Материалы по тегу: ucie
|
28.12.2025 [15:42], Владимир Мироненко
16 вычислительных тайлов и 24 стека HBM: Intel продемонстрировала свои возможности для создания будущих чиповIntel Foundry опубликовала видео с демонстрацией своих передовых решений в области упаковки микросхем с использованием технологических процессов 18A/14A, технологий Foveros 3D и EMIB-T. В видео представлены концептуальные и масштабируемые конструкции с возможностью размещения до 16 вычислительных блоков, 24 стеков HBM и многое другое. Как отметил ресурс WCCFTech, видеоролик демонстрирует, что ждёт клиентов Intel, стремящихся использовать её технологии при создании будущих чипов. Эти технологии будут устанавливать стандарты для чипов следующего поколения для HPC, ИИ, ЦОД и многого другого. Передовые решения в области упаковки также усилят позиции Intel в конкуренции с TSMC, которая представили решение CoWoS, обеспечивающее 9,5-кратное превышение размеров стандартного фотошаблона (830 мм²), использующее технологический процесс A16 и более 12 стеков HBM4E (CoWoS-L). 
Источник изображений: Intel Согласно видео, технологии Intel Foveros 3D и межкристального соединения EMIB-T позволяют объединить до 16 вычислительных кристаллов в паре с 24 стеками HBM5 в одном корпусе. При этом используются 18A-процессы Intel, включая 18A-P и 18A-PT, и 14A-процессы, которые компания готовит к массовому производству, в том числе для внешних заказчиков.  В опубликованном видеоролике Intel демонстрирует два передовых решения для корпусирования микросхем. Одна микросхема включает четыре вычислительных блока и 12 модулей HBM, а вторая — 16 вычислительных блоков и 24 модуля HBM. Также у более крупной размещено в одном корпусе вдвое больше контроллеров LPDDR5X, до 48, что значительно увеличивает плотность памяти для ИИ-нагрузок и ЦОД.  Для создания микросхем используется технология послойного объединения кристаллов, при которой базовые кристаллы, изготовленные с использованием процесса 18A-PT, используют подачу питания с обратной стороны (PowerVia) и включают SRAM-банки. На базовый тайл затем устанавливается основной вычислительный тайл, который может включать в себя ИИ-движки, CPU или другие IP-блоки. Они изготавливаются по технологическим процессам Intel 14A или 14A-E, используют транзисторы RibbonFET второго поколения и технологию PowerDirect, и соединяются с базовым тайлом с помощью технологии Foveros Direct 3D, обеспечивающей вертикальное размещение компонентов, образуя 3D-стек.  Затем несколько чиплетов соединяются и дополнительно взаимодействуют с памятью с помощью технологии упаковки EMIB-T. Верхний тайл использует 24 модуля HBM, которые могут поддерживать как существующие стандарты HBM, такие как HBM3/HBM3E, так и будущие, такие как HBM4/HBM4E или HBM5. При этом активно используется UCIe. Теперь дело за практической реализацией замыслов. Компания возвращается на рынок с ИИ-ускорителем Jaguar Shores и GPU Crescent Island для ИИ-инференса, но всё зависит от сделок со сторонними поставщиками.
06.10.2025 [10:54], Владимир Мироненко
250 Тбит/с на чип: Ayar Labs, Alchip и TSMC предложили референс-дизайн для упаковки ASIC, памяти и оптических модулей в одном чипеКомпания Ayar Labs (США), занимающаяся разработкой интерконнекта на базе кремниевой фотоники, и тайваньский производитель ASIC-решений Alchip Technologies представили референсную платформу проектирования ИИ ASIC с несколькими оптическими IO-модулями на основе технологии кремниевой фотоники TSMC COUPE (Compact Universal Photonic Engine). В начале сентября компании объявили о стратегическом партнёрстве с целью ускорения масштабирования ИИ-инфраструктуры благодаря объединению технологии CPO компании Ayar Labs, экспертизы Alchip в области создания и упаковки кастомных ASIC, а также технологии упаковки и техпроцесса компании TSMC. Как сообщил технический директор Ayar Labs Владимир Стоянович (Vladimir Stojanovic) в интервью EE Times, платформа предназначена для устранения узких мест в передаче данных, замедляющих работу ИИ-инфраструктуры, путём эффективного сокращения времени простоя системы и создания крупных высокопроизводительных ИИ-кластеров нового поколения. Партнёры отметили, что по мере роста ИИ-моделей и размеров кластеров традиционные медные соединения достигают своих физических и энергетических пределов. Путём замены меди на интегрированную оптику (CPO) решение Alchip и Ayar Labs обеспечивает расширенную дальность связи, низкую задержку, энергоэффективность и высокий радикс, необходимые для масштабных развертываний ИИ-ускорителей. «Масштабируемые сети ИИ-кластеров ограничены расстоянием медных соединений. В то же время энергоэффективность сети ограничена плотностью мощности и возможностями систем охлаждения», — пояснил Эрез Шайзаф (Erez Shaizaf), технический директор Alchip, добавив, что CPO снимает эти ограничения. 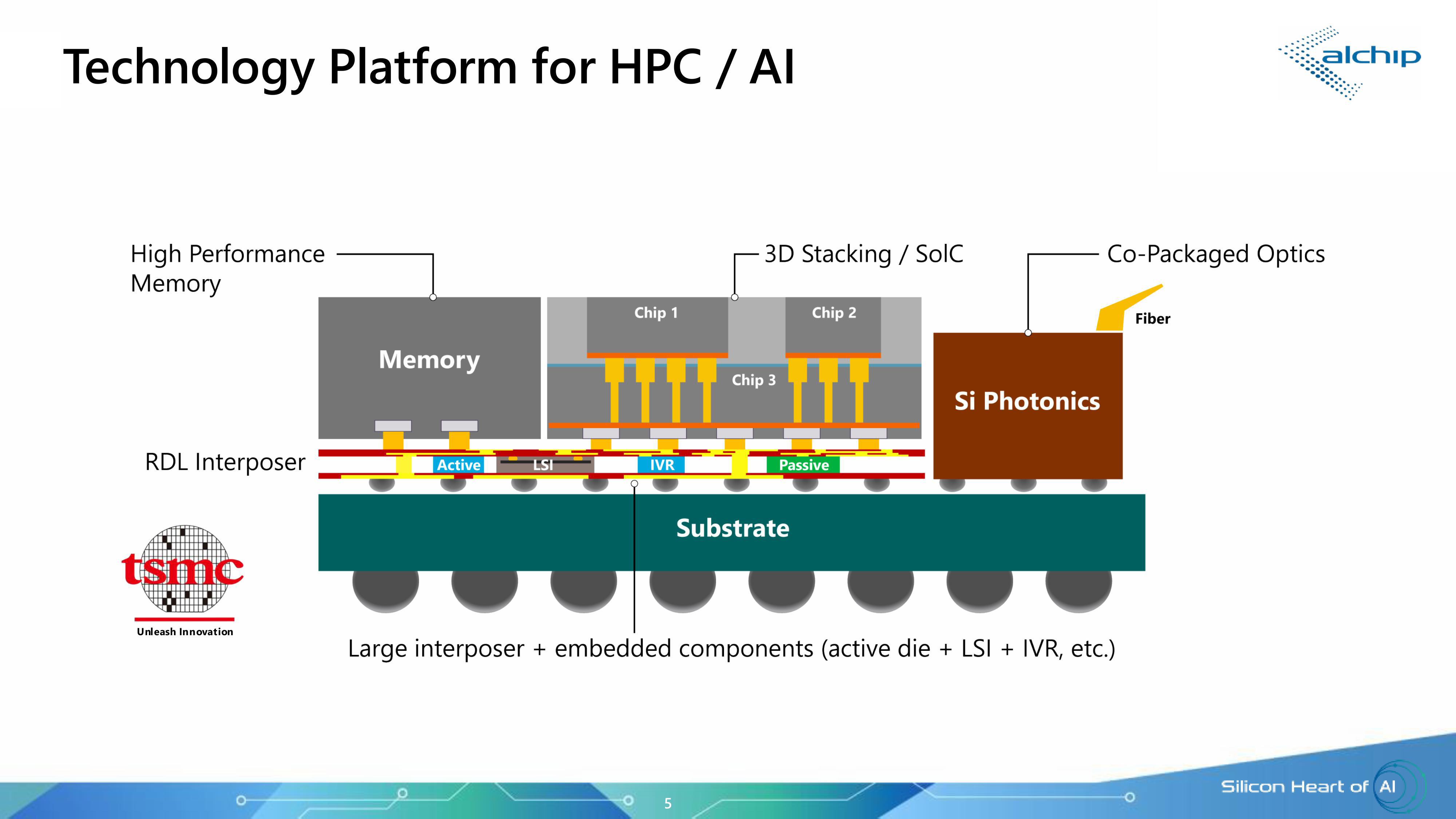
Источник изображений: Ayar Labs Новое совместное решение включает оптические модули Ayar Labs TeraPHY, размещённые вместе с решениями Alchip на общей подложке, обеспечивая прямой доступ ИИ-ускорителя к оптическому интерфейсу. Такая интеграция обеспечивает пропускную способность 100+ Тбит/с на каждый ускоритель и поддерживает более 256 оптических портов на устройство. TeraPHY не привязан к какому-либо протоколу и обеспечивает гибкую интеграцию с кастомными чиплетами. Референсный дизайн позволяет партнёрам «заложить основу» для быстрого создания подобной системы. Платформа референсного проекта включает два вычислительных кристалла с чиплетами HBM и другими чиплетами, в сочетании с восемью оптическими IO-модулями на базе чиплета TeraPHY. Такая конструкция обеспечит двустороннюю пропускную способность 200–250 Тбит/с для каждой сборки (SiP), что значительно превышает показатели современных крупных GPU, сообщил Стоянович. Это позволит масштабировать систему, а также значительно расширить объём памяти, имеющей пропускную способность, сопоставимую с HBM, добавил он. Оптический модуль Ayar Labs основан на чиплете TeraPHY PIC с двумя дополнительными слоями чиплетов, собранными с помощью TSMC COUPE. Два слоя электронных чиплетов собраны по технологии TSMC SoIC (System on Integrated Chips), которая использует вертикальное размещение нескольких кристаллов друг над другом, чтобы обеспечить более плотное соединение между ними, позволяя снизить энергопотребление, увеличить производительность и уменьшить задержки. По словам Стояновича, такой дизайн будет масштабироваться до уровня UCIe-A и выше как минимум в течение следующего десятилетия. 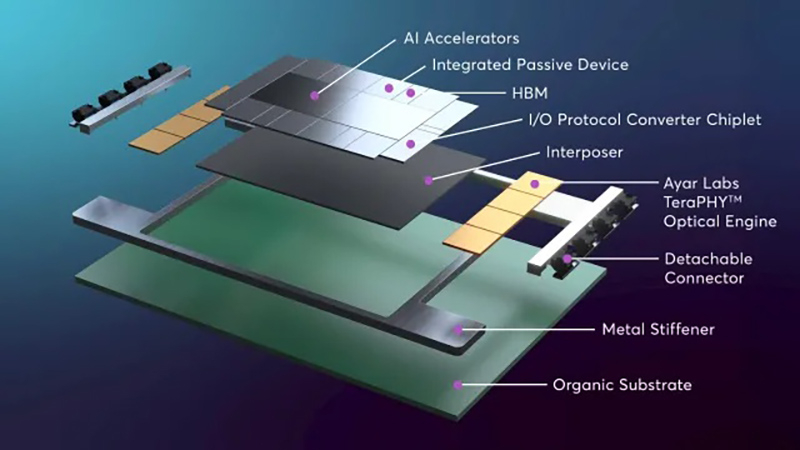 Совместное решение Alchip и Ayar Labs позволяет масштабировать многостоечную сетевую фабрику без потерь мощности и задержек, характерных для подключаемых оптических кабелей, за счёт минимизации длины электрических трасс и размещения оптических соединений вблизи вычислительного ядра. Благодаря поддержке UCIe для межкомпонентных соединений и гибкому размещению конечных точек на границе чипов, команды разработчиков могут интегрировать масштабируемое решение Alchip и Ayar Labs с существующими вычислительными блоками, стеками памяти и ускорителями, обеспечивая при этом соблюдение требований к производительности, целостности сигнала и температурному режиму на уровне всей сборки. Как сообщается, компании предоставят командам разработчиков дополнительные материалы, референсные архитектуры и варианты сборки. Платформа референсного дизайна включает в себя тестовые программы, позволяющие тестировать сборку и прошивку управления модулем, что облегчает его интеграцию в сборку. «Заказчику нужна поддержка, чтобы он понимал процессы оценки надёжности и испытаний, поэтому мы тесно сотрудничаем с Alchip, чтобы предоставить заказчику доступ ко всему этому пакету», — рассказал Стоянович.
22.08.2025 [16:33], Владимир Мироненко
Почти как у самой NVIDIA: NVLink Fusion позволит создавать кастомные ИИ-платформыТехнологии NVIDIA NVLink и NVLink Fusion позволят вывести производительность ИИ-инференса на новый уровень благодаря повышенной масштабируемости, гибкости и возможностям интеграции со сторонними чипами, которые в совокупности отвечает стремительному росту сложности ИИ-моделей, сообщается в блоге NVIDIA. С ростом сложности ИИ-моделей выросло количество их параметров — с миллионов до триллионов, что требует для обеспечения их работы значительных вычислительных ресурсов в виде кластеров ускорителей. Росту требований, предъявляемых к вычислительным ресурсам, также способствует внедрение архитектур со смешанным типом вычислений (MoE) и ИИ-алгоритмов рассуждений с масштабированием (Test-time scaling, TTS). NVIDIA представила интерконнект NVLink в 2016 году. Пятое поколение NVLink, вышедшее в 2024 году, позволяет объединить в одной стойке 72 ускорителя каналами шириной 1800 Гбайт/с (по 900 Гбайт/с в каждую сторону), обеспечивая суммарную пропускную способность 130 Тбайт/с — в 800 раз больше, чем у первого поколения.  Производительность NVLink зависит от аппаратных средств и коммуникационных библиотек, в частности, от библиотеки NVIDIA Collective Communication Library (NCCL) для ускорения взаимодействия между ускорителями в топологиях с одним и несколькими узлами. NCCL поддерживает вертикальное и горизонтальное масштабирование, а также включает в себя автоматическое распознавание топологии и оптимизацию передачи данных. 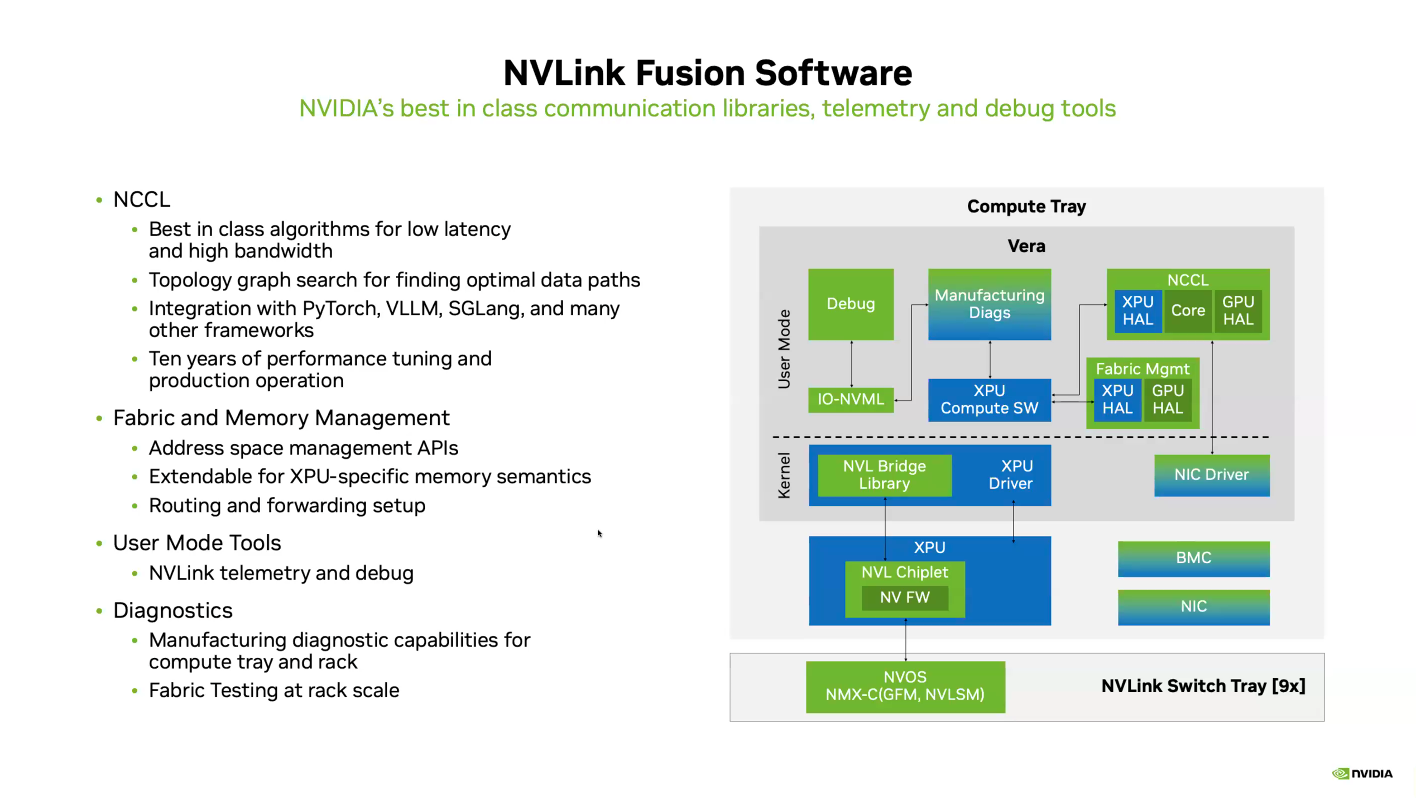 Технология NVLink Fusion призвана обеспечить гиперскейлерам доступ ко всем проверенным в производстве технологиям масштабирования NVLink. Она позволяет интегрировать кастомные микросхемы (CPU и XPU) с технологией вертикального и горизонтального масштабирования NVIDIA NVLink и стоечной архитектурой для развёртывания кастомных ИИ-инфраструктур. 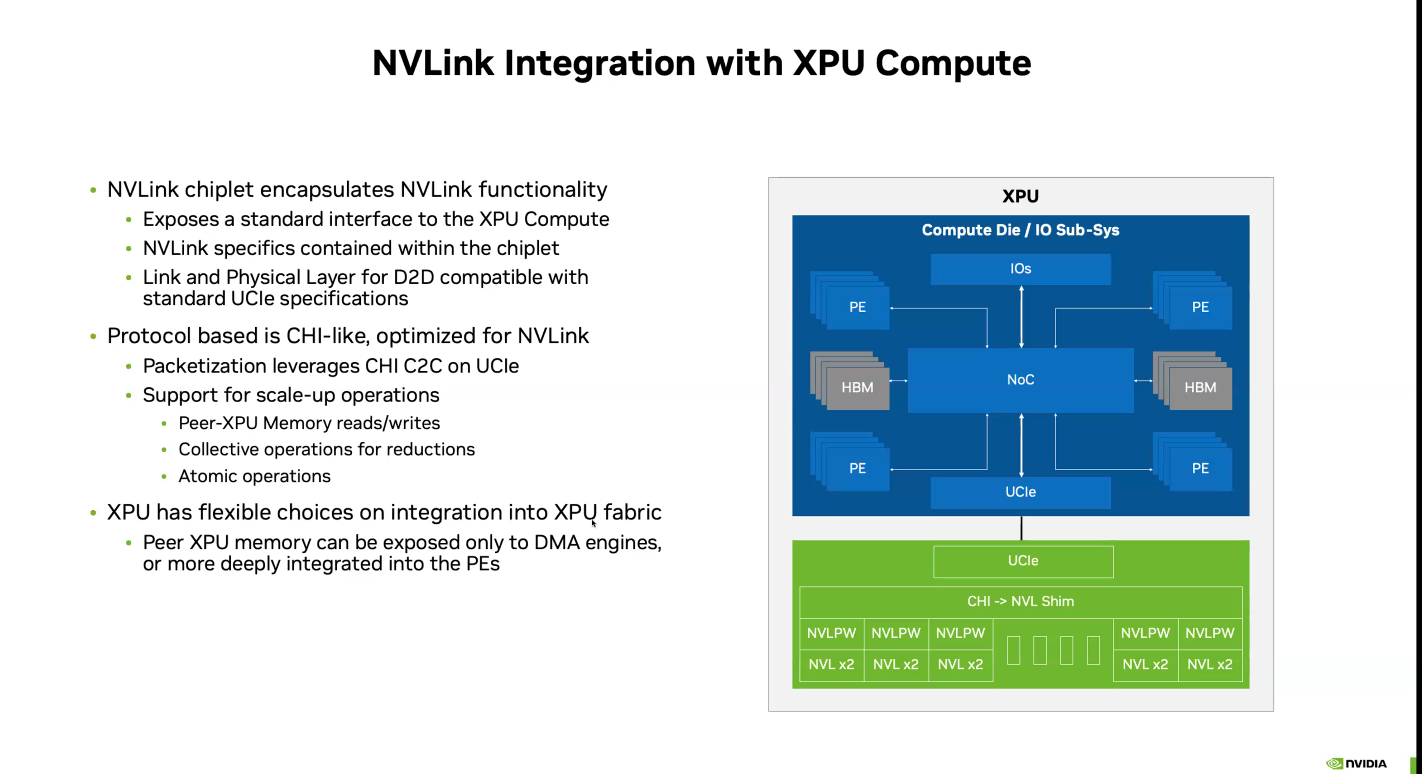 Технология охватывает NVLink SerDes, чиплеты, коммутаторы и стоечную архитектуру, предлагая универсальные решения для конфигураций кастомных CPU, кастомных XPU или комбинированных платформ. Модульное стоечное решение OCP MGX, позволяющее интегрировать NVLink Fusion с любым сетевым адаптером, DPU или коммутатором, обеспечивает заказчикам гибкость в построении необходимых решений, заявляет NVIDIA. 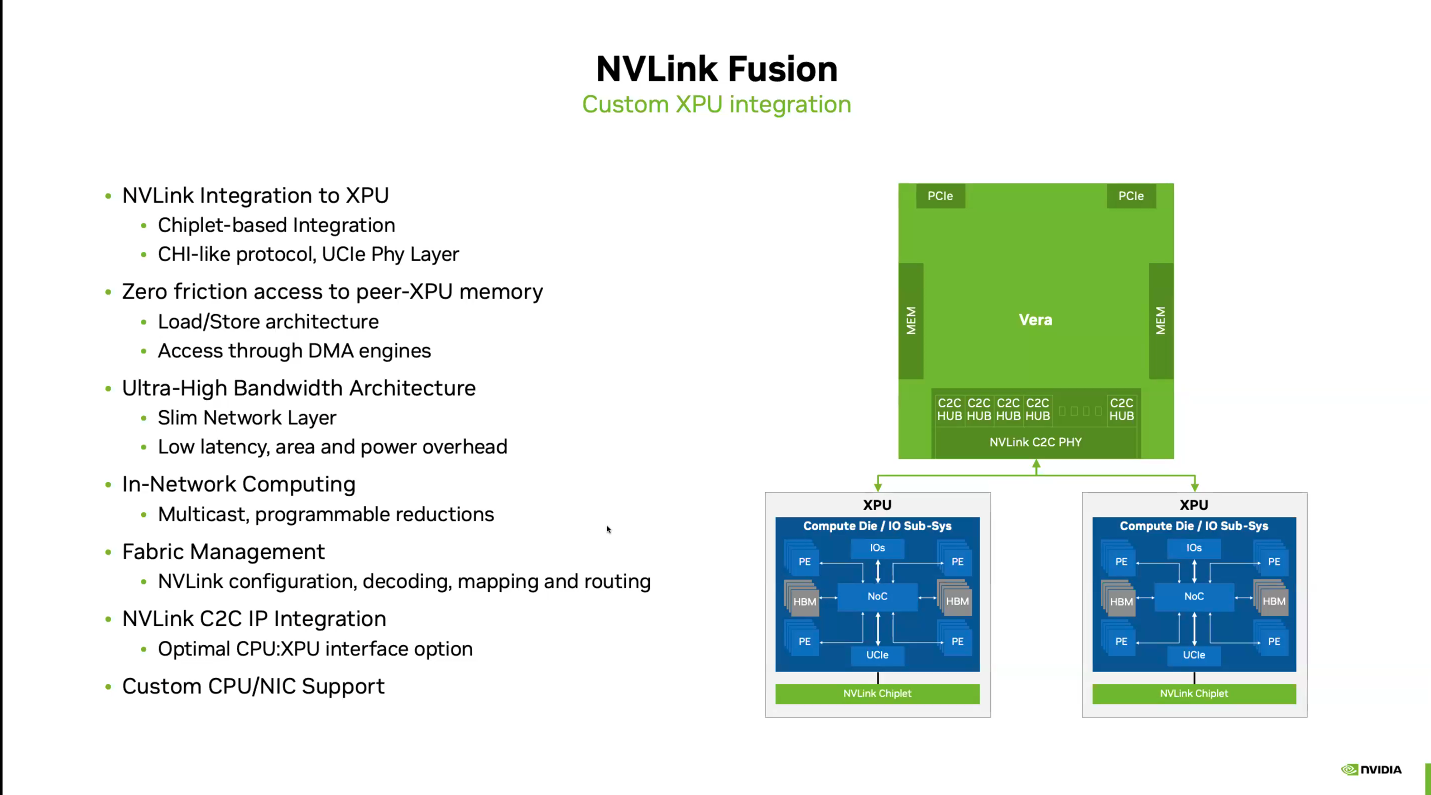 NVLink Fusion поддерживает конфигурации с кастомными CPU и XPU с использованием IP-блоков и интерфейса UCIe, предоставляя заказчикам гибкость в реализации интеграции XPU на разных платформах. Для конфигураций с кастомными CPU рекомендуется интеграция с IP NVLink-C2C для оптимального подключения и производительности GPU. При этом предлагаются различные модели доступа к памяти и DMA. 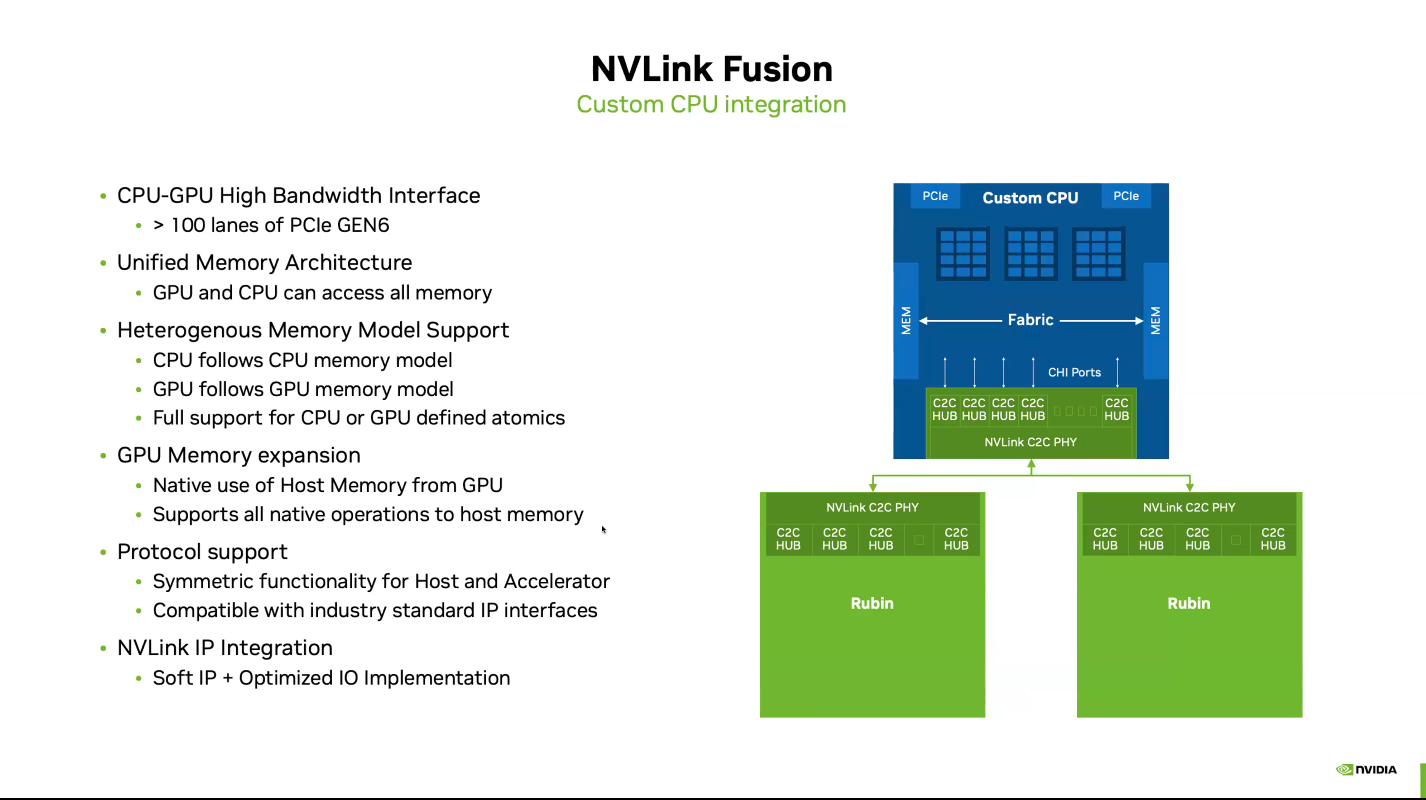 NVLink Fusion использует преимущества обширной экосистемы кремниевых чипов, в том числе от партнёров по разработке кастомных полупроводников, CPU и IP-блоков, что обеспечивает широкую поддержку и быструю разработку новых решений. Основанная на десятилетнем опыте использования технологии NVLink и открытых стандартах архитектуры OCP MGX, платформа NVLink Fusion предоставляет гиперскейлерам исключительную производительность и гибкость при создании ИИ-инфраструктур, подытожила NVIDIA.  При этом основным применением NVLink Fusion с точки зрения NVIDIA, по-видимому, должно стать объединение сторонних чипов с её собственными, а не «чужих» чипов между собой. Более открытой альтернативой NVLink должен стать UALink с дальнейшим масштабированием посредством Ultra Ethernet.
09.08.2025 [13:22], Сергей Карасёв
До 64 ГТ/с: обнародована спецификация UCIe 3.0 для объединения чиплетовКонсорциум Universal Chiplet Interconnect Express (UCIe) объявил о выпуске спецификации UCIe 3.0 для соединения чиплетов в составе высокопроизводительных систем, таких как платформы аналитики данных, HPC и ИИ. Напомним, консорциум UCIe был сформирован в 2022 году с целью создания стандартного интерконнекта, позволяющего объединять в одном корпусе чиплеты разных производителей, обладающие различными функциями и изготовленные на разных предприятиях. В состав консорциума вошли Intel, AMD, Qualcomm и TSMC, а также ведущие гиперскейлеры, включая Google Cloud, Meta✴ и Microsoft. 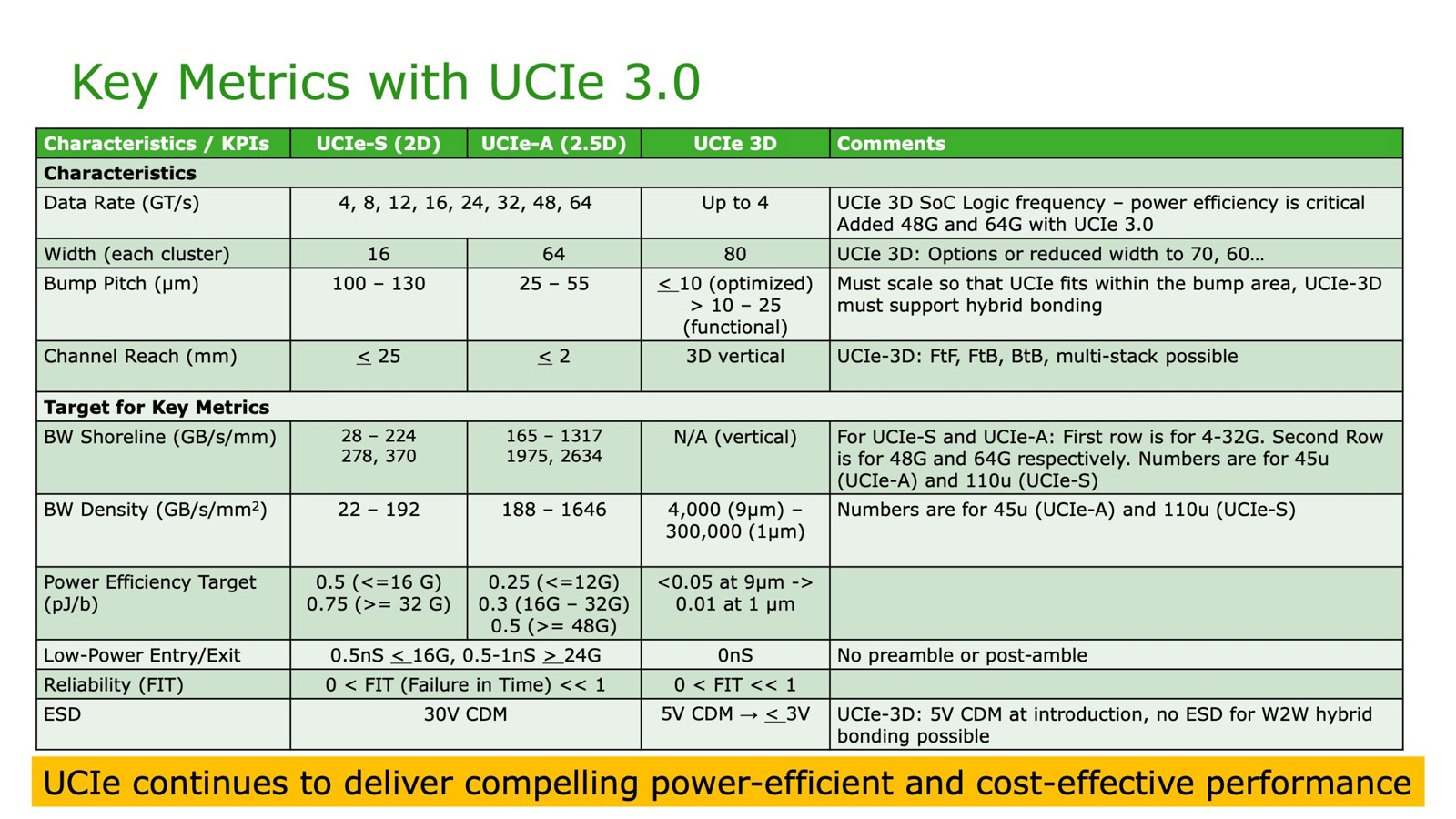
Обнародованная спецификация UCIe 3.0 предусматривает удвоение скорости по сравнению со стандартом предыдущего поколения — до 48 и 64 ГТ/с для вариантов UCIe-S (стандартная упаковка 2D) и UCIe-A (передовая упаковка 2.5D). Таким образом, достигается более высокая пропускная способность в расчёте на соединение, что имеет большое значение, когда для обмена данными между кристаллами может быть задействовано строго ограниченное количество соединений. В случае UCIe 3D скорость ограничивается 4 ГТ/с.
Для UCIe 3.0 заявлена обратная совместимость со спецификациями предыдущих поколений. Упомянута улучшенная перекалибровка во время выполнения, обеспечивающая снижение энергопотребления каналов передачи данных и чиплетов. Предусмотрены и другие усовершенствования, ориентированные на повышение плотности полосы пропускания, энергоэффективности и управляемости на системном уровне. В целом, спецификация UCIe 3.0 обеспечивает более высокую масштабируемость, гибкость и совместимость, что, как считают участники консорциума, поможет ускорить инновации в области модульной полупроводниковой архитектуры. Вместе с тем некоммерческая организация Open Compute Project Foundation (OCP) выпустила новую спецификацию Universal D2D Transaction и Link-Layer, которая охватывает в том числе UCIe.
03.04.2025 [16:42], Владимир Мироненко
Ayar Labs анонсировала фотонный UCIe-чиплет TeraPHY с пропускной способностью 8 Тбит/сКомпания Ayar Labs, занимающаяся разработкой интерконнекта на базе кремниевой фотоники, анонсировала чиплет оптического I/O TeraPHY, способный обеспечить пропускную способность 8 Тбит/с и использующий оптический источник света SuperNova с поддержкой 16 длин волн. Чиплет поддерживает интерфейс Universal Chiplet Interconnect Express (UCIe), что означает возможность объединения в одном решении чиплетов от разных поставщиков. Ayar Labs отметила, что совместимость со стандартом UCIe позволяет создать более доступную и экономичную экосистему, которая упрощает внедрение передовых оптических технологий, необходимых для масштабирования рабочих ИИ-нагрузок и преодоления ограничений традиционных медных соединений. 
Источник изображений: Ayar Labs Ayar Labs сообщила, что объединила кремниевую фотонику с производственными процессами CMOS, чтобы обеспечить использование оптических соединений в форм-факторе чиплета в многочиповых корпусах. Это позволяет GPU и другим ускорителям взаимодействовать на широком диапазоне расстояний, от миллиметров до километров, при этом эффективно функционируя как единый гигантский ускоритель. Ранее компания совместно с Fujitsu показал концепт процессора A64FXс UCIe-чиплетом TeraPHY.  Марк Уэйд (Mark Wade), генеральный директор и соучредитель Ayar Labs заявил, что в компании давно увидели потенциал совместно упакованной оптики (CPO), и поэтому занялись внедрением оптических решений в ИИ-приложениях. «Продолжая расширять границы оптических технологий, мы объединяем цепочку поставок, производство, а также процессы тестирования и проверки, необходимые клиентам для масштабного развёртывания этих решений», — подчеркнул он. Среди партнёров Ayar Labs крупнейшие компании отрасли, включая AMD, Intel, NVIDIA и TSMC. В последнем раунде финансирования, прошедшем в декабре прошлого года, компания привлекла $155 млн. Рыночная стоимость Ayar Labs, по оценкам, составляет $1 млрд.
02.04.2025 [20:32], Владимир Мироненко
Lightmatter анонсировала оптический интерконнект CPO Passage L200 и фотонный 3D-суперчип Passage M1000Lightmatter анонсировала оптический интерконнект 3D co-packaged optics (CPO) Passage L200, разработанный для интеграции с новейшими дизайнами GPU и XPU, а также коммутаторами, предназначенный для обеспечения значительного увеличения скорости обработки ИИ-нагрузок в огромных кластерах из тысяч ускорителей, благодаря устранению узких мест в полосе пропускания интерконнекта. Семейство L200 3D CPO включает версии на 32 Тбит/с (L200) и 64 Тбит/с (L200X), что в 5–10 раз превышает возможности существующих решений. L200 позволяет размещать несколько GPU в одной упаковке, обеспечивая более 200 Тбит/с общей полосы пропускания I/O, что позволяет ускорить обучение и инференс ИИ-моделей до восьми раз. 
Источник изображений: Lightmatter В обычных ЦОД ускорители соединены между собой с помощью массива сетевых коммутаторов, которые образуют многоуровневую иерархию. Эта архитектура создает слишком большую задержку, поскольку для того, чтобы один ускоритель мог взаимодействовать с другим, сигнал должен пройти через несколько коммутаторов. Как сообщил ранее в интервью ресурсу SiliconANGLE генеральный директор Lightmatter Ник Харрис (Nick Harris), Passage решает проблему громоздких сетевых соединений, интегрируя свою сверхплотную оптоволоконную технологию в чипы, чтобы улучшить пропускную способность в 100 раз по сравнению с лучшими решениями, используемыми сегодня. «Таким образом, вместо шести или семи слоев коммутации у вас есть два, и каждый GPU может подключаться к тысячам других», — пояснил он. Lightmatter назвала свою архитектуру интерконнекта «I/O без границ» (edgeless I/O) и заявила, что она может масштабировать пропускную способность по всей площади кристалла на GPU, в то время как традиционные кристаллы могут подключаться к другим кристаллам только на краю (shoreline). Интеграция Passage 3D позволяет размещать SerDes-блоки в любом месте кристалла, а не ограничиваться его краями, обеспечивая пропускную способность эквивалентную 40 подключаемых оптических трансиверов. Сообщается, что модульное решение 3D CPO использует стандартный совместимый интерфейс UCIe die-to-die (D2D) и упрощает масштабируемую архитектуру на основе чиплетов для бесшовной интеграции с XPU и коммутаторами следующего поколения. Компания заявила, что грядущий L200 CPO разработан для крупносерийного производства, и она тесно сотрудничает для его подготовки с партнёрами по производству полупроводников, такими как Global Foundries, ASE и Amkor, а также передовыми производителями CMOS. В серийное производство Lightmatter L200 и L200X поступят в следующем году. Lightmatter также анонсировала референсную платформу Passage M1000 — фотонный 3D-суперчип (3D Photonic Superchip), разработанный для XPU и коммутаторов следующего поколения. Passage M1000 обеспечивает рекордную общую оптическую пропускную способность на уровне 114 Тбит/с для самых требовательных приложений ИИ-инфраструктуры.  M1000 площадью более 4000 мм² представляет собой многосетчатый активный фотонный интерпозер, который позволяет клиентам создавать свои собственные кастомные соединения с использованием кремниевой фотоники, обеспечивая подключение к множеству GPU в одной 3D-упаковке. Как сообщается, Passage M1000 позволяет преодолеть ограничение по подключению по краям, обеспечивая I/O практически в любом месте на своей поверхности для комплекса кристаллов, размещённых сверху. Интерпозере оснащён обширной и реконфигурируемой сетью волноводов, которая передает WDM-сигналы по всему M1000. Благодаря полностью интегрированному соединению с поддержкой 256 волокон с пропускной способностью 448 Гбит/с на волокно, M1000 обеспечивает на порядок более высокую пропускную способность в меньшем размере корпуса по сравнению с обычными структурами Co-Packaged Optics (CPO) и аналогичными предложениями. Поставки Passage M1000 начнутся этим летом. Среди инвесторов Lightmatter крупные технологические компании, такие как Alphabet и HPE. В последнем раунде финансирования, прошедшем в октябре 2024 года, Lightmatter привлекла $400 млн инвестиций, в результате чего сумма привлечённых компанией средств достигла $850 млн, а её рыночная стоимость теперь оценивается в $4,4 млрд.
17.07.2024 [15:49], Руслан Авдеев
DreamBig Semiconductor получила $75 млн на развитие чиплетной платформы нового поколенияСтартап DreamBig Semiconductor получил $75 млн инвестиций. Всего, по данным Silicon Angle, за время своего существования компания привлекла $93 млн. Основанный в 2019 году стартап является создателем MARS Platform — открытой чиплетной платформы для создания решений с передовой 3D-упаковкой. Она, по словам компании, позволит создать новое поколение ИИ-чипов. Последний раунд финансирования возглавляли Samsung Catalyst Fund и Sutardja Family, участие приняли новые инвесторы в лице Hanwha, Event Horizon и Raptor. Средства дали и партнёры, уже поддержавшие проект — UMC Capital, BRV, Ignite Innovation Fund и Grandfull Fund. В компании объявили, что полученные средства потратят на ускорение развития стандарта чиплетов и коммерциализацию, а также на платформу разработки Chiplet Hub. 
Источник изображения: DreamBig Ожидается, что MARS позволит клиентам сконцентрировать усилия на достижении нужных именно им характеристик чипов, а открытость платформы позволит сэкономить средства. По словам DreamBig, стандарт чиплетов MARS позволит решит проблему масштабирования вычислений и интерконнекта. Заказчики смогут использоваться базовые чиплеты для добавления той или иной функциональности к своему чипу. Заявляется, что MARS, впервые сможет обеспечить прямой доступ к SRAM и DRAM в дополнение к HBM. Для объединения кристаллов будут использоваться UCIe и BoW (Bunch of Wires), а для общения — протоколы AMBA. Платформа подходит для конструирования вычислительных чипов, ИИ-ускорителей или сетевых решений (DPU). DreamBig стала последней в серии стартапов, занятых разработкой ИИ-чипов, сумевших привлечь миллионы долларов инвестиций в этом году. Так, Etched.ai сообщил о привлечении $120 млн для того, чтобы помериться силами с NVIDIA. DEEPX привлёк $80,5 млн, SiMA Technologies получила $70 млн, а Hailo выделили $120 млн.
27.06.2024 [23:57], Алексей Степин
Intel представила фотонный интерконнект OCI: по 2 Тбит/с в обе стороны на расстоянии 100 мIntel ведет исследования в области интегрированной фотоники уже много лет, поскольку успех в этой сфере критически важен для HPC-систем нового поколения. Два года назад компания сообщила о создании технологии, использующей существующие техпроцессы обработки 300-мм кремниевых пластин для формирования массива лазеров вкупе с модуляторами. А сейчас можно говорить о достижении новой важной вехи в этой области. На OFC 2024 Intel продемонстрировала опытный образец CPU, оснащённый 64-канальным фотонным интерконнектом OCI (Optical Compute Interconnect). Каждый канал позволяет передавать данные на скорости 32 Гбит/с на расстоянии до 100 м, что позволит решить проблему масштабирования HPC-систем и ИИ-комплексов: пропускной способности 2 Тбит/с (256 Гбайт/с) в каждом направлении хватит на многое. А в перспективе скорость будет доведена до 32 Тбит/с. 
Источник изображений: Intel В настоящее время в системах подобного класса для высокоскоростного соединения узлов используются либо решения с внешними оптическими трансиверами, что серьёзно увеличивает стоимость и энергопотреблению в целом, либо классическую «медь», серьёзно ограниченную по максимальной длине кабеля. OCI позволяет избежать обеих проблем.  Чиплет использует DWDM (восемь длин волн на волокно) и при этом экономичен: энергозатраты на передачу информации составляют всего 5 пДж/бит против 15 пДж/бит у решений с внешними оптическими трансиверами. Ранее заявленную цифру 3 пДж/бит пришлось немного увеличить, что связано с интеграцией интерфейса PCIe.  Внешне продемонстрированный образец чипа напоминает выпускавшиеся когда процессоры Xeon с поддержкой Omni-Path, но вместо электрического разъёма у него теперь оптический соединитель на восемь пар волокон. С помощью простого пассивного переходника к нему в демонстрационной системе Inel был подключен типовой оптоволоконный кабель.  Поскольку речь идёт о чиплете, теоретически ничто не мешает разместить модуль OCI в составе GPU/NPU, FPGA, DPU/IPU и вообще любой модульной SoC. При этом чиплет совместим с PCIe 5.0, так что проблем с интеграцией быть не должно, хотя это и не самый оптимальный вариант. А на уровне упаковки поддерживается и UCIe. 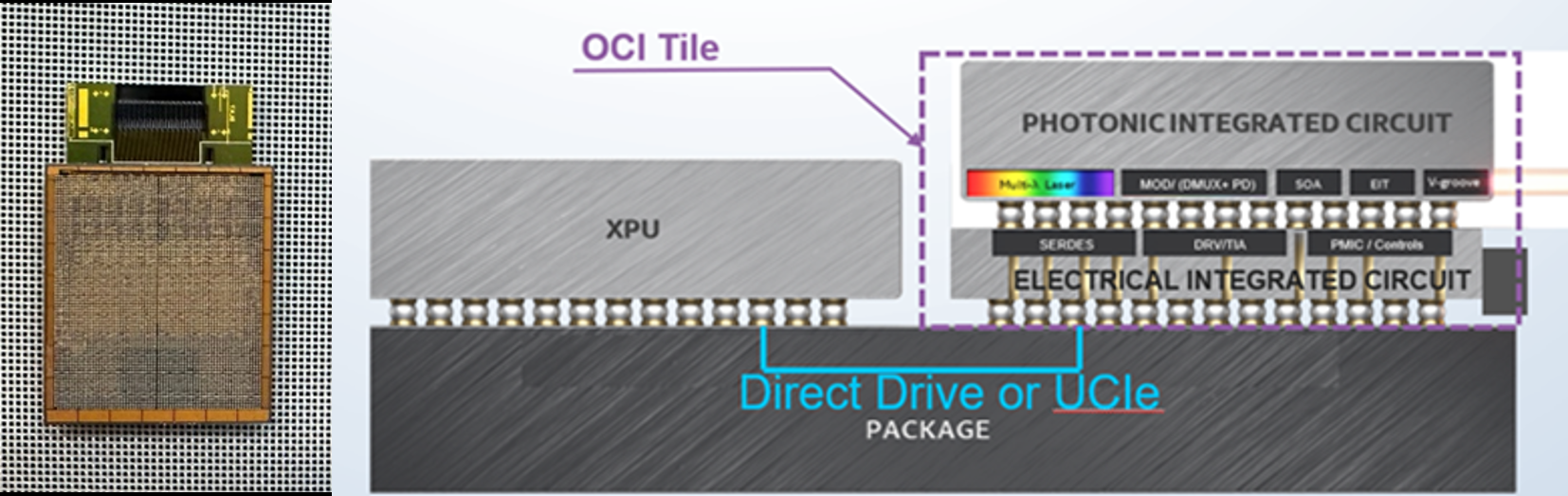 Вкупе с предельной дистанцией до 100 м новый чиплет существенно упростит системы интерконнекта: за редкими исключениями, вроде NVIDIA NVLink или Intel Gaudi 3 с его массивом Ethernet-контроллеров, связь организуется посредством PCIe-адаптера InfiniBand, либо Ethernet, в которые устанавливаются оптические трансиверы. Впрочем, и у PCI Express вскоре появится поддержка оптических подключений, что будет на руку Ultra Accelerator Link (UALink). 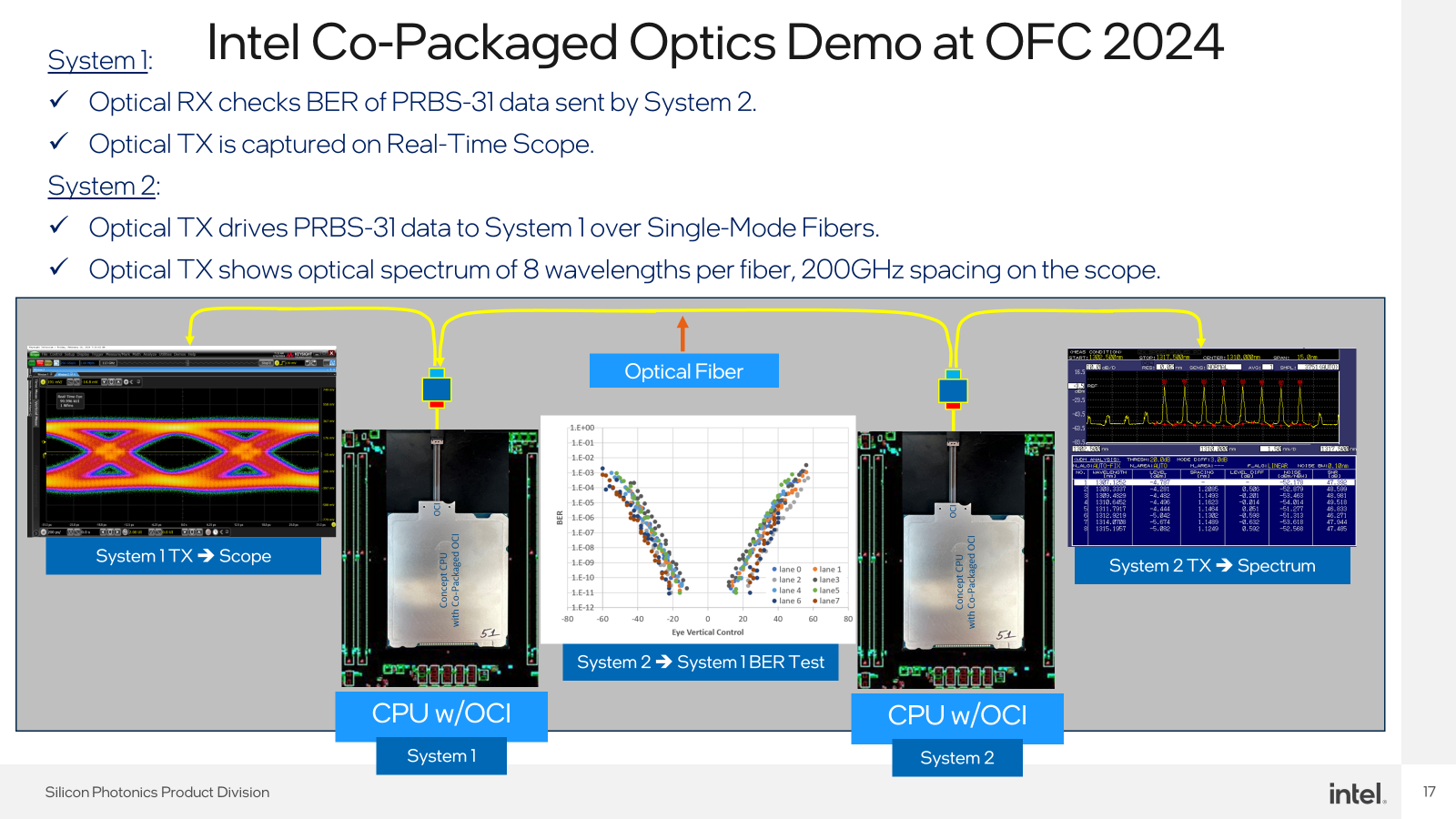 В следующем поколении пропускная способность каждой линии OCI возрастёт с 32 до 64 Гбит/с, после чего Intel планирует довести число одновременно используемых длин волн до 16. Затем, в промежутке между 2030 и 2035 годами планируется достигнуть 128 Гбит/с на линию, уже с 16 длинами волн и 16 парами волокон. Но без конкуренции здесь не обойдётся. NVLink, который уже сейчас существенно быстрее (1,8 Тбайт/с в нынешнем поколении), вскоре тоже обзаведётся оптической версией. Похожие решения развивают Celestial AI, MediaTek и Ranovus, Lightmatter и Ayar Labs.
09.11.2023 [03:15], Алексей Степин
RISC-V с приправой: модульные 192-ядерные серверные процессоры Ventana Veyron V2 можно дополнить ускорителямиВ 2022 года компания Ventana Micro Systems анонсировала первые по-настоящему серверные RISC-V процессоры Veyron V1. Анонс чипов, обещающих потягаться на равных с лучшими x86-процессорами с архитектурой x86, прозвучал громко. Популярности, впрочем, Veyron V1 не снискал, но на днях компания анонсировала второе поколение чипов Veyron V2, более полно воплотившее в себе принципы модульного дизайна и получившее ряд усовершенствований. Как и в первом поколении, компания-разработчик продолжает придерживаться концепции «процессора-конструктора» с чиплетным дизайном. В центре 4-нм Veyron V2 по-прежнему лежит I/O-хаб на базе AMBA CHI, охватывающий контроллеры памяти и шины PCI Express, а также блоки IOMMU и AIA. К нему посредством интерфейса UCIe подключаются вычислительные чиплеты. Латентность UCIe-подключения составляет менее 7 нс. 
Источник изображений здесь и далее: Ventana Micro Systems Чиплеты эти могут быть разных видов: либо с ядрами общего назначения (по 32 ядра на чиплет), образующие собственно процессор Veyron V2, либо содержащие специфические сопроцессоры под конкретную задачу (domain-specific acceleration, DSA). Последние могуть быть представлены FPGA, ИИ-ускорителями и т.д. Более того, Ventana по желанию заказчика может оптимизировать и I/O-хаб для повышения эффективности работы ядер CPU с сопроцессорами. 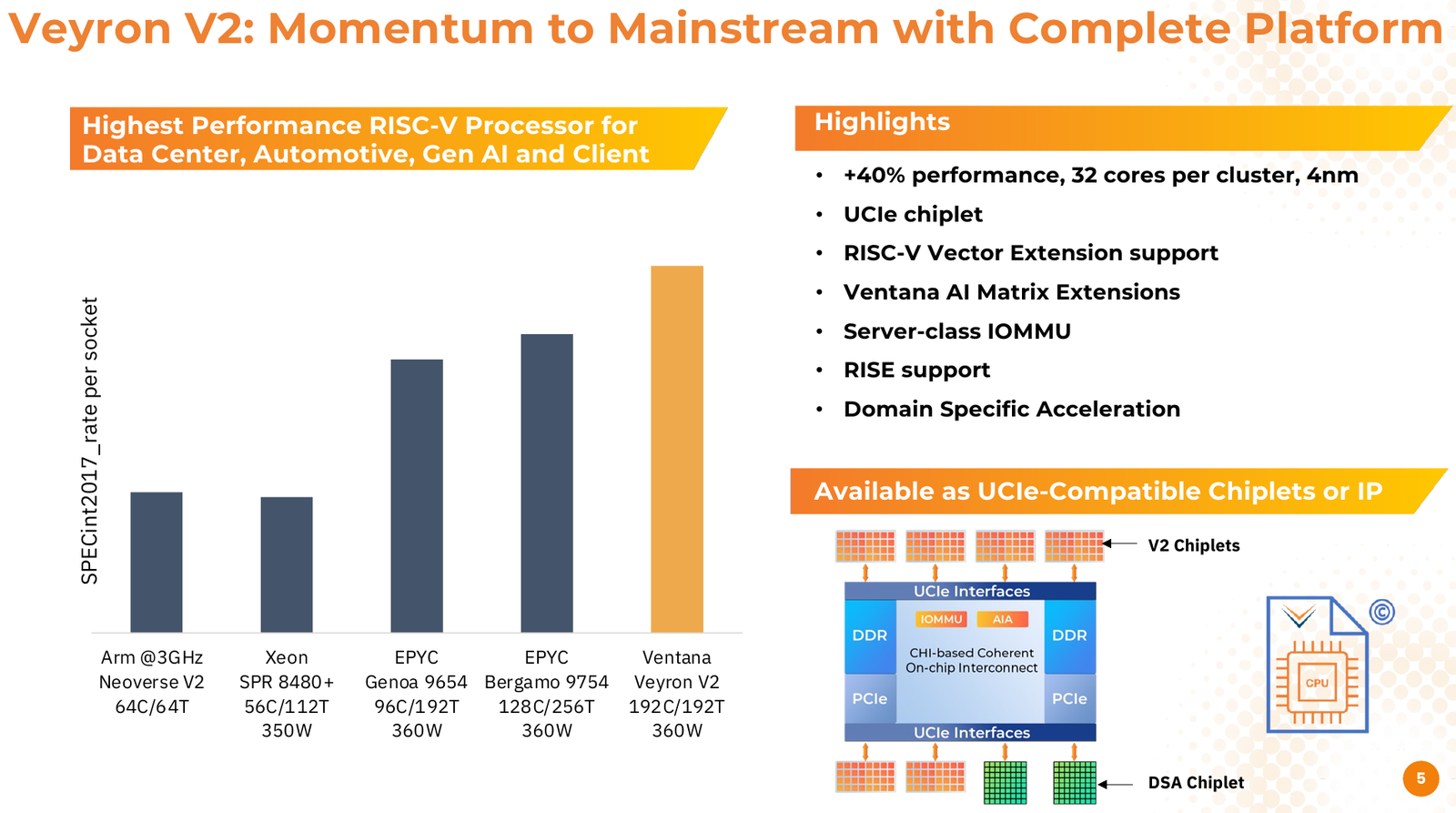 В классическом варианте Veyron V2 может иметь до шести чиплетов с RV64GC-ядрами V2, что в сумме даёт 192 ядра. Поддержка SMT отсутствует. Удельная производительность в пересчёте на ядро получается несколько ниже, чем у AMD Zen 4c, но согласно результатам тестов, предоставленных Ventana, 192-ядерный Veyron V2 заметно опережает AMD EPYC Bergamo 9754 (128C/256T) при аналогичном теплопакете в 360 Вт. 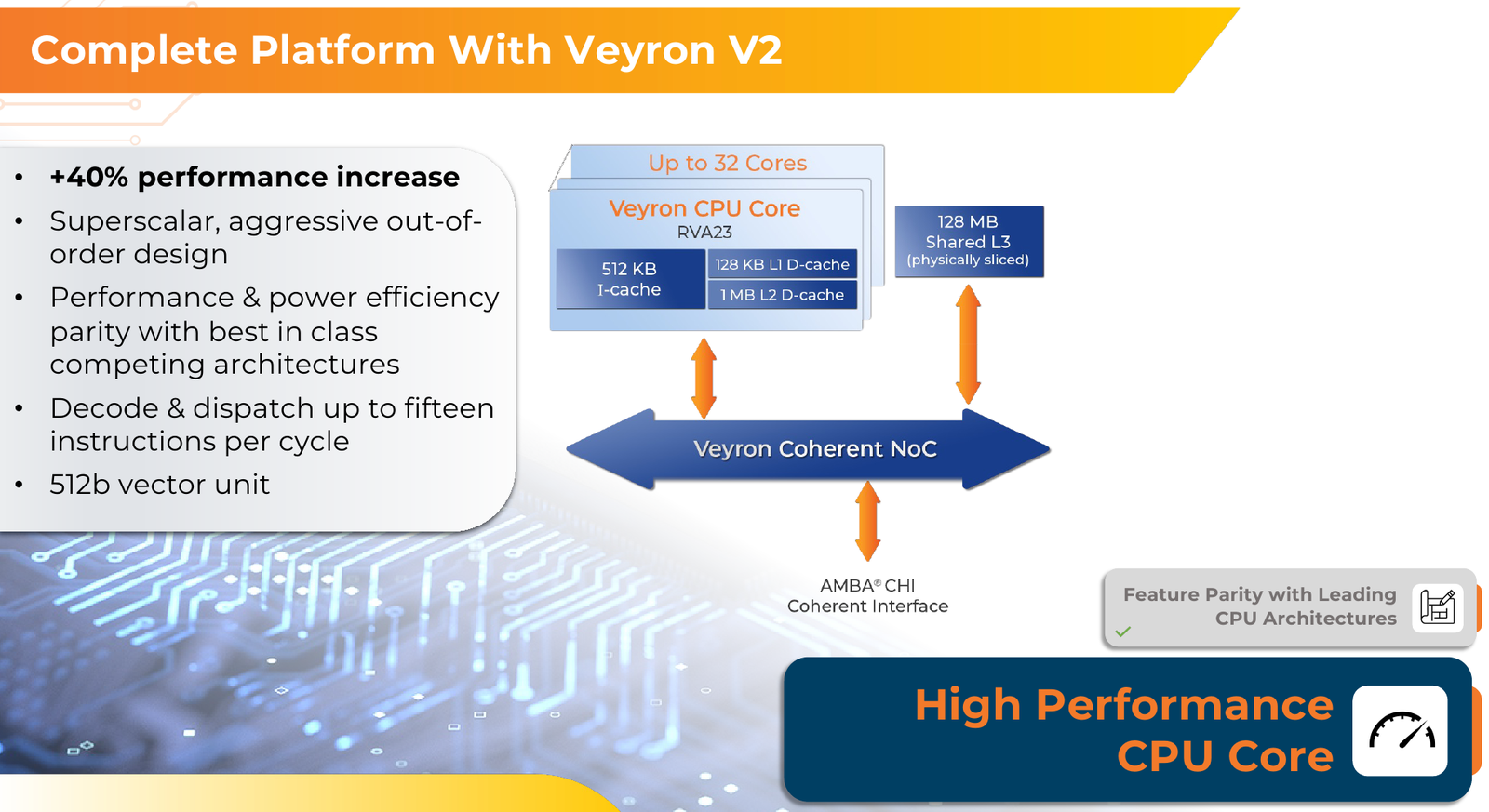 Столь неплохой результат достигнут за счёт оптимизации архитектуры Veyron: по сравнению с первым поколением говорится о 40 % прибавке производительности. Что немаловажно, во втором поколении процессоров Veyron была реализована поддержка 512-бит векторных расширений, фирменных матричных расширений, а также целого ряда других спецификаций. В целом ради совместимости разработчики предпочли остаться в рамках общего профиля RVA23. 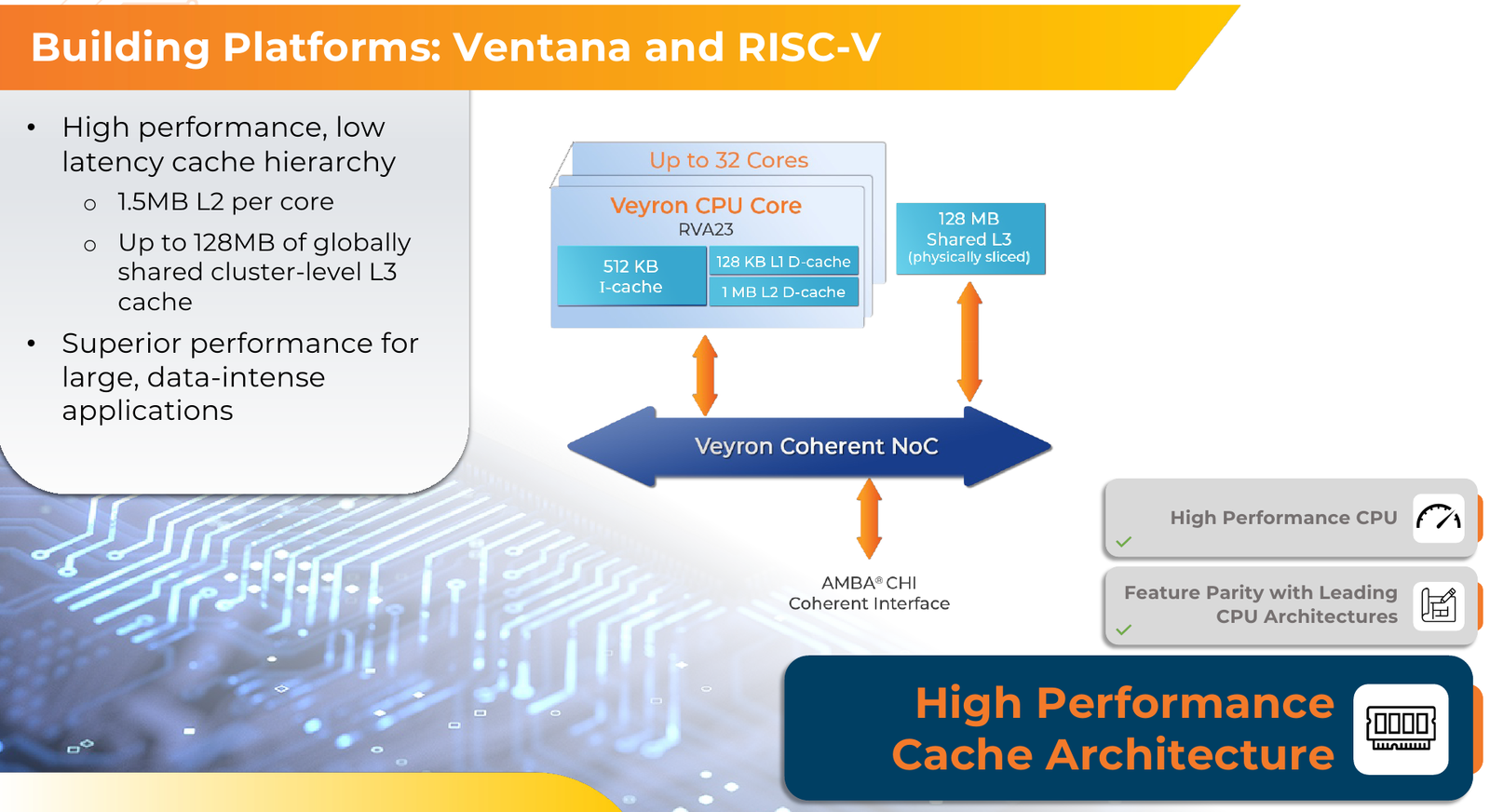 Сами ядра V2 используют суперскалярный дизайн с агрессивным внеочередным исполнением и продвинутым предсказанием ветвлений. Возможно декодирование и обработка до 15 инструкций за такт. Объём L1-кешей составляет 512 Кбайт для инструкций и 128 Кбайт для данных, дополнительно каждое ядро имеет свой кеш L2 объёмом 1 Мбайт. Общий для всего 32-ядерного чиплета L3-кеш имеет объём 128 Мбайт. Производительность внутренней когерентной шины составляет до 5 Тбайт/с. 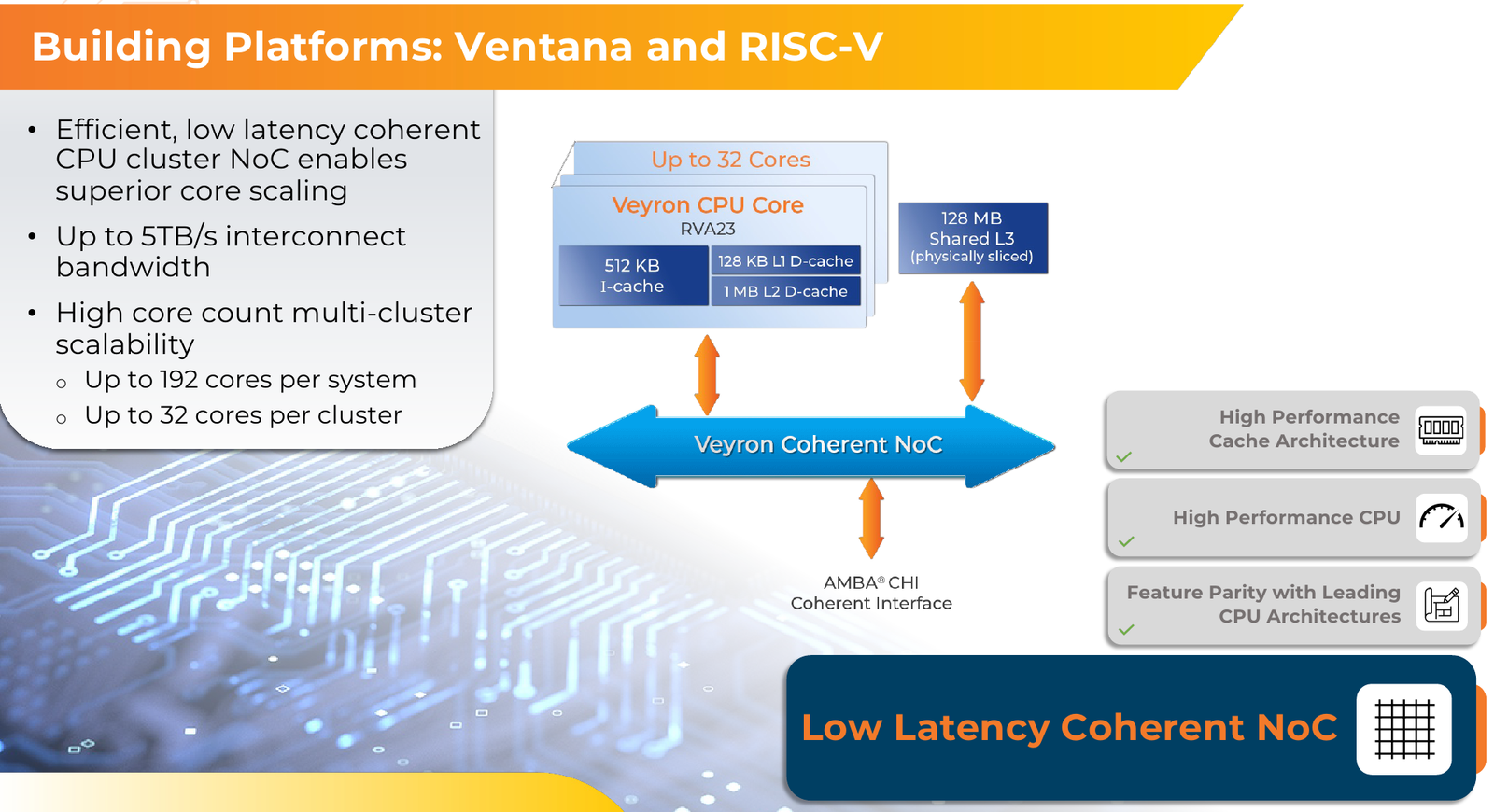 Позиционируемый в качестве решения для гиперскейлеров, крупных ЦОД и HPC, Veyron V2 имеет развитые средства предотвращения ошибок и защиты данных, от ECC-кешей и поддержки Secure Boot до аутентификации на уровне чиплета и продвинутых RAS-функций. Кроме того, реализована защита от атак по сторонним каналам. 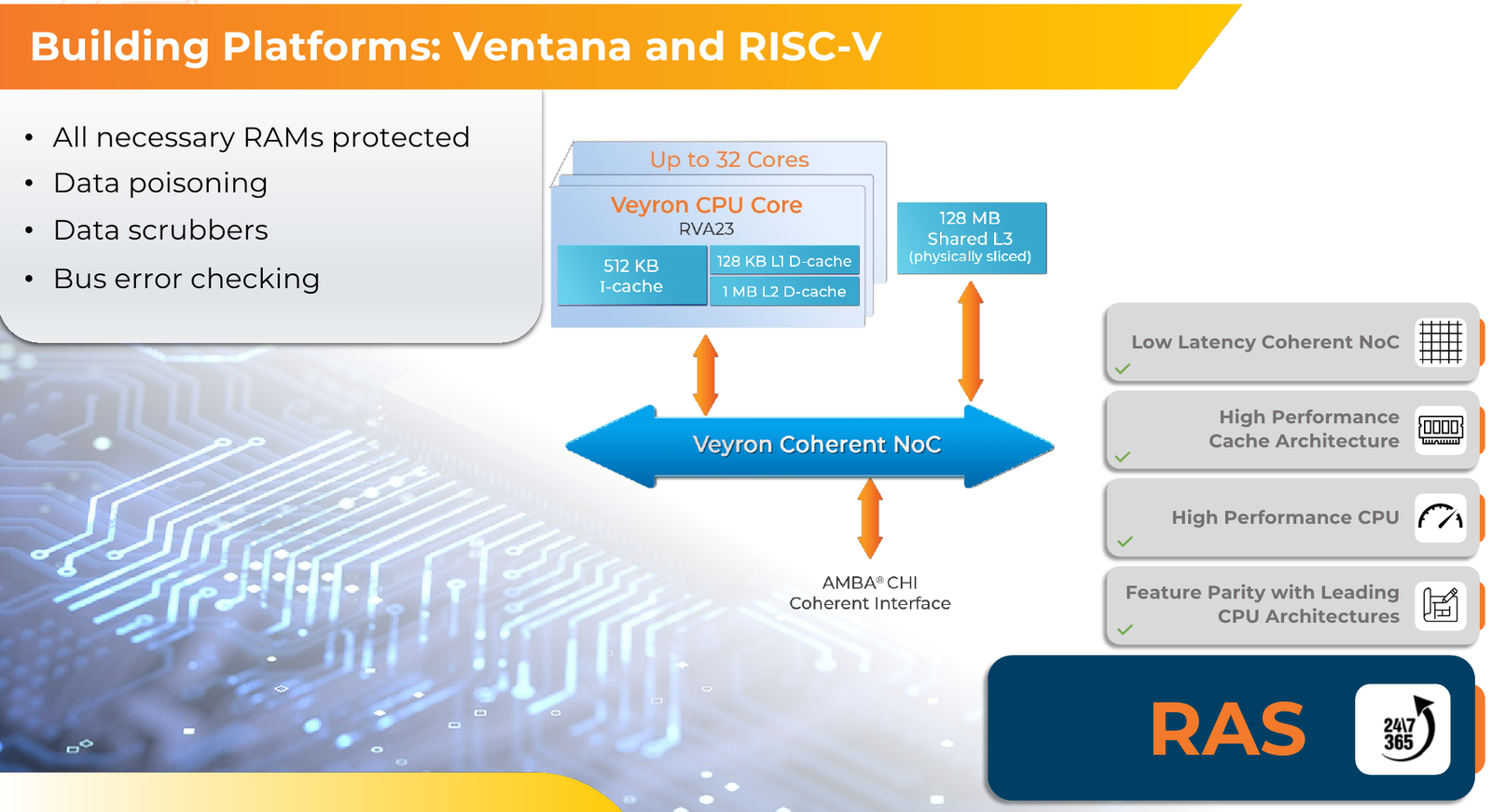 Несмотря на то, что мир RISC-V пока ещё похож на «Дикий Запад», Ventana старается опираться на развитые и популярные стандарты: в частности, это выражается в применении UCIe для подключения чиплетов, поддержку гипервизоров первого и второго типа, вложенную виртуализацию и совместимость с программной экосистемой RISC-V RISE. 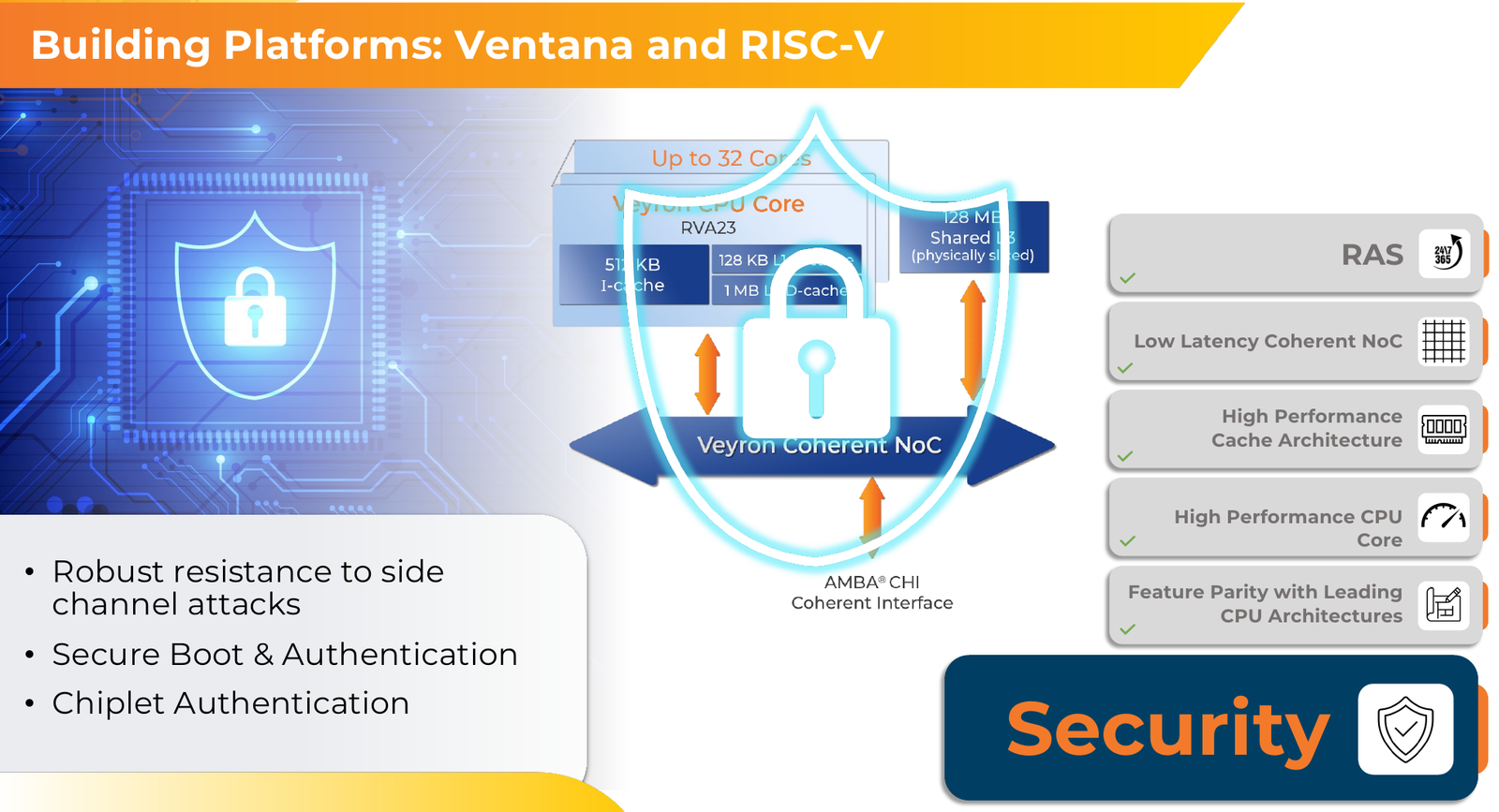 Подход Ventana позволит избежать недостатков, свойственных дискретным PCIe-ускорителям (высокая латентность, энергопотребление и стоимость) и сложным монолитным SoC (очень высокая стоимость разработки и сроки), снизить время и стоимость стоимость новых решений, а также обеспечить более низкий уровень энергопотребления. В общем, компания явно целится в гиперскейлеров. 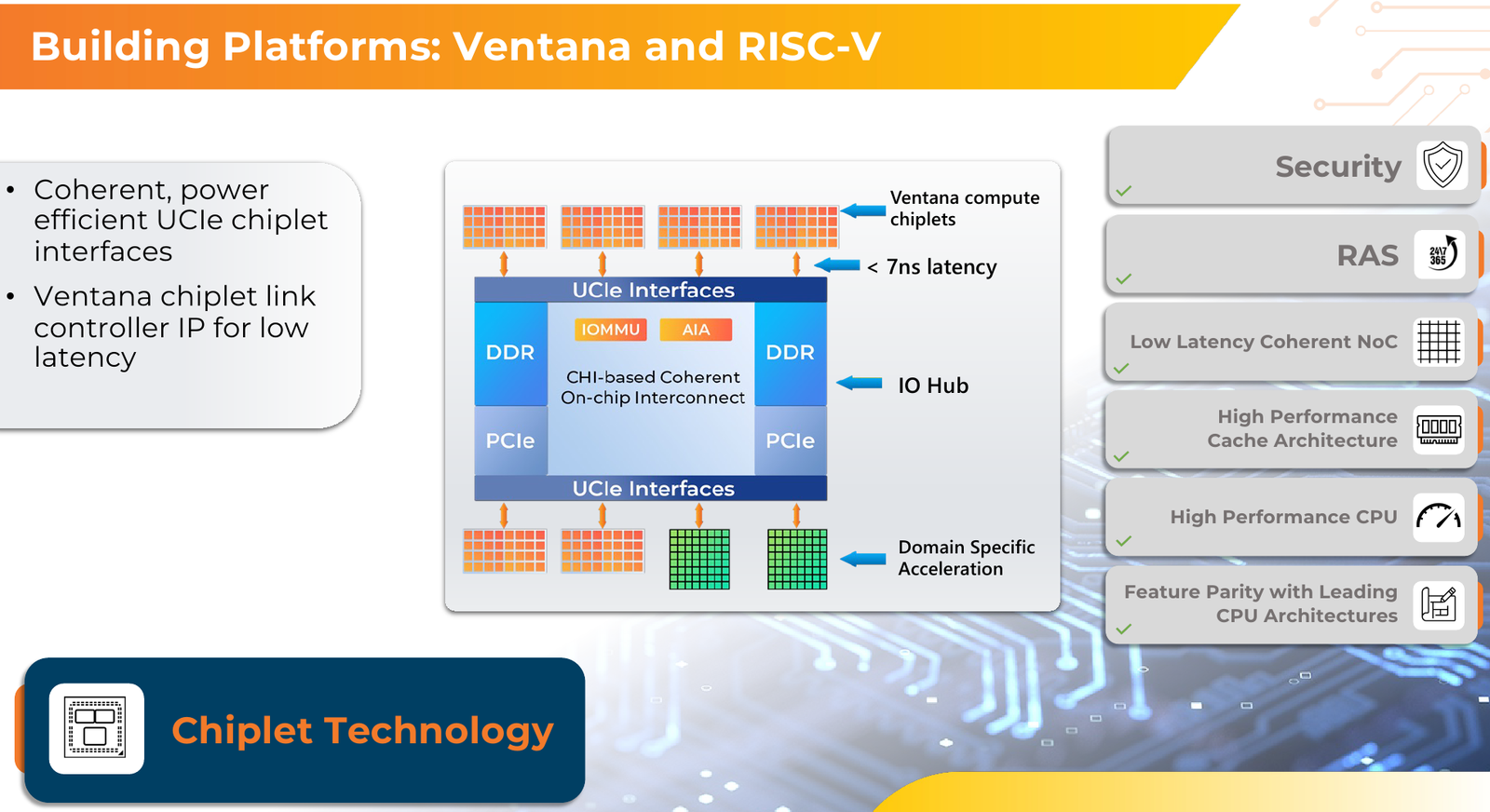 Видение сценариев применения DSA у Ventana очень широкий — от БД-ускорителей и блоков компрессии-декомпрессии данных до поддержки специфических алгоритмов в задачах аналитики и транскодеров в системах доставки контента. Также становятся ненужными дискретные DPU. Первым партнёром Ventana стала Imagination Technologies, крупный разработчик GPU. 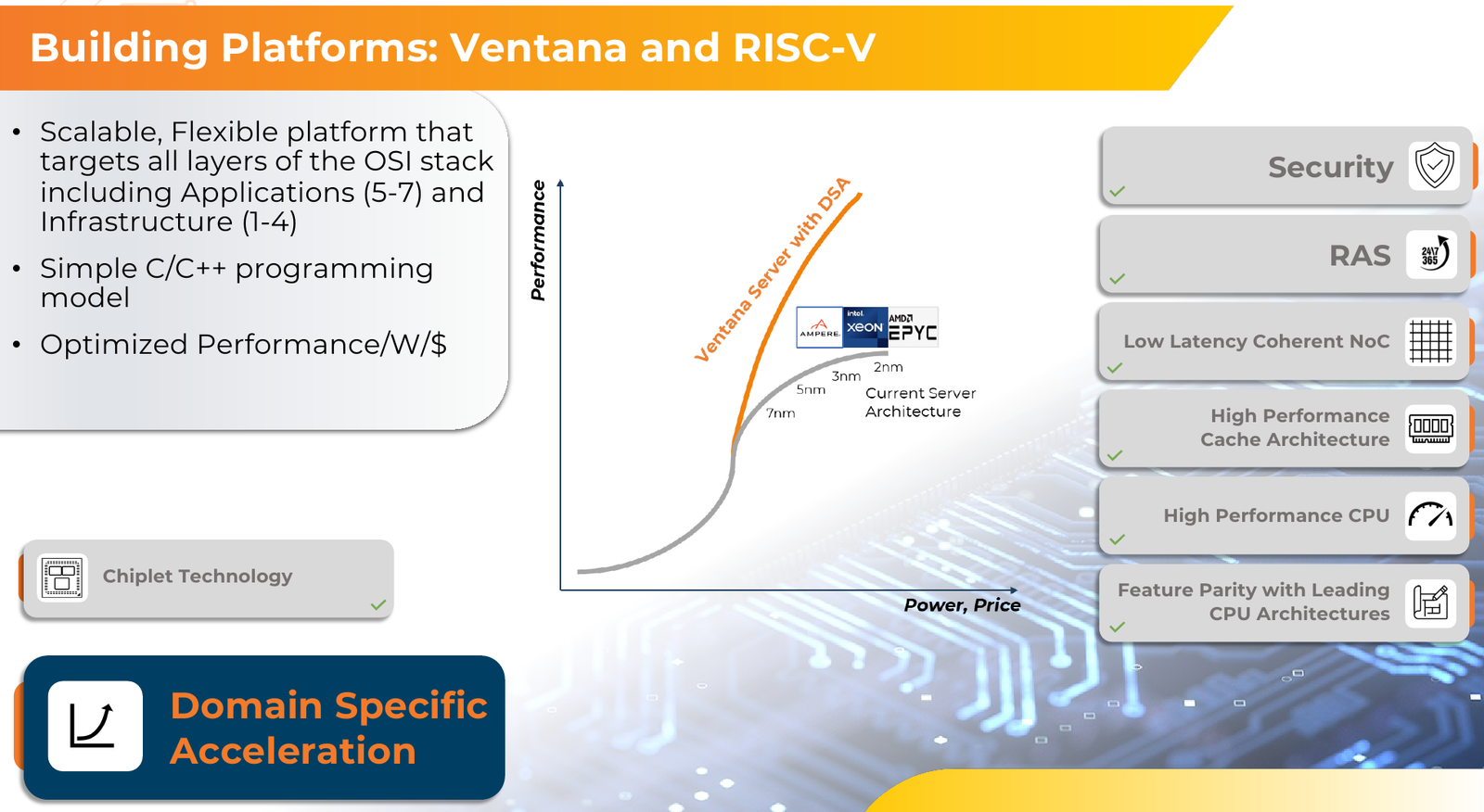 В качестве вариантов физической реализации новой платформы Ventana предлагает компактный 1U-сервер, содержащий один чип Veyron V2 со 192 ядрами, работающими на частотах до 3,6 ГГц, и 12 каналами DDR5-5600. Вероятнее всего, производителем новой платформы станет GIGABYTE. Ожидать первых поставок следует не ранее II квартала 2024 года. 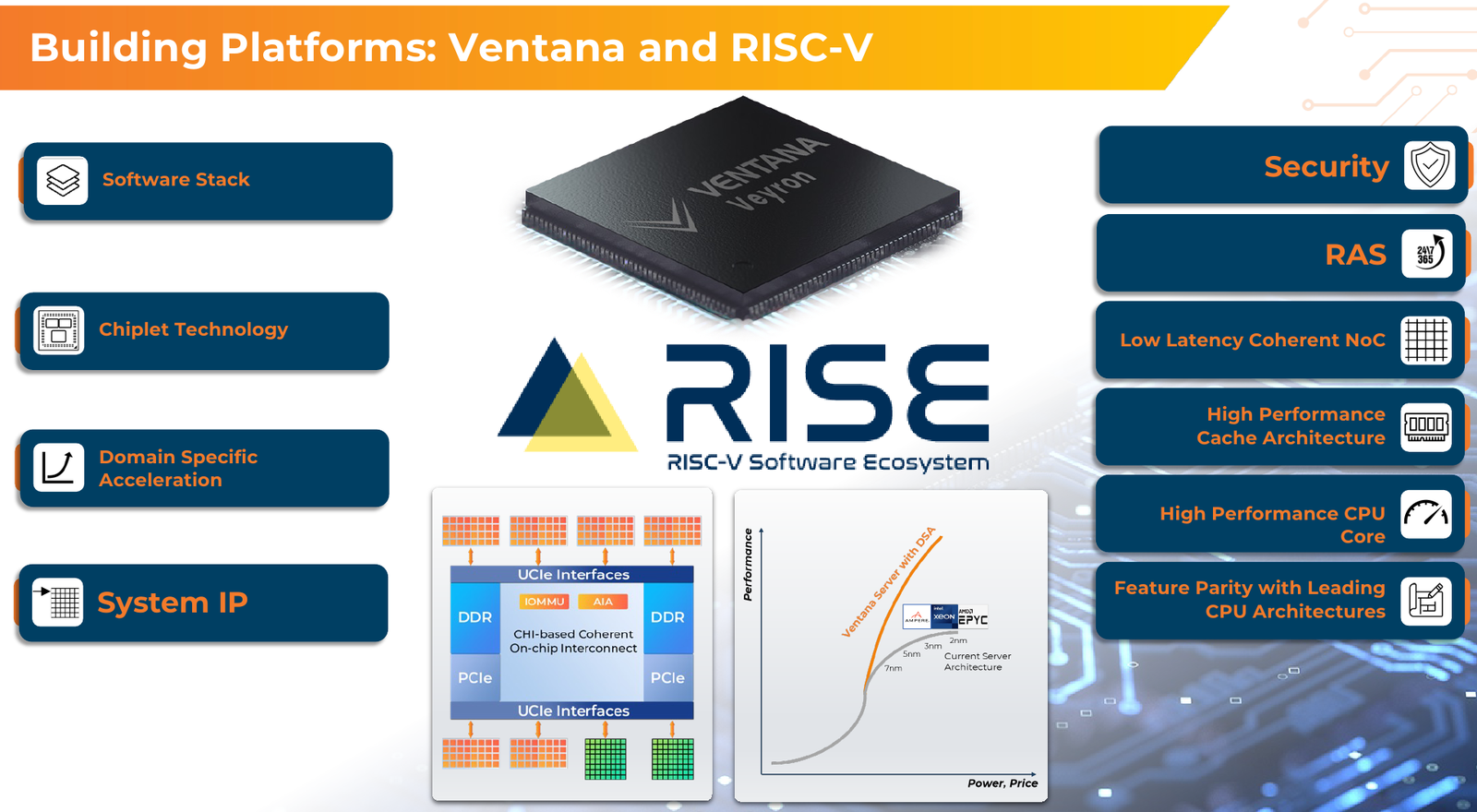 В целом, видение высокопроизводительной модульной платформы, продвигаемое Ventana, выглядит перспективно, а упор на применение DSA может выгодно отличать её большинства Arm-серверов, конкурирующих с решениями Intel/AMD лоб в лоб. Вопрос лишь в поддержке со стороны разработчиков программного обеспечения — и здесь может сыграть ставка разработчиков на максимально открытые, широкие стандарты.
06.09.2022 [22:47], Алексей Степин
Кремниевая фотоника Lightmatter Passage объединит чиплеты на скорости 96 Тбайт/сНа конференции Hot Chips 34 компания Lightmatter, занимающаяся созданием фотонного ИИ-процессора, рассказала о своей новой разработке, Lightmatter Passage, открывающей для чиплетов эру фотоники. Как известно, переход на чиплеты позволил разработчикам сложных чипов сравнительно малой кровью обойти ограничения, накладываемые технологиями на создание монолитных кристаллов большой площади. Однако современный высокоскоростной межчиплетный интерконнект всё равно весьма сложен и потребляет сравнительно много энергии. И по мере роста количества чиплетов на общей подложке проблема будет лишь обостряться. 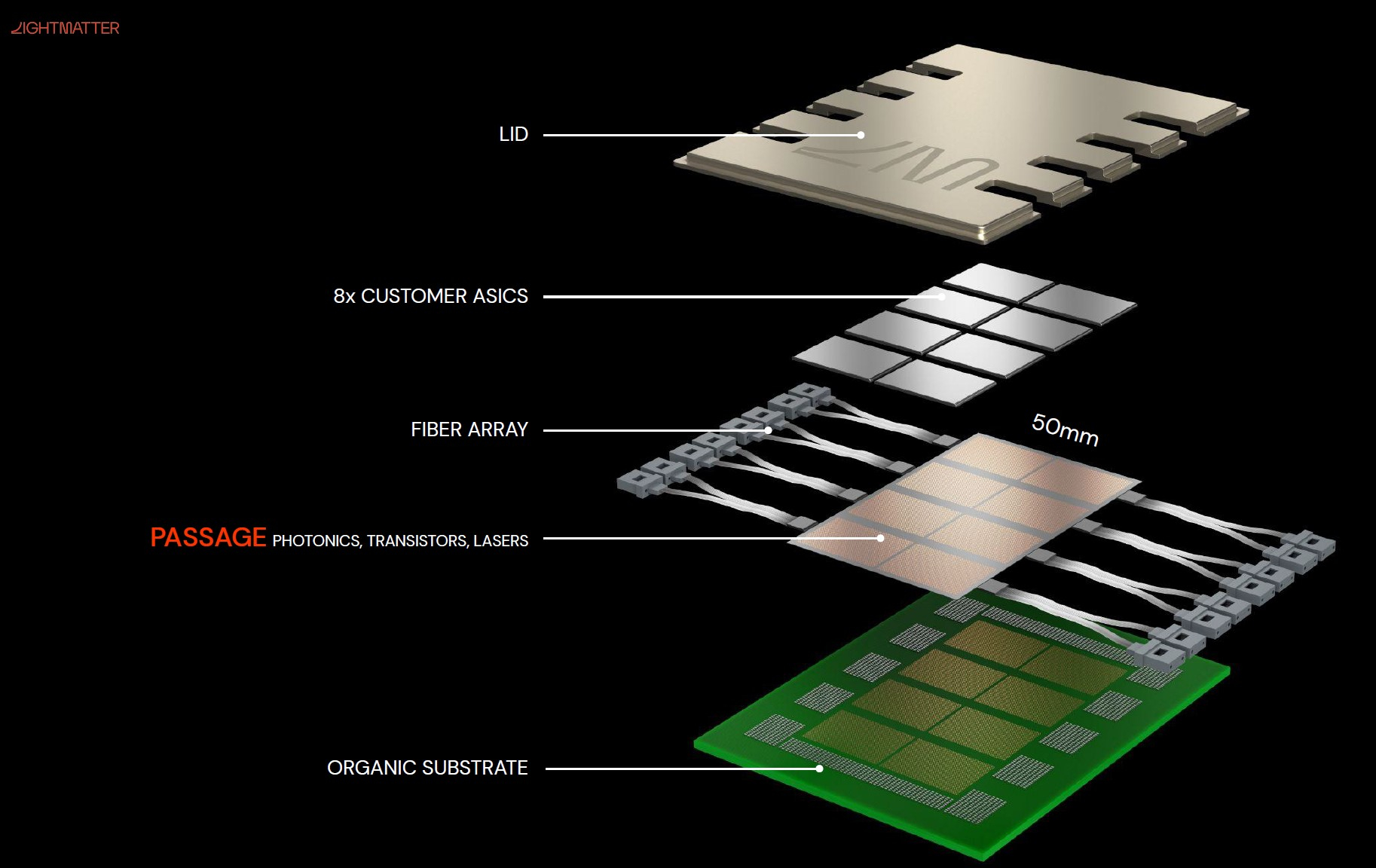
Изображения: Lightmatter (via ServeTheHome) Но технология Lightmatter Passage, призванная заменить электрический интерконнект оптическим, позволит эту проблему обойти. По сути, Passage — универсальная кремниевая прослойка, содержащая в своём составе лазеры, оптические модуляторы, фотодетекторы, волноводы, а также классические транзисторы для сопутствующей логики. Поверх этой прослойки Lightmatter и предлагает размещать чиплеты любой архитектуры. 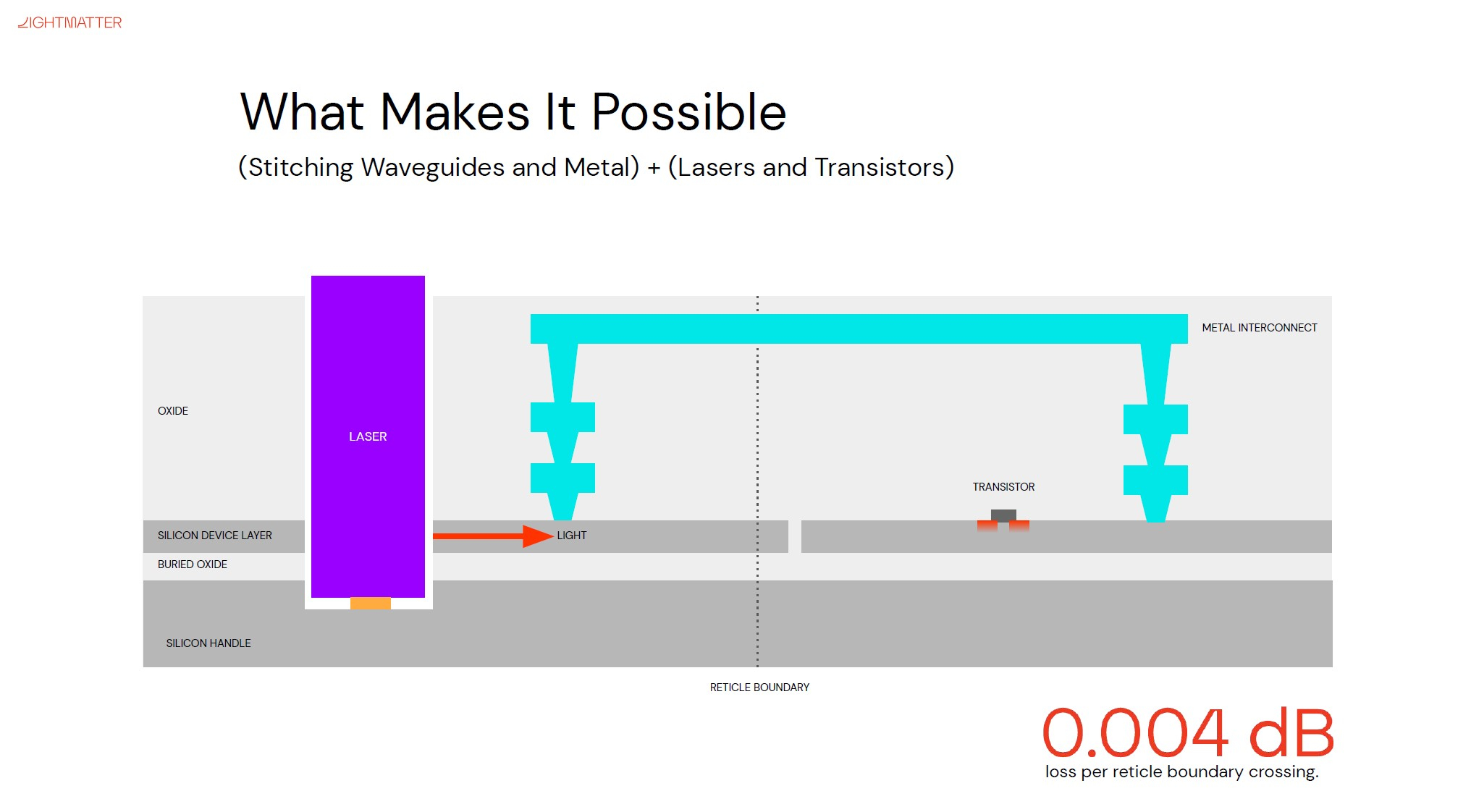 Электрическая часть Passage имеет изменяемую конфигурацию и в текущей реализации поддерживает установку до 48 чиплетов (в виде матрицы 6×8). Производится такая прослойка из 300-мм кремниевой пластины SOI, верхний и нижний слои Passage имеют классические контакты для чиплетов и установки на PCB соответственно. При этом максимальная подводимая электрическая мощность может достигать 700 Вт. Вся же коммуникация чиплетов между собой происходит внутри и является оптической. 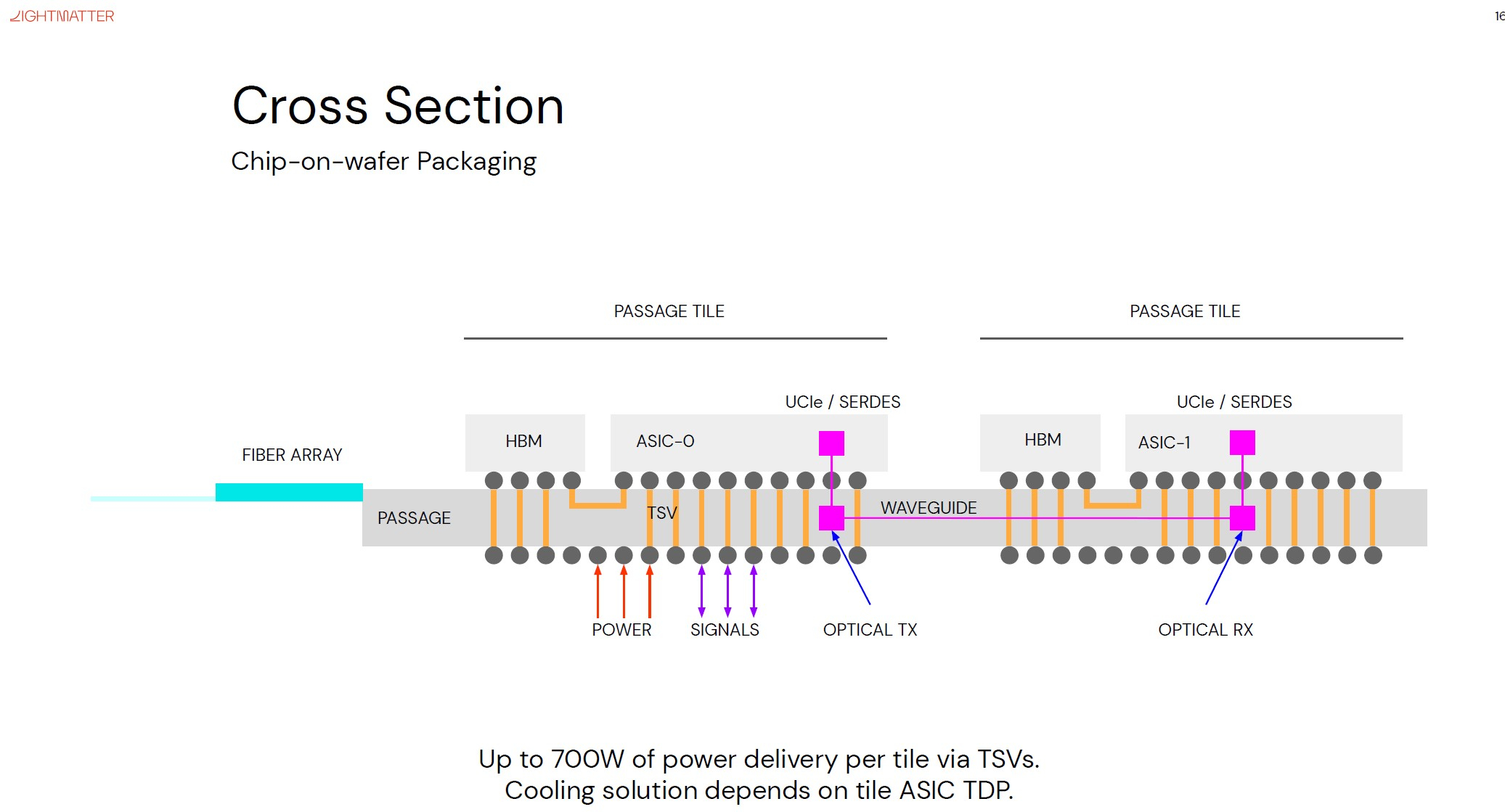 Матрица фотонных волноводов, плотность которой в 40 раз выше, чем у традиционных оптоволоконные технологий, обеспечивает латентность одного перехода на уровне менее 2 нс. Как заявляют разработчики, расстояние между чиплетами при этом роли не играет — для любого сочетания пары точек «входа» и «выхода» сигнала значение задержки одинаково. Высокая плотность волноводов позволяет «накормить» каждый чиплет потоком данных до 96 Тбайт/с, а внешние каналы Passage позволяют связать чипы с другими компонентами системы на скоростях до 16 Тбайт/с. 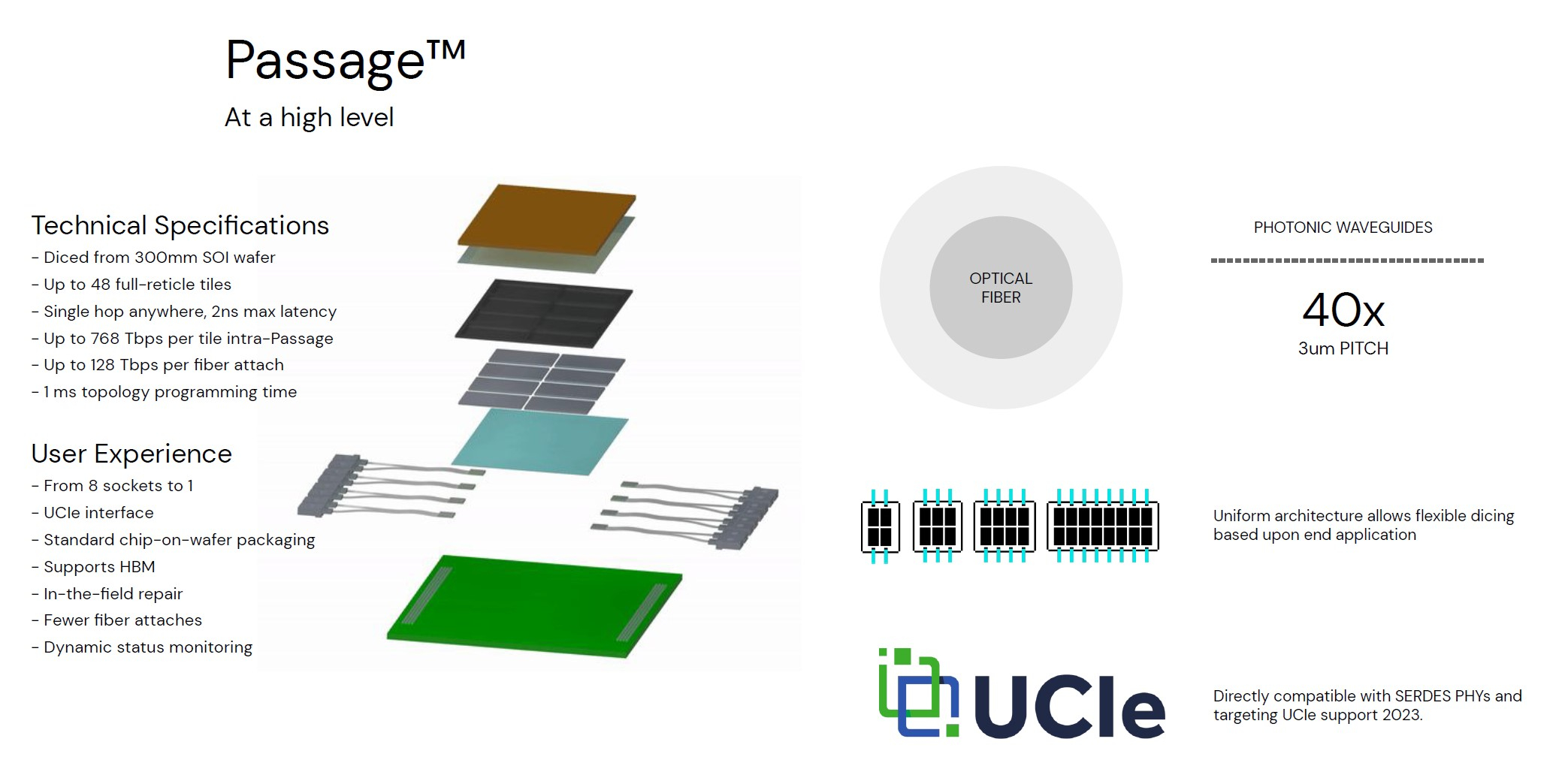 Основой данной технологии является фирменная разработка компании, позволяющая точно «сшивать» в пределах нескольких слоев SOI-кремния электрические соединения с многочисленными волноводами. Уже существующая в кремнии тестовая реализация Passage потребляет 21 Вт, позволяет устанавливать до 48 чиплетов площадью по 800 мм2, обеспечивает каждое посадочное место 32 каналами с пропускной способностью 1024 Тбит/с, причём топологию интерконнекта можно динамически менять.  Тестовая подложка Passage, полученная из 300-мм пластины, содержит 288 лазеров мощностью 50 мВт каждый. Всего в состав системы входит 150 тыс. компонентов, и это заявка на абсолютный рекорд для фотонных чипов. Кроме того, новая технология совместима со стандартом UCIe — говорится о скорости 32 Гбит/с на линию. Впрочем, в случае простого SerDes-соединения, как считают создатели, этот показатель можно поднять до 112 Гбит/с. |
|



{kind=link}