Материалы по тегу: ускоритель
|
14.10.2025 [12:46], Владимир Мироненко
OpenAI и Broadcom совместно разработают и развернут ИИ-ускорители на 10 ГВтOpenAI и Broadcom объявили о заключении соглашения о стратегическом сотрудничестве с целью совместного создания и дальнейшего развёртывания кастомных ИИ-ускорителей общей мощностью 10 ГВт. Речь идёт об вертикально интегрированных решениях уровня стоек и ЦОД. OpenAI отметила в пресс-релизе, что при разработке собственных чипов и систем сможет интегрировать имеющиеся достижения в создании передовых моделей и продуктов непосредственно в аппаратное обеспечение. «Стойки, полностью масштабируемые с использованием Ethernet и других сетевых решений Broadcom, удовлетворят растущий глобальный спрос на ИИ и будут развёрнуты на объектах OpenAI и в партнёрских ЦОД», — сообщила компания. Начало развертывания систем запланировано на II половину 2026 года, а завершение — на конец 2029 года. «Партнёрство с Broadcom — критически важный шаг в создании инфраструктуры, необходимой для раскрытия потенциала ИИ и предоставления реальных преимуществ людям и бизнесу», — заявил Сэм Альтман (Sam Altman), соучредитель и генеральный директор OpenAI. Он отметил, что разработка собственных ускорителей дополняет более широкую экосистему партнёров, которые вместе создают потенциал, «необходимый для расширения возможностей ИИ на благо всего человечества». 
Источник изображений: Broadcom Чарли Кавас (Charlie Kawwas), президент группы полупроводниковых решений Broadcom сообщил, что кастомные ускорители «прекрасно сочетаются со стандартными сетевыми решениями Ethernet для масштабирования и горизонтального масштабирования», позволяя создать оптимизированную по стоимости и производительности ИИ-инфраструктуру нового поколения. По его словам, стойки будут включать комплексный набор решений Broadcom для Ethernet, PCIe и оптических соединений. Как пишет The Register, президент OpenAI Грег Брокман (Greg Brockman) рассказал, что при разработке ускорителя компания смогла использовать собственные ИИ-модели, которые позволили оптимизировать и ускорить процесс. По его словам, благодаря этому удалось увеличить плотность размещения компонентов. «Вы берёте компоненты, которые уже оптимизированы людьми, просто указываете для них вычислительные мощности, и модель сама предлагает решение», — цитирует Брокмана SiliconANGLE. Компании не уточнили, какие именно продукты Broadcom будут использоваться в рамках партнёрства. Вполне возможно, что это будет анонсированный на прошлой неделе Ethernet-коммутатор TH6-Davisson, оптимизированный для ИИ-кластеров и обеспечивающий пропускную способность до 102,4 Тбит/с, что, по заявлению компании, вдвое превышает показатели изделий ближайшего конкурента. Также Broadcom поставляет линейку PCIe-коммутаторов серии PEX и ретаймеры. 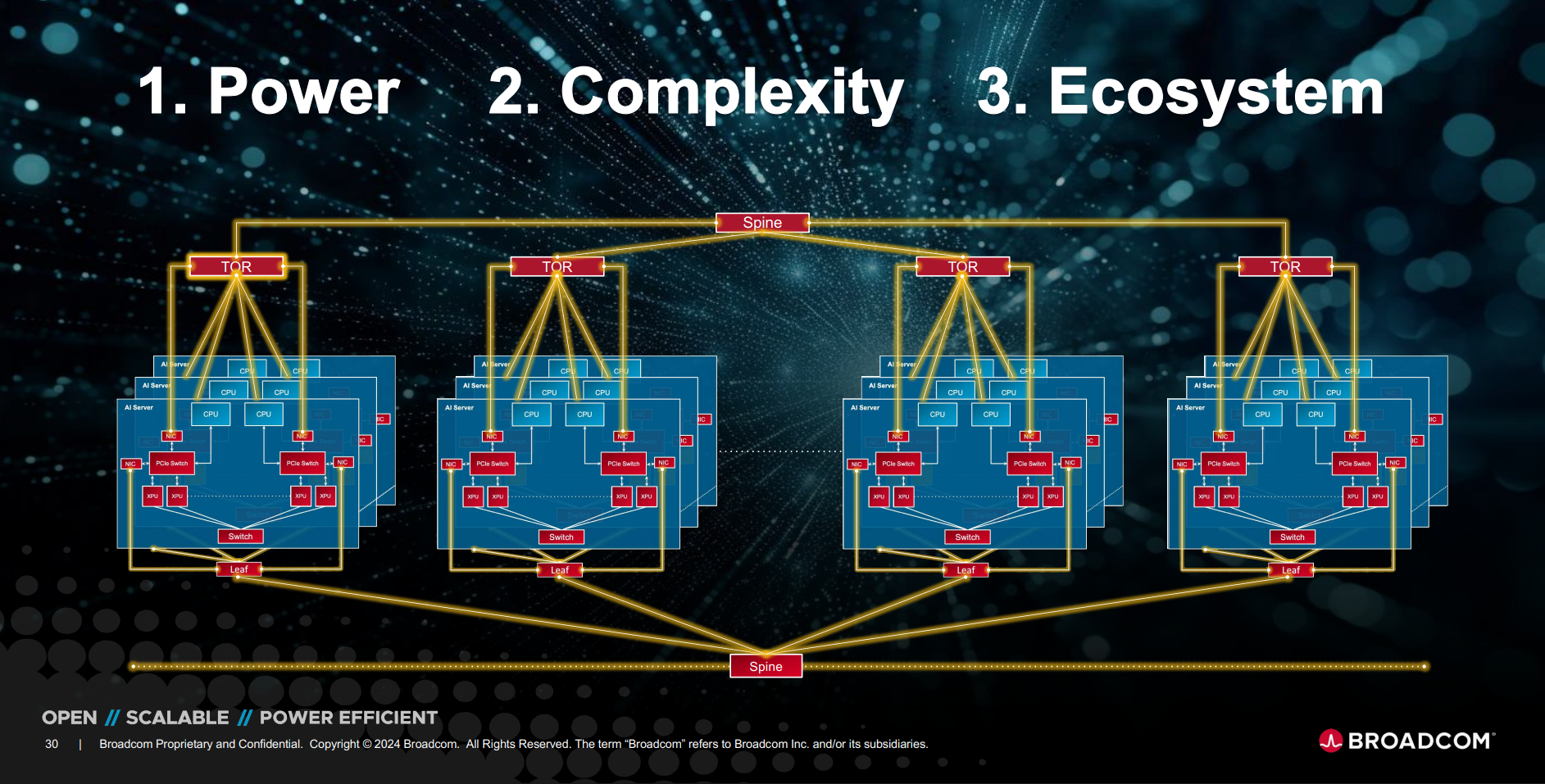 Ранее в этом месяце OpenAI заключила соглашение с AMD на поставку ИИ-ускорителей AMD нескольких поколений общей мощностью 6 ГВт для обеспечения своей ИИ-инфраструктуры. По предварительным оценкам, стоимость контракта составляет $60–$80 млрд. В сентябре NVIDIA объявила о соглашении с OpenAI на поставку ускорителей для развёртывания ИИ-инфраструктуры мощностью не менее 10 ГВт с сопутствующими инвестициями в размере $100 млрд. Broadcom в сентябре сообщила о получении заказа от нового клиента на разработку и поставку кастомного ИИ-чипа на сумму более $10 млрд. По мнению аналитиков, речь шла как раз об OpenAI. Создание сети взаимозависимостей означает, что несколько технологических компаний с оборотом в миллиарды долларов кровно заинтересованы в успехе OpenAI, отметил The Register. При этом OpenAI заявляет, что у неё не будет положительного денежного потока ещё четыре года и вместе с тем планирует в течение этого периода значительно увеличить расходы на инфраструктуру ЦОД. Такой подход вызывает опасения у экспертов, заявляющих, что подобные сделки указывают на своего рода пузырь на ИИ-рынке, поскольку компании оперируют такими терминами, как гигаватты и токены, вместо таких «скучных старых терминов», как выручка или доход.
13.10.2025 [12:14], Сергей Карасёв
IBM представила ускоритель Spyre Accelerator для ИИ-инференсаКорпорация IBM объявила о том, что с конца текущего месяца специализированные ИИ-ускорители Spyre Accelerator станут доступны в составе серверов z17 и LinuxONE 5. А в начале декабря такими картами начнут комплектоваться системы POWER11. О подготовке Spyre Accelerator стало известно в августе прошлого года. Это детище исследовательского подразделения IBM Research. Ускоритель ориентирован на задачи инференса с низкой задержкой. В частности, устройство подходит для работы с генеративными приложениями и ИИ-агентами. 
Источник изображения: IBM Изделие представляет собой плату расширения с интерфейсом PCIe 5.0 x16, в состав которой входит нейропроцессор IBM с 32 ядрами. Кроме того, есть 128 Гбайт памяти LPDDR5. Ускоритель насчитывает в общей сложности 25,6 млрд транзисторов; при производстве применяется 5-нм технология. Заявленное энергопотребление находится на уровне 75 Вт. 
Источник изображения: IBM IBM отмечает, что при использовании традиционных CPU и GPU для решения ресурсоёмких задач в области ИИ возникают сложности с масштабированием и эффективностью. Изделия Spyre Accelerator проектировались с тем, чтобы помочь в устранении указанных недостатков. При необходимости можно объединить до 16 плат в кластер в системе POWER11 и до 48 плат в составе z17. Вкупе с процессорами Telum II, которые лежат в основе z17 и LinuxONE 5, компании смогут одновременно запускать несколько ИИ-моделей. При этом возможен локальный инференс, что минимизирует обращения к сторонним сервисам: это сокращает задержки и способствует повышению безопасности. В качестве потенциальных заказчиков Spyre Accelerator называются финансовые организации, предприятия розничной торговли, государственные структуры, учреждения из сферы здравоохранения, промышленные предприятия и пр.
10.10.2025 [14:50], Руслан Авдеев
Не для себя стараемся: Microsoft развернула для OpenAI первый в мире ИИ-кластер на базе суперускорителей NVIDIA GB300 NVL72Microsoft представила первый в мире ИИ-кластер, использующий более 4,6 тыс. NVIDIA Blackwell Ultra в составе суперускорителей NVIDIA GB300 NVL72, объединённых интерконнектом Quantum-X800 InfiniBand. Этот кластер — лишь первый из многих. Компания развернёт сотни тысяч ускорителей Blackwell Ultra в ИИ ЦОД по всему миру. Благодаря им Microsoft намерена стать первой, поддерживающей обучение для моделей с сотнями триллионов параметров. Как сообщают в Microsoft, запуск в Microsoft Azure суперкластера NVIDIA GB300 NVL72 стал важным шагом в развитии передовых ИИ-технологий. Разработанная совместно с NVIDIA система представляет собой первый в мире масштабируемый ИИ-кластер на основе GB300, обеспечивающий вычислительные мощности, необходимые OpenAI для обслуживания моделей с триллионами параметров. Речь идёт о новом стандарте ускоренных вычислений, говорят компании. Новые инстансы Azure ND GB300 v6 оптимизированы для рассуждающих моделей, агентных систем и мультимодального генеративного ИИ. Каждая стойка GB300 NVL72 обслуживает 18 виртуальных машин, а сам суперускоритель с производительностью до 1,44 Эфлопс (FP4 Tensor Core) включает:

Источник изображения: Microsoft Создание передовой инфраструктуры требует переосмысления всех уровней системы, включая вычисления, память, системы охлаждения и питания, ЦОД в целом как единой структуры. Новая архитектура стоек обеспечивает высокую пропускную способность инференса при меньших задержках на крупных моделях, это позволяет агентным и мультимодальным ИИ-системам быть более масштабируемыми и эффективными, чем когда-либо, говорит компания. Для масштабирования за пределы стойки используется NVIDIA Quantum-X800 InfiniBand, что гарантирует обучения сверхбольших моделей с применением десятков тысяч ИИ-ускорителей с минимальными накладными расходами на их синхронизацию, что дополнительно повышает производительность. 
Источник изображения: Microsoft Передовые системы охлаждения Azure используют автономные теплообменники, чтобы свести к минимуму расход воды и поддерживать температурную стабильность для высокоплотных кластеров. Также продолжается разработка и внедрение новых моделей распределения питания, обеспечивающих высокую энергетическую плотность и динамический баланс нагрузок. Дополнительную помощь в оптимизации работы оказывает и модернизированное программное обеспечение. Ранее Microsoft обладала эксклюзивными правами на предоставление облачных сервисов компании OpenAI, но в январе 2025 года появилась новость, что ИИ-стартапу разрешили пользоваться и облаками других провайдеров, если у Microsoft не хватит собственных мощностей. Разногласия между компаниями продолжают нарастать. Формально первенство по создание кластера на базе GB300 NVL72 принадлежит CoreWeave, имеющей тесные отношения с NVIDIA и обслуживающей OpenAI — как напрямую, так и при посредничестве Microsoft.
10.10.2025 [10:11], Сергей Карасёв
Intel готовит новый GPU-ускоритель, оптимизированный для инференсаКорпорация Intel в ходе мероприятия Intel Tech Tour Arizona сообщила о подготовке новых ИИ-ускорителей на базе GPU. Речь идёт об изделиях, специально оптимизированных для задач инференса. Кроме того, компания поделилась планами по развитию ИИ-продуктов в целом. Ранее предполагалось, что в 2025 году Intel выведет на рынок ускорители Falcon Shores. Изначально планировалось, что это будут гибридные решения, содержащие блоки CPU и GPU. Однако впоследствии Intel сделала выбор в пользу конфигурации исключительно на основе GPU. А затем корпорация и вовсе заявила, что на коммерческом рынке изделия Falcon Shores не появятся. Вместо этого Intel решила сфокусировать внимание на выпуске ускорителей Jaguar Shores. Войдёт ли готовящийся к выпуску GPU для инференса в семейство Jaguar Shores, пока не ясно. Подробности о новинке Intel обещает раскрыть в ходе предстоящего мероприятия 2025 OCP Global Summit, которое пройдёт с 13 по 16 октября в Сан-Хосе (Калифорния, США). На сегодняшний день известно, что устройство получит улучшенную память с высокой пропускной способностью. Изделие будет ориентировано на корпоративный сектор. 
Источник изображения: Intel «Мы активно работаем над оптимизированным для инференса GPU, о котором подробнее расскажем на конференции OCP», — сообщил технический директор Intel Сачин Катти (Sachin Katti). Кроме того, Intel объявила о намерении перейти на ежегодный график выпуска ИИ-продуктов следующего поколения. Предполагается, что это поможет укрепить позиции на глобальном рынке ИИ, на котором корпорация уступила позиции NVIDIA. При этом Intel подчёркивает, что на ближайшую перспективу Jaguar Shores является основным приоритетом в области развития высокопроизводительных решений для ИИ-инфраструктуры.
02.10.2025 [13:10], Руслан Авдеев
Meta✴ приобрела Rivos, разработчика RISC-V-ускорителей, совместимых с CUDAMeta✴ Platforms приобрела занимающийся разработкой ИИ-чипов на базе RISC-V стартап Rivos. Это должно ускорить разработку собственных полупроводников и снизить зависимость от сторонних поставщиков, сообщает Silicon Angle. Условия покупки пока неизвестны, но ключевой инвестор стартапа, Walden Catalyst, с гордостью сообщил о сделке, а нынешний генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan), имевший прямое отношение к созданию и развитию стартапа, поздравил команду. Стартап был основан в 2021 году, а в 2023-м к нему присоединились около полусотни бывших инженеров Apple. Meta✴ будет использовать опыт Rivos для расширения работ над семейством собственных ИИ-ускорителей Meta✴ Training and Inference Accelerator (MTIA). Впрочем, Rivos использовала комплексный подход, разрабатывая CPU и GPUGPU-чипы с кеш-когерентностью и унифицированным доступом к памяти (DDR и HBM), дополненные интегрированным 800G-интерконнектом на базе Ultra Ethernet. Это похоже на подход NVIDIA при создании суперускорителей. В 2025 году Rivos выпустила на TSMC тестовый чип, работающий на частоте 3,1 ГГц и программный стек, совместимый с NVIDIA CUDA. Изначальная стратегия предполагала создание энергоэффективного ИИ-ускорителя с частотой до 3,5 ГГц, совместимого с существующей экосистемой, который планировалось продавать гиперскейлерам (хотя бы одному). Первую коммерческую платформу компания собиралась выпустить в следующем году, она позволила бы перекомпилировать, а не переписывать с нуля приложения, созданные для платформ NVIDIA. Компания также принимала участие в создании RISC-V RVA23 Profile. 
Источник изображения: Rivos Хотя Meta✴ не раскрыла стоимость сделки, вероятно, речь идёт о миллиардных тратах. В августе сообщалось, что стартап вёл переговоры с инвесторами о возможном раунде финансирования в объёме $300–$400 млн, а то и $500 млн, что повысило бы оценку стоимости компании до более чем $2 млрд. ИИ-проекты Meta✴ полагаются преимущественно на сторонние аппаратные решения. Компания потратила миллиарды долларов на покупку ускорителей, в основном NVIDIA, и потратит ещё миллиарды на аренду ИИ-инфраструктуры у сторонних игроков. В частности, буквально на днях она подписала новую сделку с CoreWeave на $14,2 млрд. В этом году капзатраты могут достигнуть $72 млрд, а выпуск собственных чипов позволил бы компании сэкономить миллиарды долларов, снизив зависимость от NVIDIA и облачных операторов. 
Источник изображения: Rivos По словам Constellation Research, Meta✴ является единственным крупным ИИ-предприятием, почти полностью зависящим от инфраструктурных решений NVIDIA. Имеются данные, что компания уже взаимодействовала с Rivos некоторое время, поэтому и решила приобрести стартап целиком. Если инициатива увенчается успехом, это поможет Meta✴ снизить расходы как на обучение, так и на инференс. Также сообщается, что Meta✴ работает с TSMC над выпуском своего нового чипа, и уже отправила на производство необходимую документацию для выпуска пробных образцов для оценки их эффективности.
29.09.2025 [17:53], Владимир Мироненко
Euclyd разрабатывает ИИ-ускоритель Craftwerk с фирменной памятью UBM: 1 Тбайт и 8 Пбайт/сСтартап Euclyd, вышедший из скрытого режима (stealth mode), рассказал на саммите AI Infra Summit некоторые подробности о разрабатываемом чипе, который обеспечит более низкое энергопотребление и более низкую стоимость в расчёте на токен по сравнению с существующими решениями, пишет ресурс EE Times. Сама компания называет его первым в мире «кремнием» для агентного ИИ. Ингольф Хелд (Ingolf Held), соучредитель и вице-президент по продуктам Euclyd, сообщил ресурсу EE Times, что чип представляет собой огромную конструкцию из множества чиплетов, объединённых в модуль SiP (System-in-Package) под названием Craftwerk. Он будет включать 16 384 SIMD-блоков и обеспечивать производительность до 8 Пфлопс (FP16) или 32 Пфлопс (FP4). Эти вычислительные элементы разработаны Euclyd с нуля. В устройстве будет использоваться кремниевый интерпозер с максимально крупными размерами (примерно 100 × 100 мм) с 2,5D- и 3D-компонентами. 
Источник изображений: Euclyd «Мы разработаем его сами — мы не будем наследовать ничего от Arm или RISC-V, и он будет полностью программируемым с помощью наших собственных инструментов», — сказал он. По словам Хелда, дизайн будет поддерживать программируемость, чтобы гарантировать возможность ускорения будущих нагрузок, будь то мультимодальный инференс, логические рассуждения, рекуррентные модели, модели пространства состояний или диффузионные модели. Euclyd объединит вычислительные чиплеты с кастомной памятью Ultra Bandwidth Memory (UBM) — 1 Тбайт DRAM с пропускной способностью 8000 Тбайт/с в той же упаковке Craftwerk. По словам Хелда, ИИ-ускорители со SRAM работают быстро, но при их использовании приходится разделять обработку ИИ-нагрузки между множеством чипов из-за малого объёма такой памяти. HBM имеет достаточную ёмкость, но её пропускная способность мала для решения задач, поставленных Euclyd. И хотя UBM от Euclyd отличается кастомным дизайном, для её изготовления не потребуется какой-то экзотический технологический процесс. Craftwerk позволит реализовать многоагентные рабочие процессы на одном кристалле кремния с TDP в пределах 3 кВт, отметил Хелд. По словам компании, NVIDIA DGX-B200 может обрабатывать 1038 токенов/с для одного пользователя Llama4-Maverick (400B), Cerebras предлагает 2554 токена/с для одного пользователя, а один SiP Craftwerk будет обрабатывать 20 тыс. токенов/с для одного пользователя. Стойка Euclyd будет включать 16 хост-процессоров и 32 модуля Craftwerk в шасси с жидкостным охлаждением с общим TDP 125 кВт. По оценкам Euclyd, в типичном многопользовательском сценарии эта система будет предлагать 7,68 млн токенов/с для Llama4-Maverick. 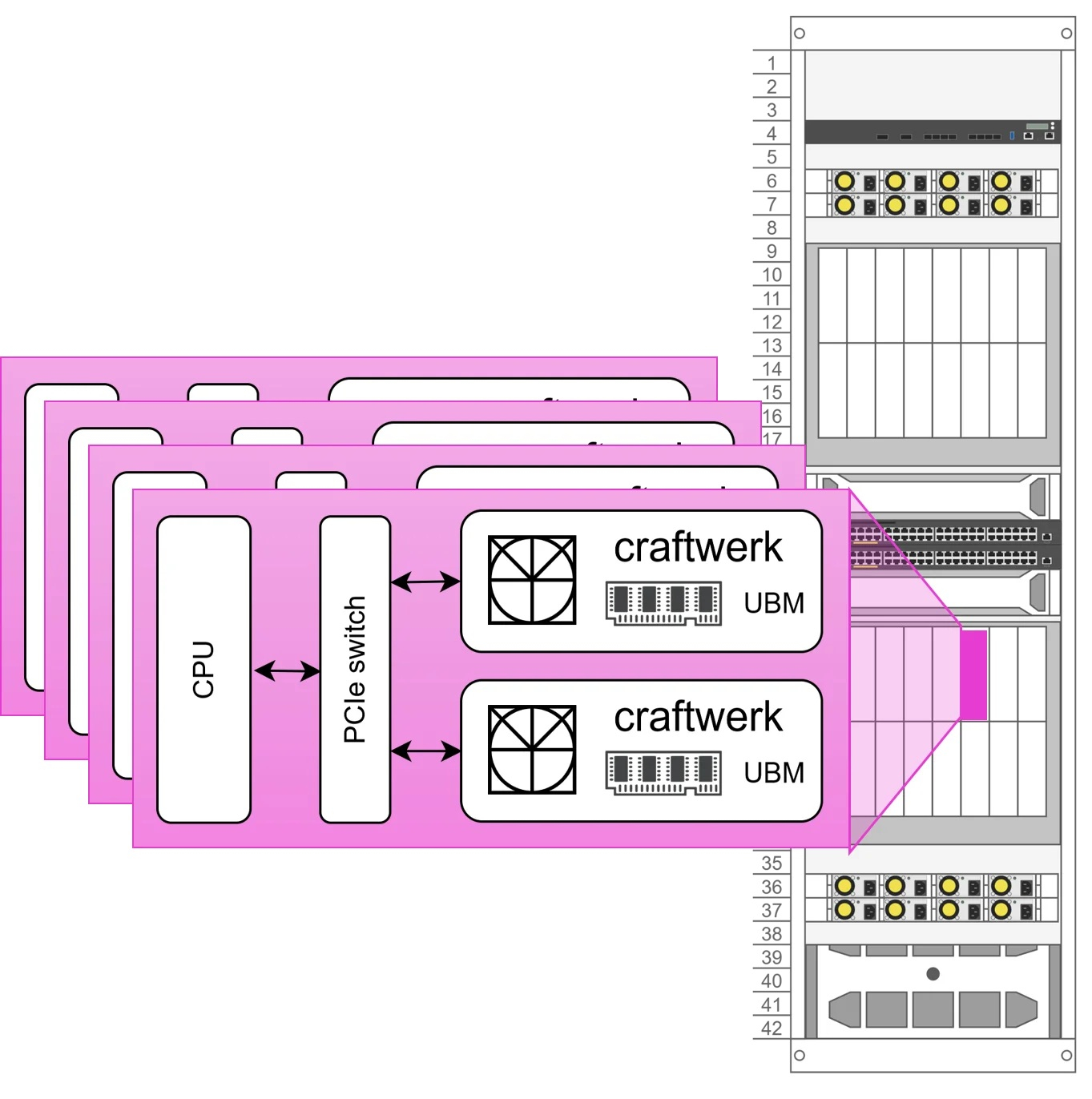 На данный момент у Euclyd три частных инвестора: Питер Веннинк (Peter Wennink, бывший генеральный директор ASML), Федерико Фаггин (Federico Faggin, один из изобретателей микропроцессора и основатель Zilog и Synaptics) и Стивен Шурман (Steven Schuurman, основатель Elastic). В ближайшее время компания планирует привлечь венчурный капитал для запуска производства и масштабирования, но, по словам Хелда, посевного финансирования должно быть достаточно для демонстрации работоспособности кремниевых чипов. Сооснователь и консультант Euclyd Атул Синха (Atul Sinha) заявил EE Times, что Европа лучшее место для талантливых дизайнеров, чем Кремниевая долина. Он подтвердил, что Euclyd планирует оставаться в юрисдикции Нидерландов со штаб-квартирой ИТ-кампусе Эйндховена, где также находится штаб-квартира NXP. «Чего люди не понимают, так это то, что в Европе есть места, где действительно есть значительный набор технологий и кадровая база, — сказал Синха. — Для полупроводников Эйндховен, безусловно, на первом месте. Я бы сказал, что лучше места нет».
18.09.2025 [14:48], Сергей Карасёв
Huawei раскрыла планы по выпуску ИИ-ускорителей AscendКитайская компания Huawei, по сообщению The Register, в ходе своей ежегодной конференции Connect обнародовала планы по выпуску ИИ-ускорителей Ascend следующего поколения. Готовящиеся изделия призваны составить конкуренцию передовым чипов NVIDIA, поставки которых в КНР запрещены и США, и ограничены самим Китаем. В настоящее время Huawei предлагает ускоритель Ascend 910C, который позиционируется в качестве конкурента NVIDIA H100: решение обеспечивает производительность на уровне 800 Тфлопс (FP16) и пропускную способность памяти до 3,2 Тбайт/с. Ранее также говорилось о подготовке более производительного изделия Ascend 910D. Как теперь стало известно, в I квартале 2026 года Huawei представит ускоритель Ascend 950PR, который обеспечит производительность до 1 Пфлопс на операциях FP8. Устройство получит 128 Гбайт памяти с пропускной способностью 1,6 Тбайт/с, тогда как скорость интерконнекта составит до 2 Тбайт/с. В последней четверти следующего года ожидается выход решения Ascend 950DT, которое сможет демонстрировать быстродействие на уровне 2 Пфлопс на операциях FP4. Этот ускоритель будет оборудован 144 Гбайт памяти с пропускной способностью 4 Тбайт/с. 
Источник изображения: Huawei В 2027 году Huawei планирует выпустить ускоритель Ascend 960: в его оснащение войдут 288 Гбайт памяти с пропускной способностью до 9,6 Тбайт/с. А на 2028-й намечен дебют модели Ascend 970, память которой сможет работать со скоростью 14,4 Тбайт/с. Как отмечает The Register, указанные показатели пропускной способности могут свидетельствовать о том, что Huawei проектирует собственную память HBM. Кроме того, Huawei сообщила о подготовке мощных ИИ-систем SuperPOD, объединяющих 8192 и 15 488 ускорителей Ascend. На основе таких платформ будут формироваться суперкластеры, насчитывающие до 500 тыс. и более экземпляров Ascend. Разработки Huawei имеют большое значение в плане развития ИИ-мощностей в Китае в свете напряжённых отношений с США. На днях стало известно, что Государственное управление по регулированию рынка КНР (SAMR) обвинило NVIDIA в нарушении антимонопольного законодательства. Кроме того, Китай запретил местным компаниям размещать заказы на разработанный специально для Поднебесной ускоритель NVIDIA RTX Pro 6000D.
18.09.2025 [12:43], Руслан Авдеев
China Unicom построила в Китае «огромный» ЦОД с ИИ-ускорителями местного производства — Alibaba T-Head предоставила 16 тыс. PPUКитайский телеком-гигант China Unicom построил «огромный» дата-центр на основе ИИ-ускорителей производства КНР. Новый ЦОД использует чипы, разработанные Alibaba и другими местными компаниями, сообщает Reuters. Объект находится в Синине (Xining) провинции Цинхай (Qinghai). В его строительство вложено порядка $390 млн. Подробные данные о мощности ЦОД пока отсутствуют. По словам местных властей, после полного завершения строительства вычислительная мощность составит 20 Эфлопс, пока же речь идёт о 3,579 Пфлопс. За работу отвечают 23 тыс. чипов местного производства. Точность вычислений не указывается, но вряд ли речь идёт об FP64. По имеющимся данным 72 % чипов разработаны подразделением T-Head компании Alibaba, прочие предоставили компании MetaX, Biren Tech и Zhonghao Xinying. В будущем планируется использовать и чипы стартапов Tecorigin, Moore Threads и Enflame. T-Head также разработала 400-Вт ускорители PPU, имеющие 96 Гбайт HBM2e, интерфейс PCIe 5.0 и 700-Гбайт/с межчиповый интерконнект. Благодаря этому они могут стать конкурентами популярным в Китае, специально ослабленным для местного рынка чипам NVIDIA H20. Ранее в этом месяце Alibaba заявила о разработке нового ускорителя для ИИ-инференса. Сейчас чип проходит тестирование и выпускается китайским производителем. China Unicom получила 16 384 T-Head PPU общей производительностью 1,945 Эфлопс. 
Источник изображения: Wang shaohong/unsplash.com Китай активно продвигает широкое внедрение чипов местного производства. 17 сентября интернет-регулятор из КНР запретил ключевым IT-гигантам тестировать и размещать заказы на разработанный специально для Китая ускоритель NVIDIA RTX Pro 6000D. За несколько дней до этого по итогам расследования Государственного управления по регулированию рынка Китая (SAMR) до власти обвинили NVIDIA в нарушении антимонопольного законодательства при покупке Mellanox. Ограничения последовали со стороны китайских властей после того, как местное правительство издало директиву, обязывающую государственные компании, действующие на рынке ЦОД, закупать более 50 % чипов у местных производителей.
10.09.2025 [13:35], Сергей Карасёв
NVIDIA представила соускоритель Rubin CPX со 128 Гбайт GDDR7 для масштабных задач ИИ-инференсаNVIDIA неожиданно анонсировала чип Rubin CPX — GPU нового класса, спроектированный для масштабных задач ИИ-инференса и работы с моделями, использующими длинный контекст. Поставки решения планируется организовать в конце 2026 года. Чип Rubin CPX выполнен в виде монолитного кристалла и оснащён 128 Гбайт памяти GDDR7. Заявленная ИИ-производительность достигает 30 Пфлопс в режиме NVFP4. Предусмотрены по четыре блока NVENC и NVDEC для кодирования и декодирования видеоматериалов. Новинка дополнит другие ускорители компании. Оркестрацией нагрузок будет заниматься платформа NVIDIA Dynamo, распределяющая нагрузки между подходящими для каждой задачи ускорителями. 
Источник изображений: NVIDIA Изделие Rubin CPX предназначено для использования вместе с Arm-процессорами Vera и ускорителями Rubin в составе новой стоечной платформы NVIDIA Vera Rubin NVL144 CPX. Эта система будет объединять 144 чипа Rubin CPX, 144 чипа Rubin и 36 процессоров Vera (88 кастомных 3-нм Arm-ядер). Говорится об использовании суммарно 100 Тбайт памяти с агрегированной пропускной способностью 1,7 Пбайт/с. Общая производительность на операциях NVFP4 — до 8 Эфлопс, что примерно в 7,5 раза больше по сравнению с системами NVIDIA GB300 NVL72. Задействована система жидкостного охлаждения. Кроме того, NVIDIA планирует выпуск двухстоечного решения, включающего стойку Vera Rubin NVL144 CPX и «обычную» стойку Vera Rubin NVL144.  «Платформа Vera Rubin ознаменует собой новый скачок производительности в области вычислений ИИ, предлагая как GPU следующего поколения Rubin, так и чип нового класса CPX. Это первый CUDA GPU, специально разработанный для ИИ с длинным контекстом, когда модели одновременно обрабатывают миллионы токенов», — отмечает Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 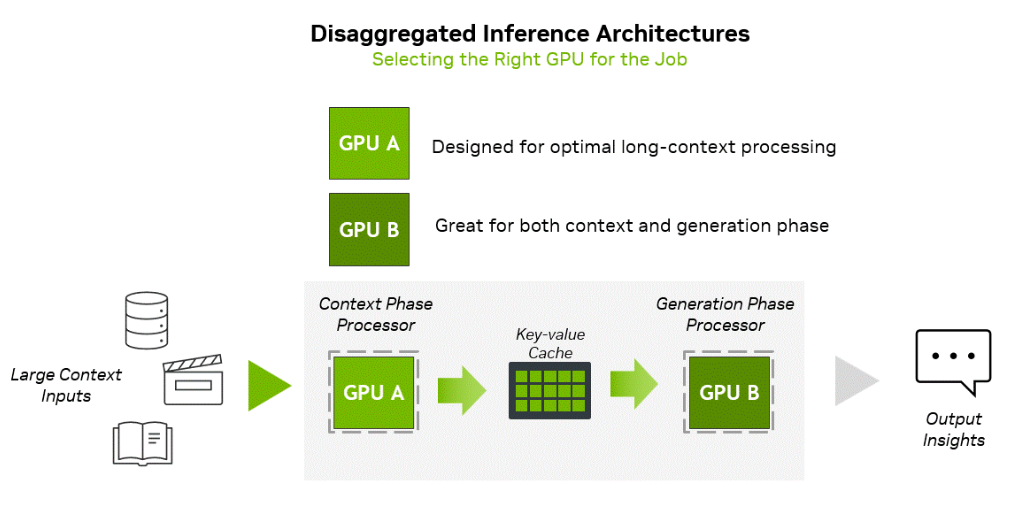 Основная задача Rubin CPX — работа с контекстом в больших моделях и создание KV-кеша. Эта операция ограничена вычислительными способностями чипа, тогда как генерация токенов зависит уже от пропускной способности памяти и интерконнекта для быстрого обмена данными. NVIDIA предложила разделить эти этапы и на аппаратном уровне. CPX лишён HBM, зато операции возведения в степень он делает втрое быстрее, чем Blackwell Ultra. 
08.09.2025 [19:09], Сергей Карасёв
Axelera AI представила ускоритель Metis M.2 Max для ИИ-задач на периферииСтартап Axelera AI B.V. из Нидерландов анонсировал ускоритель Metis M.2 Max, предназначенный для ИИ-инференса на периферии. Новинка может использоваться, в частности, для работы с большими языковыми моделями (LLM) и визуально-языковыми моделями (VLM). Metis M.2 Max представляет собой улучшенную версию изделия Metis M.2, дебютировавшего в 2023 году. В основу положен чип Axelera Metis AIPU, содержащий четыре ядра с открытой архитектурой RISC-V: ИИ-производительность достигает 214 TOPS на операциях INT8. Ускорители выполнены в форм-факторе M.2 2280, а для обмена данными служит интерфейс PCIe 3.0 x4. У модели Metis M.2 Max по сравнению с оригинальной версией в два раза повысилась пропускная способность памяти (точные значения не приводятся). Её объём в зависимости от модификации составляет 1, 4, 8 или 16 Гбайт. Реализованы расширенные средства обеспечения безопасности, включая защиту целостности прошивки. Новинка будет предлагаться в вариантах со стандартным и расширенным диапазоном рабочих температур: в первом случае он простирается от -20 до +70 °C, во втором — от -40 до +85 °C. Благодаря этому, как утверждается, Metis M.2 Max подходит для применения в самых разных областях, в том числе в промышленном секторе, розничной торговле, в сферах здравоохранения и общественной безопасности и пр. 
Источник изображения: Axelera AI Разработчикам компания Axelera AI предлагает комплект Voyager SDK, который позволяет полностью раскрыть потенциал чипа Metis AIPU и упрощает развёртывание коммерческих приложений. Продажи ИИ-ускорителя Metis M.2 Max начнутся в IV квартале текущего года. Устройство будет поставляться отдельно и в комплекте с опциональным низкопрофильным радиатором охлаждения. |
|

