Материалы по тегу: c
|
28.10.2021 [17:02], Алексей Степин
Rockport Networks представила интерконнект с пассивным оптическим коммутаторомПроизводительность любого современного суперкомпьютера или кластера во многом зависит от интерконнекта, объединяющего вычислительные узлы в единое целое, и практически обязательным компонентом такой сети является коммутатор. Однако последнее не аксиома: компания Rockport Networks представила своё видение HPC-систем, не требующее использования традиционных коммутирующих устройств. Проблема межсоединений существовала в мире суперкомпьютеров всегда, даже в те времена, когда сам процессор был набором более простых микросхем, порой расположенных на разных платах. В любом случае узлы требовалось соединять между собой, и эта подсистема иногда бывала неоправданно сложной и проблемной. Переход на стандартные сети Ethernet, Infiniband и их аналоги многое упростил — появилась возможность собирать суперкомпьютеры по принципу конструктора из стандартных элементов. 
Пассивный оптический коммутатор SHFL Тем не менее, проблема масштабирования (в том числе и на физическом уровне кабельной инфраструктуры), повышения скорости и снижения задержек никуда не делась. У DARPA даже есть особый проект FastNIC, нацеленный на 100-кратное ускорение сетевых интерфейсов, чтобы в конечном итоге сгладить разницу в скорости обмена данными внутри узлов и между ними.  Сам по себе высокоскоростной коммутатор для HPC-систем — устройство непростое, требующее использования недешёвого и сложного кремния, и вкупе с остальными компонентами интерконнекта может составлять заметную долю от стоимости всего кластера в целом. При этом коммутаторы могут вносить задержки, по определению являясь местами избыточной концентрации данных, а также требуют дополнительных мощностей подсистем питания и охлаждения.  Подход, продвигаемый компанией Rockport Networks, свободен от этих недостатков и изначально нацелен на минимизацию точек избыточности и возможных коллизий. А достигнуто это благодаря архитектуре, в которой концепция традиционного сетевого коммутатора отсутствует изначально. Вместо этого имеется специальный модуль SHFL, в котором топология сети задаётся оптически, а все логические задачи берут на себя специализированные сетевые адаптеры, работающие под управлением фирменной ОС rNOS и имеющие на борту сконфигурированную нужным образом ПЛИС. 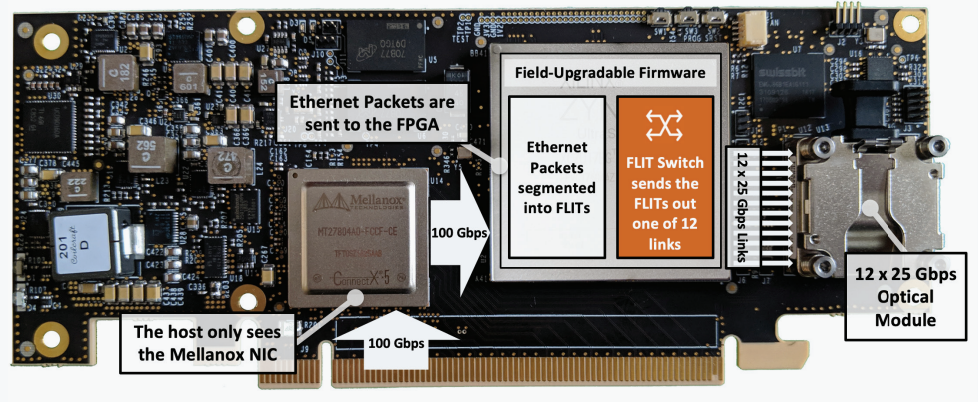 Модуль SHFL даже не требует отдельного электропитания, а вот адаптеры Rockport NC1225 его хотя и требуют, но умещаются в конструктив низкопрофильного адаптера с разъёмом PCIe x16 и потребляют всего 36 Вт. Правда, в настоящий момент речь идёт только о PCIe 3.0, поэтому полнодуплексного подключения на скорости 200 Гбит/с пока нет. Тем не менее, Техасский центр передовых вычислений (TACC) посчитал, что этого уже достаточно и стал одним из первых заказчиков — 396 узлов суперкомпьютера Frontera используют решение Rockport. 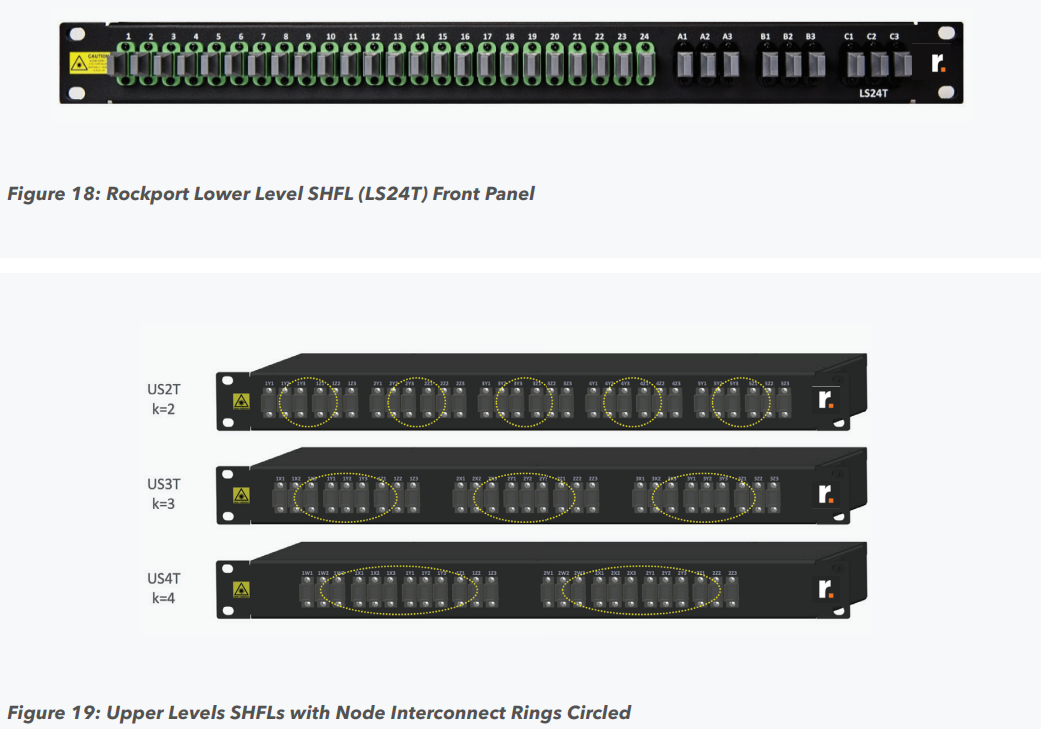 Использование не совсем традиционной оптической сети, впрочем, накладывает свои особенности: вместо популярных *SFP-корзин используются разъёмы MTP/MPO-24, а каждый кабель даёт для подключения 12 отдельных волокон, что при скорости 25 Гбит/с на волокно позволит достичь совокупной пропускной способности 300 Гбит/с. ОС и приложениям адаптер «представляется» как чип Mellanox ConnectX-5, который и входит в его состав, а потому не требует каких-то особых драйверов или модулей ядра. 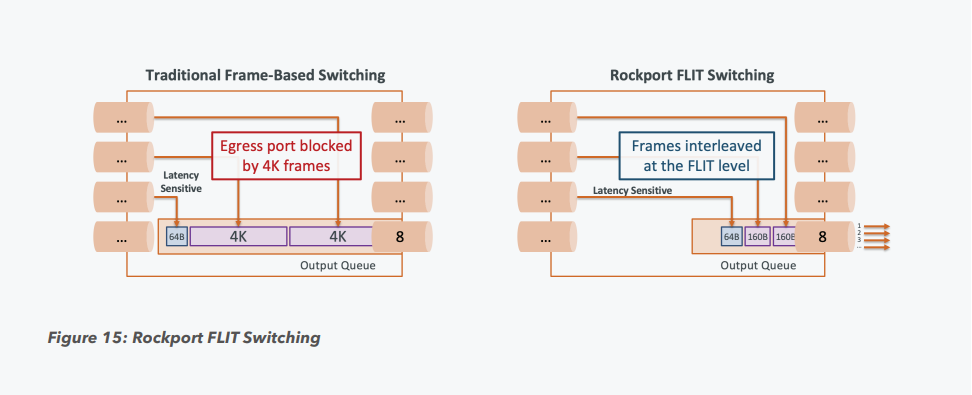 Rockport фактически занимается транспортировкой Ethernet и реализует уровень OSI 1/1.5, однако традиционной коммутации как таковой нет — адаптеры самостоятельно определяют конфигурацию сети и оптимальные маршруты передачи сигнала по отдельным волокнам с возможностью восстановления связности на лету при каких-либо проблемах. Весь трафик разбивается на маленькие кусочки (FLIT'ы) и отправляется по виртуальным каналам (VC) с чередованием, что позволяет легко управлять приоритизацией (в том числе на L2/L3) и снизить задержки.  SHFL имеет 24 разъёма для адаптеров и ещё 9 для объединения с другими SHFL и Ethernet-шлюзами для подключения к основной сети ЦОД (в ней сеть Rockport видна как обычная L2). Таким образом, в составе кластера каждый узел может быть подключён как минимум к 12 другим узлам на скорости 25 Гбит/с. Однако топологию можно менять по своему усмотрению. Компания-разработчик заявляет о преимуществе своего интерконнекта на классических HPC-задачах, могущем достигать почти 30% при сравнении c InfiniBand класса 100G и даже 200G. Кроме того, для Rockport требуется на 72% меньше кабелей.
22.10.2021 [20:03], Руслан Авдеев
Для обеспечения работы суперкомпьютера El Capitan потребуется 28 тыс. тонн воды и 35 МВт энергииК моменту ввода в эксплуатацию в 2023 году суперкомпьютер El Capitan на базе AMD EPYC Zen4 и Radeon Instinct, как ожидается, будет иметь самую высокую в мире производительность — более 2 Эфлопс. А это означает, что ему потребуются гигантские мощности для питания и охлаждения. Ливерморская национальная лаборатория (LLNL), в которой и будет работать El Capitan, поделилась подробностями о масштабном проекте, призванном обеспечить HPC-центр необходимой инфраструктурой. В основе плана модернизации лежит проект Exascale Computing Facility Modernization (ECFM) стоимостью около $100 млн. В его рамках будет обновлена уже существующая в LLNL инфраструктура. Для реализации проекта необходимо получить очень много разрешений от местных регуляторов и очень тесно взаимодействовать с местными поставщиками электроэнергии. Тем не менее, LLNL заявляет, что проект «почти готов», по некоторым оценкам — на 93%. Функционировать новая инфраструктура должна с мая 2022 года (с опережением графика).  Сам проект стартовал ещё в 2019 году и, согласно планам, должен быть полностью завершён в июле 2022 года. В его рамках модернизируют территорию центра, введённого в эксплуатацию в 2004 году, общей площадью около 1,4 га. Если раньше центр, в котором работали системы вроде лучшего для 2012 года суперкомпьютера Sequoia (ныне выведенного из эксплуатации), обеспечивал подачу до 45 МВт, то теперь инфраструктура рассчитана уже на 85 МВт. Конечно, даже для El Capitan такие мощности будут избыточны — ожидается, что суперкомпьютер будет потреблять порядка 30-35 МВт. Однако LLNL заранее думает о «жизнеобеспечении» преемника El Capitan. Следующий суперкомпьютер планируется ввести в эксплуатацию до того, как его предшественник будет отключён в 2029 году. Кроме того, для новой системы потребуется установка нескольких 3000-тонных охладителей. Если раньше общая ёмкость системы охлаждения составляла 10 000 т воды, то теперь она вырастет до 28 000 т.
22.09.2021 [21:16], Алексей Степин
Выпущена тестовая партия европейских высокопроизводительных RISC-V процессоров EPI EPAC1.0Наличие собственных высокопроизводительных процессоров и сопровождающей их технической инфраструктуры — в современном мире вопрос стратегического значения для любой силы, претендующей на первые роли. Консорциум European Processor Initiative (EPI), в течение долгого времени работавший над созданием мощных процессоров для нужд Евросоюза, наконец-то, получил первые весомые плоды. О проекте EPI мы неоднократно рассказывали читателям в 2019 и 2020 годах. В частности, в 2020 году к консорциуму по разработке мощных европейских процессоров для систем экза-класса присоединилась SiPearl. Но сегодня достигнута первая серьёзная веха: EPI, насчитывающий на данный момент 28 членов из 10 европейских стран, наконец-то получил первую партию тестовых образцов процессоров EPAC1.0. 
Источник изображений: European Processor Initiative (EPI) По предварительным данным, первичные тесты новых чипов прошли успешно. Процессоры EPAC имеют гибридную архитектуру: в качестве базовых вычислительных ядер общего назначения в них используются ядра Avispado с архитектурой RISC-V, разработанные компанией SemiDynamics. Они объединены в микро-тайлы по четыре ядра и дополнены блоком векторных вычислений (VPU), созданным совместно Барселонским Суперкомпьютерным Центром (Испания) и Университетом Загреба (Хорватия). 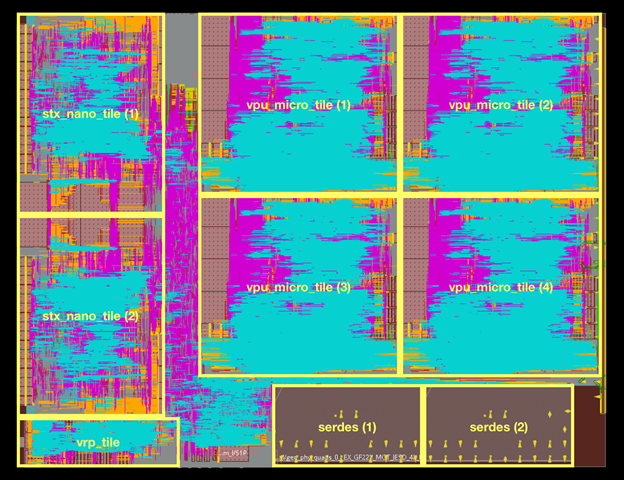
Строение кристалла EPAC1.0 Каждый такой тайл содержит блоки Home Node (интерконнект) с кешем L2, обеспечивающие когерентную работу подсистем памяти. Имеется в составе EPAC1.0 и описанный нами ранее тензорно-стенсильный ускоритель STX, к созданию которого приложил руку небезызвестный Институт Фраунгофера (Fraunhofer IIS). Дополняет картину блок вычислений с изменяемой точностью (VRP), за его создание отвечала французская лаборатория CEA-LIST. Все ускорители в составе нового процессора связаны высокоскоростной сетью, использующей SerDes-блоки от EXTOLL. 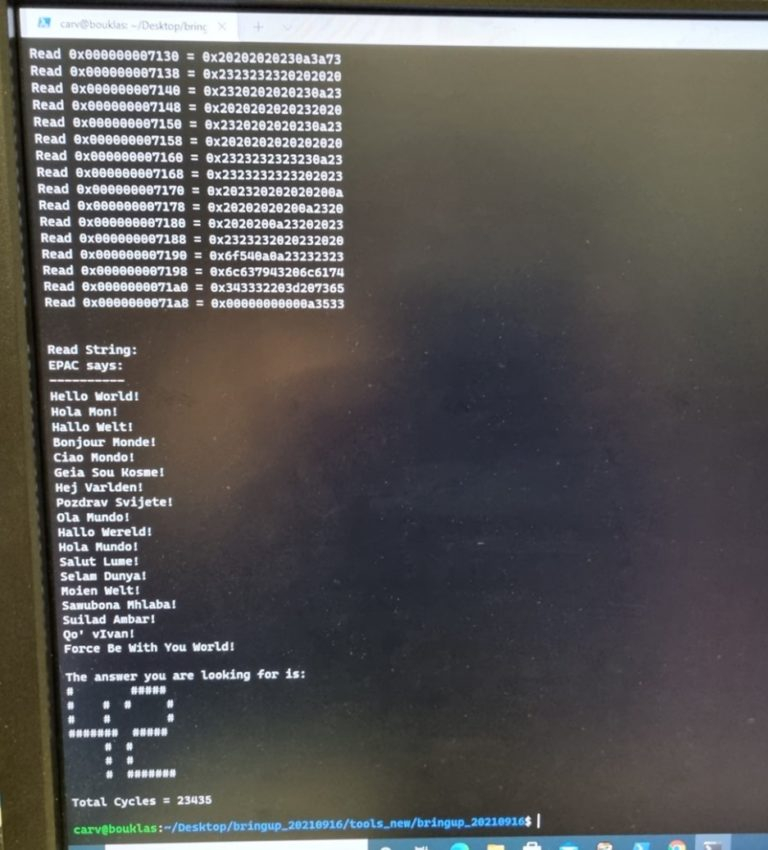 Первые 143 экземпляра EPAC произведены на мощностях GlobalFoundries с использованием 22-нм техпроцесса FDX22 и имеют площадь ядра 27 мм2. Используется упаковка FCBGA 22x22. Тактовая частота невысока, она составляет всего 1 ГГц. Отчасти это следствие использования не самого тонкого техпроцесса, а отчасти обусловлено тестовым статусом первых процессоров. Но новорожденный CPU жизнеспособен: он успешно запустил первые написанные для него программы, в числе прочего, ответив традиционным «42» на главный вопрос жизни и вселенной. Ожидается, что следующее поколение EPAC будет производиться с использованием 12-нм техпроцесса и получит чиплетную компоновку.
28.08.2021 [00:16], Владимир Агапов
Кластер суперчипов Cerebras WSE-2 позволит тренировать ИИ-модели, сопоставимые по масштабу с человеческим мозгомВ последние годы сложность ИИ-моделей удваивается в среднем каждые два месяца, и пока что эта тенденция сохраняется. Всего три года назад Google обучила «скромную» модель BERT с 340 млн параметров за 9 Пфлоп-дней. В 2020 году на обучение модели Micrsofot MSFT-1T с 1 трлн параметров понадобилось уже порядка 25-30 тыс. Пфлоп-дней. Процессорам и GPU общего назначения всё труднее управиться с такими задачами, поэтому разработкой специализированных ускорителей занимается целый ряд компаний: Google, Groq, Graphcore, SambaNova, Enflame и др.  Особо выделятся компания Cerebras, избравшая особый путь масштабирования вычислительной мощности. Вместо того, чтобы печатать десятки чипов на большой пластине кремния, вырезать их из пластины, а затем соединять друг с другом — компания разработала в 2019 г. гигантский чип Wafer-Scale Engine 1 (WSE-1), занимающий практически всю пластину. 400 тыс. ядер, выполненных по 16-нм техпроцессу, потребляют 15 кВт, но в ряде задач они оказываются в сотни раз быстрее 450-кВт суперкомпьютера на базе ускорителей NVIDIA.  В этом году компания выпустила второе поколение этих чипов — WSE-2, в котором благодаря переходу на 7-нм техпроцесс удалось повысить число тензорных ядер до 850 тыс., а объём L2-кеша довести до 40 Гбайт, что примерно в 1000 раз больше чем у любого GPU. Естественно, такой подход к производству понижает выход годных пластин и резко повышает себестоимость изделий, но Cerebras в сотрудничестве с TSMC удалось частично снизить остроту этой проблемы за счёт заложенной в конструкцию WSE избыточности. 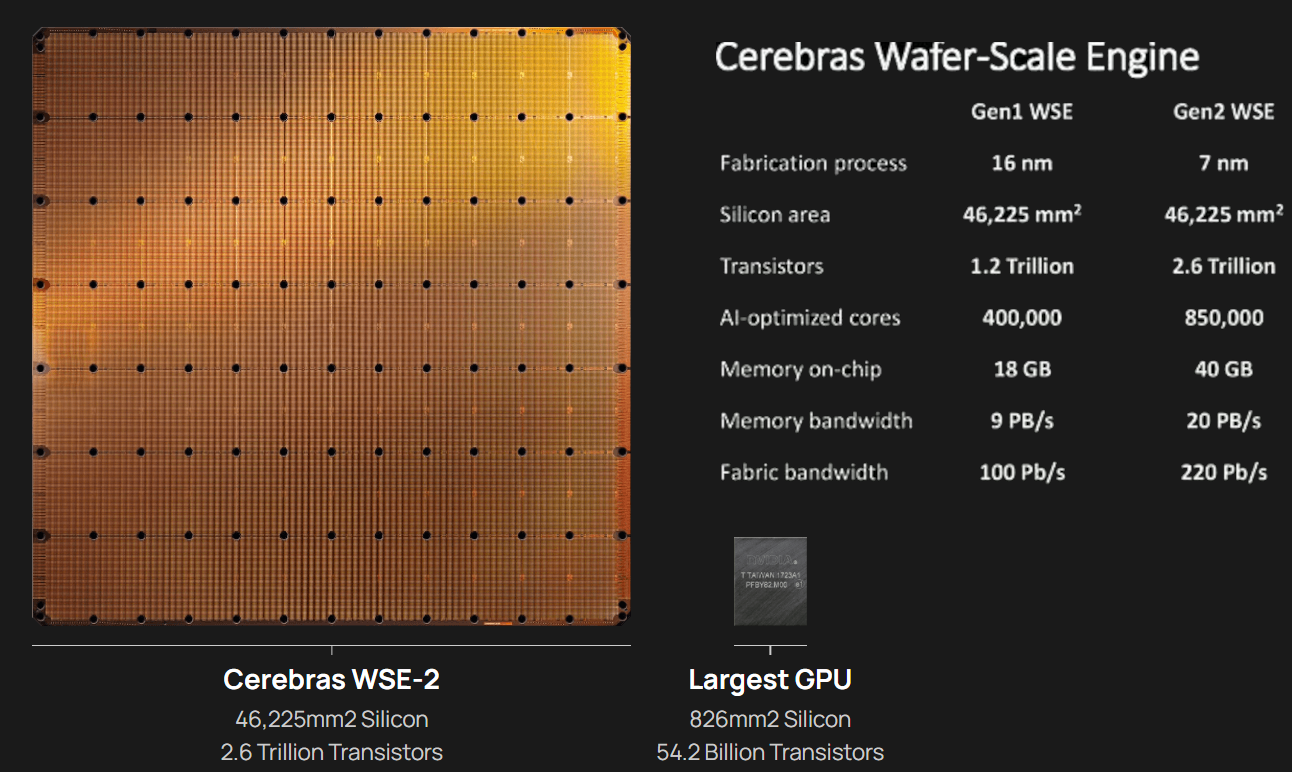 Благодаря идентичности всех ядер, даже при неисправности некоторых их них, изделие в целом сохраняет работоспособность. Тем не менее, себестоимость одной 7-нм 300-мм пластины составляет несколько тысяч долларов, в то время как стоимость чипа WSE оценивается в $2 млн. Зато система CS-1, построенная на таком процессоре, занимает всего треть стойки, имея при этом производительность минимум на порядок превышающую самые производительные GPU. Одна из причин такой разницы — это большой объём быстрой набортной памяти и скорость обмена данными между ядрами.  Тем не менее, теперь далеко не каждая модель способна «поместиться» в один чип WSE, поэтому, по словам генерального директора Cerebras Эндрю Фельдмана (Andrew Feldman), сейчас в фокусе внимания компании — построение эффективных систем, составленных из многих чипов WSE. Скорость роста сложности моделей превышает возможности увеличения вычислительной мощности путём добавления новых ядер и памяти на пластину, поскольку это приводит к чрезмерному удорожанию и так недешёвой системы.  Инженеры компании рассматривают дезагрегацию как единственный способ обеспечить необходимый уровень производительности и масштабируемости. Такой подход подразумевает разделение памяти и вычислительных блоков для того, чтобы иметь возможность масштабировать их независимо друг от друга — параметры модели помещаются в отдельное хранилище, а сама модель может быть разнесена на несколько вычислительных узлов CS, объединённых в кластер. 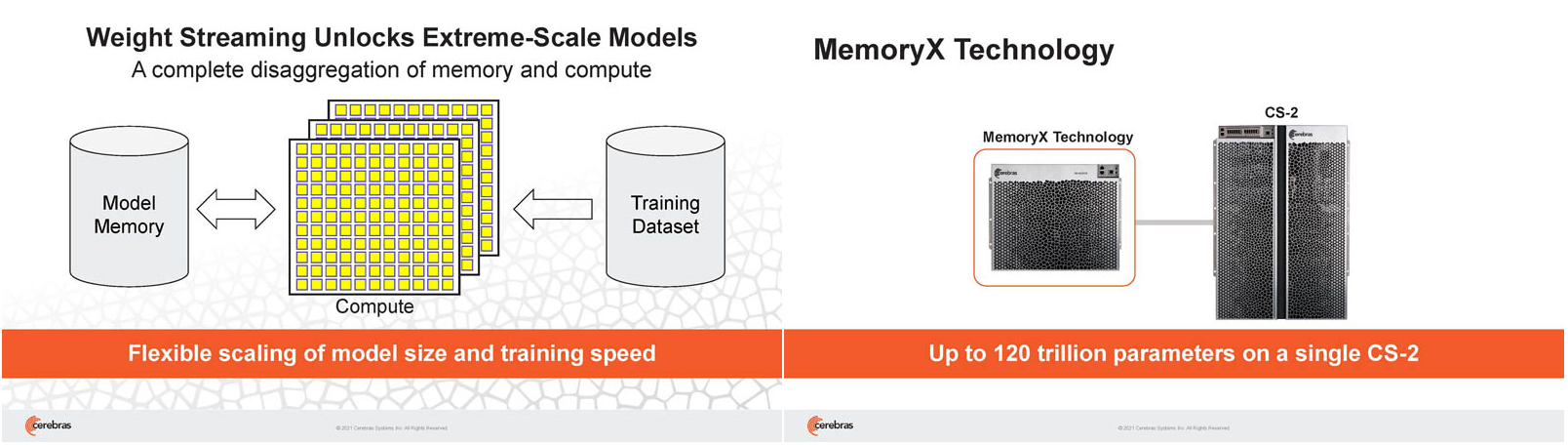 На Hot Chips 33 компания представила особое хранилище под названием MemoryX, сочетающее DRAM и флеш-память суммарной емкостью 2,4 Пбайт, которое позволяет хранить до 120 трлн параметров. Это, по оценкам компании, делает возможным построение моделей близких по масштабу к человеческому мозгу, обладающему порядка 80 млрд. нейронов и 100 трлн. связей между ними. К слову, флеш-память размером с целую 300-мм пластину разрабатывает ещё и Kioxia.  Для обеспечения масштабирования как на уровне WSE, так и уровне CS-кластера, Cerebras разработала технологию потоковой передачи весовых коэффициентов Weight Streaming. С помощью неё слой активации сверхкрупных моделей (которые скоро станут нормой) может храниться на WSE, а поток параметров поступает извне. Дезагрегация вычислений и хранения параметров устраняет проблемы задержки и узости пропускной способности памяти, с которыми сталкиваются большие кластеры процессоров. 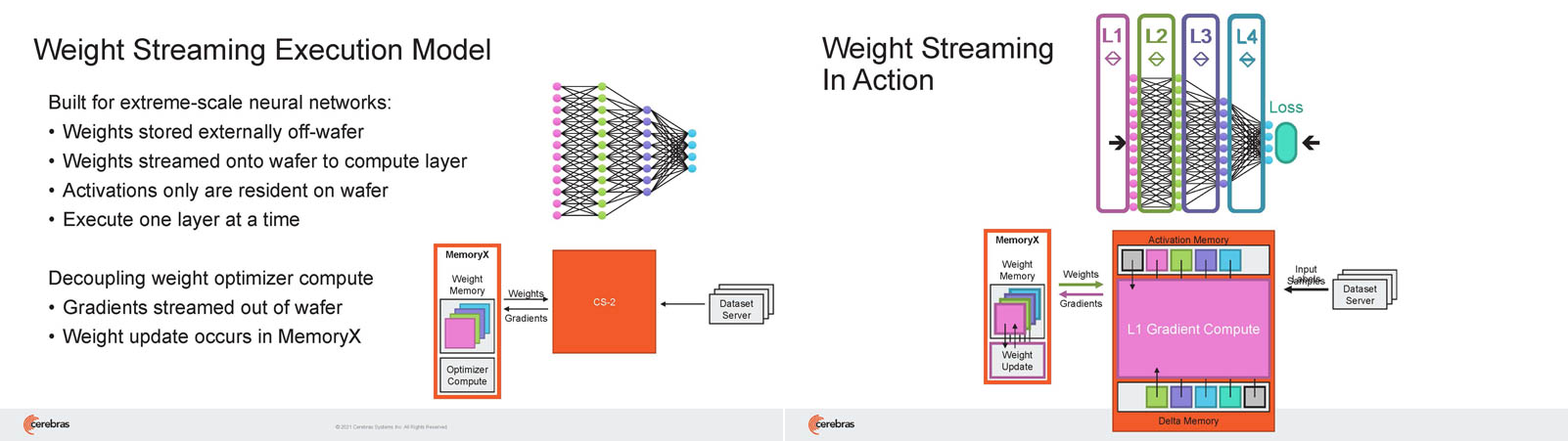 Это открывает широкие возможности независимого масштабирования размера и скорости кластера, позволяя хранить триллионы весов WSE-2 в MemoryX и использовать от 1 до 192 CS-2 без изменения ПО. В традиционных системах по мере добавления в кластер большего количества вычислительных узлов каждый из них вносит всё меньший вклад в решение задачи. Cerebras разработала интерконнект SwarmX, позволяющий подключать до 163 млн вычислительных ядер, сохраняя при этом линейность прироста производительности. 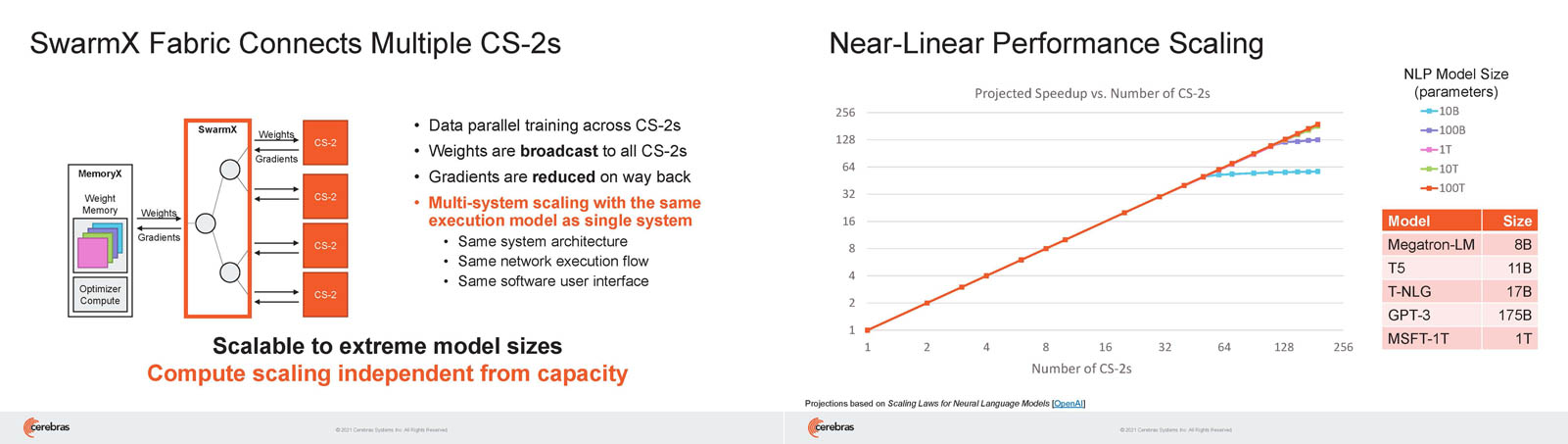 Также, компания уделила внимание разрежённости, то есть исключения части незначимых для конечного результата весов. Исследования показали, что должная оптимизации модели позволяет достичь 10-кратного увеличения производительности при сохранении точности вычислений. В CS-2 доступна технология динамического изменения разрежённости Selectable Sparsity, позволяющая пользователям выбирать необходимый уровень «ужатия» модели для сокращение времени вычислений.  «Крупные сети, такие как GPT-3, уже изменили отрасль машинной обработки естественного языка, сделав возможным то, что раньше было невозможно и представить. Индустрия перешла к моделям с 1 трлн параметров, а мы расширяем эту границу на два порядка, создавая нейронные сети со 120 трлн параметров, сравнимую по масштабу с мозгом» — отметил Фельдман.
19.08.2021 [18:04], Алексей Степин
Intel представила IPU Mount Evans и Oak Springs Canyon, а также ODM-платформу N6000 Arrow CreekВесной Intel анонсировала свои первые DPU (Data Processing Unit), которые она предпочитает называть IPU (Infrastructure Processing Unit), утверждая, что такое именования является более корректным. Впрочем, цели у этого класса устройств, как их не называй, одинаковые — перенос части функций CPU по обслуживанию ряда подсистем на выделенные аппаратные блоки и ускорители. Классическая архитектура серверных систем такова, что при работе с сетью, хранилищем, безопасностью значительная часть нагрузки ложится на плечи центральных процессоров. Это далеко не всегда приемлемо — такая нагрузка может отъедать существенную часть ресурсов CPU, которые могли бы быть использованы более рационально, особенно в современных средах с активным использованием виртуализации, контейнеризации и микросервисов. 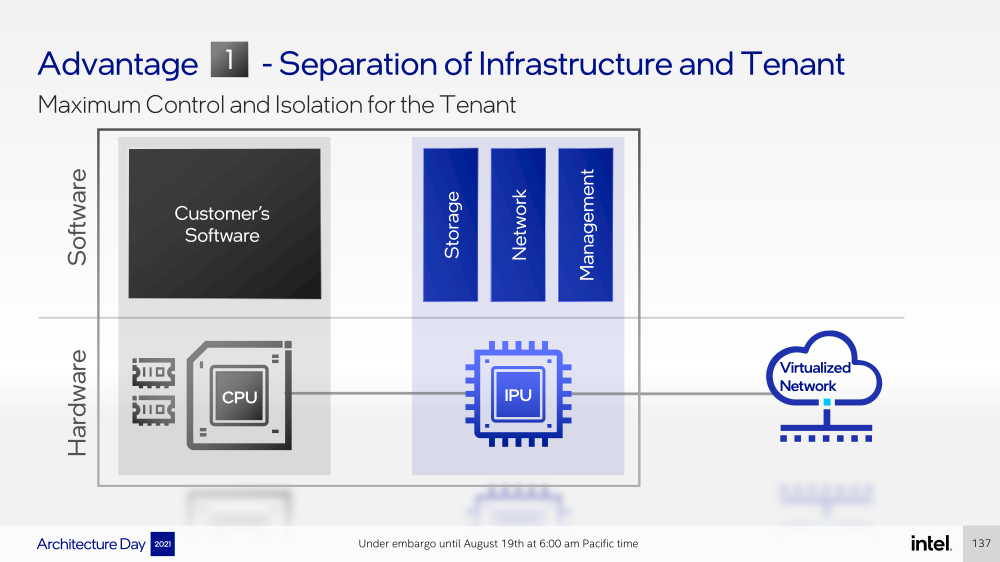 Для решения этой проблемы и были созданы DPU, которые эволюционировали из SmartNIC, бравших на себя «тяжёлые» задачи по обработке трафика и данных. DPU имеют на борту солидный пул вычислительных возможностей, что позволяет на некоторых из них запускать даже гипервизор. Однако Intel IPU имеют свои особенности, отличающие их и от SmartNIC, и от виденных ранее DPU. 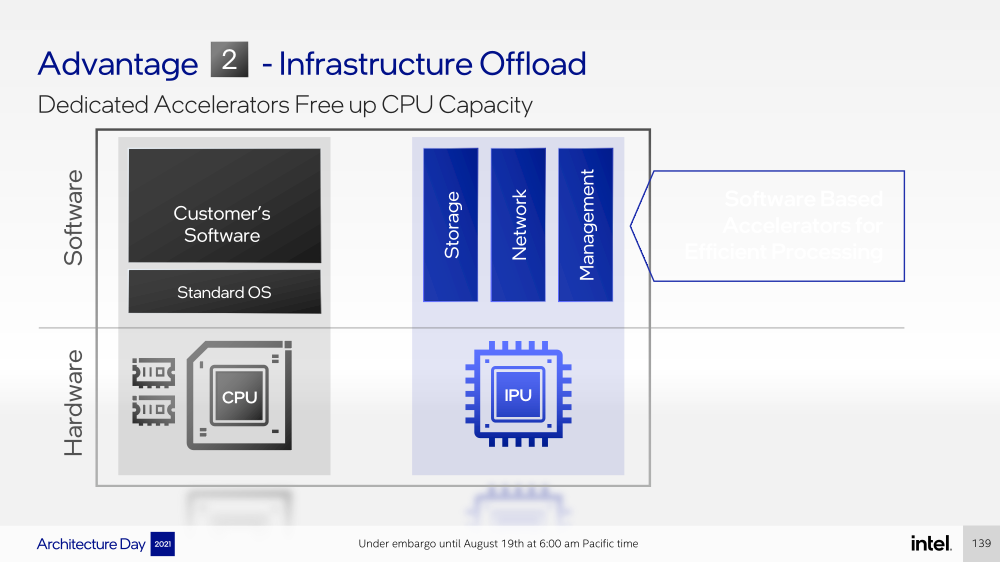 Новый класс сопроцессоров Intel должен взять на себя все заботы по обслуживанию инфраструктуры во всех её проявлениях, будь то работа с сетью, с подсистемами хранения данных или удалённое управление. При этом и DPU, и IPU в отличие от SmartNIC полностью независим от хост-системы. Полное разделение инфраструктуры и гостевых задач обеспечивает дополнительную прослойку безопасности, поскольку аппаратный Root of Trust включён в IPU. 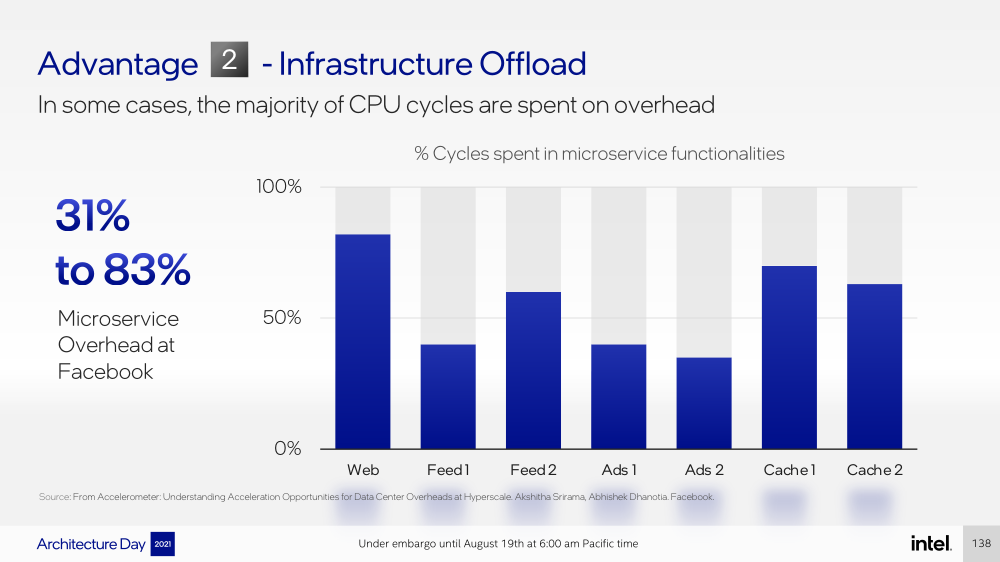 Это не единственное преимущество нового подхода. Компания приводит статистику Facebook✴, из которой видно, что иногда более 50% процессорных тактов серверы тратят на «обслуживание самих себя». Все эти такты могут быть пущены в дело, если за это обслуживание возьмётся IPU. Кроме того, новый класс сетевых ускорителей открывает дорогу к бездисковой серверной инфраструктуре: виртуальные диски создаются и обслуживаются также чипом IPU. 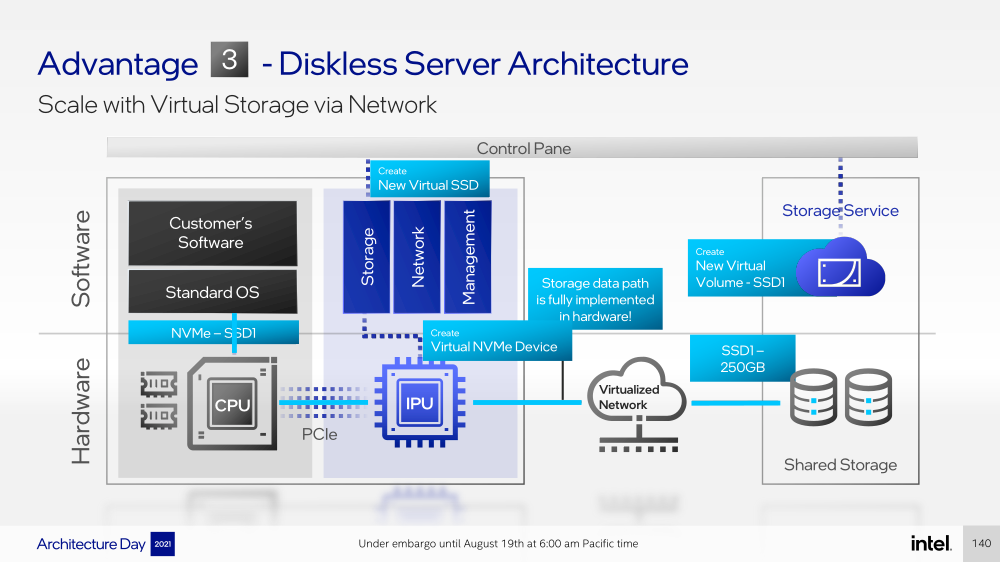 Первый чип в новом семействе IPU, получивший имя Mount Evans, создавался в сотрудничестве с крупными облачными провайдерами. Поэтому в нём широко используется кремний специального назначения (ASIC), обеспечивающий, однако, и нужную степень гибкости, За основу взяты ядра общего назначения Arm Neoverse N1 (до 16 шт.), дополненные тремя банками памяти LPDRR4 и различными ускорителями. 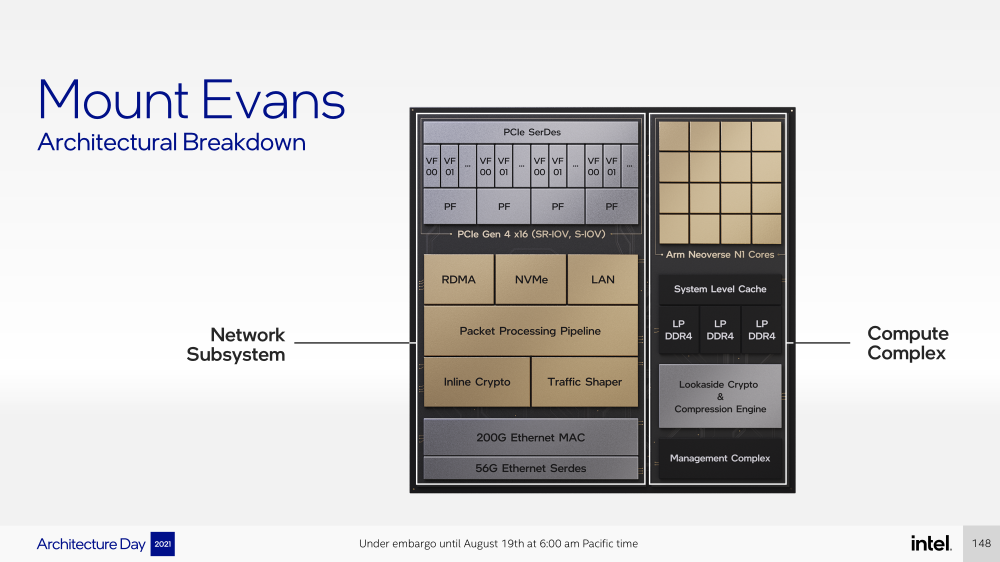 Сетевая часть представлена 200GbE-интерфейсом с выделенным P4-программируемым движком для обработки сетевых пакетов и управления QoS. Дополняет его выделенный IPSec-движок, способный на лету шифровать весь трафик без потери скорости. Естественно, есть поддержка RDMA (RoCEv2) и разгрузки NVMe-oF, причём отличительной чертой является возможность создавать для хоста виртуальные NVMe-накопители — всё благодаря контроллеру, который был позаимствован у Optane SSD.  Дополняют этот комплекс ускорители (де-)компресии и шифрования данных на лету. Они базируются на технологиях Intel QAT и, в частности, предложат поддержку современного алгоритма сжатия Zstandard. Наконец, у IPU будет выделенный блок для независимого внешнего управления. Работать с устройством можно будет посредством привычных SPDK и DPDK. Один IPU Mount Evans может обслуживать до четырёх процессоров. В целом, новинку можно назвать интересной и более доступной альтернативной AWS Nitro.  Также Intel представила платформу Oak Springs Canyon с двумя 100GbE-интерфейсами, которая сочетает процессоры Xeon-D и FPGA семейства Agilex. Каждому чипу которых полагается по 16 Гбайт собственной памяти DDR4. Платформа может использоваться для ускорения Open vSwitch и NVMe-oF с поддержкой RDMA/RocE, имеет аппаратные криптодвижки т.д. Наличие FPGA позволяет выполнять специфичные для конкретного заказчика задачи, но вместе с тем совместимость с x86 существенно упрощает разработку ПО для этой платформы. В дополнение к SPDK и DPDK доступны и инструменты OFS.  Наконец, компания показала и референсную плаформу для разработчиков Intel N6000 Acceleration Development Platform (Arrow Creek). Она несколько отличается от других IPU и относится скорее к SmartNIC, посколько сочетает FPGA Agilex, CPLD Max10 и сетевые контроллеры Intel Ethernet 800 (2 × 100GbE). Дополняет их аппаратный Root of Trust, а также PTP-блок.  Работать с устройством можно также с помощью DPDK и OFS, да и функциональность во многом совпадает с Oak Springs Canyon. Но это всё же платформа для разработки конечных решений ODM-партнёрами Intel, которые могут с её помощью имплементировать какие-то специфические протоколы или функции с ускорением на FPGA, например, SRv6 или Juniper Contrail. IPU могут стать частью высокоинтегрированной ЦОД-платформы Intel, и на этом поле она будет соревноваться в первую очередь с NVIDIA, которая активно продвигает DPU BluefIeld, а вскоре обзаведётся ещё и собственным процессором. Из ближайших интересных анонсов, вероятно, стоит ждать поддержку Project Monterey, о которой уже заявили NVIDIA и Pensando.
19.08.2021 [16:00], Игорь Осколков
Intel анонсировала ускорители Xe HPC Ponte Vecchio: 100+ млрд транзисторов, микс 5/7/10-нм техпроцессов Intel и TSMC и FP32-производительность 45+ ТфлопсКак и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.  Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.  Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.  Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.  Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков. 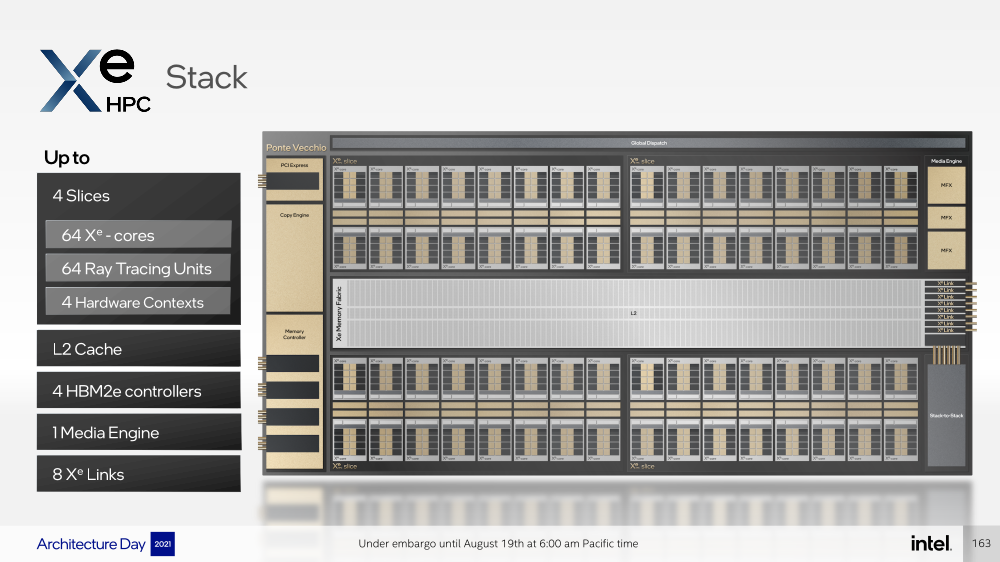 Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом. 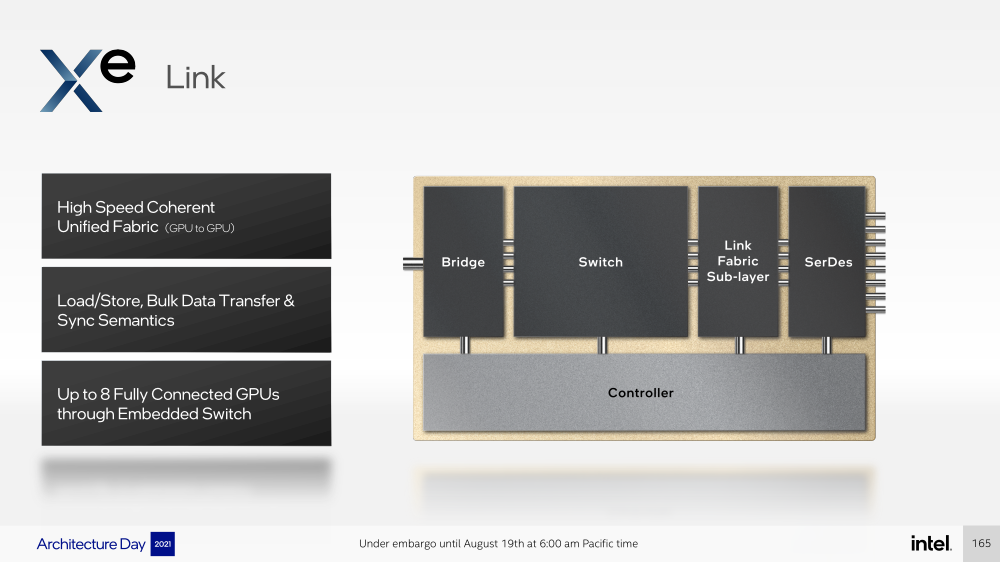  В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс. 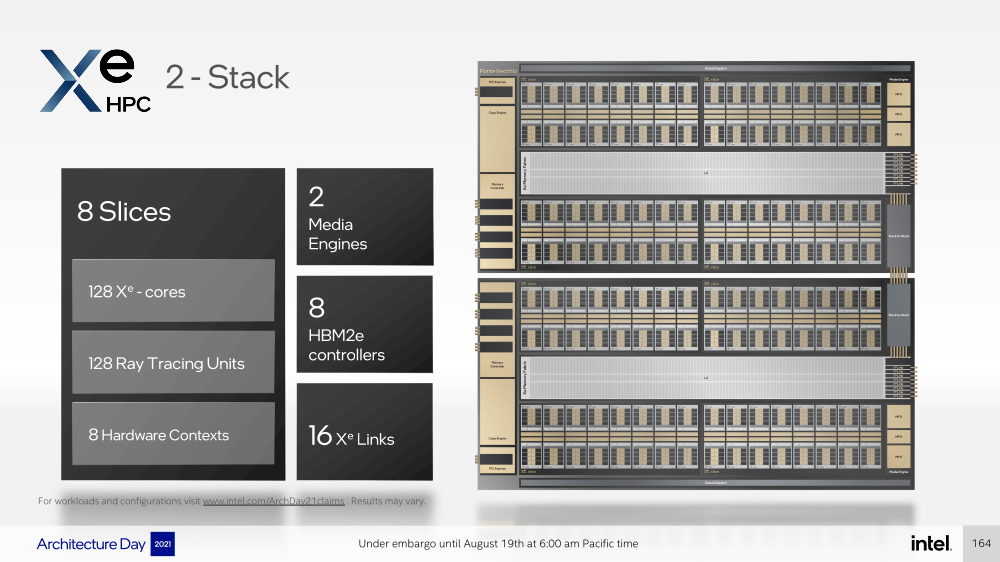 Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.  В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).  Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA.
16.07.2021 [17:31], Алексей Степин
Японский облачный суперкомпьютер ABCI подвергся модернизацииПопулярность идей машинного обучения и искусственного интеллекта приводит к тому, что многие страны и организации планируют обзавестись HPC-системами, специально предназначенными для этого класса задач. В частности, Токийский университет совместно с Fujitsu модернизировал существующую систему ABCI (AI Bridging Cloud Infrastructure), снабдив её новейшими процессорами Intel Xeon и ускорителями NVIDIA. Как правило, когда речь заходит о суперкомпьютерах Fujitsu, вспоминаются уникальные наработки компании в сфере HPC — процессоры A64FX, но ABCI имеет более традиционную гетерогенную архитектуру. Изначально этот облачный суперкомпьютер включал в себя вычислительные узлы на базе Xeon Gold и ускорителей NVIDIA V100, объединённых 200-Гбит/с интерконнектом. В качестве файловой системы применена разработка IBM — Spectrum Scale. Это одна систем, специально созданных для решения задач искусственного интеллекта, при этом доступная независимым исследователям и коммерческим компаниям. 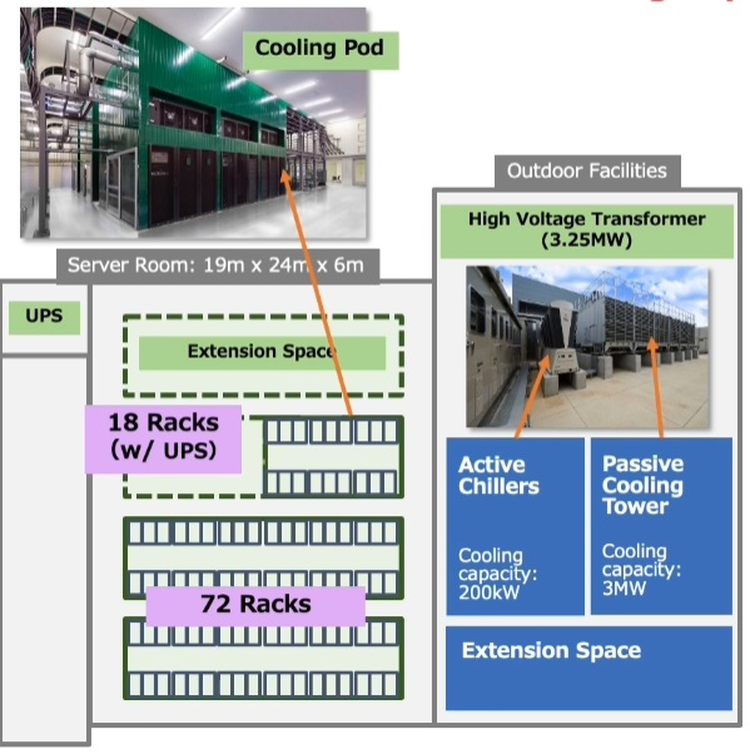 Так, 86% пользователей ABCI не входят в состав Японского национального института передовых технических наук (AIST); их число составляет примерно 2500. Но система явно нуждалась в модернизации. Как отметил глава AIST, с 2019 года загруженность ABCI выросла вчетверо, и сейчас на ней запущено 360 проектов, 60% из которых от внешних заказчиков. Сценарии использования самые разнообразные, от распознавания видео до обработки естественных языков и поиска новых лекарств. 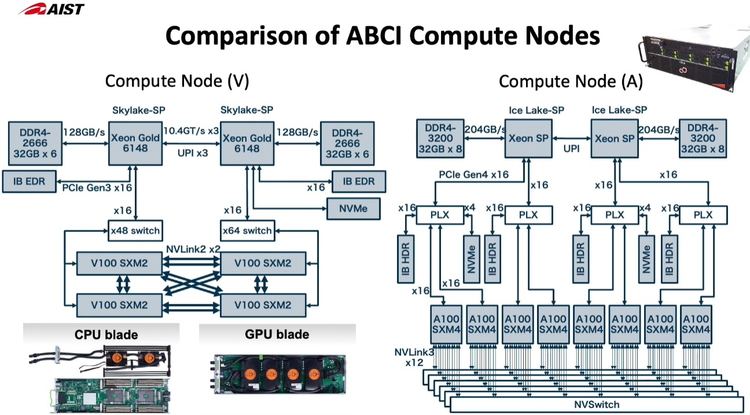
Новые узлы ABCI 2.0 заметно отличаются по архитектуре от старых Как и в большей части систем, ориентированных на машинное обучение, упор при модернизации ABCI был сделан на вычислительную производительность в специфических форматах, включая FP32 и BF16. Изначально в состав ABCI входило 1088 узлов, каждый с четырьмя ускорителями V100 формата SXM2 и двумя процессорами Xeon Gold 6148. После модернизации к ним добавилось 120 узлов на базе пары Xeon Ice Lake-SP и восьми ускорителей A100 формата SXM4. Здесь вместо InfiniBand EDR используется уже InfiniBand HDR. 
Стойка с новыми вычислительными узлами ABCI 2.0 Согласно предварительным ожиданиям, производительность обновлённого суперкомпьютера должна вырасти практически в два раза на задачах вроде ResNet50, в остальных случаях заявлен прирост производительности от полутора до трёх раз. На вычислениях половинной точности речь идёт о цифре свыше 850 Пфлопс, что вплотную приближает ABCI к системам экза-класса. Разработчики также надеются повысить энергоэффективность системы путём применения специфических ускорителей, включая ASIC, но пока речь идёт о связке Intel + NVIDIA. ABCI и сейчас можно назвать экономичной системой — при максимальной общей мощности комплекса 3,25 МВт сам суперкомпьютер при полной нагрузке потребляет лишь 2,3 МВт. Поскольку система ориентирована на предоставление вычислительных услуг сторонним заказчикам, модернизировано и системное ПО, в котором упор сместился в сторону контейнеризации.
29.06.2021 [17:49], Алексей Степин
Cornelis Networks подняла упавшее знамя Intel Omni-PathОт собственной технологии интерконнекта Omni-Path (OPA) компания Intel довольно неожиданно отказалась летом 2019 года, хотя на тот момент OPA-решения составляли достойную конкуренцию InfiniBand EDR, Ethernet и проприетарным интерконнектам как по скорости, так и по уровню задержки и поддержки необходимых для высокопроизводительных вычислений (HPC) функций. В конце прошлого года все наработки по OPA перешли к компании Cornelis Networks, образованной выходцами из Intel. В арсенале Intel были процессоры Xeon и Xeon Phi со встроенным интерфейсом Omni-Path, PCIe-адаптеры, коммутаторы и сопутствующее ПО. Казалось бы, у технологии большое будущее, однако второе поколение шины OPA, поддерживающее скорость 200 Гбит/с, так и не было выпущено, а компания сосредоточилась на Ethernet. При этом NVIDIA уже анонсировала InfiniBand NDR (400 Гбит/c), да и 200GbE-решениями сейчас никого не удивить.  Однако идеи, заложенные в Omni-Path, не умерли, и упавшее знамя нашлось, кому подхватить. Cornelis Networks быстро принялась за дело — через месяц после представления компании уже были представлены новые машины с Omni-Path, причём как на базе Intel, так и на базе AMD. А на ISC 2021 Cornelis Networks анонсировала полный спектр собственных решений под брендом Omni-Path Express, реализующих все основные достоинства технологии.  Конечно, процессоров с разъёмом Omni-Path мы по понятным причинам уже не увидим, но компания предлагает низкопрофильные хост-адаптеры с пропускной способностью до 25 Гбайт/с (100 Гбит/с в каждом направлении). Они поддерживают открытый фреймворк Open Fabrics Interface (OFI) и предлагают коррекцию ошибок с нулевой латентностью. В качестве разъёма используется популярный в индустрии QSFP28.  Также представлен ряд коммутаторов. В серии CN-100SWE есть модели с поддержкой горячей замены, которые имеют 48 портов и общую пропускную способность до 1,2 Тбайт/с при латентности, не превышающей 110 нс. Поддерживается организация виртуальных линий Omni-Path Express и фреймы большого размера, от 2 до 10 Кбайт. При этом коммутаторы компактны и занимают всего 1 слот в стандартной стойке.  Директор CN-100SWE предназначен для крупных кластерных систем. Он является модульным и может занимать от 7U до 20U, реализуя при этом от 288 до 1152 портов Omni-Path Express со скоростью 100 Гбит/с на порт. Латентность при этом не превышает 340 нс. Для сравнения, сети на базе Ethernet, как правило, оперируют значениями в десятки миллисекунд в лучшем случае.  Технологиями Cornelis Networks уже заинтересовался крупный российский поставщик HPC-систем, группа компаний РСК, которая и ранее поставляла кластеры и суперкомпьютеры с Omni-Path, в том числе с коммутаторами, снабжёнными фирменной СЖО. РСК получила наивысший партнёрский статус Elite+ у Cornelis и уже готова интегрировать Omni-Path Express в системы «РСК Торнадо» на базе третьего поколения процессоров Xeon Scalable.
28.06.2021 [13:22], Алексей Степин
Обновление NVIDIA HGX: PCIe-вариант A100 с 80 Гбайт HBM2e, InfiniBand NDR и Magnum IO с GPUDirect StorageНа суперкомпьютерной выставке-конференции ISC 2021 компания NVIDIA представила обновление платформы HGX A100 для OEM-поставщиков, которая теперь включает PCIe-ускорители NVIDIA c 80 Гбайт памяти, InfiniBand NDR и поддержку Magnum IO с GPUDirect Storage. В основе новинки лежат наиболее продвинутые на сегодняшний день технологии, имеющиеся в распоряжении NVIDIA. В первую очередь, это, конечно, ускорители на базе архитектуры Ampere, оснащённые процессорами A100 с производительностью почти 10 Тфлопс в режиме FP64 и 624 Топс в режиме тензорных вычислений INT8.  HGX A100 предлагает 300-Вт версию ускорителей с PCIe 4.0 x16 и удвоенным объёмом памяти HBM2e (80 Гбайт). Увеличена и пропускная способность (ПСП), в новой версии ускорителя она достигла 2 Тбайт/с. И если по объёму и ПСП новинки догнали SXM-версию A100, то в отношении интерконнекта они всё равно отстают, так как позволяют напрямую объединить посредством NVLink только два ускорителя.  В качестве сетевой среды в новой платформе NVIDIA применена технология InfiniBand NDR со скоростью 400 Гбит/с. Можно сказать, что InfiniBand догнала Ethernet, хотя не столь давно её потолком были 200 Гбит/с, а в плане латентности IB по-прежнему нет равных. Сетевые коммутаторы NVIDIA Quantum 2 поддерживают до 64 портов InfiniBand NDR и вдвое больше для скорости 200 Гбит/с, а также имеют модульную архитектуру, позволяющую при необходимости нарастить количество портов NDR до 2048. Пропускная способность при этом может достигать 1,64 Пбит/с.  Технология NVIDIA SHARP In-Network Computing позволяет компании заявлять о 32-крантом превосходстве над системами предыдущего поколения именно в области сложных задач машинного интеллекта для индустрии и науки. Естественно, все преимущества машинной аналитики используются и внутри самого продукта — технология UFM Cyber-AI позволяет новой платформе исправлять большинство проблем с сетью на лету, что минимизирует время простоя.  Отличным дополнением к новым сетевым возможностями является технология GPUDirect Storage, которая позволяет NVMe-накопителям общаться напрямую с GPU, минуя остальные компоненты системы. В качестве программной прослойки для обслуживания СХД новая платформа получила систему Magnum IO с поддержкой вышеупомянутой технологии, обладающую низкой задержкой ввода-вывода и по максимуму способной использовать InfiniBand NDR. 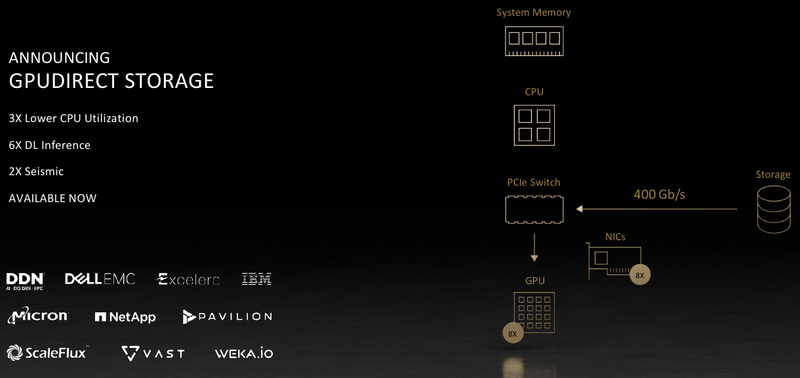 Три новых ключевых технологии NVIDIA помогут супервычислениям стать ещё более «супер», а суперкомпьютерам следующего поколения — ещё более «умными» и производительными. Достигнуты договорённости с такими крупными компаниями, как Atos, Dell Technologies, HPE, Lenovo, Microsoft Azure и NetApp. Решения NVIDIA используются как в индустрии — в качестве примера можно привести промышленный суперкомпьютер Tesla Automotive, так и в ряде других областей.  В частности, фармакологическая компания Recursion использует наработки NVIDIA в области машинного обучения для поиска новых лекарств, а национальный научно-исследовательский центр энергетики (NERSC) применяет ускорители A100 в суперкомпьютере Perlmutter при разработке новых источников энергии. И в дальнейшем NVIDIA продолжит своё наступление на рынок HPC, благо, она может предложить заказчикам как законченные аппаратные решения, так и облачные сервисы, также использующие новейшие технологии компании.
28.05.2021 [00:33], Владимир Мироненко
Perlmutter стал самым мощным ИИ-суперкомпьютером в мире: 6 тыс. NVIDIA A100 и 3,8 ЭфлопсВ Национальном вычислительном центре энергетических исследований США (NERSC) Национальной лаборатории им. Лоуренса в Беркли состоялась торжественная церемония, посвящённая официальному запуску суперкомпьютера Perlmutter, также известного как NERSC-9, созданного HPE в партнёрстве с NVIDIA и AMD. Это самый мощный в мире ИИ-суперкомпьютер, базирующийся на 6159 ускорителях NVIDIA A100 и примерно 1500 процессорах AMD EPYC Milan. Его пиковая производительность в вычислениях смешанной точности составляет 3,8 Эфлопс или почти 60 Пфлопс в FP64-вычислениях. Perlmutter основан на платформе HPE Cray EX с прямым жидкостным охлаждением и интерконнектом Slingshot. В состав системы входят как GPU-узлы, так и узлы с процессорами. Для хранения данных используется файловая система Lustre объёмом 35 Пбайт скорость обмена данными более 5 Тбайт/с, которая развёрнута на All-Flash СХД HPE ClusterStor E1000 (тоже, к слову, на базе AMD EPYC). 
Perlmutter (Phase 1). Фото: NERSC Установка Perlmutter разбита на два этапа. На сегодняшней презентации было объявлено о завершении первого (Phase 1) этапа, который начался в ноябре прошлого года. В его рамках было установлено 1,5 тыс. вычислительных узлов, каждый из которых имеет четыре ускорителя NVIDIA A100, один процессор AMD EPYC Milan и 256 Гбайт памяти. На втором этапе (Phase 2) в конце 2021 года будут добавлены 3 тыс. CPU-узлов c двумя AMD EPYC Milan и 512 Гбайт памяти., а также ещё ещё 20 узлов доступа и четыре узла с большим объёмом памяти. 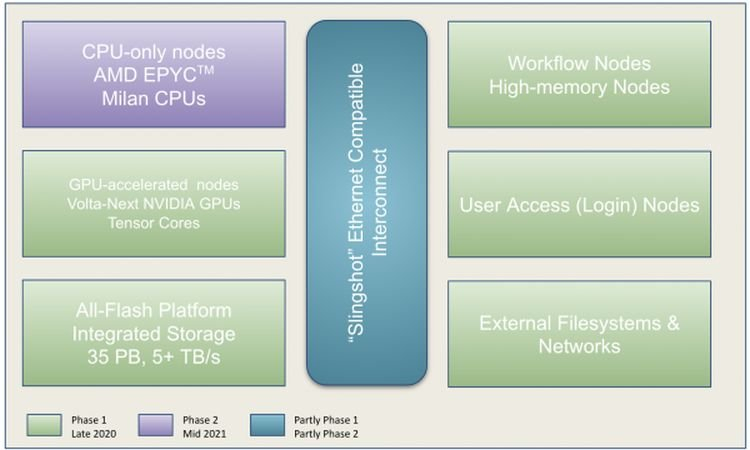
NERSC Также на первом этапе были развёрнуты служебные узлы, включая 20 узлов доступа пользователей, на которых можно подготавливать контейнеры с приложениями для последующего запуска на суперкомпьютере и использовать Kubernetes для оркестровки. Среда разработки будет включать NVDIA HPC SDK в дополнение к наборам компиляторов CCE (Cray Compiling Environment), GCC и LLVM для поддержки различных средств параллельного программирования, таких как MPI, OpenMP, CUDA и OpenACC для C, C ++ и Fortran. 
Фото: DESI Сообщается, что для Perlmutter готовится более двух десятков заявок на вычисления в области астрофизики, прогнозирования изменений климата и в других сферах. Одной из задач для новой системы станет создание трёхмерной карты видимой Вселенной на основе данных от DESI (Dark Energy Spectroscopic Instrument). Ещё одно направление, для которого задействуют суперкомпьютер, посвящено материаловедению, изучению атомных взаимодействий, которые могут указать путь к созданию более эффективных батарей и биотоплива. |
|

