Лента новостей
|
05.12.2023 [11:50], Сергей Карасёв
Vertiv купила разработчика инфраструктур СЖО для дата-центров CoolTeraКомпания Vertiv, поставляющая оборудование для ЦОД, в том числе энергетические решения и системы охлаждения, объявила о заключении окончательного соглашения по покупке фирмы CoolTera, базирующейся в Великобритании. Финансовые условия сделки не раскрываются. CoolTera была основана в 2016 году. Компания поставляет продукты и компоненты СЖО для дата-центров. Это, в частности, блоки распределения охлаждающей жидкости (CDU), коллекторы, сети вторичного хладагента и пр. Vertiv и CoolTera на протяжении трёх лет являются технологическими партнерами. Компании сообща реализовали ряд проектов по внедрению своих решений в ЦОД и вычислительных комплексах по всему миру. 
Источник изображения: Vertiv По условиям договора, Vertiv получит в своё распоряжение набор активов CoolTera, включая определенные контракты, патенты, товарные знаки и интеллектуальную собственность дочерней структуры приобретаемой фирмы. Ожидается, что сделка будет закрыта в IV квартале 2023 года при условии получения необходимых разрешений. Vertiv отмечает, что покупка укрепит положение компании в сегменте систем охлаждения для ЦОД с высокой плотностью размещения оборудования. Речь идёт в том числе о платформах для задач ИИ. Говорится также, что CoolTera располагает командой высококвалифицированных инженеров в области СЖО.
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC, включает 73 млрд транзисторов и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев.  Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200.
29.11.2023 [01:21], Руслан Авдеев
Cerebras, критиковавшая NVIDIA за сотрудничество с Китаем, сама оказалась связана с компанией, ведущей дела с ПекиномХотя стартап Cerebras, занимающийся разработкой чипов, раскритиковал NVIDIA за попытки обойти санкционные ограничения в отношении Китая и призвал соблюдать не букву, но дух американского закона, у компании, похоже, нашлись свои скелеты в шкафу. Как сообщает The Register, сейчас в США расследуют деятельность клиента Cerebras — группы G42, возможно, помогавшей Поднебесной обходить санкционные ограничения. Американские спецслужбы подозревают, что базирующаяся в ОАЭ многопрофильная компания G42 поставляет в Китай передовые технологии. Для своих ИИ-исследований компания обратилась к Cerebras с целью постройки суперкомпьютерного кластера Condor Galaxy за $100 млн, а всего стартап намерен построить девять подобных объектов на $900 млн. При этом узлы кластера используют разработанные Cerebras чипы WSE-2, подходящие для обучения ИИ-систем. 
Источник изображения: Arthur Wang/unsplash.com Как показывают предварительные результаты расследования американских журналистов, властей и спецслужб, G42 пытается сотрудничать с Пекином и работает с китайскими компаниями вроде Huawei, давно находящимися под санкциями. В самой G42 утверждают, что принимают все меры для того, чтобы соблюдать американские ограничения. При этом, по данным журналистов, G42 считают прокси-компанией для работы в интересах КНР, помогающей Пекину получать вычислительные ресурсы и подсанкционные технологии. По словам главы Cerebras Эндрю Фельдмана (Andrew Feldman), его компания точно не будет вести бизнес с Китаем. Бизнесмен попал в неловкую ситуацию после того, как появилась информация о тесных связях G42 с Пекином. На запрос журналистов в Cerebras заявили, что кластеры Condor Galaxy находятся в США, а G42 получает к ним облачный доступ, так что любая активность контролируется и соответствует американским законам — государства-противники не имеют прямого доступа к ИИ-системам. Фельдман якобы не знал о сомнительном статусе G42, а в стартапе подчеркнули, что не комментируют слухи. Бюро промышленности и безопасности США уже обратилось к поставщикам облачных инфраструктур для консультаций о целесообразности дополнительных ограничений доступа к их услугам из некоторых стран. В частности, бюро интересует, как операторы намерены выявлять разработчиков ИИ-моделей, вызывающих обеспокоеность властей и что можно предпринять для устранения угроз. Кроме того, президент США предложил новые правила, согласно которым облакам потребуется докладывать о деятельности иностранцев, связанной с обучением больших языковых моделей (LLM).
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
23.11.2023 [20:38], Сергей Карасёв
1,5 кВт на чип: ZutaCore показала высокоэффективную систему прямого жидкостного охлаждения HyperCoolКомпания ZutaCore на конференции SC23 сообщила о том, что её система прямого жидкостного охлаждения HyperCool Direct-On-Chip вошла в состав серверов Dell и Pegatron на платформе Intel Xeon Sapphire Rapids. Двухфазная система HyperCool способна эффективно отводить тепло от самых мощных серверных процессоров — с показателем TDP 1500 Вт и более. Это комплексное решение с замкнутым контуром вместо воды использует специальную диэлектрическую жидкость, благодаря чему оборудование защищено от коррозии. Платформа HyperCool обладает хорошей масштабируемостью и может быть развёрнута в новых или модернизированных дата-центрах — cтандартизированный интегрированный 6U-модуль способен отводить 100 кВт и выше. Система обеспечивает коэффициент PUE меньше 1,02. Конструкция HyperCool позволяет повторно использовать выделяемое тепло — например, для обогрева зданий. СЖО подходит для применения в ЦОД, ориентированных на решение задач ИИ и НРС. Система позволяет снизить общее энергопотребление и сократить выбросы вредных газов в атмосферу. 
Источник изображения: ZutaCore Отмечается, что недавно технология HyperCool была сертифицирована для высокопроизводительных серверов ASUS. Кроме того, в экосистему ZutaCore входят AMD, Boston Limited, Dell, Equinix, Intel, World Wide Technologies (WWT) и другие. Утверждается, что по сравнению с традиционными системами охлаждения решение HyperCool обеспечивает сокращение совокупной стоимости владения на 50 %.
23.11.2023 [09:42], Руслан Авдеев
Broadcom закрыла сделку по покупке VMware за $69 млрдСделка по приобретению VMvare компанией Broadcom, заключённая ещё во II квартале 2022 года, наконец закрыта после длительного процесса одобрения регуляторами нескольких стран. Как сообщает ServeTheHome, эта новость вызвала смешанную реакцию у клиентов VMware с учётом того, что Broadcom обычно уделяет основное внимание крупным клиентам и повышает цены на сервисы и ПО приобретённых бизнесов. Хотя в случае с VMware покупатель обещал обойтись без этого. После одобрения сделки Китаем более не осталось препятствий для завершения поглощения, ранее также получившего «добро» от США, Великобритании, ЕС, Южной Корее и Японии. Дольше всех с одобрением сделки тянул Китай, причём случилось это после визита главы этой страны Си Цзиньпина в США. Хотя многие клиенты VMware беспокоятся о возможном росте цен, покупка всё-таки состоялась из-за того, что реальной угрозы монополии на рынке не возникнет из-за множества альтернативных решений. Ранее Broadcom пообещала ежегодно выделять $2 млрд на развитие продуктов и услуг VMware. 
Источник изображения: VMware Покупка стоимостью $69 млрд даст Broadcom дополнительную точку опоры для роста на корпоративном рынке. Компания уже широко представлена в ЦОД благодаря большому портфолио сетевых решений, RAID, PCIe и т.д. Всё это оборудование Broadcom и без того активно применяется в дата-центрах, но приобретение VMware обеспечит компании дополнительное преимущество. В будущем сделка способна обеспечить Broadcom огромную выгоду в сфере корпоративной сетевой инфраструктуры. VMware уже предлагает платформу NSX и интеграцию с другими аппаратными решениями и ПО. Broadcom получит возможность интеграции большего числа своих предложений, а также доступ к другим программным решениям VMware вроде vRealize Automation и Workspace ONE. Наконец, Broadcom будет обеспечен доступ к клиентской базе VMware. Впрочем, за последние кварталы многое изменилось. Традиционно покупка производителем аппаратного обеспечения компании разработчиков ПО ведёт к росту прибыли, как было в случае Dell и VMware. Тем не менее, вектор развития IT-рынка сместился. Последние успехи NVIDIA показали, что ИИ-решения стали более значимым фактором роста прибыли и рыночной капитализации — классическая виртуализация отошла на второй план в сравнении с разработками в сфере ИИ.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ.
19.11.2023 [03:00], Сергей Карасёв
Южнокорейский стартап Sapeon представил 7-нм ИИ-чип X330ИИ-стартап Sapeon, поддерживаемый южнокорейским телекоммуникационным гигантом SK Group, анонсировал чип X330, предназначенный для инференса и обслуживания больших языковых моделей (LLM). Изделие ляжет в основу специализированных ускорителей для дата-центров. Sapeon заявляет, что новый нейропроцессор (NPU) обеспечивает примерно вдвое более высокую производительность и в 1,3 раза лучшую энергоэффективность, чем продукты конкурентов, выпущенные в этом году. По сравнению с предыдущим решением самой компании — Sapeon X220 — достигается увеличение быстродействия в четыре раза и повышение энергоэффективности в два раза. 
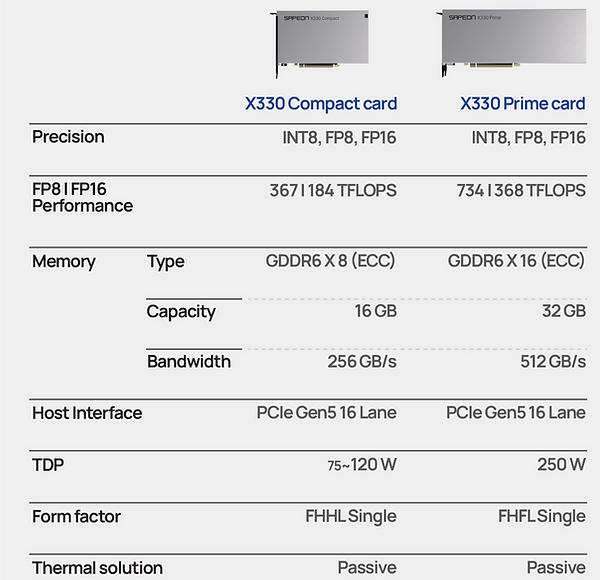
Изображения: Sapeon Новинка будет изготавливаться на TSMC по 7-нм технологии. Массовое производство запланировано на I полугодие 2024 года. На базе чипа будут предлагаться два ускорителя — X330 Compact Card и X330 Prime Card. Оба имеют однослотовое исполнение и оснащаются системой пассивного охлаждения. Для подключения применяется интерфейс PCIe 5.0 х16. Карты могут осуществлять вычисления INT8, FP8 и FP16.  Модель X330 Compact Card уменьшенной длины несёт на борту 16 Гбайт памяти GDDR6 с пропускной способностью до 256 Гбайт/с. Заявленная производительность на операциях FP8 и FP16 достигает соответственно 367 и 184 Тфлопс. Энергопотребление варьируется в диапазоне от 75 до 120 Вт. Полноразмерная модификация X330 Prime Card получила 32 Гбайт памяти GDDR6 с пропускной способностью до 512 Гбайт/с. Заявленное быстродействие FP8 и FP16 составляет до 734 и 368 Тфлопс. Энергопотребление — 250 Вт. 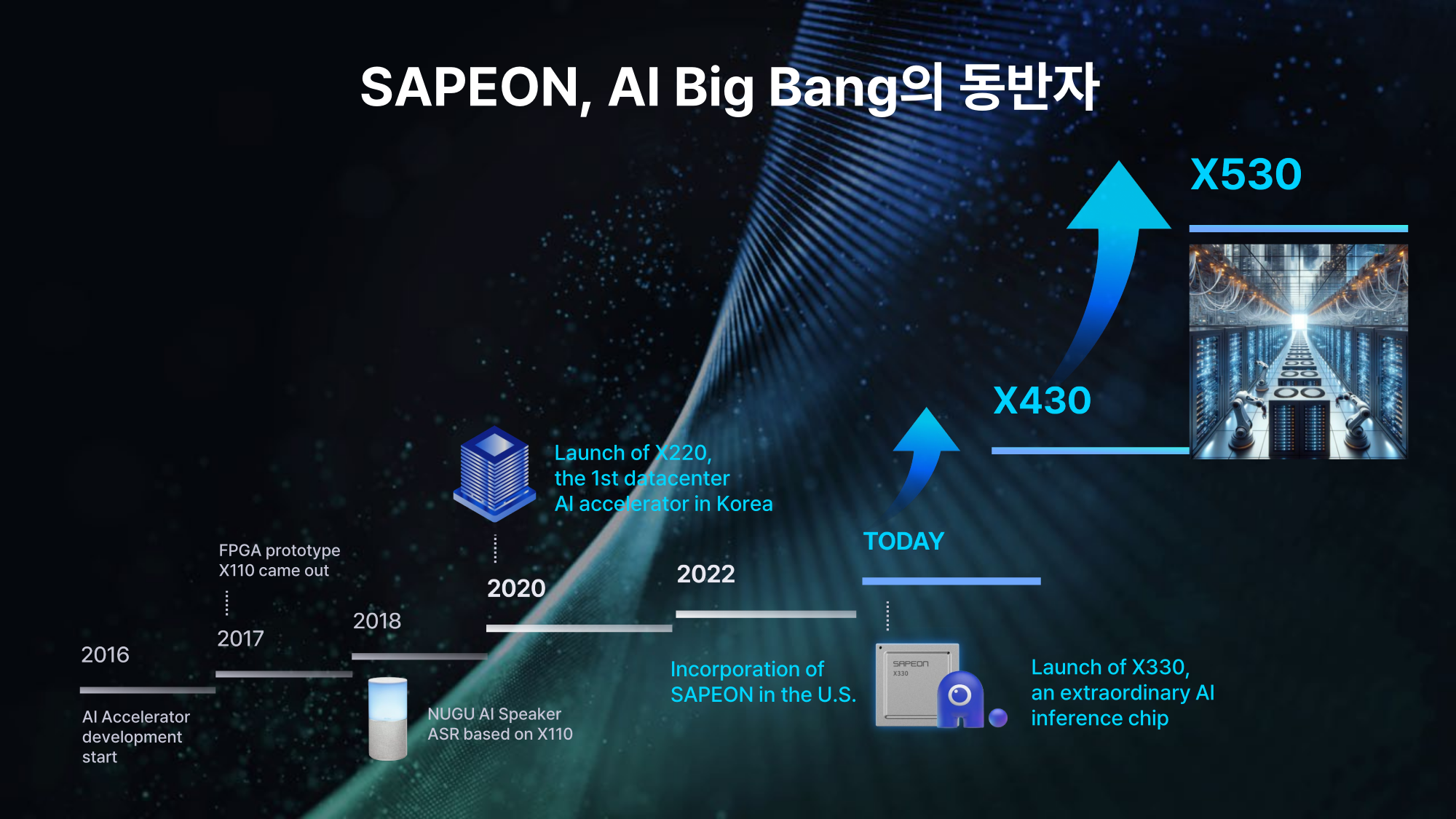 Группа SK в последнее время активно вкладывается в развитие ИИ, инвестируя напрямую или через дочерние структуры как в софт, так и в железо. С ней, в частности, связан ещё один южнокорейский разработчик ИИ-чипов Rebellions, также поддерживаемый правительством страны, которое намерено к 2030 году довести долю отечественных ИИ-чипов в местных дата-центрах до 80 %. Делается это для того, чтобы снизить зависимость от иностранных решений и избежать дефицита. Сама же Sapeon готовит ещё минимум два поколения своих чипов.
16.11.2023 [23:33], Руслан Авдеев
NTT и NEC научились оценивать снежный покров на дорогах по вибрации оптоволокнаЯпонский техногигант NTT разработал решение, которое, как надеются в компании, поможет компенсировать дефицит рабочих рук в стране, связанный со старением населения и скорым введением правил, запрещающим переработки. Как сообщает The Register, один из экспериментов компании предполагает использование уже действующих оптоволоконных кабелей, чтобы определить, стоит ли технике выезжать на расчистку дорог. NTT совместно с NEC разработали технологию, позволяющую применять имеющиеся подземные ВОЛС в качестве своеобразного сенсора, позволяющего регистрировать вибрации при прохождении света по оптоволокну. Подобные решения уже давно используются, например, в составе охранных систем. У самой NEC уже имеется система, оценивающая скорость проходящего мимо кабеля транспорта, а при участии NTT в городе Аомори (Aomori) удалось разработать механизм, позволяющий оценить снежный покров на дорогах. 
Источник изображения: Samuel Berner/unsplash.com На базе информации о скорости проходящего транспортного средства и анализ частот вибраций, характерных для того или иного вида поверхности проезжей части, система на базе машинного обучения определяет, сколько выпало снега, и даёт достоверные рекомендации, когда и где его следует чистить. Технология имеет большую ценность, поскольку быстро оценить дорожные условия дистанционно пока можно только днём, а дефицит кадров (особенно в сельской местности) означает, что для проверок персонала может не хватить. 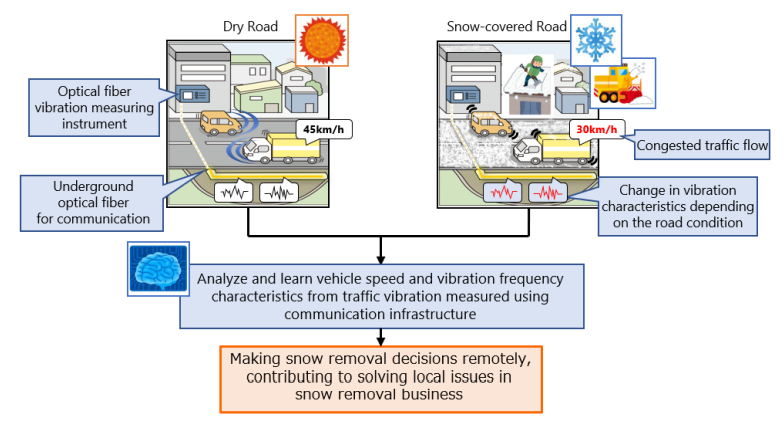
Изображение: NTT Дополнительно NTT провела на своей сети All Photonics Network эксперимент с удалённым управлением экскаватором. Для оконечного соединения оптоволокно подключается к некому беспроводному модулю, передающему данные машине и обратно. Технология позволяет передавать 4K-видео с задержкой 500 мс, которая признана допустимой для безопасной работы тяжёлой техники с участием удалённого оператора. NTT и NEC будут проводить дальнейшие эксперименты в других регионах для совершенствования технологии. Одним из дополнительных стимулов для внедрения технологии является вступление в силу в 2024 году закона, ограничивающего время ежегодных допустимых переработок для рабочих. В NTT полагают, что отсутствие необходимости в перемещении людей с площадки на площадку позволит снизить время переработок. А в конце прошлого года компания сообщила о намерении использовать в ЦОД роботов, способных в перспективе высвободить человеческие ресурсы.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200.  |
|



{kind=link}