Материалы по тегу: apu
|
18.09.2025 [16:09], Владимир Мироненко
Intel разработает для NVIDIA кастомные CPU для серверов и ПК, а NVIDIA вложит в Intel $5 млрдNVIDIA и корпорация Intel заключили соглашение о сотрудничестве с целью совместной разработки специализированных чипов для ЦОД и ПК для использования гиперскейлерами, а также другими клиентами на корпоративном и потребительском рынках. Согласно пресс-релизу, компании намерены обеспечить бесшовное объединение архитектур NVIDIA и Intel с использованием NVIDIA NVLink, реализуя преимущества NVIDIA в области ИИ и ускоренных вычислений совместно с ведущими технологиями процессоров Intel и экосистемой x86 для предоставления передовых решений для клиентов. Ранее NVIDIA представила интерконнект NVLink Fusion, который как раз и позволяет объединять решения компании с чиплетами других вендоров. Одним из первых продуктов стал чип GB10, включающий GPU Blackwell и Arm-процессор MediaTek. В рамках партнёрства Intel разработает кастомные серверные x86-процессоры для ИИ-платформ NVIDIA. Для персональных компьютеров Intel разработает SoC с архитектурой x86 и GPU-чиплетами NVIDIA RTX. Новые SoC RTX на базе x86 будут использоваться в широком спектре ПК. У Intel уже был опыт интеграции GPU AMD в свои SoC, но не слишком удачный — Kaby Lake-G были заброшены через пару лет после выхода. 
Источник изображения: NVIDIA В рамках соглашения о сотрудничестве NVIDIA инвестирует в Intel $5 млрд путём приобретения на эту сумму обыкновенных акций Intel по цене $23,28 за единицу. После этого объявления акции Intel подскочили на премаркете на 33 % до примерно $33 за единицу, сообщил ресурс CNBC. Ранее SoftBank потратила $2 млрд на покупку акций Intel по $23/шт. В конце августа власти США приобрели 9,9 % долю в Intel за $8,9 млрд, получив акции по $20,47 за бумагу. «Это историческое сотрудничество тесно связывает ИИ-технологии и ускоренные вычисления NVIDIA с CPU Intel и обширной экосистемой x86 — слиянием двух платформ мирового класса. Вместе мы расширим наши экосистемы и заложим основу для следующей эры вычислений», — отметил генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang). Как полагают аналитики CNBC, сотрудничество, по всей видимости, не включают производство чипов NVIDIA на производственных мощностях Intel.
03.09.2025 [09:47], Владимир Мироненко
Гибридный суперчип NVIDIA GB10 оказался технически самым совершенным в семействе BlackwellNVIDIA поделилась подробностями о суперчипе GB10 (Grace Blackwell), который ляжет в основу рабочих станций DGX Spark (ранее DIGITS) для ИИ-задач, пишет ресурс ServeTheHome. 
Источник изображений: NVIDIA via Wccftech Ранее сообщалось, что GB10 был создан NVIDIA в сотрудничестве MediaTek. GB10 объединяет чиплет CPU от MediaTek (S-Dielet) с ускорителем Blackwell (G-Dielet) с помощью 2.5D-упаковки. Оба кристалла изготавливаются по 3-нм техпроцессу TSMC. Как отметил ServeTheHome, GB10 технически является самым передовым продуктом на архитектуре Blackwell на сегодняшний день.  CPU включает 20 ядер на базе архитектуры Armv9.2, которые разбиты на два кластера по десять ядер (Cortex-X925 и Cortex-A725). На каждый кластер приходится 16 Мбайт кеш-памяти L3. Унифицированная оперативная память LPDDR5X-9400 ёмкостью 128 Гбайт подключена напрямую к CPU через 256-бит интерфейс с пропускной способностью 301 Гбайт/с. Объёма памяти достаточно для работы с моделями с 200 млрд параметров.  На кристалле CPU также находятся контроллеры HSIO для PCIe, USB и Ethernet. Для адаптера ConnectX-7 с поддержкой RDMA и GPUDirect выделено всего восемь линий PCIe 5.0, что не позволит работать обоим имеющимся портам в режиме 200GbE. Именно этот адаптер позволяет объединить две системы DGX Spark в пару для работы с ещё более крупными моделями.  G-Die имеет ту же архитектуру, что и B100. Ускоритель оснащён тензорными ядрами пятого поколения и RT-ядрами четвёртого поколения и обеспечивает производительность 31 Тфлопс в FP32-вычислениях. ИИ-производительность в формате NVFP4 составляет 1000 TOPS. Ускоритель подключён к CPU через шину NVLink C2C с пропускной способностью 600 Гбайт/с. G-Die оснащён 24 Мбайт кеш-памяти L2, которая также доступна ядрам CPU в качестве кеша L4, что обеспечивает когерентность памяти между CPU и GPU на аппаратном уровне. 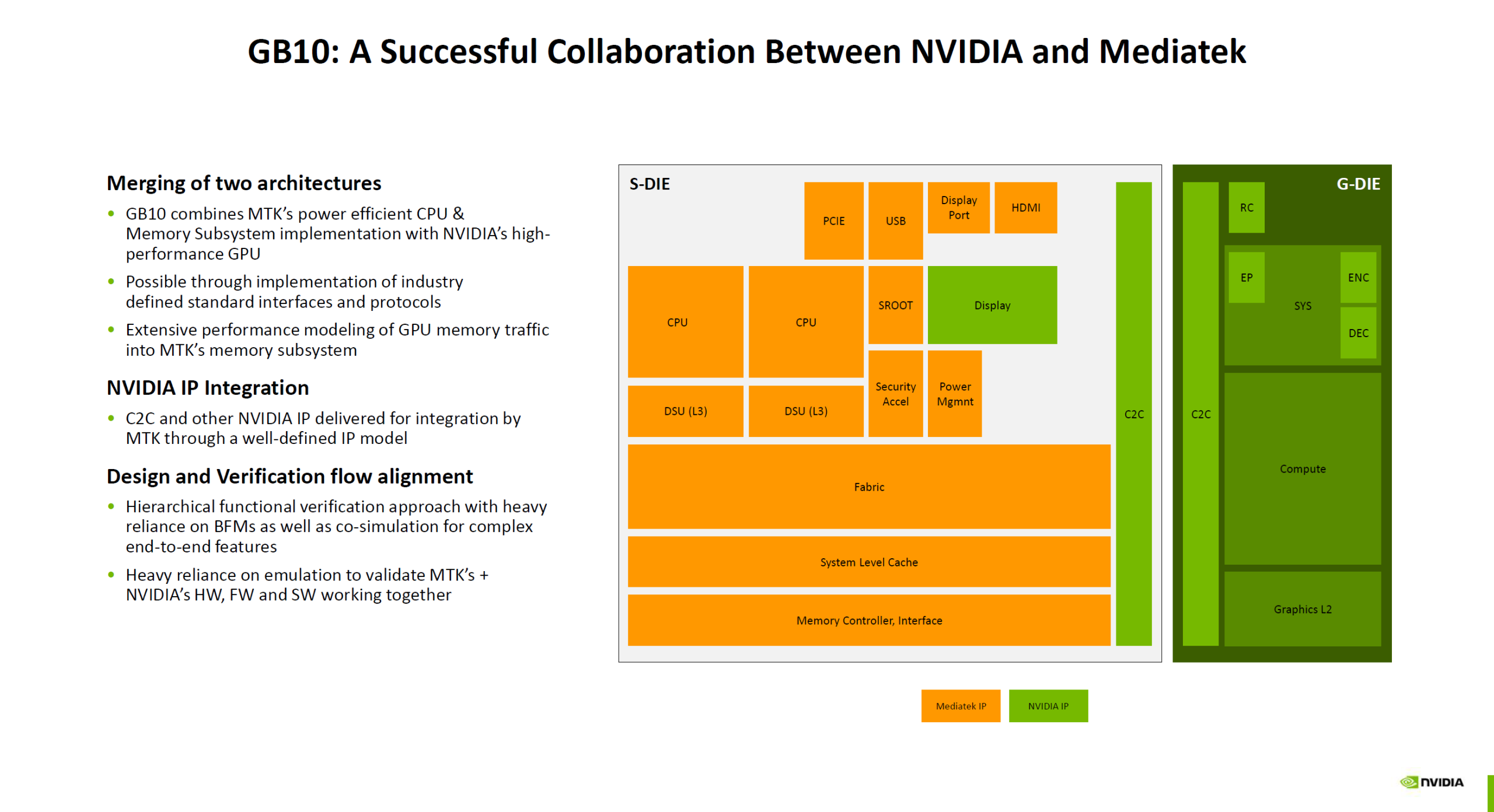 Поддерживается технология SR-IOV, интегрированы движки NVDEC и NVENC. Возможно подключение до четырёх дисплеев: три DisplayPort Alt-mode (4K@120 Гц) и один HDMI 2.1a (8K@120 Гц). Что касается безопасности, есть выделенные процессоры SROOT и OSROOT, а также поддержка fTPM и дискретного TPM (по данным Wccftech). TDP GB10 составляет 140 Вт.
29.06.2025 [00:20], Сергей Карасёв
Speedata представила ускоритель анализа данных и привлекла на развитие $44 млнСтартап Speedata, занимающийся разработкой специализированных чипов для ускорения аналитики данных, провёл раунд финансирования Series B, в ходе которого на развитие получено $44 млн. В общей сложности на сегодняшний день компания привлекла $114 млн. Speedata разработала аналитический сопроцессор (Analytics Processing Unit, APU) под названием Callisto. Утверждается, что в случае рабочих нагрузок Apache Spark это изделие способно обеспечить 100-кратный прирост производительности по сравнению с CPU. Если сравнивать с GPU, то разработчик обещает сокращение капитальных затрат на 91 %, экономию пространства на 94 % и уменьшение потребления электроэнергии на 86 %. Особенность Callisto — использование относительно новой архитектуры CGRA, в разработке которой принимали участие основатели Speedata. Подобно программируемым пользователем вентильным матрицам (FPGA) решения с архитектурой GCRA можно настроить на выполнение определённых задач с максимальной эффективностью. При этом в случае Callisto устранены ограничения с обработкой логики ветвления, с которыми могут сталкиваться GPU, говорит компания. Кроме того, Callisto содержит ряд других оптимизаций для повышения производительности при аналитике данных. 
Источник изображения: Speedata Чип Callisto является основой серверного ускорителя C200. Это решение выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Новинка обеспечивает ускорение операций, связанных с аналитикой данных на аппаратном уровне, снижая нагрузку на CPU. Speedata обещает «революционное соотношение цены и производительности», а также возможность обработки огромных массивов информации в рекордно короткие сроки. В систему типоразмера 2U могут быть установлены две карты C200. В качестве примера возможностей новинки компания Speedata приводит обработку некой рабочей нагрузки в фармацевтической области. С использованием APU задача была выполнена за 19 минут по сравнению с 90 часами при применении неспециализированного процессора. Таким образом, обеспечено ускорение в 280 раз. В раунде финансирования Series B приняли участие Walden Catalyst Ventures, 83North, Koch Disruptive Technologies, Pitango First и Viola Ventures, а также ряд стратегических инвесторов, в число которых вошли генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) и соучредитель Mellanox Technologies Эяль Вальдман (Eyal Waldman). Деньги будут направлены на дальнейшее развитие технологии.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 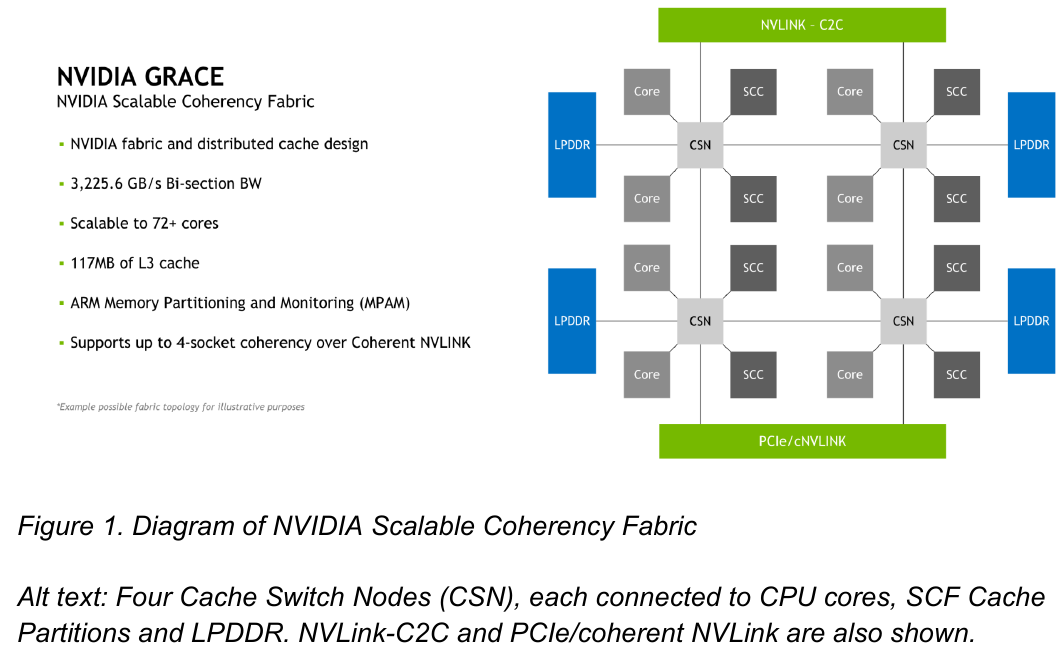
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 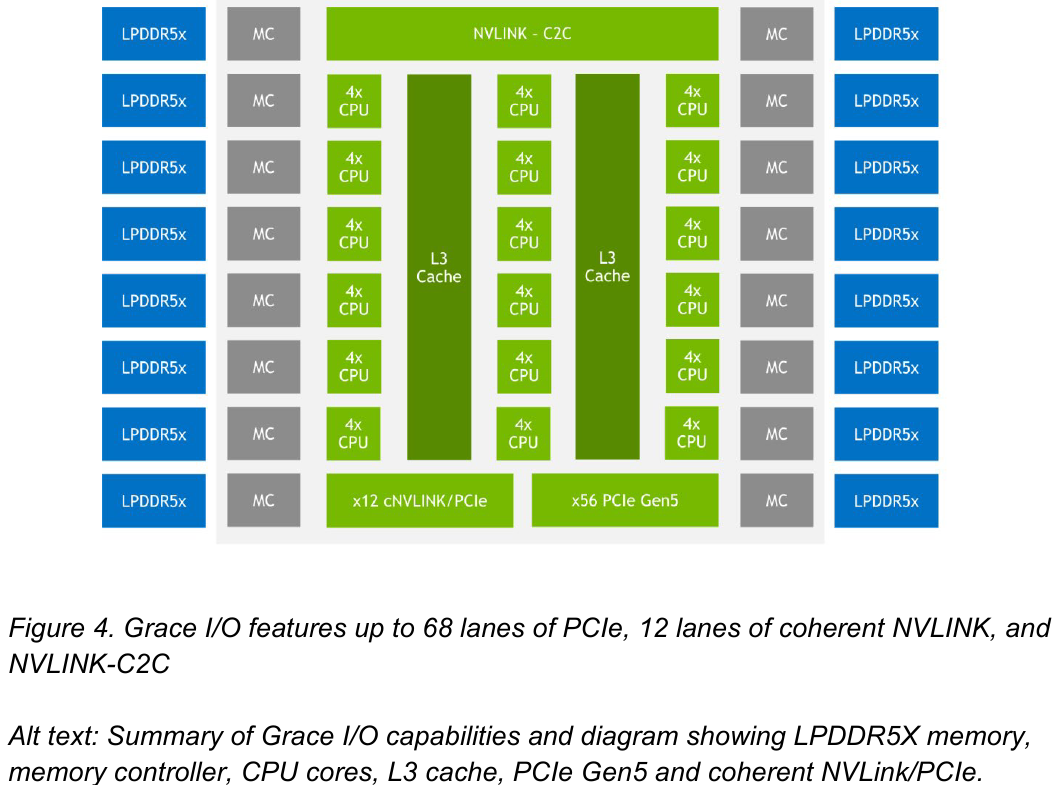
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 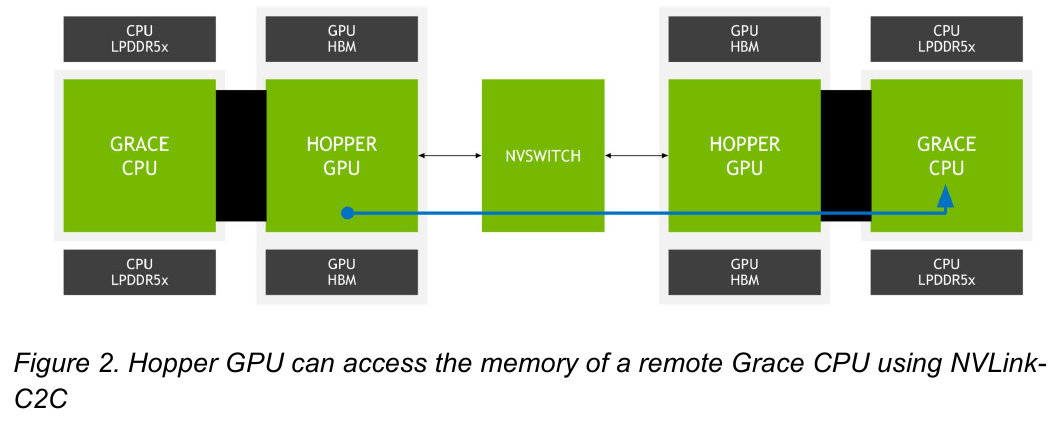
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 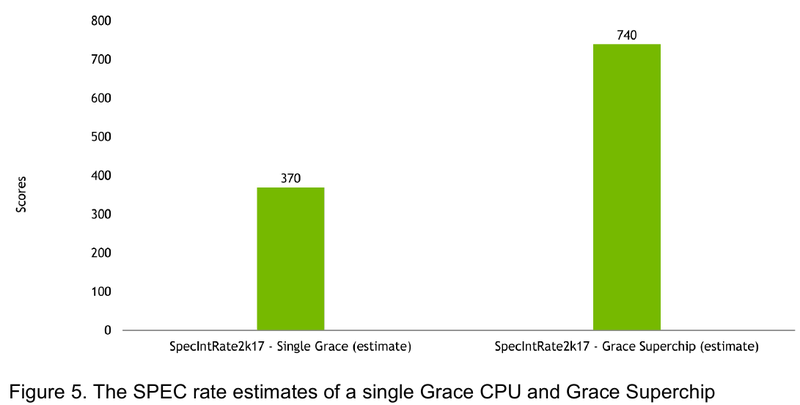
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
22.03.2022 [18:48], Игорь Осколков
NVIDIA анонсировала 144-ядерные Arm-процессоры Grace и гибрид Grace HopperГлавным событием GTC 2022 стал анонс новых ускорителей H100 (Hopper), которые станут доступны в III квартале 2022 года. Вслед за ними в первой половине 2023 года появятся давно обещанные CPU Grace и гибридная система Grace Hopper, сочетающие, как понятно из названия, процессоры Grace (ARMv9) и ускорители Hopper. Как и было сказано ранее, для связи всех компонентов между собой будет использоваться mesh-сеть на базе всё той же шины NVLink 4.0 (900 Гбайт/с) с кеш-когерентностью. А сочетание LPDDR5X (с ECC, конечно) и HBM даст суммарный объём памяти до 600 Гбайт с общей полосой пропускания порядка 2 Тбайт/с. Для Grace Hopper компания подготовит полный стек ПО, благо портированием на Arm она начала заниматься ещё 3 года назад. 
NVIDIA Grace (Изображения: NVIDIA) Двухчиповый процессор Grace Superchip для ИИ- и HPC-нагрузок имеет 144 ядра, результат которых в SPECrate2017_int_base составляет 740, что, по словам компании, в полтора раза выше, чему у пары AMD EPYC, использующихся в DGX A100. И это, честно говоря, не такой уж и впечатляющий результат.  Но NVIDIA утверждает, что новые CPU вдвое лучше по отношению производительности к энергопотреблению, чем «традиционные серверы» — использование LPDDR5X позволяет добиться пропускной способности памяти в 1 Тбайт/с, а вся сборка CPU+RAM будет потреблять менее 500 Вт. 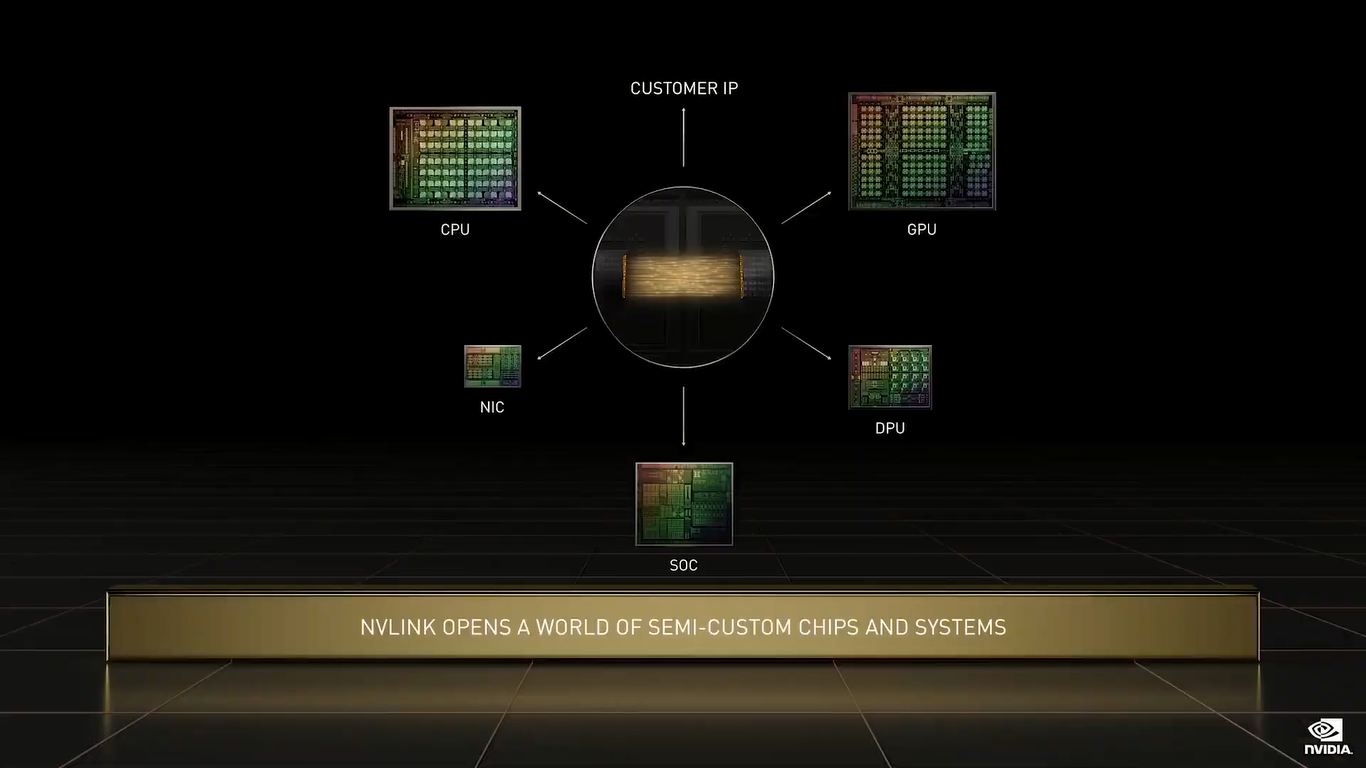 Чипы (или чиплеты, если хотите) в Grace Superchip тоже объединены посредством NVLink, только в данном случае этот интерконнект называется NVLink-C2C (Chip-to-Chip). И его NVIDIA предлагает использовать другим компаниям для создания кастомных сборок, объединяющих необходимые кристаллы, да и сама готова масштабировать и адаптировать свои решения под нужды заказчика. 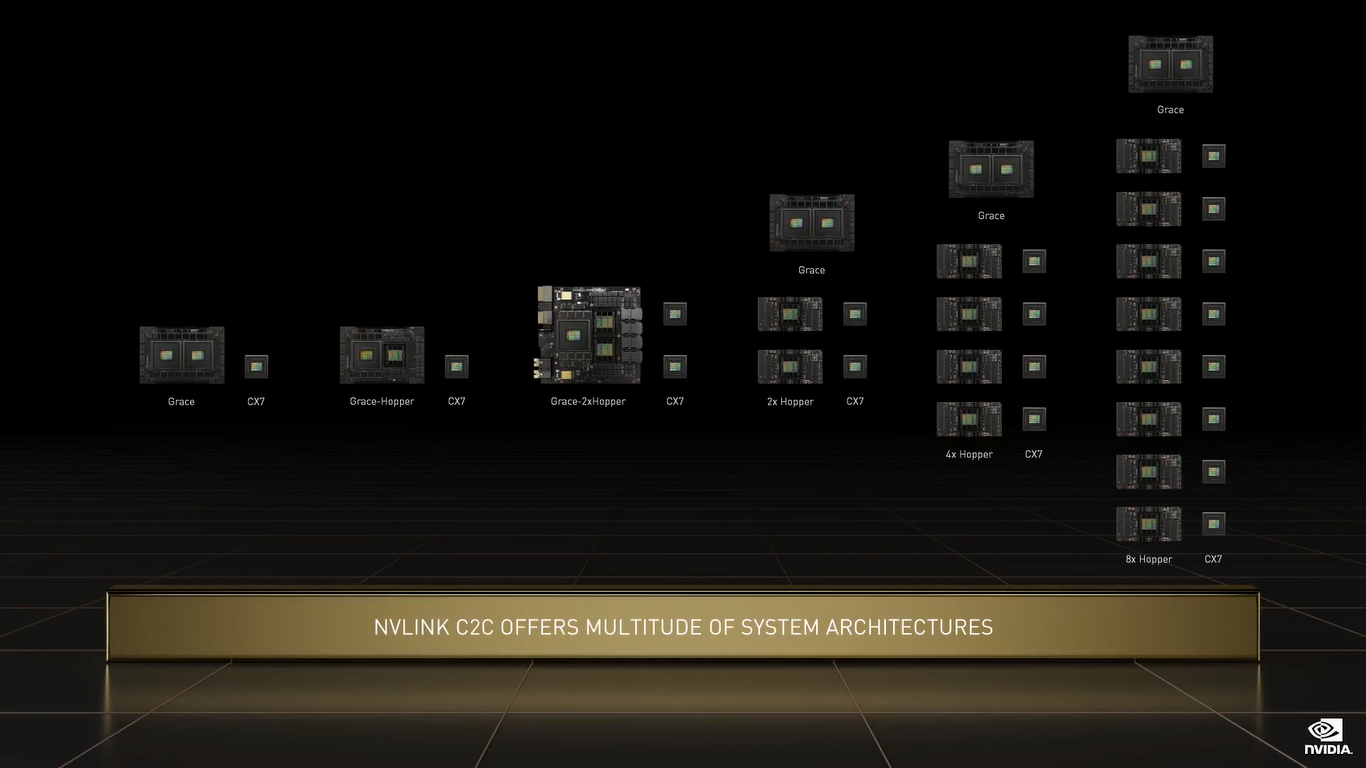 По словам NVIDIA, NVLink-C2C в 25 раз энергоэффективнее PCIe 5.0, а для его реализации нужна в 90 раз меньшая площадь кремния. Шина предлагает высокую скорость (да-да, всё те же 900 Гбайт/с), низкий уровень задержек, поддержку атомарных операций и совместимость с Arm AMBA CHI, CXL и UCIe. |
|

