В рамках Architecture Day компания Intel рассказала о грядущих серверных процессорах Sapphire Rapids, подтвердив большую часть опубликованной ранее информации и дополнив её некоторыми деталями. Intel позиционирует новинки как решение для более широкого круга задач и рабочих нагрузок, чем прежде, включая и популярные ныне микросервисы, контейнеризацию и виртуализацию. Компания обещает, что CPU будут сбалансированы с точки зрения вычислений, работой с памятью и I/O.
Новые процессоры, наконец, получили чиплетную, или тайловую в терминологии Intel, компоновку — в состав SoC входят четыре «ядерных» тайла на техпроцессе Intel 7 (10 нм Enhanced SuperFIN). Каждый тайл объединён с соседом посредством EMIB. Их системные агенты, включающие общий на всех L3-кеш объём до 100+ Мбайт, образуют быструю mesh-сеть с задержкой порядка 4-8 нс в одну сторону. Со стороны процессор будет «казаться» монолитным.

Каждые ядро или поток будут иметь свободный доступ ко всем ресурсам соседних тайлов, включая кеш, память, ускорители и IO-блоки. Потенциально такой подход более выгоден с точки зрения внутреннего обмена данными, чем в случае AMD с общим IO-блоком для всех чиплетов, которых в будущих EPYC будет уже 12. Но как оно будет на самом деле, мы узнаем только в следующем году — выход Sapphire Rapids запланирован на первый квартал 2022-го, а массовое производство будет уже во втором квартале.

Ядра Sapphire Rapids базируются на микроархитектуре Golden Cove, которая стала шире, глубже и «умнее». Она же будет использована в высокопроизводительных ядрах Alder Lake, но в случае серверных процессоров есть некоторые отличия. Например, увеличенный до 2 Мбайт на ядро объём L2-кеша или новый набор инструкций AMX (Advanced Matrix Extension). Последний расширяет ИИ-функциональность CPU и позволяет проводить MAC-операции над матрицами, что характерно для такого рода нагрузок.

Для AMX заведено восемь выделенных 2D-регистров объёмом по 1 Кбайт каждый (шестнадцать 64-байт строк). Отдельный аппаратный блок выполняет MAC-операции над тремя регистрами, причём делаться это может параллельно с исполнением других инструкций в остальной части ядра. Настройкой параметров и содержимого регистров, а также перемещением данных занимается ОС. Пока что в процессорах представлен только MAC-блок, но в будущем могут появиться блоки и для других, более сложных операций.
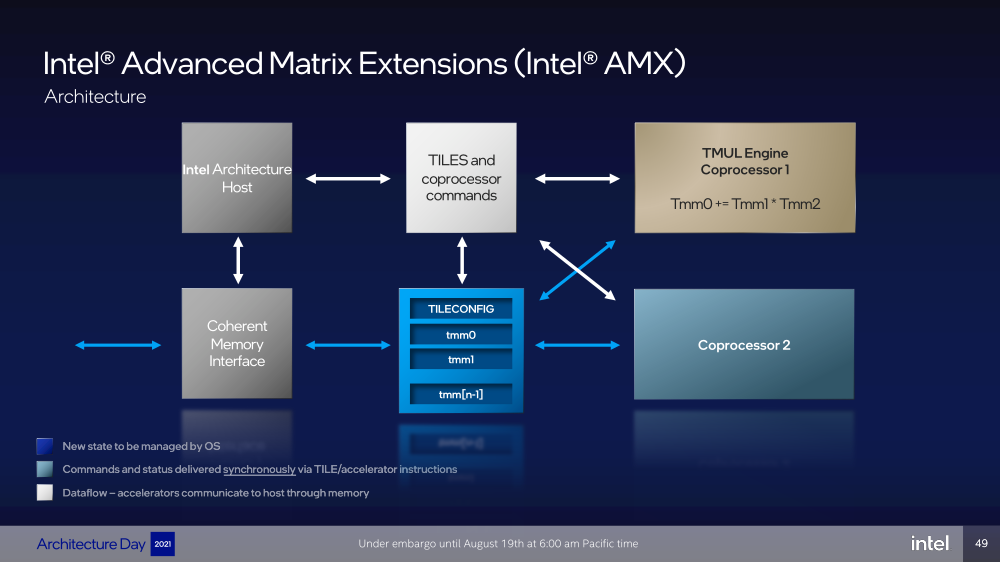
В пике производительность AMX на INT8 составляет 2048 операций на цикл на ядро, что в восемь раз больше, чем при использовании традиционных инструкций AVX-512 (на двух FMA-портах). На BF16 производительность AMX вдвое ниже, но это всё равно существенный прирост по сравнению с прошлым поколением Xeon — Intel всё так же пытается создать универсальные ядра, которые справлялись бы не только с инференсом, но и с обучением ИИ-моделей. Тем не менее, компания говорит, что возможности AMX в CPU будут дополнять GPU, а не напрямую конкурировать с ними.

К слову, именно Sapphire Rapids должен, наконец, сделать BF16 более массовым, поскольку Cooper Lake, где поддержка этого формата данных впервые появилась в CPU Intel, имеет довольно узкую нишу применения. Из прочих архитектурных обновлений можно отметить поддержку FP16 для AVX-512, инструкции для быстрого сложения (FADD) и более эффективного управления данными в иерархии кешей (CLDEMOTE), целый ряд новых инструкций и прерываний для работы с памятью и TLB для виртуальных машин (ВМ), расширенную телеметрию с микросекундными отсчётами и так далее.

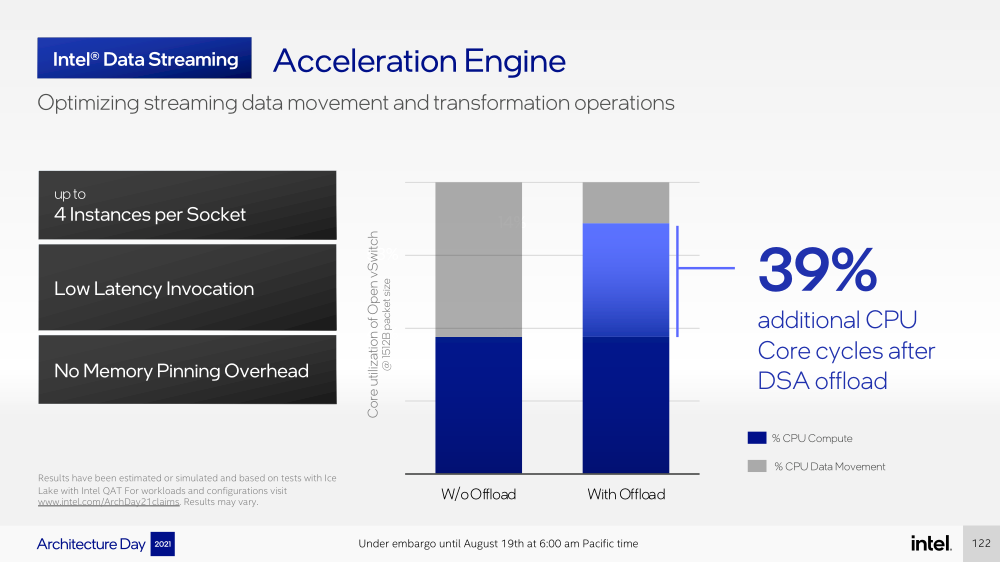
Последние пункты, в целом, нужны для более эффективного и интеллектуального управления ресурсами и QoS для процессов, контейнеров и ВМ — все они так или иначе снижают накладные расходы. Ещё больше ускоряют работу выделенные акселераторы. Пока упомянуты только два. Первый, DSA (Data Streaming Accelerator), ускоряет перемещение и передачу данных как в рамках одного хоста, так и между несколькими хостами. Это полезно при работе с памятью, хранилищем, сетевым трафиком и виртуализацией.
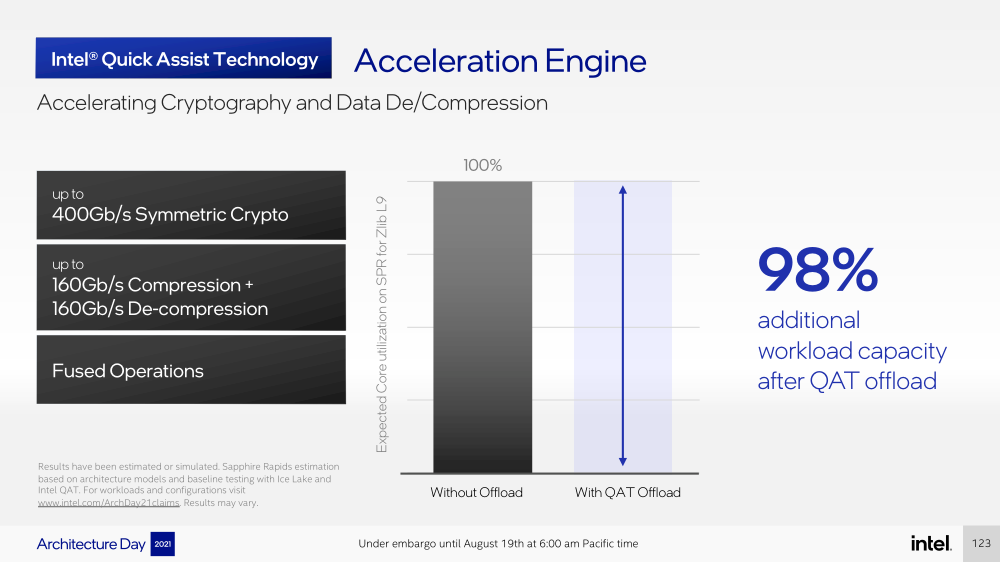
Второй упомянутый ускоритель — это движок QAT (Quick Assist Engine), на который можно возложить операции или сразу цепочки операций (де-)компрессии (до 160 Гбит/с в обе стороны одновременно), хеширования и шифрования (до 400 Гбитс/с) в популярных алгоритмах: AES GCM/XTS, ChaChaPoly, DH, ECC и т.д. Теперь блок QAT стал частью самого процессора, тогда как прежде он был доступен в составе некоторых чипсетов или в виде отдельной карты расширения. Это позволило снизить задержки и увеличить производительность блока.
Кроме того, QAT можно будет задействовать, например, для виртуализации или Intel Accelerator Interfacing Architecture (AiA). AiA — это ещё один новый набор инструкций, предназначенный для более эффективной работы с интегрированными и дискретными ускорителями. AiA помогает с управлением, синхронизацией и сигнализацией, что опять таки позволит снизить часть накладных расходов при взаимодействии с ускорителями из пространства пользователя.
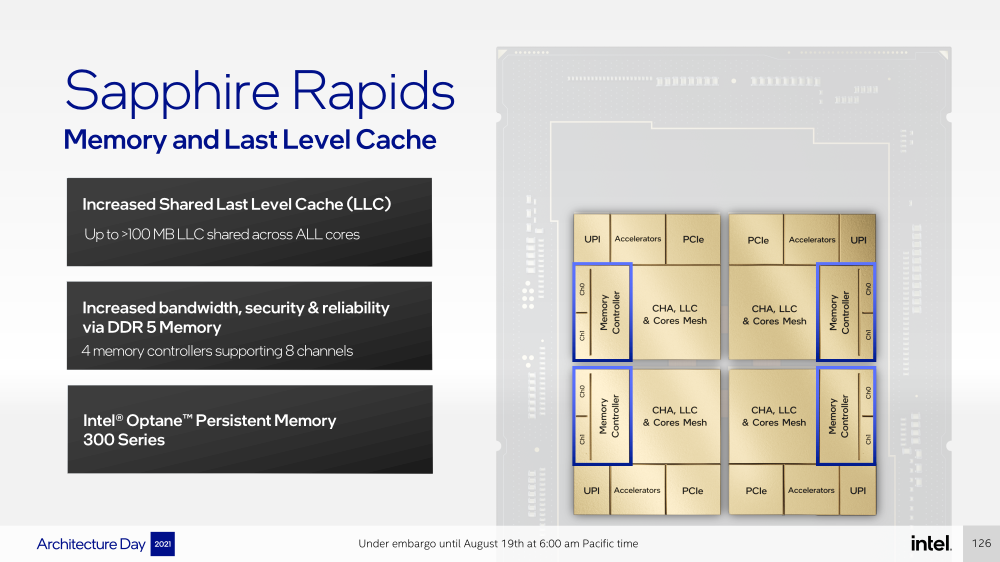
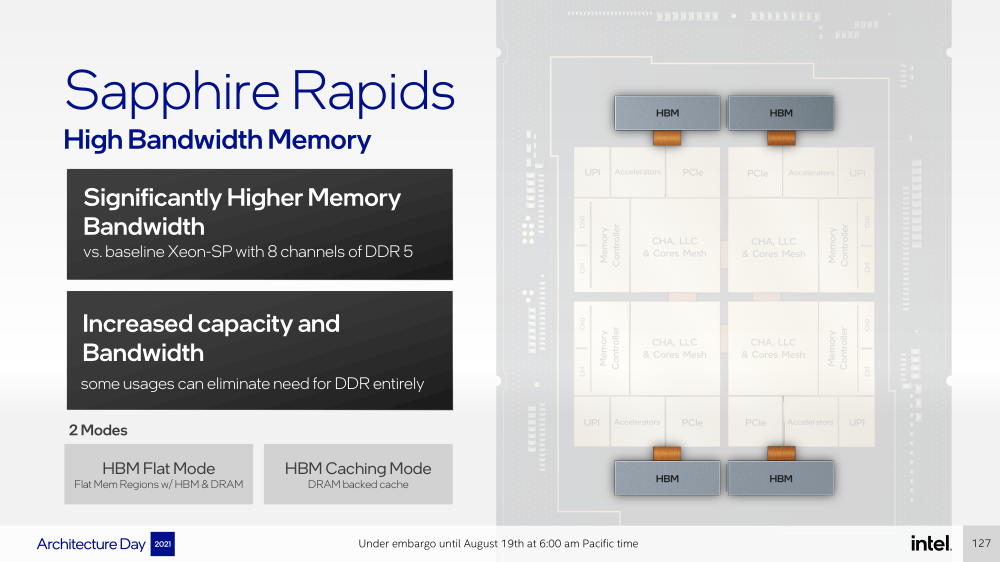
Подсистема памяти включает четыре двухканальных контроллера DDR5, по одному на каждый тайл. Надо полагать, что будут доступные четыре же NUMA-домена. Больше деталей, если не считать упомянутой поддержки следующего поколения Intel Optane PMem 300 (Crow Pass), предоставлено не было. Зато было официально подтверждено наличие моделей с набортной HBM, тоже по одному модулю на тайл. HBM может использоваться как в качестве кеша для DRAM, так и независимо. В некоторых случаях можно будет обойтись вообще без DRAM.
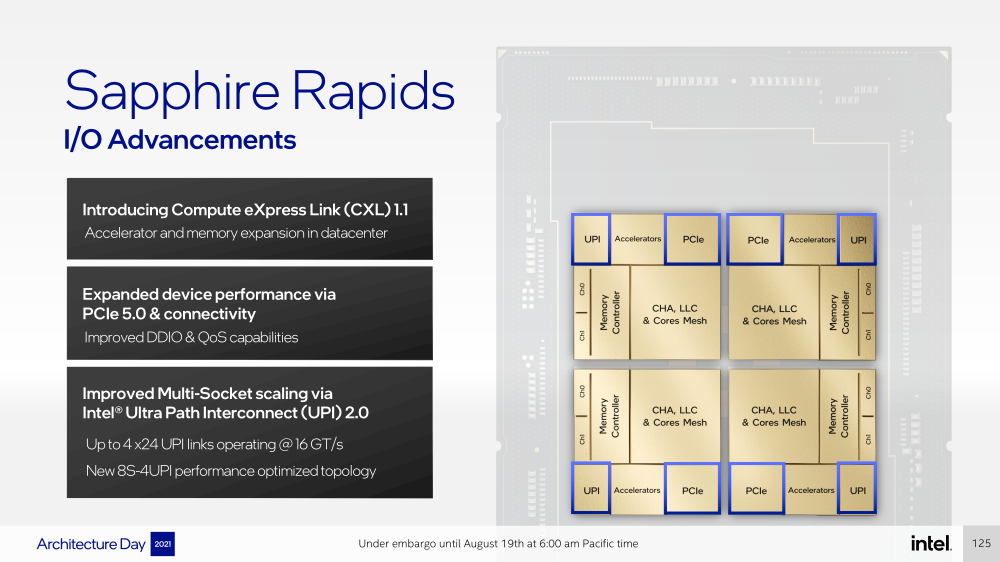
Про PCIe 5.0 и CXL 1.1 (CXL.io, CXL.cache, CXL.memory) добавить нечего, хотя в рамках другого доклада Intel ясно дала понять, что делает ставку на CXL в качестве интерконнекта не только внутри одного узла, но и в перспективе на уровне стойки. Для объединения CPU (бесшовно вплоть до 8S) всё так же будет использоваться шина UPI, но уже второго поколения (16 ГТ/с на линию) — по 24 линии на каждый тайл.
Конкретно для Sapphire Rapids Intel пока не приводит точные данные о росте IPC в сравнении с Ice Lake-SP, ограничиваясь лишь отдельными цифрами в некоторых задачах и областях. Также не был указан и ряд других важных параметров. Однако AMD EPYC Genoa, если верить последним утечкам, даже по чисто количественным характеристикам заметно опережает Sapphire Rapids.
Источник:

