Материалы по тегу: ускоритель
|
09.10.2024 [09:54], Сергей Карасёв
Фото дня: ИИ-система с NVIDIA GB200 и огромным радиатором для облака Microsoft AzureКорпорация Microsoft опубликовала в социальной сети Х фото новой ИИ-системы на базе ускорителей NVIDIA GB200 для облачной платформы Azure. Вычислительная стойка запечатлена рядом с блоком распределения охлаждающей жидкости (CDU), который является частью СЖО. Как отмечает ресурс ServeTheHome, вычислительная стойка содержит восемь узлов на основе GB200 с архитектурой Blackwell, а также ряд других компонентов. Точная конфигурация системы не раскрывается. На фотографии видно, что CDU-блок, расположенный по правую сторону от вычислительной стойки, имеет вдвое большую ширину. Он содержит крупноразмерный теплообменник жидкость — воздух, по сути, представляющий собой аналог автомобильного радиатора. Можно видеть насосы, элементы подсистемы питания, а также средства мониторинга. Наблюдатели отмечают, что обычно теплообменники шириной в две стойки предназначены для нескольких вычислительных стоек. Поэтому не исключено, что запечатленные на снимке изделия являются частью более крупной системы, где показанный CDU-блок будет отвечать за охлаждение сразу нескольких вычислительных стоек с ускорителями NVIDIA GB200. 
Источник изображения: Microsoft Напомним, ранее у Microsoft и NVIDIA возникли разногласия по поводу использования решений B200. NVIDIA настаивает на том, чтобы клиенты приобретали эти изделия в составе полноценных серверных стоек, тогда как Microsoft хочет использовать вариант стоек OCP с целью унификации инфраструктуры своих многочисленных дата-центров. Недавно также стало известно, что NVIDIA отказалась от выпуска двухстоечных суперускорителей GB200 NVL36×2 в пользу одностоечных вариантов NVL72 и NVL36. Причём Microsoft отдала предпочтение именно NVL72: корпорация начнёт получать эти системы в декабре.
09.10.2024 [09:49], Руслан Авдеев
Foxconn и NVIDIA построят крупнейший в мире завод по выпуску суперчипов GB200 в МексикеКомпания Foxconn построит в Мексике крупнейший в мире завод по упаковке суперчипов GB200 компании NVIDIA — ключевого продукта нового семейства Blackwell. По данным Reuters, Foxconn стал одним из главных выгодоприобретателей от бума ИИ, поскольку компания уже собирает серверы для систем искусственного интеллекта. По словам представителя Foxconn, речь действительно идёт о крупнейшем заводе по упаковке GB200 на планете. В мексиканском правительстве сообщили, что завод построят в городе Гвадалахара. В августе NVIDIA сообщала о начале поставок образцов чипов Blackwell партнёрам и клиентам, в период до января она рассчитывает уже заработать на новейших полупроводниках несколько миллиардов долларов. В Foxconn уверены, что сотрудничество компании с NVIDIA имеет важнейшее значение, поскольку спрос на новую платформу «ужасно огромный». 
Источник изображения: Sergio Rodríguez/unsplash.com Foxconn уже активно развивает производство в Мексике и инвестировала более $500 млн в штате Чиуауа. В компании утверждают, что цепочка поставок компании уже готова к ИИ-революции и производственные возможности включают выпуск передовых систем жидкостного охлаждения и теплоотвода, необходимых для оснащения серверов с GB200. Утверждается, что в текущем квартале компания обеспечила сильные показатели. В минувшую субботу Foxconn отчиталась о рекордной выручке в III квартале — на фоне сильного спроса на ИИ-серверы. Ещё одним приоритетом Foxconn являются амбициозные планы диверсификации бизнеса. В компании не желают, чтобы она ассоциировалась исключительно со сборкой электроники для Apple и надеются использовать технологические наработки для контрактного производства других продуктов, в т.ч. электромобилей и даже собственных машин под брендом Foxconn. Также известно, что на днях Foxconn и NVIDIA объявили о совместном строительстве самого быстрого ИИ-суперкомпьютера на Тайване с использованием платформы GB200 NVL72.
07.10.2024 [15:16], Руслан Авдеев
Intel может почти на треть сократить поставки ИИ-ускорителей Gaudi 3 в 2025 годуКомпания Intel борется за выживание на рынке ИИ-решений и в конце сентября официально представила свой новейший ускоритель — 5-нм Gaudi 3. Однако по данным аналитического агентства TrendForce, IT-гигант сократил планы поставок соответствующих чипов более чем на 30 % в 2025 году. Это может повлиять на бизнес-партнёров компании из цепочки поставок на Тайване. Агентство ссылается на отчёт Economic Daily News. В нём указывается, что новые меры могут быть связаны с изменением внутренней политики Intel и спроса, что побудило компанию сократить заказы на Тайване. После снижения объёмов выпуска место IT-гиганта на фабриках TSMC займут другие клиенты. То же касается и ASE, а также её дочерней SPIL, оказывающих Intel услуги по упаковке и тестированию микросхем. Для Alchip, проектирующей специализированные ASIC для Intel Gaudi 2 и Gaudi 3, ситуация может оказаться более сложной. Unimicron, которая считается главным поставщиком подложек для чипов Intel, тоже довольно сильно зависит от объёмов заказов последней. Но в Unimicron сохраняют оптимизм, поскольку рассчитывают, что во II половине 2024 года спрос на ИИ-ускорители и оптические модули вырастет. 
Источник изображения: Intel Отраслевые источники сообщают, что изначально в 2025 году планировалось отгрузить 300–350 тыс. ускорителей Gaudi 3, но теперь речь идёт лишь о 200–250 тыс. По имеющимся данным, после покупки израильского производителя Habana Labs в 2019 году, Intel, вероятно, весьма прохладно относится к идее совместной разработки ИИ-ускорителей нового поколения со сторонними компаниями. Более того, она ускоренно сворачивает выпуск Gaudi 2. Новость об изменениях структуры производства компании отнюдь не первая в 2024 году. В мае сообщалось, что Intel отказалась от ускорителей Ponte Vecchio в пользу Gaudi и Falcon Shores. Позже появились предположения о том, что создание Falcon Shores будет свёрнуто в рамках плана по выводу компании из кризиса, но Intel поспешила развеять сомнения, сообщив, что эту серию ускорителей всё же выпустят. Вероятно и то, что в них интегрируют элементы Gaudi.
05.10.2024 [15:55], Сергей Карасёв
Qualcomm готовит «урезанные» ИИ-ускорители Cloud AI 80Qualcomm, по сообщению Phoronix, планирует выпустить ускорители Cloud AI 80 (AIC080) для ИИ-задач. Информация о них появилась на сайте самого разработчика, а также в драйверах Linux. Речь идёт об «урезанных» версиях изделий Cloud AI 100, уже доступных на рынке. Базовая версия Cloud AI 100 Standard выполнена в виде HHHL-карты (68,9 × 169,5 мм) с интерфейсом PCIe 4.0 х8 и пассивным охлаждением. Объём памяти LPDDR4x-2133 с пропускной способностью 137 Гбайт/с составляет 16 Гбайт. Есть также 126 Мбайт памяти SRAM. TDP равен 75 Вт. Заявленное быстродействие достигает 350 TOPS на операциях INT8 и 175 Тфлопс при вычислениях FP16. От них в своё время отказалась Meta✴, сославшись на сырость программной экосистемы и предпочтя разработать собственные ИИ-ускорители MTIA. 
Источник изображений: Qualcomm Кроме того, существует решение Cloud AI 100 Ultra в виде карты FH3/4L (111,2 × 237,9 мм). Для обмена данными служит интерфейс PCIe 4.0 х16; значение TDP равно 150 Вт. В оснащение входят 128 Гбайт памяти LPDDR4x, пропускная способность которой достигает 548 Гбайт/с. Объём памяти SRAM — 576 Мбайт. INT8-производительность составляет до 870 TOPS, FP16 — до 288 Тфлопс.  Сообщается, что к выпуску готовятся «урезанные» ускорители Cloud AI 80 Standard и Cloud AI 80 Ultra. Их характеристики в точности соответствуют таковым у Cloud AI 100 Standard и Cloud AI 100 Ultra. Отличия заключаются исключительно в пониженном быстродействии. Так, у Cloud AI 80 Standard производительность INT8 находится на уровне 190 TOPS, FP16 — 86 Тфлопс. У Cloud AI 80 Ultra значения равны 618 TOPS и 222 Тфлопс.  Нужно отметить, что в старшее семейство также входит модель Cloud AI 100 Pro в формате карты HHHL с интерфейсом PCIe 4.0 х8 и TDP 75 Вт. Она несёт на борту 32 Гбайт памяти LPDDR4x (137 Гбайт/с) и 144 Мбайт памяти SRAM. Производительность INT8 составляет до 400 TOPS, FP16 — до 200 Тфлопс. Появится ли подобная модификация в серии Cloud AI 80, пока не ясно.
03.10.2024 [12:52], Руслан Авдеев
США меняют правила экспорта ИИ-чипов, упрощая продажи современных ускорителей проверенным VEU-партнёрам на Ближнем ВостокеВ ближайшее время ЦОД Ближнего Востока могут получить доступ к передовым американским ИИ-ускорителям. Правда, как сообщает Network World, компании смогут закупать современную продукцию только при соблюдении строгих мер безопасности и после серьёзных проверок. Министерство торговли США анонсировало новую политику, в соответствии с которой предусмотрено смягчение ограничений на экспорт передовых ИИ-чипов на рынки Ближнего Востока и Центральной Азии. Это может облегчить бизнес американским компаниям, занимающимся их выпуском и разработкой. ЦОД из этих регионов смогут подавать заявки на получение особого статуса, без просьб об индивидуальных экспортных лицензиях. Ранее экспортёры получали специальные индивидуальные лицензии у американских регуляторов для поставки в «страны, вызывающие озабоченность». Теперь в рамках программы «Проверенный конечный пользователь» (Validated End User, VEU) можно будет получать ИИ-чипы, например, NVIDIA на общих основаниях — американским компаниям не понадобится лицензия на экспорт. Предполагается, что обновление программы VEU снизит лицензионное бремя на отрасль, а ЦОД смогут заранее выполнять строгие требования регуляторов. 
Источник изображения: Nick Fewings/unsplash.com Проблемы с поставками начались после того, как в октябре 2023 года США ограничили отгрузки передовых чипов на Ближний Восток и в Центральную Азию, опасаясь «неправомерного» использования новых продуктов — основной угрозой назывался риск перепродажи продукции в Китай через третьи страны. В рамках программы VEU американские технологии будут защищены от подобных «злоупотреблений», рассчитывает министерство. Вероятно, решение американских властей связано с давлением со стороны американских компаний, нуждающихся в расширении рынков сбыта. Впрочем, операторам ЦОД придётся следовать ряду жёстких правил для получения технологий. Китайские структуры довольно изобретательны — не так давно выяснилось, что они покупают доступ к подсанкционному оборудованию даже в облаках на территории самих США. Также одной из главных проблем называется возможность попадания ИИ-технологий в руки Пекина через сторонние компании Ближнего Востока. Например, пристальное внимание в своё время привлекла компания G42 (ныне Core42) из ОАЭ. Хотя она отказалась от сотрудничества с бизнесом из КНР и выразила готовность соблюдать ограничения США, сделка с Microsoft на сумму $1,5 млрд вызвала озабоченность американских конгрессменов. Хотя новое правило решает ряд проблем экспортёров и импортёров, для компаний вроде G42 процедура вряд ли будет слишком простой. В рамках программы VEU дата-центры, подавшие заявку на получение соответствующего статуса, должны будут пройти строгую проверку, с оценкой клиентской базы, бизнес-активности, соблюдения протоколов кибербезопасности и контроля доступа. Получившие «добро» организации всё равно должны будут вести строгую отчётность и будут подвергаться проверкам на местах, участие в которых станут принимать должностные лица из США. Также правительства стран-импортёров должны будут предоставить гарантии безопасного и надлежащего использования технологий. По данным Министерства торговли Соединённых Штатов, каждое разрешение для защиты интересов национальной безопасности США имеет ограниченное действие, кроме того, в нём определены типы и объёмы технологий, к которым могут получить доступ VEU-партнёры. Сейчас Соединённые Штаты пытаются найти оптимальный баланс между контролем экспорта технологий и необходимостью инноваций как в стране, так и за её пределами. Это позволит отчасти умиротворить американский бизнес, в то же время сохраняя контроль использования передовых технологий за рубежом. А для стран Ближнего Востока развитие ИИ-технологий и цифровая трансформация стали одними из главных возможностей по диверсификации экономики.
03.10.2024 [10:51], Сергей Карасёв
NVIDIA отказалась от выпуска двухстоечных суперускорителей GB200 NVL36×2Компания NVIDIA, по информации аналитика Минг-Чи Куо (Ming-Chi Kuo), приняла решение отказаться от выпуска двухстоечных ИИ-систем NVL36×2 на основе ускорителей GB200 в пользу одностоечных машин NVL72 и NVL36. Объясняется это ограниченностью ресурсов и предпочтениями клиентов. Изначально планировалось выпустить три суперсистемы GB200 на базе ускорителей Blackwell для рабочих нагрузок ИИ и HPC — NVL72, NVL36 и NVL36×2. Первая объединяет в одной стойке 18 узлов 1U, каждый из которых содержит два ускорителя GB200. В сумме это даёт 72 чипа B200 и 36 процессоров Grace. Задействована шина NVLink 5, а энергопотребление системы находится на уровне 120 кВт. В свою очередь, NVL36 насчитывает 36 чипов B200, тогда как NVL36×2 объединяет две такие системы. 
Источник изображения: NVIDIA Ожидалось, что конфигурация NVL36×2 получит более широкое распространение, нежели NVL72. Дело в том, что дата-центры большинства клиентов NVIDIA не могут удовлетворить требования NVL72 в плане питания и охлаждения. С этой точки зрения NVL36×2 представляет собой компромиссное решение. С другой стороны, NVL72 требует меньше пространства для установки и обладает меньшим суммарным энергопотреблением: каждая из стоек NVL36×2 требует 66 кВт, что в сумме даёт 132 кВт. При этом обеспечивается несколько меньшая производительность. По сведениям Минг-Чи Куо, некоторые заказчики (в частности, Microsoft) отдали предпочтение NVL72 перед NVL36×2. При этом между компании ещё на этапе обсуждения возникли разногласия по поводу конфигурации стоек. Кроме того, для NVIDIA управление тремя разными проектами по созданию суперускорителей на базе GB200 стало сложной задачей. Поэтому от двухстоечной машины решено отказаться. Отмечается также, что массовое производство NVL72 может быть отложено до II половины 2025-го, хотя ранее называлось I полугодие следующего года. Впрочем, отдельные заказчики, включая Microsoft, начнут получать эти системы уже в декабре.
03.10.2024 [10:45], Сергей Карасёв
Intel не отказывается от планов по выпуску ускорителей Falcon ShoresКорпорация Intel, по сообщению ресурса HPC Wire, не намерена сворачивать проект по разработке ускорителей Falcon Shores, несмотря на реструктуризацию, направленную на укрепление позиций в сегменте продуктов с архитектурой x86. Изделия Falcon Shores, как и планировалось ранее, появятся на рынке в 2025 году. Предполагалось, что решения Falcon Shores дебютируют после выхода ускорителей серии Rialto Bridge, которые должны были прийти на смену Ponte Vecchio. Однако в марте 2023 года Intel отменила выпуск Rialto Bridge, а недавно появилась информация, что будущем Falcon Shores также туманно. Теперь в Intel развеяли сомнения. Представители корпорации заявили, что изделия Falcon Shores выйдут в виде GPU-ускорителей. Ранее Intel отказалась от применения в этих решениях гибридной конфигурации CPU + GPU. Вместе с тем говорится, что в состав новых карт войдут элементы ИИ-ускорителей Gaudi. Утверждается, что такая конструкция обеспечит Falcon Shores преимущества перед конкурирующими продуктами, использующими только GPU-блоки. 
Источник изображения: Intel «Falcon Shores — это действительно ускоритель на основе GPU, в составе которого используются технологии Gaudi», — сообщила пресс-секретарь Intel. По имеющейся информации, ускорители получат модульный дизайн, поддержку современных ИИ-фреймворков, масштабируемые интерфейсы ввода-вывода и память HBM3e. По слухам, выпуск новинок будет организован на предприятии TSMC с применением 3-нм технологии. Intel по-прежнему нацеливает Falcon Shores на рынок высокопроизводительных вычислений. Вместе с тем Intel, находящаяся в сложном финансовом положении, намерена активно развивать экосистему x86. Недавно корпорация объявила о намерении оптимизировать процессоры Xeon Granite Rapids для работы с ИИ-ускорителями NVIDIA.
29.09.2024 [00:30], Алексей Степин
Рождение экосистемы: Intel объявила о доступности ИИ-ускорителей Gaudi3 и решений на их основеПро ускорители Gaudi3 компания Intel достаточно подробно рассказала ещё весной этого года — 5-нм новинка стала дальнейшим развитием идей, заложенных в предыдущих поколениях Gaudi. Объявить о доступности новых ИИ-ускорителей Intel решила одновременно с анонсом новых серверных процессоров Xeon 6900P (Granite Rapids), которые в видении компании являют собой «идеальную пару». Впрочем, в компании признают лидерство NVIDIA, так что обещают оптимизировать процессоры для работы с ускорителями последней. А вот ускорителей Falcon Shores, вполне вероятно, с новой политикой Intel потенциальные заказчики не дождутся. 
Источник изображений здесь и далее: Intel На данный момент главной новостью является то, что в распоряжении Intel не просто есть некий ИИ-ускоритель с более или менее конкурентоспособной архитектурой и производительностью, а законченное и доступное заказчикам решение, уже успевшее привлечь внимание крупных производителей и поставщиков серверного оборудования. 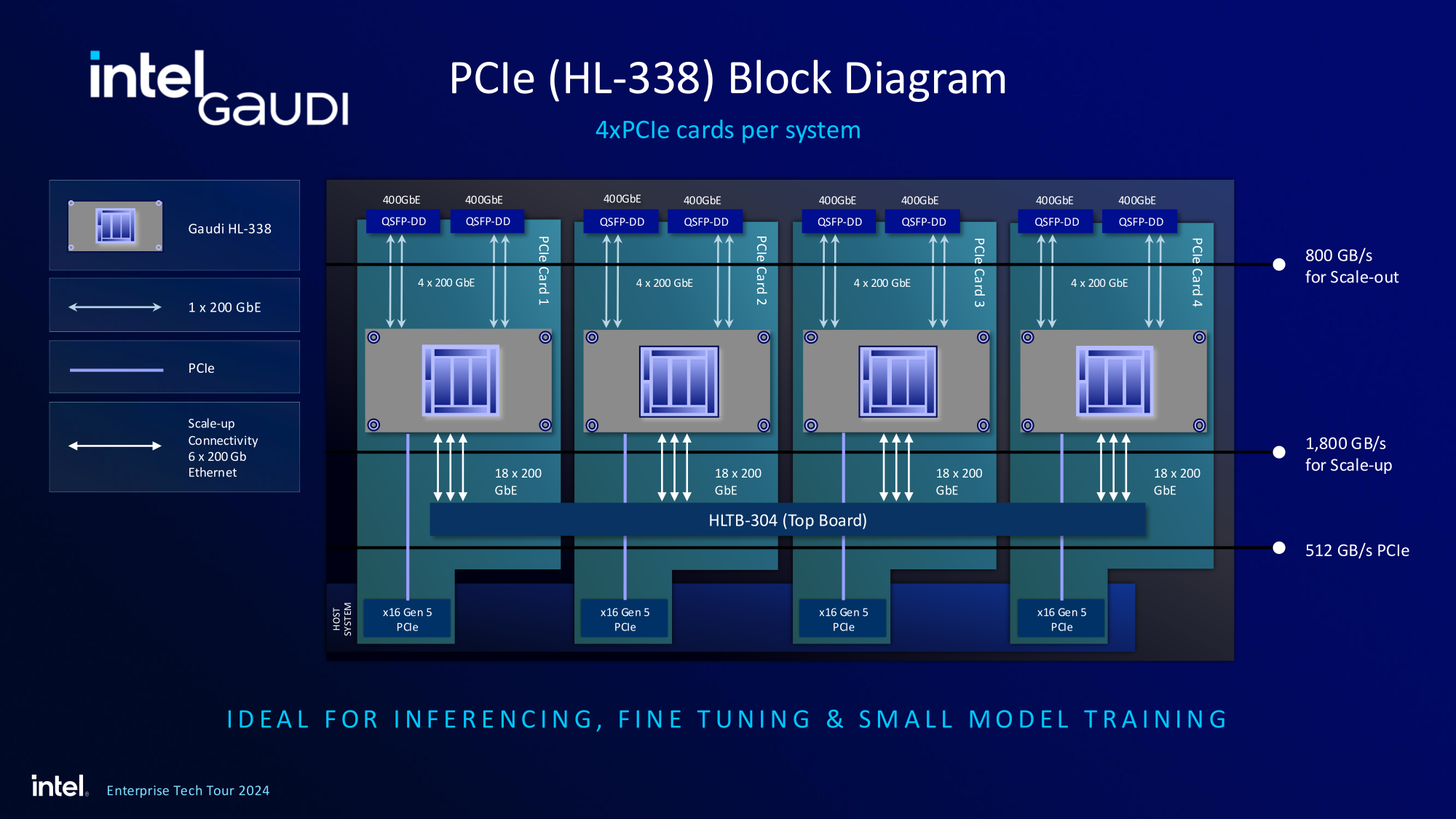 Впрочем, на презентации были продемонстрированы любопытные слайды, в частности, касающиеся архитектуры и принципов работы блоков матричной математики (MME), тензорных ядер (TPC), а также устройство подсистемы памяти. 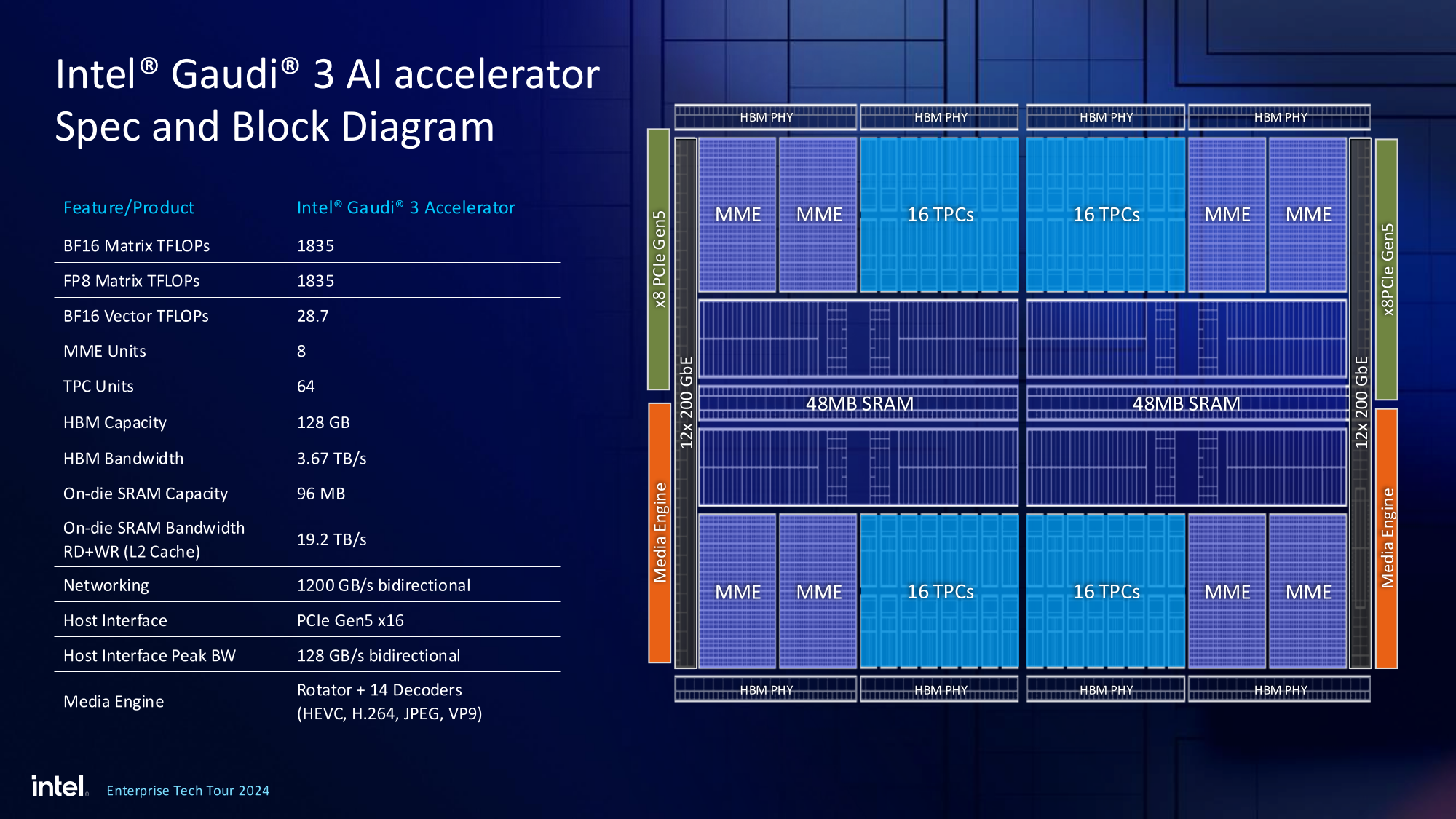 В последнем случае любопытен максимальный отход от иерархических принципов построения в пользу единого унифицированного пространства памяти, включающего в себя кеши L2 и L3, а также набортные HBM2e-стеки ускорителя. Общение с сетевым интерконнектом при этом организовано из пространства L3, что должно минимизировать задержки.  При этом сетевые порты доступны операционной системе как NIC через драйвер Gaudi3, с управлением посредством RDMA verbs. Благодаря большому количеству таких виртуальных NIC, организация интерконнекта внутри сервера-узла не требует никаких коммутаторов, а совокупная внутренняя производительность при этом достигает 67,2 Тбит/с.  Хотя основой экосистемы Gaudi3 станут в первую очередь ускорители HL-325L и UBB-платы HLB-325, есть у Intel и PCIe-вариант в виде FHFL-платы HL-338: 1,835 Пфлопс в режиме FP8 при теплопакете 600 Вт. Оно имеет только 22 200GbE-контроллера, а в остальном повторяет конфигурацию HL-325L с восемью блоками матричной математики (MME).  Эти ускорители получат пару портов QSFP-DD, каждый из которых будет поддерживать скорость 400 Гбит/с, а между собой платы в пределах одного сервера смогут общаться при помощи специального бэкплейна. 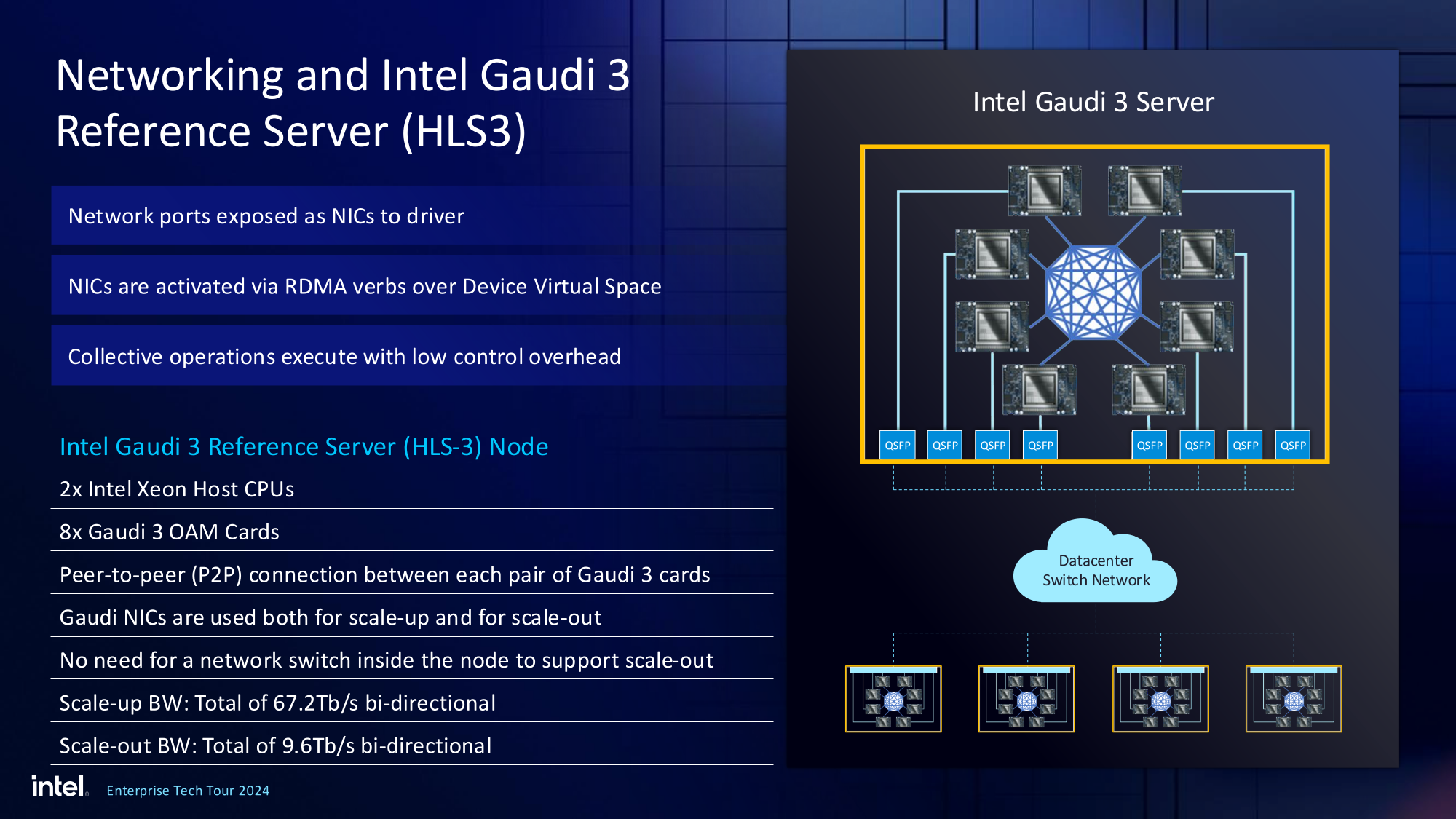 Важно то, что Gaudi3 успешно прошёл путь от анонса до становления сердцем полноценной аппаратно-программной экосистемы, в том числе благодаря ставке на программное обеспечение с открытым кодом. В настоящее время Intel в содействии с партнёрами могут предложить широчайший по масштабу спектр решений на базе Gaudi3 — от рабочих станций и периферийных серверов до вычислительных узлов, собирающихся в стойки, кластеры и даже суперкластеры. 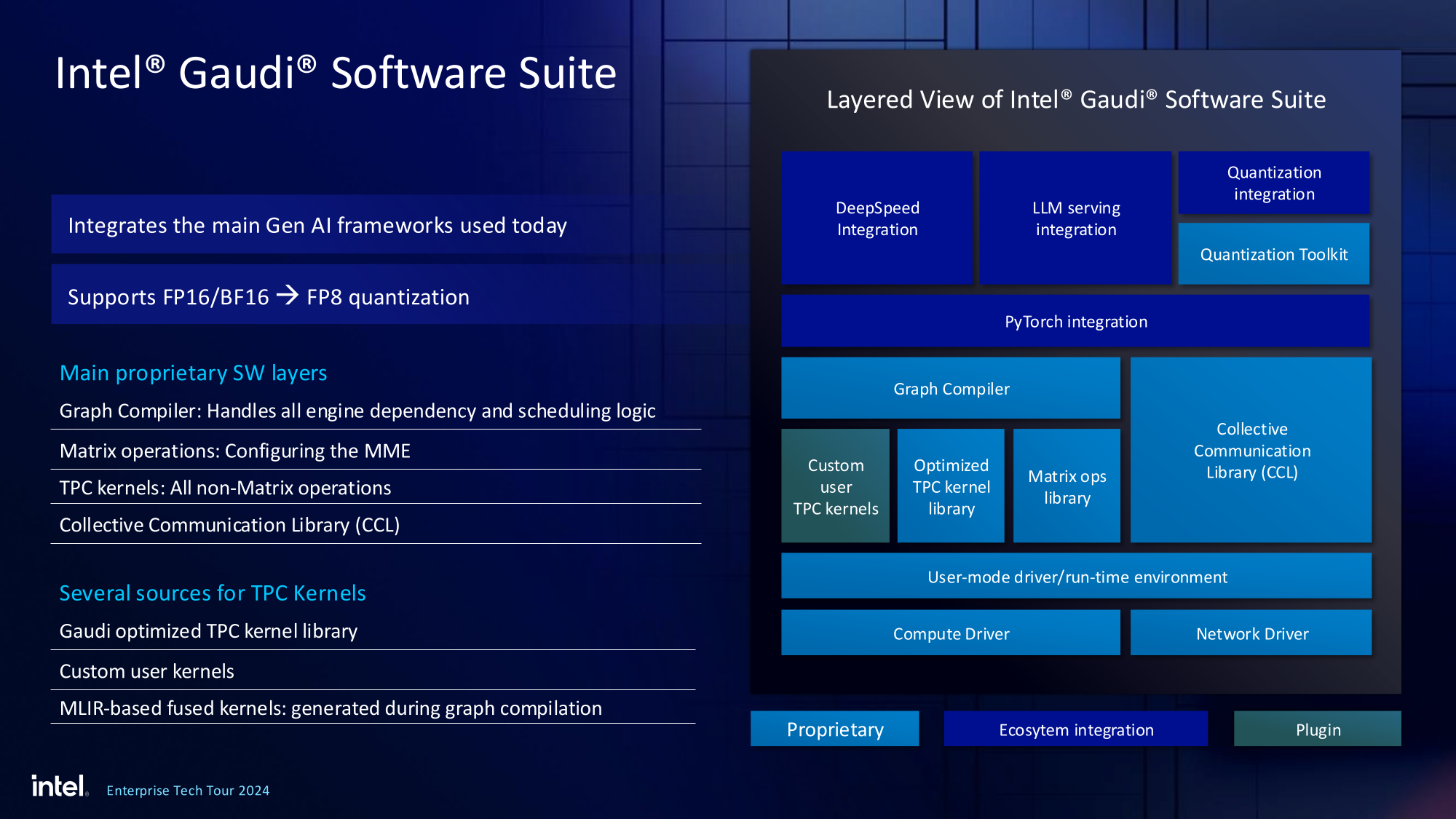 В числе крупнейших партнёров Intel по новой экосистеме есть Dell и Supermicro, представившие серверные системы c Gaudi3. Начало массовых поставок этих систем запланировано на октябрь 2024 года. Вряд ли такие серверы будут развёртываться по одному, поэтому Intel рассказала о возможностях масштабирования Gaudi3-платформ.  Один узел с восемью OAM-модулями HL-325L, развивающий 14,7 Пфлопс в режиме FP8 и располагающий 1 Тбайт HBM станет основой для 32- и 64-узловых кластеров с 256 и 512 Gaudi3 на борту, благо нехватка пропускной способности сетевой части Gaudi3 не грозит — она составляет 9,6 Тбайт/с для одного узла. Из таких кластеров может быть составлен суперкластер с 4096 ускорителями или даже мегакластер, где их число достигнет 8192. Производительность в этом случае составит 15 Эфлопс при объёме памяти 1 Пбайт и совокупной производительности сети 9,8 Пбайт/с. 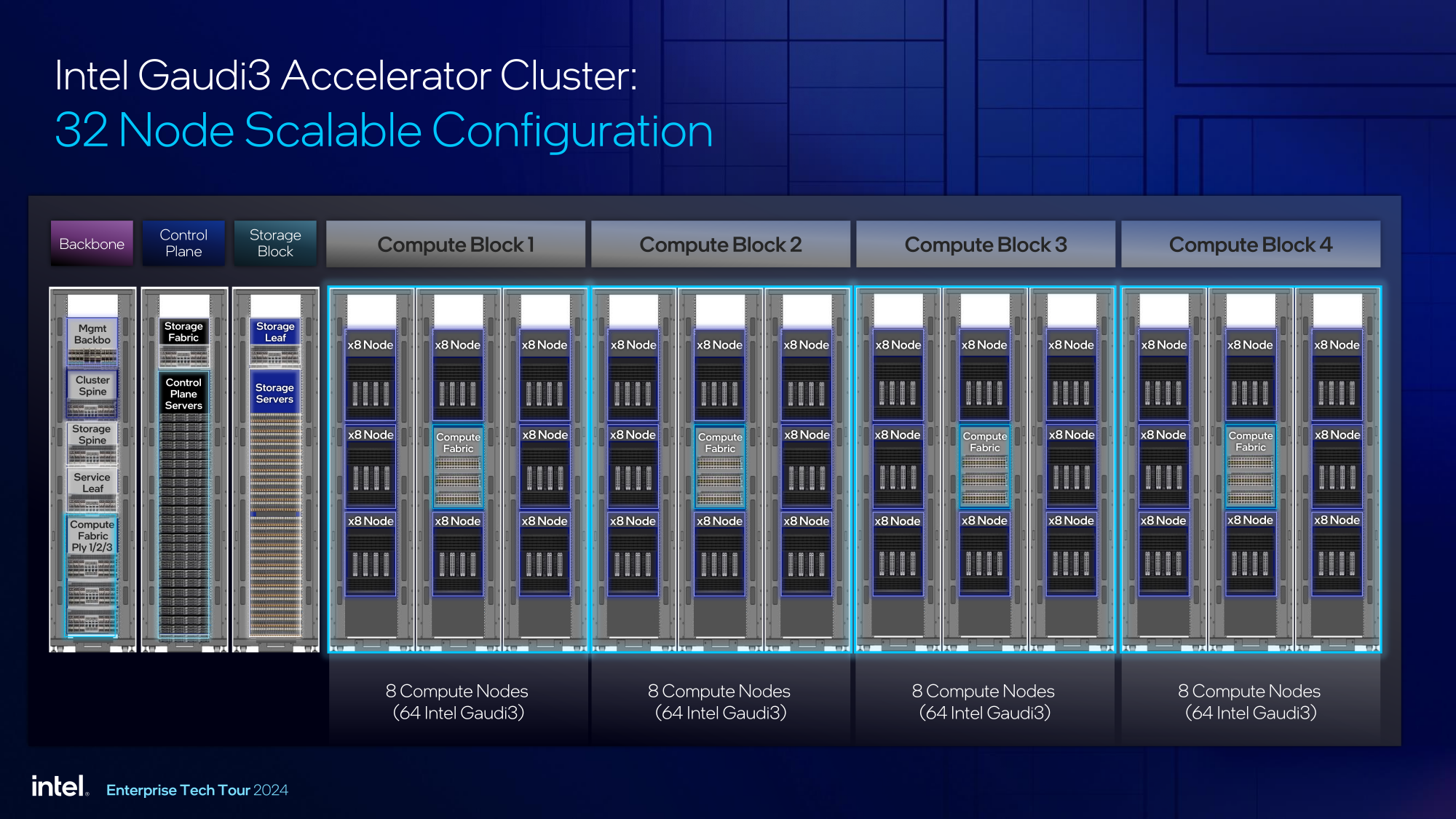 Типовой 32-узловой кластер на базе Gaudi3 Intel — это решение средней плотности с 15 стойками, содержащими не только вычислительные узлы, но и управляющие серверы, сетевые коммутаторы и подсистему хранения данных. Благодаря тому, что Intel в качестве интерконнекта для Gaudi3 избрала открытый и широко распространённый стандарт Ethernet (200GbE RoCE, 24 контроллера на ускоритель), не должно возникнуть проблем с совместимостью и привязкой к аппаратному обеспечению единственного вендора, как это имеет место быть c NVIDIA InfiniBand и NVLink.  Вкупе с программным обеспечением, основой которого является открытый OneAPI, и развитой системой техподдержки, системы на базе Gaudi3 станут надёжной основой для развёртывания ИИ-систем класса RAG, позволяющих заказчику в кратчайшие сроки запускать сети LLM с собственными датасетами без переобучения модели с нуля, говорит компания.  Именно в сферах, так или иначе связанных с большими языковыми моделями, Gaudi3 и системы на его основе должны помочь Intel укрепить свои позиции. Компания приводит данные, что Gaudi3 производительнее H100 примерно в 1,19 раза без учёта энергоэффективности, но в пересчёте «ватт на доллар» эти ускорители превосходят NVIDIA H100 уже в два раза.  Правда, H100 арсенал NVIDIA уже не ограничивается, но с массовой доступности новых решений Intel они могут оказаться привлекательнее. К тому же платформа совместима со всеми основными фреймворками, библиотеками и средствами управления. Впрочем, на примере AMD прекрасно видно, насколько индустрия привязана к решениям NVIDIA, причём в первую очередь программным.
24.09.2024 [11:32], Руслан Авдеев
Саудовская Аравия начнёт закупать передовые ИИ-чипы в случае снятия американских ограничений в 2025 годуХотя Саудовская Аравия фактически находится под санкциями США и не может закупать некоторые передовые ИИ-чипы, страна намерена получить американское разрешение на импорт уже в 2025 году. По данным DigiTimes, тогда же начнутся закупки ускорителей вроде NVIDIA H200. Саудовская Аравия уже активно вкладывает средства в развитие собственных вычислительных мощностей и к 2030 году намерена поднять вклад ИИ в национальный ВВП до 12 %. По данным саудовского ведомства Saudi Data & AI Authority (SDAIA), курирующего вопросы, связанные с ИИ-системами, США рассматривают ослабление торговых ограничений в отношении страны. Не исключается, что новейшие чипы можно будет приобретать в следующем году. Саудовские власти акцентируют внимание на том, что доступ к новому оборудованию будет содействовать развитию коммерческих операций между Саудовской Аравией и США и даст возможность стране строить собственные современные вычислительные мощности. Кроме того, местные власти в последние три года немало вкладывают в подготовку национальных IT-специалистов и информационные технологии в целом. 
Источник изображения: backer Sha/unsplash.com В частности, Саудовская Аравия немало тратит на развитие локальной ИИ-экосистемы. По данным сентябрьского доклада SDAIA, в рамках плана Vision 2030 вклад ИИ-отрасли в ВВП должен составить к 2030 году до 12 %. Инвестициями займётся фонд национального благосостояния Public Investment Fund (PIF). По мнению экспертов, при сохранении роста инвестиций в генеративный ИИ, шесть стран GCC (Саудовская Аравия, ОАЭ, Кувейт, Катар, Оман и Бахрейн) будут получать по $23,5 млрд экономической выгоды ежегодно, из которых на Саудовскую Аравию придётся $12,2 млрд. Параллельно американское правительство принимает меры, чтобы ограничить доступ к передовым чипам китайским государственным и коммерческим структурам. В мае 2024 года США расширили санкционное поле, включив в него и многие ближневосточные страны, в том числе Саудовскую Аравию и ОАЭ. Одна из причин заключается в желании КНР развивать тесные связи с Ближним Востоком. В США опасались, что Китай сможет получать современные полупроводники через своих ближневосточных партнёров. Китай является крупнейшим торговым партнёром Саудовской Аравии и крупным инвестором в саудовскую экономику в рамках плана Vision 2030. 
Источник изображения: Aramco Digital По мере того, как напряжённость между США и Китаем нарастает, критически важные технические сферы тоже становятся пространством для конкуренции, заставляя более мелких игроков принимать ту или иную сторону, и совсем не по доброй воле. По данным руководства саудовского фонда Alat, занимающегося инвестициями в ИИ-технологии и полупроводники вообще, уже поступили запросы о полном отделении от китайских технологических цепочек, иначе под угрозой окажутся отношения с США. При этом в Alat подчеркнули, что США являются не только приоритетным партнёром, но и приоритетным рынком. Сотрудничают с США и другие крупные местные игроки. Например, Aramco Digital уже объявила о партнёрстве с Cerebras, Groq и Qualcomm для развития ИИ и 5G IoT в стране. Впрочем, эксперты отмечают, что хотя саудовские власти уже приняли меры по ограничению сделок с китайскими бизнесами, если США продолжит курс на ограничение поставок ИИ-чипов в Саудовскую Аравию, та может вновь повернуться лицом к сотрудничеству с Китаем, да и сейчас некоторые планы реализуются. Весной сообщалось, что Tencent увеличит инвестиции в облака на Ближнем Востоке, в том числе в Саудовской Аравии.
20.09.2024 [21:27], Алексей Степин
От IoT до ЦОД: SiFive представила экономичные ИИ-ядра Intelligence XMРазработчик SiFive, известный своими процессорными ядрами с архитектурой RISC-V, решил подключиться к буму систем ИИ, анонсировав кластеры Intelligence XM — первые в индустрии RISC-V решения, оснащённые масштабируемым движком матричных вычислений для обработки ИИ-нагрузок. Как отмечает SiFive, новый дизайн должен помочь разработчикам чипов на базе RISC-V в создании кастомных ИИ-систем, в том числе для автономного транспорта, робототехники, БПЛА, IoT, периферийных вычислений и т.п., где роль таких нагрузок в последнее время серьёзно выросла, а требование к энергоэффективности никуда не делись. Но при желании можно создать и серверные ускорители, говорит компания. Каждый матричный блок в составе одного XM-кластера дополнен четырьмя ядрами X Core, каждое из которых имеет в своём составе два блока векторных вычислений и один блок скалярных вычислений. Все вместе они делят общий L2-кеш. XM-кластер располагает шиной с пропускной способностью 1 Тбайт/с и поддерживает подключение к памяти двух типов — когерентное через общую шину CHI, к которой подключается и внешняя память DDR/HBM, или высокоскоростной порт для SRAM. Производительность одного XM-кластера 8 Тфлопс в режиме BF16 и 16 Топс в режиме INT8 на каждый ГГц частоты. 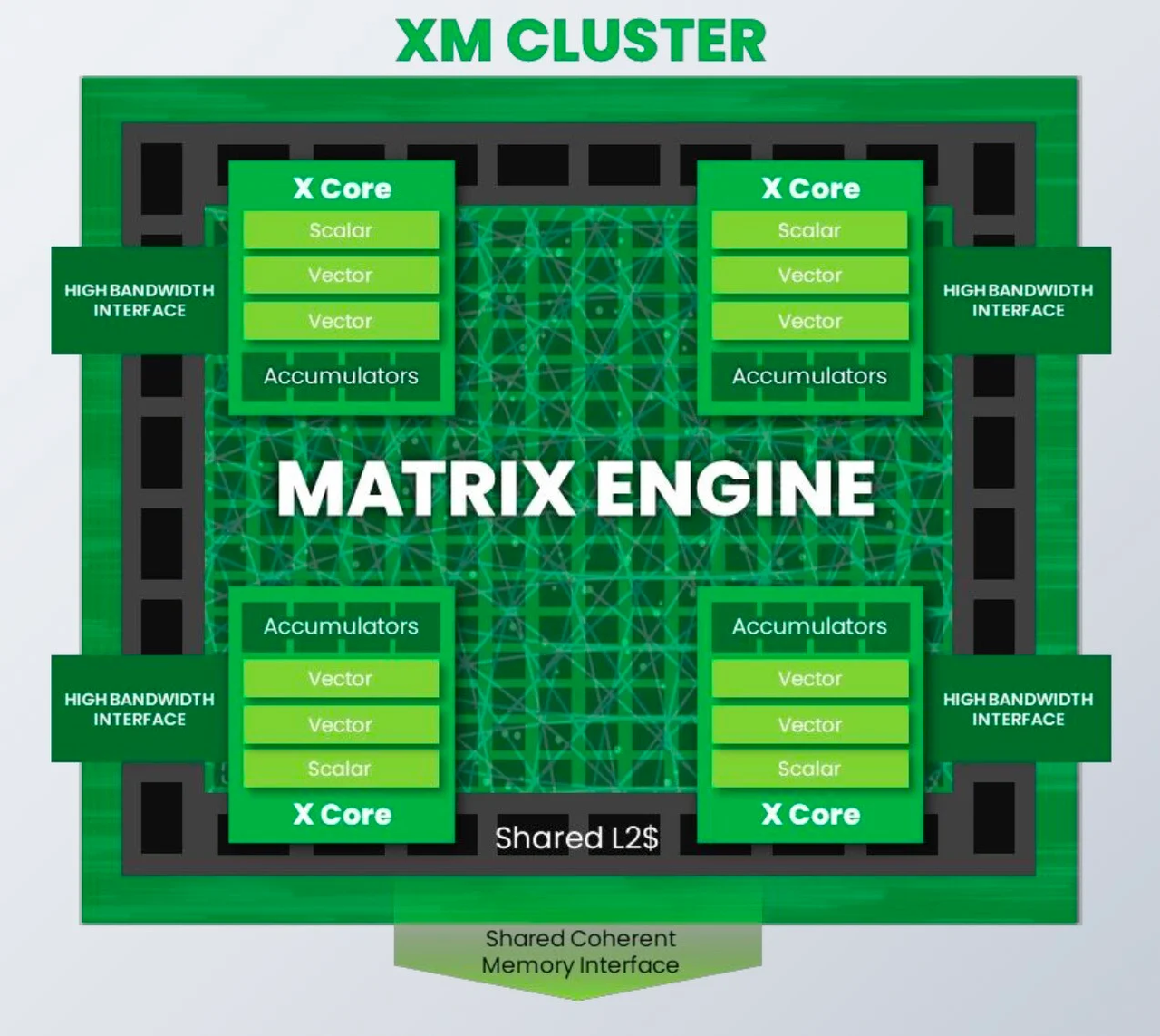
Источник здесь и далее: SiFive Тип хост-ядра не важен, это может быть RISC-V, Arm или даже x86. Впрочем, хост-ядра могут отсутствовать вовсе. Ожидается, что чипы на базе XM в среднем будут иметь от четырёх до восьми кластеров, что даст им до 8 Тбайт/с пропускной способности памяти и до 64 Тфлопс производительности в режиме BF16, и это лишь на частоте 1 ГГц при малом уровне энергопотребления. Но возможно и масштабирование до 512 XM-блоков, что даст уже 4 Пфлопс BF16. У NVIDIA Blackwell, например, в том же режиме производительность составляет 5 Пфлопс. 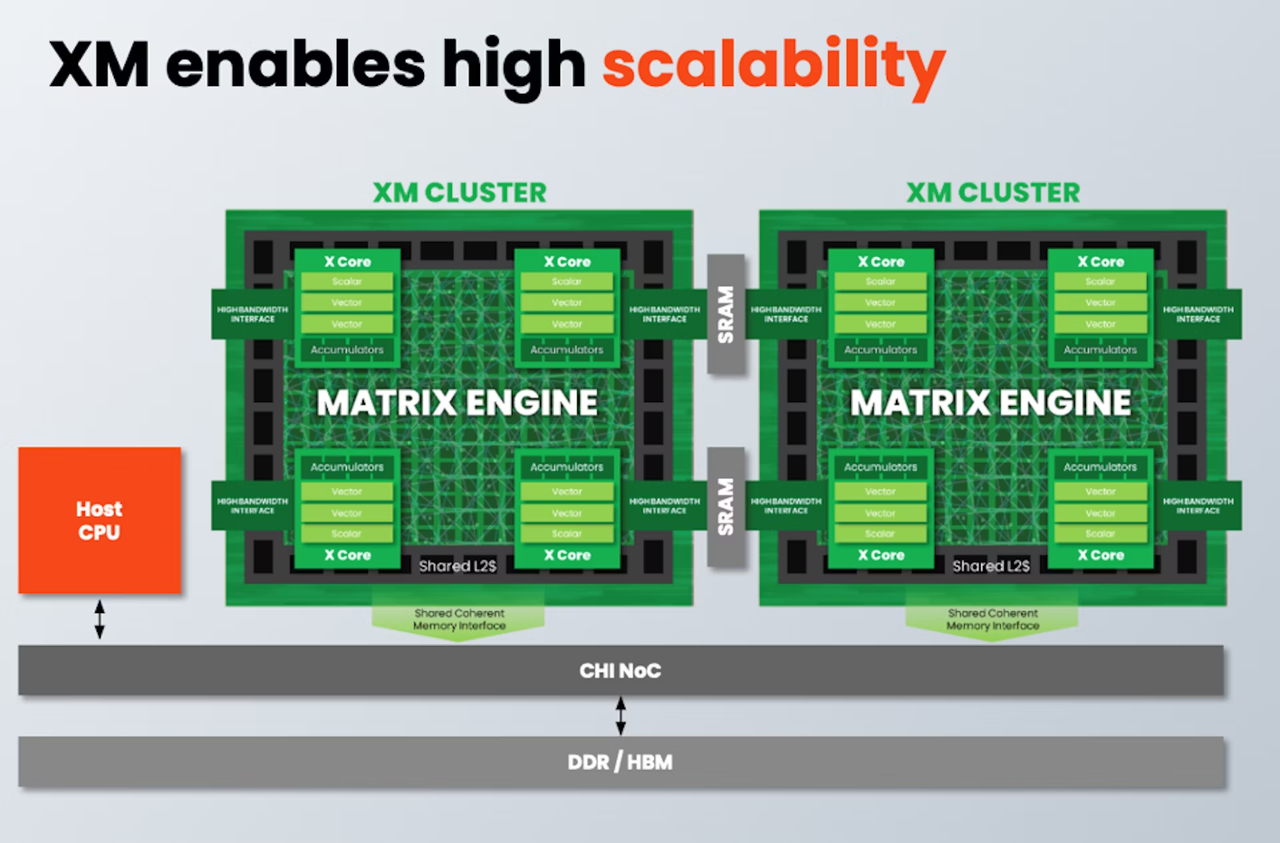 В целях дальнейшей популяризации архитектуры RISC-V компания также планирует сделать открытой (open source) референсную имплементацию SiFive Kernel Library (SKL). SKL включает оптимизированную для RISC-V ядер SiFive реализацю различных востребованных алгоритмов, в том числе для работы с нейронными сетями, обработки сигналов, линейной алгебры и т.д. 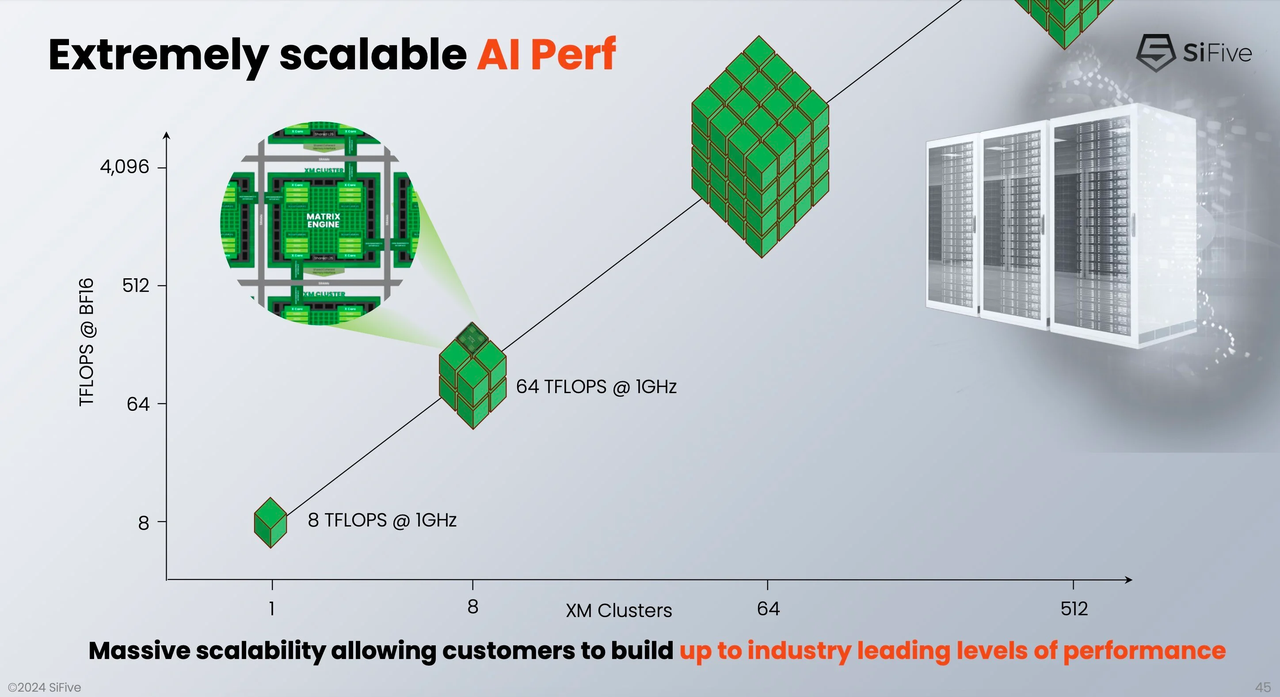 Дела у SiFive идут, судя по всему, неплохо, и, как отметил глава компании Патрик Литтл (Patrick Little), новые дизайны ядер помогут ей сохранить темпы роста и не отстать от эволюции ИИ, оставаясь в то же время поставщиком уникальных процессорных решений с открытой архитектурой. На данный момент решения SiFive уже поставляет свои решения таким гигантам, как Alphabet, Amazon, Apple, Meta✴, Microsoft, NVIDIA и Tesla. |
|

