Материалы по тегу: ускоритель
|
22.07.2024 [12:51], Руслан Авдеев
NVIDIA готовит урезанную версию флагманского ИИ-чипа Blackwell для КитаяNVIDIA работает над новым вариантом представленного весной флагманского ИИ-ускорителя серии Blackwell — теперь для китайского рынка, находящегося под давлением американских санкций. По данным Reuters, вендор работает над тем, чтобы привести оборудование в соответствие с техническими требованиями властей США к поставляемым в Китай полупроводникам. Серию Blackwell компания представила в марте 2024 года. Массовое производство планируется позже в текущем году. Выпускаемый в рамках нового семейства ускоритель B200 до 30 раз производительнее своего предшественника при выполнении некоторых задач. Над выпуском и поставками упрощённого для Китая чипа B20 вендор будет работать совместно с одним из своих крупнейших дистрибьюторов в Китае — компанией Inspur. Источники Reuters пожелали остаться неизвестными, в самой NVIDIA новость пока не комментируют, предпочитают молчать и в Inspur. 
Источник изображения: NVIDIA Вашингтон в очередной раз ужесточил контроль над поставками передовых чипов в Китай в 2023 году, пытаясь предотвратить развитие в Поднебесной собственных суперкомпьютеров. С тех пор NVIDIA разработала три чипа, специально оптимизированных для китайского рынка. Примечательно, что американские санкции помогли компаниям вроде китайского техногиганта Huawei и стартапам вроде Enflame добиться некоторых успехов на китайском рынке ИИ-ускорителей. Появление версии чипа серии Blackwell для Китая, вероятно, поможет NVIDIA избавиться от конкуренции на одном из ключевых рынков. Из-за санкций США за год, закончившийся в январе, выручка NVIDIA в Китае составила 17 % от общемировой, для сравнения, двумя годами ранее на страну приходилось 26 % всех продаж компании. Изначально предназначенный для Китая чип H20, продажи которого начались в этом году, раскупался довольно слабо, поэтому вендору пришлось снизить цену, чтобы сделать его дешевле конкурирующего решения Huawei. Теперь, по данным источников, продажи растут быстрыми темпами. По оценкам экспертов SemiAnalysis, в этом году NVIDIA намерена продать в Китае более 1 млн чипов H20 на сумму свыше $12 млрд. При этом высока вероятность, что американские власти и дальше продолжат ужесточать экспортный контроль, ограничивая поставки передовых ускорителей в КНР. Более того, США хотят, чтобы Нидерланды и Япония всё активнее включались в санкционный процесс, ограничивая с Китаем сотрудничество в области оборудования для производства полупроводников. Также, как сообщают источники, имеются предварительные планы ограничить доступ к наиболее передовым ИИ-моделям. Акции полупроводниковых компаний упали на прошлой неделе на фоне новостей о том, что США оценивают целесообразность введения правила, позволяющего просто запрещать продажи продуктов, выпущенных с помощью американских технологий. UPD: Inspur отрицает совместную работу с NVIDIA над ускорителями B20.
20.07.2024 [21:45], Владимир Мироненко
Tenstorrent начала продажи ИИ-ускорителей Wormhole и рабочие станции на их основеКанадский стартап Tenstorrent приступил к выпуску ИИ-чипов Wormhole. В настоящее время стартап предлагает построенные на них ИИ-ускорители Wormhole n150 и n300, а также рабочие станции TT-LoudBox и TT-QuietBox на их базе. ИИ-ускорители Wormhole n150 и n300 представляют собой двухслотовые FHFL-карты (PCIe 4.0 x16): n150 с одним чипом Wormhole, n300 — с двумя. Wormhole n150 и n300 имеют пассивное охлаждение и теплопакет 160 Вт и 300 Вт соответственно. Процессоры Wormhole были разработаны в 2021 году, но их внедрение происходит только сейчас. Это второе поколение ИИ-ускорителей Tenstorrent, которые придут на смену Grayskull. 
Источник изображений: Tenstorrent Wormhole n150 оснащён 72 ядрами Tensix, каждое из которых включает пять ядер RISC-V, поддерживающих различные форматы данных, и 108 Мбайт SRAM — вместе они предоставляют до 262 Тфлопс (FP8). Ускоритель также оснащён 12 Гбайт памяти GDDR6 с ПСП 288 Гбайт/с. У Wormhole n300 таких ядер 128, а частота также равна 1 ГГц. Объём SRAM составляет 192 Мбайт, а внешняя подсистема памяти включает 24 Гбайт GDDR6 с ПСП 576 Гбайт/с. Ускоритель обеспечивает производительность до 466 Тфлопс (FP8).  RISC-V ядра Tensix обладают аппаратной и программной поддержкой вертикального и горизонтального масштабирования — объединения множества ядер в единое целое как внутри одного узла, так и за его пределами с другими ядрами Tensix на нескольких чипах Wormhole. Именно эта функциональность, как надеется Tenstorrent, позволит ей отобрать долю рынка у NVIDIA. Впрочем, стоимость новинок тоже невелика: Wormhole n150 предлагается по цене $999, а n300 — за $1399.  В рабочих станциях Tenstorrent четыре Wormhole n300 могут работать как один ускоритель, который с точки зрерния ПО выглядит как единый массив ядер Tensix. Впрочем, можно отдать по одному ускорителю каждому пользователю или же одновременно обрабатывать восемь разных ИИ-моделей, причём всё это без использования виртуализации.  В состав рабочей станции TT-LoudBox помимо четырёх ускорителей n300 (суммарно восемь чипов Wormhole) входят два восьмиядерных процессора Intel Xeon 4309Y (Ice Lake-SP), 512 Гбайт RAM, NVMe-хранилище ёмкостью 4 Тбайт и пара портов 10 GbE. TT-LoudBox уже поступила в продажу по цене $12 тыс.  Рабочая станция TT-QuietBox оснащена четырьмя Wormhole n300 и 16-ядерным AMD EPYC 8124P (Siena). Для отвода тепла от компонентов используется жидкостное охлаждение, а остальные характеристики идентичны TT-LoudBox. Устройство доступно для предзаказа по цене $15 тыс. с поставкой в течение 8–10 недель.
19.07.2024 [14:29], Владимир Мироненко
OpenAI обсуждала с Broadcom возможность создания собственного ИИ-ускорителяСтало известно, что компания OpenAI вела переговоры с разработчиками чипов, включая Broadcom, по поводу создания нового серверного ИИ-ускорителя. Сообщивший об этом ресурс The Information утверждает, что данная инициатива, которую возглавил руководитель OpenAI Сэм Альтман (Sam Altman), является частью более широкого плана по увеличению вычислительной мощности компании для разработки ИИ, преодолению дефицита ИИ-ускорителей и снижению зависимости от NVIDIA. На фоне этих сообщений акции Broadcom выросли на 3 %. По словам источников The Information, компания наняла несколько сотрудников Google, участвовавших в создании ИИ-ускорителей TPU. Примечательно, что Broadcom работала с Google над созданием TPU, а это означает, что у компании есть опыт разработки чипов для обработки ИИ-приложений. И у неё есть подразделение, которое занимается созданием кастомных ASIC. «Миру нужно больше инфраструктуры ИИ — больших мощностей, энергии, ЦОД и т. д. — чем в настоящее время планируют построить, — сказал ранее Альтман. — OpenAI постарается помочь!». В настоящее время доля рынка ИИ-чипов NVIDIA оценивается от 70 % до 95 % рынка, а это означает, что компании, занимающиеся ИИ, находятся в полной зависимости от неё с точки зрения доступа к вычислениям. Если OpenAI удастся создать свой ИИ-ускоритель, то ей больше не нужно будет всецело полагаться на NVIDIA. 
Источник изображения: Broadcom Если бы такой чип был создан, его производство началось бы не раньше 2026 года, сообщил один из источников, поскольку отдельные детали всё ещё прорабатываются, включая вопросы упаковки и доступности памяти. Альтман вёл переговоры с южнокорейскими компаниями Samsung и SK Hynix о поставках HBM и обсуждал планы по производству чипов, сообщил The Information со ссылкой на информированные источники. Кроме того, Альтман общался с TSMC по поводу возможности выпуска нового чипа, а также увеличения поставок ИИ-ускорителей NVIDIA для его компании. OpenAI не стала подтверждать факты, изложенные в публикации The Information, но и не опровергла её. Представитель компании заявил, что «OpenAI ведёт постоянные переговоры с представителями отрасли и правительства о расширении доступа к инфраструктуре, необходимой для обеспечения широкой доступности преимуществ ИИ». Ускорители собственной разработки есть у Amazon (Trainium и Inferentia), Google (TPU), Microsoft (Maia), Meta✴ (MTIA), а также Tesla (D1). Однако все эти компании всё равно массово скупают ускорители NVIDIA для работы над ИИ или для предоставления их своим клиентам. И всё возрастающая стоимость оборудования их пока не останавливает, хотя новейший суперускоритель NVIDIA GB200 NVL72, как ожидается, будет стоить $3 млн.
18.07.2024 [22:35], Владимир Мироненко
TrendForce прогнозирует высокий спрос на ИИ-серверы до конца 2025 годаСогласно прогнозу аналитической компании TrendForce, высокий спрос на ИИ-серверы со стороны крупных провайдеров облачных услуг и других клиентов сохранится до конца 2024 года. Постепенное расширение производства компаниями TSMC, SK hynix, Samsung и Micron позволило значительно уменьшить дефицит во II квартале и, как следствие, время выполнения заказа на NVIDIA H100 сократилось с прежних 40–50 недель до менее чем 16. По оценкам TrendForce, поставки ИИ-серверов во II квартале выросли почти на 20 % по сравнению с предыдущим кварталом. Аналитики в своём свежем отчёте пересмотрели прогноз поставок на весь год до 1,67 млн ИИ-серверов (рост на 41,5 % в годовом исчислении). Объём рынка ИИ-серверов в 2024 году в денежном выражении, как ожидают в TrendForce, превысит $187 млрд при темпах роста 69 %, что составит 65 % от рыночной стоимости всех поставленных серверов. В отчёте также отмечено, что в этом году крупные провайдеры облачных услуг продолжают концентрироваться на закупке ИИ-серверов, что негативно отражается на темпах роста поставок серверов общего назначения. У последних ежегодные темпы роста поставок составят всего 1,9 %. Как ожидают в TrendForce, доля ИИ-серверов в штучном выражении в общем объёме поставок достигнет 12,2 %, что больше на 3,4 п.п. по сравнению с 2023 годом.  Аналитики отметили, что североамериканские гиперскейлеры постоянно расширяют выпуск собственных ASIC, впрочем, как и китайские компании, такие как Alibaba, Baidu и Huawei. Ожидается, что благодаря этому доля ASIC-серверов на рынке ИИ-серверов вырастет до 26 % в 2024 году, в то время как у ИИ-серверов с ускорителями доля будет около 71 %. При этом NVIDIA сохранит абсолютное лидерство с около 90 % рынка ИИ-серверов с ускорителями, в то время как доля AMD составит лишь около 8 %. Если же учитывать вообще все чипы, используемые в ИИ-серверах (GPU, ASIC, FPGA), то доля рынка NVIDIA в этом году составит около 64 %, ожидают в TrendForce. По оценкам аналитической фирмы Tech Insights, NVIDIA в 2023 году отгрузила приблизительно 3,76 млн серверных ускорителей на базе GPU, захватив 98 % рынка GPU для ЦОД. TrendForce считает, что спрос на передовые ИИ-серверы сохранится и в 2025 году, учитывая тот факт, что NVIDIA Blackwell (включая GB200, B100/B200) заменит Hopper. Это также будет стимулировать спрос на CoWoS (2.5D-упаковка от TSMC) и память HBM. Производственная мощность TSMC в области CoWoS, по оценкам TrendForce, достигнет 550–600 тыс. единиц к концу 2025 года, при этом темпы роста достигнут 80 %. 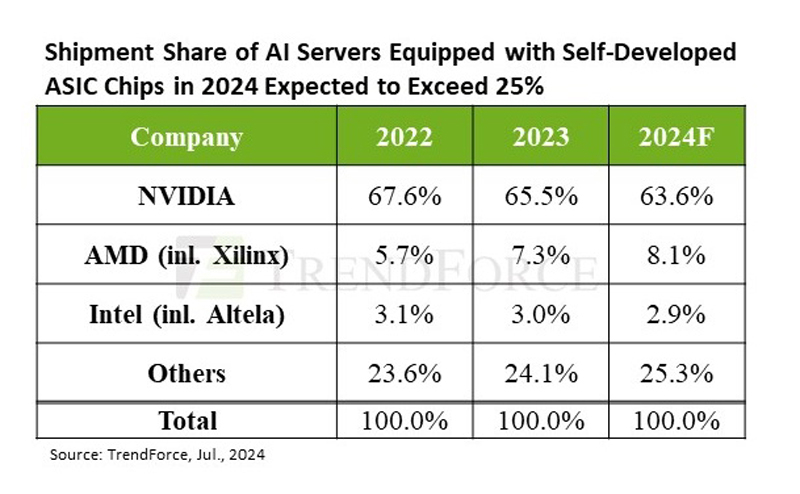
Источник изображения: TrendForce Тем не менее, ускоритель H100 получит в 2024 году наибольшее распространение. К 2025 году такие ускорители, как Blackwell Ultra от NVIDIA или MI350 от AMD, будут оснащены HBM3e ёмкостью до 288 Гбайт, что утроит количество компонентов памяти. Ожидается, что общее предложение HBM удвоится к 2025 году на фоне высокого спроса на ИИ-серверы. При этом не все уверены в светлом будущем ИИ. Так, венчурный фонд Sequoia Capital и аналитики Goldman Sachs указывают на сверхвысокие расходы на ИИ-оборудование и вместе с тем отсутсвие реальной финансовой отдачи от вложений в ИИ-решения. С другой стороны, венчурный фонд Andreessen Horowitz (a16z) уверен, что ИИ не станет очередным финансовым пузырём и сам закупает ИИ-ускорители, чтобы привлечь стартапы. А некоторые ИИ-стартапы сами приходят к крупным игрокам, поскольку не способны окупить затраты на оборудование.
17.07.2024 [23:33], Игорь Осколков
Суперускоритель по суперцене — NVIDIA GB200 NVL72, вероятно, будет стоить $3 млнКомпания NVIDIA значительно увеличила заказ на ускорители Blackwell у TSMC, сообщает TrendForce со ссылкой на United Daily News (UDN). По данным источника, NVIDIA намерена получить уже не 40 тыс., а 60 тыс. суперускорителей нового поколения, причём 50 тыс. из них придётся на стоечные системы GB200 NVL36. При этом Blackwell всё равно будут в дефиците, как и обещал ещё зимой глава NVIDIA Дженсен Хуанг (Jensen Huang). B200 включает два тайла, объединённых 2,5D-упаковкой CoWoS-L и соединённых интерконнектом NV-HBI. Чип имеет 208 млрд транзисторов, изготовленных по кастомному техпроцессу TSMC 4NP. GB200 объединяет два ускорителя B200 и один 72-ядерный Arm-процессор Grace. А суперускоритель GB200 NVL72, в свою очередь, объединяет в рамках одной стойки Oberon сразу 18 1U-узлов с парой GB200 в каждом (плата Bianca, 72 × B200 и 36 × Grace), провязанных шиной NVLink 5. Вся эта система потребляет порядка 120 кВт, оснащена СЖО и единой DC-шиной питания. Однако у GB200 NVL72 довольно специфические требования к окружению, поэтому NVIDIA предлагает суперускоритель попроще — GB200 NVL36, который как раз и должен стать наиболее массовым в данной серии. Эта платформа точно так же занимает целую стойку, но использует 2U-узлы с теми же платами Bianca (суммарно 36 × B200 и 18 × Grace), потребляя всего 66 кВт. При этом всё равно подразумевается использование двух стоек GB200 NVL36, объединённых интерконнектом, так что GB200 NVL72 всё равно получается более энергоэффективным решением. 
NVIDIA GB200 Как отмечает SemiAnalysis, GB200 NVL36 также будет доступен в варианте с платами Ariel, имеющими по одному чипу B200 и Grace. Наконец, во II квартале 2025 года появятся системы B200 NVL72 и B200 NVL36 с x86-процессорами (Miranda). Кроме того, NVIDIA представила и отдельные MGX-узлы GB200 NVL2 с парой GB200. В общем, ускорителей B200 компании понадобится много, чтобы наверняка удержать лидерство на рынке. 
Источник изображения: NVIDIA По словам UDN, GB200 NVL36 будет стоить порядка $1,8 млн, а GB200 NVL72 обойдётся уже в $3 млн. Одиночный GB200 будет стоить $60–$70 тыс., а самый простой ускоритель B100 оценён в $30–$35 тыс. Нужно подчеркнуть, что это оценки сторонних аналитиков. Сама компания официально не раскрывает стоимость своих продуктов. Это устоявшаяся практика на данном рынке, против которой пошла только Intel, публично назвавшая стоимость ИИ-ускорителей Gaudi. Впрочем, ранее глава NVIDIA намекнул, что B200 будет стоить приблизительно $30–$40 тыс.
17.07.2024 [15:49], Руслан Авдеев
DreamBig Semiconductor получила $75 млн на развитие чиплетной платформы нового поколенияСтартап DreamBig Semiconductor получил $75 млн инвестиций. Всего, по данным Silicon Angle, за время своего существования компания привлекла $93 млн. Основанный в 2019 году стартап является создателем MARS Platform — открытой чиплетной платформы для создания решений с передовой 3D-упаковкой. Она, по словам компании, позволит создать новое поколение ИИ-чипов. Последний раунд финансирования возглавляли Samsung Catalyst Fund и Sutardja Family, участие приняли новые инвесторы в лице Hanwha, Event Horizon и Raptor. Средства дали и партнёры, уже поддержавшие проект — UMC Capital, BRV, Ignite Innovation Fund и Grandfull Fund. В компании объявили, что полученные средства потратят на ускорение развития стандарта чиплетов и коммерциализацию, а также на платформу разработки Chiplet Hub. 
Источник изображения: DreamBig Ожидается, что MARS позволит клиентам сконцентрировать усилия на достижении нужных именно им характеристик чипов, а открытость платформы позволит сэкономить средства. По словам DreamBig, стандарт чиплетов MARS позволит решит проблему масштабирования вычислений и интерконнекта. Заказчики смогут использоваться базовые чиплеты для добавления той или иной функциональности к своему чипу. Заявляется, что MARS, впервые сможет обеспечить прямой доступ к SRAM и DRAM в дополнение к HBM. Для объединения кристаллов будут использоваться UCIe и BoW (Bunch of Wires), а для общения — протоколы AMBA. Платформа подходит для конструирования вычислительных чипов, ИИ-ускорителей или сетевых решений (DPU). DreamBig стала последней в серии стартапов, занятых разработкой ИИ-чипов, сумевших привлечь миллионы долларов инвестиций в этом году. Так, Etched.ai сообщил о привлечении $120 млн для того, чтобы помериться силами с NVIDIA. DEEPX привлёк $80,5 млн, SiMA Technologies получила $70 млн, а Hailo выделили $120 млн.
12.07.2024 [11:32], Руслан Авдеев
SoftBank приобрела британского разработчика ИИ-ускорителей GraphcoreЯпонская SoftBank, уже владеющая британским разработчиком процессоров Arm, приобрела британскую же компанию Craphcore, занятую разработкой ИИ-ускорителей. По данным The Register, сумма потенциальной сделки не называется, но по некоторым оценкам она составит $600 млн — для сравнения, Graphcore привлекла $700 млн в ходе всех раундов финансирования. Graphcore официально объявила о сделке в четверг, а её глава Найджел Тун (Nigel Toon) публично одобрил её, подчеркнув, что спрос на ИИ-вычисления сейчас высок и продолжает расти, а SoftBank является тем партнёром для Graphcore, который поможет «изменить ландшафт» ИИ-технологий. Штаб-квартира компании по-прежнему останется в Бристоле. Ключевые активы компании — ИИ-ускорители Intelligence Processing Units (IPU), а также стек ПО. Хотя вычислительные системы BOW POD16 оказались производительнее NVIDIA DGX A100, процветания в компании не дождались и рассматривали продажу ещё в феврале 2024 года. 
Источник изображения: Graphcore Несмотря на первоначальный успех, бизнес не смог стать прибыльным. В 2022 году выручка составила всего $2,7 млн — на 46 % меньше год к году, операционные расходы составили $206,8 млн. После этого начались увольнения — по словам представителей компании, необходимые для того, чтобы удержать бизнес на плаву. Более того, компания даже стала получать иски. Сотрудничество с китайскими бизнесами могло бы вывести Graphcore из тупика, но США ограничили продажи высокопроизводительных ускорителей в КНР. Тем временем NVIDIA закрепила своё влияние на рынке решений для генеративных ИИ-систем. Тун прогнозирует, что SoftBank, наконец, даст возможность Graphcore составить конкуренцию лидерам отрасли. 
Источник изображения: Graphcore По словам SoftBank Investment Advisers, новое поколение полупроводников и вычислительных систем имеет чрезвычайное значение для работ над т.н. «общим искусственным интеллектом» (AGI), поэтому SoftBank рада сотрудничать с Graphcore. При этом в SoftBank не акцентируют внимание на том, что компания уже является владельцем контрольного пакета акций британской Arm, на решениях которой строятся многие современные полупроводники. Последняя имеет собственные амбиции и намерена представить альтернативу решениям NVIDIA. Graphcore предлагает ещё одну альтернативу и уже имеет готовое техническое решение. С учётом финансовых ресурсов SoftBank и связей с Arm, компания, возможно, получит второе дыхание для нового старта. Другими словами, сектор ИИ-инфраструктуры сможет стать более конкурентным, что в любом случае пойдёт на благо покупателей.
10.07.2024 [16:16], Руслан Авдеев
К 2029 году на ИИ-ускорители придётся 1,5 % всего энергопотребления на ЗемлеВ мире ожидается рост энергопотребления системами, связанными с генеративным ИИ. По данным HPC Wire, в следующие пять лет расход электричества на такие системы составит 1,5 % от общемирового — это весьма значимая доля, говорят эксперты. Соответствующее предположение выдвинули аналитики TechInsights. За основу взяты прогнозы Управления энергетической информации США (US Energy Information Administration, EIA) на 2025–2029 гг., в которых глобальное энергопотребление за этот период, по оценкам, составит 153 тыс. ТВт∙ч. Исследователи предполагают, что за то же время на ИИ-ускорители придётся 2318 ТВт∙ч. Расчёты исходят из того, что каждый ускоритель требует 700 Вт, а потребление флагманских NVIDIA Blackwell и вовсе составляет 1200 Вт, хотя новинки намного производительнее решений прошлых поколений. При составлении прогнозов учитывается лишь энергопотребление самих ускорителей — без модулей памяти, сетевого оборудования и прочих компонентов ИИ-систем. По мнению экспертов, «придётся попотеть», чтобы оправдать такие расходы. 
Источник изображения: Pixabay/pexels.com Согласно опросам McKinsey, 65 % респондентов намерены использовать генеративный ИИ. Для того, чтобы удовлетворить спрос, вкладываются огромные деньги в соответствующую отрасль. Если Microsoft полагается в основном на решения NVIDIA, то Meta✴ реализует и собственный проект, а её вычислительная экосистема будет эквивалентна около 600 тыс. H100. По данным TechInsights, в 2023 году NVIDIA поставила порядка 3,76 млн ускорителей — в сравнении с 2,6 млн в 2022 году. В прошлом году Gartner выступила даже с более смелым прогнозом — по её мнению, ИИ, возможно, будет потреблять и 3,5 % мирового электричества. Впрочем, методика компании не вполне ясна и, возможно, включает энергозатраты на сопутствующую экосистему помимо ускорителей. При этом расходы на электроэнергию в любом случае будут расти, а в случае дефицита поставщики энергии будут просто поднимать цены, а не пытаться разделить доступные мощности между потребителями. Поэтому сейчас всё острее становится вопрос разумного использования энергии. Так, на криптомайнинг в США, по данным EIA, приходится 2,3 % всего энергопотребления в стране, но эксперты сходятся во мнении, что использовать ресурсы для работы ИИ-систем намного рациональнее. Впрочем, и сами майнеры активно переключаются на ИИ-проекты. Кроме того, переход на СЖО и утилизация «мусорного» повышают общую энергоэффективность ЦОД. Но есть и другой путь. Так, Microsoft совместно с производителями «железа» довольно агрессивно продвигает т.н. ИИ ПК (AI PC), оснащённые NPU или иными ускорителями для локальных ИИ-вычислений. Это фактически позволяет перенести часть нагрузок на клиентские устройства, а в облаке обсчитываются те задачи, которые устройствам не под силу. Apple использует похожий подход.
10.07.2024 [10:59], Руслан Авдеев
Венчурный инвестор Andreessen Horowitz (a16z) запасается ИИ-ускорителями, чтобы привлечь ИИ-стартапыВенчурная инвестиционная компания Andreessen Horowitz (a16z) получила тысячи современных ускорителей, включая большое количество NVIDIA H100. The Information сообщает, что компания создаёт собственные запасы для привлечения к сотрудничеству ИИ-стартапов. Компания явно не согласна с позицией венчурного фонда Sequoia Capital и аналитиков Goldman Sachs, которые опасаются, что нынешний бум ИИ — лишь пузырь. Инвестор имеет в управлении активы на $42 млрд. Как сообщают СМИ со ссылкой на источники, знакомыми с делами компании, своим подопечным компания сдаёт в аренду запасённые ускорители. Пока нет сведений, идёт ли речь о наполнении складов или компания только арендует их для передачи в субаренду. В будущем Andreessen Horowitz намерена получить более 20 тыс. ускорителей. Компания рассматривает оборудование как критически важный актив для дальнейшего развития бизнеса. 
Источник изображения: NVIDIA На запросы журналистов Andreessen Horowitz и NVIDIA пока не отвечают. Уже не в первый раз ИИ-ускорители используются не вполне традиционным способом по мере того, как нарастает ажиотаж на рынке ресурсоёмких вычислений, связанных с искусственным интеллектом. Например, в прошлом августе облачный стартап CoreWeave, поддерживаемый NVIDIA, получил в долг $2,3 млрд под залог крупной партии NVIDIA H100 для покупки ещё большего количества ускорителей. В условиях дефицита ускорителей стартапам предлагаются различные варианты решения проблемы. Так, Alibaba Cloud предлагает ИИ-стартапам GPU-мощности в обмен на долю в компании, а AWS готова выделить им миллионы долларов, но в виде кредитов для оплаты ресурсов в своём же облаке. Некоторые стартапы сами готовы поделиться интеллектуальной собственностью в обмен на доступ к ускорителям.
06.07.2024 [23:09], Владимир Мироненко
China Mobile запустила в Китае ЦОД с 4000 ИИ-ускорителей, треть из которых — отечественныеКитайская телекоммуникационная компания China Mobile объявила об официальном запуске в Пекине «интеллектуального вычислительного центра» — дата-центра площадью 57 тыс. м2, оснащённого серверами с 4 тыс. ИИ-ускорителей общей производительностью 1 Эфлопс (точность вычислений здесь и далее не указывается). Треть установленных в дата-центре ускорителей (33 %) — местного производства, сообщил ресурс China Daily. China Mobile также сообщила, что разместила у местных компаний заказ на поставку оборудования для своих «интеллектуальных вычислительных центров» на сумму $2,6 млрд. В общей сложности China Mobile закупит в период с 2024 по 2025 год 8054 единиц оборудования для своих для ЦОД, включая 7994 ИИ-сервера вместе со вспомогательным оборудованием, а также 60 коммутаторов, сообщил ресурс Data Center Dynamics. 
Источник изображения: China Mobile В числе победителей тендера — Wuhan Guangxun Technology, Kunlun Technology, Huakun Zhenyu, Boyd Computer, Powerleader и Yangtze Computing. Kunlun Technology поставляет ИИ-серверы и периферийное оборудование, Huakun Zhenyu выпускает серверы на базе Arm-процессоров Huawei Kunpeng и ИИ-ускорителей Huawei Ascend, а Powerleader специализируется на выпуске серверов и ПК для корпоративного сегмента. Ранее China Mobile сообщила, что построила крупнейший ЦОД в Хух-Хото (Внутренняя Монголия, Китай), оснащённый 20 тыс. ИИ-ускорителями общей производительностью 670 Тфлопс. В дальнейшем компания планирует построить ЦОД в Харбине (Harbin) на северо-востоке Китая и Гуйяне (Guiyang) на юге страны. Сейчас у China Mobile есть 12 «интеллектуальных» ЦОД в КНР, общая производительность которых составляет 17 Эфлопс. |
|

