Лента новостей
|
02.11.2020 [17:56], Илья Коваль
Прощание с Xeon Phi: ядро Linux лишится поддержки MIC-архитектурыФинальная партия Intel Xeon Phi была отгружена летом этого года, хотя сам закат продуктов на базе архитектуры MIC (Many Integrated Core) начался за несколько лет до этого. Теперь же можно сказать, что в их истории поставлена последняя точка — из основной ветки ядра Linux 5.10 поддержка этих процессоров убрана уже в rc2. В ядре Linux поддержка MIC появилась в 2013 году, и Intel очень активно развивала её, почти втрое увеличив объём кодовой базы. Однако в последние годы развитие прекратилось и код остался фактически заброшенным. Связано это, понятное дело, с уходом ускорителей с рынка, где они не стали массовыми, проиграв конкуренцию NVIDIA как в HPC, так и в остальных сегментах.  Intel последовательно отменила выпуск следующего поколения MIC и продуктов всех прошлых поколений Xeon Phi, переключившись на создание универсальной архитектуры GPU. HPC-ускорители на её базе должны появиться в скором времени. Шине Intel Omni-Path, которая была непосредственно интегрирована в некоторые поздние модели Xeon Phi, повезло больше — после отказа Intel разработки были переданы свежесозданной Cornelis Networks. Тем не менее, кое-какое наследие MIC в ядре всё же может сохраниться. Речь идёт подсистеме VOP (VirtIO over PCIe), которая решает некоторые проблемы виртуализации PCI Express и для устройств других вендоров. Однако в текущем она ориентирована только на поддержку продуктов и драйверов Intel, и сможет вернуться в ядро Linux лишь после доработки.
19.10.2020 [21:33], Владимир Мироненко
Microsoft построит установку для очистки сточных вод своих дата-центровАдминистрация Куинси (Массачусетс) планирует запустить летом следующего года установку по очистке сточных вод ЦОД при финансовой поддержке Microsoft. Основным пользователем установки будет корпорация, так как департамент экологии города сообщил, что именно её ЦОД способствуют слишком высокой концентрации минералов на существующих станциях очистки сточных вод. Очищенная вода будет возвращаться в ЦОД для повторного использования. Microsoft управляет ЦОД мощностью в сотни мегаватт в своем кампусе площадью 270 акров (109 га) в западном Куинси.  Глава администрации города Пэт Хейли (Pat Haley) отметил, что финансирование строительства установки возложено полностью на Microsoft, так как уровень примесей в сточных водах её ЦОД превышает установленные нормы. По его словам, стоимость проекта исчисляется миллионами долларов. В результате будет построено совершенно новое «Центральное сооружение для повторного использования сточных вод», «предназначенное специально для очистки воды, поступающей в результате обратной промывки системы охлаждения ЦОД, которую вы не можете отправить в другую систему очистки, потому что это нарушит процесс очистки», — сообщил Хейли. Хотя Microsoft будет основным арендатором установки, мэрия будет поощрять подключение к системе очистки ЦОД других провайдеров, которым придётся оплачивать прокладку трубопроводов и нести другие стандартные операционные расходы. В числе владельцев дата-центров в этом районе Хейли назвал Intuit, Vantage и Yahoo, отметив при этом, что не все компании используют для систем охлаждения воду. Другие же используют воду для охлаждения четыре или пять раз, прежде чем слить её обратно в городские магистрали для очистки.
16.10.2020 [23:17], Юрий Поздеев
DPU в стиле Intel: сетевые адаптеры с Xeon D, FPGA, HBM и SSDМир сетевых карт становится умнее. Это следующий шаг в дезагрегации ресурсов центров обработки данных. Наличие расширенных возможностей сетевых карт позволяет разгрузить центральный процессор, при этом специализированные сетевые адаптеры обеспечивают более совершенные функции и безопасность. В этой новости мы познакомим вас сразу с двумя адаптерами: Silicom SmartNIC N5010 и Inventec SmartNIC C5020X. Silicom FPGA SmartNIC N5010 предназначена для систем крупных коммуникационных провайдеров. Операторы все чаще стремятся заменить проприетарные форм-факторы от поставщиков телекоммуникационного оборудования на более стандартные варианты. В рамках этого мы видим, что производители ПЛИС не прочи освоить и эту нишу.  В Silicom FPGA SmartNIC N5010 используется Intel Stratix 10 DX с 8 Гбайт памяти HBM. Поскольку пропускная способность памяти становится все большим аспектом производительности системы, HBM будет продолжать распространяться за пределы графических процессоров и FPGA. В SmartNIC и DPU память HBM может использоваться для размещения индексных таблиц поиска и других функций для интенсивных сетевых нагрузок. Помимо HBM SmartNIC N5010 имеет еще 32 Гбайт памяти DDR4 ECC. SmartNIC N5010 потребляет до 225 Вт, что предполагает несколько вариантов исполнения карты, в том числе и с активным охлаждением.  Самая интересная особенность новой карты — 4 сетевых порта по 100 Гбит/с. На плате SmartNIC N5010 установлены две базовые сетевые карты Intel E810 (Columbiaville). На приведенной схеме можно заметить, что используется интерфейс PCIe Gen4 x16, причем их тут сразу два. Для работы четырех 100GbE-портов уже недостаточно одного интерфейса PCIe 4.0 x16. Второй порт PCIe 4.0 x16 может быть подключен через дополнительный кабель к линиям второго процессора, чтобы избежать межпроцессорного взаимодействия для передачи данных.  Вторая новинка, Inventec FPGA SmartNIC C5020X, совмещает на одной плате процессор Intel Xeon D и FPGA Intel Stratix 10. Этот адаптер предназначен для разгрузки центрального процессора в серверах крупных облачных провайдеров. На плате установлен процессор Intel Xeon D-1612 с 32-Гбайт SSD и 16 Гбайт DDR4, подключение к ПЛИС Intel Stratix 10 DX 1100 осуществляется через PCIe 3.0 x8. Нужно отметить, что FPGA Stratix имеет свои собственные 16 Гбайт памяти DDR4, а также обеспечивает сетевые подключения 25/50 Гбит/с и оснащен интерфейсом PCIe 4.0 x8, через который адаптер подключается к хосту. 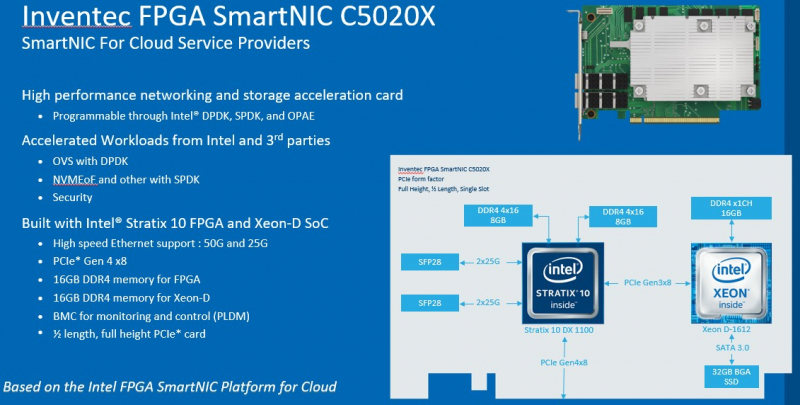 У Inventec уже есть решение на базе Arm (Inventec X250), которое использует ПЛИС Arria 10 GX660 вместе с сетевым адаптером Broadcom Stingray BCM8804, которое имеет аналогичный форм-фактор и TPD не более 75 Вт. Однако для некоторых организаций наличие единой x86 платформы, включая SmartNIC, упрощает развертывание, поэтому вариант C5020X для таких компаний более предпочтителен. Решение получилось очень интересным, однако вряд ли его можно назвать адаптером для массового рынка, как Intel Columbiaville. На примере этого адаптера Intel показала, что может объединить элементы своего портфеля для создания комплексных решений. Inventec FPGA SmartNIC C5020X является хорошей альтернативой предложению на базе Broadcom, что позволит крупным облачным провайдерам диверсифицировать свои платформы.  Несмотря на то, что обе новинки классифицируются как «умные» сетевые адаптеры SmartNIC, вторая, пожалуй, уже ближе к DPU, если сравнивать её с адаптерами NVIDIA DPU, в которых сетевая часть дополнена Arm-процессором и GPU-ускорителем. В данном случае есть и x86-ядра общего назначения, и ускоритель, хотя и на базе ПЛИС. Впрочем, устоявшегося определения DPU и списка критериев соответствия этому классу процессоров пока нет.
13.10.2020 [23:41], Владимир Мироненко
Amazon купила у радиолюбителей 4 млн IPv4-адресов за $108 млнПрезидент неправительственной организации радиолюбителей Amateur Radio Digital Communications (ARDC) из Калифорнии (США) Фил Карн (Phil Karn, KA9Q), подтвердил, что ARDC получила $108 млн от Amazon за 4 млн адресов IPv4.  С момента выделения любительскому радио в середине 1980-х годов сети 44 (44.0.0.0/8), также известной как AMPRNet, она использовалась радиолюбителями для проведения научных исследований и экспериментов с цифровыми коммуникациями по радио с целью продвижения современного уровня любительских радиосетей и обучения радиолюбителей этим методам. Этот процесс координирует некоммерческая организация ARDC. Блок (44.192.0.0/10) примерно из четырех млн IP-адресов AMPRNet из 16 млн доступных был продан Amazon организацией ARDC в середине 2019 года, но лишь сейчас была объявлена стоимость сделки. Amazon заплатила ARDC примерно $27 за каждый IPv4-адрес. «Соглашение о неразглашении информации с Amazon, которое касалось продажи наших избыточных IP-адресов, требовало от нас не сообщать точные суммы в долларах до тех пор, пока мы не обязаны по закону раскрывать их в наших ежегодных налоговых декларациях, аудиторских и финансовых отчетах. Они только что были обнародованы и доступны в Интернете на веб-сайте генерального прокурора Калифорнии (поскольку ARDC зарегистрирована в Калифорнии). Вы также можете получить некоторую справочную информацию в нашей статье в Википедии», — сообщил Фил Карн в посте на сайте AMSAT Bulletin Board (AMSAT-BB). Он пообещал, что организация будет ежегодно выделять из полученной суммы порядка $5 млн на интернет- и радиолюбительские цифровые коммуникационные проекты. «На сегодняшний день мы выделили около $2,5 млн в виде грантов, так что мы только начинаем», — добавил глава ARDC.
08.10.2020 [21:26], Владимир Мироненко
IBM разделится на две компании и сосредоточится на создании гибридного облака стоимостью $1 трлнКомпания IBM, изначально сделавшая себе имя благодаря выпуску корпоративного оборудования, делает ещё один шаг в сторону от этого наследия, углубляясь в мир облачных сервисов. Сегодня компания объявила о решении выделить подразделение управляемых инфраструктурных услуг в отдельную публичную компанию с годовой выручкой в $19 млрд, чтобы сосредоточиться на новых возможностях гибридных облачных приложений и искусственного интеллекта. Как сообщил генеральный директор IBM Арвинд Кришна (Arvind Krishna), процесс создания новой компании с условным названием NewCo (новая компания) будет завершён к концу 2021 года. У неё будет 90 тыс. сотрудников, 4600 крупных корпоративных клиентов в 115 странах, портфель заказов в размере $60 млрд, «и более чем в два раза больше, чем у ближайшего конкурента» присутствие в области инфраструктурных услуг. 
Gleb Garanich/Reuters В число конкурентов новой компании входят BMC и Microsoft. Остающийся у IBM после выделения новой компании бизнес в настоящее время приносит её около $59 млрд годового дохода. Услуги инфраструктуры включают в себя ряд управляемых сервисов, основанных на устоявшейся инфраструктуре и связанной с ней цифровой трансформации. Они включают в себя, в том числе тестирование и сборку, а также разработку продуктов и лабораторные сервисы. Этот шаг является значительным сдвигом для компании и подчеркивает большие изменения в том, как ИТ-инфраструктура предприятия развивалась и, похоже, продолжит меняться в будущем. IBM делает ставку на то, что устаревшая инфраструктура и ее обслуживание, продолжая приносить чистую прибыль, не будут расти, как это было в прошлом, и по мере того, как компания продолжит модернизацию или «цифровую трансформацию», она будет всё больше обращаться к внешней инфраструктуре и использованию облачных сервисов как для ведения своего бизнеса, так и для создания сервисов, взаимодействующих с потребителями. Объявление было сделано через год после того, как IBM приобрела компанию Red Hat, предлагающую ПО с открытым исходным кодом, за $34 млрд, рассчитывая перевести большую часть своего бизнеса в облачные сервисы. «Я очень рад предстоящему пути и огромной ценности, которую мы создадим, если две компании будут сосредоточены на том, что у них получается лучше всего, — отметил в своем заявлении Арвинд Кришна. — Это принесёт пользу нашим клиентам, сотрудникам и акционерам и выведет IBM и NewCo на траекторию улучшенного роста». «IBM сосредоточена на возможности создания гибридного облака стоимостью $1 трлн, — сказал Кришна. — Потребности клиентов в покупке приложений и инфраструктурных услуг разнятся, в то время как внедрение нашей гибридной облачной платформы ускоряется. Сейчас подходящее время для создания двух лидирующих на рынке компаний, сосредоточенных на том, что у них получается лучше всего. IBM сосредоточится на своей открытой гибридной облачной платформе и возможностях ИИ. NewCo будет более гибко проектировать, управлять и модернизировать инфраструктуру самых важных организаций мира. Обе компании будут двигаться по траектории улучшенного роста с большей способностью сотрудничать и использовать новые возможности, создавая ценность для клиентов и акционеров».
05.10.2020 [18:15], Илья Коваль
NVIDIA представила серверный ускоритель A40 с поддержкой виртуализацииНа конференции GTC 2020 компания NVIDIA анонсировала два новых ускорителя: RTX A6000 и A40. Оба являются практически идентичными копиями, но отличаются исполнением — A40 представляет собой привычную полноразмерную двухслотовую карту для серверов с пассивным охлаждением и энергопотреблением 300 Вт. A40 базируется на 8-нм чипе GA102 (10752 CUDA-ядра, 336 Tensor-ядер и 84 RT-ядра), дополненным 48 Гбайт памяти GDDR6 ECC и 384-бит шиной. Наличие NVLink3 позволяет объединить две карты, получив 96 Гбайт общей RAM. Для подключения к хостовой системе используется PCIe 4.0 x16. Увы, частот памяти и ядра, а также уровень производительности компания пока не приводит.  Новинка ориентирована на 3D/CAM и другие системы моделирования и визуализации в виртуализированных окружениях — как и у старшего собрата в A40 есть поддержка до 7 vGPU с объёмом памяти от 1 до 48 Гбайт. А вот поддержки MIG, судя по всему, пока нет. Тем не менее, прочие функциональные блоки никуда не делись, так что карту можно использовать для вычислений и машинного обучения. Также есть один блок кодирования и два блока декодирования видео, которые поддерживают в том числе и AV1.  Из любопытных особенностей отметим, что для питания используется CPU-коннектор ESP (4+4), а не восьмиконтактный PCIe. Кроме того, карта имеет три видеовыхода DisplayPort 1.4, которые по умолчанию отключены — в сервере они всё равно не нужны. Их можно принудительно включить, но тогда будет недоступна функция vGPU. Также в A40 имеется отдельный крипточип CEC 1712 для Secure Boot и прочих функций безопасности, а сама она соответствует NEBS Level 3, что даёт возможность сертифицировать устройства с ней для использования в промышленных (и прочих неблагоприятных) условиях. Поставки новинки начнутся в первом квартале следующего года. Впрочем, как и прежде, она будет ориентирована на OEM-поставщиков оборудования, поэтому увидим мы её скорее в составе готовых продуктов и облаках, а не на полках магазинов.
02.10.2020 [16:47], Алексей Степин
Groq начала поставки самой быстрой в мире ИИ-платформы TSPСистемы машинного интеллекта и особенно инференс-системы, чьей задачей является принятие решений в нейросетевых сценариях обработки, требуют особого подхода к реализации аппаратной части для достижения действительно высокой производительности при приемлемом уровне энергопотребления. Стартап Groq, который ещё осенью 2019 года анонсировал свой тензорный процессор Groq TSP, начал поставки систем на базе этого чипа. В своё время Groq наделали немало шума, заявив о создании самого быстрого ИИ-процессора с производительностью 1 Петаопс (PetaOPS, 1015 операций в секунду, обычно целочисленных), оставляющего позади даже таких монстров, как NVIDIA Tesla V100. Добиться этого удалось благодаря уникальной многоядерной архитектуре, из которой Groq исключила всё лишнее для тех задач, на которые ориентирован свой процессор.  Подход оказался плодотворным: прототип ускорителя на базе Groq TSP, работая на частоте 1 ГГц, развил 205 Тфлопс в режиме FP16 и 820 Топс в режиме INT8. Для сравнения, V100 при аналогичном потреблении 300 Ватт показала лишь 125 Тфлопс и 250 Топс соответственно. В тесте ResNet-50 новый чип смог достичь производительности на уровне 21700 распознаваний в секунду, уступив лишь проприетарному ASIC Alibaba HanGuang, недоступному для приобретения. 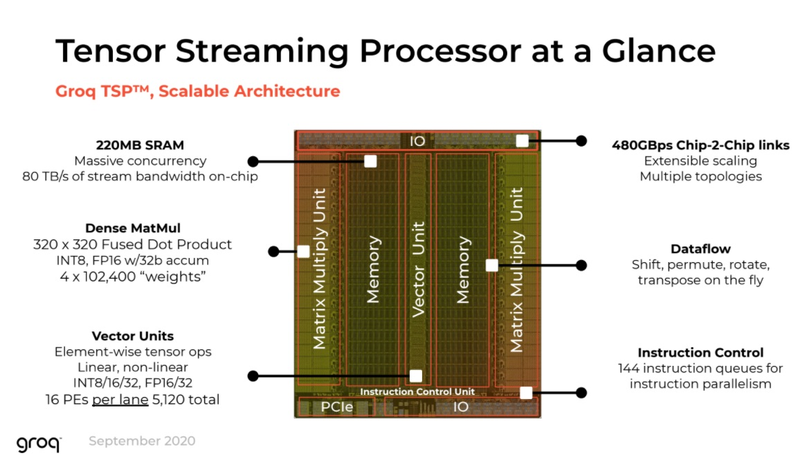
Архитектура Groq TSP (Изображение: The Next Platform) Об архитектуре Groq до недавних пор было известно немного, однако компания-разработчик, похоже, успешно набирает обороты: начались коммерческие поставки ускорителей на базе Groq TSP и даже законченных вычислительных узлов, позволяющих организовывать целые кластеры с высочайшим уровнем производительности. На днях компания рассказала The Next Platform об особенностях своих решений. 
Шасси Groq (Изображение: The Next Platform) Главной особенностью своего TSP разработчики по-прежнему называют наличие блока SRAM объёмом 220 Мбайт. Такая память обеспечивает пропускную способность на уровне 80 Тбайт/с, что является настоящим подарком для инференс-сценариев. Кроме того, теперь известно, что каждый TSP содержит два блока матричной математики (320×320 Fused Dot Product, INT8 или FP16, 32-битный аккумулятор) и один блок векторных вычислений (тензорные линейные и нелинейные вычисления в режимах INT8/16/32 и FP16/32, 5120 вычислительных элементов). 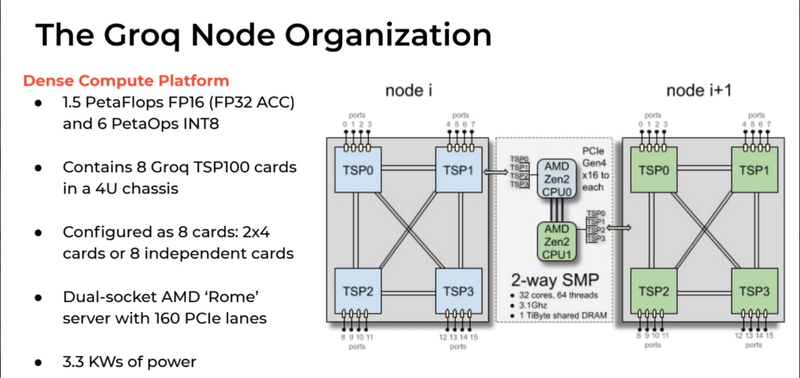
Структура узла Groq (Изображение: The Next Platform) Как обычно, по краям кристалла расположены различные блоки ввода-вывода, в частности, контроллер PCI Express 4.0, а также два I/O-модуля для межпроцессорной связи. Последние обеспечивают Groq TSP 16 линиями с общей пропускной способностью 512 Гбайт/с, так что узким местом в многопроцессорных кластерах на базе TSP они стать не должны. Кроме того, на кристалле присутствует и небольшой блок управления, могущий оперировать очередями из 144 инструкций, так что полностью отказываться от управляющих структур в TSP разработчики всё-таки не стали.  Структура вычислительной системы на базе Groq TSP довольно проста. Она состоит из трёх функциональных блоков, два из которых занимаются собственно вычислениями и управляющего блока с классическими процессорами. Каждый из вычислительных модулей содержит по четыре ускорителя Groq TSP, соединённых по схеме «каждый с каждым» и имеет 16 свободных портов для дальнейшего масштабирования и добавления новых модулей TSP. Ускорители могут использоваться независимо, каждый для своей задачи, либо работать вместе над одной задачей, развивая большую производительность. 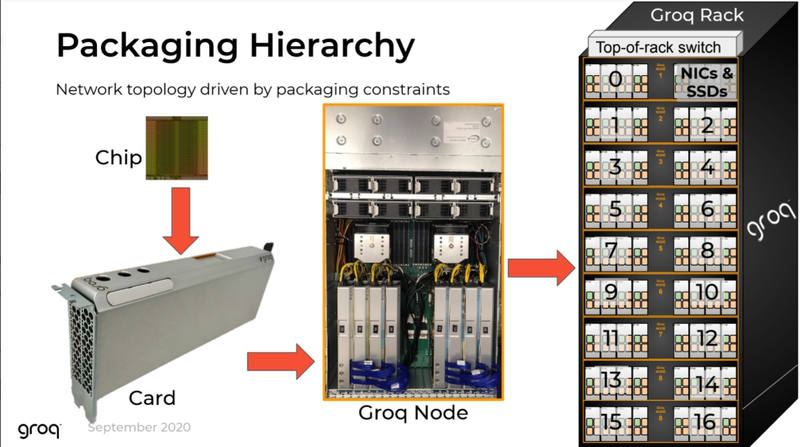
Стартовавший, как отдельный ускоритель, Groq TSP вырос в масштабируемый кластер (Изображение: The Next Platform) Управляющая часть с точки зрения архитектуры выглядит несложно: это обычная двухпроцессорная система на базе AMD EPYC 7002, и каждый из четырёх ускорителей подключен к своему процессору посредством PCI Express 4.0 x16. В этой части используются 32-ядерные процессоры AMD и установлен общий пул оперативной памяти объёмом 1 Тбайт. Вся система занимает модифицированный стоечный корпус высотой 5U и потребляет в пределе 3,3 кВт. Производительность такого комплекса заявлена на уровне 6 Петаопс в режиме INT8 и 1,5 Пфлопс в режиме FP16. 
Сервер Groq Node И это далеко не предел, недаром Groq называет своё решение Node Scalable Compute System. Новинка действительно масштабируется, поскольку каждый из ускорителей имеет по четыре свободных порта интерконнекта. Стойка, разработанная и представленная Groq, может включать в себя 17 вычислительных модулей с вышеописанной архитектурой. 18-ое место занято модулем, содержащим в себе сетевые интерфейсы и дисковую подсистему. 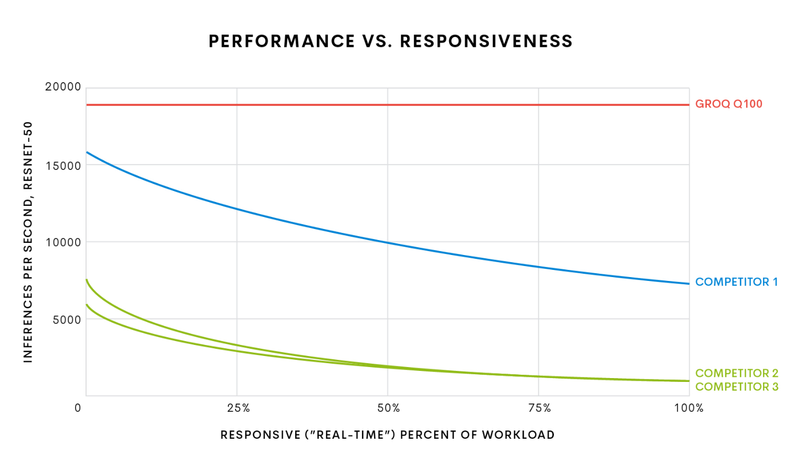 Без программного обеспечения любая система мертва, тем более, с учётом архитектурных особенностей Groq TSP, практически целиком полагающегося на компилятор. Компания сопровождает новые системы комплектом ПО Groqware SDK. Он включает в себя все необходимые средства разработки и набор API, что позволит разработчикам в кратчайшие сроки начать создавать ПО, в полной мере раскрывающее немалый потенциал новой платформы. 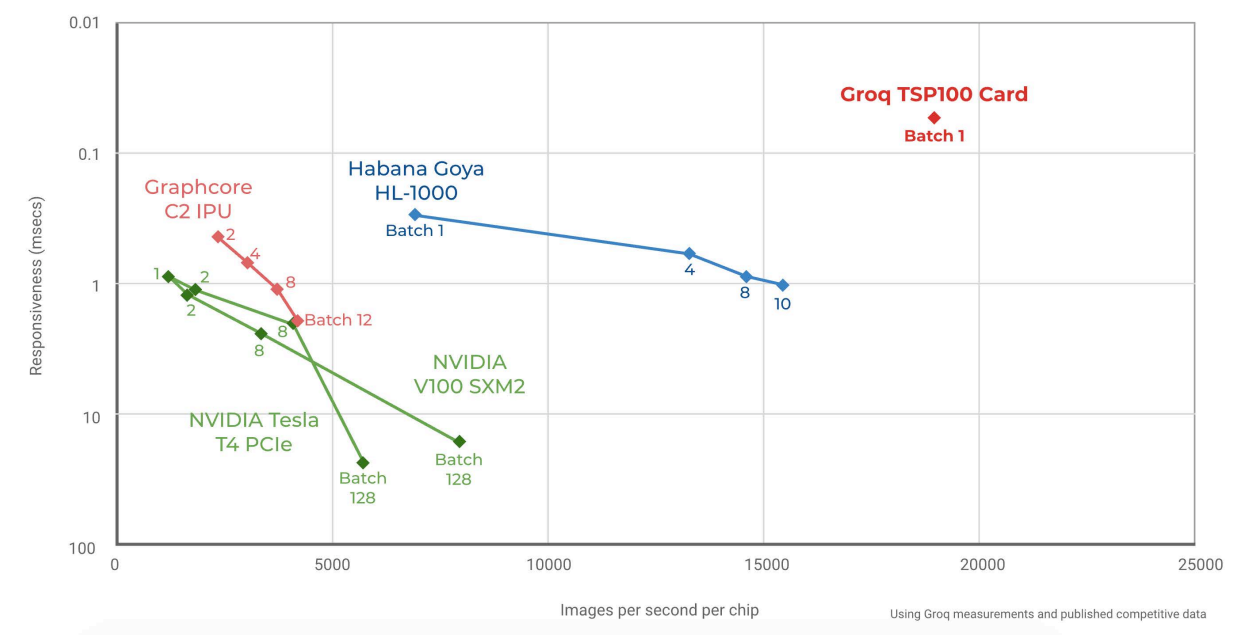 Из-за того, что Groq лучше всего раскрывается на задачах с небольшой очередью (в пределе при batch size 1), эта инференс-платформа обеспечивает великолепную латентность, что делает её привлекательной для финансовых структур. Интересна платформа и учёным, но те более заинтересованы в возможностях TSP в области классических вычислений, в частности, линейной алгебры. Из-за этого сложилась любопытная ситуация: стартовал Groq TSP как инференс-ускоритель, но первые клиенты компании потребовали большей универсальности, так что разработчикам пришлось создать сначала Groq Node, описанный выше, а потом и целый масштабируемый кластер на базе таких узлов. Таким образом, платформа, стартовавшая как узкоспециализированное решение, эволюционировала в более универсальный вычислительный комплекс, гибкий и масштабируемый.
01.10.2020 [23:24], Юрий Поздеев
Сделано в США: HPE возвращается к «белой сборке» серверовHewlett Packard Enterprise (HPE) анонсировала новую систему безопасности цепочки поставок для клиентов из государственного сектора США, которые по тем или иным причинам предпочитают покупать продукцию, произведенную на территории США. Безопасность всей цепочки поставок серверного оборудования достигается за счет строгого соблюдения отраслевых стандартов США, что снижает риски для учреждений государственного сектора. Новую инициативу назвали HPE Trusted Supply Chain. Несколько лет назад HPE представила Silicon Root of Trust — функцию, которая обеспечивает безопасность непосредственно в iLO и создает неизменяемую цифровую подпись. Если прошивка или комплект драйверов для сервера не соответствует этой цифровой подписи, сервер не загрузится и изменения конфигурации не будут приняты. HPE не ограничивается только серверами, но и предлагает подобную систему для сетевой безопасности в решениях от Aruba.  Однако, есть некоторые проблемы с автономностью цепочки поставок: пандемия Covid-19 повлекла массовый сбой в производстве многих электронных компонентов для серверов. Еще одной проблемой стали участившиеся взломы микрочипов для кражи информации с различных устройств. Обе проблемы HPE решает, создавая готовый продукт в той стране, где он продается. В США наблюдается повышенный спрос на безопасные продукты собственного производства, особенно для клиентов из федерального, государственного и финансового секторов, а также организаций здравоохранения. У HPE есть собственная производственная площадка в штате Висконсин, где работает персонал с необходимым допуском. Поскольку весь процесс производства находится под контролем, вероятность нарушения безопасности очень мала. HPE также готова доставить и установить новые серверы в ЦОД заказчика.  Первым продуктом, прошедшим весь этот процесс является сервер HPE Proliant DL380T. Не все компоненты сервера произведены непосредственно в США, но те, что имеют локальное происхождение, уже позволяют официально заявить об американском происхождении оборудования (Country of Origin USA), а не просто об американском производстве (Made in USA). HPE выходит за рамки процесса производства, распространяя повышенную безопасность на весь жизненный цикл продукта:
HPE не останавливается на достигнутом и планирует в следующем году представить подобную программу для Европы. Похоже, что «белая сборка» возвращается. Впрочем, процесс этот начался не сегодня — ещё в прошлом году крупные контрактные производители серверов, которые обслуживали крупных американских и европейских клиентов начали переносить производственные линии из материкового Китая на Тайвань и в Мексику. HPE лишь довела дело до логического завершения.
01.10.2020 [11:51], Юрий Поздеев
Hailo: новые модули ускорения ИИ для периферийных вычисленийHailo, производитель микросхем для систем искусственного интеллекта (ИИ), выпустила новые высокопроизводительные модули в форм-факторах M.2 и mini PCIe для расширения возможностей периферийных систем. 
Источник изображений: Hailo Модули на базе процессора Hailo-8 можно подключать к различным периферийным устройствам, что позволяет использовать возможности ИИ в умных домах, розничной торговле и промышленности.  Модули Hailo легко интегрируются в стандартные платформы, такие как TensorFlow и ONNX, что позволяет значительно упростить использование новинок в комплексных решениях. Заказчики могут оперативно перенести свои решения с нейронными сетями на модули Hailo-8. 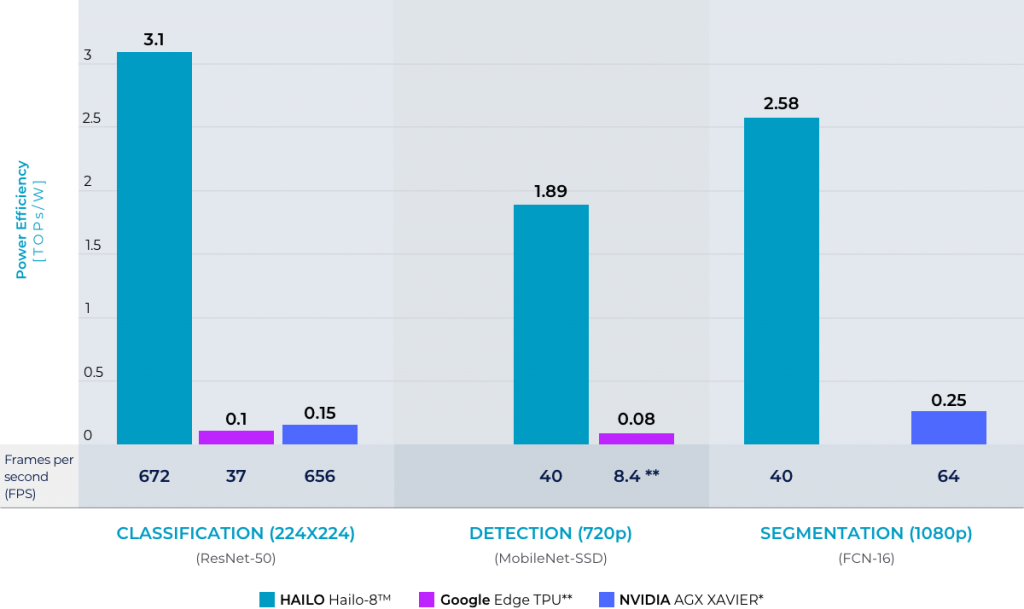 Спрос на высокопроизводительные периферийные устройства постоянно растет, поэтому безвентиляторные модули Hailo-8 будут востребованы, например, в видеоаналитике, либо для подключения большого количества внешних датчиков для сбора и обработки информации в режиме реального времени. Процессор Hailo-8 способен обеспечить 26 TOPS, при этом имеет энергоэффективность 3 TOPS/Вт. 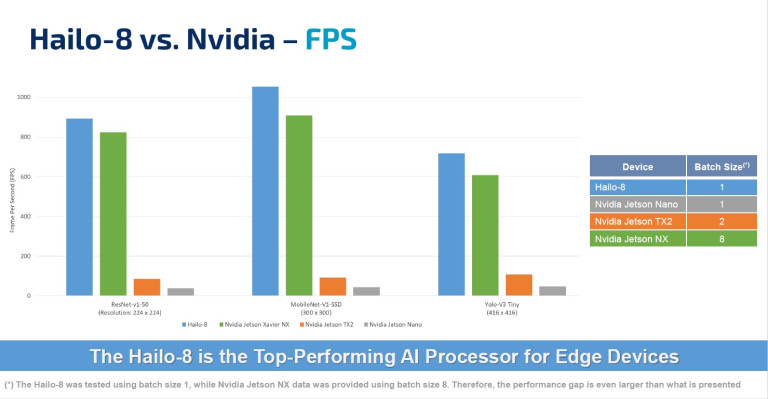 Модуль Hailo-8 M.2 уже интегрирован в следующее поколение Foxconn BOXiedge (24-ядерный мини сервер, который потребляет всего 30 Вт, при этом обладает неплохими показателями производительности). Наличие готового продукта позволит ускорить внедрение новых модулей в периферийные вычисления и значительно упростить этот процесс для конечного заказчика.
23.09.2020 [16:00], Алексей Степин
Intel представила новые 10-нм индустриальные процессоры: от Atom x6000E до Core i7 Tiger LakeНа мероприятии Intel Industrial Summit компания показала новые решения для периферийных вычислений и промышленных систем: платформу Atom x6000E, а также новые процессоры Pentium и Celeron серий N/J и индустриальные версии Core i3/i5/i7 11-го поколения известного как Tiger Lake. Для x6000E, Pentium и Celeron используется классический, «старый» 10 нм, а кристаллы Tiger Lake производятся с использованием «нового» 10 нм, так называемого SuperFIN. Платформа Intel Atom x6000E (Elkhart Lake) универсальна и позволяет решать широкий круг задач. Она может применяться в производящей промышленности и энергетике, в системах управления «умного города», в здравоохранении и медицине и во многих других отраслях, где требуется обработка достаточно серьёзных входных потоков данных в реальном времени. При этом платформа отвечает самым строгим требованиям безопасности.  По сравнению с предыдущими процессорами Atom аналогичного назначения в серии x6000E однопоточная производительность возросла в 1,7 раза, многопоточная — в 1,5 раза, а производительность графической подсистемы вдвое. Для повышенной временной точности в новинках реализована поддержка технологий Intel Time Coordinated Computing (TCC) и Time-Sensitive Networking (TSN).  Как и полагается современной SoC для периферийных вычислений, в составе x6000E имеются блоки критографических ускорителей, а для IoT имеется интегрированный микроконтроллер ARM Cortex-M7, отвечающий за работу Intel Programmable Services Engine (Intel PSE). Он работает независимо от остальных блоков и предоставляет возможности удалённого управления SoC, обработки низкоскоростного ввода-вывода от различных сенсоров, запуск приложений реального времени и синхронизацию. Есть также и чисто аппаратные средства обеспечения ИТ-безопасности, объединённые под именем Intel Safety Island. 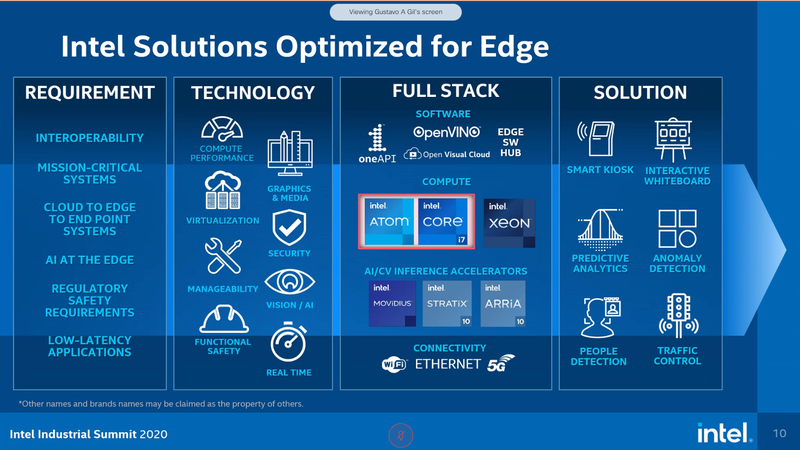 Также в целях обеспечения надёжности реализован широкий спектр средств удалённого мониторинга и управления, как в режиме in-band, так и в out-of-band. Включение, выключение, сброс и перезагрузку можно выполнять даже если система в целом не отвечает. Модели Atom x6427FE и x6200FE отвечают стандартам функциональной безопасности IEC 61508 и ISO 13849, они прошли соответствующую сертификацию, так что использовать их можно и в системах жизнеобеспечения, в комплексах управления АЭС или нефтеперабатывающего предприятия. 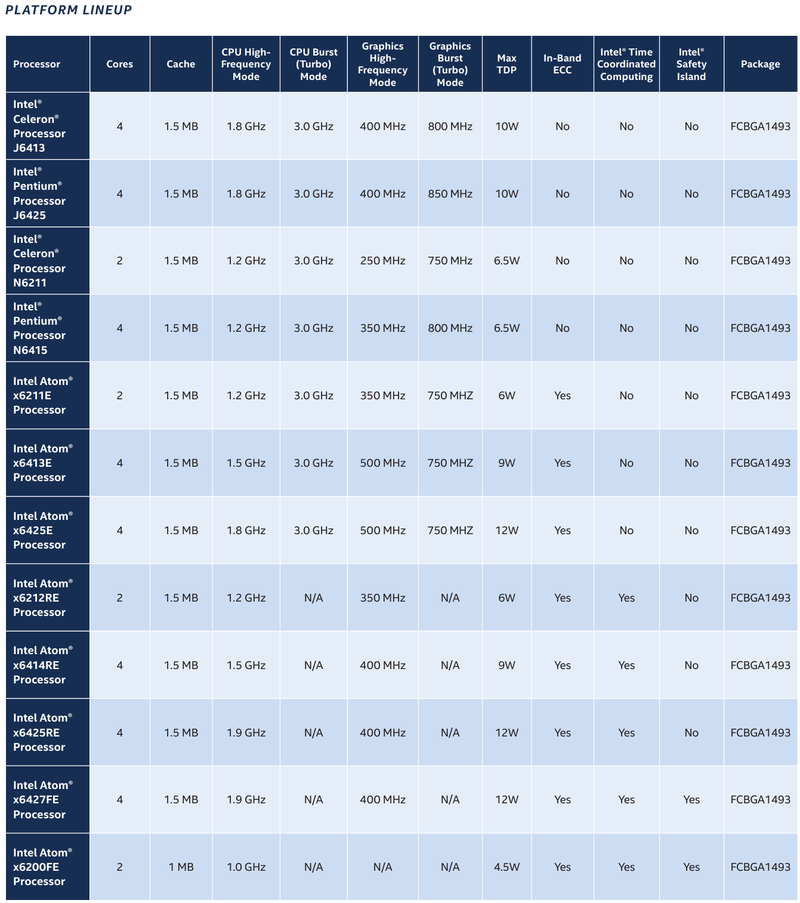 Серия Intel Atom x6000E включает в себя процессоры с двумя или четырьмя ядрами, их частотный диапазон составляет от 1,0 до 1,9 ГГц, в турборежиме частота может временно увеличиваться до 3,0 ГГц. Аналогичные частотные формулы имеют и Pentium/Celeron, базирующиеся на ядрах Tiger Lake (11 поколение). Контроллер памяти может работать либо с LPDDR4x (4×32 бита, максимум 4267 Мт/с, 16 Гбайт при 3200 МГц, всего до 64 Гбайт) или DDR4 (2×64 бита, 3200 Мт/с, максимум 32 Гбайт, всего до 64 Гбайт), есть поддержка in-band ECC для обычных модулей без ECC. Объём кеша составляет 1 Мбайт у самой младшей модели, во всех остальных случаях он равен 1,5 Мбайт. 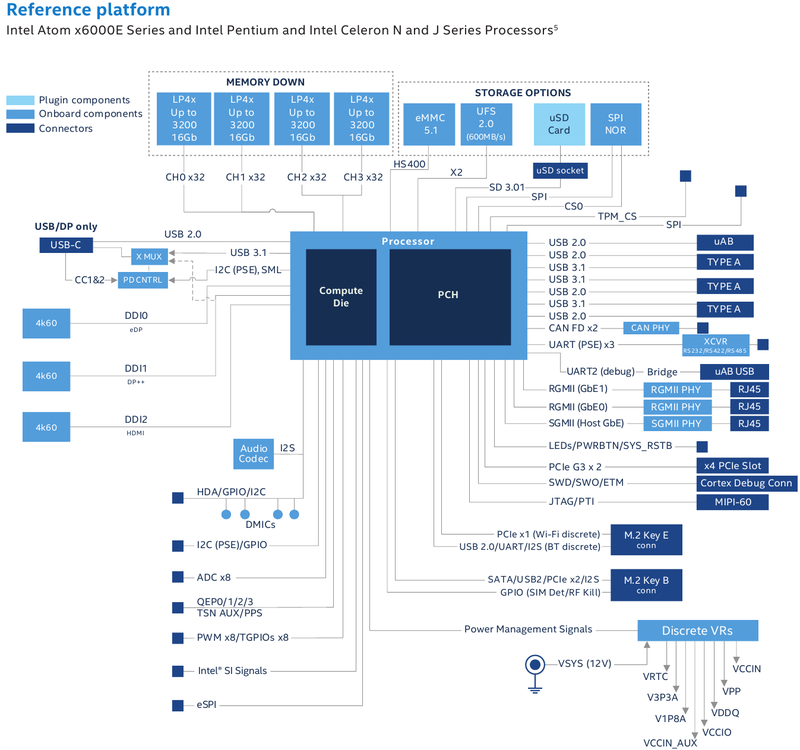 В соответствии с современными требованиями к графике, новинки Atom поддерживают подключение до трёх независимых дисплеев с разрешением 4K при 60 Гц, для этого служат интерфейсы Display Port 1.3 и HDMI 2.0b. Также поддерживается подключение экранов по eDP или MIPI DSI. Сам графический движок Intel UHD Graphics может иметь конфигурацию с 16 или 32 исполнительными блоками, работающими на частоте до 400 МГц, а в турборежиме — и до 800 МГц. Они поддерживают различные режимы вычислений для работы в качестве инференс-системы. Новые SoC Intel выполнены в едином корпусе FCBGA1493, однако под крышкой скрываются два кристалла — вычислительный и PCH. 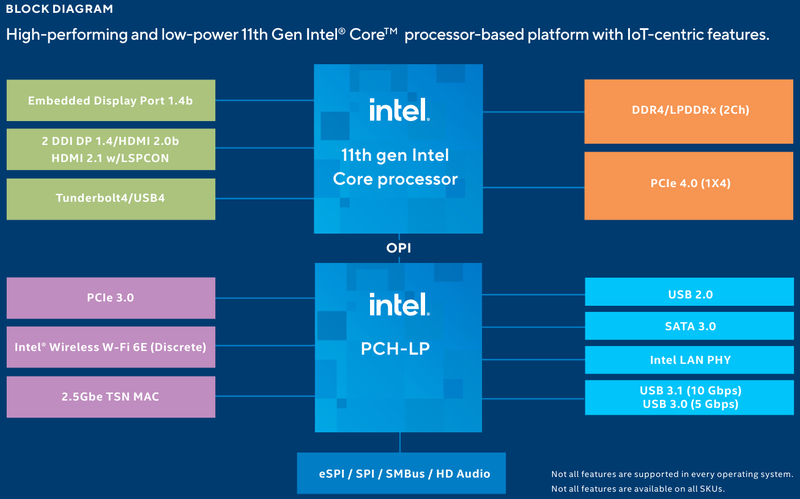 У более мощных процессоров с ядрами Tiger Lake графика тоже намного мощнее, она представлена блоками Iris Xe, которых в составе чипа может быть до 96, к тому же новая графическая архитектура лучше подходит для систем принятия решений (инференс) и задач машинного зрения. Такая графическая подсистема может одновременно обрабатывать до 40 потоков видео в формате 1080p при 30 кадрах в секунду, а выводить — либо четыре потока 4K, либо два, но уже в 8K. Подобные мощности позволяют использовать Tiger Lake в системах, для которых требуется детерминированная, строго синхронизированная по времени работа, либо в гибких системах машинного зрения с ИИ-компонентами. Безопасности способствует возможность полного шифрования содержимого оперативной памяти. 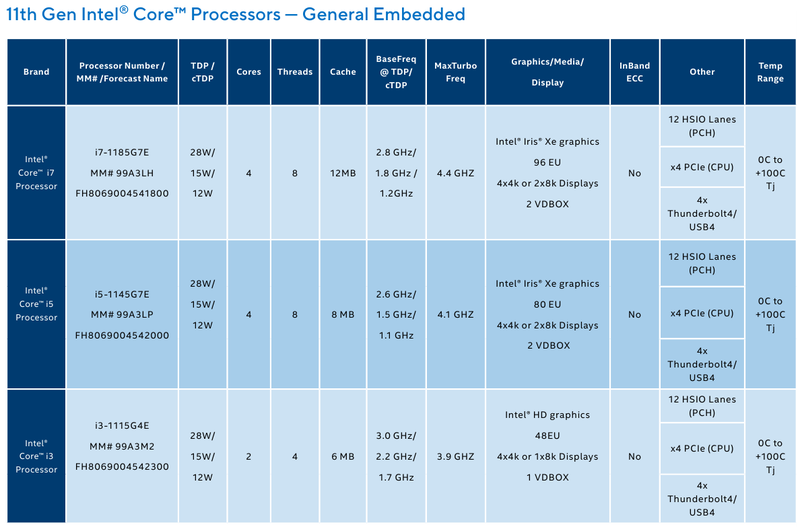 Коммуникационные возможности новых промышленных процессоров Intel также соответствуют требованиям времени: новые SoC несут на борту три MAC-контроллера, способных работать на скорости 2,5 Гбит/с, причём, в моделях с поддержкой TSN обеспечивается режим реального времени с минимальными задержками. Также общение «с внешним миром» происходит посредством 8 линий PCI Express 3.0, четырех портов USB 3.1 и 10 портов USB 2.0. Имеется два порта для подключения флеш-накопителей с интерфейсом UFS 2.0. В референсной платформе Intel реализована и поддержка UART и JTAG (разъём MIPI-60). 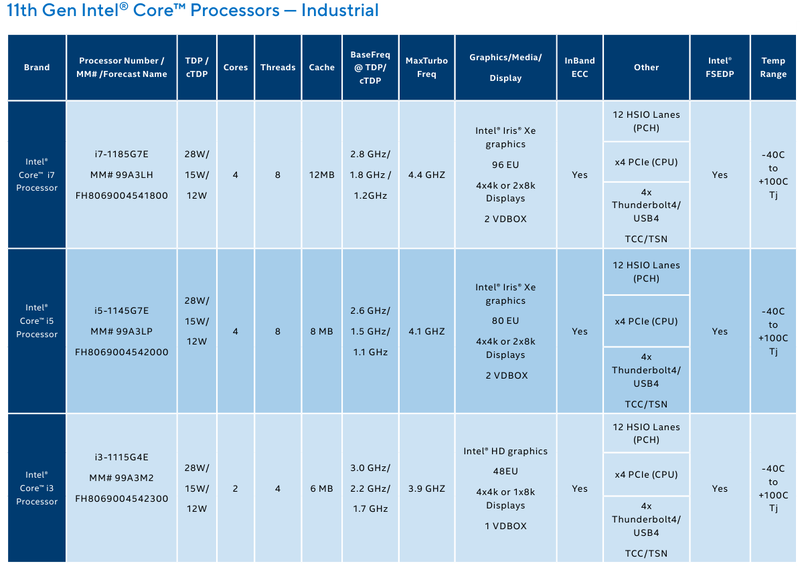 У более мощных Tiger Lake из серий i3/i5/i7 возможности несколько иные: встроенных MAC два, один из которых работает в режиме 1GbE, другой поддерживает cкорость 2,5GbE, в некоторых моделях дополнен поддержкой Time-Sensitive Networking. Поддерживается подключение дискретного сетевого контроллера I225LM/IT. Что касается беспроводной части, то имеется поддержка Wi-Fi со скоростями до 1,73 Гбит/с, а также Bluetooth 5.0. Для расширения инференс-способностей поддерживается подключение дополнительного ускорителя Intel из серии Movidius. Также реализованы стандарты PCIe 4.0 (четыре линии) и Thunderbolt/USB 4 (четыре порта).  Теплопакеты достаточно скромные: от 4,5 до 12 Ватт у Atom, до 28 Ватт у Tiger Lake. Улучшенный техпроцесс позволяет последним быть существенно быстрее аналогичных Core 8 поколения, в зависимости от характера нагрузки это до 23% (однопоточная) или до 19% (многопоточная), а графическая подсистема и вовсе практически в три раза быстрее за счёт новой архитектуры.  Новые процессоры имеют широкий спектр программной поддержки. В первую очередь, это, естественно, Microsoft Windows 10 IoT Enterprise и Yocto Project Linux, разрабатываемая сообществом Yocto совместно с Intel. Поддерживается также запуск Ubuntu, Wind River Linux LTS и Android 10 (только 64-битная версия). Для Tiger Lake также заявлена совместимость с Wind River VxWorks. 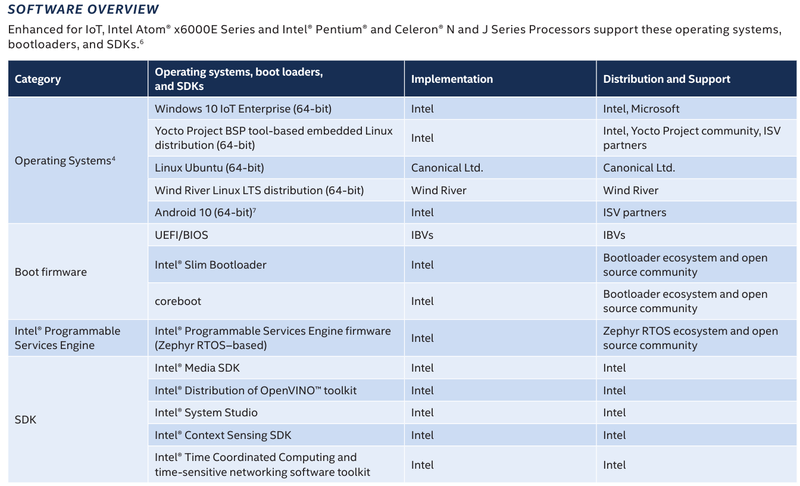 В качестве загрузчика может использоваться как обычный BIOS/UEFI, так и открытые Intel Slim Bootloader и coreboot. Часть, отвечающая за подсистемы безопасности и реального времени, работает под управлением Zephyr RTOS, также открытой. В число партнёров Intel, отвечающих за код BIOS, входят American Metatrends, Thundersoft, Byosoft, Insyde и Phoenix. 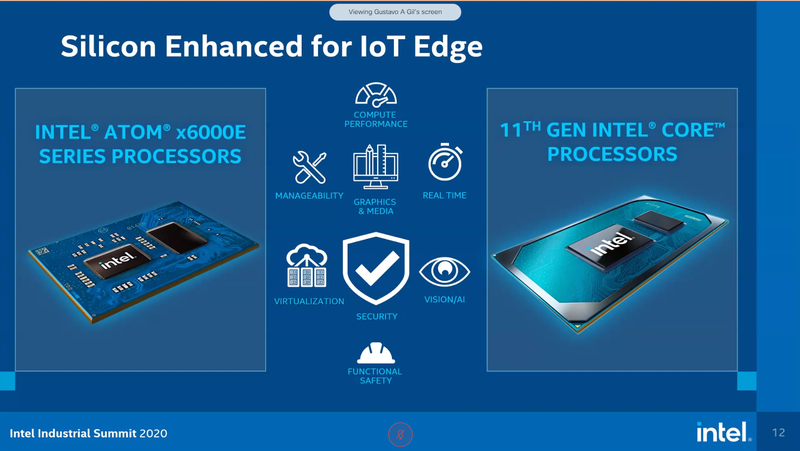 Для создания ПО компания предлагает расширенный комплект разработчика: инструменты для реализации Time Coordinated Computing, Intel Media SDK, набор Intel для OpenVINO, Intel System Studio и Intel Context Sensing SDK. Intel понимает всю важность рынка периферийных вычислений, за которым, судя по всему, будущее промышленности: любая производственная задача будет неизбежно порождать серьёзные потоки данных и требовать от системы управления минимальных задержек. Именно поэтому периферийные вычислительные устройства, к которым относятся и новые процессоры Intel, столь важны. Неудивительно, что компания уделяет много внимания как аппаратным возможностям, так и программным компонентам в новой платформе. |
|

