Материалы по тегу: ускоритель
|
27.08.2024 [12:08], Сергей Карасёв
Стартап FuriosaAI представил эффективный ИИ-ускоритель RNGD для LLM и мультимодальных моделейЮжнокорейский стартап FuriosaAI на мероприятии анонсировал специализированный чип RNGD (произносится как «Renegade»), который позиционируется в качестве альтернативы ускорителям NVIDIA. Новинка предназначена для работы с большими языковыми моделями (LLM) и мультимодальным ИИ. FuriosaAI основана в 2017 году тремя инженерами, ранее работавшими в AMD, Qualcomm и Samsung. Своё первое решение компания выпустила в 2021 году: чип Warboy представляет собой высокопроизводительный ЦОД-ускоритель, специально разработанный для рабочих нагрузок компьютерного зрения. Новое изделие RNGD, как утверждает FuriosaAI, является результатом многолетних инноваций. Чип изготавливается по 5-нм техпроцессу TSMC. ИИ-ускоритель на базе RNGD выполнен в виде карты расширения PCIe 5.0 x16. Он наделён 48 Гбайт памяти HBM3 с пропускной способностью до 1,5 Тбайт/с и 256 Мбайт памяти SRAM (384 Тбайт/с). Показатель TDP находится на уровне 150 Вт, что позволяет использовать устройство в системах с воздушным охлаждением. Для сравнения: у некоторых ускорителей на базе GPU величина TDP достигает 1000 Вт и более. 
Источник изображения: FuriosaAI Утверждается, что RNGD обеспечивает производительность до 512 Тфлопс в режиме FP8 и до 256 Тфлопс в режиме BF16. Быстродействие INT8/INT4 достигает 512/1024 TOPS. Карта позволяет эффективно запускать открытые LLM, такие как Llama 3.1 8B. Говорится, что один PCIe-ускоритель RNGD обеспечивает пропускную способность от 2000 до 3000 токенов в секунду (в зависимости от длины контекста) для моделей с примерно 10 млрд параметров. В системе можно объединить до восьми карт для работы с моделями, насчитывающими около 100 млрд параметров. RNGD основан на архитектуре свёртки тензора (Tensor Contraction Processor, TCP), которая, как отмечается, обеспечивает оптимальный баланс между эффективностью, программируемостью и производительностью. Программный стек состоит из компрессора моделей, сервисного фреймворка, среды выполнения, компилятора, профилировщика, отладчика и набора API для простоты программирования и развёртывания. Говорится, что чипы RNGD можно настроить для выполнения практически любой рабочей нагрузки LLM или мультимодального ИИ.
20.08.2024 [14:16], Руслан Авдеев
Разработчик универсальных криптоускорителей Fabric Cryptography привлёк $33 млнПредлагающий чипы для аппаратного ускорения криптографических операций стартап Fabric Cryptography Inc. в ходе раунда финансирования A сумел привлечь $33 млн для поддержки дальнейшей разработки своих продуктов. По данным Silicon Angle, общий объём внешнего финансирования достиг $39 млн. Ведущими инвесторами стали Blockchain Capital и 1kx, свой вклад сделали и криптовалютные компании Offchain Labs, Polygon и Matter Labs. Основным продуктом компании является SoC Verifiable Processing Unit (VPU), специально созданный для обработки криптографических алгоритмов. На обработку таких алгоритмов требуется немало вычислительных ресурсов при (де-)шифровании больших массивов данных. Вендор заявляет, что VPU могут более эффективно использовать криптографическое ПО, чем традиционные процессоры, снижая эксплуатационные расходы. На рынке уже имеются многочисленные чипы для криптографических задач. Однако многие из них оптимизированы лишь для определённого набора криптографических алгоритмов. Fabric Cryptography наделила VPU набором команд (ISA), оптимизированных именно для операций, применяемых при шифровании и хешировании. Это позволяет перепрограммировать VPU для новых алгоритмов. 
Источник изображений: Fabric Cryptography VPU включает RISC-V ядра, векторные блоки, быстрый неблокирующий интерконнект и унифицированную память неназванного типа. Чип FC 1000 включает один VPU. PCIe-карта VPU 8060 включает три чипа FC 1000 и 30 Гбайт памяти с пропускной способностью около 1 Тбайт/с. Сервер Byte Smasher включает до восьми VPU 8060 и обеспечивает производительность более 1 Тбайт/с на задачах хеширования. Первым целевым примером использования VPU является ускорение алгоритмов ZKP (Zero-knowledge proof, доказательство с нулевым разглашением), которые применяются некоторыми блокчейн-платформами. В Fabric Cryptography рассказали, что получили предварительные заказы на VPU на десятки миллионов долларов именно от клиентов, рассчитывающих на выполнение ZKP-задач.  Fabric Cryptography намерена использовать полученные инвестиции на разработку новой, более производительной версии ускорителя и найм разработчиков ПО. Сейчас в компании работают более 60 инженеров, перешедших из AMD, Apple, Galois, Intel, NVIDIA и т.д. В комплекте с чипами компания предлагает компилятор и несколько связанных инструментов, которые упрощают внедрение приложений, использующих VPU.
19.08.2024 [12:52], Сергей Карасёв
Ola представила индийские ИИ-чипы Bodhi 1, Ojas и Sarv 1Компания Ola-Krutrim, дочернее предприятие одного из крупнейших в Индии производителей электрических двухколёсных транспортных средств Ola Electric, по сообщению Tom's Hardware, объявила о разработке первых в стране специализированных чипов для задач ИИ. Анонсированы изделия Bodhi 1, Ojas и Sarv 1. Впоследствии выйдет решение Bodhi 2. Но, судя по всему, речь всё же идёт о совместной работе с Untether AI. Чип Bodhi 1 предназначен для инференса, благодаря чему может использоваться при обработке больших языковых моделей (LLM) и визуальных приложений. По заявлениям Ola Electric, Bodhi 1 обеспечивает «лучшую в своём классе энергоэффективность», что является критически важным параметром для ресурсоёмких ИИ-систем. Чип Sarv 1, в свою очередь, ориентирован на облачные платформы и дата-центры, обрабатывающие ИИ-нагрузки. Процессор Sarv 1 базируется на наборе инструкций Arm. Изделие Ojas предназначено для работы на периферии и может быть оптимизировано под специфичные задачи — автомобильные приложения, Интернет вещей, мобильные сервисы и пр. В частности, сама Ola Electric намерена применять Ojas в своих электрических скутерах следующего поколения для повышения эффективности зарядки, улучшения функциональности систем помощи водителю (ADAS) и пр. 
Источник изображения: Tom's Hardware В рамках презентации Ola Electric продемонстрировала, что её ИИ-решения обеспечивают более высокие производительность и энергоэффективность, нежели ускорители NVIDIA. При этом индийская компания не уточнила, с какими именно ускорителями производилось сравнение. Ожидается, что процессоры Bodhi 1, Ojas и Sarv 1 выйдут на массовый рынок в 2026 году, тогда как Bodhi 2 появится в 2028-м. О том, где планируется изготавливать изделия, пока ничего не сообщается. Одновременно с анонсом индийских чипов производитель ИИ-ускорителей Untether AI объявил о сотрудничестве с Ola-Krutrim, в рамках которого была продемонстрирована производительность текущих решений speedAI и было объявлено о совместной разработке будущих ИИ-ускорителей для ЦОД, которые будут использованы для тюнинга и инференса ИИ-моделей Krutrim. В Индии активно развивается как ИИ-индустрия (в том числе на государственном уровне), так и рынок ЦОД. Попутно страна пытается добиться технологической независимости как от азиатских, так и от западных IT-гигантов.
13.08.2024 [20:33], Владимир Мироненко
Huawei готовит к выпуску ИИ-ускоритель Ascend 910C, конкурента NVIDIA H100Huawei Technologies вскоре представит новый ИИ-ускоритель Ascend 910C, сопоставимый по производительности с NVIDIA H100, сообщила газета The Wall Street Journal со ссылкой на информированные источники. По их словам, китайские интернет-компании и операторы в последние недели тестировали этот чип и в настоящее время ByteDance (материнская компания TikTok), поисковик Baidu и государственный оператор связи China Mobile ведут переговоры по поводу его поставок. Судя по озвученным цифрам, заказы могут превысить 70 тыс. шт. на общую сумму около $2 млрд. Huawei намерена начать поставки уже в октябре, сообщили источники, но компания не стала комментировать эти сообщения. Huawei была включена в «чёрный» список Entity List Министерства торговли США в 2019 году, что лишило её возможности производить закупки передовых чипов и оборудования для их выпуска, а также размещать заказы на производство микросхем за пределами Поднебесной. Однако благодаря многомиллиардной государственной поддержке компания стала национальным лидером во многих областях, включая ИИ, и ключевой частью усилий Пекина по «удалению» американских технологий, отметила WSJ. При этом Китай наращивает поддержку отечественного производства полупроводников и в мае выделил $48 млрд в рамках третьего транша национального инвестиционного фонда для этой отрасли. 
Источник изображения: huaweicentral.com Из-за санкций США китайским клиентам NVIDIA приходится довольствоваться ИИ-ускорителем H20, разработанным специально для Китая с учётом экспортных ограничений Министерства торговли США, в то время как американские клиенты NVIDIA, такие, как OpenAI, Amazon и Google, вскоре получат доступ к гораздо более производительным чипам, включая GB200. NVIDIA также готовит для Китая чип B20, хотя есть опасения, что и он может попасть под новые ограничения США. По оценкам аналитиков SemiAnalysis, 910C может быть даже лучше, чем B20, и если Huawei сможет наладить выпуск нового чипа, а NVIDIA по-прежнему не сможет продавать китайским клиентам передовые ускорители, то у последней все шансы быстро потерять долю рынка в стране. Согласно подсчётам SemiAnalysis, в 2025 году Huawei может произвести 1,3–1,4 млн ускорителей 910C, если не столкнётся с дополнительными ограничениями США. Аналитики ожидают, что NVIDIA продаст более 1 млн H20 в Китае в этом году на сумму около $12 млрд, т.е. в штучном выражении примерно вдове больше, чем Huawei 910B. По словам источников, в последние недели Huawei начала накапливать запасы HBM-чипов, используемых в ИИ-ускорителях, в связи с опасениями ввода США новых экспортных ограничений. На прошедшей в июне конференции, посвящённой полупроводниковой промышленности, представитель руководства Huawei сообщил, что почти половина больших языковых моделей (LLM), созданных в Китае, была обучена с помощью ускорителей компании. Он также отметил, что в этих задачах 910B превосходит по производительности NVIDIA A100.
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры.
04.08.2024 [15:25], Сергей Карасёв
В Google Cloud появился выделенный ИИ-кластер для стартапов Y CombinatorОблачная платформа Google Cloud, по сообщению TechCrunch, развернула выделенный субсидируемый кластер для ИИ-стартапов, которые поддерживаются венчурным фондом Y Combinator. Предполагается, что данная инициатива поможет Google привлечь в своё облако перспективные компании, которым в будущем могут понадобиться значительные вычислительные ресурсы. Отмечается, что для ИИ-стартапов на ранней стадии одной из самых распространённых проблем является ограниченная доступность вычислительных мощностей. Крупные предприятия обладают достаточными финансами для заключения многолетних соглашений с поставщиками облачных услуг на доступ к НРС/ИИ-сервисам. Однако у небольших фирм с этим возникают сложности. Ожидается, что Google Cloud поможет в решении данной проблемы. Google предоставит выделенный кластер с приоритетным доступом для стартапов Y Combinator. Платформа базируется на ускорителях NVIDIA и тензорных процессорах (TPU) самой Google. Каждый участник программы получит кредиты на сумму $350 тыс. для использования облачных сервисов Google в течение двух лет. Кроме того, Google предоставит стартапам кредиты в размере $12 тыс. на расширенную поддержку и бесплатную годовую подписку Google Workspace Business Plus. Молодые компании также смогут консультироваться с экспертами Google в области ИИ. 
Источник изображения: Google Оказав поддержку ИИ-стартапам, Google в дальнейшем сможет рассчитывать на заключение с ними долгосрочных контрактов на обслуживание. Говорится, что за последние 18 лет примерно 5 % стартапов Y Combinator стали единорогами с оценкой $1 млрд и более. Такие компании могут принести облачной платформе Google значительную выручку в случае заключения соглашения о сотрудничестве. С другой стороны, фонд Y Combinator сможет привлечь больше перспективных ИИ-проектов, предлагая вычислительные ресурсы Google вместе со своей поддержкой. Аналогичные программы есть и у других игроков. Так, венчурный инвестор Andreessen Horowitz (a16z) тоже запасается ИИ-ускорителями, чтобы стать более привлекательным для ИИ-стартапов. AWS предлагает ИИ-стартапам доступ к облаку и сервисам, а Alibaba Cloud готова предоставить ресурсы в обмен на долю в стартапе. Сама Google на днях наняла основателей стартапа Character.AI и лицензировал его модели. Стартапу, по-видимому, не хватило средств на ИИ-ускорители для дальнейшего развития.
01.08.2024 [00:53], Игорь Осколков
Ampere анонсировала 512-ядерные Arm-процессоры AmpereOne Aurora с HBM-памятью и встроенным ИИ-ускорителемAmpere Computing анонсировала процессоры AmpereOne Aurora, которые получат до 512 однопоточных Arm-ядер собственной разработки, набортную HBM-память и фирменные IP-блоки для обучения и инференса ИИ-моделей. Речь, судя по всему, идёт о чиплетной компоновке, поскольку компания говорит не только о фирменном меш-интерконнекте для вычислительных блоков, но и об объединении разных кристаллов в рамках SoC. Предполагается, что Aurora появятся где-то на рубеже 2025–2026 гг. 
Источник изображений: Ampere Computing Что интересно, для Aurora обещана возможность использования воздушного охлаждения. Для гиперскейлеров, на которых Ampere по-прежнему ориентируется, это важный пункт. Впрочем, больше никаких подробностей о новинках компания не сообщила, отметив лишь, что встроенный ускоритель сгодится для RAG и векторных баз данных. Ну и сообщив, что по количеству ядер и производительности её ещё не выпущенный чип обгоняет все остальные чипы: 144-ядерные Intel Xeon 6 (Sierra Forest), которые вскоре станут 288-ядерными (при этом все варианты без Hyper-Threading), и 128-ядерные AMD EPYC Bergamo (256 потоков), которым на смену придут 192-ядерные EPYC Turin Dense (384 потока). 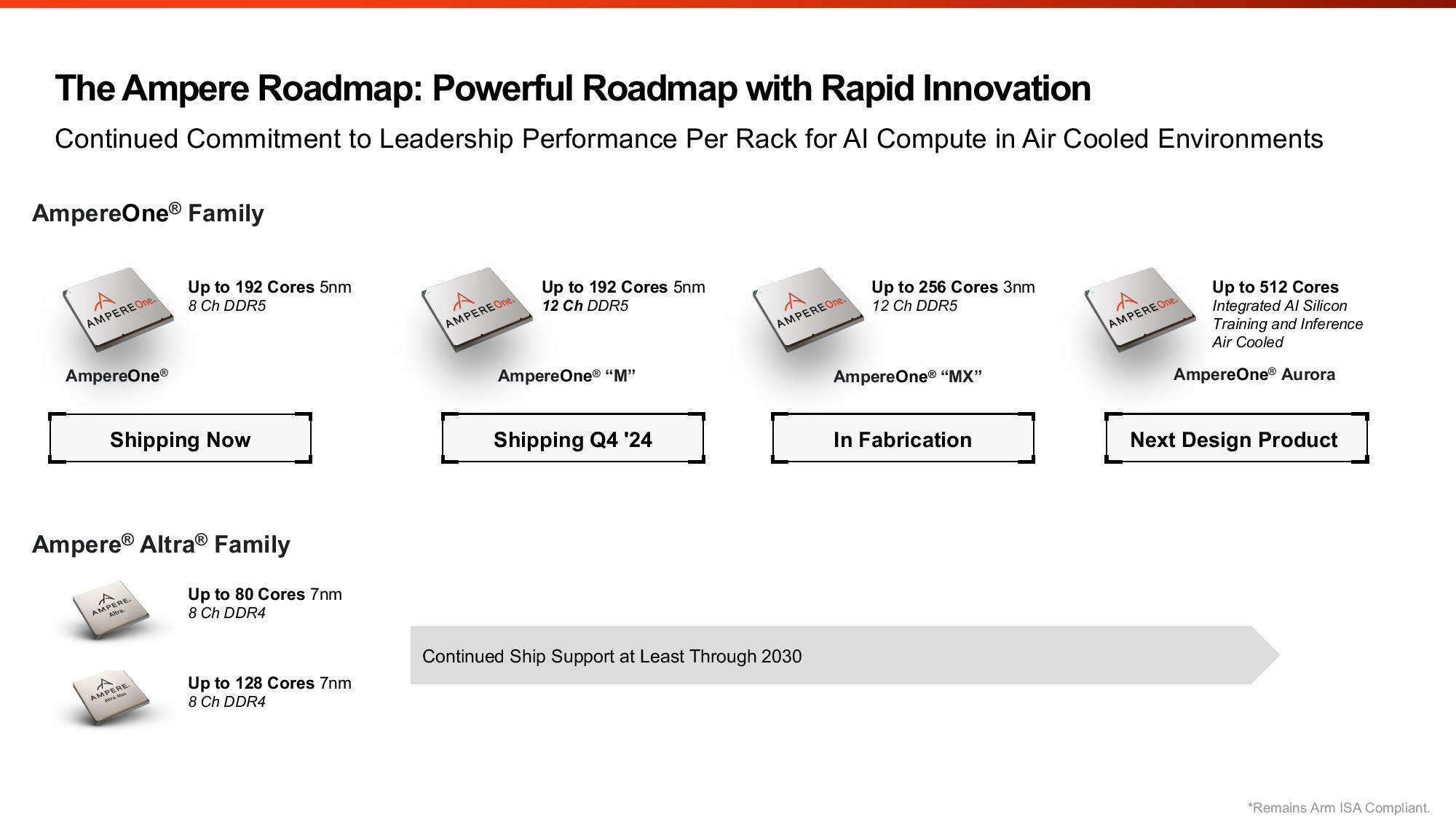 До Aurora компания выпустит ещё две серии процессоров AmpereOne: M в конце 2024 года и MX в 2025 году. 5-нм AmpereOne M получат до 192 ядер и 12-канальный контроллер памяти DDR5. 3-нм AmpereOne MX получат такой же контроллер и до 256 ядер. Заодно компания опубликовала прайс-лист актуальных CPU. В нём нет изначально заявлявшихся 136- и 172-ядерных моделей. Кроме того, остальные процессоры несколько подорожали в сравнении с прошлым поколением Altra Max, но по цене всё ещё привлекательнее решений AMD и Intel — $5555 за 192 ядра. Следует учесть, что в таблице приведён не привычный показатель TDP, а усреднённое энергопотребление чипа, из-за чего сравнивать процессоры Ampere с другими чипами затруднительно. 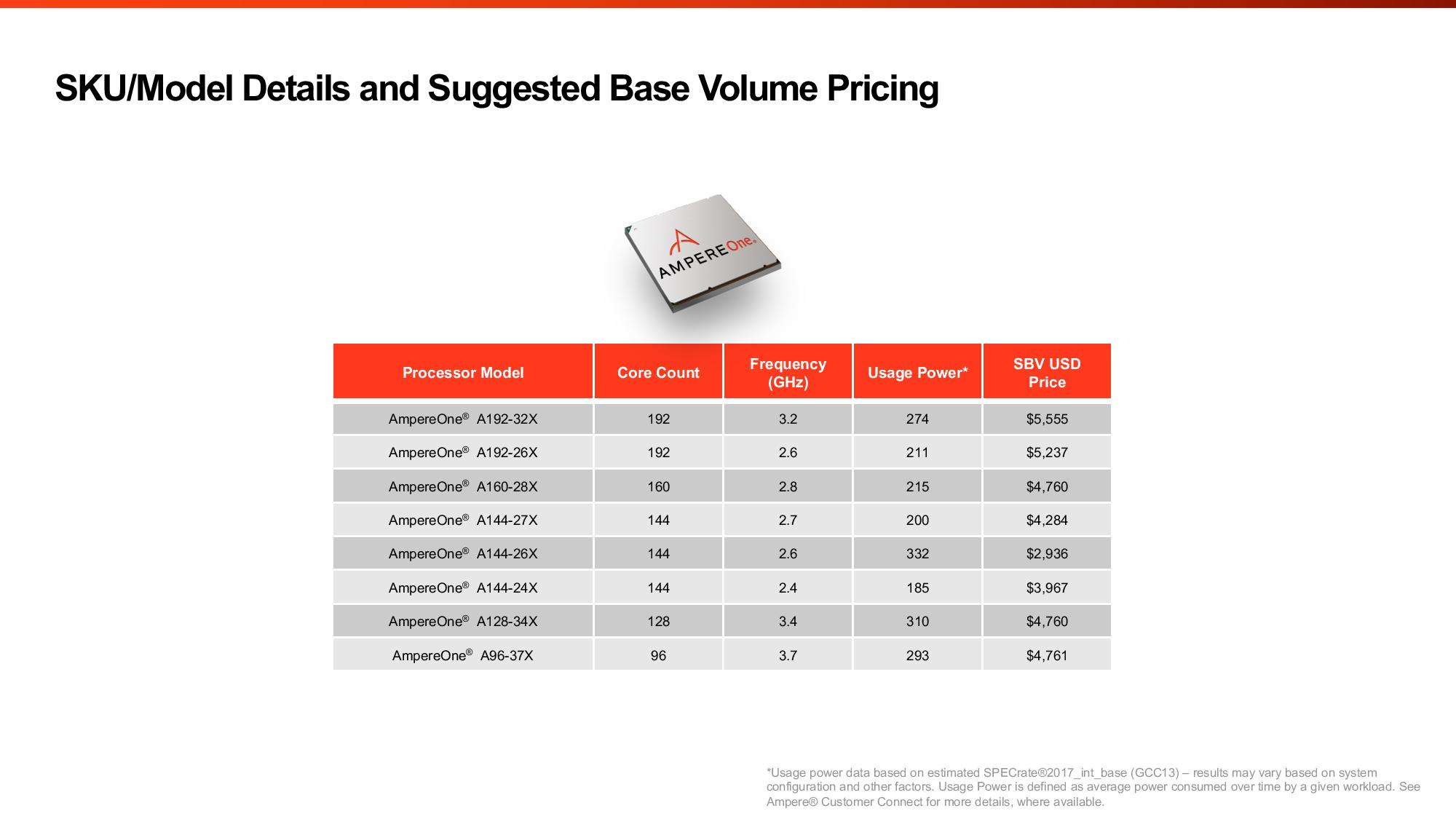 Насколько Aurora станет популярным у гиперскейлеров и других заказчиков, покажет время. У Ampere есть якорный заказчик в лице Oracle, но другие IT-гиганты уже сами разрабатывают собственные Arm-процессоры. AWS в Graviton4 довела количество ядер до 96, Microsoft анонсировала 128-ядерный Cobalt 100, Alibaba массово внедряет 128-ядерные Yitian 710, а Google готовит Axion. Fujitsu к 2027 году подготовит 144-ядерные MONAKA, которые тоже получат поддержку ИИ-нагрузок, но упор в них сделан не на HBM, а на SRAM. Собственно говоря, HBM есть только у HPC-процессоров: Fujitsu A64FX, SiPearl Rhea1 и C-DAC AUM. Даже NVIDIA Grace, которые в основном ассистируют ускорителям, обходятся LPDDR5x.
29.07.2024 [10:00], Сергей Карасёв
Kalray и Pliops объединятся для разработки передовых решений для генеративного ИИКомпании Kalray и Pliops, по сообщению ресурса Storage Newsletter, подтвердили информацию о слиянии. Объединённая структура, как утверждается, займётся разработкой передовых решений SoC (System-on-Chips) для генеративного ИИ и ускорения обработки данных. О том, что стартапы Kalray и Pliops ведут переговоры о слиянии, стало известно в июне 2024 года. Kalray проектирует DPU-ускорители на основе чипов с фирменной архитектурой MPPA. В свою очередь, Pliops разрабатывает ускорители Extreme Data Processor (XDP) для различных задач, включая реляционные базы данных, разнородные СУБД NoSQL, платформы 5G и IoT, приложения ИИ и пр. 
Источник изображения: Kalray Объединив технологии Pliops и архитектуру Kalray MPPA, стороны намерены предоставить заказчикам высокопроизводительные SoC для обработки данных в системах ИИ. Слияние будет осуществлено путём обмена ценными бумагами, при этом акционеры Kalray сохранят контрольный пакет. В рамках сделки стороны рассматривают возможность привлечения дополнительных средств из различных источников для ускорения развития. При этом Kalray уже получила финансирование в размере €15 млн в рамках возобновляемого банковского кредита. «Слияние представляет собой важную стратегическую возможность для обеих компаний. Объединив наши сильные стороны, мы намерены стать мировым лидером в области решений по ускорению обработки информации для платформ хранения данных и систем ИИ», — говорит Эрик Баиссус (Eric Baissus), генеральный директор Kalray. Отмечается, что технологии Pliops играют ключевую роль в повышении производительности массивов хранения данных на основе накопителей NVMe и приложений баз данных. Pliops привлекла около $200 млн с момента основания в 2017 году; компания насчитывает примерно 120 сотрудников в Израиле, США и Китае. В число её инвесторов входят AMD, Intel Capital, NVIDIA, SoftBank Ventures Asia, Western Digital и др. После завершения слияния существующие акционеры Pliops станут акционерами Kalray.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 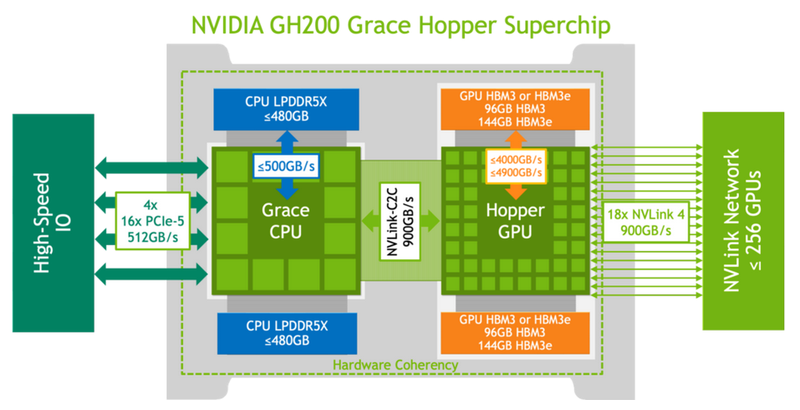
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 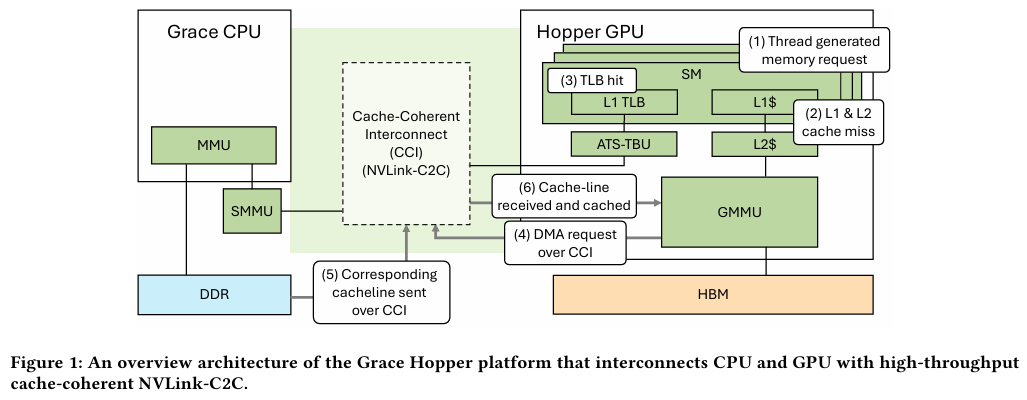
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
22.07.2024 [15:57], Руслан Авдеев
Поставки суперускорителей с чипами NVIDIA GB200 могут задержаться из-за протечек СЖОNVIDIA уже готовилась начать продажи систем на базе новейших ИИ-суперускорителей GB200, однако столкнулась с непредвиденной проблемой — TweakTown сообщает, что в системах жидкостного охлаждения этих серверов начали появляться протечки. Судя по всему, серверы на основе GB200 использовали дефектные компоненты систем СЖО охлаждения, поставляемые сторонними производителями: разветвители, быстросъёмные соединители и шланги. Некорректная работа любого из этих компонентов может привести к утечке охлаждающей жидкости. В случае с моделью GB200 NVL72 стоимостью в $3 млн это может перерасти в большую проблему. К счастью, нарушения в работе новых систем NVIDIA GB200 NVL36 и NVL72 обнаружили до начала массового производства в преддверии запуска поставок ключевым покупателям ИИ-решений. Предполагается, что на сроках поставок проблема не скажется, поскольку её успеют устранить. Впрочем, по данным источников, теперь крупные провайдеры облачных сервисов «нервничают». 
Источник изображения: NVIDIA NVIDIA предлагают свою продукцию всё больше тайваньских производителей, способных заменить бракованные компоненты для серверных систем с GB200. Однако сертификация компонентов — процесс довольно сложный, поскольку многие тайваньские компании не специализировались на их выпуске ещё в недавнем прошлом. Тем не менее, когда NVIDIA объявила, что ускорители следующего поколения получат жидкостное охлаждение, многие производители решили попробовать себя в этой сфере. Тайваньские Shuanghong и Qihong уже имеют хороший опыт в выпуске водоблоков, а теперь расширили спектр разрабатываемых товаров, предлагая разветвители, быстросъемные соединители и шланги. Именно эти компании по некоторым данным сейчас предоставляют необходимые комплектующие для замены бракованных в новых суперускорителях NVIDIA GB200 NVL36 и NVL72. Лидером на рынке серверных СЖО остаётся CoolIT, но её услугами NVIDIA, видимо, решила не пользоваться. |
|

