Материалы по тегу: sc19
|
25.11.2019 [16:29], Андрей Созинов
SC19: TMGcore OTTO — автономный роботизированный микро-ЦОД с иммерсионной СЖОКомпания TMGcore представила в рамках прошедшей конференции SC19 свою весьма необычную систему OTTO. Новинка является модульной платформой для создания автономных ЦОД, которая характеризуется высокой плотностью размещения аппаратного обеспечения, использует двухфазную иммерсионную систему жидкостного охлаждения, а также обладает роботизированной системой замены серверов. 
Версия OTTO на 600 кВт Первое, что отмечает производитель в системе OTTO — это высокая плотность размещения аппаратного обеспечения. Система состоит из довольно компактных серверов, которые размещены в резервуаре с охлаждающей жидкость. Собственно, использование двухфазной иммерсионной системы жидкостного охлаждения и позволяет размещать «железо» с максимальной плотностью. 
Версия OTTO на 60 кВт Всего OTTO будет доступна в трёх вариантах, рассчитанных на 60, 120 и 600 кВт. Системы состоят из одного или нескольких резервуаров для размещения серверов. Один такой резервуар имеет 12 слотов высотой 1U, в десяти из которых располагаются сервера, а ещё в двух — блоки питания. Также каждый резервуар снабжён шиной питания с рабочей мощностью 60 кВт. Отметим, что площадь, занимаемая самой большой 600-кВт системой OTTO составляет всего 14,9 м2. В состав системы OTTO могут входить как эталонные серверы HydroBlades от самой TMGcore, так и решения от других производителей, прошедшие сертификацию «OTTO Ready». В последнем случае серверы должны использовать корпуса и компоновку, которые позволяют использовать их в иммерсионной системе охлаждения. Например, таким сервером является Dell EMC PowerEdge C4140.  В рамках конференции SC19 был продемонстрирован и фирменный сервер OTTOblade G1611. При высоте всего 1U он включает два процессора Intel Xeon Scalable, до 16 графических процессоров NVIDIA V100, до 1,5 Тбайт оперативной памяти и два 10- или 100-гигабитных интерфейса Ethernet либо одиночный InfiniBand 100G. Такой сервер обладает производительность в 2000 Тфлопс при вычислениях на тензорных ядрах.  Мощность описанной абзацем выше машины составляет 6 кВт, то есть в системе OTTO может работать от 10 до 100 таких машин. И охладить столь компактную и мощную систему способна только двухфазная погружная система жидкостного охлаждения. Он состоит из резервуара, заполненного охлаждающей жидкостью от 3M и Solvay, и теплообменника для конденсации испарившейся жидкости.  Для замены неисправных серверов система OTTO оснащена роботизированной рукой, которая способна производить замены в полностью автоматическом режиме. В корпусе OTTO имеется специальный отсек с резервными серверами, а также отсек для неисправных систем. Такой подход позволяет производить замену серверов без остановки всей системы, и позволяет избежать контакта человека с СЖО во время работы.  Изначально TMGcore специализировалась на системах для майнинга с иммерсионным охлаждением, а после перенесла свои разработки на обычные системы. Поэтому, в частности, описанный выше OTTOblade G1611 с натяжкой можно отнести к HPC-решениям, так как у него довольно слабый интерконнект, не слишком хорошо подходящий для решения классических задач. Впрочем, если рассматривать OTTO как именно автономный или пограничный (edge) микро-ЦОД, то решение имеет право на жизнь.
21.11.2019 [13:11], Алексей Степин
SC19: СЖО Chilldyne Cool-Flo для ЦОД исключает протечкиВыгоды от использования жидкостного охлаждения очевидны. Оно открывает путь к более плотному размещению вычислительных узлов, и сама эффективность охлаждения существенно выше. Но существуют у таких систем и серьезные недостатки. Главной опасностью систем СЖО является возможность протечки теплоносителя. Такой сценарий может вывести из строя весьма дорогостоящее оборудование. Компания Chilldyne утверждает, что данную проблему ей удалось решить, и демонстрирует на SC19 систему охлаждения Cool-Flo с «отрицательным давлением». 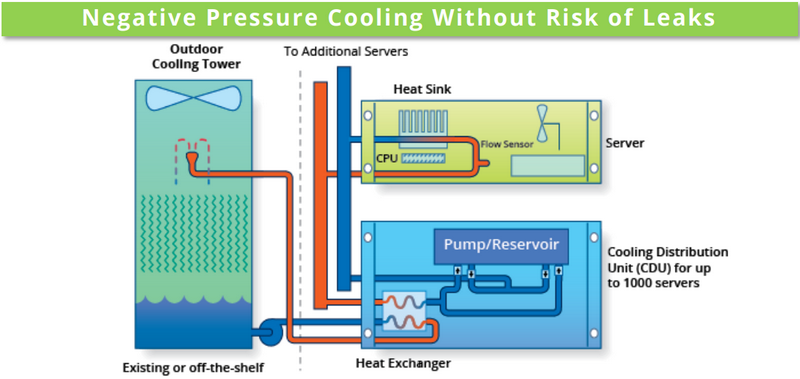
Принципиальная схема Chilldyne Cool-Flo. Обратите внимание на направление движения жидкости Главный принцип можно сравнить с вентилятором, работающим не на обдув, а на откачку воздуха из корпуса системы. Если в классическом контуре СЖО насосы нагнетают холодную жидкость в водоблоки, то насосы Cool-Flo, напротив, откачивают горячую. Если герметичность контура будет нарушена, то произойдёт не классический «залив» системной платы, а наоборот, вся жидкость будет выкачана, и вслед за ней в систему попадет воздух. 
Модуль распределения теплоносителя (CDU) Cool-Flo В таком сценарии возможен простой, но не повреждение драгоценного оборудования, поскольку контакт с жидкостью практически исключён. К тому же, сама вероятность разгерметизации серьёзно уменьшена из-за «отрицательного давления», снижающего механическую нагрузку на элементы контура. Давление в нем составляет менее 1 атмосферы, что исключает выдавливание жидкости наружу. 
Двухпроцессорное лезвие Xeon Scalable с водоблоками Cool-Flo Из прочих преимуществ системы Cool-Flo можно назвать низкую стоимость развёртывания и совместимость с существующей инфраструктурой воздушного охлаждения. Серьёзные монтажные работы с привлечением сторонних специалистов требуются только для установки CDU (системы распределения теплоносителя) и внешней башни-градирни, а монтаж стоек и серверов может осуществляться техническим персоналом ЦОД. 
Комплект водоблоков Cool-Flo для процессоров Intel в исполнении LGA2011-3. Справа ‒ разъём No-Drip Технически же в качестве водоблоков Cool-Flo может использовать модернизированные радиаторы воздушного охлаждения ЦП либо версии с теплоотводной пластиной; последний вариант идеально подходит для плотного размещения ускорителей на базе GPU и других чипов с высоким уровнем тепловыделения. В первом случае вентиляторы серверов могут работать на пониженной скорости, создавая дополнительный обдув элементов системы. 
Графический ускоритель с дополнительной пластиной охлаждения. Ни одной протечки на более чем 6 тысяч плат На выставке SC19 Chilldyne продемонстрировала как OEM-комплекты для процессоров Xeon, так и варианты для ускорителей AMD Radeon и NVIDIA Tesla. Переделка сервера, по сути, заключается в установке водоблоков и специальной заглушки с фирменным разъёмом No-Drip, напоминающим двухконтактную силовую розетку и допускающим «горячее» подключение или отключение сервера от главного контура системы. 
Стойка с ускорителями, оснащённая системой Cool-Flo Система распределения теплоносителя Cool-Flo CDU300 выполнена в виде стандартного шкафа, имеющего на передней панели экран с сенсорным управлением. Она рассчитана на температуру жидкости в районе 15‒30 градусов и при разнице температур 15 градусов способна отвести 300 киловатт тепла. Производительность водяных насосов составляет 300 литров в минуту при давлении в главном контуре менее 0,5 атмосфер. 
Комплект Cool-Flo для Radeon Fury X. Охлаждается не только GPU, но и силовая часть Предусмотрена полная система мониторинга (включая контроль качества теплоносителя) и удалённого управления, один шкаф может обслуживать до шести контуров охлаждения. Имеется возможность резервирования: резервный модуль CDU находится в активном режиме, но потребляет минимум энергии, а при необходимости мгновенно включается в работу. Компания-разработчик считает, что при использовании Cool-Flo в ЦОД можно избавиться от так называемых «горячих рядов», снизить затраты на вентиляцию и кондиционирование воздуха практически до нуля и на 75% снизить мощность, потребляемую вентиляторами серверов. Chilldyne оценивает стоимость 1 мегаватта охлаждения в $580 тысяч, в то время как классическая воздушная реализация может обойтись более чем в $1,2 миллиона. За четыре года эксплуатации ЦОД, оснащённого системой Cool-Flo экономия может составить почти $100 тысяч, и это не считая вышеупомянутых сниженных затрат на оснащение. С учётом пониженного риска повреждения оборудования в результате возможных протечек выигрыш может быть даже более серьёзным.
19.11.2019 [00:29], Андрей Созинов
Ноябрьский TOP500: больше китайских систем и меньше американских, и первая система на AMD EPYC RomeУже традиционно в рамках конференции SC была опубликована свежая версия TOP500, рейтинга пятисот самых производительных суперкомпьютеров в мире.  В новой версии списка стало больше систем из Китая, и в то же время сократилось количество систем, расположенных в США. Значительно увеличилась общая производительность всех систем, однако десятка лидеров рейтинга изменений не претерпела. 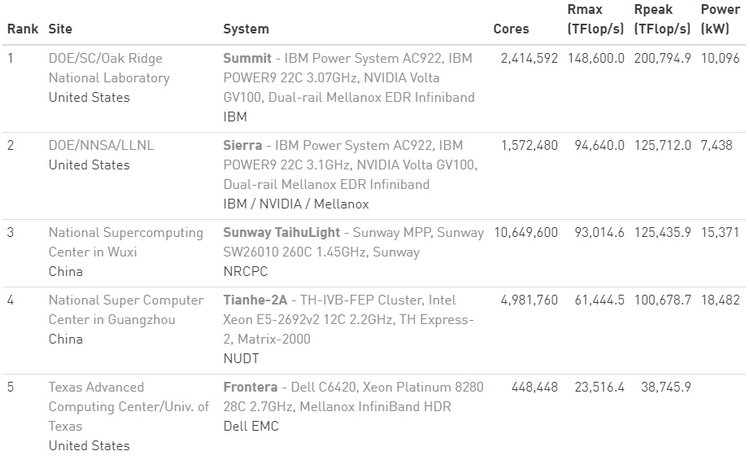 За последние шесть месяцев число китайских суперкомпьютеров в рейтинге TOP500 увеличилась с 219 до 228, и в итоге их доля составила 45,6 %. В то же время количество американских суперкомпьютеров достигло минимума в 117 систем, что составляет 23,4 %. Однако общая производительность систем из США выше — 37,1 % от общей, в то время как доля Китая здесь составляет 32,2 %. Суммарная производительность всех пятисот самых мощных суперкомпьютеров в мире составляет 1,65 Экзафлопс. Российских машин в рейтинге три. На 29 месте TOP500 теперь находится суперкомпьютер Кристофари, принадлежащий Сбербанку. 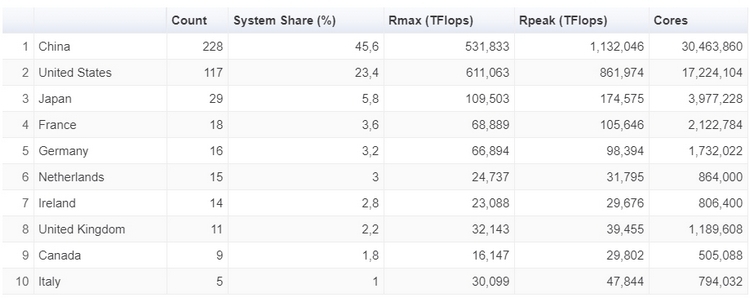 Количество систем, использующих ускорители вычислений и сопроцессоры также возросло, со 134 до 145. Большинство из них использует продукты на базе NVIDIA Volta, a также Pascal и Kepler. Что касается центральных процессоров, то здесь безоговорочным лидером остаётся Intel — 94,8 % систем из TOP500 построены на её чипах.  И здесь же хотелось бы отметить, что в свежем рейтинге TOP500 появилась первая система на процессорах AMD EPYC Rome. Это французский суперкомпьютер Joliot-Curie, построенный на платформе AtoS BullSequana XH2000, которая включает 64-ядерные процессоры AMD EPYC 7H12. Данный суперкомпьютер обладает производительностью 9,4 Пфлопс, он разместился на 59 строке рейтинга TOP500. Значительно увеличилась и минимальная производительность систем рейтинга TOP500. Теперь пятисотая система в рейтинге обладает производительностью в 1,142 Петафлопс. Полгода назад эта система располагалась на 399 месте. А чтобы претендовать на сотое место в рейтинге, системе теперь необходимо обладать производительностью более чем в 2,57 Пфлопс. 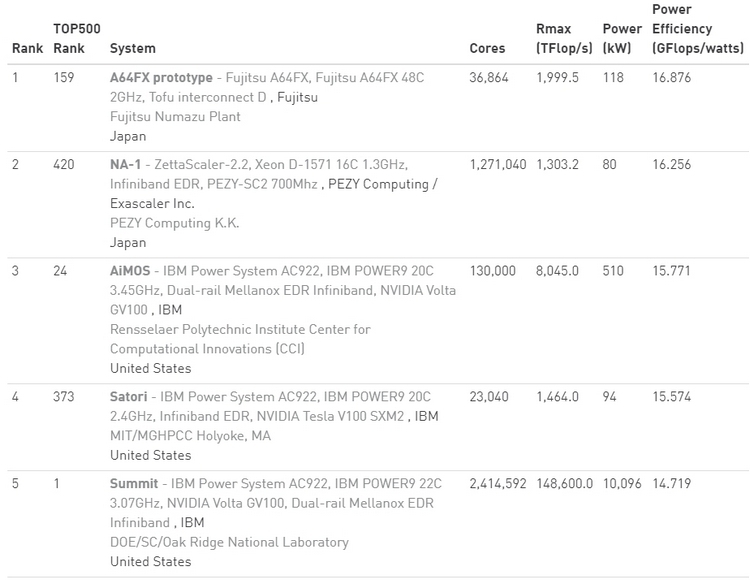 Рейтинг наиболее энергоэффективных систем — Green500 — возглавила японская система от Fujitsu. Это прототип суперкомпьютера на базе процессоров A64FX, который обеспечивает производительность в 16,9 Гфлопс на 1 ватт энергии. В общем рейтинге TOP500 данная система занимает 159 строку с общей производительностью в 2 Пфлопс. Интересно, что система обладает всего лишь 36 864 ядрами и не использует ускорители, что делает её результаты ещё более впечатляющими. Кстати, среднее количество ядер на систему из списка TOP500 также увеличилось — с 118 213 до 126 308. |
|

