Материалы по тегу: суперкомпьютер
|
29.10.2025 [16:53], Владимир Мироненко
В США построят семь новых ИИ-компьютеров на чипах NVIDIA по заказу Министерства энергетики СШАNVIDIA объявила о сотрудничестве с национальными лабораториями Министерства энергетики США (DoE) и ведущими компаниями с целью развития ИИ-инфраструктуры страны, в рамках которого будет построено семь новых суперкомпьютеров в Аргоннской (ANL) и Лос-Аламосской (LANL) национальных лабораториях. На первом этапе проекта NVIDIA и Oracle совместно построят в Аргоннской национальной лаборатории (ANL) два новых суперкомпьютера Equinox и Solstice с суммарной ИИ-производительность 2,2 Зфлопс. Также ANL планирует запустить ещё три новые ИИ-системы на базе технологий NVIDIA: Tara, Minerva и Janus. Не вдаваясь в подробности по поводу спецификаций систем, руководство лаборатории заявило, что суперкомпьютеры призваны расширить доступ исследователям в сфере ИИ из других центров по всей стране. Лос-Аламосская национальная лаборатория (LANL) получит ИИ-системы Mission и Vision нового поколения, которые будут разработаны и поставлены компанией HPE. Уже известно, что они будут базироваться на платформе NVIDIA Vera Rubin с сетевой фабрикой Quantum‑X800 InfiniBand. Как сообщает NVIDIA, система Vision основана на достижениях суперкомпьютера Venado, созданного для несекретных исследований. Как уточнили в лаборатории, Vision будет использоваться для несекретных задач в области национальной безопасности, материаловедения и ядерной науки, энергетического моделирования и биомедицинских исследований, сообщили в лаборатории, пишет The Register. 
Источник изображения: NVIDIA Mission — пятая система ATS5 (Advanced Technology System) в рамках программы усовершенствованного моделирования и вычислений (Advanced Simulation and Computing) Национального управления ядерной безопасности США (The National Nuclear Security Administration, NNSA), поддерживаемой LANL. Система предназначена для запуска секретных приложений, её ввод в эксплуатацию состоится в конце 2027 года. Vera Rubin в сочетании с Quantum‑X800 позволит учёным проводить сложное моделирование в области материаловедения, моделирования климата и квантовых вычислений. «Использование такого уровня вычислительной производительности критически важно для решения некоторых из самых сложных научных задач и задач национальной безопасности», — заявил Том Мейсон (Thom Mason), директор LANL.
28.10.2025 [22:35], Владимир Мироненко
Министерство энергетики США получит два суперкомпьютера на чипах AMD общей стоимостью $1 млрд: Discovery и Lux AI
amd
epyc
hardware
hpc
hpe
mi350
mi400
oracle
oracle cloud infrastructure
ornl
venice
ии
облако
суперкомпьютер
сша
Министерство энергетики США (DOE) заключило с AMD контракт стоимостью $1 млрд с целью строительства двух суперкомпьютеров HPE для решения масштабных научных задач в области ядерной энергетики, здравоохранения и национальной безопасности. 
Источник изображений: HPE Министр энергетики Крис Райт (Chris Wright) сообщил агентству Reuters, что создание HPC-систем даст мощный импульс развитию ядерной и термоядерной энергетики, оборонных технологий и национальной безопасности, а также разработке лекарственных препаратов. Учёные и компании пытаются воспроизвести термоядерный синтез, который, в том числе, подпитывает солнечную энергию. «Мы добились значительного прогресса, но плазма нестабильна, и нам необходимо воссоздать центр Солнца на Земле», — заявил Райт.  Он выразил уверенность, что ИИ-системы позволят открыть практические пути для использования энергии термоядерного синтеза в ближайшие два-три года, а также помогут управлять ядерным арсеналом США и ускорить разработку лекарств, моделируя способы лечения рака вплоть до молекулярного уровня. «Я надеюсь, что в ближайшие пять-восемь лет мы превратим большинство видов рака, многие из которых сегодня являются смертным приговором, в контролируемые состояния», — сказал Райт.  Первым планируется запустить в эксплуатацию в течение следующих шести месяцев суперкомпьютер Lux с облачным доступом. Он будет основан на узлах HPE ProLiant Compute XD685 с СЖО, которые объединяют ИИ-ускорителях Instinct MI355X, CPU AMD EPYC, а также DPU Pensando. Система разработана AMD совместно с HPE, Oracle (OCI) и Ок-Риджской национальной лабораторией (ORNL). Глава AMD Лизу Су (Lisa Su) сообщила, что запуск Lux будет самым быстрым развёртыванием суперкомпьютера таких размеров в её практике. «Именно такой скорости и гибкости мы хотели бы добиться для программ США в области ИИ искусственного интеллекта», — сказала она. По словам директора ORNL, Lux будет обладать примерно в три раза большей вычислительной мощностью по сравнению с существующими системами.  Второй, более продвинутый суперкомпьютер под названием Discovery станет преемником экзафлопсной машины Frontier в ORNL и будет практически на порядок быстрее её. Его разработкой занимаются ORNL, HPE и AMD. Discovery будет основан на платформе HPE Cray Supercomputing GX5000, поддерживающей до 25 кВт на узел и охлаждение водой с температорой +40 °C. Узлы получат процессоры AMD EPYC Venice, которые, как ожидается, появятся во II половине 2026 года, а также специализированные ускорители Instinct MI430X с полноценной поддержкой FP64-вычислений — они также должны появиться в следующем году. Для интерконнекта будет задействован HPE Slingshot следующего поколения, сроки выхода которого не называются.  Discovery получит новейшую СХД Cray SC Storage Systems K3000 с объектным хранилищем DAOS, которое дополнит имеющуюся СХД на базе Cray SC Storage Systems E2000 с Lustre. Ранее HPE наняла инженеров, занимавшихся разработкой DAOS в Intel, и включила их в свою команду по работе над СХД. По словам HPE, K3000 предложит до 75 млн IOPS на стойку. HPE не раскрывает, сколько узлов, процессоров и ускорителей будет использоваться в Discovery, а также какой объём памяти будет у системы. Ожидается, что Discovery будет поставлен в 2028 году и готов к эксплуатации в 2029 году. Оценочная стоимость системы — $500 млн. Министерство энергетики США разместит суперкомпьютеры, компании предоставят оборудование и средства на капитальные затраты, а вычислительные мощности будут распределены между обеими сторонами, сообщил представитель министерства. Он отметил, что эти суперкомпьютеры на базе чипов AMD станут первыми в ряду подобных партнёрств министерства с частными компаниями в стране. По аналогичной схеме будет финансироваться создание ИИ-суперкомпьютера Solstice.
28.10.2025 [21:35], Владимир Мироненко
NVIDIA и Oracle построят для США ИИ-суперкомпьютер Solstice: 100 тыс. ускорителей Blackwell и государственно-частное партнёрствоNVIDIA объявила о новом совместном проекте с Oracle по созданию крупнейшей суперкомпьютерной системы с поддержкой ИИ в интересах Министерства энергетики США (DoE) для разработок в сфере науки. В рамках партнёрства NVIDIA и Oracle построят два суперкомпьютера — Solstice и Equinox, оснащённых 100 тыс. и 10 тыс. ускорителей NVIDIA Blackwell соответственно, которые будут объединены интерконнектом NVIDIA и обеспечат суммарную ИИ-производительность в 2,2 Зфлопс. Система Equinox будет введена в эксплуатацию в I половине 2026 года. Стоимость проекта не разглашается. Solstice будет построен с использованием новой модели государственно-частного партнёрства Министерства энергетики США, включающей инвестиции cо стороны промышленности. Сообщается, что суперкомпьютеры будут размещены в Аргоннской национальной лаборатории (ANL) Министерства энергетики США. С их помощью исследователи будут разрабатывать и обучать новые передовые ИИ-модели, включая модели рассуждений, для реализации проектов открытой науки, используя библиотеку NVIDIA Megatron-Core, а также масштабировать их с помощью программного стека для инференса NVIDIA TensorRT. Эти модели станут основой рабочих процессов агентного ИИ для научных исследований. 
Источник изображения: NVIDIA Оба суперкомпьютера будут использоваться в рамках сотрудничества NVIDIA, ANL и DoE, повышая производительность исследований и разработок и ускоряя процесс научных открытий, которые будут осуществляться за счет государственных средств в течение десятилетия. Глава ANL, что новые суперкомпьютеры будут подключены к передовым экспериментальным установкам Министерства энергетики США, таким как усовершенствованный источник фотонов, что позволит решать самые насущные проблемы страны благодаря научным открытиям.
18.10.2025 [22:25], Владимир Мироненко
К полувековому юбилею суперкомпьютера Cray-1 выпущена памятная однодолларовая монетаМонетный двор США представил дизайн памятных однодолларовых монет для программы 2026 American Innovation $1 Coin Program. На одной из них изображён Cray-1 — один из самых известных суперкомпьютеров всех времён, отличавшийся инновационной для своего времени конструкцией и уникальным дизайном. В рамках этой программы, действующей с 2018 года, ежегодно выпускаются четыре монеты, представляющие «американские инновации, а также значительные инновационные и новаторские достижения отдельных лиц или групп». В этом году дизайн монет для программы был предложен штатами Айова, Висконсин, Калифорния и Миннесота. 
Источник изображения: United States Mint Дизайн монеты с изображением Cray-1 был предложен штатом Висконсин, где находится исследовательский центр Cray Research, в котором был создан Cray-1 под руководством ныне покойного Сеймура Крея (Seymour Cray) и соучредителя, главного инженера Лестера Дэвиса (Lester Davis). На лицевой стороне монеты размещено изображение вида сверху суперкомпьютера Cray-1 с круговым расположением вычислительных блоков. На С-образном корпусе машины видна надпись Cray-1 Supercomputer, а также подписи художника и скульптора Пола Романо (Paul Romano) и Джона П. Макгроу (John P. McGraw). Также есть надписи «Соединённые штаты Америки» и «Висконсин».  Памятные монеты вряд ли поступят в регулярное обращение, и их вряд ли можно будет купить в банке за доллар. Они являются законным платёжным средством, но в первую очередь — предметом коллекционирования. Предыдущие памятные долларовые монеты продавались монетным двором по цене от $13,25. Cray-1 стал первым суперкомпьютером, в котором была успешно реализована концепция векторного процессора, позволяющего повысить скорость математических операций путём оптимальной организации памяти и регистров для быстрого выполнения одной операции с большим набором данных. В предыдущих системах эта концепция была реализована с ограниченной производительностью. Cray-1 работал в несколько раз быстрее любой аналогичной конструкции и лидировал среди суперкомпьютеров с 1976 по 1982 год, достигая впечатляющих 160 Мфлопс благодаря инновационному использованию интегральных схем.  За всё время существования системы на рынке было продано более 80 машин, что сделало Cray-1 одним из самых успешных в этой категории за всю историю вычислительных систем. Он известен своей уникальной формой: относительно небольшим С-образным корпусом, окружённым кольцом «тумбочек», закрывающих блоки питания и систему охлаждения. Согласно «Википедии», после анонса Cray-1 с частотой 80 МГц в 1975 году ажиотаж вокруг него был настолько велик, что между Ливерморской национальной лабораторией имени Лоуренса (LLNL) и Лос-Аламосской национальной лабораторией (LANL) разгорелась настоящая война за право покупки первой машины. В итоге последняя выиграла тендер и получила в 1976 году первый экземпляр Cray-1 с серийным номером 001. Национальный центр атмосферных исследований США (NCAR) стал первым официальным клиентом Cray Research в 1977 году, заплатив $8,86 млн (сейчас это более $47 млн с учётом инфляции) за суперкомпьютер с серийным номером 003. Этот суперкомпьютер был выведен из эксплуатации в 1989 году.
17.09.2025 [13:15], Руслан Авдеев
Собственный ЦОД Stargate и крупнейший в стране ИИ-суперкомпьютер: американские IT-гиганты вложат более $40 млрд в развитие ИИ в Великобритании
coreweave
google
hardware
microsoft
nscale
nvidia
openai
salesforce
stargate
великобритания
ии
инвестиции
суперкомпьютер
сша
финансы
цод
Microsoft объявила о намерении вложить около $30 млрд в ИИ-проекты на территории Великобритании к 2028 году. $15,5 млрд уйдёт на капитальное расширение в течение трёх лет, а $15,1 млрд — на операции в стране, сообщает CNBC. В частности, инвестиции позволят построить «крупнейший суперкомпьютер» в Великобритании с более 23 тыс. передовых ускорителей (24 тыс. по данным NVIDIA) совместно с британской Nscale. Дата запуска не раскрывалась, но в Nscale ранее объявляли, что новый ЦОД компании заработает в 2026 году и обеспечит доступ к 46 тыс. ускорителей. Планируемая мощность составляет 50 МВт, а всего на площадку выделено 90 МВт. На фоне государственного визита в Великобританию президента США Дональда Трампа (Donald Trump), инвестировать в развитие ИИ в стране пообещали NVIDIA, Google, OpenAI и Salesforce, общая сумма превысит $40 млрд. Эксперты ожидают, что премьер-министр Великобритании Кир Стармер и Дональд Трамп подпишут 17 сентября новое соглашение, открывая путь к инвестициям и сотрудничеству в сфере ИИ, квантовых и ядерных технологий. Президент Microsoft Брэд Смит (Brad Smith) заявил, что его позиция в отношении Великобритании «потеплела» с годами, ранее он критиковал Соединённое Королевство за попытку заблокировать в 2023 году сделку Microsoft по покупке Activision-Blizzard за $69 млрд. Впрочем, в том же году она была одобрена. По словам Смита, его воодушевляют сделанные правительстовм в последние несколько лет шаги для улучшения делового климата — ещё несколько лет назад подобные инвестиции были бы немыслимы из-за действующих норм и практики. Кроме того, не было спроса на такие вложения в ИИ. NVIDIA уже объявила о намерении вложить в Великобританию совместно с Nscale и CoreWeave £11 млрд ($15 млрд). NVIDIA намерена разместить в Соединённом Королевстве 120 тыс. ИИ-ускорителей Blackwell, это станет крупнейшим в этом роде проектом компании в Европе. Утверждается, что это сделает Великобританию действительно «производителем ИИ, а не потребителем». 
Источник изображения: chan lee/unsplash.com Инвестировать в ИИ-проекты в Великобритании £5 млрд ($6,8 млрд) намерена Google. Компания откроет новый ЦОД в 19 километрах от центра Лондона. В Google уверены, что новый дата-центр поможет удовлетворить спрос на сервисы компании с ИИ-элементами: Google Cloud, Workspace, Search и Maps. Предполагается, что инвестиции позволят ежегодно создавать 8250 рабочих мест в британских компаниях. Значительный вклад внесёт и OpenAI благодаря проекту Stargate UK. Речь идёт о специализированной местной версии масштабного проекта, совместно реализуемого с SoftBank и Oracle. В Великобритании ИИ-стартап будет сотрудничать над проектом с Nscale и NVIDIA. OpenAI уже заявила, что в начале 2026 года для внедрения в Великобритании будут развёрнуты 8 тыс. ИИ-ускорителей с возможностью расширения мощностей до 31 тыс. в будущем. Первая крупная стройка для Stargate UK запланирована на территории Cobalt Park в Ньюкасле (Newcastle) на севере Англии. Salesforce объявила о планах увеличить инвестиции в Великобритании до $6 млрд, увеличив обязательства в сравнении с 2023 годом до $4 млрд. В Salesforce подчеркнули, что визит Трампа в Великобританию подтверждает важность отношений между Великобританией и США. Наконец, CoreWeave объявила о дополнительных инвестициях в размере £1,5 млрд для увеличения мощности своего ИИ ЦОД в стране. Благодаря этому обязательству общий объем инвестиций CoreWeave в этой стране достигнет £2,5 млрд. Суммарный объём инвестиций IT-гигантов превысит $40 млрд.
17.09.2025 [11:04], Сергей Карасёв
В США появится ИИ-суперкомпьютер с Arm-процессорами AmpereOne M и ускорителями Qualcomm Cloud AIУниверситет штата Нью-Йорк в Стони-Бруке (SBU) объявил о получении гранта в размере $13,77 млн от Национального научного фонда США (NSF) на приобретение и эксплуатацию высокопроизводительного энергоэффективного суперкомпьютера для задач ИИ. Средства получит Институт передовых вычислительных наук (IACS) в составе SBU. В проекте также примет участие Университет штата Нью-Йорк в Буффало (UB). Деньги выделяются в рамках программы Sustainable Cyber-infrastructure for Expanding Participation (Устойчивая киберинфраструктура для расширенной совместной работы). В основу НРС-комплекса, который пока не получил определённого названия, лягут процессоры AmpereOne M, разработанные компанией Ampere Computing специально для ресурсоёмких ИИ-нагрузок в дата-центрах. Эти чипы насчитывают до 192 кастомизированных 64-бит ядер на базе Arm v8.6+ Реализована поддержка 12 каналов DDR5-5600 и 96 линий PCIe 5.0. Кроме того, в состав суперкомпьютера войдут ИИ-ускорители Qualcomm Cloud AI, которые несут на борту до 576 Мбайт SRAM и до 128 Гбайт памяти LPDDR4x с пропускной способностью до 548 Гбайт/с. Расчётные показатели быстродействия машины пока не раскрываются.  Ожидается, что комбинация AmpereOne M и Qualcomm Cloud AI обеспечит высокую энергоэффективность, а также значительную производительность, достаточную для работы с крупными ИИ-моделями. Доступ к ресурсам суперкомпьютера планируется предоставлять исследователям, студентам и преподавателям на всей территории США. Новый НРС-комплекс поможет ускорить открытия в области геномики, биоинформатики и в других областях. Кроме того, система будет применяться при реализации проектов в сферах машинного обучения и статистического анализа.
06.09.2025 [13:42], Сергей Карасёв
Состоялся официальный запуск первого в Европе экзафлопсного суперкомпьютера JUPITERВ Юлихском исследовательском центре (FZJ) в Германии официально введён в эксплуатацию суперкомпьютер JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) — первый в Европе вычислительный комплекс экзафлопсного класса. Система будет использоваться в том числе для исследований в области климата, нейробиологии и квантового моделирования. Контракт на создание JUPITER подписан между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (Atos) и ParTec. Суперкомпьютер состоит из блока Booster для решения ресурсоёмких задач и универсального блока cCuster. В основу Booster положена платформа BullSequana XH3000 с прямым жидкостным охлаждением. Используются около 6000 вычислительных узлов с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200 (4×200G на узел, DragonFly+). В общей сложности задействованы почти 24 тыс. суперчипов NVIDIA GH200 (Grace Hopper). В июньском рейтинге TOP500 блок JUPITER Booster располагался на четвёртом месте: на тот момент его FP64-производительность составляла 793,4 Пфлопс. Теперь показатель преодолел рубеж в 1 Эфлопс. При этом ИИ-производительность, как ожидается, будет находиться на уровне 90 Эфлопс. 
Источник изображений: Forschungszentrum Jülich / Sascha Kreklau «С запуском первого в Европе эксафлопсного суперкомпьютера мы открываем новую главу в развитии науки, искусственного интеллекта и инноваций. JUPITER укрепляет цифровой суверенитет Европы и ускоряет научные исследования», — отмечает Екатерина Захариева (Ekaterina Zaharieva), еврокомиссар по стартапам, исследованиям и инновациям.  JUPITER планируется использовать для прогнозирования погоды и моделирования изменений климата, работы с европейскими большими языковыми моделями (LLM) и генеративным ИИ, разработки лекарственных препаратов и картирования человеческого мозга, моделирования молекулярной динамики и пр. Ожидается, что JUPITER сможет побить мировой рекорд по скорости обработки кубитов в квантовых вычислениях.  Между тем продолжается создание блока cCuster. В его состав войдут энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1. Эти чипы содержат 80 ядер Neoverse V1 (Zeus), 64 Гбайт HBM2e и четыре интерфейса DDR5. Модуль cCuster будет оснащён двумя такими процессорами на каждый вычислительный узел, 512 Гбайт DDR5 (в отдельных узлах 1 Тбайт) и одним NDR200-подключением. Общее количество узлов составит около 1300. Ожидаемая FP64-производительность — 5 Пфлопс.  Хранилище суперкомпьютера включает быструю СХД ExaFLASH и ёмкую ExaSTORE. ExaFLASH включает 20 All-Flash СХД IBM Storage Scale 6000: 21 Пбайт («сырая» 29 Пбайт), запись до 2 Тбайт/с, чтение до 3 Тбайт/с. В ExaSTORE под хранение будет выделена «сырая» ёмкость 300 Пбайт, а для резервного копирования и архивов будет использоваться ленточная библиотека ёмкостью 700 Пбайт. 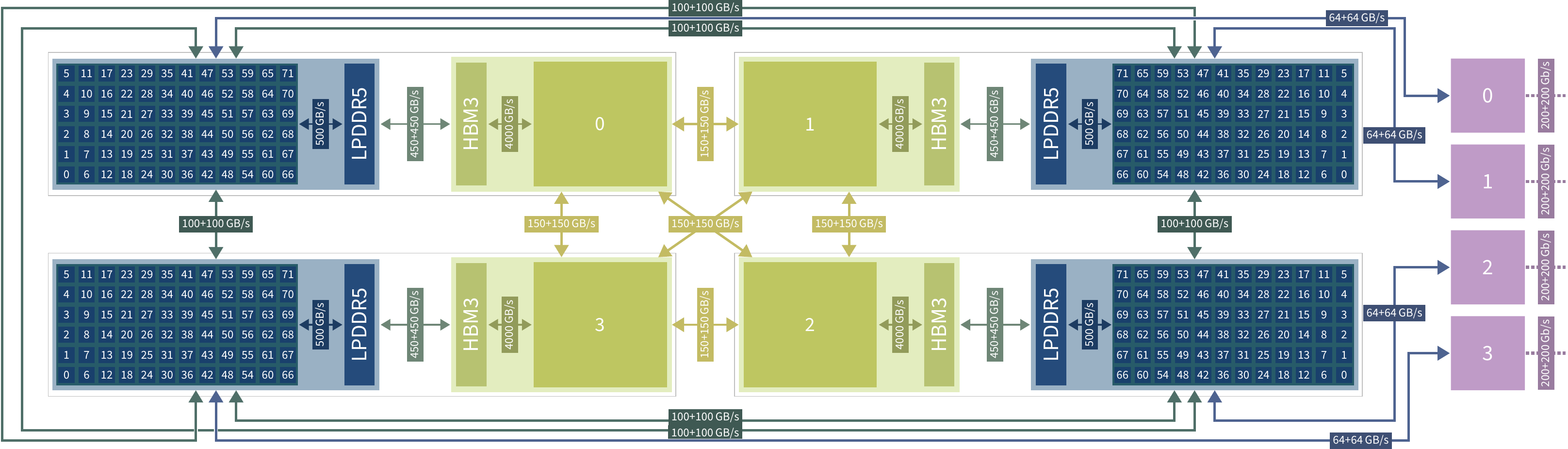
Узел Booster По оценкам, суммарные расходы на JUPITER и его эксплуатацию в течение шести лет достигнут примерно €500 млн. Половину от этой суммы предоставит EuroHPC, а остальную часть покроют Федеральное министерство образования и научных исследований Германии (BMBF) и Министерство культуры и науки земли Северный Рейн-Вестфалия (MKW NRW). Машина размещена в модульном ЦОД, что упростит дальнейшую модернизацию. Нужно отметить, что на сегодняшний день только три суперкомпьютера в мире официально преодолели планку в 1 Эфлопс. Это машины El Capitan, Frontier и Aurora: все они установлены в лабораториях Министерства энергетики США (DoE). Впрочем, Китай о своих HPC-комплексах публично практически не говорит уже несколько лет, так что реальный список экзафлопсных систем гораздо больше.
28.08.2025 [09:28], Владимир Мироненко
ASUS Cloud увеличит вычислительные мощности Тайваня на 50 %, построив 250-Пфлопс ИИ-суперкомпьютерASUS Cloud в партнёрстве с Taiwan AI Cloud (Taiwan Web Service Corp) и Национальным центром высокопроизводительных вычислений Тайваня (National Center for High-performance Computing, NCHC) в Тайнане (Тайвань) построит суперкомпьютер на ускорителях NVIDIA. Об этом сообщил гендиректор ASUS Cloud и Taiwan AI Cloud Питер Ву (Peter Wu, на фото ниже) в интервью газете South China Morning Post (SCMP). Питер Ву рассказал, что суперкомпьютер с начальной производительностью 80 Пфлопс (точность не уточняется) будет работать на 1700 ускорителях NVIDIA H200. Его запуск запланирован на декабрь, а со временем производительность новой системы вырастет до 250 Пфлопс. Ранее сообщалось, что NVIDIA также поставит два суперускорителя GB200 NVL72 и узлы HGX B300 для данной машины. По словам Ву, после запуска суперкомпьютера общая вычислительную мощность HPC-систем Тайваня вырастет минимум на 50 %. В феврале 2025 года Национальный совет по науке и технологиям Тайваня (NSTC) объявил о планах по увеличению общей вычислительной мощности систем страны примерно до 1200 Пфлопс к 2029 году с имеющихся 160 Пфлопс. 
Источник изображения: ASUS Как отметил DataCenter Dynamics, ASUS ранее сотрудничала с NVIDIA в развёртывании суперкомпьютеров на Тайване, включая 9-Плфопс машину Taiwania 2. В 2022 году ASUS и NVIDIA построили на Тайване суперкомпьютер для медицинских исследований. Taiwan AI Cloud уже реализовала аналогичные нынешнему проекты по созданию ИИ-инфраструктуры в других странах. Среди них — ЦОД в Сингапуре, а также объект во Вьетнаме с 200 ускорителями NVIDIA, который строят для государственного оператора Viettel. Этот проект стартовал в начале 2025 года после того, как правительство США одобрило поставку чипов NVIDIA. Ву отметил рост популярности агентного ИИ. Министерство цифровых технологий острова (MODA) «рекомендовало нам предоставить открытую архитектуру с фреймворком агентного ИИ», чтобы помочь местным компаниям использовать или модернизировать свои существующие приложения, сказал он. Говоря о материковом Китае, Питер Ву заявил, что компании будет «непросто» реализовывать там аналогичные проекты «из-за ситуации с поставками GPU». Китайский подход, заключающийся в «стекировании и кластеризации» малопроизводительных чипов для достижения производительности, аналогичной системам с передовыми ИИ-ускорителями, может быть осуществим с точки зрения инференса. Ву отметил, что запуск DeepSeek «рассуждающей» модели R1 в январе спровоцировал рост спроса на инференс, поскольку эта модель превосходно справляется с такими задачами. «Если рабочая нагрузка аналогична [инференсу], будет легче внедрить альтернативную технологическую схему с существующими [чипами]», — сказал Ву, добавив, что разработчики «могут столкнуться с проблемами в выборе GPU», если проект предполагает обучение или тонкую настройку ИИ-систем. Говоря о будущем, Ву сообщил, что ожидает дальнейшего развития трёх сегментов ИИ в будущем: вычислительной геномики, квантовых вычислений и так называемых цифровых двойников. «Приложение-убийца [для цифровых двойников] может появиться в сфере ухода за пожилыми людьми, помогая им получать лекарства, еду или принимать душ», — прогнозирует Ву.
22.08.2025 [13:30], Алексей Разин
NVIDIA поможет японцам создать один из мощнейших суперкомпьютеров мира FugakuNEXTВ начале этого десятилетия созданный в Японии суперкомпьютер Fugaku пару лет удерживался на верхней строчке в рейтинге мощнейших систем мира TOP500, он и сейчас занимает в нём седьмое место. В попытке технологического реванша японский исследовательский институт RIKEN доверился компании NVIDIA, которая поможет Fujitsu создать суперкомпьютер Fugaku NEXT. Помимо Arm-процессоров Fujitsu MONAKA-X, в основу нового японского суперкомпьютера лягут и ускорители NVIDIA, хотя изначально планировалось обойтись без них. NVIDIA будет принимать непосредственное участие в интеграции своих компонентов в суперкомпьютерную систему, создаваемую японскими партнёрами. По меньшей мере, скоростные интерфейсы, которыми располагает NVIDIA, пригодятся для обеспечения быстрого канала передачи информации между CPU и ускорителями. Сама NVIDIA обтекаемо говорит, что для этого можно задействовать шину NVLink Fusion. С ускорителями AMD, по-видимому, эти процессоры будут общаться более традиционно, т.е. по шине PCIe. 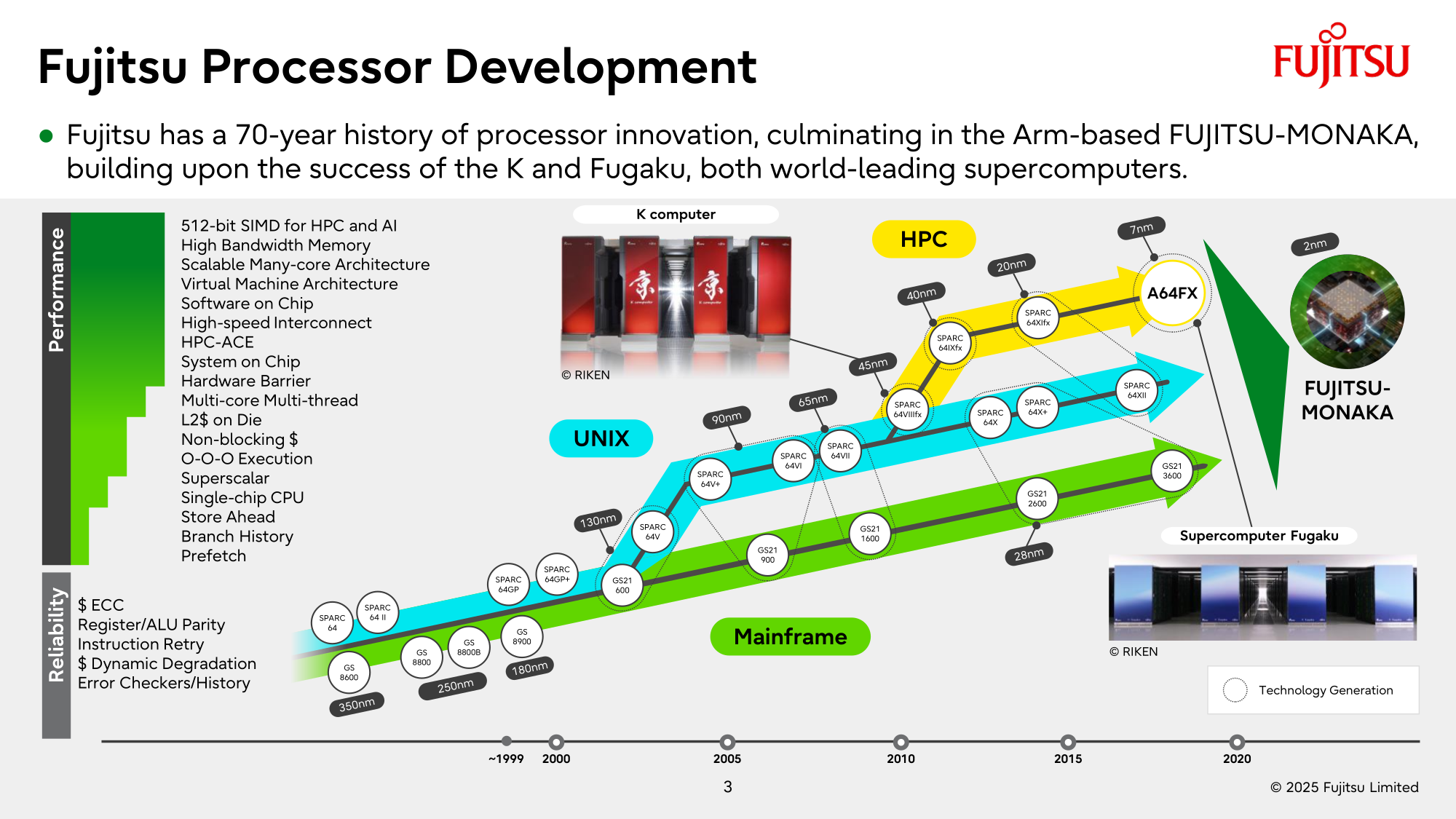
Источник изображений: Fujitsu Кроме того, NVIDIA собирается применить в составе данной системы передовые типы памяти. Применяемые при создании FugakuNEXT решения, по мнению представителей NVIDIA, смогут стать типовыми для всей отрасли в дальнейшем. Подчёркивается, что будущая платформа станет не просто техническим апгрейдом, а инвестицией в будущее страны. 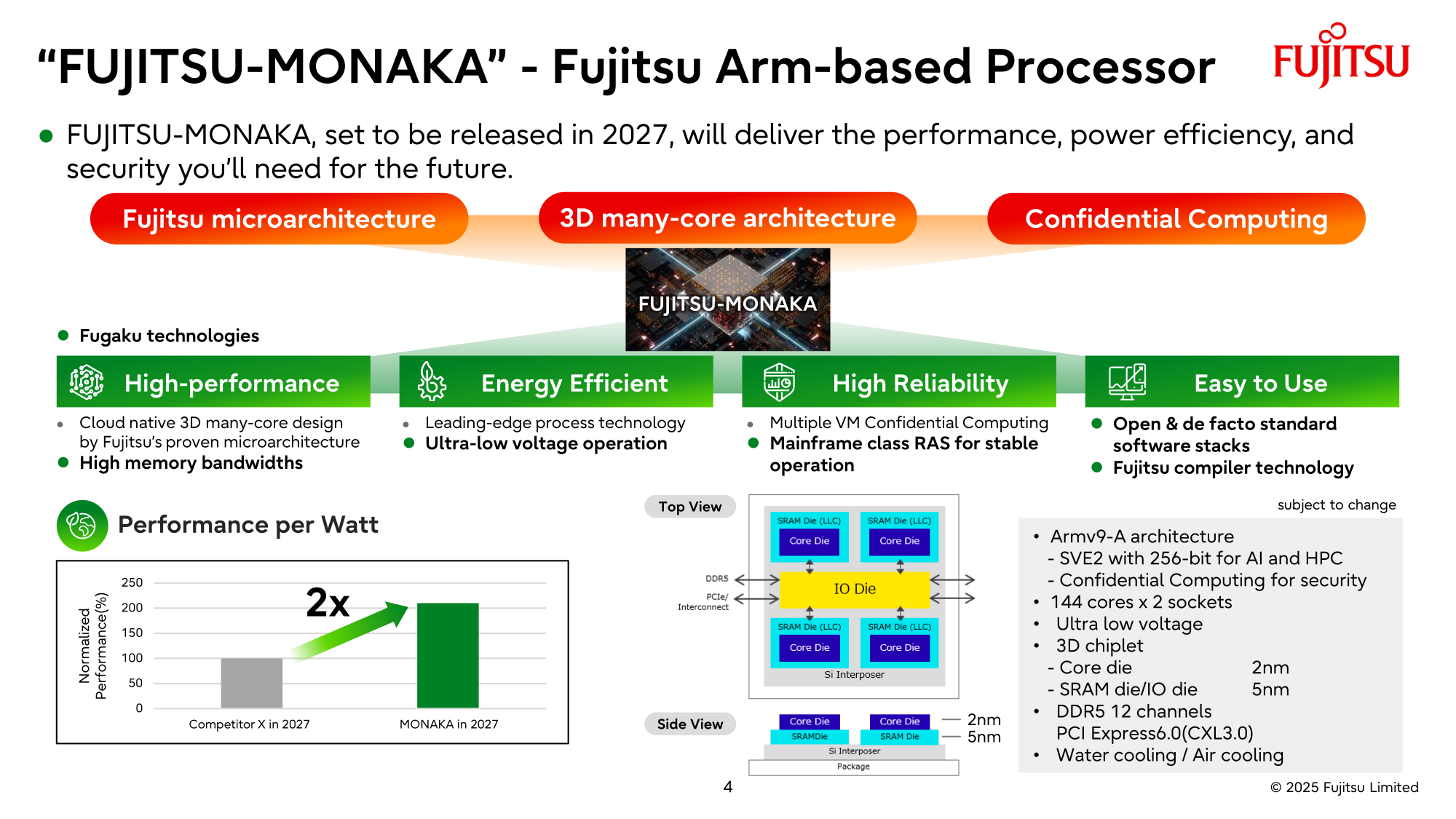 Сама архитектура системы не уточняется, поэтому сложно судить, насколько активно японские разработчики будут использовать ускорители NVIDIA, и к какому поколению они будут относиться. Создатели ставят перед собой амбициозные цели — FugakuNEXT должна стать первой системой «зетта-масштаба». Своего предшественника она должна превзойти более чем в пять раз, обеспечив быстродействие на уровне 600 Эфлопс (FP8). 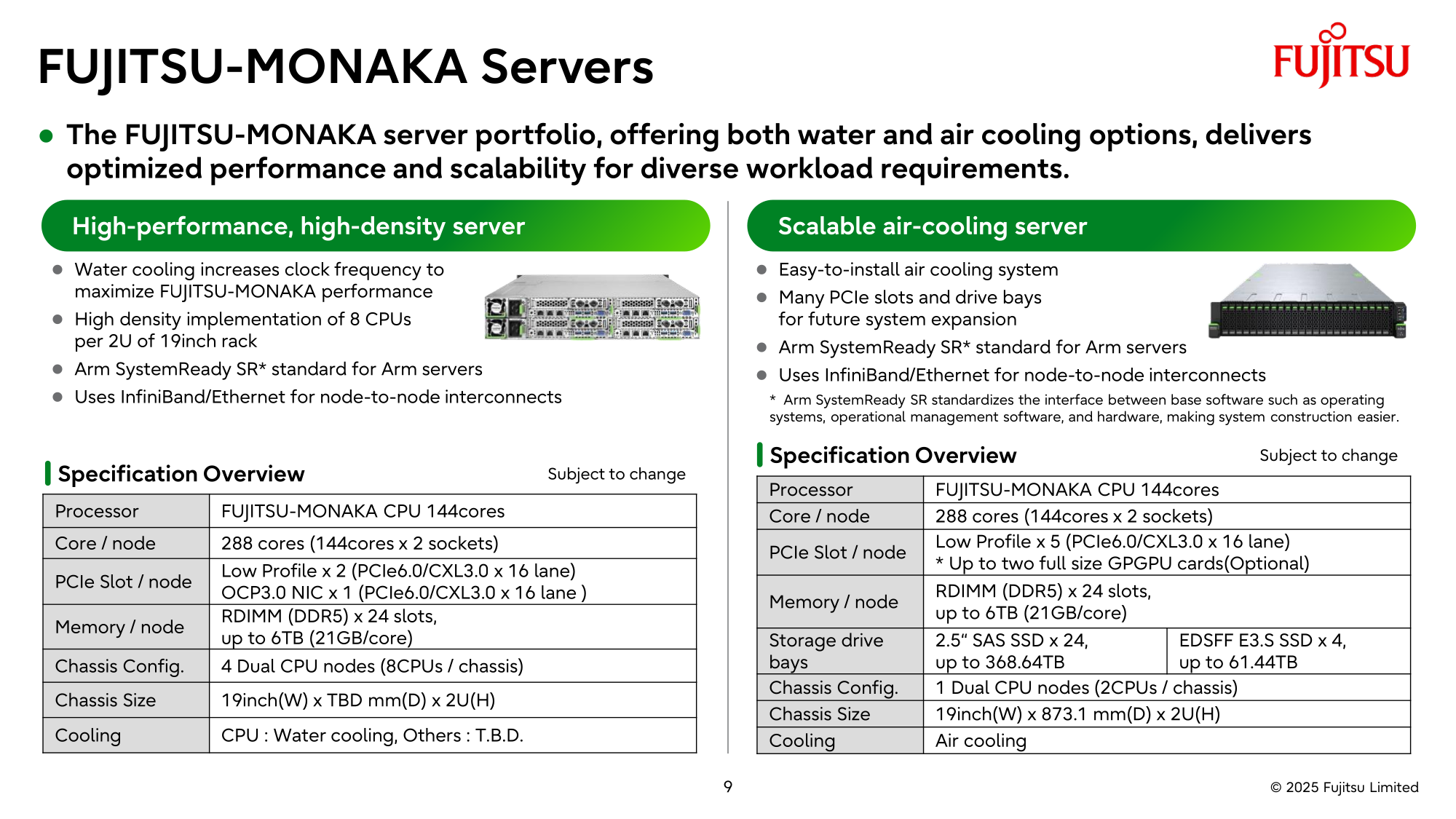 На уровне приложений прирос быстродействия может быть стократным, отмечают создатели. Новый суперкомпьютер сможет применяться для обучения больших языковых моделей. Впрочем, в строй он будет введён лишь к 2030 году, а Fujitsu ещё только предстоит выпустить свои процессоры MONAKA-X для этой системы.
08.08.2025 [11:50], Руслан Авдеев
Tesla отказалась от развития ИИ-суперкомпьютеров DojoTesla распускает команду, стоявшую за суперкомпьютером Dojo, сообщает TechCrunch со ссылкой на Bloomberg. Как сообщают анонимные источники, глава проекта Питер Бэннон (Peter Bannon) покидает компанию, а оставшихся участников команды переведут на работу с другими вычислительными проектами Tesla. О закрытии Dojo стало известно после ухода из Tesla порядка 20 сотрудников, основавших собственный ИИ-стартап DensityAI, который займётся разработкой чипов, аппаратного и программного обеспечения для ИИ ЦОД, связанных с робототехникой, ИИ-агентами и автомобильными приложениями. DensityAI основана бывшим руководителем Dojo Ганешем Венкатарамананом (Ganesh Venkataramanan), причём в не самый удачный для Tesla момент, поскольку глава компании Илон Маск (Elon Musk) ранее настоял на том, чтобы акционеры рассматривали компанию как бизнес, занимающийся ИИ и робототехникой. Решение о закрытии Dojo стало значительным изменением стратегии. Ранее Маск утверждал, что суперкомпьютер станет краеугольным камнем для удовлетворения амбиций компании в сфере ИИ и основная цель — добиться полной автономии машин благодаря способности Dojo обрабатывать огромные массивы видеоданных. В 2023 году Morgan Stanley посчитал, что Dojo может поднять капитализацию Tesla на $500 млрд за счёт новых источников дохода — проектов роботакси и программных сервисов. 
Источник изображения: Tesla В 2024 году Маск сообщил, что команда Tesla, занятая искусственным интеллектом, «удвоит ставку» на Dojo перед презентацией роботакси. Тем не менее разговоры о Dojo уже в августе того же года постепенно сошли на нет, когда Маск начал продвигать ИИ-кластер Cortex (на базе ускорителей NVIDIA) при штаб-квартире Tesla в Остине (Техас). Проект Dojo включал в себя как суперкомпьютер, так и предполагал собственное производство ИИ-ускорителей. Ещё в 2021 году Tesla во время официального анонса Dojo представила чип D1, который должен был бы использоваться совместно с ускорителями NVIDIA для обеспечения работы Dojo. Также сообщалось, что ведутся работы над чипом D2, в котором будут устранены недостатки предшественника. По данным источников Bloomberg, теперь Tesla намерена сделать ставку преимущественно на NVIDIA, а также других сторонних партнёров вроде AMD, а Samsung будет выпускать чипы на заказ. В прошлом месяце с Samsung подписан контракт на выпуск инференс-чипов AI6, которые будут работать как с автопилотами Tesla, так и использоваться в роботах Optimus и дата-центрах. Ранее Маск намекнул, что в случае с Dojo 3 (D3) и инференс-чипом AI6, речь, возможно, будет идти о едином чипе. Недавно совет директоров Tesla предложил Маску пакет акций на $29 млрд, чтобы тот оставался в Tesla и продвигал ИИ-разработки компании, вместо того чтобы отвлекаться на другие бизнесы. |
|

