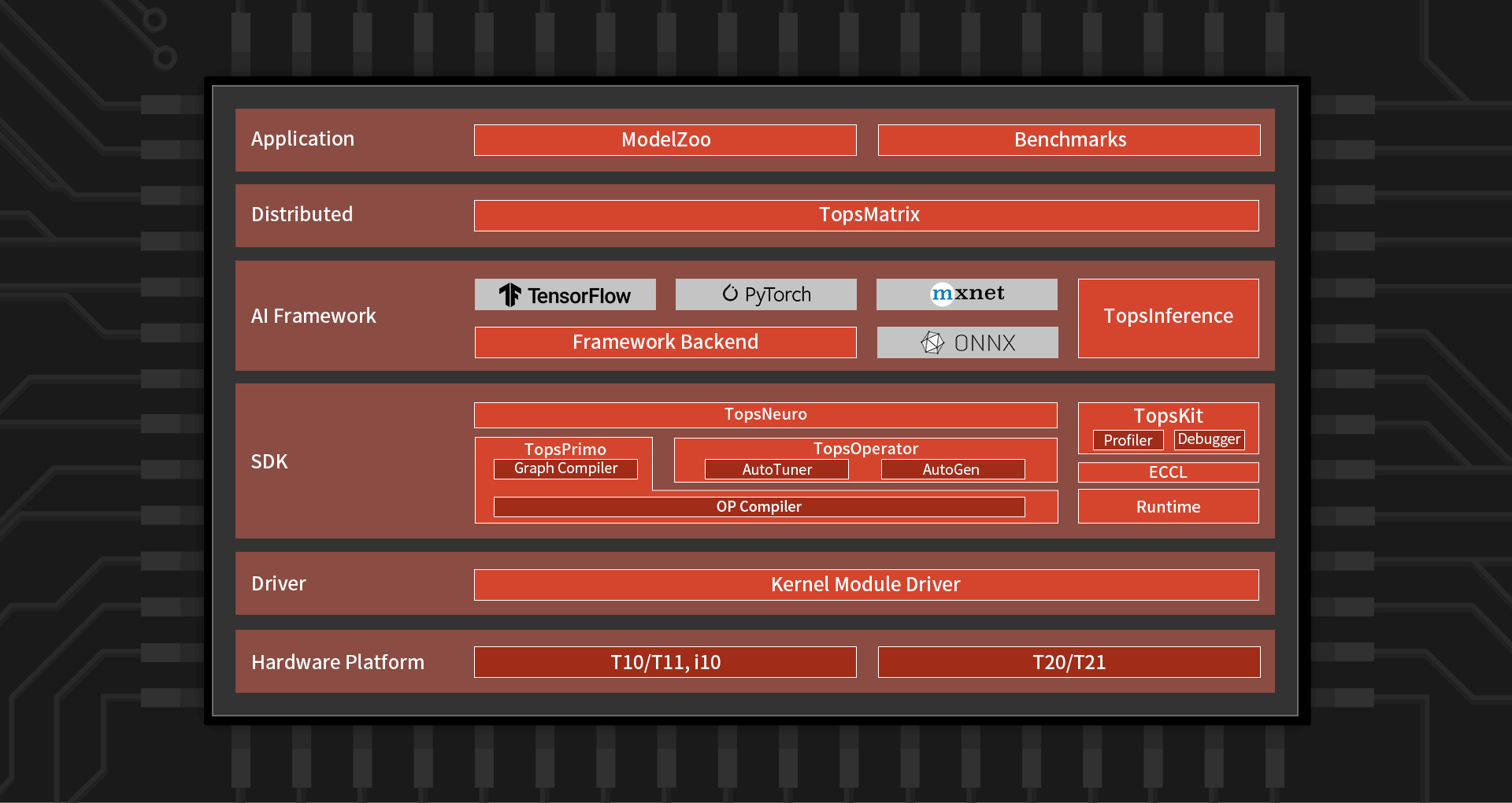 Благодаря технологии виртуализации, Yunsui i20 можно разделить на 6 независимых, изолированных друг от друга доменов — такое ранее предлагала только NVIDIA. Вместе с другими продуктами, которые также полностью переведены на новое поколение ИИ-ускорителей, Enflame рассчитывает получить значимую долю рынка в таких инновационных секторах как умные города и цифровое правительство, а также в традиционных отраслях вроде финансов, транспорта и энергетики, где будут востребованы более совершенные решения на основе ИИ.  Несмотря на очевидные успехи, достигнутые командой Enflame и другими китайскими разработчиками — SoC от YITU Technology для глубокого обучения, IoT-чип Horizon Robotics Sunrise 2 с интегрированными ИИ-возможностями, Hanguang 800 от T-Head Semiconductor («дочка» Alibaba), серии Huawei Ascend и других — иностранные производители ИИ-чипов, по данным People's Daily, по-прежнему доминируют на китайском рынке с долей более 80%. |
|

