Материалы по тегу: инференс
|
25.07.2026 [21:30], Сергей Карасёв
ИИ-платформа Liqid UltraStack объединяет 30 ускорителей AMD Instinct MI350PКомпания Liqid объявила о стратегическом сотрудничестве с AMD, направленном на создание решений следующего поколения для ИИ-инфраструктур. В рамках партнёрства представлена аппаратная платформа Liqid UltraStack 30, оптимизированная для задач инференса. В состав системы входят сервер с двумя процессорами AMD EPYC 9005 Turin и коммутатор Liqid PCIe Fabric Switch. Ключевыми компонентами являются три GPU-блока, каждый из которых содержит десять ускорителей AMD Instinct MI350P (144 Гбайт памяти HBM3E с 4096-бит шиной). Таким образом, в общей сложности задействованы 30 названных карт и 4,3 Тбайт памяти HBM3E. Заявленная производительность достигает 69 Пфлопс в режиме FP8. Говорится о возможности работы с общими пулами памяти по высокоскоростному стандарту CXL. Суммарное энергопотребление платформы находится на уровне 22 кВт. По заявлениям Liqid, система обеспечивает 3,7-кратный прирост показателя токенов в секунду по сравнению с традиционными решениями. Количество токенов в пересчете на $1 увеличивается в 2,1 раза, а токенов на 1 Вт затрачиваемой энергии — в 1,8 раза. Затраты на развёртывание могут быть уменьшены на 65 %. 
Источник изображения: Liqid Программное обеспечение Liqid Matrix объединяет GPU-ускорители и в реальном времени распределяет их ресурсы между рабочими нагрузками через высокоскоростную PCIe-шину. При этом все карты остаются в пределах одного узла. В целом, платформа Liqid UltraStack 30, как утверждается, устраняет накладные расходы, связанные с использованием нескольких узлов, обеспечивает предсказуемое линейное масштабирование и доводит загрузку GPU почти до 100 %. Упомянута поддержка Kubernetes для работы с несколькими моделями.
24.07.2026 [11:58], Сергей Карасёв
AMD и Cerebras представили платформу для ИИ-инференса со сверхнизкой задержкойКомпании AMD и Cerebras Systems объявили о сотрудничестве, в раках которого планируется вывод на рынок новой аппаратной платформы для ИИ-инференса со сверхнизкой задержкой и высокой пропускной способностью. Речь идёт об объединении стоечных решений AMD Helios и ускорителей Cerebras Wafer-Scale Engine (WSE). Это своего рода ответа на интеграцию Groq в платформу NVIDIA Vera Rubin. Напомним, система Helios двойной ширины объединяет процессоры EPYC Venice с ядрами Zen 6, ускорители Instinct MI400 и DPU Vulcano. Данная платформа спроектирована специально с прицелом на ресурсоёмкие ИИ-задачи. В свою очередь, изделия WSE, насчитывающие сотни тысяч ядер, оптимизированы для сверхбыстрого обучения и запуска ИИ-моделей. Совместное решение AMD и Cerebras объединяет сильные стороны Helios и WSE в общий рабочий процесс для достижения максимальной производительности и эффективности инференса. В частности, формируется дезагрегированная среда, в которой два основных этапа задачи оптимизируются независимо друг от друга. Стойки Helios обеспечивают сверхвысокую пропускную способность, обрабатывая запросы и большие контекстные окна. Ускорители WSE при этом отвечают за генерацию токенов с минимальной задержкой. 
Источник изображения: Cerebras В целом, новая платформа AMD и Cerebras, как утверждается, даёт возможность повысить показатель токенов в секунду на ватт (Т/с/Вт) в пять раз по сравнению с конфигурациями, в которых используются только лишь изделия WSE (при работе с мультимодальной моделью Kimi 2.6 1T, насчитывающей 1 трлн параметров). В рамках партнёрства с AMD компания Cerebras намерена развернуть системы Helios в своих дата-центрах. Новое аппаратное решение станет доступно клиентам через облако Cerebras Cloud во II половине текущего года.
21.07.2026 [13:14], Руслан Авдеев
Google создаёт ИИ-ускоритель Frozen v2, оптимизированный специально для GeminiКомпания Google работает над новым ИИ-ускорителем под неформальным названием Frozen v2, который позволит интегрировать элементы ИИ-модели Gemini непосредственно в «железо», что позволит эффективнее исполнять ИИ-нагрузки, сообщает The Information. Чип, как ожидается, поможет разрешить проблему нехватки вычислительных мощностей для ИИ, уже заставившую Google Cloud отказаться от сделок с клиентами. По имеющимся данным, Google намерена начать внедрение новых чипов в 2028 году, хотя работы над новой архитектурой продолжаются. Кроме того, пока неизвестно, какая часть модели будет «прошита» в аппаратной составляющей. Предполагается, что чипы могут быть в 6–10 раз эффективнее, чем новейшие TPU, в пересчёте на количество токенов на Вт. При этом новые чипы призваны дополнить TPU, а не заменить их. По словам представителя Google Cloud, команды компании постоянно занимаются исследованиями и экспериментируют с инновационными решениями. Проектируя аппаратное и программное обеспечения с нуля, компания обеспечивает интеграцию и высокую степень оптимизации систем. 
Источник изображения: Google Как сообщает Silicon Angle, чипы, предлагаемые «по умолчанию», обычно включают компоненты, которые клиентам не нужны вовсе. Например, использование традиционных GPU для инференса делает ненужными блоки рендеринга. Разработка кастомных чипов помогает решить проблему. Компания может исключить ненужные модули, тем самым снижая цену производства, или же заменить ненужные элементы на модули, оптимизированные для специальных задач. Повышенная эффективность будет достигнута разными способами. В частности, в компании рассчитывают, что Froxen v2 позволит снизить количество вычислений для Gemini. Также ожидается снижение масштабов перемещения данных. Google может оснастить Frozen v2 достаточным количеством памяти для запуска Gemini полностью на чипе. Подобный дизайн избавил бы от необходимости отправлять данные к RAM и обратно.
09.07.2026 [16:51], Владимир Мироненко
Parasail скрестила NVIDIA Hopper и Blackwell с d-Matrix Corsair, ускорив инференс в 10 разКомпании Parasail и d-Matrix объявили о развёртывании кастомных ускорителей d-Matrix Corsair для инференса вместе с ускорителями NVIDIA Hopper и Blackwell в рамках гетерогенной дезагрегированной инфраструктуры, что позволит в 10 раз увеличить скорость инференса. В объединённой системе ускорители NVIDIA и Corsair будут работать согласованно, выполняя вычислительные задачи с учётом их возможностей. Чтобы улучшить экономику инференса для отдельных рабочих нагрузок, Parasail использует GPUтA для ресурсоёмкого предварительного заполнения, а ускорители d-Matrix Corsair — для чувствительного к задержке декодирования. К этому же стремится и сама NVIDIA, добавившая к своим GPU ускорители Groq. 
Источник изображения: Parasail Parasail управляет облаком для инференса, которое объединяет мощности ИИ-ускорителей в более чем 40 ЦОД в 15 странах. Разработанная ею технология автоматической оптимизации позволяет динамически распределять рабочие нагрузки между гетерогенным парком исходя из требований к моделям и обработке. Parasail делает ставку на гетерогенный вычислительный подход с d-Matrix, чтобы получить больше выгоды от уже имеющейся у неё ИИ-инфраструктуры NVIDIA. d-Matrix утверждает, что сочетание Corsair с GPU позволяет выполнять задачи инференса на порядок быстрее, втрое дешевле и впятеро энергоэффективнее, сообщил TNW. Ресурс отметил, что вместо борьбы с потенциальными конкурентами NVIDIA предлагает им сотрудничество, чтобы интегрировать их в свою экосистему. Заказчикам больше не нужен один гигантский GPU для всего. Они хотят получить самый дешевый чип для каждой задачи, объединённый с другими чипами в единую систему. План NVIDIA состоит в том, чтобы обеспечить продажи или занять место рядом с тем продуктом, который одержит победу, пишет TNW.
07.07.2026 [23:59], Владимир Мироненко
Китайская DeepSeek скрытно занимается разработкой собственного ИИ-ускорителя для инференсаКитайский стартап DeepSeek работает над созданием собственного чипа для ИИ-инференса, что позволит ему снизить зависимость от NVIDIA и Huawei, чьи ускорители используются для обучения и запуска его ИИ-моделей, сообщило агентство Reuters со ссылкой на информированные источники. По данным источников, работа DeepSeek над этим проектом началась около года назад и пока находится на ранней стадии: сейчас стартап ведёт переговоры с компаниями, занимающимися проектированием чипов, производством микросхем и памяти. В последние месяцы он увеличил найм инженеров-разработчиков микросхем, причём набор ведётся в частном порядке, без особой огласки и без размещения вакансий на публичных платформах. Для DeepSeek эта инициатива имеют дополнительное стратегическое измерение, поскольку США ввели экспортные ограничения на поставку китайским компаниям передовых чипов NVIDIA, а власти Китая оказывает давление на местные компании, продвигая разработку и внедрение отечественных альтернатив. 
Источник изображения: He Junhui/unsplash.com DeepSeek не единственная компания, кто стремится снизить зависимость от NVIDIA, доминирующей на рынке ИИ-чипов. Помимо гиперскейлеров Amazon (Trainium), Alibaba (Zhenwu), Google (TPU), Meta✴ (MTIA) и Microsoft (Maia), расширяющих использование собственных чипов, ещё ряд компаний предпринимает шаги в этом направлении. Например, в прошлом месяце OpenAI представила Jalapeño, свой первый кастомный чип для инференса, разработанный совместно с Broadcom. Anthropic тоже рассматривает возможность создания собственных ИИ-чипов.
06.07.2026 [18:07], Владимир Мироненко
Selectel и ИТМО создали СП для разработки платформы по созданию ИИ-агентов для бизнесаSelectel и Национальный исследовательский университет ИТМО объявили о запуске совместного предприятия с целью разработки решений в сфере ИИ, в частности — платформы для создания, внедрения и промышленной эксплуатации мультиагентных систем на базе больших языковых моделей (LLM). Новая платформа позволит быстро создавать ИИ-решения под конкретные бизнес-процессы заказчиков, подключать их к корпоративным данным и системам, измерять качество работы и безопасно их развивать по мере изменения задач бизнеса. Коммерческая модель будет учитывать фактическое потребление вычислительных ресурсов и токенов. Оплата заказчиком использования ИИ-агентов будет производиться в зависимости от объёма, сложности и места выполнения работы: на инфраструктуре Selectel, в выделенном контуре или непосредственно у заказчика. Сообщается, что в штат СП войдёт проектная группа ИТМО и опытные эксперты индустрии. ИТМО выступит ключевым центром компетенций с готовыми наработками, а Selectel обеспечит финансирование проекта на сумму более 1 млрд руб., а также предоставит необходимую IT-инфраструктуру. Ранее сообщалось, что Selectel создал новую компанию для реализации ИИ-проектов — «Эмерджентные мультиагентные системы» (ООО «ЭМС»). По словам Олега Любимова, гендиректора Selectel, объединив экспертизу Selectel в построении специализированной инфраструктуры для ИИ с профильными компетенциями команды ИТМО, и действуя при этом как самостоятельный игрок, новое предприятие будет способствовать ускорению развития прикладных решений, необходимых крупному бизнесу на фоне перехода к агентной экономике ИИ-систем. 
Источник изображения: ИТМО Любимов уточнил в интервью ресурсу Forbes, что у Selectel доля в уставном капитале СП составляет ⅔, у ИТМО — ⅓. Руководитель ИТМО Александр Бухановский рассказал Forbes, что специалисты ИТМО разработали технологию, которая автоматизирует конструирование прикладных агентов ИИ и мультиагентных систем на их основе под комплексные бизнес-задачи. «Мы реализовали ИИ, который умеет делать ИИ», — отметил он. С 2020 года Selectel инвестировал в развитие ИИ-решений более 3,5 млрд руб. В ближайшие пять лет провайдер планирует увеличить финансирование проектов в сфере ИИ, выделив на эти цели 10 млрд руб. С конца прошлого года 25 % АО «Селектел» принадлежит компании «Каталитик Пипл», созданной МКПАО «Т-Технологии» и ХК «Интеррос».
06.07.2026 [17:55], Андрей Крупин
Представлена российская платформа «Боцман AI» для запуска ИИ-моделей внутри защищённого контура компании«Группа Астра» объявила о выпуске программного комплекса «Боцман AI», предназначенного для развёртывания языковых и других моделей искусственного интеллекта внутри защищённого контура организации, без передачи данных во внешние облачные сервисы. «Боцман AI» является расширением платформы «Боцман» — отечественного решения оркестрации контейнеров на базе Kubernetes, входящего в состав Astra Dev Platform и ориентированного на компании, которые строят внутренние платформы разработки и эксплуатируют приложения в изолированных или регулируемых IT-инфраструктурах. Решение позволяет организациям разворачивать и запускать ИИ-нагрузки внутри собственного сетевого контура — с сохранением суверенитета над данными, предсказуемыми затратами и без привязки к зарубежным провайдерам. Для работы с «Боцман AI» достаточно произвести описание ИИ-модели через стандартный Kubernetes-ресурс — всё остальное система делает автоматически, говорят разработчики. Она самостоятельно подготавливает хранилище весов и запускает среду выполнения с нужным движком — будь то vLLM, Ollama, SGLang или FasterWhisper, после чего публикует модель через единый шлюз. Отдельного внимания заслуживает механизм обновлений — они происходят без образования окна недоступности, что особенно критично при работе с дорогостоящей GPU-инфраструктурой. 
Источник изображения: Numan Ali / unsplash.com Для взаимодействия с моделями в «Боцман AI» задействован OpenAI-совместимый API. Помимо базовой функциональности, платформа предлагает ряд инструментов для промышленной эксплуатации. В неё встроены автоматическое масштабирование под нагрузку, система биллинга и управление API-ключами с контролем бюджетов, что позволяет прозрачно распределять ресурсы между командами и проектами. Установка программного решения осуществляется через «Боцман Apps & Marketplace» в виде Helm-чарта.
01.07.2026 [17:45], Владимир Мироненко
Etched заключил контракты на поставку чипов для ИИ-инференса более чем на $1 млрдСтартап Etched, вышел из скрытого режима (stealth), объявив о разработке ИИ-чипа для инференса и подписанных контрактах на его поставку более чем на $1 млрд. Также стартап сообщил о привлечении $800 млн инвестиций в рамках нескольких ранее не разглашавшихся раундов финансирования. Последний раунд финансирования прошёл в декабре 2025 года. Компания привлекла тогда $500 млн инвестиций при оценке в $5 млрд. В числе инвесторов Etched — VentureTech Alliance, Питер Тиль (Peter Thiel), Jane Street, Hudson River Trading, Jump Trading, Two Sigma, Stripes, Ribbit Capital, Radical Ventures, Primary VC, Positive Sum, а также несколько известных исследователей и предпринимателей в области ИИ. 
Источник изображений: Etched Компания сообщила, что первые прототипы чипов (A0) сошли с производственной линии N4P TSMC в начале этого года и что она планирует начать поставки своих первых стоечных систем для инференса этим летом. В настоящее время они проходят тестирование у клиентов. По данным Etched, предварительные испытания у клиентов продемонстрировали передовые показатели пропускной способности, задержки и энергоэффективности ИИ-систем при выполнении инференса.  Etched разрабатывает вертикально интегрированную инфраструктуру для ИИ-инференса, которая объединяет кастомные микросхемы, стойки, сетевое оборудование, системы охлаждения, ПО и производство. Компания сообщила, что её системы уже работают с популярными ИИ-моделями, включая DeepSeek, Qwen, Mamba и Llama, и предназначены для поддержки моделей от плотных архитектур до больших MoE-систем с произвольно большим количеством параметров.  Как сообщает ресурс Converge! Network Digest, для поддержки производства Etched открыла завод на Тайване, а также построила ЦОД мощностью 2 МВт, испытательный центр и лабораторию для прототипирования новых продуктов (NPI) в своей штаб-квартире в Сан-Хосе, с планом достижения ИИ-инфраструктурой для инференса гигаваттного масштаба к 2027 году.  Etched также сообщила о внедрении двух технологий. Первая — Low Voltage Inference (LVI), которая позволяет чипу работать с вполовину меньшим напряжением по сравнени с типовыми ускорителями, при этом устоявшаяся производительность составляет более 80 % от пиковой при разреженном инференсе триллионных MoE-моделей. Результатом является отсутствие троттлинга значительное ускорение инференса. Вторая технология, Cluster Scale Memory (CSM), сочетает SRAM и HBM с общей архитектурой памяти с низкой задержкой и запатентованный интерконнект. В итоге и задержка снижается, и высокая пропускная способность памяти сохраняется.
26.06.2026 [12:23], Владимир Мироненко
Cornelis и NextSilicon создадут эталонные архитектуры для ИИ и HPCCornelis и NextSilicon объявили о сотрудничестве с целью разработки эталонных архитектур для ИИ и HPC. В рамках проекта компании приступили к оценке возможности использования 400G-интерконнекта Cornelis CN5000 в паре с вычислительной платформой NextSilicon Maverick-2. На первом этапе проверяется совместная работа интерконнекта и вычислительных ресурсов в различных конфигурациях, причём партнёры начали с проверенных комбинаций. Компании планируют расширить тестирование на интерконнект CN6000 со скоростью 800 Гбит/с, запуск которого запланирован на II половину 2026 года. Обе компании нацелены на решение проблемы в своей сфере. Стандартный Ethernet не рассчитан на обработку небольших, чувствительных к задержке сообщений, которые генерируются в больших масштабах при выполнении задач ИИ-инференса и симуляции HPC. Возникает перегрузка, и дорогостоящие вычислительные ресурсы простаивают в ожидании данных. CN5000 разработан для устранения этого простоя. 
Источник изображений: Cornelis Networks Вычислительные ресурсы простаивают при обработке нерегулярных, зависящих от данных рабочих нагрузок, которые доминируют в ИИ и HPC. Израильская компания NextSilicon построила ускоритель Maverick-2 на основе своей интеллектуальной вычислительной архитектуры (ICA) — программно-определяемой архитектуры с управлением потоками данных (dataflow), в которой вычисления запускаются не последовательными инструкциями, а по факту поступления данных. Платформа переконфигурируется для каждой рабочей нагрузки во время выполнения без изменения существующего кода. Сочетание подходов Cornelis и NextSilicon позволяет решить обе проблемы, обеспечивая передачу данных и поддерживая постоянную работу вычислительных ресурсов. Совместные эталонные архитектуры предоставят OEM-партнерам план создания систем, которые они смогут построить и вывести на рынок.  «Операторы постоянно говорят нам, что их самые дорогие системы простаивают, ожидая подключения к сети, — говорит Лиза Спелман (Lisa Spelman), генеральный директор Cornelis. — Мы создали CN5000, чтобы положить конец этому ожиданию. NextSilicon бросает вызов аналогичной проблеме в вычислительной сфере, поэтому это сотрудничество является естественным шагом. Вместе мы можем показать партнерам и клиентам, что дают бесперебойная сеть и вычислительная архитектура, ориентированная на рабочие нагрузки, в рамках единого решения». Наряду с HPC, сотрудничество также будет направлено на переход в ИИ-инференсе к моделям смешанных экспертов (MoE) и агентному ИИ. Инференс в продуктовых средах для этих рабочих нагрузок больше не выполняется как одна модель на одном ускорителе. Он разделяется на этапы, и данные перемещаются между этапами по сети. Дезагрегированный инференс делает сетевую инфраструктуру частью вычислительного пути. Он применим для сети, которая обрабатывает небольшие, импульсные, чувствительные к задержкам сообщения без перегрузки, и вычислительных ресурсов, которые адаптируются к каждому этапу конвейера.
25.06.2026 [16:11], Владимир Мироненко
Qualcomm анонсировала HBC — альтернативу HBM на базе LPDDRQualcomm анонсировала High Bandwidth Compute (HBC), гибридное решение для вычислений и памяти, разработанное в качестве альтернативы памяти HBM и обеспечения большей производительности, эффективности и пропускной способности. В нём используется трёхмерная архитектура Near-Memory Computing (NMC), обеспечивающая предельно близкое расположение быстрой памяти к вычислительным ядра. В HBC используется память LPDDR, размещённая вертикально в несколько слоёв, соединённых сквозными кремниевыми контактами (TSV). Такой подход обеспечивает лучшую энергоэффективность, чем традиционная HBM, в которой в вертикальных слоях размещается память DDR, поскольку микросхемы LPDDR потребляют меньше энергии, обеспечивая при этом аналогичную пропускную способность и ёмкость. При этом в основании HBC лежит вычислительный кристалл, который берёт на себя часть обработки данных основного процессора, тем самым разгружая его. Как отметил ресурс Techpowerup, эта технология аналогична используемой в памяти HBM4, где базовый кристалл представляет собой логический кристалл для лучшей интеграции вычислительных решений, таких как трассировка пакетов и подготовка данных для ввода и вывода из HBM. 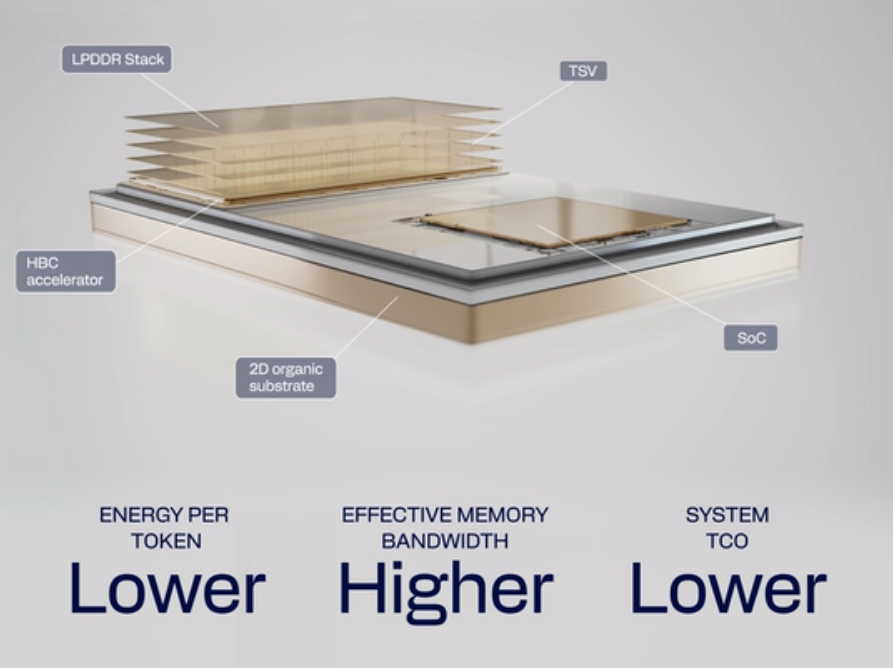
Источник изображений: Qualcomm Qualcomm сообщила, что HBC обеспечивает шестикратное увеличение пропускной способности на Вт по сравнению с HBM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне платы, а также 200-кратное увеличение ёмкости на Вт по сравнению с SRAM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне стойки.  HBC первого поколения (HBC Gen 1) достигла пропускной способности 133 Тбайт/с на ускорителе AI250, что в 18 раз больше, чем у AI200 на базе LPDDR5X. Коммерческое тестирование HBC1 с AI250 ожидается в середине 2027 года. Компания планирует выпуск решения HBC Gen 2 в 2028 году. Это решение выйдет с ИИ-ускорителем Qualcomm Dragonfly AI300 и обеспечит 54-кратное увеличение эффективной пропускной способности по сравнению с AI200 и семикратное увеличения пропускной способности на Вт по сравнению с HBM.  Dragonfly AI300 интегрирует HBC2, обеспечив высокую пропускную способность и низкую задержку для инференса больших языковых и мультимодальных моделей (LLM, LMM) и агентного ИИ. По данным Qualcomm, ожидается в 4–8 раз более высокая производительность по сравнению с существующими архитектурами на базе GPU по пропускной способности памяти на Вт на карту. Масштабирование решения будет осуществляться с помощью интерконнектов UALink и ESUN с использованием медных и оптических кабелей. Коммерческое производство образцов Dragonfly AI300 начнётся в 2028 году. |
|

