Лента новостей
|
13.03.2026 [23:19], Владимир Мироненко
VK Tech нарастила выручку в 2025 году на 38,0 %, а облако VK Cloud — на 13,5 %Разработчик корпоративного программного обеспечения VK Tech (входит в экосистему VK) опубликовал аудированные финансовые результаты за 2025 год. Выручка компании выросла на 38,0 % год к году — до 18,8 млрд руб. Наиболее высокий рост показали сервисы продуктивности VK WorkSpace (+75,1 % год к году) и бизнес-приложения (+65,7 % год к году). Компания сообщила, что рекуррентная (не связанная с оказанием единоразовых услуг клиентам) выручка выросла более чем в два раза год к году — до 12,8 млрд руб. (68 % от общего объёма выручки), что связано как с увеличением количества клиентов, использующих сервисы по модели On-Cloud, так и с ростом выручки от технической поддержки в рамках модели поставки On-Premise. Скорректированная EBITDA увеличилась на 21,6 % — до 4,8 млрд руб., рентабельность по скорректированной EBITDA составила 26 %. Количество клиентов выросло в 2,7 раза — до 31,9 тыс. VK Tech отметила, что среди них есть крупные, средние и малые компании из всех отраслей экономики. 
Источник изображения: VK Выручка облачной платформы VK Cloud, объединяющей более 50 облачных сервисов для разработки и работы с данными в рамках направления «Облачная платформа», выросла на 13,5 % — до 6,5 млрд руб., в том числе выручка от продаж по модели On-Cloud увеличилась на 51,3 %. Выручка направления «Дата-сервисы» увеличилась на 15,5 % год к году — до 2,5 млрд руб., в том числе выручка от продаж в формате On-Premise — на 16,1 %. Драйвером роста стали решения Tarantool и VK Data Platform, выручка от которых увеличилась на 61,8 %. Компания отметила, что в 2025 году был запущен первый в России облачный Data Lakehouse. Также была представлена новая версия Tarantool DB 3.0 с механизмом «охлаждения данных», а решение для обработки и хранения данных Tarantool подтвердило соответствие требованиям ФСТЭК России (№ 11). VK Tech в 2026 году усилит направление дата-сервисов за счёт ИИ-сервисов и инструментов аналитики больших данных на базе решений VK Predict, которые включают сервисы аналитики и системы поддержки принятия решений на основе анализа больших данных, технологий машинного обучения и ИИ.
13.03.2026 [18:31], Владимир Мироненко
Выручка Yandex B2B Tech в 2025 году выросла в 1,5 разаYandex B2B Tech (бизнес-группа «Яндекса»), опубликовала финансовые результаты за 2025 год в соответствии с международными стандартами финансовой отчётности (МСФО). Показатели отражают деятельность группы по двум ключевым направлениям: платформа для создания ИТ-продуктов Yandex Cloud и виртуальный офис «Яндекс 360». Выручка Yandex B2B Tech по двум направлениям за год выросла на 48 % — до 48,2 млрд руб. По оценке «Яндекса», Yandex B2B Tech растёт в 1,9 раза быстрее российского рынка корпоративных ИТ-решений. При этом выручка Yandex Cloud увеличилась на 39 % — до 27,6 млрд руб. Среднегодовой темп роста выручки платформы за последние 4 года составляет 52 % и четвёртый год подряд она показывает положительную маржинальность по EBITDA. В 2025 году 93 % выручки Yandex Cloud получено за счёт внешнего потребления. Большую часть (84 %) принесли клиенты из крупного и среднего бизнеса. Общее количество внешних клиентов платформы достигло 51 тыс. (рост год к году — на 17 %). Количество активных партнёров Yandex Cloud составляло 883 (+31 %). Выручка в партнёрском канале выросла год к году на 56 %. 
Источник изображений: «Яндекс» На ИИ- и ИБ-сервисы приходится 9 % от общей выручки Yandex Cloud за 2025 год (рост — почти вдвое). Выручка ИБ-сервисов Yandex Cloud выросла в 2,5 раза год к году. Ими пользовался каждый четвёртый клиент платформы. Выручка платформы для создания ИИ-решений Yandex AI Studio составила 2 млрд руб. (рост — почти в 2 раза). Клиенты платформы потребили через API 234 млрд токенов (в 7 раз больше год к году), в том числе, более 150 млрд — в IV квартале. 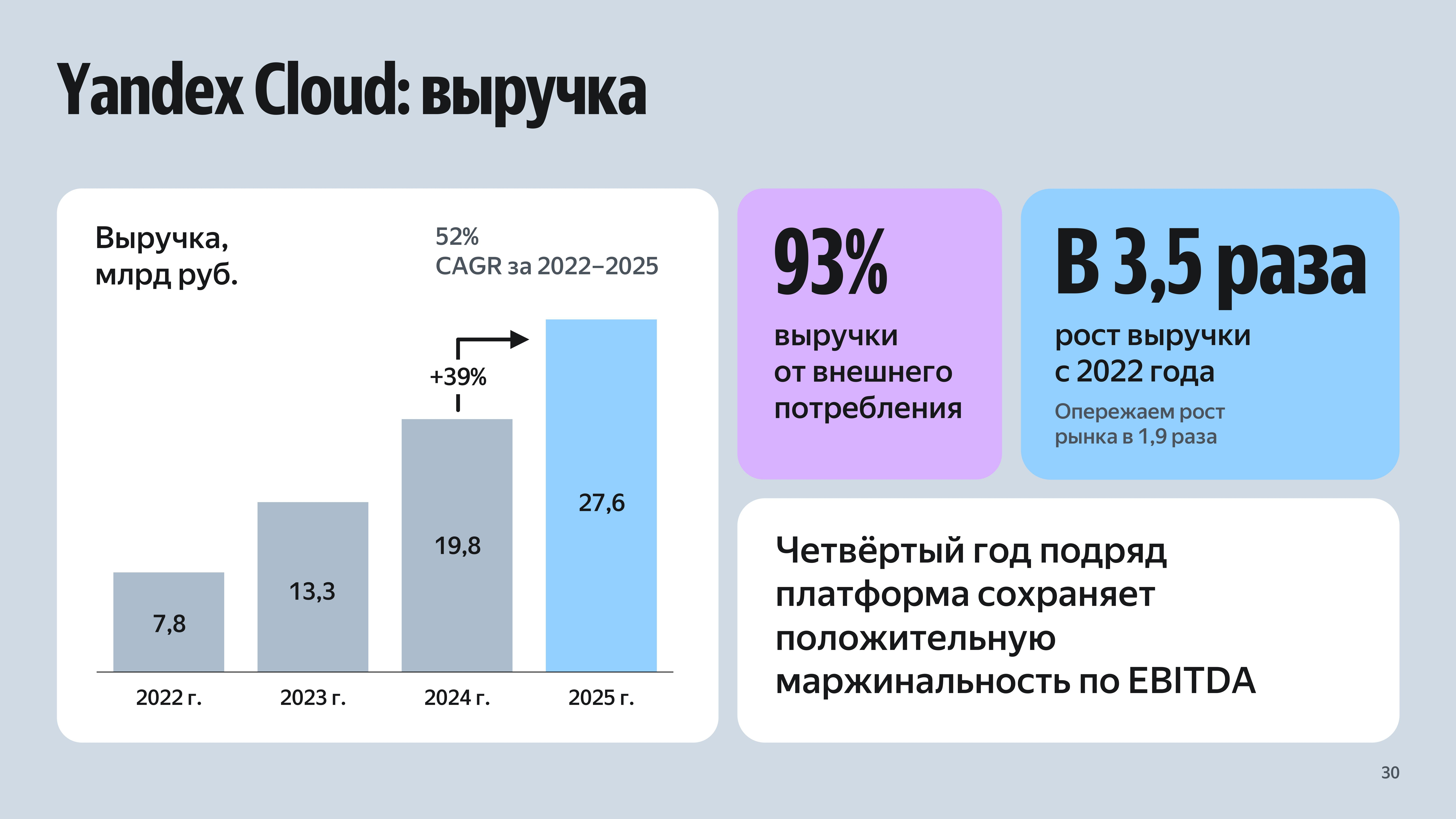 На решения в формате on-premises пришлось 3,4 % общей выручки. Формат on-premise стал доступен для всех приоритетных направлений Yandex Cloud: ИИ, информационной безопасности, платформы данных и инфраструктурных решений. Также сообщается, что выручка от решений для создания и масштабирования инфраструктуры выросла год к году в 1,3 раза. По состоянию на конец 2025 года в Yandex Cloud насчитывалось более 300 тыс. запущенных виртуальных машин, а в облачном хранилище S3 находилось 4 Эбайт данных и около 3 млн объектов. 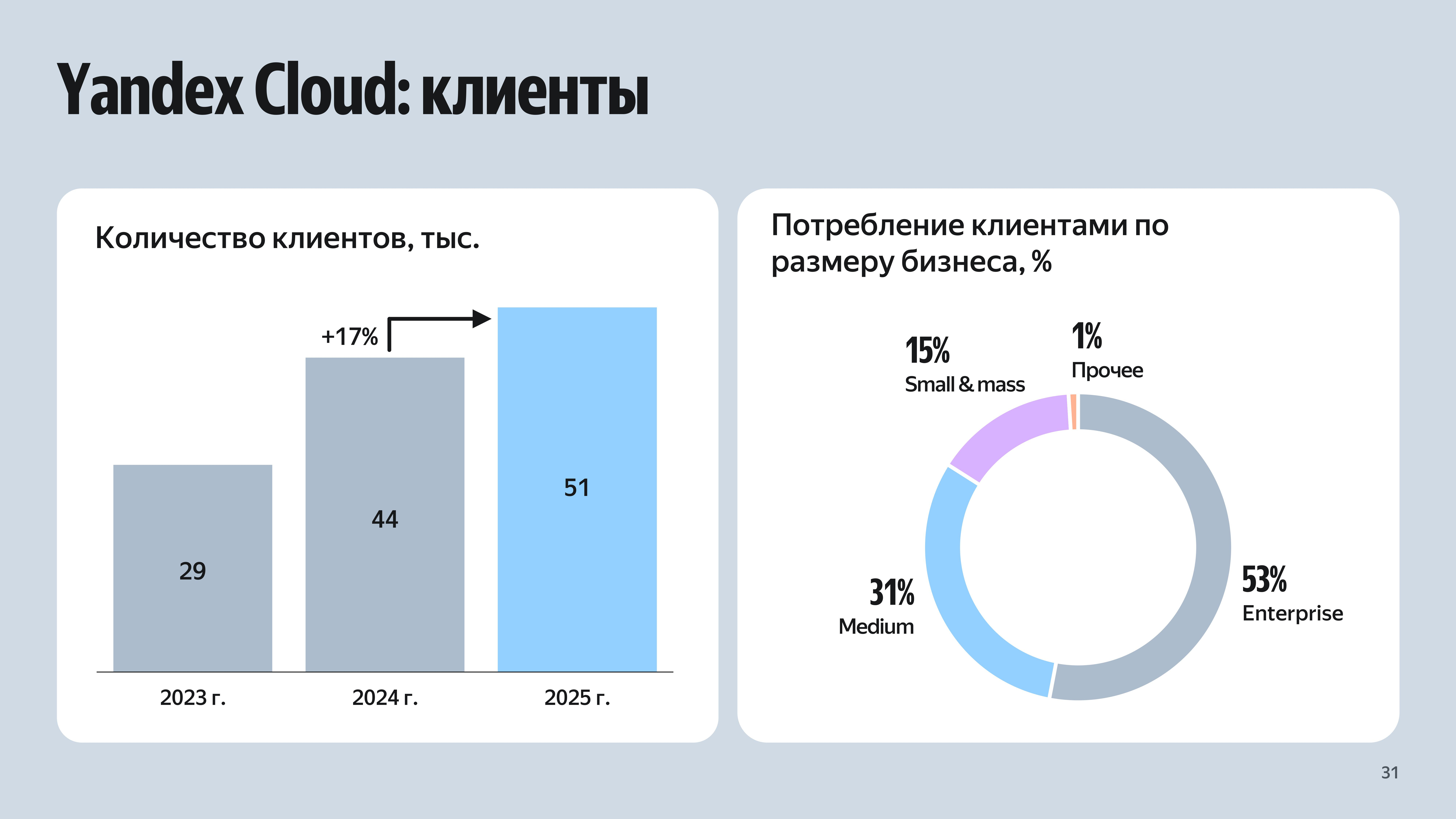 Что касается второго направления, то выручка «Яндекса 360» составила за год 18,4 млрд руб. (рост — 59 % год к году). Среднегодовой темп роста выручки за последние 4 года равен 66 %. Ежемесячная аудитория «Яндекса 360», объединяющего 13 интегрированных между собой сервисов, превышала 102 млн пользователей. Его сервисами пользовались более 170 тыс. организаций. К концу года в виртуальном офисе насчитывалось 8,1 млн платных учётных записей, из них 2,2 млн приходилось на крупные организации. Компания сообщила, что в 2026 году в формате on-premise станут доступны все ключевые сервисы «Яндекса 360».
13.03.2026 [17:10], Руслан Авдеев
Crusoe представила периферийные ИИ ЦОД Crusoe Edge Zones на базе модулей SparkКомпания Crusoe анонсировала запуск периферийных зон доступности Crusoe Edge Zones на базе модульных ЦОД Crusoe Spark, обеспечивающих ИИ-вычисления практически в любой локации. Edge Zones предоставят ИИ-инфраструктуру с низкой задержкой и позволят внедрять суверенные ИИ-решения клиентам со всего мира. Crusoe Edge Zones на базе Crusoe Spark — дальнейшее масштабирование вертикально интегрированных ИИ-фабрик. Модули Crusoe Spark выпускаются на недавно представленном заводе Spark Factory. Благодаря контролю над полным стеком работы над ИИ-инфраструктурой — от заводской сборки до облачной оркестрации — Crusoe способна развёртывать новые периферийные облака всего за три месяца. При этом они значительно дешевле, чем классические ЦОД. Зоны оптимизированы для работы с облачной платформой Crusoe Cloud и инференс-службой Managed Inference. Благодаря запатентованной технологии Crusoe MemoryAlloy можно сократить «время до первого токена» в 9,9 раза. Кроме того, система обеспечит в пять раз более высокую пропускную способность, чем стандартные конфигурации для инференса, говорит Crusoe. В результате периферийные пользователи получат доступ к сверхэффективной инфраструктуре с высоким быстродействием. 
Источник изображения: Crusoe Ключевые сценарии применения:
В компании уверены, что в будущем ИИ-инфраструктура будет включать как гигантские кампусы гигаваттного масштаба для обучения ИИ, так и распределённые модули для обработки информации на периферии. На данный момент Crusoe инвестирует в оба направления. Концепция сетей модульных ЦОД, практически независимых от крупных кампусов, в последнее время на фоне конфликта на Ближнем Востоке становится всё популярнее. Независимо от этих событий недавно Akamai пообещала развернуть тысячи ускорителей NVIDIA RTX Blackwell для распределённого инференса.
13.03.2026 [15:42], Сергей Карасёв
Пропускная способность сети фильтрации Curator превысила 6 Тбит/сКомпания Curator, специализирующаяся на обеспечении доступности интернет-ресурсов и нейтрализации DDoS-атак, объявила об увеличении пропускной способности своей глобальной сети фильтрации. В результате модернизации инфраструктуры она превысила 6 Тбит/с, что позволяет эффективно противостоять растущему масштабу современных DDoS-атак и гарантировать устойчивость и постоянную доступность сервисов клиентов. За последний год интенсивность DDoS-атак резко увеличилась. Если в 2024 году максимальная мощность атак в пике достигала 1,14 Тбит/с, то к концу 2025 года специалисты Curator фиксировали уже несколько атак интенсивностью более 3 Тбит/с. В ответ на эту тенденцию компания провела масштабную работу по развитию своей инфраструктуры. В течение последних месяцев были расширены мощности сети, а также увеличено количество центров фильтрации и география присутствия системы. 
Источник изображения: unsplash.com / Julio Lopez На данный момент сеть фильтрации Curator включает 9 собственных и 12 партнёрских центров очистки трафика. Центры фильтрации расположены в ключевых точках концентрации интернет-трафика и подключены к трансконтинентальным Tier-1 провайдерам, а также ведущим региональным магистральным интернет-провайдерам, что позволяет компании поддерживать самый высокий среди аналогов гарантированный уровень доступности приложений на уровне 99,95% и нивелировать любые сетевые атаки, достигшие в прошлом году рекордных уровней. «Мы постоянно совершенствуем защиту, гарантируя клиентам устойчивость бизнеса даже при росте угроз. Если ещё недавно атаки свыше терабита считались исключением, то сегодня атаки в несколько Тбит/с уже становятся новой реальностью. Расширение пропускной способности сети Curator до более чем 6 Тбит/с — ответ на эту динамику и необходимый шаг для обеспечения стабильной работы сервисов наших клиентов. Мы действуем на опережение, ведь наша философия — непрерывная доступность», — комментирует Дмитрий Ткачев, генеральный директор Curator. Реклама | ООО «Эйч-Эль-Эль» ИНН 7704773923 erid: F7NfYUJCUneTVSpf5bX2
13.03.2026 [15:40], Руслан Авдеев
Британский провайдер научился искать утечки воды с помощью оптоволокнаДочерняя структура BT — британский телеком-провайдер Openreach — приняла участие в необычном эксперименте совместно с Affinity Water и Lightsonic. Для выявления утечек воды в коммунальных системах использовалось оптоволокно сети широкополосного доступа Openreach, сообщает Datacenter Dynamics. Компания отметила, что пилотные испытания проходят успешно: телеком-провайдер помог партнёрам сэкономить 2 тыс. м³ воды всего за три месяца. Openreach при участии Affinity Water и Lightsonic использовали распределённое акустическое зондирование (Distributed Acoustic Sensing, DAS) — технология фактически превращает обычное оптоволокно в протяжённую сеть микрофонов высокой чувствительности. Фактически это тысячи «датчиков», готовых «услышать» места утечек воды в трубах водопровода и точно определить их местоположение. Цель проекта — поддержка водоснабжающих компаний вроде Affinity. Технология позволит решить проблему утечек. По некоторым данным, Англия и Уэльс ежегодно теряют из-за них около 3 млн м³ питьевой воды. Специальная платформа для обнаружения утечек разработана Lightsonic. Испытания проводились в пяти местах с применением оптоволокна для мониторинга 650 км водопроводов Affinity Water. Всего удалось обнаружить более 100 утечек воды. 
Источник изображения: Chris Bair/unsplash.com Как заявили в Openreach, результаты пилотных испытаний показывают, что новая оптоволоконная инфраструктура может обеспечивать не только широкополосный доступ, но и решать другие задачи. Предполагается, что технологию можно использовать и в других целях, в том числе для поиска утечек газа и мониторинга состояния мостов, тоннелей и других конструкций. Openreach подчёркивает, что технология позволяет регистрировать вибрации от утечек, строительных работ и других источников. Анализируя изменения светового сигнала и используя машинное обучение, можно точно выявлять место вибраций, при этом отфильтровывая фоновые шумы. Важно, что можно использовать уже проложенное в земле оптоволокно для круглосуточного мониторинга — это исключает необходимость дополнительных земляных работ. Если утечка будет обнаружена, система сможет выделить область исследования с точностью до нескольких метров, куда и будут направлены ремонтные бригады. Предполагается, что это поможет уменьшить перебои в работе водопроводов; при этом технологию можно легко масштабировать по всей территории Великобритании. 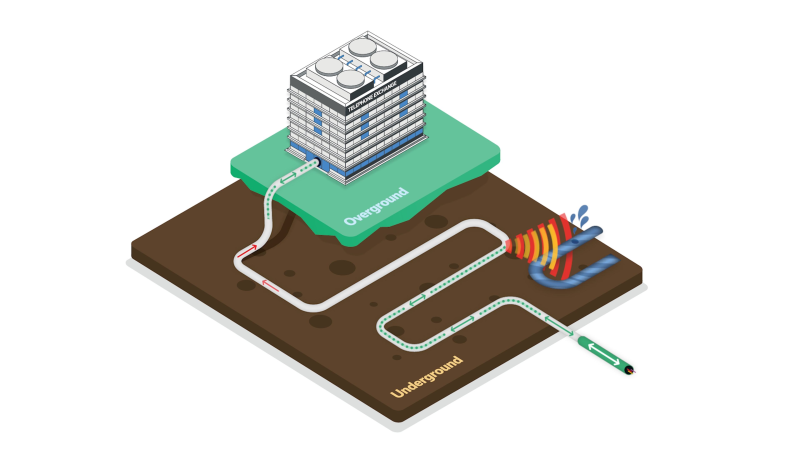
Источник изображения: Openreach По словам представителя Lightsonic, фактически речь идёт о преобразовании оптоволоконной сети в единый сенсорный слой — это открывает огромные возможности для мониторинга. Результаты эксперимента наглядно показывают, что датчики на основе ВОЛС уже сегодня могут помочь защите окружающей среды, а также создавать новые решения для более масштабного мониторинга систем коммунальных услуг в будущем. Инфраструктура различного назначения всё теснее связывается в Великобритании. Так, ещё в 2022 году сообщалось, что Южный Йоркшир протестирует прокладку оптоволокна в водопроводах. В конце 2024 года появилась информация, что один из наиболее отдалённых островов Великобритании — Папа-Уэстрей (Papa Westray) в Оркнейском архипелаге получил широкополосное оптоволоконное интернет-подключение по водопроводным трубам, а в 2025 году британским провайдерам предложила тянуть «оптику» по заброшенным газовым трубам и водопроводам компания AssetHUB.
13.03.2026 [14:32], Руслан Авдеев
Microsoft и Meta✴ заключили соглашения об аренде ЦОД ещё на $50 млрдMicrosoft и Meta✴ в последнем квартале обязались арендовать дата-центры на сумму около $50 млрд. Это свидетельствует о растущих ставках, которые техногиганты делают на ИИ-решения, сообщает Bloomberg. В последние месяцы Microsoft и Meta✴ активно свидетельствовали о стремлении увеличить вычислительные мощности для создания ИИ-решений. У Microsoft уже заключены договоры на сумму порядка $155 млрд, у Meta✴ — $104 млрд. Эти события помогли увеличить общий объём обязательств по аренде ЦОД гиперскейлерами в будущем до более чем $700 млрд. Помимо Microsoft и Meta✴, в эту группу входят Oracle и AWS. Анализ квартальных отчётов, проведённый Bloomberg, свидетельствует, что обязательства неуклонно росли в течение последнего года. Будущие расходы добавятся к уже действующим арендным договорам, но не будут отображаться в отчётности компаний, пока не начнутся платежи по новым соглашениям. Как правило, договоры аренды касаются ЦОД, но речь также может идти об аренде офисов и складов; в некоторых предусмотрено расторжение соглашений при определённых условиях. 
Источник изображения: chris robert/unsplash.com Обе компании, по данным Datacenter Dynamics, ведут переговоры о резервировании мощностей в кампусе Oracle/OpenAI в Абилине (Abilene, Техас), который строится в рамках проекта Stargate. Недавно Oracle отказалась от планов расширения на площадке, оставив доступные мощности желающим. Рост расходов особенно ощутим для Microsoft, приостановившей аренду дата-центров на большую часть 2025 года. Теперь дефицит площадей ЦОД приобрёл критическое значение для руководства компании и инвесторов. В IV календарном квартале 2025 года компания нарастила мощность своих ЦОД на 1 ГВт, потратив $6,7 млрд. Кварталом ранее речь шла о $11,1 млрд. 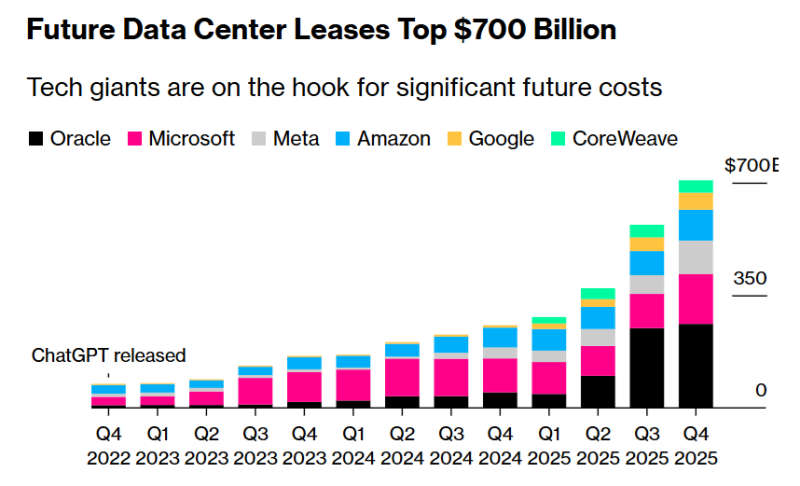
Источник изображения: Bloomberg При этом больше всего средств на аренду дата-центров потратила компания Oracle. Согласно последним данным, компания должна выплатить $261 млрд по договорам аренды, ещё не вступившим в силу. Как сообщает Datacenter Dynamics, сумма выросла с ноября 2025 года, когда Oracle говорила о $248 млрд арендных обязательств, — это на 148 % больше по сравнению с августом того же года. Впрочем, в последнем квартале обязательства у компании были меньше, чем у ключевых конкурентов, поскольку она уже подписала контракты на аренду многочисленных крупных площадок, необходимых для партнёрства с OpenAI. Значительная часть активности Oracle на рынке аренды приходилась на II–III кварталы 2025 года; приблизительно тогда же Oracle и OpenAI заключили облачную сделку на $300 млрд. По данным Evercore ISI, обязательства Oracle будут оплачиваться в течение 15–19 лет. Это свидетельствует о долгосрочной стратегии компании, ориентированной на развитие облачных технологий.
13.03.2026 [14:12], Руслан Авдеев
Китайская ByteDance обойдёт санкции США и получит доступ к чипам NVIDIA B200 на $2,5 млрдМатеринская компания TikTok — китайская ByteDance — получила доступ к современным американским ускорителям NVIDIA. Она обошла введённые властями США ограничения на доступ к технологиям, заключив соглашение с Aolani Cloud из Юго-Восточной Азии, сообщает The Wall Street Journal. В Малайзии для ByteDance будет развёрнуто около 36 тыс. ИИ-ускорителей NVIDIA B200. Источники сообщают, что Aolani закупает серверы у компании Aivres, занимающейся их сборкой. Последняя, по словам HPE, фактически принадлежит Inspur и уже давно поставляет подсанкционное оборудование в КНР и другие страны. Стоимость оборудования, вероятно, составит более $2,5 млрд. При этом Aolani сообщает, что пока располагает оборудованием на сумму $100 млн. Источники сообщают, что ByteDance намерена организовать исследования в сфере ИИ за пределами КНР и удовлетворить спрос клиентов со всего мира на решения на основе искусственного интеллекта. Уже сегодня она предлагает обычным пользователям разнообразные ИИ-приложения, бросая вызов Google, OpenAI и другим американским компаниям; четверть выручки уже поступает из-за пределов Китая. Так, она разработала более десятка приложений с ИИ-функциями, включая китайские и глобальные версии. 
Источник изображения: Esmonde Yong/unspalsh.com Согласно январскому рейтингу Andreessen Horowitz, компания курирует 5 из 50 наиболее популярных в мире пользовательских ИИ-приложений по количеству ежемесячных активных пользователей. В ByteDance работают команды исследователей в филиалах в Сингапуре и даже США. Напряжённость в отношениях между США и Китаем мешает бизнесу ByteDance: в январе компании пришлось передать американское подразделение TikTok под контроль «дружественно настроенным» к США инвесторам. Более трёх лет китайские технобизнесы имеют дело с американским экспортным контролем, не позволяющим напрямую продавать Китаю передовые ИИ-чипы вроде моделей серии Blackwell. Для развития технологий китайские компании вынуждены тратить всё больше средств на доступ к вычислительным мощностям за рубежом, благодаря чему возникла целая индустрия посредников, строящих ЦОД на продуктах NVIDIA для сдачи в аренду китайским клиентам. По имеющимся данным, в конце 2023 года инвесторы создали компанию Aolani с материнским холдингом на Каймановых островах. В числе инвесторов — сингапурская K3 Ventures. Aolani является приоритетным облачным партнёром NVIDIA, имеющим доступ к её новейшим чипам. С февраля 2025 года Aolani сдаёт ByteDance в аренду ИИ-серверы в Малайзии на основе ускорителей NVIDIA H100. За ускорители Blackwell компания ByteDance уже внесла предварительные платежи. Они будут развёрнуты в Малайзии. Помимо Малайзии, компания намерена создать мощности в Южной Корее, Австралии и Европе. 
Источник изображения: Bloomberg Подчёркивается, что бизнес сотрудничает с американской юридической компанией, чтобы соответствовать американским требованиям. По мнению юристов, изменения правовых норм будут носить «перспективный, а не ретроспективный характер». Отмечается, что Aolani соблюдает все правила экспортного контроля, а ускорители не передаются клиентам и те не имеют на них никаких прав. В NVIDIA также придерживаются позиции, что американские правила экспорта позволяют создавать облачные сервисы вне стран, подпадающих под ограничения, вроде Китая, а сам вендор проверял всех облачных партнёров, прежде чем продавать чипы прямо или косвенно. По информации The Wall Street Journal, ByteDance вела переговоры об использовании ИИ-серверов с более чем 7 тыс. B200 в ЦОД в Индонезии, а Reuters сообщает, что компания также вела переговоры с США о разрешении покупки ускорителей NVIDIA H200, но её не удовлетворили условия их использования. Ещё в 2024 году сообщалось, что китайские компании нашли лазейку в законах США для доступа к передовым ИИ-ускорителям и моделям в облаках AWS и Azure, причём на территории самих Соединённых Штатов. Также в конце 2025 года появилась информация, что китайская INF Tech обошла санкции США на доступ к ускорителям NVIDIA Blackwell через индонезийское облако.
13.03.2026 [11:29], Сергей Карасёв
Tenstorrent представила настольную ИИ-систему TT-QuietBox 2 с СЖО на базе RISC-VКанадский стартап Tenstorrent анонсировал настольную рабочую станцию TT-QuietBox 2, предназначенную для решения ресурсоёмких задач в области ИИ. Утверждается, что новинка способна поддерживать большие языковые модели, насчитывающие до 120 млрд параметров. Ключевой составляющей TT-QuietBox 2 являются четыре фирменных ускорителя Blackhole. Каждый из них содержит 16 «больших» ядер RISC-V, 120 ядер Tensix, 210 Мбайт памяти SRAM и 32 Гбайт памяти GDDR6 с пропускной способностью 512 Гбайт/с. Таким образом, в общей сложности задействованы 64 ядра RISC-V, 480 ядер Tensix и 128 Гбайт памяти GDDR6. Рабочая станция также несёт на борту 256 Гбайт памяти DDR5. 
Источник изображения: tenstorrent.com Реализована система жидкостного охлаждения. Питание осуществляется от обычной розетки: производитель подчеркивает, что станции не требуется специально оборудованное помещение или серверная стойка. На устройстве применяется платформа Ubuntu 24.04; используется полностью открытый программный стек. Заявлена поддержка популярных фреймворков, таких как PyTorch, ONNX и TensorFlow. Суммарная пиковая производительность на операциях ИИ достигает 2654 Тфлопс (BlockFP8). В качестве примера приводится работа с моделью Llama 3.1 70B (70 млрд параметров): быстродействие составляет 476,5 токена/с. А модель Boltz-2 формирует структуру белка из 686 аминокислот за 49 с (на одном чипе Blackhole). Для сравнения, современному процессору для выполнения такой задачи, как утверждается, требуется около 45 мин. Благодаря наличию сразу четырёх ускорителей Blackhole система способна параллельно моделировать структуры нескольких белков. В продажу станция TT-QuietBox 2 поступит во II квартале нынешнего года по ориентировочной цене $10 тыс.
13.03.2026 [10:00], Владимир Мироненко
Коммуникационное агентство IVS Group переходит в «Турбо Облако»Коммуникационное агентство IVS Group выбрало решение «Облачный диск» компании «Турбо Облако» (входит в ГК РТК-ЦОД) для организации безопасного и оперативного доступа сотрудников к рабочим документам. Инструмент стал технологической основой для реализации гибридных проектов агентства, объединяющих офлайн-мероприятия и цифровые каналы. IVS Group подходит к коммуникациям комплексно, не разделяя между собой различные форматы проектов. Это требует от команды умения быстро обмениваться большими объёмами информации: от стратегических презентаций до медиатек с фото- и видеоматериалами. Внедрение «Облачного диска» позволило создать единую экосистему для всех участников процессов. Теперь сотрудники компании в режиме онлайн работают с документами в защищённом корпоративном хранилище, а для проектных групп настроены командные папки с гибким разграничением прав доступа. «Турбо Облако» не просто предоставляет хранилище для работы с файлами, компания уделяет особое внимание его защищённости и прозрачности. Облачные площадки провайдера размещаются в пяти федеральных округах на базе инфраструктуры крупнейшего российского оператора дата-центров РТК-ЦОД. «Облачный диск» предлагает встроенный антивирус для надёжной защиты данных и инструменты детализированной отчётности, позволяющие отслеживать активность пользователей, чтобы гибко масштабировать ресурсы хранилища. Эти функции особенно востребованы в креативных индустриях, где команды работают с большими массивами контента и множеством внешних партнеров. 
Источник изображения: Scott Rodgerson/unsplash.com Александр Обухов, генеральный директор компании «Турбо Облако»: «Для креативных индустрий критически важна бесшовная коллаборация при работе с большими объёмами визуального контента и множеством внешних партнёров. “Облачный диск” учитывает эту специфику: мы предлагаем отказоустойчивую инфраструктуру, где гибкость доступа сочетается с корпоративным уровнем защиты интеллектуальной собственности. При этом всю ответственность за бесперебойную работу и сохранность данных мы, как облачный провайдер, берем на себя, чтобы команды могли полностью сосредоточиться на творческих и стратегических задачах». Елена Елпатова, коммерческий директор, партнер IVS Group: «Для нас технологии — не барьер, а инструмент, стирающий границы между разными форматами коммуникаций. “Облачный диск” органично вписался в наши процессы благодаря гибким настройкам прав доступа: теперь каждый сотрудник и партнёр видит только то, что нужно для работы, а кроссплатформенная синхронизация позволяет не терять время на поиск актуальных версий файлов. Мы получили по-настоящему единое рабочее пространство». «Турбо Облако» — публичная облачная платформа в составе коммерческого ИТ-кластера «Ростелекома», которая помогает бизнесу работать в режиме максимальной скорости. Компания предлагает свыше 50 сервисов: от виртуальной инфраструктуры и контейнерных платформ до готовых решений для хранения и обработки данных. Облачная платформа «Турбо Облако» является дочерней компанией «РТК-ЦОД». Она развёрнута более чем на 20 площадках в пяти федеральных округах и обеспечивает клиентам надёжность уровня Tier III. В облаке доступно более 500 000 виртуальных процессоров, включая GPU последнего поколения. Реклама | ООО "БАЗИС" ИНН 7731316059 erid: F7NfYUJCUneTVSpdZbGd
13.03.2026 [08:55], Андрей Крупин
«ТрансТелеКом» запустил сервис «Интернет с комплексной защитой»Телекоммуникационный оператор «ТрансТелеКом» сообщил о запуске для корпоративных клиентов услуги «Интернет с комплексной защитой». Решение объединяет высокоскоростной доступ в сеть и многоуровневую защиту цифровой инфраструктуры бизнеса, предоставляя услугу «все в одном» от единого провайдера. «Интернет с комплексной защитой» представляет собой бесшовное решение, при котором весь интернет-трафик компании 24/7 проходит через периметр безопасности на инфраструктуре провайдера автоматически ещё до того, как достигнет сетей клиента. Утверждается, что сервис позволяет сократить расходы на информационную безопасность более чем на 50 % за счёт единой точки управления, без затрат на дополнительные инструменты. Технически сервис работают следующим образом. На уровне сети (L3-L4) выполняется глубокая фильтрация трафика. На прикладном уровне (L7) обеспечивается защита веб-сайтов и приложений от ботов и целевых атак. Межсетевой экран нового поколения (NGFW) блокирует вредоносный контент в режиме реального времени и осуществляет проверку всех HTTP/HTTPS-соединений. Системы предотвращения вторжений анализируют содержимое трафика, выявляя угрозы и нейтрализуя их. NGFW осуществляет постоянный мониторинг веб-трафика на предмет поддельных страниц и мошеннических сайтов, предотвращает использование уязвимостей в клиентском ПО. 
Источник изображения: «ТрансТелеКом» / company.ttk.ru Таким образом, до конечного оборудования клиента доходит только «чистый» и безопасный трафик. И всё это без вмешательства в IT-инфраструктуру организации и без создания дополнительной нагрузки на её системы. |
|

