Материалы по тегу: hpc
|
03.06.2025 [12:33], Сергей Карасёв
Французские власти готовы выкупить НРС-активы Atos за €410 млнВласти Франции сделали предложение о выкупе подразделения Advanced Computing в составе группы Atos. Предполагается, что сделка поможет улучшить финансовое положение этой французской IT-компании и позволит ей сфокусировать усилия на наиболее перспективных видах деятельности. Advanced Computing объединяет направления HPC, ИИ и квантовых вычислений, а также сервисы для бизнеса. За соответствующие активы правительство Франции готово заплатить €410 млн. По оценкам, это соответствует нынешней рыночной стоимости перечисленных структур. Их суммарная выручка в 2025 году прогнозируется на уровне €800 млн. Сделка не распространяется на группу Vision AI (также входит в Advanced Computing), которая базируется в Великобритании и включает в себя прежде всего дочернюю компанию Ipsotek, приобретённую в 2021 году. Ключевым направлением работ Vision AI является видеоаналитика с применением алгоритмов ИИ. Эти технологии могут использоваться в сферах безопасности и охраны объектов, для контроля производственных операций, обнаружения оставленных в общественных местах предметов и пр. 
Источник изображения: Atos Совет директоров Atos в целом приветствует предложение французских властей. Стороны намерены подписать обязывающее соглашение в течение ближайших недель, а закрытие сделки ожидается в 2026 году. Информация о том, что Франция рассматривает возможность спасения Atos путём национализации, появилась в конце 2024 года. Atos намерена сохранить за собой высокорентабельные операции, такие как ИИ-технологии Vision AI. Компания столкнулась с ухудшением финансовых показателей: выручка падает на всех ключевых рынках, что связано в том числе с уменьшением количества заказов. При этом Atos находится в процессе сложной реструктуризации, которая включает конвертацию €2,9 млрд займов и облигаций в акционерный капитал и привлечение нового финансирования. Компания реализует четырёхлетний «стратегический план трансформации» под названием Genesis, призванный вывести её на путь «устойчивого роста». В случае успешной реструктуризации выручка группы, как ожидается, достигнет €9–10 млрд к 2028 году.
02.06.2025 [17:48], Сергей Карасёв
Dell построит один из первых суперкомпьютеров на базе NVIDIA Vera Rubin — Doudna для Министерства энергетики СШАМинистерство энергетики США (DOE) объявило о заключении контракта с Dell Technologies на создание нового суперкомпьютера под названием Doudna, в основу которого лягут ИИ-ускорители NVIDIA Vera Rubin. НРС-комплекс расположится в Национальной лаборатории им. Лоуренса в Беркли (Berkeley Lab) в Калифорнии (США). Система Doudna, также известная как NERSC-10, станет флагманским суперкомпьютером Национального вычислительного центра энергетических исследований США (NERSC) в составе Berkeley Lab. Комплекс назван в честь Дженнифер Даудны (Jennifer Doudna) — американского биохимика и генетика, исследователя геномики, одной из создателей технологии редактирования генома CRISPR-Cas9. Ожидается, что Doudna по производительности в «научных результатах» превзойдёт своего предшественника — суперкомпьютер Perlmutter — более чем в 10 раз. При этом энергопотребление возрастёт только в 2–3 раза. Теоретически, как отмечает The Register, система должна демонстрировать FP64-быстродействие до 790 Пфлопс при потреблении 5,8–8,7 МВт. Однако на практике, скорее всего, показатели будут иными. Дело в том, что детальная информация о производительности суперчипов Vera Rubin пока не раскрывается. Но в случае NVIDIA Blackwell Ultra, например, быстродействие на операциях двойной точности, которое считается необходимым для научных вычислений, было принесено в жертву широкому использованию форматов с 4-бит точностью, адаптированных для рабочих нагрузок ИИ. Так, у GB300 NVL72 FP64-производительность составляет 100 Тфлопс, а у его предшественника GB200 NVL72 — 2880 Тфлопс. Эта тенденция может сохраниться и в случае Vera Rubin. AMD, по слухам, готовит два варианта ускорителей Instinct: MI430X с поддержкой FP64 и MI450X без таковой. 
Источник изображения: Berkeley Lab Джек Донгарра (Jack Dongarra), один из крупнейших в мире специалистов области HPC и один создателей рейтинга самых мощных суперкомпьютеров в мире TOP500, предупреждает, что ИИ не сможет решить всех проблем научного сообщества, а отказ американских производителей от выпуска необходимых учёным чипов грозит большими проблемами уже всей стране. «Именно поэтому NVIDIA заявляет о более чем 10-кратном приросте "научного результата", а не производительности», — подчёркивает The Register. Таким образом, машина Doudna задумывается как нечто вроде «швейцарского армейского ножа», способного выполнять различные рабочие нагрузки, охватывающие и HPC-, и ИИ-задачи. Основой послужат системы Dell Integrated Rack Scalable Systems и серверы PowerEdge с ИИ-ускорителями NVIDIA Vera Rubin. Говорится об использовании платформы NVIDIA Quantum-X800 InfiniBand. Сообщается, что суперкомпьютер будут использовать примерно 11 тыс. специалистов и ученых, которые ведут исследования в таких областях, как термоядерная энергетика, материаловедение, разработка лекарственных препаратов, астрономия и многое другое. Машина заработает в 2026 году.
21.05.2025 [12:57], Руслан Авдеев
ИИ-платформа Microsoft Discovery создала жидкость для СЖО за 200 часов вместо нескольких месяцев
hpc
microsoft
microsoft azure
software
ии
ии-агент
квантовые вычисления
погружное охлаждение
разработка
сжо
химия
Компания Microsoft запустила для корпоративных пользователей в тестовом режиме ИИ-платформу Microsoft Discovery, использующую ИИ-агентов и HPC для помощи учёным, которым не придётся самостоятельно писать код для своих исследований. Потенциал системы продемонстрировали на примере самой Microsoft — ИИ помог создать новейшую жидкость для погружного охлаждения всего за 200 часов вместо нескольких месяцев или даже лет, сообщает VentureBeat. Microsoft Discovery использовали для поиска охлаждающей жидкости без «вечных» PFAS-химикатов, часто применяемых в иммерсионных СЖО. Регуляторы во всём мире всё чаще запрещают производство и использование этого класса вещества. ИИ Microsoft проверил 367 тыс. веществ-кандидатов, после чего химикат синтезировал один из партнёров компании. Однако сфера применения такого ИИ простирается далеко за пределы создания охлаждающих жидкостей — новые материалы и химикаты требуются в самых разных сферах, но на их поиск часто уходят годы. Microsoft Discovery позволяет взаимодействовать с «невероятными возможностями» ИИ, используя естественный язык, что полностью меняет весь процесс исследований, говорит компания. Обычно учёным приходилось изучать программирование для того, чтобы создавать вычислительные инструменты. Такая демократизация науки сыграет на руку малым исследовательским группам, у которых нет ресурсов на изучение программирования или привлечения сторонних специалистов в этой сфере. Более того, со временем платформа научится работать и с квантовыми компьютерами, написание кода для которых — ещё более сложная задача. 
Источник изображения: National Cancer Institute/unsplash.com Работа выполняется с помощью специальных ИИ-агентов, специально обученных для выполнения отдельных научных задач — от написания литературного обзора до создания компьютерной симуляции. По словам Microsoft, ИИ-агенты — это чуть ли не целая команда учёных с докторскими степенями в различных науках. Платформа интегрирует друг с другом базовые модели, занимающиеся общим планированием, и модели, специализирующиеся на физике, химии или, например, биологии. Также Microsoft Discovery позволяет комбинировать закрытые исследовательские данные и результаты уже опубликованных научных исследований по разным дисциплинам, сохраняя прозрачность моделей и контролируя процесс «рассуждений». Для работы с платформой используется интерфейс Copilot, который занимается оркестрацией агентов. Одновременно интерфейс служит и центральным хабом, в котором учёные управляют своей виртуальной ИИ-командой. 
Источник изображения: National Cancer Institute/unsplash.com В платформу встроены защитные механизмы — системе заданы «этические координаты». Также применяется модерация контента с проактивным подходом к выявлению злоупотреблений возможностями платформы — маркируются потенциально вредоносные алгоритмы и действия, поскольку все ИИ-инструменты фактически имеют «двойное назначение». С их помощью можно изобретать не только лекарства, но и опасные биологически опасные субстанции. Для своей платформы Microsoft выстраивает экосистему с участием представителей самых разных отраслей, от фармацевтики (GSK) до индустрии красоты (Estée Lauder). NVIDIA интегрирует с Discover микросервисы ALCHEMI и BioNeMo NIM для биотехнологий и фармацевтики. В полупроводниковой сфере Microsoft планирует интеграцию решений Synopsys для ускорения разработки чипов. Адаптацией под конкретные отраслевые задачи, развёртыванием и масштабированием платформы займутся Accenture и Capgemini. 
Источник изображения: Microsoft Успех Microsoft Discovery будет зависеть от того, насколько эффективно систему смогут интегрировать в текущие научные процессы — многие учёные скептически относятся к новым методикам, так что компании придётся показать всё, на что способен ИИ. По словам Microsoft, будущее науки именно за сочетанием умственных возможностей человека и масштабного ИИ. Microsoft уже провела предварительную демонстрацию Discovery для ограниченного круга структур. Цены на платформу пока не названы, но доступ к к ней будет организован посредством Azure.
20.05.2025 [12:10], Сергей Карасёв
NVIDIA открыла центр с самым мощным в мире исследовательским квантовым суперкомпьютеромКомпания NVIDIA объявила об открытии Глобального центра исследований и разработок для бизнеса в области искусственного интеллекта на базе квантовых технологий (Global Research and Development Center for Business by Quantum-AI Technology, G-QuAT). На этой площадке размещена система ABCI-Q — крупнейший в мире исследовательский суперкомпьютер, предназначенный для квантовых исследований. Система интегрирована с тремя квантовыми компьютерами. О проекте ABCI-Q сообщалось в марте 2024 года. Названный суперкомпьютер разработан Национальным институтом передовых промышленных наук и технологий Японии (AIST). В основу положены 2020 ускорителей NVIDIA H100. Задействованы интерконнект NVIDIA Quantum-2 InfiniBand, а также платформа с открытым исходным кодом NVIDIA CUDA-Q для организации гибридных квантово-классических вычислений. Ожидается, что сотрудничество NVIDIA и AIST будет способствовать ускорению разработок в таких областях, как квантовая коррекция ошибок и ИИ-приложения с поддержкой квантовых вычислений. В конечном итоге, проект призван помочь в решении некоторых из самых сложных глобальных задач, охватывающих различные отрасли, включая здравоохранение, энергетику и финансы. 
Источник изображения: NVIDIA Суперкомпьютер ABCI-Q интегрирован с процессором на сверхпроводящих кубитах Fujitsu, квантовым чипом на нейтральных атомах QuEra и фотонным процессором OptQC. Благодаря этому становится возможным выполнение рабочих нагрузок в нескольких модальностях кубитов. Исследователи смогут экспериментировать с вычислениями, основанными на GPU-ускорителях и квантовых процессорах разного типа. При этом будет обеспечиваться бесшовная интеграция квантового оборудования и классического суперкомпьютера.
20.05.2025 [12:05], Сергей Карасёв
В Казахстане заработает самый мощный суперкомпьютер в Центральной АзииМинистерство цифрового развития, инноваций и аэрокосмической промышленности Республики Казахстан (МЦРИАП) сообщило о том, что в страну доставлены узлы нового НРС-комплекса, который после сборки и запуска станет самым мощным суперкомпьютером в Центральной Азии. Система будет смонтирована в новом дата-центре МЦРИАП класса Tier III. Напомним, Минцифры Казахстана, АО «Фонд национального благосостояния «Самрук-Қазына» и компания Presight AI Ltd. из ОАЭ подписали соглашение о создании суперкомпьютера в феврале 2024 года. Проект реализуется в рамках Концепции развития искусственного интеллекта до 2029 года и является одним из ключевых этапов формирования современной ИТ-инфраструктуры Казахстана. Доставленная в республику система представляет собой первый в истории центральноазиатского региона суперкомпьютерный кластер. В его основу положены ускорители NVIDIA H200 на архитектуре Hopper. Заявленная производительность достигает примерно 2 Эфлопс (на операциях ИИ). Более подробные технические характеристики машины пока не раскрываются. 
Источник изображения: NVIDIA Ресурсы суперкомпьютера будут доступны всем участникам рынка. Мощности НРС-комплекса, в частности, смогут использовать стартапы для обучения нейросетей, университеты для проведения фундаментальных и прикладных исследований, а также научные центры и компании, внедряющие ИИ в бизнес-процессы. МЦРИАП подчеркивает, что запуск суперкомпьютера станет важным этапом в реализации послания президента страны по созданию собственной цифровой инфраструктуры и развитию национальной ИИ-экосистемы. В рамках проекта Казахстан впервые выстроил механизм ввоза высокотехнологичного оборудования без пошлин и НДС. Кроме того, во время официального визита в Казахстан наследного принца Абу-Даби, шейха Халеда бин Мохаммеда бин Зайда Аль Нахайяна состоялось открытие зарубежного офиса компании Presight (G42) в Астане. Новый офис, расположенный на территории «Экспо», выполняет функцию регионального хаба в Центральной Азии. В перспективе планируется формирование ситуационного центра, который станет интеллектуальным ядром городской инфраструктуры Астаны. Передовая платформа обеспечит мониторинг и принятие решений в различных областях, включая энергетику, общественную безопасность и управление городской инфраструктурой. «Это стратегически важный шаг в построении цифровой инфраструктуры страны. Он укрепит цифровой суверенитет Казахстана и лидирующую позицию в регионе по развитию технологий ИИ и привлечению глобальных IT-игроков», — говорит министр цифрового развития, инноваций и аэрокосмической промышленности Республики Казахстан Жаслан Мадиев.
19.05.2025 [23:55], Владимир Мироненко
NVIDIA построит на Тайване новую штаб-квартиру и развернёт два ИИ-суперкомпьютераNVIDIA построит в ближайшем будущем на Тайване новую штаб-квартиру, а также два ИИ-суперкомпьютера. Об этом сообщил гендиректор американской компании Дженсен Хуанг (Jensen Huang), подтвердив свою приверженность Тайваню как глобальному технологическому центру, пишет The Financial Times. Хуан отдал должное Тайваню, «крупнейшему региону по производству электроники в мире», назвав его «центром компьютерной экосистемы». Строительством первого ИИ-суперкомпьютера на базе 10 тыс. ускорителей Blackwell займётся Big Innovation Company, «дочка» Foxconn, в сотрудничестве с NVIDIA и при поддержке тайваньского правительства. Стоимость суперкомпьютера, который будут использоваться в технологической экосистеме Тайваня, составит сотни миллионов долларов. В числе клиентов будущего суперкомпьютера Хуанг назвал TSMC, ключевого производственного партнёра NVIDIA, которая будет использовать его вычислительные мощности для исследований и разработки новых процессов создания чипов. Второй ИИ-суперкомпьютер построит ASUS в интересах Национального HPC-центра NCHC (National Center for High-Performance Computing). Он будет ориентирован на исследование климата, разработку квантовых технологий, создание LLM и иную R&D-деятельность. Система будет в восемь раз мощнее суперкомпьютера Taiwania 2, в создании которого также принимала участие ASUS. Новинка получит узлы HGX H200 (всего 1700 ускорителей), две стойки GB200 NVL72, а также HGX B300, объединённые интерконнектом Quantum InfiniBand. Кроме того, NCHC планирует установить системы DGX Spark и развернуть облачный HGX-кластер. «Мы растём за пределы нашего текущего офиса [на Тайване]», — заявил Хуан, демонстрируя видео приземления футуристического космического корабля и его последующей трансформации в дизайн новой штаб-квартиры Constellation («Созвездие»), строительство которой начнется в ближайшее время в Бэйтоу (Beitou), районе Тайбэя. 
Источник изображения: NVIDIA Дженсен Хуанг также представил интерконнект NVLink Fusion, который позволит объединить решения NVIDIA с решениями конкурентов. Таким способом компания надеется закрепить свою технологию в качестве решения для базовой инфраструктуры. «Ничто не радует меня больше, чем, когда вы покупаете всё у NVIDIA… но мне доставляет огромную радость, если вы просто покупаете что-то у NVIDIA», — пошутил он. На вопрос о возможности создания NVIDIA нового чипа для Китая, который бы соответствовал последним экспортным ограничениям США, Хуанг заявил, что компания «оценивает, как лучше всего выйти на китайский рынок», отметив, что дальнейшие модификации H20 невозможны. Вместе с тем NVIDIA рассматривает возможность перепроектирования своих чипов с учётом новых ограничений, чтобы продолжать продавать их в Китае. На прошлой неделе стало известно о планах NVIDIA построить новый исследовательский центр в Шанхае в знак своей приверженности Поднебесной. Хуанг добавил, что «нет никаких доказательств контрабанды каких-либо ИИ-чипов» в Китай. Из-за опасений по поводу нелегальных поставок передовых чипов NVIDIA в Китай американские законодатели потребовали в прошлом месяце от компании предоставить отчёт о продажах её продукции в Китае и Юго-Восточной Азии.
19.05.2025 [11:36], Сергей Карасёв
LISA для Leonardo: итальянский суперкомпьютер получит ИИ-апгрейд за €28 млнЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) сообщило о заключении контракта с компанией Eviden на выполнение модернизации итальянского суперкомпьютера Leonardo под решение ИИ-задач. Стоимость проекта под названием LISA (Leonardo Improved Supercomputing Architecture) оценивается более чем в €28 млн. Комплекс Leonardo, запущенный в 2022 году, в текущей конфигурации использует платформы Atos BullSequana X2610 и X2135. В ноябрьском рейтинге TOP500 эта система занимает девятое место с теоретической пиковой производительностью 306,31 Пфлопс. Планируется интеграция Leonardo с квантовым компьютером IQM Radiance в конфигурации с 54 кубитами. Модернизация LISA предполагает развёртывание 166 серверных узлов, каждый из которых будет оснащён восемью ИИ-ускорителями на базе GPU. По информации The Register, будут задействованы серверы семейства BullSequana AI 600 и изделия NVIDIA H100. Общее количество ускорителей в составе сегмента LISA — 1328. Говорится о применении интерконнекта Infiniband. EuroHPC JU отмечает, что базовые узлы Leonardo и система LISA будут использовать единый многопротокольный уровень хранения, который обеспечивает возможность одновременной работы с блоками, файлами и объектами. При этом могут применяться службы данных, необходимые для поддержания ресурсоёмких вычислительных задач ИИ. 
Источник изображения: EuroHPC JU Развёртывание LISA запланировано на конец текущего года, а суммарные затраты на проект составят €28 167 942. LISA станет первым вычислительным кластером EuroHPC, разработанным с нуля специально для нагрузок ИИ. Европейское совместное предприятие EuroHPC JU сейчас занято формированием сети ИИ-фабрик: в 2025 году такие площадки появятся в Финляндии, Германии, Греции, Италии, Люксембурге, Испании и Швеции.
19.05.2025 [08:49], Владимир Мироненко
На одном ИИ не выедешь: США рискуют потерять лидерство в HPC
hardware
hpc
top500
государство
дефицит
ии
кадры
квантовые вычисления
обучение
прогноз
разработка
суперкомпьютер
сша
ускоритель
финансы
энергоэффективность
Проблемы, связанные с высокопроизводительными вычислениями (HPC), угрожают инновациям в США, утверждает Джек Донгарра (Jack Dongarra), лауреат премии А. М. Тьюринга и один создателей рейтинга самых мощных суперкомпьютеров в мире TOP500, чьи разработки и реализации многих библиотек, включая EISPACK, LINPACK, BLAS, LAPACK и ScaLAPACK, сыграли важную роль в продвижении HPC. В статье, опубликованной The Conversation, Донгарра рассказал о прогрессе HPC и проблемах с инновациями в США. Учёный отметил, что HPC являются одной из самых важных технологий в современном мире, позволяющей решать различные задачи — от прогнозирования погоды до поиска новых лекарств и обучения ИИ-моделей, которые слишком сложны или слишком велики для обычных компьютеров. Сейчас HPC находятся на переломном этапе, и выбор, который правительство США, исследователи и технологическая отрасль делают сегодня, может повлиять на будущее инноваций, национальной безопасности и мирового лидерства, предупреждает Донгарра. Используя тысячи и даже миллионы чипов с передовыми системами памяти и хранения для быстрого перемещения и сохранения огромных объёмов данных, HPC-платформы позволять выполнять чрезвычайно подробные симуляции и вычисления, говорит Донгарра. Важность HPC ещё больше возросла с развитием ИИ-технологий, требующих огромных вычислительных мощностей для обучения. «В результате ИИ и HPC теперь тесно сотрудничают, подталкивая друг друга вперёд», — отметил учёный. По словам Донгарра, сегмент HPC находится под большим давлением, чем когда-либо, с более высокими требованиями к системам по скорости, данным и энергопотреблению. Также он отметил, что HPC сталкиваются с некоторыми серьёзными техническими проблемами. Донгарра назвал одной из ключевых проблем разрыв между производительностью чипов и подсистем памяти. «Представьте себе, что у вас есть сверхбыстрый автомобиль, но вы застряли в пробке — мощность бесполезна, если дорога не может с ней справиться», — говорит учёный. Точно так же подсистемы памяти не способны «прокормить» вычислительные блоки, которые простаивают, что отражается на эффективности всей вычислительной системы. 
Источник изображения: OLCF Ещё одна проблема HPC — энергопотребление. Закон масштабирования Деннарда, согласно которому с уменьшением размеров транзистора уменьшается и энергопотребление при росте производительности, прекратил своё действие в 2006 году. Теперь, чем мощнее компьютеры, тем больше они потребляют энергии. Чтобы исправить это, исследователи ищут новые способы проектирования как аппаратного, так и программного обеспечения HPC. Также существует проблема с типами производимых чипов, отметил учёный. Сейчас индустрия чипов в основном сосредоточена на ИИ, который отлично работает с вычислениями с низкой точностью. Однако для многих научных приложений по-прежнему требуется FP64-вычисления. В частности, NVIDIA сделала ставку исключительно на ИИ, поэтому FP64-производительность новейших GB300 почти в 30 раз меньше, чему GB200. У AMD, по слухам, в следующем поколении Instinct будет сразу два варианта ускорителей MI430X с поддержкой FP64 и MI450X, полностью лишённый тензорных ядер с FP64. Но и она может сделать ставку только на ИИ. Если производители прекратят выпускать чипы, которые требуются учёным, это негативно отразится на выполнении важных исследований. Таким образом тенденции в производстве полупроводников и коммерческие приоритеты могут разниться с потребностями научного сообщества, а отсутствие специализированного оборудования может помешать прогрессу в исследованиях. Можно попытаться создавать специализированные чипы для HPC, но это дорого и сложно. Исследователи, тем не менее, изучают возможность применения новых конструкций для изготовления чипов, включая чиплеты, чтобы сделать их более доступными. В прошлом у США было преимущество в области HPC благодаря государственному финансированию, поддержке и открытости разработок, но теперь многие страны вкладывают значительные средства в HPC в стремлении снизить зависимость от иностранных технологий и выйти на лидирующие позиции в таких областях, как моделирование климата и персонализированная медицина. В Европе развивают программу EuroHPC, у Японии есть собственный суперкомпьютер Fugaku (а скоро будет ещё один), а у Китая — целая серия «автохтонных» машин. 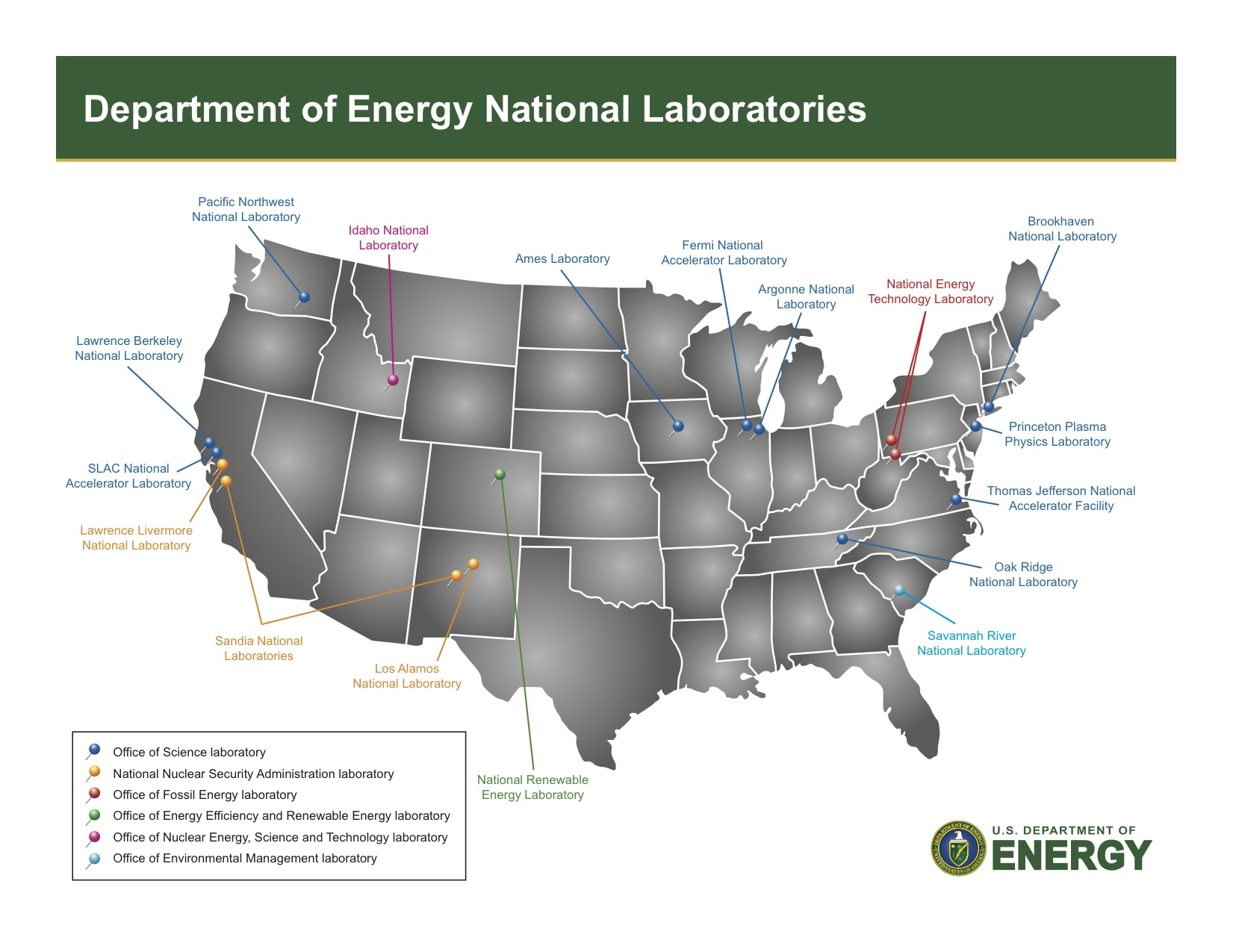
Источник изображения: WIkipedia / DoE Правительства стран понимают, что HPC являются ключом к их национальной безопасности, экономической мощи и научному лидерству, отметил Донгарра, подчеркнув, что у США всё ещё нет чёткого долгосрочного плана на будущее. Другие страны развивают это направление быстро, а без национальной стратегии США рискуют отстать, предупредил он: «Национальная стратегия США должна включать финансирование создания новых машин и обучение людей их использованию. Она также должна включать партнёрство с университетами, национальными лабораториями и частными компаниями. Самое главное, что план должен быть сосредоточен не только на оборудовании, но и на ПО и алгоритмах, которые делают HPC полезными», — заявил учёный. Он отметил, что некоторые шаги в этом направлении уже предприняты, включая принятие в 2022 году «Закона о чипах и науке» (CHIPS and Science Act) и создание управления, которое поможет превратить научные исследования в реальные продукты. В 2025 году также была сформирована целевая группа Vision for American Science and Technology, призванная объединить некоммерческие организации, академические круги и промышленность для помощи правительству в принятии решений. Кроме того, получили развитие квантовые вычисления. Но они пока находятся на ранних стадиях и, скорее всего, будут дополнять, а не заменять традиционные HPC. Поэтому важно продолжать инвестировать в оба вида вычислений. Донгарра назвал это правильными шагами, но они не решат проблему поддержки HPC в долгосрочной перспективе. Помимо краткосрочного финансирования и инвестиций в инфраструктуру, учёный предложил:
Донгарра отметил, что HPC — это больше, чем просто быстрые суперкомпьютеры. Это основа научных открытий, экономического роста и национальной безопасности. Если США примут предложенные меры, то можно гарантировать, что HPC продолжат поддерживать инновации в течение десятилетий.
08.05.2025 [19:22], Сергей Карасёв
Cadence представила суперкомпьютер Millennium M2000 на базе NVIDIA BlackwellКомпания Cadence анонсировала суперкомпьютер Millennium M2000, спроектированный для выполнения сложного моделирования с использованием ИИ. Новая НРС-система предназначена для ускорения проектирования микрочипов, разработки лекарственных препаратов следующего поколения и пр. Суперкомпьютер построен на платформе NVIDIA HGX B200. Кроме того, задействованы карты NVIDIA RTX Pro 6000 Blackwell Server Edition, оснащённые 96 Гбайт памяти GDDR7. Применены библиотеки NVIDIA CUDA-X и специализированное ПО для решения ресурсоёмких задач. Утверждается, что Millennium M2000 обеспечивает до 80 раз более высокую производительность по сравнению с системами на базе CPU в области автоматизации проектирования электроники (EDA), создания и анализа систем (SDA) и разработки медикаментов. При этом глубоко оптимизированный программно-аппаратный стек помогает существенно сократить общее энергопотребление. В качестве примера приводится моделирование подсистемы питания на уровне полупроводниковых чипов. В случае вычислительных комплексов на основе сотен традиционных CPU на выполнение такой задачи может потребоваться около двух недель. Суперкомпьютер Millennium M2000 позволит получить результат менее чем за один день. 
Источник изображения: Cadence Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) сообщил, что компания планирует приобрести десять суперкомпьютерных систем Millennium на базе GB200 NVL72 для ускорения проектирования собственных продуктов. Сторонние заказчики смогут получить доступ к Millennium M2000 через облако или купить устройство для установки в собственном дата-центре. Базовая конфигурация включает около 32 ускорителей и стоит $2 млн, но это не финальная цена.
06.05.2025 [11:12], Сергей Карасёв
Nebius внедрит системы хранения DDN в свою ИИ-инфраструктуруКомпания DataDirect Networks (DDN), специализирующаяся на системах хранения данных для НРС, объявила о заключении партнёрского соглашения с разработчиком ИИ-решений Nebius (бывшая материнская структура «Яндекса»). В рамках соглашения стороны займутся созданием высокопроизводительной подсистемы хранения данных для ресурсоёмких ИИ-задач. Речь идёт об интеграции решений DDN Infinia и EXAScaler в облачную инфраструктуру Nebius AI Cloud. Эти системы будут использоваться для хранения данных, предназначенных для обучения больших языковых моделей, инференса и поддержания работы ИИ-приложений в реальном времени. По заявлениям DDN, Infinia гарантирует надёжность и передовую производительность, благодаря чему ускоряется обучение и развёртывание моделей ИИ. Вместе с тем EXAScaler обеспечивает высокую пропускную способность и согласованность операций ввода-вывода. Другим преимуществом названных решений является возможность масштабирования в рамках облачных и локальных развёртываний: заказчики смогут быстро наращивать ресурсы в ИИ-облаке Nebius, гибридных и изолированных средах, используя параллельную файловую систему EXAScaler. 
Источник изображения: Nebius Утверждается, что Infinia и EXAScaler устраняют проблемы с задержками при обработке данных. В результате, нагрузки ИИ могут обрабатываться с максимальной эффективностью — даже в случае моделей с несколькими триллионами параметров. В целом, как отмечают партнёры, благодаря интеграции систем DDN в облако Nebius клиенты смогут решать ИИ-задачи с более высокой скоростью и с меньшими временными и финансовыми затратами. |
|

