Лента новостей
|
15.06.2026 [18:20], Андрей Крупин
МТС вложит 1 млрд рублей в модернизацию ядра сети ШПД и установку маршрутизаторов собственной разработкиКомпания «Мобильные ТелеСистемы» инвестирует в 2026–2027 гг. 1 млрд руб. в проект модернизации и расширения ядра транспортной сети фиксированного интернета в России. Реализуемый МТС проект предполагает постепенный вывод из эксплуатации иностранного сетевого оборудования и его замену сервисными маршрутизаторами МТС-BNG (Broadband Network Gateway) собственной разработки, построенными на базе архитектуры х86 и в зависимости от характеристик и конфигурации обеспечивающие пропускную способность от 40 до 200 Гбит/с. Решение устанавливается на ядре сети провайдера и выполняет функции аутентификации, авторизации и учёта (ААА) для пользователей широкополосного доступа в интернет, а также управляет трафиком и качеством обслуживания (QoS). В начале 2025 года компания получила на свой сервисный маршрутизатор МТС-BNG сертификат соответствия в области связи и на сегодня вывела в эксплуатацию первые комплекты оборудования в 22 регионах России. Внутри МТС организована структура технической поддержки нового оборудования, обучены сотрудники служб развития и эксплуатации. 
Сервисный маршрутизатор МТС-BNG (источник изображения: bng.mts.ru) На новом этапе проекта модернизации и расширения пропускной способности ядра сети ШПД и стыка между магистральной и фиксированными сетями МТС планирует установить до конца 2027 года собственные сервисные маршрутизаторы ещё в 26 регионах, включая партию устройств на сети инфраструктурного оператора МГТС, дочерней компании МТС.
15.06.2026 [17:56], Руслан Авдеев
Индийские клиенты Google Cloud уже неделю мирятся со сбоями сети из-за пожара в ЦОД в ДелиКлиенты облачных сервисов Google Cloud с ресурсами, размещёнными в Индии, вынуждены иметь дело с повышенными задержками в течение почти недели. Возвращения к нормальной работе пока не предвидится, сообщает The Register. По данным самой Google, 9 июня пожар в одном из сторонних ЦОД в Дели, используемому компанией, вынудил срочно отключить питание сетевого оборудования. В результате была изолирована одна из локальных точек присутствия (POP), доступная ёмкость сети в местной городской агломерации значительно снизилась. Отключение привело к периодическому повышению задержек и потере пакетов данных при работе с Google Cloud из Дели, Ченнаи, Мумбаи и окружающих районов. Как отметила компания, клиенты «могут испытывать» слегка увеличившиеся задержки и «неоптимальную» сетевую маршрутизацию в Google Cloud до тех пор, пока пострадавший объект полностью не восстановится. 
Источник изображения: Lai Man Nung/unsplash.com Google применила меры по «оптимизации трафика», которые, как утверждают в компании, уже позволили улучшить производительность «для некоторых клиентов Cloud», и теперь компания пытается добавить дополнительные пиринговые соединения. Также компания работает над улучшением региональной пиринговой ёмкости в Ченнаи, чтобы помочь крупным интернет-провайдерам Индии и надеется, что работа будет закончена в среду, 17 июня. Ранее пожары в ЦОД привели к крупным сбоям телеком-систем целых стран в Бангладеш и Иране. Также европейские сервисы Google Cloud серьёзно пострадали в 2023 году в результате пожара в парижском ЦОД Global Switch.
15.06.2026 [16:47], Владимир Мироненко
ByteDance ведёт переговоры о покупке китайских ИИ-ускорителей Iluvatar CoreX и BaiduByteDance, материнская компания TikTok, ведёт переговоры с шанхайской компанией Iluvatar CoreX о покупке ИИ-чипов, сообщило агентство Reuters со ссылкой на источники. В случае достижения договорённости, Iluvatar CoreX станет третьим крупным отечественным поставщиком GPU для ByteDance после Huawei и Cambricon, отметили источники агентства. По их данным, в этом году Iluvatar CoreX поставит ByteDance не менее 50 тыс. чипов, и большая часть из них будет использоваться для задач инференса, поскольку ByteDance стремится расширить клиентскую базу своего ИИ-чат-бота Doubao. Впрочем, переговоры ещё не завершены и окончательные условия сделки могут измениться. Кроме того, по данным источников Reuters, ByteDance, также рассматривает возможность использования ускорителей Baidu Kunlunxin. Раннее стало известно о разработке ByteDance собственных ИИ-чипов и закупке миллионов ИИ ASIC Qualcomm. По словам одного из источников, чипы Kunlunxin уже используются Tencent Cloud. Публикация агенства о возможных сделках в Китае свидетельствует о том, что выпуск китайскими производителями ИИ-чипов набирает обороты. Этому способствует поддержка властями использования разработанных на местном уровне чипов для повышения самодостаточности на фоне экспортного контроля США над передовыми чипами. Китайские производители GPU и чипов для ИИ в прошлом году заняли почти 41 % китайского рынка ИИ-серверов, на котором некогда доминировала NVIDIA. Рыночная доля американской компании в Китае, одном из важнейших для неё рынков, упала до нуля, утверждает глава NVIDIA Дженсен Хуанг (Jensen Huang). 
Источник изображения: Iluvatar CoreX До сих пор Iluvatar CoreX в основном поставляла чипы для государственных закупок, сообщил один из источников. Поэтому сделка с ByteDance, одной из крупнейших китайских технологических компаний и крупным инвестором в ИИ-инфраструктуру, крайне важна для неё. Iluvatar CoreX вышла на Гонконгскую биржу в январе этого года. Её выручка в 2025 году составила ¥1 млрд ($148 млн), причём около 90 % продаж пришлось на GPU. Согласно информации на сайте компании, чипы серии Tiangai предназначены для ИИ-обучения, а чипы серии Zhikai — для задач инференса. По прогнозам Huatai Securities, выручка Iluvatar CoreX в этом году достигнет ¥3,04 млрд ($449,8 млн), а общий объём поставок превысит 100 тыс. чипов (рост год к году — на 139 %). По оценкам аналитиков, средняя цена чипов Zhikai составляет ¥12 тыс. ($1775)/шт.
15.06.2026 [15:18], Руслан Авдеев
Дата-центры Amazon «выпили» почти 9,5 млн кубометров воды в 2025 годуКомпания Amazon объявила, что её дата-центрами использовано за прошлый год более 9,46 млн м3 (2,5 млрд галлонов) питьевой воды. При этом техногигант подчёркивает, что это значительно меньше, чем показатели конкурентов-гиперскейлеров. Она по-прежнему говорит о намерении стать водно-положительной к 2030 году, сообщает The Register. В своём блоге компания сообщила, что указанный расход воды касается всей её сети дата-центров в мире в 2025 году. Подчёркивается, что в США с населением около 350 млн человек приблизительно столько же ушло на полив садов и газонов. По информации Amazon, компания тратит на своих объектах 0,12 л/кВт∙ч (WUE), что значительно ниже, например, предложенных ЕС норм. При этом, по её данным, в случае с Microsoft речь в прошлом году шла о 0,27 л, а c Meta✴ — о 0,19 л, но в 2024 году. В том же году Google расходовала по 1,15 л. 
Источник изображения: Jonathan Bean/unsplash.com В Amazon уверены, что прошли уже 75 % пути к достижению «водно-положительного» баланса к 2030 году, соответствующая цель была анонсирована ещё в 2022-м. В таком случае объекты техногиганта будут возвращать больше питьевой воды в окружающую среду, чем получают, в том числе путём сбора дождевой воды и переработки сточных вод. Ранее в Сеть попала в распоряжение внутренняя документация Amazon, из которой следовало, что компания намеренно скрывает своё водопотребление и несколько манипулирует фактами, опасаясь критики за большой расход водных ресурсов. В то же время в США растёт активное сопротивление строительству дата-центров. Недавний опрос Ipsos показал, что большинство американцев не хотят ЦОД поблизости, беспокоясь из-за цен на электричество, уродливых зданий и больших расходов воды. При этом такое нежелание вынуждена была подтвердить и Microsoft. Более того, в 2022 году в ходе судебного разбирательства выяснилось, что ЦОД Google в Даллесе (Dalles, Орегон) потребляет четверть всей используемой в городке воды. 
Источник изображения: AWS Так или иначе, потребление воды ЦОД растёт. Дело как в росте числа самих объектов, так и в появлении более энергоёмких, требующих более интенсивного охлаждения в сравнении с традиционным вычислительным оборудованием. Так, в 2022 году потребление воды в кампусах Microsoft выросло на 34 % до 6,4 млн м3. В том числе причиной называется развитие ИИ-систем. Ситуация усугубляется тем, что многие новые ЦОД появятся в регионах и без того страдающих от засухи. По словам Amazon, дата-центры компании 90 % времени используют фрикулинг, хотя приходится прибегать к помощи систем испарительного охлаждения, когда погода особенно жаркая. Кроме того, говорит компания, улучшению WUE поспособствовали более эффективные системы воздушного и жидкостного охлаждения. Впрочем, как утверждают эксперты The Register, полностью отказаться от использования воды дата-центрами будет практически невозможно, что бы ни заявляли операторы ЦОД.
15.06.2026 [13:47], Владимир Мироненко
Pinterest заключила с AWS самую крупную инфраструктурную сделку, планируя потратить $4 млрд на облачные сервисы, Graviton и TrainiumФотохостинг Pinterest объявил о значительном расширении сотрудничества с AWS, начавшемся в 2010 году. Согласно новому соглашению, Pinterest выплатит AWS в период до 2031 года $4 млрд за использование её сервисов, что является крупнейшим инфраструктурным проектом в истории Pinterest. В рамках расширенного соглашения Pinterest планирует диверсифицировать использование инфраструктуры AWS для поддержки растущих потребностей в ИИ, одновременно улучшая соотношение цены и производительности. В частности, компания планирует использовать ускорители AWS Trainium для размещения и запуска больших языковых моделей и моделей визуального и языкового анализа, которые обеспечивают персонализированный визуальный поиск и поиск с помощью ИИ. Также Pinterest намерена расширить использование Arm-процессоров Graviton, которые уже обеспечивают работу примерно трети её вычислительной инфраструктуры, для запуска большего количества систем, поддерживающих поиск контента для пользователей фотохостинга, ежемесячная аудитория которого превышает 600 млн. 
Источник изображения: Amazon «Это расширенное соглашение с AWS дает нам гибкость в вычислениях, возможность выбора оборудования и эффективность инфраструктуры для ускорения нашего видения ИИ для следующего поколения визуального поиска в Pinterest», — сообщил Мэтт Мадригал (Matt Madrigal), технический директор Pinterest. В рамках соглашения Pinterest также планирует продолжить модернизацию инфраструктуры, переходя от традиционных сред на основе EC2 к архитектуре на основе Kubernetes в EKS. Это позволит повысить скорость разработки, а также операционную надёжность и эффективность инфраструктуры глобальной платформы Pinterest. Ранее Amazon заключила соглашение о стратегическом партнёрстве с OpenAI, в рамках которого инвестирует в OpenAI $50 млрд. В свою очередь, OpenAI обязалась использовать около 2 ГВт мощностей на базе ускорителей Trainium, включая Trainium3 и чипы следующего поколения Trainium4, которые появятся в 2027 году. Ещё одно крупное соглашение подписано с Anthropic. Также у Amazon есть соглашение с Snowflake, которая планирует потратить в течение пяти лет $6 млрд на инфраструктурные проекты, в том числе на Graviton и ИИ-ускорители. Кроме того, Uber объявила этой весной о планах перенести определённые нагрузки на чипы Graviton и Trainium нового поколения, а Meta✴ получит «десятки миллионов» ядер Graviton5.
15.06.2026 [12:58], Сергей Карасёв
В Сингапуре запущен суперкомпьютер ASPIRE 2B на базе NVIDIA H200 и AMD EPYC Turin с быстродействие 115 ПфлопсНациональный суперкомпьютерный центр Сингапура (NSCC) объявил о запуске вычислительного комплекса ASPIRE 2B с производительностью 115 Пфлопс. Систему планируется использовать для решения сложных задач в области климатологии и метеорологии, здравоохранения, разработки материалов, передового производства, ИИ и пр. В основу ASPIRE 2B положены 96-ядерные процессоры AMD EPYC 9655 поколения Turin: суммарное количество вычислительных ядер в составе суперкомпьютера достигает 184 320 (задействованы 1920 чипов). Быстродействие CPU-секции находится на уровне 12 Пфлопс. GPU-раздел машины объединяет 1536 ускорителей NVIDIA H200 со 141 Гбайт памяти HBM3e. Их суммарная пиковая производительность указана на отметке 103 Пфлопс. Объём системной памяти составляет 1072 Тбайт, вместимость подсистемы хранения данных — 63,5 Пбайт. Применяется интерконнект Slingshot с пропускной способностью 400 Гбит/с. Суперкомпьютер ASPIRE 2B планируется интегрировать с квантовой системой Helios компании Quantinuum, установка которой в Сингапуре запланирована на конец нынешнего года. Это позволит осуществлять гибридные квантово-классические вычисления в рамках комплексных проектов, связанных с молекулярным моделированием и созданием перспективных материалов. 
Источник изображения: NSCC Отмечается также, что NSCC меняет модель доступа пользователей к вычислительным ресурсам страны. Приоритет будет отдаваться национальным программам исследований и инноваций. Это должно способствовать ускорению развития передовых технологий и расширению сферы предпринимательства.
15.06.2026 [12:54], Руслан Авдеев
Helix Digital Infrastructure привлекла более $10 млрд на строительство ИИ-инфраструктуры «под ключ»KKR, Кувейтское инвестиционное управление (Kuwait Investment Authority, KIA), NVIDIA и крупная энергетическая компания Vistra создали совместное предприятие Helix Digital Infrastructure для строительства ИИ ЦОД для облачных гиперскейлеров, сообщает Silicon Angle. Предприятие уже привлекло более $10 млрд на свои проекты и рассчитывает привлечь и других инвесторов в будущем. Возглавляет новую структуру бывший гендиректор AWS Адам Селипски (Adam Selipsky), перешедший в KKR, а руководитель направления цифровой инфраструктуры KKR Вальдемар Шлезак (Waldemar Szlezak) стал её директором по инвестициям. Компания рассчитывает строить ЦОД на основе пакета технологий NVIDIA DSX, предназначенного для создания крупных ИИ-кластеров. Специальный инструмент для симуляций позволяет тестировать проекты ЦОД до их развёртывания, а ПО DSX OS позволяет автоматизировать повседневные задачи по обслуживанию ИИ-инфраструктуры. Helix назвала NVIDIA стратегическим партнёром, которая поможет с развёртыванием ИИ-инфраструктуры. Vistra, совокупные генерирующие мощности которой составляют 44 ГВт, станет ключевым поставщиком электроэнергии. 
Источник изображения: CHUTTERSNAP/unsplash.com Helix позиционирует себя как универсального поставщика ИИ-инфраструктуры «под ключ». Планируются не только инвестиции в ЦОД, но и в ВОЛС, энергетическую инфраструктуру, включая электростанции и ЛЭП, и связанные активы. У Blackrock есть аналогичная инициатива AIP (AI Infrastructure Partnership), в которой тоже участвуют KIA и NVIDIA, а Blackstone договорилась с Broadcom о развёртывании крупных ИИ-мощностей. Решение создать новую структуру, возможно, частично обусловлено чередой многомиллиардных сделок, подписанных строителями ИИ ЦОД за последний год. Так, в апреле CoreWeave заключила контракт на $21 млрд на поставку облачных мощностей Meta✴ Platforms до 2032 года. За несколько недель до этого Nebius Group заключила с Meta✴ аналогичный договор на $27 млрд. Тем временем Microsoft обязалась приобрести вычислительные мощности ИИ-ускорителей у Nscale. При этом CoreWeave не только строит инфраструктуру для гиперскейлеров, но и управляет собственным публичным облаком. Helix может избрать аналогичный подход. Возможно, что компания направит часть капитала на создание собственных технологий ЦОД, и это позволит получить перед конкурентами технологическое преимущество.
15.06.2026 [09:40], Владимир Мироненко
Mimulus анонсировала услугу архивирования данных с использованием ДНККомпания Mimulus сообщила о создании карты хранения данных Glacier Storage Card размером с банковскую карту, использующей кодирование данных молекулярной ДНК. Компания обещает, что новинка сможет хранить до 1 Эбайт данных не менее 10 тыс. лет. Mimulus разрабатывает технологию т.н. молекулярного архивирования (MAT) с использованием ДНК-хранилищ, обеспечивающую обычную для ДНК-хранилищ долговечность (>99,9999% целостности файлов после 10 тыс. лет), высокую плотность, невосприимчивость к вредоносным программам, воздушный зазор, химическую стабильность, отсутствие необходимости пересборки хранилища (resilvering) и низкое энергопотребление. Разработанная Mimulus технология позволяет сжимать двоичные данные и кодировать их посредством кастомного алгоритма в последовательности оснований ДНК (A, T, G, C). Они синтезируется в нити ДНК с использованием собственной платформы Mimulus MAT CMOS, позволяющей собирать молекулы ДНК с высокой производительностью (данные не приводятся). Синтезированная ДНК помещается в карту Glacier Data Storage Card. 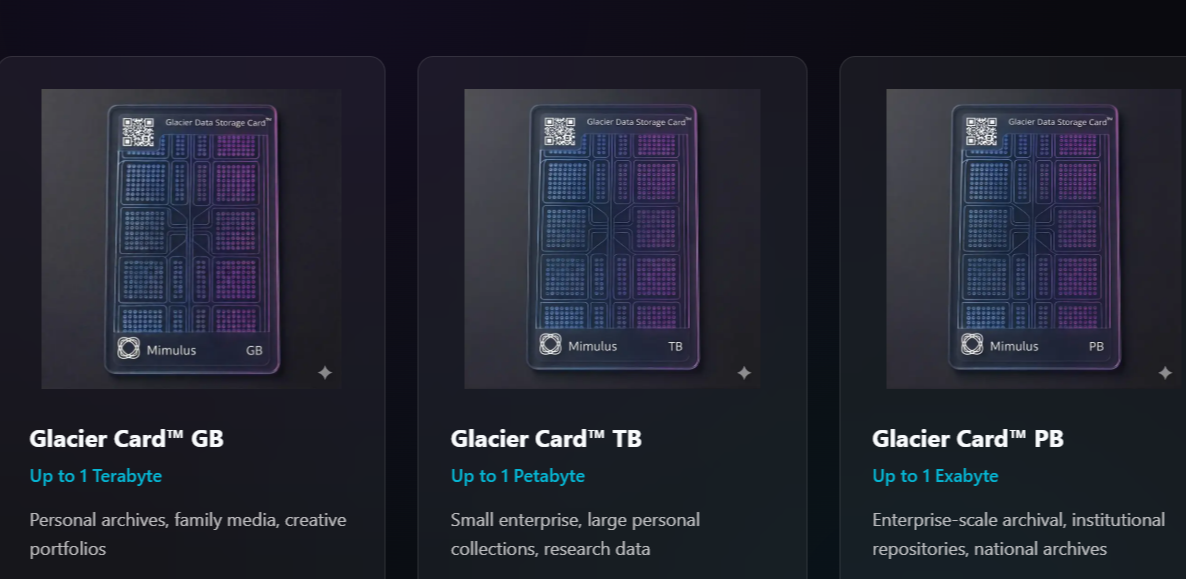
Источник изображения: Mimulus Однако как такового привода нет. Клиенты загружают свои файлы для архивирования на портал Mimulus, а через некоторое время получают запакованную карту Glacier. Когда клиенту потребуется извлечение данных, карта отправляется обратно Mimulus, сотрудники которой вскрывают контейнер, извлекают ДНК с помощью запатентованного биологического праймера, секвенируют его, восстанавливают двоичные данные и отправляют их клиенту в течение 48 ч. с момента получения карты. При этом не уточняется, получают ли клиенты свои карты назад после этого процесса, и могут ли они выбирать отдельные файлы для восстановления. Mimulus заключила соглашение с GenScript Biotech, поставщиком технологий синтеза ДНК на основе CMOS, о создании «первого в мире хранилища для молекулярного архивирования». GenScript имеет валидированную производственную платформу, способную параллельно синтезировать 8 млн олигонуклеотидов на одном чипе. Mimulus предлагает для предварительного резервирования три варианта Glacier Storage Card: GB (ёмкость до 1 Тбайт), TB (до 1 Пбайт) и PB (до 1 Эбайт). Сайт Blocks & Files отметил нестыковки: в одном месте указано, что ёмкость карты PB составляет до 1 Эбайт, в другом — что до 2,4 Эбайт.
15.06.2026 [09:32], Сергей Карасёв
96 NVMe SSD с СЖО и четыре RTX Pro 6000: Wiwynn показала сверхбыстрое хранилище на базе NVIDIA SCADAКомпания Wiwynn (дочерняя структура Wistron), по сообщению ресурса Tom's Hardware, продемонстрировала один из первых в отрасли серверов хранения NVIDIA SCADA (SCaled Accelerated Data Access). Устройство ориентировано на высокопроизводительную обработку больших объёмов данных в рамках задач обучения ИИ-моделей и инференса. 
Источник изображений: Wiwynn Новинка выполнена в MGX-шасси высотой 6U и рассчитана на монтаж в 19″ серверную стойку. Задействован процессор NVIDIA Vera, который содержит 88 ядер Olympus, или Intel Xeon (в составе HPM-). Доступны восемь слотов для модулей DDR5. Система несёт на борту четыре ускорителя NVIDIA RTX Pro 6000 Blackwell Server Edition, четыре коммутатора PCIe 6.x и четыре 800G-карты ConnectX-9 SuperNIC/DPU BlueField-4 (опционально GPU можно поменять на DPU). Реализовано полностью жидкостное охлаждение.  Сервер рассчитан на 96 накопителей EDSFF E3.S SSD с вертикальной загрузкой. При использовании изделий Micron 9650 Pro вместимостью 30,72 Тбайт с интерфейсом PCIe 6.0 суммарная ёмкость достигает 2,949 Пбайт. При этом обеспечивается показатель IOPS на операциях случайного чтения до 528 млн. Максимальное энергопотребление новинки — 9 кВт (питание DC 50 В). Кабели питания и гибкие шланги СЖО расположенные в нишах по бокам, что позволяет выдвигать лоток с накопителями и производить «горячую» замену SSD. 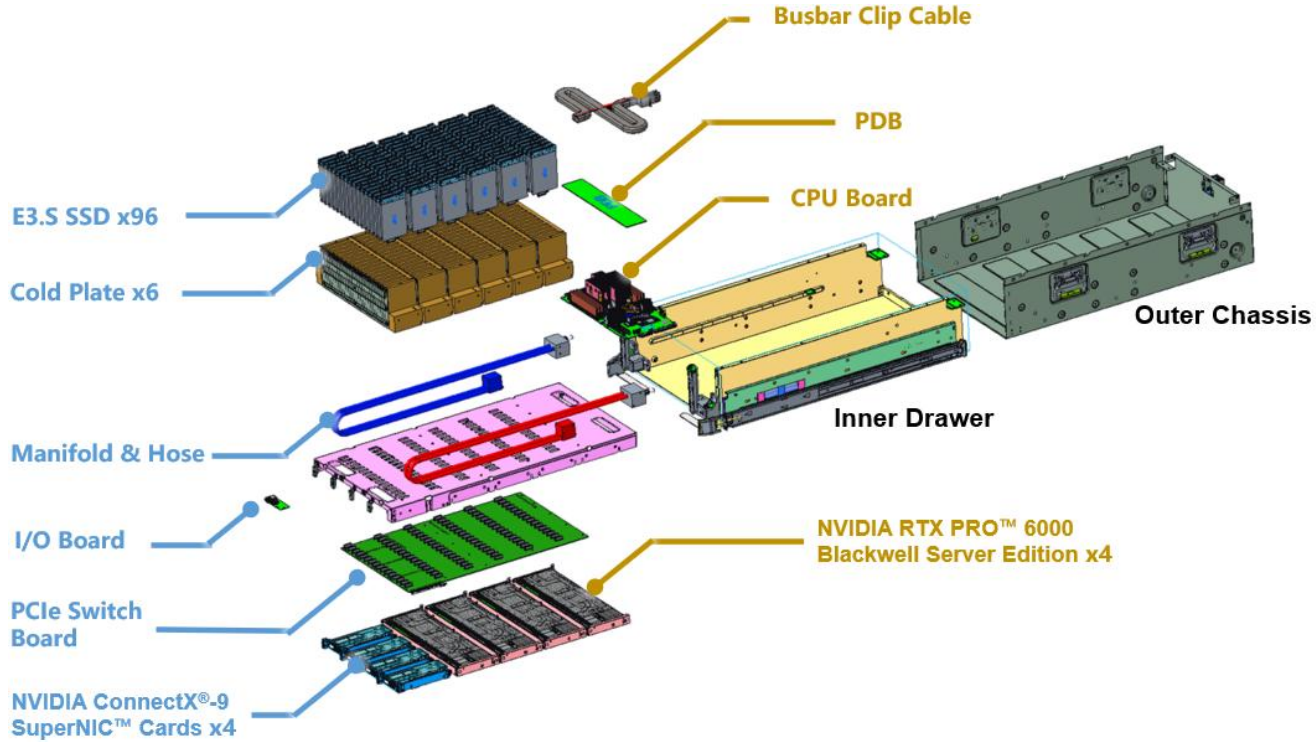 Отмечается, что традиционные серверы на основе CPU плохо справляются с такими задачами, как векторный поиск, генерация с дополненной выборкой (RAG), анализ графов и извлечение данных из KV-кеша. При таких нагрузках процессору необходимо выдавать команды, обрабатывать запросы и контролировать передачу данных, из-за чего создаются узкие места. 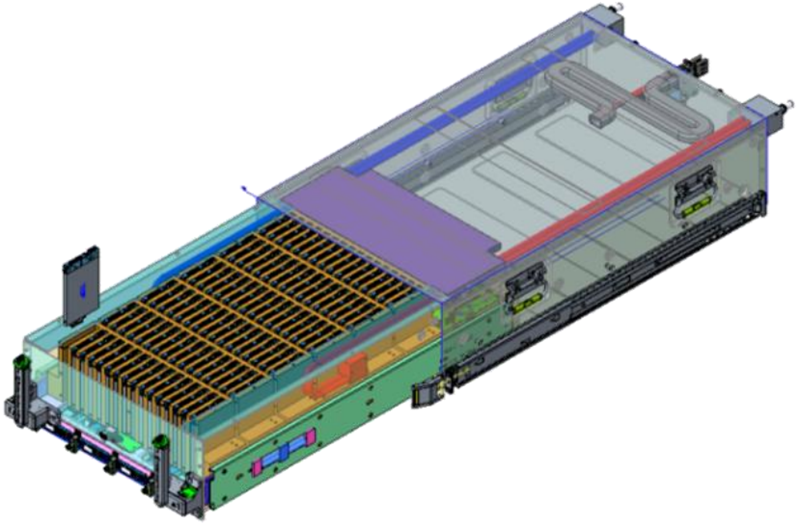 Платформа SCADA позволяет решить проблему благодаря тому, что операции ввода-вывода и обработка данных возлагаются на GPU — без участия CPU. По сути, ускорители RTX Pro 6000 Blackwell Server Edition в составе машины выполняют функции процессоров хранения, которые инициируют и обрабатывают транзакции и миллионы запросов со стороны ИИ-приложений, а также передают данные на вычислительные узлы посредством карт ConnectX-9.
15.06.2026 [01:05], Владимир Мироненко
Valvoline анонсировала жидкости Beyond by Valvoline для СЖО дата-центровКомпания Valvoline Global Operations представила Beyond by Valvoline — платформу жидкостей нового поколения, разработанную для контроля тепла и максимальной производительности, а также удовлетворения самых жёстких требований при использовании в системах охлаждения инфраструктуры для ИИ и HPC, и крупномасштабных системах хранения энергии на основе аккумуляторов. Valvoline отметила, что по мере того, как ИИ- и цифровые системы становятся всё более мощными и сложными, управление тепловыми процессами стало критически важным компонентом проектирования ЦОД. «Beyond by Valvoline была создана для решения этой проблемы, обеспечивая передовое управление температурным режимом, которое помогает максимизировать производительность, повысить эффективность и продлить срок службы критически важного вычислительного оборудования», — подчеркнула компания. 
Источник изображений: Valvoline В связи с развёртыванием GPU следующего поколения, отличающихся большей мощностью, отрасль ЦОД переходит к более широкому внедрению технологий прямого жидкостного и иммерсионного охлаждения. Запуск платформы Beyond от Valvoline обеспечивает больше возможностей для специалистов по жидкостным технологиям в поддержке растущих требований к инфраструктуре, говорит компания. Valvoline позиционирует это предложение как расширение своей экспертизы в области гидродинамики, применяя знания, полученные на автомобильном и промышленном рынках, к новым технологическим приложениям. Компания подчеркнула, что разработанные ею жидкости уже заслужили доверие ряда ведущих мировых поставщиков высокоэффективных решений для охлаждения. 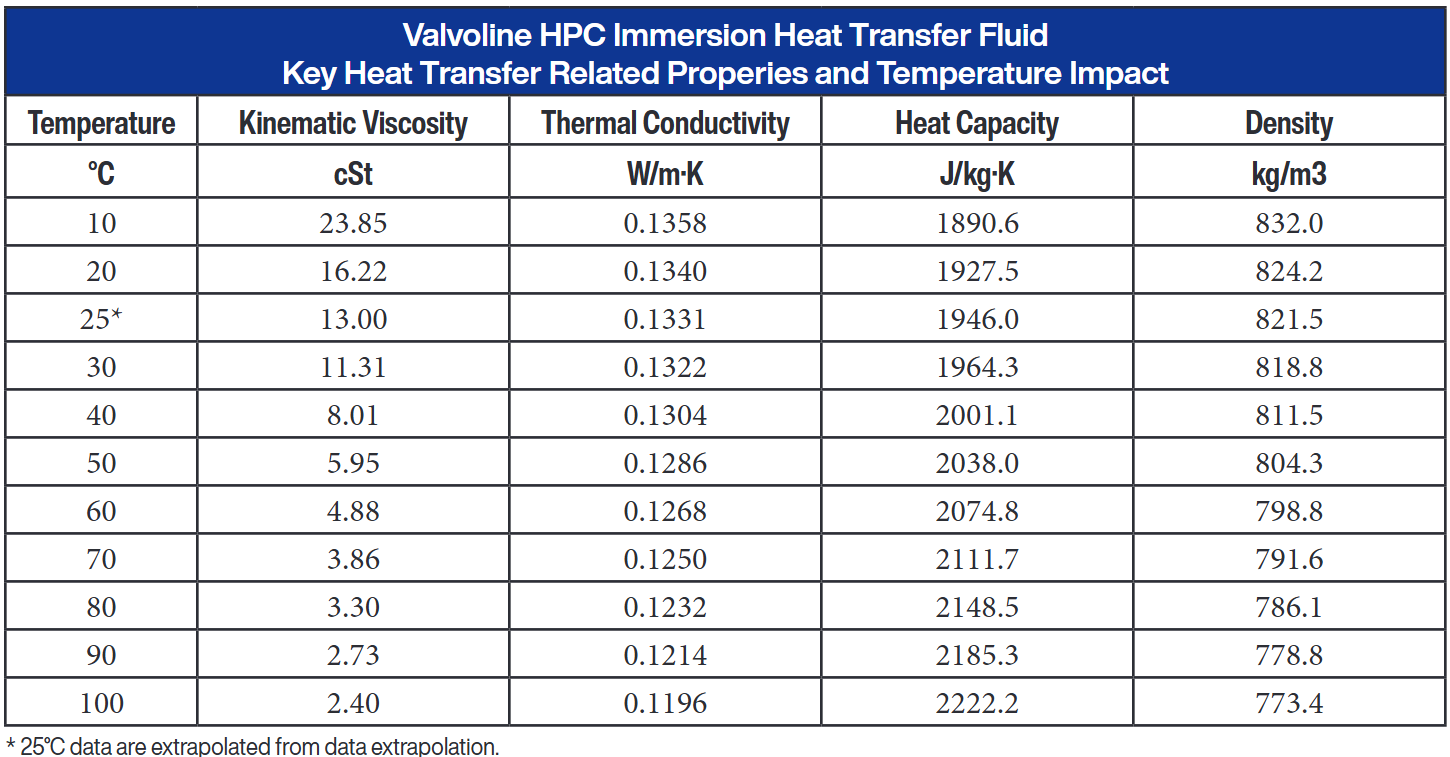 Анонс Beyond by Valvoline отражает продолжающееся развитие экосистемы иммерсионного охлаждения. Как отмечалось в многочисленных проектах и оценках технологий, успешная реализация погружного охлаждения зависит не только от конструкции серверов и резервуаров, но и от производительности, стабильности и долгосрочной надёжности самой охлаждающей жидкости. Поставщики с глубокими знаниями в области химии жидкостей всё чаще становятся участниками цепочки поставок ИИ-инфраструктуры. В настоящее время Valvoline предлагает жидкости Valvoline HPC DE1 и Valvoline PG25 Advanced. Valvoline HPC DE1 разработана для систем погружного охлаждения, где происходит прямой контакт жидкости с электрическими компонентами, например, в системах HPC, зарядных станциях и электромобилях. Для этих систем требуются низкая электропроводность и высокая диэлектрическая прочность, а для обеспечения высокой эффективности теплопередачи предпочтительны низкая вязкость и высокая теплопроводность. 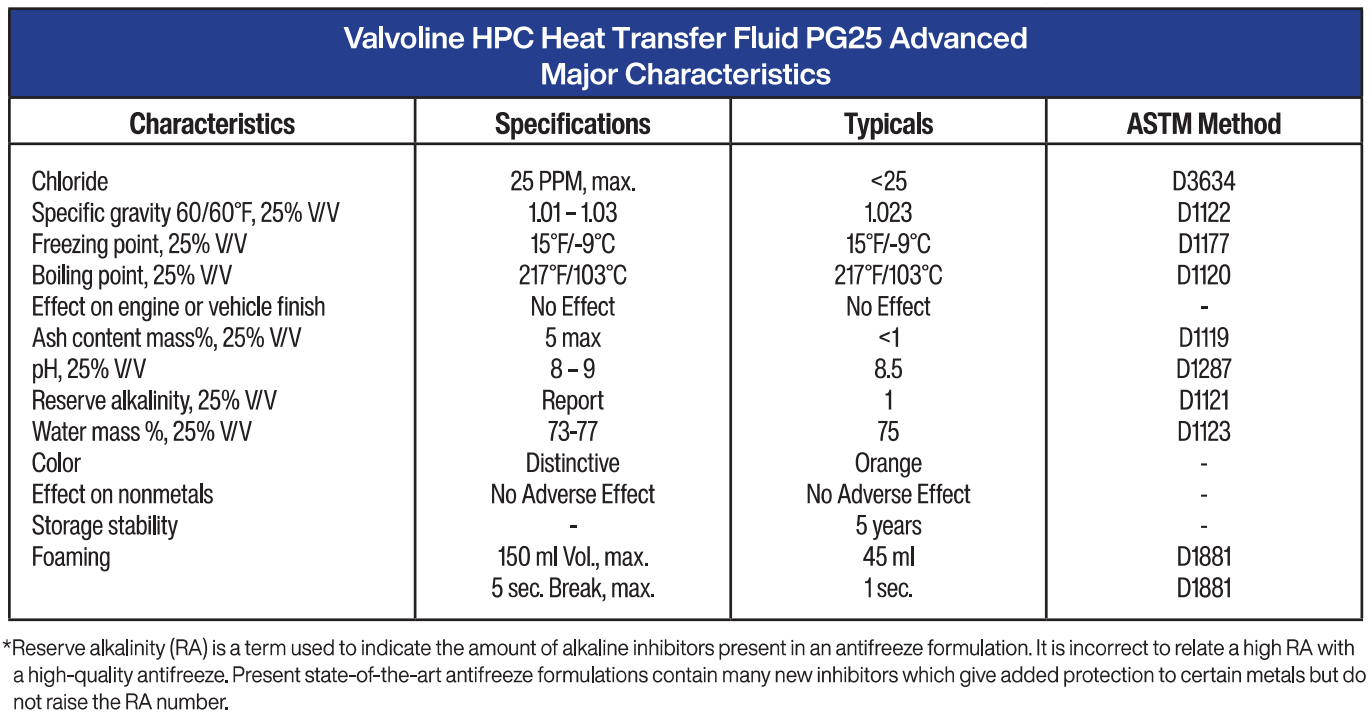 Valvoline PG25 Advanced предназначена для охлаждения вычислительной техники, отличается низкой токсичностью и обеспечивает надёжную защиту от коррозии металлических компонентов системы охлаждения. Также PG25 Advanced снижает вероятность засорения узких каналов и предотвращает образование отложений при утечках благодаря уникальному низкому содержанию твердых частиц. |
|

