Материалы по тегу: вычисления
|
02.06.2025 [09:02], Сергей Карасёв
EnCharge AI представила аналоговые ИИ-ускорители EN100Компания EnCharge AI анонсировала изделия семейства EN100 — аналоговые ИИ-ускорители для in-memory вычислений. Дебютировали устройства в форм-факторе M.2 для ноутбуков и карты расширения PCIe для настольных рабочих станций. Стартап EnCharge AI, основанный в 2022 году, разрабатывает чипы, которые дают возможность перенести ИИ-нагрузки из облака на локальные платформы. Для этого применяется концепция вычислений в оперативной памяти, позволяющая увеличить эффективность и устранить узкие места, связанные с перемещением данных. NPU-ядра EnCharge AI, как утверждает сам разработчик, обеспечивают производительность на уровне 40 Топс/Вт (8-бит точность). Ускоритель EN100 для ноутбуков имеет типоразмер M.2 2280. В оснащение входят 32 Гбайт памяти с пропускной способностью до 68 Гбайт/с. Быстродействие превышает 200 Топс при общем энергопотреблении не более 8,25 Вт. Для оркестрации задействована многопоточная архитектура RISC-V. 
Источник изображений: EnCharge AI На рабочие станции ориентированы ускорители EN100 в виде карт расширения PCIe HHHL. Они несут на борту 128 Гбайт памяти с суммарной пропускной способностью 272 Гбайт/с. Производительность составляет около 1 Попс. Изделия обоих типов изготавливаются с применением 16-нм CMOS-технологии. 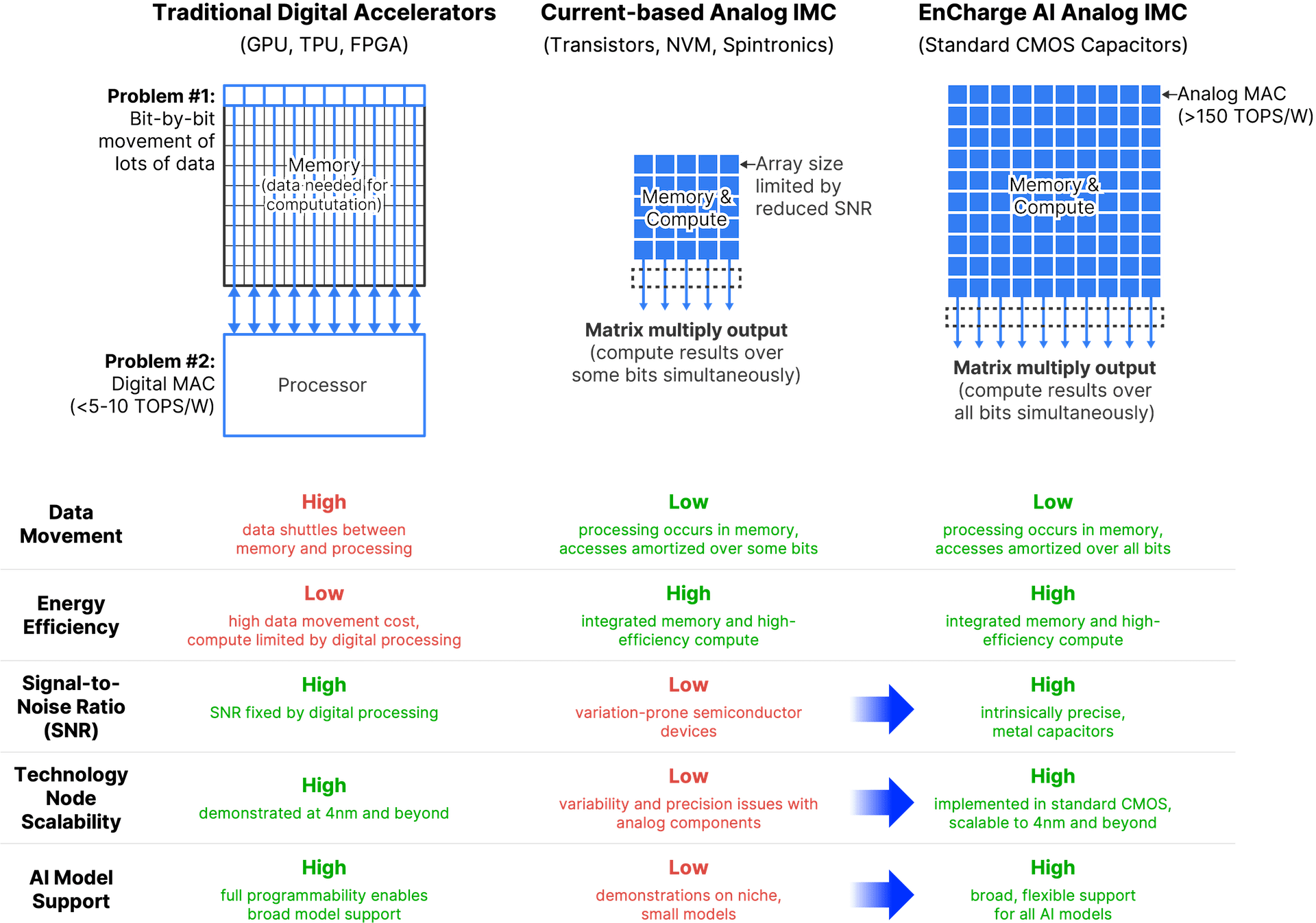 Навин Верма (Naveen Verma), генеральный директор EnCharge AI, заявляет, что решения компании позволят выполнять ресурсоёмкие задачи ИИ локально, не полагаясь на облачную инфраструктуру. Утверждается, что такие устройства по сравнению с современными ИИ-ускорителями обеспечат в 20 раз более высокую энергоэффективность (Топс/Вт) и в 9 раз более высокую плотность вычислений (Топс/мм2) при 10-кратном снижении совокупной стоимости владения (TCO).
27.05.2025 [14:12], Руслан Авдеев
Sophia Space разработала «ИИ-плитки» для сборки космических ЦОД
hardware
nvidia
nvidia jetson
qualcomm
snapdragon
ии
космос
микро-цод
облако
периферийные вычисления
спутник
сша
цод
Финансирование получил очередной космический стартап, намеренный вывести на орбиту дата-центры. Sophia Space из Сиэтла (США) привлекла $3,5 млн — раунд финансирования возглавила Unlock Ventures, участие также приняли «бизнес-ангелы», заинтересованные в орбитальных периферийных вычислениях и космических ЦОД, сообщает Datacenter Dynamics. 
Источник изображений: Sophia Space В Sophia Space заявили, что мир находится на заре новой эры, в которой спрос на ИИ-технологии не должен приносить ущерба планете из-за энергетических ограничений. Компанию основали два выходца из Лаборатории реактивного движения NASA (JPL), а также ветеран Intel и Microsoft. Компания предлагает готовую, автономную, защищённую от радиации вычислительную платформу TILE, оптимизированную для ИИ-задач, в том числе в коммерческих и оборонных секторах. Каждый сервер TILE Edge представляет «плитку» размерами 1 × 1 и толщиной 1 см, оснащённую собственной солнечной панелью и пассивной системой охлаждения. Вычислительная часть представлена связкой Qualcomm Snapdragon 865 и Cloud AI 100 или NVIDIA Jetson и Blackwell. «Плитки» можно объединять друг с другом, формируя кластер необходимой мощности.  Периферийные вычисления в космосе ценятся за возможность решить проблему перегрузки спутников, генерирующих больше данных, чем когда бы то ни было. Для использования этих огромных массивов информации требуются значительные ресурсы, поэтому предварительная обработка на периферийной платформе может сослужить неоценимую службу владельцам — предназначенные для передачи на Землю данные фильтруются ещё в космосе. Тема будет становиться всё более актуальной, поскольку правительствам и военным нужны всё более сложные системы мониторинга и съёмки на орбите. Компании вроде Axiom Space, Starcloud (ранее Lumen Orbit), NTT, Lonestar, Ramon.Space и Blue Origin давно рассматривают возможность развертывания вычислительных систем на орбите. В мае уже произошли два важных события, связанных с космическими дата-центрами. Во-первых, в начале месяца Эрик Шмидт (Eric Schmidt) купил Relativity Space, чтобы заняться запуском космических ЦОД, а несколько дней назад появилась информация, что китайская ADA Space вывела на орбиту первые 13 из 2,8 тыс. спутников для создания космического ИИ ЦОД.
23.05.2025 [13:46], Руслан Авдеев
ИИ-парковка: Tonomia интегрировала серверы в парковочные навесы с солнечными батареями и аккумуляторамиКомпания Tonomia предлагает размещение ИИ-ускорителей на… автопарковках — оборудование будет снабжаться энергией благодаря навесным солнечным элементам. Основанный в 2023 году бельгийский стартап сотрудничает с британским поставщиком оборудования Panchaea над созданием и продвижением комплекса eCloud, сообщает Datacenter Dynamics. Солнечные панели, используемые в качестве своеобразных «навесов» на парковках, нередко используются для подпитки АКБ электромобилей. Tonomia предложила использовать получаемую таким образом энергию и для питания ИИ-ускорителей своей облачной платформы. В компании полагают, что повсеместная установка таких «солнечных навесов» навесов в Европе и США позволит увеличить выработку энергии и снизить нагрузки на электросети, а интеграция вычислительного оборудования позволит получить дополнительный доход. Компания предложила объединить ИИ-серверы и действующие солнечные модули системы eParking с литий-ионными или натрий-ионными аккумуляторами. В Tonomia утверждают, что навесы способны генерировать до 600 Вт в Европе или 750 Вт в США (из-за большей площади парковок). Как утверждают в Panchaea, только в Европе есть более 350 млн наземных парковочных мест, причём большинство из них пустуют 80 % времени. Tonomia готова превратит автопарковки в «активы двойного назначения». 
Источник изображения: Tonomia Tonomia готова предложить ИИ-серверы Supermicro, MITAC или Panchaea. Конфигурации кластеров подбираются под особенности индивидуальных бизнес-моделей. Предполагается, что каждое парковочное место потенциально позволяет генерировать до 20 кВт∙ч ежедневно, т.е. около £8 ($10,74) в денежном эквиваленте, если исходить из стоимости инференса £0,40 ($0,53) за кВт·ч. Дополнительный доход может принести и зарядка электромобилей, передача энергии в электросеть и отдача избыточного тепла на обогрев близлежащих зданий. 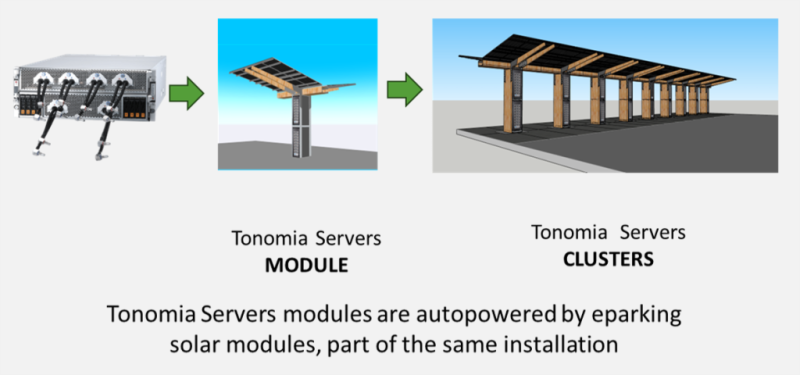
Источник изображения: Tonomia Tonomia разработала eCloud на основе оригинального продукта eParking после того, как к ней обратились игроки ИИ-сектора, заинтересованные в локальной генерации энергии. По словам компании, городам необходима подобная многофункциональная инфраструктура, а предприятиям нужны мощности для периферийных вычислений в непосредственной близости от потребителей. Кроме того, такая экоустойчивая система должна понравиться и регуляторам. Солнечная энергия активно используется в разных странах. Впрочем, как показывает европейский опыт, слишком много «зелёной» энергии — не всегда хорошо: Нидерланды уже столкнулись с определёнными проблемами.
21.05.2025 [14:34], Руслан Авдеев
Китайская ADA Space вывела на орбиту первые 13 из 2,8 тыс. спутников для создания космического ИИ ЦОДКитайская аэрокосмическая компания Chengdu Guoxing Aerospace Technology Co. (ADA Space) в рамках миссии Space Computing Constellation 021 успешно вывела на орбиту 12 спутников Xingshidai, призванных стать частью будущего космического ИИ-облака AI Cloud. Спутники вывели с помощью ракеты-носителя Чанчжэн-2D (Long March 2D), сообщает Datacenter Dynamics. Группировка Xingshidai будет состоять из 2,8 тыс. аппаратов производительностью 740 TOPS каждый. Компания рассчитывает использовать межспутниковую оптическую лазерную связь для передачи данных со скоростью до 100 Гбит/с. Спутники, как ожидаются, будут способны запускать ИИ-модели с 8 млрд параметров для помощи в астрономических наблюдениях, выполняемых с помощью различных космических инструментов, включая рентгеновский поляриметр, разработанный Университетом Гуанси (Guangxi University) и Национальной обсерваторией Китайской академии наук (National Astronomical Observatory of the Chinese Academy of Sciences). Группировка также обеспечит дистанционное зондирование и поддержку экстренных служб. По словам китайских учёных, поскольку в космосе можно получать большие объёмы данных высочайшего качества, возможность интеллектуальной обработки данных непосредственно на орбите приобрела важное значение. 
Источник изображения: Geronimo Giqueaux / Unsplash Основанная в 2018 году компания ADA Space в феврале вышла на Гонконгскую фондовую биржу. Компания, начинавшая как разработчик низкоорбитальных спутников для дистанционного зондирования, постепенно перешла на спутники для ИИ-проектов. В конце 2021 года компания успешно привлекла $55,6 млн от китайских инвестфондов в раунде финансирования серии B, возглавленном Hengjian Holding. До этого в раунде серии A+ был привлечён $21,37 млн, раунд возглавили Aplus Capital и Galaxy Holding Group. ADA Space — одна из многих компаний, которая выиграла от новой политики Китай, который с 2014 года пытается сделать аэрокосмическую отрасль, в которой доминируют государственные структуры, более открытой для частного капитала. С тех пор сотни аэрокосмических и смежных компаний получили государственную поддержку, в том числе от военных ведомств. Как заявил недавно представитель структуры China Aerospace Studies Institute, подконтрольной ВВС США, ожидается развитие сотрудничества Китая с коллегами по БРИКС, а также государства поменьше. По словам американских военных, это будет на руку как Китаю, так и другим странам, поскольку освоение космоса в ближайшие десятилетия будет весьма прибыльным делом и все нации захотят принять в этом участие. В этой группе Китай позиционирует себя безусловным лидером. В идее космических ЦОД нет ничего нового. В марте 2025 года Starcloud (бывшая Lumen Orbit) сообщила, что тестовый запуск группировки спутников состоится этим летом, а в апреле Axiom Space объявила, что планирует развернуть в космосе два узла ЦОД Orbital Data Center к концу 2025 года.
21.05.2025 [12:57], Руслан Авдеев
ИИ-платформа Microsoft Discovery создала жидкость для СЖО за 200 часов вместо нескольких месяцев
hpc
microsoft
microsoft azure
software
ии
ии-агент
квантовые вычисления
погружное охлаждение
разработка
сжо
химия
Компания Microsoft запустила для корпоративных пользователей в тестовом режиме ИИ-платформу Microsoft Discovery, использующую ИИ-агентов и HPC для помощи учёным, которым не придётся самостоятельно писать код для своих исследований. Потенциал системы продемонстрировали на примере самой Microsoft — ИИ помог создать новейшую жидкость для погружного охлаждения всего за 200 часов вместо нескольких месяцев или даже лет, сообщает VentureBeat. Microsoft Discovery использовали для поиска охлаждающей жидкости без «вечных» PFAS-химикатов, часто применяемых в иммерсионных СЖО. Регуляторы во всём мире всё чаще запрещают производство и использование этого класса вещества. ИИ Microsoft проверил 367 тыс. веществ-кандидатов, после чего химикат синтезировал один из партнёров компании. Однако сфера применения такого ИИ простирается далеко за пределы создания охлаждающих жидкостей — новые материалы и химикаты требуются в самых разных сферах, но на их поиск часто уходят годы. Microsoft Discovery позволяет взаимодействовать с «невероятными возможностями» ИИ, используя естественный язык, что полностью меняет весь процесс исследований, говорит компания. Обычно учёным приходилось изучать программирование для того, чтобы создавать вычислительные инструменты. Такая демократизация науки сыграет на руку малым исследовательским группам, у которых нет ресурсов на изучение программирования или привлечения сторонних специалистов в этой сфере. Более того, со временем платформа научится работать и с квантовыми компьютерами, написание кода для которых — ещё более сложная задача. 
Источник изображения: National Cancer Institute/unsplash.com Работа выполняется с помощью специальных ИИ-агентов, специально обученных для выполнения отдельных научных задач — от написания литературного обзора до создания компьютерной симуляции. По словам Microsoft, ИИ-агенты — это чуть ли не целая команда учёных с докторскими степенями в различных науках. Платформа интегрирует друг с другом базовые модели, занимающиеся общим планированием, и модели, специализирующиеся на физике, химии или, например, биологии. Также Microsoft Discovery позволяет комбинировать закрытые исследовательские данные и результаты уже опубликованных научных исследований по разным дисциплинам, сохраняя прозрачность моделей и контролируя процесс «рассуждений». Для работы с платформой используется интерфейс Copilot, который занимается оркестрацией агентов. Одновременно интерфейс служит и центральным хабом, в котором учёные управляют своей виртуальной ИИ-командой. 
Источник изображения: National Cancer Institute/unsplash.com В платформу встроены защитные механизмы — системе заданы «этические координаты». Также применяется модерация контента с проактивным подходом к выявлению злоупотреблений возможностями платформы — маркируются потенциально вредоносные алгоритмы и действия, поскольку все ИИ-инструменты фактически имеют «двойное назначение». С их помощью можно изобретать не только лекарства, но и опасные биологически опасные субстанции. Для своей платформы Microsoft выстраивает экосистему с участием представителей самых разных отраслей, от фармацевтики (GSK) до индустрии красоты (Estée Lauder). NVIDIA интегрирует с Discover микросервисы ALCHEMI и BioNeMo NIM для биотехнологий и фармацевтики. В полупроводниковой сфере Microsoft планирует интеграцию решений Synopsys для ускорения разработки чипов. Адаптацией под конкретные отраслевые задачи, развёртыванием и масштабированием платформы займутся Accenture и Capgemini. 
Источник изображения: Microsoft Успех Microsoft Discovery будет зависеть от того, насколько эффективно систему смогут интегрировать в текущие научные процессы — многие учёные скептически относятся к новым методикам, так что компании придётся показать всё, на что способен ИИ. По словам Microsoft, будущее науки именно за сочетанием умственных возможностей человека и масштабного ИИ. Microsoft уже провела предварительную демонстрацию Discovery для ограниченного круга структур. Цены на платформу пока не названы, но доступ к к ней будет организован посредством Azure.
20.05.2025 [12:10], Сергей Карасёв
NVIDIA открыла центр с самым мощным в мире исследовательским квантовым суперкомпьютеромКомпания NVIDIA объявила об открытии Глобального центра исследований и разработок для бизнеса в области искусственного интеллекта на базе квантовых технологий (Global Research and Development Center for Business by Quantum-AI Technology, G-QuAT). На этой площадке размещена система ABCI-Q — крупнейший в мире исследовательский суперкомпьютер, предназначенный для квантовых исследований. Система интегрирована с тремя квантовыми компьютерами. О проекте ABCI-Q сообщалось в марте 2024 года. Названный суперкомпьютер разработан Национальным институтом передовых промышленных наук и технологий Японии (AIST). В основу положены 2020 ускорителей NVIDIA H100. Задействованы интерконнект NVIDIA Quantum-2 InfiniBand, а также платформа с открытым исходным кодом NVIDIA CUDA-Q для организации гибридных квантово-классических вычислений. Ожидается, что сотрудничество NVIDIA и AIST будет способствовать ускорению разработок в таких областях, как квантовая коррекция ошибок и ИИ-приложения с поддержкой квантовых вычислений. В конечном итоге, проект призван помочь в решении некоторых из самых сложных глобальных задач, охватывающих различные отрасли, включая здравоохранение, энергетику и финансы. 
Источник изображения: NVIDIA Суперкомпьютер ABCI-Q интегрирован с процессором на сверхпроводящих кубитах Fujitsu, квантовым чипом на нейтральных атомах QuEra и фотонным процессором OptQC. Благодаря этому становится возможным выполнение рабочих нагрузок в нескольких модальностях кубитов. Исследователи смогут экспериментировать с вычислениями, основанными на GPU-ускорителях и квантовых процессорах разного типа. При этом будет обеспечиваться бесшовная интеграция квантового оборудования и классического суперкомпьютера.
19.05.2025 [08:49], Владимир Мироненко
На одном ИИ не выедешь: США рискуют потерять лидерство в HPC
hardware
hpc
top500
государство
дефицит
ии
кадры
квантовые вычисления
обучение
прогноз
разработка
суперкомпьютер
сша
ускоритель
финансы
энергоэффективность
Проблемы, связанные с высокопроизводительными вычислениями (HPC), угрожают инновациям в США, утверждает Джек Донгарра (Jack Dongarra), лауреат премии А. М. Тьюринга и один создателей рейтинга самых мощных суперкомпьютеров в мире TOP500, чьи разработки и реализации многих библиотек, включая EISPACK, LINPACK, BLAS, LAPACK и ScaLAPACK, сыграли важную роль в продвижении HPC. В статье, опубликованной The Conversation, Донгарра рассказал о прогрессе HPC и проблемах с инновациями в США. Учёный отметил, что HPC являются одной из самых важных технологий в современном мире, позволяющей решать различные задачи — от прогнозирования погоды до поиска новых лекарств и обучения ИИ-моделей, которые слишком сложны или слишком велики для обычных компьютеров. Сейчас HPC находятся на переломном этапе, и выбор, который правительство США, исследователи и технологическая отрасль делают сегодня, может повлиять на будущее инноваций, национальной безопасности и мирового лидерства, предупреждает Донгарра. Используя тысячи и даже миллионы чипов с передовыми системами памяти и хранения для быстрого перемещения и сохранения огромных объёмов данных, HPC-платформы позволять выполнять чрезвычайно подробные симуляции и вычисления, говорит Донгарра. Важность HPC ещё больше возросла с развитием ИИ-технологий, требующих огромных вычислительных мощностей для обучения. «В результате ИИ и HPC теперь тесно сотрудничают, подталкивая друг друга вперёд», — отметил учёный. По словам Донгарра, сегмент HPC находится под большим давлением, чем когда-либо, с более высокими требованиями к системам по скорости, данным и энергопотреблению. Также он отметил, что HPC сталкиваются с некоторыми серьёзными техническими проблемами. Донгарра назвал одной из ключевых проблем разрыв между производительностью чипов и подсистем памяти. «Представьте себе, что у вас есть сверхбыстрый автомобиль, но вы застряли в пробке — мощность бесполезна, если дорога не может с ней справиться», — говорит учёный. Точно так же подсистемы памяти не способны «прокормить» вычислительные блоки, которые простаивают, что отражается на эффективности всей вычислительной системы. 
Источник изображения: OLCF Ещё одна проблема HPC — энергопотребление. Закон масштабирования Деннарда, согласно которому с уменьшением размеров транзистора уменьшается и энергопотребление при росте производительности, прекратил своё действие в 2006 году. Теперь, чем мощнее компьютеры, тем больше они потребляют энергии. Чтобы исправить это, исследователи ищут новые способы проектирования как аппаратного, так и программного обеспечения HPC. Также существует проблема с типами производимых чипов, отметил учёный. Сейчас индустрия чипов в основном сосредоточена на ИИ, который отлично работает с вычислениями с низкой точностью. Однако для многих научных приложений по-прежнему требуется FP64-вычисления. В частности, NVIDIA сделала ставку исключительно на ИИ, поэтому FP64-производительность новейших GB300 почти в 30 раз меньше, чему GB200. У AMD, по слухам, в следующем поколении Instinct будет сразу два варианта ускорителей MI430X с поддержкой FP64 и MI450X, полностью лишённый тензорных ядер с FP64. Но и она может сделать ставку только на ИИ. Если производители прекратят выпускать чипы, которые требуются учёным, это негативно отразится на выполнении важных исследований. Таким образом тенденции в производстве полупроводников и коммерческие приоритеты могут разниться с потребностями научного сообщества, а отсутствие специализированного оборудования может помешать прогрессу в исследованиях. Можно попытаться создавать специализированные чипы для HPC, но это дорого и сложно. Исследователи, тем не менее, изучают возможность применения новых конструкций для изготовления чипов, включая чиплеты, чтобы сделать их более доступными. В прошлом у США было преимущество в области HPC благодаря государственному финансированию, поддержке и открытости разработок, но теперь многие страны вкладывают значительные средства в HPC в стремлении снизить зависимость от иностранных технологий и выйти на лидирующие позиции в таких областях, как моделирование климата и персонализированная медицина. В Европе развивают программу EuroHPC, у Японии есть собственный суперкомпьютер Fugaku (а скоро будет ещё один), а у Китая — целая серия «автохтонных» машин. 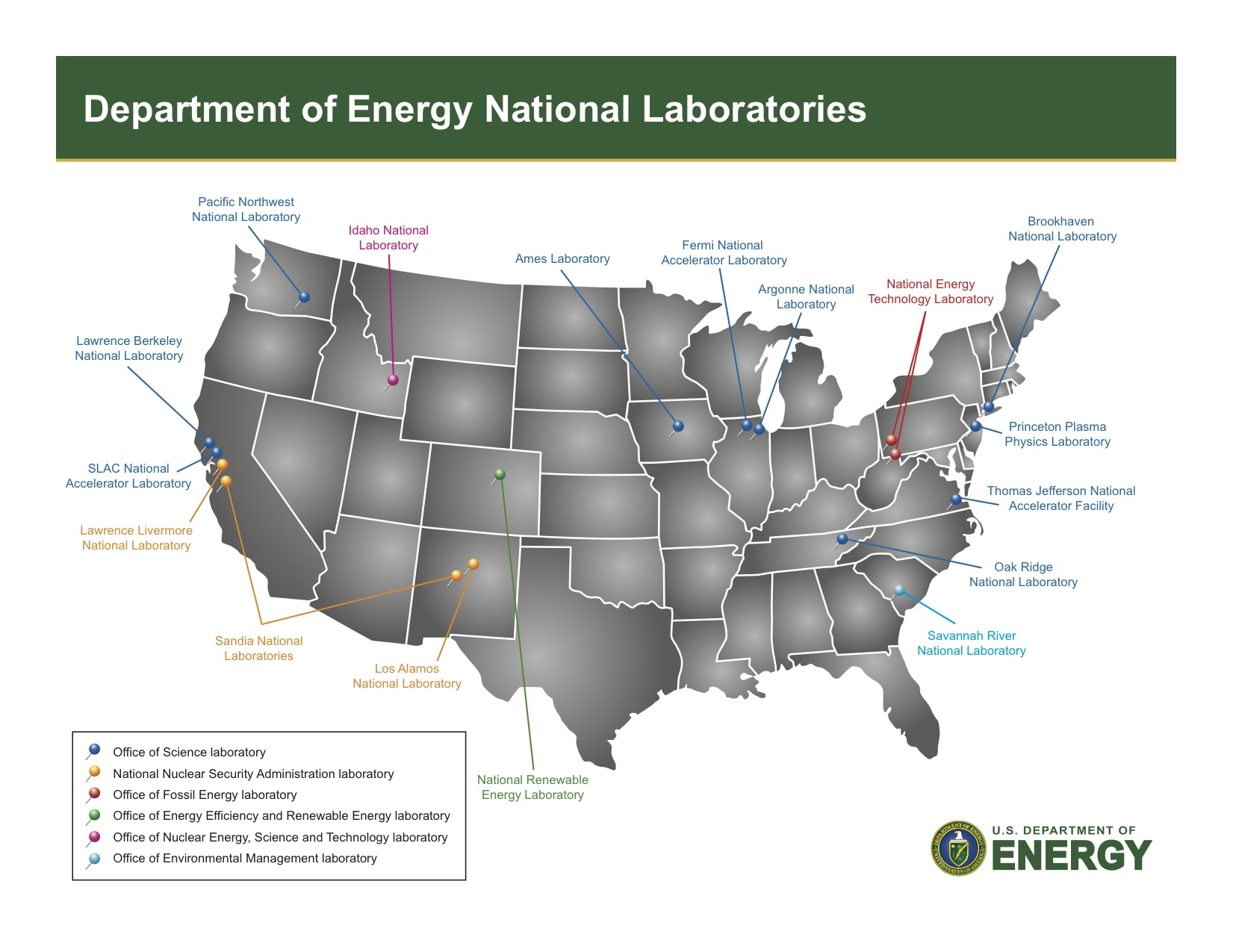
Источник изображения: WIkipedia / DoE Правительства стран понимают, что HPC являются ключом к их национальной безопасности, экономической мощи и научному лидерству, отметил Донгарра, подчеркнув, что у США всё ещё нет чёткого долгосрочного плана на будущее. Другие страны развивают это направление быстро, а без национальной стратегии США рискуют отстать, предупредил он: «Национальная стратегия США должна включать финансирование создания новых машин и обучение людей их использованию. Она также должна включать партнёрство с университетами, национальными лабораториями и частными компаниями. Самое главное, что план должен быть сосредоточен не только на оборудовании, но и на ПО и алгоритмах, которые делают HPC полезными», — заявил учёный. Он отметил, что некоторые шаги в этом направлении уже предприняты, включая принятие в 2022 году «Закона о чипах и науке» (CHIPS and Science Act) и создание управления, которое поможет превратить научные исследования в реальные продукты. В 2025 году также была сформирована целевая группа Vision for American Science and Technology, призванная объединить некоммерческие организации, академические круги и промышленность для помощи правительству в принятии решений. Кроме того, получили развитие квантовые вычисления. Но они пока находятся на ранних стадиях и, скорее всего, будут дополнять, а не заменять традиционные HPC. Поэтому важно продолжать инвестировать в оба вида вычислений. Донгарра назвал это правильными шагами, но они не решат проблему поддержки HPC в долгосрочной перспективе. Помимо краткосрочного финансирования и инвестиций в инфраструктуру, учёный предложил:
Донгарра отметил, что HPC — это больше, чем просто быстрые суперкомпьютеры. Это основа научных открытий, экономического роста и национальной безопасности. Если США примут предложенные меры, то можно гарантировать, что HPC продолжат поддерживать инновации в течение десятилетий.
09.05.2025 [15:10], Сергей Карасёв
Cisco создала чип для генерации запутанных фотонов, который станет основной масштабируемых сетей квантовых компьютеровКомпания Cisco объявила о создании прототипа специализированного сетевого квантового чипа для генерации запутанных фотонов. Изделие даёт возможность масштабировать квантовые системы и объединять квантовые процессоры в единую инфраструктуру для решения практических задач. Квантовые компьютеры оперируют т.н. кубитами. С ростом количества кубитов число одновременно обрабатываемых значений стремительно увеличивается, что позволяет квантовым компьютерам решать определённые задачи с высочайшей производительностью, недоступной классическим компьютерам. Кубиты также могут обладать квантовой запутанностью, которая выражается в наличии особой корреляции между ними. Такое состояние невозможно в классических системах. 
Источник изображений: Cisco Проблема заключается в том, что стабилизировать кубиты крайне сложно. Из-за этого, как отмечает Виджой Панди (Vijoy Pandey), старший вице-президент инкубатора перспективных технологий Cisco Outshift, даже самые амбициозные планы по созданию квантовых компьютеров предполагают создание платформ, насчитывающих только несколько тысяч кубитов к 2030 году. Однако для того, чтобы квантовые вычисления стали действительно полезными, их необходимо масштабировать до миллионов кубитов. Решением может стать использование нового чипа «квантовой сетевой запутанности», созданного в сотрудничестве с Калифорнийским университетом в Санта-Барбаре (UCSB).  Изделие генерирует пары запутанных фотонов, которые обеспечивают мгновенную связь независимо от местонахождения посредством квантовой телепортации. Альберт Эйнштейн назвал это явление «жутким действием на расстоянии» (spooky action at a distance). Чип функционирует при комнатной температуре, он выполнен в виде миниатюрной фотонной интегральной схемы. Более того, он работает на стандартных для телеком-операторов длинах волн, т.е. может использовать существующую волоконно-оптическую инфраструктуру. Заявленное энергопотребление составляет менее 1 мВт. Производительность достигает 1 млн пар запутывания высокой точности на выходной канал или до 200 млн пар запутывания в секунду в расчёте на чип. 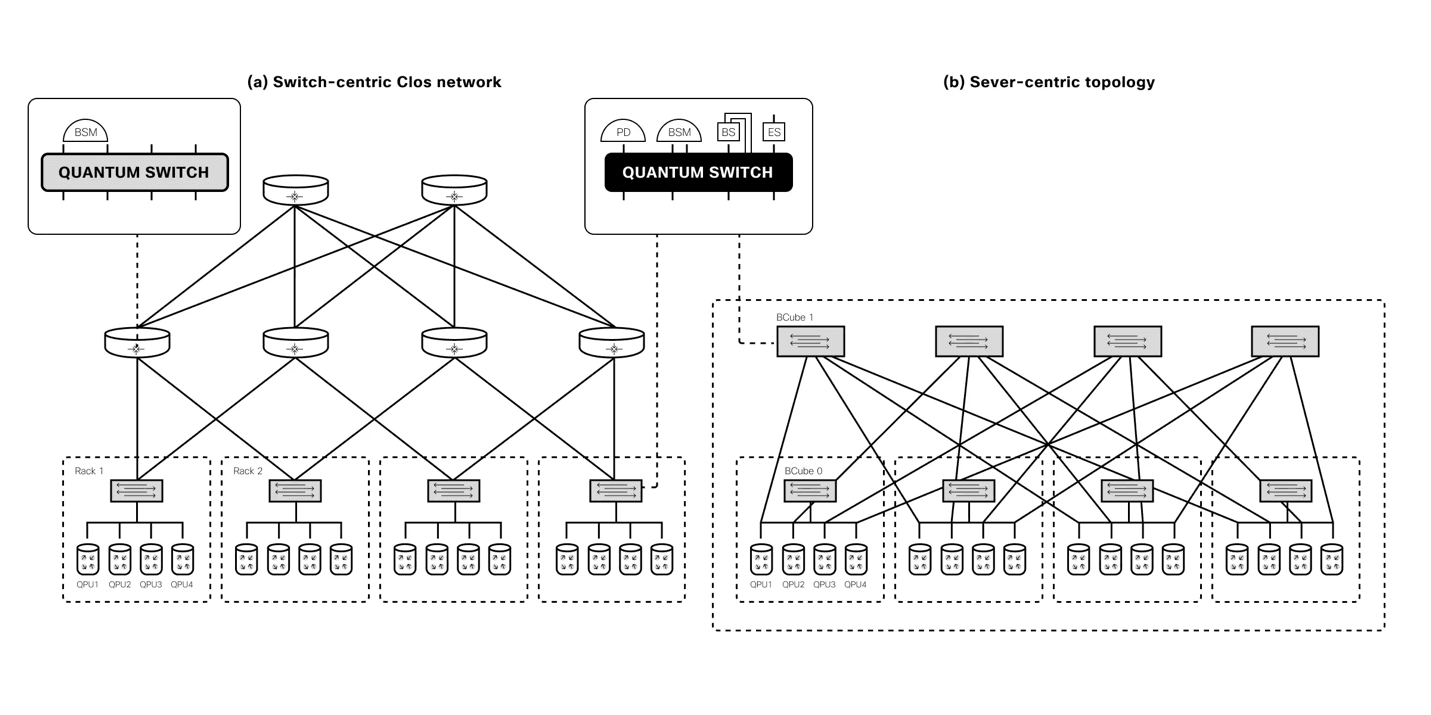 Таким образом, изделие может применяться для объединения множества квантовых компьютеров с небольшим количеством кубитов в единую распределённую систему. Иными словами, становится возможным создание масштабируемых квантовых дата-центров, способных координировать работу большого количества квантовых компьютеров и миллионов их кубитов для решения самых сложных проблем. При реализации такой концепции новый чип будет отвечать за надёжное взаимодействие квантовых систем друг с другом, где бы они ни находились. 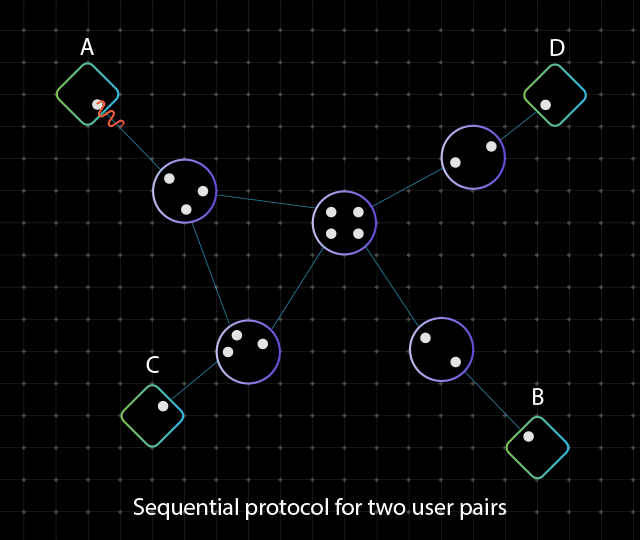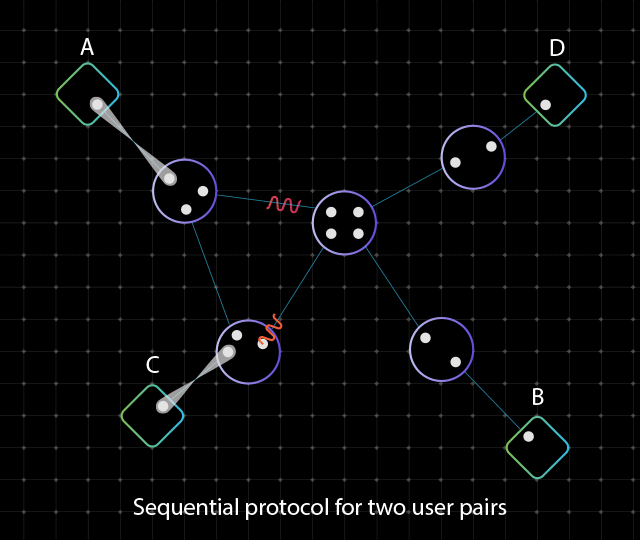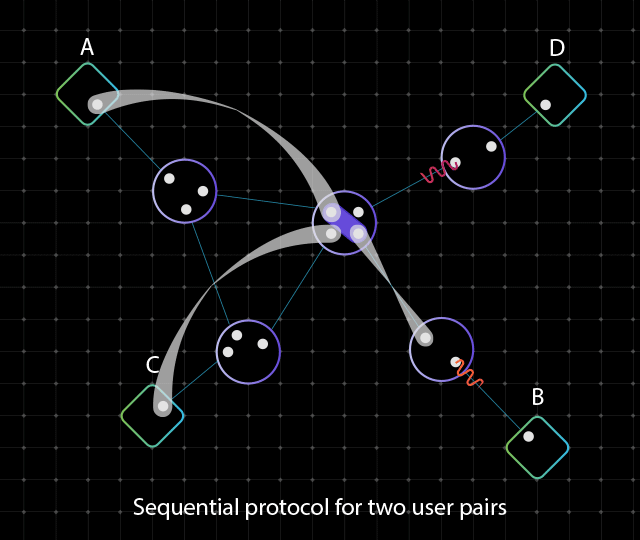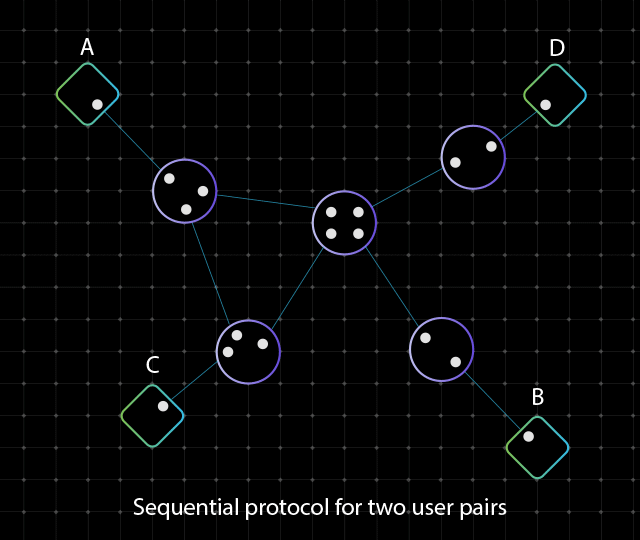 Разработка является частью комплексных усилий Cisco по формированию будущего квантовых вычислений. В рамках инициативы компания объявила об официальном открытии лаборатории Cisco Quantum Labs в Санта-Монике (Калифорния, США), специалисты которой займутся дальнейшей разработкой технологий квантовых сетей. Cisco ведёт исследования по двум основным направлениям: это квантовая сеть для квантовых систем и квантовая сеть для классических систем. В первом случае разрабатывается инфраструктура для объединения квантовых процессоров в единую масштабируемую систему, что позволит реализовать распределённые квантовые вычисления, квантовое зондирование и алгоритмы оптимизации: это даст возможность трансформировать критически важные научные области, такие как создание лекарственных препаратов следующего поколения, материаловедение и пр. В случае классического мира речь идёт об улучшении и расширении функциональности традиционных систем: например, могут обеспечиваться сверхточная синхронизация времени, сверхзащищённая связь и т.п.
28.04.2025 [14:48], Сергей Карасёв
ИИ-суперкомпьютер в чемодане — GigaIO Gryf обеспечит производительность до 30 ТфлопсКомпания GigaIO объявила о доступности системы Gryf — так называемого ИИ-суперкомпьютера в чемодане, разработанного в сотрудничестве с SourceCode. Это сравнительно компактное устройство, как утверждается, обеспечивает производительность ЦОД-класса для периферийных развёртываний. Первая информация о Gryf появилась около года назад. Устройство выполнено в корпусе с габаритами 228,6 × 355,6 × 622,3 мм, а масса составляет примерно 25 кг. Система может эксплуатироваться при температурах от +10 до +32 °C. Конструкция предусматривает использование модулей Sled четырёх типов: это вычислительный узел Compute Sled, блок ускорителя Accelerator Sled, узел хранения Storage Sled и сетевой блок Network Sled. Доступны различные конфигурации, но суммарное количество модулей Sled в составе Gryf не превышает шести. Плюс к этому в любой комплектации устанавливается модуль питания с двумя блоками мощностью 2500 Вт. Узел Compute Sled содержит процессор AMD EPYC 7003 Milan с 16, 32 или 64 ядрами, до 512 Гбайт DDR4, системный SSD формата M.2 (NVMe) вместимостью 512 Гбайт и два порта 100GbE QSFP56. Блок Storage Sled объединяет восемь накопителей NVMe SSD E1.L суммарной вместимостью до 492 Тбайт. Модуль Network Sled предоставляет два порта QSFP28 100GbE и шесть портов SFP28 25GbE. За ИИ-производительность отвечает модуль Accelerator Sled, который может нести на борту ускоритель NVIDIA L40S (48 Гбайт), H100 NVL (94 Гбайт) или H200 NVL (141 Гбайт). В максимальной конфигурации быстродействие в режиме FP64 достигает 30 Тфлопс (3,34 Пфлопс FP8), а пропускная способность памяти — 4,8 Тбайт/с. 
Источник изображения: GigaIO Архитектура новинки обеспечивает возможность масштабирования путём объединения в единый комплекс до пяти экземпляров Gryf: в общей сложности можно совместить до 30 модулей Sled в той или иной конфигурации. Заказы на Gryf уже поступили со стороны Министерства обороны США, американских разведывательных структур и пр.
11.04.2025 [16:08], Руслан Авдеев
Axiom Space планирует развернуть в космосе два узла ЦОД Orbital Data Center к концу 2025 годаAxiom Space, довольно давно сообщившая о планах построить космический дата-центр Orbital Data Center (ODC), поделилась планами на ближайшее будущее. Первые узлы в космосе она намерена построить уже к концу 2025 года, сообщает пресс-служба компании. По данным The Register, стартап также планирует создать собственную космическую станцию и использовать капсулы SpaceX для пилотируемых миссий. Узлы, которые станут частью оптической лазерной сети Kepler Communications, смогут действовать независимо от наземной инфраструктуры и, наряду с другими «умными» спутниками, способны проводить на борту довольно сложные вычисления и хранить данные. Как обещает Axiom, ODC предоставит безопасную и масштабируемую облачную платформу. Космический ЦОД сможет поддерживать задачи, связанные с ИИ и машинным обучением, работая напрямую со спутниками, их группировками и прочими космическими аппаратами на околоземной орбите. По словам представителя Axiom, компания работает над ODC с момента тестирования на МКС модуля AWS Snowcone, предназначенного для сбора, хранения и передачи данных, а также их периферийной обработки. С тех пор компания провела серию демонстраций независимых от Земли облачных решений. В скором будущем на МКС планируют отправить устройство AxDCU-1 на базе решений Red Hat. 
Источник изображения: Kepler В 2023 году Axiom Space анонсировала планы демонстрации высокоскоростной оптической межспутниковой связи (OISL) в первом модуле коммерческой космической станции компании. Впрочем, отправка модулей в космос постоянно откладывается. В конце 2024 года Axiom Space изменила планы порядка сборки космической станции. Теперь первым на орбиту должны вывести Payload Power Thermal Module (AxPPTM), следом — жилой модуль для того, чтобы побыстрее избавиться от зависимости от МКС. Первую серию спутников Kepler для космической оптической связи планируется запустить в IV квартале 2025 года. По данным самой Kepler, Axiom заключила с ней соглашение о размещении полезной нагрузки — своих первых вычислительных модулей — на двух аппаратах Kepler. Узлы ODC будут обеспечены оптической связью со скоростью до 2,5 Гбит/с с группировкой Kepler на низкой околоземной орбите и другими аппаратами, совместимыми со стандартами космической связи SDA Tranche 1. По мнению экспертов, за последние несколько лет развитие оптической связи в космосе получило большой импульс на фоне значительных инвестиций в отрасль коммерческих структур, Пентагона и NASA. В дальнейшем планируется интегрировать в систему оптической связи новые OISL-решения со скоростями передачи данных от 10 Гбит/с, а также использовать оптические модули для связи будущих узлов ODC с Землёй. Это позволит упростить коммуникации между группировками спутников и наземными станциями связи. |
|

