Материалы по тегу: hpc
|
17.11.2025 [07:45], Владимир Мироненко
NEC и OpenСhip вместе разработают векторные ускорители на базе RISC-V и суперкомпьютеры Aurora следующего поколенияБазирующийся в Барселоне разработчик чипов OpenChip, который некоторые эксперты называют каталонской NVIDIA, и компания NEC объявили о следующем этапе сотрудничества, направленного на совместную разработку векторного процессора (VPU) нового поколения. Ранее компании выполнили технико-экономическое обоснование разработки следующего поколения векторных суперкомпьютеров Aurora с использованием аппаратного и программного стека OpenChip на базе RISC-V. Как сообщается в пресс-релизе, на начальном этапе основное внимание уделялось оценке совместимости архитектуры Aurora от NEC с ускорителями OpenChip, определению логической структуры и начальной разработке программных компонентов. В результате исследования компании пришли к выводу о технической осуществимость проекта, так что теперь компании займутся совместной разработкой следующего поколения высокопроизводительных ускорителей, а также оптимизированного программного стека. Обе компании планируют запуск пилотных развёртываний у отдельных клиентов. По словам старшего вице-президента NEC Сухуна Юна (Suhun Yun), сотрудничество NEC с OpenChip является поворотным моментом в стратегическом развитии NEC в направлении вычислительных архитектур следующего поколения. В свою очередь, OpenChip отметила, что сотрудничество направлено на достижение ряда ключевых преимуществ, в числе которых повышенная производительность критически важных рабочих нагрузок, обеспечение нового уровня вычислительной мощности для HPC, ИИ и ML, а также для таких научных приложений, как геномика и моделирование климата. 
Источник изображения: NEC В 2021 году NEC анонсировала векторные ускорителя SX-Aurora TSUBASA Vector Engine 2.0 (VE20), а в 2022 — доработанные VE30. Однако в 2023 году NEC фактически прекратила разработку новых решений в серии SX-Aurora в связи с появлением ускорителей AMD и NVIDIA, значительно превосходящих её наработки, так что обещанные VE40 и VE50 так и не появились на свет. При этом у NEC и ранее были длительные перерывы в разработке векторных ускорителей, а её суперкомпьютеры на их основе по-прежнему пользуются спросом в некоторых областях, в частности, в метеорологии и климатологии. OpenChip разрабатывает SoC, использующую несколько UCIe-чиплетов, референсные проекты для аппаратных платформ, базовые комплекты разработчиков ПО и прикладные сервисы. Как сообщает ресурс HPCwire, среди других европейских стартапов, разрабатывающих решения на базе RISV-V есть:
За последние годы было поставлено более 10 млрд ядер с архитектурой RISC-V благодаря широкому внедрению архитектуры в микроконтроллерах и встраиваемых устройствах. За последнее время RISC-V стала потенциальной альтернативой проприетарным архитектурам, включая Arm и x86, в разработке ускорителей и HPC-платформ.
14.11.2025 [09:38], Сергей Карасёв
«За пределы экзафлопсного уровня»: Eviden представила суперкомпьютерную платформу BullSequana XH3500Компания Eviden, входящая в Atos Group, анонсировала конвергентную суперкомпьютерную платформу BullSequana XH3500 для ресурсоёмких нагрузок ИИ и HPC. Новинка сочетает передовые аппаратные решения с комплексной экосистемой ПО, обеспечивая возможность масштабирования «за пределы экзафлопсного уровня». BullSequana XH3500 использует открытую модульную конструкцию. Такой подход позволяет свободно комбинировать блоки CPU, GPU и сетевые компоненты от различных производителей, адаптируя конфигурации под определённые потребности. При этом устраняется зависимость от какого-либо конкретного поставщика оборудования, что обеспечивает полную технологическую свободу. По заявлениям Eviden, платформа BullSequana XH3500 по сравнению с системой предыдущего поколения позволяет добиться повышения электрической мощности более чем на 80 % в расчёте на 1 м2 и увеличения эффективности охлаждения на 30 % в расчёт на 1 кВт. Это даёт возможность удовлетворить растущие потребности в вычислительных ресурсах без необходимости расширения площадей в дата-центрах. Габариты стойки BullSequana XH3500 без модуля ультраконденсатора составляют 2270 × 900 × 1457 мм. Мощность AC достигает 284 кВт (с одной помпой). Задействовано на 100 % безвентиляторное прямое жидкостное охлаждение (DLC) пятого поколения с возможностью использования горячей воды с температурой до 40 °C. Подсистемы питания и охлаждения выполнены по схеме с резервированием N+1. Доступны 38 универсальных слотов 1U. 
Источник изображения: Eviden Для платформы BullSequana XH3500 разработаны узлы BullSequana XH3515B и BullSequana AI1242. Первый соответствует типоразмеру 1U: это одноузловое изделие оборудовано двумя чипами NVIDIA Grace CPU и четырьмя ускорителями NVIDIA Blackwell B200. Возможна установка до девяти NVMe SSD в форм-факторе E1.S. Говорится о поддержке четырёх сетевых устройств Eviden BXI V3 или InfiniBand NDR/XDR. В свою очередь, сервер BullSequana AI1242 имеет исполнение 2U. Данное решение несёт на борту два процессора AMD EPYC Turin и GPU-ускоритель AMD Instinct MI355X. Реализована поддержка восьми устройств Eviden BXI V3 или InfiniBand NDR/XDR, а также четырёх накопителей E1.S NVMe SSD.
12.11.2025 [09:28], Владимир Мироненко
Переконфигурируемый ускоритель NextSilicon Maverick-2 с dataflow-архитектурой меняет подход к вычислениямВ конце октября стартап NextSilicon объявил о выходе Maverick-2 — интеллектуального ускорителя вычислений (Intelligent Compute Accelerator, ICA), анонсированного в прошлом году. Чип уже используется в Сандийских национальных лабораториях (SNL) Министерства энергетики США (DOE) в составе суперкомпьютера Vanguard-II, а также рядом клиентов. Как утверждает глава NextSilicon Элад Раз (Elad Raz), компании в сфере научных вычислений и HPC сталкиваются с проблемой ограниченных возможностей CPU и GPU, из-за чего приходится идти на компромиссы, но архитектура Maverick решает эту проблему. По словам NextSilicon, нынешние массовые CPU «скованы» архитектурой фон Неймана 80-летней давности, в которой значительная часть отведена вспомогательной логике, включая предсказание ветвлений, внеочередное исполнение и т.д., а не собственно исполнительным устройствам. В свою очередь, GPU обеспечивают более высокую параллельную производительность, но для эффективного использования ускорителей требуются специализированные среды разработки (CUDA), управление сложными иерархиями памяти, когерентностью кешей и т.п. А ASIC, созданные для конкретных ИИ-задач, обеспечивают высокую производительность и эффективность, но их разработка требует больших затрат. 
Источник изображения: NextSilicon NextSilicon предлагает заменить эти решения чипом с управлением потоками данных (dataflow), который можно перенастраивать во время выполнения задач для устранения узких мест кода, и у которого нет ограничений, присущих CPU и GPU. «В ресурсоёмких приложениях большую часть времени выполняется лишь небольшая часть кода, — рассказал Раз. — Мы разработали интеллектуальный программный алгоритм, который непрерывно отслеживает работу приложения. Он точно определяет, какой путь кода выполняется чаще всего, и перенастраивает чип для ускорения именно этих путей. И всё это мы делаем во время исполнения кода и за наносекунды». FPGA тоже можно перепрограммировать, но для этого нужен цикл перезагрузки. 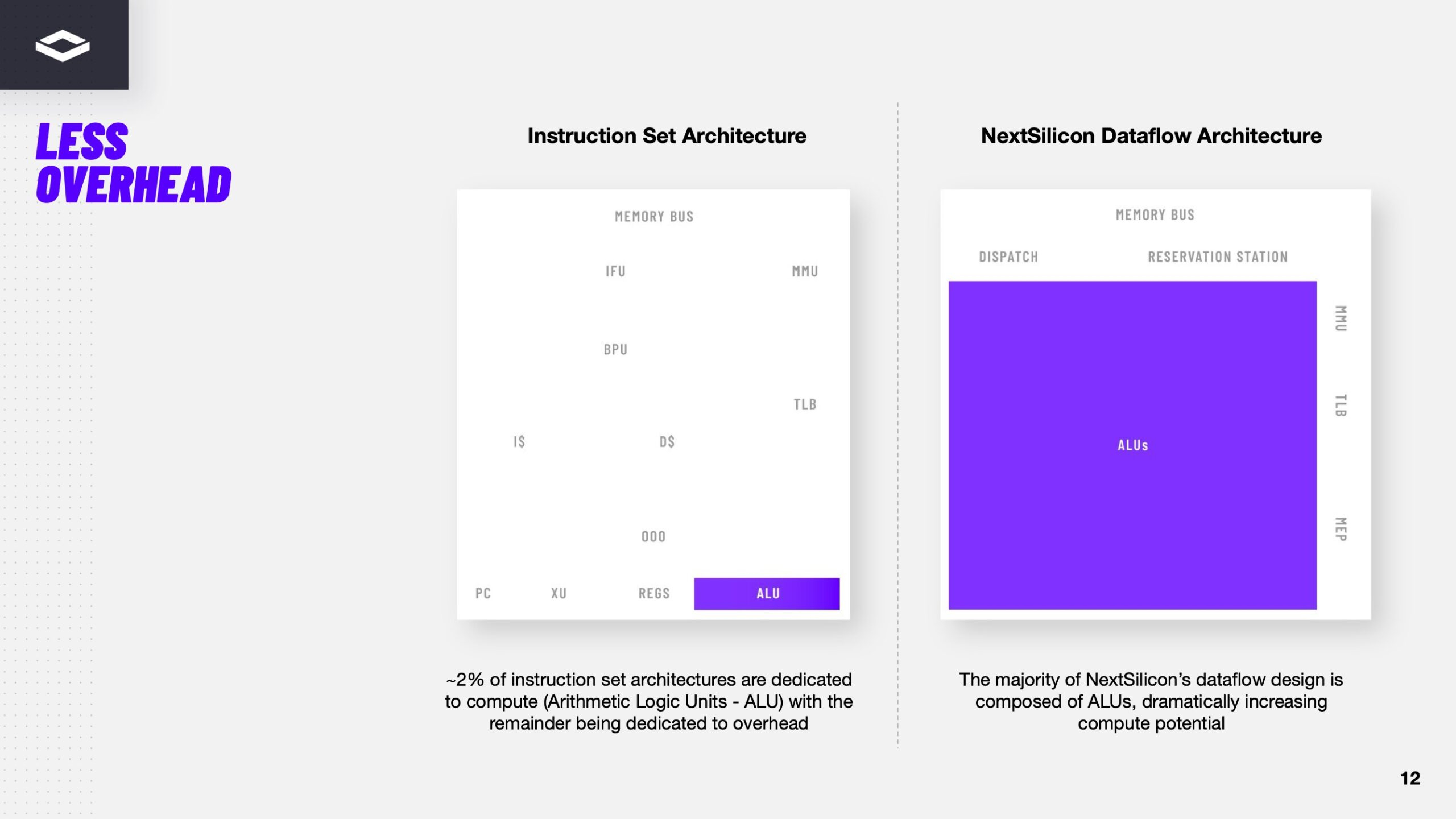
Источник изображений здесь и далее: ServeTheHome/NextSilicon Аппаратная часть Maverick представляет собой реконфигурируемую структуру ALU, которой отведена большая часть «кремния». которую можно быстро перенастраивать во время выполнения кода. Это означает больше вычислений за такт (и на Ватт), при условии, что данные находятся в нужном месте в нужное время. Алгоритм анализирует код на наличие узких мест и соответствующим образом настраивает чип во время выполнения программы. Программно-определяемая архитектура управления потоками данных позволяет достичь производительности и эффективности, близких к ASIC, не привязываясь к конкретному приложению и сохраняя гибкость алгоритмов, утверждает NextSilicon. 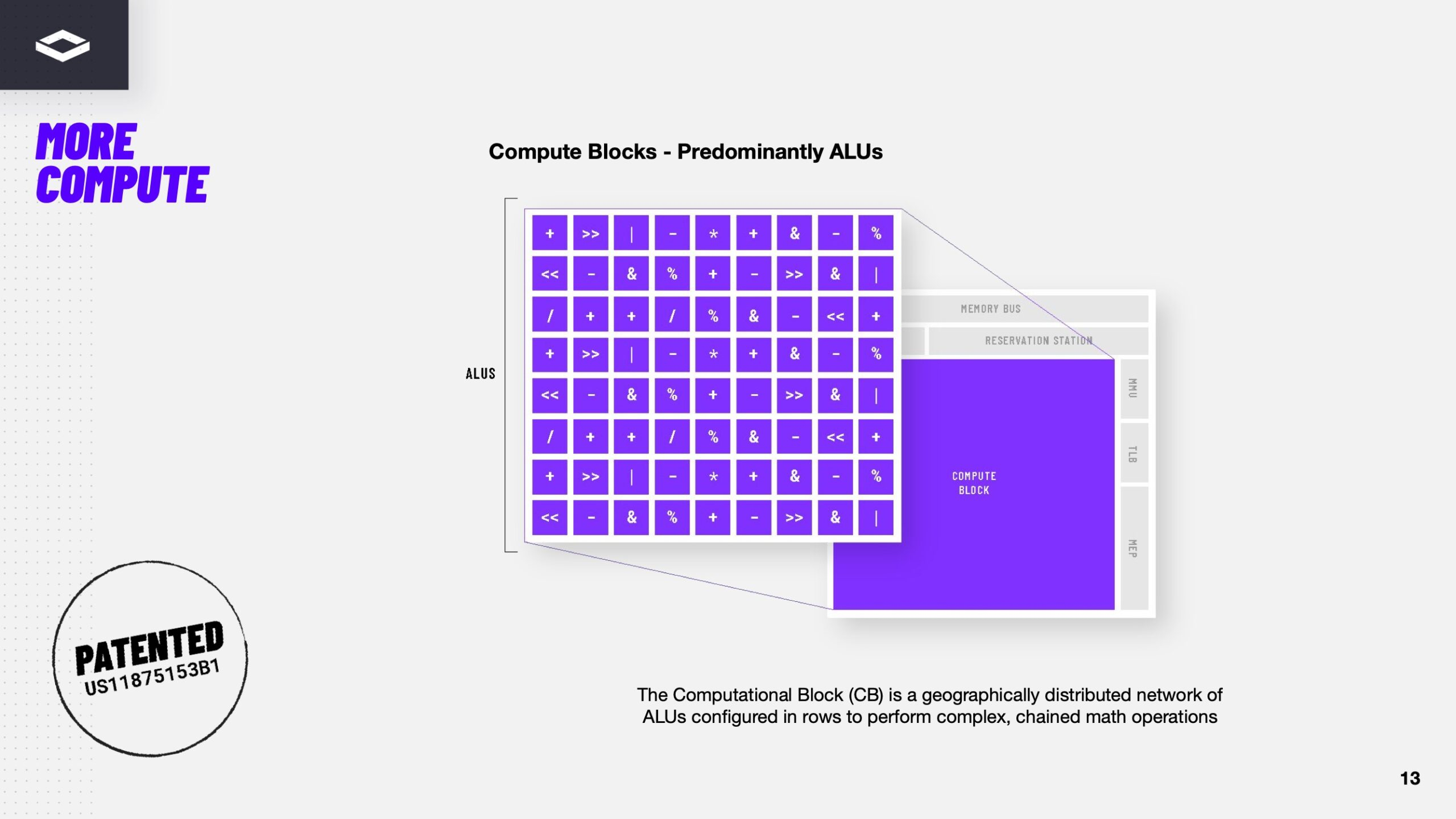 В архитектуре NextSilicon вычислительные блоки (CB) подключены к шине памяти для получения данных, которые временно хранятся в станции резервирования (RS). Диспетчер определяет время запуска вычислительного блока. (RS и диспетчер аналогичны регистрам в процессоре.) Точки входа в память (MEP-блоки) обрабатывают операции доступа к памяти, генерируя запросы к шине, а по завершении направляют ответ в RS. MMU и TLB-кеш занимаются трансляцией адресов (при необходимости). Всё остальное пространство CB занято ALU, который в первом приближении и можно считать «инструкциями». Компания не уточняет, сколько именно CB содержится в чипе, но на фото кристалла их 224. 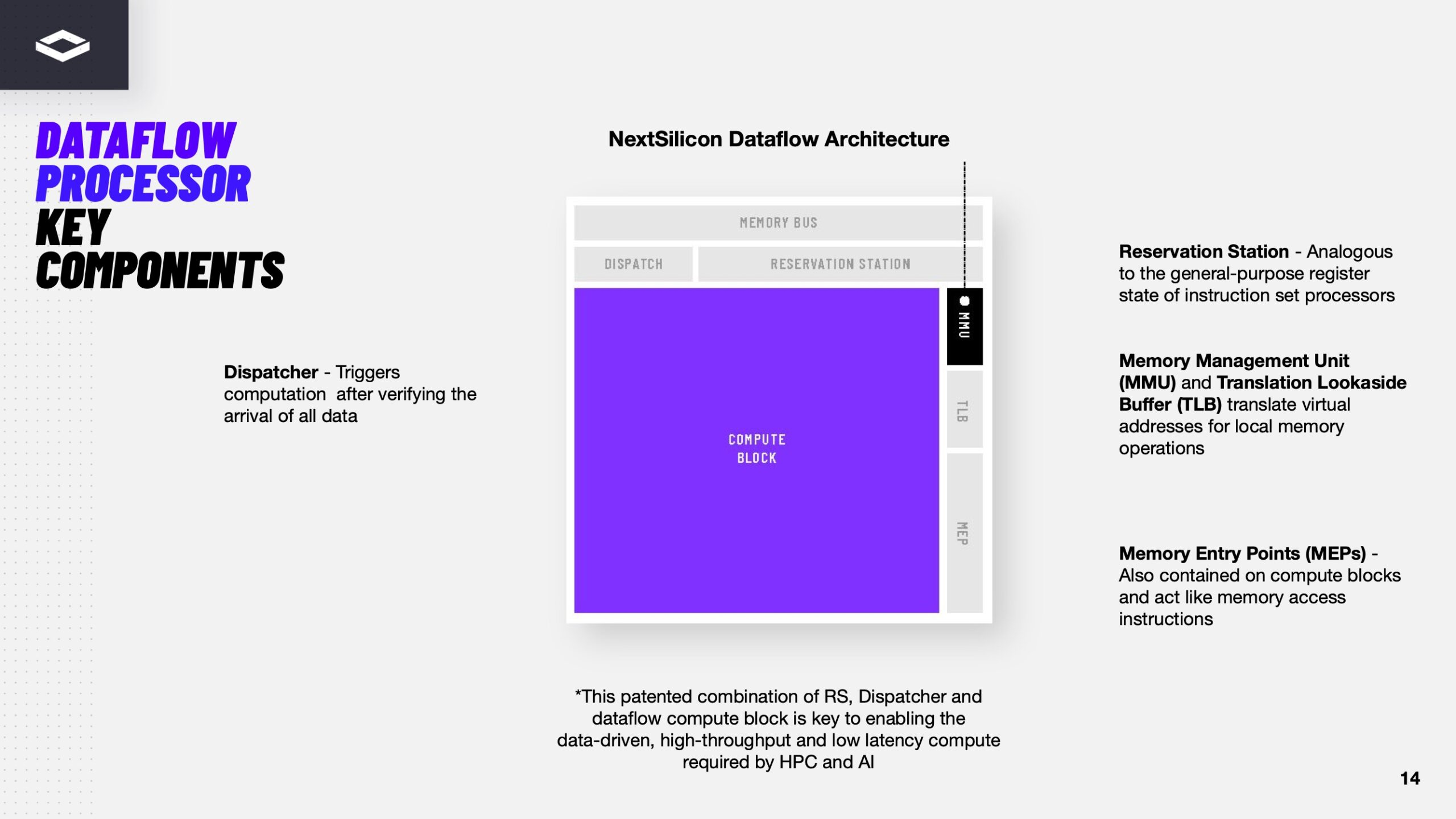 Из ALU компилятор NextSilicon формирует т.н. Mill-ядра (Mill Core) в рамках CB, фактически представляющие собой граф связанных между собой операций, которые и выполняются ALU — появление данных на входе ALU срабатывает как триггер, ALU отрабатывает свою единственную назначенную операцию и передаёт результат следующему ALU, тот следующему и т.д. до конца графа. Особенностью чипа является способность в ходе исполнения по необходимости автоматически реплицировать и оптимально размещать Mill-ядра внутри одного CB, и между несколькими CB. Пришло больше данных, которые можно параллельно обработать — будет больше Mill-ядер. Но касается это только наиболее «горячих» участков. 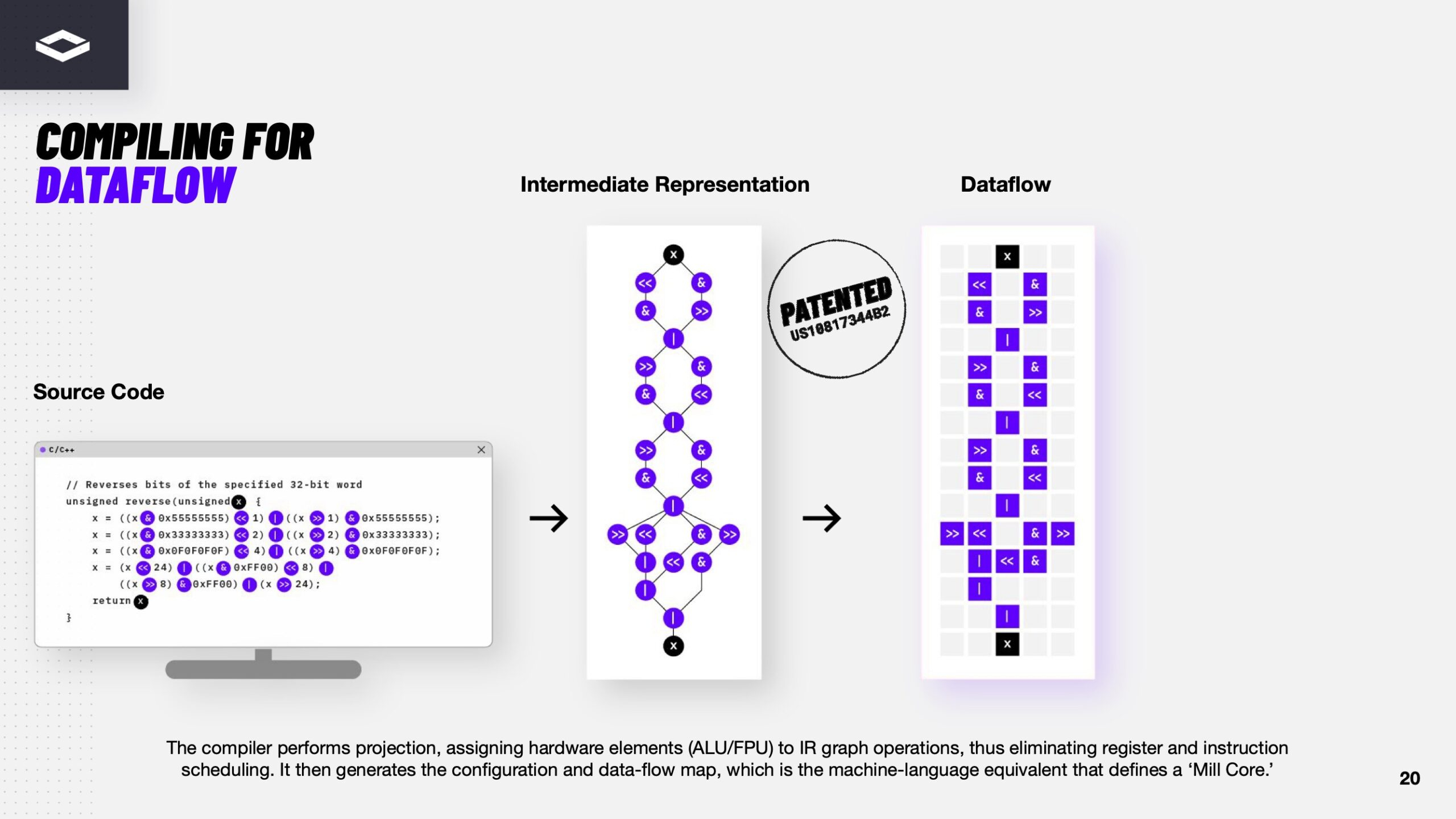 Илан Таяри (Ilan Tayari), соучредитель и вице-президент по архитектуре NextSilicon, назвал критически важным, что платформа может запускать любой код «из коробки», будь то код, написанный для CPU и GPU или ИИ-моделей. Будь то C++, Fortran, Python, CUDA, ROCm, OneAPI или даже ИИ-фреймворки, компилятор NextSilicon разделяет код на части, преобразуя их в промежуточное представление для реконфигурируемого оборудования. «Это не ограничивается тем, что существует сегодня, — сказал Таяри. — Для исследователей в сфере ИИ этот метод открывает новые захватывающие возможности. Вы получаете ускорение независимо от того, что использует ваша модель… экзотические функции активации, комплексные числа или новые математические операции: всё ускоряется сразу из коробки». 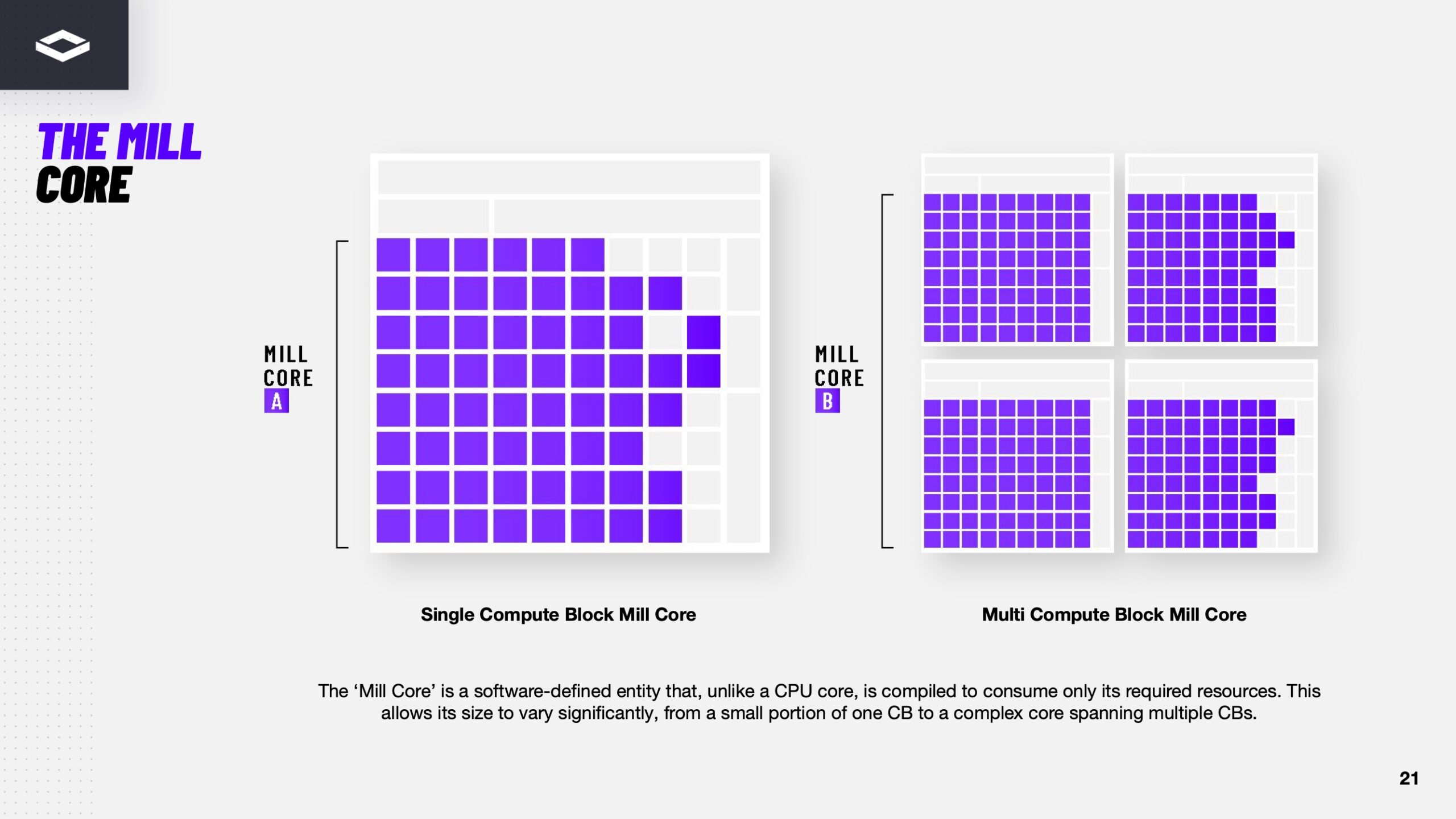 Во время выполнения приложения оперативная телеметрия на чипе непрерывно оптимизирует его. Например, в случае частого взаимодействия вычислительных подблоков граф перестраивается, чтобы приблизить их друг к другу или, например, переключиться с векторной на матричную обработку. При наличии узкого места они дублируются для обеспечения параллелизма. Это происходит автоматически, без вмешательства разработчика, в отличие, например, от VLIW-подхода. 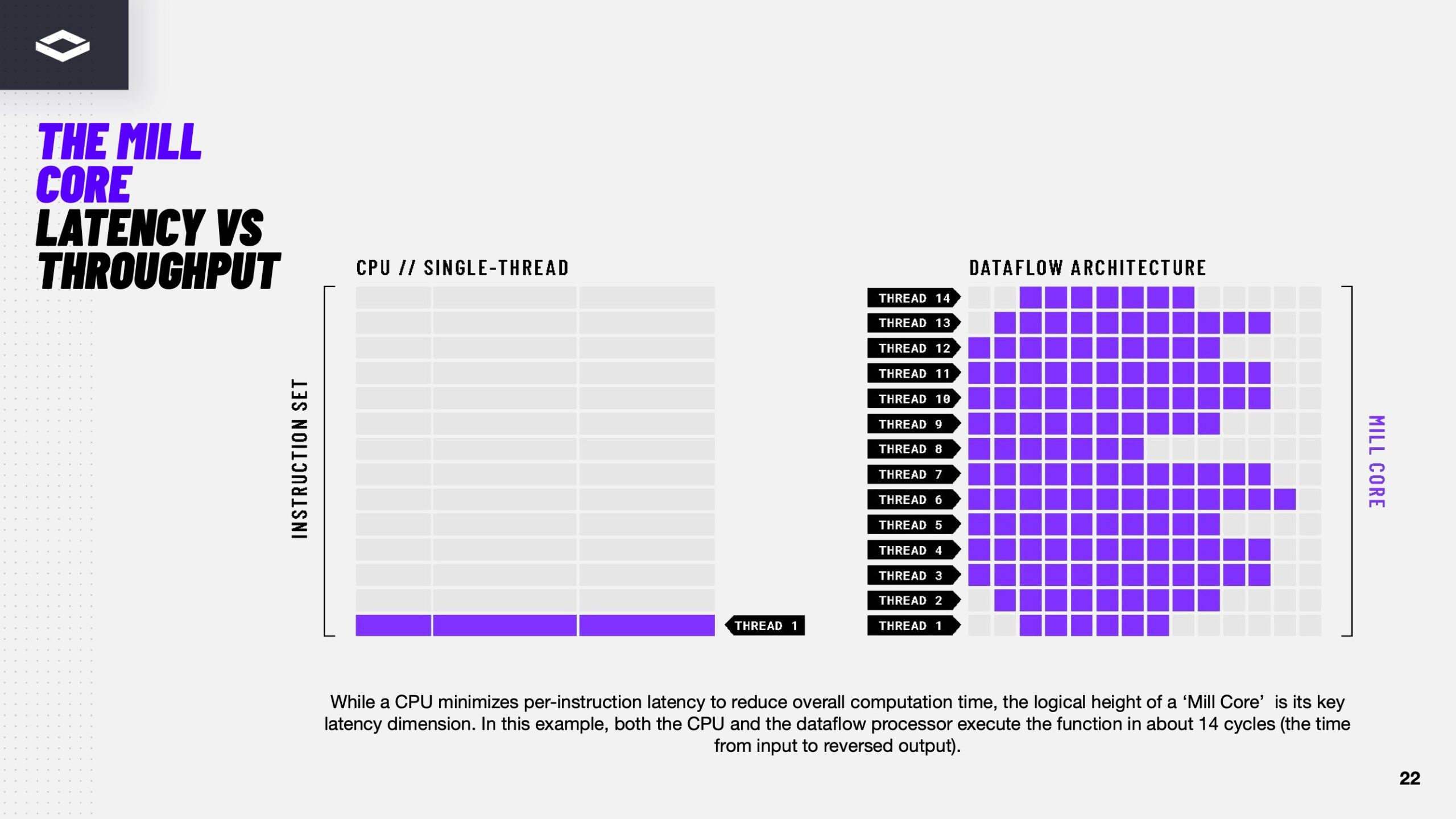 Maverick-2 выпускается по 5-нм техпроцессу TSMC в однокристальной и двухкристальной конфигурациях, работающих на частоте 1,5 ГГц. Однокристальная модель с энергопотреблением 400 Вт разработана для карт PCIe 5.0 x16, а двухкристальная модель с энергопотреблением 750 Вт — для OAM-модулей. Однокристальный вариант с воздушным охлаждением включает 32 управляющих ядра RISC-V, 96 Гбайт HBM3E, кеш 128 Мбайт и один порт 100GbE. Двухкристальный вариант OAM с жидкостным охлаждением содержит 64 управляющих ядра RISC-V, 192 Гбайт HBM3E, кеш 256 Мбайт и два интерфейса 100GbE. 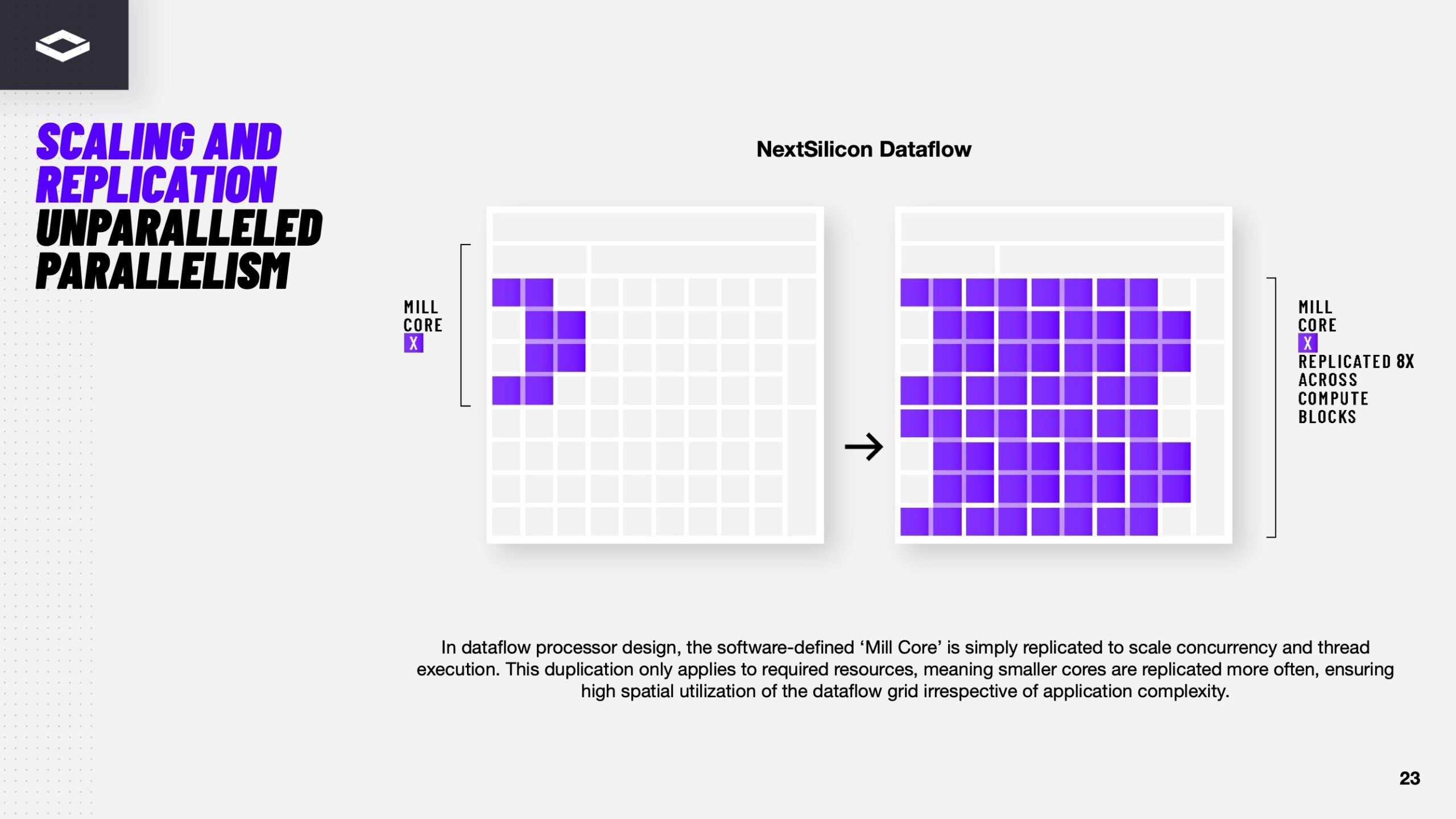 Следует отметить, что указаны максимальные значения TDP, и, как пишет ServeTheHome, ожидается, что при многих рабочих нагрузках они будут ниже. NextSilicon заявляет о возможности достижения 600 Гфлопс при потреблении 750 Вт (примерно вдвое меньше, чем у конкурентов) в бенчмарке HPCG, что составляет 4,8 Тфлопс при потреблении 6 кВт для UBB. Компания протестировала как однокристальную, так и двухкристальную версии Maverick2. В тесте STREAM пропускная способность чипа составила 5,2 Тбайт/с, в бенчмарке GUPS чип достиг 32,6 GUPS при потреблении 460 Вт, что в 22 раза быстрее, чем у CPU, и почти в шесть раз быстрее, чем у GPU для таких приложений как СУБД, агентное принятие ИИ-решений в режиме реального времени и ИИ-инференс на основе разрозненных данных. 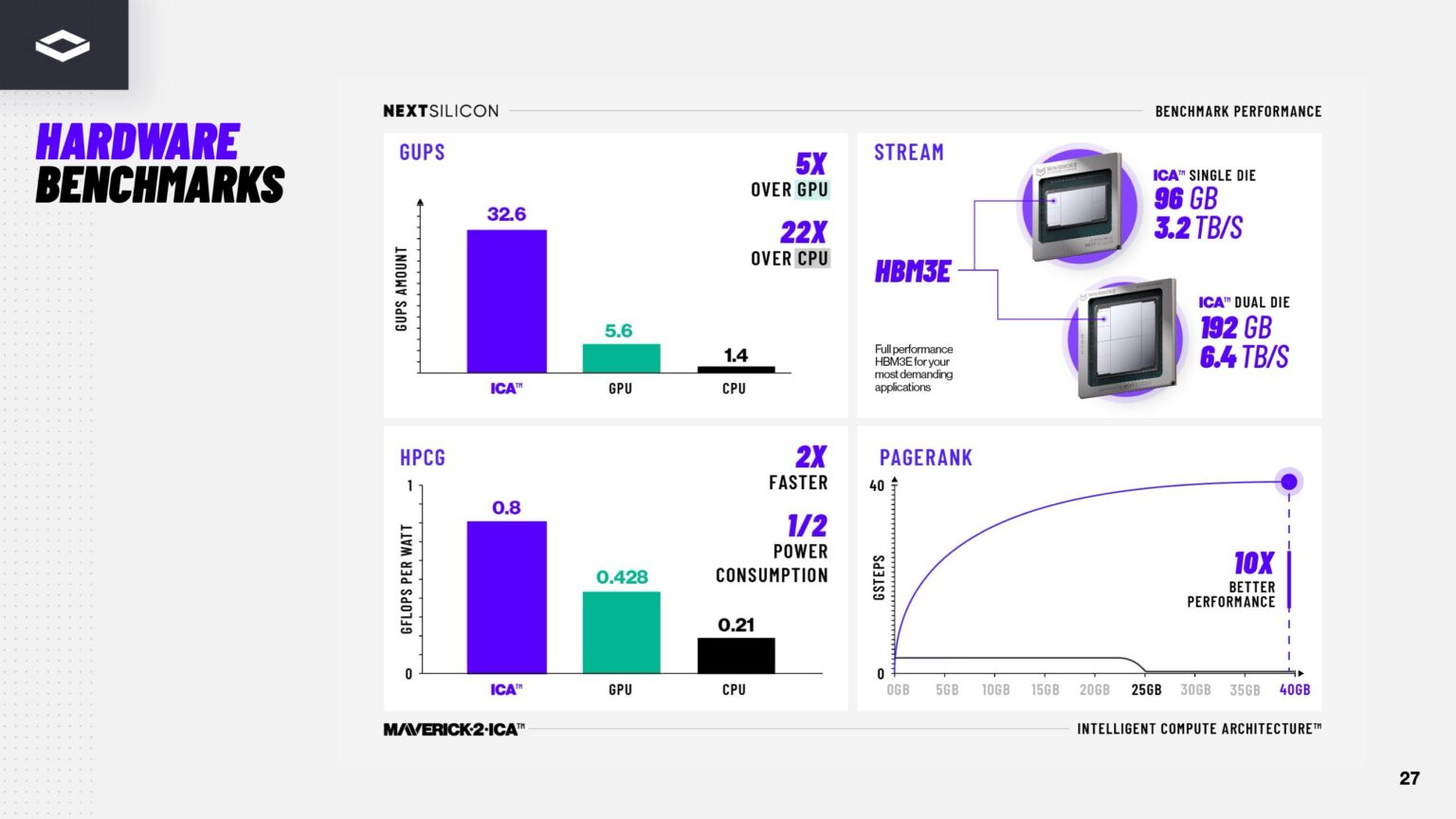 В тесте Google PageRank (PR) чип показал результат 40 Гигастраниц/с, что в 10 раз выше, чем у ведущих GPU, при вдвое меньшем энергопотреблении. Компания отметила, что при больших размерах графов (более 25 Гбайт) ведущие GPU не смогли полностью пройти тест, в то время как Maverick-2 справился с ними без труда, продемонстрировав критическую потребность в адаптивных архитектурах, способных справиться со сложными рабочими нагрузками, лежащими в основе современных ИИ-систем, социальной аналитики и сетевого интеллекта.  «[Эти результаты были] достигнуты с использованием существующего, немодифицированного кода приложения», — подчеркнул Эяль Нагар (Eyal Nagar), соучредитель и вице-президент по исследованиям и разработкам NextSilicon. «Нашим конкурентам требуются специализированные команды для модификации кода, BIOS, прошивок, ОС и параметров, чтобы достичь заявленных бенчмарков. NextSilicon обеспечивает превосходные результаты, используя уже готовое ПО», — добавил он.  NextSilicon также представила тестовый кристалл для процессора корпоративного уровня на базе ядер RISC-V, который компания планирует использовать в качестве хост-процессора в ускорителе следующего поколения Maverick-3. Процессор Arbel, разработанный с нуля, с шириной конвейера в 10 команд представляет собой эволюцию более компактных ядер RISC-V на базе Maverick-2, обрабатывающих последовательный код. По словам компании, ядра имеют производительность ядер на уровне AMD Zen 5 или Intel Lion Cove. 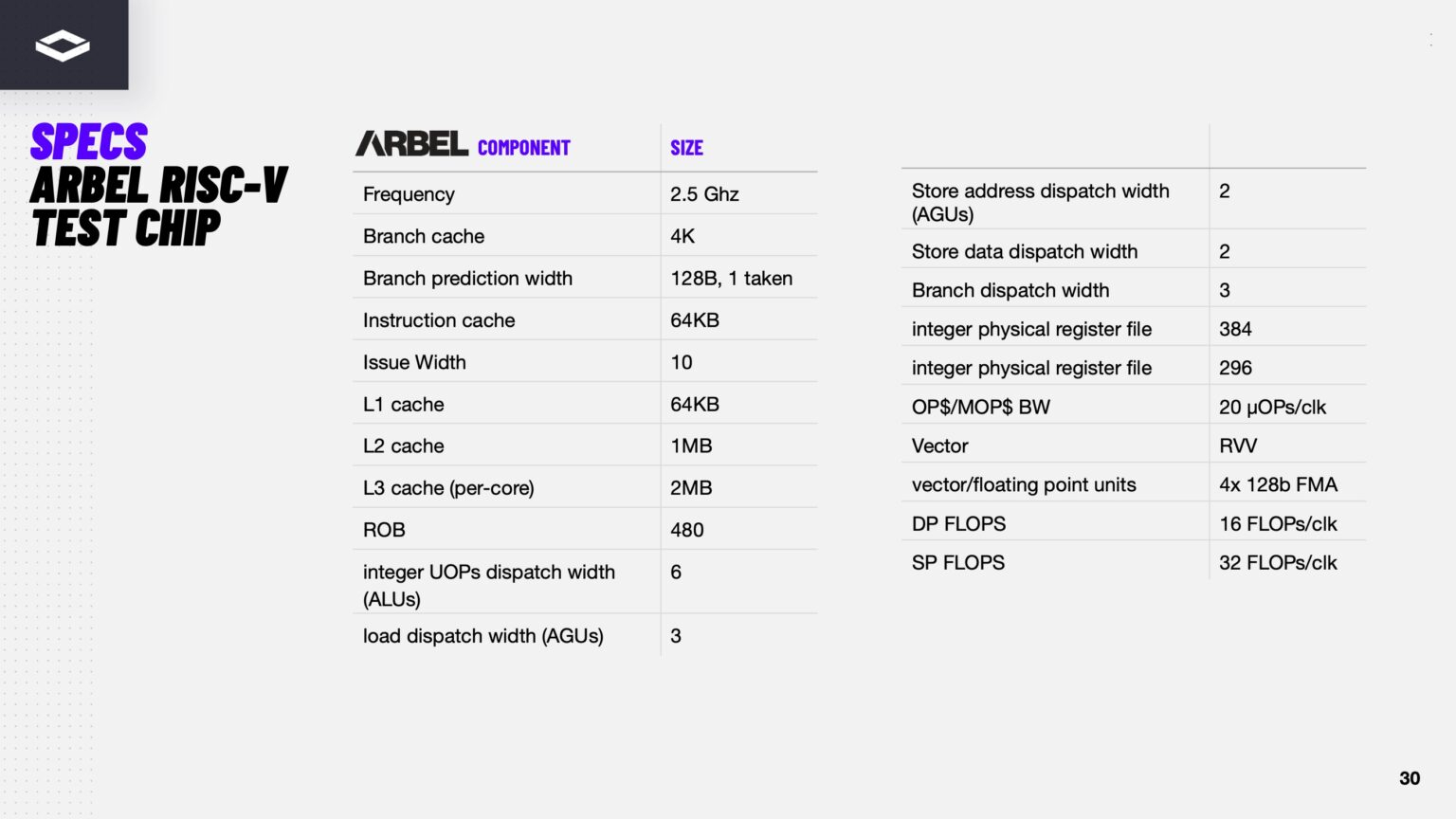 NextSilicon сообщила, что Arbel обеспечивает прорывную производительность благодаря четырём ключевым архитектурным инновациям:
«Это настоящий кремний, созданный по 5-нм техпроцессу TSMC — наша собственная запатентованная интеллектуальная собственность, а не лицензированная или заимствованная. Создан инженерами NextSilicon для воплощения видения будущего NextSilicon», — заявил Элад Раз. 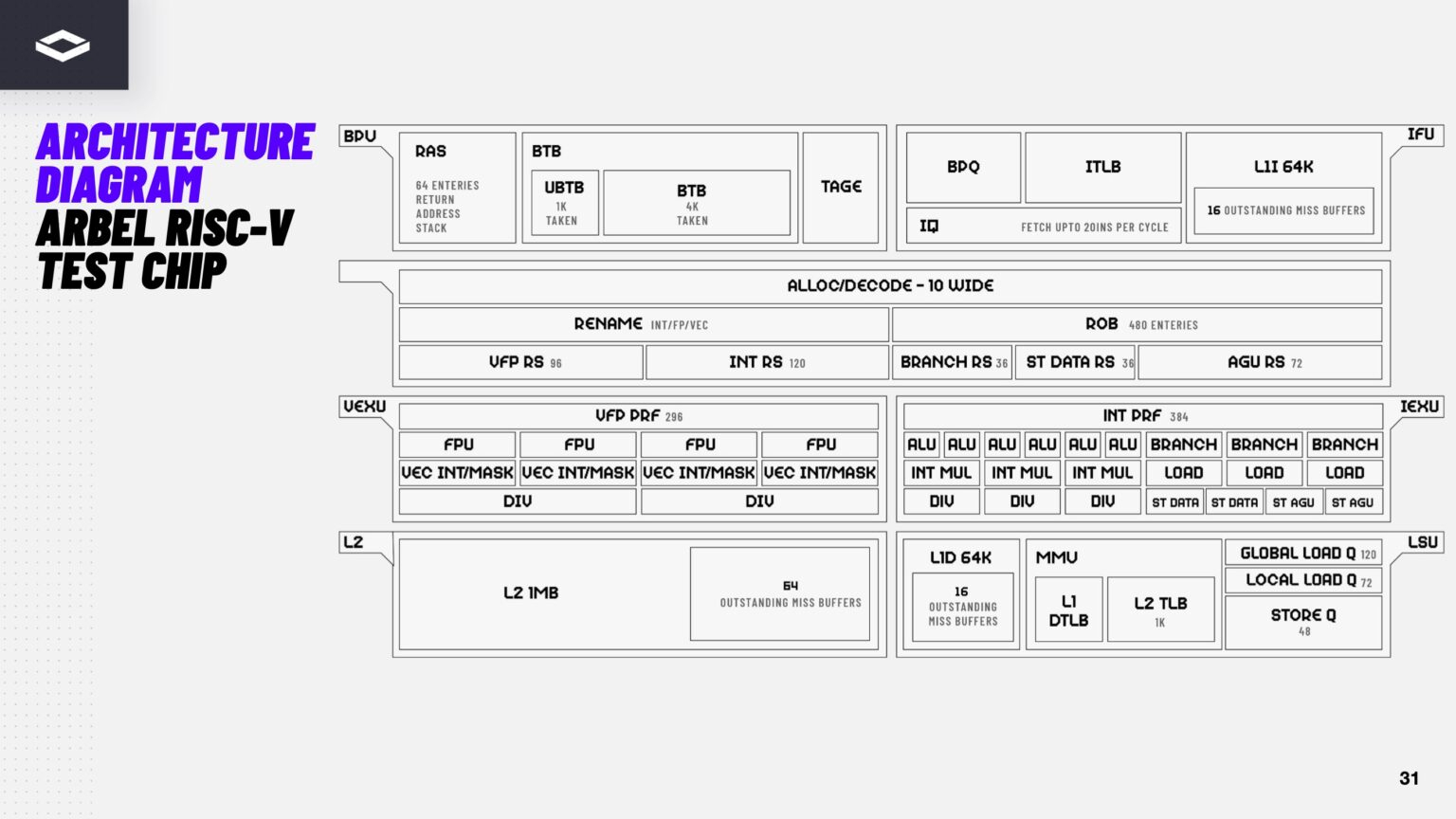 По данным компании, флагманский ускоритель Maverick2, помимо SNL, уже используется «десятками» заказчиков. Его массовые поставки начнутся в начале 2026 года, чтобы обеспечить значительный портфель заказов. NextSilicon сотрудничает с различными организациями, от Министерства энергетики США до ведущих научно-исследовательских институтов, а также коммерческих клиентов в сфере финансовых услуг, энергетики, производства и биологических наук. Программы раннего внедрения для новых клиентов уже доступны через партнёров Penguin Solutions и Dell Technologies. Ускоритель следующего поколения NextSilicon Maverick3 будет поддерживать вычисления с пониженной точностью для ИИ-задач и, как ожидается, появится в продаже в 2027 году, пишет EE Times.
11.11.2025 [10:20], Сергей Карасёв
Четырнадцатый Национальный суперкомпьютерный форум (НСКФ-2025)АНО «Национальный суперкомпьютерный форум», Институт программных систем имени А.К. Айламазяна РАН и Национальная суперкомпьютерная технологическая платформа проводят 25 ноября — 28 ноября 2025 г. Четырнадцатый Национальный суперкомпьютерный форум (НСКФ-2025). Все мероприятия форума посвящены состоянию и перспективам развития национальной суперкомпьютерной отрасли, вопросам создания и практики применения суперкомпьютерных, грид- и облачных технологий. Форум состоится в г. Переславле-Залесском, в ИПС имени А.К. Айламазяна РАН, запланированы научно-практическая конференция, выставка, тренинги, онлайн пресс-конференция, круглые столы (совещания), а также неформальное общение участников. 
Источник изображения: НСКФ-2025 На выставке планируется представить продукцию и технические достижения отечественных производителей. Научная конференция включит в себя представителей большинства ведущих научных центров, а на семинарах и тренингах участники смогут узнать основные приёмы и тонкости работы c новейшими разработками. В рамках форума также состоится онлайн пресс-конференция по наиболее ярким текущим событиям отечественной суперкомпьютерной отрасли. НСКФ-2025 предусмотрен планом работы Национальной суперкомпьютерной технологической платформы на 2025 год. Сайт мероприятия: https://2025.nscf.ru/. Подробная информация о форуме доступна в разделе «Информационные материалы». Зарегистрироваться для участия можно по адресу: https://2025.nscf.ru/kabinet-uchastnika/.
29.10.2025 [16:53], Владимир Мироненко
В США построят семь новых ИИ-компьютеров на чипах NVIDIA по заказу Министерства энергетики СШАNVIDIA объявила о сотрудничестве с национальными лабораториями Министерства энергетики США (DoE) и ведущими компаниями с целью развития ИИ-инфраструктуры страны, в рамках которого будет построено семь новых суперкомпьютеров в Аргоннской (ANL) и Лос-Аламосской (LANL) национальных лабораториях. На первом этапе проекта NVIDIA и Oracle совместно построят в Аргоннской национальной лаборатории (ANL) два новых суперкомпьютера Equinox и Solstice с суммарной ИИ-производительность 2,2 Зфлопс. Также ANL планирует запустить ещё три новые ИИ-системы на базе технологий NVIDIA: Tara, Minerva и Janus. Не вдаваясь в подробности по поводу спецификаций систем, руководство лаборатории заявило, что суперкомпьютеры призваны расширить доступ исследователям в сфере ИИ из других центров по всей стране. Лос-Аламосская национальная лаборатория (LANL) получит ИИ-системы Mission и Vision нового поколения, которые будут разработаны и поставлены компанией HPE. Уже известно, что они будут базироваться на платформе NVIDIA Vera Rubin с сетевой фабрикой Quantum‑X800 InfiniBand. Как сообщает NVIDIA, система Vision основана на достижениях суперкомпьютера Venado, созданного для несекретных исследований. Как уточнили в лаборатории, Vision будет использоваться для несекретных задач в области национальной безопасности, материаловедения и ядерной науки, энергетического моделирования и биомедицинских исследований, сообщили в лаборатории, пишет The Register. 
Источник изображения: NVIDIA Mission — пятая система ATS5 (Advanced Technology System) в рамках программы усовершенствованного моделирования и вычислений (Advanced Simulation and Computing) Национального управления ядерной безопасности США (The National Nuclear Security Administration, NNSA), поддерживаемой LANL. Система предназначена для запуска секретных приложений, её ввод в эксплуатацию состоится в конце 2027 года. Vera Rubin в сочетании с Quantum‑X800 позволит учёным проводить сложное моделирование в области материаловедения, моделирования климата и квантовых вычислений. «Использование такого уровня вычислительной производительности критически важно для решения некоторых из самых сложных научных задач и задач национальной безопасности», — заявил Том Мейсон (Thom Mason), директор LANL.
29.10.2025 [11:55], Сергей Карасёв
NVIDIA представила интерконнект NVQLink для гибридных вычислений на базе GPU и QPUКомпания NVIDIA анонсировала NVQLink — открытую системную архитектуру, предназначенную для тесной интеграции графических (GPU) и квантовых (QPU) процессоров с целью создания гибридных вычислительных платформ. В разработке интерконнекта NVQLink приняли участие Брукхейвенская национальная лаборатория (BNL), Национальная ускорительная лаборатория им. Ферми (Fermilab), Национальная лаборатория имени Лоуренса в Беркли (LBNL), Лос-Аламосская национальная лаборатория (LANL), Национальная лаборатория Ок-Ридж (ORNL), Национальные лаборатории Сандия (SNL) и Тихоокеанская северо-западная национальная лаборатория (PNNL), которые принадлежат Министерству энергетики США (DoE). Кроме того, были вовлечены специалисты Линкольнской лаборатории Массачусетского технологического института (MIT Lincoln Laboratory). 
Источник изображения: NVIDIA Отмечается, что NVQLink обеспечивает открытый подход к квантовой интеграции. Максимальная пропускная способность в системах GPU — QPU заявлена в 400 Гбит/с, тогда как минимальная задержка (FPGA-GPU-FPGA) составляет менее 4 мкс. Интерконнект может применяться в составе ИИ-платформ, обладающих производительностью до 40 Пфлопс (FP4). Решение NVQLink оптимизировано для крупномасштабных квантовых вычислений в реальном времени. В целом, NVQLink обеспечивает возможность непосредственного взаимодействия QPU разных типов и систем управления квантовым оборудованием с ИИ-суперкомпьютерами. Технология предоставляет готовое унифицированное решение для преодоления ключевых проблем интеграции, с которыми сталкиваются исследователи в области квантовых вычислений при масштабировании своих систем. Разработчики могут получить доступ к NVQLink благодаря интеграции с программной платформой NVIDIA CUDA-Q. В число партнёров, вносящих вклад в NVQLink, входят разработчики квантового оборудования Alice & Bob, Anyon Computing, Atom Computing, Diraq, Infleqtion, IonQ, IQM Quantum Computers, ORCA Computing, Oxford Quantum Circuits, Pasqal, Quandela, Quantinuum, Quantum Circuits, Quantum Machines, Quantum Motion, QuEra, Rigetti, SEEQC и Silicon Quantum Computing, а также разработчики квантовых систем управления, включая Keysight Technologies, Quantum Machines, Qblox, QubiC и Zurich Instruments.
28.10.2025 [22:35], Владимир Мироненко
Министерство энергетики США получит два суперкомпьютера на чипах AMD общей стоимостью $1 млрд: Discovery и Lux AI
amd
epyc
hardware
hpc
hpe
mi350
mi400
oracle
oracle cloud infrastructure
ornl
venice
ии
облако
суперкомпьютер
сша
Министерство энергетики США (DOE) заключило с AMD контракт стоимостью $1 млрд с целью строительства двух суперкомпьютеров HPE для решения масштабных научных задач в области ядерной энергетики, здравоохранения и национальной безопасности. 
Источник изображений: HPE Министр энергетики Крис Райт (Chris Wright) сообщил агентству Reuters, что создание HPC-систем даст мощный импульс развитию ядерной и термоядерной энергетики, оборонных технологий и национальной безопасности, а также разработке лекарственных препаратов. Учёные и компании пытаются воспроизвести термоядерный синтез, который, в том числе, подпитывает солнечную энергию. «Мы добились значительного прогресса, но плазма нестабильна, и нам необходимо воссоздать центр Солнца на Земле», — заявил Райт.  Он выразил уверенность, что ИИ-системы позволят открыть практические пути для использования энергии термоядерного синтеза в ближайшие два-три года, а также помогут управлять ядерным арсеналом США и ускорить разработку лекарств, моделируя способы лечения рака вплоть до молекулярного уровня. «Я надеюсь, что в ближайшие пять-восемь лет мы превратим большинство видов рака, многие из которых сегодня являются смертным приговором, в контролируемые состояния», — сказал Райт.  Первым планируется запустить в эксплуатацию в течение следующих шести месяцев суперкомпьютер Lux с облачным доступом. Он будет основан на узлах HPE ProLiant Compute XD685 с СЖО, которые объединяют ИИ-ускорителях Instinct MI355X, CPU AMD EPYC, а также DPU Pensando. Система разработана AMD совместно с HPE, Oracle (OCI) и Ок-Риджской национальной лабораторией (ORNL). Глава AMD Лизу Су (Lisa Su) сообщила, что запуск Lux будет самым быстрым развёртыванием суперкомпьютера таких размеров в её практике. «Именно такой скорости и гибкости мы хотели бы добиться для программ США в области ИИ искусственного интеллекта», — сказала она. По словам директора ORNL, Lux будет обладать примерно в три раза большей вычислительной мощностью по сравнению с существующими системами.  Второй, более продвинутый суперкомпьютер под названием Discovery станет преемником экзафлопсной машины Frontier в ORNL и будет практически на порядок быстрее её. Его разработкой занимаются ORNL, HPE и AMD. Discovery будет основан на платформе HPE Cray Supercomputing GX5000, поддерживающей до 25 кВт на узел и охлаждение водой с температорой +40 °C. Узлы получат процессоры AMD EPYC Venice, которые, как ожидается, появятся во II половине 2026 года, а также специализированные ускорители Instinct MI430X с полноценной поддержкой FP64-вычислений — они также должны появиться в следующем году. Для интерконнекта будет задействован HPE Slingshot следующего поколения, сроки выхода которого не называются.  Discovery получит новейшую СХД Cray SC Storage Systems K3000 с объектным хранилищем DAOS, которое дополнит имеющуюся СХД на базе Cray SC Storage Systems E2000 с Lustre. Ранее HPE наняла инженеров, занимавшихся разработкой DAOS в Intel, и включила их в свою команду по работе над СХД. По словам HPE, K3000 предложит до 75 млн IOPS на стойку. HPE не раскрывает, сколько узлов, процессоров и ускорителей будет использоваться в Discovery, а также какой объём памяти будет у системы. Ожидается, что Discovery будет поставлен в 2028 году и готов к эксплуатации в 2029 году. Оценочная стоимость системы — $500 млн. Министерство энергетики США разместит суперкомпьютеры, компании предоставят оборудование и средства на капитальные затраты, а вычислительные мощности будут распределены между обеими сторонами, сообщил представитель министерства. Он отметил, что эти суперкомпьютеры на базе чипов AMD станут первыми в ряду подобных партнёрств министерства с частными компаниями в стране. По аналогичной схеме будет финансироваться создание ИИ-суперкомпьютера Solstice.
28.10.2025 [21:35], Владимир Мироненко
NVIDIA и Oracle построят для США ИИ-суперкомпьютер Solstice: 100 тыс. ускорителей Blackwell и государственно-частное партнёрствоNVIDIA объявила о новом совместном проекте с Oracle по созданию крупнейшей суперкомпьютерной системы с поддержкой ИИ в интересах Министерства энергетики США (DoE) для разработок в сфере науки. В рамках партнёрства NVIDIA и Oracle построят два суперкомпьютера — Solstice и Equinox, оснащённых 100 тыс. и 10 тыс. ускорителей NVIDIA Blackwell соответственно, которые будут объединены интерконнектом NVIDIA и обеспечат суммарную ИИ-производительность в 2,2 Зфлопс. Система Equinox будет введена в эксплуатацию в I половине 2026 года. Стоимость проекта не разглашается. Solstice будет построен с использованием новой модели государственно-частного партнёрства Министерства энергетики США, включающей инвестиции cо стороны промышленности. Сообщается, что суперкомпьютеры будут размещены в Аргоннской национальной лаборатории (ANL) Министерства энергетики США. С их помощью исследователи будут разрабатывать и обучать новые передовые ИИ-модели, включая модели рассуждений, для реализации проектов открытой науки, используя библиотеку NVIDIA Megatron-Core, а также масштабировать их с помощью программного стека для инференса NVIDIA TensorRT. Эти модели станут основой рабочих процессов агентного ИИ для научных исследований. 
Источник изображения: NVIDIA Оба суперкомпьютера будут использоваться в рамках сотрудничества NVIDIA, ANL и DoE, повышая производительность исследований и разработок и ускоряя процесс научных открытий, которые будут осуществляться за счет государственных средств в течение десятилетия. Глава ANL, что новые суперкомпьютеры будут подключены к передовым экспериментальным установкам Министерства энергетики США, таким как усовершенствованный источник фотонов, что позволит решать самые насущные проблемы страны благодаря научным открытиям.
18.10.2025 [22:25], Владимир Мироненко
К полувековому юбилею суперкомпьютера Cray-1 выпущена памятная однодолларовая монетаМонетный двор США представил дизайн памятных однодолларовых монет для программы 2026 American Innovation $1 Coin Program. На одной из них изображён Cray-1 — один из самых известных суперкомпьютеров всех времён, отличавшийся инновационной для своего времени конструкцией и уникальным дизайном. В рамках этой программы, действующей с 2018 года, ежегодно выпускаются четыре монеты, представляющие «американские инновации, а также значительные инновационные и новаторские достижения отдельных лиц или групп». В этом году дизайн монет для программы был предложен штатами Айова, Висконсин, Калифорния и Миннесота. 
Источник изображения: United States Mint Дизайн монеты с изображением Cray-1 был предложен штатом Висконсин, где находится исследовательский центр Cray Research, в котором был создан Cray-1 под руководством ныне покойного Сеймура Крея (Seymour Cray) и соучредителя, главного инженера Лестера Дэвиса (Lester Davis). На лицевой стороне монеты размещено изображение вида сверху суперкомпьютера Cray-1 с круговым расположением вычислительных блоков. На С-образном корпусе машины видна надпись Cray-1 Supercomputer, а также подписи художника и скульптора Пола Романо (Paul Romano) и Джона П. Макгроу (John P. McGraw). Также есть надписи «Соединённые штаты Америки» и «Висконсин».  Памятные монеты вряд ли поступят в регулярное обращение, и их вряд ли можно будет купить в банке за доллар. Они являются законным платёжным средством, но в первую очередь — предметом коллекционирования. Предыдущие памятные долларовые монеты продавались монетным двором по цене от $13,25. Cray-1 стал первым суперкомпьютером, в котором была успешно реализована концепция векторного процессора, позволяющего повысить скорость математических операций путём оптимальной организации памяти и регистров для быстрого выполнения одной операции с большим набором данных. В предыдущих системах эта концепция была реализована с ограниченной производительностью. Cray-1 работал в несколько раз быстрее любой аналогичной конструкции и лидировал среди суперкомпьютеров с 1976 по 1982 год, достигая впечатляющих 160 Мфлопс благодаря инновационному использованию интегральных схем.  За всё время существования системы на рынке было продано более 80 машин, что сделало Cray-1 одним из самых успешных в этой категории за всю историю вычислительных систем. Он известен своей уникальной формой: относительно небольшим С-образным корпусом, окружённым кольцом «тумбочек», закрывающих блоки питания и систему охлаждения. Согласно «Википедии», после анонса Cray-1 с частотой 80 МГц в 1975 году ажиотаж вокруг него был настолько велик, что между Ливерморской национальной лабораторией имени Лоуренса (LLNL) и Лос-Аламосской национальной лабораторией (LANL) разгорелась настоящая война за право покупки первой машины. В итоге последняя выиграла тендер и получила в 1976 году первый экземпляр Cray-1 с серийным номером 001. Национальный центр атмосферных исследований США (NCAR) стал первым официальным клиентом Cray Research в 1977 году, заплатив $8,86 млн (сейчас это более $47 млн с учётом инфляции) за суперкомпьютер с серийным номером 003. Этот суперкомпьютер был выведен из эксплуатации в 1989 году.
14.10.2025 [20:58], Владимир Мироненко
Oracle анонсировала крупнейший в мире зеттафлопсный ИИ-кластер OCI Zettascale10: до 800 тыс. ускорителей NVIDIA в нескольких ЦОД
800gbe
ethernet
hardware
hpc
nvidia
oracle
oracle cloud infrastructure
stargate
ии
интерконнект
кластер
сша
цод
Oracle анонсировала облачный ИИ-кластер OCI Zettascale10 на базе сотен тысяч ускорителей NVIDIA, размещённых в нескольких ЦОД, который имеет пиковую ИИ-производительность 16 Зфлопс (точность вычислений не указана). OCI Zettascale10 — это инфраструктура, на которой базируется флагманский ИИ-суперкластер, созданный совместно с OpenAI в техасском Абилине (Abilene) в рамках проекта Stargate и основанный на сетевой архитектуре Oracle Acceleron RoCE нового поколения. OCI Zettascale10 использует NVIDIA Spectrum-X Ethernet — первую, по словам NVIDIA, Ethernet-платформу, которая обеспечивает высокую масштабируемость, чрезвычайно низкую задержку между ускорителями в кластере, лидирующее в отрасли соотношение цены и производительности, улучшенное использование кластера и надежность, необходимую для крупномасштабных ИИ-задач. Как отметила Oracle, OCI Zettascale10 является «мощным развитием» первого облачного ИИ-кластера Zettascale, который был представлен в сентябре 2024 года. Кластеры OCI Zettascale10 будут располагаться в больших кампусах ЦОД мощностью в гигаватты с высокоплотным размещением в радиусе двух километров, чтобы обеспечить наилучшую задержку между ускорителями для крупномасштабных задач ИИ-обучения. Именно такой подход выбран для кампуса Stargate в Техасе. Oracle отметила, что помимо возможности создавать, обучать и развёртывать крупнейшие ИИ-модели, потребляя меньше энергии на единицу производительности и обеспечивая высокую надёжность, клиенты получат свободу работы в распределённом облаке Oracle со строгим контролем над данными и суверенитетом ИИ. 
Источник изображения: OpenAI Изначально кластеры OCI Zettascale10 будут рассчитаны на развёртывание до 800 тыс. ускорителей NVIDIA, обеспечивая предсказуемую производительность и высокую экономическую эффективность, а также высокую пропускную способность между ними благодаря RoCEv2-интерконнекту Oracle Acceleron со сверхнизкой задержкой. Acceleron предлагает 400G/800G-подключение со сверхнизкой задержкой, двухуровневую топологию, множественное подключение одного NIC к нескольким коммутатором с физической и логической изоляцией сетевых потоков, поддержку LPO/LRO и гибкость конфигурации. DPU Pensando от AMD в Acceleron место тоже нашлось. 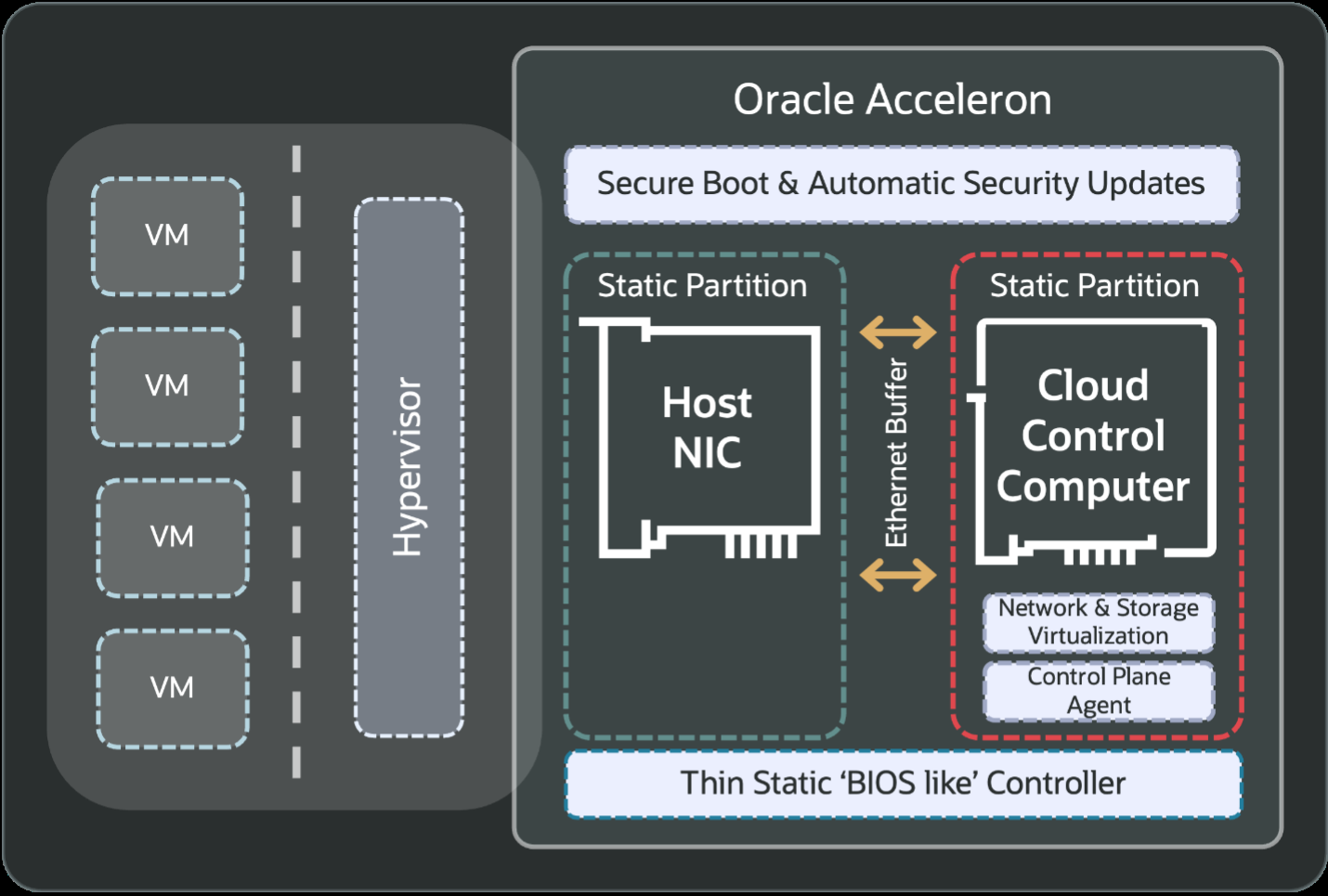
Источник изображения: Oracle OCI уже принимает заказы на OCI Zettascale10, который поступит в продажу во II половине следующего календарного года. В августе NVIDIA анонсировала решение Spectrum-XGS Ethernet для объединения нескольких ЦОД в одну ИИ-суперфабрику, которым, по-видимому, воспользуется не только Oracle, но и Meta✴. |
|

