Материалы по тегу: hpc
|
08.07.2025 [00:23], Владимир Мироненко
CoreWeave всё-таки купила оператора ЦОД Core Scientific, но в девять раз дороже, чем когда-то планировалаCoreWeave объявила о приобретении Core Scientific, поставщика инфраструктуры ЦОД, за $9 млрд. Благодаря этой сделке CoreWeave получит 1,3 ГВт мощности ЦОД Core Scientific с возможностью добавления более чем 1 ГВт. Год назад CoreWeave уже пыталась купить Core Scientific за $1 млрд, но та посчитала предложенную сумму слишком маленькой. В итоге CoreWeave постепенно нарастила аренду мощностей, став ключевым клиентом Core Scientific. Согласно условиям сделки, акционеры Core Scientific получат 0,1235 новых выпущенных акций CoreWeave класса A за каждую акцию Core Scientific на основе фиксированного обменного коэффициента. Выплата производится исходя из стоимости обыкновенных акций CoreWeave класса A по состоянию на 3 июля 2025 года и премии примерно в 66 % к стоимости акции Core Scientific по состоянию на 25 июня текущего года. Окончательная стоимость сделки будет определена во время её завершения, которое ожидается в IV квартале 2025 года. По оценкам CoreWeave, после закрытия сделки доля акционеров Core Scientific в объединённой компании составит менее 10 %. «Это приобретение ускоряет реализацию нашей стратегии по масштабированию рабочих нагрузок ИИ и HPC», — заявил Майкл Интратор (Michael Intrator), генеральный директор, председатель совета директоров и соучредитель CoreWeave. После объявления о сделке, акции CoreWeave упали на 4,4 % в ходе предварительных торгов в Нью-Йорке, пишет Bloomberg. Акции Core Scientific потеряли в цене 14 %. Core Scientific, как и сама CoreWeave, ранее предлагавшая услуги майнинга, сейчас на фоне дефицита мощностей ЦОД и сложности с их обеспечением электроэнергии из-за бума ИИ-технологий решила выйти за рамки криптовалютного рынка. Согласно прогнозу JPMorgan от октября прошлого года, у криптомайнеров осталось всего девять месяцев, чтобы переключиться на ИИ. 
Источник изображения: Core Scientific Согласно пресс-релизу CoreWeave, компания рассчитывает получить значительную экономию средств путём оптимизации бизнес-операций и устранения накладных расходов на аренду ЦОД. Также отмечено, что возможности создания дата-центров Core Scientific дополняют и расширяют обширный опыт CoreWeave в области закупок электроэнергии и земли, строительства и управления инфраструктурными активами. Попутно CoreWeave сокращает зависимость от других колокейшн-партнёров. Как отметил ресурс The Register, у Core Scientific есть десять кампусов ЦОД разной степени готовности в Алабаме, Джорджии, Кентукки, Северной Каролине, Северной Дакоте, Оклахоме и Техасе. Около 500 МВт из 1,3 ГВт имеющихся у Core Scientific мощностей ЦОД в настоящее время потребляются майнинговыми установками. Ещё 590 МВт было выделена CoreWeave в аренду. Провайдеры облачной инфраструктуры спешат расширять свои ЦОД, чтобы идти в ногу со спросом на вычислительные мощности компаний в сфере ИИ, отметил Bloomberg. На прошлой неделе ресурс сообщил, что Oracle дополнительно арендует у Oracle 4,5 ГВт мощностей ЦОД в США. В свою очередь, CoreWeave заключила в начале июня соглашение с Applied Digital об аренде сроком на 15 лет 250 МВт ЦОД за $7 млрд в кампусе в Эллендейле (Ellendale, Северная Дакота). Ещё 200 МВт CoreWeave получила от Galaxy Digital, которая тоже отказалась от криптомайнинга.
06.07.2025 [00:44], Владимир Мироненко
Esperanto, создатель уникального тысячеядерного RISC-V-ускорителя, закрывается — всех инженеров переманили крупные компанииСтартап Esperanto, специализирующийся на разработке серверных ускорителей на базе архитектуры RISC-V, сворачивает свою деятельность, сообщил ресурс EE Times. В настоящее время компания, которую уже покинуло большинство сотрудников, ищет покупателя на свои технологии или заинтересованных в лицензировании её разработок. Компания известна созданием тысячеядерного ИИ-ускорителя ET-SoC-1. Генеральный директор Esperanto Арт Свифт (Art Swift) сообщил EE Times о закрытии дочерних предприятий в Европе — у неё была значительная инженерная команда в Испании и ещё одна небольшая в Сербии. В штаб-квартире Esperanto в Маунтин-Вью (Калифорния) численность персонала сократилась на 90 %. Свифт и еще несколько инженеров остались, чтобы продать или лицензировать разработки компании и содействовать любой потенциальной передаче технологий. По словам Свифта, компания подверглась атаке со стороны богатых конкурентов, которые предлагали зарплату «в два, три, даже в четыре раза выше», чем могла предложить небольшая Esperanto. «Они фактически уничтожили наши команды — очень жаль, но мы не смогли конкурировать с ними», — говорит Свифт, отмечая, что уже несколько компаний проявило интерес к приобретению технологии или её лицензированию на неисключительной основе. Он добавил, что у Esperanto был крупный клиент, которому есть что предложить, что добавляет оптимизма. Ранее компания, судя по всему, пыталась предложить свои чипы Meta✴. 
Источник изображения: Esperanto Technologies Интерес рынка к RISC-V для чипов ЦОД остаётся высоким, особенно в Европе, где инвестирует в новую экосистему чипов на основе RISC-V. Вместе с тем именно ключевое преимущество разработок Esperanto — энергоэффективность — оказалось труднореализуемым, говорит гендиректор: «При неограниченном бюджете на электроэнергию энергоэффективность на самом деле не имеет значения». Esperanto готовила к выпуску чиплет второго поколения, который должен был поступить в производство на мощностях Samsung по 4-нм техроцессу в 2026 году. Чиплет предложил бы до 16 Тфлопс в FP64-вычислениях или до 256 Тфлопс в FP8-расчётах при потреблении 15–60 Вт. В один чип можно объединить до восьми чиплетов. Третье поколение технологии удвоило бы вычислительную мощность чиплетов. «Компании действительно были заинтересованы в получении этой технологии, так что посмотрим», — говорит Свифт. В прошлом году Esperanto договорилась с корпорацией NEC о сотрудничестве в области НРС с целью создания программных и аппаратных решений следующего поколения с архитектурой RISC-V. Также сообщалось о разработке чипа ET-SoC-2 для НРС и ИИ-задач. На пике развития штат Esperanto составлял 140 человек. По словам Свифта, 95 % бывших сотрудников стартапа уже нашли новую работу. В аналогичной ситуации оказалась Codasip, объявившая о готовности продать свои активы, поскольку обострение конкуренции на рынке RISC-V и отсутствие достаточного запаса средств ограничивают возможности небольших компаний, которые зачастую не могут конкурировать с IT-гигантами. ИИ-стартап Untether AI тоже провалил тест на выживание, объявив о закрытии бизнеса после того, как AMD переманила ряд его ведущих специалистов.
30.06.2025 [11:11], Сергей Карасёв
Албания присоединилась к европейской суперкомпьютерной программе EuroHPC JUЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) сообщило о том, что Албания стала 36-м государством — участником проекта. Соответствующее решение принято по итогам 49-го заседания совета управляющих EuroHPC. Отмечается, что Албания принимает активное участие в программе Европейского союза по исследованиям и инновациям с 2008 года. Доступ к вычислительным ресурсам EuroHPC предоставляется научно-исследовательским институтам, государственным органам и промышленным предприятиям Албании. Теперь эта страна становится полноправным участником EuroHPC. Албанские специалисты смогут подавать заявки на исследовательские и инновационные инициативы EuroHPC JU, финансируемые в рамках программы Horizon Europe. Кроме того, Албания сможет внести свой вклад в развёртывание так называемых европейских фабрик ИИ — EuroHPC AI Factories. В 2025 году такие площадки появятся в Финляндии, Германии, Греции, Италии, Люксембурге, Испании и Швеции. В целом, EuroHPC JU курирует создание 13 фабрик ИИ по всей Европе, которые будут предоставлять ресурсы малым и средним компаниям, а также стартапам. 
Источник изображения: EuroHPC JU Албания присоединилась к другим странам — членам EuroHPC JU, которые участвуют в программе Horizon Europe и при этом не входят в Европейский союз. Среди них — Исландия, Черногория, Северная Македония, Норвегия, Сербия, Турция и Великобритания. В целом, EuroHPC активно развивает инфраструктуру высокопроизводительных вычислений в Европе. В рамках инициативы на сегодняшний день развёрнуты десять НРС-систем. Три из суперкомпьютеров EuroHPC входят в десятку самых мощных НРС-комплексов мира: это Jupiter в Германии, который занимает 4-е место в июньском списке ТОР500, а также LUMI в Финляндии (9-я строка) и Leonardo в Италии (10-е место). Подписано соглашение с французским национальным агентством высокопроизводительных вычислений (GENCI) о размещении второго в Европе (после Jupiter) суперкомпьютера экзафлопсного класса — системы Alice Recoque. Кроме того, EuroHPC JU формирует европейскую инфраструктуру квантовых вычислений. В частности, в конце 2024 года была начата подготовка к созданию передовых сетей, которые соединят суперкомпьютеры, квантовые компьютеры и дата-центры Евросоюза. Вместе с тем Юлихский суперкомпьютерный центр в Германии (JSC) получил 100-кубитный квантовый компьютер на нейтральных атомах. EuroHPC также развернёт в Европе специализированные индустриальные суперкомпьютеры.
29.06.2025 [21:11], Сергей Карасёв
Таёжное облако: ИИ-кластер Northern Data Njoerd вошёл в рейтинг TOP500
h100
hardware
hpc
hpe
intel
northern data
nvidia
sapphire rapids
xeon
великобритания
ии
облако
суперкомпьютер
Немецкая компания Northern Data Group, поставщик решений в области ИИ и НРС, объявила о том, что её система Njoerd вошла в июньский рейтинг мощнейших суперкомпьютеров мира TOP500. Этот вычислительный комплекс, расположенный в Великобритании, построен на платформе HPE Cray XD670. Машина Njoerd попала на 26-е место списка TOP500. Она объединяет 244 узла, каждый из которых содержит восемь ускорителей NVIDIA H100. В общей сложности задействованы примерно 28,5 млн ядер CUDA. Кроме того, в составе системы используются процессоры Intel Xeon Platinum 8462Y+ (32C/64C, 2,8–4,1 ГГц, 300 Вт). Применён интерконнект Infiniband NDR400. FP64-производительность Njoerd достигает 78,2 Пфлопс, а теоретическое пиковое быстродействие составляет 106,28 Пфлопс. При рабочих нагрузках ИИ суперкомпьютер демонстрирует производительность 3,86 Эфлопс в режиме FP8 и 1,93 Эфлопс в режиме FP16. Заявленный показатель MFU (Model FLOPs Utilization) при предварительном обучении современных больших языковых моделей (LLM) находится на уровне 50–60 %. Таким образом, как утверждается, система Njoerd на сегодняшний день представляет собой наиболее эффективный кластер H100 подобного размера, оптимизированный для ресурсоёмких рабочих нагрузок ИИ и HPC. Суперкомпьютер входит в состав Taiga Cloud — одной из крупнейших в Европе облачных платформ, ориентированных на задачи генеративного ИИ. Эта вычислительная инфраструктура использует на 100 % безуглеродную энергию. Показатель PUE варьируется от 1,15 до 1,06. Доступ к ресурсам предоставляется посредством API или через портал самообслуживания. Одним из преимуществ Taiga Cloud компания Northern Data Group называет суверенитет данных. 
Источник изображения: Northern Data Group
24.06.2025 [16:15], Руслан Авдеев
400-кВт ЦОД Deep Green будет отапливать бассейн развлекательного центра в МанчестереDeep Green, внедряющая небольшие дата-центры при бассейнах, намерена развернуть объект близ Манчестера (Великобритания). Компания разместит оборудование на 400 кВт на площади 150 м2 в развлекательном центре Move Urmston в районе Урмстон (Urmston, Большой Манчестер), сообщает Datacenter Dynamics. Тепло дата-центра будет использоваться для подогрева воды. Система будет использовать комбинацию прямого жидкостного охлаждения и воздушное охлаждение. ЦОД получит восемь стоек мощностью до 60 кВт каждая, размещённых в контейнере. Целевой PUE — не более 1,2. В Deep Green подчеркнули, что ЦОД не просто обеспечит развлекательный центр теплом на десятки тысяч фунтов, но и позволить сократить углеродные выбросы на сотни тонн. Deep Green размещает HPC-серверы в местах, где их тепло можно будет использовать в полной мере. Само тепло предлагается пользователям, в том числе плавательным бассейнам, бесплатно. Деятельность Deep Green началась в 2023 году, первое вычислительное оборудование было размещено в развлекательном центре в Эксмуте (Exmouth, Девон). Клиентами Deep Green уже являются британский облачный провайдер Civo и постпродакшн-компания Dirty Looks. Инвестором Deep Green является британская коммунальная компания Octopus Energy. На сайте компании сообщается, что у неё уже есть один действующий объект, три в стадии строительства и один — в стадии планирования. 
Источник изображения: David Romualdo/unsplash.com Уже действует объект DG03 в Суиндоне (Swindon, Уилтшир) на 1,1 МВт. Описываемый выше 400-кВт ЦОД DG01 в Манчестере пока строится, как и ещё один объект на 500 кВт — DG02 в Йорке (York, Норт-Йоркшир). Более крупный 4-МВт ЦОД возводится в Брэдфорде (Bradford, Уэст-Йоркшир). Ещё один объект на 20 МВт планируется построить в Линкольне (Lincoln, Линькольншир), но официальных подробностей пока немного. Также планируется дата-центр DG06 мощностью более 20 МВт, который расположится в Лансинге, столице американского штата Мичиган. Всего Deep Green намерена развернуть 300 МВт в Европе и США. Схожие решения создаёт французская компания Qarnot. В Великобритании производитель «цифровых бойлеров» Heata и облачный оператор Civo уже предлагают устанавливать серверы для отопления зданий. А Aventuur планирует обогревать аквапарк в Новой Зеландии теплом дата-центра, питающегося от солнечных элементов. При этом ещё в 2023 году сообщалось, что на практике такие решения дороги, а иногда и вовсе бессмысленны.
23.06.2025 [11:58], Сергей Карасёв
Подземный суперкомпьютер Olivia стал самым мощным в НорвегииВ Норвегии введён в эксплуатацию самый мощный в стране суперкомпьютер — система Olivia, созданная корпорацией HPE. Комплекс расположен в дата-центре Лефдаль (Lefdal Mine Datacenter, LMD) на базе бывшего рудника, а для его охлаждения используется холодная вода из близлежащего фьорда. Машина построена на платформе HPE Cray Supercomputing EX (EX254n). В её состав входят 252 узла, каждый из которых содержит два 128-ядерных процессора AMD EPYC 9745 (Turin). В сумме это даёт 64 512 CPU-ядер. Кроме того, задействован GPU-кластер с 76 узлами, оснащёнными четырьмя гибридными суперчипами NVIDIA GH200: таким образом, в общей сложности применены 304 ускорителя. Используется интерконнект HPE Slingshot 11. За хранение данных отвечает система HPE Cray ClusterStor E1000 вместимостью 5,3 Пбайт. В текущей конфигурации GPU-кластер Olivia обладает производительностью 13,2 Пфлопс (FP64) и пиковым быстродействием 16,8 Пфлопс. При этом энергопотребление составляет 219 кВт. Таким образом, машина демонстрирует производительность в 60,274 Гфлопс/Вт. В июньском рейтинге мощнейших суперкомпьютеров мира TOP500 GPU-комплекс Olivia располагается на 117-й позиции, тогда как в списке самых энергоэффективных суперкомпьютеров GREEN500 он занимает 22-ю строку. CPU-блок Olivia занимает 271-е место в рейтинге с фактической и пиковой FP64-производительностью 4,25 и 4,95 Пфлопс соответственно. 
Источник изображения: Sigma2 Olivia эксплуатируется государственной компанией Sigma2. Применять суперкомпьютер планируется для проведения исследований в различных областях, включая изменения климата, здравоохранение, ИИ и пр. Суперкомпьютер обладает возможностями для дальнейшего расширения. В частности, количество ядер CPU может быть увеличено до 119 808. Кроме того, могут быть добавлены ещё 224 ускорителя.
19.06.2025 [17:13], Руслан Авдеев
Экзафлопсный суперкомпьютер Fugaku Next получит Arm-процессоры Fujitsu MONAKA-XЯпонская Fujitsu получила контракт на разработку преемника суперкомпьютера Fugaku, получившего условное название FugakuNEXT (Fugaku Next), сообщает Datacenter Dynamics. Информация об этом появилась ещё в прошлом году, но теперь заключено официальное соглашение. Новую машину разместят рядом с уже действующей в институте Riken (Япония) системой. Контракт включает и поставку вычислительного оборудования, а первая фаза проектирования продлится до конца февраля 2026 года. Fujitsu разрабатывает энергоэффективные 2-нм 144-ядерные Arm-процессоры MONAKA с 3.5D-упаковкой, начало выпуска которых запланировано на 2027 год. Для FugakuNEXT компания создаст процессоры MONAKA-X, которые позволят не только ускорить работу уже существующих приложений для Fugaku, но и добавят современные возможности ускорения ИИ-вычислений. В компании уверены, что новые процессоры пригодятся не только в очередном суперкомпьютере, но и в самых разных сферах экономики, общественной жизни и промышленности. Кроме того, компания направит усилия на создание NPU следующего поколения. 
Источник изображения: Van Tay Media/unspalsh.com Введённый в эксплуатацию весной 2020 года суперкомпьютер Fugaku несколько лет подряд занимал первые места в TOP500 и других рейтингах. В последнем списке TOP500 он занимает седьмую позицию. Министерством образования, культуры, спорта, науки и технологий Японии (MEXT) разработку FugakuNEXT анонсировало в августе 2024 года. Тогда утверждалось, что компьютер станет первой вычислительной машиной зеттафлопсного уровня. Впрочем, такая пиковая производительность относится только к ИИ-вычислениям. Так или иначе, ранее MEXT публиковало документ, согласно которому каждый узел Fugaku Next должен обеспечить пиковую производительность в сотни Тфлопс (FP64), что в совокупности может составить 1 Эфлопс.
10.06.2025 [19:00], Игорь Осколков
Июньский TOP500 суперкомпьютеров: без сюрпризов, но не безынтересно65-я редакция TOP500 самых мощных суперкомпьютеров мира никаких особенных сюрпризов не преподнесла, но кое-какие новые и интересные машины в него попали. Лидерами списка среди стран всё ещё являются США (175 систем) и Китай (47 систем), вот только вклад их совершенно разный. Тройка лидеров по-прежнему представлена экзафлопсными суперкомпьютерами El Capitan, Frontier и Aurora Министерства энергетики США (DoE). Китайских же систем такого класса в списке нет, хотя никто не сомневается в их существовании. Хуже того, от КНР в этот раз снова не было подано ни одной заявки. Теперь к Китаю по количеству позиций в TOP500 приближается Германия — 41 машина, причём одна из них взобралась на четвёртое место июньской редакции списка. Она же является и единственным новичком в первой десятке. Это JUPITER Booster, совместный проект EuroHPC и Юлихского суперкомпьютерного центра (Jülich Supercomputing Centre). JUPITER (JU Pioneer for Innovative and Transformative Exascale Research) станет первым европейским экзафлопсным суперкомпьютером. Причём это изначально модульная система, «кусочек» которой под названием JETI (JUPITER Exascale Transition Instrument) уже попал в прошлогодний TOP500. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau JUPITER Booster по-прежнему использует платформу Atos/Eviden BullSequana XH3000 с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200. FP64-производительность представленного в TOP500 сегмента (это только часть всей машины) составила 793,4 Пфлопс при теоретическом пике в 930 Пфлопс. Энергопотребление составляет чуточку больше 13 МВт, но при этом в GREEN500 машина занимает только 21-е место. А на первом месте там… всё так же система JEDI на ровно той же аппаратной платформе, что неудивительно, ведь она тоже является «кусочком» JUPITER. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau На 11-ом месте оказался ещё один «сборный» суперкомпьютер — вторая фаза британского Isambard-AI на базе опять-таки NVIDIA GH200, которая добралась до отметки 216,5 Пфлопс (пик 278,6 Пфлопс). 13-е место досталось нидерландской системе ISEG2 от Nebius (когда-то Yandex) на базе Xeon Platinum 8468 (Sapphire Rapids), NVIDIA H200 (141 Гбайт) и InfiniBand NDR400. Неожиданностью можно назвать появление двух систем на базе векторных ускорителей SX-Aurora Type 10AE, разработку которых NEC уже забросила. Две безымянные машины на 113-м и 157-м местах принадлежат немецким метеорологам Deutscher Wetterdienst. Ближе к концу списка затесались ещё две любопытные системы из Норвегии, тоже безымянные. Интересны они тем, что сделаны xFusion (бывшее серверное подразделение Huawei, выделенное в проданную впоследствии независимую компанию), оснащены процессорами Intel Xeon 6900P (Granite Rapids-AP) и AMD EPYC 9005 (Turin), и… 100G-интерконнектом Intel Omni-Path. Буквально на днях Cornelis Networks догнала остальных разработчиков интерконнекта, представив, наконец, 400G-поколение CN5000. В целом же ситуация поменялась мало. На InfiniBand полагаются 54,2 % всех систем текущего списка, на Ethernet — суммарно по всем поколениям чуть больше трети. 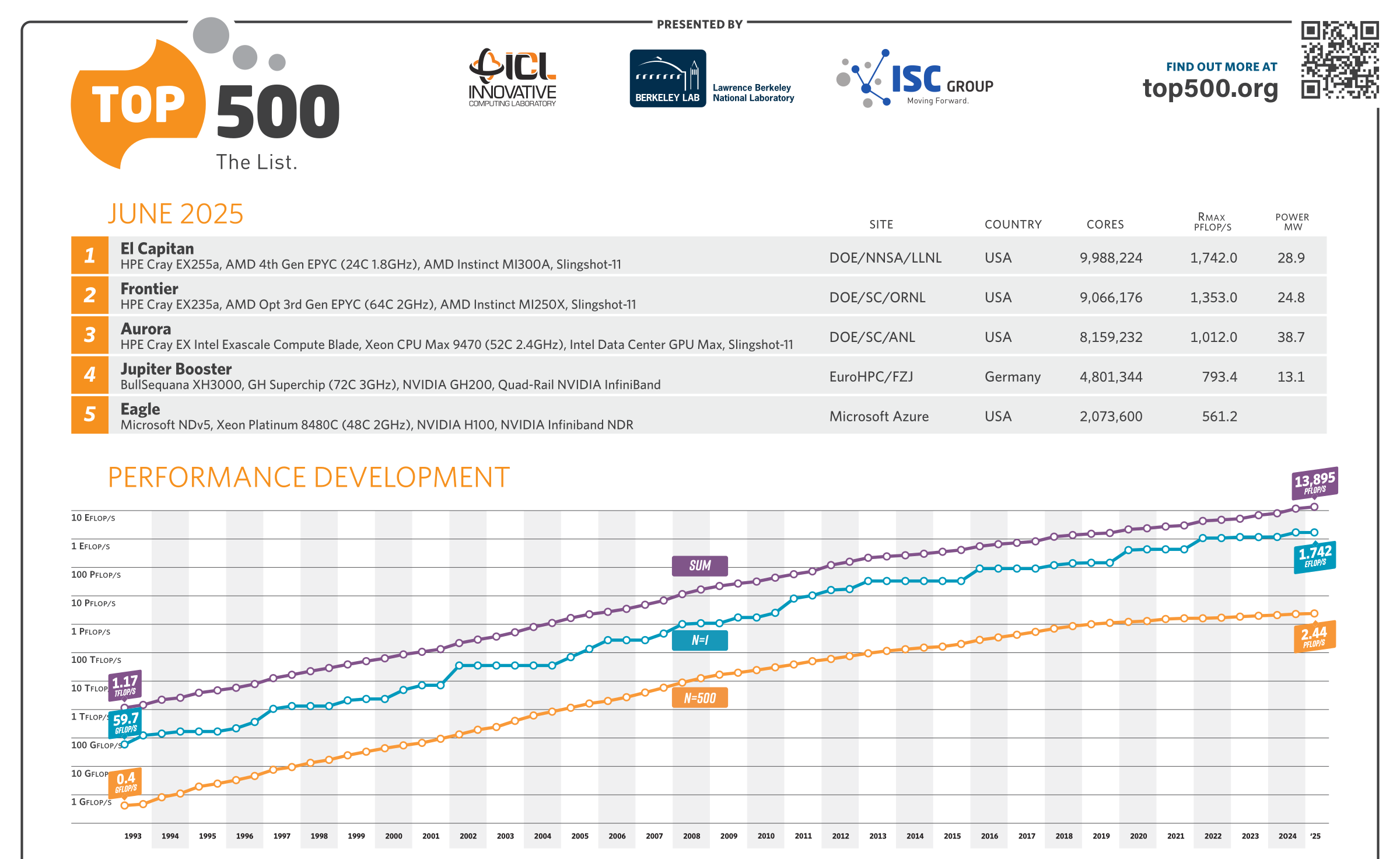
Источник: TOP500 Но если считать по Флопсам, то 48,2 % приходится на Slingshot, т.е. практически целиком на системы HPE, производительность которых суммарно составляет 47,9 % от производительности всего списка TOP500. Второе место по этому показателю у Atos/Eviden. По количеству суперкомпьютеров в списке HPE при этом занимает лишь второе место, уступая Lenovo и обгоняя Dell. Иными словам, HPE и Atos/Eviden преимущественно занимаются крупными машинами, а Lenovo, Dell и даже сама NVIDIA берут скорее числом. 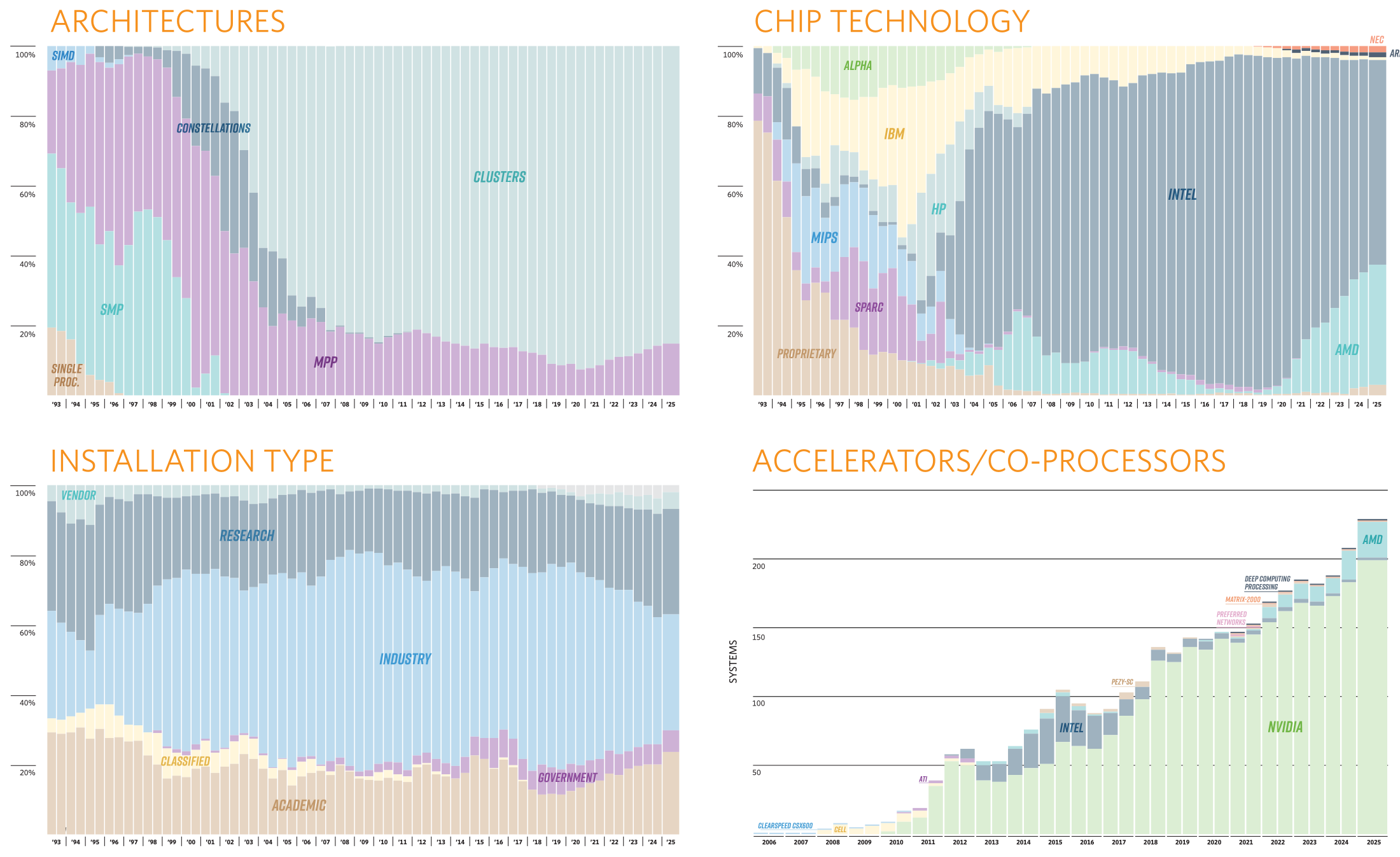
Источник: TOP500 В бенчмарке HPCG новым лидером стал El Capitan с показателем 17,407 Пфлопс, который сместил остальных участников на одну позицию вниз, отобрав первое место у Fugaku, которое она занимала несколько лет подряд. В бенчмарке HPL-MxP (HPL-AI) в расчётах смешанной точности первые места снова у El Capitan, Aurora и Frontier с показателями 16,7 Эфлопс, 11,6 Эфлопс и 11,4 Эфлопс соответственно. 
Источник изображения: NVIDIA Интересно, что в нынешнем TOP500 так и осталась только одна машина с AMD Instinct MI300X, а среди новинок всё больше MI300A да NVIDIA GH200 (а также более традиционных H100/H200). Очевидно, что новейшие NVIDIA B300 и Instinct MI325X в рейтинг могли и не попасть, но не исключено, что и в будущем вендоры будут по-прежнему ставить устаревающие ускорители как минимум NVIDIA. Всё дело в том, что в новых поколениях чипов NVIDIA сделала ставку на ИИ-нагрузки — разница между GB200 и GB300 в FP64-расчётах почти тридцатикратная. AMD якобы готовит Instinct MI430X с поддержкой FP64 и MI450X без таковой. Уже в анонсах суперкомпьютеров следующего поколения на базе Vera Rubin сама NVIDIA аккуратно обходит стороной вопрос «чистой» производительности, говоря лишь о «научных результатах» в случае системы Doudna. А в случае Blue Lion компания говорит о «слиянии симуляций, данных и ИИ». Возможно, это не совсем то, чего ждут учёные.
10.06.2025 [18:55], Руслан Авдеев
Германия получит суперкомпьютер Blue Lion на новейших ускорителях NVIDIA Vera RubinНемецкий Суперкомпьютерный центр Лейбница (Leibniz Supercomputing Centre, LRZ), входящий в HPC-группу Gauss Centre for Supercomputing, получит в своё распоряжение суперкомпьютер Blue Lion на базе ускорителей Vera Rubin. Ожидается, что он будет приблизительно в 30 раз производительнее своего предшественника — SuperMUC-NG. Ожидается, что платформа NVIDIA нового поколения кардинально изменит подход к научным исследованиям, сообщается в блоге компании. Это второй анонс машины на базе Vera Rubin после американского суперкомпьютера Doudna. По словам NVIDIA, новая аппаратная платформа — это «слиянии симуляций, данных и ИИ в единый движок для науки с высокой пропускной способностью, низкой задержкой, когерентными вычислениями и общей памятью». Непосредственно суперкомпьютер будет использовать платформу HPE Cray нового поколения с СЖО с тёплой водой (до +40 °C) на входе и 100-% безвентиляторным дизайном. Тепло системы будет использоваться для отопления близлежащих зданий. 
Источник изображения: NVIDIA Суперкомпьютер будет использоваться для исследований в областях климата, турбулентности, физики и машинного обучения — с комбинацией классических компьютерных симуляций и современного ИИ-моделирования. Также он станет помощником для реализации международных исследовательских проектов по всей Европе. Постройка новых компьютеров имеет важное значение, поскольку речь идёт о новой вехе в развитии суперкомпьютеров, которые теперь проектируются с прицелом на работу в реальном времени. ИИ более не является простым дополнением исследованиям, а данные постоянно находятся «в движении», поэтому стоящие за этим системы приходится постоянно поддерживать в актуальном состоянии, говорит NVIDIA.
05.06.2025 [17:27], Руслан Авдеев
1 Тбит/с на 4,7 тыс. км: Nokia протестировала сверхбыструю квантово-защищённую сеть для ИИ-суперкомпьютеровNokia, финский центр CSC (Finnish IT Center for Science) и ассоциация образовательных и исследовательских учреждений Нидерландов SURF успешно испытали сверхбыструю (1,2 Тбит/с) квантово-безопасную магистраль передачи данных между Амстердамом и Каяани (Kajaani, Финляндия). Эксперимент направлен на подготовку инфраструктуры для HPC- и ИИ-систем, каналы связи которой защищены от взлома квантовыми компьютерами будущего, сообщает Converge. Испытание, проведённое в мае 2025 года, позволило установить связь по ВОЛС на расстоянии более 3,5 тыс. км, а длина одного из тестовых маршрутов через Норвегию составила 4,7 тыс. км (1 Тбит/с). Инициатива рассчитана на поддержку и развитие возможностей финского ИИ-суперкомпьютера LUMI-AI. Также речь идёт о поддержке будущих ИИ-фабрик (AI Factories), которым потребуются защищённые каналы со сверхвысокой пропускной способностью. Тестовый запуск включал передачу синтезированных и реальных исследовательских данных «с диска на диск» через пять исследовательских и образовательных сетей, включая SURF (Нидерланды), NORDUnet (преимущественно скандинавские страны), Sunet (Швеция), SIKT (Норвегия) и Funet (Финляндия). Эксперимент подтвердил возможность обработки огромных непрерывных потоков данных, необходимых для современных нагрузок, обучения и эксплуатации ИИ-моделей. 
Источник изображения: LUMI В сети использовали маршрутизаторы Nokia IP/MPLS с поддержкой FlexE (Flexible Ethernet) для гибкого разделения физических интерфейсов на логические каналы с гарантированной пропускной способностью и квантово-защищённой передачу данных. Новая веха свидетельствует о готовности европейской инфраструктуры к интенсивному использованию данных, в том числе пакетов климатической информации петабайтных объёмов, информации для обучения ИИ-моделей и т.д. Эксперимент также подтвердил возможность безопасных, дальних многодоменных передач между разными сетями или административными границами. Это насущная потребность для современных международных проектов, где данные нужно передавать через разные сети без ущерба производительности и безопасности. По словам финских исследователей, исследовательские сети проектируются с учётом потребностей будущего. В ЦОД CSC в Каяани уже размещен общеевропейский суперкомпьютер LUMI, а с реализацией подпроекта LUMI-AI и ввода других ИИ-фабрик EuroHPC наличие надёжной и масштабируемой системы связи Европе просто необходима. |
|

