Материалы по тегу: hpc
|
05.05.2025 [13:28], Сергей Карасёв
GigaIO и d-Matrix предоставят инференс-платформу для масштабных ИИ-развёртыванийКомпании GigaIO и d-Matrix объявили о стратегическом партнёрстве с целью создания «самого масштабируемого в мире» решения для инференса, ориентированного на крупные предприятия, которые разворачивают ИИ в большом масштабе. Ожидается, что новая платформа поможет устранить узкие места в плане производительности и упростить внедрение крупных ИИ-систем. В рамках сотрудничества осуществлена интеграция ИИ-ускорителей d-Matrix Corsair в состав НРС-платформы GigaIO SuperNODE. Архитектура Corsair основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости около 150 Тбайт/с. По заявлениям d-Matrix, ускоритель обеспечивает непревзойдённую производительность и эффективность инференса для генеративного ИИ. Устройство выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Быстродействие достигает 2,4 Пфлопс с (8-бит вычисления). Изделие имеет двухслотовое исполнение, а показатель TDP равен 600 Вт. В свою очередь, SuperNODE использует фирменную архитектуру FabreX на базе PCIe, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE обеспечивает более эффективное использование ресурсов. 
Источник изображения: d-Matrix Новая модификация SuperNODE поддерживает десятки ускорителей Corsair в одном узле. Производительность составляет до 30 тыс. токенов в секунду при времени обработки 2 мс на токен для таких моделей, как Llama3 70B. По сравнению с решениями на базе GPU обещаны трёхкратное повышение энергоэффективности и в три раза более высокое быстродействие при сопоставимой стоимости владения. «Наша система избавляет от необходимости создания сложных многоузловых конфигураций и упрощает развёртывание, позволяя предприятиям быстро адаптироваться к меняющимся рабочим нагрузкам ИИ, при этом значительно улучшая совокупную стоимость владения и операционную эффективность», — говорит Alan Benjamin (Алан Бенджамин), генеральный директор GigaIO.
05.05.2025 [12:47], Сергей Карасёв
Терабитное облако: Backblaze запустила S3-хранилище B2 Overdrive для рабочих нагрузок ИИ и HPCАмериканская компания Backblaze анонсировала облачное S3-хранилище B2 Overdrive, оптимизированное для нагрузок с интенсивным обменом данными, таких как задачи ИИ и НРС. Утверждается, что платформа в плане соотношения производительности/цены значительно превосходит предложения конкурентов. Backblaze отмечает, что при работе с ресурсоёмкими приложениями ИИ, машинного обучения, доставки контента или аналитики, клиенты зачастую сталкиваются с выбором: платить больше за максимальную скорость доступа к облаку или жертвовать производительностью, чтобы сохранить расходы на приемлемом уровне. B2 Overdrive, как утверждается, решает эту проблему. Новый сервис обеспечивает пропускную способность до 1 Тбит/с, а цена начинается с $15 за 1 Тбайт в месяц. Минимальный заказ — несколько Пбайт. Заявленный показатель безотказного функционирования — 99,9 %. Предоставляется бесплатный вывод данных из облака в трехкратном среднем ежемесячном объёме хранения клиента. После превышения этого значения стоимость составляет $0,01 за 1 Гбайт. Скидки за объём и сроки хранения доступны с сервисом B2 Reserve. 
Источник изображения: Backblaze Для хранения данных в облаке B2 Overdrive применяются HDD. Подключение к инфраструктуре клиента осуществляется через защищённую частную сеть. Информацию в экзабайтном масштабе можно свободно перемещать в любой кластер GPU или HPC с неограниченным бесплатным выводом. Среди прочих преимуществ B2 Overdrive компания Backblaze выделяет отсутствие требований к минимальному размеру файлов, уведомления о событиях, а также бесплатное удаление информации. Приём заявок на подключение к сервису уже начался.
03.05.2025 [16:00], Руслан Авдеев
В Рио-де-Жанейро построят крупнейший в Латинской Америке кампус ЦОД Rio AI CityВ Рио-де-Жанейро объявлено о строительстве нового ИИ ЦОД. После завершения проекта кампус дата-центров станет крупнейшим в Латинской Америке и одним из крупнейших в мире, сообщает Datacenter Dynamics. Кампус Rio AI City расположится на территории Olympic Park. Первые 1,8 ГВт намерены ввести в строй к 2027 году, а к 2032 году возможно расширение до 3 ГВт. Ожидается, что в кампусе будут обеспечены условия для развёртывания новейших суперкомпьютеров. По словам мэра города, анонсировавшего проект, главная цель строительства нового кампуса — повысить роль Рио в развитии ИИ и закрепить за городом статус «столицы инноваций Латинской Америки». Город намерен стать движущей силой «ИИ-революции» и обеспечить гарантии того, что развитие искусственного интеллекта пойдёт обществу на благо. Мэр пообещал, что кампус будет целиком обеспечиваться «чистой» энергией и получит «неограниченный» запас воды для охлаждения оборудования. 
Источник изображения: Davi Costa/unsplash.com Кампус напрямую связан с проектом Porto Maravilha, предполагающим восстановление в городе старого портового района. По словам муниципальных властей, район станет центром экоустойчивых инноваций, а вычислительные мощности Rio AI City станут использовать для поддержки роста локальных стартапов. По данным Data Center Map, в Рио-де-Жанейро в настоящее время действует 21 дата-центр. В городе работают операторы Ascenty, Elea и Equinix. В прошлом месяце Equinix запустила в городе свой третий ЦОД — RJ3. Буквально на днях появилась информация, что ByteDance рассматривает строительство в Бразилии дата-центра TikTok, но он будет находиться в отдалении от Рио, в штате Сеара.
28.04.2025 [14:48], Сергей Карасёв
ИИ-суперкомпьютер в чемодане — GigaIO Gryf обеспечит производительность до 30 ТфлопсКомпания GigaIO объявила о доступности системы Gryf — так называемого ИИ-суперкомпьютера в чемодане, разработанного в сотрудничестве с SourceCode. Это сравнительно компактное устройство, как утверждается, обеспечивает производительность ЦОД-класса для периферийных развёртываний. Первая информация о Gryf появилась около года назад. Устройство выполнено в корпусе с габаритами 228,6 × 355,6 × 622,3 мм, а масса составляет примерно 25 кг. Система может эксплуатироваться при температурах от +10 до +32 °C. Конструкция предусматривает использование модулей Sled четырёх типов: это вычислительный узел Compute Sled, блок ускорителя Accelerator Sled, узел хранения Storage Sled и сетевой блок Network Sled. Доступны различные конфигурации, но суммарное количество модулей Sled в составе Gryf не превышает шести. Плюс к этому в любой комплектации устанавливается модуль питания с двумя блоками мощностью 2500 Вт. Узел Compute Sled содержит процессор AMD EPYC 7003 Milan с 16, 32 или 64 ядрами, до 512 Гбайт DDR4, системный SSD формата M.2 (NVMe) вместимостью 512 Гбайт и два порта 100GbE QSFP56. Блок Storage Sled объединяет восемь накопителей NVMe SSD E1.L суммарной вместимостью до 492 Тбайт. Модуль Network Sled предоставляет два порта QSFP28 100GbE и шесть портов SFP28 25GbE. За ИИ-производительность отвечает модуль Accelerator Sled, который может нести на борту ускоритель NVIDIA L40S (48 Гбайт), H100 NVL (94 Гбайт) или H200 NVL (141 Гбайт). В максимальной конфигурации быстродействие в режиме FP64 достигает 30 Тфлопс (3,34 Пфлопс FP8), а пропускная способность памяти — 4,8 Тбайт/с. 
Источник изображения: GigaIO Архитектура новинки обеспечивает возможность масштабирования путём объединения в единый комплекс до пяти экземпляров Gryf: в общей сложности можно совместить до 30 модулей Sled в той или иной конфигурации. Заказы на Gryf уже поступили со стороны Министерства обороны США, американских разведывательных структур и пр.
21.04.2025 [17:05], Татьяна Золотова
Для российских исследователей будут созданы суперкомпьютерный центр и роботизированные лабораторииПрезидент России поручил рассмотреть вопрос о внедрении инновационных технологий в промышленности. Для этого необходимо создать национальный суперкомпьютерный центр, роботизированные лаборатории, активнее внедрять искусственный интеллект. Об этом говорится в «Перечне поручений по итогам пленарного заседания и посещения выставки Форума будущих технологий, встречи с учеными». Как указано в документе, до 1 июня 2025 года премьер-министр РФ Михаил Мишустин должен представить предложения о создании единой межотраслевой цифровой базы данных свойств высокотехнологичных материалов и их компонентов, разработанной совместно с «Российской академией наук» и «Росатомом». В срок до 15 июля 2025 года необходимо также представить предложения о создании роботизированных лабораторий для проведения научных исследований с применением технологий ИИ. Среди поручений к середине июля 2025 года также необходимо рассмотреть вопрос о создании национального суперкомпьютерного центра. При этом доступ к его вычислительным мощностям получат все российские исследователи. 
Источник изображения: Eli Alvarez / Unsplash Кроме того, президент поручил до 1 августа 2025 года представить предложения о расширении применения технологий ИИ и компьютерного моделирования для сокращения сроков разработки и внедрения новых материалов в химической отрасли. Ожидается, что благодаря внедрению ИИ и компьютерного моделирования сроки разработки и внедрения новых материалов в России можно уменьшить до 5–10 лет, а со временем и до двух-трёх лет. К 1 сентября 2025 года Правительство РФ совместно с «Российской академией наук», «Росатомом» и «Курчатовским институтом» должно разработать предложения о создании межотраслевого центра аддитивных технологий или 3D-печати для ускорения внедрения промышленными предприятиями таких технологий.
21.04.2025 [11:36], Сергей Карасёв
CoolIT представила 2-МВт блок распределения охлаждающей жидкости CHx2000 для ИИ и HPC ЦОДКомпания CoolIT Systems анонсировала блок распределения охлаждающей жидкости (CDU) CHx2000 для дата-центров, ориентированных на задачи ИИ и НРС. Новинка обеспечивает отвод более 2 МВт тепла: это, как утверждается, на сегодняшний день самый высокий показатель для CDU данного класса. Устройство выполнено в виде шкафа с размерами основания 750 × 1200 мм. Заявленный расход жидкости составляет 1,2 л/мин. на кВт (LPM/kW): допускается охлаждение до двенадцати стоек NVIDIA GB200 NVL72 мощностью 120 кВт. По сравнению со своим предшественником (модель CHx1500) новинка обеспечивает повышение охлаждающей способности на 66 %. При создании CHx2000 компания CoolIT Systems сделала упор на долговечность, безотказную работу и простоту обслуживания. Применены два насоса с возможностью горячей замены (N+N), обеспечивающие производительность 1500 л/мин. Трубы изготовлены из нержавеющей стали. В конструкции используются 4″ муфты Victaulic. Благодаря резервированию критически важных компонентов доступность находится на уровне 99,9999 %. 
Источник изображения: CoolIT Systems Предусмотрена интегрированная система управления и мониторинга (Redfish, SNMP, TCP/IP, Modbus, BACnet и др.). Причём допускается групповое управление одновременно до 20 экземпляров CDU. Во время обслуживания возможен доступ с лицевой и тыльной сторон с поддержкой горячей замены насосов, фильтров и датчиков. Заявленная потребляемая мощность составляет 12,24 кВт при работе одного насоса (1500 л/мин). Во фронтальной части корпуса располагается информационный дисплей. Блок CHx2000 уже доступен для заказа. CoolIT Systems предоставляет комплексную поддержку и услуги по проектированию, монтажу и обслуживанию в более чем 70 странах по всему миру.
16.04.2025 [14:20], Сергей Карасёв
Уникальный суперкомпьютер Anton 3 для задач молекулярной динамики введён в эксплуатациюПиттсбургский суперкомпьютерный центр (PSC) ввёл в эксплуатацию вычислительный комплекс Anton 3 — специализированный суперкомпьютер следующего поколения, предназначенный для биомолекулярного моделирования. Система позволяет ускорить исследование ферментов, создание новых лекарственных препаратов, ремоделирование мембран и пр. Проект Anton реализуется частной компанией D. E. Shaw Research. Данная серия суперкомпьютеров названа в честь Антони ван Левенгука (Antoni van Leeuwenhoek) — нидерландского натуралиста, конструктора микроскопов и пионера микробиологии. Системы Anton разрабатываются специально для ускорения процесса моделирования молекулярной динамики. 
Источник изображений: D. E. Shaw Research С помощью этих суперкомпьютеров исследователи могут получить ценную информацию о движениях и взаимодействиях белков и других биологически важных молекул. Многие из решаемых на базе Anton задач не могут быть выполнены за разумное время с помощью любого другого современного суперкомпьютера общего назначения или программного обеспечения для молекулярной динамики, доступного академическому сообществу.  Комплекс Anton 3 имеет 64-узловую конфигурацию. Задействованы 512 кастомных ASIC, а энергопотребление суперкомпьютера находится на уровне 400 кВт. Anton 3 обеспечивает быстродействие до 980 тыс. шагов моделирования в секунду (timesteps per second, TPS). По производительности на задачах молекулярной динамики система, как утверждается, на два порядка превосходит существующие универсальные суперкомпьютеры. Впрочем, по словам Cerebras, её царь-ускорители справляются и с этой задачей. 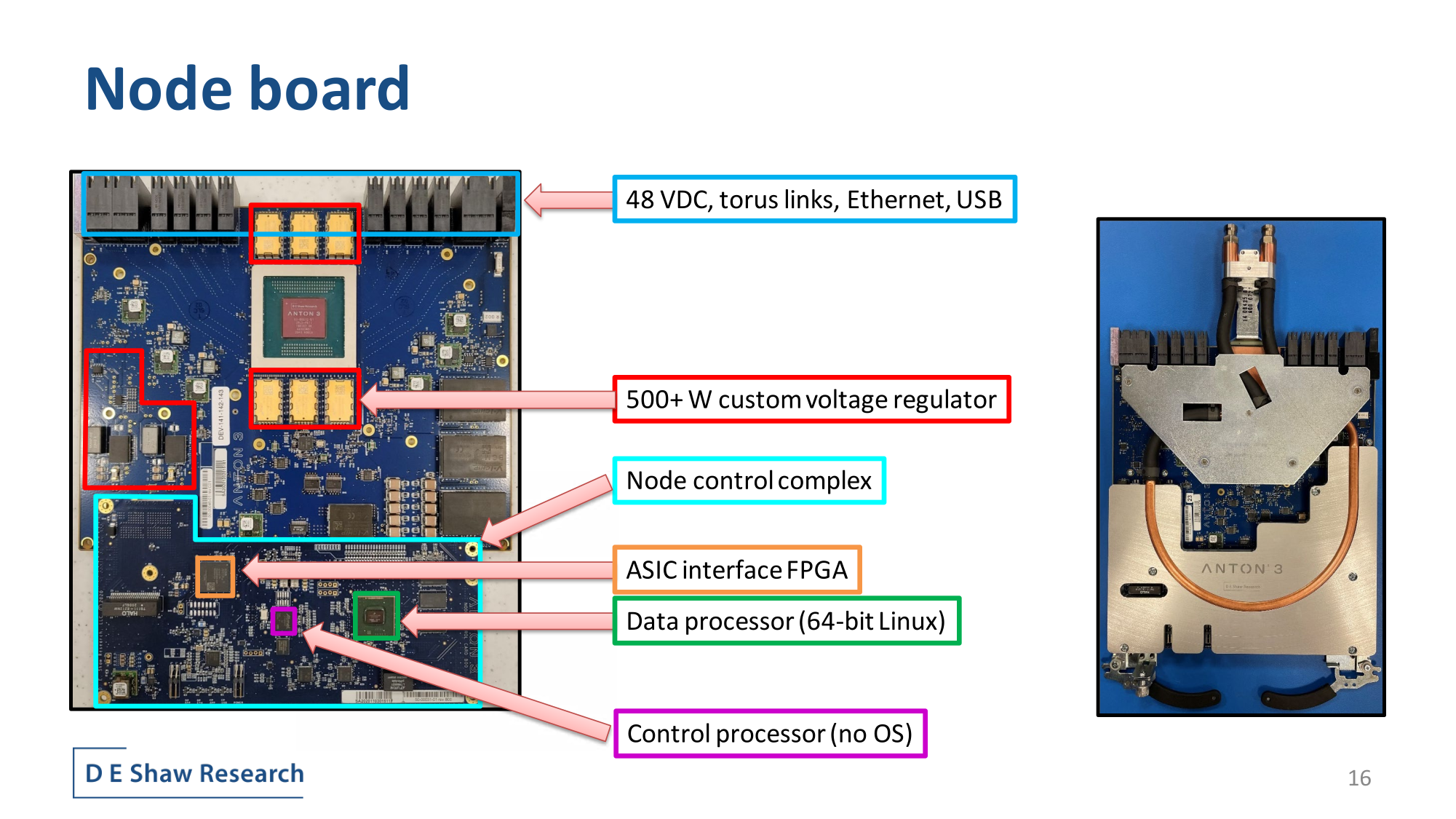 «Благодаря новейшей системе Anton мы сможем предоставить исследователям уникальный ресурс, способный за считанные дни выдавать результаты, на которые при использовании любого другого суперкомпьютера ушли бы годы», — отмечает доктор Филип Блад (Philip Blood), научный директор PSC. Разработкой систем для ускорения расчётов молекулярной динамики также занимается RIKEN в рамках проекта MDGRAPE.
10.04.2025 [19:31], Руслан Авдеев
ИИ-континент: Евросоюз намерен как минимум утроить ёмкость дата-центров в ближайшие годыВ следующие пять-семь лет Евросоюз намеревается более чем втрое нарастить ёмкость своих дата-центров. Это позволит снизить зависимость от вычислительных мощностей, находящихся в других регионах мира, сообщает Computer Weekly, и сформировать крупный единый рынок общим набором «правил безопасности», которые обеспечат ИИ-технологий. Основные векторы развития подробно изложены в проекте ЕС AI Continent Action Plan. В проекте документа заявляется, что сейчас ЕС отстаёт по объёму доступных мощностей ЦОД от США и Китая, в значительной степени используя облачную инфраструктуру из других регионов мира. Это вызывает обеспокоенность у бизнеса и политиков. Для того, чтобы удовлетворить потребности предприятий и государственных органов в ИИ и вычислениях в целом, а также обеспечить суверенитет и конкурентоспособность, предлагается наращивать собственные облачные мощности и мощности ЦОД вообще. Для этого проводятся консультации по разработке «Закона о развитии облачных технологий и ИИ» (Cloud and AI Development Act), который позволит ускоренно строить новые ЦОД в Евросоюзе. В документе указывается, что сегодня среднее время получения разрешения на строительство и эколицензий в Европе часто превышает 48 месяцев, при этом площадки для строек и энергию ещё поискать надо. Новый закон должен устранить препятствия. Проектам ЦОД, соответствующим требованиям по эффективному использованию энергии и воды, разрешения будут выдавать в упрощённом порядке. Также предполагается «улучшить» конкуренцию на рынке облачных услуг, предоставив возможность выхода на него большему числу облачных провайдеров. Эти и другие действия — часть проекта Евросоюза по созданию собственного, особого подхода к развитию искусственного интеллекта, основанного на сильных сторонах объединения, позволяющих превратить ЕС в «континент ИИ». 
Источник изображения: Maks Key/unsplash.com В документе упоминается, что в ЕС действуют 6300 стартапов в области ИИ, более 600 из них работают над созданием систем генеративного ИИ. Тем не менее, нужно принимать меры, чтобы обеспечить компании и исследователей ресурсами, необходимые для успешной реализации проектов. Для этого необходимо будет расширить общедоступную ИИ-инфраструктуру с созданием «гигафабрик» с энергоэффективными и высокопроизводительными вычислительными системами, которые можно будет объединить в сети. ЕС уже обязался выделить €20 млрд на финансирование ИИ-инфраструктуры, чтобы частично компенсировать расходы на создание в Европе пяти ИИ-фабрик, также стороны приглашаются к созданию государственно-частных партнёрств для ускоренного строительства соответствующих объектов. Гигафабрики станут своеобразными центрами притяжения для сотрудничества исследователей, предпринимателей и инвесторов в проектах разной направленности, от здравоохранения до робототехники и науки в целом. 
Источник изображения: Alessio Ferretti/unsplash.com Превращение Евросоюза в «ИИ-сверхдержаву» также потребует доступа к более качественным данным, и активной разработки ИИ в самом ЕС, а также поощрения внедрения ИИ-систем в стратегически важных секторах. Также в документе упоминается необходимость наращивания базы талантов в сфере искусственного интеллекта — этого можно будет добиться, упростив легальную миграцию профильных квалифицированных специалистов. Документ ЕС во многом перекликается с недавно представленным проектом превращения Великобритании в «ИИ-сверхдержаву». В частности, там тоже намерены стимулировать инновации в области ИИ, наращивать вычислительные и энергетические мощности и др.
09.04.2025 [00:49], Алексей Степин
Все против NVIDIA: представлена открытая альтернатива NVLink — интерконнект UALink 200G 1.0Консорциум UALink, в состав которой входят AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft, опубликовала первые спецификации на разрабатываемую в рамках альянса более доступную альтернативу проприетарным решениям NVIDIA. Интерконнект UALink призван заменить в первую очередь NVLink и во многом опирается на AMD Infinity Fabric, хотя пока что по скоростям составляет конкуренцию скорее Ethernet и InfiniBand. Консорциум Ultra Accelerator Link был сформирован в конце прошлого года с целью создания высокоскоростного интерконнекта с низкими задержками, базирующегося на открытых технологиях. Речь здесь не только о приверженности открытым стандартам, но и о солидном потенциальном куске рынка — только за прошедший финансовый год сетевое подразделение NVIDIA выручило $13 млрд. 
Источник здесь и далее: UALink Появление более доступной и открытой альтернативы теоретически должно пошатнуть позиции последней в этом секторе, а также позволить разработчикам HPC-систем и ИИ-кластеров избежать жёсткой привязки к одному вендору. В том числе речь идёт о возможности организации сети UALink, включающей в себя GPU и ускорители разных поставщиков. Упор в первой версии стандарта сделан на общий доступ к памяти ускорителей с высокой скоростью, низкими задержками и простыми атомарными операциями 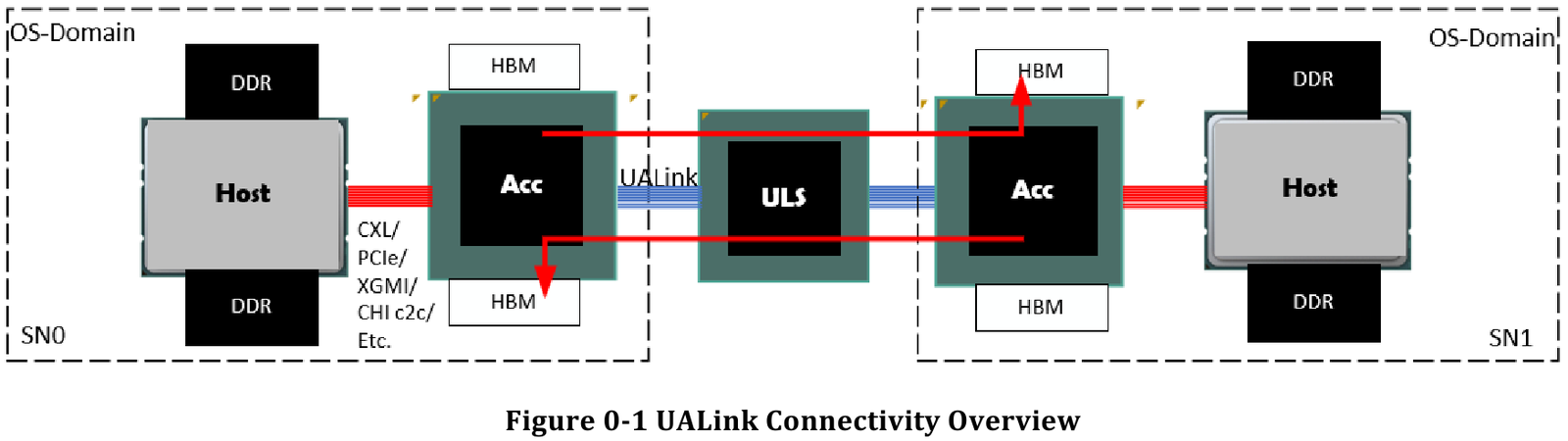 Впервые опубликованные спецификации описывают стандарт UALink 200G 1.0. В основе лежит коммутируемая сеть с пропускной способностью 200 Гбит/с на каждую линию, во многом наследующая AMD Infinity Fabric, но дополненная разработками других участников альянса. Максимальное количество линий на один ускоритель может достигать четырёх, что позволяет поднять пропускную способность до 800 Гбит/с. Поддерживается бифуркация. 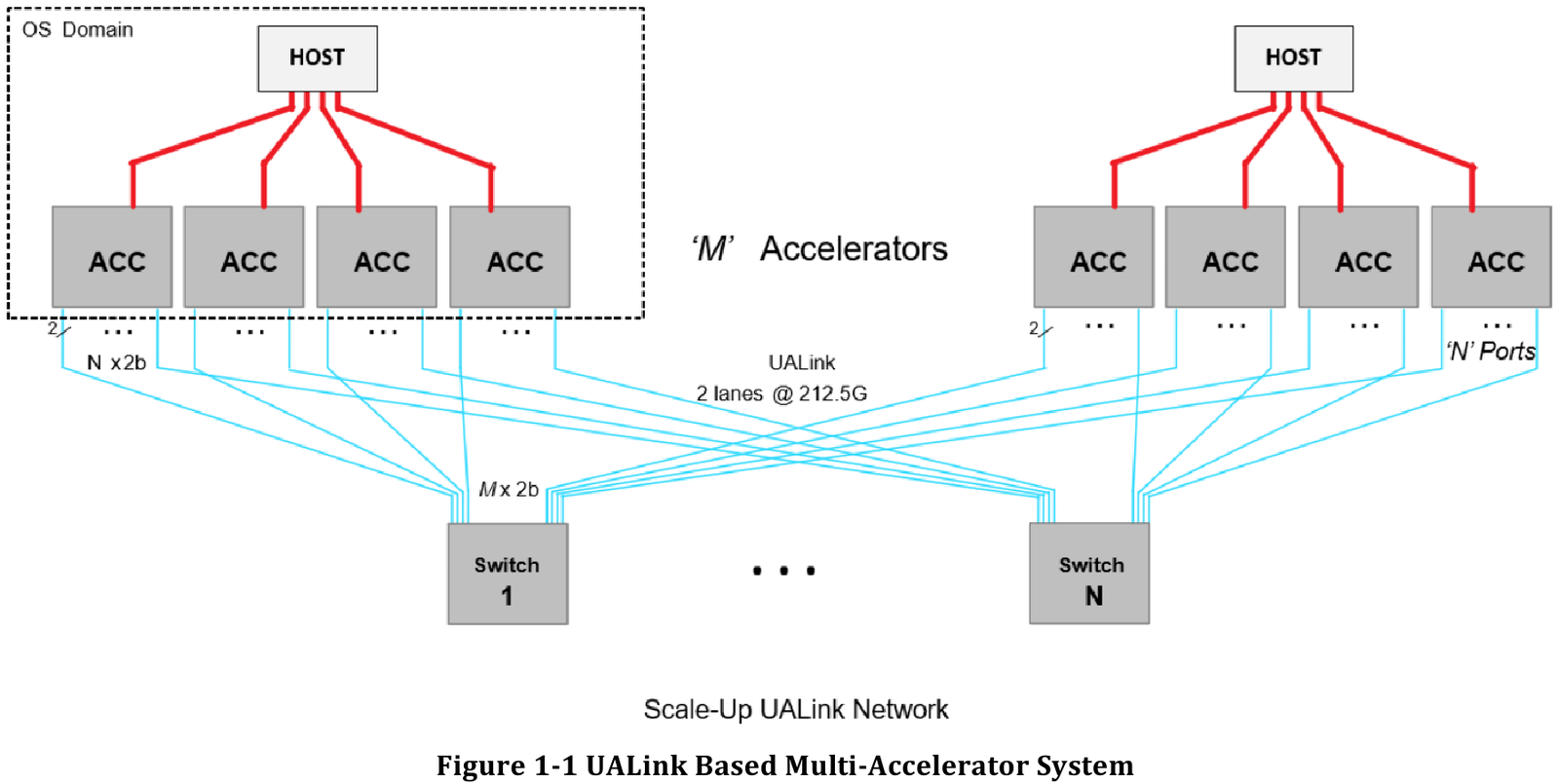 Размер кластера в данной версии стандарта UALink ограничен 1024 узлами, не считая коммутаторов. При этом гарантируются линейные скорости на уровне соответствующих версий Ethernet, но c энергопотреблением от трети до половины от аналогичного показателя последних, при времени отклика на уровне коммутируемых вариантов PCI Express. Задержка от порта к порту должна составить менее 100 нс, на уровне коммутаторов UASwitch — 100–150 нс. Для сравнения: NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене со скоростью до 0,9–1,8 Тбайт/с на ускоритель.  Также предусмотрена совместная работа с Ethernet в составе GPU-кластера, где хост-процессоры общаются между собой посредством традиционной сети (в том числе Ultra Ethernet), а ускорители могут использовать либо прямое, либо коммутируемое подключение UALink. 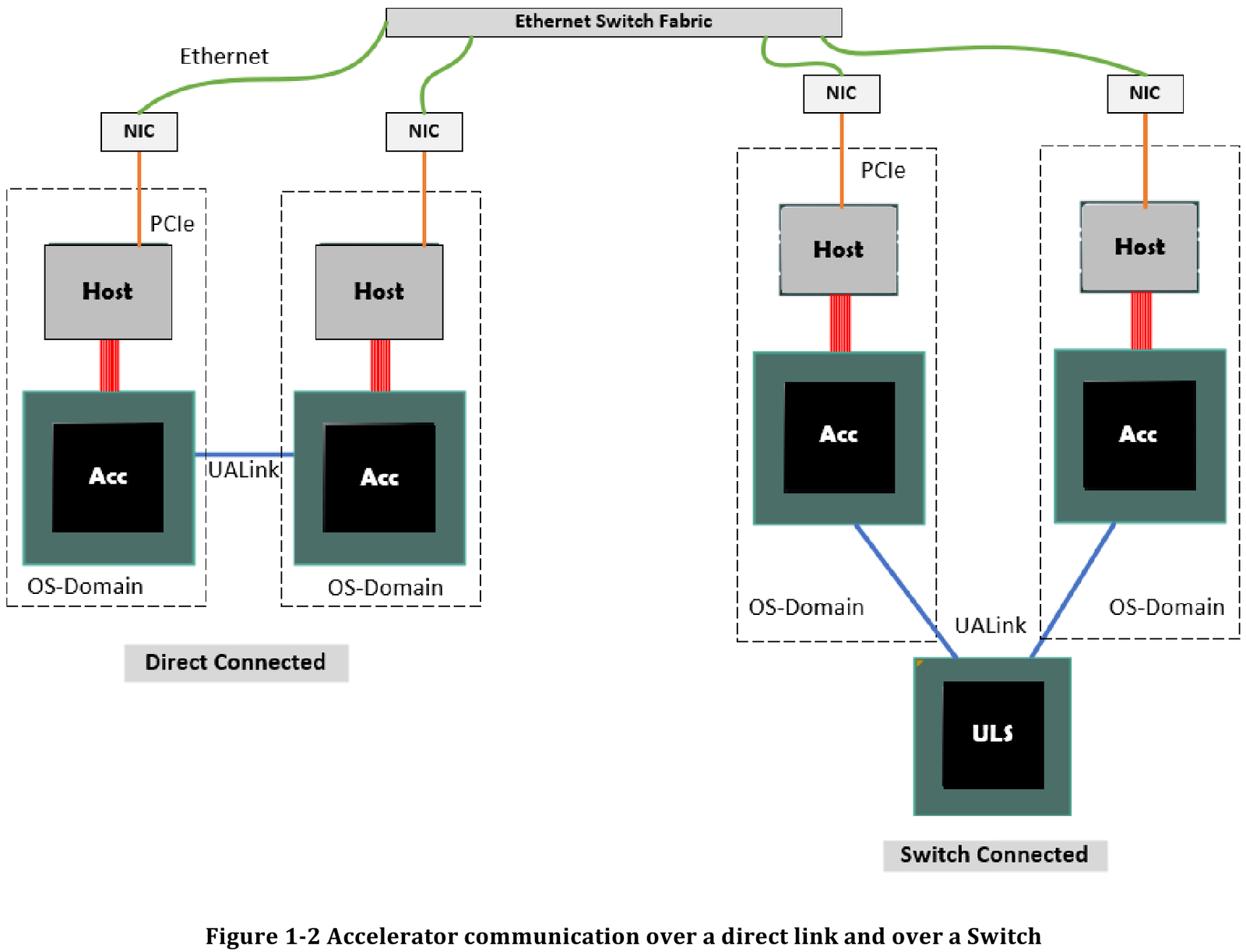 Передача данных осуществляется словами длиной 680 байт: 640-байт флит-пакеты + 40 байт накладных расходов на упреждающую коррекцию ошибок (FEC) и кодирование 256B/257B. Реализованы механизмы доступа к удалённой памяти, но когерентность на аппаратном уровне не поддерживается, также имеются различия на подуровне PCS (Physical coding sublayer). На физическом уровне используется стандарт IEEE 802.3dj: 200GBASE-KR1/CR1, 400GBASE-KR2/CR2 и 800GBASE-KR4/CR4. Имеющиеся ретаймеры для Ethernet также совместимы с UALink. 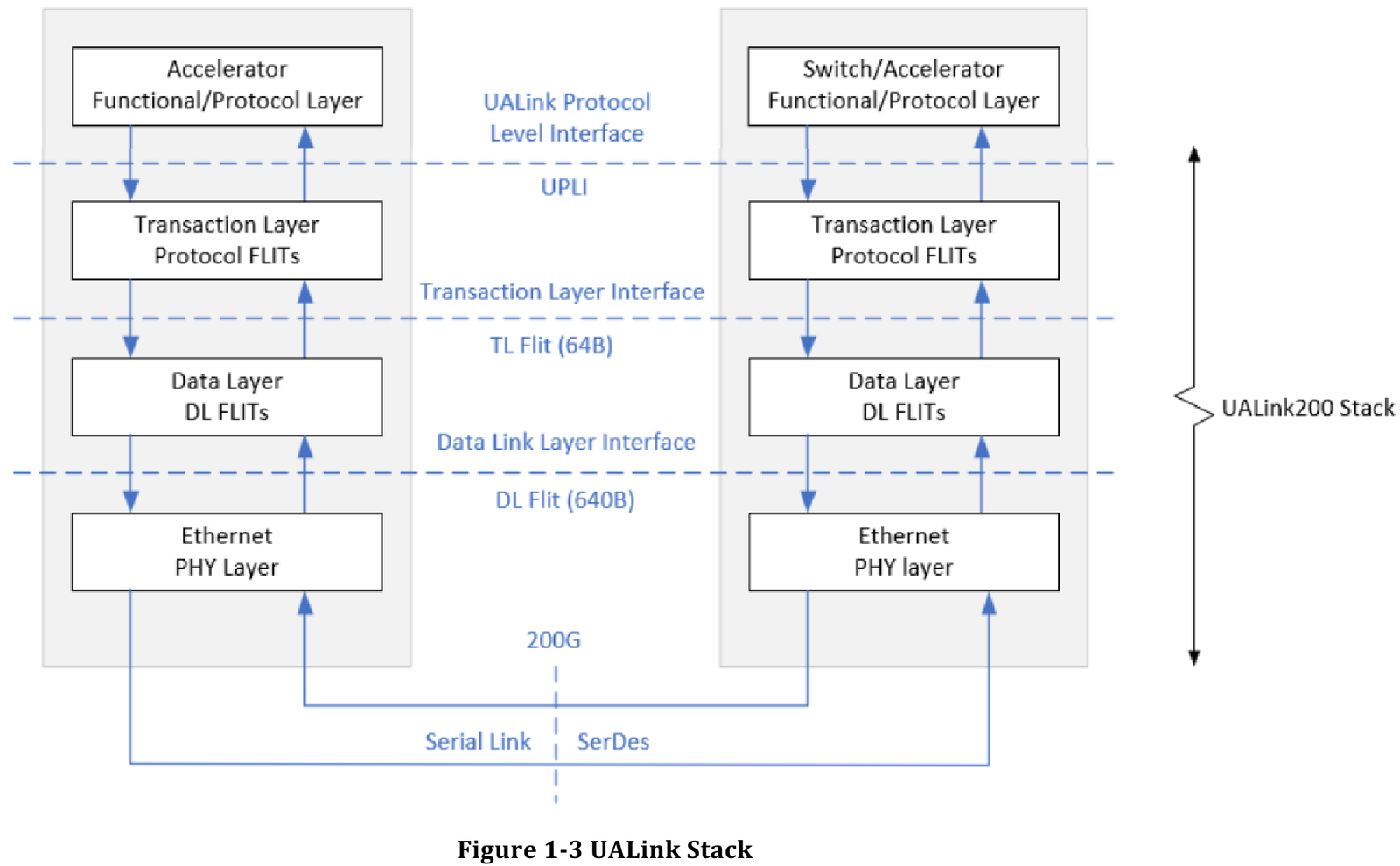 Спецификации UALink 200G 1.0 доступны на сайте проекта. Глава консорциума UALink, Кёртис Боумен (Kurtis Bowman) настроен оптимистично и говорит примерно о 18 месяцах до появления первых аппаратных решений, что на полгода быстрее типичных сценариев воплощения спецификаций «в железо». Тем временем, альянс уже начал работу над второй версией UALink, использующей стек технологий 400G.
08.04.2025 [13:29], Сергей Карасёв
Eviden создаст для Сербии суперкомпьютер стоимостью €36 млнВласти Сербии, по сообщению ресурса Datacenter Dynamics, заключили контракт с Eviden (подразделение Atos Group) на создание нового суперкомпьютера. Речь идёт о приобретении системы BullSequana последнего поколения, которая будет поставлена к концу текущего года. Технические подробности проекта пока не раскрываются. Отмечается лишь, что контракт с Eviden является частью более широкого соглашения стоимостью €50 млн, подписанного между правительствами Сербии и Франции. Из этой суммы €36 млн пойдёт непосредственно на создание суперкомпьютера. Оставшаяся часть средств будет потрачена на ИИ-инициативы в таких сферах, как здравоохранение, энергетика, транспорт и государственное управление. На сегодняшний день, как отмечается, Сербия эксплуатирует как минимум один неназванный НРС-комплекс, созданный NVIDIA и размещённый в государственном дата-центре в Крагуеваце (столица административного региона Шумадия). Система, запущенная в декабре 2021 года, обошлась в €30 млн. В перспективе в модернизацию этого суперкомпьютера планируется инвестировать €40 млн, что позволит поднять его производительность в семь раз. 
Источник изображения: Правительство Сербии Глава сербского управления по IT и электронному правительству Михайло Йованович (Mihailo Jovanovic) заявил, что новый суперкомпьютер, поставкой которого займётся Eviden, будет насчитывать «в 20 раз больше чипов, чем [нынешняя] система NVIDIA», и получит почти в 30 раз больше памяти. Какие именно чипы имеются в виду, Йованович уточнять не стал. Работа над государственным ЦОД в Крагуеваце стоимостью €30 млн началась в 2019 году, а открытие состоялось в 2020-м. Дата-центр состоит из двух объектов общей площадью около 14 тыс. м2 — это примерно в пять раз больше по сравнению с прежней ЦОД-площадкой в Белграде. Комплекс в Крагуеваце соответствует стандарту Tier IV: он предоставляет услуги хостинга для предприятий и правительственных структур. |
|

