Лента новостей
|
22.09.2020 [20:32], Игорь Осколков
От периферии до облаков: Arm представила серверные платформы Neoverse V1 Zeus и N2 Perseus с поддержкой SVE, PCIe 5.0, DDR5 и HBMКомпания Arm объявила о расширении своего портфолио серверных решений семейства Neoverse, представив сразу два варианта платформы. Новая серия V и её первенец V1 под кодовым именем Zeus вместе с N2 (Perseus) получат поддержку SIMD-расширений SVE и формата bfloat16, а также интерфейсы PCIe 5.0, DDR5 и HBM. Однако отличия между ними весьма существенны. В Neoverse V1 в отличие от N2 Arm отказывается от традиционной оптимизации сразу по трём направлениям — энергопотребление, производительность и площадь кристалла — и делает упор на мощность. Вероятно, основой для них станут вариации Cortex-X1. Эти чипы будут потреблять больше энергии и будут физически больше, но взамен предложат значительное увеличение размеров буферов, кешей, окон и очередей. Показатель IPC для одного потока будет увеличен на впечатляющие 50% в сравнении с Neoverse N1. 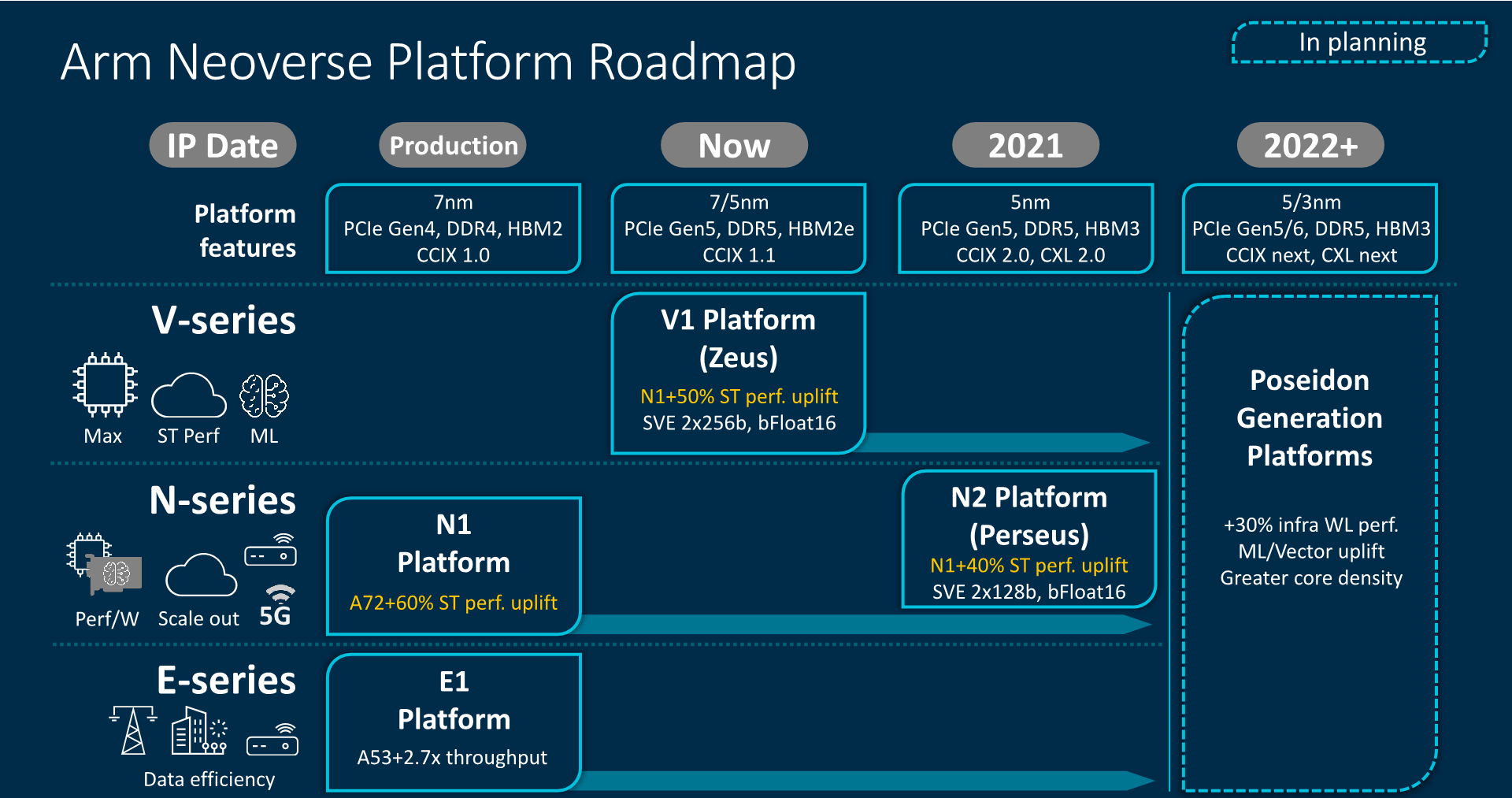 А новые техпроцессы 5 и 7 нм позволят повысить частоты будущих процессоров. Так что они потенциально смогут соревноваться с грядущими платформами x86-64 не только по показателю производительность на Ватт, но и в чистой производительности. Поспособствует этому и долгожданное официальное появление векторных инструкций Scalable Vector Extension (SVE) в составе самого ядра. Их отличительной чертой (от SSE/AVX) является нефиксированная ширина — производители конкретных SoC могут реализовать поддержку от 128 до 2048 бит с шагом в 128 бит. При этом SVE-код будет работать на любом из них, просто скорость обработки данных будет разной. 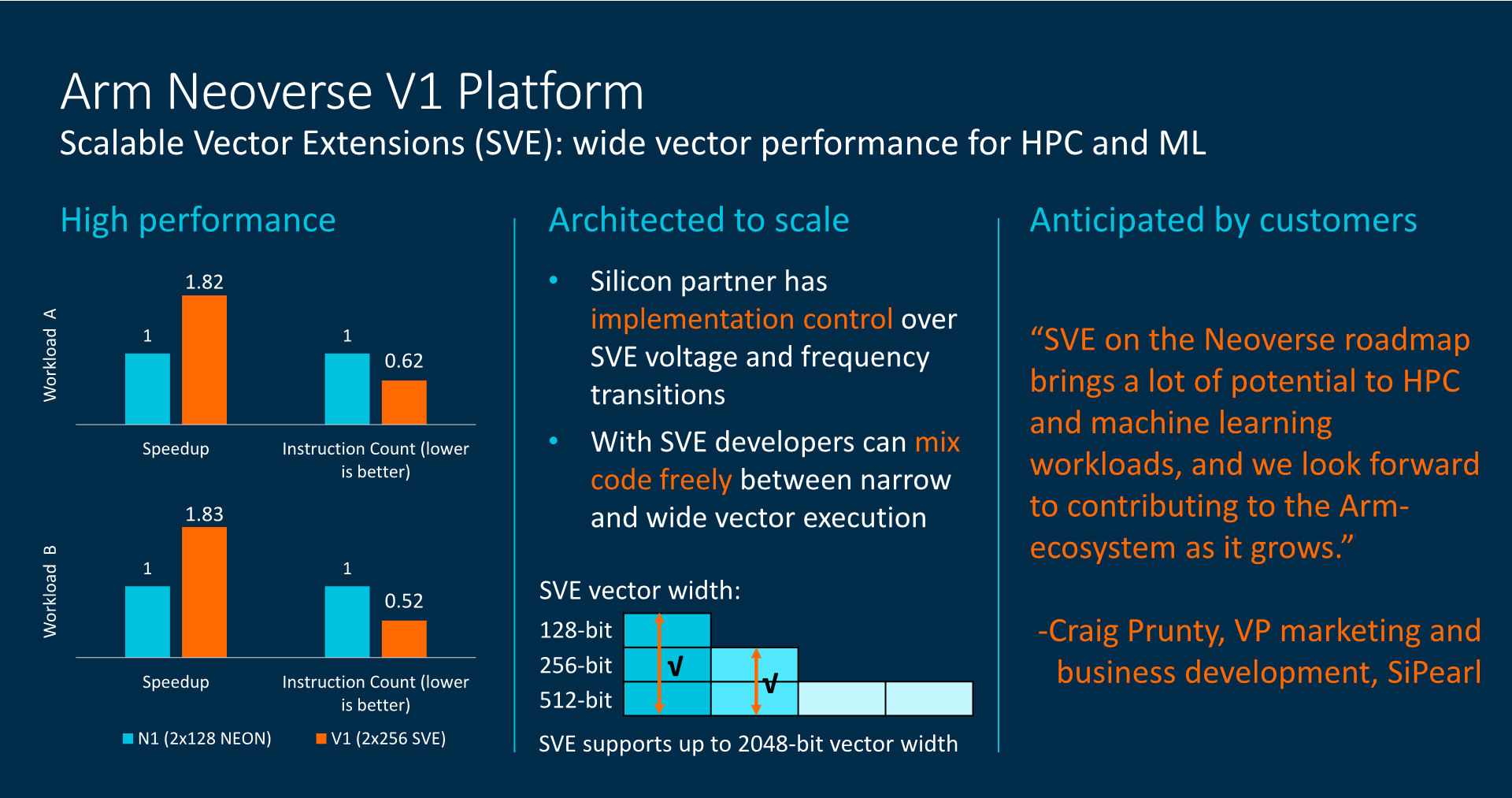 Конкретно в V1 Arm заложила два блока SVE-256. Это явно хуже пары SVE-512 в Fujitsu A64FX, единственном «кремнии», который уже поддерживает новые инструкции, но всё равно в два раза лучше, чем у N1 с двумя «старыми» 128-бит NEON. Так что мы вполне можем увидеть в будущем ориентированные на высокопроизводительные вычисления решения от других компаний. Этому поспособствует и поддержка памяти HBM2e. Опять-таки, в A64FX она была нужна именно для того, чтобы SVE-блоки не «голодали». Кроме того, обновлённые спецификации SVE включают и поддержку формата bfloat16, актуального для нейронных сетей. 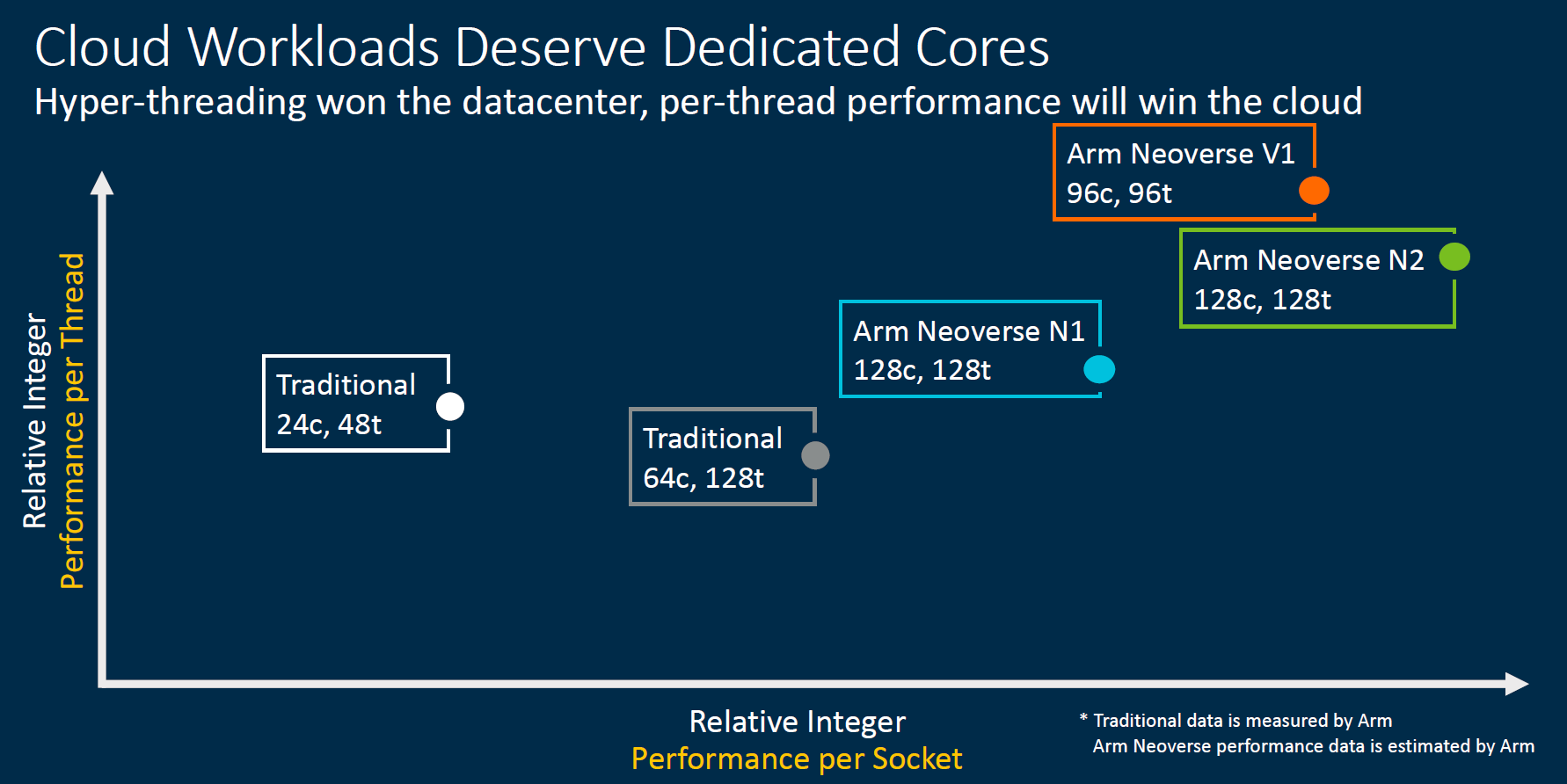 Arm Neoverse V1 формально доступен уже сейчас. Первыми процессорами на базе этой архитектуры должны стать 72-ядерные SiPearl Rhea, которые вместе с другими чипами, уже на базе открытой архитектуры RISC-V, лягут в основу будущих европейских суперкомпьютеров. Таким образом Евросоюз надеется получить большую независимость от технологий США. Впрочем, объявленная сделка между NVIDIA и Arm может расстроить эти планы. Следующим крупным лицензиатом V1 может стать Ampere, которая готовится выпустить в 2022 году процессоры Siryn. 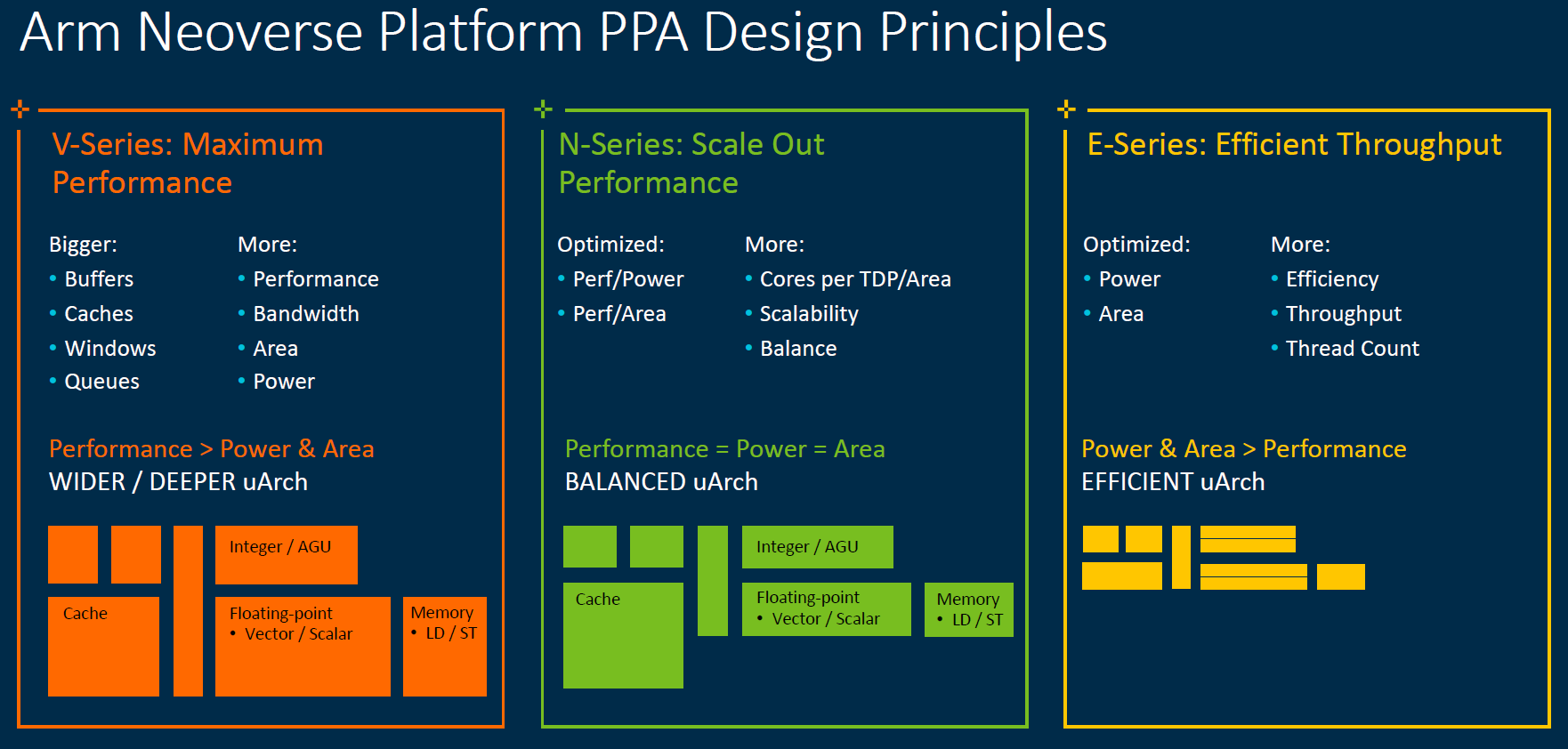 Что касается архитектуры Neoverse N2, то она появятся уже в следующем году, а лицензирование начнётся в конце этого. Она также получит поддержку SVE и bfloat16, но в виде двух 128-бит блоков. Будет внедрена поддержка HBM3, CXL 2.0 и CCIX 2.0. В N2 Arm придерживается своего традиционного подхода, так что прирост IPC в однопотоке составит «всего лишь» до 40% в сравнении с N1, но при этом сохранятся те же уровень энергопотребления и площадь ядра. Можно предположить, что основной для неё станет Cortex-A78. 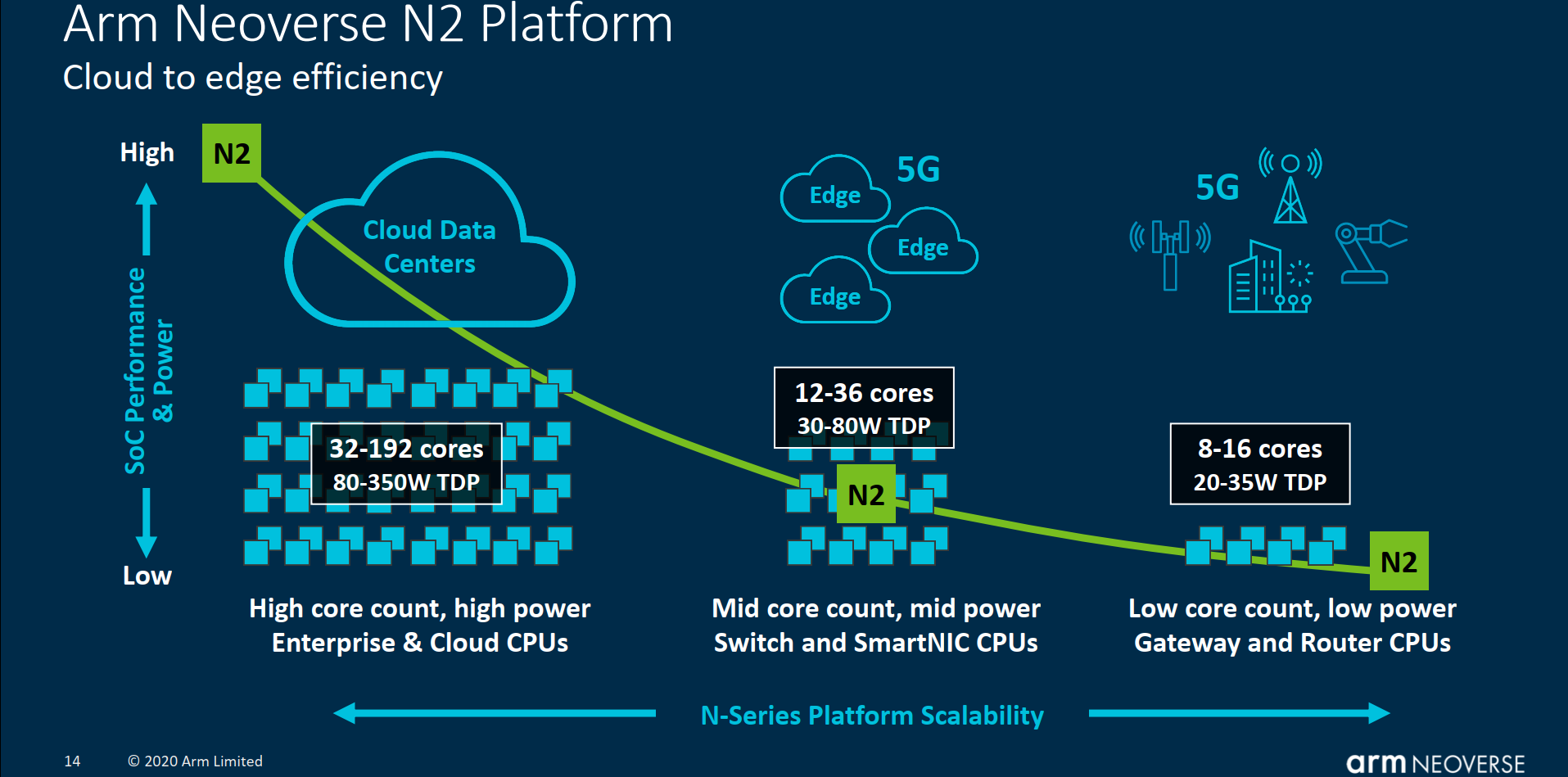 Именно N2 должна стать наиболее массовой платформой благодаря масштабируемости. Arm видит различные варианты дизайнов будущих SoC. От 8 до 16 ядер с TDP 20-35 Вт пойдут в экономичные решения на самой границе сети, варианты на 12-36 ядер с TDP от 30 до 80 Вт могут стать основой периферийных вычислений, а сборки с числом ядер от 32 до 192 и с TDP от 80 до 350 Вт займут место в мощных серверах, включая облачные. Пока что единственным более-менее массовым решением на базе Neoverse N1 владеет Amazon — в мае в AWS появились инстансы на базе 64-ядерных Graviton2.  После 2022 года выйдет следующее поколение Neoverse под кодовым именем Poseidon. Про него пока говорится в общих чертах, что оно станет производительнее на 30%, получит улучшения по части векторных инструкций и машинного обучения, обзаведётся поддержкой будущих версий CCIX и CXL, а также предложит более плотную упаковку ядер.
18.09.2020 [15:55], Алексей Степин
ИИ-ускоритель Qualcomm Cloud AI 100 обещает быть быстрее и экономичнее NVIDIA T4Ускорители работы с нейросетями делятся, грубо говоря, на две категории: для обучения и для исполнения (инференса). Именно для последнего случая важна не столько «чистая» производительность, сколько сочетание производительности с экономичностью, так как работают такие устройства зачастую в стеснённых с точки зрения питания условиях. Компания Qualcomm предлагает новые ускорители Cloud AI 100, сочетающие оба параметра.  Сам нейропроцессор Cloud AI 100 был впервые анонсирован ещё весной прошлого года, и Qualcomm объявила, что этот чип разработан с нуля и обеспечивает вдесятеро более высокий уровень производительности в пересчёте на ватт, в сравнении с существовавшими на тот момент решениями. Начало поставок было запланировано на вторую половину 2019 года, но как мы видим, по-настоящему ускорители на базе данного чипа на рынке появились только сейчас, причём речь идёт о достаточно ограниченных, «пробных» объёмах поставок. 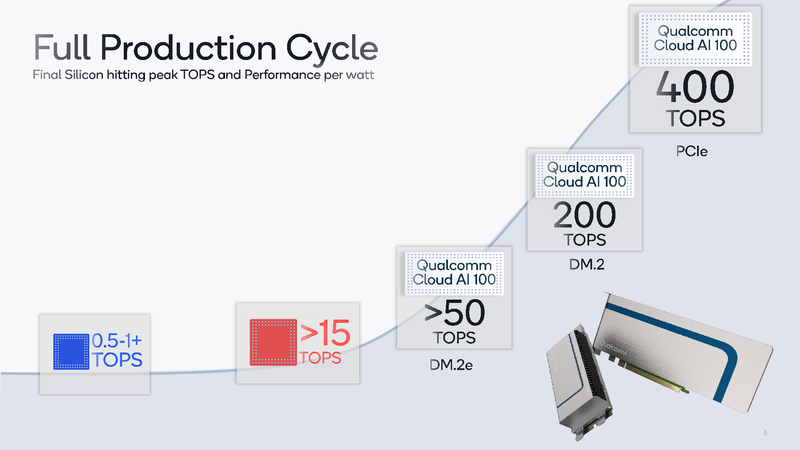 В отличие от графических процессоров и ПЛИС-акселераторов, которые часто применяются при обучении нейросетей и, будучи универсальными, потребляют при этом серьёзные объёмы энергии, инференс-чипы обычно представляют собой специализированные ASIC. Таковы, например, Google TPU Edge, к этому же классу относится и Cloud AI 100. Узкая специализация позволяет сконцентрироваться на достижении максимальной производительности в определённых задачах, и Cloud AI 100 более чем в 50 раз превосходит блок инференс-процессора, входящий в состав популярной SoC Qualcomm Snapdragon 855. 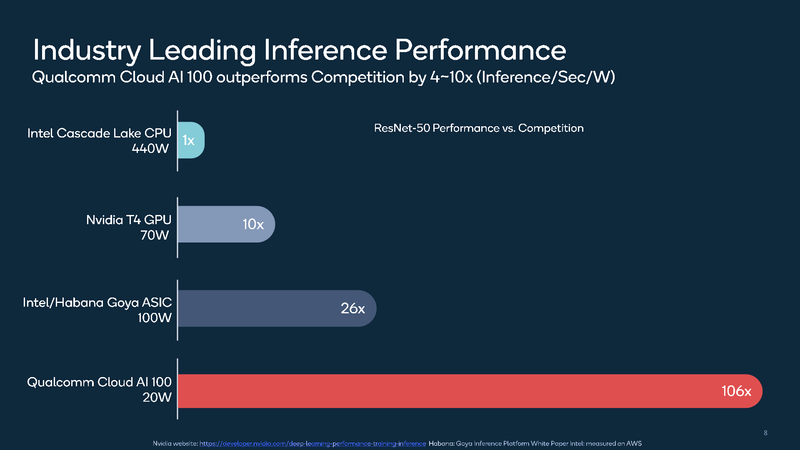 На приводимых Qualcomm слайдах архитектура Cloud AI 100 выглядит достаточно простой: чип представляет собой набор специализированных интеллектуальных блоков (IP, до 16 юнитов в зависимости от модели), дополненный контроллерами LPDDR (4 канала, до 32 Гбайт, 134 Гбайт/с), PCI Express (до 8 линий 4.0), а также управляющим модулем. Имеется некоторый объём быстрой набортной SRAM (до 144 Мбайт). С точки зрения поддерживаемых форматов вычислений всё достаточно универсально: реализованы INT8, INT16, FP16 и FP32. Правда, bfloat16 не «доложили». 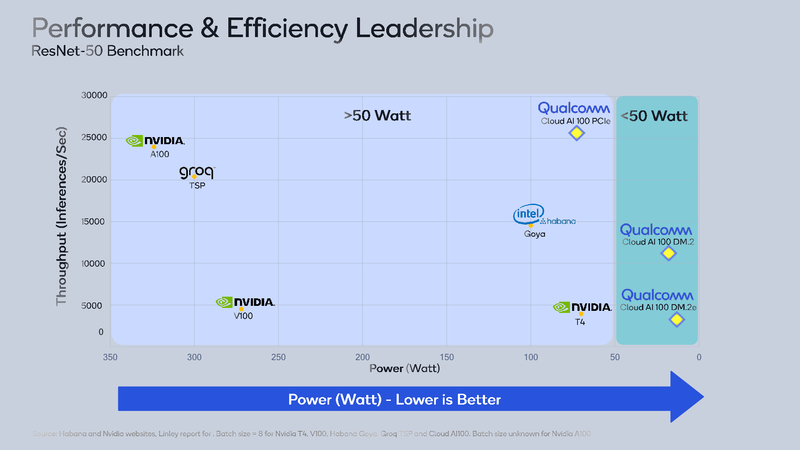 Об эффективности новинки говорят приведённые самой Qualcomm данные: если за базовый уровень принять систему на базе процессоров Intel Cascade Lake с потреблением 440 Ватт, то Qualcomm Cloud AI 100 в тесте ResNet-50 быстрее на два порядка при потреблении всего 20 Ватт. Это, разумеется, не предел: на рынок новый инференс-ускоритель может поставляться в трёх различных вариантах, два из которых компактные, форм-факторов M.2 и M.2e с теплопакетами 25 и 15 Ватт соответственно. Даже в этих вариантах производительность составляет 200 и около 500 Топс (триллионов операций в секунду), а существует и 75-Ватт PCIe-плата формата HHHL производительностью 400 Топс; во всех случаях речь идёт о режиме INT8. 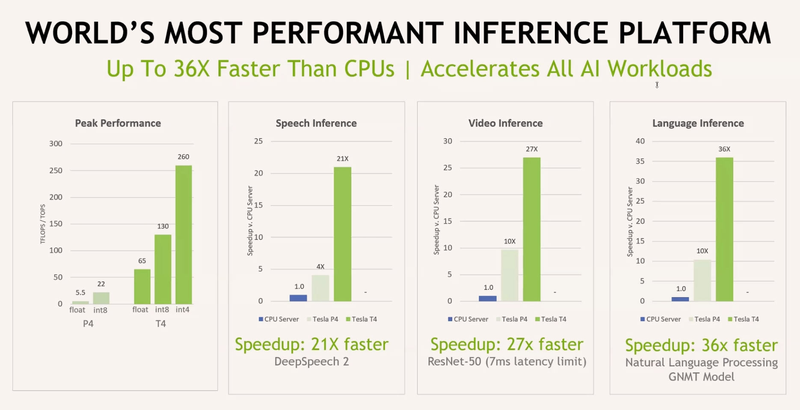
Данные для NVIDIA Tesla T4 и P4 приведены для сравнения Основными конкурентами Cloud AI 100 можно назвать Intel/Habana Gaia и NVIDIA Tesla T4. Оба этих процессора также предназначены для инференс-систем, они гибче архитектурно — особенно T4, который, в сущности, базируется на архитектуре Turing —, однако за это приходится платить как ценой, так и повышенным энергопотреблением — это 100 и 70 Ватт, соответственно. Пока речь идёт о распознавании изображений с помощью популярной сети ResNet-50, решение Qualcomm выглядит великолепно, оно на голову выше основных соперников. Однако в иных случаях всё может оказаться не столь однозначно. 
Новые ускорители Qualcomm будут доступны в разных форм-факторах Как T4, так и Gaia, а также некоторые другие решения, вроде Groq TSP, за счёт своей гибкости могут оказаться более подходящим выбором за пределами ResNet в частности и INT8 вообще. Если верить Qualcomm, то компания в настоящее время проводит углублённое тестирование Cloud AI 100 и на других сценариях в MLPerf, но в открытом доступе результатов пока нет. Разработчики сосредоточены на удовлетворении конкретных потребностей заказчиков. Также заявлено о том, что высокая производительность на крупных наборах данных может быть достигнута путём масштабирования — за счёт использования в системе нескольких ускорителей Cloud AI 100.  В настоящее время для заказа доступен комплект разработчика на базе Cloud Edge AI 100. Основная его цель заключается в создании и отработке периферийных ИИ-устройств. Система достаточно мощная, она включает в себя процессор Snapdragon 865, 5G-модем Snapdragon X55 и ИИ-сопроцессор Cloud AI 100. Выполнено устройство в металлическом защищённом корпусе с четырьмя внешними антеннами. Начало крупномасштабных коммерческих поставок намечено на первую половину следующего года.
17.09.2020 [00:39], Владимир Мироненко
Крупнейшее IPO за всю историю софтверной индустрии — Snowflake оценена в $33,6 млрдАкции провайдера услуг хранилища данных для корпоративных клиентов Snowflake начали торговаться в среду на Нью-Йоркской фондовой бирже. Компания привлекла в ходе первичного размещения акций (IPO) порядка $3,36 млрд при оценке её рыночной стоимости в $33,6 млрд. Это было крупнейшее IPO для компании-разработчика программного обеспечения за все время существования софтверной индустрии. 
Getty Images Компания Snowflake, основанная в 2012 году, предоставляет специализированное облачное хранилище данных (Data Warehouse), работающее в AWS, Azure и Google. В Snowflake было инвестировано около $1,4 млрд венчурного капитала ещё до IPO, а в феврале в ходе G-раунда на $479 млн компания была оценена в $12,4 млрд. Тогда у компании насчитывалось более 3400 клиентов. К лету оценка стоимости выросла уже до $20 млрд. Snowflake привлекла больше средств, чем изначально планировалось, продав 28 млн акций по $120 за штуку, что превысило целевой диапазон, находившийся в пределах от $100 до $110. Успешному IPO компании способствовало заявление Уоррена Баффета (Warren Buffet) о том, что его инвестиционный бизнес Berkshire Hathaway вложит $250 млн в Snowflake, а также известие о том, что нынешний инвестор Salesforce вкладывает в её акции ещё $250 млн.
15.09.2020 [19:33], Алексей Степин
Microsoft Natick может стать будущим периферийных ЦОД, надёжность доказанаЛюбой современный ЦОД — это не только помещение, занимающее определённую площадь, но ещё и серьёзные системы питания и, особенно, охлаждения. Ряд компаний считает, что с точки зрения последнего фактора имеет смысл рассмотреть возможность размещения ЦОД под водой, на дне моря, где температура постоянна и достаточно низка. В их числе Microsoft со своей разработкой Project Natick. Первый прототип Natick, доказавший работоспособность концепции, успешно проработал 105 дней в водах Калифорнийского залива, однако действительно серьёзная мощность была достигнута лишь во второй фазе, о которой и идёт речь в данной заметке. Второй прототип Natick являет собой 12,2-метровый цилиндрический контейнер стандарта ISO 40, внутри размещено 12 стоек с 864 серверами Microsoft (в составе присутствуют ПЛИС-ускорители) и СХД общим объёмом 27,6 Пбайт. Система охлаждения во втором варианте была разработана французской группой Naval Group на основе теплообменников, использующихся в современных подводных лодках.  На этот раз местом размещения подводного ЦОД был выбран район Оркнейских островов в 193 километрах (120 миль) от берега, глубина погружения составляла примерно 35 метров. Для питания и данных использовался общий кабель, содержащий как силовые линии, способные передать около четверти мегаватта, так и оптические волокна. Проект создавался с прицелом на пятилетний срок работы без обслуживания, с прицелом на 20 лет в будущем. Для обеспечения повышенной надёжности внутреннее пространство контейнера заполнено азотом, который практически инертен и способствует уменьшению износа оборудования.  14 сентября Microsoft сообщила об окончании второй фазы Project Natick, которая продлилась два года. Сам контейнер был извлечён из моря ещё летом, и специалисты и эксперты занялись изучением состояния аппаратного обеспечения, входившего в состав второго прототипа автономного ЦОД. Результат проекта признан очень успешным, возглавляющий Project Natick Бен Катлер (Ben Cutler) заявил, что «дело сделано, и второй вариант Natick можно с полным правом назвать подходящим строительным блоком». Согласно статистике, около 50% населения планеты проживает недалеко от берега моря, поэтому размещение подводных ЦОД в прибрежных областях вполне оправдано, а Европейский центр морской энергетики (Europetn Marine Energy Centre) вообще говорит о возможности использования для питания таких ЦОД приливных турбин и волновых конвертеров, что сделает их практически автономными, не считая оптоволоконного подключения. 
Часть системы охлаждения Natick Тонкости функционирования Natick ещё предстоит изучить, но предварительные результаты оказались несколько обескураживающими: ЦОД в герметичном контейнере, покоившийся на дне моря, и, естественно, лишённый обслуживания, оказался в восемь раз надёжнее, нежели его копия, расположенная на суше. Причины примерно ясны: стабильные температуры, отсутствие окисляющей атмосферной среды, а также каких-либо серьёзных вибраций. Компания считает, что эти данные могут помочь и в проектировании более надёжных наземных ЦОД.  Microsoft признала, что проект всё ещё далёк от завершения, но считает, что стандартный ЦОД Azure в подводном варианте уже может быть создан. Вице-президент отдела Azure по системам класса mission critical Вильям Чэппел (William Chappell) отметил, что его команда особенно заинтересована в пост-квантовых методах шифрования, критичных для такого рода периферийных центров обработки данных. Также заявлено, что Natick успешно может служить в качестве периферийного ЦОД или ЦОД с повышенной безопасностью; последнее достаточно очевидно — получить доступ к оборудованию, находящемуся под водой, намного сложнее, нежели в обычном ЦОД. Надёжнее в этом плане может быть только сервер на орбите, но по понятным причинам такое решение намного дороже и сложнее, нежели Natick, оно менее мощное, а также не гарантирует постоянной низкой латентности, которая может быть критичной в edge-сценариях использования.
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 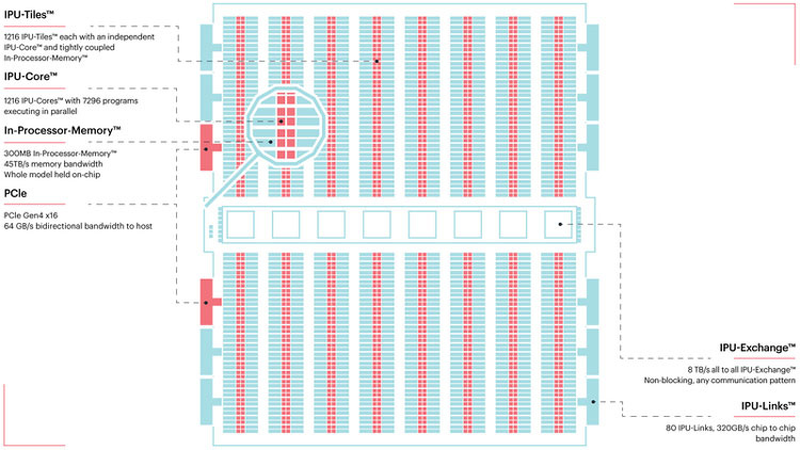
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 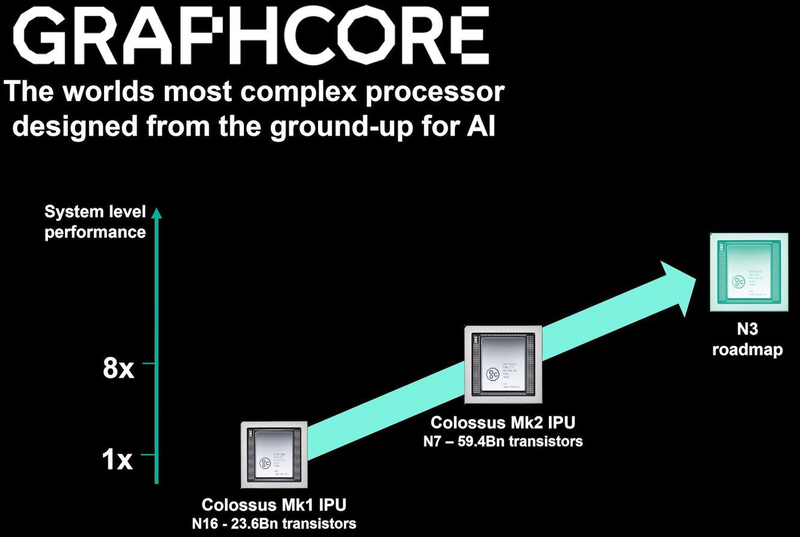
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC.
19.08.2020 [19:04], Игорь Осколков
Третий сокет: Fungible представляет новый класс процессоров — DPUИдея дезагрегации ресурсов, которые в последнее время становятся всё более разнообразными, далеко не нова. Выделенные аппаратные блоки, которые помогают перемещать данные между ресурсами, тоже в том или ином виде развиваются не первый год. Fungible же решила довести эту концепцию до логического конца, создав DPU (Data Processing Unit).  На конференции HotChips 32 компания рассказала о двух процессорах: Fungible F1 и S1. Первому из них и был посвящён основной доклад. F1 ориентирован на работу с хранилищами и безопасную обработку больших потоков данных, которые требуются современным системам ИИ и аналитики. 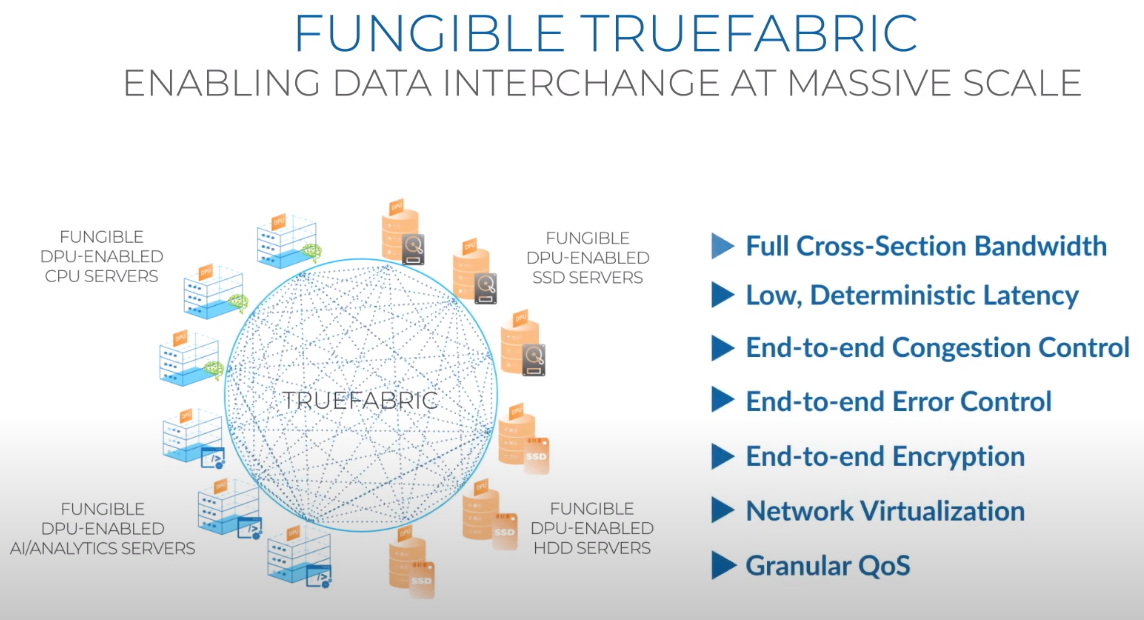 При взгляде «свысока» F1 представляет собой чип c двумя основными интерфейсами: 8 каналов 100GbE и 4 контроллера PCIe 3.0/4.0 x16. Тем не менее, это не просто очередная реализация RDMA или, допустим, NVMe-oF. Со стороны сети предполагается организация общей фабрики между всем узлами, которую разработчики называют TruFabric. 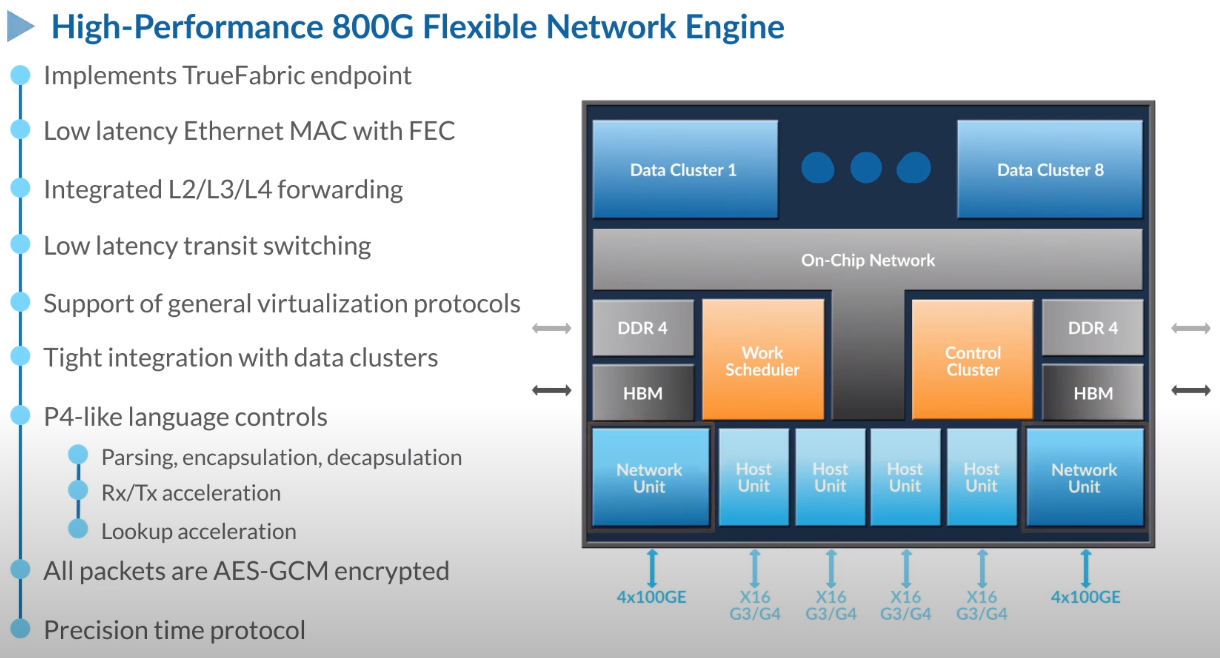 В отличие от многих других решений для фабрики здесь используется стандартный и относительно дешёвый Ethernet, а не PCIe, InfiniBand, Fibre Channel или какой-то проприетарный интерконнект. Весь трафик шифруется, а для реализации собственных функций разгрузки предлагается P4-подобный язык программирования. 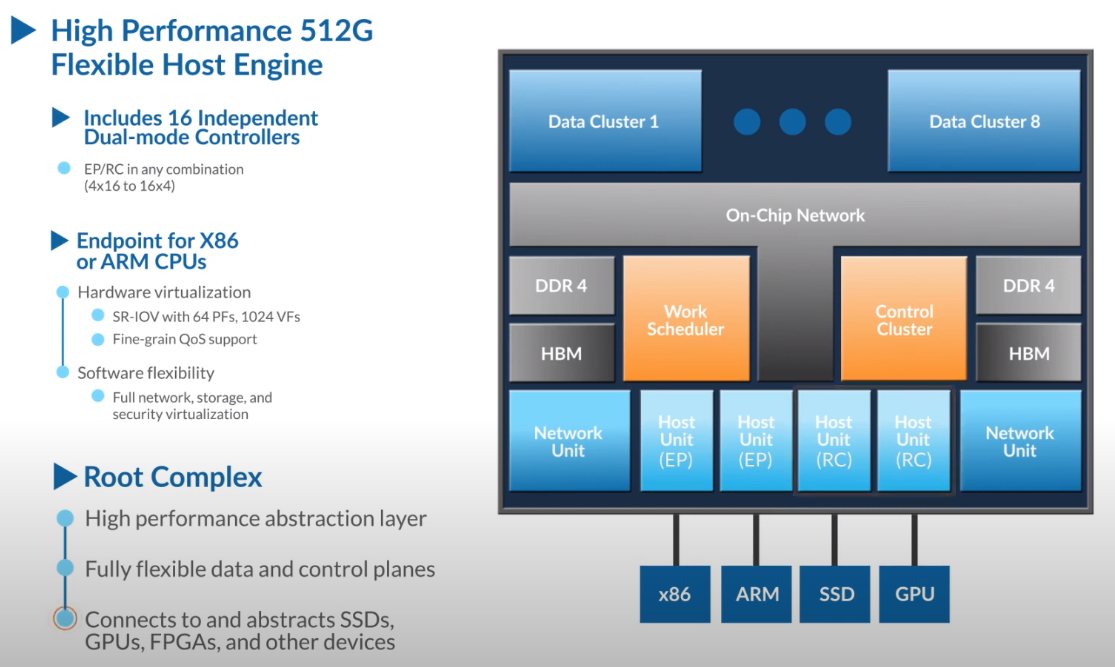 Со стороны PCIe F1 может «представляться» серверу как ещё один адаптер (с SR-IOV), а может предоставлять и собственный root-комплекс для прямого подключения и абстракции других устройств: CPU, GPU, FPGA, NVMe SSD, HDD и так далее. 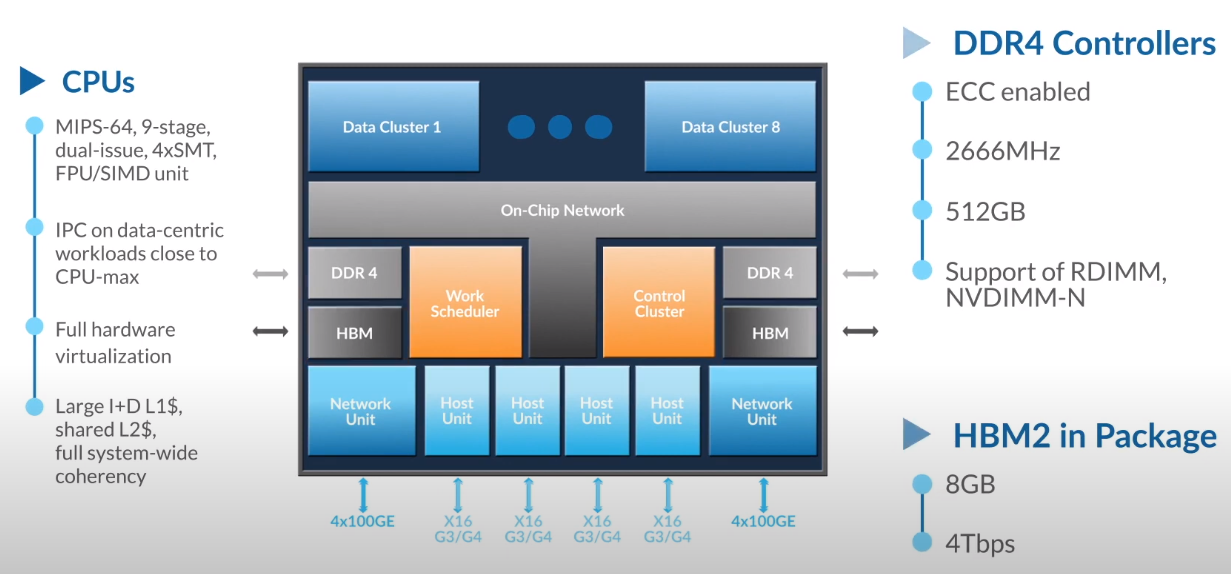 Fungible F1 помимо Ethernet и PCIe включает общий контроллер памяти, планировщик, управляющий блок и собственно блоки обработки данных. Все они объединены внутренней сверхбыстрой шиной. Контроллеры памяти обслуживают 8 Гбайт набортной HBM (4 Тбит/с) + внешние модули DDR4-2666 ECC с поддержкой NVDIMM-N, суммарный объём которых может достигать 512 Гбайт. 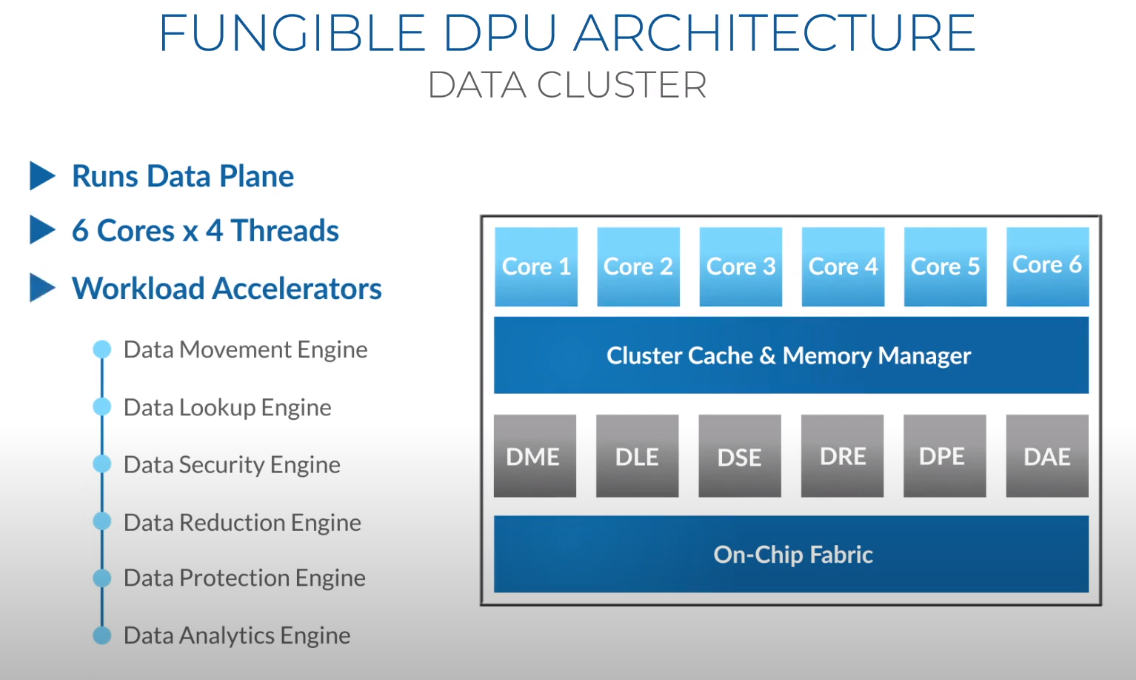 Блоков обработки данных (Data Cluster) в сумме восемь. Каждый из них имеет 6 ядер MIPS-64 общего назначения c SMT4. Их дополняют отдельные аппаратные акселераторы для поиска, передачи и сжатия объёма передаваемых данных, безопасности и защиты информации, а также для аналитики данных. Все ядра и акселераторы имеют общий кеш и менеджер памяти. Суммарно на чип приходится 48 ядер и 192 потока для обработки данных. 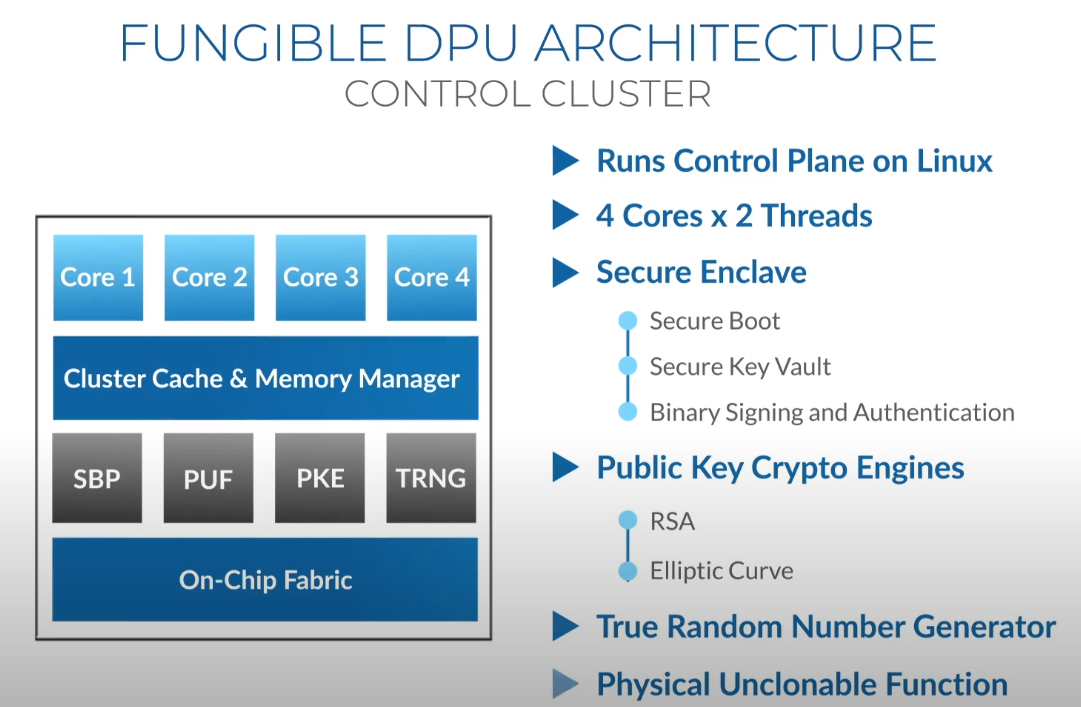 Управляет ими отдельный блок (Control Cluster), включающий 4 ядра MIPS-64 с SMT2, а также модули безопасности: изолированный анклав, генератор случайных чисел, аппаратный акселератор для работы с ключами шифрования. MIPS-ядра также имеют блоки FPU/SIMD и поддержку аппаратной виртуализации. 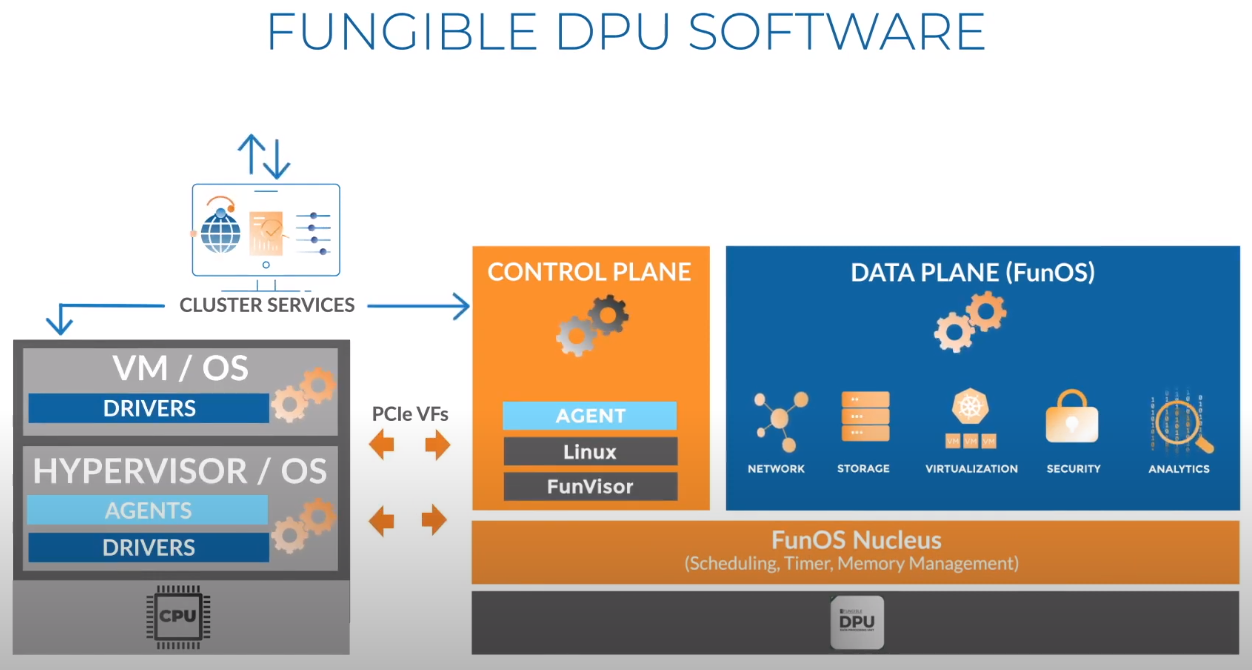 Программная часть представлена мини-ОС FunOS Nucleus, которая обеспечивает самые базовые функции. В блоках Data Cluster «живёт» FunOS, которая обслуживает пять программных стеков: сеть, хранилище, виртуализация, безопасность и аналитика. В Control Cluster работает сверхтонкий гипервизор FunVisor, поверх которого запущен Linux. Для ОС, гипервизора и ВМ, работающим на хост-процессоре x86 или ARM предлагаются драйверы и агенты. 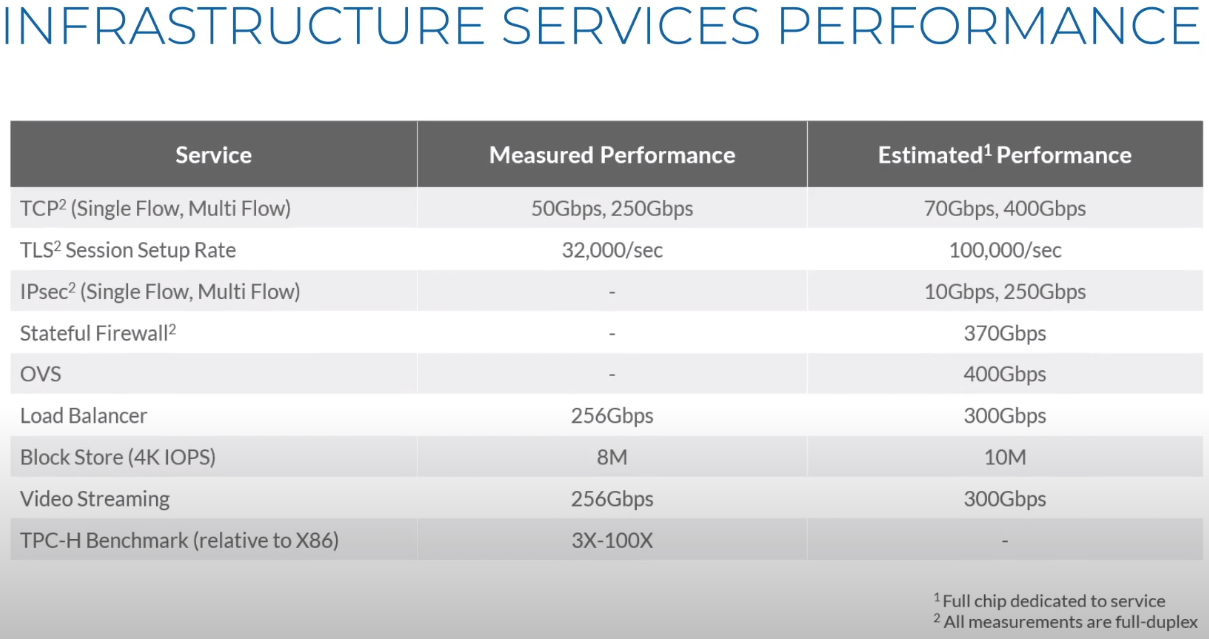 Предварительные тесты действительно показывают значительное ускорение в некоторых нагрузках, а также достаточно высокий уровень производительности самих DPU и TrueFabric. При этом в отличие от SmartNIC и других подобных решений DPU от Fungible обещают быть намного универсальнее и вместе с тем проще в работе. 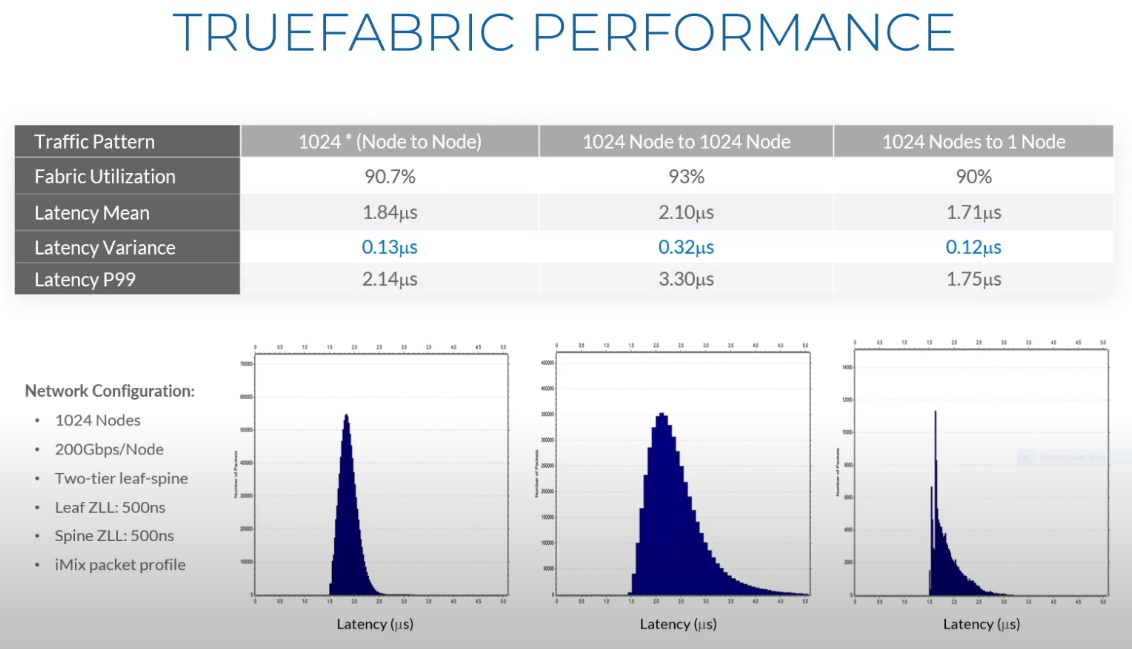 Fungible даже считает, что DPU должны стать одним из ключевых компонентов современных серверов в дата-центре, заняв третий по счёту сокет в системе после CPU и GPU. Таким образом, можно будет на лету «собирать» оптимизированные под конкретные задачи конфигурации из разрозненных ресурсов, объединённых DPU-хабами в единую фабрику.
18.08.2020 [22:16], Алексей Степин
Серверные ARM-процессоры Marvell ThunderX3: 60 ядер в SCM, 96 ядер в MCM, SMT4 в подарокПоследние дни оказались богатыми на анонсы новых процессоров. Компания IBM представила новейшие POWER10 с поддержкой памяти OMI DDR5 и PCI Express 5.0, Intel анонсировала Xeon Ice Lake-SP, которые, наконец, получили поддержку PCIe 4.0. Третьей в этом списке можно назвать Marvell, которая на мероприятии Hot Chips 32 рассказала подробности о последнем, третьем поколении ARM-процессоров ThunderX, формально анонсированном ещё весной этого года. 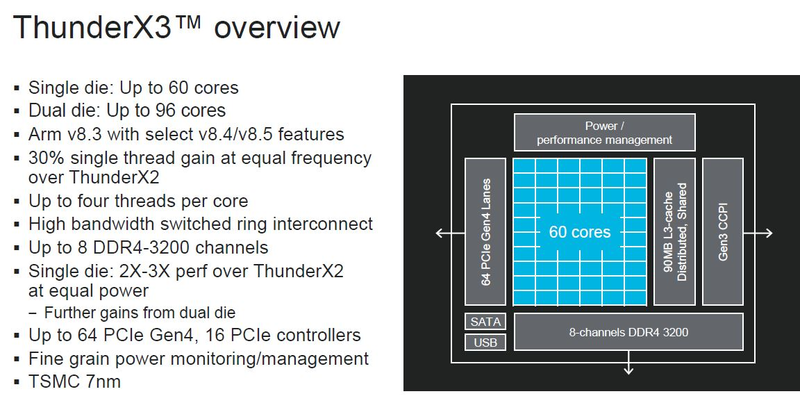
Источник изображений: ServeTheHome Процессоры с архитектурой ARM покорили сегмент мобильных устройств, но в последние несколько лет интереснее другая тенденция — данная архитектура ложится в основу всё новых и новых «крупных» процессоров, предназначенных для серверного применения. И как показывает практика, когда-то считавшаяся «слабой» архитектура оказывается вовсе не такой. 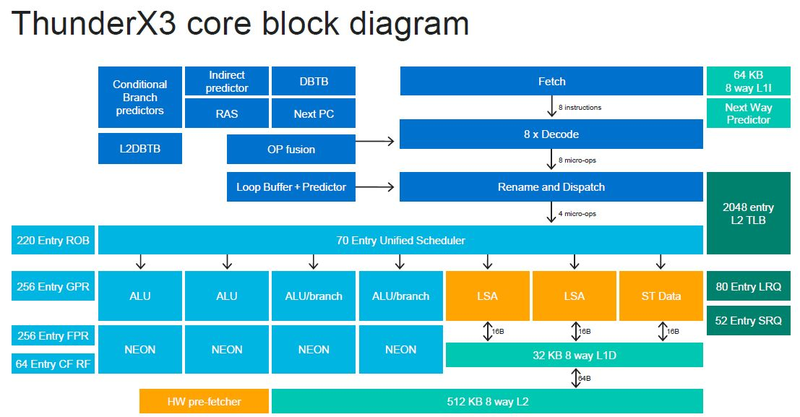 Она успешно соперничает с x86, особенно там, где необходима высокая плотность упаковки вычислительных мощностей и высокая энергоэффективность. Примеры AWS Graviton2 и кастомных процессоров Google тому доказательством, а разработка Fujitsu, процессор A64FX, и вовсе лежит в основе мощнейшего суперкомпьютера планеты, японского кластера Fugaku. 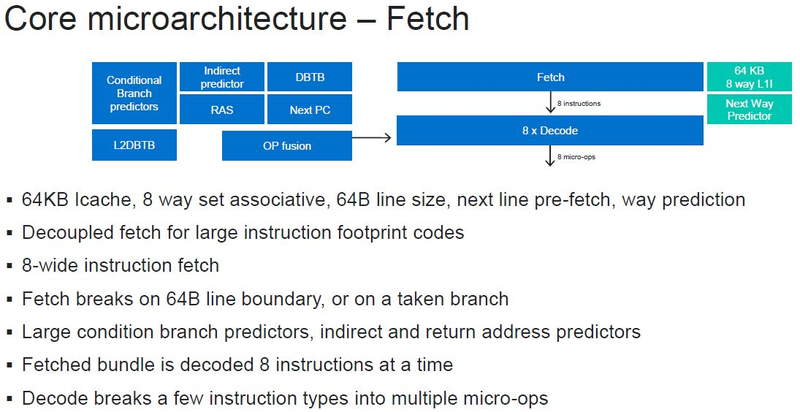 Одной из компаний, прилагающих серьёзные усилия к освоению серверного рынка с помощью архитектуры ARM, является Marvell. Если первые процессоры ThunderX, доставшиеся в наследство от Broadcom, сложно назвать успешным, то уже второе поколение показало себя неплохо, и, судя по всему, третье, наконец, готово к массовому внедрению. Напомним, в отличие от домашних проектов AWS и Google, процессоры ThunderX3 должны получить развитую поддержку многопоточности, на уровне SMT4, что больше, чем у x86, но меньше, чем у POWER10. 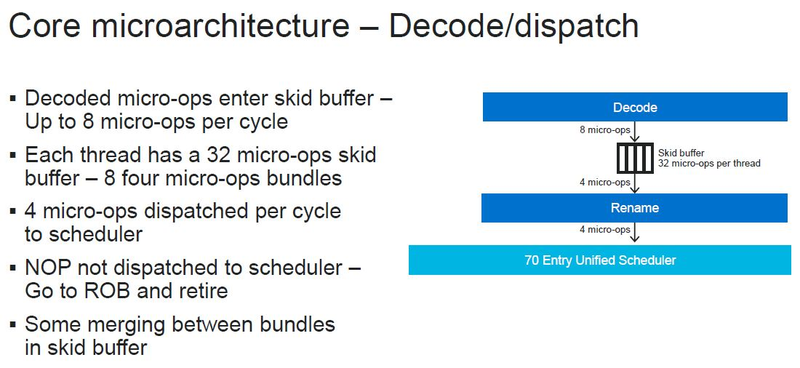 При этом максимальное количество ядер у ThunderX3 впечатляет. Теперь известно, что о 96 ядрах речь идёт только в двухкристалльной компоновке (этим подход Marvell напоминает IBM POWER10, также существующий в двух вариантах). Один кристалл может нести до 60 ядер, что меньше, чем у Graviton2, но, во-первых, ненамного, а во-вторых, с лихвой компенсируется наличием SMT. SMT4 может дать 240 или 384 потока в зависимости от версии, и наверняка это понравится крупным облачным провайдерам, поскольку позволит разместить беспрецедентное количество VM в рамках одного сокета. 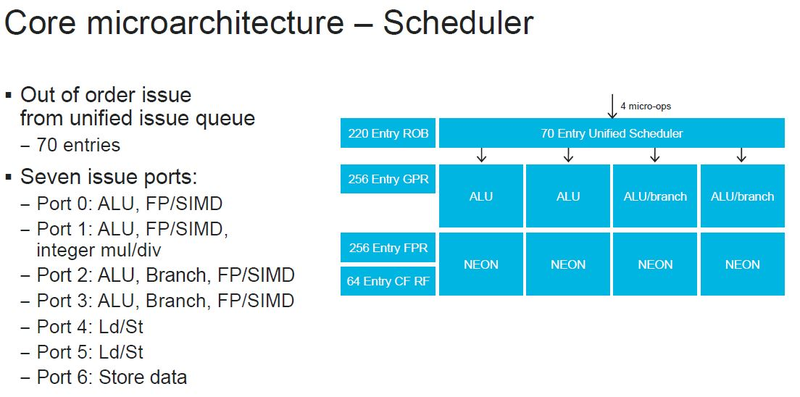 Однопоточная производительность не осталась без внимания. Компания заявила о 30% превосходстве над ThunderX2 в пересчёте на поток. В целом же, третье поколение ThunderX должно быть в 2-3 раза быстрее второго. Архитектурно процессор основывается на наборе инструкций ARM v8.3, однако сказано о частичной поддержке ARM v8.4/8.5. 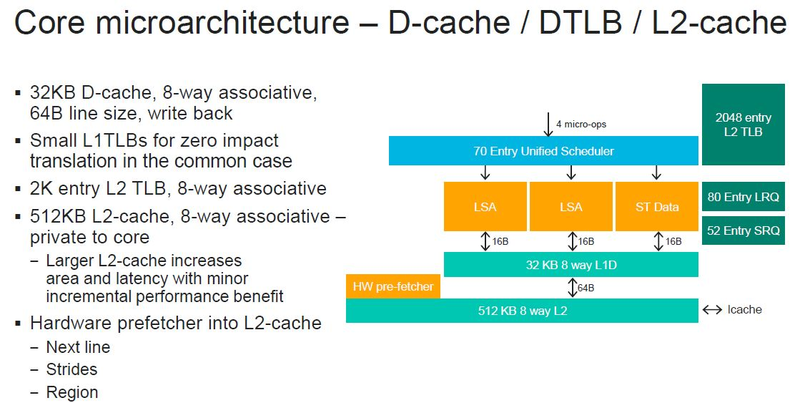 В споре о том, что эффективнее для связи ядер между собой, кольцевые шины или единая mesh-сеть, единого мнения нет. Intel предпочитает первый подход, но Marvell остановила свой выбор на втором. Как обычно, на внешнем кольце расположены кеш (80 Мбайт L3 на кристалл), блоки управление питанием, а также контроллеры памяти, PCI Express и межпроцессорной шины (в данном случае CCPI). 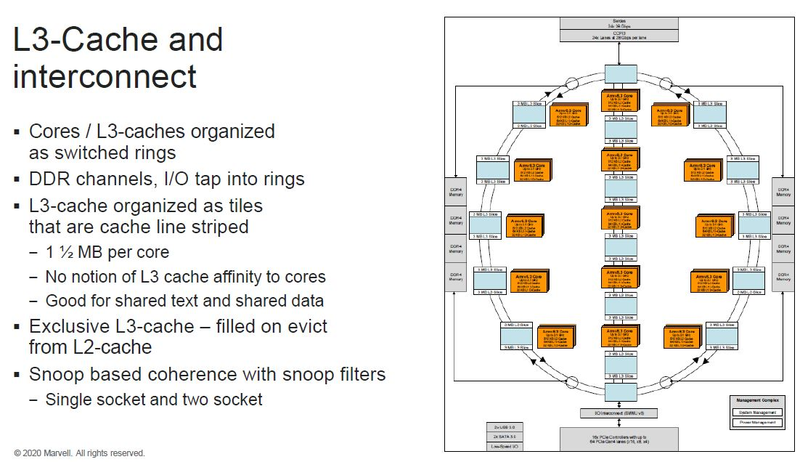 Поддержка SMT4 реализована полностью аппаратно. С точки зрения операционной системы каждый поток ThunderX3 выглядит, как обычный процессор с архитектурой ARM. При этом реализация столь развитой многопоточности привела всего лишь к 5% увеличению площади кристалла в сравнении с однопоточной реализацией.  Разделение ресурсов ядра у нового процессора динамическое, осуществляется оно в четырёх точках: выборка, когда потока с меньшим количеством инструкций получают более высокий приоритет; выполнение, работающее по такому же принципу; планирование, которое базируется на «возрасте» потока; наконец, «отставка» — здесь приоритет получают потоки с наибольшим количеством инструкций. Оптимизация многопоточности позволяет Marvell говорить о практически линейной масштабируемости новых процессоров, по крайней мере, в пределах одного разъёма. В зависимости от числа инструкций на ядро коэффициент прироста может варьироваться от x1,28 до 2,21. 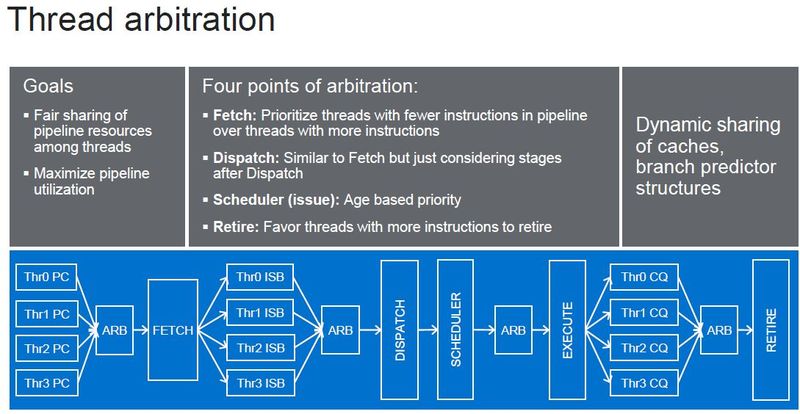 Подсистема ввода-вывода у новинок достаточно развитая. Контроллер памяти имеет 8 каналов и поддерживает DDR4-3200. За поддержку PCI Express отвечают 16 раздельных контроллеров, поддерживающих четвёртую версию стандарта. Это должно обеспечивать высокий уровень производительности при подключении 16 NVMe-накопителей, на каждый из которых придётся по четыре линии PCIe. 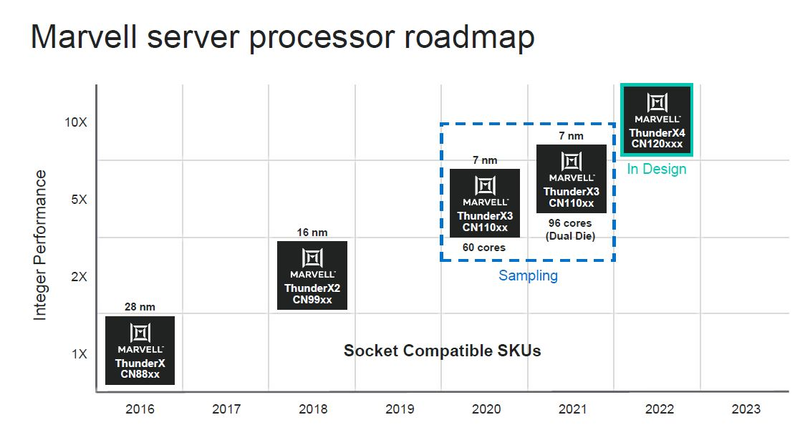 Заявлено о «тонком» управлении питанием, но деталей Marvell не приводит и остаётся только догадываться, насколько эта подсистема ThunderX3 продвинута. Производится новый процессор на мощностях TSMC с использованием техпроцесса 7 нм. Версия с одним 60-ядерным кристаллом выйдет на рынок уже в этом году, а вариант с двумя кристаллами и большим общим количеством ядер начнет поставляться позже, в 2021 году. Компания уже работает над ThunderX4, ожидается что эти процессоры будут использовать техпроцесс 5 нм и увидят свет в 2022 году.
17.08.2020 [15:32], Алексей Степин
Подробности о процессорах IBM POWER10: SMT8, OMI DDR5, PCIe 5.0 и PowerAXON 2.0Мы внимательно следим за судьбой и развитием архитектуры POWER, которая наряду с ARM представляет определённую угрозу для x86 в сфере серверов и суперкомпьютеров — недаром одна из самых мощных в мире HPC систем, суперкомпьютер Ок-Риджской национальной лаборатории Summit, использует процессоры POWER9. Ранее ожидалось что по ряду причин выход следующей в семействе архитектуры, POWER10, откладывается до 2021 года, хотя IBM и продвигала активно новые решения вроде универсального стандарта оперативной памяти OMI. Однако официальный анонс IBM POWER10 состоялся сегодня, а немецкий портал Hardwareluxx выложил слайды презентации компании.  Как компания уже отмечала ранее, она делает упор на большие системы и гибридные облака. С учётом этих тенденций и были разработаны новые процессоры. Поскольку в крупных облачных ЦОД упаковка вычислительных плотностей достигает уже невиданного ранее уровня, всё острее встаёт вопрос с энергоэффективностью и отводом тепла. Но именно здесь, как считает IBM, POWER10 и должен показать себя с наилучшей стороны — новые процессоры производятся с использованием 7-нм техпроцесса и могут демонстрировать трёхкратное преимущество в энергоэффективности в сравнении с POWER9. 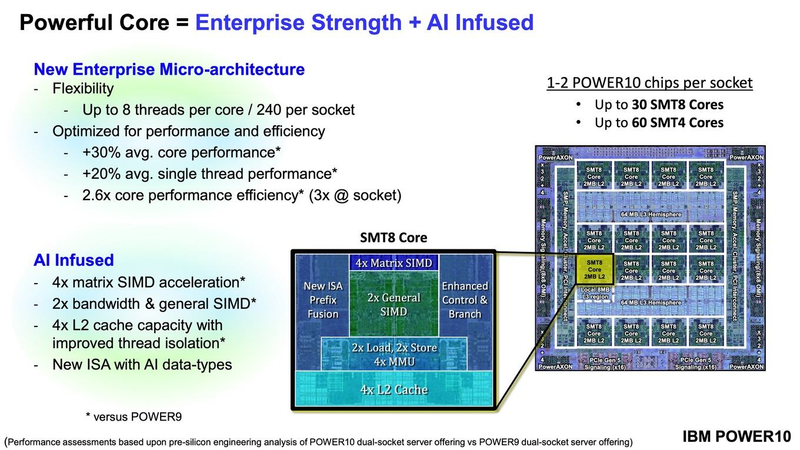 POWER10 — первый коммерческий процессор IBM, использующий нормы производства 7 нм; любопытно, что теперь Intel отстаёт не только от AMD, которая стала пионером в использовании столь тонкого техпроцесса в «крупных» серверных процессорах, но и от IBM. В отличие от AMD EPYC, производимых на мощностях TSMC, новинки IBM «куются» в полупроводниковых кузнях Samsung. Площадь кристалла, состоящего из 18 миллиардов транзисторов, у новых процессоров достигает 602 мм2, что меньше, чем у новейших графических ядер, но всё равно цифра довольно солидная. 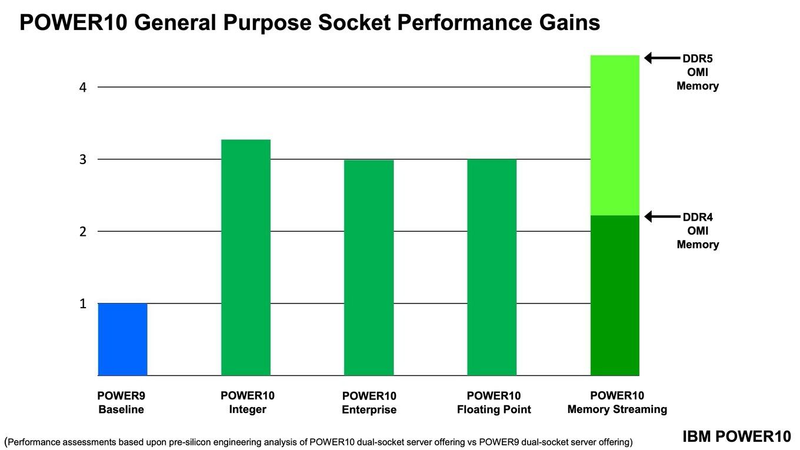 Техпроцесс POWER10 является совместной разработкой Samsung и IBM. В нём реализованы некие особенности, которые, предположительно, должны позитивно сказаться на характеристиках отдельных транзисторов. Не забыта и мода на установку нескольких кристаллов в один корпус: POWER10 доступны как в классическом варианте (SCM), так и в виде сборки из двух кристаллов (DCM), так что для каждого сценария использования можно выбрать подходящий вариант. В варианте SCM тактовая частота ядер составляет 4 ГГц, количество процессорных разъёмов в системе может достигать 16. В версии DCM частота снижена до 3,5 ГГц. 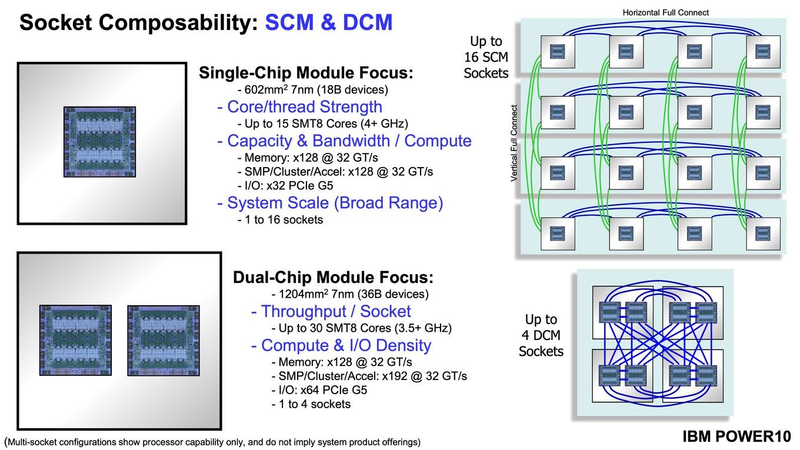 Базовый кристалл POWER10 имеет 16 вычислительных ядер, хотя используется из них только 15, каждое ядро дополнено 2 Мбайт кеша L2, а общий объём кеша L3 может достигать внушительных 120 Мбайт. Степень параллелизма была увеличена с SMT4 до SMT8, так что процессор может исполнять одновременно до 120 потоков, хотя, естественно, не в любой задаче такое распараллеливание ресурсов ядер будет эффективным. Производительность блоков SIMD была существенно увеличена, они вдвое быстрее аналогичных блоков POWER9, а на матричных операциях — быстрее в четыре раза. 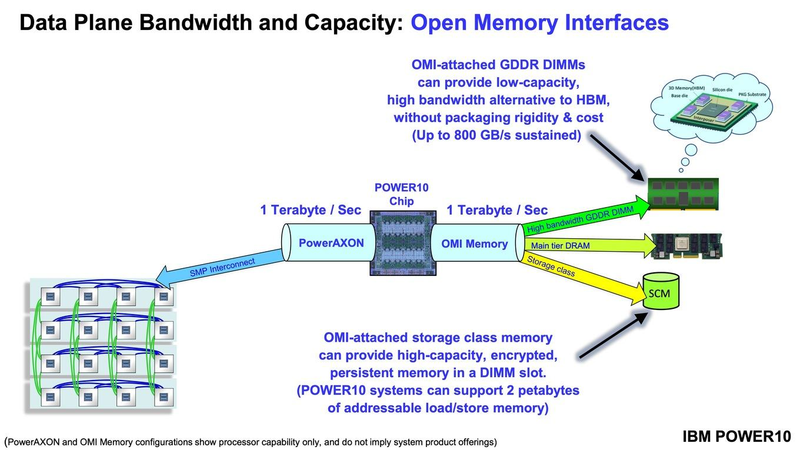 За общение процессора с «внешним миром» отвечают интерфейсы PowerAXON 2.0 и PCI Express 5.0, в первом случае поддерживается открытый стандарт OpenCAPI, во втором реализовано 64 линии со скоростью 32 ГТ/с на линию, как и предписано стандартом. Компоновка связей у DCM и SCM разная. В первом случае сокетов может быть только 4, зато используется топология «каждый с каждым», а вот в 16-сокетном варианте SCM «по диагонали» между собой процессоры напрямую не общаются. 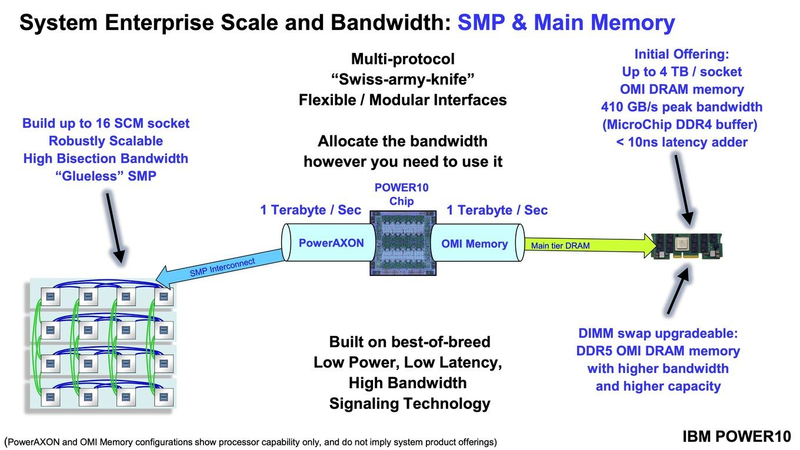 Интерфейс PowerAXON универсален, он использовался, в числе прочего, для реализации протокола NVLink для подключения ускорителей на базе графических процессоров NVIDIA. Проблем с пропускной способностью быть не должно, у каждого процессора в системе PowerAXON обеспечивает до 1 Тбайт/с. Кроме подключения ускорителей и общения процессоров между собой, у PowerAXON есть и ещё одно интересное и важное применение, о котором ниже. 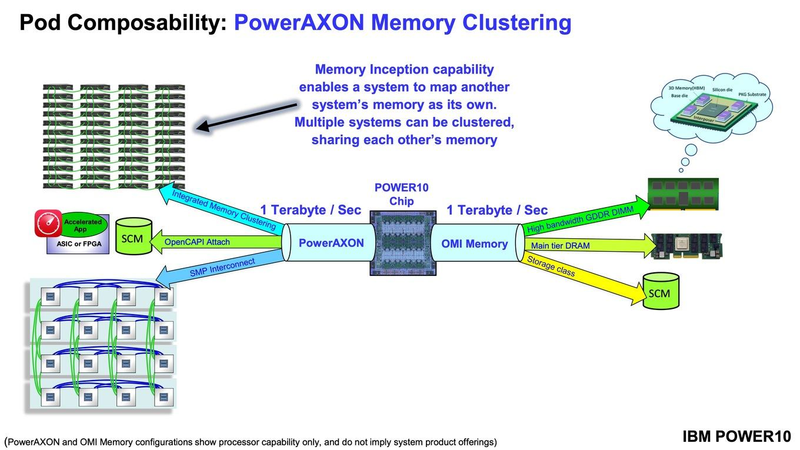 О преимуществах унифицированного интерфейса OMI, позволяющего «малой кровью» модернизировать подсистему памяти, мы уже рассказывали читателям ранее. В новом процессоре эти возможности задействованы полностью. Каждый базовый кристалл POWER10 имеет 16 линков OMI x8, общая пропускная способность достигает 1 Тбайт/с. Латентность, разумеется, возросла, поскольку контроллер DDR у OMI, по сути, внешний, но прирост небольшой и составляет менее 10 наносекунд. ✴-media" data-instgrm-captioned=" " data-instgrm-permalink="https://www.instagram.com/p/B5I5Dmpj0rw/?utm_source=ig_embed&utm_campaign=loading" data-instgrm-version="12"> Универсальность и возможность модернизации этот недостаток искупают с лихвой. В текущем варианте пиковая пропускная способность достигает 410 Гбайт/с на разъём, объём — 4 Тбайт на разъём, однако с внедрением более быстрых типов памяти (DDR5, GDDR или даже HBM) может быть достигнута цифра 800 Гбайт/с на разъём. Отдельно упоминается возможность работы с SCM, но без конкретики. На данный момент такая память массово представлена только 3D XPoint в виде Intel Optane DCPMM. 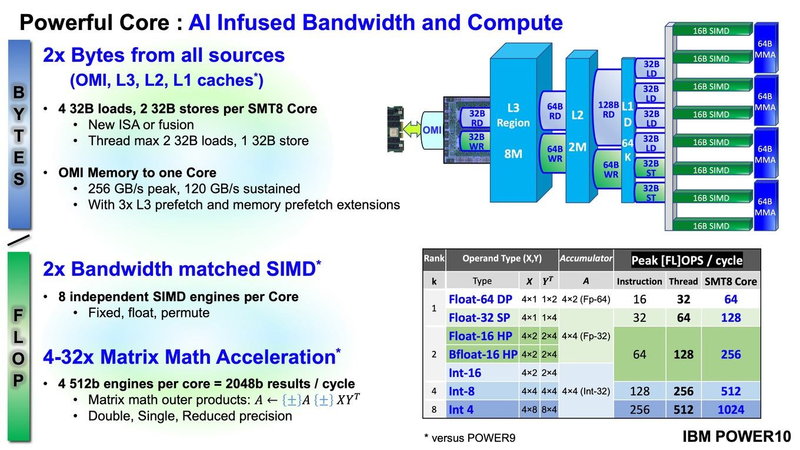 Любопытна технология Memory Clustering. С помощью PowerAXON система может обращаться к оперативной памяти в другой системе, как к собственной. Латентность при этом составляет 50 ‒ 100 нс, для систем типа NUMA совсем немного. Общий объем на одну систему POWER10 может достигать 2 Пбайт; с учётом применения систем IBM для запуска таких «пожирателей памяти», как SAP HANA такие объемы очень к месту. 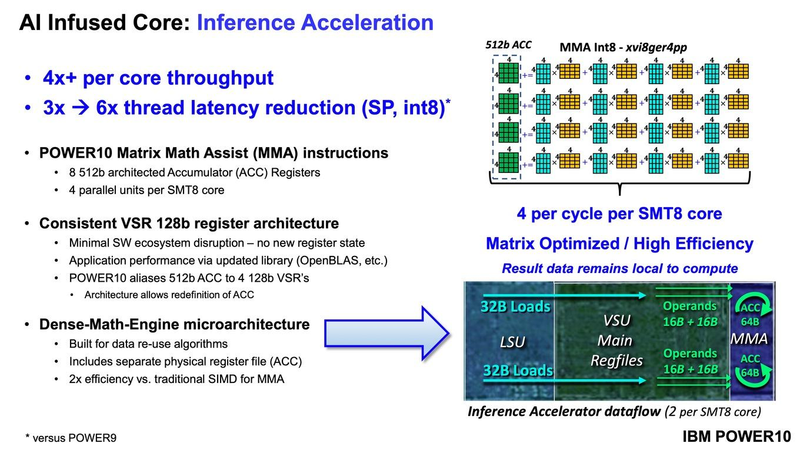 Следуя текущей моде на машинное обучение, разработчики реализовали в POWER10 развитую поддержку форматов вычислений, отличных от традиционных FP32/64. Блок плавающих вычислений в новом процессоре носит название Matrix Math Accelerator. В сравнении с POWER9 он быстрее в 10, 15 и 20 раз в режимах FP32, BFloat16 и INT8 соответственно. Иными словами, именно для инференс-систем POWER10 станет хорошим выбором. 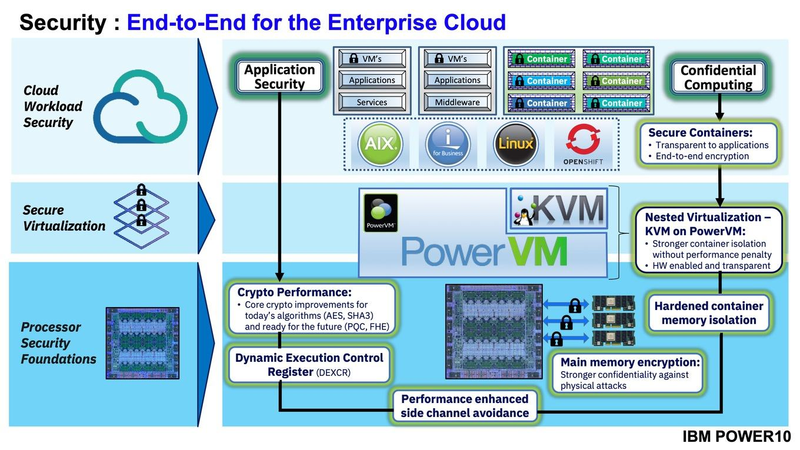 Поскольку одним из применений POWER10 компания видит облачные комплексы, серьёзное внимание уделено обеспечению безопасности. Новые процессоры поддерживают полное шифрование содержимого оперативной памяти, а для ускорения криптографических процедур в их составе есть соответствующие аппаратные блоки, причём не только для широко распространённого стандарта AES. Они достаточно гибки, чтобы поддерживать и шифрование будущего класса quantum safe. Также поддерживается защита и изоляция контейнеров на аппаратном уровне. Успешная атака на один контейнер в пределах машины не означает и успеха с другими контейнерами.  В качестве программной основы IBM предлагает Red Hat OpenShift, и архитектура POWER10 была соответствующим образом оптимизирована, чтобы показывать наилучшие результаты именно с этой средой. В целом, можно уверенно сказать: новые процессоры Голубого Гиганта получились интересными и весьма достойно выглядящими решениями даже на фоне успеха AMD EPYC.  Официальный анонс состоялся сегодня, но развёртывание массового производства должно занять определённое время, так что появления первых серверов на базе IBM POWER10 стоит ожидать не ранее начала следующего, 2021 года. А планы компании говорят о том, что POWER11 уже находится в разработке.
12.08.2020 [01:04], Илья Коваль
ARM-процессоры NUVIA Phoenix обещают быть быстрее и энергоэффективнее AMD EPYC и Intel XeonМощными серверными ARM-процессорами сейчас уже никого не удивить: A64FX трудятся в самом быстром в мире суперкомпьютере Fugaku, ThunderX и Altra стараются быть универсальными, а Graviton2 осваивается в облаке Amazon. Вот с последним как раз и хочет побороться NUVIA, молодой, но перспективный разработчик процессоров. SoC NUVIA Orion, в составе которого будет ARM-процессор Phoenix, ориентирован в первую очередь на облачных провайдеров и гипескейлеров, то есть на весьма «жирный» кусок рынка серверных процессоров, где сейчас доминирует Intel и архитектура x86-64 вообще. В этом сегменте, где число активных серверов исчисляется миллионами, крайне важны не расходы на закупку, а расходы на обслуживание и содержание такого огромного парка. 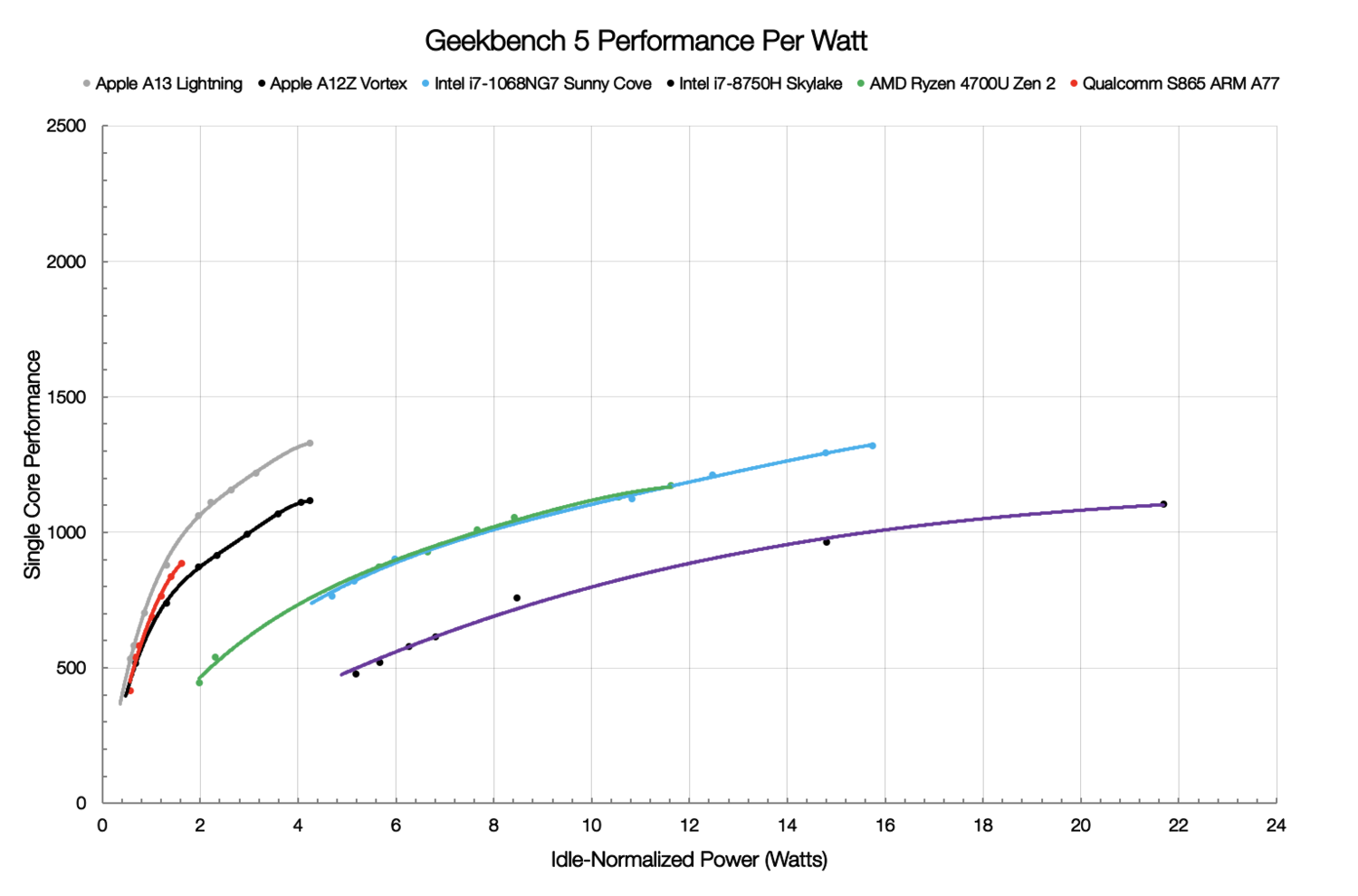
Источник изображений: NUVIA Одним из основных пунктов являются затраты на энергопотребление (питание и охлаждение), поэтому в NUVIA справедливо считают, что таким заказчикам нужен быстрый и энергоэффективный процессор. Решения на базе x86-64 компания к таковым не причисляет: они действительно имеют высокую производительность, однако рост мощности непропорционален росту TDP и потребления, и в этом их основная проблема в отличие от ARM. Для подкрепления своей точки зрения NUVIA провела собственные тесты в Geekbench 5 современных мобильных платформ ARM и x86-64. Выбор бенчмарка обусловлен тем, что он включает современные и разнообразные нагрузки на CPU. А мобильные платформы выбраны потому, что они, как и сервера в ЦОД гиперскейлеров, имеют вынужденные ограничения по питанию и охлаждению. И действительно, та же Facebook✴ для собственных платформ стремится к значению в 400 – 600 Вт на шасси. 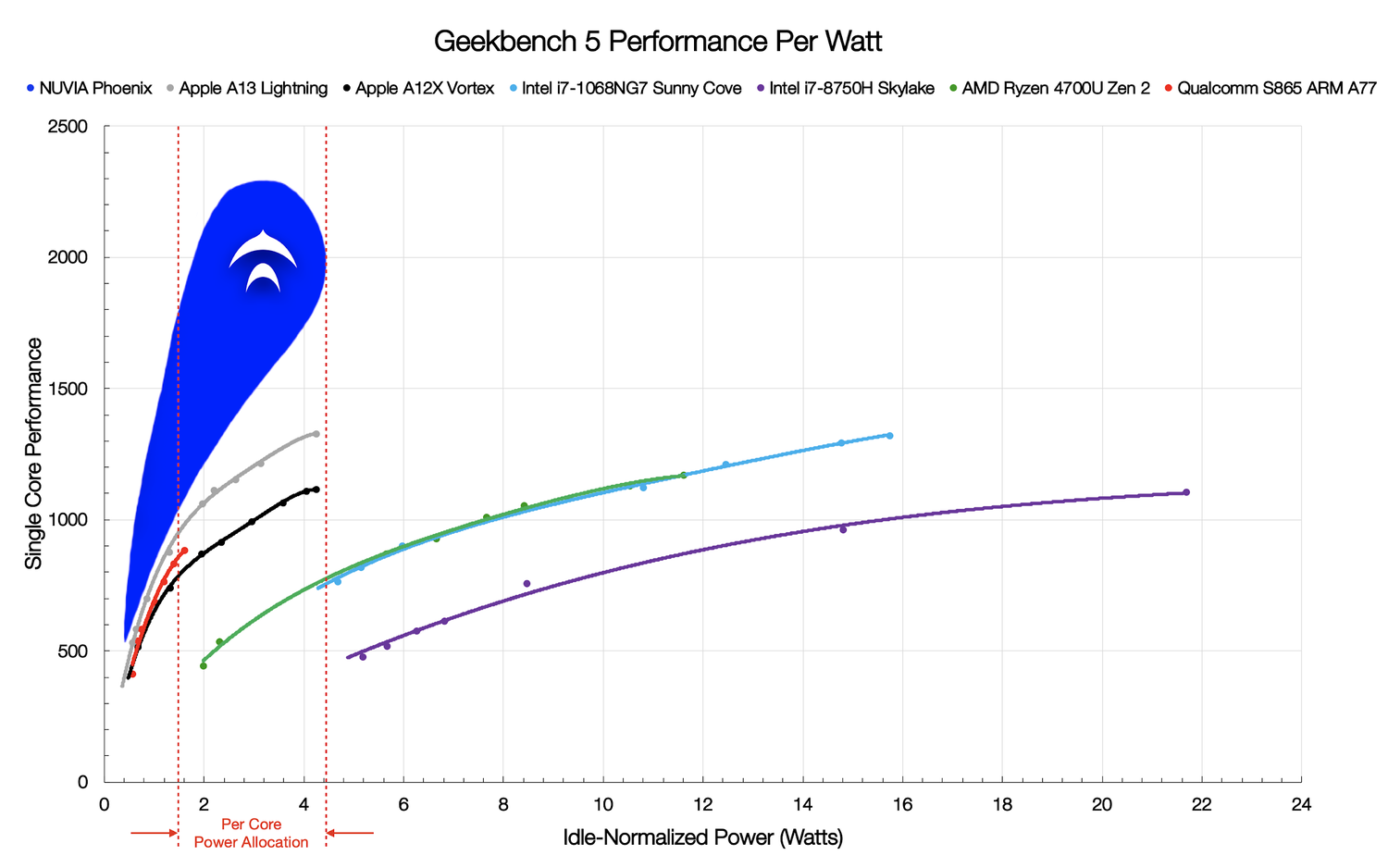 Приведённый график наглядно показывает, что производительность ядер ARM-процессоров нарастает намного быстрее при увеличении мощности. И именно к этому и стремится NUVIA — ядра Phoenix будут быстрее на 50-100% других и при этом в три-четыре раза экономичнее ядер x86-64. Но надо учесть, что сама NUVIA ориентируется на потребление в диапазоне примерно от 0,5 до 5 Вт на ядро. Компания полагает, что в ближайшее время все серверные процессоры будут иметь от 64 до 128 ядер и TDP на уровне 250 – 300 Вт, так что её SoC с такими параметрами ядер вписывается в эти параметры.
10.08.2020 [09:18], Юрий Поздеев
OCS и Dell Technologies представляют СХД PowerStoreРоссийский бизнес начинает понемногу восстанавливаться после пандемии COVID-19 и приходит время реализовать все отложенные ИТ-проекты. В условиях, когда бизнес требует быстро увеличить производительность основных сервисов, а бюджеты ограничены, особенно важно сделать правильный выбор решения для построения отказоустойчивого кластера. Новые СХД одного из ведущих вендоров Dell Technologies идеально подходят для размещения бизнес-критичных данных, а широкий набор функций поможет гибко сконфигурировать решение именно под вашу конкретную задачу.  Dell Technologies анонсировала СХД среднего уровня PowerStore в мае, и новинка сразу привлекла внимание. В чем же основные особенности семейства Dell EMC PowerStore?
Модельный ряд PowerStore включает следующие модели:  Для России доступны модели 1000, 5000, 9000, а по специальному заказу, согласованному с вендором, — также 3000 и 7000. Все их можно заказать у авторизованного дистрибьютора Dell Technologies, компании OCS, представительства которой расположены в 26 городах. Компания много лет занимает ведущие позиции на рынке проектной ИТ-дистрибуции, и одной из сильных сторон работы дистрибьютора традиционно является высокий уровень технической экспертизы. Это относится и к поставкам PowerStore: благодаря наличию сертифицированных инженеров в штате OCS партнеры компании — системные интеграторы могут рассчитывать не только на квалифицированные консультации при выборе оптимальной для их задач конфигурации СХД, на помощь в подготовке и расчете спецификаций, но и на техническую поддержку со стороны OCS при инсталляции системы, монтаже и пусконаладочных работах. Кроме того, в OCS создается демо-фонд оборудования PowerStore — партнерам для тестирования и демонстрации заказчикам будут доступны СХД PowerStore 1000 и 5000. Большим плюсом также является возможность для партнеров повышать собственную квалификацию: OCS совместно с Dell Technologies уже представили новое семейство СХД PowerStore участникам российского ИТ-рынка в ходе серии онлайн-конференций, прошедших в нескольких регионах (на Дальнем Востоке и в Сибири, на Урале, в Южном ФО), а на ближайшее будущее планируется цикл обучающих вебинаров. Для специалистов, желающих подтвердить свою квалификацию в области систем хранения данных и получить сертификат международного образца, OCS предлагает услуги авторизованного центра тестирования Pearson VUE, который создан на базе московского офиса дистрибьютора. Здесь можно сдать сертификационные экзамены ведущих мировых производителей ПО и оборудования, в том числе весь спектр тестов, разработанных для прохождения в тест-центрах, по СХД Dell EMC. |
|

