Материалы по тегу: x
|
28.06.2021 [13:22], Алексей Степин
Обновление NVIDIA HGX: PCIe-вариант A100 с 80 Гбайт HBM2e, InfiniBand NDR и Magnum IO с GPUDirect StorageНа суперкомпьютерной выставке-конференции ISC 2021 компания NVIDIA представила обновление платформы HGX A100 для OEM-поставщиков, которая теперь включает PCIe-ускорители NVIDIA c 80 Гбайт памяти, InfiniBand NDR и поддержку Magnum IO с GPUDirect Storage. В основе новинки лежат наиболее продвинутые на сегодняшний день технологии, имеющиеся в распоряжении NVIDIA. В первую очередь, это, конечно, ускорители на базе архитектуры Ampere, оснащённые процессорами A100 с производительностью почти 10 Тфлопс в режиме FP64 и 624 Топс в режиме тензорных вычислений INT8.  HGX A100 предлагает 300-Вт версию ускорителей с PCIe 4.0 x16 и удвоенным объёмом памяти HBM2e (80 Гбайт). Увеличена и пропускная способность (ПСП), в новой версии ускорителя она достигла 2 Тбайт/с. И если по объёму и ПСП новинки догнали SXM-версию A100, то в отношении интерконнекта они всё равно отстают, так как позволяют напрямую объединить посредством NVLink только два ускорителя.  В качестве сетевой среды в новой платформе NVIDIA применена технология InfiniBand NDR со скоростью 400 Гбит/с. Можно сказать, что InfiniBand догнала Ethernet, хотя не столь давно её потолком были 200 Гбит/с, а в плане латентности IB по-прежнему нет равных. Сетевые коммутаторы NVIDIA Quantum 2 поддерживают до 64 портов InfiniBand NDR и вдвое больше для скорости 200 Гбит/с, а также имеют модульную архитектуру, позволяющую при необходимости нарастить количество портов NDR до 2048. Пропускная способность при этом может достигать 1,64 Пбит/с.  Технология NVIDIA SHARP In-Network Computing позволяет компании заявлять о 32-крантом превосходстве над системами предыдущего поколения именно в области сложных задач машинного интеллекта для индустрии и науки. Естественно, все преимущества машинной аналитики используются и внутри самого продукта — технология UFM Cyber-AI позволяет новой платформе исправлять большинство проблем с сетью на лету, что минимизирует время простоя.  Отличным дополнением к новым сетевым возможностями является технология GPUDirect Storage, которая позволяет NVMe-накопителям общаться напрямую с GPU, минуя остальные компоненты системы. В качестве программной прослойки для обслуживания СХД новая платформа получила систему Magnum IO с поддержкой вышеупомянутой технологии, обладающую низкой задержкой ввода-вывода и по максимуму способной использовать InfiniBand NDR. 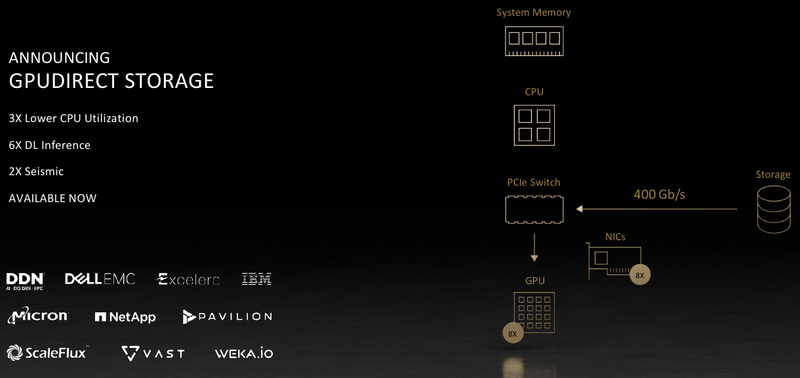 Три новых ключевых технологии NVIDIA помогут супервычислениям стать ещё более «супер», а суперкомпьютерам следующего поколения — ещё более «умными» и производительными. Достигнуты договорённости с такими крупными компаниями, как Atos, Dell Technologies, HPE, Lenovo, Microsoft Azure и NetApp. Решения NVIDIA используются как в индустрии — в качестве примера можно привести промышленный суперкомпьютер Tesla Automotive, так и в ряде других областей.  В частности, фармакологическая компания Recursion использует наработки NVIDIA в области машинного обучения для поиска новых лекарств, а национальный научно-исследовательский центр энергетики (NERSC) применяет ускорители A100 в суперкомпьютере Perlmutter при разработке новых источников энергии. И в дальнейшем NVIDIA продолжит своё наступление на рынок HPC, благо, она может предложить заказчикам как законченные аппаратные решения, так и облачные сервисы, также использующие новейшие технологии компании.
29.01.2021 [17:17], Андрей Галадей
Itanium забыт и заброшен: Линус Торвальдс констатировал смерть архитектурыОдной из проблем и в то же время достоинств Linux является поддержка многих старых архитектур процессоров. Это увеличивает размеры ядра и усложняет сопровождение. Но теперь, похоже, на одну архитектуру станет меньше. В ядре Linux 5.11, как выяснилось, оказалась нарушена поддержка Itanium IA-64. После исправления выяснилось, что это не единственная проблема такого рода, однако истинную причину выяснить не удалось из-за отсутствия доступа к «железу». Так что Линус Торвальдс (Linus Torvalds) в итоге принял решение пометить данную архитектуру как orphaned, то есть заброшенную, и прямо заявил, что она мертва. А это первый шаг к полному исключению её из ядра, как это уже случилось с другим продуктом Intel — Xeon Phi. 
Изображения: wikipedia.org Два последних крупных игрока на рынке Itanium-систем — сама Intel и её клиент HPE — уже давно забросили поддержку этой архитектуры в Linux, да и энтузиасты к ней охладели. И это объяснимо. Последнее поколение Itanium 9700 Kittson вышло в 2017 году, а приём заказов на них прекратился год назад. Поставки формально будут свёрнуты 29 июля 2021 года, но эти CPU с высокой степенью вероятности практически никто не закупил хоть в сколько-то значимых объёмах. 
Несбывшиеся надежды В дистрибутивах же поддержку процессоров убрали давно. Red Hat не поддерживает чипы с RHEL 5, SUSE перестала поддерживать после SUSE Linux 11. Так что теперь поддержка будет осуществляться лишь теми компаниями, которые явно заинтересованы в этом. Разумеется, если такие остались. В своё время спор между Oracle и HPE подорвал репутацию платформы. Впрочем, Linux не является единственным вариантом — поддержка HP-UX, наследника классических UNIX, версии 11i v3 для ряда продуктов HPE будет осуществляться до 31 декабря 2025. Аналогичная ситуация сложилась и вокруг SPARC c Solaris, так как большую часть разработчиков обоих продуктов Oracle уволила ещё в 2017 году. Oracle обязалась сопровождать Solaris 11 максимум до 2034 года. В частности, на днях она выпустила патч безопасности для sudo и восстановила некоторые старые материалы. Однако Solaris 12 мы вряд ли когда-либо увидим. Сейчас компании гораздо более интересны облака, Linux и Arm-процессоры Ampere.
08.12.2020 [23:24], Андрей Галадей
Место CentOS займёт CentOS Stream, вечная бета-версия RHELВ конце 2021 года Red Hat прекратит разработку привычного дистрибутива CentOS в пользу проекта CentOS Stream, так что CentOS 9 ждать не стоит. Новая версия представляет собой rolling-релиз Red Hat Enterpise Linux (RHEL), предназначенный для формирования следующего промежуточного выпуска RHEL. Фактически CentOS Stream станет «вечной бета-версией», за счёт чего будет упрощено тестирование конечного продукта, ведь теперь в релизе будет один дистрибутив, а не два. Впрочем, Red Hat продолжит выкладывать исходные коды в общий доступ, поэтому есть шанс на появление некоей альтернативы CentOS. Напомним, что сам проект перешёл под крыло Red Hat почти сем лет назад. На текущий момент единственным совместимым с актуальной веткой RHEL альтернативным дистрибутивом от крупных игроков, похоже, является только Oracle Linux. 
youtube.com Что касается поставки обновлений для CentOS 8, то она прекратится 31 декабря 2021 года, хотя поддержка CentOS 7 продлится до 2024 года. Пользователям рекомендуется с 2022 года перейти на CentOS Stream. Разработчики утверждают, что новый дистрибутив будет мало отличаться от RHEL, а патчи будут выходить регулярно. Напомним, что ранее мы писали о росте роли CentOS в развитии Red Hat Enterprise Linux. Похоже, именно переход на CentOS Stream и станет таким шагом. Однако сама природа Stream-версии вряд ли придётся по душе всем, кто использует CentOS в рабочем окружении. Red Hat подготовила FAQ и предлагает обратиться к ней, если возникнут какие-то сомнения или вопросы. Можно предположить, что компания таким образом пытается подтолкнуть пользователей к переходу на платные подписки и, быть может, будет готова предложить особые условия для перехода. На текущий момент акутальной является версия CentOS 8.3 (2011). Этот дистрибутив полностью бинарно совместим с RHEL 8.3. Он поддерживает архитектуры x86_64, Aarch64 (ARM64) и ppc64le.
02.11.2020 [17:56], Илья Коваль
Прощание с Xeon Phi: ядро Linux лишится поддержки MIC-архитектурыФинальная партия Intel Xeon Phi была отгружена летом этого года, хотя сам закат продуктов на базе архитектуры MIC (Many Integrated Core) начался за несколько лет до этого. Теперь же можно сказать, что в их истории поставлена последняя точка — из основной ветки ядра Linux 5.10 поддержка этих процессоров убрана уже в rc2. В ядре Linux поддержка MIC появилась в 2013 году, и Intel очень активно развивала её, почти втрое увеличив объём кодовой базы. Однако в последние годы развитие прекратилось и код остался фактически заброшенным. Связано это, понятное дело, с уходом ускорителей с рынка, где они не стали массовыми, проиграв конкуренцию NVIDIA как в HPC, так и в остальных сегментах.  Intel последовательно отменила выпуск следующего поколения MIC и продуктов всех прошлых поколений Xeon Phi, переключившись на создание универсальной архитектуры GPU. HPC-ускорители на её базе должны появиться в скором времени. Шине Intel Omni-Path, которая была непосредственно интегрирована в некоторые поздние модели Xeon Phi, повезло больше — после отказа Intel разработки были переданы свежесозданной Cornelis Networks. Тем не менее, кое-какое наследие MIC в ядре всё же может сохраниться. Речь идёт подсистеме VOP (VirtIO over PCIe), которая решает некоторые проблемы виртуализации PCI Express и для устройств других вендоров. Однако в текущем она ориентирована только на поддержку продуктов и драйверов Intel, и сможет вернуться в ядро Linux лишь после доработки.
18.08.2020 [22:16], Алексей Степин
Серверные ARM-процессоры Marvell ThunderX3: 60 ядер в SCM, 96 ядер в MCM, SMT4 в подарокПоследние дни оказались богатыми на анонсы новых процессоров. Компания IBM представила новейшие POWER10 с поддержкой памяти OMI DDR5 и PCI Express 5.0, Intel анонсировала Xeon Ice Lake-SP, которые, наконец, получили поддержку PCIe 4.0. Третьей в этом списке можно назвать Marvell, которая на мероприятии Hot Chips 32 рассказала подробности о последнем, третьем поколении ARM-процессоров ThunderX, формально анонсированном ещё весной этого года. 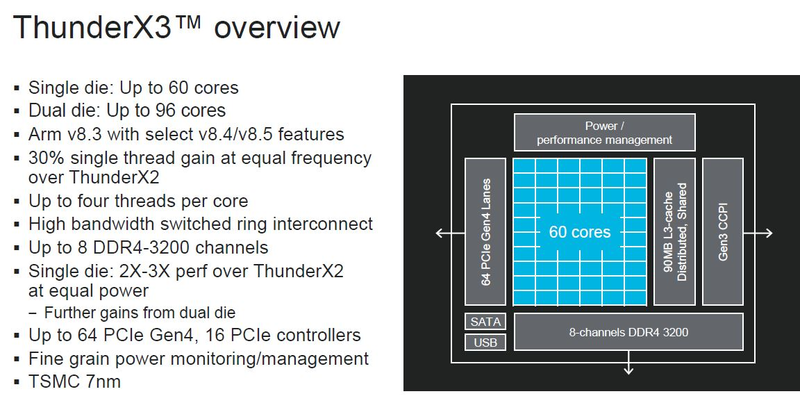
Источник изображений: ServeTheHome Процессоры с архитектурой ARM покорили сегмент мобильных устройств, но в последние несколько лет интереснее другая тенденция — данная архитектура ложится в основу всё новых и новых «крупных» процессоров, предназначенных для серверного применения. И как показывает практика, когда-то считавшаяся «слабой» архитектура оказывается вовсе не такой. 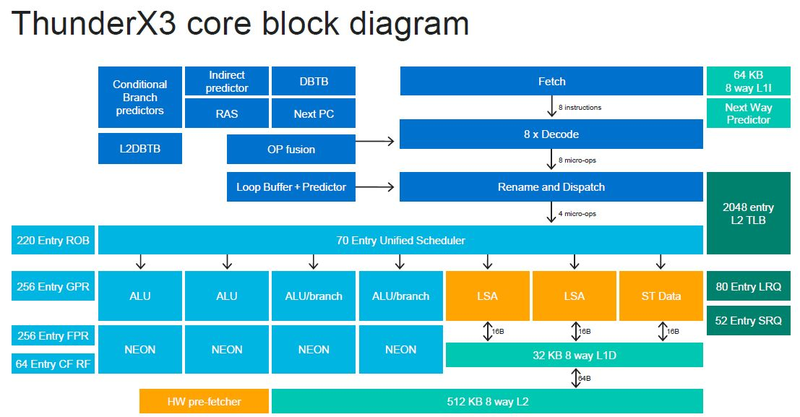 Она успешно соперничает с x86, особенно там, где необходима высокая плотность упаковки вычислительных мощностей и высокая энергоэффективность. Примеры AWS Graviton2 и кастомных процессоров Google тому доказательством, а разработка Fujitsu, процессор A64FX, и вовсе лежит в основе мощнейшего суперкомпьютера планеты, японского кластера Fugaku. 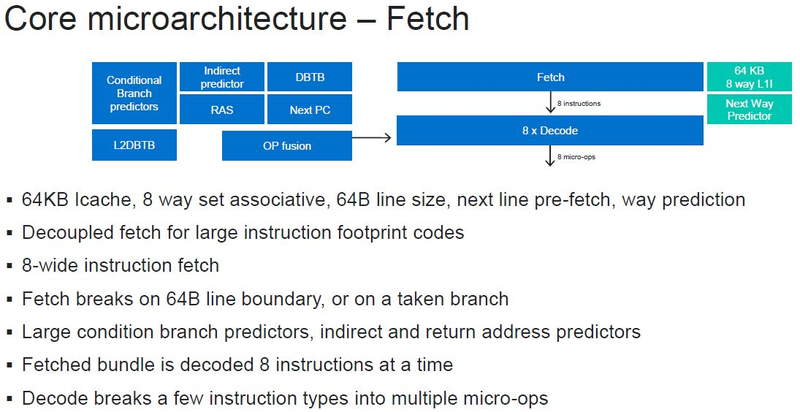 Одной из компаний, прилагающих серьёзные усилия к освоению серверного рынка с помощью архитектуры ARM, является Marvell. Если первые процессоры ThunderX, доставшиеся в наследство от Broadcom, сложно назвать успешным, то уже второе поколение показало себя неплохо, и, судя по всему, третье, наконец, готово к массовому внедрению. Напомним, в отличие от домашних проектов AWS и Google, процессоры ThunderX3 должны получить развитую поддержку многопоточности, на уровне SMT4, что больше, чем у x86, но меньше, чем у POWER10. 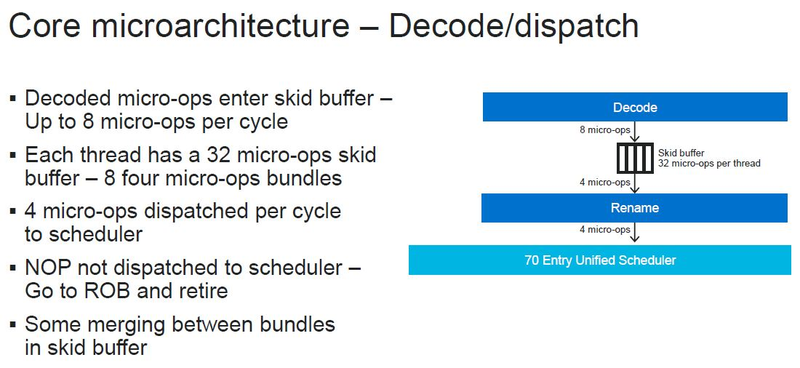 При этом максимальное количество ядер у ThunderX3 впечатляет. Теперь известно, что о 96 ядрах речь идёт только в двухкристалльной компоновке (этим подход Marvell напоминает IBM POWER10, также существующий в двух вариантах). Один кристалл может нести до 60 ядер, что меньше, чем у Graviton2, но, во-первых, ненамного, а во-вторых, с лихвой компенсируется наличием SMT. SMT4 может дать 240 или 384 потока в зависимости от версии, и наверняка это понравится крупным облачным провайдерам, поскольку позволит разместить беспрецедентное количество VM в рамках одного сокета. 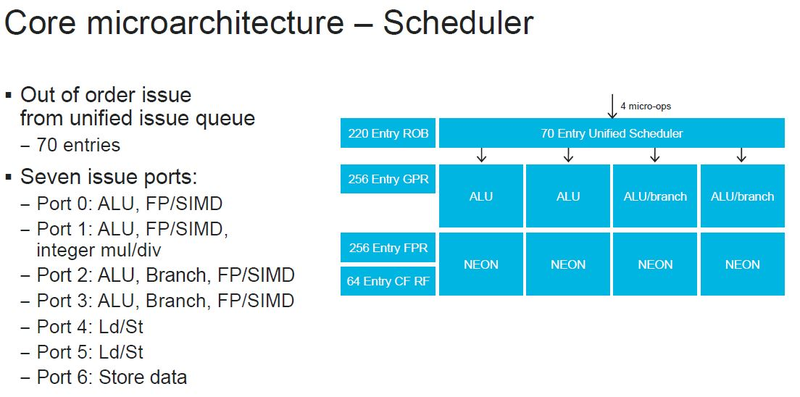 Однопоточная производительность не осталась без внимания. Компания заявила о 30% превосходстве над ThunderX2 в пересчёте на поток. В целом же, третье поколение ThunderX должно быть в 2-3 раза быстрее второго. Архитектурно процессор основывается на наборе инструкций ARM v8.3, однако сказано о частичной поддержке ARM v8.4/8.5. 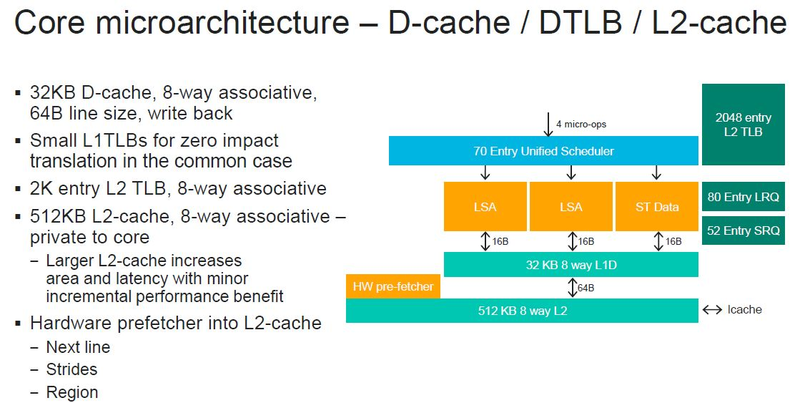 В споре о том, что эффективнее для связи ядер между собой, кольцевые шины или единая mesh-сеть, единого мнения нет. Intel предпочитает первый подход, но Marvell остановила свой выбор на втором. Как обычно, на внешнем кольце расположены кеш (80 Мбайт L3 на кристалл), блоки управление питанием, а также контроллеры памяти, PCI Express и межпроцессорной шины (в данном случае CCPI). 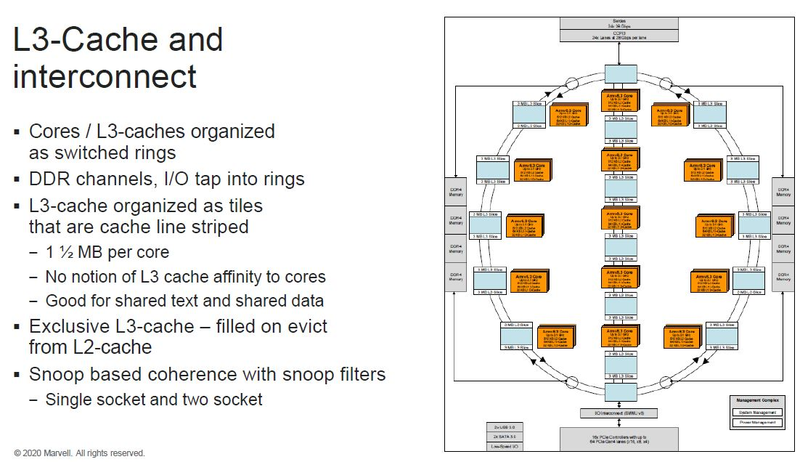 Поддержка SMT4 реализована полностью аппаратно. С точки зрения операционной системы каждый поток ThunderX3 выглядит, как обычный процессор с архитектурой ARM. При этом реализация столь развитой многопоточности привела всего лишь к 5% увеличению площади кристалла в сравнении с однопоточной реализацией.  Разделение ресурсов ядра у нового процессора динамическое, осуществляется оно в четырёх точках: выборка, когда потока с меньшим количеством инструкций получают более высокий приоритет; выполнение, работающее по такому же принципу; планирование, которое базируется на «возрасте» потока; наконец, «отставка» — здесь приоритет получают потоки с наибольшим количеством инструкций. Оптимизация многопоточности позволяет Marvell говорить о практически линейной масштабируемости новых процессоров, по крайней мере, в пределах одного разъёма. В зависимости от числа инструкций на ядро коэффициент прироста может варьироваться от x1,28 до 2,21. 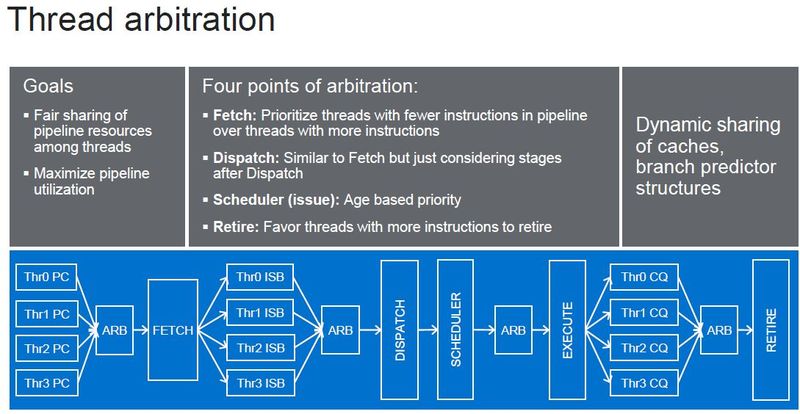 Подсистема ввода-вывода у новинок достаточно развитая. Контроллер памяти имеет 8 каналов и поддерживает DDR4-3200. За поддержку PCI Express отвечают 16 раздельных контроллеров, поддерживающих четвёртую версию стандарта. Это должно обеспечивать высокий уровень производительности при подключении 16 NVMe-накопителей, на каждый из которых придётся по четыре линии PCIe. 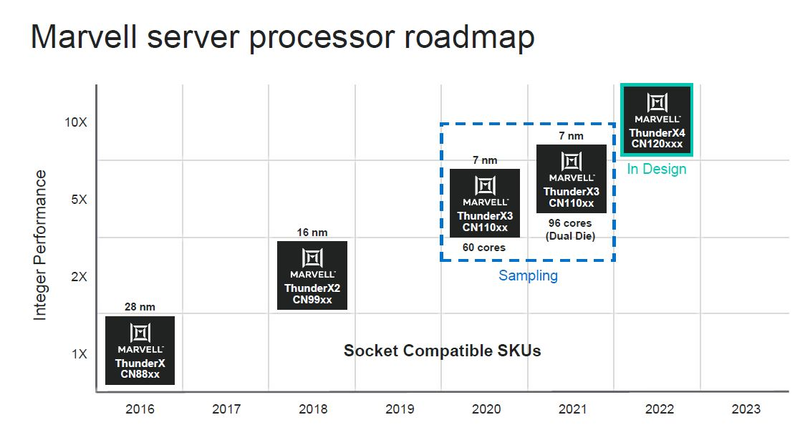 Заявлено о «тонком» управлении питанием, но деталей Marvell не приводит и остаётся только догадываться, насколько эта подсистема ThunderX3 продвинута. Производится новый процессор на мощностях TSMC с использованием техпроцесса 7 нм. Версия с одним 60-ядерным кристаллом выйдет на рынок уже в этом году, а вариант с двумя кристаллами и большим общим количеством ядер начнет поставляться позже, в 2021 году. Компания уже работает над ThunderX4, ожидается что эти процессоры будут использовать техпроцесс 5 нм и увидят свет в 2022 году.
14.05.2020 [18:52], Рамис Мубаракшин
NVIDIA представила ускорители A100 с архитектурой Ampere и систему DGX A100 на их основеNVIDIA официально представила новую архитектуру графических процессоров под названием Ampere, которая является наследницей представленной осенью 2018 года архитектуры Turing. Основные изменения коснулись числа ядер — их теперь стало заметно больше. Кроме того, новинки получили больший объём памяти, поддержку bfloat16, возможность разделения ресурсов (MIG) и новые интерфейсы: PCIe 4.0 и NVLink третьего поколения. NVIDIA A100 выполнен по 7-нанометровому техпроцессу и содержит в себе 54 млрд транзисторов на площади 826 мм2. По словам NVIDIA, A100 с архитектурой Ampere позволяют обучать нейросети в 40 раз быстрее, чем Tesla V100 с архитектурой Turing. 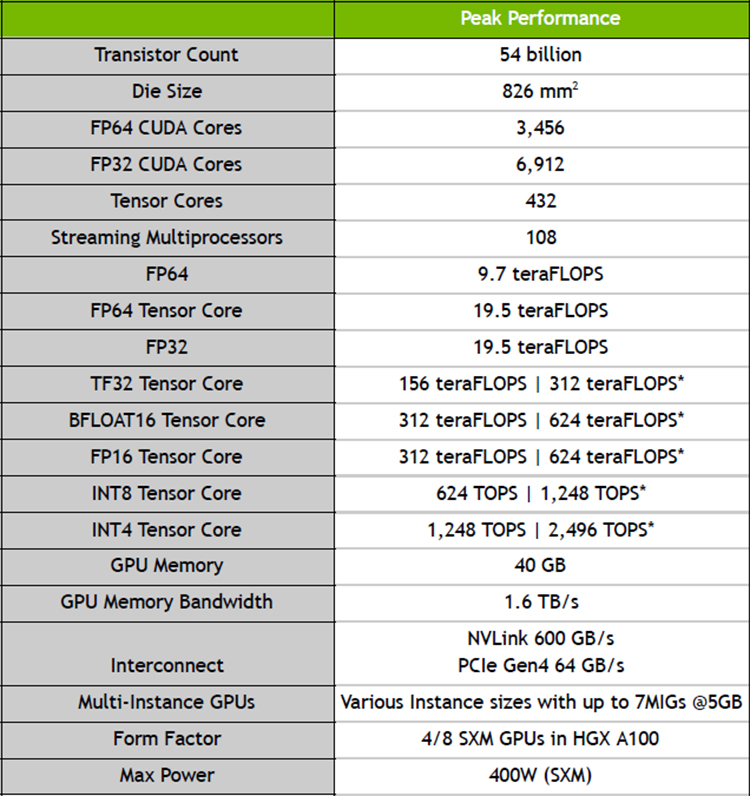
Характеристики A100 Первой основанной на ней вычислительной системой стала фирменная DGX A100, состоящая из восьми ускорителей NVIDIA A100 с NVSwitch, имеющих суммарную производительность 5 Пфлопс. Стоимость одной системы DGX A100 равна $199 тыс., они уже начали поставляться некоторым клиентам. Известно, что они будут использоваться в Аргоннской национальной лаборатории для поддержания работы искусственного интеллекта, изучающего COVID-19 и ищущего от него лекарство. Так как некоторые группы исследователей не могут себе позволить покупку системы DGX A100 из-за ее высокой стоимости, их планируют купить поставщики услуг по облачным вычислений и предоставлять удалённый доступ к высоким мощностям. На данный момент известно о 18 провайдерах, готовых к использованию систем и ускорителей на основе архитектуры Ampere, и среди них есть Google, Microsoft и Amazon. 
Система NVIDIA DGX A100 Помимо системы DGX A100, компания NVIDIA анонсировала ускорители NVIDIA EGX A100, предназначенная для периферийных вычислений. Для сегмента интернета вещей компания предложила плату EGX Jetson Xavier NX размером с банковскую карту.
18.10.2019 [20:36], Алексей Степин
ARMv8 на китайский лад — представлена Micro-ATX плата с 3-ГГц Phytium FT2000/4Китайская компания-разработчик Phytium, известная созданием CPU для суперкомпьютеров Tiahne-1A и Tiahne-2, занимавших первую строку в рейтинге TOP500, уже несколько лет работает над новым поколением 64-ядерных ARMv8-процессоров FeiTeng FT-2000 для будущего Tiahne-3. В сентябре компания анонсировала упрощённый вариант CPU всего с четырьмя ядрами — Phytium FT2000/4. А на днях в сети была замечена первая системная плата формата Micro-ATX на базе этой SoC. 
Так выглядит системная плата на базе данного ЦП Phytium FT2000/4 производится с использованием 16-нм техпроцесса TSMC, диапазон его тактовых частот лежит в пределах 2,6-3,0 ГГц. Имеется 4 Мбайт кеша L2 (по 2 Мбайт на пару ядер) и 4 Мбайт общего кеша L3. Теплопакет невелик и не превышает 10 Вт. Процессор размером 35 × 35 мм имеет упаковку FCBGA 1144. 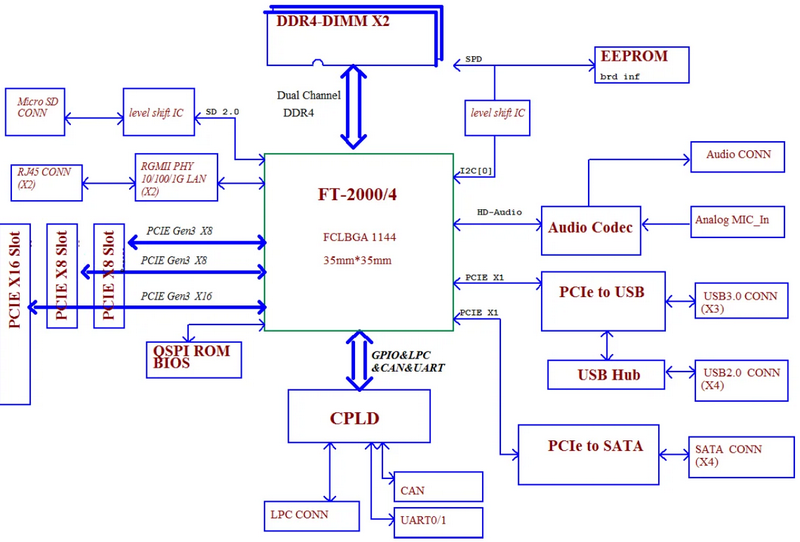
Возможности процессора FT2000/4 SoC предлагает 34 линии PCI-Express 3.0: две x1 и две x16, которые можно разделить, получив четыре x8. Линни x1 отведены под контроллеры USB 3.0 (3 скоростных порта и 4 версии 2.0) и Serial ATA (4 порта). Также есть встроенные интерфейсы HD Audio и 1GbE. Кроме того, имеется отдельный блок аппаратного ускорения шифрования, поддерживающий китайские стандарты SM2/SM3/SM4. Память работает в двухканальном режиме, но слотов DDR4 DIMM всего два, что может ограничить её объём. Встроенного графического адаптера нет, однако есть поддержка некоторых чипов AMD Radeon и GPU китайского производителя Jingjia. На уровне ПО заявлена совместимость с Linux-дистрибутивом Kylin OS. Phytium позиционирует FT2000/4 как основу для создания промышленных компьютеров, встраиваемых решений, тонких клиентов и терминалов (в том числе ноутбуков и моноблоков). А новая материнская плата пригодится для разработчиков. Как упомянутых выше решений, так и приложений для будущего суперкомпьютера.
29.06.2018 [13:00], Геннадий Детинич
Опубликованы финальные спецификации CCIX 1.0: разделяемый кеш и PCIe 4.0Чуть больше двух лет назад в мае 2016 года семёрка ведущих компаний компьютерного сектора объявила о создании консорциума Cache Coherent Interconnect for Accelerators (CCIX, произносится как «see six»). В число организаторов консорциума вошли AMD, ARM, Huawei, IBM, Mellanox, Qualcomm и Xilinx, хотя платформа CCIX объявлена и развивается в рамках открытых решений Open Compute Project и вход свободен для всех. В основе платформы CCIX лежит дальнейшее развитие идеи согласованных (когерентных) вычислений вне зависимости от аппаратной реализации процессоров и ускорителей, будь то архитектура x86, ARM, IBM Power или нечто уникальное. Скрестить ежа и ужа — вот едва ли не буквальный смысл CCIX. 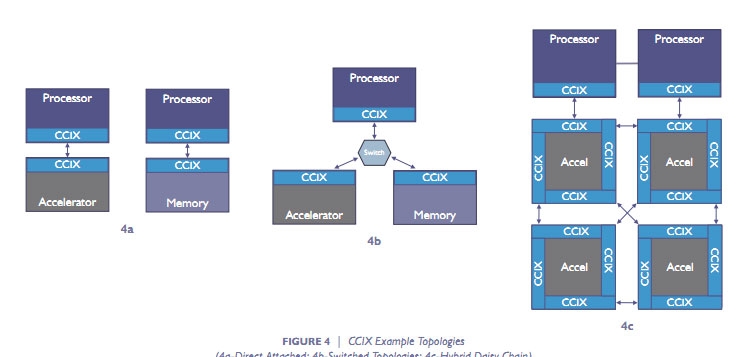
Варианты топологии CCIX На днях консорциум сообщил, что подготовлены и представлены финальные спецификации CCIX первой версии. Это означает, что вскоре с поддержкой данной платформы на рынок может выйти первая совместимая продукция. По словам разработчиков, CCIX позволит организовать новый класс подсистем обмена данными с согласованием кеша с низкими задержками для следующих поколений облачных систем, искусственного интеллекта, больших данных, баз данных и других применений в инфраструктуре ЦОД. Следующая ступенька в производительности невозможна без эффективных гетерогенных (разнородных) вычислений, которые смешают в одном котле исполнение кода общего назначения и спецкода для ускорителей на базе GPU, FPGA, «умных» сетевых карт и энергонезависимой памяти. 
Решение CCIX IP компании Synopsys Базовые спецификации CCIX Base Specification 1.0 описывают межчиповый и «бесшовный» обмен данными между вычислительными ресурсами (процессорными ядрами), ускорителями и памятью во всём её многообразии. Все эти подсистемы объединены разделяемой виртуальной памятью с согласованием кеша. В основе спецификаций CCIX 1.0, добавим, лежит архитектура PCI Express 4.0 и собственные наработки в области быстрой коррекции ошибок, что позволит по каждой линии обмениваться данными со скоростью до 25 Гбайт/с. 
Тестовая платформа с поддержкой CCIX Synopsys на FPGA матрице Но главное, конечно, не скорость обмена, хотя это важная составляющая CCIX. Главное — в создании программируемых и полностью автономных процессов по обмену данными в кешах процессоров и ускорителей, что реализуется с помощью новой парадигмы разделяемой виртуальной памяти для когерентного кеша. Это радикально упростит создание программ для платформ CCIX и обеспечит значительный прирост в ускорении работы гетерогенных платформ. Вместо механизма прямого доступа к памяти (DMA), со всеми его тонкостями для обмена данными, на платформе CCIX достаточно будет одного указателя. Причём обмен данными в кешах будет происходить без использования драйвера на уровне базового протокола CCIX. Ждём в готовой продукции. Кто первый, AMD, ARM или IBM? 
Тестовый набор CCIX 
Рабочая демо-система с неназванным CPU и FPGA, соединённых шиной CCIX |
|

