Материалы по тегу: ultra ethernet
|
14.04.2026 [12:44], Владимир Мироненко
Panmnesia привлёк $10 млн на разработку интерконнекта следующего поколения для ИИ ЦОДЮжнокорейский стартап Panmnesia, специализирующийся на разработке интерконнекта для ИИ-инфраструктур, сообщил о получении финансирования в размере около $10 млн на разработку интерконнекта следующего поколения для ИИ ЦОД. Проект включает разработку контроллеров и коммутаторов на основе открытых стандартов, таких как UALink и протоколов интерконнекта на основе Ethernet. Уже имея обширный портфель продуктов CXL, Panmnesia теперь расширяет свою деятельность в области интерконнекта, ориентированного на ускорители. Компания отметила, что по мере распространения крупномасштабных ИИ-моделей в различных отраслях, ИИ ЦОД всё чаще полагаются на ИИ-ускорители разных вендоров. В этом контексте технологии интерконнекта, обеспечивающие высокоскоростную передачу данных между ускорителями, стали критически важным фактором, определяющим общую производительность ИИ-системы. 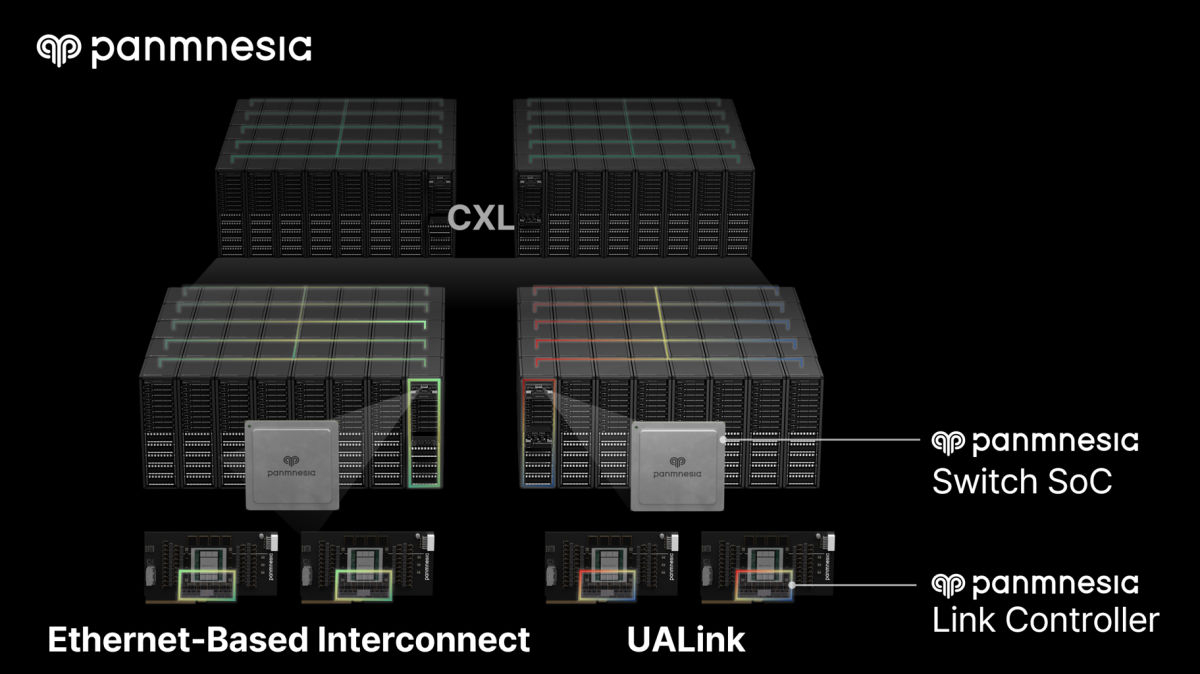
Источник изображений: Panmnesia Также Panmnesia планирует оптимизировать топологию разработанных устройств для ускорения обмена данными между ними и провести валидацию на уровне стойки. Ожидается, что чип-коммутатор с поддержкой интерконнекта, ориентированного на ускорители, такого как UALink, станет доступен во II половине 2027 года.  Портфолио продуктов CXL компании включает комплексные решения, в том числе контроллеры и IP-блоки PCIe/CXL, аппаратные SoC, такие, как коммутаторы PCIe/CXL, и специализированные кремниевые решения. В прошлом году Panmnesia представила архитектуру CXL-over-XLink, которая интегрирует специализированные каналы связи для ускорителей (известные как XLink), включая UALink, с CXL для обеспечения расширенной связи в крупных ИИ ЦОД.
13.04.2026 [13:05], Сергей Карасёв
Aria Networks представила «думающую» сетевую платформу Deep Networking для высокоэффективных ИИ-инфраструктурКомпания Aria Networks анонсировала сетевую платформу Deep Networking, призванную повысить эффективность работы ИИ-систем. Предложенное решение объединяет специализированное коммутационное оборудование, сетевую ОС SONiC, высокоточную телеметрию на коммутаторах, трансиверах и сетевых картах, а также ИИ-алгоритмы на разных уровнях вычислительной инфраструктуры. Стартап Aria Networks основан в январе 2025 года Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019-м приобрёл американский производитель сетевого оборудования Juniper Networks. Aria Networks занимается разработкой высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным ПО для управления большим количеством модульных коммутаторов как единой системой. На сегодняшний день стартап привлёк в общей сложности $125 млн инвестиций от Sutter Hill Ventures, Atreides Management, Valor Equity Partners и Eclipse Ventures. Идея Deep Networking заключается в том, чтобы рассматривать сеть в качестве активного участника кластера ИИ, а не в роли пассивного слоя. Это достигается путём сбора детальной телеметрии с коммутационных ASIC, внедрения интеллектуальных агентов на каждом уровне и постоянного распространения обновлений ПО через облако. 
Источник изображений: Aria Networks В качестве ключевых показателей быстродействия Aria Networks рассматривает MFU (уровень утилизации оборудования при обучении) и Token Efficiency (эффективность токенов). Первый параметр отражает, какой процент от теоретической максимальной производительности ИИ-ускорителя (пиковых FLOPS) реально тратится на полезные вычисления для обучения или инференса. В свою очередь, эффективность токенов показывает, уровень MFU или время на обработку одного токена. Основное техническое преимущество Deep Networking заключается в получении детализированной телеметрии. Традиционные инструменты мониторинга сети собирают данные постфактум — с относительно невысокой точностью. Решение Aria Networks обрабатывает телеметрию в реальном времени непосредственно с ASIC. Благодаря этому обеспечивается адаптивная настройка параметров DLB (динамическая балансировка нагрузки) и DCQCN (механизм управления перегрузками).  Сама платформа Deep Networking имеет многоуровневую архитектуру. На самых нижних уровнях ИИ-агенты в течение микросекунд реагируют на такие события, как сбои в работе трансиверов, перенаправляя трафик между коммутаторами. На более высоких уровнях принимаются стратегические решения о перераспределении потоков в кластере. Кроме того, внешние системы, например, планировщики заданий и маршрутизаторы, могут напрямую запрашивать сведения о состояние сети и интегрировать их в процесс принятия собственных решений. С аппаратной точки зрения инфраструктура Deep Networking базируется на коммутаторах Aria Switch 800G, Aria Switch 1.6T High Radix и Aria Switch 1.6T, оснащённых чипами Broadcom. Платформа непрерывно настраивает каждый аспект сетевой инфраструктуры для конкретного обслуживаемого ИИ-кластера без ручного вмешательства, что сводит к минимуму задержки и устраняет ошибки, обусловленные человеческим фактором. Администраторам достаточно указать свои потребности, после чего платформа соответствующим образом оптимизирует сеть. При этом система постоянно оценивает состояние сети и в режиме реального времени принимает меры для обеспечения наилучшей производительности и бесперебойной работы.  Aria Networks утверждает, что один неисправный сетевой адаптер в кластере из 10 тыс. XPU может снизить показатель MFU на 1,7 %. А сбой трансивера способен спровоцировать некорректную переадресацию трафика, что приведёт к существенным финансовым потерям. Архитектура Deep Networking позволяет эффективно решать подобные проблемы, одновременно улучшая производительность. Так, повышение MFU на 3 % в кластере из 10 тыс. XPU, по оценкам стартапа, приводит к увеличению годовой выручки на $49,8 млн.
06.02.2026 [11:30], Сергей Карасёв
102,4 Тбит/с и СЖО: Aria Networks представила коммутаторы на платформе Broadcom Tomahawk 6 для ИИ-инфраструктурСтартап Aria Networks, базирующийся в Санта-Кларе (Калифорния, США), вышел из скрытого режима, анонсировав высокопроизводительные коммутаторы для крупномасштабных кластеров ИИ. В основу устройств положена аппаратная платформа Broadcom Tomahawk 6 (TH6). В новое семейство вошли три модели: Aria Tomahawk 6 (High Radix), Aria Tomahawk 6 (Liquid) и Aria Tomahawk 6 (Air). Все они обеспечивают суммарную коммутационную способность до 102,4 Тбит/с. Разработчик заявляет, что устройства могут применяться в составе ИИ-платформ с любыми типами ускорителей, будь то GPU NVIDIA и AMD, тензорные чипы или специализированные решения вроде Cerebras. 
Источник изображения: Aria Networks Модель Aria Tomahawk 6 (Air) выполнена в форм-факторе 4U и оборудована воздушным охлаждением. Задействованы 512 блоков SerDes 200G. Коммутатор располагает 64 портами с пропускной способностью 1,6 Тбит/с каждый. Модификация Aria Tomahawk 6 (Liquid) имеет аналогичные технические характеристики, но заключена в 2U-корпус с жидкостным охлаждением. Наконец, вариант Aria Tomahawk 6 (High Radix) типоразмера 4U использует 1024 блока SerDes 100G. Устройство оборудовано 128 портами 800GbE; применяется воздушное охлаждение. На базе этого коммутатора могут формироваться кластеры с простой двухуровневой топологией, насчитывающие до 32 тыс. ИИ-ускорителей. Компания Aria Networks основана Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019 году приобрёл американский производитель сетевого оборудования Juniper Networks. Стартап Aria Networks фокусируется на разработке высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным программным уровнем, позволяющим управлять большим количеством модульных коммутаторов как единой системой. Утверждается, что этот унифицированный программный слой оптимизирует производительность и гарантирует надёжность инфраструктуры. Для эффективного управления коммутаторами применяются ИИ-алгоритмы.
22.01.2026 [16:04], Владимир Мироненко
Upscale AI привлёк $200 млн для запуска ИИ-интерконнекта и коммутатора SkyHammerСтартап Upscale AI, специализирующий на разработке ИИ-интерконнекта, объявил о привлечении $200 млн в рамках раунда финансирования серии А. С учётом предыдущего раунда общая сумма инвестиций в Upscale AI достигла $300 млн, а оценка его рыночной стоимости превысила $1 млрд, что придало ему статус «единорога». Это большая сумма для любой технологической компании со 150 сотрудниками, большинство из которых инженеры. Раунд серии А возглавили Tiger Global, Premji Invest и Xora Innovation, также в нём приняли участие Maverick Silicon, StepStone Group, Mayfield, Prosperity7 Ventures, Intel Capital и Qualcomm Ventures. Upscale AI отметил, что поддержка инвесторов отражает растущее в отрасли мнение, что сети являются критически узким местом для масштабирования ИИ, а традиционные сетевые архитектуры, предназначенные для соединения вычислительных ресурсов общего назначения и хранилищ, принципиально не подходят для эпохи ИИ. Устаревшие сетевые решения для ЦОД были разработаны до появления ИИ, и слабо подходят для масштабного, синхронизированного масштабирования на уровне стоек. Когда Upscale AI был основан в начале 2024 года, консорциум UALink и стандарт ESUN, предложенный Meta✴ Platforms, ещё не были обнародованы, но идея гетерогенной инфраструктуры, безусловно, уже была, отметил ресурс The Next Platform. Созданная Upscale AI платформа объединяет GPU, ИИ-ускорители, память, хранилище и сетевые возможности в единый синхронизированный ИИ-движок. Для этого стартап разработал ASIC SkyHammer, который поддерживает ESUN, UALink, Ultra Ethernet, SONiC и Switch Abstraction Interface (SAI). Фактически Upscale AI хочет составить конкуренцию NVIDIA NVSwitch, дав возможность выбора интерконнекта при создании ИИ-инфраструктур. 
Источник изображения: Upscale AI Upscale AI сообщил, что благодаря дополнительному финансированию представит первую полнофункциональную, готовую к использованию платформу, охватывающую кремниевые компоненты, системы и ПО. Также полученные средства будут направлены на расширение инженерных, торговых и операционных команд по мере перехода к коммерческому внедрению решения. По словам Арвинда Шрикумара (Arvind Srikumar), старшего вице-президента по продуктам и маркетингу компании, поставки образцов SkyHammer клиентам начнутся в конце 2026 года, а массовые поставки — в 2027 году, когда в это же время выйдут новые поколения GPU, XPU, коммутаторов и стоек. Коммутаторы должны быть у OEM/ODM-производителей за два квартала до того, как вычислительные ядра будут готовы к поставкам, чтобы они могли собрать системы и протестировать их. «Я всегда считал, что гетерогенные вычисления — это правильный путь, и гетерогенные сети — это тоже правильный путь», — сообщил Шрикумар изданию The Next Platform. Он отметил, что Upscale AI фокусируется на демократизации интерконнекта для ИИ. Шрикумар признал, что у NVIDIA отличные технологии, и что это «потрясающая» компания, когда дело касается инноваций. Вместе с тем он считает, что в будущем, с учётом темпов развития ИИ, вряд ли одна компания сможет предоставить все необходимые технологии для ИИ. Шрикумар считает, что PCIe-коммутация хорошо работает, когда несколько СPU взаимодействуют с несколькими GPU, относительная пропускная способность памяти GPU довольно низкая, а СPU и GPU расположены довольно близко друг к другу в серверном узле. В то же время Upscale AI скептически относится к попыткам создания коммутаторов UALink, ESUN или SUE путем использования ASIC-чипов для PCIe или путём извлечения начинки ASIC-чипов Ethernet-коммутаторов. «Те, кто давно занят в сфере ASIC, знают, что можно удалить много блоков, но основные элементы остаются прежними. Базовая ДНК каждого ASIC остается неизменной», — отметил Шрикумар. Поэтому в Upscale AI решили создать ASIC с нуля, а затем обеспечить поддержку протоколов семантики памяти по мере их появления.
24.11.2025 [08:45], Сергей Карасёв
Cornelis анонсировала 800G-адаптер CN6000 SuperNIC с поддержкой Omni-Path, RoCEv2 и Ultra Ethernet для ИИ и НРСКомпания Cornelis Networks анонсировала сетевой адаптер CN6000 SuperNIC со скоростью передачи данных до 800 Гбит/с, разработанный для систем ИИ и НРС. О намерении использовать решение объявили многие отраслевые игроки, включая Lenovo, Synopsys и Atipa Technologies. В устройстве реализована архитектура Omni-Path. Говорится о полной совместимости со стандартами Ultra Ethernet и RoCEv2. Таким образом, адаптер может применяться в высоконагруженных средах, где требуются максимальная пропускная способность при низких задержках. Адаптер CN6000 SuperNIC обеспечивает быстродействие до 1,6 млрд сообщений в секунду. Утверждается, что новинка поможет организациям ускорить обучение крупных ИИ-моделей при одновременном снижении расходов на электроэнергию и эксплуатацию дата-центров. 
Источник изображения: Cornelis Networks Cornelis заявляет, что традиционные архитектуры RoCEv2 испытывают трудности при масштабировании в рамках масштабных GPU-кластеров из-за требований к ресурсам памяти при управлении парами связанных очередей (Queue Pair, QP) для отправки и приёма данных. CN6000 SuperNIC позволяет решить проблему благодаря принципиально иной конструкции: задействованы «облегчённые» алгоритмы QP и аппаратно-ускоренные таблицы RoCEv2 In-Flight (RiF), что даёт возможность отслеживать миллионы одновременных операций с минимальными требованиями к ресурсам. Это гарантирует предсказуемую задержку при максимальной пропускной способности в системах любого масштаба. Пробные поставки CN6000 SuperNIC планируется начать к середине 2026 года, после чего будет организовано массовое производство.
17.11.2025 [12:14], Сергей Карасёв
Nokia представила коммутаторы с пропускной способностью до 102,4 Тбит/сКомпания Nokia анонсировала высокопроизводительные коммутаторы семейства 7220 IXR-H6 для дата-центров, ориентированных на ресурсоёмкие нагрузки ИИ. Новинки соответствуют спецификациям Ultra Ethernet Consortium (UEC), поддерживая расширенные функции для оптимизации и управления потоками данных, предотвращения перегрузок и повышения эффективности в крупномасштабных средах. Коммутаторы обеспечивают пропускную способность до 102,4 Тбит/с благодаря интерфейсам 800GbE и 1.6TbE, что вдвое больше по сравнению с решениями предыдущего поколения. В серию 7220 IXR-H6 вошли две модели с 64 портами (1.6TbE), оборудованные воздушным и жидкостным охлаждением. В первом случае допускается горячая замена блоков вентиляторов. Кроме того, дебютировала модификация со 128 портами (800GbE). О типе применённого чипсета пока ничего не сообщается. 
Источник изображения: Nokia Устройства комплектуются блоками питания с резервированием и возможностью горячей замены. Предусмотрены сетевой порт управления RJ45, разъём USB 3.0 и консольный порт. Коммутаторы могут поставляться с сетевой операционной системой SR Linux NOS или SONiC (Software for Open Networking in the Cloud). По заявлениям Nokia, решения семейства 7220 IXR-H6 могут применяться в составе платформ облачных провайдеров и гиперскейлеров, а также в ИИ-кластерах, насчитывающих более 1 млн ускорителей разных типов (XPU). Говорится о совместимости с серверными стойками различных конфигураций. В продажу коммутаторы поступят в I квартале следующего года.
12.11.2025 [23:23], Владимир Мироненко
От ИИ ЦОД до роботов: AMD анонсировала долгосрочную стратегию роста
amd
cpu
dpu
epyc
hardware
instinct
mi400
mi500
ocp
pensando systems
ualink
ultra ethernet
venice
verano
xilinx
ии
ускоритель
финансы
AMD представила на мероприятии Financial Analyst Day 2025 план по достижению лидерства на рынке вычислительных технологий объёмом $1 трлн. Долгосрочная стратегия роста AMD построена на четырех столпах: лидерство в сфере ЦОД, повышение производительности ИИ, открытое ПО и расширение присутствия на рынках встраиваемых и полукастомных кремниевых решений. AMD ожидает, что только её бизнес в сфере ЦОД будет приносить более $100 млрд годовой выручки, с увеличением совокупного среднегодового темпа роста (CAGR) до более чем 60 %, при этом CAGR дохода от ИИ-решений увеличится до более чем 80 %. Генеральный директор AMD Лиза Су (Lisa Su) заявила, что следующий этап будет основан на унифицированной вычислительной платформе AMD, объединяющей процессоры EPYC, ускорители Instinct, сетевые решения Pensando и ПО ROCm. Новый план развития AMD призван обеспечить ей конкуренцию с NVIDIA и Intel на корпоративных рынках и в борьбе за заказы гиперскейлеров. 
Источник изображений: AMD  Ускорители серии Instinct MI350, уже развёрнутые Oracle (ещё 50 тыс. MI450 будут развёрнуты во II половине 2026 г.), являются самыми популярными ускорителями AMD на сегодняшний день. Следующей платформой станет серия MI450, которая будет запущена вместе со стоечной платформой Helios в III квартале 2026 года. Helios обеспечит пропускную способность интерконнекта 3,6 Тбайт/с на каждый ускоритель и до 72 ускорителей на стойку с совокупной пропускной способностью 260 Тбайт/с, соединённых между собой посредством UALink и Ultra Ethernet (UEC). Система поддерживает разделяемую память между ускорителями, что обеспечивает обучение крупномасштабных моделей с бесперебойным доступом к памяти и отказоустойчивой сетью с шестью плоскостями.  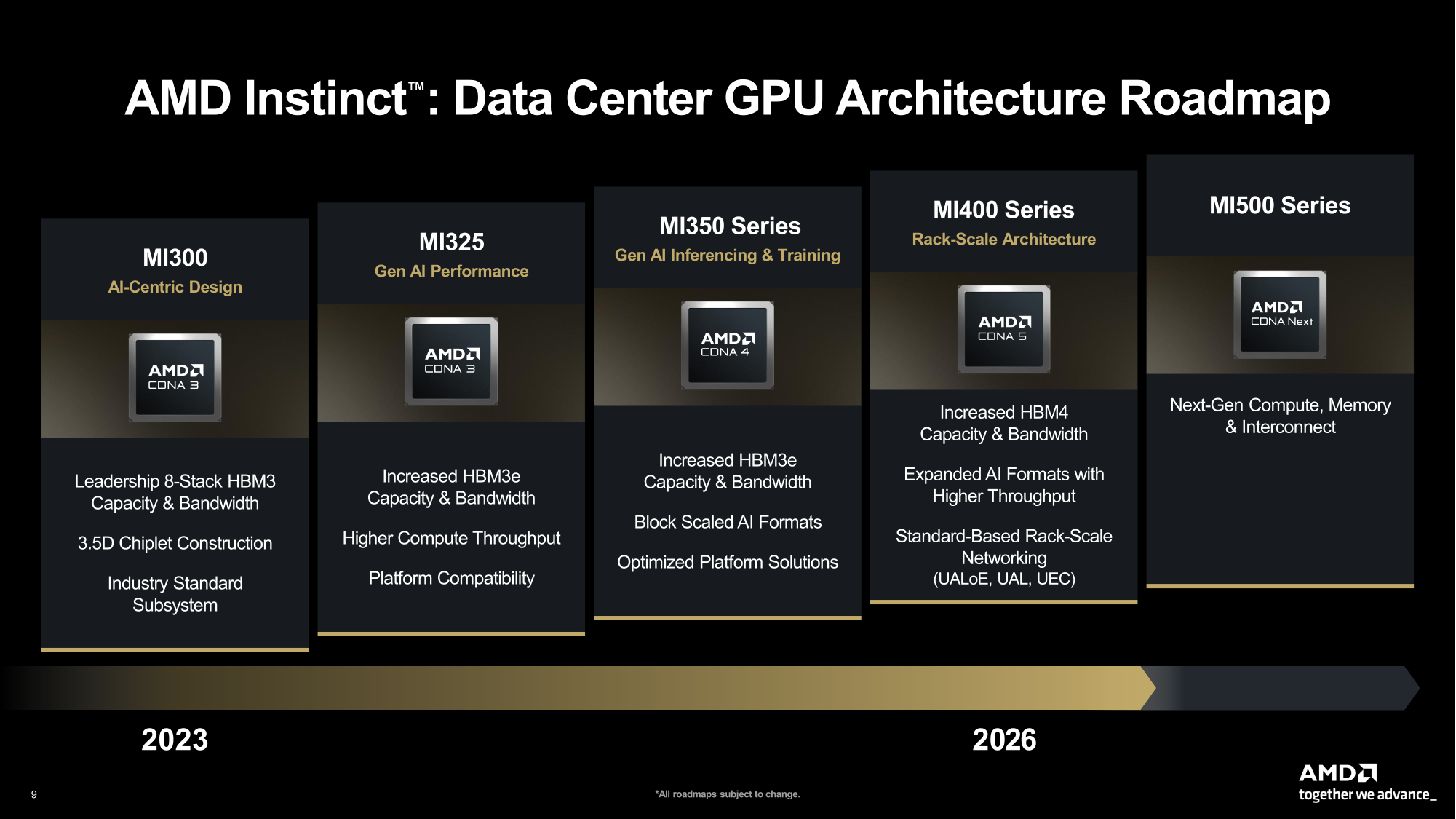 AMD характеризует Helios как свою первую ИИ-платформу стоечного масштаба — полностью интегрированную систему с открытой архитектурой, которая объединяет вычислительные мощности, ускорение, сетевые технологии и ПО в единую структуру. В отличие от традиционных серверных кластеров, Helios реализует всю стойку как единый высокопроизводительный вычислительный домен. Каждая стойка объединяет процессоры AMD EPYC Venice, CDNA5-ускорители Instinct MI450X (будет и вариант MI430X с полноценными FP64-блоками) и 400G/800G-карты Pensando Vulcano, связанные Infinity Fabric пятого поколения (PCIe 6.0, CXL 3.1, UCIe) и UALink.  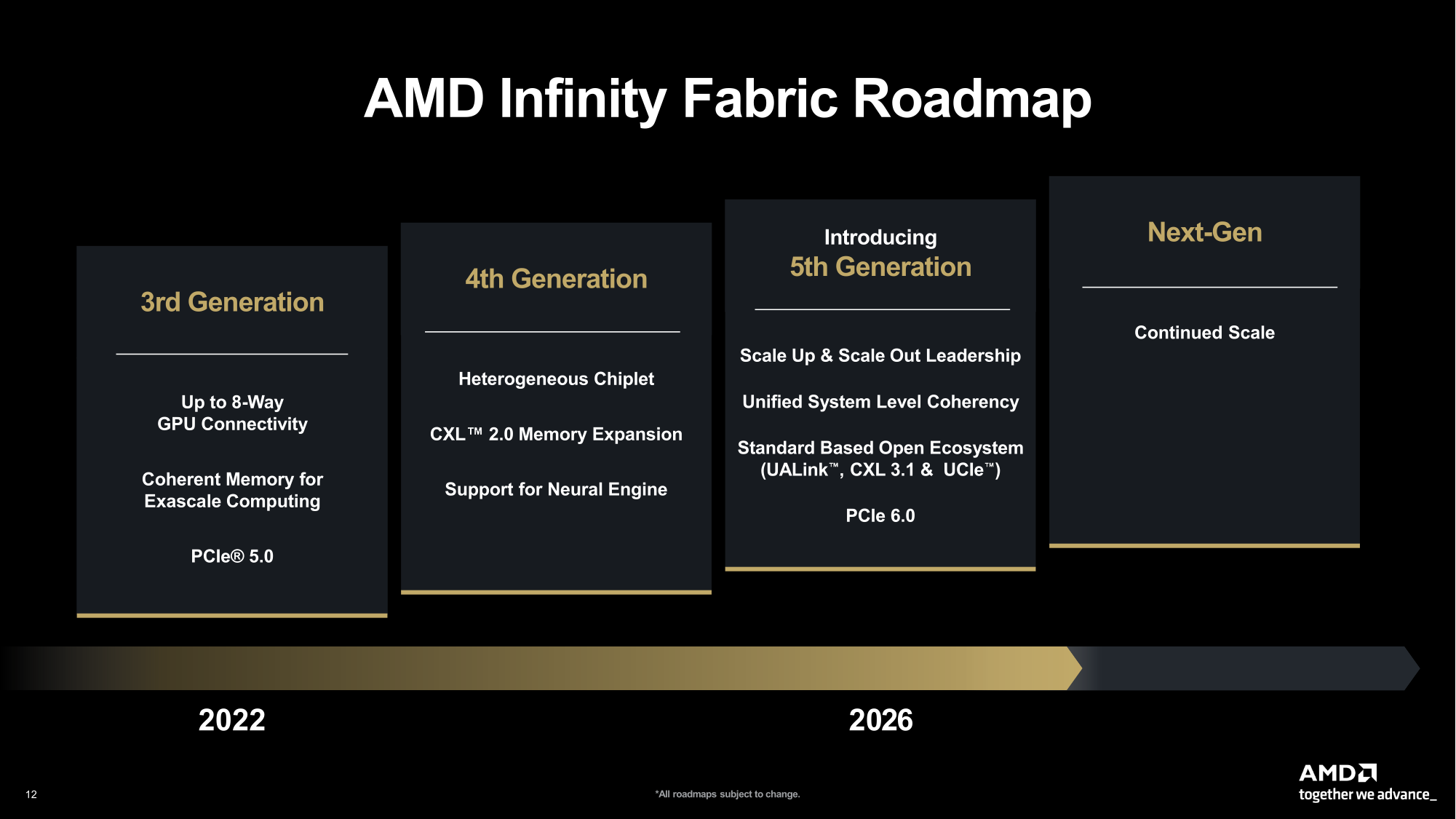 Эта архитектура минимизирует накладные расходы на перемещение данных, увеличивает пропускную способность между ускорителями и обеспечивает эффективность класса экзафлопсных вычислений в компактном корпусе. Helios фактически представляет собой проект AMD для ИИ-фабрики будущего с возможностью модульного расширения, позволяя объединять сотни стоек в одну систему в ЦОД.  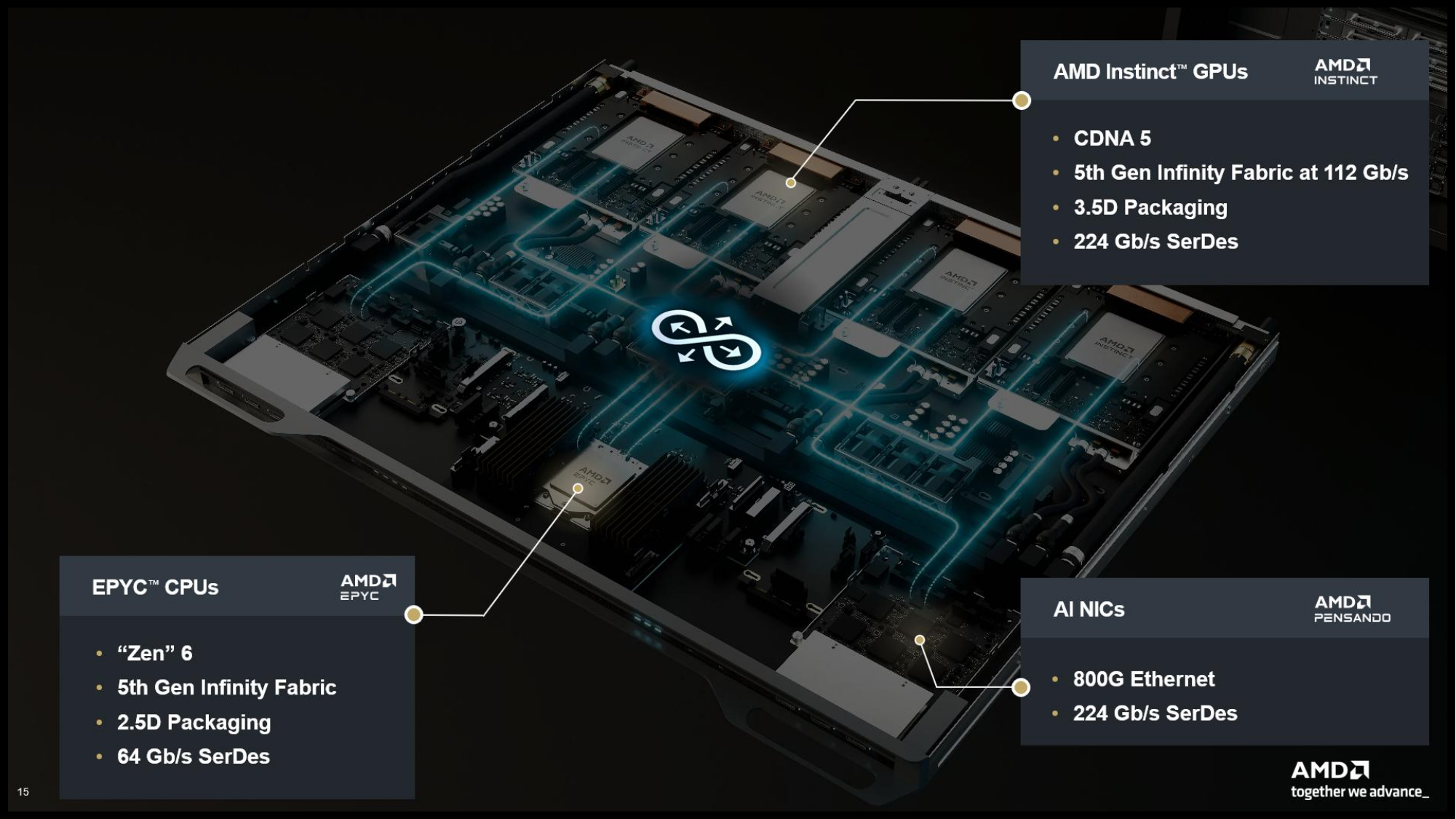 В 2027 году AMD планирует выпустить ускорители серии MI500 и процессоры EPYC Verano, продолжая тем самым ежегодный цикл совместной разработки процессоров, ускорителей и сетей. AMD заявила, что EPYC Venice, намеченные к выпуску в 2026 году, будут обладать лучшими в отрасли показателями плотности (1,3x по количеству потоков в сравнении с текущими решениями) и энергоэффективности (1,7x). Они пополнятся оптимизированными для ИИ наборами инструкций для обработки инференса и выполнения вычислений общего назначения. Указанные компоненты станут основой ИИ-фабрики, способной масштабироваться от одной стойки до глобально распределённых кластеров.  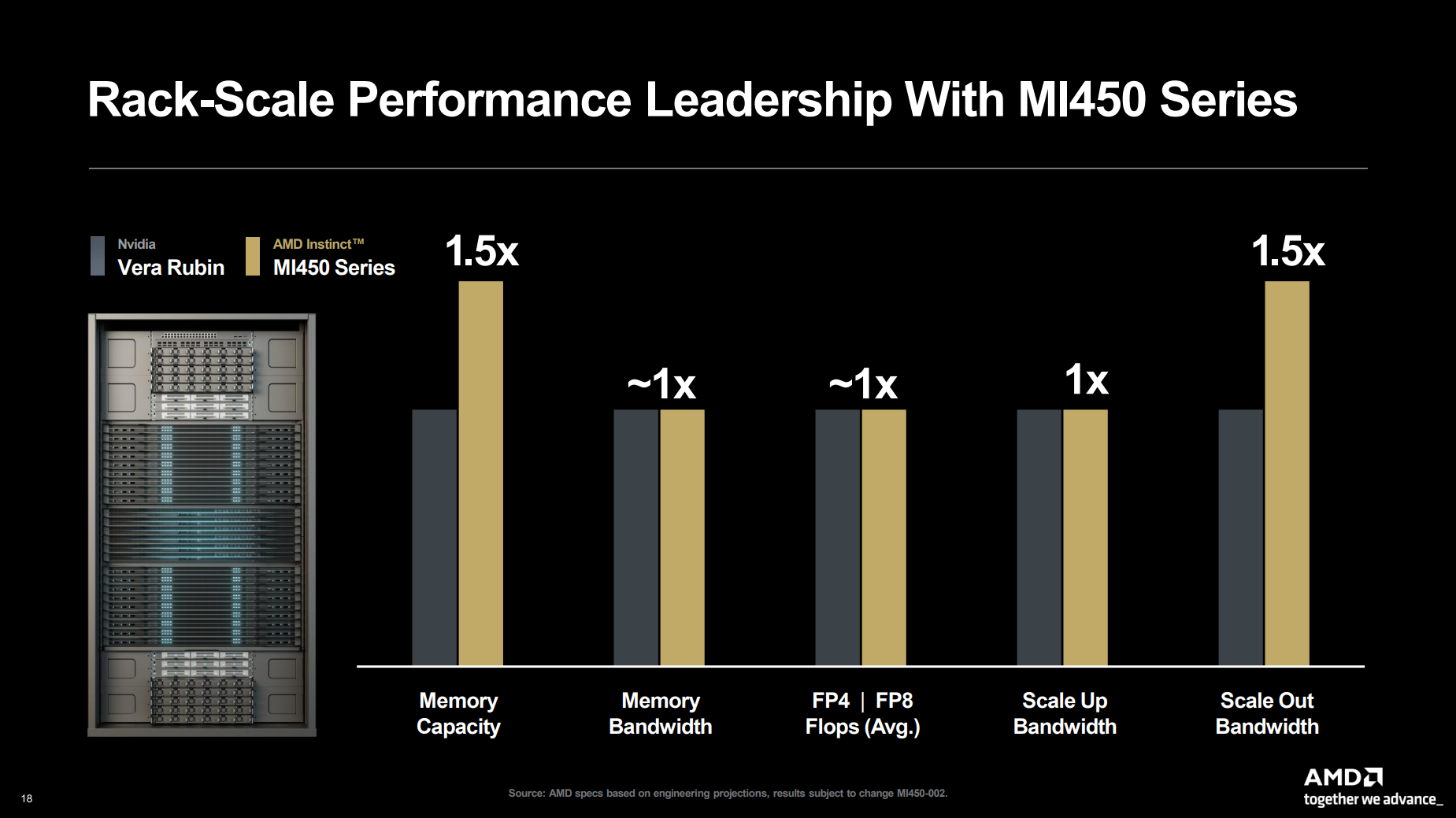 Исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) подчеркнул в своём выступлении, что производительность ИИ всё больше зависит от сети. Сетевые карты AMD Pensando Pollara и Vulcano для ИИ образуют связующую ткань архитектуры Helios. Сетевая карта Pollara 400 обеспечивает пропускную способность 400 Гбит/с, а готовящаяся к выходу сетевая карта Vulcano удвоит её до 800 Гбит/с, обеспечивая связь Ultra Ethernet между крупными кластерами ускорителей.   AMD представила четырёхуровневую архитектуру сети для масштабных ИИ-инфраструктур. Front-End часть обслуживает пользователей, хранилище и приложения. Она опирается на DPU Pensando и P4-движки, отвечающие за разгрузку сетевых функций, функции безопасности и шифрования, и работу с СХД. Вертикальное масштабирование в пределах стойки обеспечивает 3,6-Тбайт/с подключение на каждый GPU. Горизонтальное масштабирование реализуется благодаря UEC — внутренние тесты показали снижение затрат на коммутацию до 58 % по сравнению с традиционными сетями типа Fat-Tree. Наконец, Scale-Across (пространственное масштабирование) позволит объединить географически распределённые ЦОД в кластеры с интеллектуальным управлением трафиком и адаптивной балансировкой нагрузки.   AMD отметила, что открытый программный стек ROCm (Radeon open compute) по-прежнему лежит в основе её стратегии в области ИИ-платформ. По сравнению с прошлым годом число его загрузок выросло в десять раз и теперь на HuggingFace поддерживается более 2 млн моделей. ROCm интегрируется с ведущими фреймворками, включая PyTorch, TensorFlow, JAX, Triton, vLLM, ComfyUI и Ollama, и поддерживает проекты с открытым исходным кодом, такие как Unsloth. 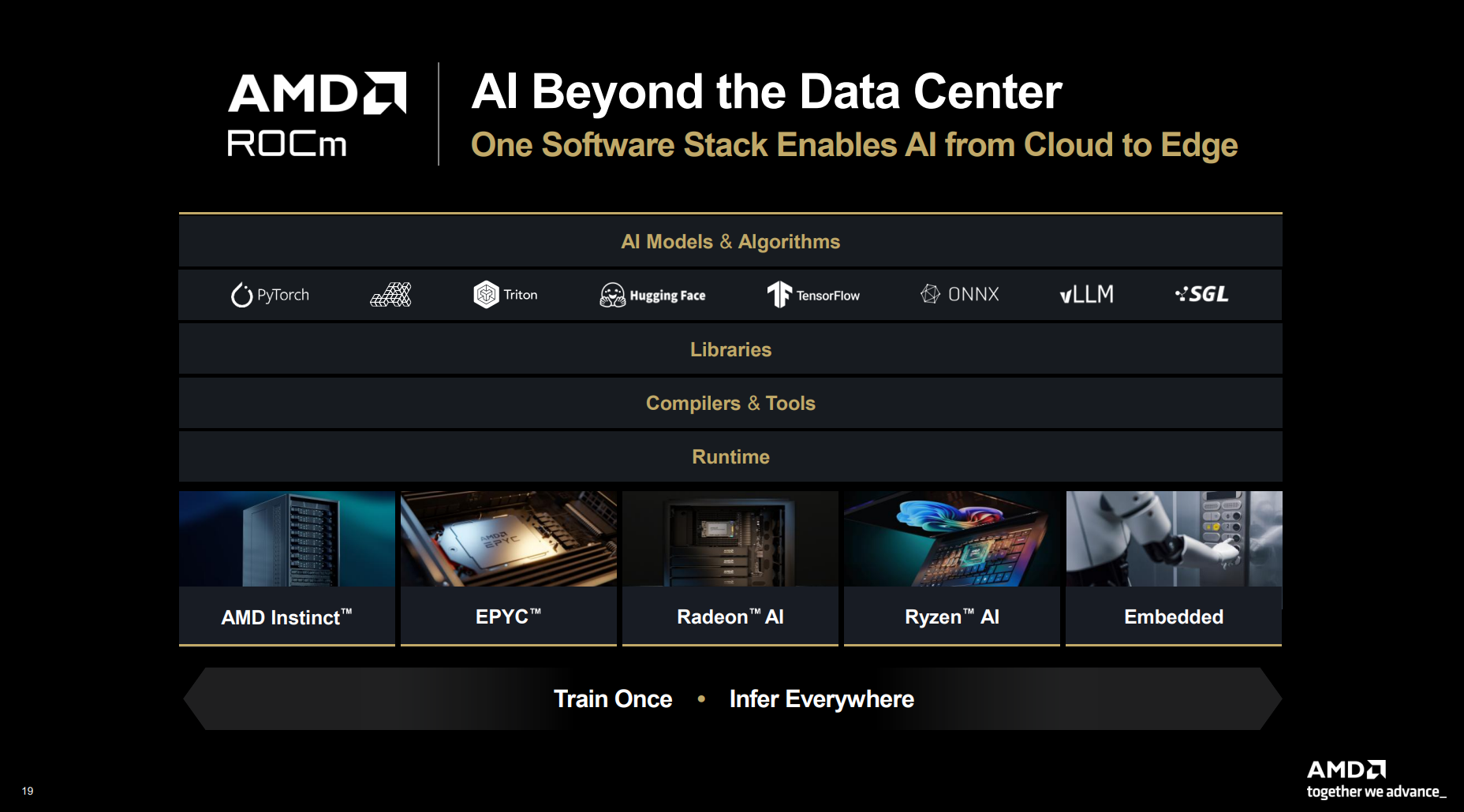  AMD также расширила своё видение «физического ИИ», когда вычисления выходят за рамки облака и охватывают роботов, транспортные средства и промышленные системы. Подразделение встраиваемых систем, усиленное приобретением Xilinx в 2022 году, превратилось из бизнеса, ориентированного на FPGA, в многоплатформенный двигатель роста, охватывающий адаптивные системы на кристалле (SoC), встраиваемые x86-процессоры и заказные кремниевые решения. По словам компании, с 2022 года решения в этой области принесли более $50 млрд. AMD рассчитывает превысить 70 % доли рынка адаптивных вычислений.   Говоря о перспективах, компания отметила, что ЦОД остаются основным драйвером роста, но наряду с этим она будет диверсифицировать свою деятельность по всем сегментам. Финансовые цели AMD включают:
15.10.2025 [14:00], Сергей Карасёв
Broadcom представила первые в мире 800GbE-адаптеры Thor Ultra с поддержкой Ultra Ethernet для масштабных ИИ-кластеровКомпания Broadcom анонсировала изделия Thor Ultra: это, как утверждается, первые в отрасли сетевые Ethernet-адаптеры (NIC) стандарта 800G, которые могут использоваться в составе масштабных ИИ-кластеров, объединяющих сотни тысяч ускорителей XPU для обработки моделей с триллионами параметров. Изделия выполнены в соответствии с открытой спецификацией Ultra Ethernet Consortium (UEC). Реализованы передовые возможности RDMA, включая многоканальное распределение на уровне пакетов для эффективной балансировки нагрузки, избирательную ретрансляцию для высокопроизводительной передачи данных, доставку пакетов вне очереди напрямую в память XPU, а также программируемые алгоритмы управления перегрузкой на уровне отправителя и получателя. 
Источник изображений: Broadcom Адаптеры Thor Ultra доступны в виде карт PCIe и OCP 3.0. Используется хост-интерфейс PCIe 6.0 x16. Реализован один порт с возможностью использования в режимах 800/400/200/100G/50/25GbE. Допускается шифрование и дешифрование данных на линейной скорости, что освобождает CPU/XPU от ресурсоёмких вычислительных задач. Благодаря применению 200G/100G PAM4 SerDes обеспечивается большая дальность пассивного медного соединения.  В качестве ключевых сфер использования названы серверы для задач ИИ и машинного обучения, публичные и частные облачные платформы, высокопроизводительные серверы хранения, а также системы HPC. Адаптеры Thor Ultra совместимыми с такими коммутационными решениями, как Broadcom Tomahawk 6. Упомянуты развитые функции телеметрии и обеспечения безопасности.
08.09.2025 [09:29], Сергей Карасёв
DE-CIX запустила первую в мире платформу обмена ИИ-трафикомОператор точек обмена трафиком DE-CIX объявил о запуске первой в мире специализированной платформы, призванной обеспечить высокоскоростное и надёжное взаимодействие между агентами, сетями и приложениями на базе ИИ. Инфраструктура сформирована в рамках первой фазы проекта AI Internet Exchange (AI-IX). К платформе уже подключены более 50 сетей, ориентированных на задачи ИИ. Это, в частности, провайдеры инференс-услуг и GPUaaS, а также поставщики облачных сервисов. AI-IX, как утверждается, обеспечивает отказоустойчивое и высокозащищённое соединение с низкими задержками, специально предназначенное для сценариев использования ИИ в режиме реального времени. Это могут быть мультимодальные агенты, робототехнические устройства, системы автономного вождения и пр. Платформа использует проприетарную масштабируемую систему маршрутизации. Вторая фаза проекта AI-IX предполагает поддержку Ultra Ethernet для формирования географически распределённой среды обучения ИИ. Задачей консорциума Ultra Ethernet, созданного в июле 2023 года, является разработка ИИ/HPC-интерконнекта на базе Ethernet. DE-CIX отмечает, что с появлением Ultra Ethernet меняется подход к проектированию инфраструктуры для ресурсоёмких вычислений. Становится возможным объединение географически распределённых узлов, что предоставляет компаниям новые возможности в плане создания отказоустойчивой и более экономичной частной инфраструктуры ИИ. 
Источник изображения: DE-CIX В целом, как подчёркивает DE-CIX, пиринговые сети ИИ предлагают ряд преимуществ как для задач инференса, так и для обучения моделей. Среди них — снижение затрат, повышение безопасности, увеличение производительности и повышение гибкости.
05.08.2025 [10:39], Сергей Карасёв
HyperPort на 3,2 Тбит/с: Broadcom выпустила чип-коммутатор Jericho4 для распределённой ИИ-инфраструктурыКомпания Broadcom объявила о начале поставок коммутационного чипа Jericho4, специально разработанного для распределённой инфраструктуры ИИ. Изделие, как утверждается, позволяет объединять более миллиона ускорителей (GPU, TPU) в географически разнесённых дата-центрах, преодолевая традиционные ограничения масштабирования. Отмечается, что по мере роста размера и сложности моделей ИИ требования к инфраструктуре ЦОД повышаются: создаётся необходимость в объединении ресурсов нескольких площадок, каждая из которых обеспечивает мощность в десятки или сотни мегаватт. Для этого требуется оборудование нового поколения, оптимизированное для сверхширокополосной и безопасной передачи данных на значительные расстояния. Новинка позволяет решить проблему. Jericho4 обладает коммутационной способностью 51,2 Тбит/с. Благодаря глубокой буферизации и интеллектуальному управлению перегрузкой изделие обеспечивает поддержку RoCE без потерь на расстоянии более 100 км, что позволяет формировать распределённую инфраструктуру ИИ, говорит Broadcom. 
Источник изображений: Broadcom Могут быть задействованы интерфейсы 50GbE, 100GbE, 200GbE, 400GbE, 800GbE и 1.6TbE. Реализована технология HyperPort, которая объединяет четыре порта 800GbE в один канал с пропускной способность 3,2 Тбит/с, что упрощает проектирование и управление сетью. Единая инфраструктура на базе Jericho4 может масштабироваться до 36 тыс. портов HyperPort, каждый из которых работает со скоростью 3,2 Тбит/с. Jericho4 поддерживает шифрование MACsec на каждом порту на полной скорости для защиты передаваемой между ЦОД информации без ущерба для производительности — даже при самых высоких нагрузках. Новинка полностью соответствует спецификациям, разработанным консорциумом Ultra Ethernet (UEC): благодаря этому достигается бесшовная интеграция с широкой экосистемой сетевых карт, коммутаторов и программных стеков. 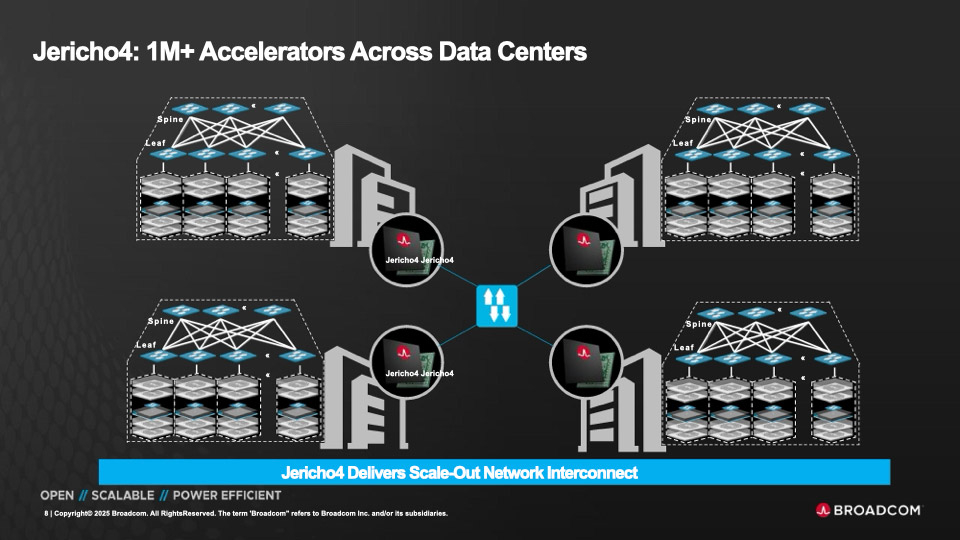 Чип Jericho4 производится по 3-нм технологии. Он оснащён модулями Broadcom PAM4 SerDes 200G. Это устраняет необходимость в дополнительных компонентах, таких как ретаймеры, что способствует снижению энергопотребления и повышению надёжности системы в целом. В частности, энергозатраты уменьшены на 40 % в расчёте на бит по сравнению с решениями предыдущего поколения. Это помогает организациям снижать эксплуатационные расходы и достигать целей устойчивого развития, говорит Broadcom. |
|

