Материалы по тегу: c
|
17.11.2025 [10:02], Сергей Карасёв
ИИ-производительность японского суперкомпьютера FugakuNEXT превысит 600 ЭфлопсКомпания Fujitsu поделилась информацией о суперкомпьютере следующего поколения FugakuNEXT (Fugaku Next), который создаётся совместно с японским Институтом физико-химических исследований (RIKEN). Проект реализуется при поддержке Министерства образования, культуры, спорта, науки и технологий Японии (MEXT). FugakuNEXT придёт на смену вычислительному комплексу Fugaku, который в 2020 году стал самым высокопроизводительным суперкомпьютером в мире. В рейтинге ТОР500 от июня 2025 года эта НРС-система занимает седьмое место с FP64-быстродействием приблизительно 442 Пфлопс (теоретическая пиковая производительность достигает 537,21 Пфлопс). Разработку архитектуры FugakuNEXT планируется полностью завершить к середине 2028 года, после чего начнутся производство и монтаж суперкомпьютера. В эксплуатацию система будет введена не ранее середины 2030 года. Известно, что в основу FugakuNEXT лягут Arm-процессоры Fujitsu MONAKA-X, при производстве которых предполагается использовать 1,4-нм технологию. Чипы получат до 144 вычислительных ядер. Кроме того, в состав машины войдут ИИ-ускорители NVIDIA, для связи которых с CPU планируется задействовать шину NVLink Fusion. Платформа также получит новые интерконнекты для горизонтального и вертикального масштабирования. 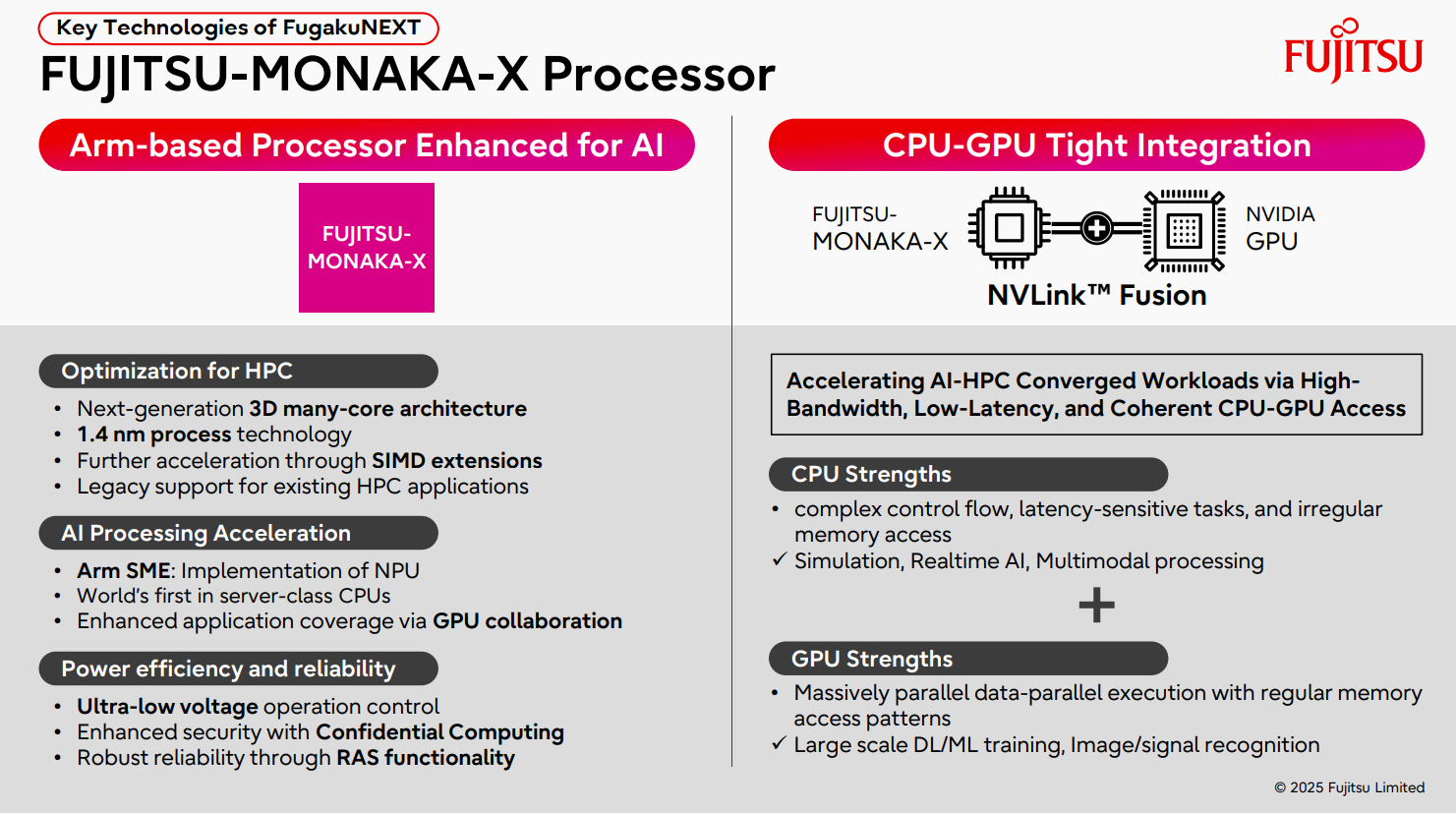
Источник изображений: Fujitsu В материалах Fujitsu говорится, что FugakuNEXT получит в общей сложности свыше 3400 узлов CPU и GPU. Их объём памяти превысит 10 ПиБ (Пебибайт). Агрегированная пропускная способность памяти в случае CPU-блоков составит более 7 Пбайт/с, GPU-модулей — свыше 800 Пбайт/с против 163 Пбайт/с у нынешней системы Fugaku.  Кроме того, раскрываются ожидаемые показатели ИИ-быстродействия FugakuNEXT. У CPU-секции производительность превысит 48 Пфлопс в режиме FP64, 1,5 Эфлопс на операциях FP16/BF16 и 3 Эфлопс в режиме FP8. В случае GPU-раздела быстродействие FP64, FP16/BF16, FP8 и FP8 Sparse составит более 2,6 Эфлопс, 150 Эфлопс, 300 Эфлопс и 600 Эфлопс соответственно.
17.11.2025 [07:45], Владимир Мироненко
NEC и OpenСhip вместе разработают векторные ускорители на базе RISC-V и суперкомпьютеры Aurora следующего поколенияБазирующийся в Барселоне разработчик чипов OpenChip, который некоторые эксперты называют каталонской NVIDIA, и компания NEC объявили о следующем этапе сотрудничества, направленного на совместную разработку векторного процессора (VPU) нового поколения. Ранее компании выполнили технико-экономическое обоснование разработки следующего поколения векторных суперкомпьютеров Aurora с использованием аппаратного и программного стека OpenChip на базе RISC-V. Как сообщается в пресс-релизе, на начальном этапе основное внимание уделялось оценке совместимости архитектуры Aurora от NEC с ускорителями OpenChip, определению логической структуры и начальной разработке программных компонентов. В результате исследования компании пришли к выводу о технической осуществимость проекта, так что теперь компании займутся совместной разработкой следующего поколения высокопроизводительных ускорителей, а также оптимизированного программного стека. Обе компании планируют запуск пилотных развёртываний у отдельных клиентов. По словам старшего вице-президента NEC Сухуна Юна (Suhun Yun), сотрудничество NEC с OpenChip является поворотным моментом в стратегическом развитии NEC в направлении вычислительных архитектур следующего поколения. В свою очередь, OpenChip отметила, что сотрудничество направлено на достижение ряда ключевых преимуществ, в числе которых повышенная производительность критически важных рабочих нагрузок, обеспечение нового уровня вычислительной мощности для HPC, ИИ и ML, а также для таких научных приложений, как геномика и моделирование климата. 
Источник изображения: NEC В 2021 году NEC анонсировала векторные ускорителя SX-Aurora TSUBASA Vector Engine 2.0 (VE20), а в 2022 — доработанные VE30. Однако в 2023 году NEC фактически прекратила разработку новых решений в серии SX-Aurora в связи с появлением ускорителей AMD и NVIDIA, значительно превосходящих её наработки, так что обещанные VE40 и VE50 так и не появились на свет. При этом у NEC и ранее были длительные перерывы в разработке векторных ускорителей, а её суперкомпьютеры на их основе по-прежнему пользуются спросом в некоторых областях, в частности, в метеорологии и климатологии. OpenChip разрабатывает SoC, использующую несколько UCIe-чиплетов, референсные проекты для аппаратных платформ, базовые комплекты разработчиков ПО и прикладные сервисы. Как сообщает ресурс HPCwire, среди других европейских стартапов, разрабатывающих решения на базе RISV-V есть:
За последние годы было поставлено более 10 млрд ядер с архитектурой RISC-V благодаря широкому внедрению архитектуры в микроконтроллерах и встраиваемых устройствах. За последнее время RISC-V стала потенциальной альтернативой проприетарным архитектурам, включая Arm и x86, в разработке ускорителей и HPC-платформ.
16.11.2025 [12:35], Сергей Карасёв
Qualcomm представила чипы Dragonwing IQ-X для индустриальных Windows-компьютеровКомпания Qualcomm анонсировала новые SoC семейства Dragonwing IQ-X — изделия IQ-X5181 и IQ-X7181, ориентированные на индустриальный сектор. Чипы предназначены для построения промышленных Windows-компьютеров, систем автоматизации, робототехнических платформ, медицинского оборудования и пр. Решение IQ-X5181 объединяет восемь кастомизированных ядер Qualcomm Oryon (Armv8) с тактовой частотой до 3,4 ГГц, модификация IQ-X7181 — двенадцать. В состав SoC входит графический ускоритель Qualcomm Adreno с частотой соответственно 1,1 и 1,25 ГГц. Младшая версия способна справляться с декодированием видеоматериалов 4Kp60 VP9/AV1 и кодированием 4Kp30 AV1, старшая — 4K120 VP9/AV1 и 4Kp60 AV1. Чипы обеспечивают ИИ-производительность до 45 TOPS с учётом блоков CPU, GPU и Hexagon NPU. 
Источник изображения: Qualcomm Возможно использование до 64 Гбайт оперативной памяти LPDDR5X-4200, флеш-накопителей UFS 4.0 и карт SD/MMC (SD 3.0). Реализованы интерфейсы eDP (eDP1.4b) с поддержкой разрешения до 4096 × 2160 пикселей при 60 Гц и DisplayPort v1.4a (через USB) с поддержкой разрешения до 5120 × 2880 точек при 60 Гц. Изделие IQ-X5121 располагает двумя интерфейсами камер CSI на четыре линии каждый, IQ-X7181 — четырьмя. Для обеих новинок заявлена поддержка 2 × USB 3.1, 3 × USB 4.0 Type-C (DisplayPort v1.4a Alt Mode), 6 × eUSB 2.0 и 221 × GPIO (UART, SPI, I3C, I2C via QUP). В случае IQ-X5181 реализованы интерфейсы 2 × PCIe 4.0 х4 и 2 × PCIe 3.0 х2, в случае IQ-X7181 — PCIe 4.0 х8, PCIe 4.0 х4 и 2 × PCIe 3.0 х2. Кроме того, говорится о поддержке Ethernet (чип-компаньон QPS615), Wi-Fi и Bluetooth (посредством модуля M.2 PCIe), Wi-Fi 7 / Wi-Fi 6E (через WCN785/WCN6856), а также 5G (модем Snapdragon X65). Изделия выполнены в корпусе 1747-ball BGM с размерами 58 × 58 мм с максимальной толщиной 3 мм. Диапазон рабочих температур простирается от -40 до +105 °C. Говорится о совместимости с Windows 10/11 IoT Enterprise LTSC, Qt, CODESYS, EtherCAT и пр. Гарантирована доступность чипов в течение более чем 10 лет.
14.11.2025 [09:38], Сергей Карасёв
«За пределы экзафлопсного уровня»: Eviden представила суперкомпьютерную платформу BullSequana XH3500Компания Eviden, входящая в Atos Group, анонсировала конвергентную суперкомпьютерную платформу BullSequana XH3500 для ресурсоёмких нагрузок ИИ и HPC. Новинка сочетает передовые аппаратные решения с комплексной экосистемой ПО, обеспечивая возможность масштабирования «за пределы экзафлопсного уровня». BullSequana XH3500 использует открытую модульную конструкцию. Такой подход позволяет свободно комбинировать блоки CPU, GPU и сетевые компоненты от различных производителей, адаптируя конфигурации под определённые потребности. При этом устраняется зависимость от какого-либо конкретного поставщика оборудования, что обеспечивает полную технологическую свободу. По заявлениям Eviden, платформа BullSequana XH3500 по сравнению с системой предыдущего поколения позволяет добиться повышения электрической мощности более чем на 80 % в расчёте на 1 м2 и увеличения эффективности охлаждения на 30 % в расчёт на 1 кВт. Это даёт возможность удовлетворить растущие потребности в вычислительных ресурсах без необходимости расширения площадей в дата-центрах. Габариты стойки BullSequana XH3500 без модуля ультраконденсатора составляют 2270 × 900 × 1457 мм. Мощность AC достигает 284 кВт (с одной помпой). Задействовано на 100 % безвентиляторное прямое жидкостное охлаждение (DLC) пятого поколения с возможностью использования горячей воды с температурой до 40 °C. Подсистемы питания и охлаждения выполнены по схеме с резервированием N+1. Доступны 38 универсальных слотов 1U. 
Источник изображения: Eviden Для платформы BullSequana XH3500 разработаны узлы BullSequana XH3515B и BullSequana AI1242. Первый соответствует типоразмеру 1U: это одноузловое изделие оборудовано двумя чипами NVIDIA Grace CPU и четырьмя ускорителями NVIDIA Blackwell B200. Возможна установка до девяти NVMe SSD в форм-факторе E1.S. Говорится о поддержке четырёх сетевых устройств Eviden BXI V3 или InfiniBand NDR/XDR. В свою очередь, сервер BullSequana AI1242 имеет исполнение 2U. Данное решение несёт на борту два процессора AMD EPYC Turin и GPU-ускоритель AMD Instinct MI355X. Реализована поддержка восьми устройств Eviden BXI V3 или InfiniBand NDR/XDR, а также четырёх накопителей E1.S NVMe SSD.
14.11.2025 [09:36], Сергей Карасёв
HPE представила CPU- и GPU-узлы суперкомпьютерной платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения для НРС-задач, являющиеся частью суперкомпьютерной платформы Cray Supercomputing GX5000. В частности, дебютировали узлы GX250 Compute Blade, GX350a Accelerated Blade и GX440n Accelerated Blade, а также высокопроизводительная СХД Storage Systems K3000. Устройство HPE Cray Supercomputing GX250 Compute Blade представляет собой CPU-сервер, оснащённый восемью процессорами AMD EPYC Venice (появятся во II половине 2026 года). В одной стойке могут быть размещены до 40 таких серверов, что обеспечивает самую высокую в отрасли плотность компоновки x86-ядер следующего поколения, говорит компания. В паре с CPU-узлами могут функционировать новые GPU-модули. Так, изделие HPE Cray Supercomputing GX350a Accelerated Blade несёт на борту один чип AMD EPYC Venice и четыре ускорителя AMD Instinct MI430X. В стойку могут устанавливаться до 28 таких серверов, что даёт в сумме 112 ускорителей MI430X. В свою очередь, HPE Cray Supercomputing GX440n Accelerated Blade содержит четыре NVIDIA Vera CPU и восемь NVIDIA Rubin GPU. Допускается монтаж до 24 подобных серверов на стойку, что обеспечивает 192 ускорителя Rubin. Все новинки оборудованы жидкостным охлаждением. СХД HPE Cray Supercomputing Storage Systems K3000 выполнена на сервере HPE ProLiant Compute DL360 Gen12. Могут устанавливаться 8, 12, 16 или 20 накопителей NVMe вместимостью 3,84, 7,68 или 15,36 Тбайт каждый. Объём памяти DRAM — 512 Гбайт, 1 или 2 Тбайт. Применяется платформа DAOS, разработанная для требовательных рабочих нагрузок, таких как анализ данных и машинное обучение. Поддерживаются технологии HPE Slingshot 200, HPE Slingshot 400, InfiniBand NDR и 400GbE. 
Источник изображения: HPE via The Next Platform Кроме того, HPE сообщила о том, что для платформы HPE Cray Supercomputing GX5000 доступен интерконнект HPE Slingshot 400. Соответствующие коммутаторы с прямым жидкостным охлаждением наделены 64 портами на 400 Гбит/с. Возможны конфигурации с 8, 16 и 32 коммутаторами, что в сумме позволяет использовать до 512, 1024 и 2048 портов соответственно. 
Источник изображения: HPE О выборе платформы HPE Cray Supercomputing GX5000 для НРС-комплексов нового поколения уже объявили Центр высокопроизводительных вычислений Штутгартского университета (HLRS) и Центр суперкомпьютеров имени Лейбница (LRZ) Баварской академии естественных и гуманитарных наук (BADW). Кроме того, новая платформа является основой суперкомпьютера Discovery Министерства энергетики США (DOE).
13.11.2025 [12:12], Руслан Авдеев
Anthropic инвестирует $50 млрд в американскую ИИ-инфраструктуруИИ-стартап Anthropic объявил о намерении инвестировать $50 млрд в вычислительную инфраструктуру в США. Компания создаст ЦОД совместно с Fluidstack в Техасе, Нью-Йорке и других. местах. Объекты проектируются с учётом запросов Anthropic для обеспечения максимальной эффективности рабочих нагрузок. Fluidstack выбрана в качестве партнёра стартапа за «исключительную гибкость», позволяющую быстро получить гигаватты мощностей. Первые объекты должны ввести в эксплуатацию в 2026 году. ЦОД позволят создать 800 постоянных рабочих мест. План поможет выполнению инициативы администрации Дональда Трампа в области ИИ (AI Action Plan) — она направлена на сохранение лидерства США в сфере искусственного интеллекта. В компании заявляют, что приближаются к созданию ИИ, способного ускорить научные открытия и решать сложные задачи невозможными ранее способами. Для этого необходима инфраструктура, способная поддерживать непрерывное развитие — новые площадки помогут создавать более эффективные ИИ-системы, способные обеспечить новые исследовательские прорывы и создавать рабочие места для американцев. Anthropic с её ИИ-моделями Claude обслуживает более 300 тыс. корпоративных клиентов, а число клиентов, приносящих более $100 тыс. ежегодно, за последний год выросло почти в семь раз. Огромный масштаб инвестиций необходим для удовлетворения растущего спроса на Claude среди сотен тысяч компаний с сохранением передовых позиций в сфере исследований ИИ-технологий. В компании обещают отдавать приоритет «экономически эффективным» и «капиталоэффективным» подходам для достижения своих целей. 
Источник изображения: Invest Europe/unsplash.com По данным Datacenter Dynamics, в случае с техасским ЦОД, возможно, речь идёт о ранее анонсированном объекте Fluidstack и TeraWulf на 168 МВт в Абернати (Abernathy) или о совместном c Cipher Mining проекте на 244 МВт. В случае с Нью-Йоркским ЦОД, речь, возможно, идёт о кампусе Lake Mariner — совместном проекте Fluidstack и TeraWulf. Google, имеющая долю 14 % в Anthropic, поддержала оба проекта с участием TeraWulf. Ранее в этом году компания обеспечила гарантии по её кредитам, а также предоставила гарантии по арендным обязательствам Fluidstack на сумму $1,4 млрд для сделки с Cipher, получив в TeraWulf долю 5,4 %, а в бизнесе Fluidstack — 14 %. В октябре Anthropic анонсировала сделку с Google Cloud объёмом более 1 ГВт, которая даст ей доступ к миллиону ускорителей Google TPU. Предстоит уточнить, идёт ли в новом анонсе Anthropic речь о том же самом контракте с участием Fluidstack в качестве посредника — или речь идёт о новой сделке. AWS тоже владеет долей в Anthropic. В октябре она запустила для Anthropic кластер Project Rainier на основе собственных ИИ-ускорителей Tranium2. На площадку потратят $11 млрд (при полной загрузке). Стоимость вычислений Anthropic растёт, но The Information располагает информацией, что ИИ-стартап надеется использовать более эффективные модели, требующие меньших вычислительных мощностей в пересчёте на каждого пользователя. Это снизит затраты и позволит скорее добиться прибыльности бизнеса. По оценкам, $50 млрд инвестиций дадут компании доступ к примерно 5 ГВт ЦОД.
12.11.2025 [23:23], Владимир Мироненко
От ИИ ЦОД до роботов: AMD анонсировала долгосрочную стратегию роста
amd
cpu
dpu
epyc
hardware
instinct
mi400
mi500
ocp
pensando systems
ualink
ultra ethernet
venice
verano
xilinx
ии
ускоритель
финансы
AMD представила на мероприятии Financial Analyst Day 2025 план по достижению лидерства на рынке вычислительных технологий объёмом $1 трлн. Долгосрочная стратегия роста AMD построена на четырех столпах: лидерство в сфере ЦОД, повышение производительности ИИ, открытое ПО и расширение присутствия на рынках встраиваемых и полукастомных кремниевых решений. AMD ожидает, что только её бизнес в сфере ЦОД будет приносить более $100 млрд годовой выручки, с увеличением совокупного среднегодового темпа роста (CAGR) до более чем 60 %, при этом CAGR дохода от ИИ-решений увеличится до более чем 80 %. Генеральный директор AMD Лиза Су (Lisa Su) заявила, что следующий этап будет основан на унифицированной вычислительной платформе AMD, объединяющей процессоры EPYC, ускорители Instinct, сетевые решения Pensando и ПО ROCm. Новый план развития AMD призван обеспечить ей конкуренцию с NVIDIA и Intel на корпоративных рынках и в борьбе за заказы гиперскейлеров. 
Источник изображений: AMD  Ускорители серии Instinct MI350, уже развёрнутые Oracle (ещё 50 тыс. MI450 будут развёрнуты во II половине 2026 г.), являются самыми популярными ускорителями AMD на сегодняшний день. Следующей платформой станет серия MI450, которая будет запущена вместе со стоечной платформой Helios в III квартале 2026 года. Helios обеспечит пропускную способность интерконнекта 3,6 Тбайт/с на каждый ускоритель и до 72 ускорителей на стойку с совокупной пропускной способностью 260 Тбайт/с, соединённых между собой посредством UALink и Ultra Ethernet (UEC). Система поддерживает разделяемую память между ускорителями, что обеспечивает обучение крупномасштабных моделей с бесперебойным доступом к памяти и отказоустойчивой сетью с шестью плоскостями. 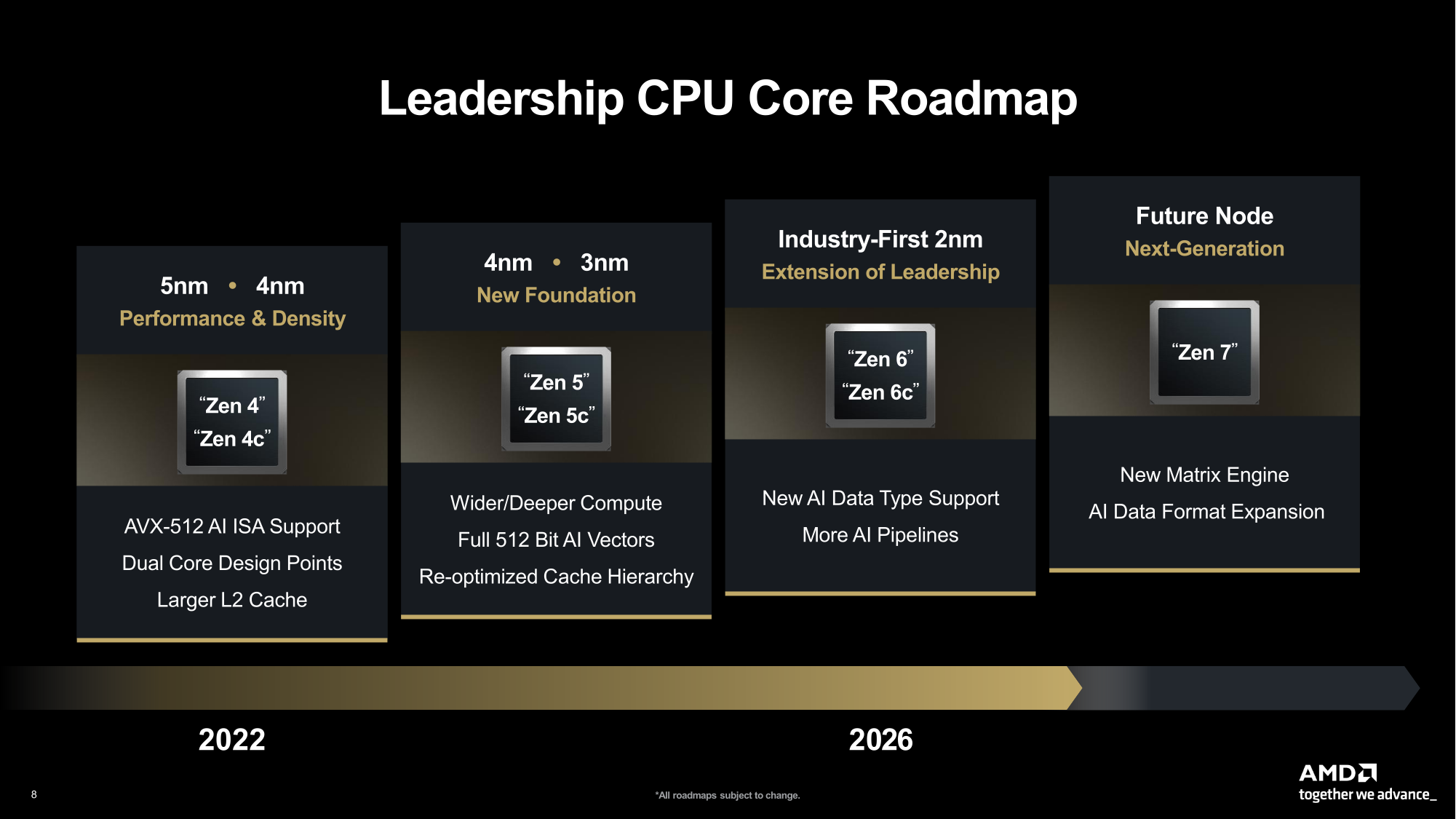 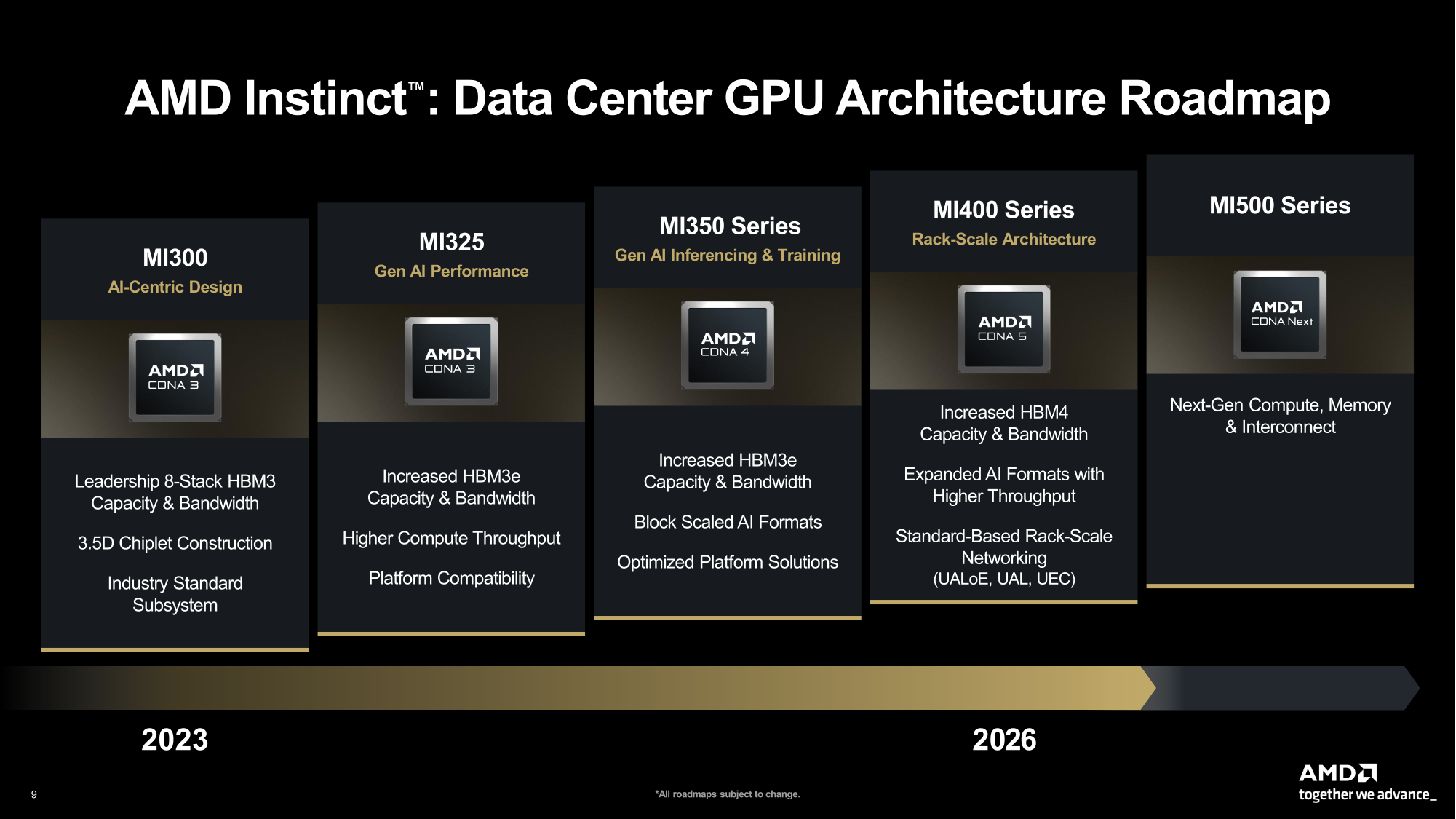 AMD характеризует Helios как свою первую ИИ-платформу стоечного масштаба — полностью интегрированную систему с открытой архитектурой, которая объединяет вычислительные мощности, ускорение, сетевые технологии и ПО в единую структуру. В отличие от традиционных серверных кластеров, Helios реализует всю стойку как единый высокопроизводительный вычислительный домен. Каждая стойка объединяет процессоры AMD EPYC Venice, CDNA5-ускорители Instinct MI450X (будет и вариант MI430X с полноценными FP64-блоками) и 400G/800G-карты Pensando Vulcano, связанные Infinity Fabric пятого поколения (PCIe 6.0, CXL 3.1, UCIe) и UALink.  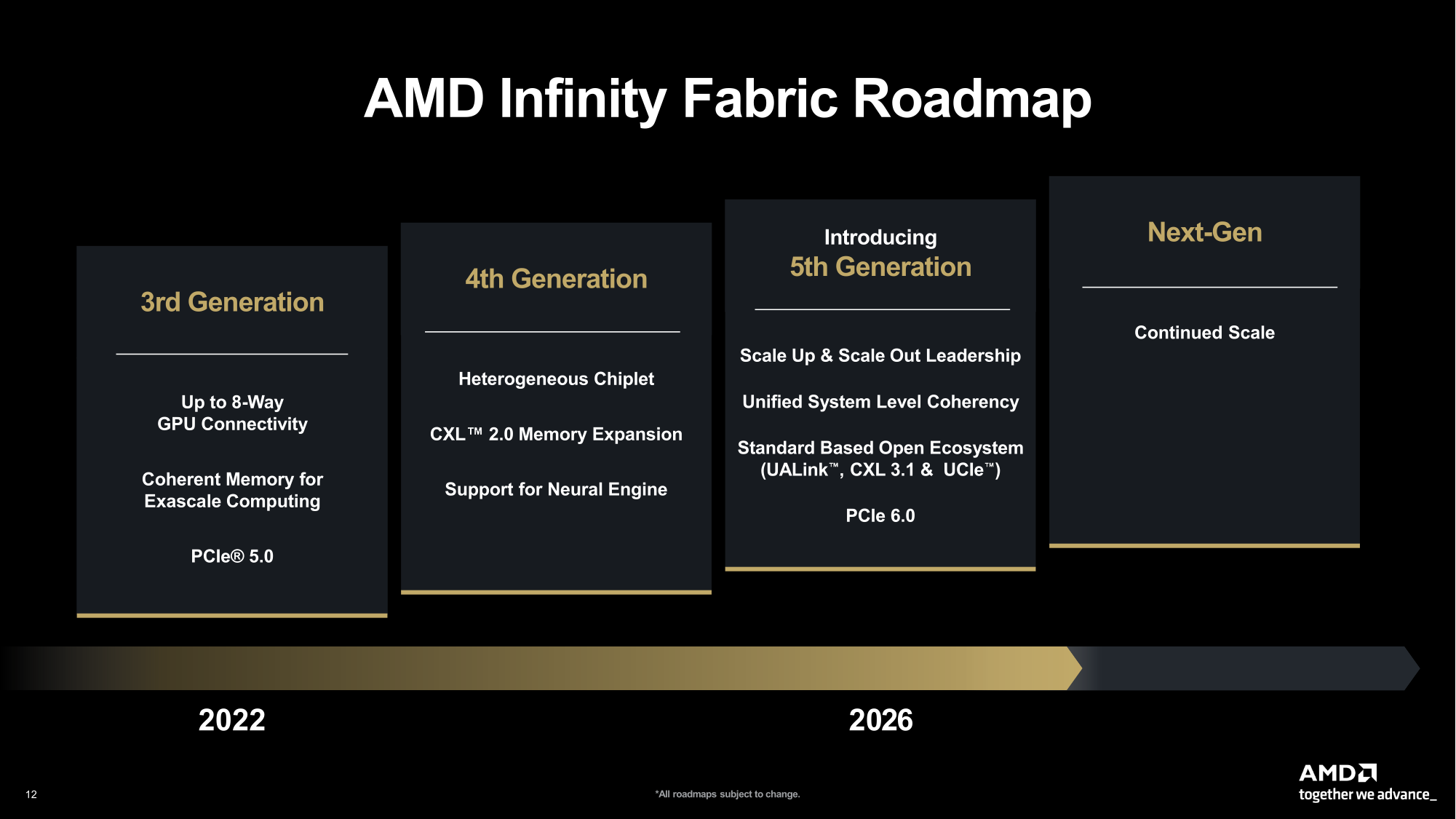 Эта архитектура минимизирует накладные расходы на перемещение данных, увеличивает пропускную способность между ускорителями и обеспечивает эффективность класса экзафлопсных вычислений в компактном корпусе. Helios фактически представляет собой проект AMD для ИИ-фабрики будущего с возможностью модульного расширения, позволяя объединять сотни стоек в одну систему в ЦОД.   В 2027 году AMD планирует выпустить ускорители серии MI500 и процессоры EPYC Verano, продолжая тем самым ежегодный цикл совместной разработки процессоров, ускорителей и сетей. AMD заявила, что EPYC Venice, намеченные к выпуску в 2026 году, будут обладать лучшими в отрасли показателями плотности (1,3x по количеству потоков в сравнении с текущими решениями) и энергоэффективности (1,7x). Они пополнятся оптимизированными для ИИ наборами инструкций для обработки инференса и выполнения вычислений общего назначения. Указанные компоненты станут основой ИИ-фабрики, способной масштабироваться от одной стойки до глобально распределённых кластеров.  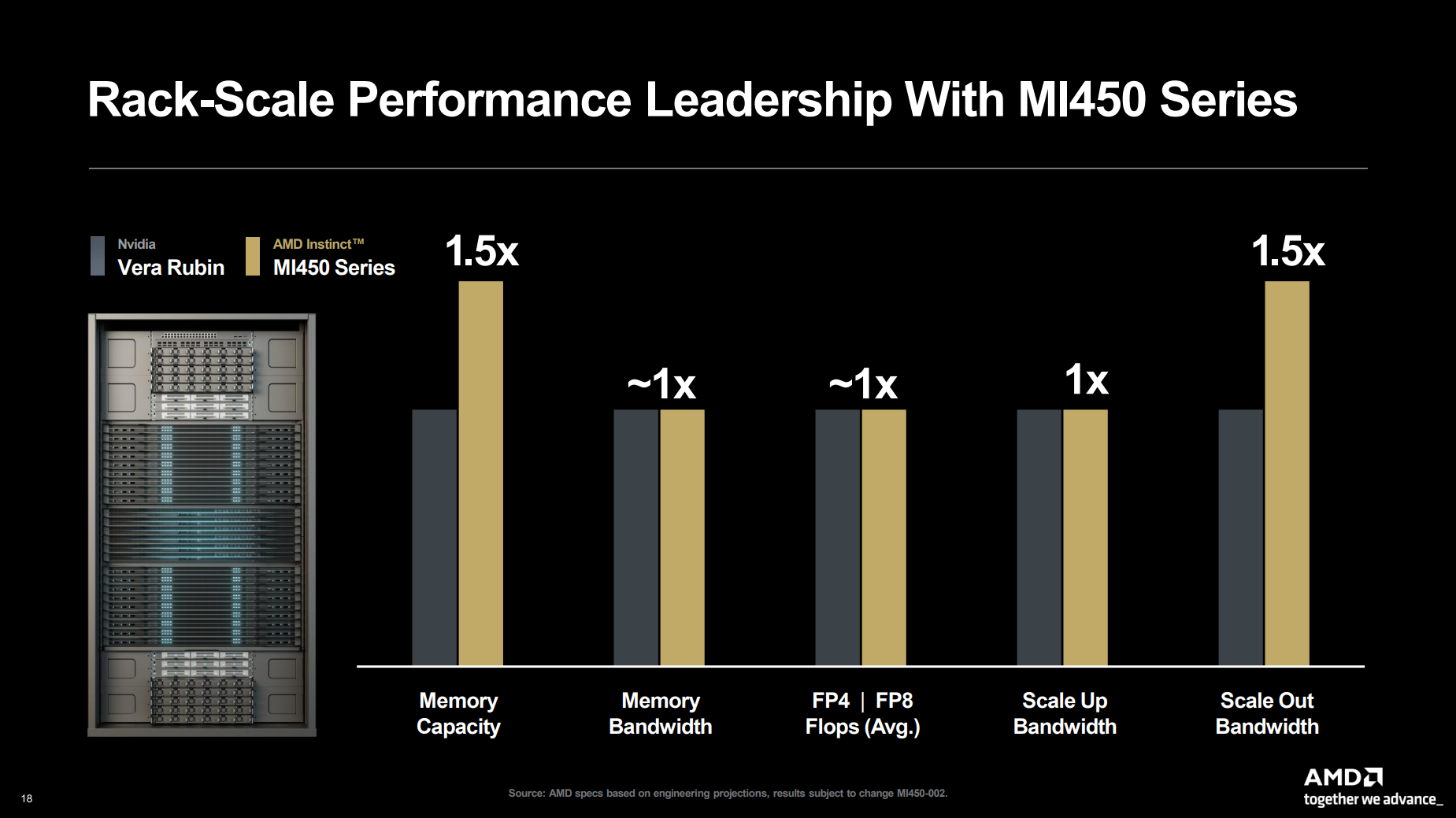 Исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) подчеркнул в своём выступлении, что производительность ИИ всё больше зависит от сети. Сетевые карты AMD Pensando Pollara и Vulcano для ИИ образуют связующую ткань архитектуры Helios. Сетевая карта Pollara 400 обеспечивает пропускную способность 400 Гбит/с, а готовящаяся к выходу сетевая карта Vulcano удвоит её до 800 Гбит/с, обеспечивая связь Ultra Ethernet между крупными кластерами ускорителей.   AMD представила четырёхуровневую архитектуру сети для масштабных ИИ-инфраструктур. Front-End часть обслуживает пользователей, хранилище и приложения. Она опирается на DPU Pensando и P4-движки, отвечающие за разгрузку сетевых функций, функции безопасности и шифрования, и работу с СХД. Вертикальное масштабирование в пределах стойки обеспечивает 3,6-Тбайт/с подключение на каждый GPU. Горизонтальное масштабирование реализуется благодаря UEC — внутренние тесты показали снижение затрат на коммутацию до 58 % по сравнению с традиционными сетями типа Fat-Tree. Наконец, Scale-Across (пространственное масштабирование) позволит объединить географически распределённые ЦОД в кластеры с интеллектуальным управлением трафиком и адаптивной балансировкой нагрузки.   AMD отметила, что открытый программный стек ROCm (Radeon open compute) по-прежнему лежит в основе её стратегии в области ИИ-платформ. По сравнению с прошлым годом число его загрузок выросло в десять раз и теперь на HuggingFace поддерживается более 2 млн моделей. ROCm интегрируется с ведущими фреймворками, включая PyTorch, TensorFlow, JAX, Triton, vLLM, ComfyUI и Ollama, и поддерживает проекты с открытым исходным кодом, такие как Unsloth.   AMD также расширила своё видение «физического ИИ», когда вычисления выходят за рамки облака и охватывают роботов, транспортные средства и промышленные системы. Подразделение встраиваемых систем, усиленное приобретением Xilinx в 2022 году, превратилось из бизнеса, ориентированного на FPGA, в многоплатформенный двигатель роста, охватывающий адаптивные системы на кристалле (SoC), встраиваемые x86-процессоры и заказные кремниевые решения. По словам компании, с 2022 года решения в этой области принесли более $50 млрд. AMD рассчитывает превысить 70 % доли рынка адаптивных вычислений.   Говоря о перспективах, компания отметила, что ЦОД остаются основным драйвером роста, но наряду с этим она будет диверсифицировать свою деятельность по всем сегментам. Финансовые цели AMD включают:
12.11.2025 [09:28], Владимир Мироненко
Переконфигурируемый ускоритель NextSilicon Maverick-2 с dataflow-архитектурой меняет подход к вычислениямВ конце октября стартап NextSilicon объявил о выходе Maverick-2 — интеллектуального ускорителя вычислений (Intelligent Compute Accelerator, ICA), анонсированного в прошлом году. Чип уже используется в Сандийских национальных лабораториях (SNL) Министерства энергетики США (DOE) в составе суперкомпьютера Vanguard-II, а также рядом клиентов. Как утверждает глава NextSilicon Элад Раз (Elad Raz), компании в сфере научных вычислений и HPC сталкиваются с проблемой ограниченных возможностей CPU и GPU, из-за чего приходится идти на компромиссы, но архитектура Maverick решает эту проблему. По словам NextSilicon, нынешние массовые CPU «скованы» архитектурой фон Неймана 80-летней давности, в которой значительная часть отведена вспомогательной логике, включая предсказание ветвлений, внеочередное исполнение и т.д., а не собственно исполнительным устройствам. В свою очередь, GPU обеспечивают более высокую параллельную производительность, но для эффективного использования ускорителей требуются специализированные среды разработки (CUDA), управление сложными иерархиями памяти, когерентностью кешей и т.п. А ASIC, созданные для конкретных ИИ-задач, обеспечивают высокую производительность и эффективность, но их разработка требует больших затрат. 
Источник изображения: NextSilicon NextSilicon предлагает заменить эти решения чипом с управлением потоками данных (dataflow), который можно перенастраивать во время выполнения задач для устранения узких мест кода, и у которого нет ограничений, присущих CPU и GPU. «В ресурсоёмких приложениях большую часть времени выполняется лишь небольшая часть кода, — рассказал Раз. — Мы разработали интеллектуальный программный алгоритм, который непрерывно отслеживает работу приложения. Он точно определяет, какой путь кода выполняется чаще всего, и перенастраивает чип для ускорения именно этих путей. И всё это мы делаем во время исполнения кода и за наносекунды». FPGA тоже можно перепрограммировать, но для этого нужен цикл перезагрузки. 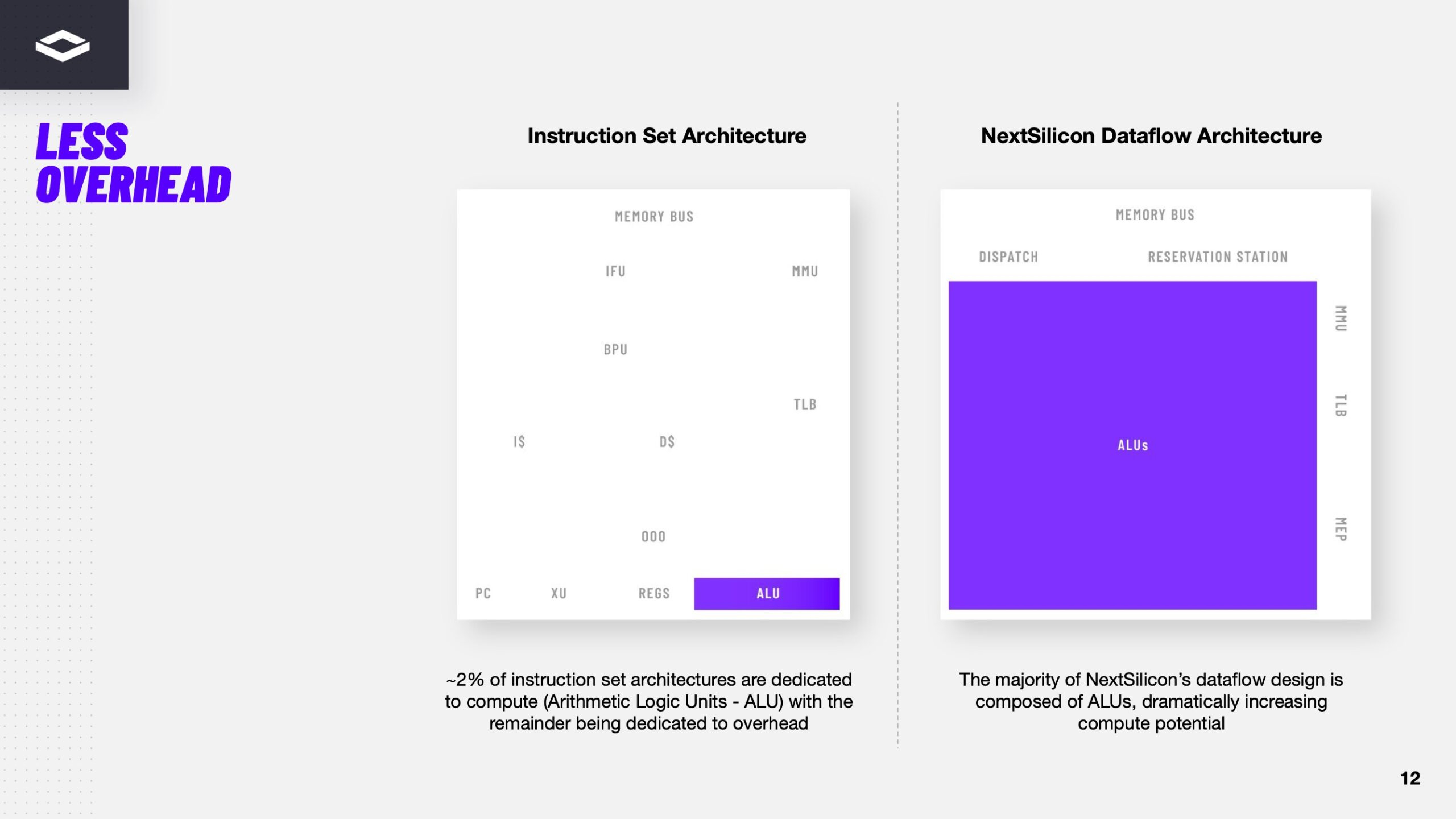
Источник изображений здесь и далее: ServeTheHome/NextSilicon Аппаратная часть Maverick представляет собой реконфигурируемую структуру ALU, которой отведена большая часть «кремния». которую можно быстро перенастраивать во время выполнения кода. Это означает больше вычислений за такт (и на Ватт), при условии, что данные находятся в нужном месте в нужное время. Алгоритм анализирует код на наличие узких мест и соответствующим образом настраивает чип во время выполнения программы. Программно-определяемая архитектура управления потоками данных позволяет достичь производительности и эффективности, близких к ASIC, не привязываясь к конкретному приложению и сохраняя гибкость алгоритмов, утверждает NextSilicon. 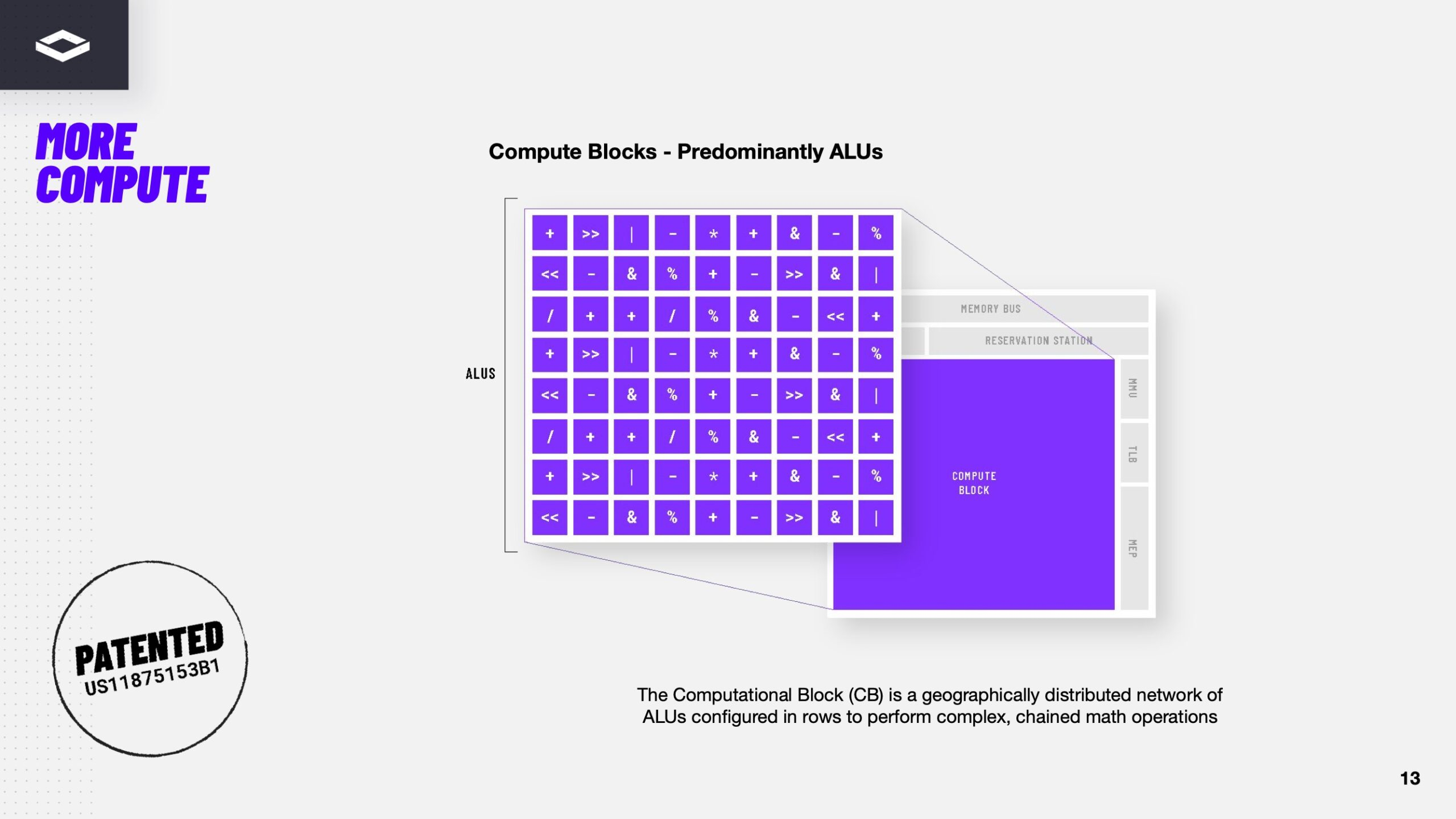 В архитектуре NextSilicon вычислительные блоки (CB) подключены к шине памяти для получения данных, которые временно хранятся в станции резервирования (RS). Диспетчер определяет время запуска вычислительного блока. (RS и диспетчер аналогичны регистрам в процессоре.) Точки входа в память (MEP-блоки) обрабатывают операции доступа к памяти, генерируя запросы к шине, а по завершении направляют ответ в RS. MMU и TLB-кеш занимаются трансляцией адресов (при необходимости). Всё остальное пространство CB занято ALU, который в первом приближении и можно считать «инструкциями». Компания не уточняет, сколько именно CB содержится в чипе, но на фото кристалла их 224. 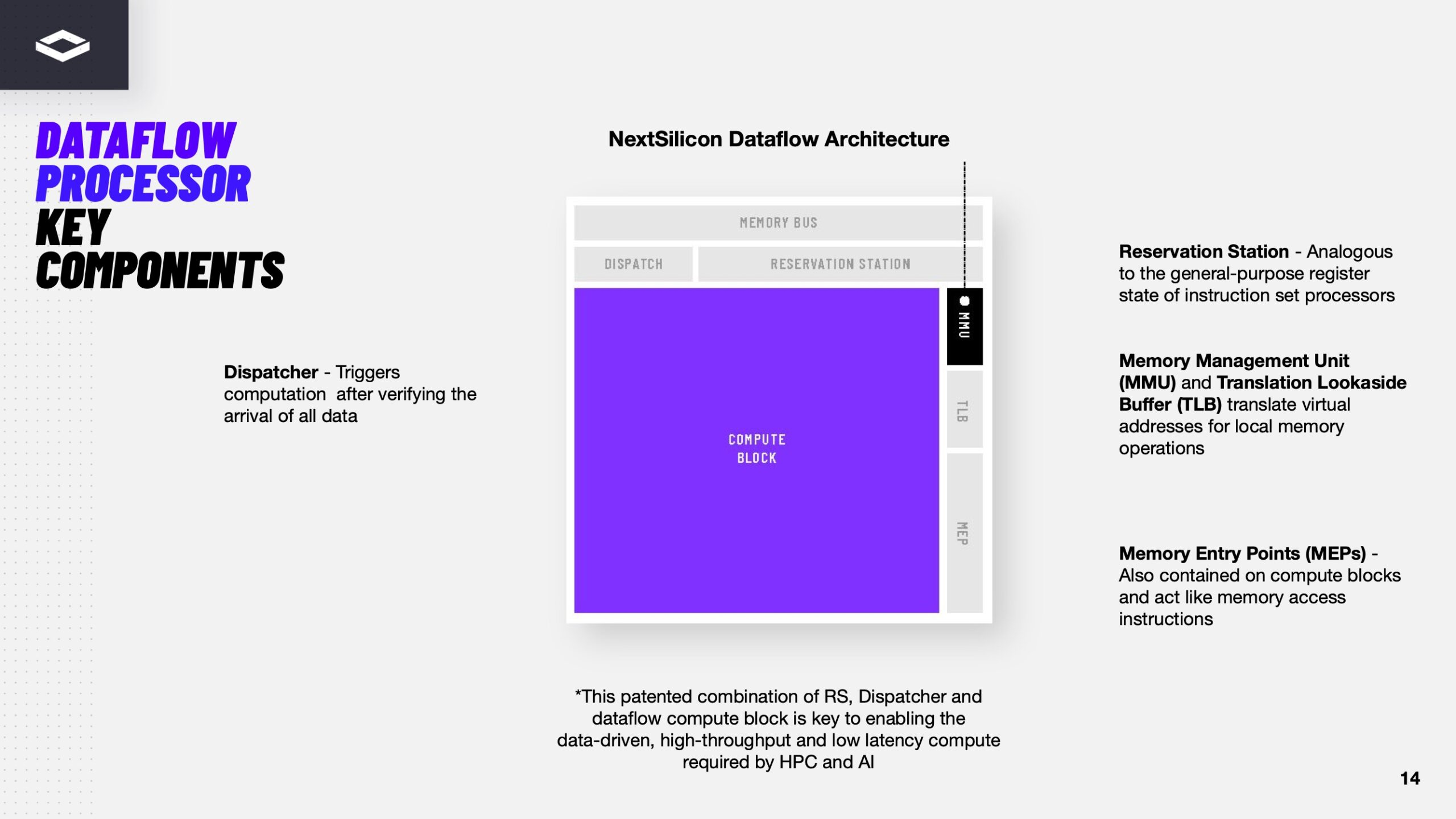 Из ALU компилятор NextSilicon формирует т.н. Mill-ядра (Mill Core) в рамках CB, фактически представляющие собой граф связанных между собой операций, которые и выполняются ALU — появление данных на входе ALU срабатывает как триггер, ALU отрабатывает свою единственную назначенную операцию и передаёт результат следующему ALU, тот следующему и т.д. до конца графа. Особенностью чипа является способность в ходе исполнения по необходимости автоматически реплицировать и оптимально размещать Mill-ядра внутри одного CB, и между несколькими CB. Пришло больше данных, которые можно параллельно обработать — будет больше Mill-ядер. Но касается это только наиболее «горячих» участков. 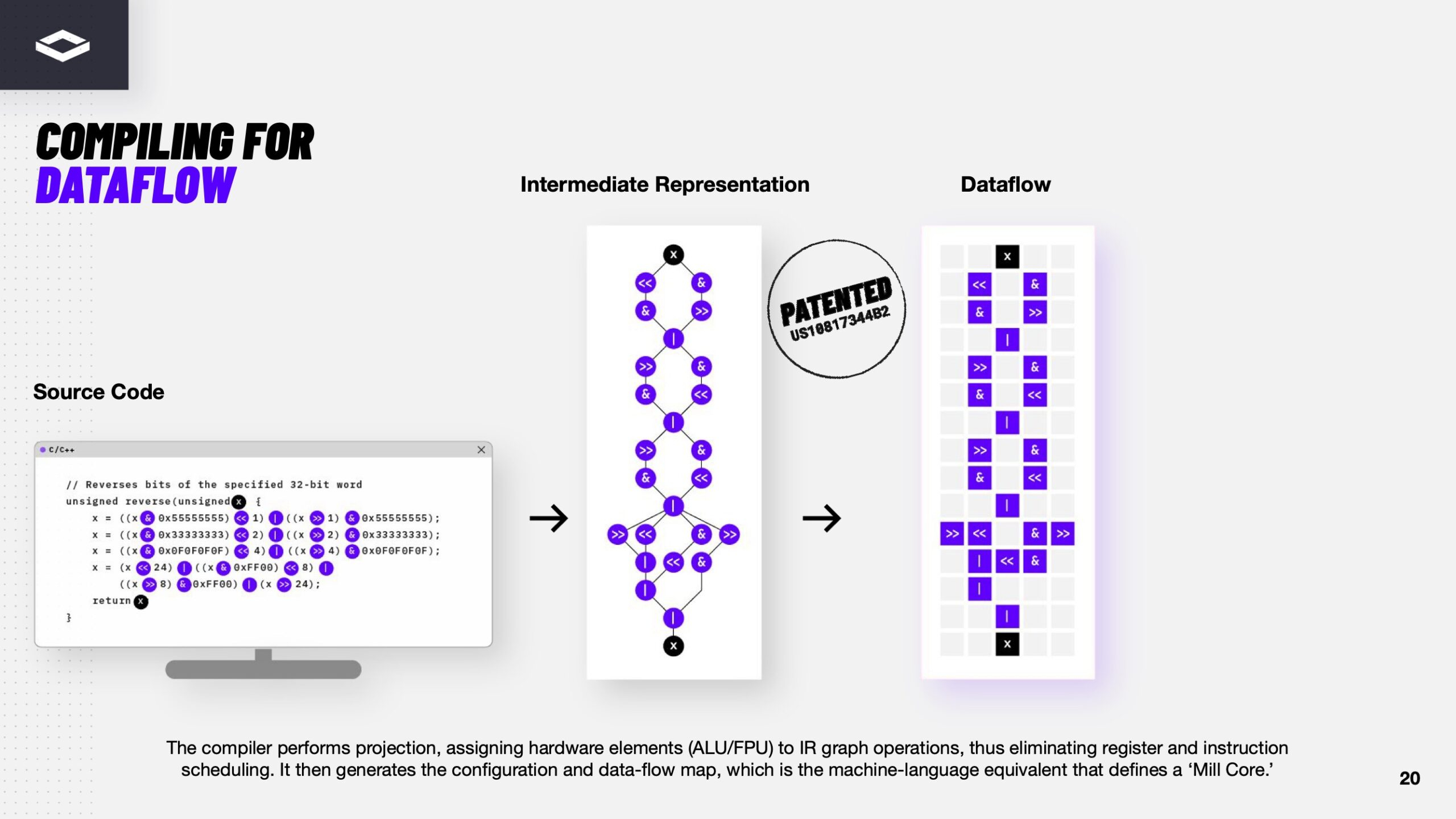 Илан Таяри (Ilan Tayari), соучредитель и вице-президент по архитектуре NextSilicon, назвал критически важным, что платформа может запускать любой код «из коробки», будь то код, написанный для CPU и GPU или ИИ-моделей. Будь то C++, Fortran, Python, CUDA, ROCm, OneAPI или даже ИИ-фреймворки, компилятор NextSilicon разделяет код на части, преобразуя их в промежуточное представление для реконфигурируемого оборудования. «Это не ограничивается тем, что существует сегодня, — сказал Таяри. — Для исследователей в сфере ИИ этот метод открывает новые захватывающие возможности. Вы получаете ускорение независимо от того, что использует ваша модель… экзотические функции активации, комплексные числа или новые математические операции: всё ускоряется сразу из коробки». 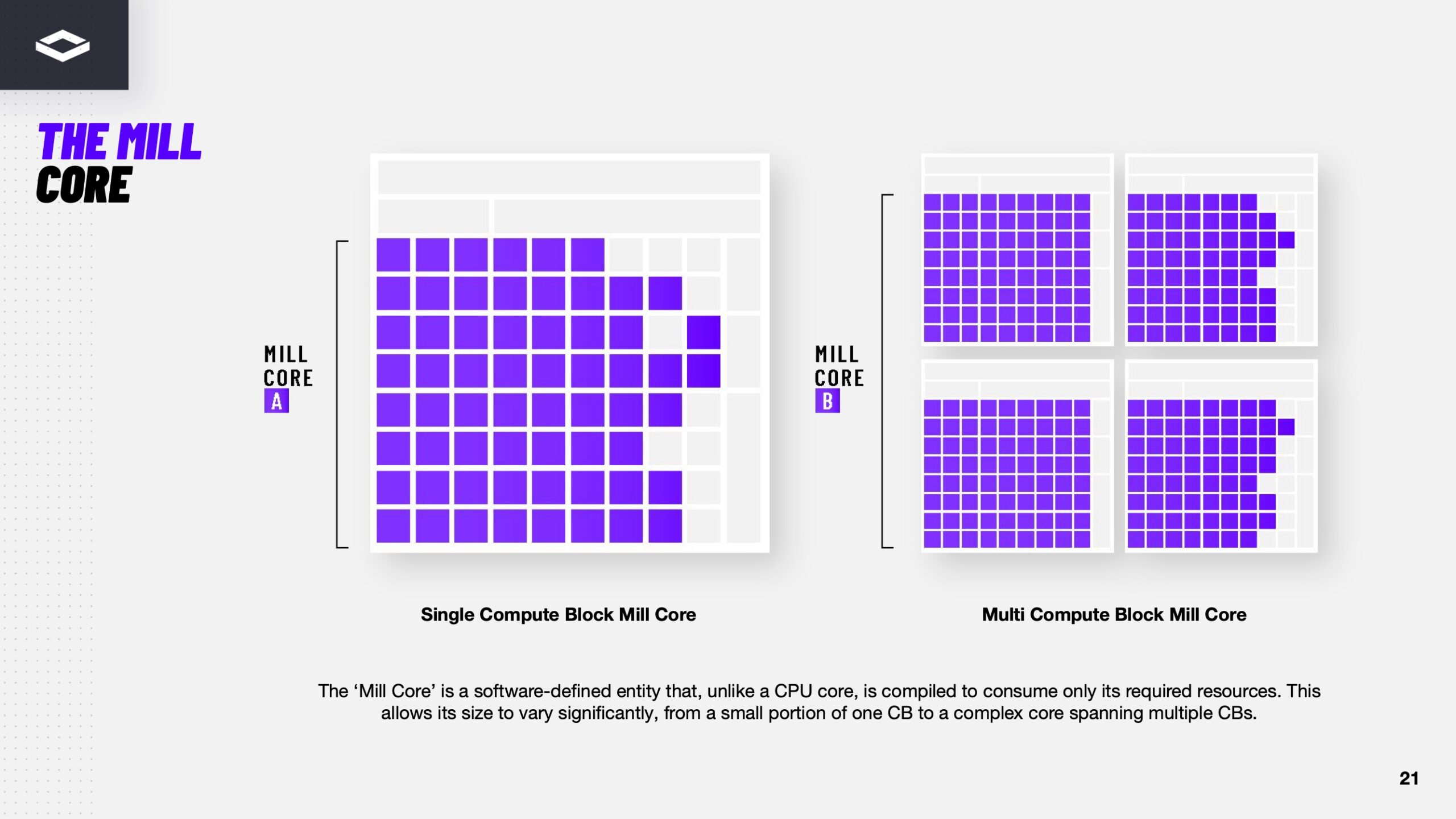 Во время выполнения приложения оперативная телеметрия на чипе непрерывно оптимизирует его. Например, в случае частого взаимодействия вычислительных подблоков граф перестраивается, чтобы приблизить их друг к другу или, например, переключиться с векторной на матричную обработку. При наличии узкого места они дублируются для обеспечения параллелизма. Это происходит автоматически, без вмешательства разработчика, в отличие, например, от VLIW-подхода. 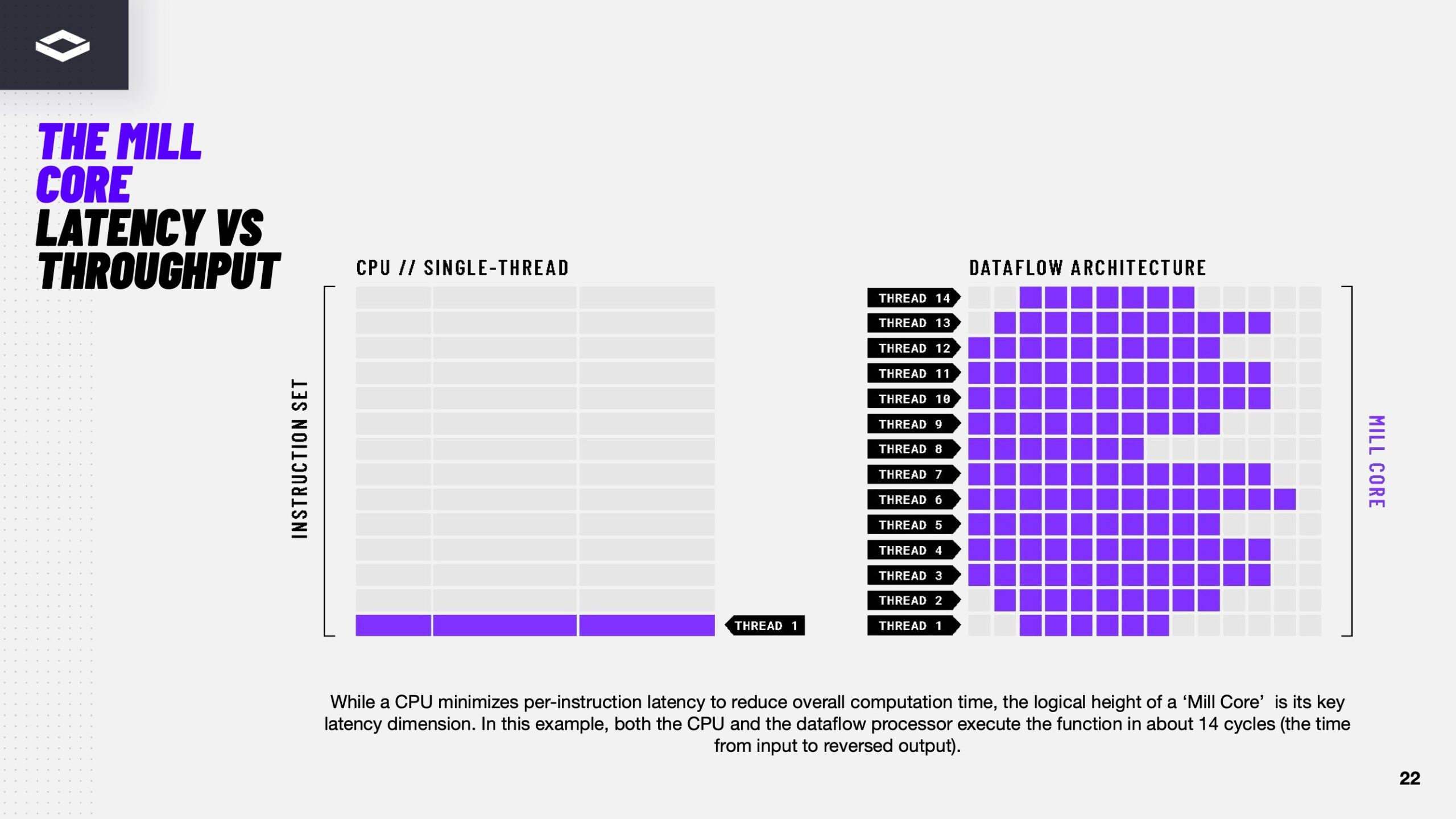 Maverick-2 выпускается по 5-нм техпроцессу TSMC в однокристальной и двухкристальной конфигурациях, работающих на частоте 1,5 ГГц. Однокристальная модель с энергопотреблением 400 Вт разработана для карт PCIe 5.0 x16, а двухкристальная модель с энергопотреблением 750 Вт — для OAM-модулей. Однокристальный вариант с воздушным охлаждением включает 32 управляющих ядра RISC-V, 96 Гбайт HBM3E, кеш 128 Мбайт и один порт 100GbE. Двухкристальный вариант OAM с жидкостным охлаждением содержит 64 управляющих ядра RISC-V, 192 Гбайт HBM3E, кеш 256 Мбайт и два интерфейса 100GbE. 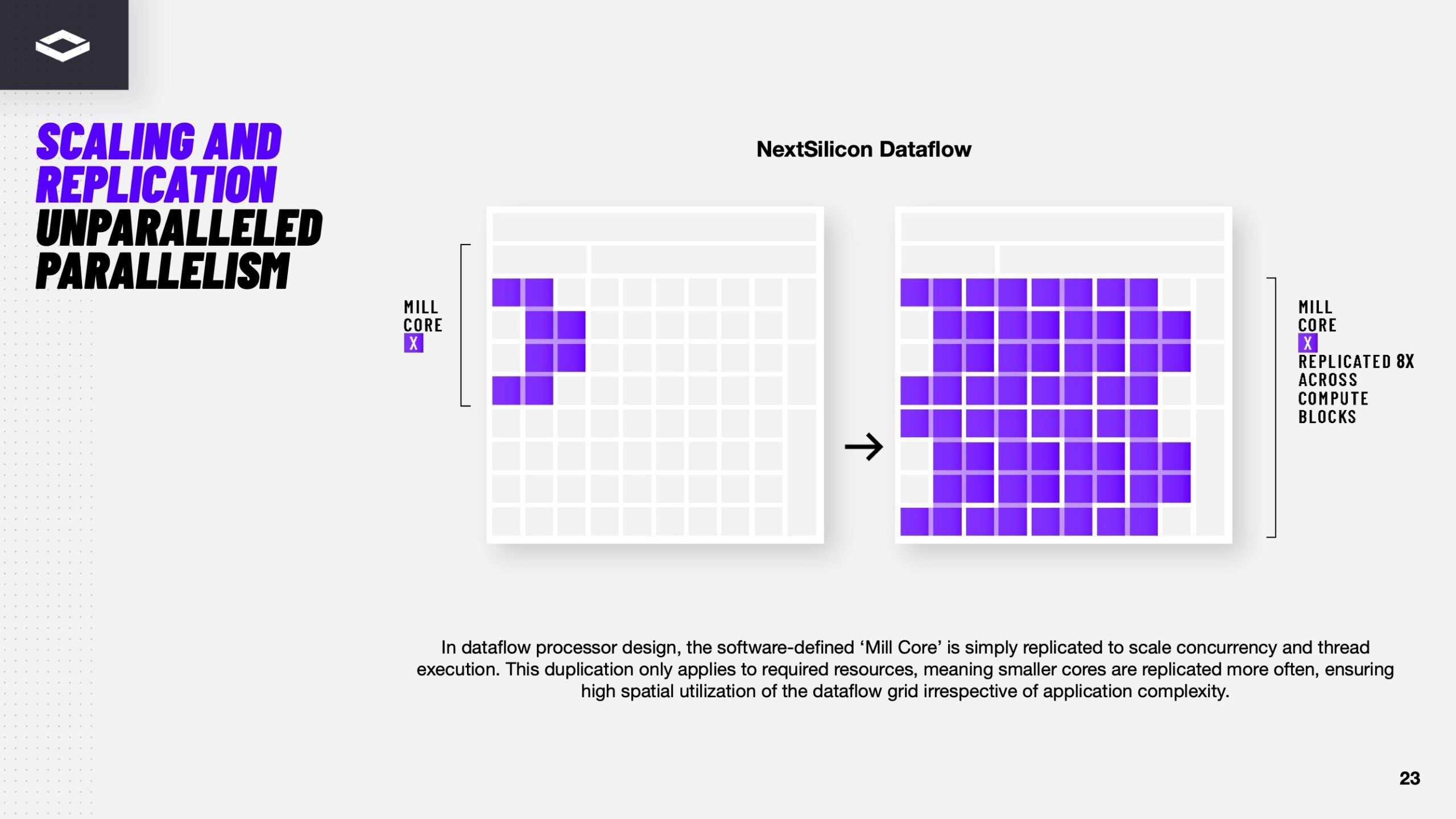 Следует отметить, что указаны максимальные значения TDP, и, как пишет ServeTheHome, ожидается, что при многих рабочих нагрузках они будут ниже. NextSilicon заявляет о возможности достижения 600 Гфлопс при потреблении 750 Вт (примерно вдвое меньше, чем у конкурентов) в бенчмарке HPCG, что составляет 4,8 Тфлопс при потреблении 6 кВт для UBB. Компания протестировала как однокристальную, так и двухкристальную версии Maverick2. В тесте STREAM пропускная способность чипа составила 5,2 Тбайт/с, в бенчмарке GUPS чип достиг 32,6 GUPS при потреблении 460 Вт, что в 22 раза быстрее, чем у CPU, и почти в шесть раз быстрее, чем у GPU для таких приложений как СУБД, агентное принятие ИИ-решений в режиме реального времени и ИИ-инференс на основе разрозненных данных. 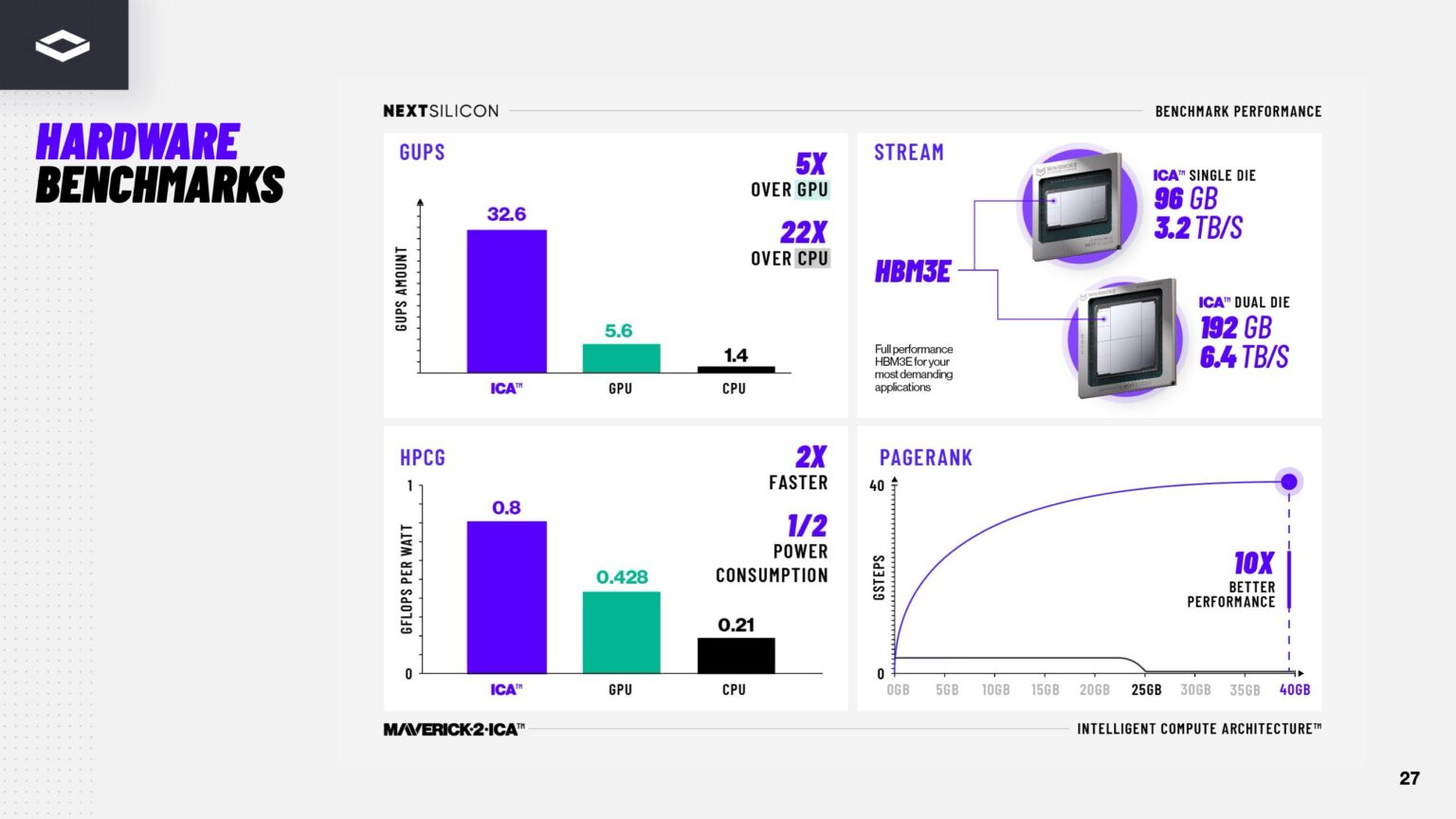 В тесте Google PageRank (PR) чип показал результат 40 Гигастраниц/с, что в 10 раз выше, чем у ведущих GPU, при вдвое меньшем энергопотреблении. Компания отметила, что при больших размерах графов (более 25 Гбайт) ведущие GPU не смогли полностью пройти тест, в то время как Maverick-2 справился с ними без труда, продемонстрировав критическую потребность в адаптивных архитектурах, способных справиться со сложными рабочими нагрузками, лежащими в основе современных ИИ-систем, социальной аналитики и сетевого интеллекта.  «[Эти результаты были] достигнуты с использованием существующего, немодифицированного кода приложения», — подчеркнул Эяль Нагар (Eyal Nagar), соучредитель и вице-президент по исследованиям и разработкам NextSilicon. «Нашим конкурентам требуются специализированные команды для модификации кода, BIOS, прошивок, ОС и параметров, чтобы достичь заявленных бенчмарков. NextSilicon обеспечивает превосходные результаты, используя уже готовое ПО», — добавил он.  NextSilicon также представила тестовый кристалл для процессора корпоративного уровня на базе ядер RISC-V, который компания планирует использовать в качестве хост-процессора в ускорителе следующего поколения Maverick-3. Процессор Arbel, разработанный с нуля, с шириной конвейера в 10 команд представляет собой эволюцию более компактных ядер RISC-V на базе Maverick-2, обрабатывающих последовательный код. По словам компании, ядра имеют производительность ядер на уровне AMD Zen 5 или Intel Lion Cove. 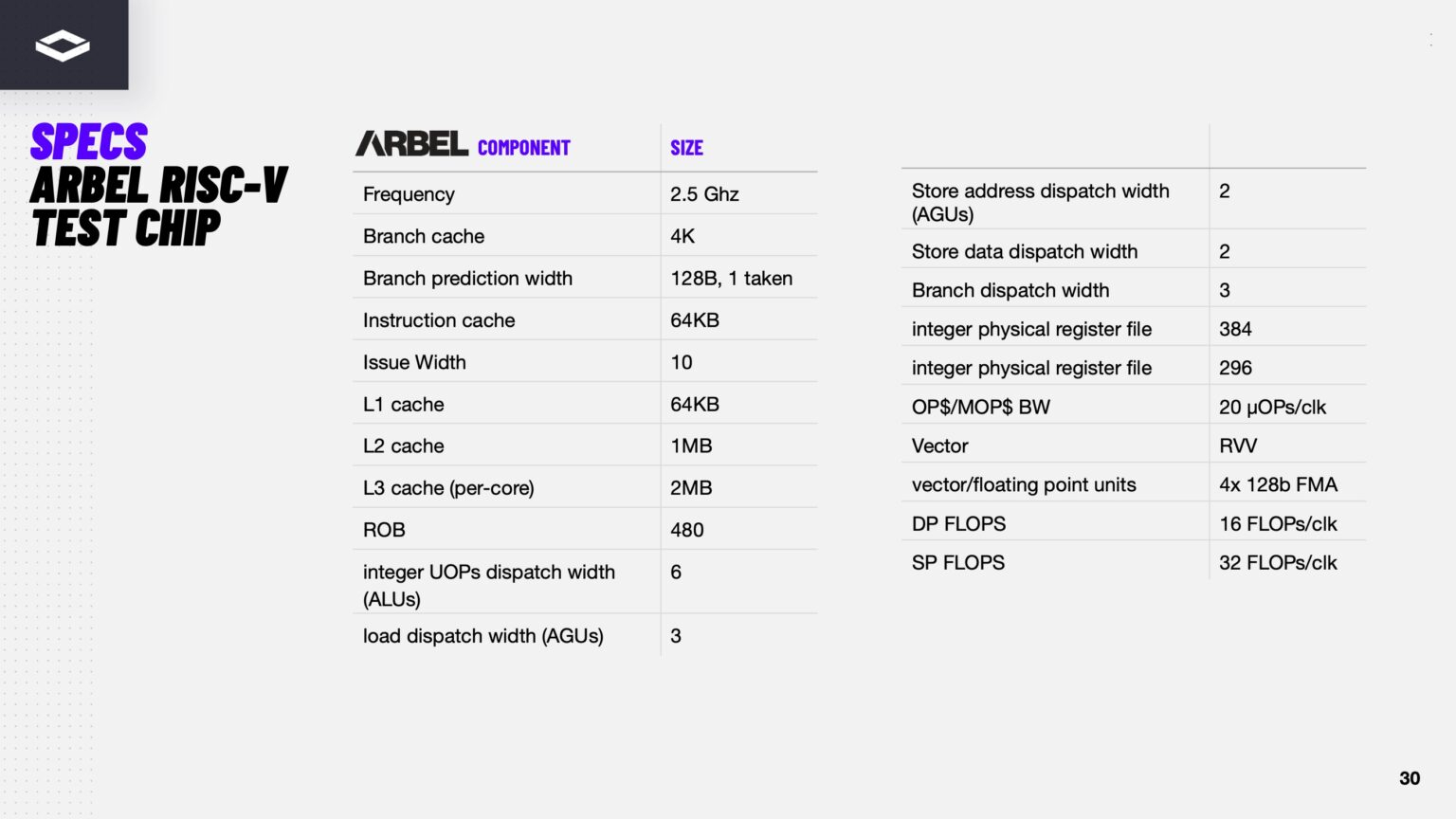 NextSilicon сообщила, что Arbel обеспечивает прорывную производительность благодаря четырём ключевым архитектурным инновациям:
«Это настоящий кремний, созданный по 5-нм техпроцессу TSMC — наша собственная запатентованная интеллектуальная собственность, а не лицензированная или заимствованная. Создан инженерами NextSilicon для воплощения видения будущего NextSilicon», — заявил Элад Раз. 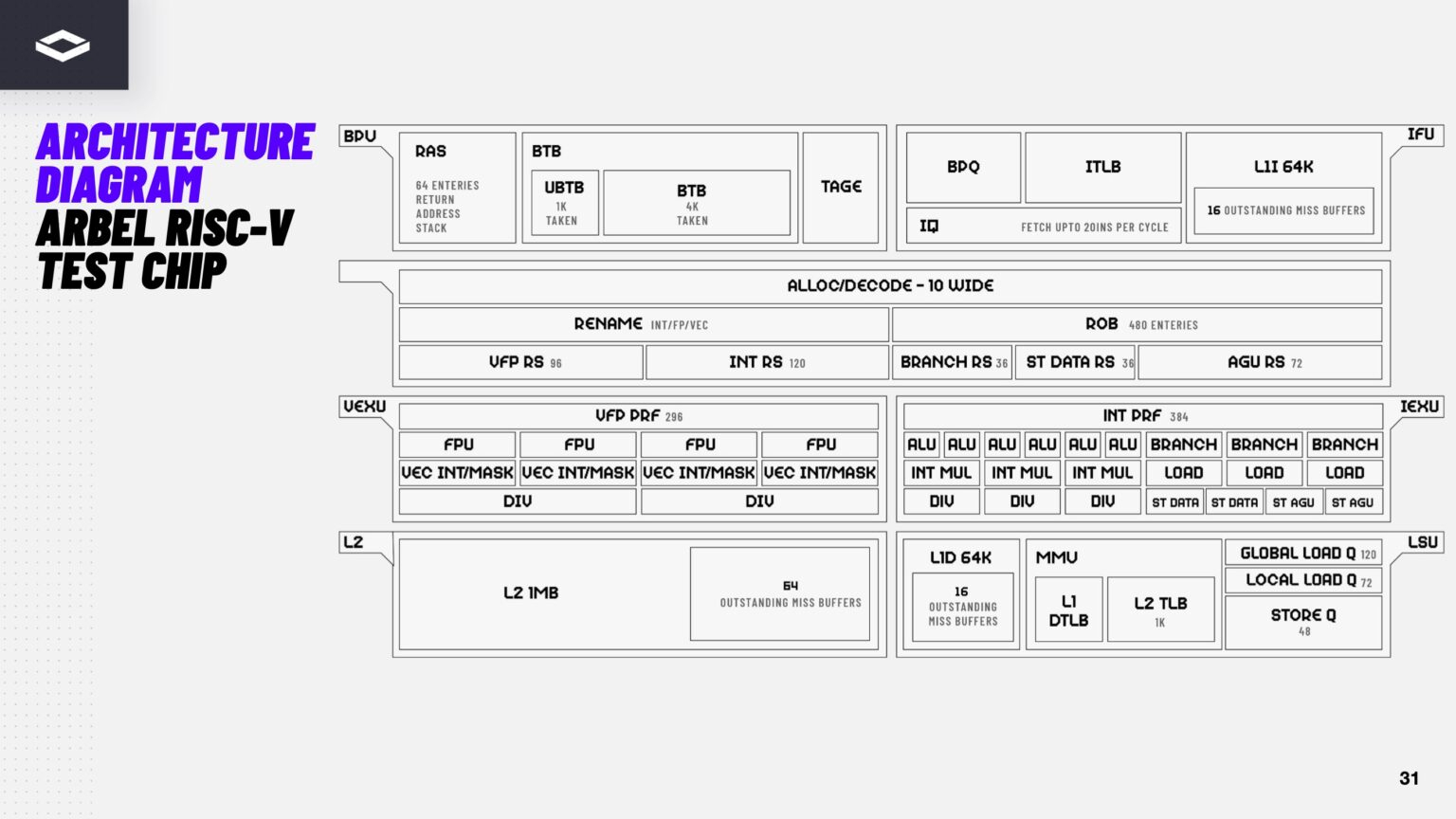 По данным компании, флагманский ускоритель Maverick2, помимо SNL, уже используется «десятками» заказчиков. Его массовые поставки начнутся в начале 2026 года, чтобы обеспечить значительный портфель заказов. NextSilicon сотрудничает с различными организациями, от Министерства энергетики США до ведущих научно-исследовательских институтов, а также коммерческих клиентов в сфере финансовых услуг, энергетики, производства и биологических наук. Программы раннего внедрения для новых клиентов уже доступны через партнёров Penguin Solutions и Dell Technologies. Ускоритель следующего поколения NextSilicon Maverick3 будет поддерживать вычисления с пониженной точностью для ИИ-задач и, как ожидается, появится в продаже в 2027 году, пишет EE Times.
11.11.2025 [10:20], Сергей Карасёв
Четырнадцатый Национальный суперкомпьютерный форум (НСКФ-2025)АНО «Национальный суперкомпьютерный форум», Институт программных систем имени А.К. Айламазяна РАН и Национальная суперкомпьютерная технологическая платформа проводят 25 ноября — 28 ноября 2025 г. Четырнадцатый Национальный суперкомпьютерный форум (НСКФ-2025). Все мероприятия форума посвящены состоянию и перспективам развития национальной суперкомпьютерной отрасли, вопросам создания и практики применения суперкомпьютерных, грид- и облачных технологий. Форум состоится в г. Переславле-Залесском, в ИПС имени А.К. Айламазяна РАН, запланированы научно-практическая конференция, выставка, тренинги, онлайн пресс-конференция, круглые столы (совещания), а также неформальное общение участников. 
Источник изображения: НСКФ-2025 На выставке планируется представить продукцию и технические достижения отечественных производителей. Научная конференция включит в себя представителей большинства ведущих научных центров, а на семинарах и тренингах участники смогут узнать основные приёмы и тонкости работы c новейшими разработками. В рамках форума также состоится онлайн пресс-конференция по наиболее ярким текущим событиям отечественной суперкомпьютерной отрасли. НСКФ-2025 предусмотрен планом работы Национальной суперкомпьютерной технологической платформы на 2025 год. Сайт мероприятия: https://2025.nscf.ru/. Подробная информация о форуме доступна в разделе «Информационные материалы». Зарегистрироваться для участия можно по адресу: https://2025.nscf.ru/kabinet-uchastnika/.
06.11.2025 [14:05], Руслан Авдеев
Нас не купишь: акционеры Core Scientific неожиданно отказались продавать компанию своему ключевому заказчику — CoreWeaveCore Scientific анонсировала итоги специального собрания акционеров. По результатам собрания не удалось набрать количества голосов, необходимого для того, чтобы окончательно продать компанию CoreWeave, сообщает пресс-служба Core Scientific. Ещё в июне 2024 года CoreWeave намеревалась приобрести Core Scientific за $1 млрд, видимо, устав арендовать у компании ЦОД, но на тот момент потенциальные продавцы сочли сумму слишком маленькой. В июле 2025 года появилась информация, что CoreWeave всё-таки заключила «окончательную сделку» по покупке Core Scientific, но уже в девять раз дороже, чем годом ранее. Впрочем, похоже, оказалось мало и этого. Как сообщают в Core Scientific, 30 октября «согласно и в соответствии» с соглашением о слиянии, компания разорвала договор о покупке, решение вступило в силу немедленно. Core Scientific сохранит статус участвующей в публичных торгах компании и её обычные акции продолжат продавать на биржах Nasdaq под тикером CORZ. 
Источник изображения: Core Scientific В пресс-релизе Core Scientific утверждается, что компания намерена перепрофилировать оставшиеся объекты, пока используемые для майнинга цифровых активов, на предоставление колокейшн-сервисов высокой плотности. В CoreWeave заявили, что уважают мнение акционеров и партнёрство продолжится, хотя сама CoreWeave намерена продолжить покупать интересные ей бизнесы. Окончательные результаты голосования будут переданы в форме 8K в Комиссию по ценным бумагам и биржам США (SEC). |
|

