Материалы по тегу: hardware
|
02.12.2025 [12:41], Руслан Авдеев
Американский ИИ-стартап ищет деньги, чтобы снабдить китайцев чипами NVIDIA через ЯпониюБазирующийся в США стартап PaleBlueDot AI ищет, у кого бы занять $300 млн, чтобы купить ускорители NVIDIA и разместить их в токийском ЦОД — и всё это в интересах китайской медиакомпании RedNote (Xiaohongshu), сообщает Bloomberg. В своё время RedNote получила известность за пределами КНР благодаря временному запрету TikTok в Соединённых Штатах — тогда американцы начали массово регистрироваться в китайской соцсети. PaleBlueDot AI из Кремниевой долины обратилась к банкам и частным кредитным компаниям для получения финансирования. Сообщается, что JPMorgan Chase & Co. причастен к подготовке маркетинговых материалов для потенциальных заёмщиков, но от участия в самой сделке, вероятно, откажется. Источники утверждают, что сделка обсуждается, как минимум, в последние три месяца, хотя неизвестно, каков прогресс. По словам PaleBlueDot AI, «упомянутая информация не соответствует действительности», в JPMorgan от комментариев отказались, а NVIDIA и Xiaohongshu просто не ответили на запросы. PaleBlueDot AI позиционирует себя как посредника, предлагающего безопасные и экономически эффективные вычислительные решения. Примечательно, что у истоков компании и в её руководстве числятся бизнесмены китайского происхождения. 
Источник изображения: zhang kaiyv/unsplash.com Планируемый заём наглядно демонстрирует, как именно намерены технологические компании обходить ограничения на продажу в Китай передовых ИИ-чипов, неоднократно ужесточавшиеся с 2022 года. Хотя китайские компании теперь не могут покупать оборудование напрямую, они могут вполне легально получать доступ к ЦОД в странах за пределами Китая. Буквально на днях сообщалось, что Alibaba и ByteDance стали обучать передовые ИИ-модели в дата-центрах Юго-Восточной Азии. Финансирование подобных проектов всегда воспринимается с осторожностью. Это связано с озабоченностью тем, что американские власти могут наложить дополнительные санкции. Хотя сама NVIDIA давно критикует политику полных запретов поставок ИИ-чипов в Китай, компания постоянно обещает, что будет строго придерживаться политики, предотвращающей попадание чипов «не в те руки». Впрочем, подход американских властей может измениться. По слухам, уже рассматривается возможность поставок в КНР относительно устаревших вариантов — NVIDIA H200.
02.12.2025 [11:28], Сергей Карасёв
MiTAC выпустила двухузловой сервер M2810Z5 на базе AMD EPYC TurinКомпания MiTAC анонсировала 2U2N-сервер M2810Z5, ориентированный на современные дата-центры и облачные платформы. Новинка может использоваться для решения таких задач, как CDN, виртуализация, хостинг, ресурсоёмкие вычисления на базе CPU и поддержка приложений с интенсивным обменом данными. Устройство, выполненное в форм-факторе 2U, имеет двухузловую конструкцию. Каждый узел допускает установку одного процессора AMD EPYC 9005 Turin в исполнении Socket SP5 с показателем TDP до 500 Вт и 12 модулей DDR5-5600/6000/6400 RDIMM или RDIMM-3DS суммарным объёмом до 3 Тбайт. Доступен один слот OCP 3.0 (PCIe 5.0 x16). 
Источник изображений: MiTAC Каждый из узлов располагает четырьмя отсеками для накопителей формата E1.S (NVMe) с поддержкой горячей замены. MiTAC говорит о возможности установки SSD семейства Kioxia XD8 с интерфейсом PCIe 5.0. Эти изделия обеспечивают скорость чтения информации до 12,5 Гбайт/с и скорость записи до 5,8 Гбайт/с. Вместимость достигает 7,68 Тбайт. Кроме того, есть два коннектора M.2 (в расчёте на узел) для SSD типоразмера 22110/2280 с интерфейсом PCIe 4.0. Узлы наделены контроллером Aspeed AST2600, сетевым портом 1GbE на базе Intel I210-AT, выделенным сетевым портом управления 1GbE (Realtek RTL8211FD-CG), аналоговым разъёмом D-Sub, а также двумя портами USB 2.0.  Сервер M2810Z5 оборудован двумя блоками питания с резервированием мощностью 2000 Вт (80 Plus Titanium). Опционально может быть установлен модуль TPM. Применяется воздушное охлаждение с четырьмя вентиляторами диаметром 80 мм с возможностью горячей замены. Диапазон рабочих температур — от +10 до +35 °C. Габариты системы составляют 760 × 448 × 86 мм.
02.12.2025 [09:39], Владимир Мироненко
Миллионы IOPS, без посредников: NVIDIA SCADA позволит GPU напрямую брать данные у SSDNVIDIA разрабатывает SCADA (Scaled Accelerated Data Access, масштабируемый ускоренный доступ к данным) — новую IO-архитектуру, где GPU инициируют и управляют процессом работы с хранилищами, сообщил Blocks & Files. SCADA отличается от существующего протокола NVIDIA GPUDirect, который, упрощённо говоря, позволяет ускорить обмен данными с накопителями, напрямую связывая посредством RDMA память ускорителей и NVMe SSD. В этой схеме CPU хоть и не отвечает за саму передачу данных, но оркестрация процесса всё равно ложится на его плечи. SCADA же предлагает перенести на GPU и её. Обучение ИИ-моделей обычно требует передачи больших объёмов данных за сравнительно небольшой промежуток времени. При ИИ-инференсе осуществляется передача небольших IO-блоков (менее 4 Кбайт) во множестве потоков, а время на управление каждой передачей относительно велико. Исследование NVIDIA показало, что инициирование таких передач самим GPU сокращает время и ускоряет инференс. В результате была разработана схема SCADA. NVIDIA уже сотрудничает с партнёрами по экосистеме хранения данных с целью внедрения SCADA. Так, Marvell отмечает: «Потребность в ИИ-инфраструктуре побуждает компании, занимающиеся СХД, разрабатывать SSD, контроллеры, NAND-накопители и др. технологии, оптимизированные для поддержки GPU, с акцентом на более высокий показатель IOPS для ИИ-инференса. Это будет принципиально отличаться от технологий для накопителей, подключенных к CPU, где главными приоритетами являются задержка и ёмкость». 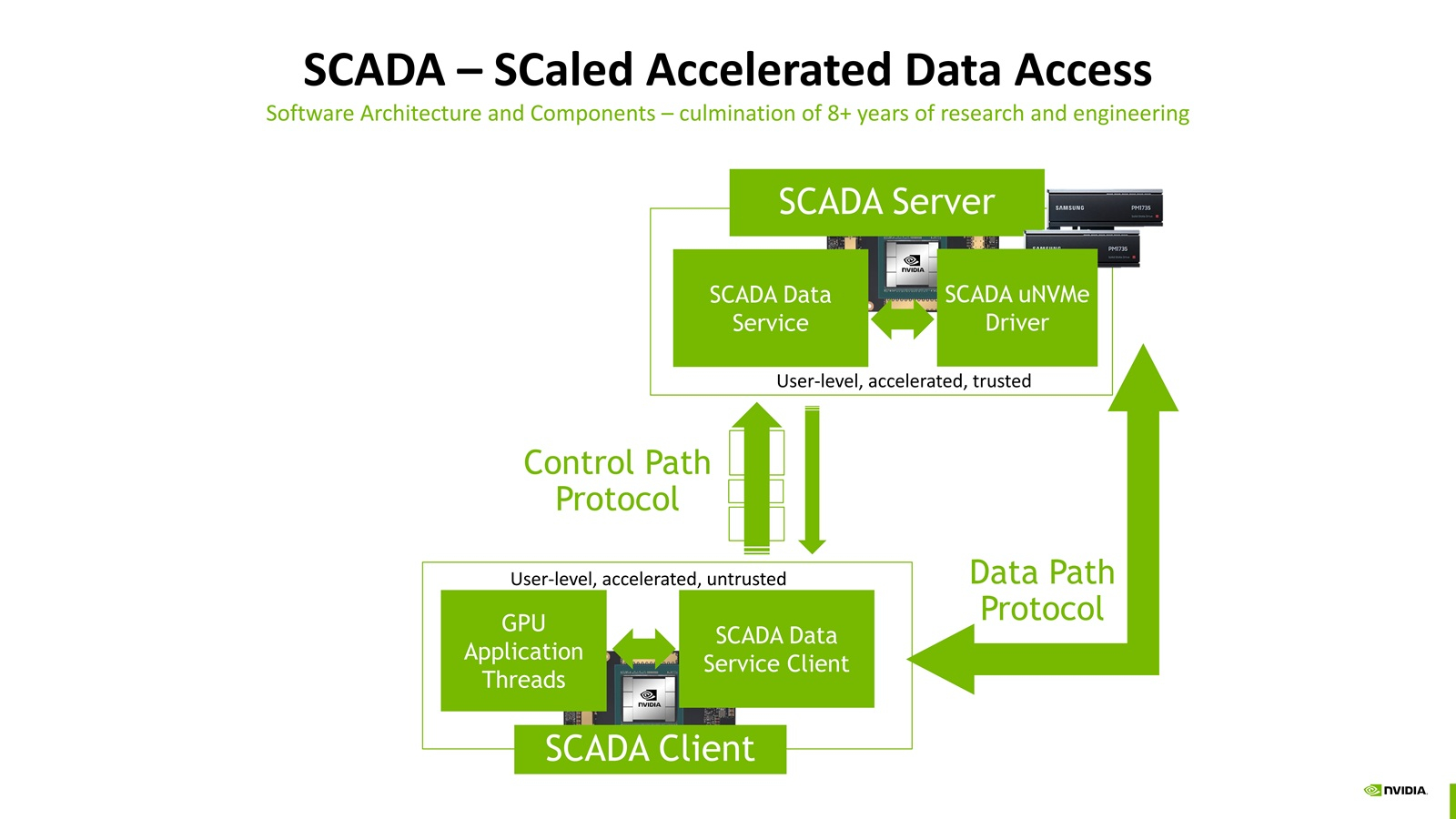
Источник изображения: NVIDIA По словам Marvell, в рамках SCADA ускорители используют семантику памяти при работе с накопителями. Однако сами SSD мало подходят для таких задач, поскольку не могут обеспечить необходимый уровень IOPS, когда во время инференса тысячи параллельных потоков запрашивают наборы данных размером менее 4 Кбайт. Это приводит к недоиспользованию шины PCIe, «голоданию» GPU и пустой трате циклов. В CPU-центричной архитектуре, которая подходит для обучения моделей, параллельных потоков данных десятки, а не тысячи, а блоки данных крупные — от SSD требуется высокие ёмкость и пропускная способность, а также малая задержка, поскольку свою задержку в рамках СХД также внесут PCIe и Ethernet. Внедрение PCIe 6.0 и PCIe 7.0, конечно, само по себе ускорит обмен данными, но контроллеры SSD также нуждаются в обновлении. Они должны уметь использовать возможности SCADA, иметь оптимальные схемы коррекции ошибок для малых блоков данных и быть мультипротокольными (PCIe, CXL, Ethernet). Компания Micron также участвует в разработке SCADA. 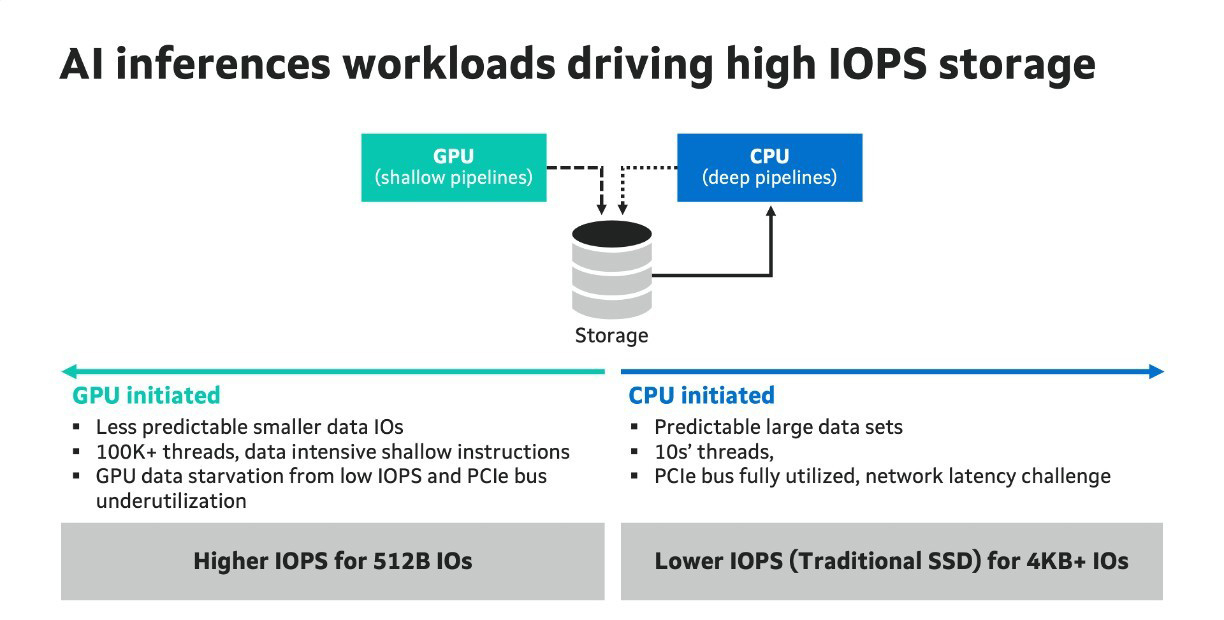
Источник изображения: Micron В рамках SC25 Micron показала прототип SCADA-хранилища на базе платформы H3 Platform Falcon 6048 с PCIe 6.0 (44 × E1.S NVMe SSD + 6 × GPU/DPU/NIC), оснащённой 44 накопителями Micron 9650 (7,68 Тбайт, до 5,4 млн на случайном чтении 4K-блоками с глубиной очереди 512, PCIe 6.0), тремя коммутаторами Broadcom PEX90000 (144 линии PCIe 6.0 в каждом), одним процессором Intel Xeon (PCIe 5.0) и тремя ускорителями NVIDIA H100 (PCIe 5.0). Micron заявила, что система «демонстрирует линейное масштабирование производительности от 1 до 44 SSD», доходя до 230 млн IOPS, что довольно близко к теоретическому максимуму в 237,6 млн IOPS. «В сочетании с PCIe 6.0 и высокопроизводительными SSD архитектура [SCADA] обеспечивает доступ к данным в режиме реального времени для таких рабочих нагрузок, как векторные базы данных, графовые нейронные сети и крупномасштабные конвейеры инференса», — подытожила Micron.
01.12.2025 [19:10], Владимир Мироненко
Дефицит памяти добрался и до Raspberry Pi: цены на четвёртую и пятую «малинку» вырослиРост цен на компоненты для вычислительных систем, который в основном объясняют бумом на ИИ-рынке, привёл к удорожанию даже традиционно дешёвых одноплатных компьютеров Raspberry Pi. Как сообщила компания, после увеличения в октябре цен на вычислительные модули CM4/CM5 из-за ограничений поставок памяти DDR4, ей пришлось повысить цены на Raspberry Pi 4 и 5. Для тех, кто ищет более доступный вариант, компания выпустила модель Raspberry Pi 5 1 Гбайт. Однако его цена выше традиционных $35 — сразу $45. Впрочем, цена Raspberry Pi 4 1 Гбайт не изменилась и по-прежнему составляет $35. Напомним, что в октябре цена CM4/CM5 с 4 Гбайт памяти выросла на $5, с 8 Гбайт памяти — на $10. Стоимость Raspberry Pi 500 была увеличена на $10 — до $100. Компания пообещала вернуть цены к прежним значениям, как только снизится цена памяти. Ранее она так уже делала. 
Источник изображений: Raspberry Pi «…, чтобы компенсировать недавний беспрецедентный рост стоимости памяти LPDDR4, мы объявляем о повышении цен на некоторые модели Raspberry Pi 4 и 5. Эти изменения во многом отражают повышение цен на наши вычислительные модули, о котором мы объявили в октябре, и помогут нам обеспечить поставки памяти в условиях всё более ограниченного рынка в 2026 году», — объявила Raspberry Pi. Ниже показано, как изменились цены на компьютеры Raspberry Pi. В перечне не указаны модели Raspberry Pi 4 2 Гбайт, Raspberry Pi 3+ и более ранние модели, а также семейство Raspberry Pi Zero, которых не коснулось изменение цен. 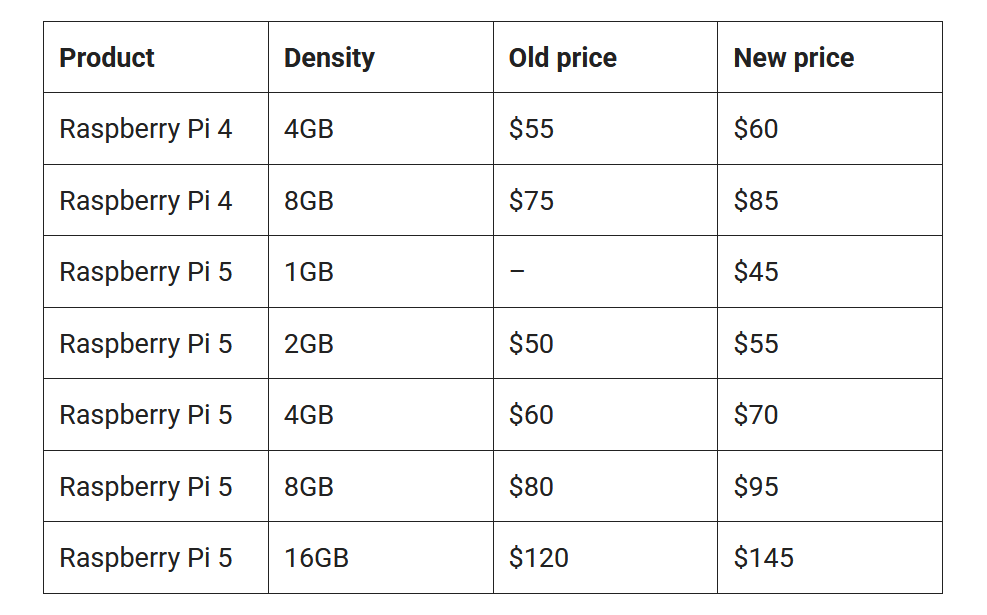 Как отметил ресурс CNX Software, Raspberry Pi 5 1 Гбайт доступен ограниченно, поскольку, по всей видимости, он продаётся в основном через европейских реселлеров, а также через Canakit в США и Канаде. Однако найти его в Азии будет сложно, и ни у одного из реселлеров «остального мира» эта модель не имеется в наличии, отметил ресурс.
01.12.2025 [15:59], Руслан Авдеев
Индийская Adani намерена вложить до $5 млрд в ЦОД для Google на фоне бума ИИ-проектовИндийская компания Adani Group рассчитывает инвестировать до $5 млрд в проект ИИ ЦОД, реализуемый Google в Индии, сообщает Reuters. В октябре Google объявила, что вложит $15 млрд в течение пяти лет в строительство ИИ ЦОД в штате Андхра-Прадеш (Andhra Pradesh) на юге Индии, это крупнейшая инвестиция компании в стране на текущий момент. Adani Group сообщает, что проект Google включает инвестиции до $5 млрд для Adani Connex — совместного предприятия Adani Enterprises и частного оператора ЦОД EdgeConneX. В компании заявили, что заключить партнёрские соглашения с Adani готова не только Google, но и другие потенциальные клиенты, особенно, когда ёмкость ЦОД достигнет 1 ГВт и выше. Google увеличила прогноз по капзатратам в уходящем году до $91–$93 млрд, в основном средства пойдут на расширение ёмкости дата-центров. Индийские миллиардеры Гуатам Адани (Gautam Adani) и Мукеш Амбани (Mukesh Ambani) также анонсировали намерение инвестировать в расширение ёмкости ЦОД. 
Источник изображения: Yogi Ravi Teja Yedla/unsplash.com Кампус в городе-порту Вишакхапатнам (Visakhapatnam) должен обеспечить первоначальную мощность 1 ГВт с возможностью дальнейшего увеличения. В прочем, в первой половине октября сообщалось, что техногиганты из Соединённых Штатов приостановили развитие ЦОД в Индии, хотя ранее обещали вложить в них миллиарды долларов.
01.12.2025 [12:30], Сергей Карасёв
Giga Computing развернёт производство серверного оборудования в ИндииКомпания Giga Computing, подразделение Gigabyte Group, объявила о заключении соглашения о стратегическом партнёрстве с Syrma SGS Technology Limited — индийским поставщиком услуг в области производства электроники. Речь идёт о выпуске серверной продукции Giga Computing на заводе в Индии. Отмечается, что Syrma SGS обладает богатым опытом изготовления различного IT-оборудования, включая серверы, материнские платы для ноутбуков и настольных компьютеров. Кроме того, эта фирма специализируется на системной интеграции. Предприятие Syrma SGS располагается в Ченнаи (столица штата Тамилнад на востоке Индии) неподалёку от локального представительства Giga Computing. По условиям соглашения, Syrma SGS на первом этапе начнёт сборку серверных материнских плат Gigabyte, включая модели MS73-HB0 и MZ33-AR1 для процессоров Intel Xeon и AMD EPYC соответственно. Впоследствии сотрудничество планируется расширять: в частности, на заводе Syrma SGS будут производиться полноценные серверные системы Giga Computing с возможностью экспорта. 
Источник изображения: Giga Computing Предполагается, что партнёрство позволит, с одной стороны, поддержать инициативу Make in India. С другой стороны, Giga Computing получит возможность усилить позиции на индийском рынке, а также укрепить цепочки поставок в Южной Азии, что поможет повысить эффективность и гибкость работы. «Индия — один из самых динамичных и перспективных рынков в сегменте вычислительной инфраструктуры, и локальное изготовление продукции играет важную роль в поддержании этого роста. Партнёрство с Syrma SGS открывает нам доступ к проверенному производству высококачественной электроники, а клиентам в Индии — к материнским платам и серверам мирового класса», — говорит Энди Нео (Andy Neo), директор по продажам Giga Computing.
01.12.2025 [12:28], Сергей Карасёв
MiTAC представила ИИ-сервер G4826Z5 с ускорителями AMD Instinct MI355X и СЖОКомпания MiTAC анонсировала высокопроизводительный GPU-сервер G4826Z5 на аппаратной платформе AMD, предназначенный для ресурсоёмких задач ИИ и НРС. Кроме того, представлены стойки и вычислительные кластеры на его основе. Сервер G4826Z5U2BC-355X-755 выполнен в форм-факторе 4U. Нижняя 2U-секция содержит два процессора AMD EPYC 9005 Turin и 24 слота для модулей оперативной памяти DDR5-6400. Во фронтальной части расположены восемь отсеков для SFF-накопителей; кроме того, есть два внутренних коннектора M.2 для SSD (NVMe). Верхний 2U-модуль несёт на борту восемь ускорителей AMD Instinct MI355X, оборудованных 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Машина G4826Z5 получила систему жидкостного охлаждения, которая охватывает CPU- и GPU-секции. Предусмотрена функция обнаружения утечек. Подсистема питания с резервированием выполнена по схеме: 1+1 мощностью 3200 Вт и 3+3 мощностью 15 600 Вт. Все блоки питания имеют сертификат 80 Plus Titanium и допускают горячую замену. 
Источник изображений: MiTAC На основе G4826Z5 формируется стоечная система (MR1100L-64355X-01): она содержит восемь GPU-серверов, что в сумме даёт 64 ускорителя и 18,4 Тбайт памяти HBM3E. Стойка также укомплектована коммутаторами 400GbE на 64 и 32 порта, двумя коммутаторами 1GbE на 48 портов, сервером управления B8056G68CE12HR-2T-TU, сервером хранения B8056T70AE26HR-2T-HE-TU и блоком распределения охлаждающей жидкости (CDU) в формате 4U.  В свою очередь, стойки объединяются в кластеры из четырёх и восьми штук. Это в сумме обеспечивает 32 и 64 сервера GPU и 256 и 512 ускорителей Instinct MI355X соответственно. Таким образом, максимальная конфигурация включает приблизительно 147 Тбайт памяти HBM3E.
01.12.2025 [09:59], Сергей Карасёв
Рабочая станция ASRock GAI4G-R9700 получила четыре ускорителя AMD Radeon AI PRO R9700 Creator и Ryzen Threadripper PRO 9000 WXКомпания ASRock анонсировала рабочую станцию GAI4G-R9700 для задач, связанных с ИИ и другими ресурсоёмкими нагрузками. Новинка, выполненная в форм-факторе 4U, может монтироваться в стойку или использоваться отдельно в виде «настольной» системы. В основу положена аппаратная платформа AMD. Применена материнская плата ASRock WRX90 WS EVO с поддержкой одного процессора Socket sTR5: это может быть чип Ryzen Threadripper PRO 9000 WX (до 96 вычислительных ядер). Доступны восемь слотов для модулей оперативной памяти DDR5-6400 RDIMM/RDIMM-3DS суммарным объёмом до 2 Тбайт. Рабочая станция несёт на борту четыре ускорителя AMD Radeon AI PRO R9700 Creator, каждый из которых содержит 32 Гбайт GDRR6 (256 бит) и предлагает по четыре интерфейса DisplayPort 2.1a. Предусмотрены два посадочных места для SFF-накопителей, а также по одному коннектору M.2 M-key 22110/2280/2260 (PCIe 5.0 x4) и M.2 M-key 2280/2260 (PCIe 4.0 x4) для SSD. 
Источник изображения: ASRock Новинка получила контроллер ASPEED BMC AST2600, два сетевых порт 10GbE на базе Intel X710-AT2 и выделенный сетевой порт управления (Realtek RTL8211F). На фронтальную панель выведены два разъёма USB 3.2 Gen1 Type-A. Сзади находятся интерфейс DisplayPort 1.1a (BMC), три гнезда RJ45, четыре порта USB 3.2 Type-A, по два порта USB 4 Type-C и USB 3.1 Type-A, интерфейс SPDIF и 3,5-мм аудиогнёзда. Установлен блок питания мощностью 2500 Вт с сертификатом 80 PLUS Platinum. Применяется воздушное охлаждение с пятью вентиляторами (3 × 120 мм и 2 × 80 мм), скорость вращения которых регулируется ШИМ-методом. Габариты рабочей станции составляют 526 × 430 × 175 мм (без монтажных элементов и ножек).
01.12.2025 [09:15], Руслан Авдеев
Японская Daikin намерена утроить продажи систем охлаждения ЦОД в Северной Америке, надеясь на гиперскейлеров и ИИ-бумЯпонская Daikin Industries рассчитывает утроить продажи охлаждающего оборудования для ЦОД в Северной Америке на фоне бума ИИ-технологий — до более чем ¥300 млрд ($1,92 млрд) к 2030 финансовому году, сообщает Nikkei Asian Review. Сейчас Daikin скупает технологии охлаждения американских компаний и намерена учредить отдельную штаб-квартиру для североамериканского рынка в 2026 финансовом году. Основная цель — работа со всеми гиперскейлерами. По оценкам Daikin, на Северную Америку приходится 40 % мирового рынка решений для охлаждения ЦОД, и её доля, вероятно, продолжит расти. Ключевыми заказчиками являются гиперскейлеры, и Daikin уже работает с Google и Amazon. Крупные HVAC-системы нередко приобретаются для нескольких зданий одновременно, так что объёмы единовременных продаж обычно составляют десятки миллионов долларов. Доля Daikin на североамериканском рынке, по её собственным оценкам, составляет около 12 %. Она занимает третье место в своём сегменте. К 2030 году компания намерена довести долю до 30 %. Конкуренцию ей составит как минимум LG, которая будет поставлять свои системы охлаждения для ИИ ЦОД Microsoft. 
Источник изображения: Daikin В 2007 году Daikin купила малайзийскую OYL Industries, которая владела американским производителем кондиционеров McQuay International (бренд Applied). В 2023 году за ¥30 млрд ($192 млн) она купила американскую Alliance Air Products, специалиста по оборудованию для обработки воздуха. В августе того же года она приобрела американскую же Dynamic Data Centers Solutions, разрабатывавшую технологию индивидуального охлаждения стоек. Наконец, в ноябре компания купила американский стартап Chilldyne, специализирующийся на СЖО. Массовое производство систем воздушного и жидкостного охлаждения для серверов начнётся весной следующего года. По прогнозам Daikin, приблизительно 70 % рынка к 2030 году будет приходиться на системы воздушного охлаждения и около 30 % — на СЖО. Daikin намерена предлагать оптимальные комбинации этих методов для операторов ЦОД и отраслевых подрядчиков. Дополнительно она предлагает и системы контроля охлаждения. Также компания сообщает, что намерена создать в США хаб по выпуску решений для ЦОД в 2026 фискальном году для контроля над североамериканским рынком. По данным индийской Fortune Business Insights, мировой рынок систем охлаждения для ЦОД должен вырасти более чем вдвое с 2024 по 2032 гг. до $42,4 млрд. Впрочем, гиперскейлеры работают над собственными решениями, которые позволят обрести им «суверенитет» от независимых вендоров. Например, собственную СЖО всего за 11 месяцев разработала и запустила в производство AWS. А Meta✴ пришлось пойти на ухищрения, чтобы обойтись воздушным охлаждением ИИ-стоек.
30.11.2025 [17:37], Сергей Карасёв
Для невышедших Intel Xeon Granite Rapids-WS уже представлена материнская плата Adlink ISB-W890 формата CEBAdlink подготовила к выпуску материнскую плату ISB-W890, предназначенную для создания рабочих станций и небольших серверов. Новинка, построенная на наборе логики Intel W890, допускает установку процессоров Intel Xeon Granite Rapids-WS (официальный анонс ожидается в I половине 2026 года) в исполнении Socket E2. Плата выполнена в форм-факторе CEB с размерами 305 × 267 мм. Предусмотрены восемь слотов для модулей оперативной памяти DDR5-6400 RDIMM ECC суммарным объёмом до 1 Тбайт. Доступны два коннектора M.2 M-Key 2280/22110/25110 для SSD (NVMe), два интерфейса SlimSAS и восемь портов SATA-3 с возможностью формирования массивов RAID 0/1/5/10. Возможны конфигурации Expert (128 линий PCIe) и Mainstream (80 линий PCIe). В первом случае слоты расширения выполнены по схеме 2 × PCIe 5.0 x16, 1 × PCIe 4.0 x16, 1 × PCIe 5.0 x8, 1 × PCIe 4.0 x8, 1 × PCIe 5.0 x4 и 1 × PCIe 4.0 x4, во втором — 2 × PCIe 5.0 x16, 1 × PCIe 5.0 x8, 1 × PCIe 4.0 x8, 1 × PCIe 5.0 x4 и 1 × PCIe 4.0 x4. В обоих вариантах доступны четыре коннектора MCIO ×8. 
Источник изображения: Adlink Материнская плата располагает контроллером Aspeed AST2600, сетевыми адаптерами 1GbE (Intel I210) и 2.5GbE (Intel I226). Интерфейсный блок содержит коннекторы D-Sub и DP, пять портов USB 3.2 Gen2x1 Type-A, порт USB 3.2 Gen2 Type-С, гнёзда RJ45 для сетевых кабелей, последовательный порт (RS-232/422/485) и набор аудиогнёзд на 3,5 мм. Через внутренние разъёмы могут быть задействованы порты USB 3.2 Gen1 и USB 2.0. Гарантирована совместимость с Windows 11 LTSC и Ubuntu 24.04. Диапазон рабочих температур простирается от 0 до +60 °C. |
|

