Материалы по тегу: x
|
13.01.2023 [23:24], Владимир Мироненко
IBM полностью передала разработку ОС AIX своему индийскому офисуIBM полностью передала разработку платформы AIX своему индийскому офису. Об этом сообщил ресурс The Register. До этой передачи, которая, по данным The Register, произошла в III квартале 2022 года, разработка AIX, согласно его источнику, была равномерно распределена между специалистами IBM в США и Индии. С наступлением 2023 года все работы были перемещены в Индию. Согласно данным The Register, пострадало порядка 80 разработчиков AIX в США, которым было предложено подыскать другую работу в компании, выделив на решение вопроса неограниченное время. Сообщается, что большая часть программистов перешла на другие должности в IBM, хотя некоторые оказались в «подвешенном состоянии». По словам собеседника The Register, это в основном пожилые сотрудники, имеющие право на получение пенсии. 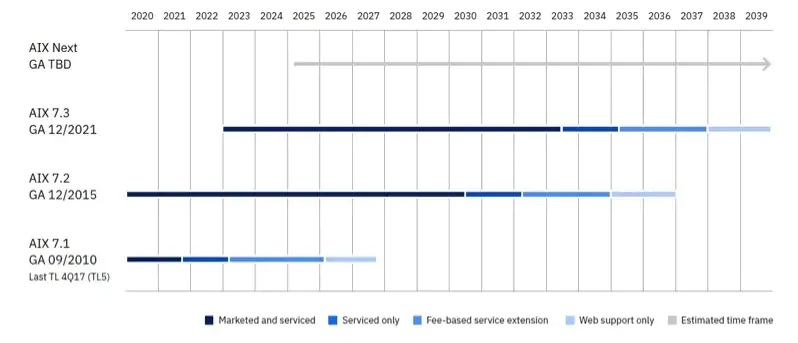
Изображения: IBM «Среди моих коллег общее мнение состоит в том, что перераспределение используется для того, чтобы вытолкнуть пожилых сотрудников из компании и сделать это таким образом, чтобы избежать проверки, которая проводится при увольнениях», — говорит источник. При увольнении работника обычно выплачивается выходное пособие, что отражается в отчётности. Перераспределение (направление работников на поиск другой должности внутри компании, возможно, с переездом) позволяет избежать этих затрат и заполнения лишних бумаг. Кроме того, это может побудить работника уволиться по собственному желанию.  Известно, что против IBM было подано множество исков с обвинением компании в дискриминации пожилых сотрудников и неправомерном их увольнении. IBM намеренно усложнила проверку таких обвинений, перестав в 2014 году раскрывать возрастные демографические данные об уволенных сотрудниках. Имея доступ к таким данным было бы проще оценить средний возраст тех, кого подвергают перераспределению. В феврале 2022 года директор по персоналу IBM директор по работе с персоналом IBM Никль Ламоро (Nickle LaMoreaux) выступила с опровержением «ложных утверждений о возрастной дискриминации в компании». В последнее время многие из исков против IBM были урегулированы компанией на условиях конфиденциальности, нередко без признания своей вины и без возможности формирования коллективных исков.
11.01.2023 [03:00], Игорь Осколков
Асимметричный ответ: Intel официально представила процессоры Xeon Sapphire RapidsIntel официально представила серверные процессоры Xeon семейства Sapphire Rapids (SPR), выход которых изрядно задержался, а также ускорители ранее известные как Ponte Vecchio и теперь объединённые вместе с HBM-версиями SPR в отдельную HPC-серию Max. В этом поколении Intel не смогла догнать AMD EPYC Genoa по числу ядер, числу каналов памяти и линий PCIe, но заготовила ассиметричный, хотя и очень странно реализованный ответ. Всего представлено 52 модели с числом P-ядер от 8 до 60 и с TDP от 125 до 350 Вт. По числу ядер это существенный апгрейд по сравнению с Ice Lake-SP (до 40 ядер), да и IPC вырос у Golden Cove на 15 % в сравнении с Sunny Cove. Но это существенный проигрыш в сравнении с Genoa (до 96 ядер), особенно если учитывать их максимальный TDP в 360 Вт (cTDP до 400 Вт). Правда, у Sapphire Rapids есть ещё и экономичный режим работы, в котором энергопотребление снижается на 20 %, а производительность для некоторых нагрузок — всего на 5 %. 
Изображения: Intel Sapphire Rapids предлагают 8 каналов памяти DDR5-4800 (1DPC) и DDR5-4400 (2DPC). 2DPC у Genoa пока что нет. Кроме того, контроллеры поддерживают и модули Optane PMem 300 (Crow Pass), но с учётом того, что производство 3D XPoint прекращено, достаться они могут не всем (впрочем, не всем они и нужны). Ну а маленькая серия Max также включает 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с). Остались и отличия в максимальном объёме SGX-анклавов в зависимости от модели CPU. 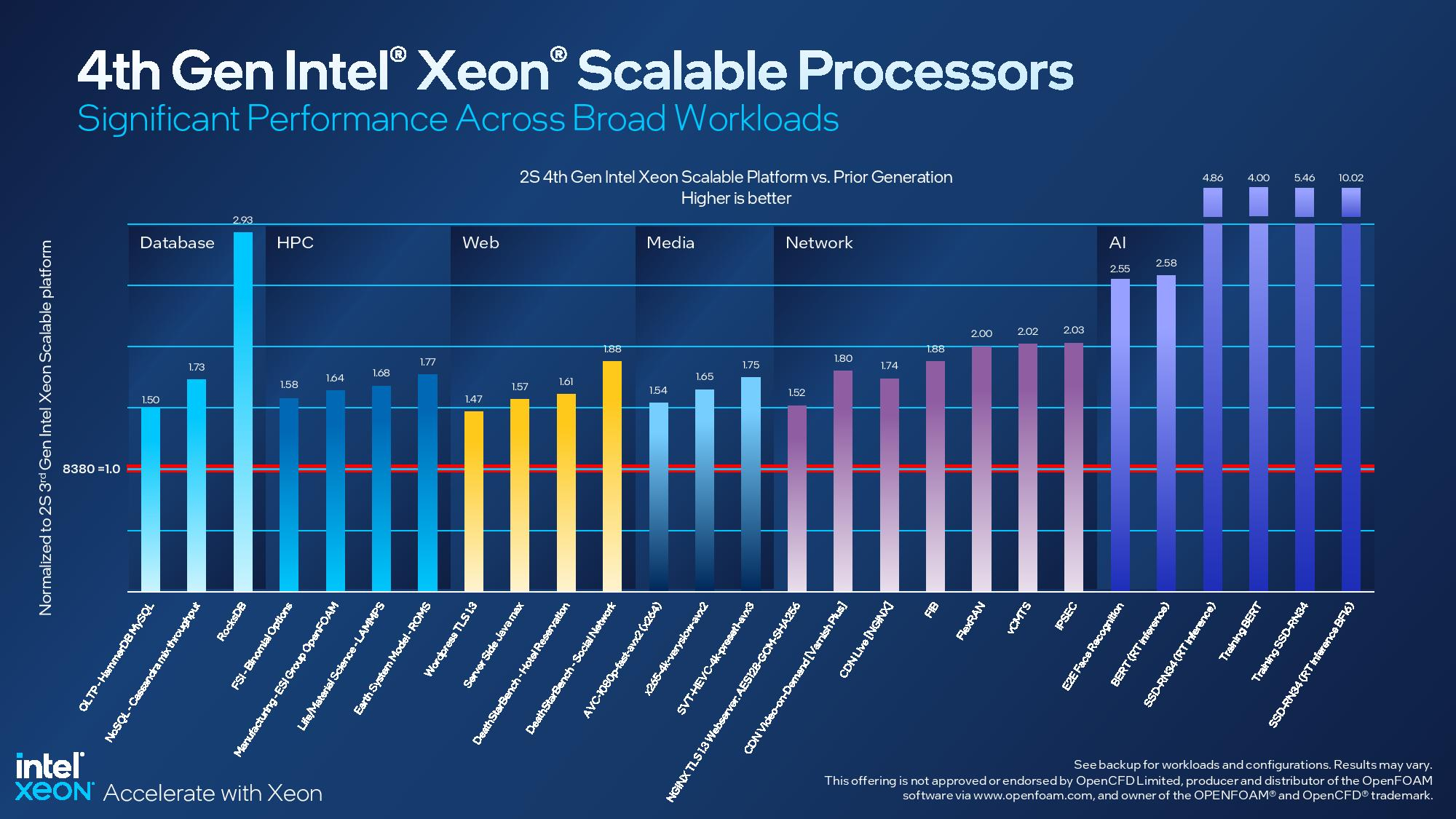 Однако по числу ядер на узел всё равно лидирует Intel. Если AMD поддерживает только 2S-конфигурации, то Intel снова предлагает и 4S, и 8S (а с момента выхода Cooper Lake-SP прошло немало времени) — на процессор доступно до 4 линий UPI 2.0 (16 ГТ/с в сравнении с 11,2 ГТ/с у Ice Lake-SP). В 2S-платформах Sapphire Rapids также формально обгоняет Genoa по числу линий PCIe 5.0, которых тут по 80 шт. на сокет. Формально потому, что в случае Genoa при желании всё же можно получить 160 линий, пожертвовав скоростью шины между CPU, но в односокетном варианте EPYC в любом случае интереснее Xeon. 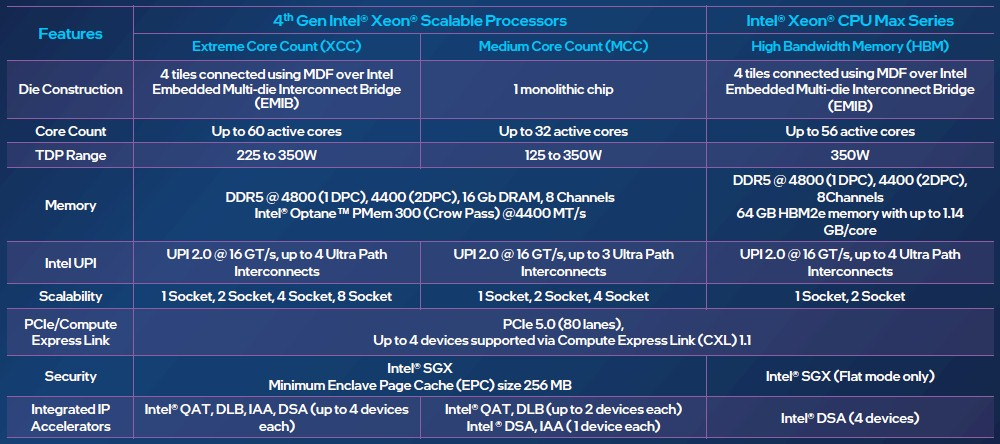 Без нюансов тут не обошлось. Так, при бифуркации до 8 x2 скорость падает до PCIe 4.0. Зато каждый root-комплекс поддерживает CXL 1.1, тогда как у Genoa CXL есть только у половины! Впрочем, поддержка всё равно ограничена 4x CXL-устройствами на CPU. Что ещё более странно, официально заявлена поддержка только устройств Type 1 и Type 2, но не Type 3, хотя последние весьма пригодились бы в ряде конфигураций, где требуется больше относительно недорогой, пусть и несколько более медленной, RAM. 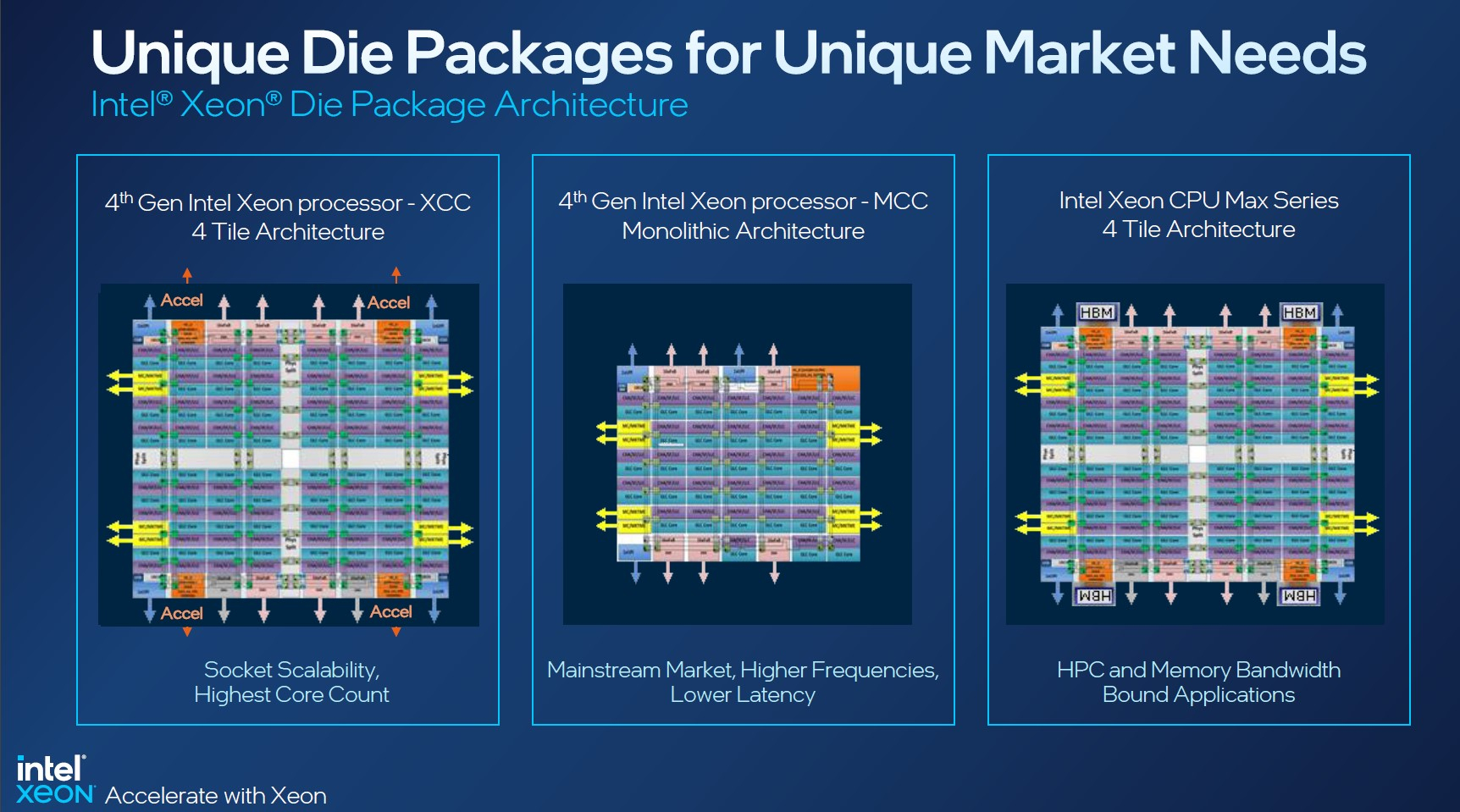 Сохранилось традиционное разделение на серии Platinum (8000), Gold (6000/5000), Silver (4000) и Bronze (3000), к которым теперь добавилась серия Max (9400). Список суффиксов, означающих оптимизацию под те или иные задачи и наличие каких-то особенностей, стал чуть шире: Y (SST-PP 2.0), Q (рассчитаны на работу с СЖО), U (односокетные общего назначения), T (увеличенный жизненный цикл), H (in-memory СУБД, аналитика, виртуализация), N (сетевые решения, в том числе для 5G), облачные P/V/M (IaaS/Paa/медиа), S (СХД и HCI). 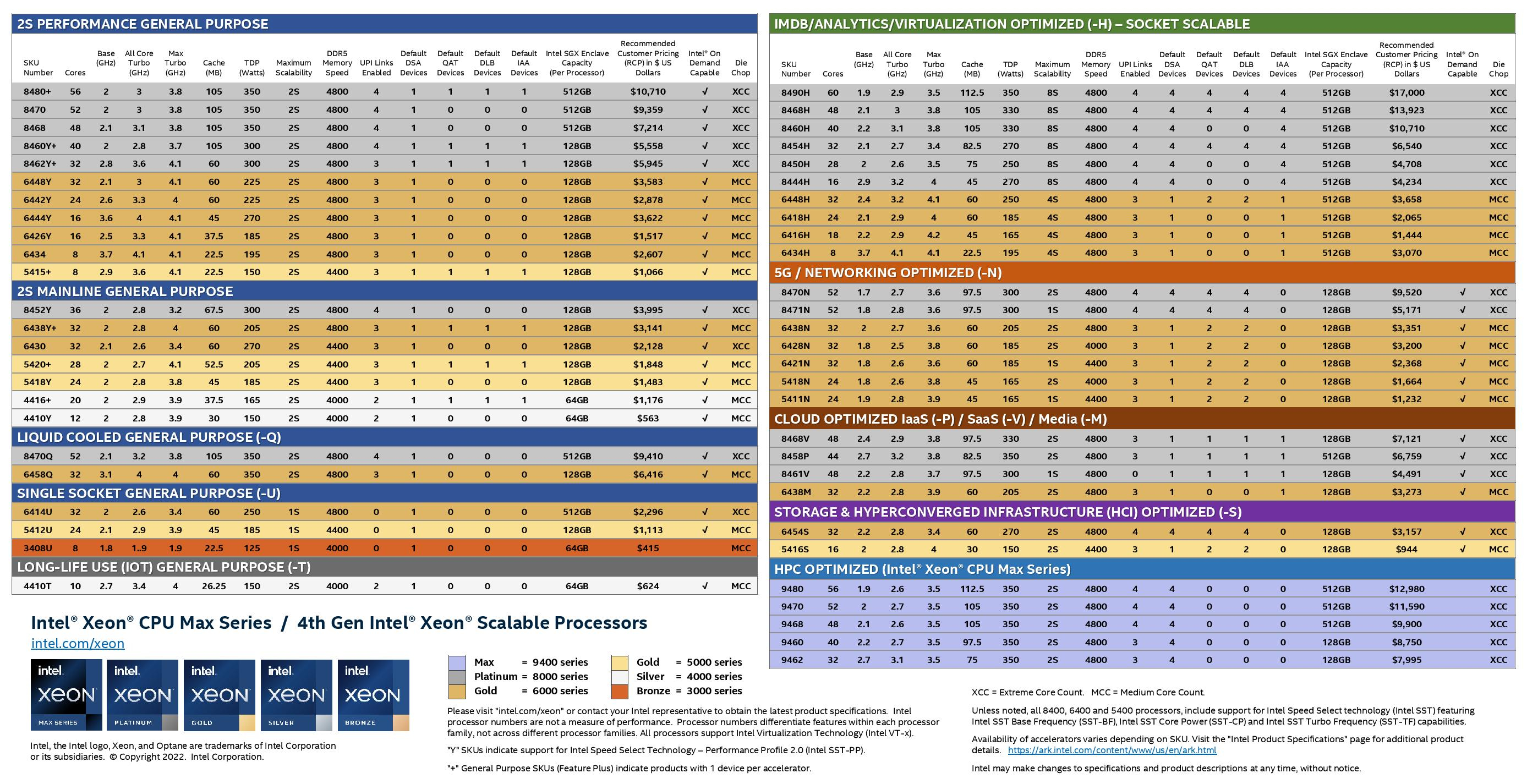 Но некоторые модели также имеют в названии «+». И вот тут начинается самое интересное! Все процессоры получили «традиционную» (в сравнении с Genoa) реализацию AVX-512, включая DL Boost, а также целый новый набор ИИ-инструкций AMX (до 10 раз быстрее обучение и инференс в сравнении с Ice Lake-SP). Есть и всяческие Speed Select, DDIO, TDX, CET и т.д. Но Sapphire Rapids также получили четыре отдельных ускорителя:
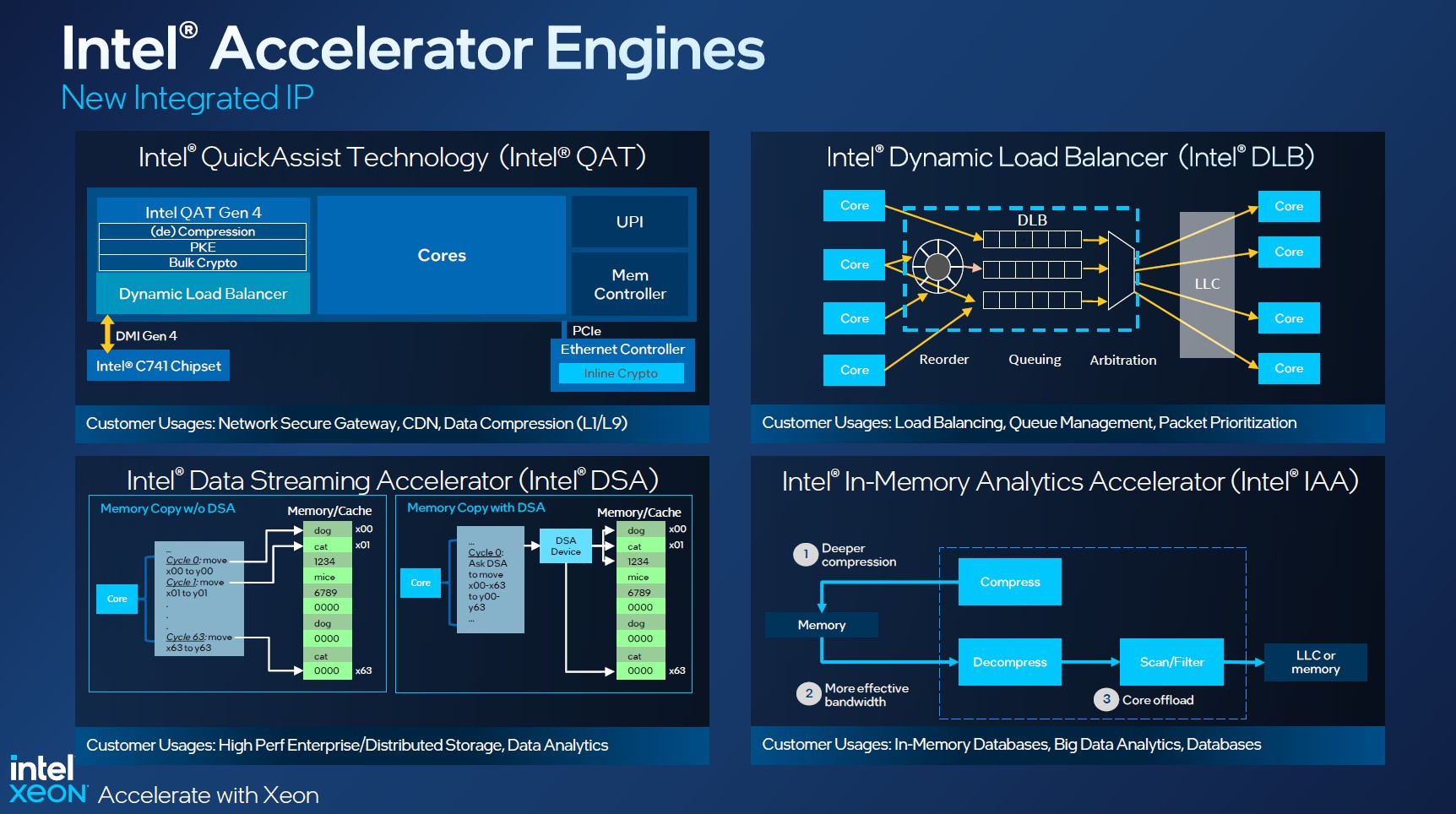 Intel заявляет, что средний прирост производительности Sapphire Rapids в сравнении с Ice Lake-SP составил 1,53 раза. А вот для ряда нагрузок, которые могут задействовать новые ускорители прирост производительности на Вт составляет уже до 2,9 раз! То есть Intel продолжает придерживаться стратегии создания максимально универсальных CPU для различных нагрузок. И действительно, спорить с гибкостью Sapphire Rapids трудно. Но какой ценой это достигается? Т.е. буквально: во сколько это обойдётся заказчику? Ответа пока нет.  Дело в том, что в зависимости от модели отличается число доступных и число активированных ускорителей. Фактически в новом поколении используется два вида кристаллов: XCC, «сшитые» из четырёх отдельных тайлов, и монолитные MCC (до 32 ядер, причём 32-ядерных моделей в серии большинство). У каждого тайла в XCC есть по одному блоку QAT, DSA, DLB и IAA, т.е. суммарно на CPU приходится до четырёх ускорителей каждого типа. В случае MCC может быть по два QAT и DLB и по одному DSA и IAA на процессор. Например, у тех моделей, что помечены «+», активно по одному блоку каждого типа, а минимум один DSA активен есть вообще у всех CPU.  За не активированные по умолчанию ускорители придётся заплатить в рамках программы Intel On Demand (SDSi), причём есть опции как с единовременным платежом за постоянную активацию, так и с оплатой по факту использования (это удобно в случае облаков и платформ по типу HPE Greenlake). Исключением являются H-модели, куда входит и самый дорогой ($17000) 60-ядерный процессор 8490H с полностью разблокированными ускорителями и поддержкой 8S-конфигураций, а также процессоры Max, которым доступно только четыре DSA-блока и 2S-платформы, например, 56-ядерный 9480 ($12980). 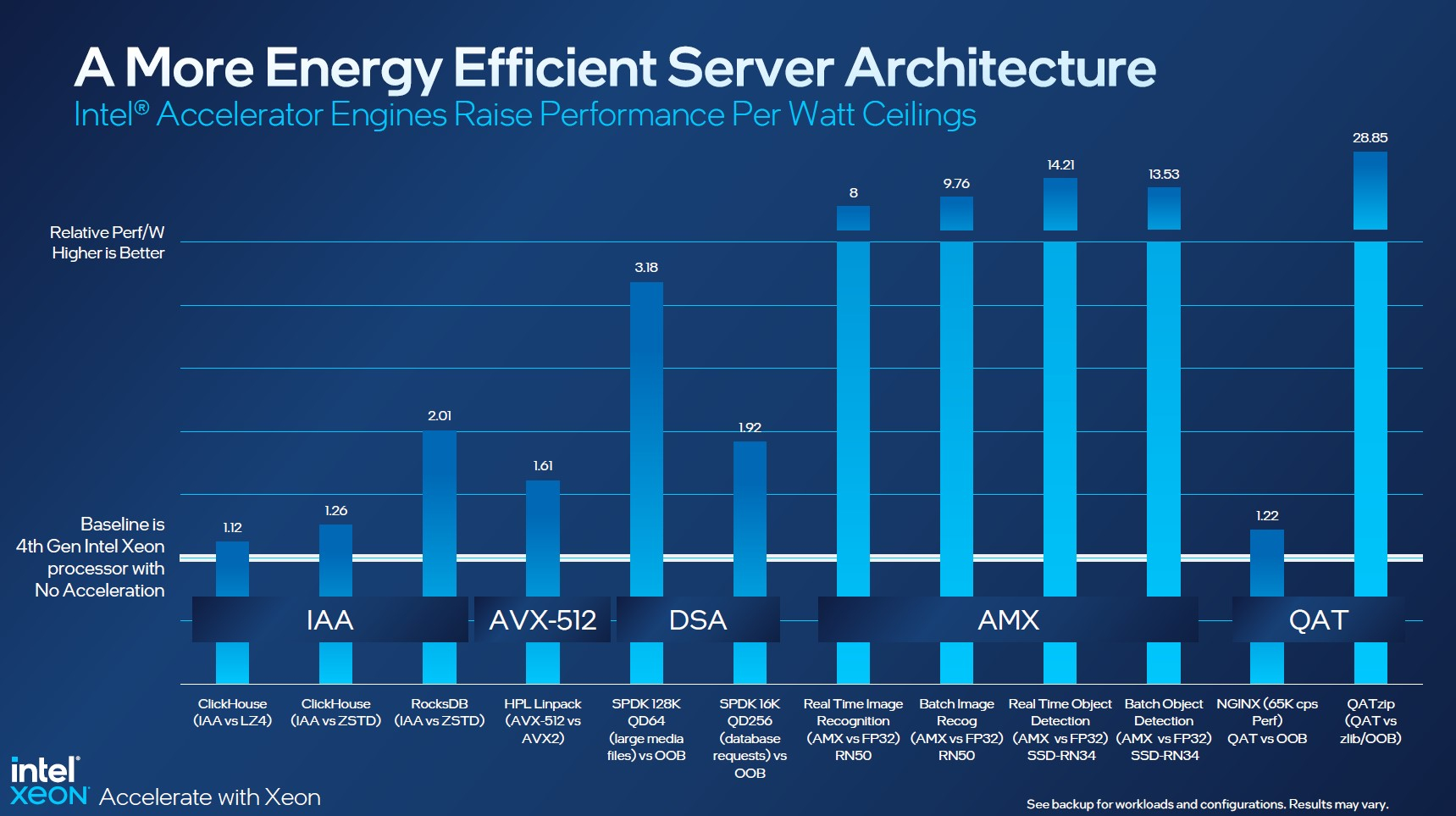 С одной стороны, желание Intel предоставить больше гибкости заказчикам, а заодно чуть увеличить выход годных к продаже процессоров, понятно. С другой — не очень-то и похоже, что CPU без «лишних» ускорителей отдаются с какой-то существенной скидкой. При этом транзисторный бюджет на них всё равно расходуется. Кроме того, есть ещё момент востребованности этих ускорителей и готовности ПО. У Intel есть и опыт ресурсы для помощи разработчикам, но процесс адаптации в любом случае не мгновенен.  Впрочем, у Intel по сравнению с AMD есть и ещё одно важное преимущество — в среднем более высокая доступность процессоров для большинства заказчиков. Так что с Sapphire Rapids может повториться та же история, что с Ice Lake-SP, когда вендоры здесь и сейчас готовы были предложить Intel-платформы.  В целом же, в новом семействе наиболее любопытны Xeon Max, которые, по словам Intel, по сравнению с прошлым поколением в 3,7 раз производительнее в задачах, завязанных на пропускную способность памяти (а это целый пласт HPC-нагрузок), и которые не так уж дороги. Правда, и здесь без приключений не обошлось — несчастный суперкомпьютер Aurora ожидает утомительный апгрейд его 10 тыс. узлов c простых Xeon Sapphire Rapids на Xeon Max — по полчаса на каждый узел.
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 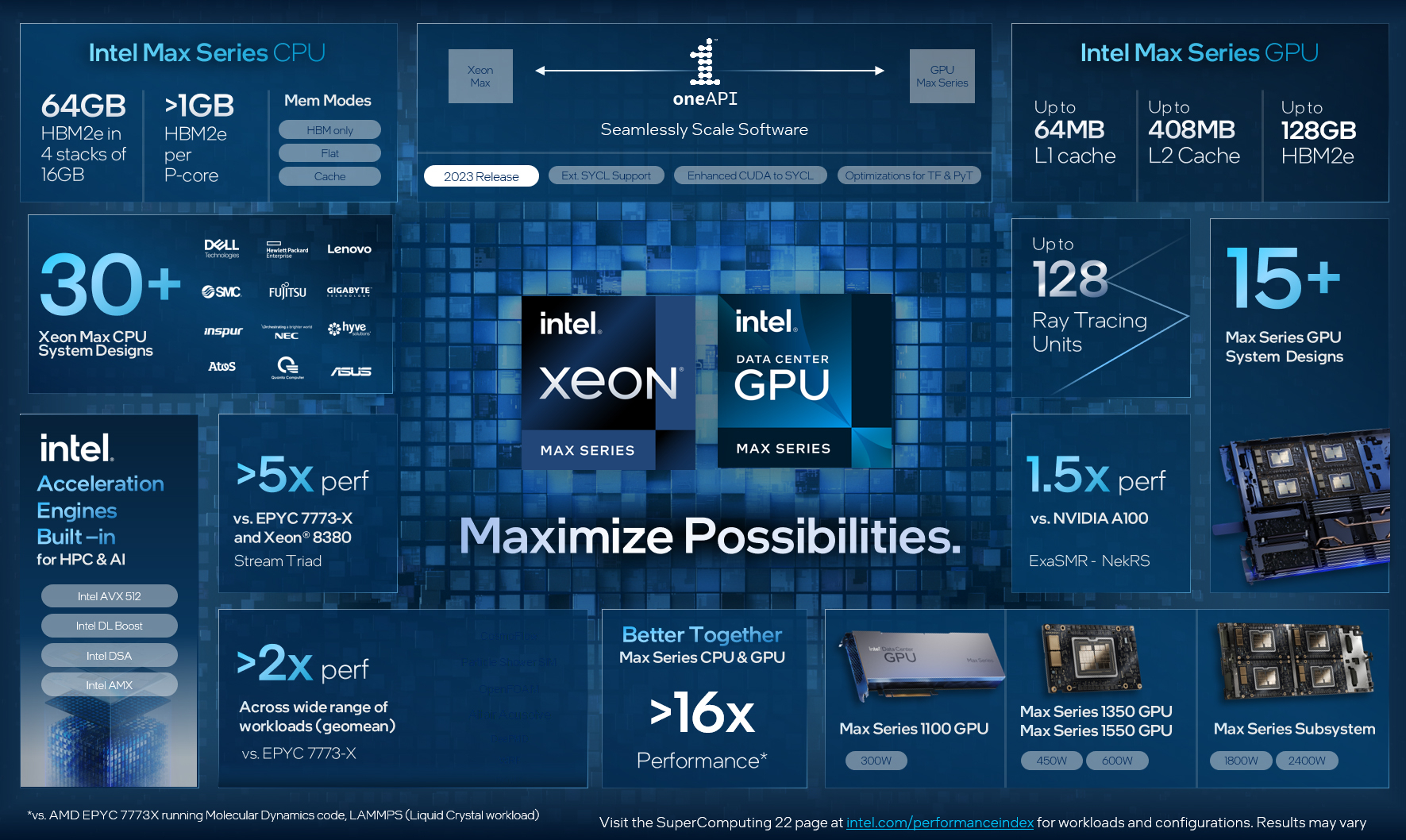
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 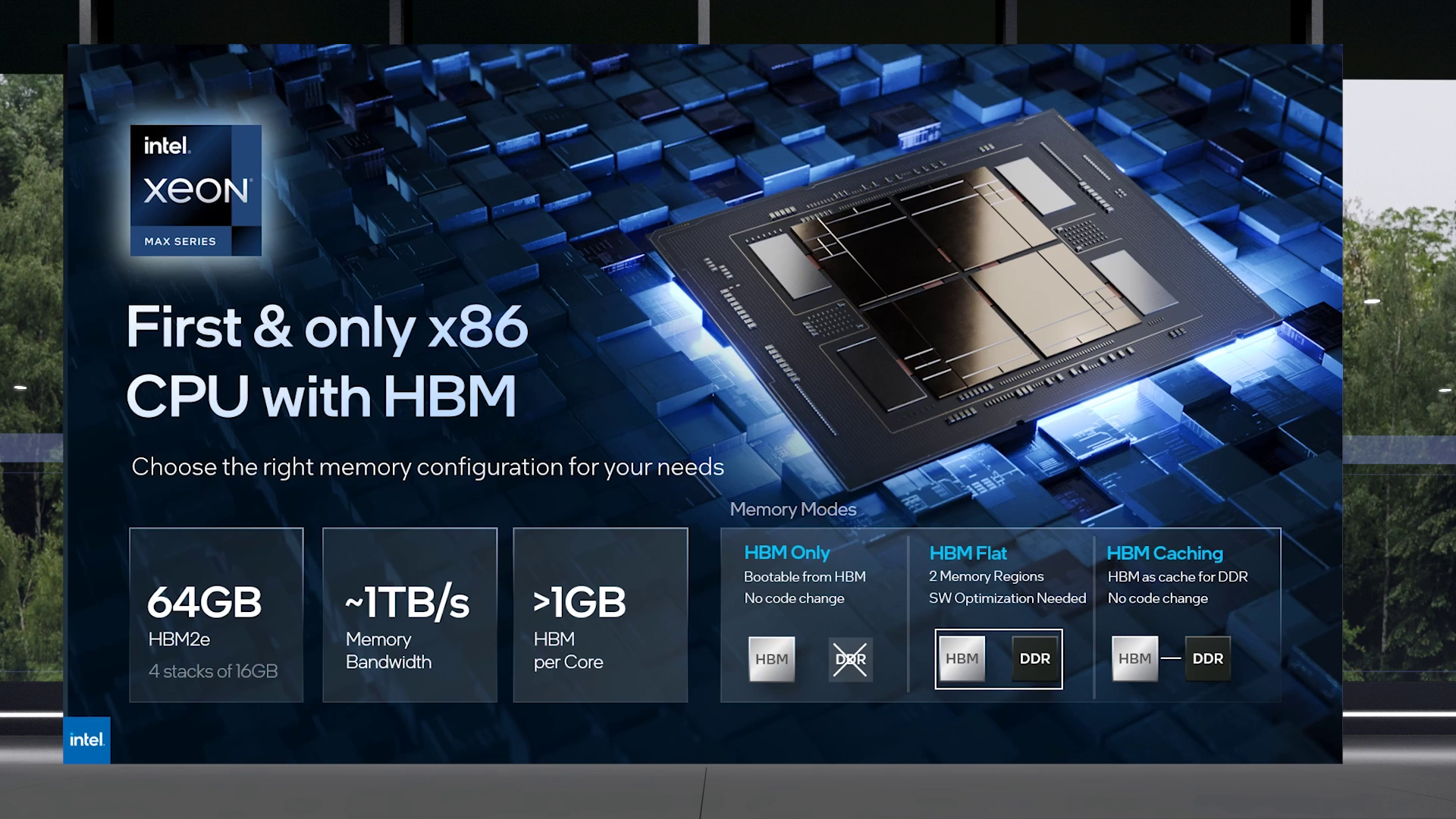 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA.
21.09.2022 [19:32], Алексей Степин
NVIDIA представила ускорители L40 и новую Omniverse-платформу OVX на их основеНа конференции GTC 2022 NVIDIA анонсировала второе поколение систем для симуляции и запуска «цифровых двойников» OVX. Это вовсе не развлечение: использование точных моделей реальных физических объектов, пространств и устройств потенциально весьма выгодно, поскольку симуляция городского квартала для обучения автопилотов или фабрики для оценки взаимодействия роботов с живыми работниками априори будет стоить намного меньше, нежели проведение натурных испытаний. Зачастую такие симуляции используют тензорные и матричные вычисления, поэтому основой новой платформы OVX стали новые ускорители NVIDIA L40 с архитектурой Ada Lovelace, располагающие ядрами трассировки лучей третьего поколения и тензорными ядрами четвёртого поколения. Они поддерживают как классический трассировку лучей (ray tracing), так и трассировку путей (path tracing), что важно для корректной симуляции поведения различных материалов. 
NVIDIA L40. Здесь и далее источник изображений: NVIDIA Физически L40 представляют собой двухслотовую FHFL-плату расширения PCIe с пассивным охлаждением — теплопакет новинки ограничен рамками 300 Вт. Объём оперативной памяти GDDR6 составляет 48 Гбайт, вдвое больше, нежели у игровых GeForce RTX 4090, и, в отличие от последних, поддерживается совместная работа двух карт в режиме NVLink, что может оказаться полезным в симуляциях с большим объёмом данных. Для вывода изображения служат четыре порта DP 1.4a. 
NVIDIA OVX Server Каждый сервер NVIDIA OVX будет содержать 8 ускорителей L40 и три сетевых адаптера ConnectX-7 с портами класса 200GbE и поддержкой шифрования сетевого трафика на лету. От 4 до 16 таких серверов составят OVX POD, а 32 или более —кластер SuperPOD. Такие кластеры станут домом для новой облачной платформы NVIDIA Omniverse Cloud, услуги которой компания планирует предоставлять робототехникам, создателям автономных транспортных средств, «умной инфраструктуры» и вообще всем, кому нужна точная симуляция сложных объектов и систем с качественной визуализацией результатов.
21.09.2022 [01:10], Алексей Степин
NVIDIA представила платформу IGX для «умной» промышленности и медициныПомимо новых GPU с архитектурой Ada компания NVIDIA на конференции GTC 2022 анонсировала множество новинок и не последней из них стала новая периферийная платформа IGX, призванная вывести «умную» промышленность на новый уровень. Главный упор в IGX сделан на обеспечении повышенной безопасности, причём как информационной, так и физической. Использовать совместный труд роботов в промышленности пытаются уже давно, но до недавних пор такие решения были нестандартными и весьма дорогостоящими. IGX призвана обеспечить безопасность, стандартизацию и высокий уровень производительности, достаточный для современной робототехники. Сердцем платформы IGX являются высокоинтегрированные модули серии Jetson AGX Orin, сочетающие в себе достаточно мощный процессор общего назначения, GPU-ускоритель, ускорители ИИ, машинного зрения, а также отдельный сопроцессор sMCU, отвечающий за обеспечение безопасности в проактивном режиме. Последний работает в комплексе с новыми программными расширениями, легко интегрируемыми в большинство коммерческих ОС благодаря сопутствующему программному стеку NVIDIA AI Enterprise. 
NVIDIA IGX. Здесь и далее источник изображений: NVIDIA Что касается проактивной защиты, то, к примеру, получив сигнал с видеокамер о том, что человек приближается к «зоне ответственности» роботов, система автоматически изменит траекторию движения последних, предупредит сотрудников, а также на основании полученных данных скорректирует поведение роботов в дальнейшем. Также с помощью технологии «цифровых двойников» можно будет провести симуляцию, дабы заранее выяснить возможные точки потенциально опасных столкновений машин и людей. 
NVIDIA IGX сделает подобные сценарии безопасными Производительность центрального модуля IGX составляет 275 Топс в режиме INT8. Обеспечение сетевых возможностей возложено на плечи современного сетевого адаптера ConnectX-7, гарантирующего прецизионные тайминги, позволяющие использовать платформу не только в промышленности, но и в медицине, где вопросы безопасности и точности жизненно важны. Естественно, индустрия нового поколения не может обойтись без унифицированных средств управления и обеспечения кибербезопасности. Весь комплекс решений на базе новой платформы IGX может развёртываться и управляться с единой консоли с помощью облачной системы NVIDIA Fleet Command. За безопасность при этом отвечает выделенный контроллер. На более высоком уровне за интеграцию новой платформы в единую экосистему отвечает фреймворк NVIDIA Metropolis, с помощью которого можно создавать по-настоящему крупномасштабные комплексы, включая целые «умные города». 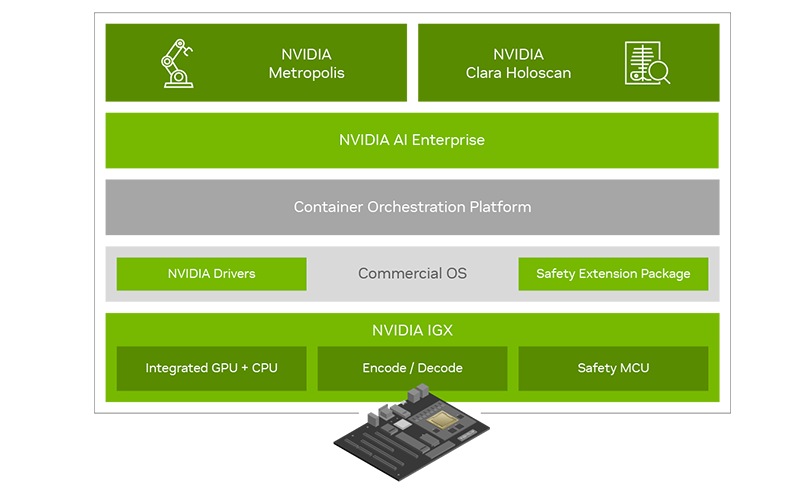
Программно-аппаратный состав новой платформы Отдельного упоминания заслуживает то, что новая платформа NVIDIA IGX избрана в качестве основы разработчиками медицинских систем, в частности, цифровой и робо-хирургии, такими как Activ Surgical, Moon Surgical и Proximie. Это стало возможным как благодаря аппаратным свойствам платформы, таким как низкая латентность и гарантированное время отклика, так и сочетанию фреймворков MONAI и Clara Holoscan.  Первый позволяет обучать специфические ИИ-модели на основании массивов медицинских данных. Эти модели затем могут интегрироваться с помощью Clara Holoscan SDK в реальные системы ультразвукового сканирования, эндоскопии или робохирургии. Помимо встроенных средств ускорения IGX, Clara Holoscan поддерживает и внешние ускорители NVIDIA RTX A6000, а технология Rivermax обеспечит передачу видеоданных для робота-хирурга на скорости 100 Гбит/с прямо в набортную память GPU. 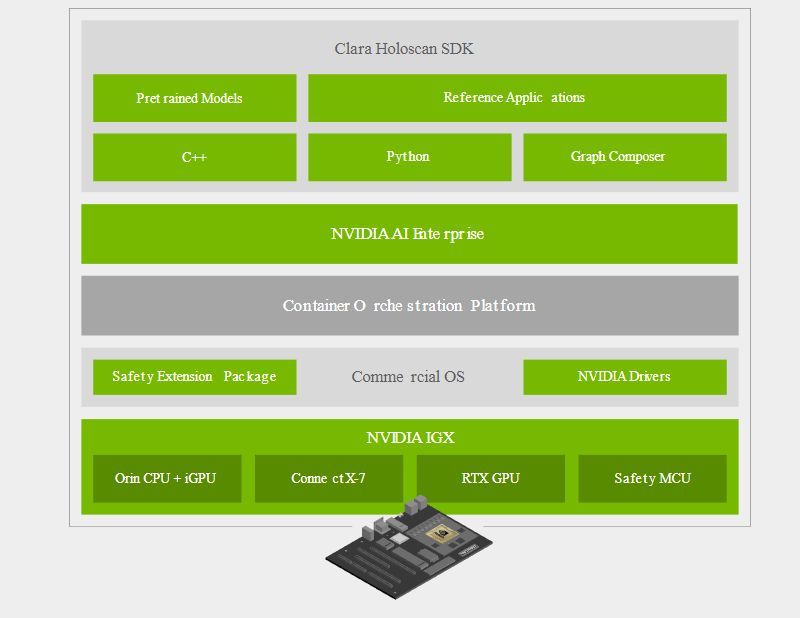 Комплекты разработчика IGX Orin будут доступны заказчикам в начале следующего года. Уже достигнуты соглашения с производителями встраиваемого оборудования ADLINK, Advantech, Dedicated Computing, Kontron, Leadtek, MBX, Onyx, Portwell, Prodrive Technologies и YUAN; уже испытывает новинку в деле Siemens. Также NVIDIA сотрудничает с Canonical, Red Hat и SUSE в целях обеспечения долговременной поддержки платформы, срок которой составит не менее 10 лет.
24.05.2022 [07:00], Игорь Осколков
NVIDIA представила референсные платформы CGX, OVX и HGX на базе собственных Arm-процессоров GraceНа весенней конференции GTC 2022 NVIDIA поделилась подробностями о грядущих серверных Arm-процессорах Grace Superchip и гибридах Grace Hopper Superchip, а на Computex 2022 представила первые референсные платформы на базе этих чипов для OEM-производителей и объявила о расширении программы NVIDIA Certified. Последнее, впрочем, не означает отказ от x86-систем, поскольку программа будет просто расширена. Да и портирование стороннего и собственного ПО займёт некоторое время. Первые несколько десятков моделей серверов от ASUS, Foxconn, GIGABYTE, QCT, Supermicro и Wiwynn появятся в первой половине 2023 года. Представлены они будут в трёх категориях, причём все, за исключением одной, базируются на «сдвоенных» процессорах Grace Superchip, насчитывающих до 144 ядер. 
Источник: NVIDIA Системы серии OVX, представленной ранее, всё так же будут предназначены для цифровых двойников и Omniverse — NVIDIA продолжает наставить на том, что любое современное производство или промышленное предприятие должно быть интеллектуальным. Arm-версия OVA получит неназванные ускорители NVIDIA и DPU Bluefield-3. Новая платформа NVIDIA CGX очень похожа на OVX — она тоже получит DPU Bluefield-3 и до четырёх ускорителей NVIDIA A16. CGX создана специального для облачных гейминга и работы с графикой. А вот новое поколение платформы NVIDIA HGX гораздо интереснее. Оно заметно отличается от предыдущих, которые в основном представляли собой различные комбинации базовых плат NVIDIA с четырьмя или восемью ускорителями, вокруг которых OEM-партнёры строили системы в меру своих умений и фантазий. Нынешняя инкарнация NVIDIA HGX всё же несколько более комплексная, поскольку сейчас предлагается два варианта узлов, специально спроектированных для высокоплотных систем и явно ориентированных на высокопроизводительные вычисления (HPC). 
Источник: NVIDIA Первый вариант — это 1U-лезвие (до 84 шт. в стандартной стойке), которое включает один процессор Grace Superchip, до 1 Тбайт LPDDR5x-памяти с пропускной способностью (ПСП) до 1 Тбайт/с и DPU BlueField-3. Иные варианты сетевого подключения оставлены на усмотрение конечного производителя. Заявленный уровень TDP составляет 500 Вт, так что на выбор доступны системы с воздушным и жидкостным охлаждением. Второй вариант базируется на гибридных чипах Grace Hopper Superchip, объединяющих в себе посредством шины NVLink-C2C процессорную часть с 512 Гбайт LPDDR5x-памяти и ускоритель NVIDIA H100 c 80 Гбайт HBM3-памяти (ПСП до 3,5 Тбайт/с). Помимо DPU BlueField-3 опционально доступен и интерконнект NVLink 4.0, но и здесь вендору оставлена свобода выбора. Уровень TDP для данной платформы составляет 1 кВт, но вот обойтись одним только воздушным охлаждением (а такой вариант есть) при полном заполнении стойки всеми 42-мя 2U-лезвиями будет трудно.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 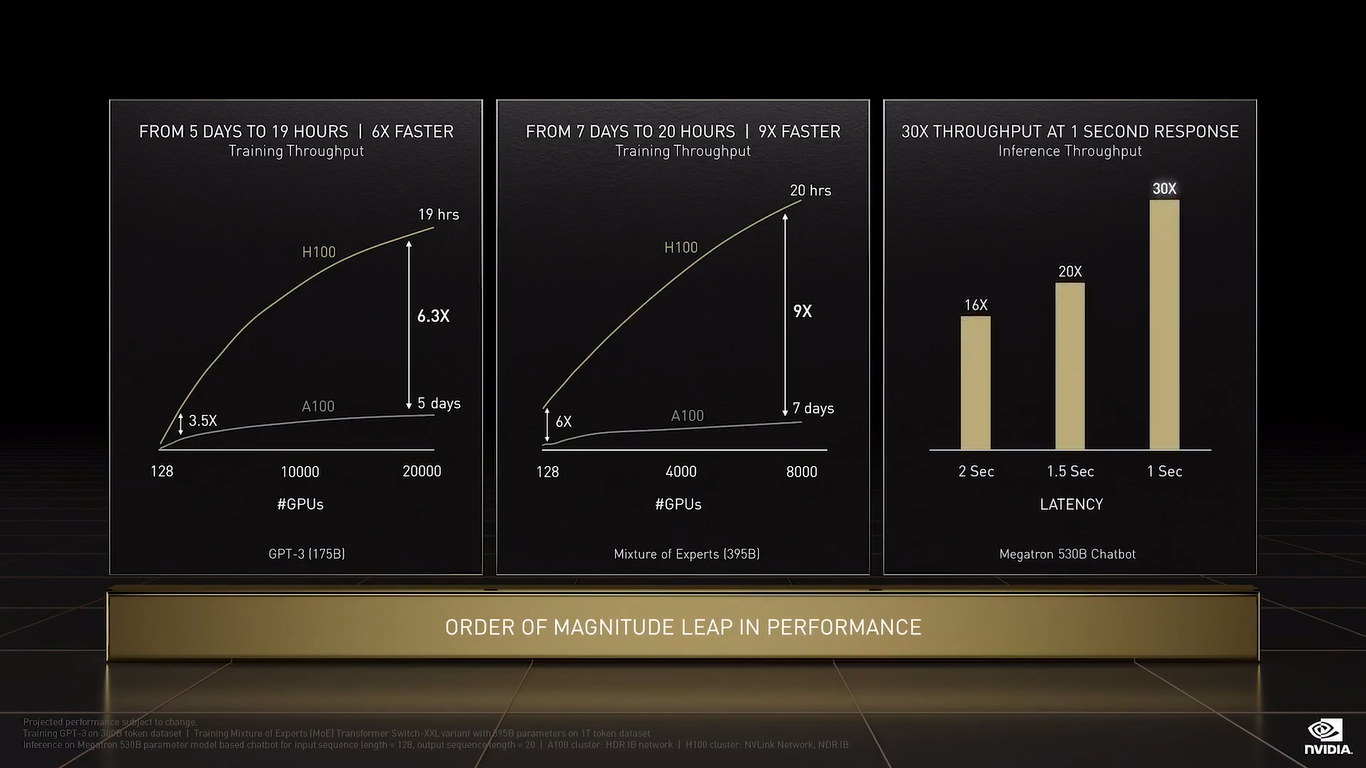 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4.
11.03.2022 [20:59], Алексей Степин
Ростелеком и Мегафон отлучили от лондонской точки обмена интернет-трафиком LINXЛондонская точка обмена интернет-трафиком LINX (London Internet Exchange Network), объединяющая сети более 950 различных операторов, хотя и не является коммерческой компанией, тем не менее, как сообщают зарубежные источники, тоже оказалась вынуждена применить санкции — совет директоров LINX принял решение отключить две крупные телекоммуникационные компании: Мегафон (AS 1133) и Ростелеком (AS 12389). В приводимом источником письме из внутренней рассылки для клиентов LINX говорится, что решение вступило в силу сразу после принятия и что LINX продолжит проверку в отношении других российских клиентов, которые могут быть связаны с владельцами двух вышеназванных компаний. Пока неясно, как это скажется на функционировании сетей, принадлежащих Ростелеком и Мегафону, но предполагается, что эффект будет более мягким, чем отключение от магистральных сетей Cogent и Lumen. Среди других крупных российских клиентов LINX есть, к примеру, Вымпелком, МТС и ТрансТелеКом. 
Источник: Twitter/woodyatpch Публичного подтверждения LINX о принятых мерах пока получено не было. Сейчас LINX является одним из крупнейших в Европе сетевым хабом с пиковым на текущий момент трафиком 6,89 Тбит/с. Напомним, что в 2017 году LINX стала участником скандала, приняв инициативу, позволяющую руководителям организации не сообщать клиентам об установке следящего оборудования несмотря на то, что законы ряда стран компаний-участников LINX запрещают массовую слежку за пользователями всемирной сети. UPD: «Мегафон» и «Ростелеком» подтвердили отключение от LINX, но уточнили, что обмен трафиком с этой точкой и так был невелик, поэтому отключение не скажется на абонентах.
27.02.2022 [01:01], Владимир Мироненко
Облако ждёт: к 2030 году Fujitsu откажется от мейнфреймов и UNIX-системFujitsu подтвердила, что выпуску её мейнфреймов и серверных систем c Unix подходит конец. Согласно новым планам компании, она прекратит производство и продажу мейнфреймов к 2030 году, а выпуск серверных систем UNIX — к концу 2029 года. Сопровождение обоих продуктов продлится в течение ещё пяти лет и закончится в 2035 году и в 2034 году соответственно. Как надеется компания, к тому времени пользователи подобных систем окончательно перейдут в облако. 
Источник изображений: Fujitsu Тем не менее, Fujitsu по-прежнему планирует выпустить в 2024 году новую модель в серии мейнфреймов GS21. Также планируется обновление семейства UNIX-серверов Fujitsu SPARC M12 в конце этого года и в 2026 году. Впрочем, это пока предварительные планы. Компания уже составила график перехода с мейнфреймов и UNIX-серверов в облако в рамках нового бизнес-бренда Fujitsu Uvance. Теперь у пользователей мейнфреймов Fujitsu есть чётко обозначенный срок, к которому они должны перенести свои приложения на другую платформу или воспользоваться возможностью создать их с нуля в рамках более современной инфраструктуры.  Сомнительной альтернативой может быть уход на платформу IBM z. Филип Доусон (Philip Dawson), вице-президент Gartner Research сообщил The Register, что отказ от UNIX пройдёт менее болезненно, так как рабочие нагрузки могут быть относительно легко перенесены на Linux: «По сути, Linux заменил UNIX. Но такой замены нет для мейнфреймов. Когда аппаратное обеспечение исчезнет, что вы будете делать с приложениями?». Фактически Fujitsu в наследство достались две разные серии мейнфреймов от Amdahl Corporation (GS21) и Siemens (BS2000), если не считать старые решения ICL.
31.08.2021 [00:56], Владимир Мироненко
Судебная тяжба 18-летней давности между IBM и SCO закончена, но противостояние по поводу прав на Linux продолжаетсяПохоже, что затянувшийся судебный спор между компаниями Santa Cruz Operation (SCO) и IBM по поводу прав на код ядра Linux может закончиться в ближайшее время. Суд США по делам о банкротстве округа Делавэр объявил, что TSG Group, которая представляет интересы должников обанкротившейся SCO, урегулировала все оставшиеся претензии с IBM. «В соответствии с Мировым соглашением стороны договорились разрешить все споры между собой по выплате Доверительному управляющему [TLD] от имени IBM в размере $14 250 000», — указано в постановлении суда. В свою очередь, TLD отказывается от всех прав и интересов по всем судебным искам, находящимся на рассмотрении или которые могут быть предъявлены в будущем против IBM и Red Hat, а также по любым обвинениям в том, что Linux нарушает интеллектуальную собственность SCO Unix или Unixware. Как пояснил представитель TLD, даже если бы SCO удалось доказать суду присяжных, что около 20 лет назад действительно были нарушены права и была нечестная конкуренция, размер ущерба всё было бы нельзя определить. И выплаты, вероятно, были бы значительно меньше, чем при мировом соглашении. 
Источник изображения: SCO Впрочем, речь идёт о завершении лишь части судебного противостояния, длящегося 18 лет. Дело в том, что Xinuos, которая купила продукты SCO Unix и её интеллектуальную собственность в 2011 году, подала в суд на IBM и Red Hat в связи с «незаконным копированием программного кода Xinuos для своих серверных операционных систем». Хотя во время сделки она обещала, что не намерена вести какие-либо судебные разбирательства, связанные с активами группы SCO. Во-первых, Xinuos утверждает, что IBM украла её интеллектуальную собственность, которую использовала для создания и продажи продукта, чтобы конкурировать с самой Xinuos. Во-вторых, по её мнению, IBM и Red Hat незаконно договорились разделить соответствующий рынок и использовать свои растущие силы на рынке для преследования конкурентов и подавления инноваций. И, наконец, в-третьих, по версии Xinuos, IBM приобрела Red Hat, чтобы укрепить положение на рынке и использовать незаконную схему на постоянной основе. |
|


