Материалы по тегу: ускоритель
|
17.09.2024 [20:59], Владимир Мироненко
Объявленный Intel план реструктуризации ставит под сомнение будущее ускорителей Falcon ShoresВ начале недели Intel разослала сотрудникам письмо с описанием плана выхода из кризиса, который ставит под сомнение будущее ускорителей Falcon Shores, ранее намеченных к выпуску в 2025 году, пишет ресурс HPCwire. Согласно плану, компания сосредоточится на выпуске продуктов на архитектуре x86, что может отразиться на производстве Falcon Shores, поскольку глава Intel Пэт Гелсингер (Pat Gelsinger) ранее заявил, что не будет конкурировать с NVIDIA и AMD в области обучения ИИ. Следующий этап реструктуризации также включает сокращение расходов ещё на $10 млрд и увольнение 15 тыс. сотрудников, из которых 7,5 тыс. уже выразили согласие сделать это на добровольной основе. «Мы должны сосредоточиться на нашей сильной франшизе x86, поскольку мы реализуем нашу стратегию ИИ, одновременно оптимизируя наш портфель продуктов для обслуживания клиентов и партнёров Intel», — подчеркнул в письме Гелсингер. В прошлом месяце на аналитической конференции Deutsche Bank он заявил, что компания покидает рынок обучения ИИ с тем, чтобы сосредоточиться на инференсе, используя сильную сторону чипов x86. 
Источник изображения: Intel Желание Intel сократить расходы и отказаться от неактуальных продуктов может повлиять на реализацию проекта по выпуску Falcon Shores, ускорителя для ЦОД, выход которого неоднократно откладывался. Он является преемником ускорителя Intel Ponte Vecchio (Data Center GPU Max 1550) на базе архитектуры Xe, массовый выпуск которого был фактически прекращён после ввода в эксплуатацию суперкомпьютера Aurora. Ранее Intel отказалась от ускорителей серии Rialto Bridge, а в Falcon Shores было решено отказаться от гибридного подхода, к которому к этому моменту пришли и AMD, и NVIDIA. Впрочем, от ИИ-ускорителей Gaudi компания не отрекается. Intel не ответила на запрос о комментарии о будущем Falcon Shores. И основные разработчики, занимавшиеся этим проектом — Джейсон Маквей (Jason McVeigh) и Раджа Кодури (Raja Koduri) — либо ушли, либо были назначены на другие должности. Гелсингер признал, что Intel сильно отстаёт от своих конкурентов в области GPU и чипов для обучения ИИ, включая NVIDIA, AWS, Google Cloud и AMD. Впрочем, для AWS Intel будет производить в США кастомные процессоры Xeon 6 и ИИ-ускорители (вероятно, это наследники Trainium/Inferentia). 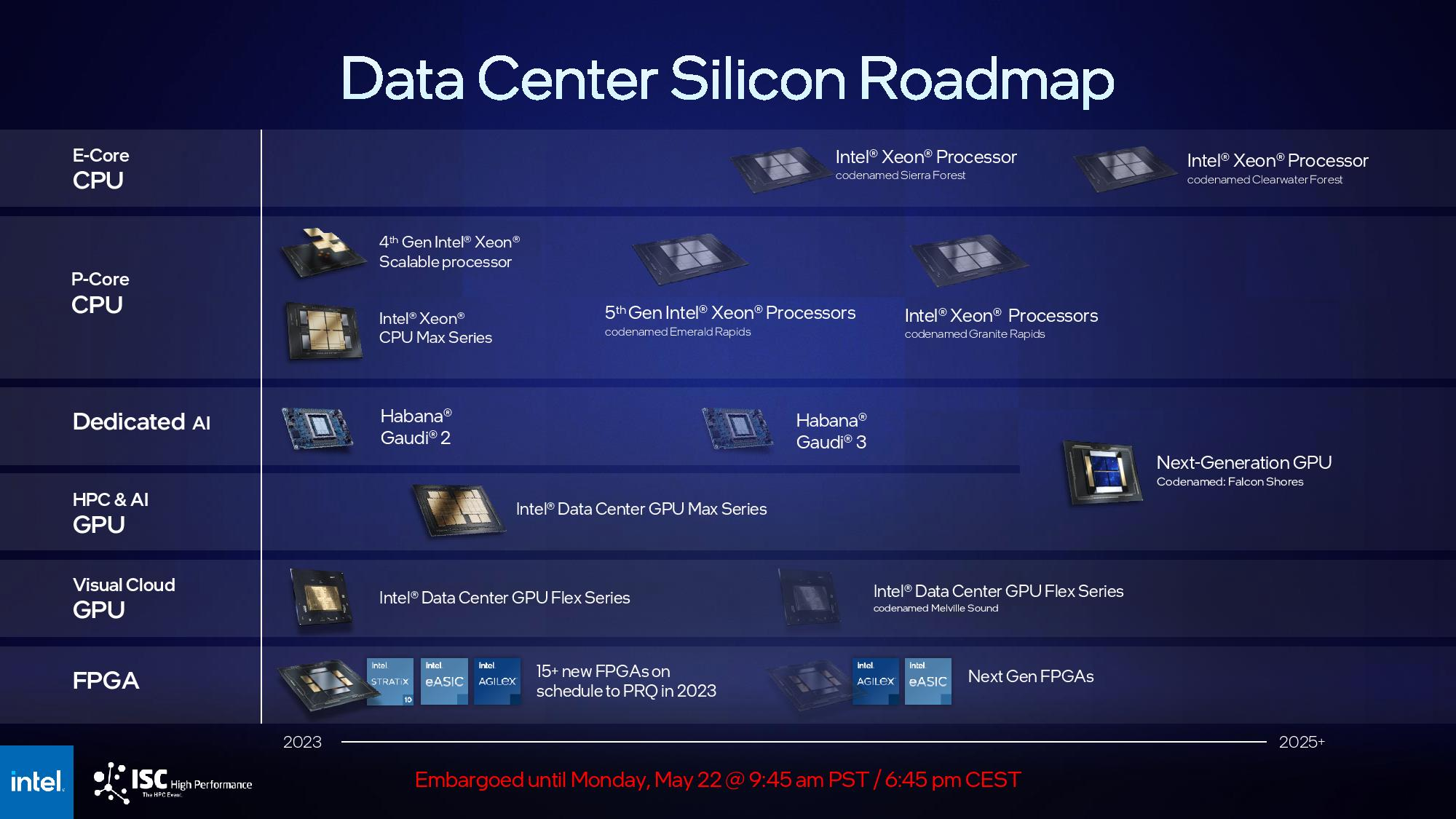
Источник изображения: Intel Также компания отметила отставание на рынке серверов для ЦОД, где сейчас большим спросом пользуются серверы с ИИ-ускорителями. «Где мы ещё не полностью вывели бизнес на хорошие позиции, так это в области CPU для ЦОД», — сообщил в этом месяце финансовый директор Intel Дэйв Цинснер (Dave Zinsner) на конференции Citi Global Technology Conference. Процессоры Xeon Emerald Rapids не оправдали ожиданий компании. Обычный цикл обновления гиперскейлеров в этот раз значительно растянулся, поскольку они активно вкладываются в развитие ИИ-инфраструктуры, попутно увеличивая срок службы традиционных серверов. Следующее поколение Granite Rapids (Xeon 6) должно выйти в начале следующего года. А Diamond Rapids, которые будут выпускаться по техпроцессу Intel 18A (1,8 нм), как ожидается, помогут вывести Intel на лидирующие позиции. Выход на производство по техпроцессу 18A с использованием новой структуры транзисторов RibbonFET и технологии PowerVia является для Intel одной из приоритетных задач. В частности, это техпроцес будет использоваться для выпуска серверных процессоров Clearwater Forest. Пока Intel под натиском AMD активно теряет долю рынка серверных CPU.
17.09.2024 [14:54], Руслан Авдеев
ByteDance разрабатывает собственные ИИ-ускорителями, но и от закупок чипов NVIDIA пока не отказываетсяПо данным The Information, китайская ByteDance, владеющая популярной социальной сетью TikTok, работает над выпуском собственных ИИ-чипов. Два вида чипов начнут производить на TSMC к 2026 году. Предполагается, что собственные разработки позволят китайскому IT-гиганту избавиться от зависимости от поставщиков вроде NVIDIA. Принято считать, что решения NVIDIA использует большинство компаний, участвующих в разработке ИИ-систем. Тем не менее, получить передовые ускорители довольно сложно из-за американских санкций, не раз ужесточавшихся и распространившихся даже на ослабленные ускорители. Из-за этого ByteDance приходится искать альтернативы. Экспорт чипов из США и других стран, использующих американские технологии, неоднократно ограничивали, а в июне появилась информация о том, что ByteDance сотрудничает с Broadcom над 5-нм решением, соответствующим всем ограничениям — его будет производить тайваньская TSMC. Также сообщалось, что ByteDance закупила в прошлом году чипы Ascend 910B, разработанные и продаваемые Huawei. Однако, по данным The Information, ByteDance пока что всё равно заказала 200 тыс. ускорителей NVIDIA H20 за более чем $2 млрд. С ними намного проще и удобнее работать, чем с решениями Huawei. 
Источник изображения: Claudio Schwarz/unsplash.com Разработка собственных чипов в ByteDance объясняется ростом интереса менеджмента компании к ИИ-технологиям — они применяются во многих решениях IT-гиганта, в том числе в рекомендательных системах TikTok. Разработка собственных продуктов позволит повысить производительность систем ByteDance при обучении моделей и инференсе. В Китае над собственными решениями в сфере ИИ-ускорителей работает не только ByteDance, но и, например, Baidu. ИИ-ускоритель Kunlun 3 тоже будет производить TSMC. При этом у Baodi гораздо более богатый опыт разработки ускорителей. Начав в 2010 году с FPGA, к 2020 году она перешла к созданию ASIC. В августе 2022 года ByteDance представила чат-бота на основе ИИ Doubao, он стал главным конкурентом Ernie Bot (разработан Baidu) в Китае. В мае под «зонтиком» бренда Doubao компания ByteDance представила большие языковые модели (LLM), рассчитанные на корпоративных клиентов. Модели относительно дёшевы в сравнении с продуктами конкурентов, предлагающими аналогичную функциональность.
17.09.2024 [10:57], Руслан Авдеев
Intel будет выпускать для AWS кастомные Xeon 6 и ИИ-ускорителиIntel и Amazon Web Services (AWS) объявили о намерении совместно инвестировать в разработку и выпуск кастомных чипов в рамках многомиллиардного многолетнего проекта, в котором будет задействовано производство Intel. Пресс-служба компании сообщает, что расширение сотрудничества поможет клиентам AWS справиться почти с любыми рабочими нагрузками и повысить производительность ИИ-приложений. Intel будет выпускать ИИ-ускорители для AWS по техпроцессу Intel 18A в рамках инициативы AI Fabric, а также кастомные процессоры серии Xeon 6 по техпроцессу Intel 3. По словам руководства Intel и AWS, взаимодействие на новом уровне для работ в сфере ИИ и машинного обучения не только будут способствовать росту обеих компаний, но и обеспечат устойчивую цепочку поставок ИИ-решений непосредственно на территории США. При этом производственное подразделение Intel Foundry фактически превратится в независимую дочернюю компанию Intel. Заявление о расширенном сотрудничестве подкрепляет обязательства компаний по ускоренной организации производства полупроводников на территории США и созданию динамичной ИИ-экосистемы в Огайо. Intel по-прежнему планирует создание передовых производств полупроводников в этом штате (в районе Нью-Олбани), а AWS намерена вложить $7,8 млрд в расширение ЦОД в Центральном Огайо — помимо тех $10,3 млрд, которые уже инвестированы в штат с 2015 года. Власти Огайо приветствуют инициативу и предполагают, что это поможет укрепить позиции штата в качестве лидера ИИ-сферы и демонстрирует приверженность Intel развитию национальных производственных площадок, а AWS — инвестициям в штат в качестве оператора ЦОД. 
Источник изображения: Intel В AWS подчёркивают, что сотрудничество с Intel началось ещё в 2006 году с создания EC2-инстансов на чипах последней. История отношений Intel и AWS насчитывает более 18 лет. В дальнейшем компании намерены изучить потенциал новых разработок на основе техпроцесса Intel 18A, а также перспективных Intel 18AP и Intel 14A. Соответствующие технологии будут, как ожидается, внедряться на фабрике в Огайо, которую ещё предстоит построить. Правда, в своём пресс релизе Intel не преминула добавить стандартную приписку, что заявления относительно выгод и влияния сотрудничества на бизнес основаны на ожиданиях руководства компаний и влекут за собой «риски неопределённости», поскольку многие факторы находятся вне контроля партнёров.
12.09.2024 [21:46], Сергей Карасёв
SiMa.ai представила чипы Modalix для мультимодальных рабочих нагрузок ИИ на периферииСтартап SiMa.ai анонсировал специализированные изделия Modalix — «системы на чипе» с функциями машинного обучения (MLSoC), спроектированные для обработки ИИ-задач на периферии. Эти решения предназначены для дронов, робототехники, умных камер видеонаблюдения, медицинского диагностического оборудования, edge-серверов и пр. В семейство Modalix входя четыре модификации — М25, М50, М100 и М200 с ИИ-производительностью 25, 50, 100 и 200 TOPS соответственно (BF16, INT8/16). Изделия наделены процессором общего назначения с восемью ядрами Arm Cortex-A65, работающими на частоте 1,5 ГГц. Кроме того, присутствует процессор обработки сигналов изображения (ISP) на базе Arm Mali-C71 с частотой 1,2 ГГц. В оснащение входят 8 Мбайт набортной памяти. Изделия производятся по 6-нм технологии TSMC и имеют упаковку FCBGA с размерами 25 × 25 мм. 
Источник изображения: SiMa.ai Чипы Modalix располагают узлом компьютерного зрения Synopsys ARC EV-74 с частотой 1 ГГц. Говорится о возможности декодирования видеоматериалов H.264/265/AV1 в формате 4K со скоростью 60 к/с и кодировании H.264 в формате 4K со скоростью 30 к/с. Реализована поддержка восьми линий PCIe 5.0, четырёх портов 10GbE, четырёх интерфейсов MIPI CSI-2 (по четыре линии 2.5Gb), восьми каналов памяти LPDDR4/4X/5-6400 (до 102 Гбайт/с). Таким образом, по словам SiMa.ai, Modalix покрывает практически весь цикл работы с данными, не ограничиваясь только ускорением ИИ-задач. 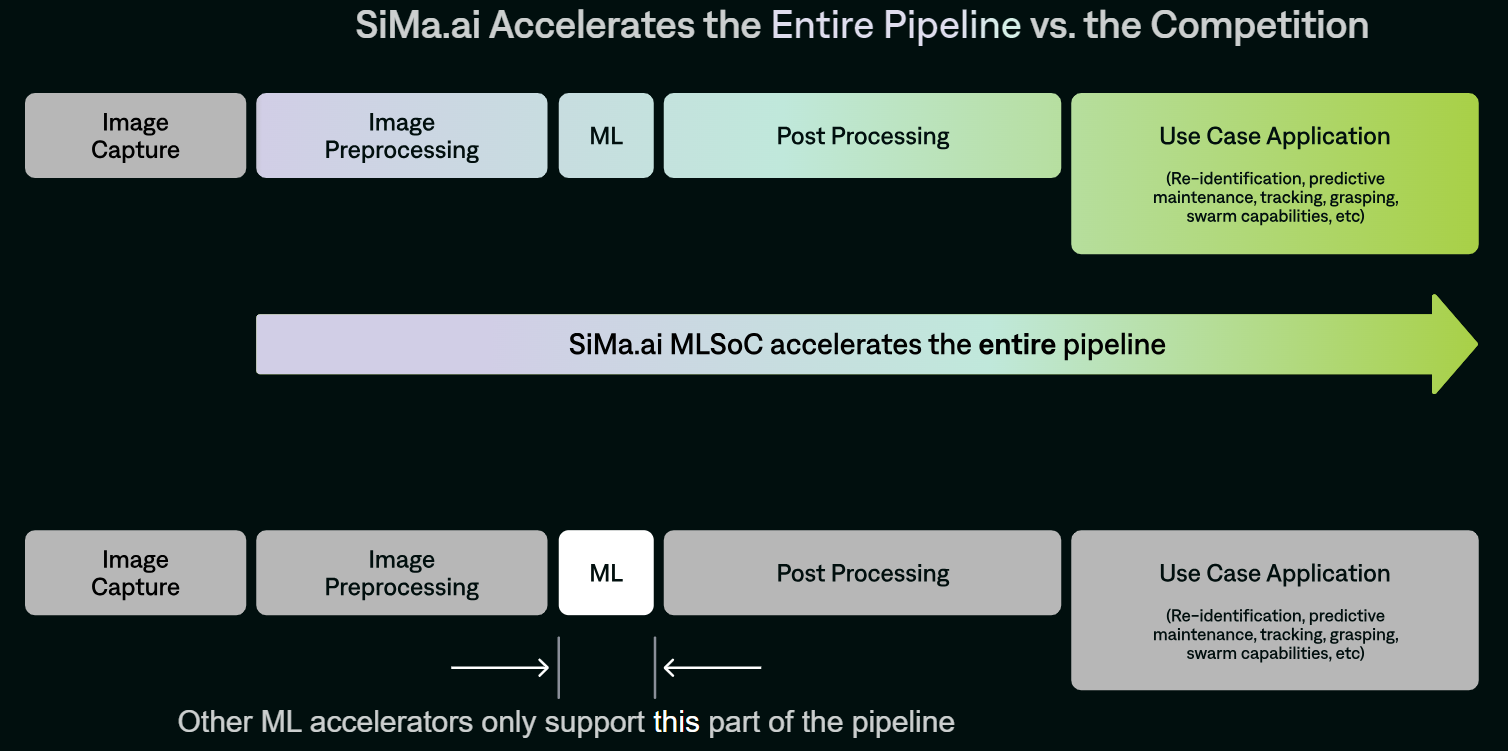
Источник изображения: SiMa.ai По заявлениям SiMa.ai, чипы Modalix можно применять для работы с большими языковыми моделями (LLM), генеративным ИИ, трансформерами, свёрточными нейронными сетями и мультимодальными приложениями. Среди возможных вариантов использования названы медицинская визуализация и роботизированная хирургия, интеллектуальные приложения для розничной торговли, автономные транспортные средства, беспилотники для инспекции зданий и пр. Есть поддержка популярных фреймворков PyTorch, ONNX, Keras, TensorFlow и т.д. Также предоставляется специализированный набор инструментов под названием Pallet, упрощающий создание ПО для новых процессоров.
04.09.2024 [23:45], Руслан Авдеев
Неудобное ПО, технические дефекты и проблемы с производительностью не помешали Huawei поднять цену на ИИ-ускорители AscendУсилия Китая, направленные на достижение технологического суверенитета в сфере полупроводников, не всегда полностью успешны. Как сообщает Financial Times, клиенты часто жалуются на различные проблемы с ИИ-ускорителями Huawei, которая сама считает их достойной альтернативой продуктам NVIDIA в условиях антикитайских санкций со стороны США и их союзников. Huawei лидирует на китайском рынке ИИ-чипов. Ускорители Ascend активно используются местными компаниями и государственными структурами как минимум для инференса. Однако некоторые китайские эксперты утверждают, что китайская продукция всё ещё сильно отстаёт от решений NVIDIA. В частности, работа чипов нестабильна, они используют довольно медленный межчиповый интерконнект и сопровождаются некачественным базовым ПО CANN, а использовать Ascend для обучения моделей по-прежнему затруднительно. Программная платформа CUDA считается одним из ключевых факторов успеха NVIDIA. Huawei пытается создать альтернативу CUDA. Правда, пока на CANN жалуются даже некоторые сотрудники Huawei, в частности, на плохую документацию, что затрудняет поиск ошибок и проблем. Кроме того, некоторые пользователи сообщают о слишком частом выходе чипов из строя. Вместе с тем Huawei гораздо более тесно сотрудничает с клиентами, чем NVIDIA. Китайская компания готова на месте помогать клиентам с переносом решений с платформы CUDA на CANN, а команды специалистов Huawei уже прописались в Baidu, iFlytek и Tencent. 
Источник изображения: Huawei По имеющимся данным, из 207 тыс. сотрудников китайской компании, более половины работают в сфере R&D, куда относятся и специалисты, направляемые для отладки технологий на территории клиентов. Другими словами, в отличие от NVIDIA у Huawei большая команда специалистов поддержки, готовых оперативно устранять возникающие у клиентов проблемы. Кроме того, у Huawei есть специальный портал для отзывов разработчиков, связанных с улучшением программной экосистемы. По данным источников издания, после того как США ужесточили санкции, Huawei подняла стоимость чипов Ascend 910B на 20–30 %. Кроме того, клиенты обеспокоены ограниченными объёмами поставок — имеющиеся в Китае мощности не могут работать в полную силу из-за санкций, мешающих покупать оборудование для выпуска чипов, например, у ASML. В то же время дела у Huawei идут хорошо — в компании отмечают сильный спрос на ИИ-чипы, а в I выручка выросла на 34 %. Правда, статистику представили без разбивки по направлениям бизнеса. Летом на конференции World Artificial Intelligence Conference представители Huawei объявили, что на чипах Ascend обучено и протестировано более 50 ИИ-моделей. Например, iFlytek заявила, что её модель обучена исключительно на ускорителях Huawei, хотя и не без помощи последней. Вместе с тем ещё в прошлом году китайские компании стали массово скупать урезанные версии ускорителей NVIDIA (A800 и H800), предназначенные для рынка КНР, в ожидании очередной волны санкций со стороны США. А Tencent даже похвасталась, что смогла накопить достаточно ускорителей для дальнейшего развития ИИ-проектов. При этом для NVIDIA рынок Китая по-прежнему крайне важен, поэтому она готова выпускать всё новые и новые варианты ускорителей специально для него.
31.08.2024 [00:39], Алексей Степин
Новые мейнфреймы IBM z получат ИИ-ускорители SpyreВместе с процессорами Telum II для систем z17 компания IBM представила и собственные ускорители Spyre, ещё больше расширяющие возможности будущих мейнфреймов в области обработки ИИ-нагрузок. Они станут дополнением к встроенным в Telum ИИ-блокам. 
Источник изображений: IBM Spyre представляет собой плату расширения с интерфейсом PCIe 5.0 x16 и теплопакетом 75 Вт. Помимо самого нейропроцессора IBM на ней установлено 128 Гбайт памяти LPDDR5, а производительность в ИИ-задачах оценивается производителем в более чем 300 Топс, т.е. новинки подходят для инференса крупных моделей. Сам чип приозводится с использованием 5-нм техпроцесса Samsung 5LPE и содержит 26 млрд транзисторов, а площадь его кристалла составляет 330 мм2.  Spyre включает 32 ядра, каждое из которых дополнено 2 Мбайт быстрой скрэтч-памяти. Отдельно отмечено, что последняя не является кешем. При этом заявлена эффективность использования доступных вычислительных ресурсов — свыше 55 % на ядро. Каждое ядро содержит 78 матричных блоков и раздельные FP16-аккумуляторы, по восемь на «вход» и «выход». Интересно, что ядра Spyre и скрэтч-память используют отдельные кольцевые двунаправленные шины разной разрядности (32 и 128 бит соответственно), причём с оперативной памятью на скорости 200 Гбайт/с соединена именно вторая.  Каждый узел (drawer) на базе Telum II способен вместить восемь плат Spyre, которые формируют логический кластер, располагающий 1 Тбайт памяти с совокупной ПСП 1,6 Тбайт/с, но, разумеется, каждая плата будет ограничена 128 Гбайт/с из-за интерфейса PCIe 5.0 x16. Spyre создан с упором на предиктивный и генеративный ИИ, благо в полной комплектации новые мейнфреймы могут нести 96 таких ускорителей и развивать до 30 ПОпс (Петаопс).  Новинки рассчитаны на работу в средах zCX или Linux on Z, сопровождаются оптимизированным набором библиотек и совместимы с популярными фреймворками Pytoch, TensorFlow и ONNX. Они станут частью программных платформ IBM watsonx и Red Hat OpenShift. Новые мейнфреймы IBM z17 должны дебютировать на рынке в 2025 году. А в собственном облаке IBM будет также полагаться и на Intel Gaudi 3.
30.08.2024 [13:11], Руслан Авдеев
ИИ-ускорители Intel Gaudi 3 дебютируют в облаке IBM CloudКомпании Intel и IBM намерены активно сотрудничать в сфере облачных ИИ-решений. По данным HPC Wire, доступ к ускорителям Intel Gaudi 3 будет предоставляться в облаке IBM Cloud с начала 2025 года. Сотрудничество обеспечит и поддержку Gaudi 3 ИИ-платформой IBM Watsonx. IBM Cloud станет первым поставщиком облачных услуг, принявшим на вооружение Gaudi 3 как для гибридных, так и для локальных сред. Взаимодействие компаний позволит внедрять и масштабировать современные ИИ-решения, а комбинированное использование Gaudi 3 с процессорами Xeon Emerald Rapids откроет перед пользователями дополнительные возможности в облаках IBM. Gaudi 3 будут применяться и в задачах инференса на платформе Watsonx — клиенты смогут оптимизировать исполнение таких нагрузок с учётом соотношения цены и производительности. Для помощи клиентам в различных отраслях, в том числе тех, деятельность которых жёстко регулируется, компании предложат возможности IBM Cloud для гибкого масштабирования нагрузок, а интеграция Gaudi 3 в среду IBM Cloud Virtual Servers for VPC позволит компаниям, использующим аппаратную базу x86, быстрее и безопаснее использовать свои решения, чем до интеграции. 
Источник изображения: Intel Ранее сообщалось, что модель Gaudi 3 готова бросить вызов ускорителям NVIDIA. В своё время Intel выступила с заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при значительно меньшей стоимости. Позже Intel публично раскрыла стоимость новых ускорителей, нарушив негласные правила рынка.
29.08.2024 [11:44], Сергей Карасёв
МТС Web Services нарастила GPU-мощности для обучения ИИ на 40 %Компания MTS Web Services (MWS), дочернее предприятие МТС, объявила о наращивании мощностей, предназначенных для обработки ресурсоёмких ИИ-нагрузок. В дата-центрах «Федоровский» в Санкт-Петербурге и GreenBushDC в Москве развёрнуты новые кластеры виртуальной инфраструктуры на базе GPU. Отмечается, что всё больше российских компаний переносят работу с ИИ в облако. Это связано с тем, что для обучения больших языковых моделей (LLM) и обеспечения их работоспособности требуются огромные вычислительные ресурсы и привлечение дорогостоящих специалистов. На фоне высокого спроса MWS расширяет свою инфраструктуру. Утверждается, что благодаря запуску двух новых сегментов GPU-мощности MWS поднялись на 40 %. При этом компания не уточняет, какие именно ускорители задействованы в составе этих кластеров. До конца 2024 года MWS рассчитывает увеличить свои GPU-ресурсы ещё в 3–4 раза. Подчёркивается, что вычислительная инфраструктура подходит для работы с любыми ИИ-моделями во всех отраслях экономики. Доступ к мощностям можно получить из любой точки России. 
Источник изображения: pixabay.com В дальнейшие планы MWS входят создание платформы для разработки, обучения и развёртывания моделей машинного обучения, внедрение уже готовых моделей ИИ для разных индустрий и направлений с доступом посредством API, а также предоставление ИИ-сервисов по модели SaaS. «Мы стремимся, чтобы как можно больше компаний вне зависимости от их величины получили возможность обучать и внедрять в бизнес свои ИИ-модели», — говорит директор по новым облачным продуктам МТС Web Services.
28.08.2024 [09:14], Владимир Мироненко
Google поделилась подробностями истории создания ИИ-ускорителей TPUВ огромной лаборатории в штаб-квартире Google в Маунтин-Вью (Калифорния, США) установлены сотни серверных стоек с ИИ-ускорителями TPU (Tensor Processing Unit) собственной разработки, с помощью которых производится обучение больших языковых моделей, пишет ресурс CNBC, корреспонденту которого компания устроила небольшую экскурсию. Первое поколение Google TPU, созданное ещё в 2015 году, и представляет собой ASIC для обработки ИИ-нагрузок. Сейчас компания использует такие, хотя и более современные ускорители для обучения и работы собственного чат-бота Gemini. С 2018 года TPU Google доступны облачным клиентам компании. В июле этого года Apple объявила, что использует их для обучения моделей ИИ, лежащих в основе платформы Apple Intelligence. 
TPU v1 (Источник изображений здесь и далее: Google) «В мире есть фундаментальное убеждение, что весь ИИ, большие языковые модели, обучаются на (чипах) NVIDIA, и, конечно, на решения NVIDIA приходится львиная доля объёма обучения. Но Google пошла по собственному пути», — отметил гендиректор Futurum Group Дэниел Ньюман (Daniel Newman). Благодаря расширению использованию ИИ подразделение Google Cloud увеличило доход, и в последнем квартальном отчёте холдинг Alphabet сообщил, что выручка от облачных вычислений выросла на 29 %, впервые превысив $10 млрд за квартал. Google была первым провайдером облачных вычислений, создавшим кастомные ИИ-чипы. Лишь спустя три года Amazon Web Services анонсировала свой первый ИИ-ускоритель Inferentia, Microsoft представила ИИ-ускоритель Azure Maia 100 в ноябре 2023 года, а в мае того же года Meta✴ рассказала об семействе MTIA. Однако лидирует на рынке генеративного ИИ компания OpenAI, обученная на ускорителях NVIDIA, тогда как нейросеть Gemini была представлена Google спустя год после презентации ChatGPT.  В Google рассказали, что впервые задумались о создании собственного чипа в 2014 году, когда в руководстве решили обсудить, насколько большими вычислительными возможностями нужно обладать, чтобы дать возможность всем пользователям поговорить с поиском Google в течение хотя бы 30 с каждый день. По оценкам, для этого потребовалось бы удвоить количество серверов в дата-центрах. «Мы поняли, что можем создать специальное аппаратное обеспечение, <…> в данном случае тензорные процессоры, для обслуживания [этой задачи] гораздо, гораздо более эффективно. Фактически в 100 раз эффективнее, чем было бы в противном случае», — отметил представитель Google. С выходом второго поколения TPU в 2018 году Google расширила круг выполняемых чипом задач, добавив к инференсу обучение ИИ-моделей. Процесс создания ИИ-ускорителя не только отличается высокой сложностью, но и требует больших затрат. Так что реализация таких проектов в одиночку не по силам даже крупным гиперскейлерам. Поэтому с момента создания первого TPU Google сотрудничает с разработчиком чипов Broadcom, который также помогает её конкуренту Meta✴ в создании собственных ASIC. Broadcom утверждает, что потратила более $3 млрд в рамках реализации совместных проектов.  В рамках сотрудничества Google отвечает за собственно вычислительные блоки, а Broadcom занимается разработкой I/O-блоков, SerDes и иных вспомогательных компонентов, а также упаковкой. Самы чипы выпускаются на TSMC. С 2018 года в Google трудятся ещё одни кастомные чипы — Video Coding Unit (VCU) Argos, предназначенной для обработки видео. Что касается TPU, то в этом году клиентам Google будет доступно шестое поколение TPU Trillium. Более того, им станут доступны и первые Arm-процессоры Axion собственной разработки. Google выходит на этот рынок с большим отставанием от конкурентов. Amazon выпустила первый собственный процессор Graviton в 2018 году, Alibaba Yitian 710 появились в 2021 году, а Microsoft анонсировала Azure Cobalt 100 в ноябре. Все эти чипы основаны на архитектуре Arm — более гибкой и энергоэффективной альтернативе x86. Энергоэффективность имеет решающее значение. Согласно последнему экологический отчёту Google, с 2019 по 2023 год выбросы компании выросли почти на 50 %, отчасти из-за увеличения количества ЦОД для ИИ-нагрузок. Для охлаждения ИИ-серверов требуется огромное количество воды. Именно поэтому начиная с третьего поколения TPU компания использует прямое жидкостное охлаждение, которое только теперь становится практически обязательным для современных ИИ-ускорителей вроде NVIDIA Blackwell.
27.08.2024 [17:46], Руслан Авдеев
ИИ-ускорители Rebellions Rebel Quad получат 144 Гбайт памяти Samsung HBM3eЮжнокорейский стартап Rebellions представила на днях план развития своих ИИ-ускорителей. Как сообщает Business Korea, компания ускорит выпуск ИИ-чипов нового поколения, которые получат 4-нм модули памяти HBM3e производства Samsung. Samsung же будет отвечать за объединение чипов и HBM в одной упаковке. Изначально к концу 2024 года планировалось наладить выпуск продукта Rebel Single с одним модулем памяти, но потом было решено выпустить гораздо более производительный вариант Rebel Quad с четырьмя 12-слойными (12-Hi) модулями HBM3e суммарной ёмкостью 144 Гбайт, тоже к концу текущего года. Новинка придёт на смену ускорителю ATOM, который оснащён всего лишь 16 Гбайт GDDR6. Использование ёмкой и быстрой HBM3e-памяти считается одним из главных преимуществ Rebel Quad, по этому показателю новинки сравнимы с последними ускорители NVIDIA семейства Blackwell. При этом обещано, что новинки будут значительно энергоэффективнее решений NVIDIA и даже ускорителей Groq. Это по-прежнему серверные ускорители для обработки LLM вроде ChatGPT, но подойдут ли они для обучения ИИ-моделей, пока не уточняется. 
Источник изображения: Rebellions Сейчас Rebellions ориентируется на поставки комплексных ИИ-решений «стоечного уровня». В рамках концепуии Rebellion Scalable Design (RDS) будет предложены программно-аппаратные комплексы, которые позволят органично взаимодействовать многочисленным ускорителями и серверам с максимальной производительностью и энергоэффективностью. Речь идёт о решении, теоретически способном конкурировать с NVIDIA CUDA. |
|

