Материалы по тегу: nvidia
|
14.11.2025 [10:03], Руслан Авдеев
NVIDIA ужесточит контроль над выпуском ИИ-платформ, задвинув Foxconn и других партнёров на второй планКомпания NVIDIA готовится изменить текущую бизнес-модель в контексте ИИ-серверов. Она намерена получить под свой контроль производство ИИ-платформ целиком, а не отдельные элементы цепочек поставок, сообщает Wccftech. Если обычно экосистема поставок NVIDIA опирается на партнёров, выпускающих компоненты конечных продуктов — Foxconn, Quanta (QCT) и Wistron (Wiwynn) — со своими собственными разработками, то в будущем компания фактически возьмёт под контроль всё производство вплоть до уровня стоек. До сих пор NVIDIA поставляла в основном ключевые компоненты, такие как ИИ-ускорители и системные платы вроде Bianca Port UPB. Тем не менее, в ходе отчёта Wistron за III квартал 2025 года представитель JPMorgan заявил, что компания, похоже, переходит к «прямым поставкам» полноценных систем. Если раньше NVIDIA отвечала за ключевые элементы стоек — ИИ-ускорители и платы, — то за остальную архитектуру отвечали подрядчики вроде Foxconn, Quanta и других компаний. Теперь, как полагают в JPMorgan, NVIDIA станет напрямую поставлять системы Level-10 (почти полный блок серверной стойки). Компания унифицирует конструкцию систем, заставит подрядчиков строго придерживаться предлагаемых чертежей и дизайна и запретит использование проприетарных архитектур, созданных самими подрядчиками. 
Источник изображения: NVIDIA Фактически — это развитие философии MGX-архитектуры, предполагающей единые стандарты от серверного узла до полнофункциональной ИИ-фабрики. При этом время развёртывания таких комплексных систем сократится с 9–12 мес. до 90 дней, т.е. 3 мес. Поскольку 80 % наполнения систем будет предварительно определяться NVIDIA, новые платформы вроде Rubin/Rubin CPX можно будет внедрять ускоренными темпами. NVIDIA выиграет от быстрого вывода систем на рынок, роста маржинальности и расширения так называемого «общего адресуемого рынка» (TAM). В Wistron утверждают, что новая модель выгодна и заказчикам, поскольку ключевые работы по созданию ИИ-оборудования всё равно выполняет компания-подрядчик. В целом NVIDIA стремится перейти от роли обычного поставщика ИИ-чипов к модели, при которой IT-гигант контролирует развёртывание инфраструктуры целиком. Это как ускорит выпуск ИИ-систем, так и укрепит позиции компании. Впрочем, пока информация об изменениях поступает из сторонних источников — в самой NVIDIA её не подтверждали. При этом для гиперскейлеров, которые самостоятельно занимаются разработкой ИИ-платформ, пока, по-видимому, ничего не поменяется.
14.11.2025 [09:38], Сергей Карасёв
«За пределы экзафлопсного уровня»: Eviden представила суперкомпьютерную платформу BullSequana XH3500Компания Eviden, входящая в Atos Group, анонсировала конвергентную суперкомпьютерную платформу BullSequana XH3500 для ресурсоёмких нагрузок ИИ и HPC. Новинка сочетает передовые аппаратные решения с комплексной экосистемой ПО, обеспечивая возможность масштабирования «за пределы экзафлопсного уровня». BullSequana XH3500 использует открытую модульную конструкцию. Такой подход позволяет свободно комбинировать блоки CPU, GPU и сетевые компоненты от различных производителей, адаптируя конфигурации под определённые потребности. При этом устраняется зависимость от какого-либо конкретного поставщика оборудования, что обеспечивает полную технологическую свободу. По заявлениям Eviden, платформа BullSequana XH3500 по сравнению с системой предыдущего поколения позволяет добиться повышения электрической мощности более чем на 80 % в расчёте на 1 м2 и увеличения эффективности охлаждения на 30 % в расчёт на 1 кВт. Это даёт возможность удовлетворить растущие потребности в вычислительных ресурсах без необходимости расширения площадей в дата-центрах. Габариты стойки BullSequana XH3500 без модуля ультраконденсатора составляют 2270 × 900 × 1457 мм. Мощность AC достигает 284 кВт (с одной помпой). Задействовано на 100 % безвентиляторное прямое жидкостное охлаждение (DLC) пятого поколения с возможностью использования горячей воды с температурой до 40 °C. Подсистемы питания и охлаждения выполнены по схеме с резервированием N+1. Доступны 38 универсальных слотов 1U. 
Источник изображения: Eviden Для платформы BullSequana XH3500 разработаны узлы BullSequana XH3515B и BullSequana AI1242. Первый соответствует типоразмеру 1U: это одноузловое изделие оборудовано двумя чипами NVIDIA Grace CPU и четырьмя ускорителями NVIDIA Blackwell B200. Возможна установка до девяти NVMe SSD в форм-факторе E1.S. Говорится о поддержке четырёх сетевых устройств Eviden BXI V3 или InfiniBand NDR/XDR. В свою очередь, сервер BullSequana AI1242 имеет исполнение 2U. Данное решение несёт на борту два процессора AMD EPYC Turin и GPU-ускоритель AMD Instinct MI355X. Реализована поддержка восьми устройств Eviden BXI V3 или InfiniBand NDR/XDR, а также четырёх накопителей E1.S NVMe SSD.
14.11.2025 [09:36], Сергей Карасёв
HPE представила CPU- и GPU-узлы суперкомпьютерной платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения для НРС-задач, являющиеся частью суперкомпьютерной платформы Cray Supercomputing GX5000. В частности, дебютировали узлы GX250 Compute Blade, GX350a Accelerated Blade и GX440n Accelerated Blade, а также высокопроизводительная СХД Storage Systems K3000. Устройство HPE Cray Supercomputing GX250 Compute Blade представляет собой CPU-сервер, оснащённый восемью процессорами AMD EPYC Venice (появятся во II половине 2026 года). В одной стойке могут быть размещены до 40 таких серверов, что обеспечивает самую высокую в отрасли плотность компоновки x86-ядер следующего поколения, говорит компания. В паре с CPU-узлами могут функционировать новые GPU-модули. Так, изделие HPE Cray Supercomputing GX350a Accelerated Blade несёт на борту один чип AMD EPYC Venice и четыре ускорителя AMD Instinct MI430X. В стойку могут устанавливаться до 28 таких серверов, что даёт в сумме 112 ускорителей MI430X. В свою очередь, HPE Cray Supercomputing GX440n Accelerated Blade содержит четыре NVIDIA Vera CPU и восемь NVIDIA Rubin GPU. Допускается монтаж до 24 подобных серверов на стойку, что обеспечивает 192 ускорителя Rubin. Все новинки оборудованы жидкостным охлаждением. СХД HPE Cray Supercomputing Storage Systems K3000 выполнена на сервере HPE ProLiant Compute DL360 Gen12. Могут устанавливаться 8, 12, 16 или 20 накопителей NVMe вместимостью 3,84, 7,68 или 15,36 Тбайт каждый. Объём памяти DRAM — 512 Гбайт, 1 или 2 Тбайт. Применяется платформа DAOS, разработанная для требовательных рабочих нагрузок, таких как анализ данных и машинное обучение. Поддерживаются технологии HPE Slingshot 200, HPE Slingshot 400, InfiniBand NDR и 400GbE. 
Источник изображения: HPE via The Next Platform Кроме того, HPE сообщила о том, что для платформы HPE Cray Supercomputing GX5000 доступен интерконнект HPE Slingshot 400. Соответствующие коммутаторы с прямым жидкостным охлаждением наделены 64 портами на 400 Гбит/с. Возможны конфигурации с 8, 16 и 32 коммутаторами, что в сумме позволяет использовать до 512, 1024 и 2048 портов соответственно. 
Источник изображения: HPE О выборе платформы HPE Cray Supercomputing GX5000 для НРС-комплексов нового поколения уже объявили Центр высокопроизводительных вычислений Штутгартского университета (HLRS) и Центр суперкомпьютеров имени Лейбница (LRZ) Баварской академии естественных и гуманитарных наук (BADW). Кроме того, новая платформа является основой суперкомпьютера Discovery Министерства энергетики США (DOE).
14.11.2025 [01:55], Владимир Мироненко
NVIDIA вновь впереди всех в новом раунде MLPerf Training v5.1Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training v5.1. На этот раз был установлен новый рекорд по разнообразию представленных систем. Участники этого раунда тестирования представили 65 уникальных систем, оснащённых 12 различными аппаратными ускорителями и различными программными платформами. Почти половина заявок была для многоузловых систем, что на 86 % больше, чем в раунде MLPerf Training 4.1 год назад, причём они так же отличались разнообразием сетевых архитектур. Раунд MLPerf Training v5.1 включает в себя результаты 20 компаний, подавших заявки: AMD, ASUS, Cisco, Dell, Giga Computing, HPE, Krai, Lambda, Lenovo, MangoBoost, MiTAC, Nebius, NVIDIA, Oracle, Quanta Cloud Technology (QCT), Supermicro, Supermicro + MangoBoost, Университет Флориды, Verda (DataCrunch), Wiwynn. 
Источник изображений: NVIDIA Также сообщается, что структура заявок свидетельствует о растущем внимании к тестам, ориентированным на задачи генеративного ИИ: количество заявок на тест Llama 2 70B LoRa увеличилось на 24 %, а на новый тест Llama 3.1 8B — на 15 % по сравнению с тестом, который он заменил (BERT). NVIDIA объявила, что её чипы на архитектуре NVIDIA Blackwell заняли первые позиции во всех семи тестах MLPerf Training v5.1, обеспечив максимально быстрое обучение в работе с большими языковыми моделями (LLM), генерацией изображений, рекомендательными системами, компьютерным зрением и графическими нейронными сетями. 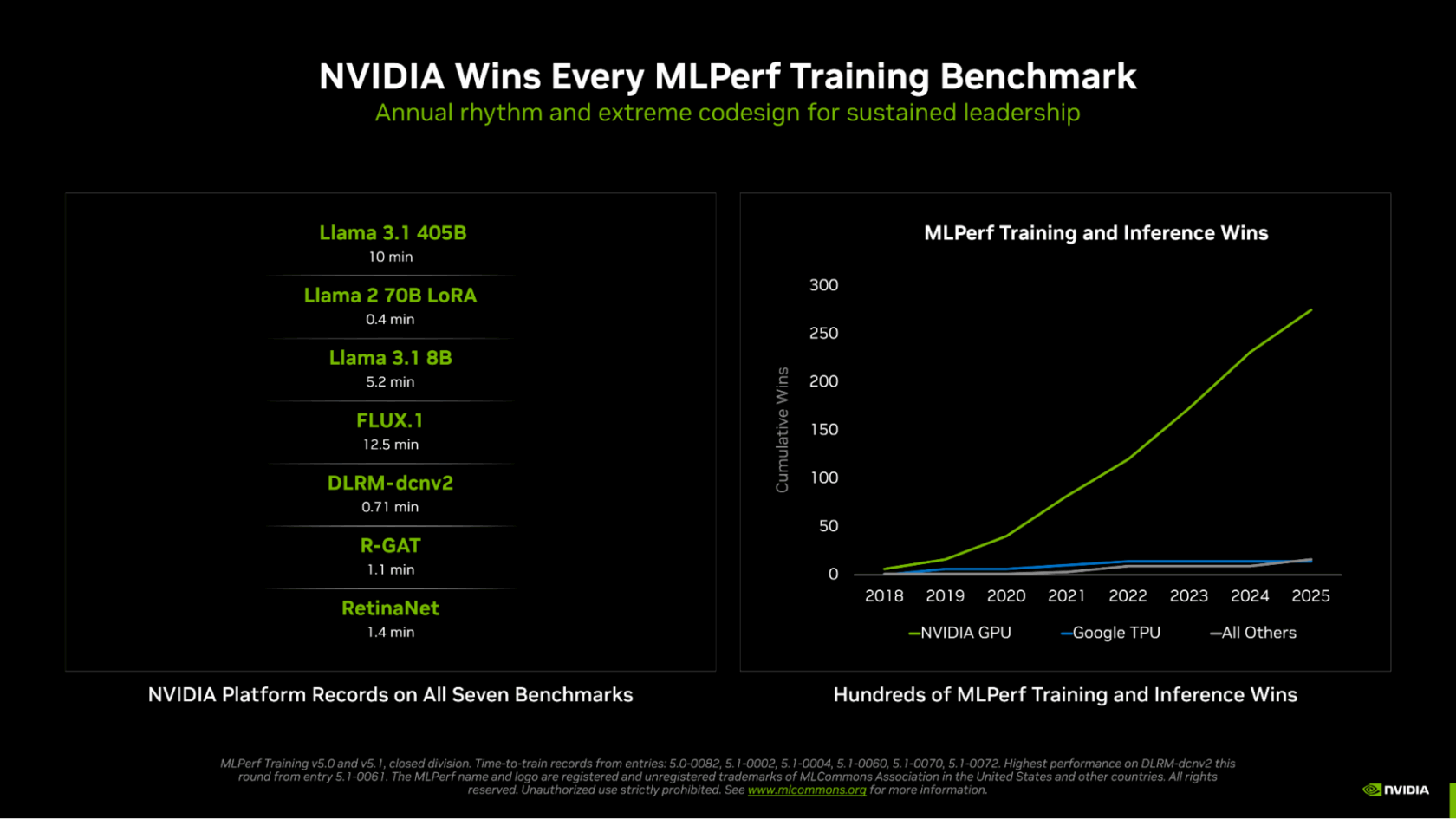 NVIDIA подчеркнула, что была единственной платформой, которая предоставила результаты по всем тестам — это, по словам компании, «подчёркивает широкие возможности программирования ускорителей NVIDIA, а также зрелость и универсальность программного стека CUDA». Компания сообщила, что в этом раунде MLPerf Training дебютировала стоечная система GB300 NVL72, работающая на базе ускорителя NVIDIA Blackwell Ultra, показав рекордные результаты и доказав, что является наилучшим выбором для интенсивных рабочих ИИ-нагрузок. При предварительном обучении Llama 3.1 40B ускорители GB300 обеспечивают более чем вчетверо большую производительность по сравнению с H100 и почти вдвое — по сравнению с GB200. Аналогичным образом, при точной настройке Llama 2 70B восемь ускорителей GB300 обеспечили в пять раз большую производительность по сравнению с H100.  NVIDIA отметила, что этого удалось достичь благодаря архитектурным усовершенствованиям Blackwell Ultra, включая новые тензорные ядра, которые обеспечивают ИИ-производительность в формате NVFP4 в размере 15 Пфлопс, вдвое большую производительность в работе механизма внимания (attention-layer compute) и 279 Гбайт HBM3e, а также новые методы обучения, которые позволили повысить вычислительную производительность архитектуры NVFP4. В MLPerf также дебютировала 800G-платформа Quantum-X800 InfiniBand, объединяющая несколько систем GB300 NVL72, которая удвоила пропускную способность сети по сравнению с предыдущим поколением. Но по словам компании, «ключом к выдающимся результатам в этом раунде было выполнение вычислений с использованием NVFP4 — впервые в истории MLPerf Training». NVIDIA обеспечила поддержку FP4 для обучения LLM на каждом уровне, что позволило удвоить скорость вычислений по сравнению с FP8. Ускоритель NVIDIA Blackwell может выполнять вычисления в формате FP4 (в т.ч. NVFP4 и др.) с удвоенной скоростью по сравнению с FP8, а Blackwell Ultra — с утроенной.  На сегодняшний день NVIDIA является единственной платформой, которая представила результаты MLPerf Training с вычислениями, выполненными с использованием FP4 при соблюдении строгих требований к точности в тесте. Эти результаты были получены с использованием 5120 ускорителей Blackwell GB200, которым потребовалось всего 10 мин. на бенчмарк Llama 3.1 405B, что является новым рекордом. Это в 2,7 раза быстрее, чем лучший результат с использованием архитектуры Blackwell, показанный в предыдущем раунде бенчмарка. NVIDIA также установила рекорды производительности в двух новых тестах: Llama 3.1 8B и FLUX.1. Llama 3.1 8B — компактная, но обладающая высокой производительностью LLM — заменила модель BERT-large, добавив в линейку базовых моделей современную LLM малого размера. NVIDIA представила результаты с использованием до 512 ускорителей Blackwell Ultra, потратив 5,2 мин. на прохождение теста. FLUX.1 — современная модель генерации изображений — заменила Stable Diffusion v2, и только платформа NVIDIA представила результаты этого теста. NVIDIA представила результаты с использованием 1152 ускорителей Blackwell, установив рекорд — 12,5 мин. обучения.
12.11.2025 [15:17], Руслан Авдеев
Microsoft инвестирует $10 млрд в ИИ ЦОД в ПортугалииMicrosoft потратит $10 млрд на ИИ ЦОД на побережье Португалии. Это станет одной из крупнейших инвестиций компании в Европе в 2025 году, сообщает Bloomberg. Речь о проекте кампуса в Синише (Sines) в 150 км от Лиссабона. Строительством парка занимается Microsoft совместно с португальской Start Campus и британским стартапом Nscale. Информацию о проекте и сумме подтвердил президент Microsoft Брэд Смит (Brad Smith). Как отмечает Datacenter Dynamics, в начале года в кампусе введён в эксплуатацию первый из шести планируемых объектов — ЦОД SIN01. $10 млрд покроют расходы на развитие второй фазы проекта. Второй ЦОД SIN02 обеспечит 180 МВт и уже строится. Общая мощность кампуса должна составить 1,2 ГВт. Пока неизвестно, в скольких проектах ЦОД на площадке Microsoft и Nscale будут участвовать совместно. Партнёрство Microsoft, Nscale и Start Campus было анонсировано в октябре 2025 года. Nscale развернёт для Microsoft в Синише 12,6 тыс. ускорителей NVIDIA GB300. Столкнувшись с нехваткой мощностей, компания подписала соглашения с несколькими неооблаками на $60 млрд, в том числе с CoreWeave, Nebius, IREN и Lambda. Только за последний квартал на аренду потрачено $11,1 млрд. Мощности Nscale компания намерена арендовать в Великобритании, США и Норвегии. Всего Microsoft намерена арендовать у Nscale 116 тыс. ускорителей GB300. Хотя большинство ЦОД расположены в районе Лиссабона (присутствуют объекты AtlasEdge, Claranet, Edged, Tata Communications и Equinix), прибрежный город Синиш с населением порядка 15 тыс. человек становится ключевым инвестиционным хабом Португалии. Отсюда проложены и подводные кабели, ещё больше появится в будущем — Medusa, New CAM Ring, Nuvem и Olisipo. 
Источник изображения: Maksym Kaharlytskyi/unsplash.com В мае китайская CALB Group начала строить в городе фабрику по производству аккумуляторов за €2 млрд ($2,3 млрд). Также Синиш, возможно, станет домом для «ИИ-гигафабрики», поддерживаемой Евросоюзом.
10.11.2025 [15:00], Владимир Мироненко
Фирменные ИИ-ускорители Amazon всё ещё не могут конкурировать с чипами NVIDIA, считают некоторые стартапыНекоторые стартапы считают, что ИИ-чипы Trainium и Inferenetia собственной разработки Amazon менее конкурентоспособны, чем ускорители NVIDIA, сообщил ресурс Business Insider со ссылкой на внутреннюю документацию AWS. Согласно июльскому «конфиденциальному» внутреннему документу Amazon, ИИ-стартап Cohere обнаружил, что чипы Amazon Trainium 1 и 2 «уступают по производительности» ускорителям NVIDIA H100. Стартап отметил, что доступ к Trainium2 был «крайне ограничен», а в работе наблюдались частые перебои. Amazon и её подразделение Annapurna Labs всё еще изучают возникшие у Cohere «проблемы с производительностью», но прогресс в решении этих проблем был «ограниченным», отмечено в официальном документе. Также в нём упоминается стартап Stability AI, разработавший, в том числе, ИИ-генератор изображений Stable Diffusion, который высказывал схожие претензии. В частности, говорится, что чипы Amazon Trainium2 уступают NVIDIA H100 по задержке, что делает их «менее конкурентоспособными» с точки зрения скорости и стоимости. Ставка Amazon на чипы собственной разработки является частью её усилий по обеспечению конкурентоспособности в ИИ-гонке. Её прибыльность основана в том числе на использовании собственных процессоров Graviton вместо дорогостоящих чипов Intel. И сейчас Amazon тоже стремится задействовать собственные чипы для обработки ИИ-нагрузок. Если некоторые клиенты AWS не захотят использовать Trainium и будут настаивать на том, чтобы AWS запускала свои облачные ИИ-системы с использованием чипов NVIDIA, которые гораздо дороже её собственных решений, это отразится на её прибыли от облачных вычислений, отметил Business Insider. 
Источник изображений: AWS Рынок стартапов давно является важным для AWS, поэтому их претензии имеют большое значение для компании. Представитель Amazon заявил, что компания «благодарна» клиентам за отзывы, которые помогают сделать её чипы «еще лучше и более широко используемыми». Он добавил, что кейс с Cohere «не является актуальным», отметив, что её чипы Trainium и Inferentia «достигли отличных результатов» с такими клиентами, как Ricoh, Datadog и Metagenomi. «Мы очень довольны ростом и внедрением Trainium2, который на данном этапе в основном используется небольшим числом очень крупных клиентов, таких как Anthropic», — написал представитель в электронном письме ресурсу Business Insider. AWS утверждает, что ее собственные ИИ-ускорители предлагают на 30-40 % лучшие ценовые характеристики, чем нынешнее поколение GPU. Компания обладает «невероятными талантами» в области проектирования чипов и работает над новыми поколениями ускорителей. «Мы рассчитываем привлечь больше клиентов, начиная с Trainium 3, превью которого ожидается позже в этом году», — сказал представитель Amazon. Генеральный директор Amazon Энди Джасси (Andy Jassy) заявил во время отчёта о доходах компании, что чипы Trainium2 «полностью распределены по подписке» и теперь являются «многомиллиардным» бизнесом, который последовательно увеличивается на 150 % от квартала к кварталу.  Жалобы клиентов Amazon на её чипы поступали и раньше. Согласно июльскому документу, стартап Typhoon обнаружил, что устаревшие ускорители NVIDIA A100 в три раза экономичнее для определённых рабочих нагрузок, чем чипы Inferentia2 от AWS, ориентированные на инференс. В свою очередь, исследовательская группа AI Singapore установила, что серверы AWS G6, оснащённые ускорителями NVIDIA, более экономичны по сравнению с Inferentia2 при различных вариантах использования. В прошлом году клиенты облака Amazon также отмечали «проблемы при внедрении» её пользовательских ИИ-чипов, которые создают «проблемные области», что ведёт к снижению их использования. Эти проблемы нашли отражение в доле рынка Amazon. По данным исследовательской компании Omdia, NVIDIA доминирует на рынке ИИ-чипов с долей более 78 %. За ней следуют Google и AMD, владеющие по чуть более 4 %. AWS занимает лишь шестое место с 2 % рынка.  Наглядно иллюстрирует проблемы Amazon в этом отношении соглашение AWS и OpenAI стоимостью $38 млрд. Сделка предполагает использование облачных ИИ-серверов на базе ускорителей NVIDIA, без упоминания чипов Trainium. Ускорители NVIDIA не только обеспечивают высокую производительность, но подкрепляются широко распространённой платформой CUDA. Это качество особенно ценно при разработке крупных проектов в области ИИ с высоким уровнем риска, когда надёжность и имеющийся опыт могут сыграть решающую роль. В июльском документе сотрудники Amazon отметили, что технические ограничения и другие проблемы, связанные со сравнением пользовательских ИИ-чипов компании и ускорителей NVIDIA, стали «критическим препятствием» для клиентов, задумывающихся о переходе на чипы AWS. До публикации отчёта о доходах Amazon на прошлой неделе аналитики Bank of America соблюдали осторожность в оценке прогресса Tranium. В аналитической заметке, опубликованной в конце октября, они предупредили, что инвесторы «скептически» относятся к возможностям Trainium, и что «неясно», проявится ли высокий спрос на них «за пределами Anthropic».  Недавно AWS запустила проект Project Rainier — ИИ-кластер из полумиллиона чипов Trainium2, которые будут использоваться для обучения LLM следующего поколения Anthropic. Ожидается, что к концу года Anthropic получит более 1 млн чипов Trainium2, но решение по этому вопросу ещё не принято. Если реализация проекта будет успешной, это станет огромным подспорьем для Amazon. Вместе с тем в прошлом месяце Anthropic подписала многомиллиардный контракт на использование Google TPU, отметив, что продолжит использовать Trainium. Хотя Anthropic публично признала сложность использования архитектур с разными чипами, представитель Amazon сообщил Business Insider, что Anthropic продолжает расширять использование Trainium и подчеркнул стремление компании предлагать клиентам широкий спектр аппаратных опций в рамках своих облачных сервисов. В ходе общения с аналитиками на прошлой неделе Джасси подчеркнул, что AWS сосредоточена на предоставлении «нескольких вариантов чипов». Он отметил, что цель состоит не в том, чтобы заменить чипы NVIDIA, а в том, чтобы предоставить клиентам больше выбора. Этой стратегии AWS придерживается и в других областях облачных вычислений, сказал он. «В истории AWS никогда не было случая, чтобы какой-то один игрок в течение длительного периода времени владел всем сегментом рынка, а затем мог удовлетворить потребности всех во всех аспектах», — сказал Джасси. В долгосрочной перспективе не слишком удачные продажи собственных ускорителей не лучшим образом скажутся на AWS. Компания понимает, что её решения могут быть менее производительны и удобны, поэтому и предлагает их по меньшей цене, чем ускорители NVIDIA. Однако стоимость их производства сравнима со стоимостью производства чипов такого же класса, и со временем она будет только расти. Проще говоря, Amazon меньше зарабатывает на своих чипах, а в худшем случае может терять на них деньги.
09.11.2025 [13:38], Сергей Карасёв
Nebius Аркадия Воложа развернула в Великобритании платформу AI Cloud на базе NVIDIA HGX B300Компания Nebius (бывшая материнская структура «Яндекса» Yandex N.V.) объявила о своём первом развёртывании ИИ-инфраструктуры в Великобритании. Кластер Nebius AI Cloud расположен в кампусе Longcross Park на площадке Ark Data Centres недалеко от Лондона. Как отмечает основатель и генеральный директор Nebius Аркадий Волож, Великобритания является одним из ведущих ИИ-центров в мире. Поэтому для компании создание кластера на территории этой страны имеет большое значение. Кластер состоит из 126 стоек с оборудованием, размещённых в трёх машинных залах. В рамках первой фазы проекта установлены 4 тыс. ускорителей NVIDIA HGX B300 (Blackwell Ultra) в составе серверов пятого поколения (Gen5) собственной разработки Nebius. Вторая фаза предполагает монтаж ещё 3 тыс. ускорителей B300. Общая мощность системы — 16 МВт. По заявлениям Nebius, британский кластер AI Cloud использует передовые энергоэффективные технологии охлаждения, сетевое подключение NVIDIA Quantum-X800 InfiniBand с низкой задержкой и надёжную локальную систему генерации электроэнергии. Говорится о полной интеграции с программной платформой NVIDIA AI Enterprise, предназначенной для разработки и развёртывания ИИ-приложений. 
Источник изображения: Nebius Объединяя нашу облачную инфраструктуру с новейшими технологиями NVIDIA, мы предоставляем организациям по всей Великобритании возможность обучать, развёртывать и масштабировать модели и приложения ИИ быстрее, безопаснее и эффективнее, чем когда-либо», — говорит Волож. Британский кластер использует облачную платформу Nebius AI Cloud 3.0 Aether, которая разработана специально для создания и использования ИИ в таких областях, как здравоохранение, финансы, науки о жизни, корпоративный сектор и государственная сфера. Говорится о поддержке сквозного шифрования и о полном соответствии стандартам защиты данных GDPR и CCPA. Ранее Nebius сообщила о запуске своего первого кластера AI Cloud в Израиле, который расположился на площадке в Модиине (Modiin). У Nebius также имеются дата-центры в Финляндии, Франции и США.
05.11.2025 [10:16], Владимир Мироненко
NVIDIA и Deutsche Telekom строят в Германии ИИ-фабрику стоимостью €1 млрд
b200
deutsche telekom
dgx
hardware
nvidia
omniverse
германия
ии
конфиденциальность
промышленность
цод
NVIDIA и Deutsche Telekom представили первое в мире промышленное ИИ-облако (Industrial AI Cloud) — суверенную корпоративную платформу, запуск которой запланирован на начало 2026 года в рамках совместного проекта стоимостью €1 млрд. Платформа использует передовое оборудование NVIDIA, включая системы DGX B200 и серверы RTX PRO, а также ПО, в том числе NVIDIA AI Enterprise, CUDA-X и Omniverse, полностью интегрированное в облачную и сетевую экосистему Deutsche Telekom. Deutsche Telekom сообщила, что NVIDIA поставит более тысячи систем NVIDIA DGX B200 и серверов NVIDIA RTX PRO с 10 тыс. ускорителей NVIDIA Blackwell. Оборудование уже устанавливается в модернизированном дата-центре в Мюнхене. Объект начнёт работу в I квартале 2026 года, ИИ-производительность его систем составит 500 Пфлопс (точность вычислений не указана). Сообщается, что благодаря запуску этой ИИ-фабрики вычислительная мощность ИИ-решений в Германии увеличится сразу на 50 %. Управление объектом площадью в несколько тысяч квадратных метров будет осуществлять Deutsche Telecom, а компания SAP, занимающаяся разработкой корпоративного программного обеспечения, предоставит свою платформу SAP Business Technology Platform и соответствующие приложения. Европейская компания Polarise, занимающаяся разработкой ЦОД, также будет участвовать в проекте, пишет DataCenter Dynamics. «Благодаря этим вычислительным мощностям Германия станет ведущей в Европе суверенной точкой ИИ-доступа, созданной в рамках исключительно частной инициативы», — отметила Deutsche Telekom. 
Источник изображения: NVIDIA Сообщается, что Industrial AI Cloud — один из первых флагманских проектов инициативы Made for Germany («Сделано для Германии»), в которой участвуют более 100 компаний. Цель инициативы — укрепить позиции Германии как бизнес-площадки и ускорить цифровизацию экономики и управления страны. Компании смогут резервировать вычислительные мощности для разработки промышленных приложений ИИ. Облако также будет обслуживать государственные службы и оборонный сектор, пишет Reuters. Deutsche Telekom сообщила, что среди первых партнёров проекта — Agile Robots, чьи роботы, по слухам, будут использоваться для установки серверных стоек на объекте. Благодаря использованию NVIDIA Omniverse она расширит свои возможности по обучению, тестированию и валидации базовых моделей робототехники для целых парков роботов. Также в числе первых партнёров компания Perplexity, которая будет использовать новый ИИ ЦОД для предоставления услуг ИИ-инференса немецким пользователям и компаниям. Siemens сообщила, что будет использовать облачную платформу для ускорения внедрения промышленного ИИ, в том числе для собственных сервисов и для предложения решений на базе ИИ клиентам и партнёрам. По данным Siemens, такие автопроизводители, как Mercedes-Benz и BMW, будут использовать Industrial AI Cloud для проведения сложных симуляций с использованием цифровых двойников на базе ИИ, что значительно ускорит разработку автомобилей.
04.11.2025 [01:00], Владимир Мироненко
OpenAI потратит $38 млрд на аренду ускорителей NVIDIA у AWS, а AWS за $5,5 млрд арендует мощности у Cipher MiningAWS и OpenAI объявили о многолетнем стратегическом партнёрстве, в рамках которого AWS предоставит OpenAI ИИ-инфраструктуру. В рамках соглашения стоимостью $38 млрд OpenAI на семь лет получает доступ к вычислительным ресурсам AWS, включающим сотни тысяч ускорителей NVIDIA GB200/GB300 NVL72 в составе EC2 UltraServer, с возможностью расширения до десятков миллионов чипов для быстрого масштабирования агентных рабочих нагрузок. Согласно пресс-релизу, OpenAI сразу же начнёт использовать вычислительные ресурсы AWS. На первом этапе сделки будут использоваться существующие дата-центры AWS, а Amazon в конечном итоге развернёт дополнительную инфраструктуру для OpenAI. Развёртывание вычислительных мощностей планируется завершить до конца 2026 года. В 2027 году и далее возможно их расширение. В интервью ресурсу CNBC Дэйв Браун (Dave Brown), вице-президент по вычислительным сервисам и сервисам машинного обучения AWS, отметил, что OpenAI достанутся отдельные мощности, часть из которых уже доступна и используется. «Масштабирование передовых ИИ-технологий требует мощных и надёжных вычислений, — заявил генеральный директор OpenAI Сэм Альтман (Sam Altman). — Наше партнёрство с AWS укрепляет обширную вычислительную экосистему, которая станет движущей силой новой эры и сделает передовой ИИ доступным каждому». Примечательно, что для OpenAI будут развёрнуты узлы с преимущественно NVIDIA Connect-X, а не EFA, ради которых AWS переработала стойки GB300 NVL72, передаёт SemiAnalysis. Также OpenAI не будет использовать фирменные инструменты вроде SageMaker HyperPod, а задействует собственные решения для управления инфраструктурой. Т.е. речь идёт скорее о сдаче в аренду серверов, а не облачных сервисах. По-видимому, Project Ceiba также не относится к сделке. 
Источник изображения: Amazon Вместе с тем OpenAI продолжит активно сотрудничать с Microsoft, обязавшись приобрести сервисы Azure на $250 млрд. Сделка была заключена после завершения реструктуризации OpenAI, в связи с чем ей уже нет необходимости получать одобрение Microsoft на покупку вычислительных сервисов у других компаний. В 2019–2023 гг. OpenAI использовала только вычислительные мощности Microsoft, являвшейся её основным инвестором. За последние 18 месяцев, несмотря на жалобы OpenAI на то, что ей не удалось получить от Microsoft всю необходимую вычислительную мощность, технологический гигант позволил стартапу заключить отдельные соглашения с двумя другими облачными провайдерами, пишет The New York Times. В последнее время OpenAI активно заключает сделки, в том числе, с такими компаниями, как AMD, CoreWeave, NVIDIA, Broadcom, Oracle и Google. Общая сумма сделок составила около $1,4 трлн, что побудило некоторых экспертов заявить о грядущем пузыре в сфере ИИ. Они также высказывают сомнения в наличии у США необходимых ресурсов и возможностей для воплощения этих амбициозных обещаний в реальность. Попутно стало известно о заключении AWS договора с оператором майнинговых дата-центров Cipher Mining на сумму около $5,5 млрд, согласно которому ей будут предоставлены в аренду на 15 лет площади и электропитание в ЦОД последней. Как сообщает Data Center Dynamics, согласно условиям договора, Cipher Mining предоставит AWS в 2026 году 300 МВт с поддержкой воздушного и жидкостного охлаждения стоек. Ранее Cipher Mining заключила сделку с Google и Fluidstack.
02.11.2025 [11:15], Сергей Карасёв
NVIDIA может инвестировать до $1 млрд в ИИ-стартап Poolside, чтобы тот мог купить побольше её же ускорителейКомпания NVIDIA, по информации Bloomberg, может принять участие в крупном раунде финансирования стартапа Poolside, специализирующегося на ИИ-технологиях. Предполагается, что в рамках этой программы компания привлечет до $2 млрд, увеличив свою оценку в четыре раза. Фирма Poolside, базирующаяся в Париже, была основана в начале 2023 года бывшим техническим директором GitHub Джейсоном Уорнером (Jason Warner) и Эйсо Кантом (Eiso Kant), предпринимателем в сфере ПО. Стартап занимается разработкой ИИ-инструментов для автоматизации написания программного кода. В конце 2024 года рыночная стоимость Poolside составляла около $3 млрд. По имеющимся данным, NVIDIA может инвестировать в Poolside от $500 млн до $1 млрд. Участие в новом раунде финансирования также может принять Magnetar, которая вкладывает средства в высокотехнологичные проекты, такие как CoreWeave. В случае привлечения запланированных $2 млрд рыночная стоимость Poolside может увеличиться до $12 млрд. Полученные деньги стартап намерен направить на приобретение десятков тысяч ускорителей NVIDIA для задач ИИ. 
Источник изображения: NVIDIA Представители Poolside, NVIDIA и Magnetar отказались давать комментарии по поводу инвестиционной программы. При этом отмечается, что Poolside ставит своей долгосрочной целью создание ИИ общего назначения (AGI). Такие системы будут обладать способностью к самообучению и интеллектом, подобным человеческому. Они теоретически смогут эффективно решать любые задачи, а не только специализированные, для которых изначально обучались. Нужно также отметить, что не так давно компания Poolside заключила соглашение с CoreWeave в рамках проекта по строительству кампуса ЦОД Project Horizon мощностью 2 ГВт на территории ранчо Longfellow в Западном Техасе. Для энергоснабжения объекта будет использоваться природный газ, добываемый в местном Пермском бассейне. По условиям договора, CoreWeave предоставит Poolside кластер NVIDIA GB300 NVL72 с более чем 40 тыс. чипов для обучения ИИ-моделей. |
|

