Материалы по тегу: ускоритель
|
19.12.2025 [18:35], Сергей Карасёв
NVIDIA выпустила ускоритель RTX Pro 5000 Blackwell с 72 Гбайт памяти для рабочих станцийКомпания NVIDIA сообщила о доступности ускорителя RTX Pro 5000 Blackwell с 72 Гбайт памяти GDDR7 (ECC) для мощных рабочих станций, ориентированных на ИИ-задачи, включая «тонкую» настройку больших языковых моделей (LLM). Новинка является собратом ранее выпущенной версии RTX Pro 5000 Blackwell с 48 Гбайт GDDR7, по сравнению с которой объём памяти увеличился в полтора раза. Оба ускорителя построены на чипе Blackwell с 14 080 ядрами CUDA. Задействованы тензорные ядра пятого поколения и RT-ядра четвёртого поколения. Говорится об использовании 512-бит шины памяти; пропускная способность — 1344 Гбайт/с. Новинка выполнена в виде двухслотовой карты расширения полной высоты с интерфейсом PCIe 5.0 x16. 
Источник изображения: NVIDIA Выпущенный ускоритель располагает четырьмя разъёмами DisplayPort 2.1b. Возможен одновременный вывод изображения на несколько мониторов в следующих конфигурациях: четыре с разрешением до 4096 × 2160 пикселей и частотой обновления 120 Гц, четыре с разрешением 5120 × 2880 точек и частотой 60 Гц или два с разрешением 7680 × 4320 пикселей и частотой 60 Гц. Заявлена поддержка DirectX 12, Shader Model 6.6, OpenGL 4.63, Vulkan 1.33, а также CUDA 12.8, OpenCL 3.0 и DirectCompute. Заявленная ИИ-производительность достигает 2142 TOPS. Карта оборудована 16-контактным разъёмом дополнительного питания. Энергопотребление находится на уровне 300 Вт. Применено активное охлаждение с вентилятором. Ускоритель RTX Pro 5000 Blackwell с 72 Гбайт памяти предлагается через партнёрские каналы, включая Ingram Micro, Leadtek, Unisplendour и xFusion.
16.12.2025 [17:50], Владимир Мироненко
Универсальный ИИ-процессор Electron E1 в 100 раз энергоэффективнее традиционных CPUСтартап из Питтсбурга (Pittsburgh) Efficient Computer выпустил оценочный набор универсального процессора Electron E1 (EVK). Как сообщает компания, Electron E1 представляет собой настоящую альтернативу чипам с использованием традиционной архитектуры фон Неймана, способную обеспечить значительно более высокую энергоэффективность, в 100 раз превышающую показатели обычных маломощных процессоров, таких как Arm Cortex-M33 и Cortex-M85. Electron E1 предназначен для выполнения сложных задач обработки сигналов и инференса. Он основан на т.н. Efficient Fabric, разработанной компанией запатентованной архитектуре пространственного потока данных, которая позволяет снизить «чрезмерное» энергопотребление, связанное с перемещением данных между памятью и вычислительными ядрами, характерное для традиционных систем фон Неймана. При этом «разработчики по-прежнему получают привычный опыт программирования, но с существенно более высокой энергоэффективностью». Генеральный директор Efficient Брэндон Лючия (Brandon Lucia) в интервью EE Times заявил, что предыдущие попытки отойти от подхода фон Неймана так и не были полностью реализованы: «Были мимолётные альтернативы, которые появлялись и исчезали». Он отметил, что одним из ограничений во многих альтернативах был отказ от универсальности вычислений: «Это действительно критически важно». Нечто похожее предлагает и NextSilicon Maverick. 
Источник изображения: Efficient Computer Процессор включает 128 Кбайт сверхэкономичной кеш-памяти, 3 Мбайт SRAM и 4 Мбайт энергонезависимой MRAM, а его производительность может достигать 21,6 GOPS (млрд операций в секунду) при 200 МГц в высоковольтном режиме и 5,4 GOPS при 50 МГц в низковольтном режиме. Архитектура Fabric коренным образом переосмысливает способ выполнения вычислений, уменьшая необходимость в перераспределении данных между памятью и процессорами, говорит Лючия. Это достигается за счёт пространственного отображения операций по сетке вычислительных элементов, каждый из которых активируется только тогда, когда доступны его входные данные в отличие от непрерывного цикла инструкций и косвенной адресации данных, которые доминируют в традиционных конвейерах CPU. Лючия отметил, что универсальный процессор важен для ИИ-технологий, поскольку он представляет собой нечто гораздо большее, чем просто алгоритмы в физическом мире — он обеспечивает, в том числе, интеграцию данных с датчиков, цифровую обработку сигналов, шифрование и преобразование: «Если ваша архитектура специализируется только на одном типе вычислений, все остальные функции остаются невостребованными». 
Источник изображения: Efficient Computer По словам главы Efficient, Electron E1 разработан для поддержки всего кода, необходимого для работы приложения, что делает его идеальным для периферийных вычислений, встроенных систем и ИИ-приложений: «Разработчики могут использовать уже имеющийся у них код». Лючия отметил, что процессор лучше всего подходит для устройств, требующих длительного времени автономной работы, а также условий ограниченного энергопотребления, например, для использования в дронах и промышленных датчиках. Чип уже используется в устройствах партнёра Efficient, компании BrightAI, позволяя обрабатывать ИИ-нагрузки в реальном времени на периферии и снижая потребность в энергоемких облачных вычислениях для таких задач, как обработка сигналов и инференс. Лючия сообщил, что компания видит большие перспективы для использования чипа в робототехнике, автомобилестроении, космосе и оборонных приложениях, которые имеют ограничения по размерам и мощности. Что касается E1 EVK, то он, по словам компании, разработан для того, чтобы максимально упростить изучение потенциала нового процессора. Независимо от того, разрабатываете ли вы новое ПО, проводите анализ энергопотребления или портируете существующее ПО, EVK предоставляет:
В случае отсутствия оборудования можно использовать решение Electron E1 Cloud EVK, которое предоставляет размещённую среду со всеми возможностями физической платы. Как физический EVK, так и облачный EVK доступны в рамках программы раннего доступа Efficient Computer.
12.12.2025 [21:35], Руслан Авдеев
Крошечные чипы для гигантской экономии: PowerLattice пообещала удвоить производительность ИИ-ускорителей на ваттЕсли энергоснабжение организовано неэффективно, на обеспечение работы ИИ-ускорителя мощностью 700 Вт может понадобиться и 1700 Вт. Решить это проблему поможет стартап PowerLattice, который миниатюризировал и переупаковал высоковольтные регуляторы, сообщает IEEE Spectrum. В компании утверждают, что её новые чиплеты позволяют снизить реальное энергопотребление наполовину, удвоив таким образом производительность на ватт. Чиплеты можно разместить максимально близко к вычислительным кристаллам. Традиционные системы питания ИИ-чипов преобразуют переменный ток из сети в постоянный, а затем понижают напряжение до уровня, подходящего ускорителям (порядка 1 В). При значительном падении напряжения сила тока на финальном участке пути к чипу резко возрастает для сохранения нужного уровня мощности. Именно здесь и происходят существенные энергопотери и тепловыделение, которые можно снизить, разместив питающую электронику как можно ближе к потребителю — на расстоянии в несколько миллиметров, а не сантиметров, т.е. буквально внутри чипа. 
Источник изображения: PowerLattice PowerLattice упаковала все необходимые компоненты в один чиплет размеров с пару ластиков, которые ставятся на карандаши. Чиплеты располагаются под подложкой корпуса вычислительного чипа. Одной из ключевых задач было уменьшение индукторов, помогающих поддерживать стабильное выходное напряжение. Пришлось применять специальный магнитный сплав, позволяющий очень эффективно использовать пространство, работая на высоких частотах, в сто раз выше, чем при использовании традиционного варианта. Уникальность решения в том, что сплав сохраняет лучшие магнитные свойства на высоких частотах, чем сопоставимые материалы. Утверждается, что полученные чиплеты более чем в 20 раз компактнее по площади, чем современные стабилизаторы. При этом толщина каждого из них составляет всего 100 мкм, что сопоставимо с толщиной волоса. Такие чиплеты действительно можно размещать очень близко к кристаллам процессора. При этом заказчики могут использовать несколько чиплетов в зависимости от прожорливости и требований конкретных чипов. Энергорасход можно снизить на 50 %, обещает компания, но эксперты пока сомневаются в этом — для достижения такого уровня экономии нужно динамическое управление электропитанием в режиме реального времени в зависимости от текущей нагрузки, что с решением PowerLattice может быть недостижимо. 
Источник изображения: PowerLattice Сейчас PowerLattice тестирует свой продукт на надёжность, а первые клиенты получат чиплеты приблизительно через два года. Intel тоже работает над модулем Fully Integrated Voltage Regulator, которая тоже помогает решить похожие проблемы. В самом стартапе Intel в качестве конкурента не рассматривается, поскольку подход у компаний разный, кроме того, Intel вряд ли будет предлагать свои решения конкурирующим производителям чипов. Эксперты утверждают, что ещё 10 лет назад у компании не было шансов на успех, поскольку поставщики процессоров давали гарантию на них только при покупке их же модулей питания. Например, Qualcomm продавала свои чипсеты только вкупе с чипами управления питанием её же производства. Однако сейчас всё чаще практикуется гетерогенный подход, когда заказчики комбинируют компоненты разных компаний для оптимизации своих систем. Хотя поставщики уровня Intel и Qualcomm, вероятно, будут иметь фору при работе с крупными клиентами, более мелкие разработчики чипов и ИИ-инфраструктуры, возможно, будут искать альтернативные модули управления электропитанием.
12.12.2025 [15:43], Владимир Мироненко
В МФТИ изучили альтернативы ИИ-ускорителям NVIDIA — китайские Moore Threads и MetaX оказались неплохиВ связи с прекращением поставок в Россию ускорителей NVIDIA, ограничениями на загрузку драйверов и отсутствием их техподдержки Институт искусственного интеллекта МФТИ провёл исследование рынка альтернативных ускорителей, включая продукты китайских производителей Moore Threads и MetaX с целью оценки их способности обеспечить полный цикл работы современных ИИ-моделей. Исследование включало анализ архитектурных особенностей ускорителей, драйверов, совместимости с фреймворками и тестирование под нагрузкой при работе с LLM, инференсом, задачами компьютерного зрения и распределённых вычислений. Проведена оценка скорости и воспроизводимости вычислений, устойчивости при росте нагрузки и стабильности поведения моделей на разных типах ускорителей. Исследователи пришли к выводу, что ускорители Moore Threads s4000 и MetaX C500 могут применяться в широком спектре сценариев, обеспечивая стабильный запуск популярных LLM, корректную работу современных фреймворков, предсказуемую производительность и устойчивость работы при длительных нагрузках. В отдельных типах вычислений альтернативные ускорители не уступали или даже обгоняли NVIDIA A100. Особое внимание было уделено возможности работы альтернативных ускорителей в составе вычислительных узлов и кластеров. Разработанный стек ПО позволяет эффективно распределять ресурсы, объединять мощности для работы с крупными моделями и создавать кластерные конфигурации, сообщили в МФТИ. В МФТИ планируют и дальше тестировать новые поколения ускорителей, расширив перечень поддерживаемых моделей, а также намерены подготовить отраслевые рекомендации для создания автономной ИИ-инфраструктуры. 
Источник изображения: Walter Frehner / Unsplash На основе исследования в МФТИ был создан Центр компетенций по решениям, не зависящим от NVIDIA, который объединяет лучшие инженерные практики, методики тестирования, оптимизированные конфигурации и опыт взаимодействия с поставщиками. Он будет оказывать помощь компаниям в подборе оборудования, проведении нагрузочного тестирования под конкретные задачи, настройке вычислительных цепочек, а также может сопровождать платформы в процессе эксплуатации.
04.12.2025 [14:19], Руслан Авдеев
Cambricon Technologies утроит выпуск ИИ-чипов, чтобы заместить ускорители NVIDIA в КитаеКитайская Cambricon Tecnologies намерена в 2026 году более чем втрое увеличить выпуск ИИ-чипов. Предполагается, что это поможет ей отвоевать в КНР долю рынка у Huawei и заполнить вакуум, образовавшийся после вынужденного ухода с рынка NVIDIA, сообщает Bloomberg. По словам источников, знакомых с ситуацией, пекинская компания намерена поставить в 2026 году 500 тыс. ИИ-ускорителей. В том числе речь идёт о 300 тыс. наиболее современных чипов Siyuan 590 и 690. В первую очередь будет использоваться производственный техпроцесс SMIC, известный как 7-нм «N+2». Китайские производители чипов стремительно развиваются после того, как Пекин в 2025 году начал активно препятствовать использованию ускорителей NVIDIA на территории КНР. Это часть долгосрочной стратегии по обретению независимости от американских технологий. В 2026 году вдвое нарастить производство самых передовых ИИ-чипов намерена и Huawei. Перспективная Moore Threads Technology также намерена дебютировать с новыми продуктами. В ноябре глава NVIDIA Дженсен Хуанг (Jensen Huang) жаловался, что деятельность его компании фактически блокируется в Китае, что может привести усилению конкуренции на внутреннем рынке местных игроков. Хотя американские власти рассматривают разрешение продаж в КНР ускорителей NVIDIA H200, нет гарантий, что Пекин не будет препятствовать их распространению. 
Источник изображения: Cambricon Cambricon стала одним из главных бенефициаров ситуации, в сентябрьском квартале увеличив выручку в 14 раз год к году. Её рыночная капитализация взлетела девятикратно в сравнении с 2021 годом. Теперь у неё все шансы получить крупнейшие заказы от китайских ИИ-гигантов, включая Alibaba Group. Одним из основных заказчиков считается ByteDance, на её долю уже приходится более 50 % заказов Cambricon. Достижение Cambricon своих целей не в последнюю очередь зависит от способности получить доступ к производственным мощностям китайской SMIC — главного контрактного производителя материкового Китая. Проблема в том, что на те же мощности претендует Huawei, а также другие компании. В 2025 году, по оценкам Goldman Sachs, Cambricon выпустит всего 142 тыс. ИИ-чипов. Препятствием могут стать и возможности самой SMIC. При выпуске передовых Cambricon Cambricon 590 и 690 процент выхода годных чипов составляет всего 20 %, что значительно повышает их себестоимость. Для сравнения, у тайваньской TSMC процент выхода составляет не менее 60 % в рамках 2-нм техпроцесса, который, по некоторым оценкам, опережает технологии SMIC на три поколения — приблизительно на семь лет. Ещё одна проблема — дефицит высокоскоростной памяти. С этой технологии имеются проблемы у китайских производителей, например, новейшие ускорители Huawei 910С по-прежнему используют южнокорейские модули SK Hynix и Samsung Electronics.
Источник изображения: Cambricon Тем не менее, стремление Пекина к «полупроводниковому суверенитету» может привлечь только в 2025 году $98 млрд в развитие ИИ-технологий. Huawei и Cambricon — лишь крупнейшие компании быстрорастущей отрасли. В гонку включились и быстро развивающиеся конкуренты вроде Hygon, и стартапы уровня Moore Threads и MetaX. В долгосрочной перспективе поставки отечественных ИИ-чипов будут иметь для китайских игроков от DeepSeek до Alibaba решающее решение — они надеются на равных конкурировать с OpenAI и Google. Китай раскритиковал попытки США ограничить поставки американских ИИ-чипов в страну и заявил, что будет наращивать внутренний потенциал, чтобы минимизировать зависимость от политических капризов Вашингтона. Как заявляют эксперты Bloomberg, хотя новые инициативы Huawei, Baidu и Cambricon привели к заметному росту поставок в Китае ИИ-ускорителей местного производства, существующий в стране спрос эта продукция удовлетворить не может. Дисбаланс усугубляется высоким процентом брака 7-нм техпроцесса SMIC, что, вероятно, не изменится в ближайшем будущем. При этом направление развития, вероятно, останется неизменным, поскольку неопределённость относительно доступности чипов NVIDIA подталкивает китайские ИИ-компании к выбору местных поставщиков ускорителей. В Bloomberg утверждают, что в итоге не исключено «раздвоение» глобальной экосистемы ИИ на китайскую и американскую.
03.12.2025 [13:25], Сергей Карасёв
AWS представила ИИ-ускорители Trainium3: 144 Гбайт памяти HBM3E и 2,52 Пфлопс в режиме FP8Облачная платформа Amazon Web Services (AWS) анонсировала ускорители Trainium3 для задач ИИ, а также серверы Trainium3 UltraServer (Trn3 UltraServer). Эти машины, как утверждается, превосходят решения предыдущего поколения — Trainium2 UltraServer — в 4,4 раза по производительности, в 4 раза по энергоэффективности и почти в 4 раза по пропускной способности памяти. Чипы Trainium3 изготавливаются по 3-нм технологии TSMC. Они оснащены 144 Гбайт памяти HBM3E с пропускной способностью до 4,9 Тбайт/с. По сравнению с Trainium2 объём памяти увеличился в 1,5 раза, её пропускная способность — в 1,7 раза. Ранее сообщалось, что энергопотребление новых ускорителей может достигать 1 кВт. 
Источник изображений: AWS Изделие Trainium3 предназначено для высокоплотных и сложных параллельных рабочих нагрузок с использованием расширенных типов данных (MXFP8 и MXFP4). По утверждениям AWS, на операциях FP8 быстродействие достигает 2,52 Пфлопс. Для сравнения, AMD Instinct MI355X показывает результат в 10,1 Пфлопс, а чип поколения NVIDIA Blackwell — 9 Пфлопс. Как уточняет The Register, ускорители Trainium3 используют структурированную разрежённость (structured sparsity) формата 16:4, что фактически поднимает производительность в четыре раза — до 10 Пфлопс — на таких задачах, как обучение ИИ-моделей.   Системы Trainium3 UltraServer объединяют 144 ускорителя Trainium3, которые соединены посредством интерконнекта NeuronSwitch-v1: эта технология, по оценкам AWS, увеличивает пропускную способность в два раза по сравнению с машинами UltraServer предыдущего поколения. Усовершенствованная сетевая архитектура Neuron Fabric сокращает задержки при передаче данных между чипами до менее чем 10 мкс. Каждая система Trainium3 UltraServer оперирует 20,7 Тбайт памяти HBM3E с общей пропускной способностью 706 Тбайт/с. Заявленная производительность достигает 362 Пфлопс в режиме FP8. 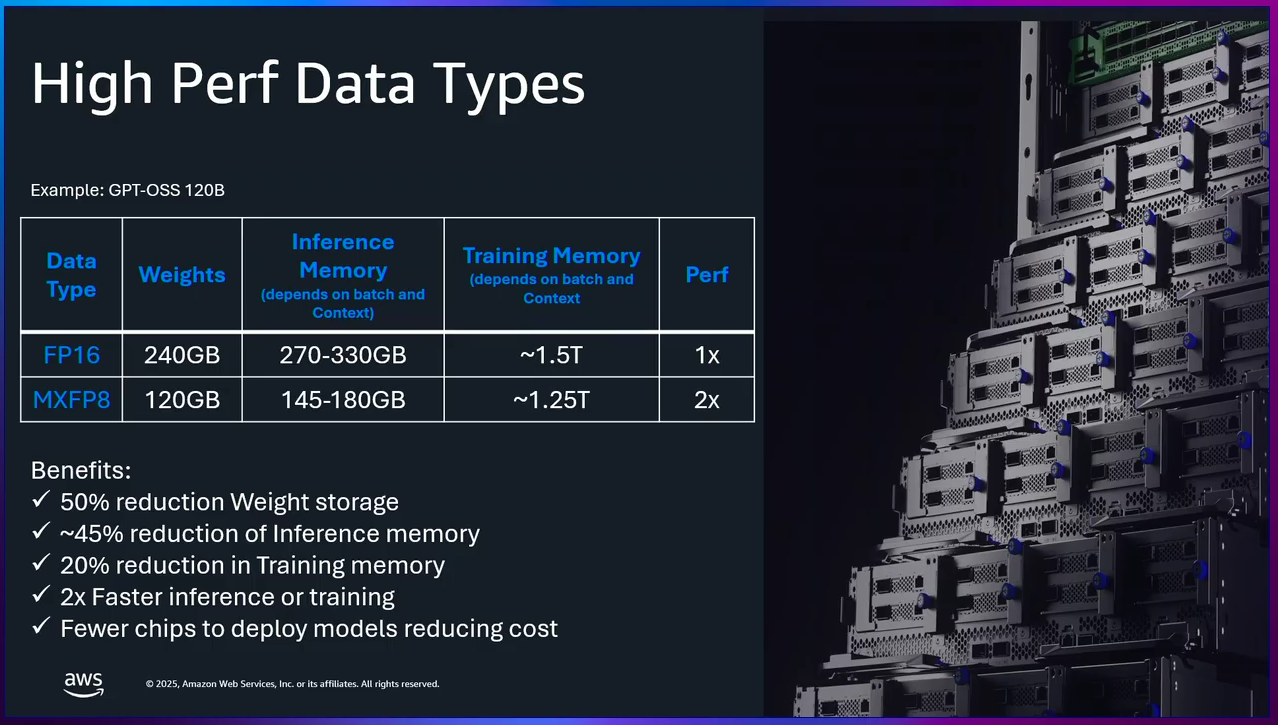  Применённые в Trainium3 технологии, как заявляет AWS, дают возможность создавать приложения ИИ с практически мгновенным откликом. Платформа EC2 UltraClusters 3.0 позволяет объединять тысячи систем UltraServer, содержащих до 1 млн ускорителей Trainium, что в 10 раз больше, чем в случае изделий предыдущего поколения. При этом следующее поколение ускорителей Trainium4 получит интерконнект NVLink Fusion шестого поколения.
03.12.2025 [01:28], Владимир Мироненко
AWS «сдалась на милость» NVIDIA: анонсированы ИИ-ускорители Trainium4 с шиной NVLink FusionAWS готовит Arm-процессоры Graviton5, которые составят компанию ИИ-ускорителям Trainium4 с интерконнектом NVLink Fusion, фирменными EFA-адаптерам и DPU Nitro 6 с движком Nitro Isolation Engine. Но что более важно, все они будут «упакованы» в стойки стандарта NVIDIA MGX. Amazon и NVIDIA объявили о долгосрочном партнёрстве, в рамках которого ИИ-ускорители Trainium4 получит шину NVIDIA NVLink Fusion шестого поколения (по-видимому, 3,6 Тбайт/с в дуплексе), которая позволит создать стоечную платформу нового поколения, причём, что интересно, на базе архитектуры NVIDIA MGX, которая передана в OCP. Пикантность ситуации в том, что AWS годами практически игнорировала OCP, самостоятельно создавая стойки, их компоненты, включая СЖО, и архитектуру ИИ ЦОД в целом. Даже в нынешнем поколении стоек с GB300 NVL72 отказалась от референсного дизайна NVIDIA. NVIDIA же напирает на то, что для гиперскейлерам крайне трудно заниматься кастомными решениями — циклы разработки стоечной архитектуры занимают много времени, поскольку помимо проектирования специализированного ИИ-чипа, гиперскейлеры должны озаботиться вертикальным и горизонтальным масштабированием, интерконнектами, хранилищем, а также самой конструкцией стойки, включая лотки, охлаждение, питание и ПО. 
Источник изображения: NVIDIA Вместе с тем управление цепочкой поставок отличается высокой сложностью, так как требуется обеспечить согласованную работу десятков поставщиков, ответственных за десятки тысяч компонентов. И даже одна задержка поставки или замена одного компонента может поставить под угрозу весь проект. Платформа NVIDIA если не устраняет целиком, то хотя бы смягчает эти проблемы, предлагая готовые стандартизированные решения, которые могут поставлять множество игроков рынка. 
Источник изображения: NVIDIA По словам NVIDIA, в отличие от других подходов к масштабированию сетей, NVLink — проверенная и широко распространённая технология. В сочетании с фирменным ПО NVLink Switch обеспечивает увеличение производительности и дохода от ИИ-инференса до трёх раз, объединяя 72 ускорителя в одном домене. Пользователи, внедрившие NVLink Fusion, могут использовать любую часть платформы — каждый компонент может помочь им быстро масштабироваться для удовлетворения требований интенсивного инференса и обучения моделей агентного ИИ, говорит NVIDIA. 
Источник изображения: AWS Что касается самих ускорителей Trainium4, то в сравнении с Trainium3 они будут вшестеро быстрее в FP4-расчётах, втрое быстрее в FP8-вычислениях, а пропускная способность памяти будет увеличена вчетверо. Впрочем, пока собственные ускорители Amazon не всегда могут составить конкуренцию чипам NVIDIA. Любопытно и то, что в рассказе о Trainium3 компания отметила о переходе от PCIe к UALink в коммутаторах NeuronSwitch для фирменного интерконнекта NeuronLink, объединяющего до 144 чипов Trainium. Однако после крупных инвестиций NVIDIA в Synopsys развитие UALink как открытой альтернативы NVLink теперь под вопросом.
25.11.2025 [11:24], Сергей Карасёв
Стартап Kneron представил чип KL1140 для работы с ИИ-моделями на периферииАмериканский стартап Kneron, по сообщению ресурса SiliconANGLE, разработал ИИ-чип KL1140, предназначенный для запуска больших языковых моделей (LLM) на периферийных устройствах. Утверждается, что изделие обеспечивает ряд существенных преимуществ перед облачными развёртываниями. Kneron, основанная в 2015 году, базируется в Сан-Диего (Калифорния, США). Стартап проектирует чипы для всевозможного оборудования с ИИ-функциями: это могут быть роботы, подключённые автомобили и пр. Ранее Kneron представила решение KL730, которое объединяет четырёхъядерный CPU на архитектуре Arm и акселератор для задач инференса. В 2023 году компания привлекла на развитие $49 млн от Foxconn and HH-CTBC Partnership (Foxconn Co-GP Fund), Alltek, Horizons Ventures, Liteon Technology Corp, Adata и Palpilot. В общей сложности на сегодняшний день Kneron получила более $200 млн от различных инвесторов. 
Источник изображения: Kneron Характеристики нового чипа KL1140 полностью пока не раскрываются. Kneron заявляет, что это первый нейронный процессор, способный полноценно работать с сетями-трансформерами на периферии. Связка из четырёх чипов KL1140, как утверждается, обеспечивает производительность на уровне GPU при работе с ИИ-моделями, насчитывающими до 120 млрд параметров. При этом энергопотребление сокращается на 50–66 %. Суммарные затраты на оборудование могут быть снижены в 10 раз по сравнению с существующими облачными решениями. Среди других преимуществ запуска LLM на периферийных устройствах названы уменьшение задержки, отсутствие необходимости отправки конфиденциальных данных на внешние серверы и возможность использования даже без подключения к интернету. Чип KL1140 ориентирован на такие задачи, как обработка естественного языка в реальном времени, голосовые интерфейсы, системы машинного зрения, интеллектуальные платформы видеонаблюдения и др. Разработчики могут применять изделие для безопасного локального развёртывания приложений ИИ без необходимости использования облачных ресурсов.
24.11.2025 [15:14], Сергей Карасёв
Технологии тысячеядерного RISC-V-ускорителя Esperanto будут переданы в open sourceСтартап Ainekko, специализирующийся на разработке аппаратных и программных решений в сфере ИИ, по сообщению EE Times, приобрёл интеллектуальную собственность и некоторые активы компании Esperanto Technologies. Речь идёт о дизайне чипов, программных инструментах и фреймворке. Фирма Esperanto, основанная в 2014 году, специализировалась на создании высокопроизводительных ускорителей с архитектурой RISC-V для задач НРС и ИИ. В частности, было представлено изделие ET-SoC-1, объединившее 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Основной сферой применения чипа был заявлен инференс для рекомендательных систем, в том числе на периферии. Однако в июле нынешнего года стало известно, что Esperanto сворачивает деятельность и ищет покупателя на свои разработки — ключевых инженеров переманили крупные компании. А продать чипы Meta✴, в чём, по-видимому, и заключался изначальный план, не удалось. Как рассказала соучредитель Ainekko Таня Дадашева (Tanya Dadasheva), её компания работает с чипами Esperanto в течение примерно полугода. Изначально компания планировала использовать чипы Esperanto для запуска своего софтверного стека. В частности, удалось перенести llama.cpp up и tinygrad. Когда стало понятно, что Esperanto вряд ли выживет, было принято решение выкупить разработки стартапа. Во всяком случае, это лучше, чем просто закрыть компанию, оставив её заказчиков ни с чем, как поступила AMD с Untether AI. 
Источник изображения: Esperanto Ainekko планирует передать сообществу open source технологии Esperanto, связанные с многоядерной архитектурой RISC-V, включая RTL, референсные проекты и инструменты разработки. Предполагается, что решения Esperanto будут востребованы прежде всего в области периферийных устройств, где большое значение имеет энергоэффективность. Архитектура Esperanto, как утверждается, подходит для таких задач, как робототехника и дроны, системы безопасности, встраиваемое оборудование с ИИ-функциями и пр. Второй соучредитель Ainekko Роман Шапошник (Roman Shaposhnik) добавляет, что многоядерная архитектура Esperanto подходит не только для разработки ИИ-чипов, но и для создания «универсальной вычислительной платформы». Сама Ainekko намерена выпустить чип с восемью ядрами Esperanto и 16 Мбайт памяти MRAM, разработанной стартапом Veevx. Отмечается, что соучредитель и генеральный директор Veevx, ветеран Broadcom Даг Смит (Doug Smith), является ещё одним сооснователем Ainekko. В дальнейшие планы входит разработка процессора с 256 ядрами: по производительности он будет сопоставим с чипом Broadcom BCM2712 (4 × 64-бит Arm Cortex-A76), лежащим в основе Raspberry Pi 5, но оптимизирован для инференса.
18.11.2025 [16:55], Владимир Мироненко
d-Matrix привлекла ещё $275 млн и объявила о разработке первого ИИ-ускорителя с 3D-памятью Raptord-Matrix сообщила о завершении раунда финансирования серии C, в ходе которого было привлечено $275 млн инвестиций с оценкой рыночной стоимости компании в $2 млрд. Общий объём привлечённых компанией средств достиг $450 млн. Полученные средства будут направлены на расширение международного присутствия компании и помощь клиентам в развёртывании ИИ-кластеров на основе её технологий. Раунд C возглавил глобальный консорциум, включающий BullhoundCapital, Triatomic Capital и суверенный фонд благосостояния Сингапура Temasek. В раунде приняли участие Qatar Investment Authority (QIA) и EDBI, M12, венчурный фонд Microsoft, а также Nautilus Venture Partners, Industry Ventures и Mirae Asset. Сид Шет (Sid Sheth), генеральный директор и соучредитель d-Matrix, отметил, с самого начала компания была сосредоточена исключительно на инференсе. «Мы предсказывали, что когда обученным моделям потребуется непрерывная масштабная работа, инфраструктура не будет готова. Последние шесть лет мы потратили на разработку решения: принципиально новой архитектуры, которая позволяет ИИ работать везде и всегда. Это финансирование подтверждает нашу концепцию, поскольку отрасль вступает в эпоху ИИ-инференса», — добавил он. d-Matrix разработала ускоритель инференса Corsair на базе архитектуры с вычислениями в памяти DIMC (digital in-memory computing) — процессорные компоненты в нём встроены в память. Ускоритель предлагается вместе с сетевой картой JetStream. Также предлагается референсная архитектура SquadRack, которая упрощает создание ИИ-кластеров на базе Corsair. Она поддерживает до восьми серверов в стойке, каждая из которых содержит восемь ускорителей Corsair. Шасси SquadRack позволяет запускать ИИ-модели размером до 100 млрд параметров, хранящиеся полностью в SRAM. По данным d-Matrix, такая конфигурация обеспечивает на порядок большую производительность по сравнению с чипами с HBM. Вместе с оборудованием компания предлагает программный стек Aviator, который автоматизирует часть работы, связанной с развертыванием ИИ-моделей на ускорителе. Aviator также включает набор инструментов для отладки моделей и мониторинга производительности. 
Источник изображения: d-Matrix В следующем году d-Matrix планирует выпустить более производительный ускоритель инференса Raptor. Это первый в мире ускоритель на базе 3D DRAM. Решение разрабатывается в партнёрстве с Alchip, известной разработками в области ASIC. Благодаря сотрудничеству уже реализована ключевая технология d-Matrix 3DIMC, представленная в тестовом кристалле d-Matrix Pavehawk. По словам компаний, новинка обеспечит до 10 раз более быстрый инференс по сравнению с решениями на базе HBM4, что позволит повысить эффективность генеративных и агентных рабочих ИИ-нагрузок. Также в Raptor будет использоваться процессор AndesCore AX46MPV от Andes Technology. Компании заявили, что их сотрудничество представляет собой конвергенцию вычислений, ориентированных на память, и инноваций в области процессоров на основе открытых стандартов для рабочих ИИ-нагрузок в масштабах ЦОД. Andes AX46MPV будет отвечать за оркестрацию наргрузок, распределение памяти, векторные вычисления и функции активации. AX46MPV — 64-бит многоядерный RISC-V-процессор с поддержкой Linux. Он включает 2048-бит блок векторной обработки (RVV 1.0), высокоскоростную векторную память (HVM) и ряд других аппаратных блоков для работы с массивными вычислениями. В совокупности эти функции обеспечивают запас производительности и гибкость ПО, необходимые для систем инференса уровня ЦОД. Референсные ядра, являющиеся ключевыми для рабочих нагрузок ИИ-трансформеров и LLM, демонстрируют прирост производительности до 2,3 раза по сравнению с предшественником AX45MPV. |
|

