Материалы по тегу: ускоритель
|
17.11.2025 [07:45], Владимир Мироненко
NEC и OpenСhip вместе разработают векторные ускорители на базе RISC-V и суперкомпьютеры Aurora следующего поколенияБазирующийся в Барселоне разработчик чипов OpenChip, который некоторые эксперты называют каталонской NVIDIA, и компания NEC объявили о следующем этапе сотрудничества, направленного на совместную разработку векторного процессора (VPU) нового поколения. Ранее компании выполнили технико-экономическое обоснование разработки следующего поколения векторных суперкомпьютеров Aurora с использованием аппаратного и программного стека OpenChip на базе RISC-V. Как сообщается в пресс-релизе, на начальном этапе основное внимание уделялось оценке совместимости архитектуры Aurora от NEC с ускорителями OpenChip, определению логической структуры и начальной разработке программных компонентов. В результате исследования компании пришли к выводу о технической осуществимость проекта, так что теперь компании займутся совместной разработкой следующего поколения высокопроизводительных ускорителей, а также оптимизированного программного стека. Обе компании планируют запуск пилотных развёртываний у отдельных клиентов. По словам старшего вице-президента NEC Сухуна Юна (Suhun Yun), сотрудничество NEC с OpenChip является поворотным моментом в стратегическом развитии NEC в направлении вычислительных архитектур следующего поколения. В свою очередь, OpenChip отметила, что сотрудничество направлено на достижение ряда ключевых преимуществ, в числе которых повышенная производительность критически важных рабочих нагрузок, обеспечение нового уровня вычислительной мощности для HPC, ИИ и ML, а также для таких научных приложений, как геномика и моделирование климата. 
Источник изображения: NEC В 2021 году NEC анонсировала векторные ускорителя SX-Aurora TSUBASA Vector Engine 2.0 (VE20), а в 2022 — доработанные VE30. Однако в 2023 году NEC фактически прекратила разработку новых решений в серии SX-Aurora в связи с появлением ускорителей AMD и NVIDIA, значительно превосходящих её наработки, так что обещанные VE40 и VE50 так и не появились на свет. При этом у NEC и ранее были длительные перерывы в разработке векторных ускорителей, а её суперкомпьютеры на их основе по-прежнему пользуются спросом в некоторых областях, в частности, в метеорологии и климатологии. OpenChip разрабатывает SoC, использующую несколько UCIe-чиплетов, референсные проекты для аппаратных платформ, базовые комплекты разработчиков ПО и прикладные сервисы. Как сообщает ресурс HPCwire, среди других европейских стартапов, разрабатывающих решения на базе RISV-V есть:
За последние годы было поставлено более 10 млрд ядер с архитектурой RISC-V благодаря широкому внедрению архитектуры в микроконтроллерах и встраиваемых устройствах. За последнее время RISC-V стала потенциальной альтернативой проприетарным архитектурам, включая Arm и x86, в разработке ускорителей и HPC-платформ.
13.11.2025 [21:25], Владимир Мироненко
Baidu анонсировала суверенные ИИ-ускорители Kunlun M100 и M300 для инференса и обученияКомпания Baidu представила на технологической конференции Baidu World 2025 в Пекине два новых ИИ-ускорителя, разработанных её подразделением Kunlunxin Technology, — Kunlun M100 и Kunlun M300, пишет ресурс TrendForce. Также было объявлено о предстоящем выходе суперузлов Tianchi256 и Tianchi512. Компания сообщила о планах выпускать новые продукты ежегодно в течение следующих пяти лет, чтобы поддержать развитие ИИ-технологий в Китае и сохранить их независимость от зарубежных поставщиков. Кроме того, компания намерена активно развивать не только «железо», но и постоянно оптимизировать ПО для него. Baidu сообщила, что ИИ-ускоритель Kunlun M100 оптимизирован для крупномасштабных сценариев инференса с упором на «максимальную экономичность», используя преимущества архитектуры собственной разработки, что значительно повышает производительность инференса MoE-моделей. Он выйдет в начале 2026 года. 
Источник изображений: Baidu ИИ-ускоритель Kunlun M300 предназначен не только для инференса, но и обучения сверхбольших мультимодальных моделей с триллионами параметров с упором на «максимальную производительность». Старт поставок Kunlun M300 намечен на начало 2027 года. Также сообщается, что выпуск чипов Kunlun серии N запланирован на 2029 год.   Что касается суперускорителей для обработки массивных ИИ-нагрузок, то выход Baidu Tianchi 256 и 512 запланирован на следующий год. Tianchi256, включающий до 256 чипов Kunlun P800, как ожидается, выйдет в I половине 2026 года, а Tianchi512 — во II полугодии. Сообщается, что один Baidu Tianchi512 может завершить обучение модели с триллионом параметров. В дальнейшем компания намерена выпустить узлы Tianchi сначала с 1 тыс. ускорителей, а затем и с 4 тыс. В целом, компания планирует к 2030 году увеличить максимальный размер кластера с 30 тыс. ускорителей до 1 млн.   Облачное подразделение Baidu Intelligent Cloud Group, используя чипы Kunlun и вычислительную платформу ИИ Baige, предоставляет предприятиям высокопроизводительные масштабируемые вычислительные мощности для обработки ИИ-нагрузок и шесть лет подряд занимает первое место на китайском рынке облачных ИИ-решений.
12.11.2025 [23:23], Владимир Мироненко
От ИИ ЦОД до роботов: AMD анонсировала долгосрочную стратегию роста
amd
cpu
dpu
epyc
hardware
instinct
mi400
mi500
ocp
pensando systems
ualink
ultra ethernet
venice
verano
xilinx
ии
ускоритель
финансы
AMD представила на мероприятии Financial Analyst Day 2025 план по достижению лидерства на рынке вычислительных технологий объёмом $1 трлн. Долгосрочная стратегия роста AMD построена на четырех столпах: лидерство в сфере ЦОД, повышение производительности ИИ, открытое ПО и расширение присутствия на рынках встраиваемых и полукастомных кремниевых решений. AMD ожидает, что только её бизнес в сфере ЦОД будет приносить более $100 млрд годовой выручки, с увеличением совокупного среднегодового темпа роста (CAGR) до более чем 60 %, при этом CAGR дохода от ИИ-решений увеличится до более чем 80 %. Генеральный директор AMD Лиза Су (Lisa Su) заявила, что следующий этап будет основан на унифицированной вычислительной платформе AMD, объединяющей процессоры EPYC, ускорители Instinct, сетевые решения Pensando и ПО ROCm. Новый план развития AMD призван обеспечить ей конкуренцию с NVIDIA и Intel на корпоративных рынках и в борьбе за заказы гиперскейлеров. 
Источник изображений: AMD  Ускорители серии Instinct MI350, уже развёрнутые Oracle (ещё 50 тыс. MI450 будут развёрнуты во II половине 2026 г.), являются самыми популярными ускорителями AMD на сегодняшний день. Следующей платформой станет серия MI450, которая будет запущена вместе со стоечной платформой Helios в III квартале 2026 года. Helios обеспечит пропускную способность интерконнекта 3,6 Тбайт/с на каждый ускоритель и до 72 ускорителей на стойку с совокупной пропускной способностью 260 Тбайт/с, соединённых между собой посредством UALink и Ultra Ethernet (UEC). Система поддерживает разделяемую память между ускорителями, что обеспечивает обучение крупномасштабных моделей с бесперебойным доступом к памяти и отказоустойчивой сетью с шестью плоскостями. 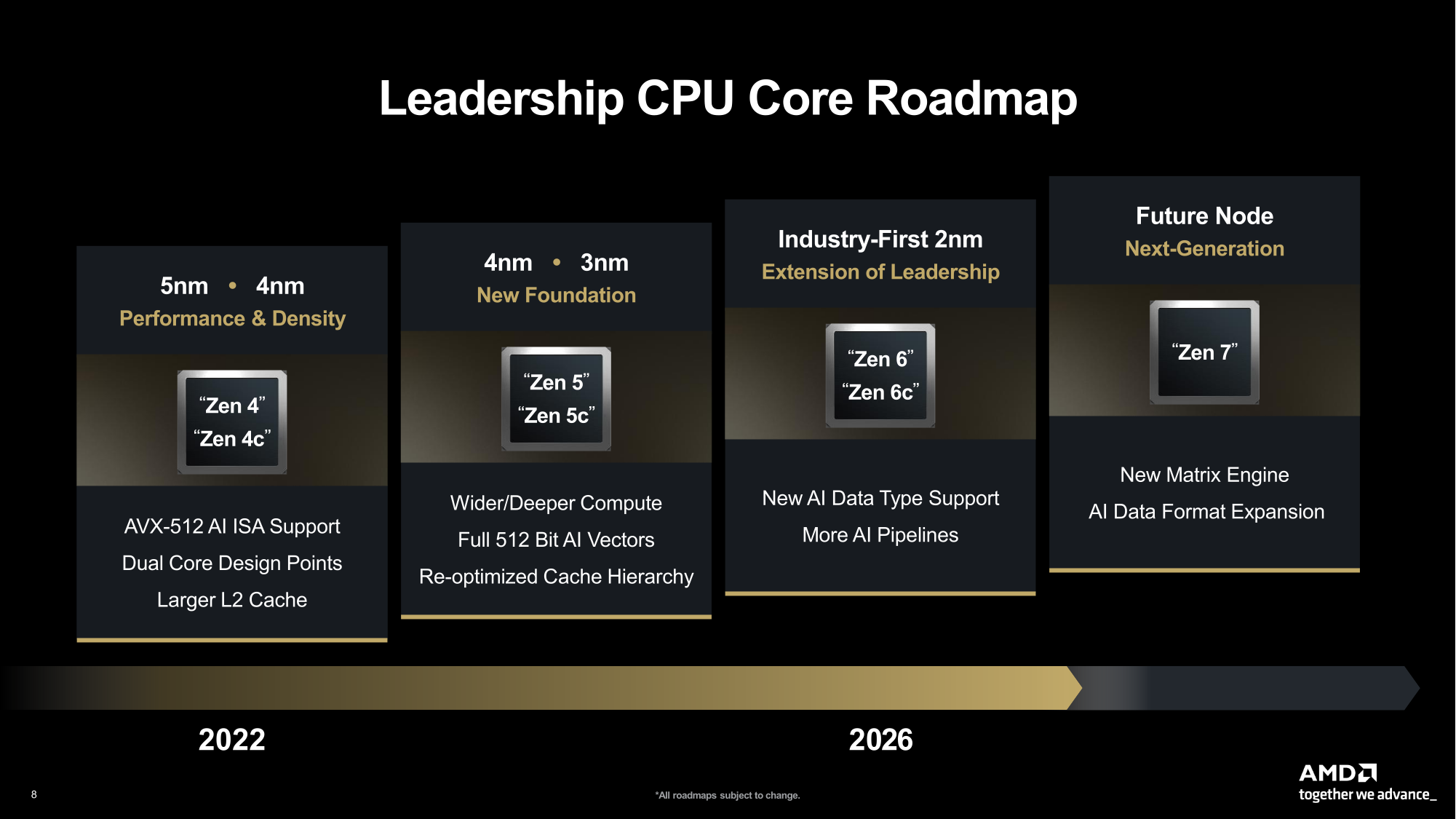 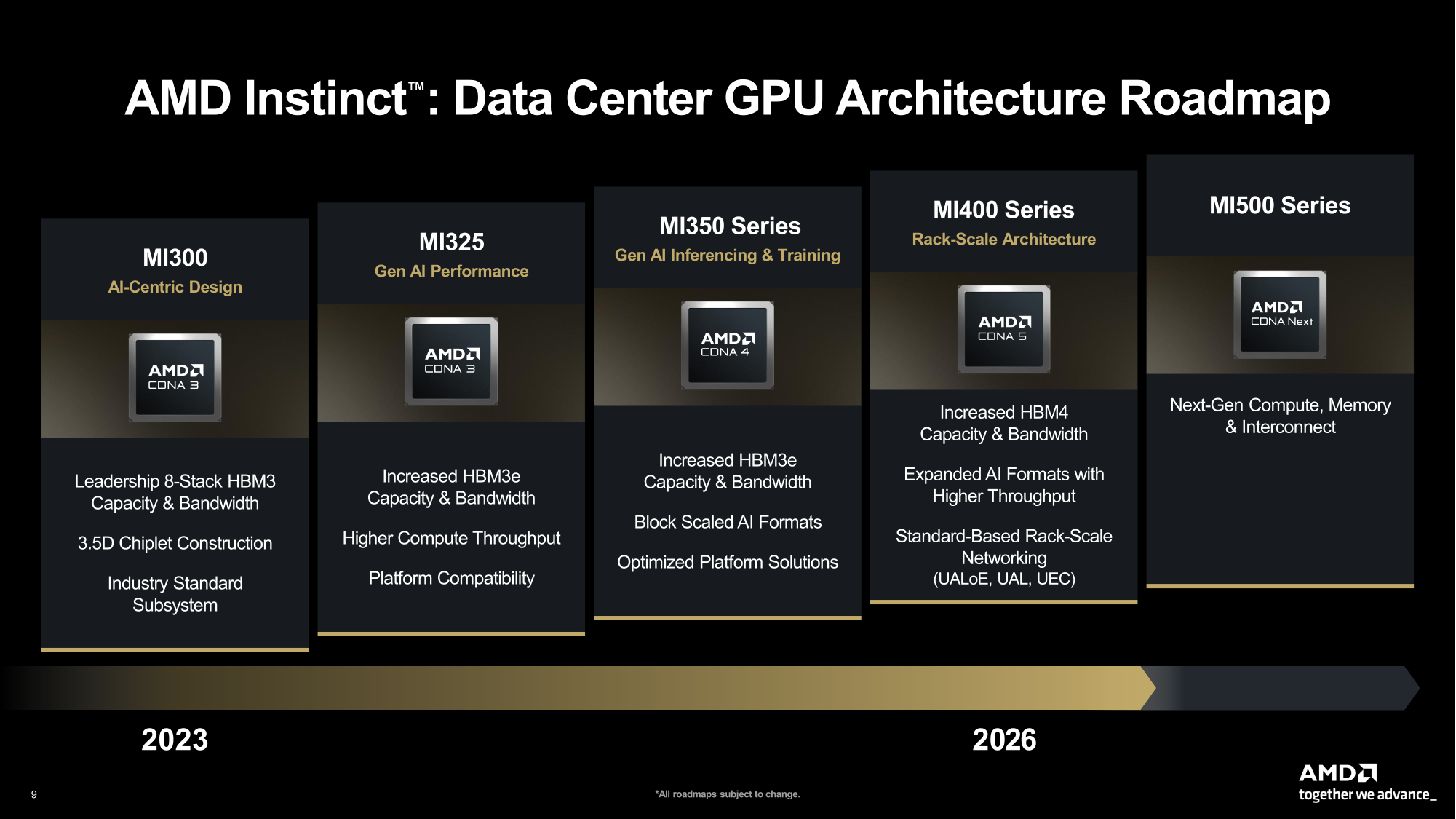 AMD характеризует Helios как свою первую ИИ-платформу стоечного масштаба — полностью интегрированную систему с открытой архитектурой, которая объединяет вычислительные мощности, ускорение, сетевые технологии и ПО в единую структуру. В отличие от традиционных серверных кластеров, Helios реализует всю стойку как единый высокопроизводительный вычислительный домен. Каждая стойка объединяет процессоры AMD EPYC Venice, CDNA5-ускорители Instinct MI450X (будет и вариант MI430X с полноценными FP64-блоками) и 400G/800G-карты Pensando Vulcano, связанные Infinity Fabric пятого поколения (PCIe 6.0, CXL 3.1, UCIe) и UALink.  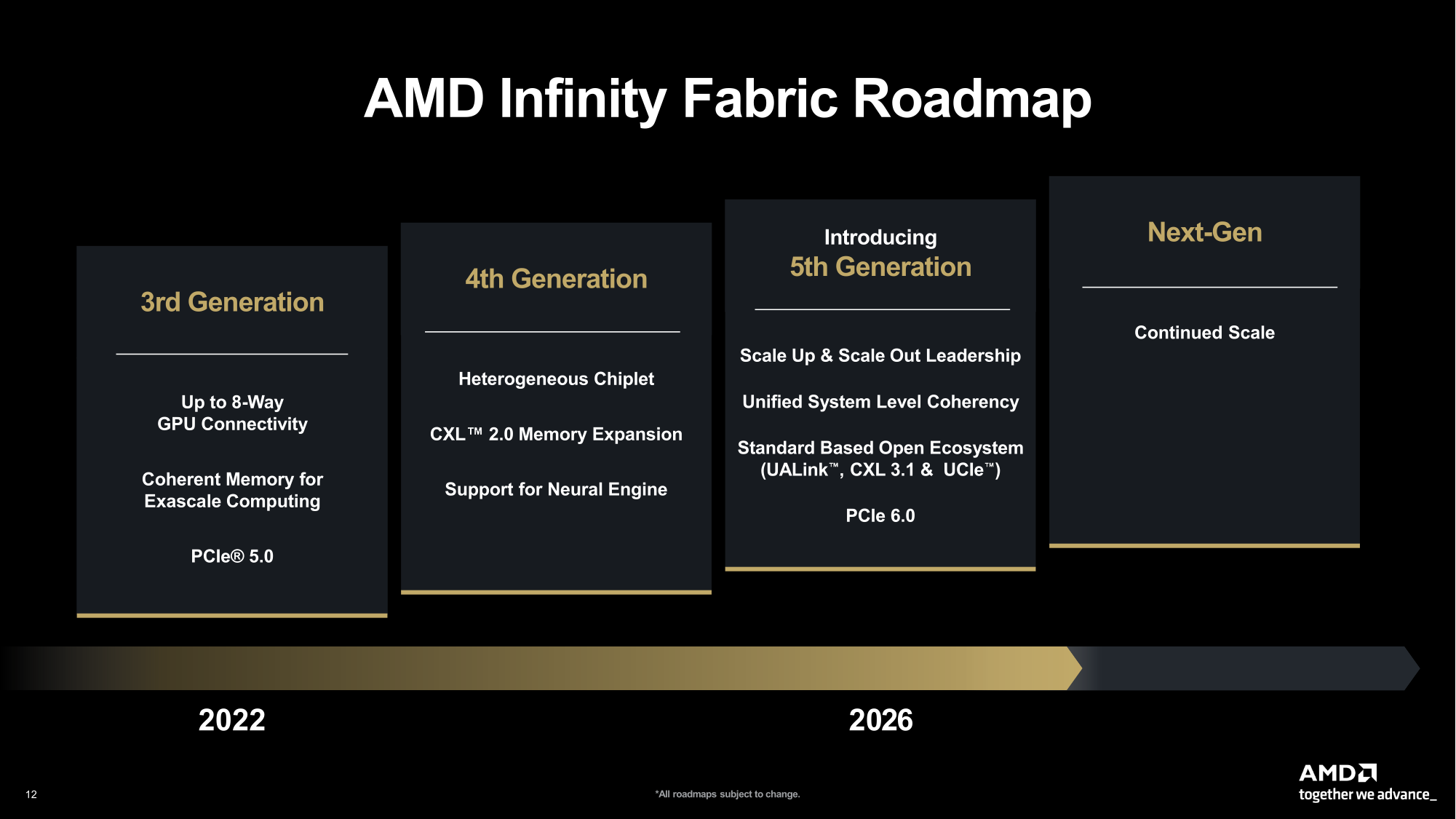 Эта архитектура минимизирует накладные расходы на перемещение данных, увеличивает пропускную способность между ускорителями и обеспечивает эффективность класса экзафлопсных вычислений в компактном корпусе. Helios фактически представляет собой проект AMD для ИИ-фабрики будущего с возможностью модульного расширения, позволяя объединять сотни стоек в одну систему в ЦОД.  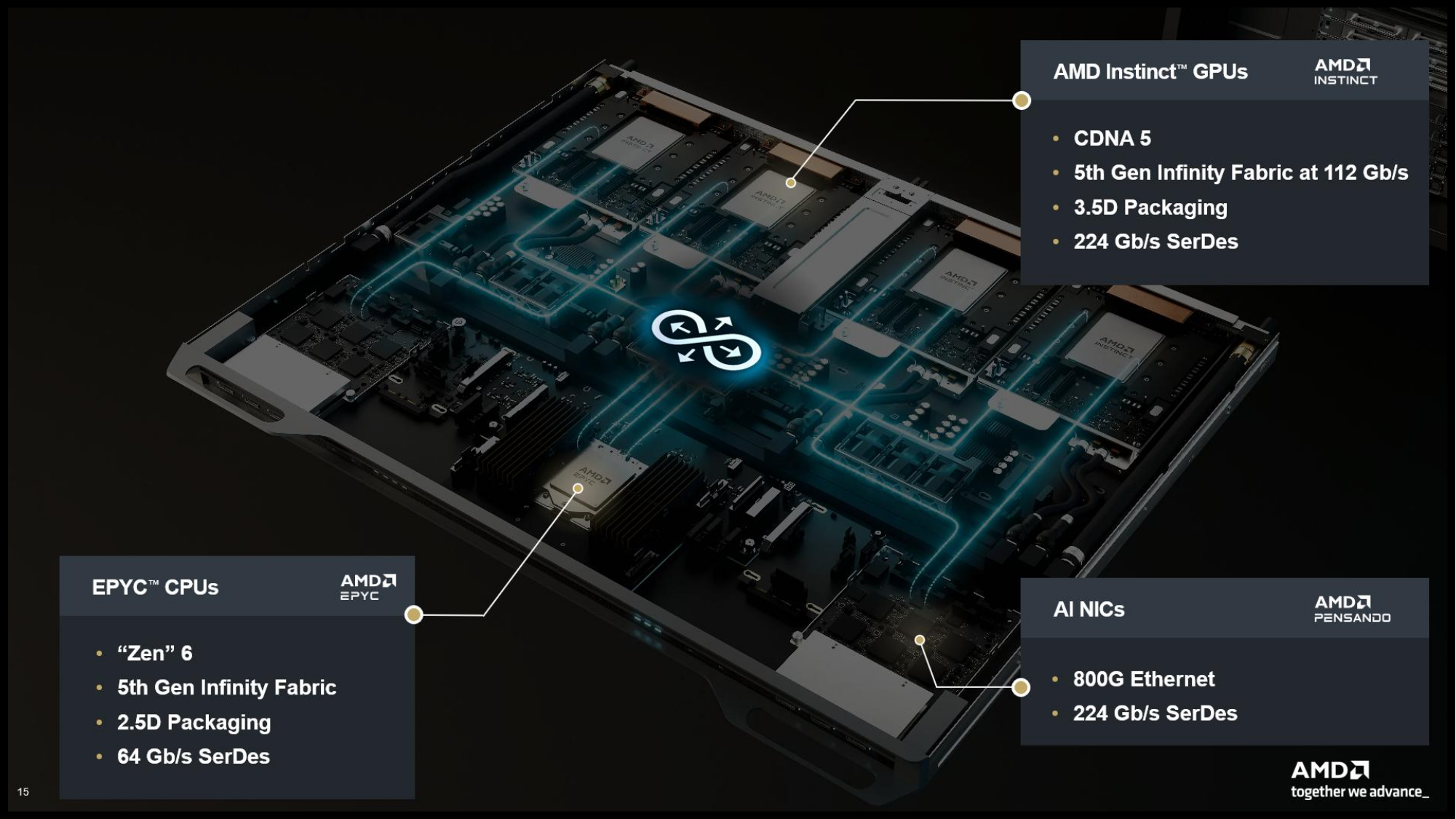 В 2027 году AMD планирует выпустить ускорители серии MI500 и процессоры EPYC Verano, продолжая тем самым ежегодный цикл совместной разработки процессоров, ускорителей и сетей. AMD заявила, что EPYC Venice, намеченные к выпуску в 2026 году, будут обладать лучшими в отрасли показателями плотности (1,3x по количеству потоков в сравнении с текущими решениями) и энергоэффективности (1,7x). Они пополнятся оптимизированными для ИИ наборами инструкций для обработки инференса и выполнения вычислений общего назначения. Указанные компоненты станут основой ИИ-фабрики, способной масштабироваться от одной стойки до глобально распределённых кластеров.  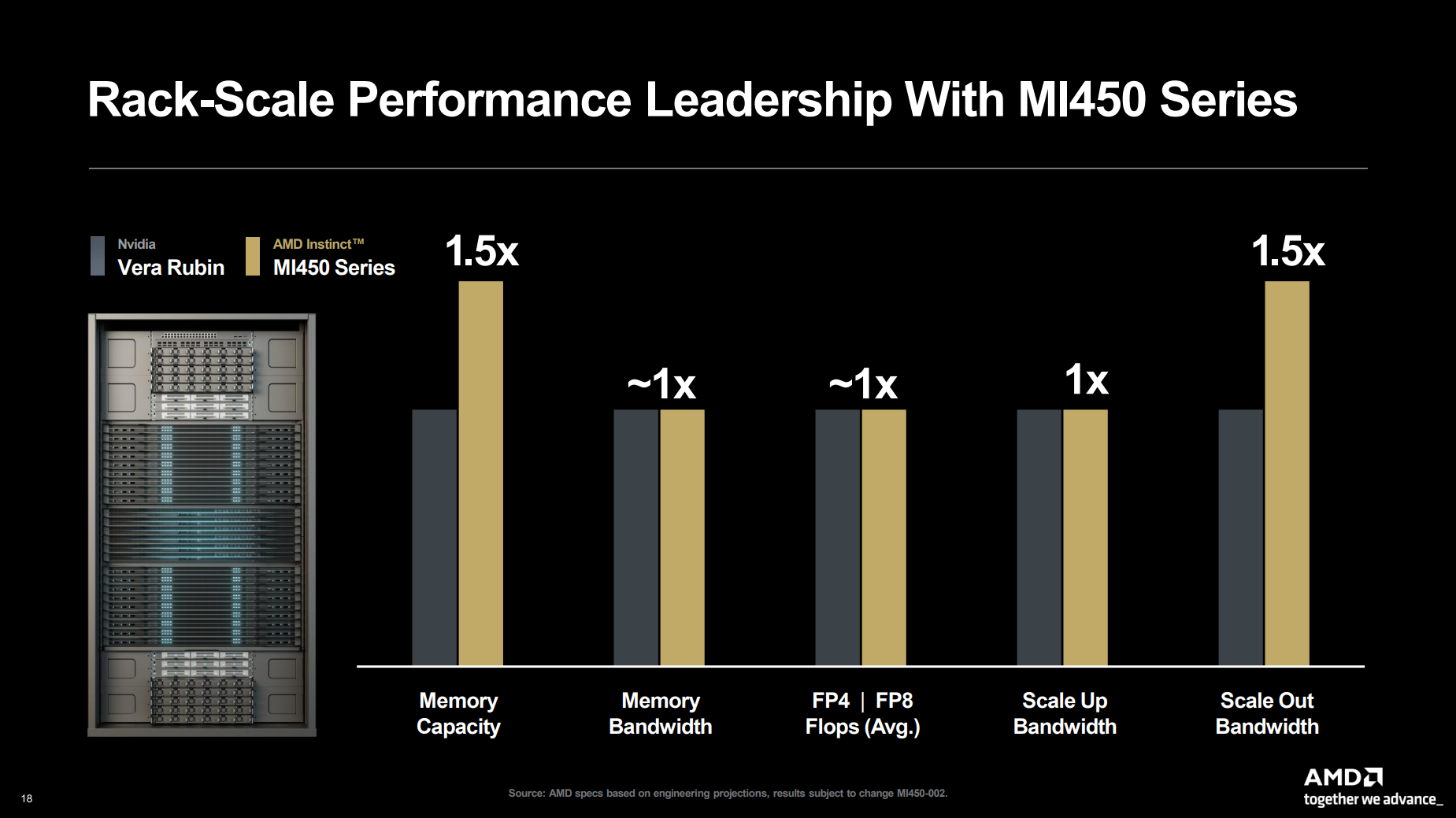 Исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) подчеркнул в своём выступлении, что производительность ИИ всё больше зависит от сети. Сетевые карты AMD Pensando Pollara и Vulcano для ИИ образуют связующую ткань архитектуры Helios. Сетевая карта Pollara 400 обеспечивает пропускную способность 400 Гбит/с, а готовящаяся к выходу сетевая карта Vulcano удвоит её до 800 Гбит/с, обеспечивая связь Ultra Ethernet между крупными кластерами ускорителей.   AMD представила четырёхуровневую архитектуру сети для масштабных ИИ-инфраструктур. Front-End часть обслуживает пользователей, хранилище и приложения. Она опирается на DPU Pensando и P4-движки, отвечающие за разгрузку сетевых функций, функции безопасности и шифрования, и работу с СХД. Вертикальное масштабирование в пределах стойки обеспечивает 3,6-Тбайт/с подключение на каждый GPU. Горизонтальное масштабирование реализуется благодаря UEC — внутренние тесты показали снижение затрат на коммутацию до 58 % по сравнению с традиционными сетями типа Fat-Tree. Наконец, Scale-Across (пространственное масштабирование) позволит объединить географически распределённые ЦОД в кластеры с интеллектуальным управлением трафиком и адаптивной балансировкой нагрузки.   AMD отметила, что открытый программный стек ROCm (Radeon open compute) по-прежнему лежит в основе её стратегии в области ИИ-платформ. По сравнению с прошлым годом число его загрузок выросло в десять раз и теперь на HuggingFace поддерживается более 2 млн моделей. ROCm интегрируется с ведущими фреймворками, включая PyTorch, TensorFlow, JAX, Triton, vLLM, ComfyUI и Ollama, и поддерживает проекты с открытым исходным кодом, такие как Unsloth. 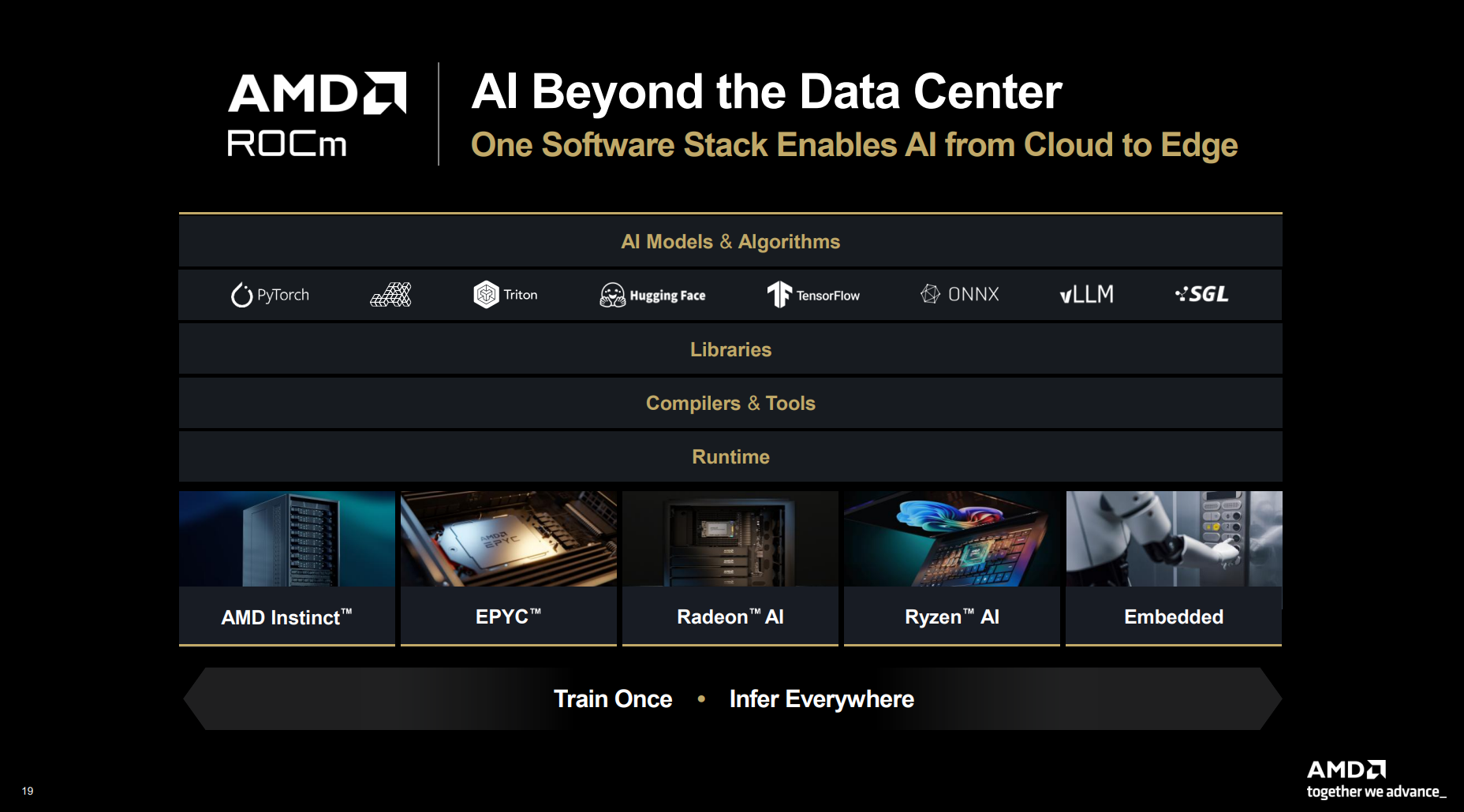  AMD также расширила своё видение «физического ИИ», когда вычисления выходят за рамки облака и охватывают роботов, транспортные средства и промышленные системы. Подразделение встраиваемых систем, усиленное приобретением Xilinx в 2022 году, превратилось из бизнеса, ориентированного на FPGA, в многоплатформенный двигатель роста, охватывающий адаптивные системы на кристалле (SoC), встраиваемые x86-процессоры и заказные кремниевые решения. По словам компании, с 2022 года решения в этой области принесли более $50 млрд. AMD рассчитывает превысить 70 % доли рынка адаптивных вычислений.   Говоря о перспективах, компания отметила, что ЦОД остаются основным драйвером роста, но наряду с этим она будет диверсифицировать свою деятельность по всем сегментам. Финансовые цели AMD включают:
12.11.2025 [09:28], Владимир Мироненко
Переконфигурируемый ускоритель NextSilicon Maverick-2 с dataflow-архитектурой меняет подход к вычислениямВ конце октября стартап NextSilicon объявил о выходе Maverick-2 — интеллектуального ускорителя вычислений (Intelligent Compute Accelerator, ICA), анонсированного в прошлом году. Чип уже используется в Сандийских национальных лабораториях (SNL) Министерства энергетики США (DOE) в составе суперкомпьютера Vanguard-II, а также рядом клиентов. Как утверждает глава NextSilicon Элад Раз (Elad Raz), компании в сфере научных вычислений и HPC сталкиваются с проблемой ограниченных возможностей CPU и GPU, из-за чего приходится идти на компромиссы, но архитектура Maverick решает эту проблему. По словам NextSilicon, нынешние массовые CPU «скованы» архитектурой фон Неймана 80-летней давности, в которой значительная часть отведена вспомогательной логике, включая предсказание ветвлений, внеочередное исполнение и т.д., а не собственно исполнительным устройствам. В свою очередь, GPU обеспечивают более высокую параллельную производительность, но для эффективного использования ускорителей требуются специализированные среды разработки (CUDA), управление сложными иерархиями памяти, когерентностью кешей и т.п. А ASIC, созданные для конкретных ИИ-задач, обеспечивают высокую производительность и эффективность, но их разработка требует больших затрат. 
Источник изображения: NextSilicon NextSilicon предлагает заменить эти решения чипом с управлением потоками данных (dataflow), который можно перенастраивать во время выполнения задач для устранения узких мест кода, и у которого нет ограничений, присущих CPU и GPU. «В ресурсоёмких приложениях большую часть времени выполняется лишь небольшая часть кода, — рассказал Раз. — Мы разработали интеллектуальный программный алгоритм, который непрерывно отслеживает работу приложения. Он точно определяет, какой путь кода выполняется чаще всего, и перенастраивает чип для ускорения именно этих путей. И всё это мы делаем во время исполнения кода и за наносекунды». FPGA тоже можно перепрограммировать, но для этого нужен цикл перезагрузки. 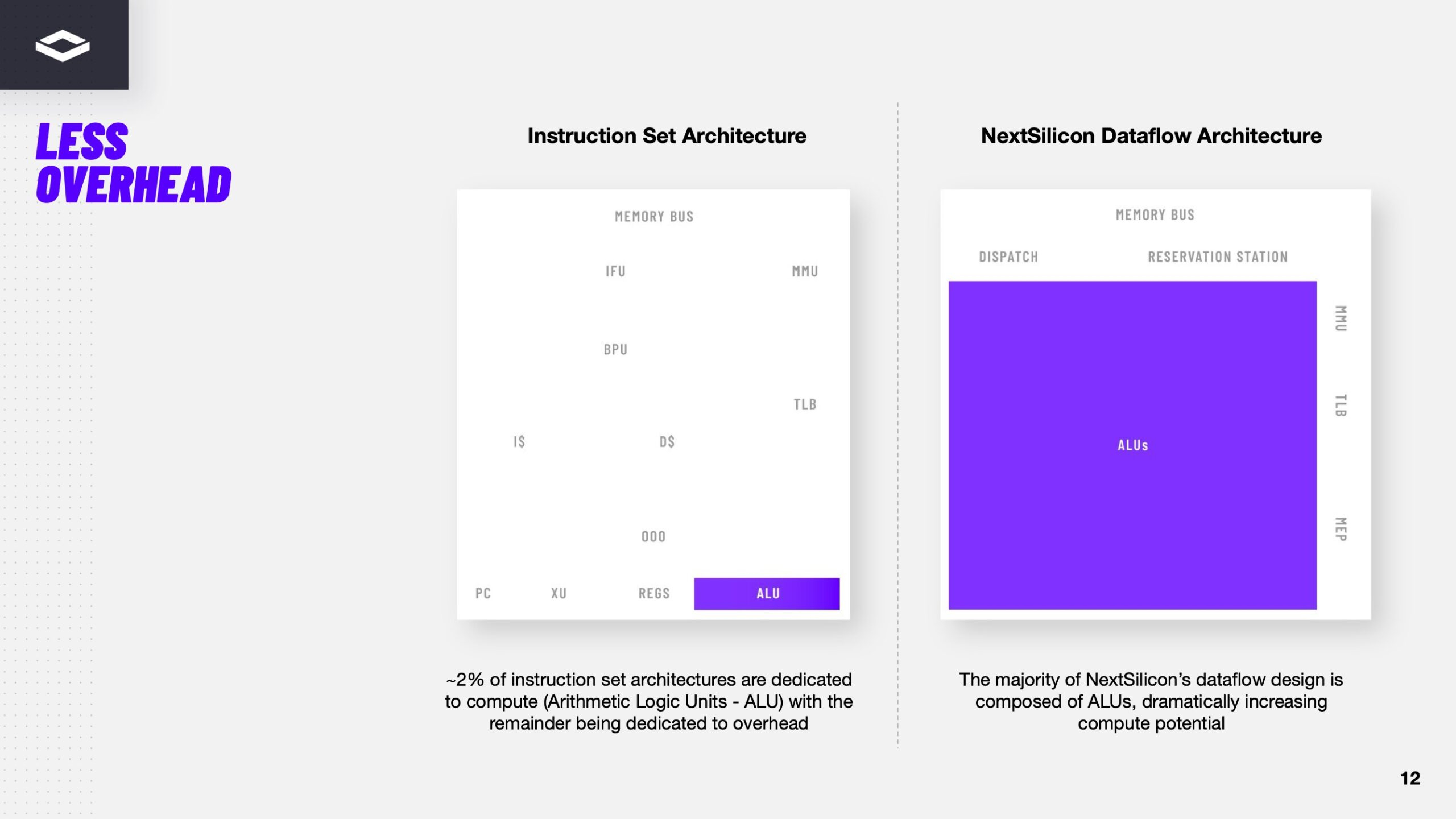
Источник изображений здесь и далее: ServeTheHome/NextSilicon Аппаратная часть Maverick представляет собой реконфигурируемую структуру ALU, которой отведена большая часть «кремния». которую можно быстро перенастраивать во время выполнения кода. Это означает больше вычислений за такт (и на Ватт), при условии, что данные находятся в нужном месте в нужное время. Алгоритм анализирует код на наличие узких мест и соответствующим образом настраивает чип во время выполнения программы. Программно-определяемая архитектура управления потоками данных позволяет достичь производительности и эффективности, близких к ASIC, не привязываясь к конкретному приложению и сохраняя гибкость алгоритмов, утверждает NextSilicon. 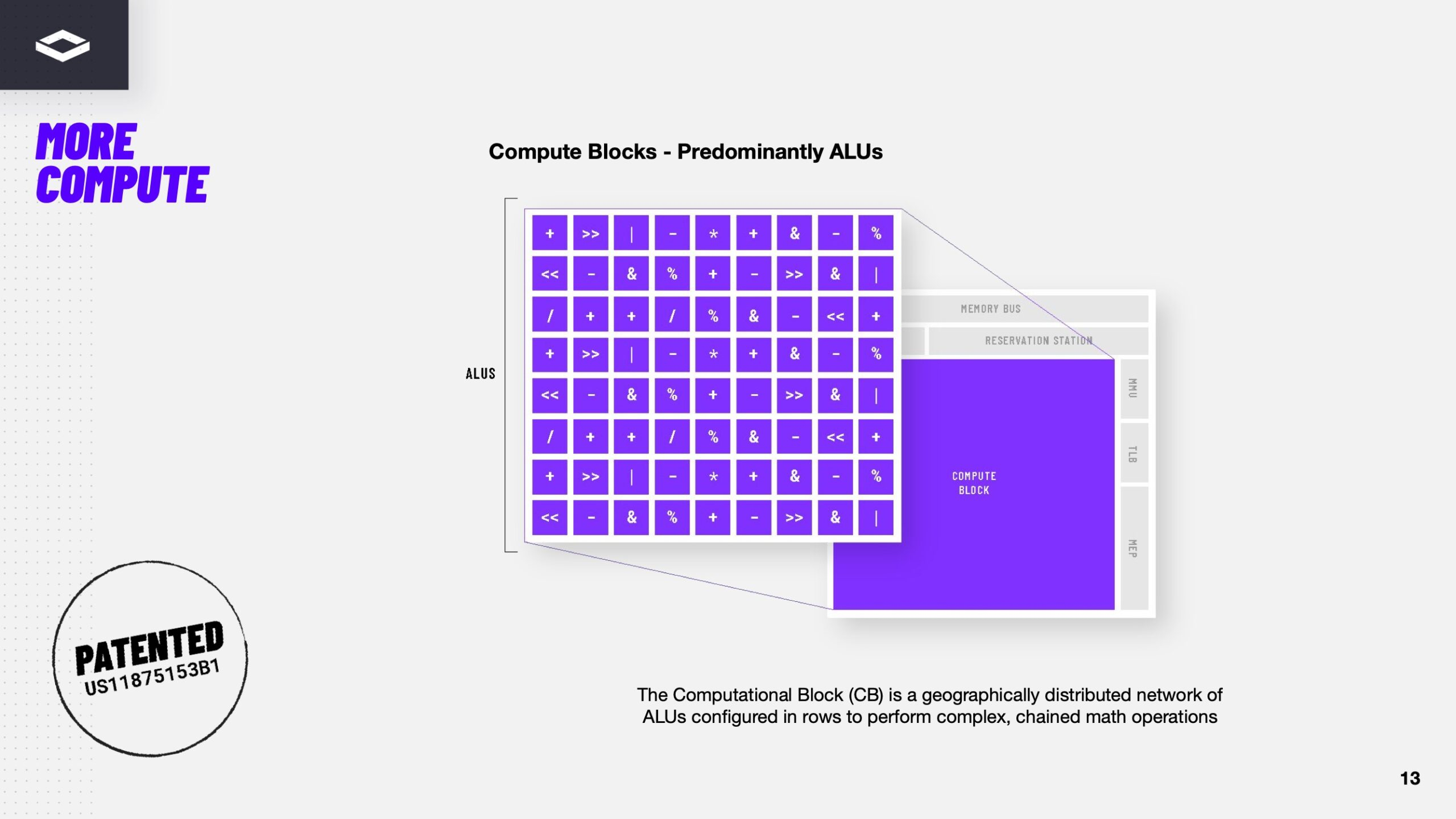 В архитектуре NextSilicon вычислительные блоки (CB) подключены к шине памяти для получения данных, которые временно хранятся в станции резервирования (RS). Диспетчер определяет время запуска вычислительного блока. (RS и диспетчер аналогичны регистрам в процессоре.) Точки входа в память (MEP-блоки) обрабатывают операции доступа к памяти, генерируя запросы к шине, а по завершении направляют ответ в RS. MMU и TLB-кеш занимаются трансляцией адресов (при необходимости). Всё остальное пространство CB занято ALU, который в первом приближении и можно считать «инструкциями». Компания не уточняет, сколько именно CB содержится в чипе, но на фото кристалла их 224. 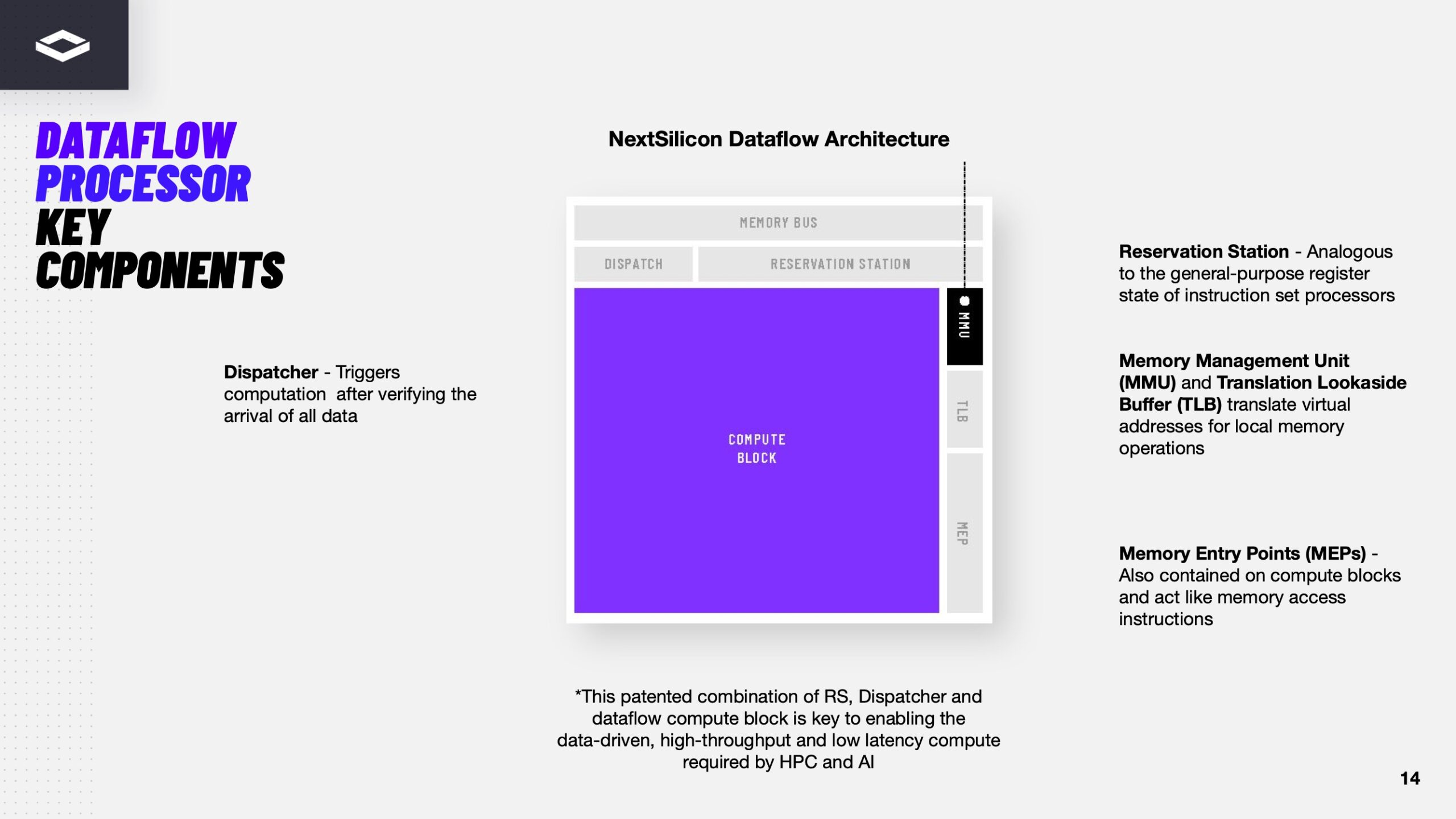 Из ALU компилятор NextSilicon формирует т.н. Mill-ядра (Mill Core) в рамках CB, фактически представляющие собой граф связанных между собой операций, которые и выполняются ALU — появление данных на входе ALU срабатывает как триггер, ALU отрабатывает свою единственную назначенную операцию и передаёт результат следующему ALU, тот следующему и т.д. до конца графа. Особенностью чипа является способность в ходе исполнения по необходимости автоматически реплицировать и оптимально размещать Mill-ядра внутри одного CB, и между несколькими CB. Пришло больше данных, которые можно параллельно обработать — будет больше Mill-ядер. Но касается это только наиболее «горячих» участков. 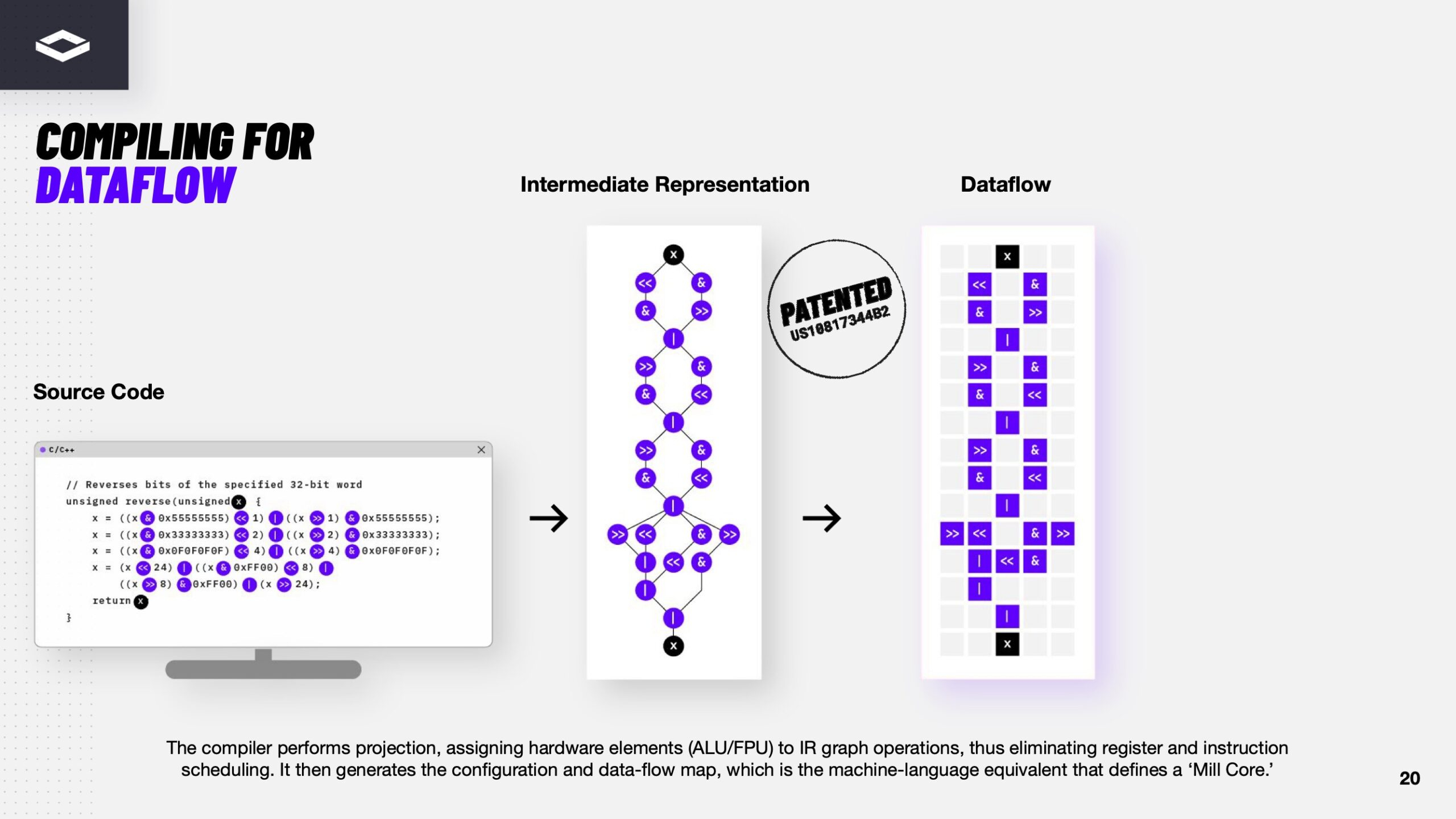 Илан Таяри (Ilan Tayari), соучредитель и вице-президент по архитектуре NextSilicon, назвал критически важным, что платформа может запускать любой код «из коробки», будь то код, написанный для CPU и GPU или ИИ-моделей. Будь то C++, Fortran, Python, CUDA, ROCm, OneAPI или даже ИИ-фреймворки, компилятор NextSilicon разделяет код на части, преобразуя их в промежуточное представление для реконфигурируемого оборудования. «Это не ограничивается тем, что существует сегодня, — сказал Таяри. — Для исследователей в сфере ИИ этот метод открывает новые захватывающие возможности. Вы получаете ускорение независимо от того, что использует ваша модель… экзотические функции активации, комплексные числа или новые математические операции: всё ускоряется сразу из коробки». 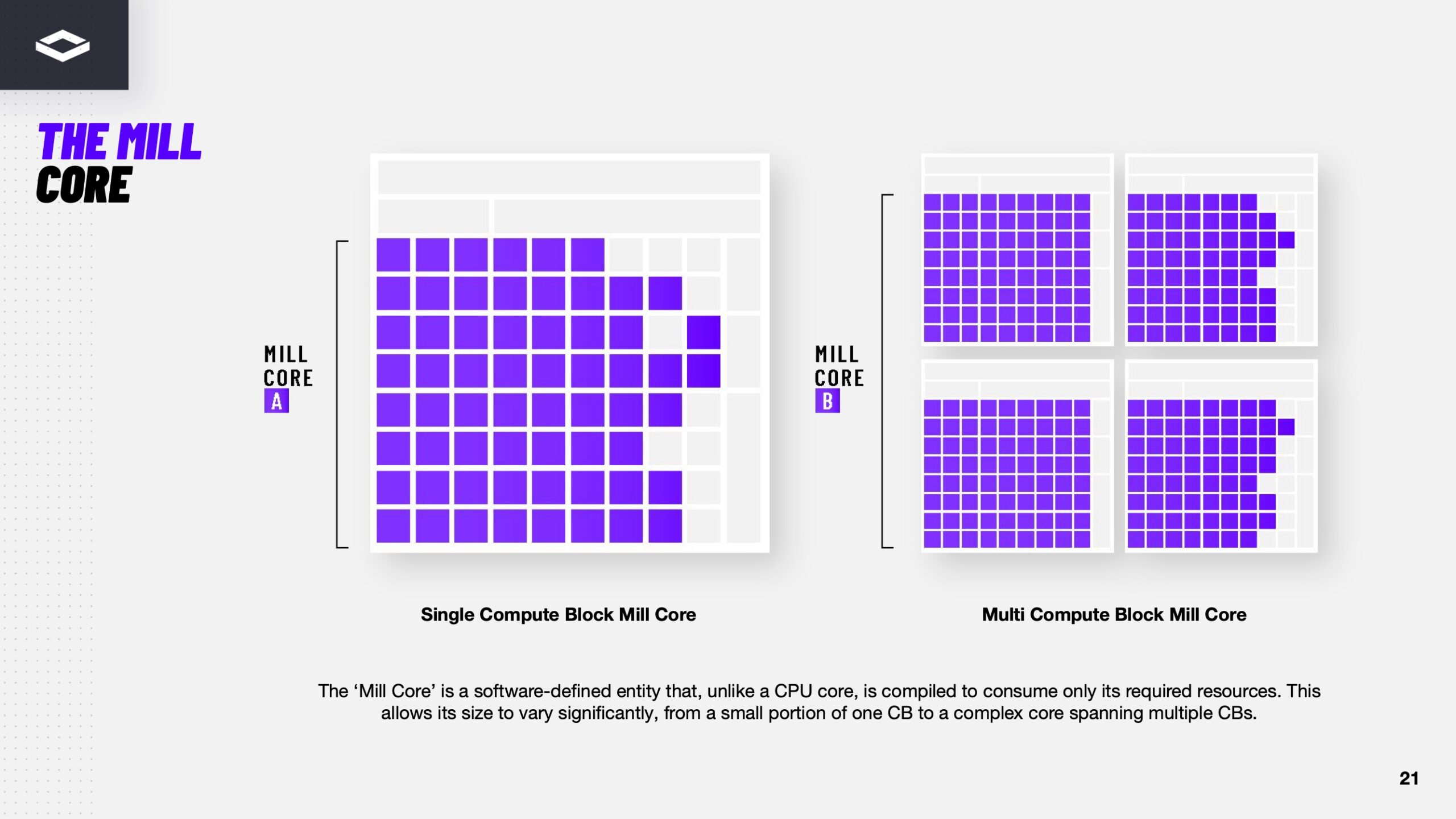 Во время выполнения приложения оперативная телеметрия на чипе непрерывно оптимизирует его. Например, в случае частого взаимодействия вычислительных подблоков граф перестраивается, чтобы приблизить их друг к другу или, например, переключиться с векторной на матричную обработку. При наличии узкого места они дублируются для обеспечения параллелизма. Это происходит автоматически, без вмешательства разработчика, в отличие, например, от VLIW-подхода. 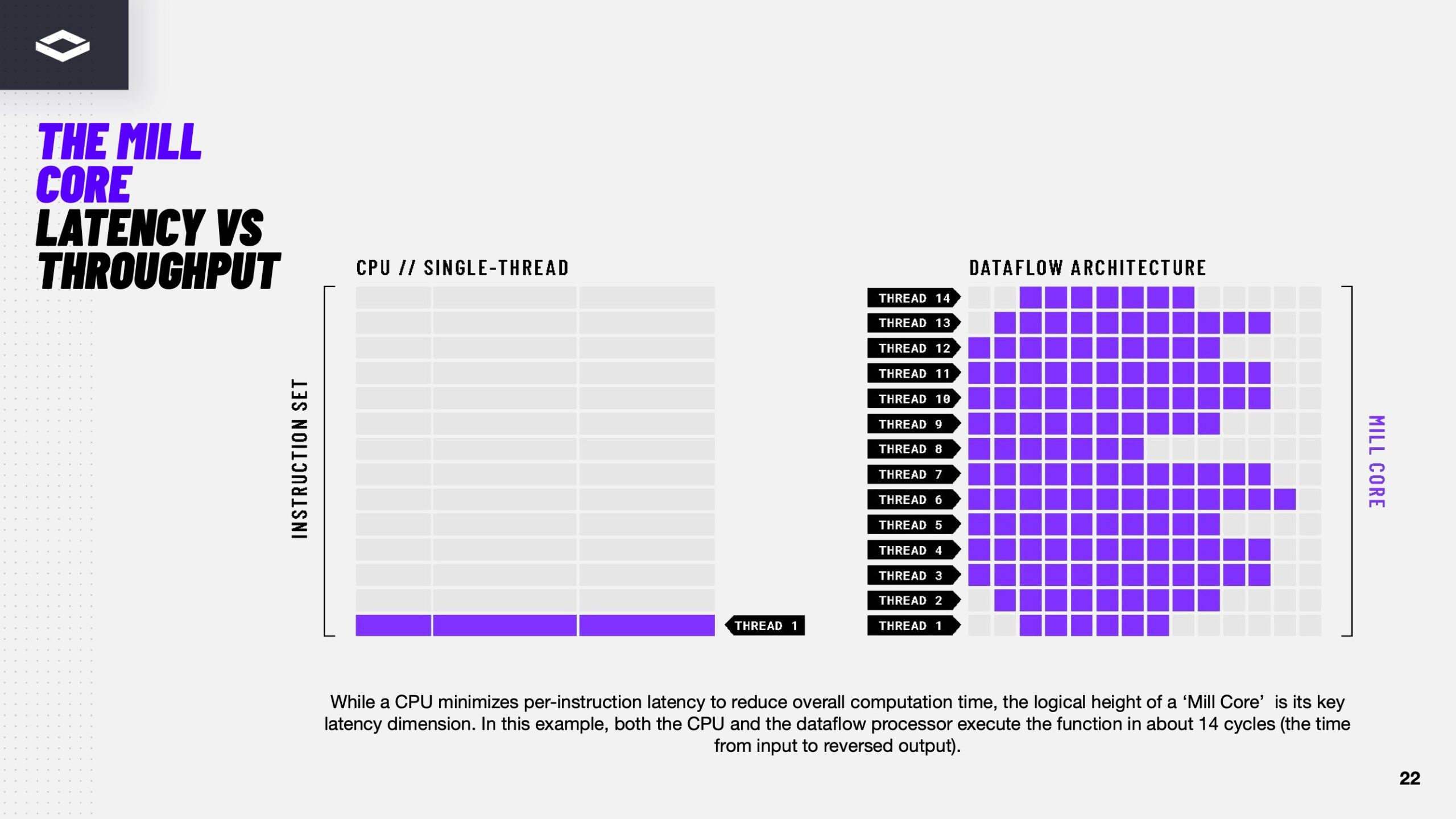 Maverick-2 выпускается по 5-нм техпроцессу TSMC в однокристальной и двухкристальной конфигурациях, работающих на частоте 1,5 ГГц. Однокристальная модель с энергопотреблением 400 Вт разработана для карт PCIe 5.0 x16, а двухкристальная модель с энергопотреблением 750 Вт — для OAM-модулей. Однокристальный вариант с воздушным охлаждением включает 32 управляющих ядра RISC-V, 96 Гбайт HBM3E, кеш 128 Мбайт и один порт 100GbE. Двухкристальный вариант OAM с жидкостным охлаждением содержит 64 управляющих ядра RISC-V, 192 Гбайт HBM3E, кеш 256 Мбайт и два интерфейса 100GbE. 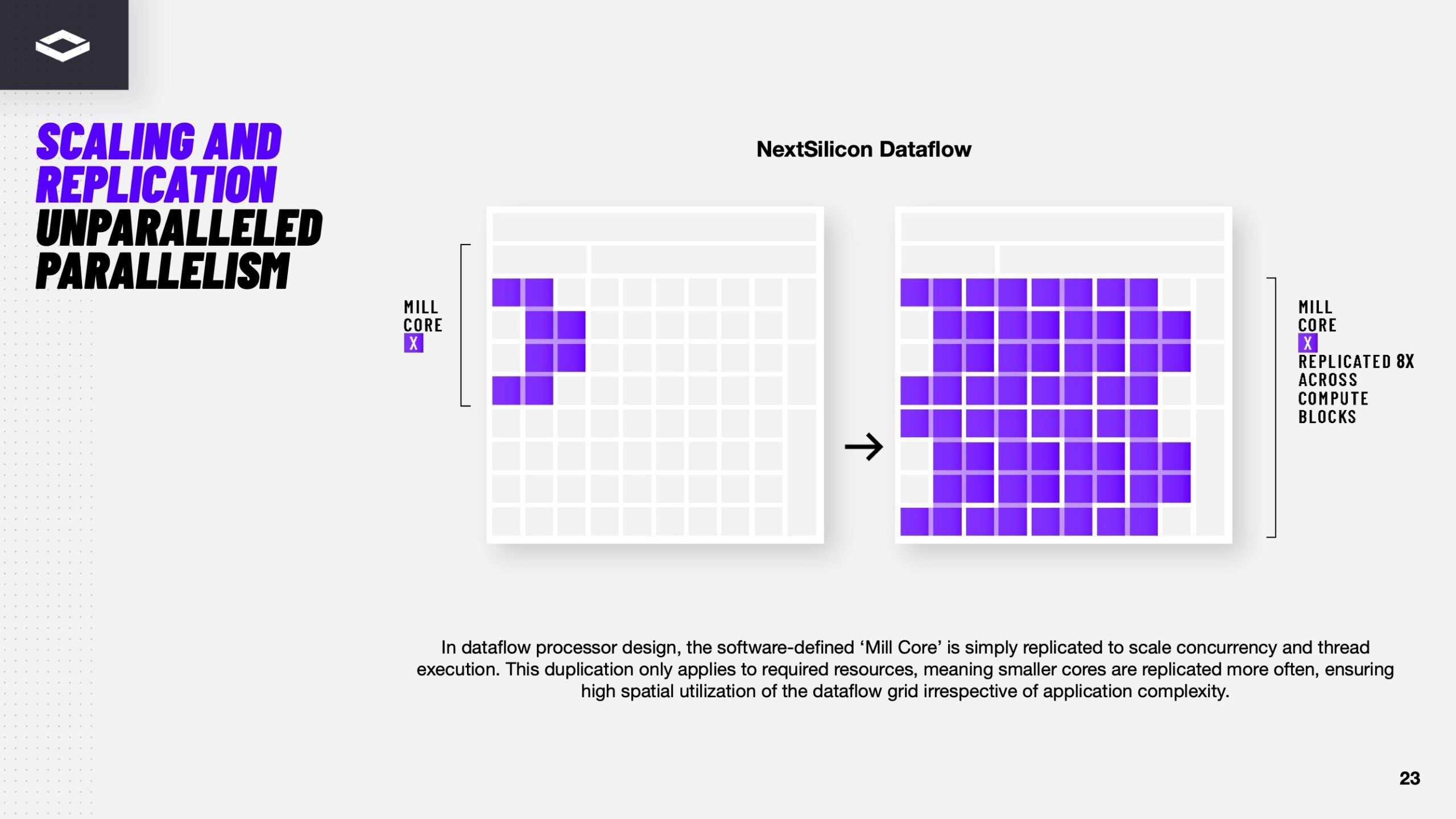 Следует отметить, что указаны максимальные значения TDP, и, как пишет ServeTheHome, ожидается, что при многих рабочих нагрузках они будут ниже. NextSilicon заявляет о возможности достижения 600 Гфлопс при потреблении 750 Вт (примерно вдвое меньше, чем у конкурентов) в бенчмарке HPCG, что составляет 4,8 Тфлопс при потреблении 6 кВт для UBB. Компания протестировала как однокристальную, так и двухкристальную версии Maverick2. В тесте STREAM пропускная способность чипа составила 5,2 Тбайт/с, в бенчмарке GUPS чип достиг 32,6 GUPS при потреблении 460 Вт, что в 22 раза быстрее, чем у CPU, и почти в шесть раз быстрее, чем у GPU для таких приложений как СУБД, агентное принятие ИИ-решений в режиме реального времени и ИИ-инференс на основе разрозненных данных. 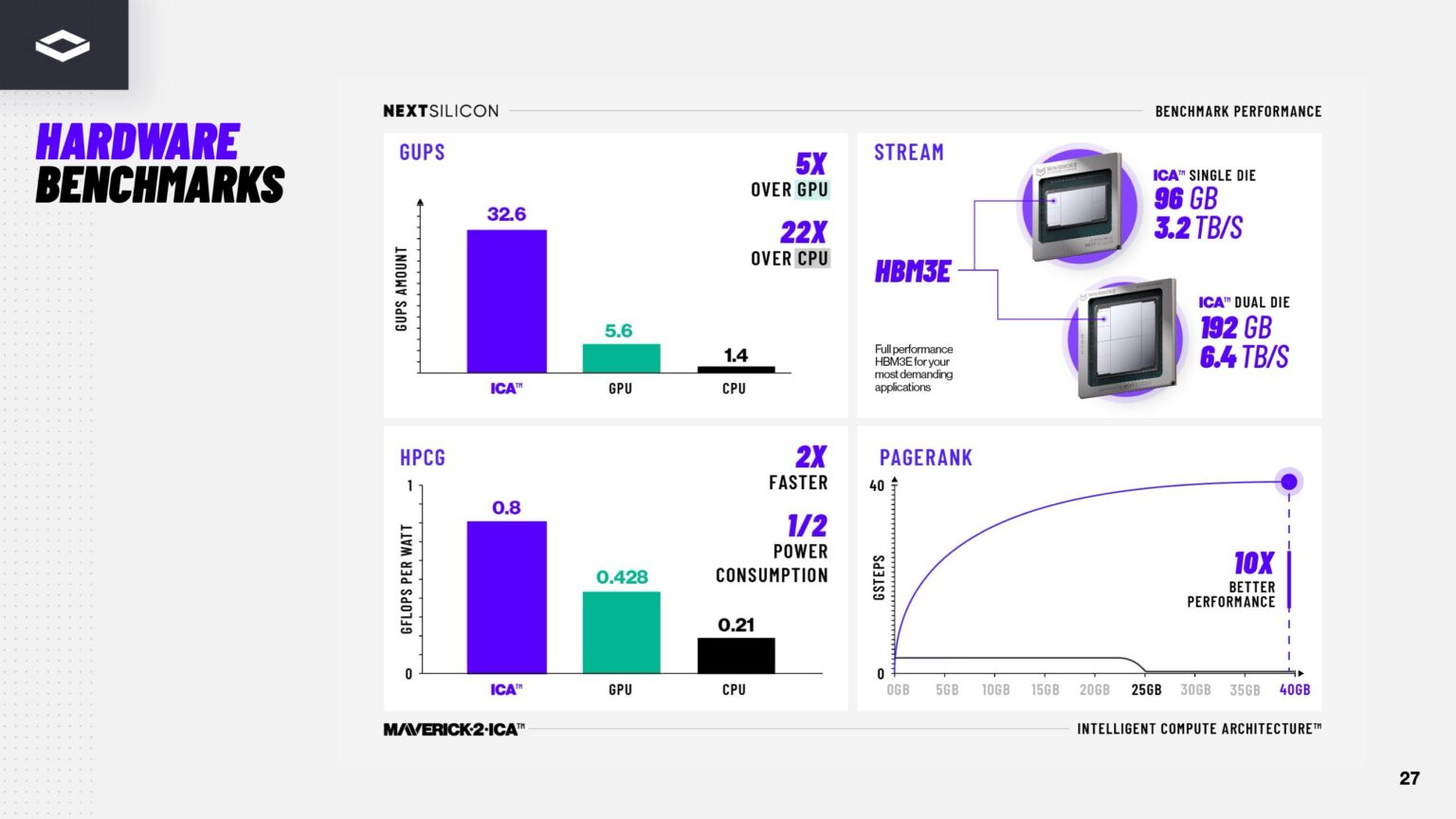 В тесте Google PageRank (PR) чип показал результат 40 Гигастраниц/с, что в 10 раз выше, чем у ведущих GPU, при вдвое меньшем энергопотреблении. Компания отметила, что при больших размерах графов (более 25 Гбайт) ведущие GPU не смогли полностью пройти тест, в то время как Maverick-2 справился с ними без труда, продемонстрировав критическую потребность в адаптивных архитектурах, способных справиться со сложными рабочими нагрузками, лежащими в основе современных ИИ-систем, социальной аналитики и сетевого интеллекта.  «[Эти результаты были] достигнуты с использованием существующего, немодифицированного кода приложения», — подчеркнул Эяль Нагар (Eyal Nagar), соучредитель и вице-президент по исследованиям и разработкам NextSilicon. «Нашим конкурентам требуются специализированные команды для модификации кода, BIOS, прошивок, ОС и параметров, чтобы достичь заявленных бенчмарков. NextSilicon обеспечивает превосходные результаты, используя уже готовое ПО», — добавил он.  NextSilicon также представила тестовый кристалл для процессора корпоративного уровня на базе ядер RISC-V, который компания планирует использовать в качестве хост-процессора в ускорителе следующего поколения Maverick-3. Процессор Arbel, разработанный с нуля, с шириной конвейера в 10 команд представляет собой эволюцию более компактных ядер RISC-V на базе Maverick-2, обрабатывающих последовательный код. По словам компании, ядра имеют производительность ядер на уровне AMD Zen 5 или Intel Lion Cove. 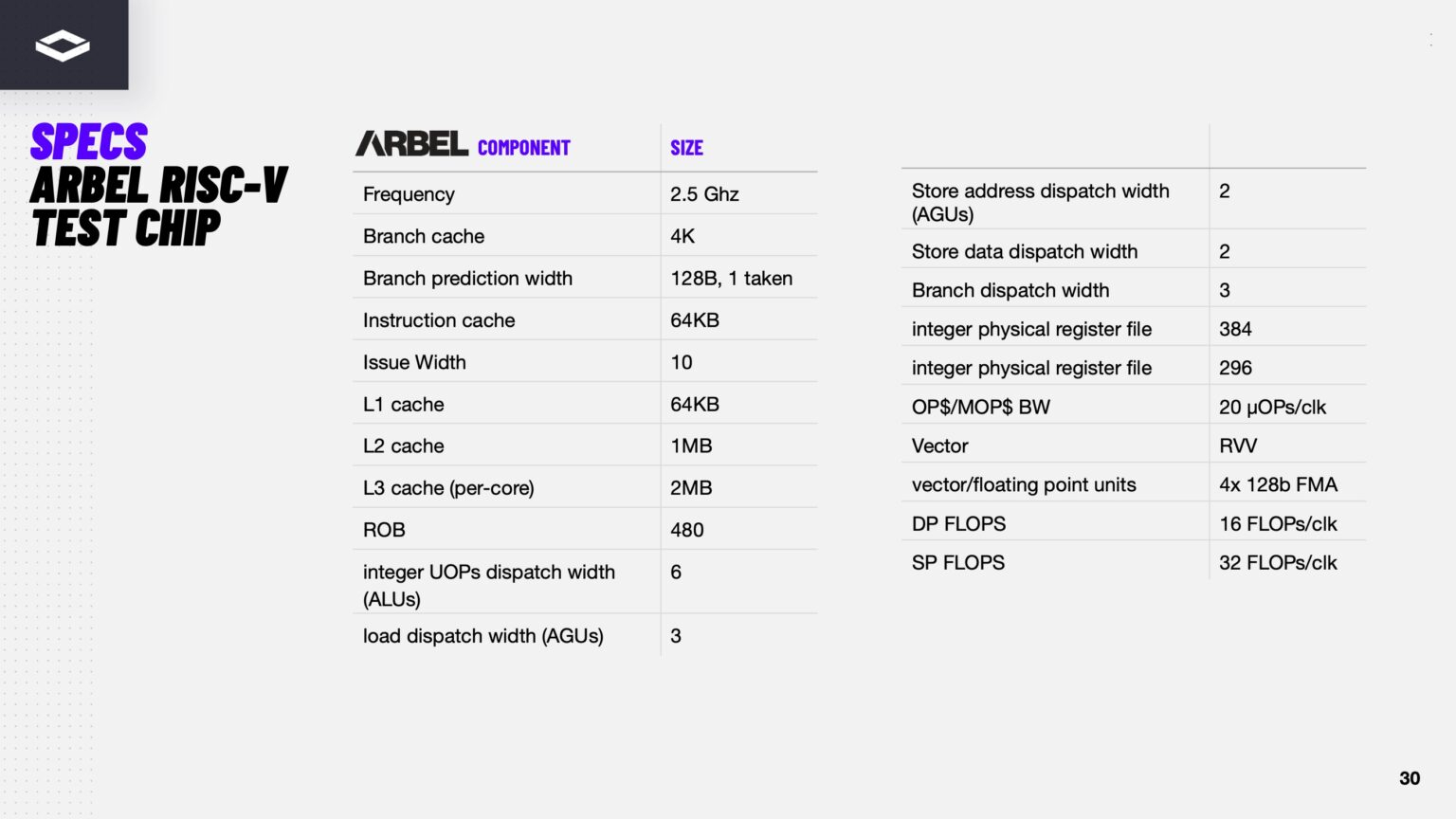 NextSilicon сообщила, что Arbel обеспечивает прорывную производительность благодаря четырём ключевым архитектурным инновациям:
«Это настоящий кремний, созданный по 5-нм техпроцессу TSMC — наша собственная запатентованная интеллектуальная собственность, а не лицензированная или заимствованная. Создан инженерами NextSilicon для воплощения видения будущего NextSilicon», — заявил Элад Раз. 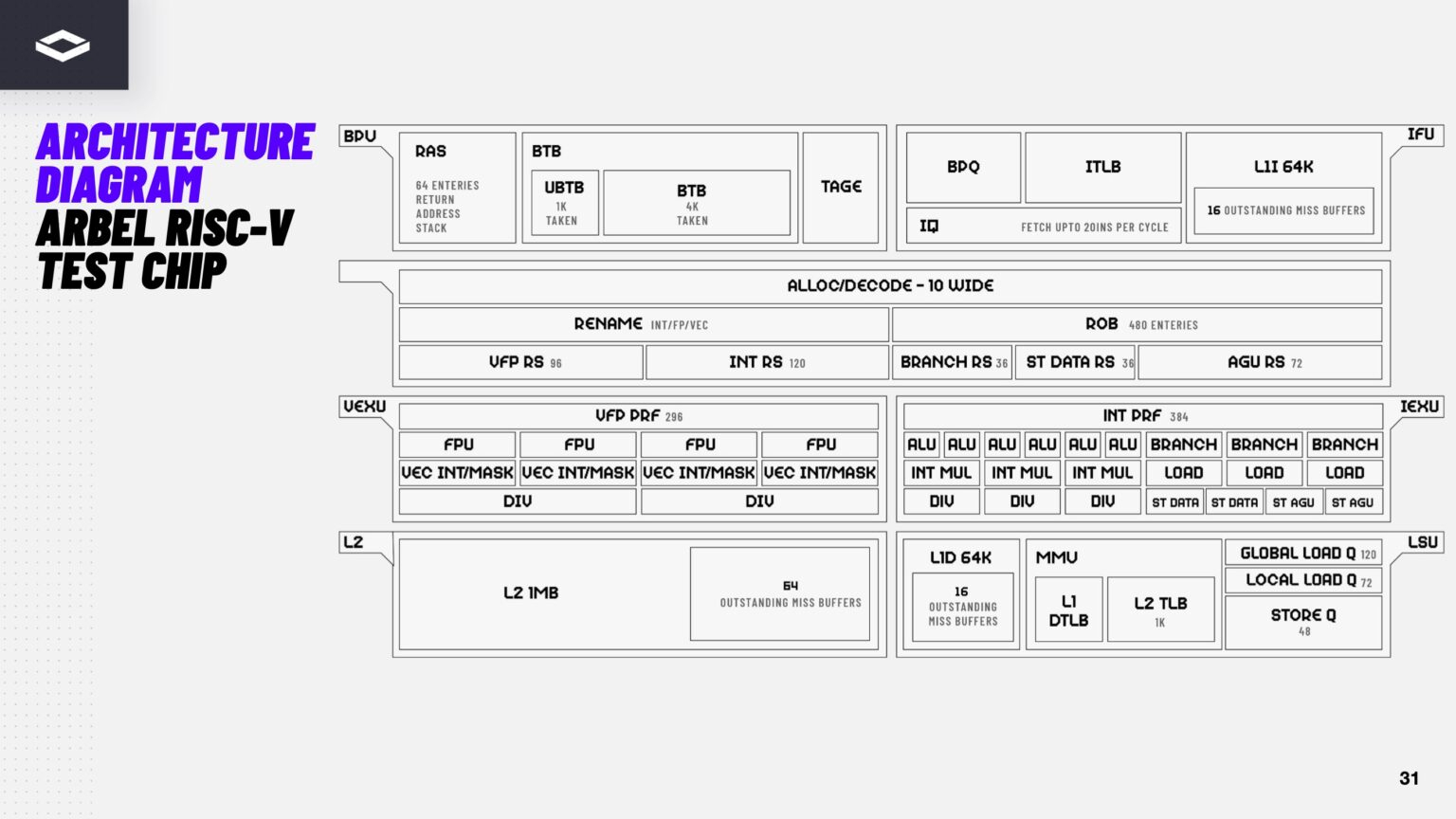 По данным компании, флагманский ускоритель Maverick2, помимо SNL, уже используется «десятками» заказчиков. Его массовые поставки начнутся в начале 2026 года, чтобы обеспечить значительный портфель заказов. NextSilicon сотрудничает с различными организациями, от Министерства энергетики США до ведущих научно-исследовательских институтов, а также коммерческих клиентов в сфере финансовых услуг, энергетики, производства и биологических наук. Программы раннего внедрения для новых клиентов уже доступны через партнёров Penguin Solutions и Dell Technologies. Ускоритель следующего поколения NextSilicon Maverick3 будет поддерживать вычисления с пониженной точностью для ИИ-задач и, как ожидается, появится в продаже в 2027 году, пишет EE Times.
07.11.2025 [14:16], Владимир Мироненко
Google объявила о доступности фирменных ИИ-ускорителей TPU Ironwood и кластеров на их основеGoogle объявила о доступности в ближайшие недели ИИ-ускорителя седьмого поколения TPU v7 Ironwood, специально разработанного для самых требовательных рабочих нагрузок: от обучения крупномасштабных моделей и сложного обучения с подкреплением (RL) до высокопроизводительного ИИ-инференса и обслуживания моделей с малой задержкой. Google отметила, что современные передовые ИИ-модели, включая Gemini, Veo, Imagen от Google и Claude от Anthropic, обучаются и работают на TPU. Многие компании смещают акцент с обучения этих моделей на обеспечение эффективного и отзывчивого взаимодействия с ними. Постоянно меняющаяся архитектура моделей, рост агентных рабочих процессов и практически экспоненциальный рост спроса на вычисления определяют новую эру инференса. В частности, ИИ-агенты, требующие оркестрации и тесной координации между универсальными вычислениями и ускорением машинного обучения, создают новые возможности для разработки специализированных кремниевых процессоров и вертикально оптимизированных системных архитектур. TPU Ironwood призван обеспечить новые возможности для инференса и агентных рабочих нагрузок. 
Источник изображений: Google TPU Ironwood был представлен в апреле этого года. По данным Google, он обеспечивает десятикратное увеличение пиковой производительности по сравнению с TPU v5p и более чем четырёхкратное увеличение производительности на чип как для обучения, так и для инференса по сравнению с TPU v6e (Trillium), что делает Ironwood самым мощным и энергоэффективным специализированным кристаллом компании на сегодняшний день. Ускорители объединяются в «кубы» — 64 шт. TPU в 3D-торе, объединённых интерконнектом Inter-Chip Interconnect (ICI) со скоростью 9,6 Тбит/с на подключение.  Google сообщила, что на базе Ironwood можно создавать кластеры, включающие до 9216 чипов (42,5 Эфлопс в FP8), объединённых ICI с агрегированной скоростью 88,5 Пбит/с с доступом к 1,77 Пбайт общей памяти HBM, преодолевая узкие места для данных даже самых требовательных моделей. Компания отметила, что в таком масштабе сервисы требуют бесперебойной доступности. Её гарантирует технология оптической коммутации (OCS), которая реализуется как динамическая реконфигурируемая инфраструктура. А если клиенту требуется больше мощности, Ironwood масштабируется в кластеры из сотен тысяч TPU.  Своим клиентам, пользующимся решениями на TPU, компания предлагает возможности Cluster Director в Google Kubernetes Engine. Это включает в себя расширенные возможности обслуживания и понимания топологии для интеллектуального планирования и создания высокоустойчивых кластеров. 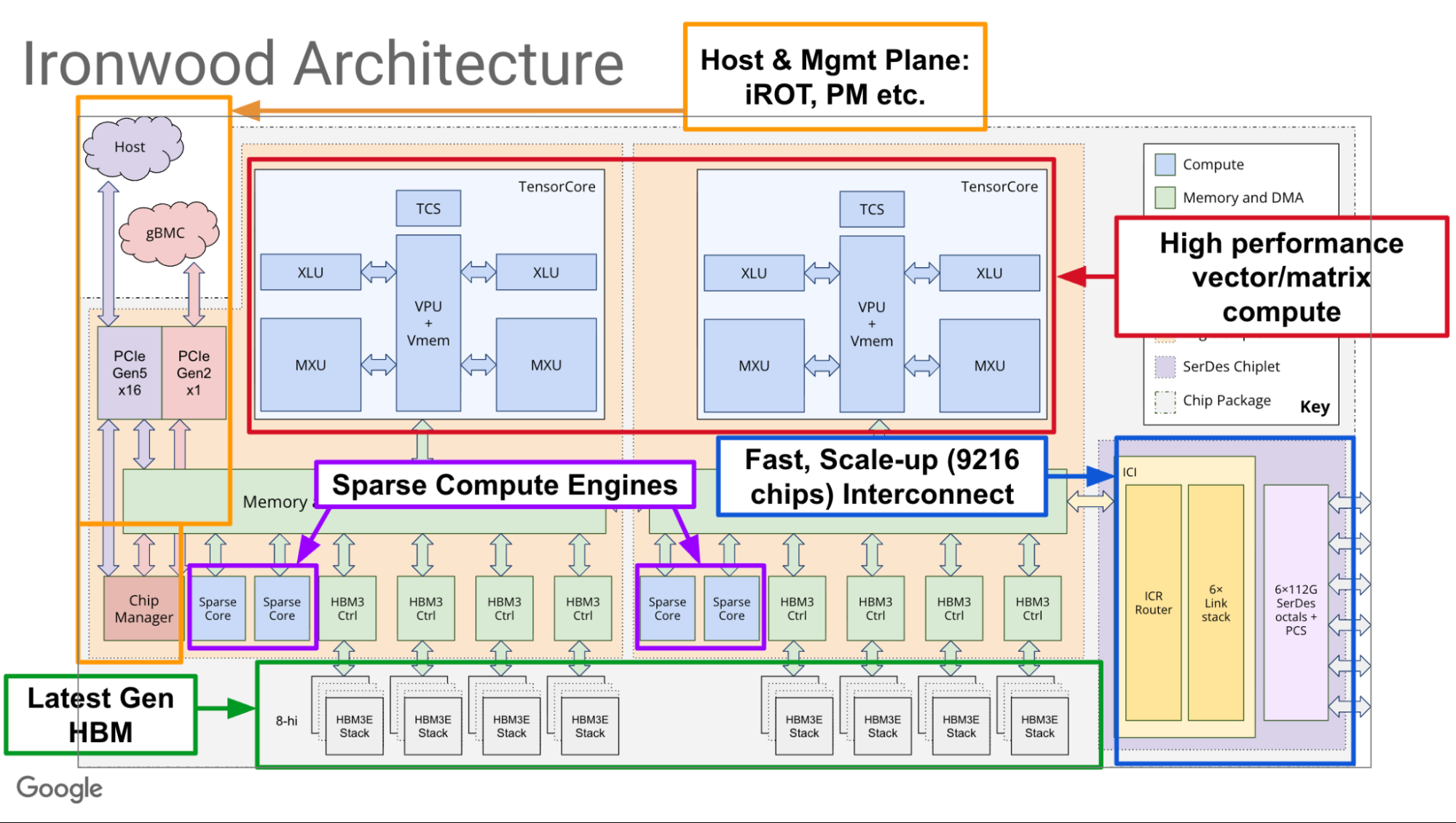 Для предобучения и постобучения компания предлагает новые улучшения MaxText, высокопроизводительного фреймворка LLM с открытым исходным кодом, которые упрощают внедрение новейших методов оптимизации обучения и обучения с подкреплением, таких как контролируемая тонкая настройка (SFT) и оптимизация политики генеративного подкрепления (GRPO) — алгоритм обучения с подкреплением (RL). Также улучшена поддержка vLLM, что позволит с минимальными усилиями перенести инференс с GPU на TPU. А GKE Inference Gateway позволит снизить задержку выдачи первого токена (TTFT). Никуда не делась и поддержка JAX с PyTorch.
27.10.2025 [22:50], Владимир Мироненко
Qualcomm анонсировала ИИ-ускорители AI200 и AI250 — прошлое поколение чипов популярным не стало, но компания обещала исправитьсяQualcomm Technologies представила решения нового поколения для ЦОД, оптимизированные для ИИ-инференса — стоечные суперускорители Qualcomm AI200 и AI250. После их анонса акции Qualcomm подскочили на 15 %, показав самый большой внутридневной рост за более чем шесть месяцев, сообщил Bloomberg. Ожидается, что новые решения станут новой точкой роста компании. Она демонстрировала уверенный рост прибыли в течение последних двух лет, но инвесторы отдавали предпочтение акциям других технологических компаний. Qualcomm AI200 — специализированное стоечное решение для ИИ-инференса, обеспечивающее низкую совокупную стоимость владения (TCO). Платформа оптимизирована для инференса больших языковых и мультимодальных моделей (LLM, LMM) и других ИИ-нагрузок. AI200 включает карты с 768 Гбайт LPDDR. Чип основан на NPU Hexagon, которые используются в последних поколениях Snapdragon. Qualcomm AI250 получил инновационную архитектуру, построенную на принципах предельно близкого расположения быстрой памяти к вычислительным ядрам (Near-Memory Computing, NMC), что обеспечит качественно новый уровень эффективности и производительности ИИ-инференса. По словам Qualcomm, новая архитектура обеспечивает более чем десятикратный прирост эффективной пропускной способности памяти и значительное снижение энергопотребления. Это позволит проводить дезагрегированный ИИ-инференс для более эффективного использования оборудования. 
Источник изображений: Qualcomm Оба продукта будут предлагаться отдельно и в составе стоек с полным жидкостным охлаждением, PCIe-коммутаторами для вертикального масштабирования и Ethernet — для горизонтального, а также поддержкой конфиденциальных вычислений. Энергопотребление стойки составит 160 кВт, что ставит новинки в один ряд с GB200 NVL72. Компания отметила, что её программный ИИ-стек гиперскейл-класса, охватывающий все этапы — от прикладного уровня до системного ПО — оптимизирован для ИИ-инференса. Стек поддерживает ведущие фреймворки машинного обучения, механизмы инференса, фреймворки генеративного ИИ и методы оптимизации инференса LLM/LMM, такие как дезагрегированное обслуживание. Обещаны бесшовный перенос моделей и развёртывание моделей платформы Hugging Face в один клик посредством библиотеки Efficient Transformers и пакета Qualcomm AI Inference Suite от Qualcomm. Qualcomm отметила, что её ПО предоставляет готовые к использованию приложения и ИИ-агенты, комплексные инструменты, библиотеки, API и сервисы. Прошлое поколение ускорителей CloudAI 100 не снискало успеха во многом из-за слабой программной экосистемы. От этого же страдала и AMD, которая ускоренными темпами навёрстывает упущенное.  Qualcomm AI200 и AI250 поступят в продажу в 2026 и 2027 годах соответственно. Qualcomm также сообщила, что придерживается ежегодного плана развития направления ЦОД, ориентированного на достижение лидирующей в отрасли производительности ИИ-инференса, энергоэффективности и минимальной совокупной стоимости владения (TCO). Кроме того, компания решила вернуться на рынок серверных процессоров. Первым заказчиком анонсированных решений Qualcomm станет саудовский государственный ИИ-стартап Humain, который планирует развернуть 200 МВт ИИ ЦОД на базе новых чипов, начиная с 2026 года. Ранее было заключено соглашение с Cerebras, в рамках которого планировалось использовать для инференса именно чипы Qualcomm, в том числе в Саудовской Аравии. Ещё одним крупным игроком в ИИ-сделках здесь является Groq. Qualcomm запоздало пытается занять заметную долю рынка ИИ-оборудования. Компания считает, что новые решения в области памяти и энергоэффективности, основанные на технологиях для мобильных устройств, привлекут клиентов, несмотря на относительно поздний выход на рынок. Под руководством Криштиану Амона (Cristiano Amon) компания стремится диверсифицировать бизнес, больше не полагаясь на смартфоны, рост продаж которых замедлился. Qualcomm «занимала эту нишу, не торопясь и наращивая мощь», — заявил Дурга Маллади (Durga Malladi), старший вице-президент компании. По его словам, Qualcomm ведёт переговоры со всеми крупнейшими заказчиками о развёртывании стоек на базе своего оборудования.
27.10.2025 [11:16], Сергей Карасёв
Axelera AI представила ИИ-чип Europa с производительностью 629 TOPSНидерландский стартап Axelera AI анонсировал ИИ-ускоритель (AIPU) под названием Europa, предназначенный для таких задач, как генеративные сервисы и приложения компьютерного зрения. По заявлениям разработчиков, чип может использоваться в оборудовании разного класса — от периферийных устройств до корпоративных серверов. В состав Europa AIPU входят восемь «ядер ИИ второго поколения», которые используют векторные движки и технологию цифровых вычислений в оперативной памяти (D-IMC), разработанные специалистами Axelera. Заявленная ИИ-производительность достигает 629 TOPS на операциях INT8. Кроме того, чип содержит 16 специализированных векторных ядер с архитектурой RISC-V, сгруппированных в два кластера: они предназначены для операций пред- и постобработки, не связанных с ИИ. Пиковая производительность блока RISC-V достигает 4915 GOPS (млрд операций в секунду). Интегрированный декодер H.264/H.265 ускоряет выполнение медиазадач. 
Источник изображения: Axelera AI Процессор располагает 256-бит интерфейсом памяти LPDDR5 с пропускной способностью 200 Гбайт/с и 128 Мбайт памяти L2 SRAM. Новинка будет предлагаться в различных форм-факторах, включая компактное исполнение с размерами 35 × 35 мм и карты расширения PCIe 4.0 х4 в различных конфигурациях, в частности, с одним чипом и 16 Гбайт памяти, а также с четырьмя чипами и 256 Гбайт памяти. Разработчикам предоставляет комплект Voyager SDK, который позволяет полностью раскрыть потенциал процессора. В целом, как утверждается, новинка обеспечивает в 3–5 раз более высокую производительность в расчёте на 1 Вт и $1 по сравнению с ведущими отраслевыми решениями в той же категории. Поставки Europa AIPU и PCIe-карт начнутся в I половине 2026 года.
20.10.2025 [16:00], Сергей Карасёв
Экономичный гибрид: Intel объединила ускорители Gaudi 3 и NVIDIA B200 в одной ИИ-платформеКорпорация Intel показала гибридную стоечную систему Устройство объединяет посредством Ethernet массивы ускорителей Gaudi3 и NVIDIA B200. Платформа Gaudi3 Rack Scale 64 содержит до 16 вычислительных узлов. Каждый из них оснащён двумя неназванными процессорами Intel Xeon, четырьмя OAM-ускорителями Intel Gaudi 3 (64 в одном домене), четырьмя 400GbE-адаптерами NVIDIA ConnectX-7 и одним DPU NVIDIA BlueField-3, отмечает SemiAnalysis. Суммарно доступно 8,2 Тбайт HBM2e, а агрегированная пропускная способность составляет 76,8 Тбайт/с. Мощность суперускорителя составляет 120 кВт. Кроме того, задействованы 12 коммутаторов на чипах Broadcom Tomahawk 5 (51,2 Тбит/с). Для масштабирования и связи с другими узлами, в том числе NVIDIA, используется именно Ethernet. В составе гибридной системы ускорители Intel Gaudi 3 используются на decode-стадии, т.е. для генерации токенов, где важен объём и пропускная способность памяти, тогда как чипы NVIDIA B200 отвечают за prefill-задачи инференса, т.е. за обработку контекста и заполнение KVCache, где важна скорость вычислений. NVIDIA сама стремится к этому же подходу и уже анонсировала соускорители Rubin CPX, которые как раз будут заниматься работой с контекстом в сверхбольших моделях и созданием KV-кеша. 
Источник изображений: Intel Intel утверждает, что гибридная конфигурация из Gaudi3 и B200 позволяет достичь 1,7-кратного прироста производительности в расчёте на доллар совокупной стоимости владения (TCO) по сравнению с платформами, использующими только B200. Однако, как отмечается, эти заявления пока не подтверждены независимыми тестами. К тому же, программная платформа Gaudi3 отстаёт от платформы NVIDIA и является закрытой. Кроме того, нынешняя архитектура Gaudi приближается к концу своего существования, что ставит под сомнение жизнеспособность предложенной платформы в долгосрочной перспективе.  Для Intel это, возможно, один из немногих шансов продать остатки Gaudi3. Между тем Intel недавно анонсировала GPU-ускоритель Crescent Island, разработанный специально для ИИ-инференса. Решение, в основу которого положена архитектура Xe3P, получит 160 Гбайт памяти LPDDR5X. Массовые поставки будет организованы не ранее 2027 года. Ранее компания отказалась от планов по выпуску Falcon Shores, сосредоточившись на Jaguar Shores. Сейчас же компания начала сворачивать поддержку ускорителей Ponte Vecchio (Intel Max) и Arctic Sound (Flex).
20.10.2025 [12:13], Сергей Карасёв
ИИ-ускоритель Huawei Atlas 300I Duo получил однослотовое исполнениеВ распоряжении сетевых источников оказалась информация о необычном ускорителе Atlas 300I Duo, разработанном компанией Huawei для решения задач в области ИИ: это двухпроцессорное изделие, оснащенное пассивной системой охлаждения. Карта получила однослотовое исполнение. В оснащение входят два GPU серии Ascend 310 и 96 Гбайт памяти LPDDR4X, пропускная способность которой достигает 408 Гбайт/с. Используется интерфейс PCIe 4.0 х16. Утверждается, что Atlas 300I Duo может декодировать до 256 потоков видео в формате Full HD со скоростью 30 к/с или 32 потока 4K со скоростью 60 к/с. Возможно кодирование 48 видеопотоков Full HD со скоростью 30 к/с. ИИ-производительность на операциях INT8 достигает 280 TOPS. При этом показатель TDP находится на отметке 150 Вт. 
Источник изображений: Gamers Nexus via YouTube Применённая пассивная система охлаждения предусматривает использование радиаторов в области каждого GPU, соединённых тепловыми трубками. Кроме того, имеется металлическая пластина для рассеяния тепла. Для подачи дополнительного питания используется специальный 8-контактный разъём, не совместимый со стандартными гнёздами. Стоимость Huawei Atlas 300I Duo составляет около $1600.  Между тем Huawei продолжает развивать семейство ИИ-ускорителей Ascend. В I квартале 2026 года компания намерена представить ускоритель Ascend 950PR, который обеспечит производительность до 1 Пфлопс на операциях FP8. После этого последуют устройства Ascend 950DT, Ascend 960 и Ascend 970.
15.10.2025 [09:13], Сергей Карасёв
Intel представила GPU-ускоритель Crescent Island для ИИ-инференсаКорпорация Intel, как и ожидалось, представила на мероприятии OCP Global Summit в Сан-Хосе (Калифорния, США) графический процессор нового поколения для дата-центров. Изделие с кодовым названием Crescent Island специально оптимизировано для задач ИИ-инференса. В основу GPU положена архитектура Xe3P. Она представляет собой усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake для ноутбуков и компактных настольных ПК. Говорится об улучшенном показателе производительности в расчёте на 1 Вт затрачиваемой энергии. Ускоритель на базе Crescent Island получит 160 Гбайт памяти LPDDR5X. Как отмечает ресурс Tom's Hardware, максимальный объём чипов LPDDR5X составляет 8 Гбайт. При этом используются два 16-бит канала памяти, что в сумме даёт 32 бита. Таким образом, для обеспечения 160 Гбайт памяти требуются 20 чипов LPDDR5X. Это означает, что ускоритель получит либо один массивный GPU с 640-бит интерфейсом памяти для подключения всех 20 чипов LPDDR5X, либо два менее крупных процессора с 320-бит интерфейсом, каждый из которых будет обслуживать 10 чипов LPDDR5X. 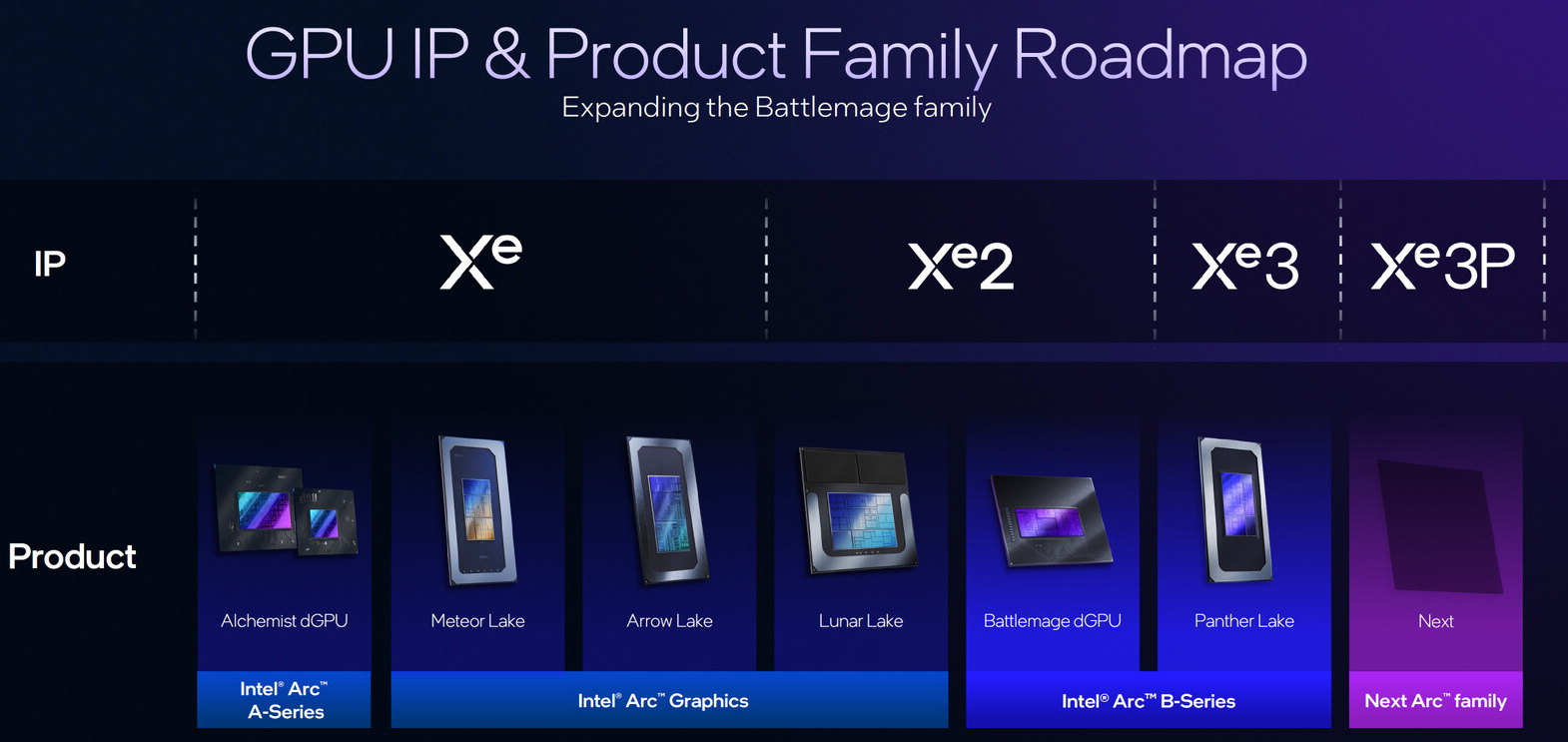
Источник изображения: Intel Прочие технические детали не раскрываются. При этом Intel отмечает, что изделие Crescent Island предназначено для использования в серверах с воздушным охлаждением. GPU поддерживает работу с широким спектром типов данных, благодаря чему может применяться в составе облачных платформ «токен как услуга» (tokens-as-a-service). 
Источник изображения: Intel Пробные поставки новинки планируется начать во II половине 2026 года, тогда как широкая доступность ожидается не ранее 2027-го. Решениям на основе Crescent Island предстоит конкурировать с ИИ-ускорителями AMD и NVIDIA следующего поколения, такими как Rubin CPX. |
|

