Материалы по тегу: s
|
06.02.2026 [11:04], Руслан Авдеев
Cerebras привлекла ещё $1 млрд инвестиций после сделки с OpenAIЧерез четыре месяца после завершения раунда финансирования в объёме $1,1 млрд Cerebras Systems заявила о привлечении ещё $1 млрд, во многом от прежних инвесторов, сообщает Datacenter Dynamics. Сделку серии H возглавила Tiger Global, к ней присоединились AMD, Fidelity Management, Atreides Management, Alpha Wave Global, Altimeter, Coatue, 1789 Capital и другие компании. Сегодня оценка рыночной капитализации Cerebras составляет $23 млрд. Новый раунд привлечения средств объявлен через несколько недель после того, как компания заключила с OpenAI сделку на $10 млрд. Cerebras сегодня предлагает суперчип WSE-3 с 4 трлн транзисторов, это в 19 раз больше, чем может обеспечить NVIDIA Blackwell B200. Чип включает 44 Гбайт SRAM, что, как считается, позволяет добиться большей скорости инференса и меньше зависеть от поставок всё более дефицитных HBM и DDR. 
Источник изображения: Cerebras В сентябре 2024 года Cerebras подала заявку на IPO. Тогда компания сообщала, что в I полугодии 2024 года её выручка составила $136,4 млн, это более чем в 10 раз выше год к году. Убытки за тот же период сократились с $77,8 млн до $66,6 млн. В 2025 году компания отозвала заявку на IPO, посчитав, что документ более не отражает состояние бизнеса. В частности, в 2025 году значительно выросла выручка и теперь компания рассчитывает повторно подать документы для выхода на биржу уже во II квартале 2026 года.
04.02.2026 [18:37], Сергей Карасёв
«Рикор» выпустил российские 2U-серверы на базе Intel Xeon Emerald RapidsКомпания «Рикор» анонсировала российские серверы Rikor 7212DSP5 и Rikor 7225DSP5, построенные на аппаратной платформе Intel Xeon Emerald Rapids. Устройства, как утверждается, подходят для решения широко спектра задач, включая виртуализацию, гиперконвергентную инфраструктуру, облачные сервисы, анализ данных, машинное обучение и приложения ИИ. Новинки выполнены в форм-факторе 2U. Допускается установка двух процессоров Xeon и 32 модулей оперативной памяти DDR5 суммарным объёмом до 8 Тбайт. Реализована поддержка интерфейса PCIe 5.0. Серверы различаются конфигурацией подсистемы хранения данных: модель Rikor 7212DSP5 рассчитана на 12 накопителей с доступом через фронтальную панель, а модификация Rikor 7225DSP5 — на 25. Прочие технические характеристики пока не раскрываются. 
Источник изображения: «Рикор» Одним из ключевых преимуществ решений производитель называет использование корпусов собственной разработки. Это, как утверждается, обеспечивает контроль качества металла и сборки, а также ускоряет процесс выпуска систем. Кроме того, «Рикор» может предлагать заказчикам уникальные решения по оптимизации внутреннего пространства. В результате, клиенты получают «более гибкие, технологичные и экономически выгодные серверы, наиболее полно соответствующие требованиям по локализации и технологической независимости». Производство серверов осуществляется на роботизированном заводе. «Рикор» уже принимает заказы на новые модели, а их отгрузки начнутся в ближайшее время. Компания гарантирует стабильность поставок.
03.02.2026 [17:15], Руслан Авдеев
OpenAI не устроили чипы NVIDIA для инференса, теперь она ищет альтернативыПо данным многочисленных отраслевых источников, компания OpenAI недовольна некоторыми ИИ-чипами NVIDIA и с прошлого года ищет им альтернативы. Потенциально это усложнит отношения между крупнейшими игроками рынка на фоне бума ИИ, сообщает Reuters. Изменения стратегии OpenAI связаны с усилением акцента на инференсе. NVIDIA доминирует в нише ускорителей для обучения ИИ-моделей, но теперь инференс стал отдельным рынком с сильной конкуренцией. Решение OpenAI — вызов доминированию NVIDIA в сфере ИИ и препятствие $100-млрд сделки между компаниями, обеспечивающей разработчику чипов долю в ИИ-стартапе в обмен на доступ к передовым ускорителям. Предполагалось, что сделка будет закрыта за недели, но вместо этого переговоры ведутся месяцами. В то же время OpenAI заключила соглашение с AMD и Cerebras (её в своё время даже хотели купить) для получения «альтернативных» чипов, а также разрабатывает собственный ИИ-ускоритель при участии Broadcom. Amazon тоже не прочь предоставить OpenAI собственные ускорители, равно как и Google. Изменение планов OpenAI изменило и потребности в вычислительных мощностях и замедлило переговоры с NVIDIA. 
Источник изображения: Robin Jonathan Deutsch / Unsplash В минувшую субботу глава NVIDIA Дженсен Хуанг (Jensen Huang) опроверг слухи о проблемах с OpenAI, назвав их «чепухой» и подчеркнув, что клиенты продолжают выбирать NVIDIA для инференса, поскольку компания обеспечивает наилучшее соотношение производительности и совокупной стоимости владения, причём в больших масштабах. Отдельно представитель OpenAI заявлял, что компания полагается на NVIDIA для поставок большинства чипов для инференса, причём именно NVIDIA обеспечивает наилучшую производительность на каждый вложенный доллар. Глава OpenAI Сэм Альтман (Sam Altman) отметил, что NVIDIA выпускает «лучшие чипы в мире» и есть надежда, что OpenAI останется её «гигантским» клиентом очень долгое время. При этом, как сообщает Reuters со ссылкой на семь источников, OpenAI не удовлетворена производительностью инференса, на которую способны чипы NVIDIA. В частности, речь идёт о специализированных задачах вроде разработки ПО с помощью ИИ и коммуникаций ИИ с другим ПО. По данным одного из источников, компании понадобится новое аппаратное обеспечение, которое в конечном счёте обеспечит в будущем порядка 10 % вычислительных мощностей для инференса. 
Источник изображения: OpenAI OpenAI обсуждала возможности работы с ИИ-стартапами, включая Cerebras и Groq для обеспечения чипов с более быстрым инференсом, но NVIDIA фактически поглотила Groq на $20 млрд, что привело к прекращению переговоров с компанией. Хотя формально речь идёт неэксклюзивном лицензировании технологий Groq, что в теории позволяет сторонним компаниям получить доступ к решениям Groq, фактически все разработчики перешли в NVIDIA, а оставшаяся небольшая команда отвечает за выполнение облачных контрактов с имеющимися заказчиками. Чипы NVIDIA хорошо подходят для обработки больших объёмов данных при обучении больших ИИ-моделей вроде тех, что стоят за ChatGPT. Тем не менее прогресс требует массового использования уже обученных моделей для дальнейшего инференса и ИИ-рассуждений. Как сообщается, OpenAI с 2025 года ищет альтернативы ускорителям NVIDIA с упором на компании, создающие чипы с большими объёмами интегрированной SRAM. Maia 200 от Microsoft, по-видимому, компании не очень подходит. 
Источник изображения: Hermann Wittekopf - kmkb / Unsplash Инференс моделей более требователен к памяти, чем обучение, а вычислительная нагрузка, наоборот, не так велика. В тоге нередко на доступ к данным уходит больше времени, чем на расчёты. NVIDIA и AMD полагаются на внешнюю память, что замедляет соответствующие процессы общения с чат-ботами. В OpenAI проблемы отметили при эксплуатации системы Codex, активно продвигаемой компанией для создания кода. В компании считают, что некоторые слабости системы связаны именно с оборудованием NVIDIA. Конкуренты OpenAI полагаются на альтернативное оборудование. Anthropic активно использует AWS Trainium и Google TPU, а Google уже много лет использует свои TPU, которые с недавних пор готова отдавать на сторону. TPU оптимизированы в том числе для инференса и в некоторых отношениях более производительны, чем GPU общего назначения AMD и NVIDIA. Когда OpenAI недвусмысленно выразила отношение к технологиям NVIDIA, та предложила компаниям, создающим ускорители с упором на SRAM, включая Cerebras и Groq, купить их бизнес. Cerebras отказалась и заключила прямую сделку с OpenAI. Groq вела переговоры с OpenAI о предоставлении вычислительных мощностей, что вызвало интерес у инвесторов, оценивших капитализацию компании на уровне $14 млрд.
03.02.2026 [14:45], Руслан Авдеев
Спутник-платформа RuVDS для разработки космического ПО успешно выведен на орбитуРазработанный ОКБ «Пятое поколение» (АО «ОКБ5») материнский космический аппарат Mule 4T успешно вывел на орбиту спутник-платформу RUVDSSat1 российского хостинг-провайдера RuVDS, предназначенную для тестирования ПО в космосе и выполнения других испытательных задач. Все спутники формата TriSAT, в том числе RUVDSSat1, управляются ОКБ с Земли. Пуск всех аппаратов TriSAT состоялся 28 декабря 2025 года с помощью ракеты-носителя «Союз-2.1б». С этого дня до начала февраля RUVDSSat1 был пристыкован к Mule 4T и функционировал в сервисном режиме. После расстыковки с материнским аппаратом руководство проекта начало испытания аппаратов в самостоятельном полёте. По словам главы RuVDS, с февраля начался самостоятельный орбитальный этап проекта — цель первого этапа достигнута, на орбиту доставлены «лучшие статьи техноэнтузиастов». На следующих этапах планируется предоставить разработчикам ПО для спутников доступ к RUVDSSat1. Пока проводится подготовка, после неё аппарат начнёт выполнять обязанности «спутника-платформы». Расчётный срок службы аппарата RUVDSSat1 составляет 1 год. 
Источник изображения: RuVDS По словам ОКБ «Пятое поколение», пуск можно назвать успешным в полной мере, поскольку Mule 4T штатно вывел нагрузку на целевые орбиты. Принадлежащий RUVDS спутник перешёл к автономной работе и лётных испытаний. Пока ОКБ ожидает подтверждения лётных характеристик по результатам программы испытаний. Возможные отклонения параметров и режимов, получив телеметрию, проанализирует наземная команда. Миссия, в рамках которой планируется реализовать несколько инициатив, направленных на отработку перспективных IT-решений для космоса, носит научно-исследовательский характер. Компания RuVDS известна необычными проектами. Например, ещё в 2024 году сообщалось, что она развернёт ЦОД на дрейфующей льдине в Арктике, сбросив оборудование с борта самолёта. Летом 2025 года она запустила виртуальный ЦОД на мощностях «Ростелекома» в Заполярье. А свой первый т.н. тайнисат компания запустила в 2023 году.
03.02.2026 [11:33], Сергей Карасёв
86 P-ядер, 128 линий PCIe 5.0 и 8 каналов DDR5-6400/8800: Intel представила чипы Xeon 600 для рабочих станцийКорпорация Intel представила процессоры семейства Xeon 600 для рабочих станций. В основу чипов положена архитектура Xeon 6700P Granite Rapids. Изделия приходят на смену Xeon W-2500/W-3500 (Sapphire/Emerald Rapids), которые дебютировали летом 2024 года. Процессоры Xeon 600 содержат вычислительные ядра Redwood Cove, количество которых варьируется от 12 до 86. Для сравнения, решения Xeon W-3500 насчитывают максимум 60 ядер. Важно отметить, что задействованы исключительно производительные Р-ядра (энергоэффективные Е-ядра в конструкцию не входят). Благодаря технологии многопоточности возможна обработка одновременно до 172 потоков инструкций. Базовая тактовая частота у новых CPU варьируется от 2,0 ГГц до 3,5 ГГц, а частота в турбо-режиме — от 4,6 до 4,9 ГГц. Объём кеша третьего уровня составляет от 48 до 336 Мбайт, показатель TDP — от 150 до 350 Вт. В серию вошли модели с разблокированным множителем для разгона («Х» в обозначении). 
Источник изображений: Intel Чипы Xeon 630 начального уровня предлагает четыре канала памяти DDR5 и 80 линий PCIe 5.0, в то время как более мощные процессоры Xeon 650/670/690 содержат восемь каналов памяти и 128 линий PCIe 5.0. Говорится о возможности использования модулей RDIMM-6400 и MRDIMM-8000 (только Xeon 670/690). Максимально допустимый объём ОЗУ составляет 4 Тбайт. Реализована поддержка CXL 2.0, что позволяет формировать дополнительны пулы памяти. 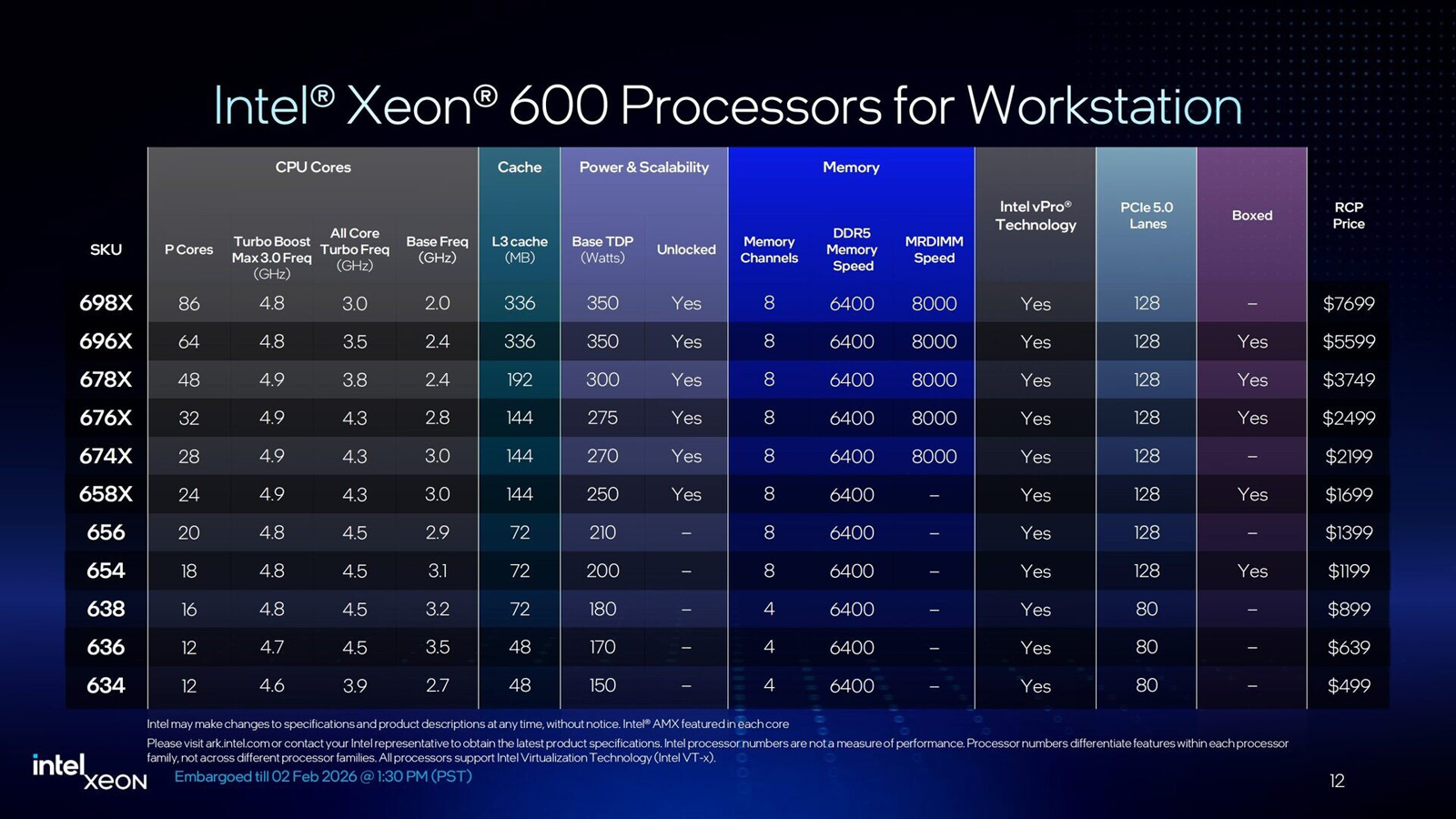 По заявлениям Intel, по сравнению с процессорами для рабочих станций предыдущего поколения прирост производительности в однопоточном режиме у Xeon 600 составляет до 9 %, в многопоточном режиме — до 61 %. Улучшения затронули встроенный аппаратный ускоритель Intel AMX (Advanced Matrix Extensions), предназначенный для повышения производительности в задачах ИИ, глубокого обучения и анализа данных. Если ранее он поддерживал операции INT8 и BFloat16, то теперь добавлен режим FP16. Среди прочего упомянуты технологии Intel vPro Enterprise и Intel Deep Learning Boost.
В паре с процессорами Xeon 600 будет использоваться новый набор логики Intel W890. Для подключения к CPU служит канал DMI 4.0 x8, обеспечивающий пропускную способность немногим менее 16 Гбайт/с. Чипсет предусматривает поддержку интерфейса USB 3.2 Gen 2×2 (20 Гбит/с), портов SATA-3, дополнительных линий PCIe 4.0, сетевых интерфейсов 1GbE и 2,5GbE, а также Wi-Fi 7. 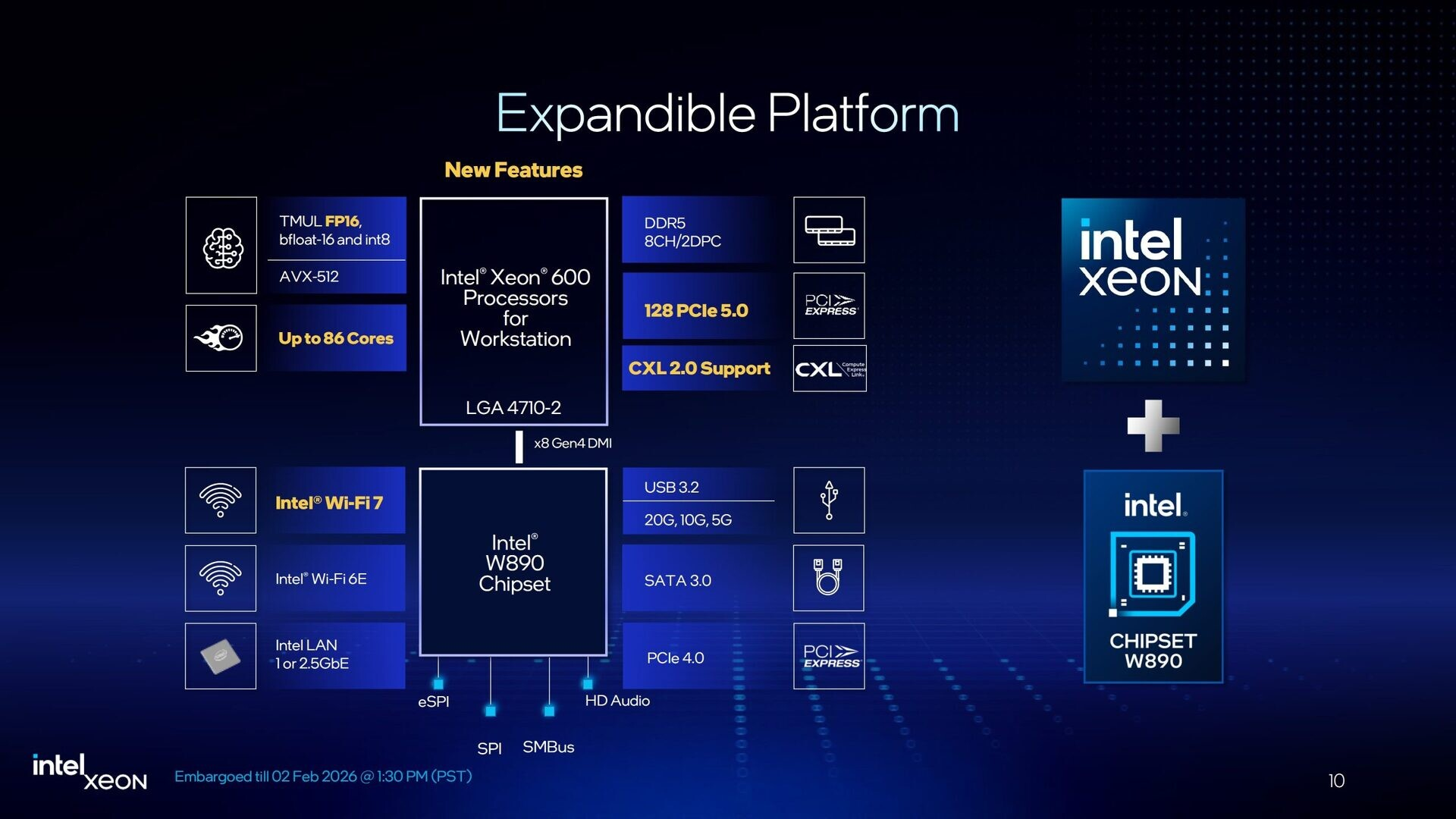 При заказе процессоров Xeon 600 корпорация Intel призывают клиентов убедиться, что новая платформа подходит для их рабочих нагрузок. Чипы поступят в продажу в конце марта по цене от $499 до $7699. Некоторые модели будут доступны в коробочной версии: это изделия Xeon 654 (18 ядер), Xeon 658X (24 ядра), Xeon 676X (32 ядра), Xeon 678X (48 ядер) и Xeon 696X (64 ядра). Материнские платы на чипсете W890 готовят такие компании, как ASUS, Supermicro и Gigabyte. Готовые системы на основе Xeon 600 предложат Dell, HP, Supermicro, Boxx, Pudget Systems и другие поставщики. Вместе с тем, как отмечает The Register, время для анонса Xeon 600 выбрано не совсем удачно. Чипы выходят на рынок на фоне проблем с цепочками поставок, из-за которых резко подскочили цены на память. Так, комплект из восьми модулей DDR5 RDIMM на 32 Гбайт каждый обойдётся более чем в $4000: это примерно на $1500 больше, чем шестью месяцами ранее. Сформировавшаяся ситуация может негативно отразиться на спросе на Xeon 600 среди потребителей.
03.02.2026 [08:38], Владимир Мироненко
VDURA предложила программу Flash Relief Program для смягчения дефицита флеш-памятиVDURA, заявившая, что теперь SSD корпоративного класса уже в 16 раз дороже HDD аналогичной ёмкости, анонсировала программу Flash Relief Program, в рамках которой клиенты получат доступ к хранилищам, по ёмкости и быстродействию не уступающие массивам VAST Data и WEKA, но вполовину дешевле с точки зрения TCO. В условиях дефицита NAND-памяти цены на SSD выросли в два-три раза, а гибридная архитектура VDURA, использующая накопители разных типов, обеспечивает превосходную производительность и ёмкость при вдвое меньшей стоимости, заявила компания. 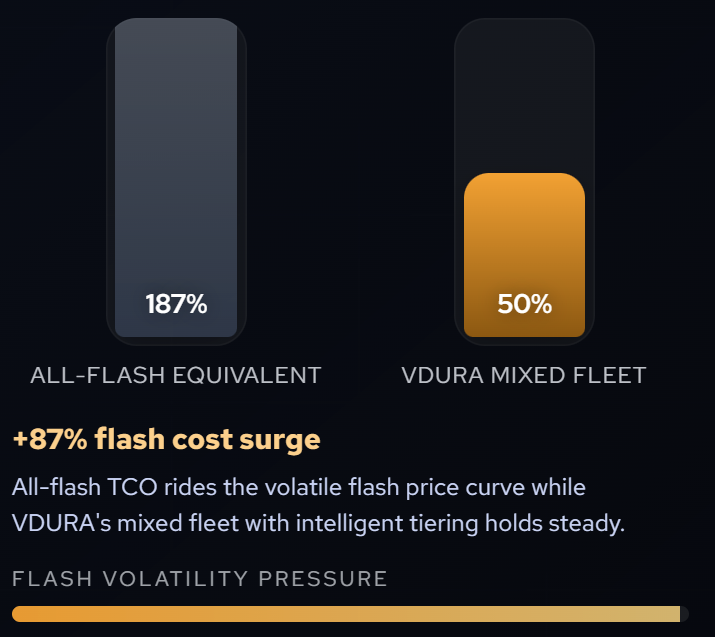
Источник изображения: VDURA Как сообщает VDURA, клиенту достаточно предоставить требования к конфигурации файлового хранилища VAST, WEKA или любой другой высокопроизводительной All-Flash СХД, включая требования по производительность (пропускная способность, IOPS, задержка) и требования к ёмкости (сырая, полезная, эффективная), а VDURA в течение 24 ч. предоставит конкурирующее предложение, которое:
VDURA называет следующие преимущества своего продукта:
Предложение VDURA заключается в том, что её гибридная параллельная ФС на основе SSD/HDD может компенсировать рост цен на SSD лучше, чем что-либо, предлагаемое производителями массивов All-Flash, отметил ресурс Blocks & Files. Если цены на SSD продолжат расти и не будет решена проблема дефицита, подобные заявления могут заставить потенциальных покупателей массивов All-Flash переключиться на гибридные системы СХД с автоматическим многоуровневым хранением данных. И даже использование б/у SSD, как предлагает VAST Data, вряд ли поможет в такой ситуации.
30.01.2026 [20:24], Руслан Авдеев
От технологического наследия к построению будущего — Atos перезапустила бренд Bull для HPC, ИИ и квантовых инновацийПечально известная своими финансовыми проблемами французская компания Atos официально перезапустила один из своих ведущих брендов. Теперь Bull позиционируется как глобальный лидер в HPC-, ИИ- и квантовых системах. Bull разрабатывает, внедряет и обслуживает оборудование и ПО, в том числе суперкомпьютеры. Bull позиционируется, как единственный европейский игрок, способный разрабатывать, выпускать и внедрять решения такого класса. Работа поддерживается командой исследователей и инженеров, производственными возможностями и др. Bull, как сообщают в самой компании, позволяет странам и отраслям полностью контролировать свои ИИ-мощности и данные. Бизнес Bull основан на более чем вековом опыте в сфере вычислений и исследований, связанных с data science. Как утверждают в Atos, возрождение Bull — стратегически важная веха на пути бренда к формированию частной, независимой компании после подписания соглашения о покупке акций Францией 31 июля 2025 года. Корни у бренда европейские, но сейчас он, по словам Atos, занимает лидирующие позиции ещё и в Латинской Америке и Индии. Bull владеет полным технологическим стеком, от разработки интегральных микросхем и интерконнектов до ИИ-платформ и приложений. Бренд обеспечивает надёжные решения промышленного уровня для критически важных секторов, включая, например, оборону и энергетику, одновременно снижая совокупную стоимость владения. По словам руководства бренда, с запуском Bull осуществляется «переподключение» к технологическому наследию для строительства будущего. Миссией компании называется обеспечение мощных, устойчивых и суверенных вычислений и ИИ-технологий, позволяющих уверенно и осмысленно внедрять инновации на уровне отраслей и целых наций. 
Источник изображения: Bull Примечательна судьба самой Atos Group. Хотя сама компания позиционирует себя как лидера в сфере цифровой трансформации с 63 тыс. сотрудников и ежегодной выручкой €8 млрд, действующим в 61 странах под двумя брендами (Atos для сервисов и Eviden для продуктов), дела у компании идут, мягко говоря, непросто. Atos не первый год теряет выручку по всем направлениям, а будущее компании всё более туманно. Поэтому Atos заключила сделку с французским государством, согласно которой ему будут переданы «золотые акции» Bull SA. После неоднократных попыток спасти компанию, частой смены директоров и даже новостей о её возможной национализации Францией, летом 2025 года появилась информация, что власти Франции сделали предложение купить подразделение Advanced Computing в составе группы Atos.
29.01.2026 [10:39], Руслан Авдеев
NVIDIA, Microsoft и Amazon ведут переговоры об инвестициях до $60 млрд в OpenAINVIDIA, Microsoft и Amazon ведут переговоры о новых инвестициях в OpenAI. Предполагается, что компании готовы вложить в бизнес партнёра до $60 млрд, сообщает The Information. Как заявляет The Information со ссылкой на «лицо, знакомое с ситуацией», NVIDIA — действующий инвестор, чьи чипы активно используются для работы с ИИ-моделями OpenAI, ведёт переговоры о том, чтобы вложить до $30 млрд. Microsoft, давно поддерживающая OpenAI, также ведёт переговоры, но готова потратить лишь менее $10 млрд. При этом Amazon (AWS), готовая стать новым инвестором, обсуждает о вложении значительно больше $10 млрд, потенциально — даже более $20 млрд. Сообщается, что OpenAI близка к тому, чтобы получить юридически не обязывающие меморандумы о договорённостях (term sheets) или инвестиционные обязательства от названных компаний. NVIDIA, Microsoft, Amazon и OpenAI пока новости не комментируют. Ранее сообщалось, что SoftBank Group ведёт переговоры об инвестициях дополнительных $30 млрд в OpenAI. Масштаб инвестиций Amazon может зависеть от отдельных переговоров, предусматривающих возможное расширение сделки по аренде облачных серверов у Amazon компанией OpenAI и заключение коммерческого соглашения о продаже OpenAI своих продуктов — Amazon может оформить корпоративные подписки на ChatGPT. 
Источник изображения: Allef Vinicius/unsplash.com Сейчас OpenAI пытается бороться с ростом цен на обучение и эксплуатацию своих ИИ-моделей на фоне ужесточающейся конкуренцией с компанией Google и более мелкими игроками. Впрочем, плохо контролируемые инвестиции могут быть весьма опасными. Так, американские банки уже крайне неохотно дают деньги Oracle, из-за уже имеющихся обязательств последней перед OpenAI. На днях сообщалось, что OpenAI готовит крупнейший в своей истории раунд финансирования на $50 млрд при участии инвесторов Ближнего Востока.
27.01.2026 [12:57], Сергей Карасёв
Встраиваемый модуль Innodisk EXEC-Q911 на чипе Qualcomm обладает ИИ-быстродействием до 200 TOPSКомпания Innodisk анонсировала встраиваемый модуль EXEC-Q911 и сопутствующую интерфейсную плату (комплект COM-HPC Mini Starter Kit) для решения ИИ-задач на периферии, в том числе в неблагоприятных условиях при температурах от -40 до +85 °C. В основу новинки положена аппаратная платформа Qualcomm. Задействован чип DragonWing IQ-9075 (QCS9075). Это изделие содержит восемь вычислительных ядер Kryo Gen 6 (Cortex-A78C) с тактовой частотой до 2,36 ГГц и четыре ядра реального времени Cortex-R52 с частотой до 1,85 ГГц. В состав процессора входит графический блок Adreno 663 с поддержкой Vulkan 1.2, OpenGL ES 3.2, OpenCL 2.0 FP, Adreno NN Direct. Встроенный модуль Adreno VPU 765 способен декодировать видео AV1/HEVC/H.265/H.264/VP9/MPEG-2 в формате вплоть до 8Kp60, а также кодировать материалы H.264/H.265/HEIF/HEIC до 4Kp60 (два потока). Интегрированный нейропроцессорный узел (NPU) обеспечивает ИИ-производительность до 200 TOPS на операциях INT8: заявлена поддержка фреймворков TensorFlow, PyTorch, ONNX, Paddle, Caffe, DarkNet и пр. 
Источник изображения: Innodisk Изделие EXEC-Q911 несёт на борту 36 Гбай LPDDR5X, флеш-модули UFS 3.1 вместимостью 128 Гбайт, eMMC на 32 Гбайт и NOR Flash ёмкостью 32 Мбайт. Упомянута совместимость с Yocto Linux (Kernel 6.6) и Ubuntu 24.04 (Kernel 6.8). Интерфейсная плата располагает двумя разъёмами DisplayPort 1.2, двумя сетевыми портами 2.5GbE RJ45, тремя портами USB 3.1 Type-A, одним коннектором USB 3.1 Type-C и двумя портами USB 2.0 Type-A. Кроме того, есть 3,5-мм аудиогнездо (кодек WM8904), интерфейсы eDP, MIPI-CSI (два по 4 линии) и RS-232/RS-422/RS-485 (последовательный порт). Доступны слоты M.2 Key-M 2280 (PCIe 4.0 x4) для SSD, M.2 Key-B 3052 (USB 3.2 Gen2, USB 2.0) для модема 4G/5G и M.2 Key-E 2230 (PCIe 4.0 x2, USB 2.0) для адаптера Wi-Fi/Bluetooth. Питание в диапазоне 9–36 В подаётся через 2-контактный коннектор. Размеры составляют 146 × 102 × 56,99 мм (вместе с модулем COM-HPC), масса — 1,7 кг вместе с кулером, в состав которого входят радиатор и вентилятор.
24.01.2026 [14:15], Сергей Карасёв
Nokia и Hypertec построили в Канаде 15-Пфлопс суперкомпьютер Nibi с погружным охлаждением
amd
emerald rapids
granite rapids
h100
hardware
hpc
intel
mi300
nokia
nvidia
ии
канада
отопление
погружное охлаждение
суперкомпьютер
Компании Nokia и Hypertec объявили о запуске суперкомпьютера Nibi, смонтированного в Университете Ватерлоо (University of Waterloo) в Канаде. Эта НРС-платформа будет использоваться для решения широкого спектра задач, в том числе в области ИИ. Проект Nibi финансируется канадским Министерством инноваций, науки и экономического развития через Канадский альянс цифровых исследований, а также Министерством колледжей, университетов, научных исследований и безопасности через некоммерческую организацию Compute Ontario. 
Источник изображения: Nokia Система насчитывает в общей сложности более 750 вычислительных узлов. Это, в частности, 700 узлов CPU, каждый из которых несёт на борту два процессора Intel Xeon 6972P поколения Granite Rapids-AP (96C/192T, до 3,9 ГГц) и 748 Гбайт оперативной памяти. Кроме того, задействованы 10 узлов с двумя чипами Xeon 6972P и 6 Тбайт памяти каждый. 
Источник изображений: Университет Ватерлоо В состав суперкомпьютера также входят 36 узлов GPU, которые содержат по два процессора Intel Xeon Platinum 8570 серии Emerald Rapids (56C/112T, до 4 ГГц), 2 Тбайт оперативной памяти и восемь ускорителей NVIDIA H100 SXM (80 GB), связанных посредством NVLink. Наконец, Nibi оперирует шестью узлами с четырьмя ускорителями AMD Instinct MI300A.  Подсистема хранения VAST Data выполнена на основе SSD суммарной вместимостью 25 Пбайт. Пропускная способность каналов передачи данных между CPU- и GPU-узлами составляет 200 Гбит/с. Подключение к хранилищу обеспечивается благодаря 24 линиям на 100 Гбит/с. Заявленная пиковая производительность Nibi достигает 15 Пфлопс. Новая НРС-платформа оборудована высокоэффективной системой погружного жидкостного охлаждения. Сгенерированное тепло используется для обогрева центра квантовых и нанотехнологий имени Майка и Офелии Лазаридис (Mike and Ophelia Lazaridis Quantum-Nano Centre). |
|


