Лента новостей
|
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
09.11.2023 [16:15], Сергей Карасёв
NVIDIA готовит для Китая три новых ускорителя взамен подпавших под санкции: H20, L20 и L2Компания NVIDIA, по сообщению Reuters, планирует выпустить три новых ИИ-ускорителя, модифицированных специально для Китая с учётом дополнительных санкций со стороны США. Изделия фигурируют под обозначениями HGX H20 (SXM), L20 (PCIe) и L2 (PCIe), а их официальная презентация состоится не раньше 16 ноября. Напомним, в середине октября 2023 года США ввели новые ограничения на поставку передовых чипов NVIDIA в Китай: они затронули решения A800 и H800 — модифицированные версии A100 и H100, созданные специально для рынка КНР с учетом ранее действовавших американских ограничений. После этого NVIDIA пришлось искать новые регионы сбыта для «урезанных» ускорителей, предназначавшихся для Поднебесной. Как теперь сообщается, NVIDIA снова нашла возможность поставлять ускорители на китайский рынок, который потенциально может обеспечить значительную выручку. Решения H20, L20 и L2 не подпадают ни под одно из действующих экспортных ограничений. Обратной стороной медали является то, что производительность у них серьёзно снижена (см. характеристики в таблице выше), передаёт SemiAnalysis. 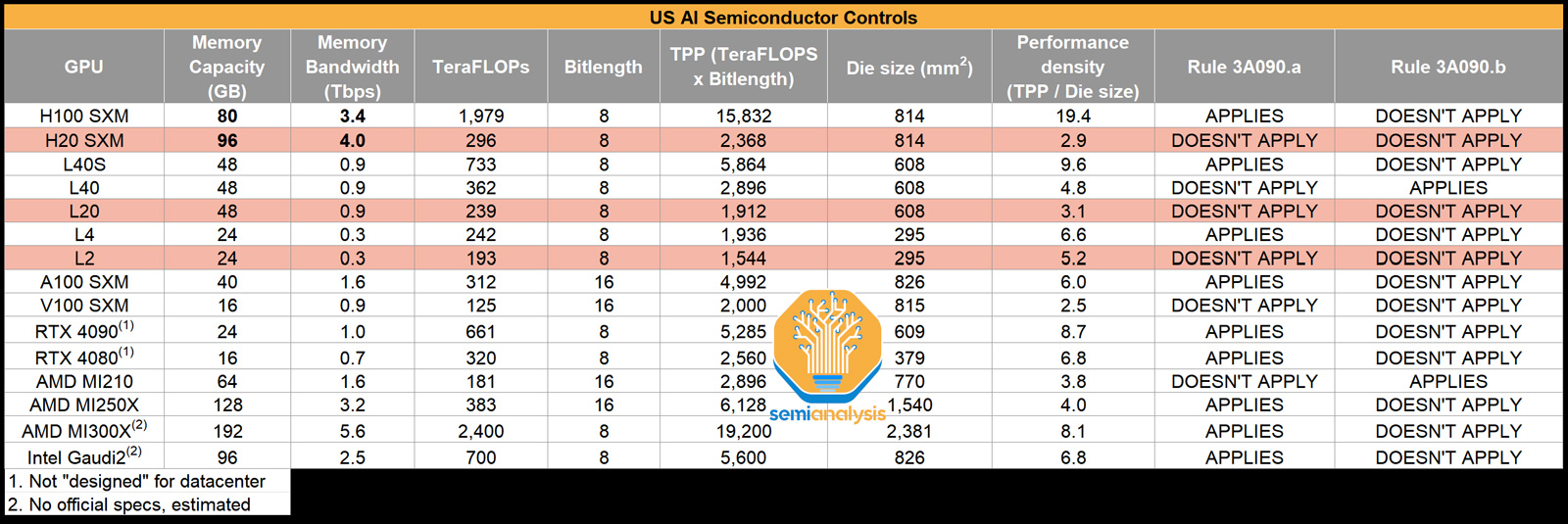
Источник: SemiAnalysis Отмечается, что у NVIDIA уже готовы образцы новых ускорителей для китайского рынка, а их массовое производство будет организовано в течение следующего месяца. Сама компания какие-либо комментарии по поводу обнародованной в интернете информации не даёт.
09.11.2023 [03:15], Алексей Степин
RISC-V с приправой: модульные 192-ядерные серверные процессоры Ventana Veyron V2 можно дополнить ускорителямиВ 2022 года компания Ventana Micro Systems анонсировала первые по-настоящему серверные RISC-V процессоры Veyron V1. Анонс чипов, обещающих потягаться на равных с лучшими x86-процессорами с архитектурой x86, прозвучал громко. Популярности, впрочем, Veyron V1 не снискал, но на днях компания анонсировала второе поколение чипов Veyron V2, более полно воплотившее в себе принципы модульного дизайна и получившее ряд усовершенствований. Как и в первом поколении, компания-разработчик продолжает придерживаться концепции «процессора-конструктора» с чиплетным дизайном. В центре 4-нм Veyron V2 по-прежнему лежит I/O-хаб на базе AMBA CHI, охватывающий контроллеры памяти и шины PCI Express, а также блоки IOMMU и AIA. К нему посредством интерфейса UCIe подключаются вычислительные чиплеты. Латентность UCIe-подключения составляет менее 7 нс. 
Источник изображений здесь и далее: Ventana Micro Systems Чиплеты эти могут быть разных видов: либо с ядрами общего назначения (по 32 ядра на чиплет), образующие собственно процессор Veyron V2, либо содержащие специфические сопроцессоры под конкретную задачу (domain-specific acceleration, DSA). Последние могуть быть представлены FPGA, ИИ-ускорителями и т.д. Более того, Ventana по желанию заказчика может оптимизировать и I/O-хаб для повышения эффективности работы ядер CPU с сопроцессорами. 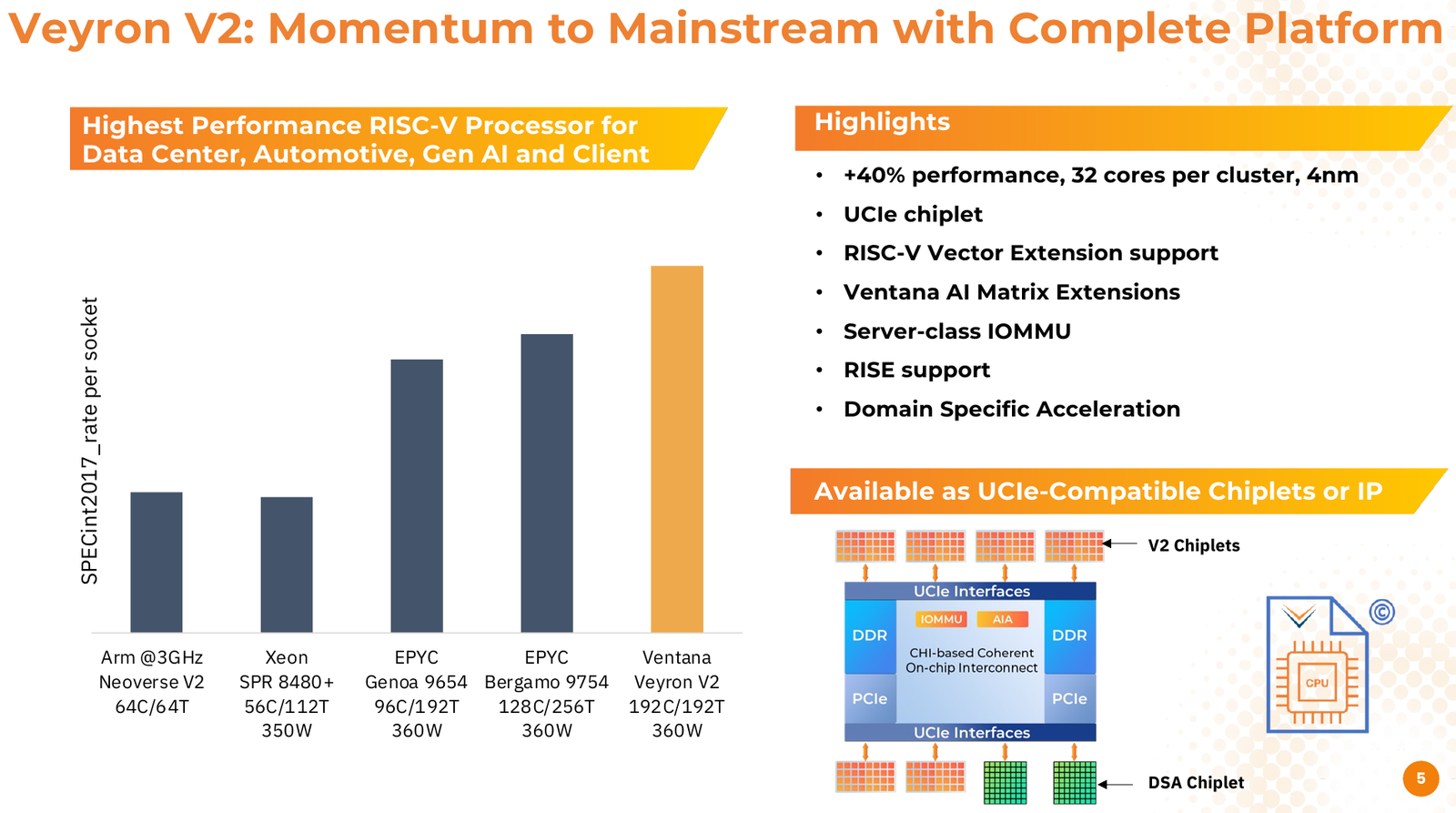 В классическом варианте Veyron V2 может иметь до шести чиплетов с RV64GC-ядрами V2, что в сумме даёт 192 ядра. Поддержка SMT отсутствует. Удельная производительность в пересчёте на ядро получается несколько ниже, чем у AMD Zen 4c, но согласно результатам тестов, предоставленных Ventana, 192-ядерный Veyron V2 заметно опережает AMD EPYC Bergamo 9754 (128C/256T) при аналогичном теплопакете в 360 Вт. 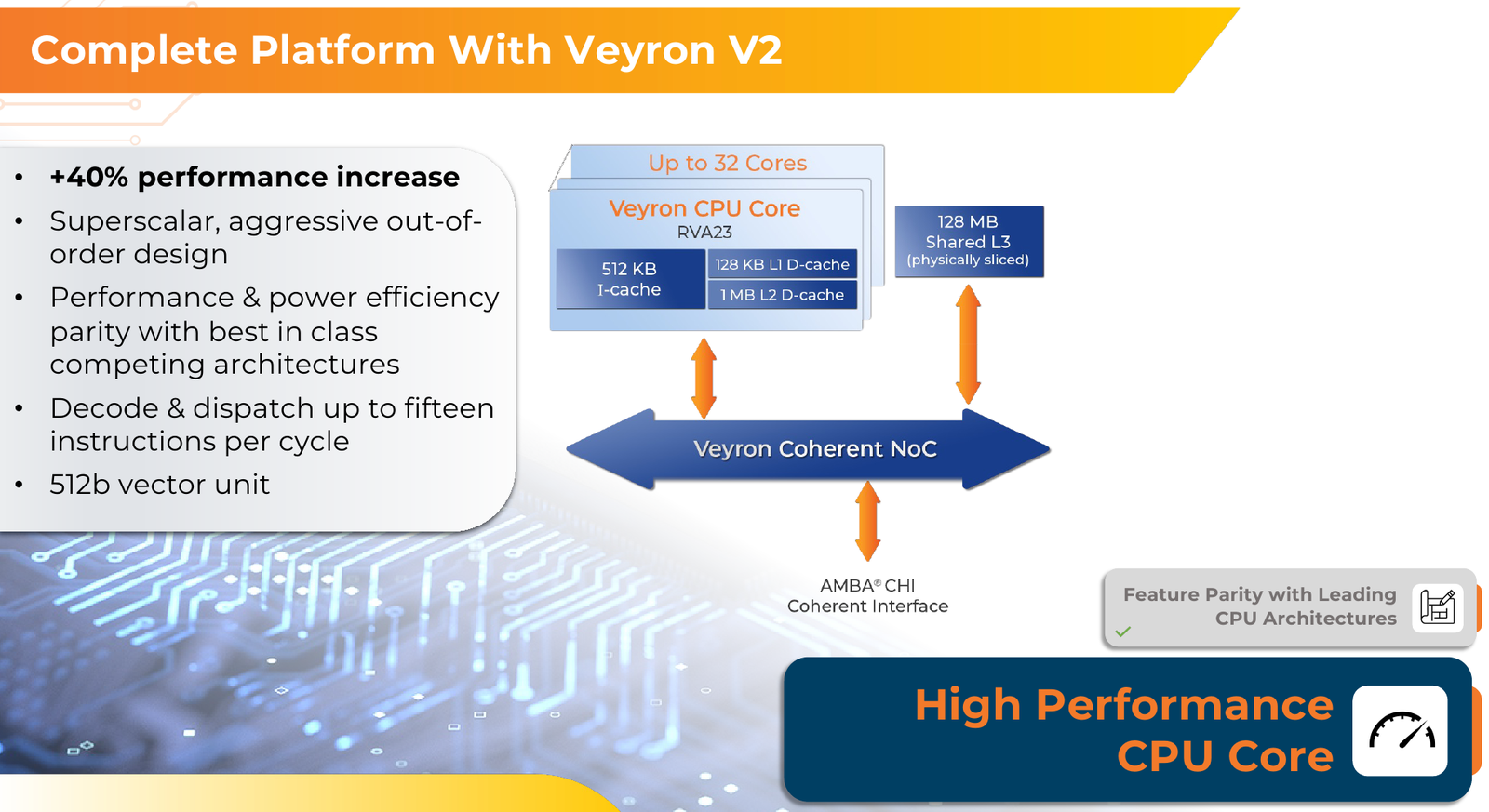 Столь неплохой результат достигнут за счёт оптимизации архитектуры Veyron: по сравнению с первым поколением говорится о 40 % прибавке производительности. Что немаловажно, во втором поколении процессоров Veyron была реализована поддержка 512-бит векторных расширений, фирменных матричных расширений, а также целого ряда других спецификаций. В целом ради совместимости разработчики предпочли остаться в рамках общего профиля RVA23. 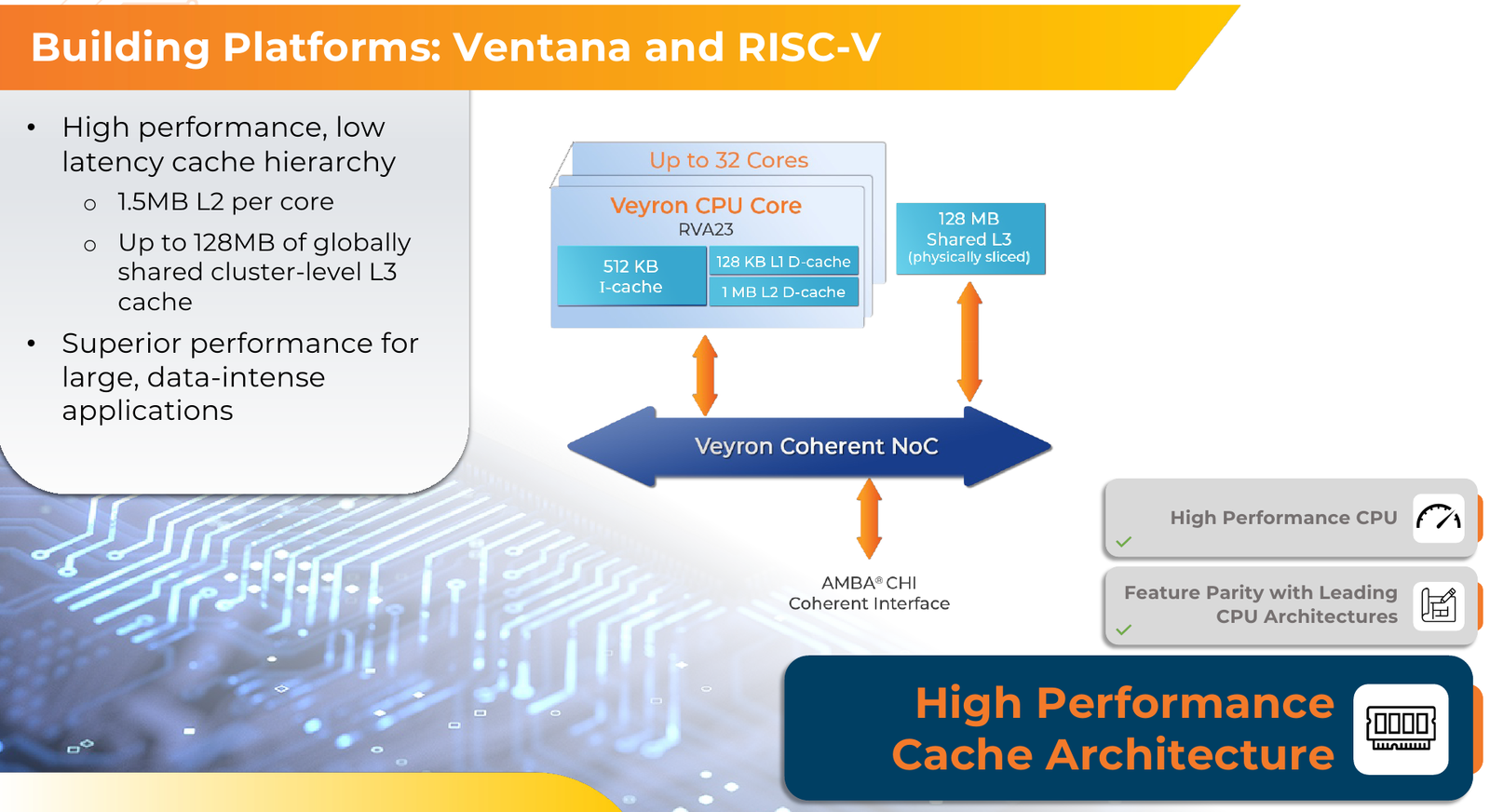 Сами ядра V2 используют суперскалярный дизайн с агрессивным внеочередным исполнением и продвинутым предсказанием ветвлений. Возможно декодирование и обработка до 15 инструкций за такт. Объём L1-кешей составляет 512 Кбайт для инструкций и 128 Кбайт для данных, дополнительно каждое ядро имеет свой кеш L2 объёмом 1 Мбайт. Общий для всего 32-ядерного чиплета L3-кеш имеет объём 128 Мбайт. Производительность внутренней когерентной шины составляет до 5 Тбайт/с.  Позиционируемый в качестве решения для гиперскейлеров, крупных ЦОД и HPC, Veyron V2 имеет развитые средства предотвращения ошибок и защиты данных, от ECC-кешей и поддержки Secure Boot до аутентификации на уровне чиплета и продвинутых RAS-функций. Кроме того, реализована защита от атак по сторонним каналам.  Несмотря на то, что мир RISC-V пока ещё похож на «Дикий Запад», Ventana старается опираться на развитые и популярные стандарты: в частности, это выражается в применении UCIe для подключения чиплетов, поддержку гипервизоров первого и второго типа, вложенную виртуализацию и совместимость с программной экосистемой RISC-V RISE.  Подход Ventana позволит избежать недостатков, свойственных дискретным PCIe-ускорителям (высокая латентность, энергопотребление и стоимость) и сложным монолитным SoC (очень высокая стоимость разработки и сроки), снизить время и стоимость стоимость новых решений, а также обеспечить более низкий уровень энергопотребления. В общем, компания явно целится в гиперскейлеров. 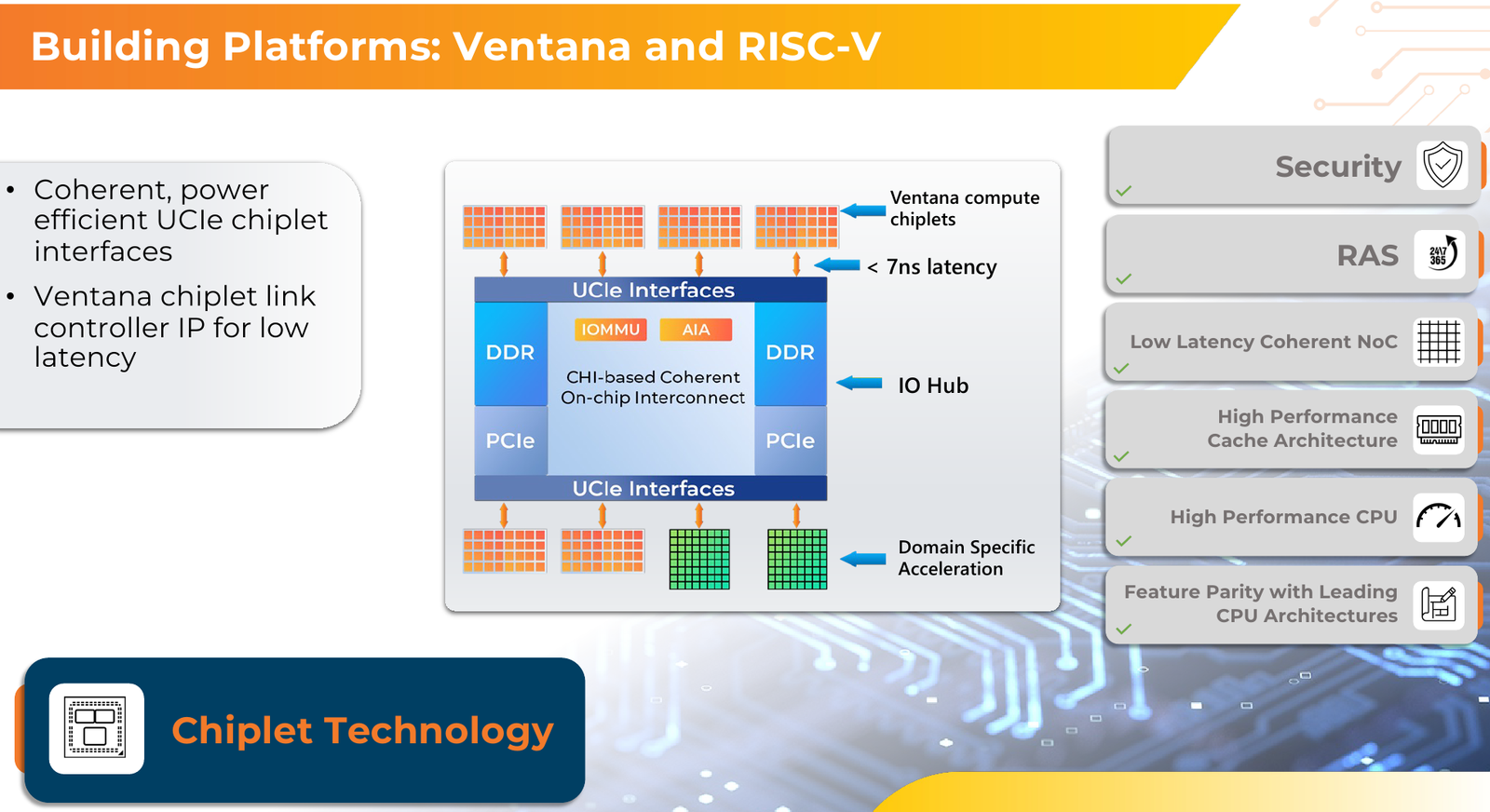 Видение сценариев применения DSA у Ventana очень широкий — от БД-ускорителей и блоков компрессии-декомпрессии данных до поддержки специфических алгоритмов в задачах аналитики и транскодеров в системах доставки контента. Также становятся ненужными дискретные DPU. Первым партнёром Ventana стала Imagination Technologies, крупный разработчик GPU. 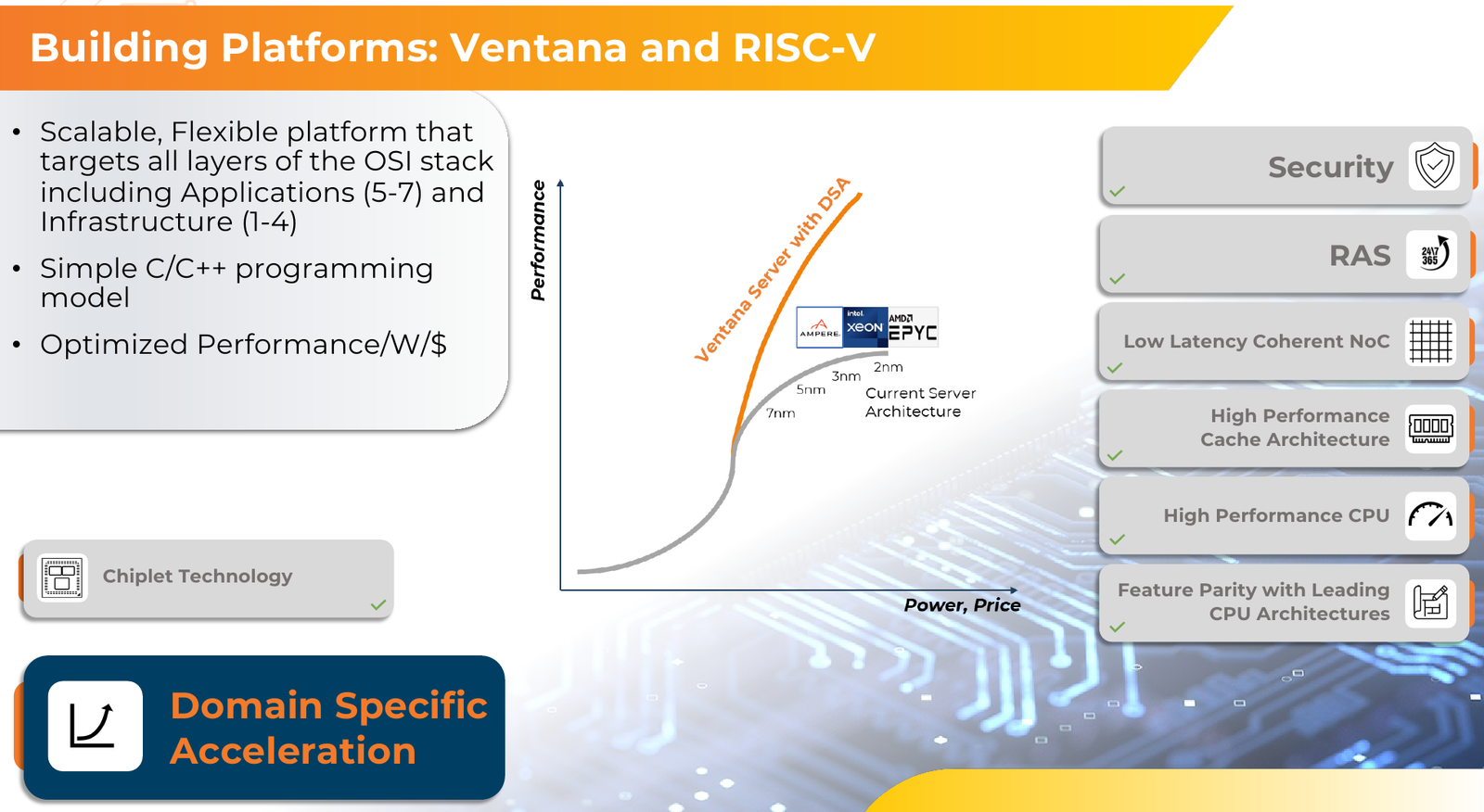 В качестве вариантов физической реализации новой платформы Ventana предлагает компактный 1U-сервер, содержащий один чип Veyron V2 со 192 ядрами, работающими на частотах до 3,6 ГГц, и 12 каналами DDR5-5600. Вероятнее всего, производителем новой платформы станет GIGABYTE. Ожидать первых поставок следует не ранее II квартала 2024 года. 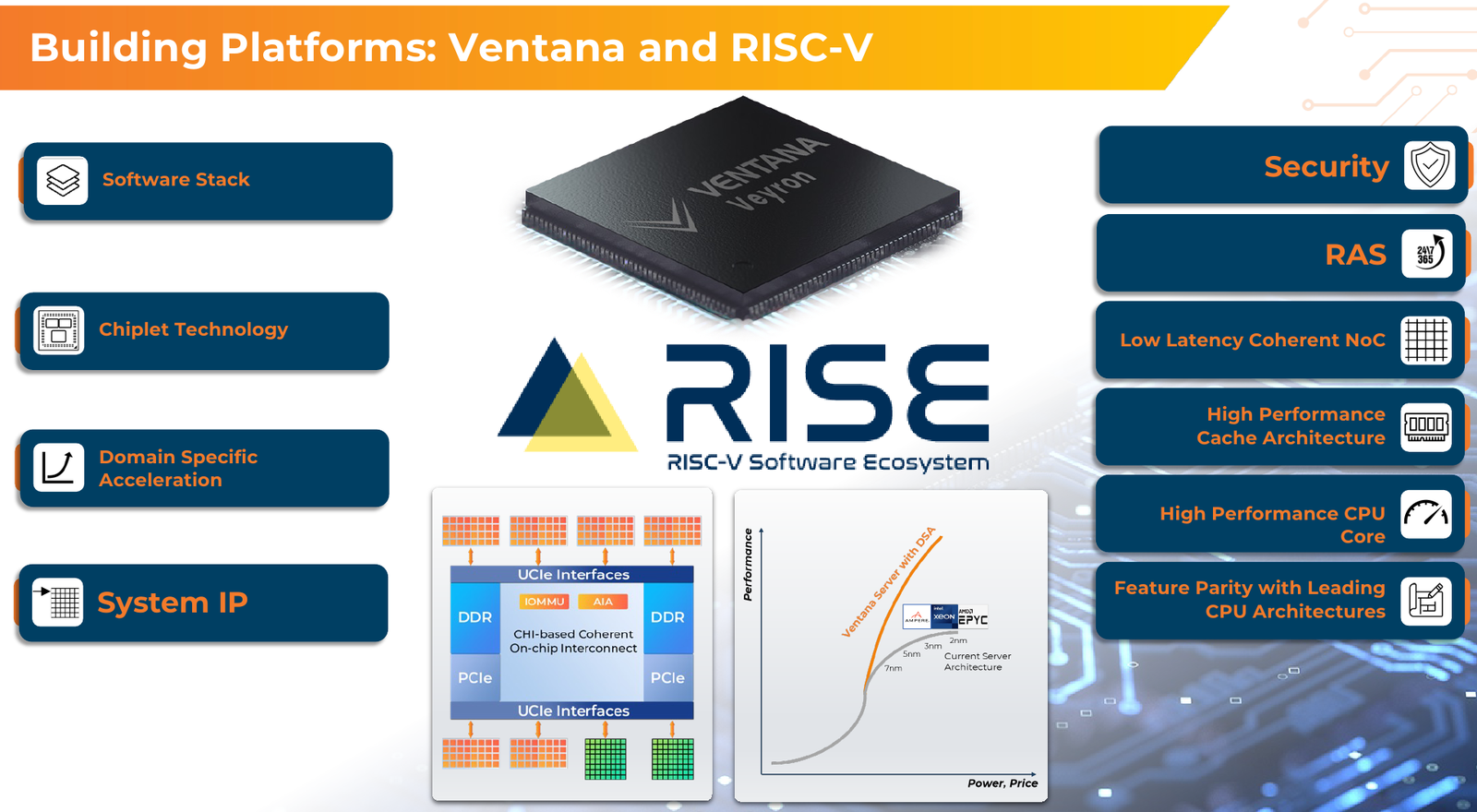 В целом, видение высокопроизводительной модульной платформы, продвигаемое Ventana, выглядит перспективно, а упор на применение DSA может выгодно отличать её большинства Arm-серверов, конкурирующих с решениями Intel/AMD лоб в лоб. Вопрос лишь в поддержке со стороны разработчиков программного обеспечения — и здесь может сыграть ставка разработчиков на максимально открытые, широкие стандарты.
01.11.2023 [22:53], Владимир Мироненко
Intel продала производство оптических трансиверов компании JabilАмериканская компания Jabil Inc., занимающаяся контрактным проектированием и производством электроники, объявила о покупке у Intel подразделения по производству оптических трансиверов на основе кремниевой фотоники. Для Jabil эта сделка означает расширение присутствия на рынке комплектующих для ЦОД, а для Intel это очередной шаг по оптимизации портфолио путём избавления от непрофильных направлений. Jabil продолжит выпуск нынешних серий подключаемых оптических трансиверов Intel, а также будет заниматься разработкой трансиверов следующих поколений. Сумма сделки не раскрывается. По словам Мэтта Кроули (Matt Crowley), старшего вице-президента по облачной и корпоративной инфраструктуре Jabil, сделка позволит компании «расширить своё присутствие в цепочке создания стоимости ЦОД». Он добавил, что новое производство поможет Jabil лучше удовлетворять потребности клиентов, включая гиперскейлеров, облака следующего поколения и ЦОД для ИИ. Jabil планирует поставлять компаниям улучшенные оптические сетевые решения, предлагая полные возможности фотоники, включая проектирование компонентов, сборку систем и оптимизированное управление цепочкой поставок. 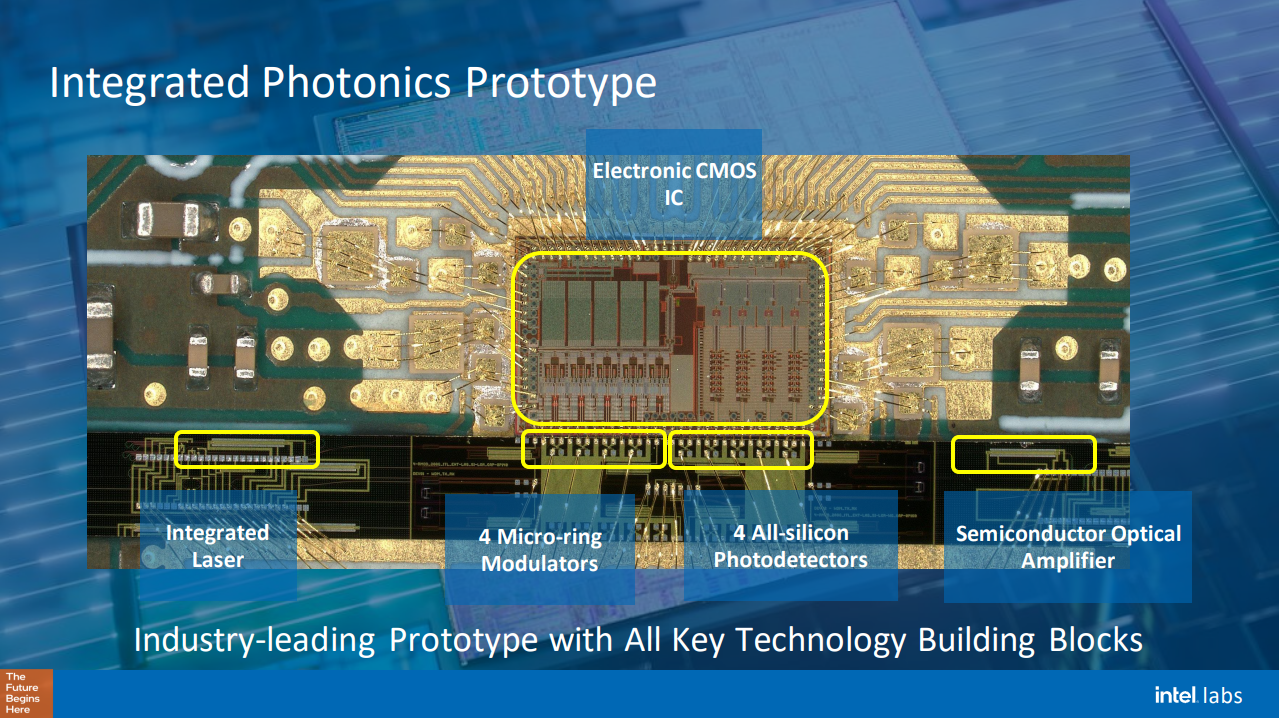
Изображение: Intel «Мы рассчитываем на тесное сотрудничество с Jabil, нашими клиентами и поставщиками, чтобы обеспечить плавный переход, поскольку Intel переключает свое внимание на компоненты кремниевой фотоники для существующих рынков и новых приложений», — заявил Сафроаду Йебоа-Аманква (Safroadu Yeboah-Amankwah), старший вице-президент и директор по стратегии Intel. Под руководством Пэта Гелсингера (Pat Gelsinger) Intel последовательно проводит реструктуризацию. Компания уже продала, закрыла или отделила следующие направления бизнеса: Optane и NAND, производство серверов и NUC, коммутаторы и Pathfinder for RISC-V, IMS Nanofabrication и PSG (FPGA Altera), а также ASIC для майнинга. Стоит отметить, что в области кремниевой фотоники Intel была одним из пионеров и лидером в некоторых сегментах.
26.10.2023 [17:00], Руслан Авдеев
Подводные интернет-кабели Google Honomoana и Tabua свяжут территории тихоокеанского бассейна от Австралии до СШАGoogle анонсировала проект South Pacific Connect, в рамках которого компания проложит два транстихоокеанских подводных кабеля — Honomoana и Tabua. Как сообщается в блоге компании, это поможет повысить надёжность и устойчивость связи в регионе. В проекте примут участие Fiji International Telecommunications, Управление почт и телекоммуникаций Французской Полинезии, а также APTelecom, Vocus Group, местные власти и другие компании. Прокладка кабелей позволит связать новыми каналами не только Австралию и США, но также Фиджи и Французскую Полинезию, с дополнительными ответвлениями на другие островные объекты. Фактически в Тихоокеанском регионе создаётся целая сеть, имеющая ответвления для подключения других стран и территорий Океании — это один из первых проектов такого рода в регионе, часто страдающем от природных катаклизмов. Honomoana станет информационной магистралью для Австралии и США со станцией во Французской Полинезии. Tabua свяжет Австралию, США и Фиджи. Кроме того, будут созданы посадочные станции для прямой связи Фиджи и Французской Полинезии. Комплекс принятых мер повысит надёжность и ёмкость каналов, а также снизит время задержки сигнала. Ожидается, что прокладка новых кабельных маршрутов окажет благоприятное влияние на качество связи не только в регионе, но и в мире. 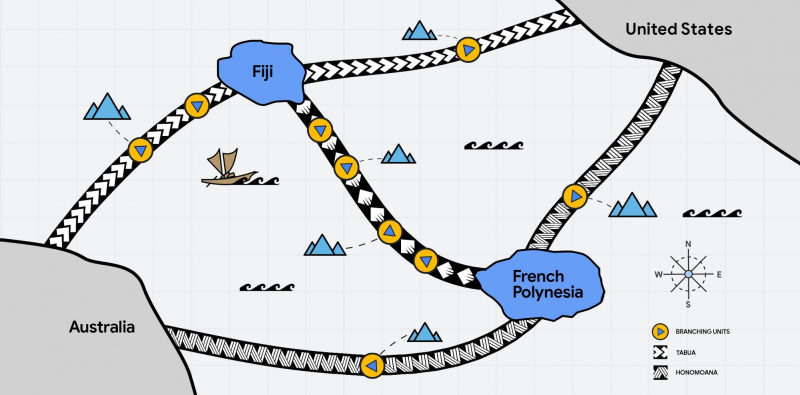
Источник изображения: Google Также сообщается, что система кабелей предусматривает создание трёх посадочных станций в Австралии, что также укрепит связи континента с миром и Соединёнными Штатами в частности. Google намерена развивать кабельные сети и в Атлантике. В конце сентября компания анонсировала прокладку кабеля Nuvem, который свяжет Соединённые Штаты, Бермуды и Португалию, а в 2022 году запустила кабельную систему Grace Hopper.
25.10.2023 [11:49], Сергей Карасёв
Экзафлопсный суперкомпьютер Frontier назван лучшим изобретением 2023 года по версии TimeЕжегодно американский журнал Time публикует список из лучших изобретений человечества в самых разных сферах. В нынешнем году в рейтинг вошли 200 продуктов и технологий, которые сгруппированы более чем в 35 категорий. Это, в частности, ПО, связь, виртуальная и дополненная реальность, ИИ, потребительская электроника, чистая энергии, здравоохранение, безопасность, робототехника и многое другое. Одним из направлений являются экспериментальные системы и устройства. В данной категории победителем назван вычислительный комплекс Frontier — самый мощный суперкомпьютер 2023 года. Исследователи уже используют его для самых разных целей: от изучения чёрных дыр до моделирования климата. «Специалисты сравнивают это с эквивалентом высадки на Луну с точки зрения инженерных достижений. Это больше, чем чудо. Это статистическая невозможность», — сказал Ник Дюбе (Nic Dubé), руководитель проекта в HPE. 
Источник изображения: ORNL Система Frontier, созданная специалистами HPE, установлена в Национальной лаборатории Окриджа (ORNL) Министерства энергетики США. Она занимает первое место в рейтинге TOP500 с производительностью 1,194 Эфлопс. В составе системы применяются процессоры AMD EPYC Milan, ускорители Instinct MI250X и интерконнект Cray Slingshot. В общей сложности задействованы 8 699 904 вычислительных ядра. Теоретическое пиковое быстродействие достигает 1,680 Эфлопс.
23.10.2023 [20:57], Алексей Степин
Новый нейроморфный ИИ-процессор IBM NorthPole на порядок превосходит современные GPUПо большей части современные нейросетевые технологии используют ускорители на базе GPU или родственных архитектур как для обучения, так и для инференса. Впрочем, разработчики альтернативных решений не дремлют. В число последних входит компания IBM, недавно сообщившая об успешном завершении испытаний нового нейроморфного процессора NorthPole. Разработкой чипов, в том или ином виде пытающихся имитировать работу живого мозга, компания занимается давно — чипы IBM TrueNorth второго поколения увидели свет более пяти лет назад. Уже тогда разработчики отошли от традиционных архитектур, отказавшись от понятия памяти как внешнего устройства. 
Источник изображений здесь и далее: IBM Research В итоге TrueNorth получил 400 Мбит (~50 Мбайт) сверхбыстрой интегрированной памяти SRAM (~100 Кбайт на ядро, всего 4096 ядер) и мог эмулировать 1 млн нейронов с 256 млн межнейронных связей. Чип моделировал бинарные нейроны, а вес каждого синапса был закодирован двумя битами. 
FPGA (слева) используется только в качестве PCIe-моста Новый 12-нм нейрочип NorthPole устроен несколько иначе: он состоит из 256 ядер, которые, впрочем, всё так же используют внутреннюю память общим объёмом 192 Мбайт. Дополнительно имеется буфер объёмом 32 Мбайт для IO-тензоров. Каждое из ядер NorthPole за такт способно выполнять 2048 операций с 8-бит точностью вычислений. В режимах 4- и 2-бит точности производительность растёт соответствующим образом. По словам IBM, новый NPU превосходит предшественника в 4000 раз и на частоте 400 МГц мог бы развивать производительность в районе 840 Топс. Из-за довольно ограниченного объёма памяти NorthPole не подходит для запуска сложных нейросетей вроде GPT-4, но его главное назначение не в этом — чип позиционируется в качестве основы систем машинного зрения, в том числе в системах автопилотов, хирургических роботов и т.п. И в этом качестве новинка, состоящая из 22 млрд транзисторов и имеющая площадь кристалла 800 мм2, проявляет себя очень хорошо. 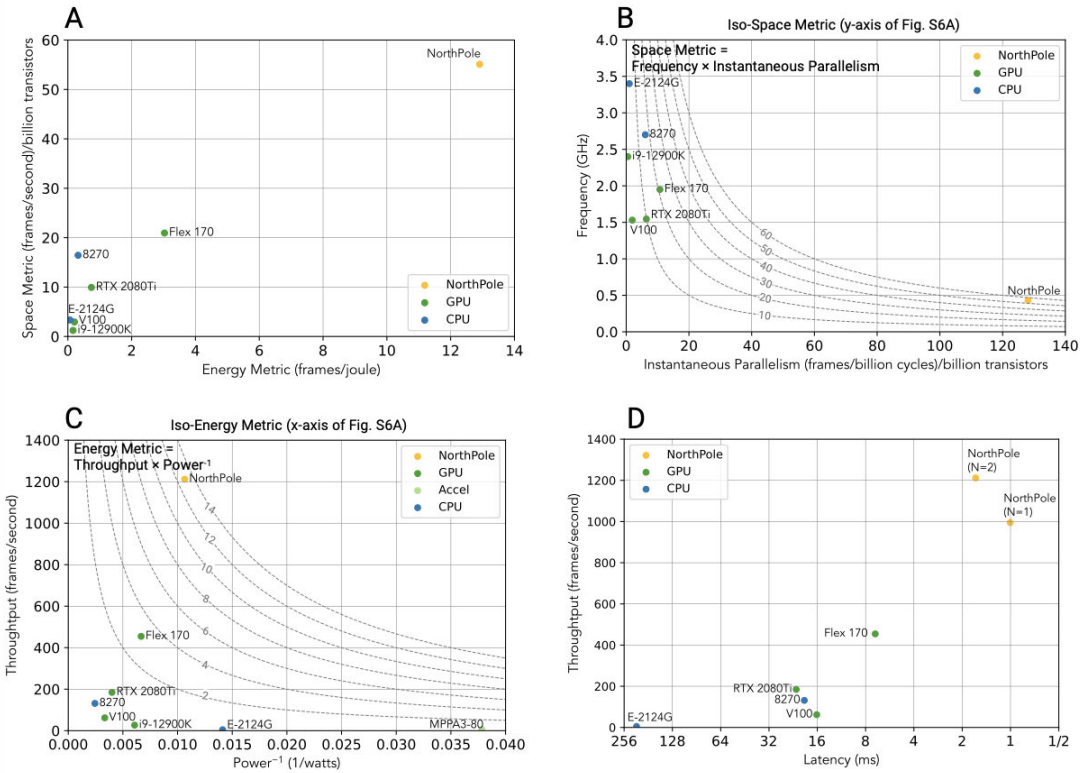
Результаты тестов на эффективность архитектуры NorthPole Так, в тестах ResNet-50 NorthPole в 25 раз превзошёл по энергоэффективности сопоставимые по техпроцессу GPU, а показатели латентности при этом оказались в 22 раза лучше. В пересчёте на транзисторную сложность IBM говорит о превосходстве даже над новейшими 4-нм решениями NVIDIA. Полные результаты тестирования доступны на science.org. К сожалению, речь всё ещё идёт об экспериментальном прототипе с довольно грубым по современным меркам 12-нм техпроцессом. По словам исследователей, производительность NorthPole благодаря более совершенным техпроцессам удалось поднять бы ещё в 25 раз. Параллельно IBM ведёт разработки в области ИИ-чипов с элементами аналоговой логики. Достигнутые в рамках 14-нм техпроцесса результаты позволяют говорить об удельной производительности в районе 10,5 Топс/Вт или 1,59 Топс/мм2.
23.10.2023 [16:30], Сергей Карасёв
Cloudflare избавляется от BMC на серверных материнских платахАмериканская компания Cloudflare, предоставляющая услуги CDN, по сообщению ресурса The Register, приняла решение отказаться от интегрированных BMC-контроллеров на серверных материнских платах. Предполагается, что это в числе прочего снизит затраты на развёртывание масштабных платформ для дата-центров. BMC, или Baseboard Management Controller, контролирует работу платформы и выполняет ряд важных функций, таких как управление питанием, мониторинг датчиков, возможность удаленного обновления прошивки, регистрация событий, формирование отчетов об ошибках и т.д. 
Источник изображения: The Register Современные серверные материнские платы с поддержкой DDR5 и PCIe 5.0 насчитывают 14 или более слоёв. Вместе с тем для BMC достаточно от восьми до десяти слоёв. Поэтому целесообразно отделить модуль BMC от основной материнской платы, выполнив его в виде отдельного узла OCP DC-SCM (DataCenter-ready Secure Control Module). Модули DC-SCM можно использовать повторно, что снижает стоимость серверов и сокращает объём «электронного мусора» при обновлении оборудования для ЦОД. Поскольку DC-SCM является отдельным компонентом, к серверу можно добавлять новые модули с целью апгрейда функций без необходимости замены материнской платы. Cloudflare предлагает собственную версию DC-SCM под названием Project Argus в рамках Open Compute Project (OCP). В основу положен контроллер Aspeed AST2600. При использовании совместимой прошивки OpenBMC обеспечивается богатый набор функций, необходимых для удалённого управления сервером. Project Argus уже используется в 12-м поколении серверов CloudFlare, а производственным партнёром компании выступает Lenovo.
21.10.2023 [16:09], Сергей Карасёв
В Аргоннской национальной лаборатории запущена ИИ-система GroqАргоннская национальная лаборатория Министерства энергетики США сообщила о запуске вычислительного кластера, использующего специализированные ИИ-решения Groq. Ресурсы системы предоставляются исследователям на базе тестовой площадки ALCF (Argonne Leadership Computing Facility). Groq является разработчиком чипов GroqChip, спроектированных с прицелом на решение задач ИИ и машинного обучения. Эти изделия, наделённые 230 Мбайт памяти SRAM, обеспечивают производительность до 750 TOPS INT8 и до 188 Тфлопс FP16. 
Источник изображения: Аргоннская национальная лаборатория Процессоры GroqChip являются основой ускорителей GroqCard с интерфейсом PCIe 4.0 x16. Восемь таких карт входят в состав сервера GroqNode формата 4U. Наконец, до восьми серверов GroqNode используются в кластерах GroqRack. И именно такие узлы являются основой новой ИИ-платформы ALCF. Заявленная производительность каждого узла достигает 48 POPS (INT8) или 12 Пфлопс (FP16). Экосистема программного и аппаратного обеспечения Groq предназначена для ускорения решения сложных ИИ-задач, в частности, инференса. Исследователи будут применять НРС-платформу при реализации ресурсоёмких научных проектов в таких областях, как визуализация, термоядерная энергия, материаловедение, создание лекарственных препаратов нового поколения и пр. Отмечается, что уникальная архитектура Groq и универсальный компилятор обеспечат повышенную производительность для широкого спектра ИИ-моделей. В рамках сотрудничества Аргоннская национальная лаборатория и Groq работают над лекарствами от коронавируса, спровоцировавшего пандемию COVID-19: говорится, что время получения результатов сократилось с дней до минут. Создавая модели вируса и помогая исследователям быстро сравнивать их с базой данных, содержащей миллиарды молекул препаратов, модели ИИ позволяют идентифицировать перспективные соединения, которые будут использоваться в клинических терапевтических испытаниях.
21.10.2023 [01:01], Алексей Степин
Собери сам: Arm открывает эру кастомных серверных процессоров инициативой Total DesignСегодня на наших глазах в мире процессоростроения происходит серьёзная смена парадигм: от унифицированных архитектур общего назначения и монолитных решений разработчики уходят в сторону модульности и активного использования специфических аппаратных ускорителей. Разумеется Arm не осталась в стороне — на мероприятии 2023 OCP Global Summit компания рассказала о новой инициативе Arm Total Design. Эта инициатива должна помочь как создателям новых процессоров за счёт ускорения процесса разработки и снижения его стоимости, так и владельцам крупных вычислительных инфраструктур. Последние всё больше склоняются к специализации и дифференциации в процессорных архитектурах новых поколений, но ожидают также энергоэффективности, дружественности к экологии и как можно более низкой совокупной стоимости владения. 
Источник изображений здесь и далее: Arm В основе инициативы Arm лежит анонсированная ещё в августе на HotChips 2023 процессорная платформа Arm Neoverse Compute Subsystem (CSS). Neoverse CSS N2 (Genesis) представляет собой готовый набор IP-решений Arm, включающий в себя процессорные ядра, внутреннюю систему интерконнекта, подсистемы памяти, ввода-вывода, управлениям питанием, но оставляющий место для интеграции партнёрских разработок — различных движков, ускорителей и т.п. 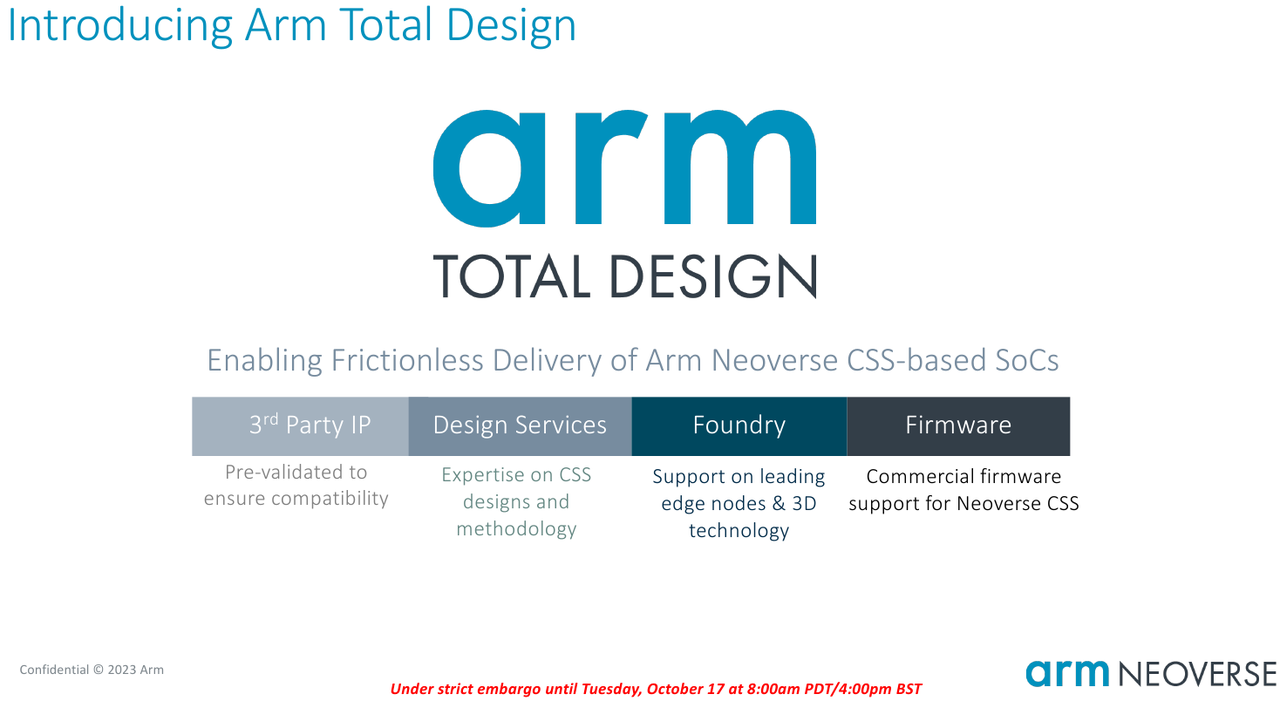 По сути, речь идёт о почти готовых процессорах, не требующих длительной разработки процессорной части с нуля и всех связанных с этим процессом действий — верификации, тестирования на FPGA, валидации дизайна и многого другого. По словам Arm такой подход позволяет сэкономить разработчикам до 80 человеко-лет труда инженеров. 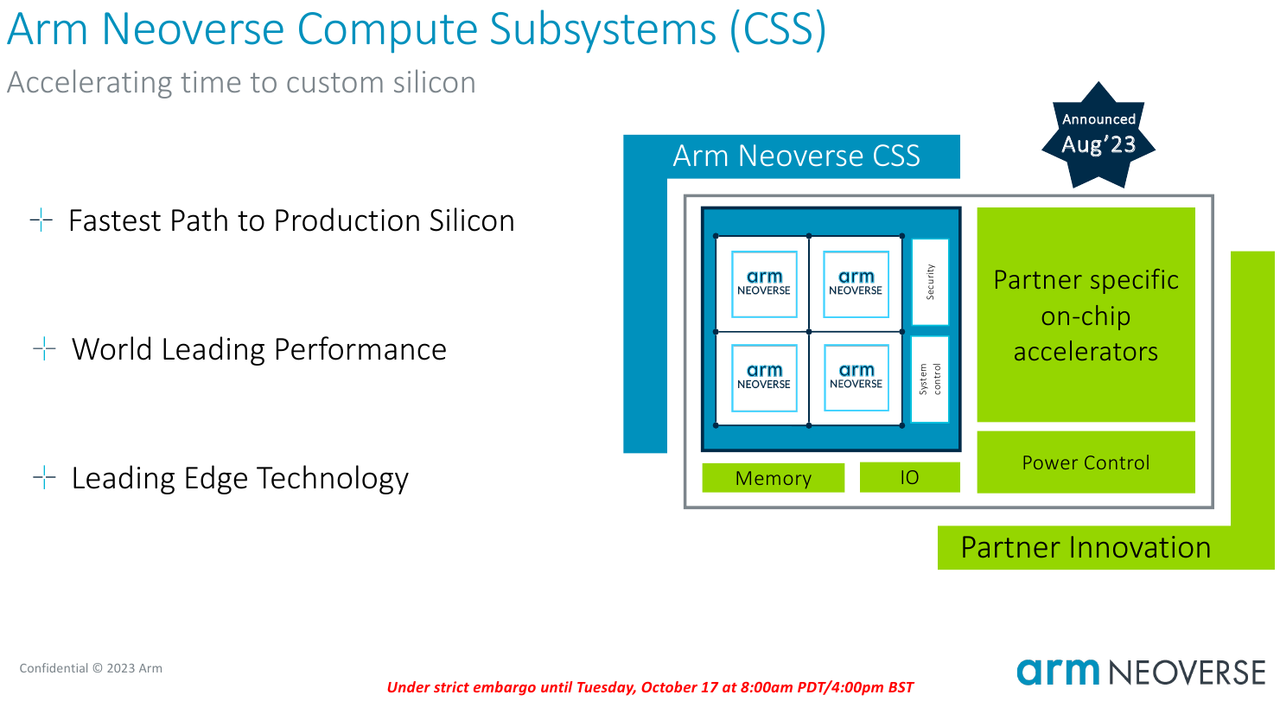 Дизайн Neoverse CSS N2 довольно гибок: финальный процессор может включать в себя от 24 до 64 ядер Arm, работающих в частотном диапазоне 2,1–3,6 ГГц. Предусмотрено по 64 Кбайт кеша инструкций и данных, а вот объёмы кешей L2 и L3 настраиваются и могут достигать 1 и 64 Мбайт соответственно. Ядра реализуют набор инструкций Arm v9 и содержат по два 128-битных векторных блока SVE2. Имеется поддержка инструкций, характерных для ИИ-задач и криптографиии. 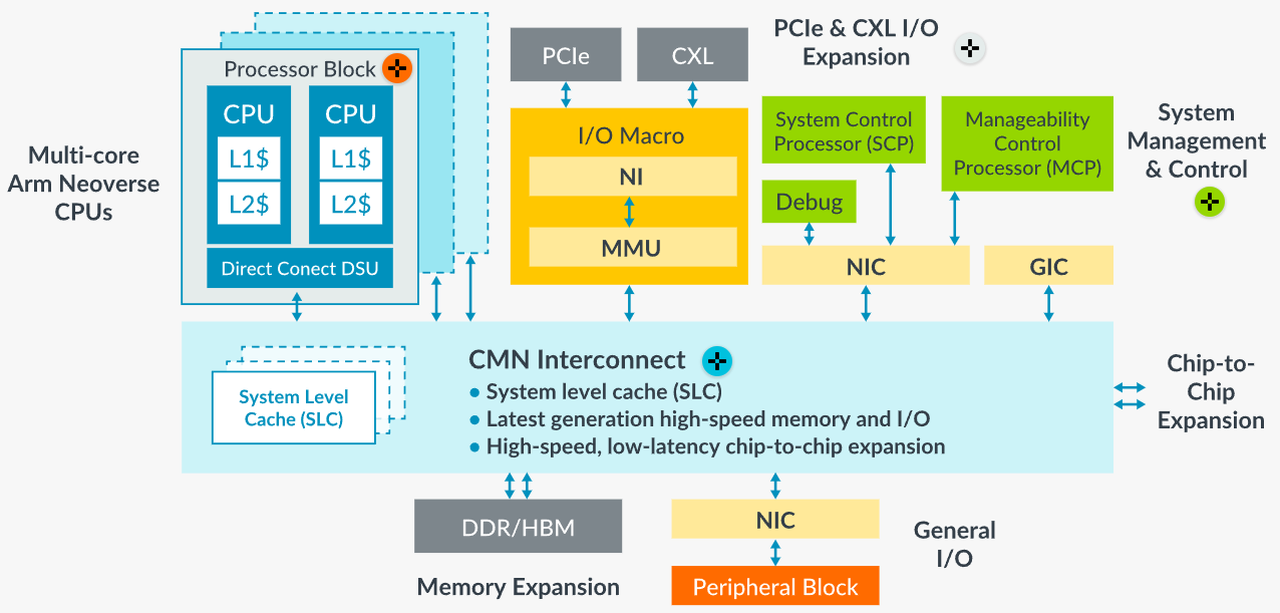 Подсистема памяти может иметь до 8 каналов DDR5, а возможности ввода-вывода включают в себя 4 блока по 16 линий PCIe или CXL. Также возможно объединение двух чипов CSS N2 в едином корпусе, что даёт до 128 ядер на чип. В качестве внутреннего интерконнекта используется меш-сеть Neoverse CMN-700. В дизайне Neoverse CSS N2 имеются и вспомогательные ядра Cortex-M7. Они работают в составе блоков System Control Processor (SCP) и Management Control Processor (MCP), то есть управляют работой основного вычислительного массива, в том числе отвечая за его питание и тактовые частоты.  Инициатива Arm Total Design расширяет рамки Neoverse Compute Subsystem: речь идёт о создании полноценной экосистемы, обеспечивающей эффективную коммуникацию между партнёрами программы Neoverse CSS и предоставление им полноценного IP-инструментария и EDA, созданных при участии Cadence, Rambus, Synopsys и др. Также подразумевается поддержка ведущих производителей «кремния» и разработчиков прошивок, в частности, AMI. В число участников проекта уже вошли такие компании, как ADTechnology, Alphawave Semi, Broadcom, Capgemini, Faraday, Socionext и Sondrel. Ожидается поддержка от Intel Foundry Services и TSMC, позволяющая говорить об эффективной реализации необходимых для мультичиповых решений технологий AMBA CHI C2C и UCIe. 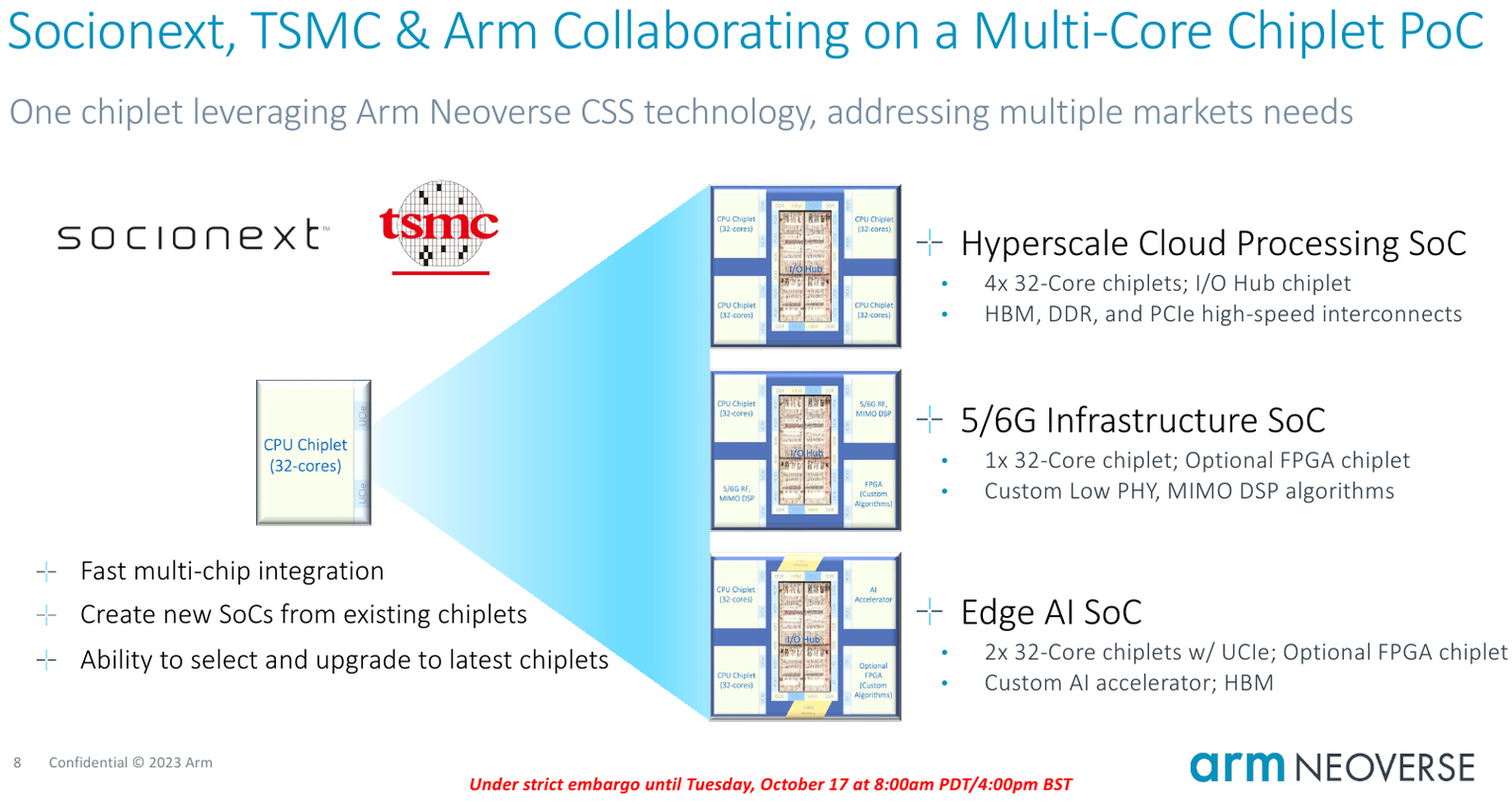 Будучи объединённым под одной крышей инициативы Arm Total Design, такой конгломерат ведущих разработчиков и производителей микроэлектроники и системного ПО для него, сможет в кратчайшие сроки не просто создавать новые процессоры, но и гибко отвечать на вызовы рынка ЦОД и HPC, наделяя чипы поддержкой востребованных технологий и ускорителей. В качестве примера можно привести совместный проект Arm, Socionext и TSMC, в рамках которого ведётся разработка универсального чиплетного процессора, который в различных вариантах компоновки будет востребован гиперскейлерами, поставщиками инфраструктуры 5G/6G и разработчиками периферийных ИИ-систем. |
|

