Материалы по тегу: ии
|
21.05.2026 [00:43], Владимир Мироненко
Postgres Professional представила СУБД Postgres Pro AXE для гибридных нагрузокРоссийский разработчик Postgres Professional объявил о выходе новой СУБД Postgres Pro AXE для аналитических и гибридных нагрузок, которая, как заявляется, позволит компаниям заместить зарубежные аналитические платформы, упростить ИТ-ландшафт и при этом снизить совокупную стоимость владения (TCO) компонентами для хранения и обработки аналитических данных. После ухода с российского рынка ряда западных поставщиков СУБД и прекращения ими поддержки своих решений, включая Oracle Exadata и SAP HANA, отечественные компании столкнулись с усложнением IT-ландшафта и ростом затрат на его эксплуатацию из-за высокой фрагментации, использования разрозненных системам для транзакций и аналитики, проблем с наймом квалифицированных специалистов и т.д., говорит компания. Как сообщает разработчик, Postgres Pro AXE предназначена для выполнения тяжелых аналитических запросов и может использоваться как в качестве аналитической СУБД рядом с уже имеющимися системами, так и в составе уже привычной в эксплуатации Postgres Pro Enterprise. В последнем случае AXE расширяет возможности основной системы аналитической функциональностью на существующих узлах. Это позволяет не разворачивать лишние кластера и не нанимать дополнительный штат администраторов, с наймом которых сейчас наблюдаются проблемы, под узкие аналитические системы. Это также обеспечивает эффективный подход к организации ИТ-стека: уровень надёжности не снижается, но при этом устраняются дублирование инфраструктуры и кратный рост операционных затрат. 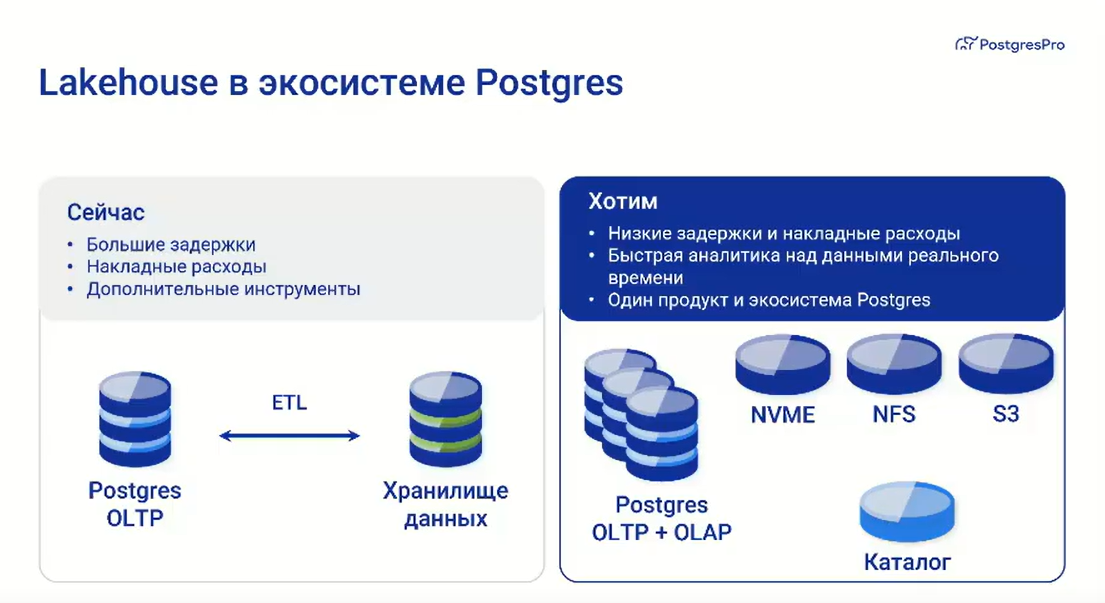
Источник изображения: Postgres Professiona Согласно результатам внутренних испытаний на отраслевых бенчмарках ClickBench, TPC-H и TPC-DS, новое решение обеспечивает:
СУБД поддерживает работу с разными типами хранилищ: от локального сервера до сетевого файлового доступа и S3-хранилищ. Аналитические данные хранятся в формате Parquet, используемом для аналитики больших данных (Big Data) и систем класса Data Lake и Warehouse. Метаданные, определяющие эти данные, также фиксируются по открытой спецификации. В итоге это позволяет работать с любыми BI-инструментами, без привязки к одному поставщику. В настоящее время решение тестируется в пилотном режиме в более чем в десяти организациях в промышленности, сферах финансов, ретейла и телекома. По итогам пилотов заказчики отметили упрощение аналитического контура, ускорение работы с данными и снижение нагрузки на команды эксплуатации. Ряд крупных российских компаний уже выбрал это решение для промышленной эксплуатации. Компания отметила, что вывод Postgres Pro AXE на рынок является частью её долгосрочной стратегии по формированию в России полного импортонезависимого стека для работы с данными. До этого, в прошлом году компания представила платформу Tengri Data для работы со сверхбольшими массивами данных с разделением вычислений и хранения. С выходом нового решения продуктовый портфель компании покрывает весь спектр задач — от транзакционных систем до петабайтных аналитических озёр данных.
20.05.2026 [20:05], Владимир Мироненко
Alibaba представила ИИ-ускоритель Zhenwu M890, который втрое быстрее предшественникаAlibaba Group представила ИИ-ускоритель Zhenwu M890, разработанный её подразделением T-Head Semiconductor (Pingtouge Semiconductor), сообщило агентство Reuters. Согласно опубликованным сведениям о Zhenwu M890, это самый высокопроизводительный продукт, созданный T-Head на сегодняшний день. Он позиционируется как конкурент ускорителю NVIDIA H100, хотя и уступает ему по ряду показателей. Чип поддерживает форматы FP32/BF16/FP16 для обучения и FP8/FP4/INT8/INT4 — для инференса. Новый ускоритель был специально разработан для новой волны ИИ-агентов. Сообщается, что новинка примерно в три раза превосходит предшественника Zhenwu 810E по производительности, но точные характеристики не приводятся. Ускоритель имеет 144 Гбайт HBM и интерфейс PCI 5.0 x16. Каждый M890 имеет 8 портов интерконнекта ICN (800 Гбайт/с) и поддерживает бесшовное объединение до 64 карт. Также была представлена серверная система Panjiu AL128, которая объединяет 128 ускорителей Zhenwu M890 в одной стойке. Система вместе с фирменным стеком T-SAIL уже сейчас доступна китайским корпоративным клиентам через платформу Alibaba Cloud для внутреннего рынка, известную как Bailian. 
Источник изображений: T-Head По словам компании, новый чип хорошо подходит для обработки больших объёмов памяти и коммуникационных нагрузок агентских приложений, для которых модели должны сохранять длительные периоды контекста и координировать свои действия в реальном времени. T-Head сообщила, что на сегодняшний день отгрузила более 560 тыс. ускорителей семейства Zhenwu, и более 400 внешних клиентов из 20 отраслей, включая автопроизводителей и финансовые компании, уже их внедрили. В начале апреля Alibaba и оператор China Telecom заявили о запуске ЦОД на юге Китая, работающего на собственных чипах компании.  Alibaba также представила план разработки чипов на несколько лет вперёд, согласно которому в III квартале 2027 года выйдет преемник под названием V900, а в III квартале 2028 года — чип следующего поколения — J900. Согласно заявлению Alibaba, запланированный к выпуску в следующем году V900 обеспечит примерно трёхкратное увеличение производительности по сравнению с M890. По имеющейся информации, ускорители Alibaba Group производятся по техпроцессам, которые китайские заводы могут использовать без контролируемого США литографического оборудования, что является ограничивающим фактором, определяющим весь цикл производства микросхем в Китае. Поскольку ни один экземпляр H200 из одобренных США для поставки десяти китайским покупателям так и не был отгружен, китайские клиенты ускоряют переход к альтернативам местных компаний: Alibaba Zhenwu, Huawei Ascend, Cambricon Siyuan и др. По мнению Counterpoint Research, Zhenwu даст местным компаниям ещё один вариант для их ИИ-инфраструктуры, хотя остаются вопросы о том, сколько чипов Alibaba сможет выпустить на местных полупроводниковых заводах (SMIC): «M890 — это небольшой, но реальный вклад в самодостаточность Китая в области ИИ… С точки зрения чистой производительности кремния, M890 не является настоящим конкурентом H200. Но в этом и нет нужды. Для китайского рынка это достойная замена H200».
20.05.2026 [15:41], Руслан Авдеев
Никуда они не денутся: Baidu объявила о росте выручки от облачных GPU на 184 %Китайский IT-гигант Baidu объявил инвесторам, что новым высокомаржинальным направлением бизнеса становится облачная ИИ-инфраструктура. По словам компании, без неё корпоративные клиенты компании уже не могут обойтись, сообщает The Register. Подводя итоги I квартала 2026 года, компания сообщила, что выручка облачного направления, связанная с ИИ-ускорителями (GPU) выросла на 184 % г/г, значительно опередив темпы роста облачного рынка в целом. В компании отмечают, что GPU-сегмент значительно более маржинален, чем CPU. Этому способствует высокий спрос, дефицит предложения, а также более высокие технологические барьеры и возможности поддерживать высокие цены. Кроме того, ИИ-приложения сами по себе высокомаржинальны благодаря, не в последнюю очередь благодаря подпискам. Компания уверена, что при ограниченном предложении качественных облачных ИИ-мощностей клиентам приходится ориентироваться не только на цену, но и, в первую очередь, на надёжность и стабильность работы инфраструктуры. Утверждается, что корпоративные заказчики ценят не только и не столько пиковую производительность чипов, сколько устойчивость работы масштабных систем, совместимость с востребованными ИИ-моделями и фреймворками, стоимость и простоту миграции, поддержку крупномасштабных кластеров и, конечно, экономическую эффективность. Компания отметила резкий спрос на ИИ-инфраструктуру, при этом наибольший рост демонстрирует инференс. Это свидетельствует о том, что клиенты в целом отходят от обучения моделей и занялись их внедрением в бизнес-процессы, что обещает дальнейший рост. 
Источник изображения: Hoyoun Lee/unsplash.com Одно из важнейших преимуществ Baidu — разработка собственных ИИ-чипов Kunlunxin, в том числе новейших вариантов на основе проприетарных решений. Собственная аппаратная платформа и полный ИИ-стек позволит и дальше снижать издержки и наращивать маржинальность. В январе сообщалось, что Kunlunxin, подразделение Baidu по выпуску ИИ-чипов, тайно подала заявку на IPO. В компании признают, что китайские ИИ-ускорители ещё уступают передовым зарубежным решениям при некоторых сложных сценариев обучения моделей, но для инференса они уже вполне годятся. При этом развитию мешают ограниченные производственные мощности и требующие развития цепочки поставок, спрос растёт быстрее предложения. Отдельно компания рассказала о перспективах развития сервиса роботакси Apollo Go, которому ещё предстоит заслужить полное доверие пользователей. Также компания развивает т. н. индустрию «цифровых людей» (Digital Human). Этих ИИ-аватаров клиенты используют для онлайн-коммуникаций с поддержкой десятков языков и регионов. Подход Baidu во многом схож с Alibaba, у которой тоже есть собственное аппаратное подразделение T-Head, и резко контрастирует с развитием Tencent. Несмотря на быстрый рост, ИИ-направление пока приносит Baidu не так уж много выручки в глобальном масштабе. Так, выручка ИИ-облака достигла ¥8,8 млрд (около $1,3 млрд). Тем не менее, впервые в истории компании более 50 % выручки пришлось именно на ИИ-продукты, ¥13,6 млрд ($2 млрд) из общеквартальной выручки в ¥26 млрд ($3,8 млрд). При этом, если бы ИИ-сегмент не рос, квартальная выручка Baidu фактически даже снизилась бы.
20.05.2026 [14:13], Руслан Авдеев
Российские процессоры «Иртыш» на китайской архитектуре LoongArch заподозрили в недостаточном уровне «отечественности»Минпромторг РФ настаивает на привлечении новых экспертов к проверке российских процессоров «Иртыш», разработанных «Трамплин электроникс». В министерстве считают, что такие процессоры, положенные в основу оборудования для критической информационной инфраструктуры (КИИ), потенциально создают угрозу национальной безопасности страны, сообщает CNews со ссылкой на письмо Минпромторга в Торгово-промышленную палату (ТПП) РФ. Подчёркивается, что в России уже разработаны опытные образцы серверов на процессорах «Иртыш». Минпромторг ссылается на сообщения СМИ о том, что в 2025 году «Трамплин Электроникс» приобрела право на использование иностранной архитектуры LoongArch, принадлежащей китайской Loongson, а её чипы практически повторяют процессоры серии C3600. Минпромторг подчёркивает недопустимость попадания в реестр российской продукции чипов на готовых схематических решениях, разработанных за границей. Опрошенные изданием эксперты говорят, что присвоение таким чипам статуса отечественных может негативно сказаться на развитии российской микроэлектроники. 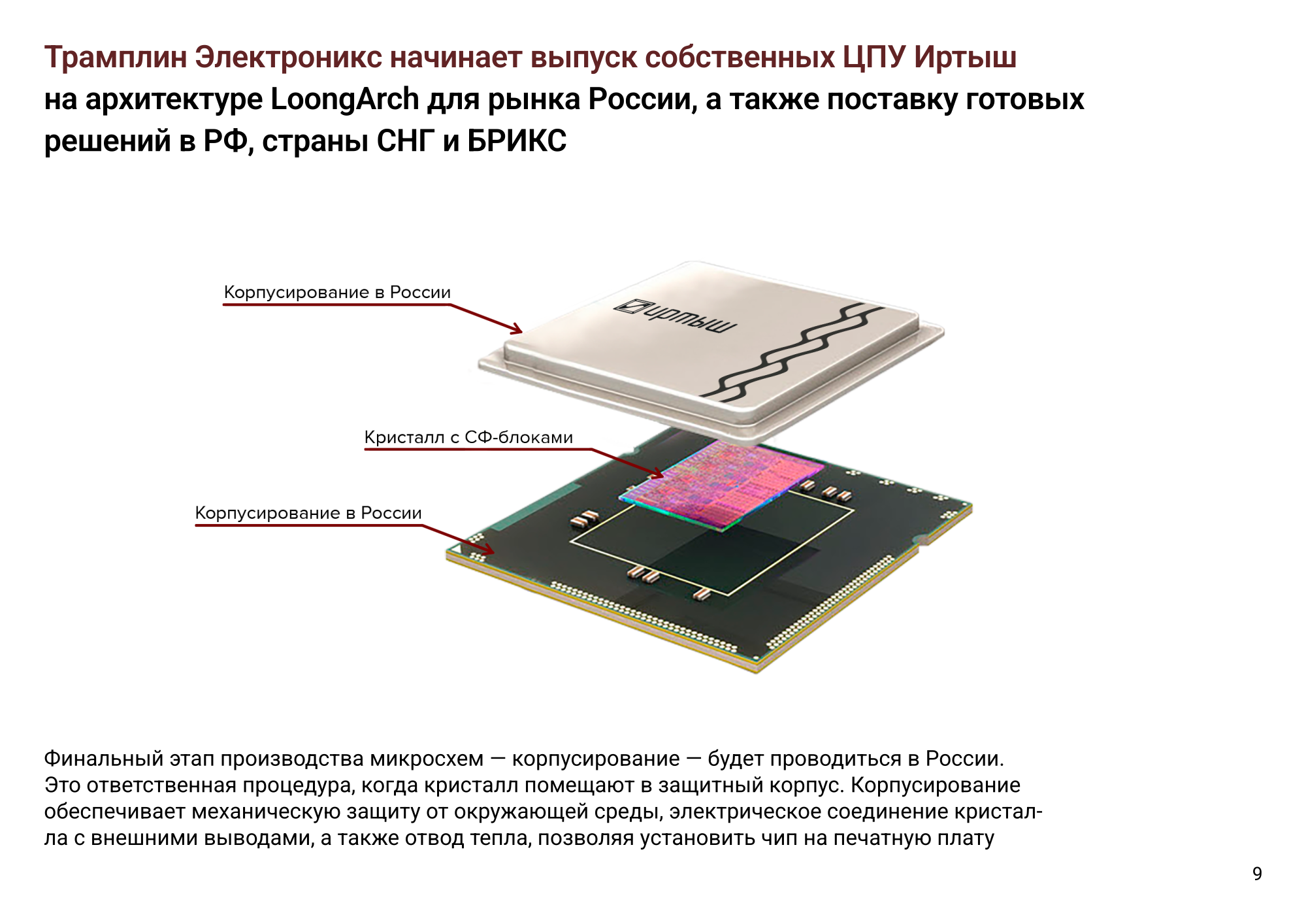
Источник изображения: «Трамплин электроникс» «Трамплин электроникс» посетовала на «попытки заранее сформировать позицию и мнение экспертов» и заявила CNews, что утверждения о полной идентичности «Иртыш» китайским чипам голословны и сделаны без учёта собственных проектных и конструкторских работ, выполненных на территории РФ, включая «интеграцию, адаптацию, производство и испытания», выразив уверенность в компетентности и объективности экспертизы ТПП и готовность продемонстрировать «и лицензии, и глубину освоения технологий, а также контроль жизненного цикла процессоров».  Вместе с тем экспертами отмечается, что за год существования «Трамплин электроникс» разработать собственные решения физически невозможно. При этом в 2022 КНР запретил экспорт чипов Loongson в другие страны, включая РФ. Компания намерена начать серийные поставки процессоров «Иртыш» C616, C632 и C664 в III квартале 2026 года. Корпусирование процессоров будет проводиться в России, но где производятся сами чипы, не уточняется.
20.05.2026 [10:31], Сергей Карасёв
«Байкал Электроникс» готовит ИИ-ускорители с FP8-производительностью до 1 Пфлопс и совместимостью с CUDAРоссийская компания «Байкал Электроникс» на конференции ЦИПР 2026 в Нижнем Новгороде раскрыла информацию о собственных ИИ-ускорителях Baikal-AI-E1000 и Baikal-AI-D1000. Первый ориентирован на выполнение задач на периферии, второй — в дата-центрах. Известно, что изделие Baikal BE-AI-D1000 получит от 48 до 64 Гбайт памяти типа GDDR. Производительность в режиме FP8 заявлена на уровне 1000 Тфлопс (1 Пфлопс), на операциях FP16 — 500 Тфлопс. Таким образом, новинка сможет составить конкуренцию решениям NVIDIA L40S. Ориентировочная цена составит $10 тыс. 
Источник изображений: «Байкал Электроникс» Для ускорителя Baikal BE-AI-D1000 планируется реализовать совместимость с экосистемой CUDA. По заявлениям «Байкал Электроникс», устройство рассматривается в качестве компонента суверенных дата-центров, ориентированных на ИИ-нагрузки. Вывести устройство на коммерческий рынок компания рассчитывает в 2029–2030 гг.  В свою очередь, Baikal-AI-E1000 станет альтернативой модулю NVIDIA Jetson Orin NX. Указываются тактовая частота и энергопотребление — до 2 ГГц и не более 30 Вт. Для решений уже разработано GPGPU-ядро, построенное на базе FPGA.  Кроме того, «Байкал Электроникс» представила архитектуру ИИ ЦОД с серверами, оснащёнными отечественными комплектующими. Помимо ускорителя Baikal BE-AI-D1000, в таких системах предлагается задействовать процессор Baikal S2, выполненный на архитектуре Neoverse-N2 (ARMv9). Ранее говорилось, что чип получит 128 ядер с частотой на уровне 3 ГГц, 8 каналов DDR5, 192 линии PCIe 5.0, поддержку CXL 2.0 и CCIX 2.0.  Нужно также отметить, что «Байкал Электроникс» столкнулась с трудностями при производстве своих процессоров из-за сформировавшейся геополитической обстановки. В результате, компания была вынуждена отменить выпуск и продажи изделий Baikal-S. Позднее появилась информация, что отгрузки этих чипов будут возобновлены.
20.05.2026 [09:09], Владимир Мироненко
От теории к практике ИИ: Dell анонсировала масштабное обновление платформы AI Factory with NVIDIA
dell
nvidia
software
ии
конфиденциальность
оркестрация
охлаждение
рабочая станция
сервер
схд
частное облако
Компания Dell Technologies объявила о масштабном обновлении платформы AI Factory with NVIDIA, призванном помочь предприятиям перейти от планирования к практическому применению ИИ. Платформа отличается модульной архитектурой данных для ИИ, где их преобразование, обработка и хранение работают вместе как специально разработанный стек. Компания отметила, что AI Factory используют более 5 тыс. клиентов по всему миру, и обновлённая версия платформы обеспечит более интегрированный подход к управлению данными и инфраструктурой, что позволит сократить время, необходимое для развёртывания решений ИИ. Одним из ключевых анонсов мероприятия стала презентация Dell Deskside Agentic AI. Это новое предложение, которое объединяет рабочие станции Dell, эталонный программный стек NemoClaw от NVIDIA и среду выполнения OpenShell, позволяя предприятиям создавать, запускать и управлять автономными агентами на системах, хранящих данные локально или на периферии сети, а не полагаться исключительно на облачную инфраструктуру. Dell позиционирует это предложение как решение для контроля затрат, снижения задержки и суверенитета данных, особенно для разработки ПО, исследований и регулируемых сред. Локальный подход разработан для таких секторов, как разработка ПО, академические исследования и регулируемые отрасли, позволяя этим группам хранить данные внутри компании и преобразовывать переменные расходы на облачные сервисы в предсказуемые инвестиции в инфраструктуру. Dell заявила, что этот подход позволит достичь паритета затрат с публичными облаками в течение трёх месяцев. 
Источник изображений: Dell Dell также интегрирует NVIDIA OpenShell во все продукты портфеля Dell AI Factory, чтобы обеспечить «безопасную песочницу для запуска, создания, тестирования и тонкой настройки агентов» локально. Это обеспечивает Dell единый уровень среды выполнения и политик, охватывающий все уровни — от настольных рабочих станций до серверов Dell PowerEdge XE, с поддержкой Ubuntu и Red Hat AI. Dell также продвигает эталонную архитектуру Dell-NVIDIA AI-Q 2.0, работающую на базе Dell AI Data Platform with NVIDIA, как готовую к продуктовому развёртыванию основу для многоагентных рабочих процессов в таких секторах, как финансовые услуги, производство и госсектор, где требуется более жёсткий контроль над данными и операциями. Dell объявила о ряде улучшений платформы Dell AI Data Platform. В ней были расширены возможности механизма оркестрации данных Dell AI Data Platform путём глубокой интеграции MetadataIQ со всем портфелем хранилищ Dell, начиная с PowerScale — файлового механизма в рамках Dell AI Data Platform with NVIDIA — и расширяя его на другие платформы в будущем. 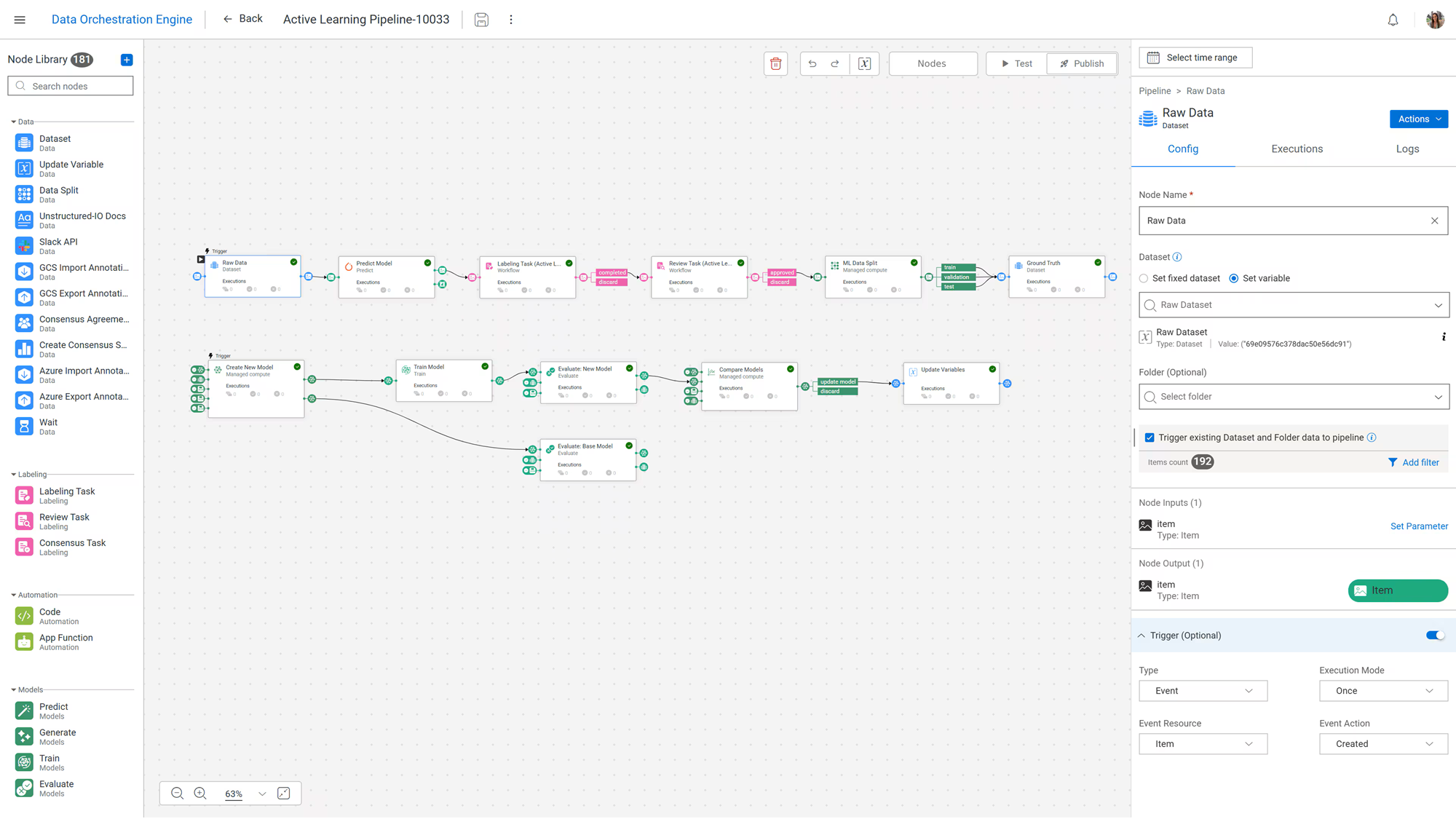 Уровень оркестрации теперь поддерживает индексирование миллиардов неструктурированных файлов и их привязку к управляемым конвейерам обработки данных. Благодаря партнёрству со Starburst и NVIDIA платформа предлагает аналитику SQL с ускорением на GPU через улучшенный Dell Data Analytics Engine, до шести раз быстрее на оборудовании NVIDIA Blackwell и с будущей поддержкой NVIDIA Vera. Это позволяет ускорить получение данных как для традиционной аналитики, так и для ресурсоёмких приложений ИИ с использованием агентов. Возможности хранения данных были расширены с помощью новой системы ObjectScale X7700, которая обеспечивает на 45 % большую ёмкость, чем предыдущее поколение, с гибким масштабированием вычислительных ресурсов и хранилища. В будущем появится поддержка флеш-накопителей объёмом 245 Тбайт, что более чем втрое увеличит плотность хранения. Благодаря интеграции с NVIDIA Omniverse корпоративные хранилища данных могут быть напрямую связаны с цифровыми двойниками и физическими рабочими процессами ИИ.  По мере роста объёма данных для ИИ, объектное хранилище становится логичным местом для обучающих данных, контрольных точек и долгосрочных баз знаний. Dell ObjectScale — объектный движок в рамках Dell AI Data Platform с NVIDIA — создан для выполнения этой роли, обладая высокопроизводительной архитектурой облачного масштаба и, по словам компании, лучшей в отрасли киберустойчивостью. Dell ObjectScale на серверах PowerEdge R7725xd также получил сертификацию NVIDIA Foundation, что означает его пригодность для высокоскоростного доступа к данным в средах с большим количеством GPU. Dell также расширила перечень инфраструктурных решений, запустив PowerRack, готовую систему стоечного масштаба, которая объединяет вычислительные ресурсы, сети, хранилище данных, охлаждение и управление в предварительно спроектированные блоки для развёртывания систем ИИ и HPC. Сообщается, что система может быть полностью настроена и введена в эксплуатацию в течение 6,5 ч. после доставки.  Как отметил ресурс Techzine, это не новая концепция, поскольку Dell поставляла комплексные решения и раньше, но компания расширяет возможности PowerRack по трём направлениям. Сетевой вариант обеспечивает коммутационную способность 800 Тбит/с благодаря восьми новым коммутаторам PowerSwitch SN6600 на стойку. Это в первую очередь предназначено для так называемого трафика east-west, поддерживающего рабочие нагрузки ИИ-инференса. Dell также интегрирует PowerFlex (решение «4-в-1») в свою архитектуру хранения данных Exascale, обеспечивая поддержку блочного, файлового и объектного хранения в стоечном исполнении через PowerFlex, PowerScale, Lightning File System и ObjectScale для нагрузок ИИ, HPC и ресурсоёмких корпоративных рабочих нагрузок. Dell также представила Pro Precision 7 R1 — стоечную рабочую станцию высотой 1U с ускорителями NVIDIA RTX PRO Blackwell Max-Q Workstation Edition и объёмом хранилища до 64 Тбайт. Обновлённые версии Dell Integrated Rack Controller и OpenManage Enterprise расширяют возможности на уровне стойки. В то же время новый PowerCool CDU C7000 разработан для отвода тепла от платформ NVIDIA следующего поколения в компактном стоечном форм-факторе. Это первый CDU для установки в стойку, отвечающий потребностям в охлаждении платформы NVIDIA Vera Rubin NVL72 в компактном форм-факторе 4U (19″) и расширяющий возможности охлаждения Dell и поддержку использования горячей воды с температурой до +40 °C.  Сообщается, что Dell PowerRack для вычислительных систем уже доступна, PowerRack для сетей будет доступна в сентябре 2026 года, а для хранилищ — во II половине 2026 года. Также уже доступны решение Dell Deskside Agentic AI, поддержка NVIDIA OpenShell, NVIDIA AI-Q 2.0 для Dell AI Factory и эталонная архитектура Dell-NVIDIA AI-Q 2.0. В свою очередь, Dell Pro Precision 7 R1 будет доступна в июле 2026 года, Data Orchestration Engine с MetadataIQ — во II квартале 2026 года, CDU — в III квартале 2026 года, а Data Analytics Engine with Starburst — в I квартале 2027 года.
19.05.2026 [21:50], Руслан Авдеев
«Обезгугленные» TPU: Blackstone и Google развернут 500-МВт облако с фирменными ИИ-ускорителями Google без участия Google CloudBlackstone и Google создали совместное предприятие для строительства в США новой облачной платформы, клиенты которой получат доступ к фирменным ИИ-ускорителям Google TPU, но без участия Google Cloud, сообщает Datacenter Dynamics. Blackstone инвестирует $5 млрд собственного капитала. Компании намерены ввести в эксплуатацию 500 МВт вычислительных мощностей к 2027 году. В будущем планируется расширение платформы. Google выступит поставщиком TPU и другого оборудования, а также программного обеспечения и сопутствующих сервисов. Генеральным директором компании назначен топ-менеджер Google Бенджамин Трейнор Сносс (Benjamin Treynor Sloss), более двадцати лет проработавший в компании. По словам Blackstone, партнёрство с Google позволит объединить высококлассные TPU и компетенции последней в сфере ИИ с «исключительными преимуществами» Blackstone в сфере энергетики и цифровой инфраструктуры. В ходе последнего финансового отчёта Google рассказала о планах предлагать свои TPU клиентам за пределами Google Cloud Platform. Предполагалось, что TPU начнут поставлять избранной группе клиентов, которые смогут использовать их в собственных ЦОД для расширения потенциала рынка. По такой схеме будет действовать Anthropic, которая купит TPU напрямую у Broadcom, но с тем нюансом, что размещаться они будут в ЦОД Fluidstack, за которой сейчас тоже стоит Google. Meta✴ тоже получит TPU, но у неё, в отличие от Anthropic, хотя бы есть обширный опыт строительства и эксплуатации дата-центров. 
Источник изображения: Google Ранее Blackstone объявила о намерении вывести на IPO созданный недавно REIT-фонд, специализирующийся на инвестициях в недвижимость — преимущественно в дата-центры. Подразделение будет покупать стабильные, недавно построенные ЦОД, в основном на рынках первого эшелона в Северной Америке. Компания неоднократно инвестировала значительные средства в сегмент ЦОД. Ей принадлежит QTS и AirTrunk, а также доли в Vnet, Lumina CloudInfra, Copeland, Park Place Technologies и Winthrop Technologies. Кроме того, Blackstone не так давно приобрела миноритарный, но крупный пакет акций американской Rowan, также специализирующейся на дата-центрах. В апреле Blackstone объявила о создании специального ИИ-подразделения Blackstone N1 (BXN1). Представители последней заявили, что для создания масштабных ИИ-платформ недостаточно просто денег. Необходимо правильно выбранные партнёры, правильная структура взаимодействия и убеждённость в необходимости поддержки тех или иных уникальных возможностей. TPU Google, развивающиеся более десяти лет, стали важной частью ИИ-экономики и именно для инвестиций в подобные решения создавалась BXN1.
19.05.2026 [20:19], Сергей Карасёв
YADRO представила российский 2U-сервер Vegman R215 G4 на базе AMD EPYC TurinКомпания YADRO, входящая в «ИКС Холдинг», расширила ассортимент отечественных серверов, анонсировав модель Vegman R215 G4 в форм-факторе 2U. Новинка, как утверждается, подходит для широкого спектра корпоративных и облачных нагрузок. Устройство, выполненное на аппаратной платформе AMD, имеет односокетную конфигурацию. Может устанавливаться процессор EPYC 9005 Turin или EPYC 9004 Genoa с показателем TDP до 500 Вт (до 192 вычислительных ядер). Реализованы 24 слота для модулей оперативной памяти DDR5-6400 (2 DPC) (L)RDIMM ECC суммарным объёмом до 6 Тбайт. Предусмотрены два варианта исполнения подсистемы хранения данных: 12 × LFF SAS/SATA/NVMe или 24 × SFF SAS/SATA/(16 × NVMe). Отсеки для накопителей располагаются во фронтальной части. Кроме того, могут быть установлены два SSD формата M.2/E1.S или два диска SFF SATA в тыльной зоне корпуса. 
Источник изображений: YADRO Упомянуты два сетевых порта 1GbE (RJ45) и выделенный сетевой порт управления 1GbE (RJ45). Спереди находятся по одному разъёму USB 2.0 Type-A и D-Sub, а также два порта USB 3.1 Type-C. Сзади сосредоточены два разъёма USB 3.1 Type-A, последовательный порт (разъём USB Type-C, RS-232) и интерфейс Mini DisplayPort (BMC). Сервер предоставляет до восьми слотов PCIe 5.0 (с учетом отсеков OCP 3.0 SFF и гнезда под контроллер RAID/HBA). Доступны различные HBA- или RAID-контроллеры (с поддержкой RAID 0/1/5/6/50/60), а также опциональный суперконденсатор для защиты содержимого кеш-памяти при отключении питания.  Питание обеспечивают два блока мощностью до 3400 Вт с сертификатом 80 Plus Platinum. Применена система воздушного охлаждения с шестью вентиляторами диаметром 60 мм с горячей заменой. Диапазон рабочих температур — от +10 до +35 °C. Говорится о совместимости с Astra Linux, ALT Linux, РЕД ОС, zVirt, VDP. 
19.05.2026 [17:00], Руслан Авдеев
Arm-процессоры NVIDIA Vera поставили в ведущие ИИ-лаборатории мира — Oracle развернёт сотни тысяч таких CPUПервые CPU Vera, разработанные компанией NVIDIA, поставили в Anthropic, OpenAI, Oracle Cloud Infrastructure (OCI) и SpaceX/xAI. Процессоры специально разработаны с учётом особенностей «агентных» ИИ-систем и отличаются от обычных CPU. Это первый кастомный процессор NVIDIA, специально разработанный для агентных систем. Он обеспечивает оркестрацию, вызов инструментов, RL-нагрузки, анализ данных, «песочницы» для агентов и др. Процессор предназначен для ИИ-лабораторий, облачных провайдеров и компаний, масштабно работающих с агентными ИИ-системами. Модель получила 88 кастомных ядер Olympus, а пропускная способность памяти составляет 1,2 Тбайт/с. Глава NVIDIA Дженсен Хуанг (Jensen Huang) позиционирует Vera как новый многомиллиардный вектор развития компании. Как сообщает NVIDIA, агентный ИИ создаёт намного более высокую нагрузку на вычислительную инфраструктуру, от компиляции и тестирования программного кода до анализа данных, поиска файлов и др. При этом ИИ-агенты не просто используют ускорители, но и требуют оркестрации, управления агентными «песочницами», и т. п., это работа для CPU. Поток параллельных задач перегружает не рассчитанные на это CPU, но характеристики Vera позволяют повысить эффективность ИИ-фабрик целиком. 
Источник изображения: NVIDIA OCI намерена развернуть сотни тысяч CPU Vera для обеспечения работы нового поколения корпоративного ИИ. Это первый облачный провайдер, намеренный внедрить Vera в таких масштабах. Для корпоративных клиентов это означает, что будет создана агентная ИИ-инфраструктура уровня, недоступного другим облачным провайдерам. Ранее сообщалось, что Oracle строит «вчерашние» ЦОД, не имея на это достаточно средств и теперь, компания, похоже, готова опровергнуть этот тезис. 
Источник изображения: NVIDIA Процессор не только является самостоятельным CPU, но и лежит в основе платформы Vera Rubin NVL72, где он посредством NVLink-C2C второго поколения связан с парой GPU Rubin. Стоит отметить, что работы с Vera фактически ведутся уже давно. Например, ещё в марте HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000.
19.05.2026 [12:49], Руслан Авдеев
AMD и NVIDIA свернули не туда: следующий крупный американский суперкомпьютер может получить HPC-чипы NextSiliconБольшая часть самых мощнейших суперкомпьютеров мира в рейтинге TOP500 полагаются на ускорители на основе GPU, однако Национальные лаборатории США начали искать новые архитектуры чипов, обеспечивающие высокую производительность в FP64-расчётах, востребованных для симуляций Министерства энергетики США (DoE). Последнее занимается не только вопросами энергетиками, но и управляет одними из мощнейших суперкомпьютеров мира, в т.ч. для моделирования физики ядерного оружия, виртуальных экспериментов, касающихся биологического оружия, а также решения задач обеспечения общественного здоровья и безопасности, сообщает The Register. С запуска суперкомпьютера Titan в 2012 году всё больше систем стали использовать ускорители NVIDIA, а впоследствии и чипы AMD. Однако новый суперкомпьютер Spectra Сандийских национальных лабораторий (SNL), созданный Penguin Solutions и NextSilicon, использует другие решения. В сравнении с экзафлопсными системами уровня Frontier или El Capitan он занимает относительно мало места и состоит всего из 64 узлов. Spectra используют в качестве тестовой площадки для чипов Maverick-2, успешно прошедших все приёмочные испытания. Это открывает возможность их использования в боле крупных системах. 
Источник изображения: SNL Maverick-2 используют перенастраиваемую потоковую (dataflow) архитектуру. Фактически внутри чипа находится сеть связанных вычислительных блоков, работающих не по жёстко заданной схеме, а как узлы графа. В ходе выполнения задачи каждый блок можно настроить под отдельную задачу — сложение, умножение и т.п., благодаря чему происходит адаптация под разные типы вычислений с более эффективной обработкой потоков данных. Главная особенность — возможность одновременных вычислений и передачи данных. В NextSilicon утверждают, что это значительно повышает производительность и энергоэффективность в реальных задачах. Groq, Cerebras и SambaNova и ранее предлагали чипы на «потоковых» архитектурах, но все они были ориентированы на обучение и инференс ИИ, тогда как NextSilicon ориентируется именно на HPC. Подобные архитектуры очень сложны для программирования, поэтому разработчики обычно предлагают готовые сервисы, а не просто продают серверы на их основе. NextSilicon пытается решить подобную проблему, предложив собственный компилятор, позволяющий использовать имеющиеся программы на C, Python, Fortran и CUDA без серьёзной доработки. В Сандийских лабораториях уже проверили технологию на важных HPC-нагрузках, включая HPCG, LAMMPS и Sparta, подтвердив пригодность системы для научных вычислений. 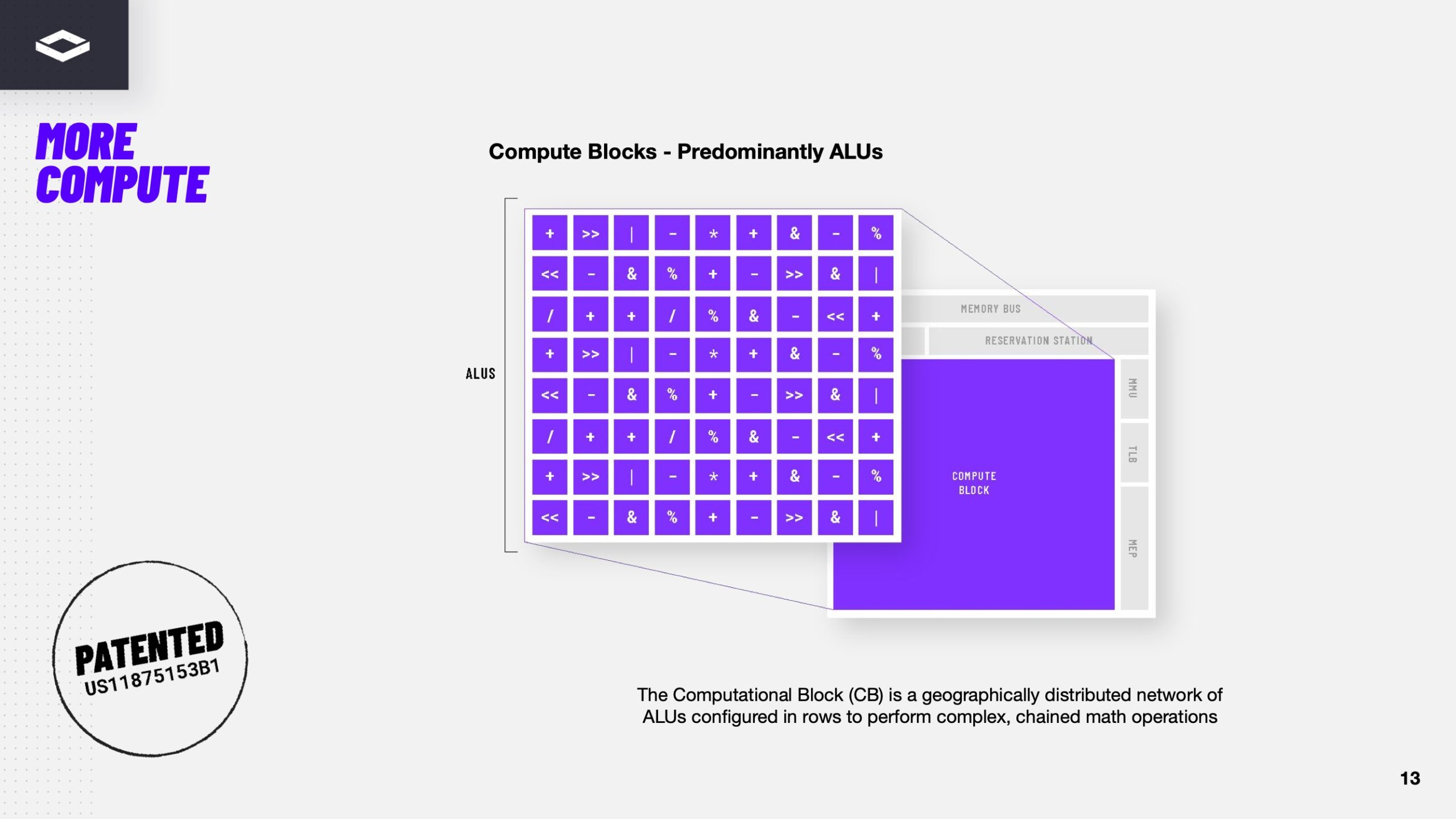
Источник изображения: NextSilicon Ставка разработчика на HPC контрастирует с вектором развития ИИ-ускорителей NVIDIA. В Rubin компания делает ставку на ИИ-вычисления, снижая «чистую» производительность FP64, полагаясь на эмуляцию посредством схемы Озаки. Если в некоторых HPC-задачах это работает, то в других эффективность подобных обходных решений весьма низкая. AMD помимо ориентированных на ИИ Instinct MI455X готовит и MI430X, где сохранены аппаратные HPC-блоки. Именно на подобные нагрузки ориентируется NextSilicon со своими наработками. Полных системных бенчмарков Maverick-2 и суперкомпьютера пока нет, но компания утверждает, что один такой ускоритель способен обеспечить порядка 600 Гфлопс в тесте HPCG (FP64). По данным стартапа, это сопоставимо по производительности с ведущими GPU, причём энергопотребление у новинки вдвое ниже. Для США главной проблемой может оказаться давление акционеров компаний, поставляющих чипы. Если ИИ сделал NVIDIA финансовым и технологическим гигантом, то рынок решений для HPC остаётся важным, но всё ещё нишевым направлением. Хотя стартапам вроде NextSilicon ещё предстоит доказать право своих продуктов на место под солнцем, Китай уже давно продемонстрировал, что GPU вовсе не обязательны для успешной конкуренции с лучшими суперкомпьютерами Запада. OceanLight и Tianhe-3 полагаются на кастомные процессоры и ускорители на базе DSP вроде Matrix 2000. Последние, по слухам, были созданы в ответ на запрет поставок Intel Xeon Phi в КНР. Также недавно появились данные о новом Arm-суперкомпьютере LineShine. |
|

