Лента новостей
|
21.12.2020 [18:41], Алексей Степин
128-ядерные супепроцессоры Tachyum Prodigy стали на шаг ближе к реальностиЛетом уходящего года компания Tachyum объявила о том, что собирается отправить Xeon «на свалку истории». Сделать это должен 128-ядерный процессор нового поколения Prodigy. Хотя массово он пока не производится, компания продолжает активно работать над проектом и совсем недавно объявила начало предзаказов на эмуляторы нового процессора, как программные, так и базирующиеся на ПЛИС. Также она продемонстрировала рабочий UEFI для будущих CPU. 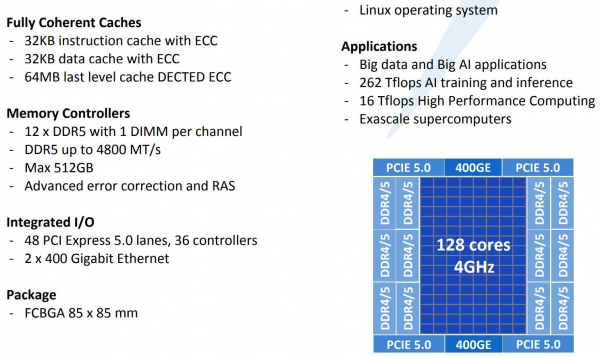 Молодая словацкая компания замахнулась на многое. Её процессор должен получить до 128 ядер, работающих на частоте до 4 ГГц. Чтобы «накормить» его данными, предусмотрен 12-канальный контроллер памяти DDR5. С периферией Prodigy будет общаться посредством 48 линий PCIe 5.0, но также получит и два контроллера Ethernet класса 400G. Характеристики весьма впечатляют.  Разработчики заявляют, что Prodigy найдёт своё место в системах класса Big Data и мощных системах машинного обучения. Если верить Tachyum, производительность разрабатываемого процессора должна достигнуть 16 и 8 Тфлопс на классичесих вычислениях FP32/FP64. В режиме машинного обучения и инференса возможности новой архитектуры выглядят ещё внушительнее, поскольку речь идёт о цифре 262 Тфлопс. 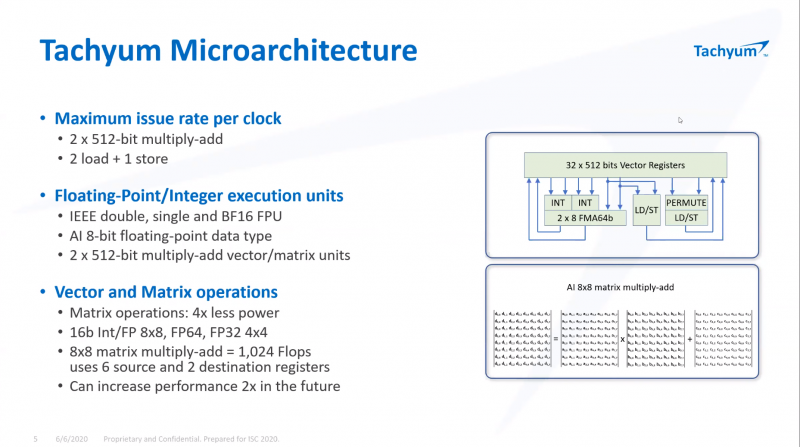 Столь громкие анонсы в истории вычислительной техники часто заканчивались «на бумаге», но Tachyum действительно работает над реализацией Prodigy. Как это обычно бывает, новая процессорная архитектура отрабатывается разработчиками с помощью эмуляции — как чисто программной, так и базирующейся на мощных ПЛИС. Это позволяет понять возможности и особенности поведения архитектуры, пусть и работающей с меньшей производительностью.  В начале декабря Tachyum объявила об открытии предзаказов на ПЛИС-эмулятор Prodigy, позволяющий начать разработку программного обеспечения для будущих систем на базе нового процессора уже сейчас. Поставки должны начаться в первом квартале 2021 года. В середине месяца Tachyum анонсировала и возможность заказа программного эмулятора Prodigy. Главная ценность такого эмулятора — более низкая стоимость в сравнении с вариантом на базе ПЛИС. Любой процессор неработоспособен без сопутствующего системного программного обеспечения — BIOS или, что сейчас встречается намного чаще, UEFI. В начале месяца Tachyum объявила о том, что передаст OEM и ODM-партнёрам UEFI, разработанное для новой архитектуры. При этом ПО будет поставляться не только в бинарном виде, разработчики получат и исходные коды. 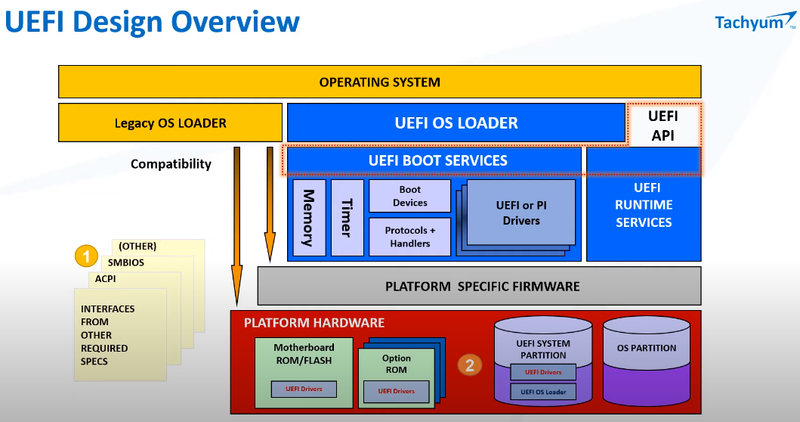 К настоящему времени, таким образом, компания предлагает программные и ПЛИС-эмуляторы нового процессора, и сопутствующее программное обеспечение. К чести Tachym, разработан не только UEFI — имеется и ядро Linux с поддержкой новой архитектуры, набор средств разработки, включая компиляторы (в том числе, для ИИ-задач) и отладчики кода. Успешно продемонстрирована возможность работы на Prodigy бинарного кода, созданного для архитектур x86, ARM и RISC-V. Первые чипы Prodigy должны появиться уже в следующем году. Если запуск будет успешным, Tachym может сильно изменить привычную картину мира в сфере HPC и ИИ, ведь новая архитектура обещает быть производительнее классических Xeon и EPYC при на порядок более низком энергопотреблении, втрое более низкой стоимостью в пересчёте на MIPS, и вчетверо более низкой стоимостью владения. Более того, Prodigy угрожает даже ускорителям, обеспечивая сравнимый или более высокий уровень производительности в задачах, где последние традиционно сильны, например, в системах машинного обучения. Остаётся лишь пожелать Tachyum удачи в столь смелом начинании.
08.12.2020 [23:24], Андрей Галадей
Место CentOS займёт CentOS Stream, вечная бета-версия RHELВ конце 2021 года Red Hat прекратит разработку привычного дистрибутива CentOS в пользу проекта CentOS Stream, так что CentOS 9 ждать не стоит. Новая версия представляет собой rolling-релиз Red Hat Enterpise Linux (RHEL), предназначенный для формирования следующего промежуточного выпуска RHEL. Фактически CentOS Stream станет «вечной бета-версией», за счёт чего будет упрощено тестирование конечного продукта, ведь теперь в релизе будет один дистрибутив, а не два. Впрочем, Red Hat продолжит выкладывать исходные коды в общий доступ, поэтому есть шанс на появление некоей альтернативы CentOS. Напомним, что сам проект перешёл под крыло Red Hat почти сем лет назад. На текущий момент единственным совместимым с актуальной веткой RHEL альтернативным дистрибутивом от крупных игроков, похоже, является только Oracle Linux. 
youtube.com Что касается поставки обновлений для CentOS 8, то она прекратится 31 декабря 2021 года, хотя поддержка CentOS 7 продлится до 2024 года. Пользователям рекомендуется с 2022 года перейти на CentOS Stream. Разработчики утверждают, что новый дистрибутив будет мало отличаться от RHEL, а патчи будут выходить регулярно. Напомним, что ранее мы писали о росте роли CentOS в развитии Red Hat Enterprise Linux. Похоже, именно переход на CentOS Stream и станет таким шагом. Однако сама природа Stream-версии вряд ли придётся по душе всем, кто использует CentOS в рабочем окружении. Red Hat подготовила FAQ и предлагает обратиться к ней, если возникнут какие-то сомнения или вопросы. Можно предположить, что компания таким образом пытается подтолкнуть пользователей к переходу на платные подписки и, быть может, будет готова предложить особые условия для перехода. На текущий момент акутальной является версия CentOS 8.3 (2011). Этот дистрибутив полностью бинарно совместим с RHEL 8.3. Он поддерживает архитектуры x86_64, Aarch64 (ARM64) и ppc64le.
24.11.2020 [18:54], Игорь Осколков
«ВКонтакте» использует FPGA Intel Arria для обработки изображений на летуГод назад на Intel Experience Day 2019 «ВКонтакте» поделилась результатами первых экспериментов по использованию FPGA-ускорителей для обработки изображений на лету. За прошедшее время компания внедрила ПЛИС в свою инфраструктуру, ускорив работу и сэкономив место в хранилище, где уже находится 1,2 Эбайта различного контента. У «ВКонтакте» почти 100 млн активных пользователей, которые ежеминутно загружают порядка 100 Гбайт изображений. Для каждого из них после загрузки генерируется более десятка копий различных формата и размера, которые используются в разных частях социальной сети. Основная проблема в том, что на таких масштабах все эти дополнительные изображения отъедают очень много места — до двух третей от общего объёма. 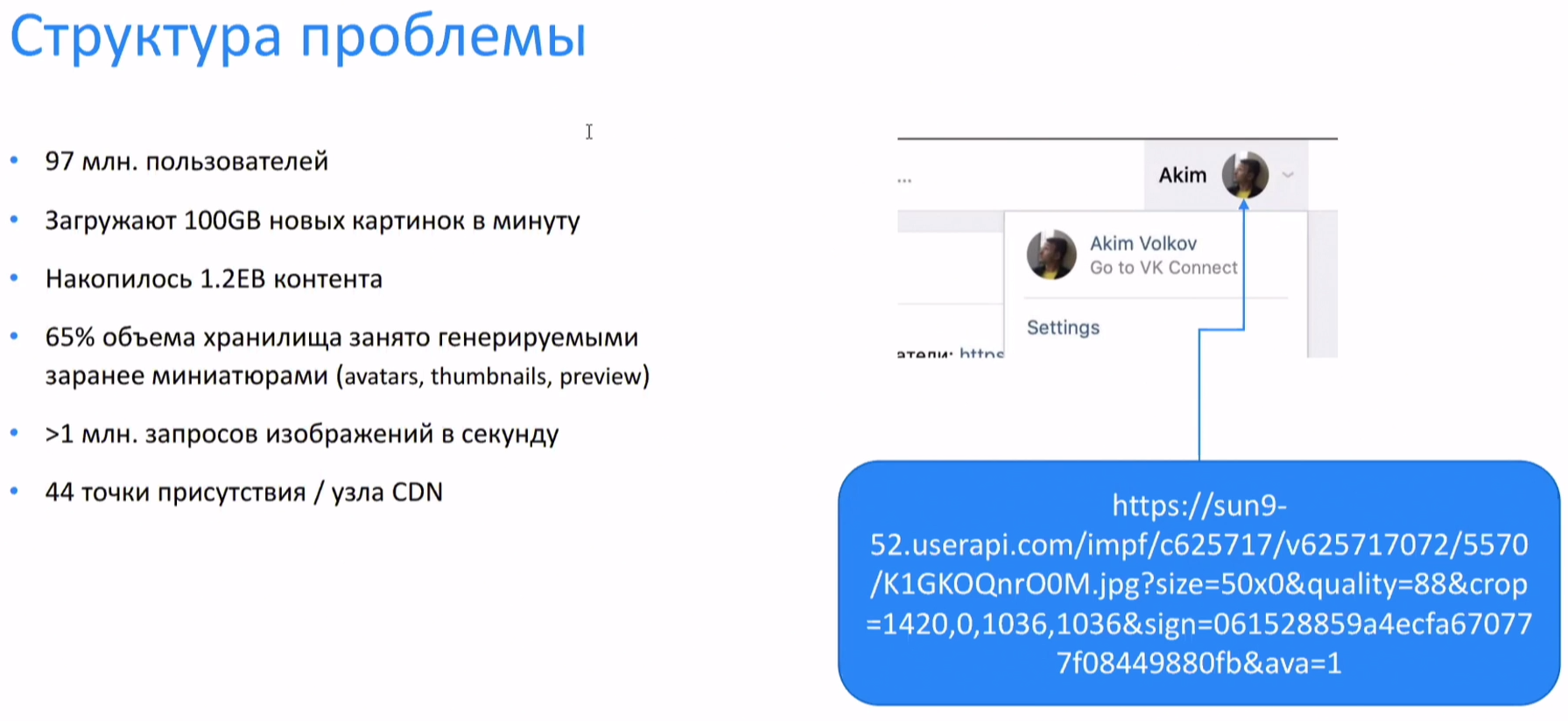 Оптимальнее было бы генерировать их на лету, однако это очень существенная вычислительная нагрузка. Тестовые машины с Intel Xeon E5-2620 v4, которые на тот момент составляли значительную часть серверного парка, могли обработать до 200-220 изображений в секунду, чего явно было недостаточно. Поэтому и было принято решение попробовать для решения этой задачи FPGA, в данном случае это Arria 10. 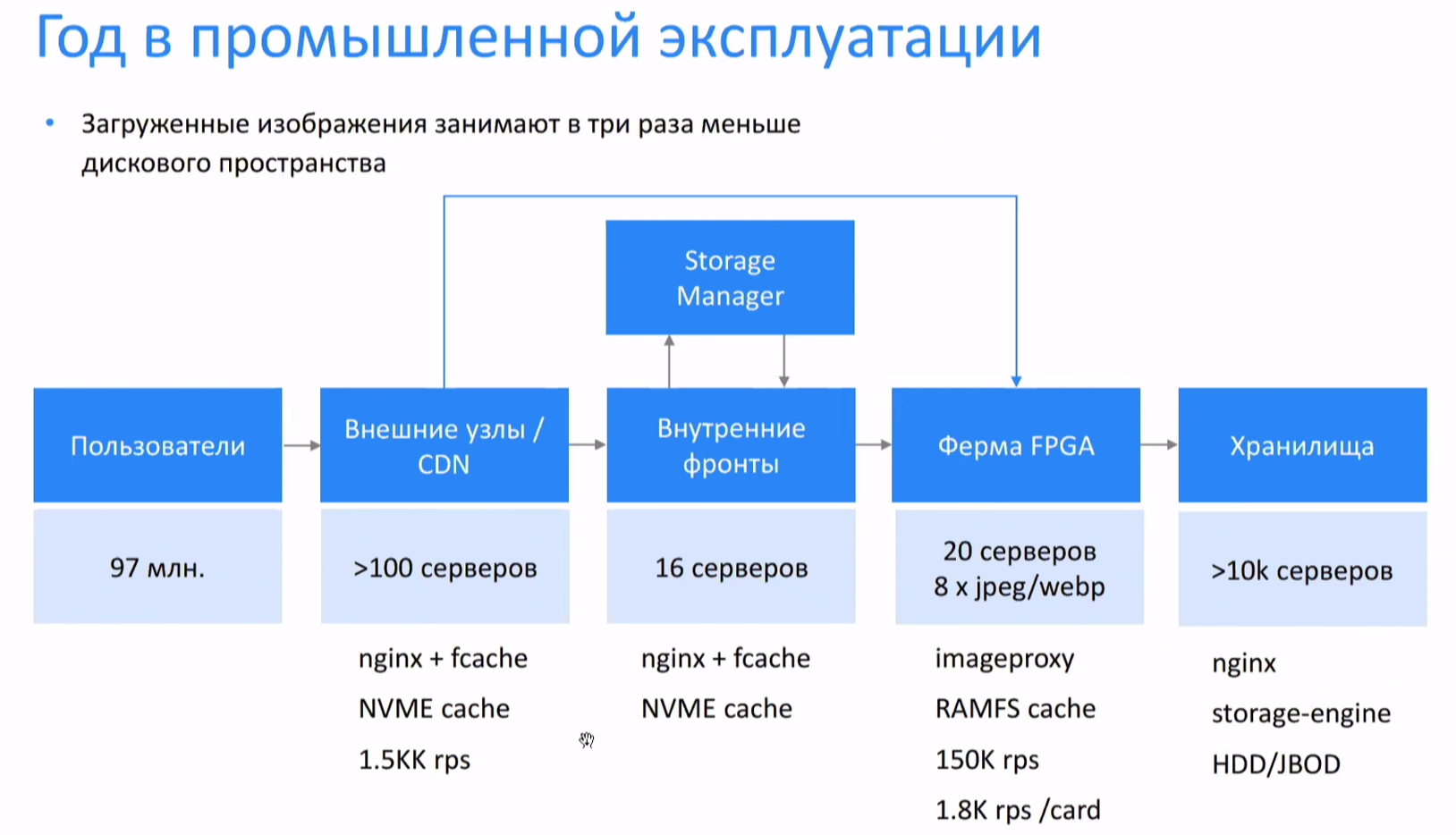 Теперь изображения с нужными характеристиками можно сформировать, указав параметры в URL. Если оно уже не закешировано на одной из конечных точек для отдачи контента, то запрос уходит «вниз» и из хранилища (а это более 10 тыс. серверов) извлекается оригинал и отправляется на FPGA-ферму, которая состоит всего из 20 серверов с ПЛИС, которых достаточно для удовлетворения всех запросов. На FPGA изображения конвертируются и отправляются «наверх», где кешируются и отдаются клиенту. Основными форматами, с которыми работает FPGA-ферма, являются JPEG и WebP, но компания рассматривает и другие, более современные. Кроме того, VK планирует изучить возможности FPGA для декодирования медиафайлов, сжатия данных (zstd) со стороны хранилища, а также опробовать в деле более современные модели ПЛИС.
23.11.2020 [23:34], Владимир Мироненко
Б/У серверы Facebook✴ и Microsoft будут отапливать теплицы с помидорами
ff
hardware
itrenew
microsoft
ocp
микро-цод
нидерланды
отопление
периферийные вычисления
сельское хозяйство
сжо
экология
Производитель OCP-систем ITRenew объединил усилия с голландским облачным хостинг-провайдером Blockheating, чтобы предложить контейнеризированные дата-центры «всё-в-одном», которые поставляют ненужное тепло в теплицы. Blockheating производит микро-ЦОД с жидкостным охлаждением, благодаря чему «мусорное» тепло может передаваться с водой (t°=65 °C) в близлежащие теплицы. В рамках партнёрства контейнеры будут укомплектованы стоечными серверами и системами хранения Sesame от ITRenew. Согласно совместному заявлению компаний, в Нидерландах имеется более 3700 га коммерческих теплиц. Один микро-ЦОД может обогревать два гектара теплиц летом и полгектара зимой. Этого, по словам Blockheating, достаточно для выращивания тонны помидоров в год. Что более важно, тепло, выделяемое в виде отходов ЦОД, обходится намного дешевле природного газа, сжигаемого фермерами для обогрева теплиц. Blockheating заявила о разработке «нового способа водяного охлаждения серверов», который делает его рентабельным. В 2019 году компания провела испытания тестового ЦОД мощностью 60 кВт в Венло, недалеко от границы с Германией (на фото выше). Сейчас решения Blockheating имеют мощность 200 уже кВт. Поскольку они охлаждаются жидкостью, это устраняет потребность в установке оборудования для кондиционирования воздуха и повышает энергоэффективность. 
Blockheating В свою очередь системы ITRenew Sesame, устанавливаемые в микро-ЦОД, используют б/у-оборудование гиперскейлеров вроде Facebook✴ и Microsoft. Таким образом, снижается стоимость покупки и владения, почти на четверть сокращаются выбросы CO2 и объёмы электронного мусора, связанные с ИТ-индустрией.
20.11.2020 [16:45], Сергей Карасёв
NEC выводит на рынок векторный ускоритель SX-Aurora TSUBASA Vector Engine 2.0Компания NEC сообщила о том, что с января следующего года заказчикам по всему миру станет доступен акселератор Vector Engine 2.0 серии SX-Aurora TSUBASA, анонсированный ещё летом. Изделие Type 20B выполнено в виде двухслотовой карты расширения с интерфейсом PCIe. Оно содержит восемь векторных блоков с частотой 1,6 ГГц, обеспечивающих производительность на уровне 2,45 Тфлопс FP64, и 48 Гбайт памяти HBM2 с пропускной способностью приблизительно 1,53 Тбайт/с. При этом энергопотребление находится на уровне 200 Вт. Также есть версия ускорителя Type 20A, которая имеет 10 векторных блоков и производительность 3,07 Тфлопс FP64.  Благодаря векторной архитектуре крупные объёмы данных можно обрабатывать в пределах каждого цикла. Это открывает широкие возможности при решении задач в области искусственного интеллекта, машинного обучения, интенсивных научных вычислений и пр. 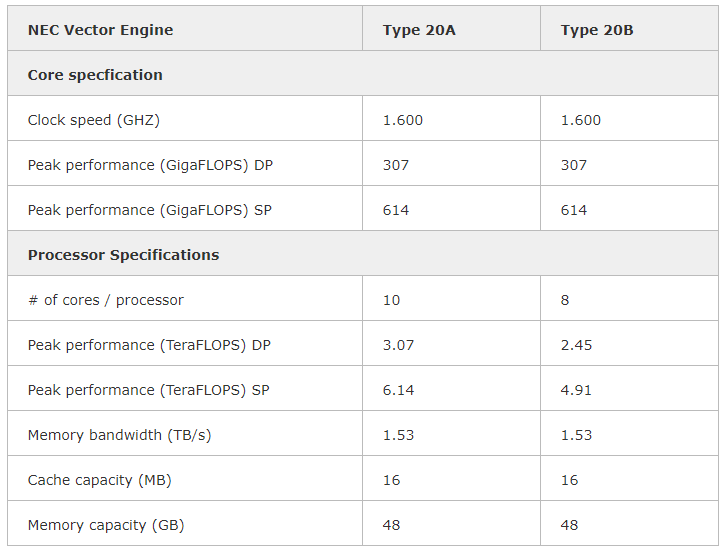 Векторный ускоритель Vector Engine 2.0 может использоваться в составе стандартных серверов и рабочих станций с архитектурой х86 от сторонних поставщиков оборудования. Таким образом, заказчики смогут сформировать вычислительную платформу в соответствии со своими требованиями и объёмом финансирования. Данное решение, по словам NEC, ориентировано на предприятия малого и среднего бизнеса, у которых есть потребность в формировании платформы высокопроизводительных вычислений (HPC).
18.11.2020 [00:17], Владимир Мироненко
SC20: РСК представила all-flash СХД Tornado AFS с функцией высокой доступностиГруппа компаний РСК, российский разработчик HPC-решений, представила на всемирной виртуальной суперкомпьютерной выставке SC20 целый ряд новых решений. В частности, было объявлено, что высокоплотные и энергоэффективные вычислительные узлы «РСК Торнадо» будут поддерживать 10-нм серверные процессоры Intel с кодовым наименованием Ice Lake-SP, намеченные к выпуску в начале 2021 года. Как ожидается, новые чипы получат поддержку интерфейса PCI Express 4.0 и памяти Intel Optane DC второго поколения. Также была представлена интеллектуальная СХД Tornado AFS с поддержкой функции высокой доступности для создания систем хранения с большим объемом данных. Решение отличается высокой надёжностью и доступностью данных благодаря объединению узлов Tornado AFS в функциональные пары, так как в случае выхода из строя одного из узлов работа обеспечивается с помощью второго.  Это обеспечивает надёжное хранение данных объёмом до 2 Пбайт в форм-факторе 2U с помощью 64-х NVMe SSD в форм-факторе E1.L. Также используются процессоры семейства Intel Xeon Scalable 2-го поколения, твердотельные диски Optane SSD и модули энергонезависимой PMem-памяти Optane DC Persistent Memory (DCPMM). В RSC Tornado AFS используется 100 % жидкостное охлаждение в режиме «горячая вода» с показателем эффективности использования электроэнергии PUE на уровне 1,04. РСК подтвердила заявленную ранее поддержку DAOS в решениях RSC Storage on-Demand и объявила о переходе на обновлённую платформу оркестрации «РСК БазИС» для создания высокопроизводительных составных архитектур хранения данных. Это позволит вместо жёсткого регламентирования конфигурации применять компонуемый подход для управления DAOS. Использование высокопроизводительных адаптеров с поддержкой RDMA, NVMe-накопителей и памяти Optane DCPMM позволит произвести такую дезагрегацию и дальнейшую компоновку «по запросу» без снижения производительности. Такой подход позволит заметно увеличить допустимый объем системы хранения данных благодаря отмене ограничений по объёму PMem в DAOS. При этом благодаря компонуемости, неиспользуемые в какой-то момент времени диски можно подключить к другому серверу на основе DAOS или Lustre. В дополнение можно разделить серверы с DAOS и серверы c NVMe-дисками на два пула, тем самым максимально устранив ограничения аппаратной архитектуры сервера (нехватку линий шины PCIe, используемой как накопителями, так и сетевыми адаптерами, а также физических ограничений шасси сервера по размещению дополнительных устройств и их охлаждению). РСК также разработала пользовательский интерфейс для RSC Storage on-Demand, позволяющий быстро создать сложную многоуровневую компонуемую систему хранения «по требованию». Новый интерфейс поддерживает создание параллельных файловых систем Lustre, распределённых объектных систем хранения DAOS и их комбинаций.
16.11.2020 [20:44], Алексей Степин
Подробности об архитектуре AMD CDNA ускорителей Instinct MI100Лидером в области использования графических архитектур для вычислений долгое время была NVIDIA, однако давний соперник в лице AMD вовсе не собирается сдавать свои позиции. В ответ на анонс архитектуры Ampere и ускорителей нового поколения A100 на её основе компания AMD сегодня ответила своим анонсом первого в мире ускорителя на основе архитектуры CDNA — сверхмощного процессора Instinct MI100. Достаточно долго подход к проектированию графических чипов оставался унифицированным, однако быстро выяснилось, что то, что хорошо для игр, далеко не всегда хорошо для вычислений, а некоторые возможности для областей применения, не связанных с рендерингом 3D-графики, попросту избыточны. Примером могут служить модули растровых операций (RBE/ROP) или наложения текстур. Произошло то, что должно было произойти: слившиеся на какое-то время воедино ветви эволюции «графических» и «вычислительных» процессоров вновь начали расходиться. И новый процессор AMD Instinct MI100 относится к чисто вычислительной ветви развития подобного рода чипов.  Теперь AMD имеет в своём распоряжении две основных архитектуры, RDNA и CDNA, которые и представляют собой вышеупомянутые ветви развития GPU. Естественно, новый процессор Instinct MI100 унаследовал у своих собратьев по эволюции многое — в частности, блоки исполнения скалярных и векторных инструкций: в конце концов, всё равно, работают ли они для расчёта графики или для вычисления чего-либо иного. Однако новинка содержит и ряд отличий, позволяющих ей претендовать на звание самого мощного и универсального в мире ускорителя на базе GPU. 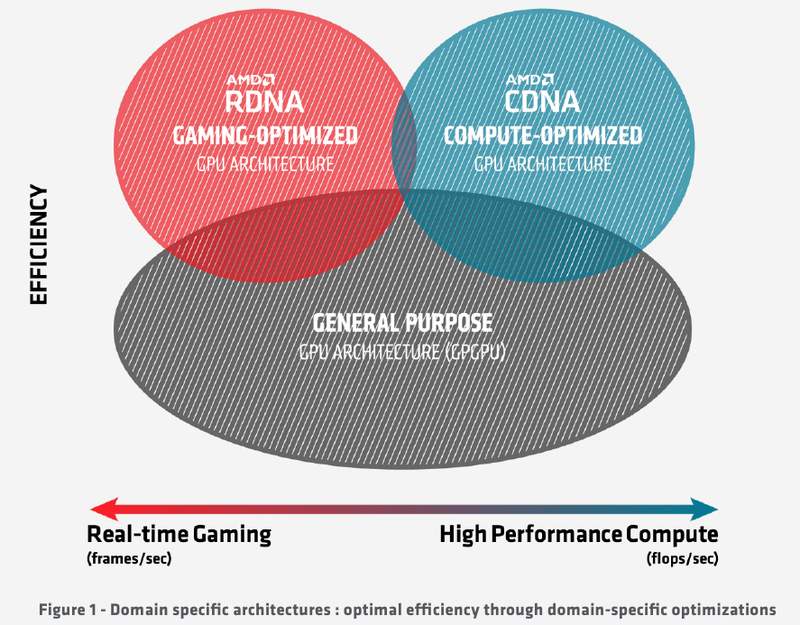
Схема эволюции графических процессоров: налицо дивергенция признаков AMD в последние годы существенно укрепила свои позиции, и это отражается в создании собственной единой IP-инфраструктуры: новый чип выполнен с использованием 7-нм техпроцесса и все системы интерконнекта, как внутренние, так и внешние, в MI100 базируются на шине AMD Infinity второго поколения. Внешние каналы имеют ширину 16 бит и оперируют на скорости 23 Гт/с, однако если в предыдущих моделях Instinct их было максимум два, то теперь количество каналов Infinity Fabric увеличено до трёх. Это позволяет легко организовывать системы на базе четырёх MI100 с организацией межпроцессорного общения по схеме «все со всеми», что минимизирует задержки. 
Ускорители Instinct MI100 получили третий канал Infinity Fabric Общую организацию внутренней архитектуры процессор MI100 унаследовал ещё от архитектуры GCN; его основу составляют 120 вычислительных блоков (compute units, CU). При принятой AMD схеме «64 шейдерных блока на 1 CU» это позволяет говорить о 7680 процессорах. Однако на уровне вычислительного блока архитектура существенно переработана, чтобы лучше отвечать требованиям, предъявляемым современному вычислительному ускорителю. В дополнение к стандартным блокам исполнения скалярных и векторных инструкций добавился новый модуль матричной математики, так называемый Matrix Core Engine, но из кремния MI100 удалены все блоки фиксированных функций: растеризации, тесселяции, графических кешей и, конечно, дисплейного вывода. Универсальный движок кодирования-декодирования видеоформатов, однако, сохранён — он достаточно часто используется в вычислительных нагрузках, связанных с обработкой мультимедийных данных. 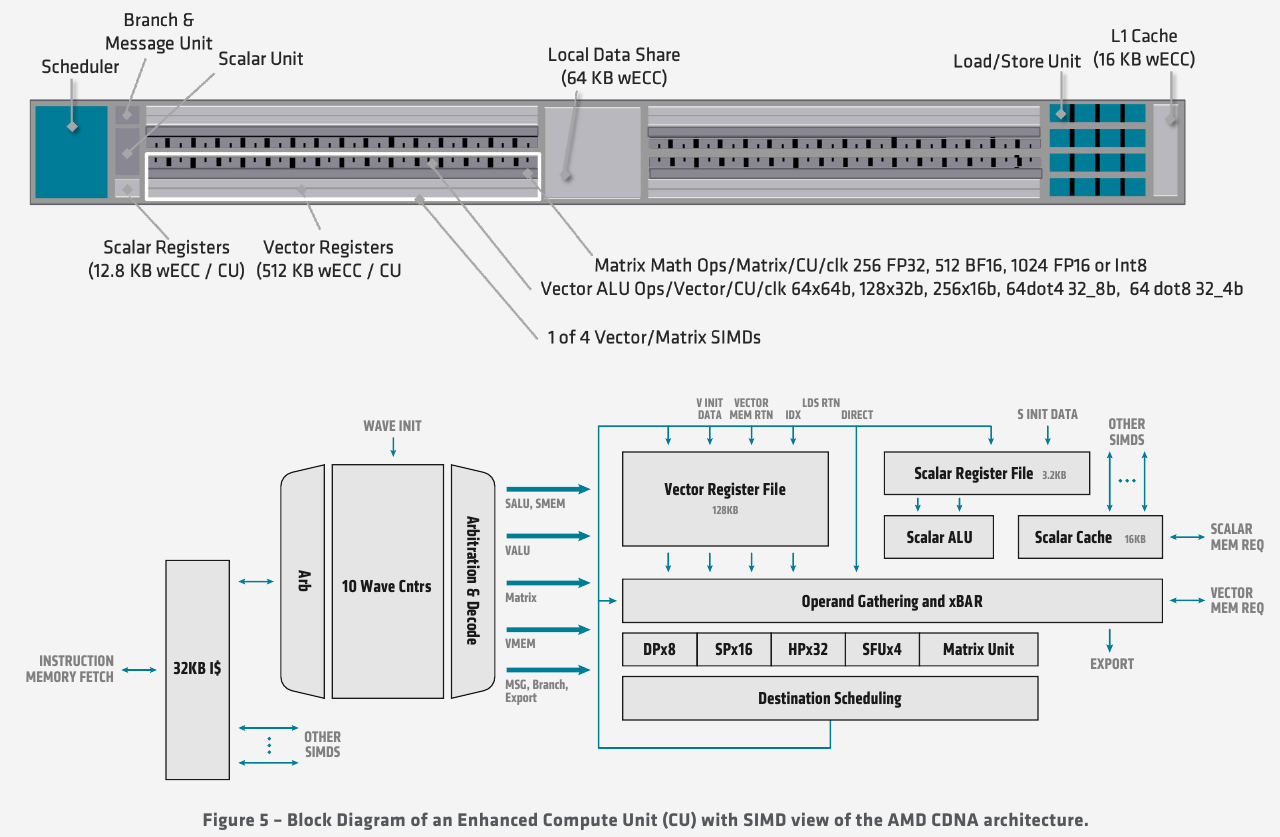
Структурная схема вычислительных модулей в MI100 Каждый CU содержит в себе по одному блоку скалярных инструкций со своим регистровым файлом и кешем данных, и по четыре блока векторных инструкций, оптимизированных для вычислений в формате FP32 саналогичными блоками. Векторные модули имеют ширину 16 потоков и обрабатывают 64 потока (т.н. wavefront в терминологии AMD) за четыре такта. Но самое главное в архитектуре нового процессора — это новые блоки матричных операций. Наличие Matrix Core Engines позволяет MI100 работать с новым типом инструкций — MFMA (Matrix Fused Multiply-Add). Операции над матрицами размера KxN могут содержать смешанные типы входных данных: поддерживаются режимы INT4, INT8, FP16, FP32, а также новый тип Bfloat16 (bf16); результат, однако, выводится только в форматах INT32 или FP32. Поддержка столь многих типов данных введена для универсальности и MI100 сможет показать высокую эффективность в вычислительных сценариях разного рода. 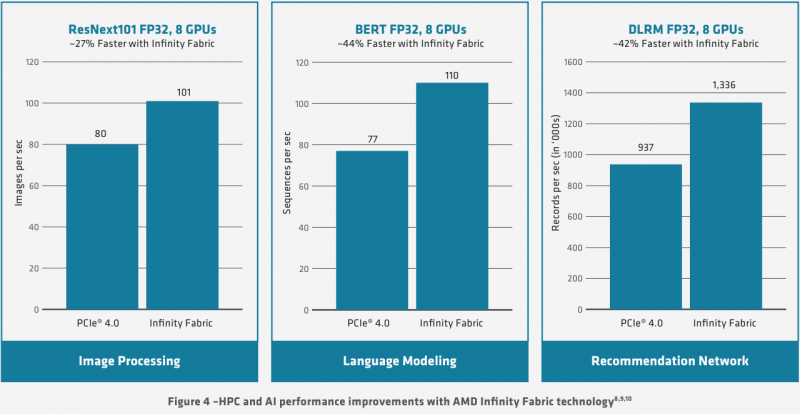
Использование Infinity Fabric 2.0 позволило ещё более увеличить производительность MI100 Каждый блок CU имеет свой планировщик, блок ветвления, 16 модулей load-store, а также кеши L1 и Data Share объёмами 16 и 64 Кбайт соответственно. А вот кеш второго уровня общий для всего чипа, он имеет ассоциативность 16 и объём 8 Мбайт. Совокупная пропускная способность L2-кеша достигает 6 Тбайт/с. Более серьёзные объёмы данных уже ложатся на подсистему внешней памяти. В MI100 это HBM2 — новый процессор поддерживает установку четырёх или восьми сборок HBM2, работающих на скорости 2,4 Гт/с. Общая пропускная способность подсистемы памяти может достигать 1,23 Тбайт/с, что на 20% быстрее, нежели у предыдущих вычислительных ускорителей AMD. Память имеет объём 32 Гбайт и поддерживает коррекцию ошибок. 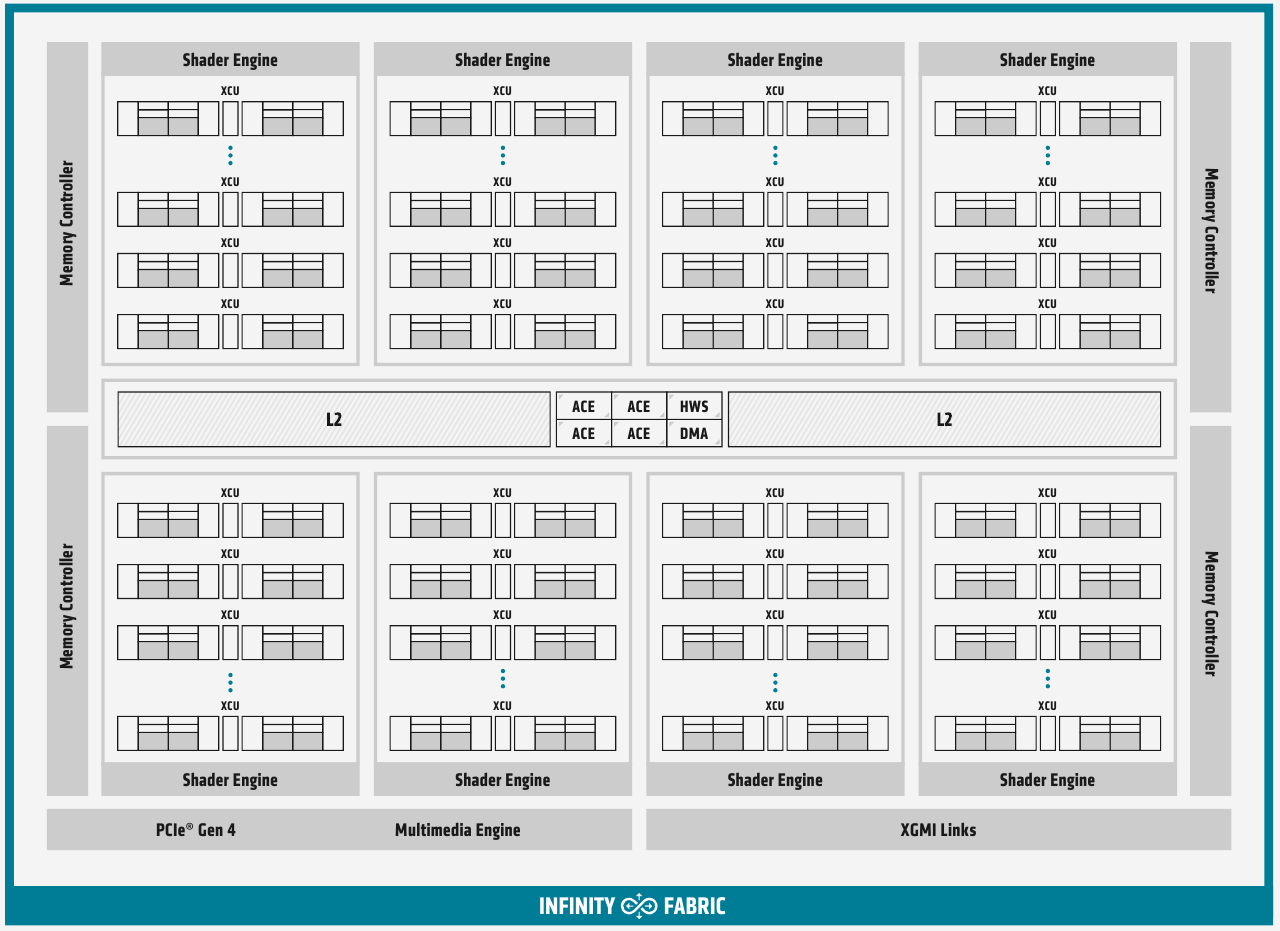
Общая блок-схема Instinct MI100 «Мозг» чипа Instinct MI100 составляют четыре командных процессора (ACE на блок-схеме). Их задача — принять поток команд от API и распределить рабочие задания по отдельным вычислительным модулям. Для подключения к хост-процессору системы в составе MI100 имеется контроллер PCI Express 4.0, что даёт пропускную способность на уровне 32 Гбайт/с в каждом направлении. Таким образом, «уютнее всего» ускоритель Instinct MI100 будет чувствовать себя совместно с ЦП AMD EPYC второго поколения, либо в системах на базе IBM POWER9/10. Избавление от лишних архитектурных блоков и оптимизация архитектуры под вычисления в как можно более широком числе форматов позволяют Instinct MI100 претендовать на универсальность. Ускорители с подобными возможностями, как справедливо считает AMD, станут важным строительным блоком в экосистеме HPC-машин нового поколения, относящихся к экзафлопсному классу. AMD заявляет о том, что это первый ускоритель, способный развить более 10 Тфлопс в режиме двойной точности FP64 — пиковый показатель составляет 11,5 Тфлопс. 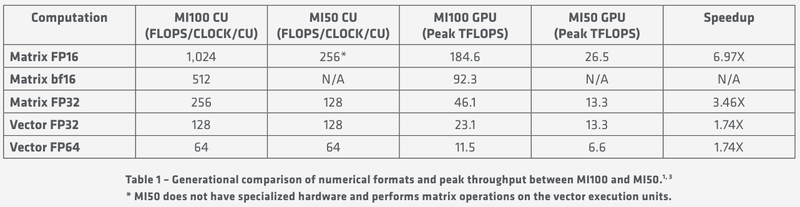
Удельные и пиковые показатели производительности MI100 В менее точных форматах новинка пропорционально быстрее, и особенно хорошо ей даются именно матричные вычисления: для FP32 производительность достигает 46,1 Тфлопс, а в новом, оптимизированном под задачи машинного обучения bf16 — и вовсе 92,3 Тфлопс, причём, ускорители Instinct предыдущего поколения таких вычислений выполнять вообще не могут. В зависимости от типов данных, превосходство MI100 перед MI50 варьируется от 1,74х до 6,97x. Впрочем, NVIDIA A100 в этих задача всё равно заметно быстрее, а вот в FP64/FP32 проигрывают.
16.11.2020 [17:00], Игорь Осколков
SC20: NVIDIA представила ускоритель A100 с 80 Гбайт HBM2e и настольный «суперкомпьютер» DGX STATIONNVIDIA представила новую версию ускорителя A100 с увеличенным вдвое объёмом HBM2e-памяти: 80 Гбайт вместо 40 Гбайт у исходной A100, представленной полгода назад. Вместе с ростом объёма выросла и пропускная способность — с 1,555 Тбайт/с до 2 Тбайт/с. В остальном характеристики обоих ускорителей совпадают, даже уровень энергопотребления сохранился на уровне 400 Вт. Тем не менее, объём и скорость работы быстрой набортной памяти влияет на производительность ряда приложений, так что им такой апгрейд только на пользу. К тому же MIG-инстансы теперь могут иметь объём до 10 Гбайт. PCIe-варианта ускорителя с удвоенной памятью нет — речь идёт только об SXM3-версии, которая используется в собственных комплексах NVIDIA DGX и HGX-платформах для партнёров. 
NVIDIA A100 80 Гбайт  Последним ориентировочно в первом квартале следующего года будут предоставлены наборы для добавления новых A100 в существующие решения, включая варианты плат на 4 и 8 ускорителей. У самой NVIDIA обновлению подверглись, соответственно, DGX A100 POD и SuperPOD for Enterprise. Недавно анонсированные суперкомпьютеры Cambridge-1 и HiPerGator на базе SuperPOD одними из первых получат новые ускорители с 80 Гбайт памяти. Ожидается, что HGX-решения на базе новой A100 будут доступны от партнёров компании — Atos, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta и Supermicro — в первой половине 2021 года.   Но, пожалуй, самый интересный анонс касается новой рабочей станции NVIDIA DGX STATION A100, которую как раз и можно назвать настольным «суперкомпьютером». В ней используются четыре SXM3-ускорителя A100 с не требующей обслуживания жидкостной системой охлаждения и полноценным NVLink-подключением. Будут доступны две версии, со 160 или 320 Гбайт памяти с 40- и 80-Гбайт A100 соответственно. Базируется система на 64-ядерном процессоре AMD EPYC, который можно дополнить 512 Гбайт RAM.   Для ОС доступен 1,92-Тбайт NVMe M.2 SSD, а для хранения данных — до 7,68 Тбайт NVMe U.2 SSD. Сетевое подключение представлено двумя 10GbE-портами и выделенным портом управления. Видеовыходов четыре, все mini Display Port. DGX STATION A100 отлично подходит для малых рабочих групп и предприятий. В том числе благодаря тому, что функция MIG позволяет эффективно разделить ресурсы станции между почти тремя десятками пользователей. В продаже она появится у партнёров компании в феврале следующего года.  Вероятно, все выпускаемые сейчас A100 c увеличенным объёмом памяти идут на более важные проекты. Новинкам предстоит конкурировать с первым ускорителем на базе новой архитектуры CDNA — AMD Instinct MI100.
13.11.2020 [18:00], Алексей Степин
Южная Корея близка к созданию собственного процессора для суперкомпьютеровМощные многоядерные процессоры, могущие служить основой суперкомпьютерных комплексов и кластерных систем могут разрабатывать, а тем более производить, не так уж много стран. Но любое государство, претендующее на независимость в IT, хорошо понимает, что в современном мире такая возможность может оказаться ключевой. Именно поэтому создан консорциум European Processor Initiative, именно для этого КНР, Япония и Россия разрабатывают свои многоядерные чипы. Теперь в игру вступает и Южная Корея. Концепция процессора для сферы супервычислений может отличаться кардинально: так, Европа и Япония предпочитают архитектуру ARM, Европа присматривается и к RISC-V, а Россия делает основную ставку на VLIW (семейство «Эльбрус»). Японские процессоры Fujitsu A64FX тоже основаны на ARM, но заметно отличаются от всех остальных чипов: набор инструкций SVE, HBM-память и встроенный интерконнект.  Южнокорейский институт электроники и телекоммуникаций (ETRI), ведущий свой проект совместно с ARM, объявил о том, что стал ещё на шаг ближе к созданию собственного уникального процессора класса HPC. Уникальность южнокорейской разработки в том, что она должна обеспечивать как высокую производительность в традиционных суперкомпьютерных задачах, обычно использующих вычисления двойной точности (FP64), так и невысокий уровень энергопотребления в «низкоточных» задачах (инференс, машинное обучение и тому подобные сценарии). 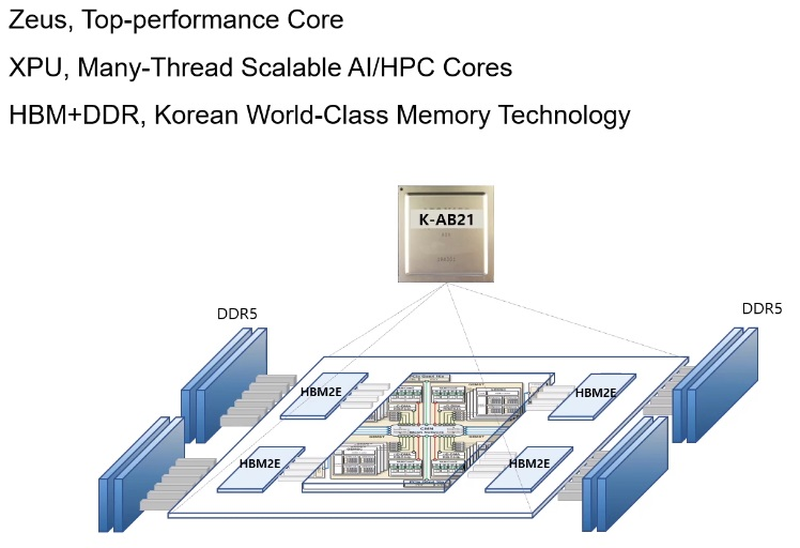 Спецификации, поставленные перед южнокорейскими разработчиками, довольно серьёзны: финальный вариант процессора должен обеспечивать 2,5-кратное превосходство над классическими ускорителями (обычно на базе графических чипов), но при этом быть на 60% экономичнее них. Это должно достигаться за счёт уникальной реализации управления питанием и тактовыми частотами отдельных компонентов процессора. Речь идёт как об аппаратной составляющей, так и о разработке собственного программного стека, позволяющего тонко манипулировать режимами работы нового ЦП. Заявлена возможность интеграции собственных блоков ускорителей, совместимых с уже существующими фреймворками за счёт поддержки OpenMP и OpenCL. Процессор в полной мере сохранит классический режим вычислений с двойной точностью. Текущий прототип получил название K-AB21, причём AB означает «Artificial Brain» (искусственный мозг) — разработчики заявляют, что за счет активного использования матричных ядер (XPU) им удалось достичь производительности 16 Тфлопс на процессор. Это обещает до 1600 Тфлопс на стойку. Процессор с такой производительностью должен открыть Южной Корее дорогу к собственным суперкомпьютерам экзафлопсного класса. 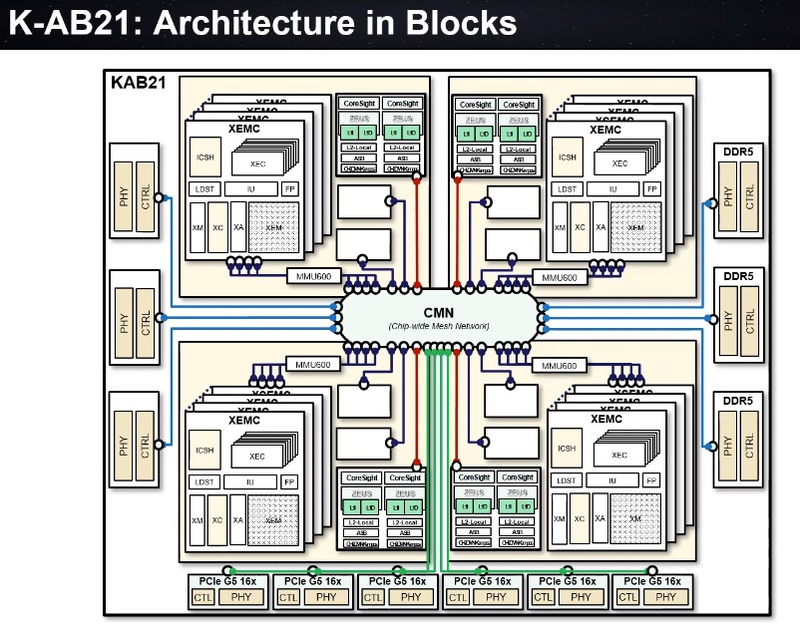 Компоновкой K-AB21 отчасти напоминает Fujitsu A64FX, поскольку также предусматривает наличие пула HBM2 в виде четырёх сборок, однако это не единственная его память. HBM выступает скорее в роли ещё одного уровня кеша, а основной объём составляют модули DDR5. Вычислительная часть состоит из классических ARM-ядер Zeus и многопоточных масштабируемых ядер XPU собственной разработки ETRI. Их-то разработчики и называют «матричными ядрами», поскольку работа с матричной математикой главная задача этих ядер. Группы таких ядер, называемые доменами XEMC на схеме (всего их в каждом процессоре 4), имеют свой MMU, а также собственные подсистемы кешей и программируемых блоков логики с поддержкой SMT. За соединение частей процессора между собой отвечает внутренняя сеть с ячеистой (mesh) топологией. Текущая реализация K-AB21 также включает в себя шесть контроллеров шины PCI Express 5.0, каждый на 16 линий. В настоящее время разработчики заняты финализацией отдельных элементов дизайна K-AB21, но в целом разработка близка к завершению. Полноценная реализация «в кремнии» ожидается к концу 2021 года, что для проекта такого масштаба достаточно быстро и позволит Южной Корее вовремя войти в эру суперкомпьютеров экза-класса. В настоящее время самым мощным южнокорейским кластером является Nurion, занимающий 17 место в Top500. Однако это система Cray CS500 на базе Intel Xeon Phi 7250, которая целиком базируется на технологиях США, а выпуск собственного HPC-процессора позволит Южной Корее стать более независимой в этом аспекте.
02.11.2020 [17:56], Илья Коваль
Прощание с Xeon Phi: ядро Linux лишится поддержки MIC-архитектурыФинальная партия Intel Xeon Phi была отгружена летом этого года, хотя сам закат продуктов на базе архитектуры MIC (Many Integrated Core) начался за несколько лет до этого. Теперь же можно сказать, что в их истории поставлена последняя точка — из основной ветки ядра Linux 5.10 поддержка этих процессоров убрана уже в rc2. В ядре Linux поддержка MIC появилась в 2013 году, и Intel очень активно развивала её, почти втрое увеличив объём кодовой базы. Однако в последние годы развитие прекратилось и код остался фактически заброшенным. Связано это, понятное дело, с уходом ускорителей с рынка, где они не стали массовыми, проиграв конкуренцию NVIDIA как в HPC, так и в остальных сегментах.  Intel последовательно отменила выпуск следующего поколения MIC и продуктов всех прошлых поколений Xeon Phi, переключившись на создание универсальной архитектуры GPU. HPC-ускорители на её базе должны появиться в скором времени. Шине Intel Omni-Path, которая была непосредственно интегрирована в некоторые поздние модели Xeon Phi, повезло больше — после отказа Intel разработки были переданы свежесозданной Cornelis Networks. Тем не менее, кое-какое наследие MIC в ядре всё же может сохраниться. Речь идёт подсистеме VOP (VirtIO over PCIe), которая решает некоторые проблемы виртуализации PCI Express и для устройств других вендоров. Однако в текущем она ориентирована только на поддержку продуктов и драйверов Intel, и сможет вернуться в ядро Linux лишь после доработки. |
|

