Материалы по тегу: hpc
|
14.10.2025 [20:58], Владимир Мироненко
Oracle анонсировала крупнейший в мире зеттафлопсный ИИ-кластер OCI Zettascale10: до 800 тыс. ускорителей NVIDIA в нескольких ЦОД
800gbe
ethernet
hardware
hpc
nvidia
oracle
oracle cloud infrastructure
stargate
ии
интерконнект
кластер
сша
цод
Oracle анонсировала облачный ИИ-кластер OCI Zettascale10 на базе сотен тысяч ускорителей NVIDIA, размещённых в нескольких ЦОД, который имеет пиковую ИИ-производительность 16 Зфлопс (точность вычислений не указана). OCI Zettascale10 — это инфраструктура, на которой базируется флагманский ИИ-суперкластер, созданный совместно с OpenAI в техасском Абилине (Abilene) в рамках проекта Stargate и основанный на сетевой архитектуре Oracle Acceleron RoCE нового поколения. OCI Zettascale10 использует NVIDIA Spectrum-X Ethernet — первую, по словам NVIDIA, Ethernet-платформу, которая обеспечивает высокую масштабируемость, чрезвычайно низкую задержку между ускорителями в кластере, лидирующее в отрасли соотношение цены и производительности, улучшенное использование кластера и надежность, необходимую для крупномасштабных ИИ-задач. Как отметила Oracle, OCI Zettascale10 является «мощным развитием» первого облачного ИИ-кластера Zettascale, который был представлен в сентябре 2024 года. Кластеры OCI Zettascale10 будут располагаться в больших кампусах ЦОД мощностью в гигаватты с высокоплотным размещением в радиусе двух километров, чтобы обеспечить наилучшую задержку между ускорителями для крупномасштабных задач ИИ-обучения. Именно такой подход выбран для кампуса Stargate в Техасе. Oracle отметила, что помимо возможности создавать, обучать и развёртывать крупнейшие ИИ-модели, потребляя меньше энергии на единицу производительности и обеспечивая высокую надёжность, клиенты получат свободу работы в распределённом облаке Oracle со строгим контролем над данными и суверенитетом ИИ. 
Источник изображения: OpenAI Изначально кластеры OCI Zettascale10 будут рассчитаны на развёртывание до 800 тыс. ускорителей NVIDIA, обеспечивая предсказуемую производительность и высокую экономическую эффективность, а также высокую пропускную способность между ними благодаря RoCEv2-интерконнекту Oracle Acceleron со сверхнизкой задержкой. Acceleron предлагает 400G/800G-подключение со сверхнизкой задержкой, двухуровневую топологию, множественное подключение одного NIC к нескольким коммутатором с физической и логической изоляцией сетевых потоков, поддержку LPO/LRO и гибкость конфигурации. DPU Pensando от AMD в Acceleron место тоже нашлось. 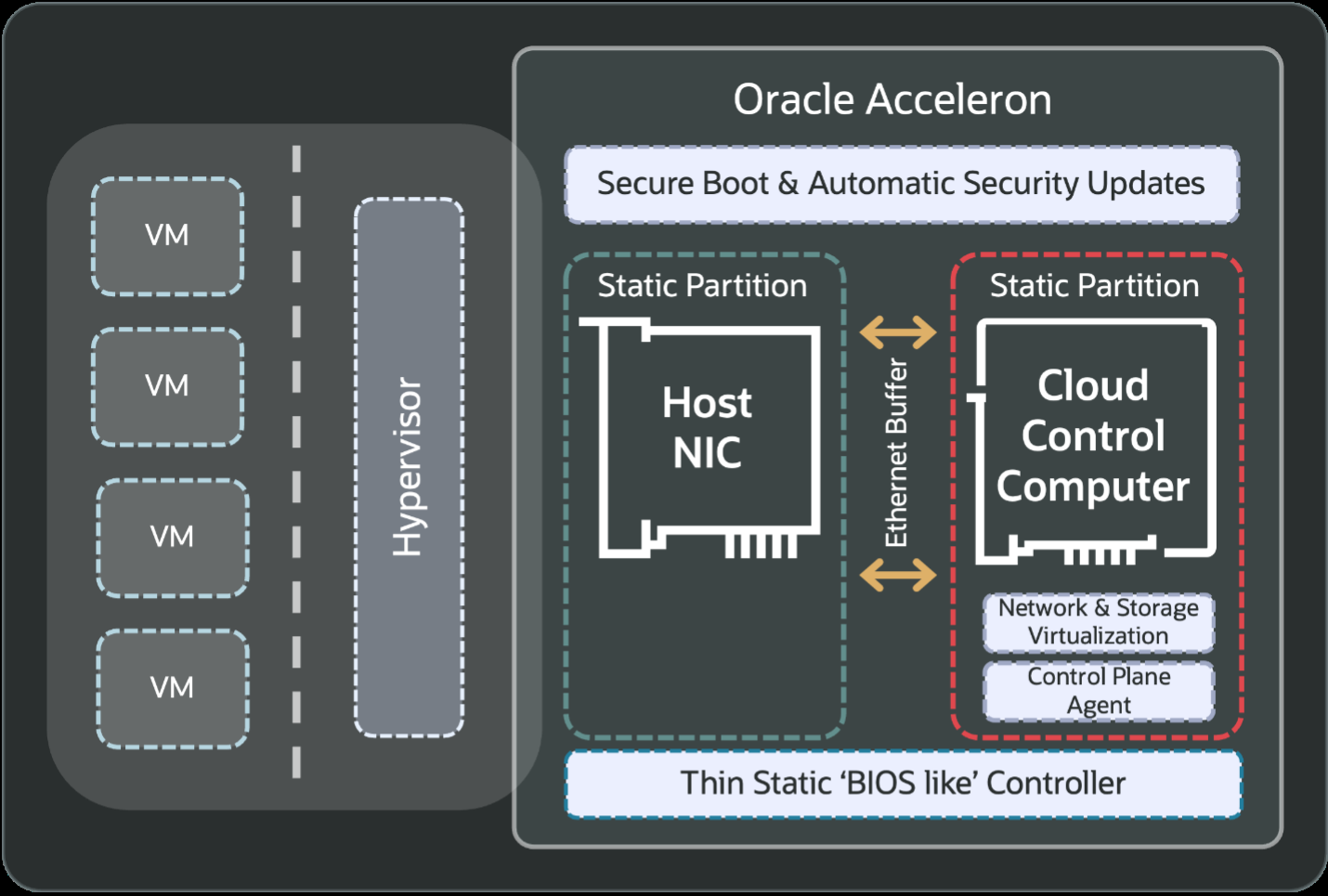
Источник изображения: Oracle OCI уже принимает заказы на OCI Zettascale10, который поступит в продажу во II половине следующего календарного года. В августе NVIDIA анонсировала решение Spectrum-XGS Ethernet для объединения нескольких ЦОД в одну ИИ-суперфабрику, которым, по-видимому, воспользуется не только Oracle, но и Meta✴.
11.10.2025 [11:45], Сергей Карасёв
Молдова стала участником европейской суперкомпьютерной программы EuroHPC JUЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о том, что Молдова стала 37-м государством, присоединившимся к данному проекту. Решение принято в ходе очередного заседания Совета управляющих EuroHPC JU. Отмечается, что с января 2012 года Молдова активно участвует в инициативах Европейского союза по исследованиям и инновациям. В частности, в рамках программы Horizon 2020 специалистам из академических кругов, исследовательских институтов, органов государственной власти и индустриального сектора Молдовы предоставляется доступ к суперкомпьютерам EuroHPC. 
Источник изображения: EuroHPC JU Теперь Молдова стала полноправным участником EuroHPC: ожидается, что это позволит укрепить взаимодействие между страной и другими европейскими исследователями. В частности, молдавские ученые смогут подавать заявки на исследовательские и инновационные инициативы EuroHPC JU, финансируемые по программе Horizon Europe. Речь идёт о разработке суперкомпьютерных технологий и сопутствующих программных продуктов. Кроме того, Молдова сможет принять участие в запуске фабрик ИИ (EuroHPC AI Factories), которые формируются по всей Европе. Эти площадки призваны помочь в создании высококонкурентной и инновационной европейской экосистемы ИИ. Молдова присоединилась к другим государствам — участникам программы EuroHPC JU, которые не являются членами Евросоюза. В их число также входят Албания, Исландия, Израиль, Черногория, Северная Македония, Норвегия, Сербия, Турция и Великобритания. Эти страны сотрудничают с ЕС с целью достижения стратегической независимости в области HPC, ИИ, квантовых вычислений и суперкомпьютерных технологий. В настоящее время EuroHPC JU курирует реализацию 13 проектов по созданию фабрик ИИ. Недавно при участии EuroHPC JU был официально введён в эксплуатацию первый в Европе суперкомпьютер экзафлопсного класса — система JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research), которая размещена в Юлихском исследовательском центре (FZJ) в Германии. EuroHPC JU также разворачивает европейскую инфраструктуру квантовых вычислений, интегрируя квантовые технологии с существующими суперкомпьютерами.
07.10.2025 [09:13], Сергей Карасёв
«Росатом» создал российский интерконнет «Альфа»: до 80 Гбит/с на порт и до 4096 узловНаучно-производственное объединение «Критические информационные системы» (НПО КИС), входящее в «Росатом», представило коммуникационную сеть Альфа, предназначенную для передачи данных между узлами вычислительных систем с высокой скоростью и малой задержкой. В качестве сфер применения сети «Альфа» названы СХД, СУБД, суперкомпьютеры и кластеры (в том числе на основе GPU), бортовые вычислительные комплексы и пр. Архитектура «Альфы» предполагает использование чипа на базе ПЛИС и хост-интерфейса PCIe 3.0 x16. Топология — 5D-тор, Fat Tree, Dragonfly+. Реализована поддержка медных и оптических кабелей, прямого доступа в память удалённого узла (RDMA), атомарных операций и вызовов удалённых прерываний, а также счётчиков производительности и исключительных ситуаций. Передача данных происходит без участия ядра ОС (в пространстве пользователя). 
Источник изображения: «Росатом» Заявленная пропускная способность достигает 80 Гбит/с на порт, пропускная способность MPI (Message Passing Interface) — 72,5 Гбит/с. Задержка между соседними узлами составляет 1,7 мкс, задержка узла — 0,5 мкс. Темп выдачи сообщений — 50 МТ/с. Возможно масштабирование до 4096 узлов. 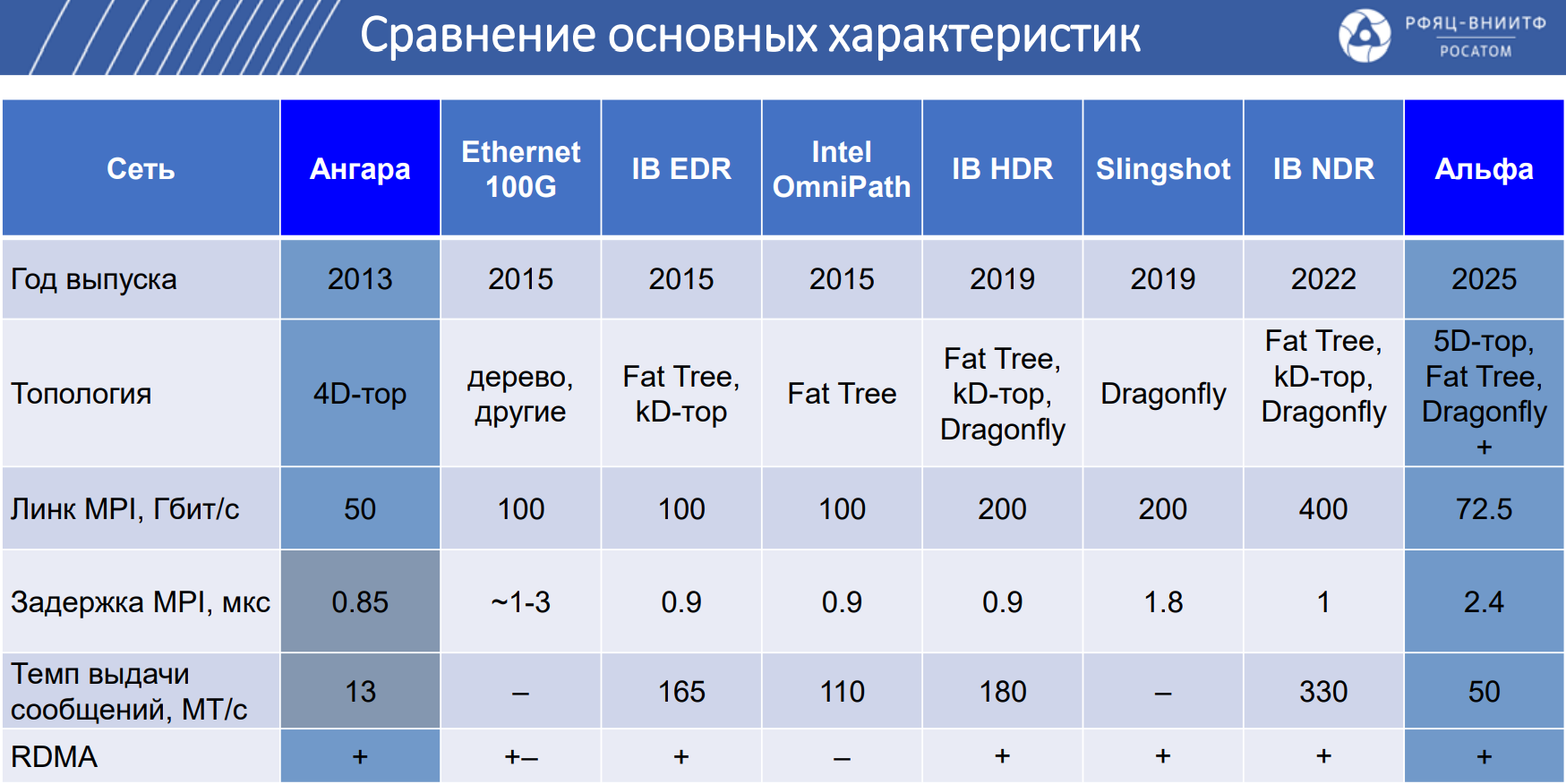
Источник изображения: «Росатом» Для сети «Альфа» разработаны адаптер и коммутатор. Первый выполнен в виде HHHL-карты с интерфейсом PCIe 3.0 x16. Предусмотрены два порта QSFP-DD. Применяется пассивная система охлаждения, потребляемая мощность — до 29,5 Вт. Изделие имеет размеры 142,25 × 68,9 × 17,25 мм. Возможно объединение в кольцо до восьми адаптеров без использования коммутатора. 
Источник изображения: НПО КИС В свою очередь, коммутатор располагает 32 портами QSFP-DD: устройство представляет собой четыре модуля коммутации, соединённых в кольцо. Решение выполнено в форм-факторе 1U с габаритами 650 × 43,6 × 440 мм. Используется активное воздушное охлаждение, а энергопотребление не превышает 300 Вт. Коммутатор получил блок питания с резервированием.
04.10.2025 [12:56], Сергей Карасёв
Fujitsu и NVIDIA создадут вычислительную ИИ-инфраструктуру нового поколенияЯпонская корпорация Fujitsu объявила о расширении стратегического сотрудничества с NVIDIA с целью создания полнофункциональной инфраструктуры ИИ следующего поколения, в состав которой войдут ИИ-агенты. Предполагается, что инициатива поможет ускорить развитие таких отраслей, как здравоохранение, производство, робототехника и др. Партнёры намерены работать по ряду направлений. В частности, Fujitsu и NVIDIA займутся созданием передовой вычислительной инфраструктуры для задач ИИ. Речь идёт об объединении серверных процессоров Fujitsu Monaka на архитектуре Arm с высокопроизводительными GPU разработки NVIDIA. Для этого будет задействована технология NVLink Fusion, позволяющая применять скоростные интерконнекты NVLink со сторонними чипами. Конечной целью является предоставление комплексной экосистемы HPC-ИИ с интегрированным софтом Fujitsu для Arm-процессоров и NVIDIA CUDA. Кроме того, сотрудничество предусматривает создание «саморазвивающейся» платформы ИИ-агентов. Она, как ожидается, обеспечит высокую производительность и безопасность. Планируется внедрение механизма, который позволит агентам и моделям ИИ развиваться автономно с возможностью оптимизации под запросы конкретных отраслей. В конечном итоге, такие агенты будут предоставляться заказчикам в виде микросервисов NVIDIA NIM. 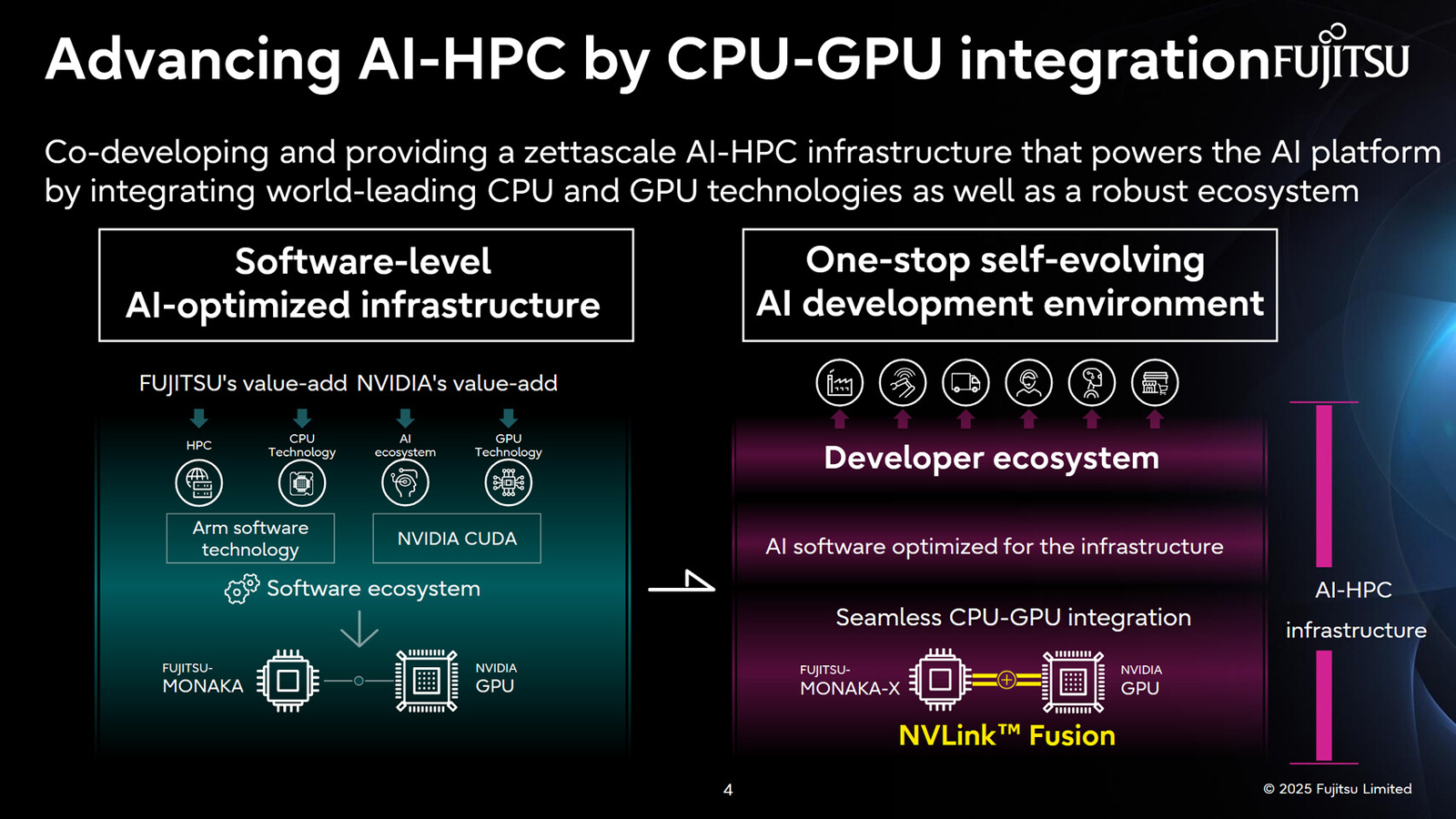
Источник изображений: Fujitsu Ещё одним направлением сотрудничества названо формирование партнёрской экосистемы для расширения использования агентов и моделей ИИ. Планируется также разработка передовых квантовых технологий, включая гибридные квантово-классические вычислительные системы на основе чипов Monaka и НРС-решений NVIDIA.  В целом, как отмечается, к 2030 году спрос на вычислительные мощности для ИИ в Японии вырастет в 320 раз по сравнению с 2020-м. На этом фоне местные компании, включая Fujitsu, SoftBank и KDDI, активно реализуют различные проекты, направленные на развитие рынка ИИ.
02.10.2025 [15:28], Руслан Авдеев
Дата-центр радиотелескопа Square Kilometre Array (SKA) «засадили» сразу в две клетки Фарадея для защиты сверхчувствительных антенн от радиопомехРаботы в дата-центре, предназначенным для обслуживания радиообсерватории Square Kilometre Array (SKA) на западе Австралии, практически завершены. В числе прочего установлены две клетки Фарадея, блокирующие радиоволны — это делается, чтобы ЦОД не повлияли на работу сверхчувствительных антенн гигантского радиотелескопа, сообщает The Register. SKA представляет собой международный проект, предусматривающий строительство 131 072 антенн. Это крупнейший радиоинтерферометр в мире, потенциально позволяющий совершенно по-новому взглянуть на Вселенную. Работы начались в 2022 году. По имеющимся данным, уже установлено 12 100 антенн, работы по прокладке силовых кабелей и оптоволокна тоже в основном завершены. Работы над дата-центром в Мерчисоне (Murchison, штат Виктория), отдалённой части SKA, тоже завершены. Мерчисон выбран потому, что там почти нет людей и, следовательно, современной техники, что позволяет соблюдать режим радиомолчания. В дата-центре размещены около 100 стоек с серверами на базе FPGA, которые отвечают за фильтрацию терабайт данных, ежедневно собираемых SKA. Ценная информация будет отправляться по 10-Тбайт/с ВОЛС суперкомпьютеру в городе Перт (Perth). 
Источник изображения: SKA Observatory Несмотря на то, что в Мерчисоне в целом мало электронных устройств, компьютеры генерируют немало радиопомех. Хотя в большинстве случаев в ЦОД и офисах это не проблема, в случае с SKA дело обстоит совсем иначе, поскольку тот настроен на поиск даже самых слабых сигналов. Именно поэтому ЦОД поместили сразу в две «клетки Фарадея». Экранированы даже входы в здание, а внутренняя дверь не откроется, пока не закрыта внешняя. Строительство на объекте SKA, вероятно, продолжится до 2029 года. В 2026 году учёным предложат представить собственные предложения по использованию радиотелескопа, некоторые выберут для испытаний SKA в 2027 году — к тому времени SKA уже будет самым большим «физическим низкочастотным радиотелескопом на планете». Руководство SKA уверено, что даже тесты 2027 года уже дадут результаты, достойные включения в научные труды. Одно из препятствий — поиск дополнительных средств. У SKA пока есть лишь 80 % средств для завершения проекта.
02.10.2025 [10:56], Сергей Карасёв
РСК представила внешний JBOG-массив RSC ScaleStream-CГруппа компаний РСК представила на международной конференции «Суперкомпьютерные дни в России», прошедшей в МГУ имени Ломоносова, внешний массив PCIe-коммутации RSC ScaleStream-C (JBOG). Это решение предназначено для установки ускорителей GPU/TPU с целью повышения производительности серверов при работе с различными ресурсоёмкими приложениями, включая задачи ИИ и НРС. Решение RSC ScaleStream-C выполнено в форм-факторе 3U. Допускается установка до десяти карт с интерфейсом PCIe x16 (до 600 Вт), связанных интерконнектом NVLink. При использовании ускорителей на базе GPU применяется гибридное охлаждение, при работе с TPU — воздушное. Питание обеспечивают четыре блока мощностью 2200 Вт каждый. Массив может монтироваться в стандартную 19″ серверную стойку. Задействованы средства управления и мониторинга на базе Redfish, RESTful API, GUI разработки РСК. К системе RSC ScaleStream-C могут быть подсоединены до четырёх серверов посредством внешних кабелей на базе стандарта PCIe 4.0 x16. Ресурсы GPU/TPU могут динамически перераспределяться между подключенными серверами, что, как утверждается, обеспечивает уникальные возможности по созданию оптимальных конфигураций под конкретную нагрузку. Благодаря этому достигается наиболее эффективное использование вычислительных мощностей ИИ-ускорителей, используемых в составе массива. РСК заявляет, что утилизация GPU в некоторых случаях повышается на десятки процентов по сравнению с применением ускорителей в составе традиционных серверных платформах. 
Источник изображения: РСК В целом, RSC ScaleStream-C обеспечивает производительность до 300 ТФлопс (FP64) на массив в случае применения десяти ускорителей NVIDIA H200. При установке карт LinQ HPQ, разработанных российской компании «ХайТэк», быстродействие достигает 960 TOPS на операциях INT8. Среди ключевых сфер применения новинки названы: машинное обучение и ИИ (инференс и работа с большими языковыми моделями), НРС-нагрузки (научные исследования и моделирование), анализ больших данных, виртуализация, криптография и блокчейн (майнинг криптовалют и задачи распределенных реестров).
21.09.2025 [13:23], Сергей Карасёв
В Германии запущена квантово-классическая система с суперчипами NVIDIA GH200Компании Quantum Machines и Arque Systems развернули в Юлихском суперкомпьютерном центре в Германии (Jülich Supercomputing Centre, JSC) гибридную квантово-классическую вычислительную систему на платформе NVIDIA DGX Quantum. Это первый подобный проект, реализованный на базе крупной НРС-площадки в Европе. Новая система сочетает суперчипы NVIDIA GH200, 5-кубитный квантовый процессор Arque Systems и гибридный квантово-классический контроллер Quantum Machines OPX1000. Использованная архитектура, как утверждается, обеспечивает возможность квантовой коррекции ошибок (QEC), что является критически важным требованием при организации практических квантовых вычислений. Контроллер OPX1000, как отмечается, обеспечивает бесшовное взаимодействие между классическими и квантовыми вычислительными ресурсами. Достигается двусторонняя передача данных с задержкой менее 4 мкс, что в 1000 раз лучше, чем в предыдущих подобных реализациях. 
Источник изображения: Arque Systems Ключевыми задачами проекта названы ускорение процедур калибровки кубитов и тестирование производительности квантовой коррекции ошибок. Кроме того, на базе комплекса планируется осуществлять разработку гибридных квантово-классических вычислительных алгоритмов. Одним из главных преимуществ платформы названа возможность запуска нейронных сетей и моделей машинного обучения на высокопроизводительных GPU с сохранением взаимодействия с квантовой подсистемой с низкой задержкой. Такой уровень интеграции, как подчёркивается, недоступен ни в одной другой современной системе квантовых вычислений. «Объединяя квантовые и классические вычислительные ресурсы на базе ведущего европейского суперкомпьютерного центра, мы открываем новые возможности для исследователей в плане изучения гибридных квантово-классических алгоритмов», — говорит доктор Кристель Михильсен (Kristel Michielsen), директор JSC. Нужно отметить, что JSC является оператором первого в Европе экзафлопсного суперкомпьютера — машины JUPITER, которая была официально запущена в эксплуатацию в сентябре 2025 года. Система использует примерно 6000 вычислительных узлов с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200 (4×200G на узел, DragonFly+): в общей сложности задействованы почти 24 тыс. NVIDIA GH200.
17.09.2025 [11:04], Сергей Карасёв
В США появится ИИ-суперкомпьютер с Arm-процессорами AmpereOne M и ускорителями Qualcomm Cloud AIУниверситет штата Нью-Йорк в Стони-Бруке (SBU) объявил о получении гранта в размере $13,77 млн от Национального научного фонда США (NSF) на приобретение и эксплуатацию высокопроизводительного энергоэффективного суперкомпьютера для задач ИИ. Средства получит Институт передовых вычислительных наук (IACS) в составе SBU. В проекте также примет участие Университет штата Нью-Йорк в Буффало (UB). Деньги выделяются в рамках программы Sustainable Cyber-infrastructure for Expanding Participation (Устойчивая киберинфраструктура для расширенной совместной работы). В основу НРС-комплекса, который пока не получил определённого названия, лягут процессоры AmpereOne M, разработанные компанией Ampere Computing специально для ресурсоёмких ИИ-нагрузок в дата-центрах. Эти чипы насчитывают до 192 кастомизированных 64-бит ядер на базе Arm v8.6+ Реализована поддержка 12 каналов DDR5-5600 и 96 линий PCIe 5.0. Кроме того, в состав суперкомпьютера войдут ИИ-ускорители Qualcomm Cloud AI, которые несут на борту до 576 Мбайт SRAM и до 128 Гбайт памяти LPDDR4x с пропускной способностью до 548 Гбайт/с. Расчётные показатели быстродействия машины пока не раскрываются.  Ожидается, что комбинация AmpereOne M и Qualcomm Cloud AI обеспечит высокую энергоэффективность, а также значительную производительность, достаточную для работы с крупными ИИ-моделями. Доступ к ресурсам суперкомпьютера планируется предоставлять исследователям, студентам и преподавателям на всей территории США. Новый НРС-комплекс поможет ускорить открытия в области геномики, биоинформатики и в других областях. Кроме того, система будет применяться при реализации проектов в сферах машинного обучения и статистического анализа.
06.09.2025 [13:42], Сергей Карасёв
Состоялся официальный запуск первого в Европе экзафлопсного суперкомпьютера JUPITERВ Юлихском исследовательском центре (FZJ) в Германии официально введён в эксплуатацию суперкомпьютер JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) — первый в Европе вычислительный комплекс экзафлопсного класса. Система будет использоваться в том числе для исследований в области климата, нейробиологии и квантового моделирования. Контракт на создание JUPITER подписан между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (Atos) и ParTec. Суперкомпьютер состоит из блока Booster для решения ресурсоёмких задач и универсального блока cCuster. В основу Booster положена платформа BullSequana XH3000 с прямым жидкостным охлаждением. Используются около 6000 вычислительных узлов с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200 (4×200G на узел, DragonFly+). В общей сложности задействованы почти 24 тыс. суперчипов NVIDIA GH200 (Grace Hopper). В июньском рейтинге TOP500 блок JUPITER Booster располагался на четвёртом месте: на тот момент его FP64-производительность составляла 793,4 Пфлопс. Теперь показатель преодолел рубеж в 1 Эфлопс. При этом ИИ-производительность, как ожидается, будет находиться на уровне 90 Эфлопс. 
Источник изображений: Forschungszentrum Jülich / Sascha Kreklau «С запуском первого в Европе эксафлопсного суперкомпьютера мы открываем новую главу в развитии науки, искусственного интеллекта и инноваций. JUPITER укрепляет цифровой суверенитет Европы и ускоряет научные исследования», — отмечает Екатерина Захариева (Ekaterina Zaharieva), еврокомиссар по стартапам, исследованиям и инновациям.  JUPITER планируется использовать для прогнозирования погоды и моделирования изменений климата, работы с европейскими большими языковыми моделями (LLM) и генеративным ИИ, разработки лекарственных препаратов и картирования человеческого мозга, моделирования молекулярной динамики и пр. Ожидается, что JUPITER сможет побить мировой рекорд по скорости обработки кубитов в квантовых вычислениях.  Между тем продолжается создание блока cCuster. В его состав войдут энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1. Эти чипы содержат 80 ядер Neoverse V1 (Zeus), 64 Гбайт HBM2e и четыре интерфейса DDR5. Модуль cCuster будет оснащён двумя такими процессорами на каждый вычислительный узел, 512 Гбайт DDR5 (в отдельных узлах 1 Тбайт) и одним NDR200-подключением. Общее количество узлов составит около 1300. Ожидаемая FP64-производительность — 5 Пфлопс.  Хранилище суперкомпьютера включает быструю СХД ExaFLASH и ёмкую ExaSTORE. ExaFLASH включает 20 All-Flash СХД IBM Storage Scale 6000: 21 Пбайт («сырая» 29 Пбайт), запись до 2 Тбайт/с, чтение до 3 Тбайт/с. В ExaSTORE под хранение будет выделена «сырая» ёмкость 300 Пбайт, а для резервного копирования и архивов будет использоваться ленточная библиотека ёмкостью 700 Пбайт. 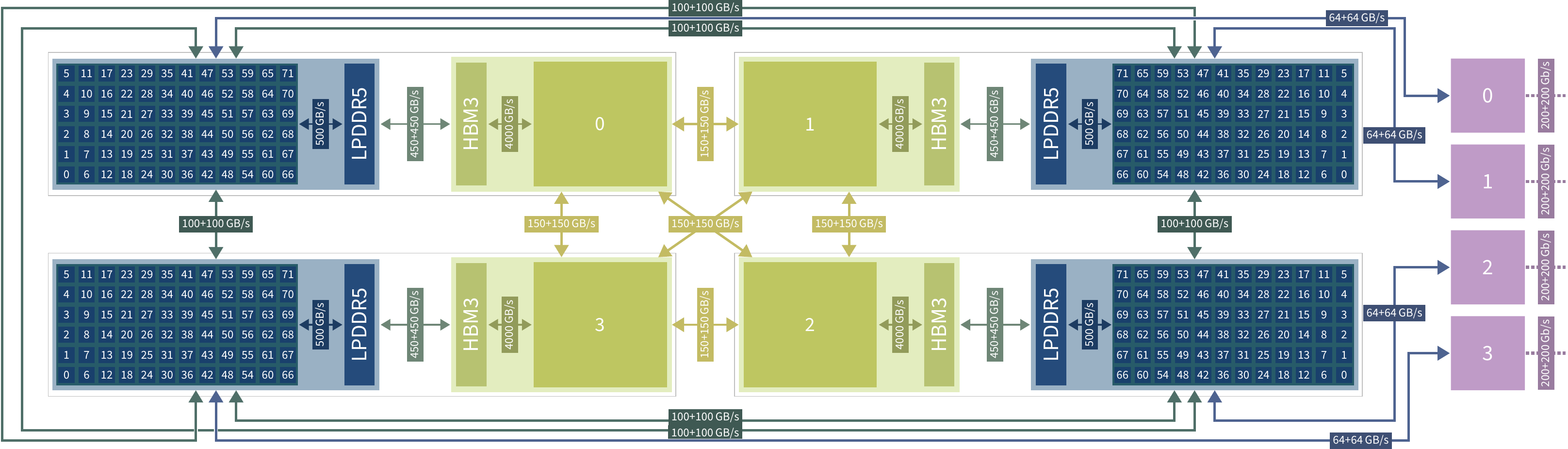
Узел Booster По оценкам, суммарные расходы на JUPITER и его эксплуатацию в течение шести лет достигнут примерно €500 млн. Половину от этой суммы предоставит EuroHPC, а остальную часть покроют Федеральное министерство образования и научных исследований Германии (BMBF) и Министерство культуры и науки земли Северный Рейн-Вестфалия (MKW NRW). Машина размещена в модульном ЦОД, что упростит дальнейшую модернизацию. Нужно отметить, что на сегодняшний день только три суперкомпьютера в мире официально преодолели планку в 1 Эфлопс. Это машины El Capitan, Frontier и Aurora: все они установлены в лабораториях Министерства энергетики США (DoE). Впрочем, Китай о своих HPC-комплексах публично практически не говорит уже несколько лет, так что реальный список экзафлопсных систем гораздо больше.
28.08.2025 [09:28], Владимир Мироненко
ASUS Cloud увеличит вычислительные мощности Тайваня на 50 %, построив 250-Пфлопс ИИ-суперкомпьютерASUS Cloud в партнёрстве с Taiwan AI Cloud (Taiwan Web Service Corp) и Национальным центром высокопроизводительных вычислений Тайваня (National Center for High-performance Computing, NCHC) в Тайнане (Тайвань) построит суперкомпьютер на ускорителях NVIDIA. Об этом сообщил гендиректор ASUS Cloud и Taiwan AI Cloud Питер Ву (Peter Wu, на фото ниже) в интервью газете South China Morning Post (SCMP). Питер Ву рассказал, что суперкомпьютер с начальной производительностью 80 Пфлопс (точность не уточняется) будет работать на 1700 ускорителях NVIDIA H200. Его запуск запланирован на декабрь, а со временем производительность новой системы вырастет до 250 Пфлопс. Ранее сообщалось, что NVIDIA также поставит два суперускорителя GB200 NVL72 и узлы HGX B300 для данной машины. По словам Ву, после запуска суперкомпьютера общая вычислительную мощность HPC-систем Тайваня вырастет минимум на 50 %. В феврале 2025 года Национальный совет по науке и технологиям Тайваня (NSTC) объявил о планах по увеличению общей вычислительной мощности систем страны примерно до 1200 Пфлопс к 2029 году с имеющихся 160 Пфлопс. 
Источник изображения: ASUS Как отметил DataCenter Dynamics, ASUS ранее сотрудничала с NVIDIA в развёртывании суперкомпьютеров на Тайване, включая 9-Плфопс машину Taiwania 2. В 2022 году ASUS и NVIDIA построили на Тайване суперкомпьютер для медицинских исследований. Taiwan AI Cloud уже реализовала аналогичные нынешнему проекты по созданию ИИ-инфраструктуры в других странах. Среди них — ЦОД в Сингапуре, а также объект во Вьетнаме с 200 ускорителями NVIDIA, который строят для государственного оператора Viettel. Этот проект стартовал в начале 2025 года после того, как правительство США одобрило поставку чипов NVIDIA. Ву отметил рост популярности агентного ИИ. Министерство цифровых технологий острова (MODA) «рекомендовало нам предоставить открытую архитектуру с фреймворком агентного ИИ», чтобы помочь местным компаниям использовать или модернизировать свои существующие приложения, сказал он. Говоря о материковом Китае, Питер Ву заявил, что компании будет «непросто» реализовывать там аналогичные проекты «из-за ситуации с поставками GPU». Китайский подход, заключающийся в «стекировании и кластеризации» малопроизводительных чипов для достижения производительности, аналогичной системам с передовыми ИИ-ускорителями, может быть осуществим с точки зрения инференса. Ву отметил, что запуск DeepSeek «рассуждающей» модели R1 в январе спровоцировал рост спроса на инференс, поскольку эта модель превосходно справляется с такими задачами. «Если рабочая нагрузка аналогична [инференсу], будет легче внедрить альтернативную технологическую схему с существующими [чипами]», — сказал Ву, добавив, что разработчики «могут столкнуться с проблемами в выборе GPU», если проект предполагает обучение или тонкую настройку ИИ-систем. Говоря о будущем, Ву сообщил, что ожидает дальнейшего развития трёх сегментов ИИ в будущем: вычислительной геномики, квантовых вычислений и так называемых цифровых двойников. «Приложение-убийца [для цифровых двойников] может появиться в сфере ухода за пожилыми людьми, помогая им получать лекарства, еду или принимать душ», — прогнозирует Ву. |
|

